Sehaa: A Big Data Analytics Tool for Healthcare Symptoms and Diseases Detection Using Twitter, Apache Spark, and Machine Learning



Abstract
:1. Introduction
2. Background
2.1. Big Data
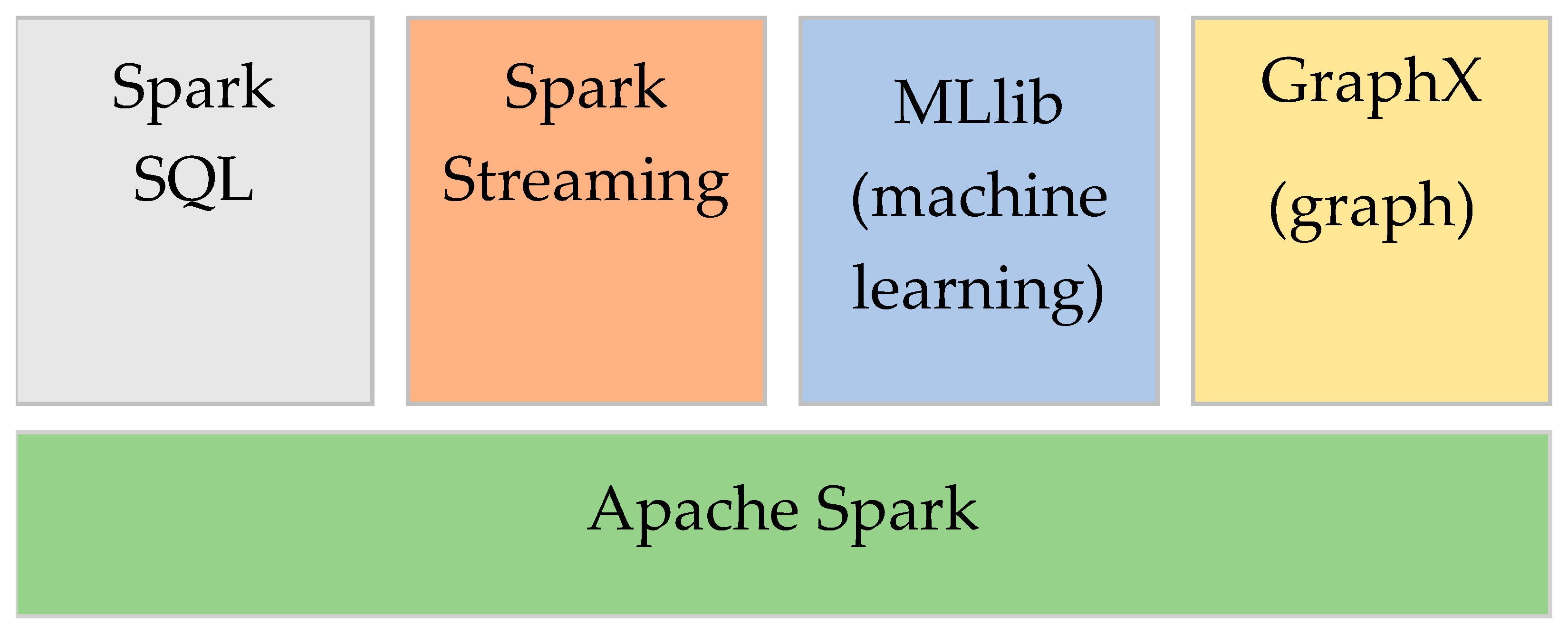
2.2. Apache Spark
2.3. Machine Learning
2.3.1. Logistic Regression (LR)
2.3.2. Naïve Bayes (NB)
2.4. Feature Extraction
2.4.1. N-Gram
2.4.2. TF-IDF
2.4.3. CountVectorizer
2.4.4. HashingTF
3. Literature Review
3.1. Twitter Data Analytics in Healthcare
3.2. Twitter Data Analytics in Healthcare (Arabic)
3.3. Research Gap
4. Sehaa Tool: Methodology and Design
4.1. Sehaa: An Overview
4.2. Data Collection Module
4.2.1. Keywords and Geolocation
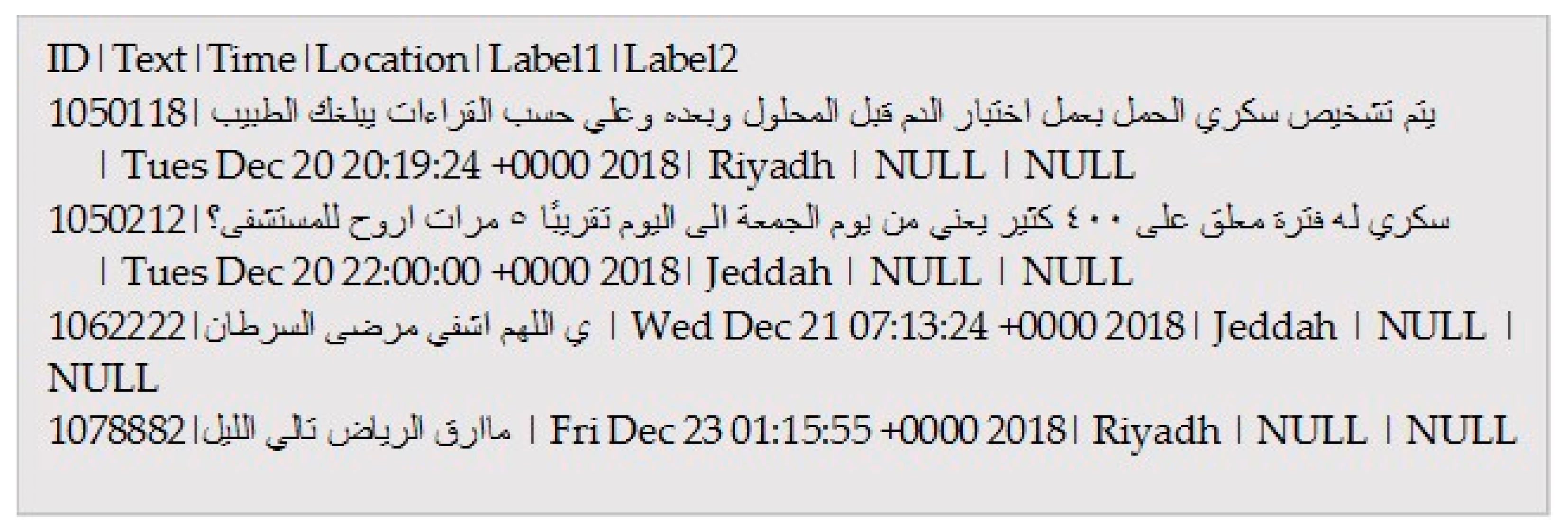
4.2.2. The Data Set
4.2.3. The JSON Parser
| Algorithm 1: Sehaa JSON Parser |
 |
4.3. Data Pre-Processing Module
Labeling the Tweets
| Algorithm 2: Sehaa Pre-Processing Algorithm |
 |
4.4. Classification Module
4.5. Validation Module
4.5.1. Visualization
4.5.2. External Validation
5. Sehaa: Results and Discussions
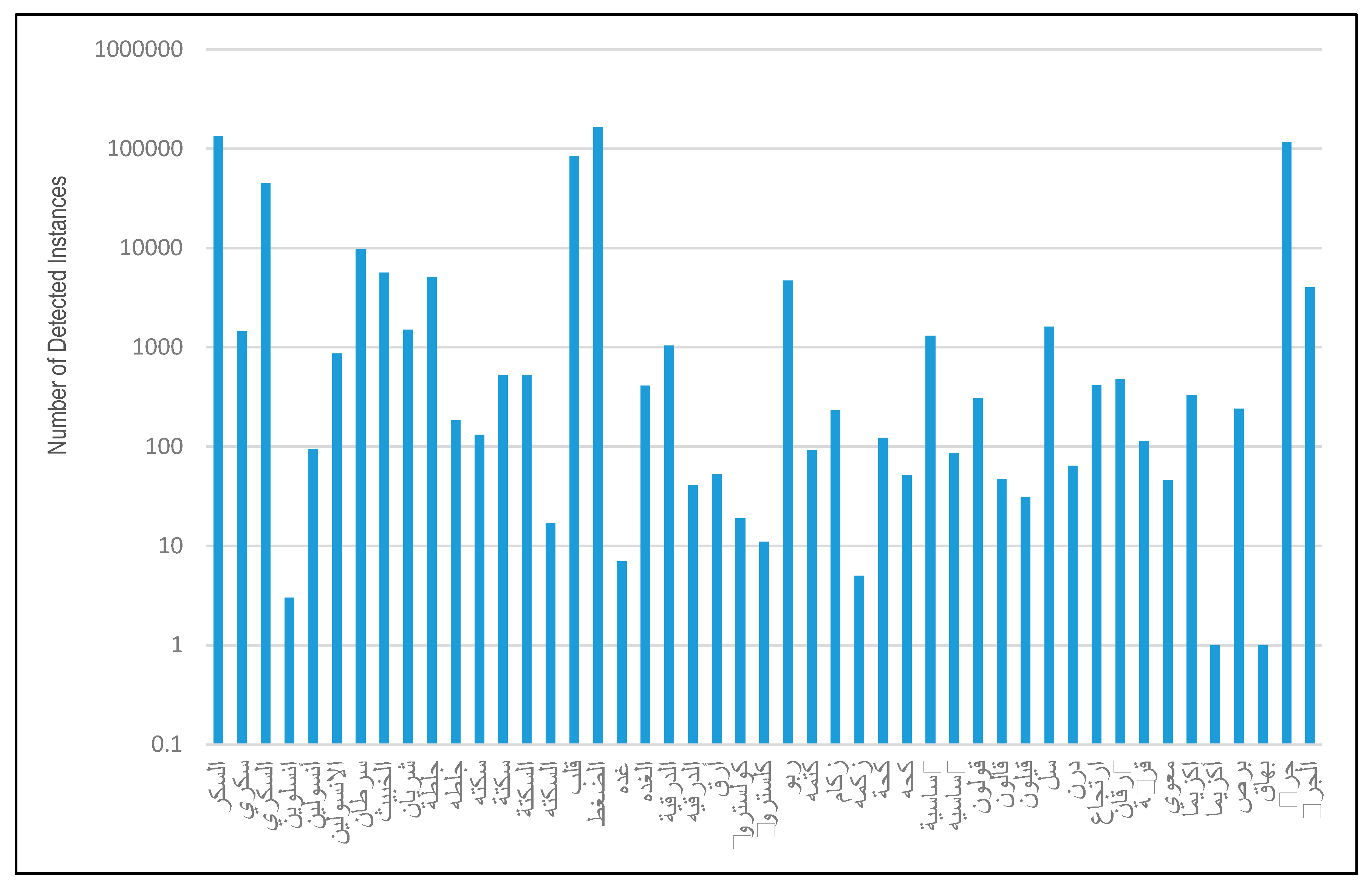
5.1. Pre-Classification Results
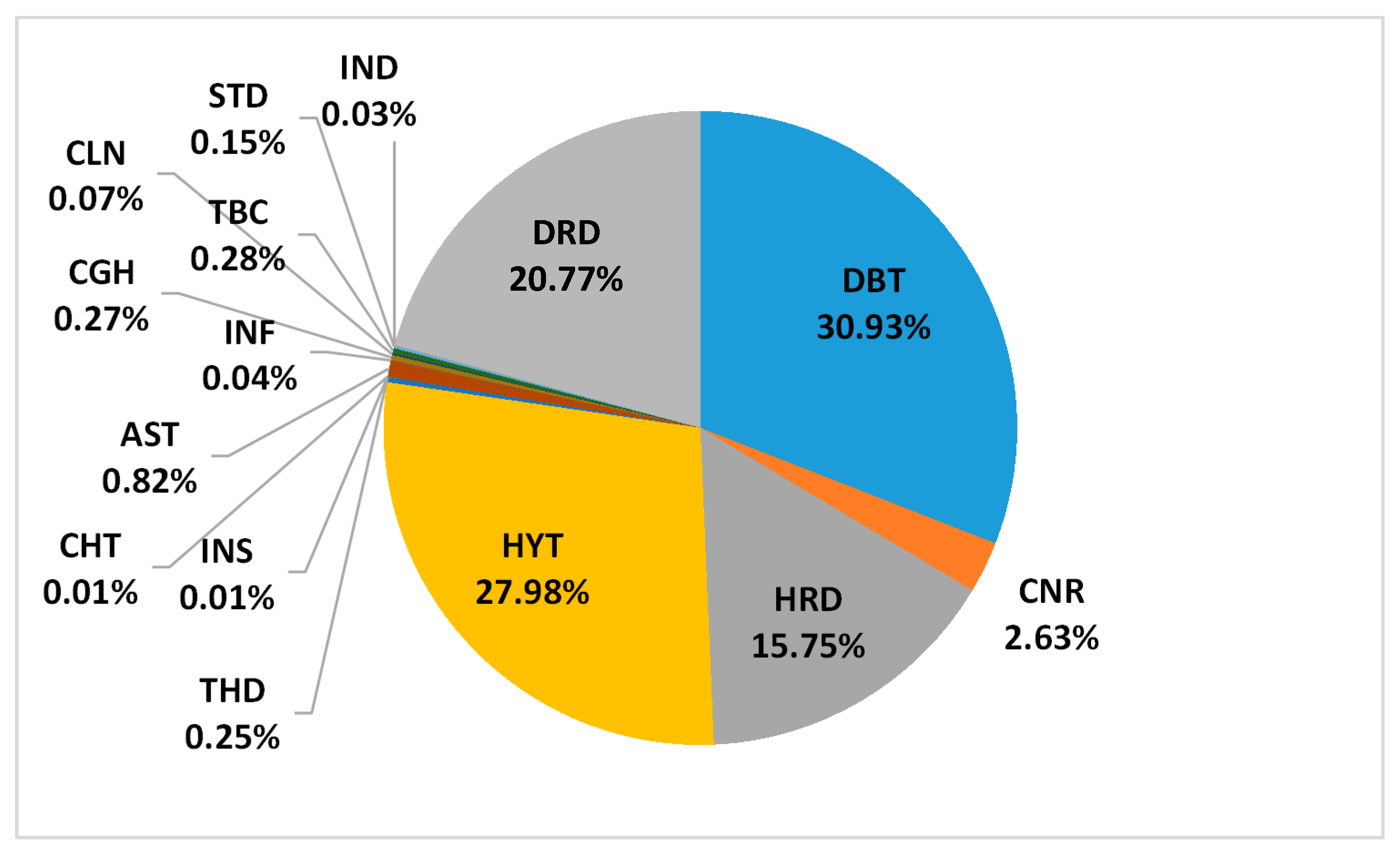
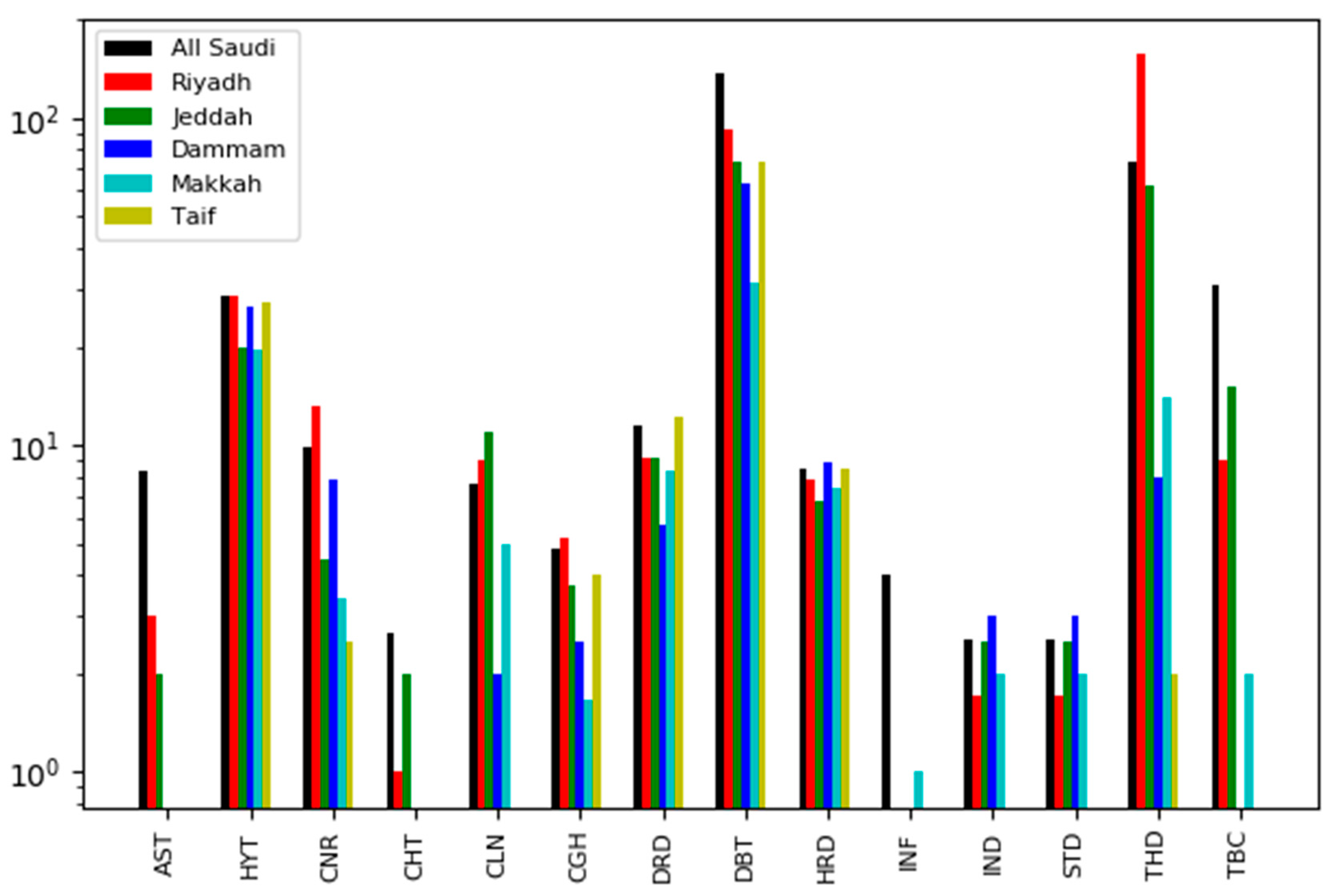
5.2. Post-Classification Results (First-Level)
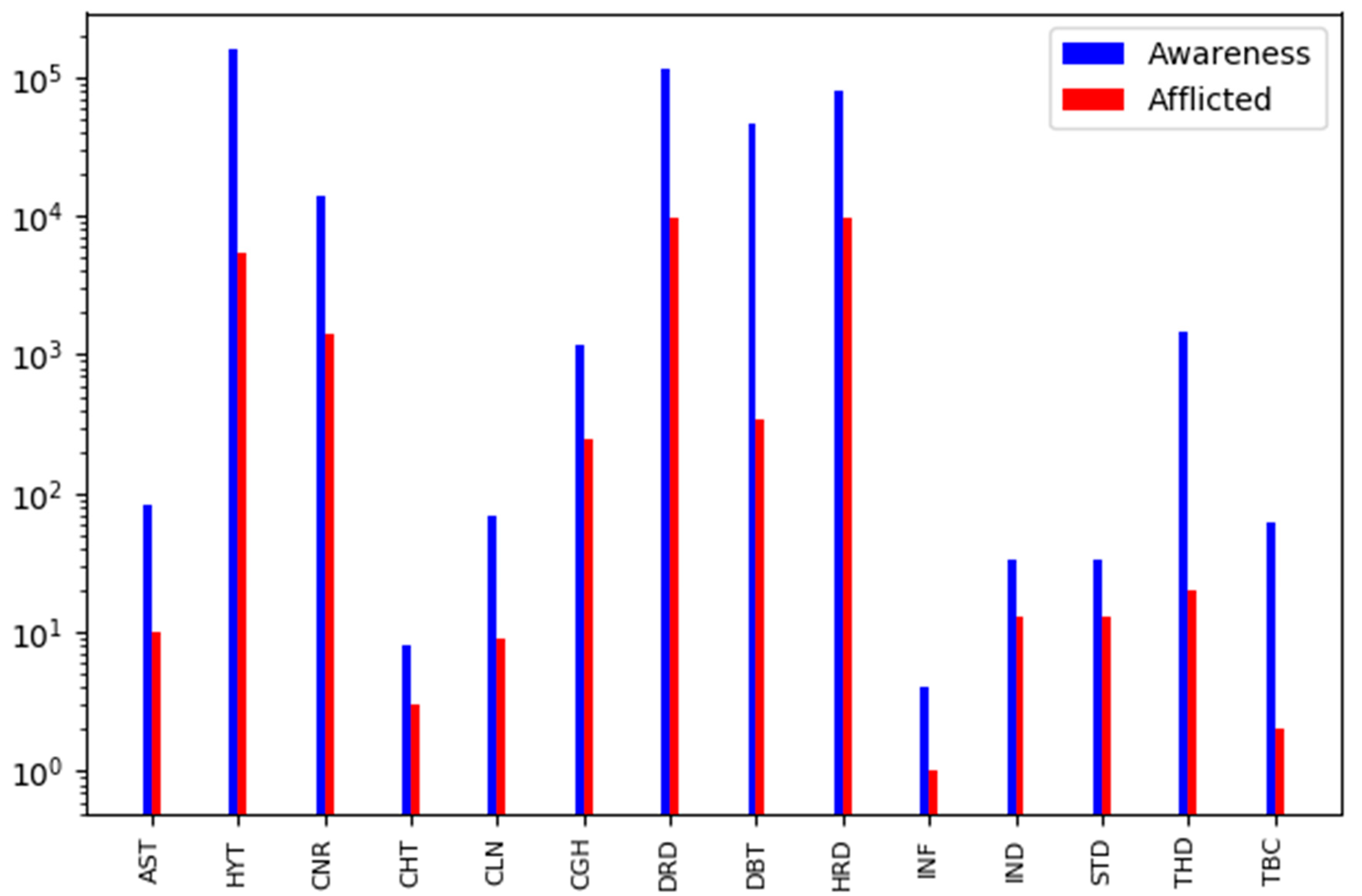
5.3. Awareness vs. Afflicted Tweets
6. Results Validation
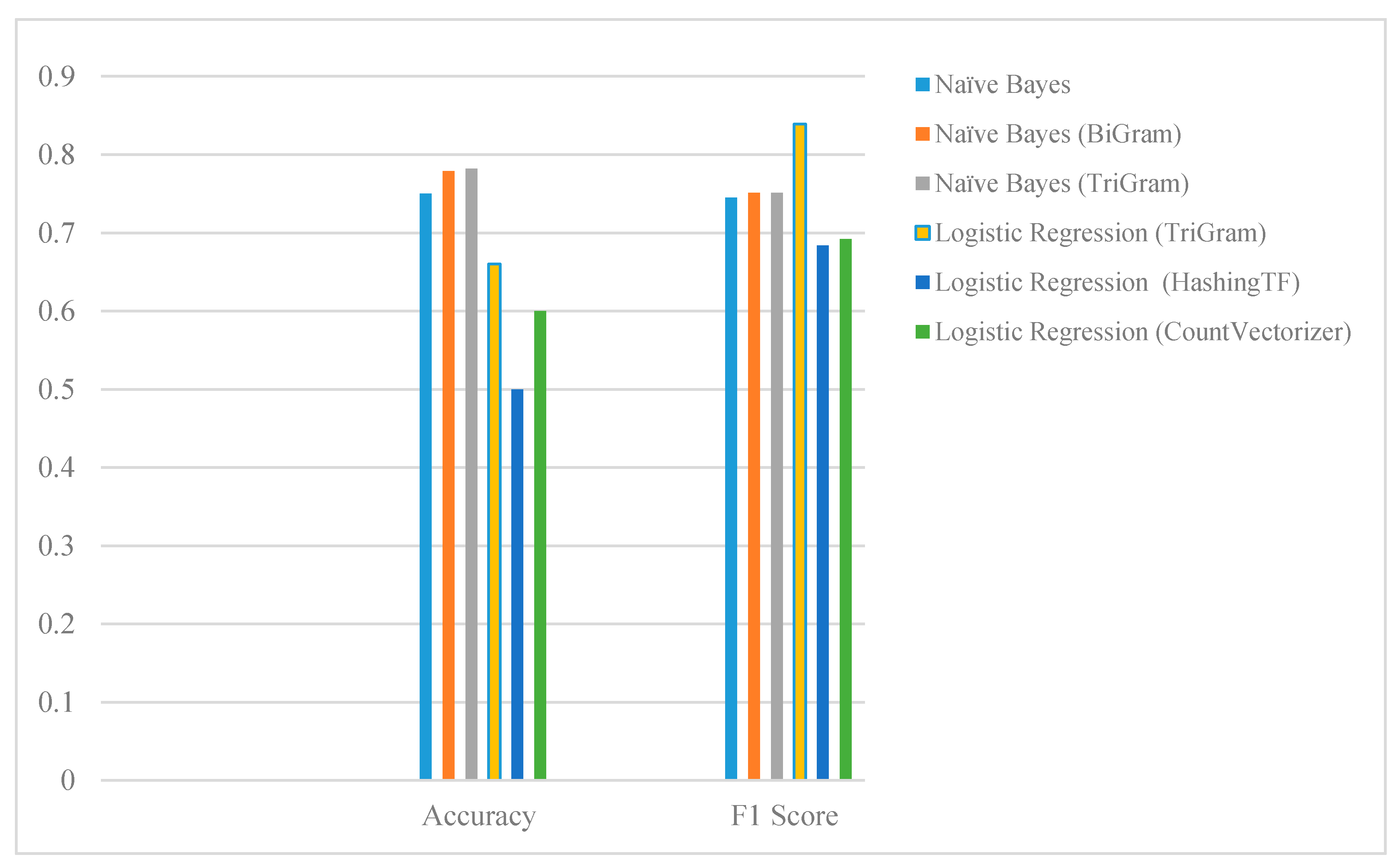
6.1. Numerical Evaluation
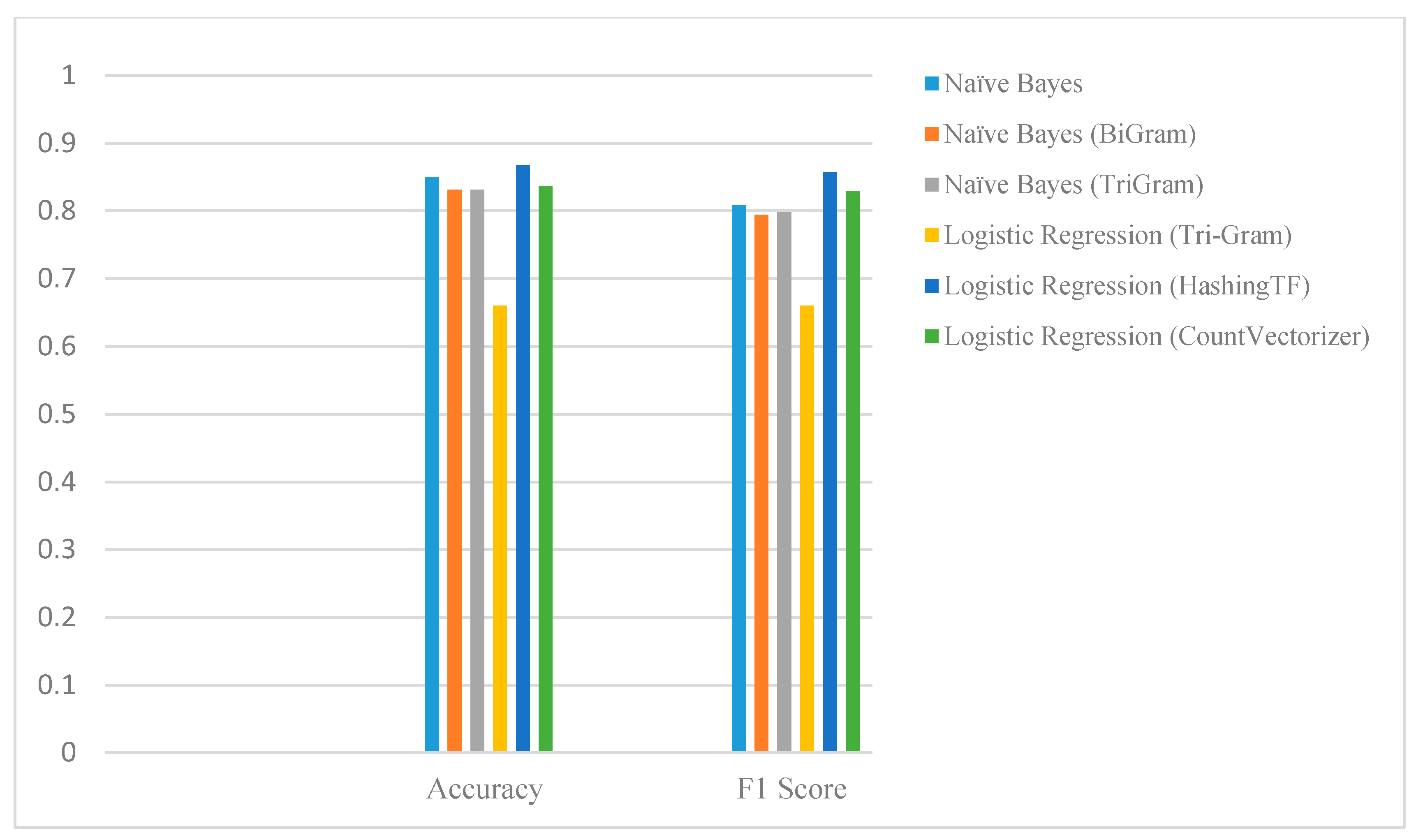
6.2. External Validation
7. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Mehmood, R.; Katib, S.S.I.; Chlamtac, I. (Eds.) Smart Infrastructure and Applications: Foundations for Smarter Cities and Societies; EAI/Springer Innovations in Communication and Computing, Springer International Publishing, Springer Nature Switzerland AG: Basel, Switzerland, 2020. [Google Scholar]
- Just How Big Is the Healthcare Industry? Here’s What You Need to Know—Dreamit Ventures. Available online: https://www.dreamit.com/journal/2018/4/24/size-healthcare-industry (accessed on 8 February 2020).
- Getting the Right Care to the Right People at the Right Cost: An Interview With Ron Walls | McKinsey. Available online: https://www.mckinsey.com/industries/healthcare-systems-and-services/our-insights/getting-the-right-care-to-the-right-people-at-the-right-cost-an-interview-with-ron-walls (accessed on 8 February 2020).
- Sherman, E. U.S. Health Care Spending Hit $3.65 Trillion in 2018. Fortune. 21 February 2019. Available online: https://fortune.com/2019/02/21/us-health-care-costs-2/ (accessed on 12 January 2020).
- Finding the Future of Care Provision: The Role of Smart Hospitals | McKinsey. Available online: https://www.mckinsey.com/industries/healthcare-systems-and-services/our-insights/finding-the-future-of-care-provision-the-role-of-smart-hospitals (accessed on 8 February 2020).
- Kemp, S. Digital Trends 2019: Every Single Stat You Need to Know about the Internet. thenextweb.com. 30 January 2019. Available online: https://thenextweb.com/contributors/2019/01/30/digital-trends-2019-every-single-stat-you-need-to-know-about-the-internet/ (accessed on 10 January 2020).
- Statista. Countries with Most Twitter Users 2019 | Statistic. Statista. 20 November 2019. Available online: https://0-www-statista-com.brum.beds.ac.uk/statistics/242606/number-of-active-twitter-users-in-selected-countries/ (accessed on 19 April 2019).
- Lin, Y. 10 Twitter Statistics Every Marketer Should Know in 2020. Oberlo. 30 November 2019. Available online: https://www.oberlo.com/blog/twitter-statistics (accessed on 11 January 2020).
- witter by the Numbers (2019): Stats, Demographics & Fun Facts. Omnicore. 10 February 2020. Available online: https://www.omnicoreagency.com/twitter-statistics/ (accessed on 11 January 2020).
- Alotaibi, S.; Mehmood, R.; Katib, I. Sentiment Analysis of Arabic Tweets in Smart Cities: A Review of Saudi Dialect. In Proceedings of the 2019 Fourth International Conference on Fog and Mobile Edge Computing (FMEC), Rome, Italy, 10–13 June 2019; pp. 330–335. [Google Scholar]
- Gohil, S.; Vuik, S.; Darzi, A. Sentiment analysis of health care tweets: Review of the methods used. J. Med. Internet Res. 2018, 4, 43. [Google Scholar] [CrossRef] [PubMed]
- AlSukhni, E.; Alequr, Q. Investigating the Use of Machine Learning Algorithms in Detecting Gender of the Arabic Tweet Author. Int. J. Adv. Comput. Sci. Appl. 2016, 7, 319–328. [Google Scholar] [CrossRef] [Green Version]
- Al-Hussaini, H.; Al-Dossari, H. Lexicon-based Approach to Build Service Provider Reputation from Arabic Tweets in Twitter. Int. J. Adv. Comput. Sci. Appl. 2017, 8, 445–454. [Google Scholar] [CrossRef] [Green Version]
- Al-Ayyoub, M.; Khamaiseh, A.A.; Jararweh, Y.; Al-Kabi, M.N. A comprehensive survey of arabic sentiment analysis. Inf. Process. Manag. 2019, 56, 320–342. [Google Scholar] [CrossRef]
- Alayba, A.M.; Palade, V.; England, M.; Iqbal, R. Arabic Language Sentiment Analysis on Health Services. In Proceedings of the International Workshop on Arabic and derived Script Analysis and Recognition, Nancy, France, 3–5 April 2017; pp. 114–118. [Google Scholar]
- Alkouz, B.; Al Aghbari, Z. Analysis and prediction of influenza in the UAE based on Arabic tweets. In Proceedings of the 2018 IEEE 3rd International Conference on Big Data Analysis (ICBDA 2018), Shanghai, China, 9–12 March 2018; pp. 61–66. [Google Scholar]
- Ilyas, M.U.; Alowibdi, J.S. Disease Tracking in GCC Region Using Arabic Language Tweets. In Proceedings of the Companion of the Web Conference 2018—WWW’18, Lyon, France, 13–17 April 2018; pp. 417–423. [Google Scholar]
- Alomari, E.; Mehmood, R.; Katib, I. Sentiment Analysis of Arabic Tweets for Road Traffic Congestion and Event Detection. In Smart Infrastructure and Applications; Springer: Cham, Switzerland, 2020; pp. 37–54. [Google Scholar]
- Suma, S.; Mehmood, R.; Albeshri, A. Automatic Detection and Validation of Smart City Events Using HPC and Apache Spark Platforms. In Smart Infrastructure and Applications: Foundations for Smarter Cities and Societies; Springer: Cham, Switzerland, 2019; pp. 55–78. [Google Scholar]
- Alomari, E.; Mehmood, R.; Katib, I. Road Traffic Event Detection Using Twitter Data, Machine Learning, and Apache Spark. In Proceedings of the 3rd IEEE International Conference on Smart City Innovations (SCI 2019), Leicester, UK, 19–23 August 2019. [Google Scholar]
- Lau, R.Y. Toward a social sensor based framework for intelligent transportation. In Proceedings of the 2017 IEEE 18th International Symposium on A World of Wireless, Mobile and Multimedia Networks (WoWMoM), Macau, China, 12–15 June 2017; pp. 1–6. [Google Scholar]
- Pandhare, K.R.; Shah, M.A. Real time road traffic event detection using Twitter and spark. In Proceedings of the 2017 International Conference on Inventive Communication and Computational Technologies (ICICCT), Coimbatore, India, 10–11 March 2017; pp. 445–449. [Google Scholar]
- Salas, A.; Georgakis, P.; Nwagboso, C.; Ammari, A.; Petalas, I. Traffic Event Detection Framework Using Social Media. In Proceedings of the IEEE International Conference on Smart Grid and Smart Cities, Singapore, 23–26 July 2017; pp. 303–307. [Google Scholar]
- Chen, M.; Mao, S.; Liu, Y. Big data: A survey. Mob. Netw. Appl. 2014, 19, 171–209. [Google Scholar] [CrossRef]
- Mehmood, R.; Faisal, M.A.; Altowaijri, S. Future Networked Healthcare Systems: A Review and Case Study. In Big Data: Concepts, Methodologies, Tools, and Applications; Information Resources Management Association, Ed.; IGI Global: Hershey, PA, USA; pp. 2429–2457.
- “Apache SparkTM - Unified Analytics Engine for Big Data.” [Online]. Available online: https://spark.apache.org/ (accessed on 28 December 2019).
- Shalev-Shwartz, S.; Ben-David, S. Understanding Machine Learning: From Theory to Algorithms; Cambridge University Press: Cambridge, UK, 2014. [Google Scholar]
- Logistic Regression — ML Glossary documentation. Available online: https://ml-cheatsheet.readthedocs.io/en/latest/logistic_regression.html (accessed on 29 December 2019).
- Graphical Models Lecture 2: Bayesian Network Representatioon. Available online: https://people.cs.umass.edu/~mccallum/courses/gm2011/02-bn-rep.pdf (accessed on 2 January 2020).
- Extracting, Transforming and Selecting Features—Spark 2.4.4 Documentation. Available online: https://spark.apache.org/docs/latest/mL-features#tf-idf (accessed on 7 February 2020).
- Mehmood, R.; Bhaduri, B.; Katib, I.; Chlamtac, I. (Eds.) Smart Societies, Infrastructure, Technologies and Applications. In Proceedings of the Lecture Notes of the Institute for Computer Sciences, Social Informatics and Telecommunications Engineering (LNICST), Jeddah, Saudi Arabia, 27–29 November 2017; Springer: Cham, Switzerland, 2018; Volume 224. [Google Scholar]
- Muhammed, T.; Mehmood, R.; Albeshri, A. Enabling reliable and resilient IoT based smart city applications. In Proceedings of the Lecture Notes of the Institute for Computer Sciences, Social-Informatics and Telecommunications Engineering (LNICST), Jeddah, Saudi Arabia, 27–29 November 2017; Springer: Cham, Switzerland, 2018; Volume 224, pp. 169–184. [Google Scholar]
- Alam, F.; Mehmood, R.; Katib, I.; Albogami, N.N.; Albeshri, A. Data Fusion and IoT for Smart Ubiquitous Environments: A Survey. IEEE Access 2017, 5, 9533–9554. [Google Scholar] [CrossRef]
- Muhammed, T.; Mehmood, R.; Albeshri, A.; Katib, I. UbeHealth: A personalized ubiquitous cloud and edge-enabled networked healthcare system for smart cities. IEEE Access 2018, 6, 32258–32285. [Google Scholar] [CrossRef]
- Muhammed, T.; Mehmood, R.; Albeshri, A.; Alzahrani, A. HCDSR: A Hierarchical Clustered Fault Tolerant Routing Technique for IoT-Based Smart Societies. In Smart Infrastructure and Applications; Springer: Cham, Switzerland, 2020; pp. 609–628. [Google Scholar]
- Mehmood, R.; Alam, F.; Albogami, N.N.; Katib, I.; Albeshri, A.; Altowaijri, S.M. UTiLearn: A Personalised Ubiquitous Teaching and Learning System for Smart Societies. IEEE Access 2017, 5, 2615–2635. [Google Scholar] [CrossRef]
- Alomari, K.M.; ElSherif, H.M.; Shaalan, K. Arabic Tweets Sentimental Analysis Using Machine Learning. In Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2017; pp. 602–610. [Google Scholar]
- Alomari, E.; Mehmood, R. Analysis of Tweets in Arabic Language for Detection of Road Traffic Conditions; Springer: Cham, Switzerland, 2018; pp. 98–110. [Google Scholar]
- Mehmood, R.; Graham, G. Big Data Logistics: A health-care Transport Capacity Sharing Model. Procedia Comput. Sci. 2015, 64, 1107–1114. [Google Scholar] [CrossRef] [Green Version]
- Mehmood, R.; Meriton, R.; Graham, G.; Hennelly, P.; Kumar, M. Exploring the influence of big data on city transport operations: A Markovian approach. Int. J. Oper. Prod. Manag. 2017, 37, 75–104. [Google Scholar] [CrossRef]
- Arfat, Y.; Usman, S.; Mehmood, R.; Katib, I. Big Data Tools, Technologies, and Applications: A Survey; Springer: Cham, Switzerland, 2020; pp. 453–490. [Google Scholar]
- Arfat, Y.; Usman, S.; Mehmood, R.; Katib, I. Big Data for Smart Infrastructure Design: Opportunities and Challenges; Springer: Cham, Switzerland, 2020; pp. 491–518. [Google Scholar]
- Arfat, Y.; Suma, S.; Mehmood, R.; Albeshri, A. Parallel Shortest Path Big Data Graph. Computations of US Road Network Using Apache Spark: Survey, Architecture, and Evaluation; Springer: Cham, Switzerland, 2020; pp. 185–214. [Google Scholar]
- Usman, S.; Mehmood, R.; Katib, I. Big Data and HPC Convergence for Smart Infrastructures: A Review and Proposed Architecture; Springer: Cham, Switzerland, 2020; pp. 561–586. [Google Scholar]
- Muhammed, T.; Mehmood, R.; Albeshri, A.; Katib, I. SURAA: A Novel Method and Tool for Loadbalanced and Coalesced SpMV Computations on GPUs. Appl. Sci. 2019, 9, 947. [Google Scholar] [CrossRef] [Green Version]
- Alyahya, H.; Mehmood, R.; Katib, I. Parallel Iterative Solution of Large Sparse Linear Equation Systems on the Intel MIC Architecture. In Smart Infrastructure and Applications; Springer: Cham, Switzerland, 2020; pp. 377–407. [Google Scholar]
- Usman, S.; Mehmood, R.; Katib, I.; Albeshri, A.; Altowaijri, S.M. ZAKI: A Smart Method and Tool for Automatic Performance Optimization of Parallel SpMV Computations on Distributed Memory Machines. Mob. Netw. Appl. 2019, 1–20. [Google Scholar] [CrossRef]
- Usman, S.; Mehmood, R.; Katib, I.; Albeshri, A. ZAKI+: A Machine Learning Based Process Mapping Tool for SpMV Computations on Distributed Memory Architectures. IEEE Access 2019, 7, 81279–81296. [Google Scholar] [CrossRef]
- Arfat, Y.; Aqib, M.; Mehmood, R.; Albeshri, A.; Katib, I.; Albogami, N.; Alzahrani, A. Enabling Smarter Societies through Mobile Big Data Fogs and Clouds. Procedia Comput. Sci. 2017, 109, 1128–1133. [Google Scholar] [CrossRef]
- Mehmood, R.; Faisal, M.A.; Altowaijri, S. Future Networked Healthcare Systems: A Review and Case Study. In Handbook of Research on Redesigning the Future of Internet Architectures; Boucadair, M., Jacquenet, C., Eds.; IGI Global: Hershey, PA, USA, 2015; pp. 531–558. [Google Scholar]
- Lo’ai, A.T.; Bakhader, W.; Mehmood, R.; Song, H. Cloudlet-Based Mobile Cloud Computing for Healthcare Applications. In Proceedings of the 2016 IEEE Global Communications Conference (GLOBECOM), Washington, DC, USA, 4–8 December 2016; pp. 1–6. [Google Scholar]
- Schlingensiepen, J.; Mehmood, R.; Nemtanu, F.C.; Niculescu, M. Increasing Sustainability of Road Transport in European Cities and Metropolitan Areas by Facilitating Autonomic Road Transport Systems (ARTS). In Proceedings of the 2013 5th International Conference on Sustainable Automotive Technologies (ICSAT 2013), Ingolstadt, Germany, 25–27 September 2013; Springer: Cham, Switzerland, 2014; pp. 201–210. [Google Scholar]
- Alam, F.; Mehmood, R.; Katib, I.; Altowaijri, S.M.; Albeshri, A. TAAWUN: A Decision Fusion and Feature Specific Road Detection Approach for Connected Autonomous Vehicles. Mob. Netw. Appl. 2019, 1–17. [Google Scholar] [CrossRef]
- Alotaibi, S.; Mehmood, R.; Katib, I. The Role of Big Data and Twitter Data Analytics in Healthcare Supply Chain Management. In Smart Infrastructure and Applications; Springer: Cham, Switzerland, 2020; pp. 267–279. [Google Scholar]
- Alamoudi, E.; Mehmood, R.; Albeshri, A.; Gojobori, T. A Survey of Methods and Tools for Large-Scale DNA Mixture Profiling. In Smart Infrastructure and Applications; Springer: Cham, Switzerland, 2020; pp. 217–248. [Google Scholar]
- Alotaibi, S.; Mehmood, R. Big data enabled healthcare supply chain management: Opportunities and challenges. In Lecture Notes of the Institute for Computer Sciences, Social-Informatics and Telecommunications Engineering (LNICST); Springer: Cham, Switzerland, 2018; Volume 224, pp. 207–215. [Google Scholar]
- Aqib, M.; Mehmood, R.; Alzahrani, A.; Katib, I.; Albeshri, A.; Altowaijri, S.M. Altowaijri. Smarter Traffic Prediction Using Big Data, In-Memory Computing, Deep Learning and GPUs. Sensors 2019, 19, 2206. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Aqib, M.; Mehmood, R.; Alzahrani, A.; Katib, I.; Albeshri, A.; Altowaijri, S.M. Rapid Transit Systems: Smarter Urban Planning Using Big Data, In-Memory Computing, Deep Learning, and GPUs. Sustainability 2019, 11, 2736. [Google Scholar] [CrossRef] [Green Version]
- Al-Dhubhani, R.; Mehmood, R.; Katib, I.; Algarni, A. Location Privacy in Smart Cities Era. In Lecture Notes of the Institute for Computer Sciences, Social-Informatics and Telecommunications Engineering, LNICST; Springer: Cham, Switzerland, 2018; Volume 224, pp. 123–138. [Google Scholar]
- Khanum, A.; Alvi, A.; Mehmood, R. Towards a semantically enriched computational intelligence (SECI) framework for smart farming. In Lecture Notes of the Institute for Computer Sciences, Social-Informatics and Telecommunications Engineering, LNICST; Springer: Cham, Switzerland, 2018; Volume 224, pp. 247–257. [Google Scholar]
- Liu, B. Sentiment Analysis and Opinion Mining. Synth. Lect. Hum. Lang. Technol. 2012, 5, 1–167. [Google Scholar] [CrossRef] [Green Version]
- Andreu-Perez, J.; Poon, C.C.; Merrifield, R.D.; Wong, S.T.; Yang, G.Z. Big Data for Health. IEEE J. Biomed. Heal. Inf. 2015, 19, 1193–1208. [Google Scholar] [CrossRef]
- Parker, J.; Yates, A.; Goharian, N.; Frieder, O. Health-related hypothesis generation using social media data. Soc. Netw. Anal. Min. 2015, 5, 1–15. [Google Scholar] [CrossRef]
- Paul, M.J.; Dredze, M. A model for mining public health topics from Twitter. Health 2012, 11, 1. [Google Scholar]
- Paul, M.J.; Dredze, M. You are what you Tweet: Analyzing Twitter for public health. In Proceedings of the Fifth International Conference on Weblogs and Social Media (ICWSM-2011), Barcelona, Spain, 17–21 July 2011; pp. 265–272. [Google Scholar]
- Aramaki, E. Twitter Catches the Flu: Detecting Influenza Epidemics Using Twitter. Comput. Linguist. 2011, 2011, 1568–1576. [Google Scholar]
- Wakamiya, S.; Kawai, Y.; Aramaki, E. Twitter-based influenza detection after flu peak via tweets with indirect information: Text mining study. J. Med. Internet Res. 2018, 4, 65. [Google Scholar] [CrossRef] [PubMed]
- Wakamiya, S.; Morita, M.; Kano, Y.; Ohkuma, T.; Aramaki, E. Tweet classification toward twitter-based disease surveillance: New data, methods, and evaluations. J. Med. Internet Res. 2019, 21, e12783. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lamb, A.; Paul, M.; Dredze, M. Separating fact from fear: Tracking flu infections on Twitter. In Proceedings of the 2013 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Atlanta, GA, USA, 9–14 June 2013; pp. 789–795. [Google Scholar]
- Smith, M.; Broniatowski, D.A.; Paul, M.J.; Dredze, M. Towards Real-Time Measurement of Public Epidemic Awareness: Monitoring Influenza Awareness through Twitter. In Proceedings of the AAAI Workshop on World Wide Web and Public Health Intelligence, Austin, TX, USA, 25–26 January 2015; Volume 20052. [Google Scholar]
- Bian, J.; Topaloglu, U.; Yu, F. Towards large-scale twitter mining for drug-related adverse events. In Proceedings of the 2012 International Workshop on Smart Health and Wellbeing 2012, Maui, HI, USA, 29 October 2012; pp. 25–32. [Google Scholar] [CrossRef] [Green Version]
- Myslín, M.; Zhu, S.H.; Chapman, W.; Conway, M. Using Twitter to Examine Smoking Behavior and Perceptions of Emerging Tobacco Products. J. Med. Internet Res. 2013, 15, e174. [Google Scholar] [CrossRef]
- Jashinsky, J.; Burton, S.H.; Hanson, C.L.; West, J.; Giraud-Carrier, C.; Barnes, M.D.; Argyle, T. Tracking Suicide Risk Factors through Twitter in the US. Crisis 2014, 35, 51–59. [Google Scholar] [CrossRef]
- Achrekar, H.; Gandhe, A.; Lazarus, R.; Yu, S.H.; Liu, B. Twitter Improves Seasonal Influenza Prediction. In Proceedings of the International Conference on Health Informatics (HEALTHINF 2012), Vilamoura, Algarve, 1–4 February 2012; pp. 61–70. [Google Scholar] [CrossRef] [Green Version]
- Broniatowski, D.A.; Paul, M.J.; Dredze, M. National and local influenza surveillance through twitter: An analysis of the 2012–2013 influenza epidemic. PLoS ONE 2013, 8, e83672. [Google Scholar] [CrossRef] [Green Version]
- Ram, S.; Zhang, W.; Williams, M.; Pengetnze, Y. Predicting Asthma-Related Emergency Department Visits Using Big Data. IEEE J. Biomed. Heal. Inf. 2015, 19, 1216–1223. [Google Scholar] [CrossRef]
- Culotta, A. Detecting influenza outbreaks by analyzing Twitter messages. arXiv 2009, arXiv:1007.4748. [Google Scholar]
- Suma, S.; Mehmood, R.; Albugami, N.; Katib, I.; Albeshri, A. Enabling Next Generation Logistics and Planning for Smarter Societies. Procedia Comput. Sci. 2017, 109, 1122–1127. [Google Scholar] [CrossRef]
- Suma, S.; Mehmood, R.; Albeshri, A. Automatic event detection in smart cities using big data analytics. In International Conference on Smart Cities, Infrastructure, Technologies and Applications (SCITA 2017): Lecture Notes of the Institute for Computer Sciences, Social-Informatics and Telecommunications Engineering, LNICST; Springer: Cham, Switzerland, 2017; Volume 224, pp. 111–122. [Google Scholar]
- Statistical Yearbook. Available online: https://www.moh.gov.sa/en/Ministry/Statistics/book/Pages/default.aspx (accessed on 6 November 2019).
- Suthaharan, S. Machine Learning Models and Algorithms for Big Data Classification: Thinking with Examples for Effective Learning. Integr. Ser. Inf. Syst. 2015, 36, 1–12. [Google Scholar]
- Saudi Arabia | Institute for Health Metrics and Evaluation. Available online: http://www.healthdata.org/saudi-arabia (accessed on 6 November 2019).
- WHO | Saudi Arabia. Available online: https://www.who.int/countries/sau/en/ (accessed on 6 November 2019).
- CDC Global Health-Saudi Arabia. Available online: https://www.cdc.gov/globalhealth/countries/saudi_arabia/default.htm (accessed on 26 November 2019).
- Al-Nozha, M.M.; Ali, M.S.; Osman, A.K. Arterial hypertension in Saudi Arabia. Ann. Saudi Med. 1997, 17, 170–174. [Google Scholar] [CrossRef] [Green Version]
- Aljohani, H.A. Association between Hemoglobin Level and Severity of Chronic Periodontitis. JKAU Med. Sci. 2010, 17, 53–64. [Google Scholar] [CrossRef]
- Health Days 2017—World Hypertension Day. Available online: https://www.moh.gov.sa/en/HealthAwareness/healthDay/2017/Pages/HealthDay-2017-05-17.aspx (accessed on 9 January 2020).
- حالات الدرن الرئوي حسب المنطقة وفئة العمر خلال عام 1439 هـ (2018م) - البيانات - البوابة السعودية للبيانات المفتوحة. Available online: https://data.gov.sa/Data/ar/dataset/pulmonary_tuberculosis_by_region-_age_group_during_1439h_-2018g- (accessed on 17 December 2019).
- Ahmad, N.; Mehmood, R. Enterprise systems and performance of future city logistics. Prod. Plan. Control. 2016, 27, 500–513. [Google Scholar] [CrossRef]
- Ahmad, N.; Mehmood, R. Enterprise Systems for Networked Smart Cities. In Smart Infrastructure and Applications; Springer: Cham, Switzerland, 2020; pp. 1–33. [Google Scholar]
- Graham, G.; Ahmad, N.; Mehmood, R. Enterprise systems: Are we ready for future sustainable cities. Supply Chain Manag. 2015, 20, 264–283. [Google Scholar]
- How Data Science Is Shaping the Modern NHS. Available online: https://www.newstatesman.com/science-tech/technology/2018/11/how-data-science-shaping-modern-nhs (accessed on 8 February 2020).
- Shafiabady, N.; Lee, L.H.; Rajkumar, R.; Kallimani, V.P.; Akram, N.A.; Isa, D. Using unsupervised clustering approach to train the Support Vector Machine for text classification. Neurocomputing 2016, 211, 4–10. [Google Scholar] [CrossRef]
- Giraldo, J.; Sarkar, E.; Cardenas, A.A.; Maniatakos, M.; Kantarcioglu, M. Security and Privacy in Cyber-Physical Systems: A Survey of Surveys. IEEE Des. Test. 2017, 34, 7–17. [Google Scholar] [CrossRef]
- Ayres, G.; Mehmood, R. LocPriS: A security and privacy preserving location based services development framework. In Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics), LNAI; Springer: Berlin/Heidelberg, Germany, 2010; Volume 6279, pp. 566–575. [Google Scholar]
- Ayres, G.; Mehmood, R.; Mitchell, K.; Race, N.J. Localization to enhance security and services in Wi-Fi networks under privacy constraints. In Lecture Notes of the Institute for Computer Sciences, Social-Informatics and Telecommunications Engineering, LNICST; Springer: Berlin/Heidelberg, Germany, 2009; Volume 16, pp. 175–188. [Google Scholar]
- Al-Dhubhani, R.S.; Cazalas, J.; Mehmood, R.; Katib, I.; Saeed, F. A framework for preserving location privacy for continuous queries. In Advances in Intelligent Systems and Computing; Springer: Cham, Switzerland, 2020; Volume 1073, pp. 819–832. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Keywords (Symptoms, Diseases, and Medications) | Corresponding Disease | Abbreviation | Symptoms (Symptoms, Diseases, and Medications) | Corresponding Disease | Abbreviation |
|---|---|---|---|---|---|
| السكر سكري السكري انسلوين أنسولين الانسولين | Diabetes السكري | DBT | زكام زكمه أنفلونزا | Influenza الانفلونزا | INF |
| سرطان الخبيث | Cancer السرطان | CNR | كحة كحه حساسية حساسيه | Cough #x627;لكحة | CGH |
| شريان جلطة جلطه سكته سكتة السكتة السكته قلب | Heart Disease أمراض القلب | HRD | قولون قالون قيلون | Colon القولون | CLN |
| الضغط | Hypertension ضغط الدم | HYT | سل درن | Tuberculosis السل | TBC |
| غدة غده الغده درقيه الدرقية الدرقيه | Thyroid Diseases الغدة الدرقية | THD | ارتجاع حرقان حرقان معدة | Stomach Disorders ألآم المعدة | STD |
| أرق | Insomnia الارق | INS | قرحة معوي نزلة معوية نزله معويه | Intestinal Disorders ألآم الأمعاء | IND |
| كولسترول كلسترول | Cholesterol الكوليسترول | CHT | اكزيما أكزيما برص بهاق جرب الجرب | Dermal Diseases أمراض الجلدية | DRD |
| ربو كتمه | Asthma الربو | AST |
| No. | Tweet’s Text (Arabic and Its Literal Translation) | Context Type | 1st Level Label | 2nd Level Label |
|---|---|---|---|---|
| 1 | يتم تشخيص سكري الحمل بعمل اختبار الدم قبل المحلول وبعده وعلي حسب القراءات يبلغك الطبيب Pregnancy diabetes is diagnosed by blood test before and after the syrup and based on the results, the doctor will tell you. | Medical information (awareness tweet) | R | A |
| 2 | سكري له فترة معلق على ٤٠٠ كثير يعني من يوم الجمعة الى اليوم تقريبًا ٥ مرات اروح للمستشفى؟ I am diabetic and my sugar level is more than 400 since Friday, five times a day, do I need to go to the hospital? | Complaint (afflicted by disease) | R | I |
| 3 | أرق على أرق ومن مثلي يأ رق Sleepless upon sleepless and who is like me? | Complaint | R | I |
| 4 | ماارق الرياض تالي الليل Riyadh is being delicate at late night. | Poem | U | U |
| 5 | اللهم اشفي مرضى السرطان May Allah cure cancer’s patients | Supplication | U | U |
| 6 | ليس مرض بل شخص كـ قطعة سكر It is not a disease, just a person such as sugar. | Joke | U | U |
| 7 | لايفوتكم تمر سكري مكنوز مجروش فاخر للتواصل وتس أب كيلو ب 60 ريال والتوصيل لجميع مناطق المملكة Do not miss the chance, luxury mjarwsh sukari dates, for delivery to all Saudi cities with 60 riyals. | Advertisement | U | U |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alotaibi, S.; Mehmood, R.; Katib, I.; Rana, O.; Albeshri, A. Sehaa: A Big Data Analytics Tool for Healthcare Symptoms and Diseases Detection Using Twitter, Apache Spark, and Machine Learning. Appl. Sci. 2020, 10, 1398. https://0-doi-org.brum.beds.ac.uk/10.3390/app10041398
Alotaibi S, Mehmood R, Katib I, Rana O, Albeshri A. Sehaa: A Big Data Analytics Tool for Healthcare Symptoms and Diseases Detection Using Twitter, Apache Spark, and Machine Learning. Applied Sciences. 2020; 10(4):1398. https://0-doi-org.brum.beds.ac.uk/10.3390/app10041398
Chicago/Turabian StyleAlotaibi, Shoayee, Rashid Mehmood, Iyad Katib, Omer Rana, and Aiiad Albeshri. 2020. "Sehaa: A Big Data Analytics Tool for Healthcare Symptoms and Diseases Detection Using Twitter, Apache Spark, and Machine Learning" Applied Sciences 10, no. 4: 1398. https://0-doi-org.brum.beds.ac.uk/10.3390/app10041398