Deep Learning-Based Template Matching Spike Classification for Extracellular Recordings

 , ,
, ,
Abstract
:1. Introduction
2. Materials and Methods
2.1. Dataset
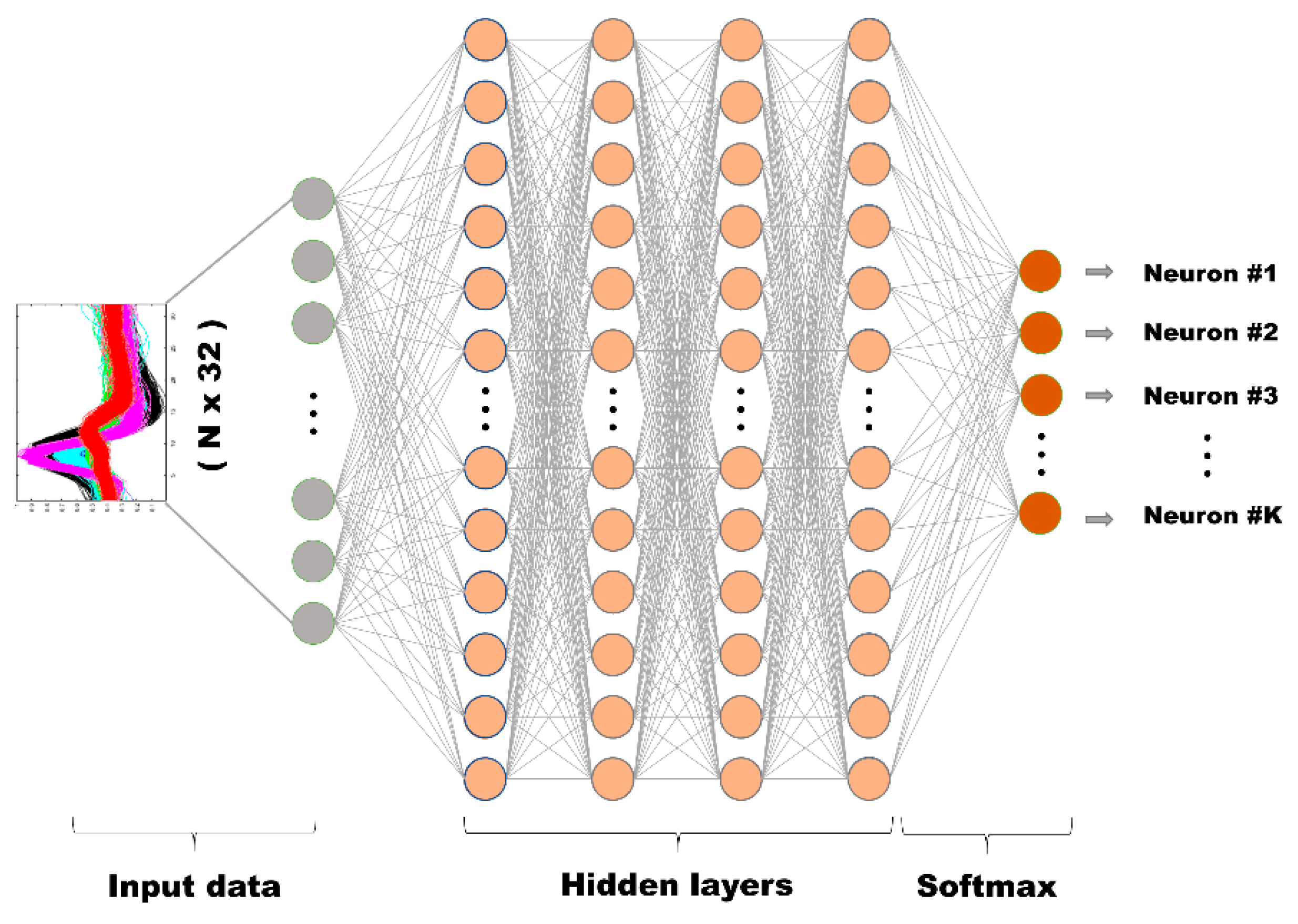
2.2. Deep Learning Model
2.3. Conventional Methods
2.3.1. Mean Squared Error-Based Template Matching
2.3.2. Cross-Correlation
2.3.3. PCA K-Means Clustering
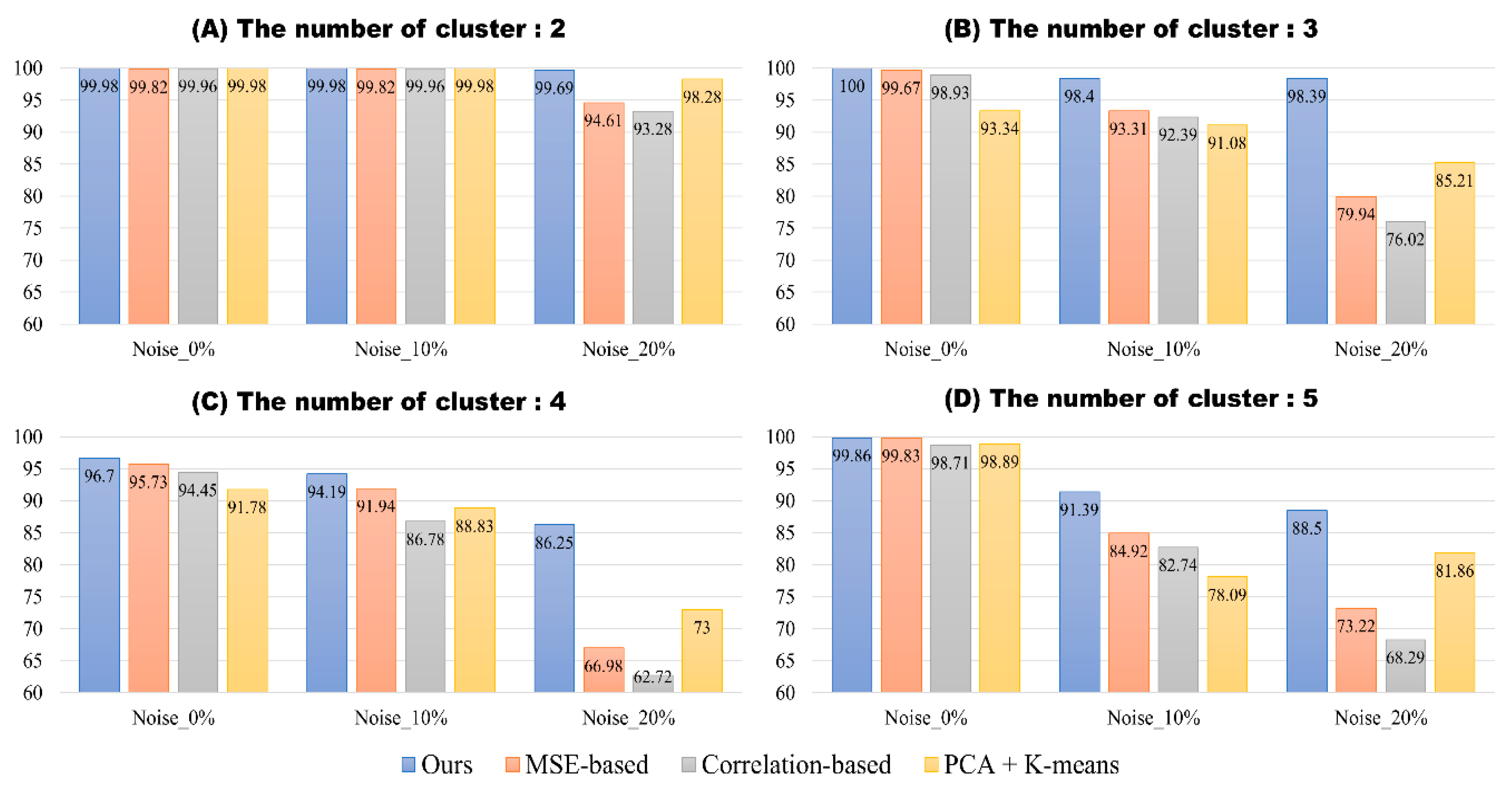
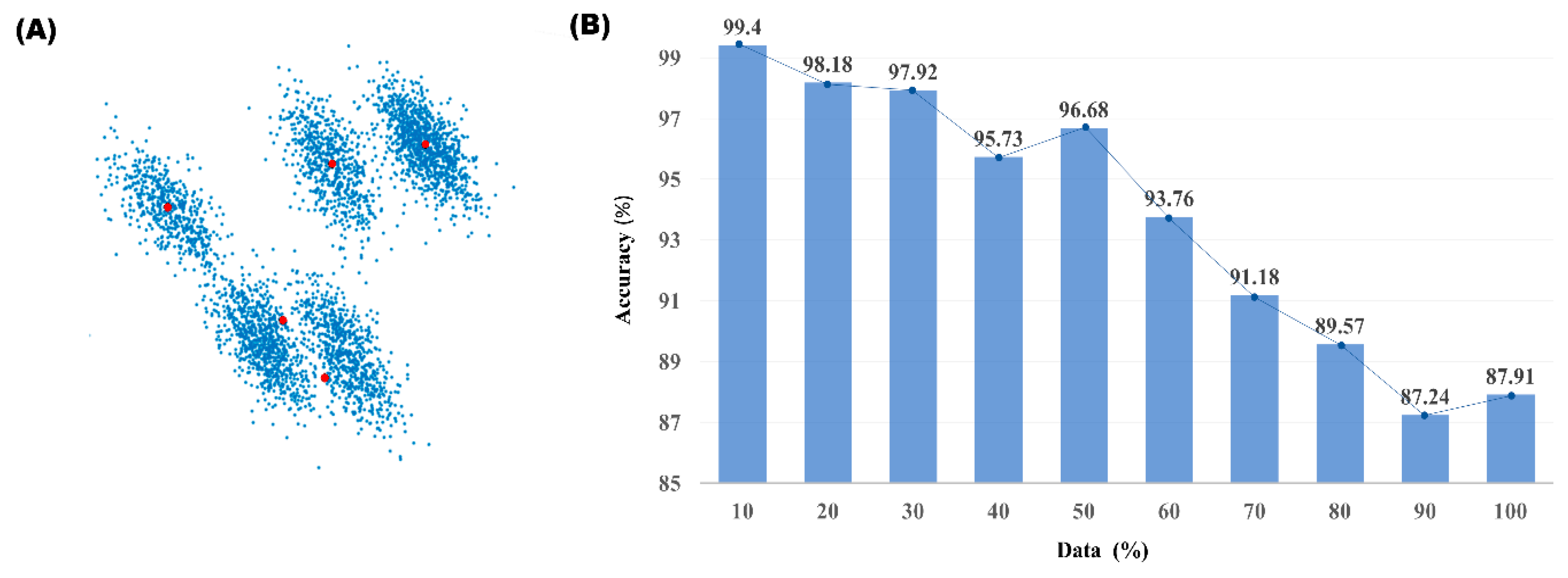
3. Results
4. Discussion
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Camuñas-Mesa, L.A.; Quiroga, R.Q. A detailed and fast model of extracellular recordings. Neural Comput. 2013, 25, 1191–1212. [Google Scholar] [CrossRef]
- Gold, C.; Henze, D.A.; Koch, C.; Buzsaki, G. On the origin of the extracellular action potential waveform: A modeling study. J. Neurophysiol. 2006, 95, 3113–3128. [Google Scholar] [CrossRef]
- Harris, K.D.; Quiroga, R.Q.; Freeman, J.; Smith, S.L. Improving data quality in neuronal population recordings. Nat. Neurosci. 2016, 19, 1165. [Google Scholar] [CrossRef] [Green Version]
- Dey, D.; Chaudhuri, S.; Munshi, S. Obstructive sleep apnoea detection using convolutional neural network based deep learning framework. Biomed. Eng. Lett. 2018, 8, 95–100. [Google Scholar] [CrossRef]
- Schmitzer-Torbert, N.L.; Jackson, J.; Henze, D.; Harris, K.; Redish, A.D. Quantitative measures of cluster quality for use in extracellular recordings. Neuroscience 2005, 131, 1–11. [Google Scholar] [CrossRef]
- Shoham, S.; Fellows, M.R.; Normann, R.A. Robust, automatic spike sorting using mixtures of multivariate t-distributions. J. Neurosci. Methods 2003, 127, 111–122. [Google Scholar] [CrossRef]
- Yger, P.; Spampinato, G.L.; Esposito, E.; Lefebvre, B.; Deny, S.; Gardella, C.; Stimberg, M.; Jetter, F.; Zeck, G.; Picaud, S.; et al. A spike sorting toolbox for up to thousands of electrodes validated with ground truth recordings In Vitro and In Vivo. eLife 2018, 7, e34518. [Google Scholar] [CrossRef]
- Souza, B.C.; Lopes-dos-Santos, V.; Bacelo, J.; Tort, A.B. Spike sorting with Gaussian mixture models. Sci. Rep. 2019, 9, 3627. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Rey, H.G.; Pedreira, C.; Quiroga, R.Q. Past, present and future of spike sorting techniques. Brain Res. Bull. 2015, 119, 106–117. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Fee, M.S.; Mitra, P.P.; Kleinfeld, D. Automatic sorting of multiple unit neuronal signals in the presence of anisotropic and non-Gaussian variability. J. Neurosci. Methods 1996, 69, 175–188. [Google Scholar] [CrossRef]
- Sahani, M. Latent Variable Models for Neural Data Analysis; California Institute of Technology: Pasadena, CA, USA, 1999. [Google Scholar]
- Franke, F.; Quiroga, R.Q.; Hierlemann, A.; Obermayer, K. Bayes optimal template matching for spike sorting–combining fisher discriminant analysis with optimal filtering. J. Comput. Neurosci. 2015, 38, 439–459. [Google Scholar] [CrossRef] [PubMed]
- Jain, A.K.; Duin, R.P.W.; Mao, J. Statistical pattern recognition: A review. IEEE Trans. Pattern Anal. Mach. Intell. 2000, 22, 4–37. [Google Scholar] [CrossRef] [Green Version]
- Wold, S.; Esbensen, K.; Geladi, P. Principal component analysis. Chemom. Intell. Lab. Syst. 1987, 2, 37–52. [Google Scholar] [CrossRef]
- Hartigan, J.A.; Wong, M.A. Algorithm AS 136: A k-means clustering algorithm. J. R. Stat. Soc. Ser. C Appl. Stat. 1979, 28, 100–108. [Google Scholar] [CrossRef]
- Zhang, P.M.; Wu, J.Y.; Zhou, Y.; Liang, P.J.; Yuan, J.Q. Spike sorting based on automatic template reconstruction with a partial solution to the overlapping problem. J. Neurosci. Methods 2004, 135, 55–65. [Google Scholar] [CrossRef] [PubMed]
- Sato, T.; Suzuki, T.; Mabuchi, K. Fast Automatic Template Matching for Spike Sorting Based on Davies-Bouldin Validation Indices. In Proceedings of the 2007 29th Annual International Conference of the IEEE Engineering in Medicine and Biology Society 2007, Lyon, France, 22–26 August 2007; pp. 3200–3203. [Google Scholar]
- Bankman, I.N.; Johnson, K.O.; Schneider, W. Optimal detection, classification, and superposition resolution in neural waveform recordings. IEEE Trans. Biomed. Eng. 1993, 40, 836–841. [Google Scholar] [CrossRef]
- Jansen, R.F.; Ter Maat, A. Automatic wave form classification of extracellular multineuron recordings. J. Neurosci. Methods 1992, 41, 123–132. [Google Scholar] [CrossRef]
- Kaneko, H.; Suzuki, S.S.; Okada, J.; Akamatsu, M. Multineuronal spike classification based on multisite electrode recording, whole-waveform analysis, and hierarchical clustering. IEEE Trans. Biomed. Eng. 1999, 46, 280–290. [Google Scholar] [CrossRef]
- Gozani, S.N.; Miller, J.P. Optimal discrimination and classification of neuronal action potential waveforms from multiunit, multichannel recordings using software-based linear filters. IEEE Trans. Biomed. Eng. 1994, 41, 358–372. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Advances in Neural Information Processing Systems; The MIT Press: Cambridge, CA, USA, 2012; pp. 1097–1105. [Google Scholar]
- Metcalfe, B.W.; Nielsen, T.N.; Donaldson, N.D.N.; Hunter, A.J.; Taylor, J.T. First demonstration of velocity selective recording from the pig vagus using a nerve cuff shows respiration afferents. Biomed. Eng. Lett. 2018, 8, 127–136. [Google Scholar] [CrossRef] [Green Version]
- Saif-ur-Rehman, M.; Lienkämper, R.; Parpaley, Y.; Wellmer, J.; Liu, C.; Lee, B.; Klaes, C. SpikeDeeptector: A deep-learning based method for detection of neural spiking activity. J. Neural Eng. 2019, 16, 056003. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Rácz, M.; Liber, C.; Németh, E.; Fiáth, R.; Rokai, J.; Harmati, I.; Márton, G. Spike detection and sorting with deep learning. J. Neural Eng. 2019. [Google Scholar] [CrossRef] [PubMed]
- Eom, J.; Kim, S.; Jang, H.; Shin, H.; Hwang, J.H.; Park, S.; Huh, Y.; Choi, H.J.; Hwang, D. Neural spike classification via deep neural network. IBRO Rep. 2019, 6, S139–S140. [Google Scholar] [CrossRef]
- Quiroga, R.Q.; Nadasdy, Z.; Ben-Shaul, Y. Unsupervised spike detection and sorting with wavelets and superparamagnetic clustering. Neural Comput. 2004, 16, 1661–1687. [Google Scholar] [CrossRef] [Green Version]
- Keshtkaran, M.R.; Yang, Z. Noise-robust unsupervised spike sorting based on discriminative subspace learning with outlier handling. J. Neural Eng. 2017, 14, 036003. [Google Scholar] [CrossRef]
- Pedreira, C.; Martinez, J.; Ison, M.J.; Quiroga, R.Q. How many neurons can we see with current spike sorting algorithms? J. Neurosci. Methods 2012, 211, 58–65. [Google Scholar] [CrossRef] [Green Version]
- Huh, Y.; Cho, J. Differential responses of thalamic reticular neurons to nociception in freely behaving mice. Front. Behav. Neurosci. 2016, 10, 223. [Google Scholar] [CrossRef] [Green Version]
- Huh, Y.; Cho, J. Discrete pattern of burst stimulation in the ventrobasal thalamus for anti-nociception. PLoS ONE 2013, 8, e67655. [Google Scholar] [CrossRef]
- Huh, Y.; Bhatt, R.; Jung, D.; Shin, H.S.; Cho, J. Interactive responses of a thalamic neuron to formalin induced lasting pain in behaving mice. PLoS ONE 2012, 7, e30699. [Google Scholar] [CrossRef] [Green Version]
- Liu, X.; Wan, H.; Shi, L. Quality Metrics of Spike Sorting Using Neighborhood Components Analysis. Open Biomed. Eng. J. 2014, 8, 60. [Google Scholar] [CrossRef] [Green Version]
- Jahankhani, P.; Kodogiannis, V.; Revett, K. EEG Signal Classification Using Wavelet Feature Extraction and Neural Networks. In Proceedings of the IEEE John Vincent Atanasoff 2006 International Symposium on Modern Computing (JVA’06), Sofia, Bulgaria, 3–6 October 2006; pp. 120–124. [Google Scholar]
- Oğulata, S.N.; Şahin, C.; Erol, R. Neural network-based computer-aided diagnosis in classification of primary generalized epilepsy by EEG signals. J. Med. Syst. 2009, 33, 107–112. [Google Scholar] [CrossRef] [PubMed]
- Chandaka, S.; Chatterjee, A.; Munshi, S. Cross-correlation aided support vector machine classifier for classification of EEG signals. Expert Syst. Appl. 2009, 36, 1329–1336. [Google Scholar] [CrossRef]
- Bezdek, J.C. Pattern Recognition with Fuzzy Objective Function Algorithms; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2013. [Google Scholar]
- Chiu, S.L. Fuzzy model identification based on cluster estimation. J. Intell. Fuzzy Syst. 1994, 2, 2–267. [Google Scholar] [CrossRef]
- Rai, P.; Singh, S. A survey of clustering techniques. Int. J. Comput. Appl. 2010, 7, 1–5. [Google Scholar] [CrossRef]
- Güneş, S.; Polat, K.; Yosunkaya, Ş. Efficient sleep stage recognition system based on EEG signal using k-means clustering based feature weighting. Expert Syst. Appl. 2010, 37, 7922–7928. [Google Scholar] [CrossRef]
- Prabhu, P.; Anbazhagan, N. Improving the performance of k-means clustering for high dimensional data set. Int. J. Comput. Sci. Eng. 2011, 3, 2317–2322. [Google Scholar]
- Raykov, Y.P.; Boukouvalas, A.; Baig, F.; Little, M.A. What to do when k-means clustering fails: A simple yet principled alternative algorithm. PLoS ONE 2016, 11, e0162259. [Google Scholar] [CrossRef]
- Eo, T.; Jun, Y.; Kim, T.; Jang, J.; Lee, H.J.; Hwang, D. KIKI-net: cross-domain convolutional neural networks for reconstructing undersampled magnetic resonance images. Magn. Reson. Med. 2018, 80, 2188–2201. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Data | Noise | Ours | MSE-Based Template Matching | Correlation-Based Template Matching | PCA + K-Means Clustering |
|---|---|---|---|---|---|
| Easy1 | 0.05 | 100 (99.26) | 100 (99.30) | 100 (99.14) | 100 (99.40) |
| 0.1 | 100 (99.43) | 100 (95.51) | 100 (99.34) | 100 (99.65) | |
| 0.15 | 100 (99.25) | 100 (99.11) | 100 (99.10) | 100 (99.48) | |
| 0.2 | 100 (99.19) | 100 (99.00) | 99.88 (98.76) | 100 (99.51) | |
| Easy2 | 0.05 | 100 (98.68) | 100 (98.41) | 100 (98.79) | 99.96 (98.21) |
| 0.1 | 99.85 (98.49) | 95.54 (97.31) | 94.91 (98.89) | 99.96 (98.18) | |
| 0.15 | 97.99 (97.19) | 89.53 (88.82) | 94.86 (94.25) | 98.79 (96.77) | |
| 0.2 | 96.50 (95.20) | 93.50 (87.44) | 93.37 (90.35) | 95.46 (93.84) | |
| Difficult1 | 0.05 | 100 (98.78) | 100 (98.80) | 100 (98.98) | 100 (98.84) |
| 0.1 | 99.96 (98.93) | 99.34 (95.12) | 99.48 (98.84) | 100 (98.93) | |
| 0.15 | 99.77 (97.55) | 90.15 (84.82) | 98.55 (96.83) | 99.77 (97.32) | |
| 0.2 | 98.08 (96.62) | 81.99 (92.10)) | 97.22 (93.75) | 95.69 (92.95) | |
| Difficult2 | 0.05 | 99.61 (98.49) | 98.08 (97.52) | 91.62 (93.76) | 86.04 (87.28) |
| 0.1 | 96.62 (94.66) | 92.34 (68.51) | 90.56 (88.54) | 84.11 (83.90) | |
| 0.15 | 83.23 (82.20) | 83.03 (73.61) | 80.82 (74.36) | 74.43 (72.63) | |
| 0.2 | 71.15 (51.55) | 62.72 (32.00) | 67.75 (33.24) | 65.92 (32.22) | |
| Total | 96.42 (94.09) | 92.89 (87.96) | 94.32 (91.06) | 93.76 (90.57) |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Park, I.Y.; Eom, J.; Jang, H.; Kim, S.; Park, S.; Huh, Y.; Hwang, D. Deep Learning-Based Template Matching Spike Classification for Extracellular Recordings. Appl. Sci. 2020, 10, 301. https://0-doi-org.brum.beds.ac.uk/10.3390/app10010301
Park IY, Eom J, Jang H, Kim S, Park S, Huh Y, Hwang D. Deep Learning-Based Template Matching Spike Classification for Extracellular Recordings. Applied Sciences. 2020; 10(1):301. https://0-doi-org.brum.beds.ac.uk/10.3390/app10010301
Chicago/Turabian StylePark, In Yong, Junsik Eom, Hanbyol Jang, Sewon Kim, Sanggeon Park, Yeowool Huh, and Dosik Hwang. 2020. "Deep Learning-Based Template Matching Spike Classification for Extracellular Recordings" Applied Sciences 10, no. 1: 301. https://0-doi-org.brum.beds.ac.uk/10.3390/app10010301