3.1. Dataset Statistics
The total number of soil samples was 188, which were split into a training set and a testing set by the Kennard–Stone (KS) method at the proportion of 7:3 [
26], which is often used with VIS-NIR spectroscopy for model construction and model testing. The number of training sets was 131, and the number of testing datasets was 57. The data statistics are presented in
Table 3.
Table 3 also reveals that the data distribution of the available potassium content of the soil in the training set is similar to that in the testing set.
The pretreatment method is indispensable during the training of a regression model and is also a key step for quantifying the analysis of the VIS-NIR spectrum. Information on the VIS-NIR spectrum of soil would be effective to filter noise and reduce the complexity of the pretreatment methods, but different methods have different effects on various regression models.
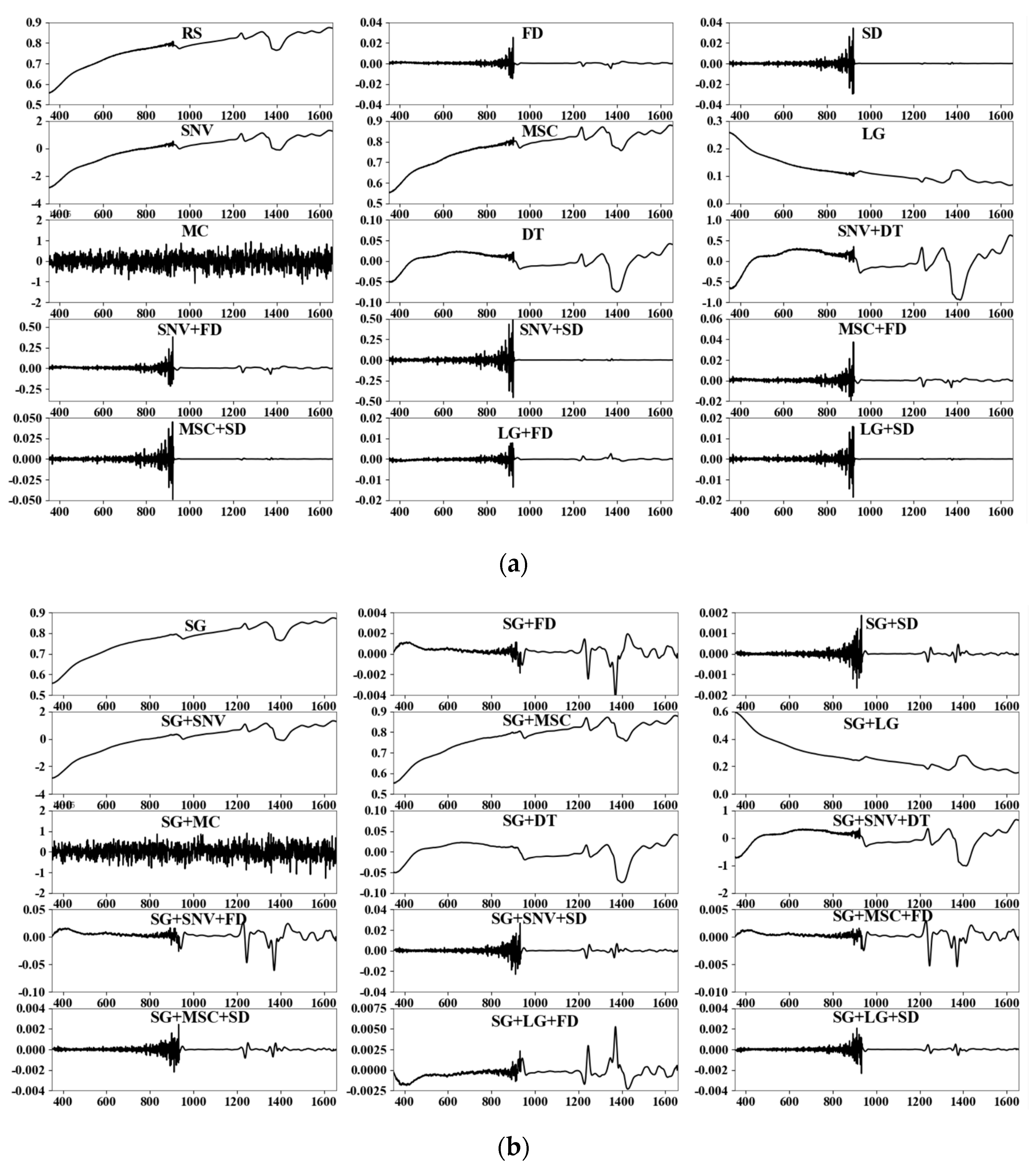
Figure 3 shows the VIS-NIR spectrum with 29 pretreatment methods and a reflection spectrum (RS).
Figure 3a is without the SG method, and
Figure 3b is the SG method. The SG method reduces the noise of the spectrum and makes the curve smoother. The DT method creates pristine peaks in the spectrum, but the peak value of the original spectrum becomes zero. MC not only reduces the spectral offset but also weakens the characteristic points of the spectrum. The two scattering correction methods of SNV and MSC did not significantly change the spectral curve. FD, SD, and LG made great changes to the VIS-NIR.
3.2. Performance of Regression Models with Different Pretreatment Methods
This study compares 240 regression models with eight regression algorithms and 29 pretreatment transformations for the VIS-NIR spectrum.
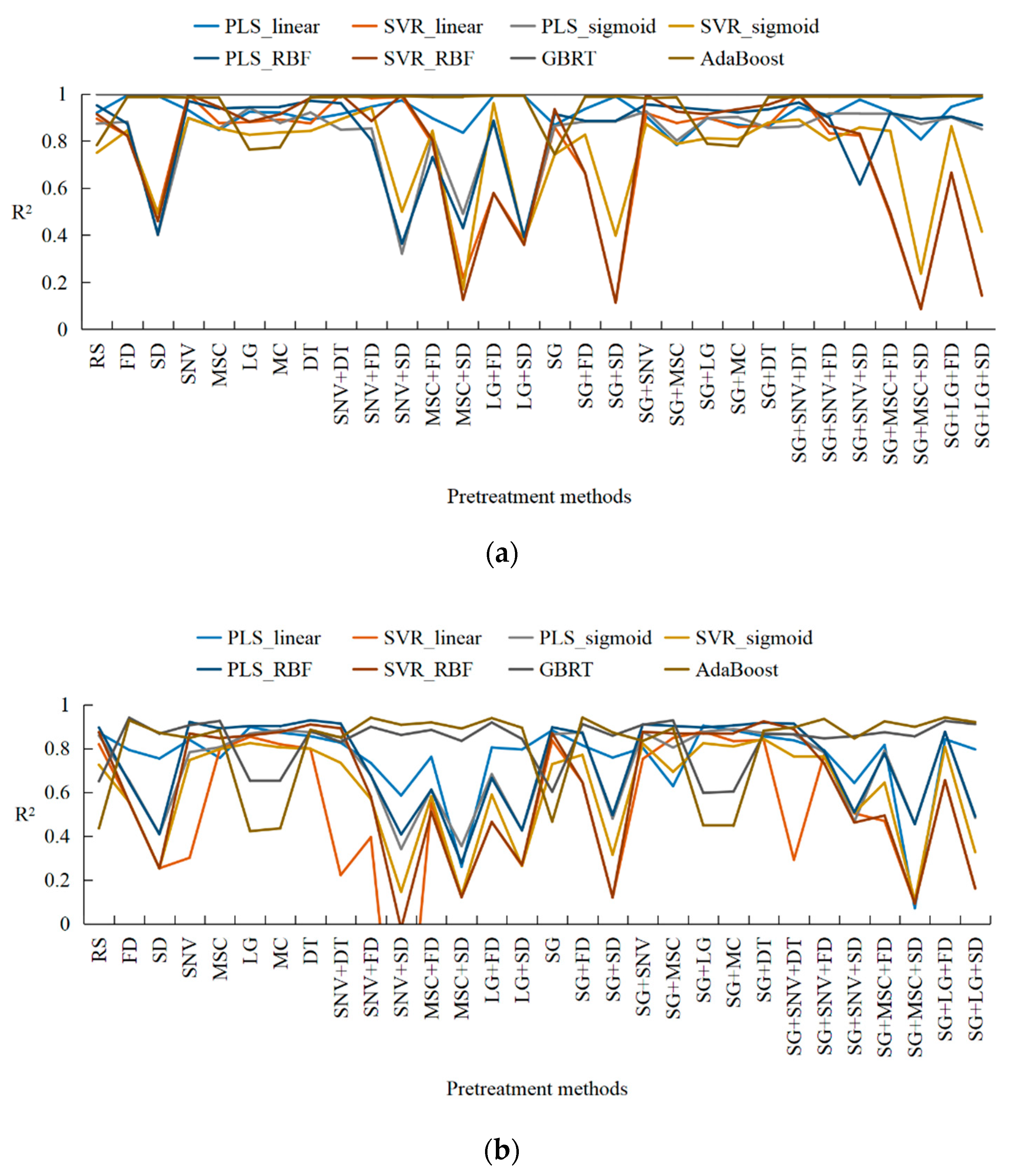
Figure 4 exhibits the
R2 values for the training and testing sets of the regression models, and
Figure 4a,b represent the prediction
R2 values for the training and testing datasets, respectively. With different pretreatment methods,
Table 4 and
Figure 5 exhibit the RPD levels and RPIQ of the regression models.
The nonlinear function was employed to train PLS and SVR. Therefore, the PLS models with linear, sigmoid, and RBF functions are respectively referred to as PLS_linear, PLS_sigmoid, and PLS_RBF, and the SVR models with linear, sigmoid, and RBF functions are respectively named SVR_linear, SVR_sigmoid, and SVR_RBF. RS indicates the VIS-NIR without any pretreatment. Thus, the results show that a few of the pretreatment datasets exhibit worse model performance than the RS dataset. In particular, the SVR algorithm has more models with
R2 values lower than 0.2 compared with the PLS algorithm in
Figure 4. Following the consideration of the pretreatment methods, the
R2 value of PLS_linear with SG + MSC + SD was determined to be less than 0.2. However,
R2 values of SVR linear with MSC + SD, SG + SD, SG + LG + FD and SG + LG + SD are less than 0.2, but the
R2 value of PLS with a nonlinear function (sigmoid and RBF) is not only greater than 0.2 but also better than that of SVR. Therefore, PLS with a nonlinear function is more suitable for the regression prediction of VIS-NIR. In
Figure 4, the
R2 values of the boosting algorithms are all greater than 0.4, which means that the boosting regression algorithm is preferable to the other methods. In particular, the
R2 of GBRT with the testing dataset is considerably greater than 0.5, and the
R2 with the training dataset is close to 1. Therefore, it is significant to choose adaptive pretreatment and regression algorithms to predict the content of soil-available potassium by VIS-NIR.
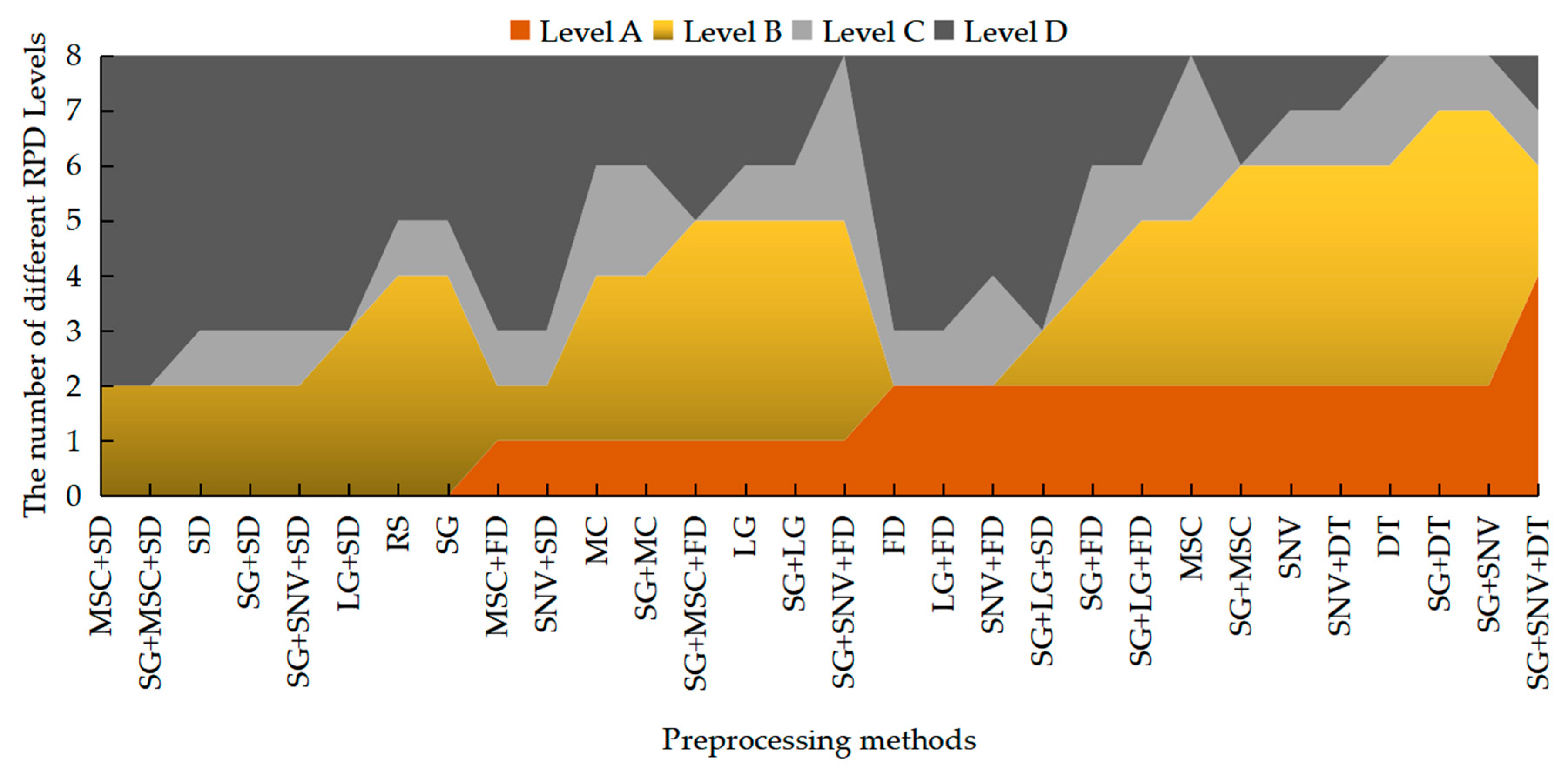
In
Table 4, the RPD level of the regression models is compared to determine the influence of the different pretreatment methods based on the testing dataset. Level A denotes that the regression model has the best stability, and level D means the worst. The RPD using the RS dataset as a baseline shows that a level A model is difficult to achieve without pretreatment. SVR_sigmoid, GBRT, and AdaBoost on the RS dataset are level D, but the PLS algorithm with linear and nonlinear functions was level B. The regression of the RBF kernel function using partial pretreatment methods could achieve level A, but the model with linear and sigmoid kernel functions could not attain level A, even if all pretreatment methods were used. In conclusion, regression algorithms and pretreatment methods are significant for the prediction of the VIS-NIR of soil-available potassium, as shown in
Table 4.
Table 4 reveals that the prediction performance of different pretreatment methods at different levels.
Through the statistics,
Figure 5 shows the visualization of the RPD level of models with 29 pretreatment methods and RS in order. The black areas represent level D, the grey areas represent level C, the yellow areas represent level B, and the orange areas represent level A. There are six pretreatment methods, and RS could not achieve level A with any regression algorithms. Only the SG + SNV + DT method has four models with RPD level A, and SG + DT and SG + SNV not only have two models with RPD level A and five models with RPD level B but also have only one model with RPD level C and zero models with RPD level D. Therefore, SG + DT, SG + SNV, and SG + SNV + DT are the most stable pretreatment methods for the prediction of soil-available potassium with regression algorithms.
Table 5 shows the number of models with different RPD levels. The statistics show that the number of PLS_RBFs with level A is the highest, but the boosting algorithms represent more stability because GBRT and AdaBoost show the highest numbers of models with level A and level B, showing that these levels were both meaningful for predicting the content of soil-available potassium. Therefore, the boosting algorithms are better than PLS and SVR with linear and nonlinear functions.
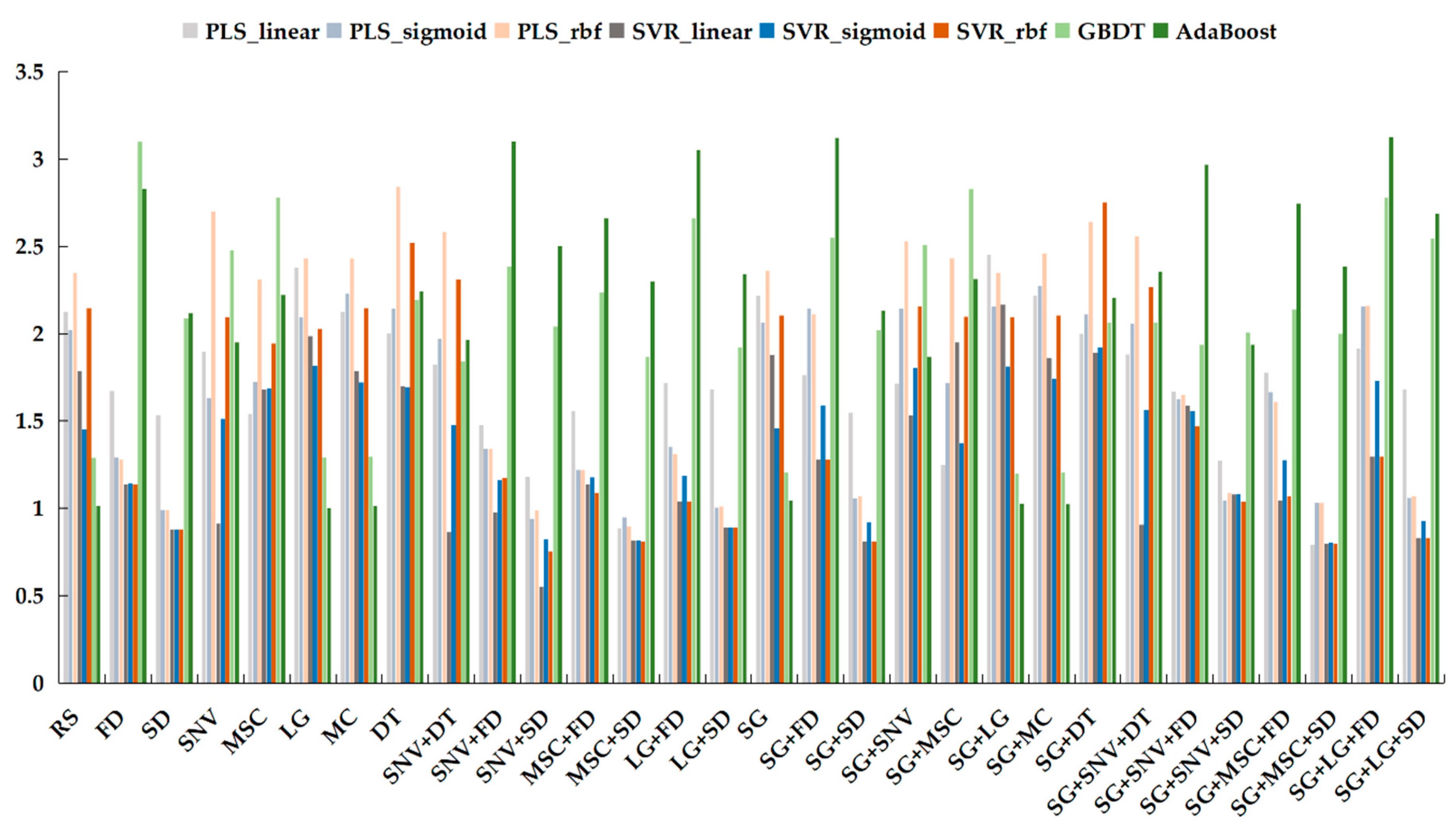
Figure 5 and
Table 5 indicate that there are few models at level A; therefore, other evaluation metrics are needed. The RPIQ value was computed as an important evaluation metric and is presented in
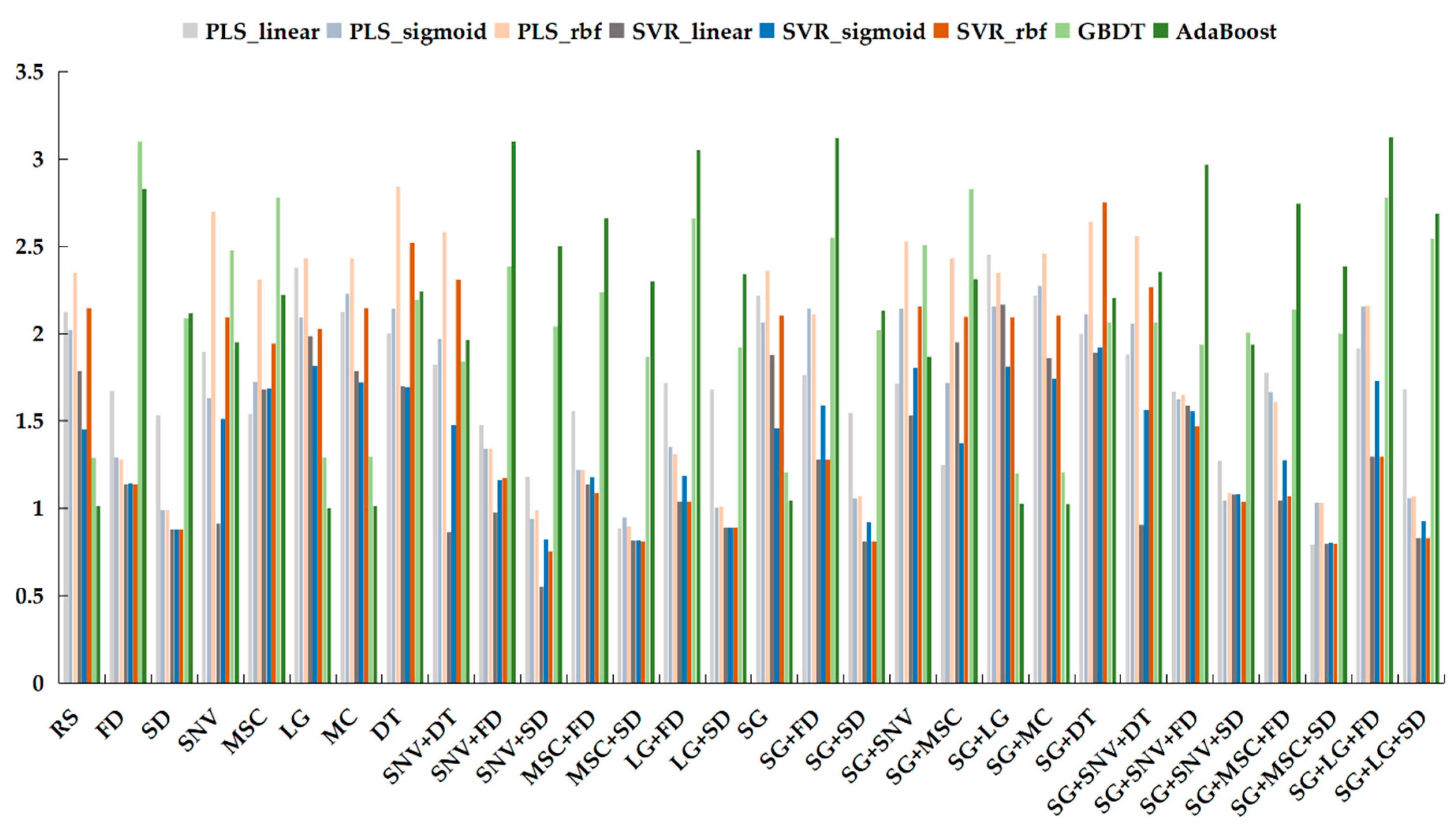
Figure 6 because the content of soil-available potassium has a biased normal distribution. The green color represents the RPIQ values of GBRT and AdaBoost on the testing dataset.
Figure 6 shows that most of the pretreatment datasets exhibited improved performance when boosting regression algorithms were used for prediction of the content of soil-available potassium. Dark green indicates the RPIQ values for AdaBoost with all pretreatment methods. AdaBoost performed extremely well with SNV + FD, LG + FD, SG + FD, SG + SNV + FD, and SG + LG + FD because the RPIQ values were greater than 3. Additional methods all had values less than 3, except for GBRT with DF. The RPIQ value of SG + LG + FD is the maximum for AdaBoost. As a result, the next part is the comparison and analysis of the best regression models.
3.3. The Best Regression Models of Visible Near-Infrared (VIS-NIR)
This manuscript demonstrates the performance of all the best models that not only contain PLS, SVR, and boosting but also ElasticNet, Lasso, and Ridge [
27,
28] because these three methods are also used frequently.
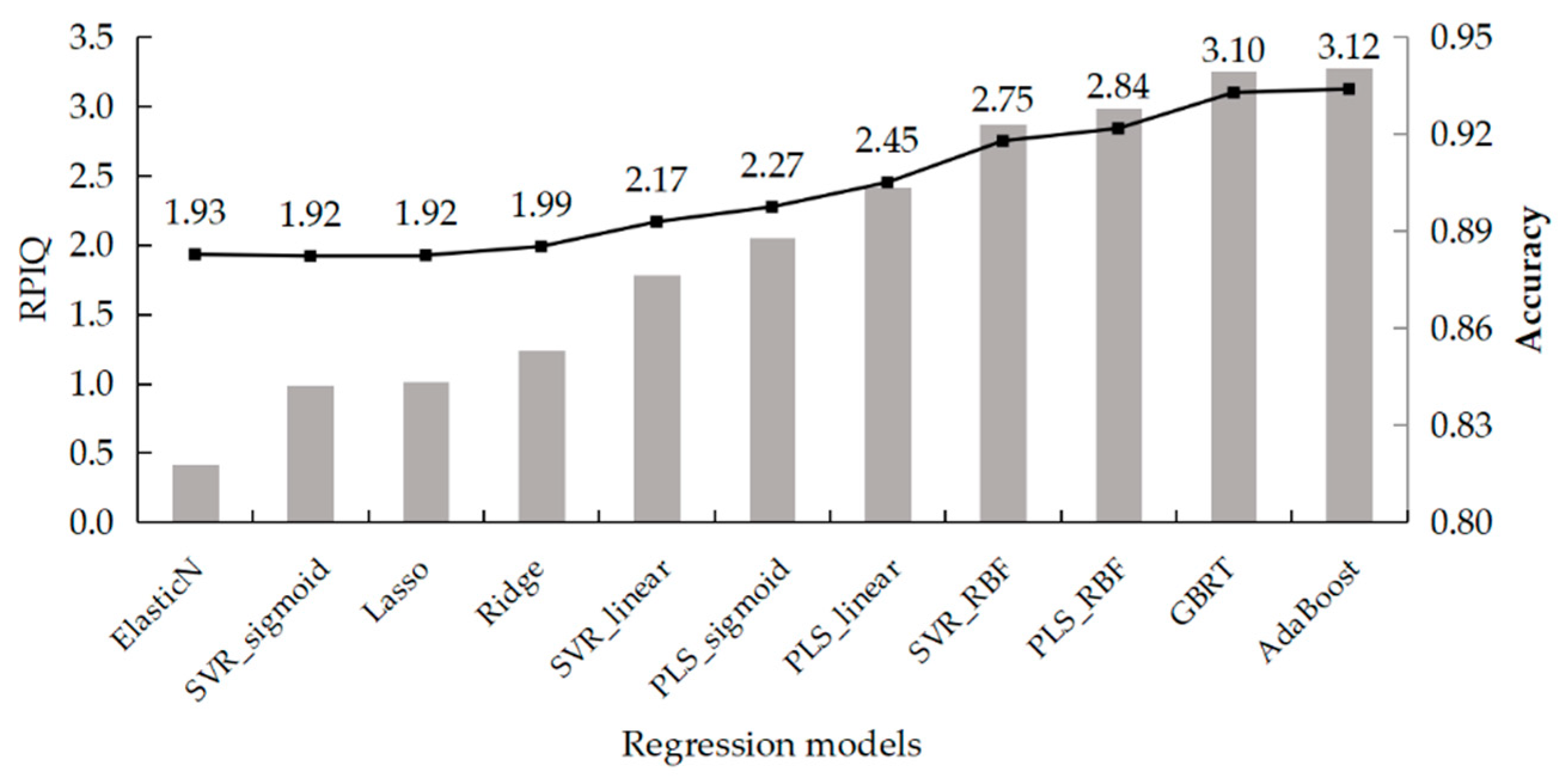
Table 6 shows that PLS, SVR, and boosting algorithms are the best because the RPD levels of ElasticNet, Lasso, and Ridge are only level B or level C. The best model for the PLS algorithm is PLS_RBF, which has LV and Gamma parameters of 27 and 0.1, respectively. The LVs of PLS_linear and PLS_sigmoid are 14 and 16, respectively. The best model for the SVR algorithm is SVR_RBF, which has C and Gamma parameters of 150,000 and 0.1, respectively. The kernel function of RBF is shown to be better than the linear and sigmoid functions. The C values of SVR_linear and SVR_sigmoid are 40,000 and 1,270,000, respectively. The number of estimators is 3100 and 100, respectively, for GBRT and AdaBoost. Considering the
R2 of these best models, PLS_linear, PLS_RBF, SVR_RBF, GBRT, and AdaBoost are over 0.9 with the testing dataset, and the RPD level of only PLS_linear is B. The best pretreatment methods for PLS_RBF, SVR_RBF, GBRT, and AdaBoost are DT, SG + DT, FD, SG + LG + FD, respectively. Therefore, different regression algorithms correspond to different pretreatment datasets to achieve optimal performance.
Figure 7 shows the RPIQ values of the best models from the discrete levels of the RPD value. The values of SVR_RBF, PLS_RBF, GBRT, and AdaBoost are more important than those of the other methods, and GBRT and AdaBoost are preferable to PLS_RBF and SVR_RBF.
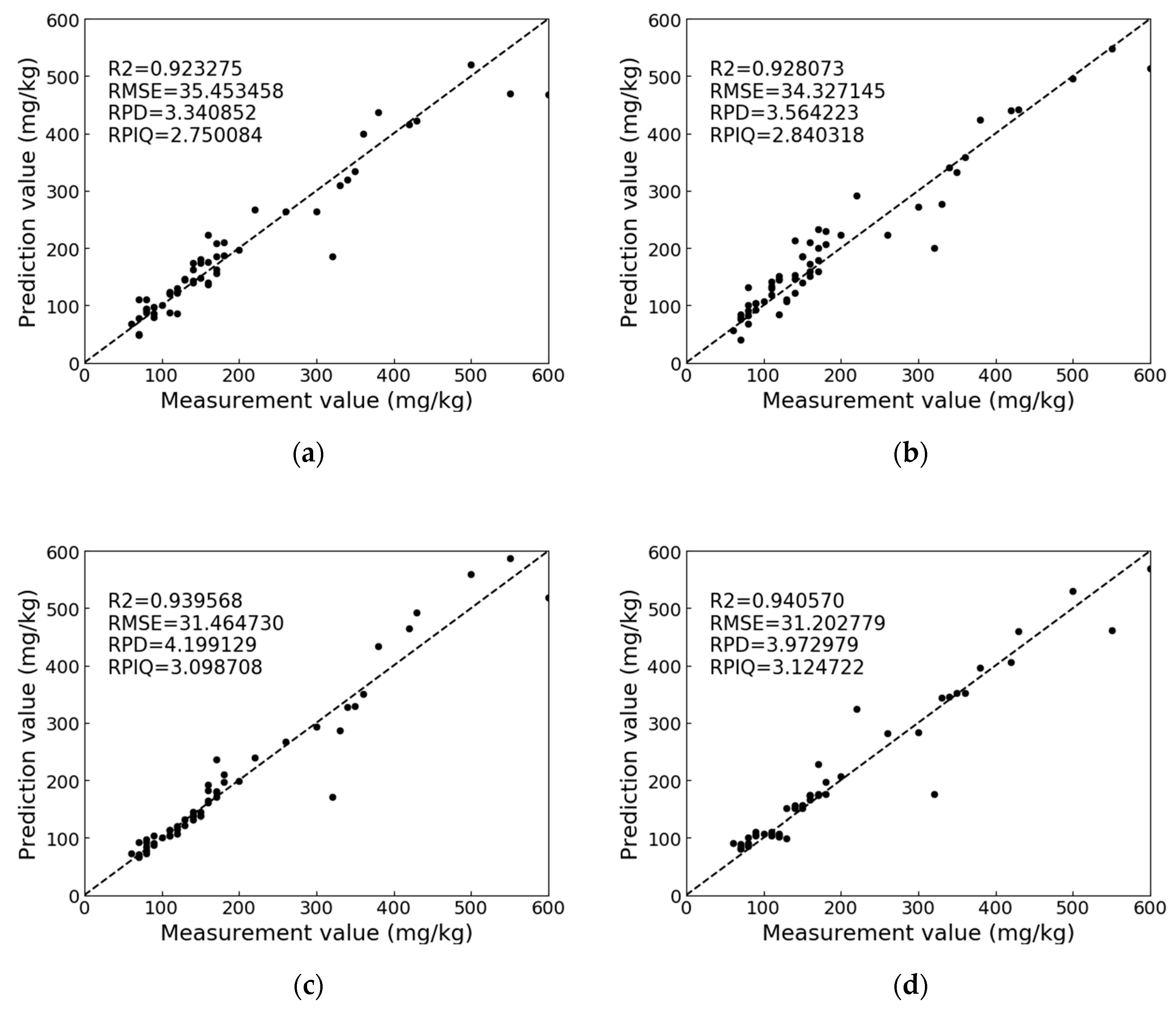
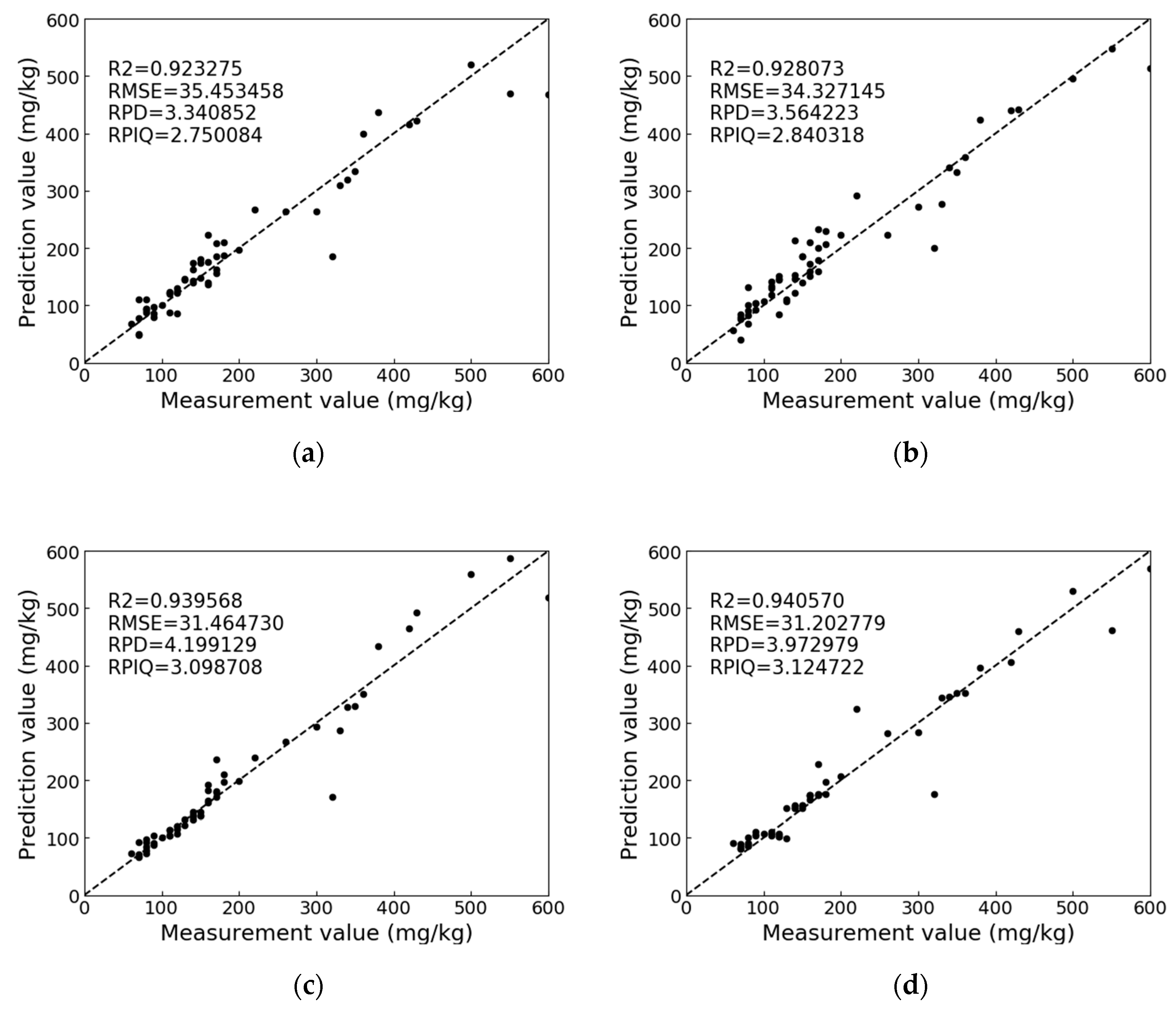
Figure 8 shows the comparison diagram of SVR_RBF, PLS_RBF, GBRT, and AdaBoost with the testing dataset. The details of the evaluation metrics show that the RPD value of GBRT is higher than that of AdaBoost, but AdaBoost has better accuracy and stability than GBRT from the comparison of RPIQ values. Meanwhile, the
R2 and RMSE values of AdaBoost are also preferable to those of GBRT. Through the above analysis, the AdaBoost algorithm was determined to exhibit the best performance in predicting the soil-available potassium content by VIS-NIR.
3.4. Two Sub-Ranges of Soil-Available Potassium by Boosting Methods
From the data in
Table 3, the soil-available potassium concentration range was between 60–670 ppm for the training set and 60–600 ppm for the test set, with the average lying at approximately 190 ppm. In addition, given that the concentration range is so wide and the average is below 200 ppm, the concentration range was split into two sub-ranges. A ‘low concentration’ between 60 and 300 ppm and a ‘high concentration’ between 300 and 600 ppm were trained by two boosting algorithms for a more robust and trustworthy model.
The samples were separated into two sub-ranges, and the number of low- and high-concentration samples was 148 and 40, respectively.
Table 7 and
Table 8 show the statistics.
GBRT and AdaBoost are trained and tested with all pretreatment methods.
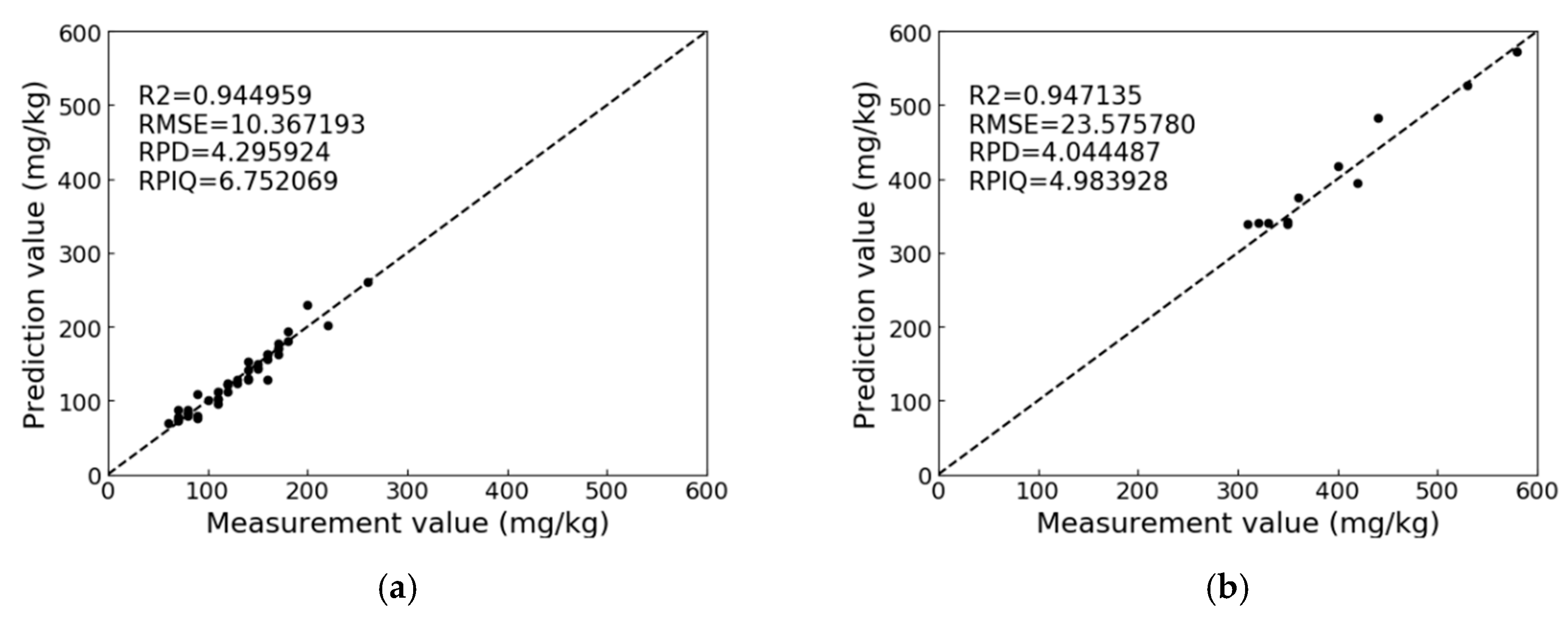
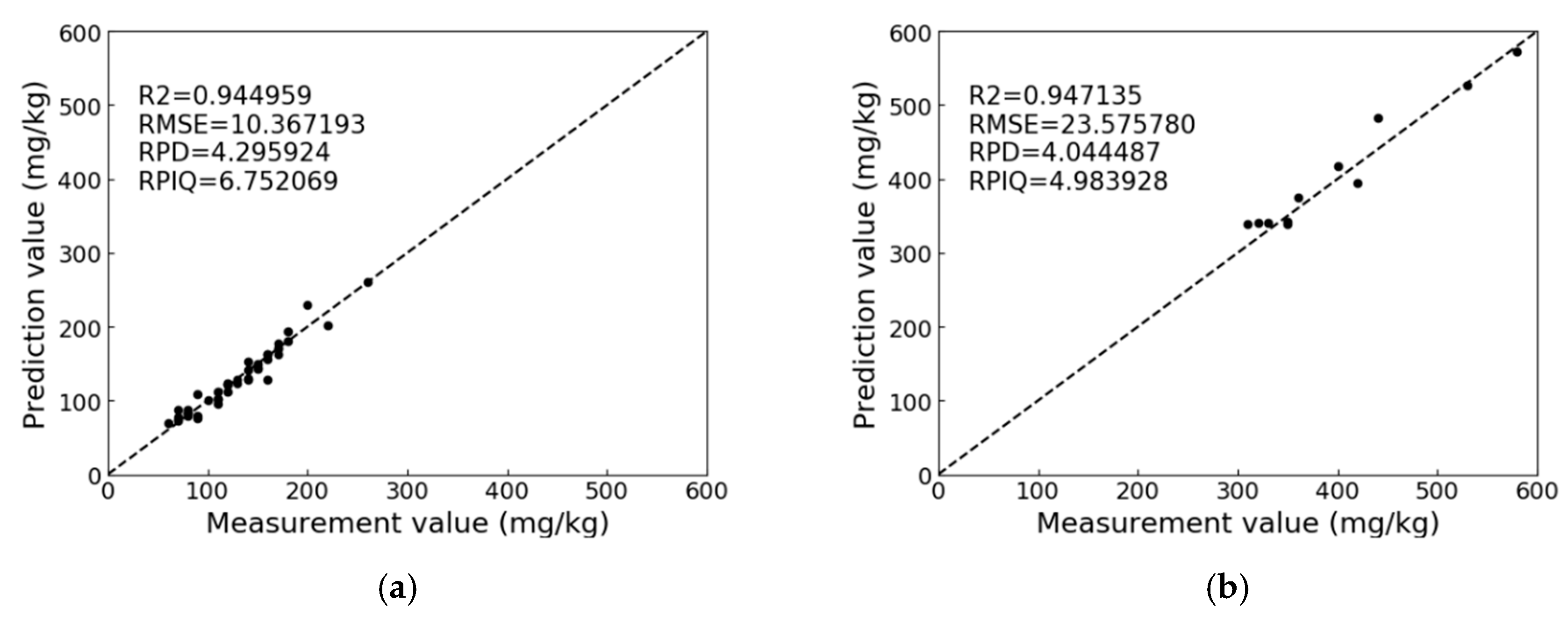
Figure 9 shows the best prediction with the low concentration and high concentration. For the low concentration, the AdaBoost with 2000 estimators is the best. The pretreatment method for this model is SG + SNV + DT. The best
R2, RPD and RPIQ values of the low concentrations are 0.945, 4.3 and 6.75, respectively. For the high concentration, the GBRT with 400 estimators is the best, and the pretreatment method is SG + SNV + FD. The best
R2, RPD, and RPIQ values of high concentrations are 0.947, 4.04, and 4.98, respectively.
Figure 9 shows that the AdaBoost and GBRT methods have accurate and stabilized predictions of soil-available potassium.
3.5. Discussion
Based on VIS-NIR spectroscopy, training and testing datasets were established with the original spectral reflectance and 29 pretreatments. These pretreatment methods include Savitzky–Golay (SG), first derivative (FD), second derivative (SD), standard normal variate (SNV), multiplicative scatter correction (MSC), logarithmic transformation (LG), mean center (MC), dislodge tendency (DT), and various combinations of these methods. However, not all pretreatment methods are effective, and SG, SNV, FD, and MSC are used more frequently than the other methods [
8,
19,
29,
30]. As a standard preparation of the soil spectral curves, Savitzky–Golay appears in almost every application [
30]. In this manuscript, the performance shows that MSC + SD, SG + MSC + SD, SD, SG + SD, SG + SNV + SD, and LG + SD are worse than RS. In paticular for SD, only SNV + SD and SG + LG + SD achieved RPD level A, and the best models were entirely without the SD method. The SD method may be seriously disturbed by the features of the VIS-NIR. Therefore, the SD pretreatment method was not useful for the prediction of the VIS-NIR spectrum of the soil-available potassium content. Twenty-three pretreatment methods were better than RS, 10 without SG and 13 with SG. Only three of the methods did not include SG from the best 11 models. Therefore, the SG method has a great influence on the prediction of soil-available potassium content. The frequency of the DT method is most common after SG in the best models, and the DT is a transformation that usually occurs after SNV. Hence, SG + SNV + DT is the best pretreatment method in this study, with most models at RPD level A.
The different regression models have linear and nonlinear kernel functions. From
Table 6 of this manuscript, the linear regression models are more stabilized, especially PLS_linear, which has the fewest number of models with RPD level D. The sigmoid kernel function is the worst, and the RBF kernel function is better than linear functions. The best models of PLS and SVR are PLS_RBF and SVR_RBF. The accuracy of the regression model with the RBF function reached the best performance. Therefore, the feature of the VIS-NIR follows the normal distribution. The methods of PLS [
9,
10,
29,
30] and SVR [
17,
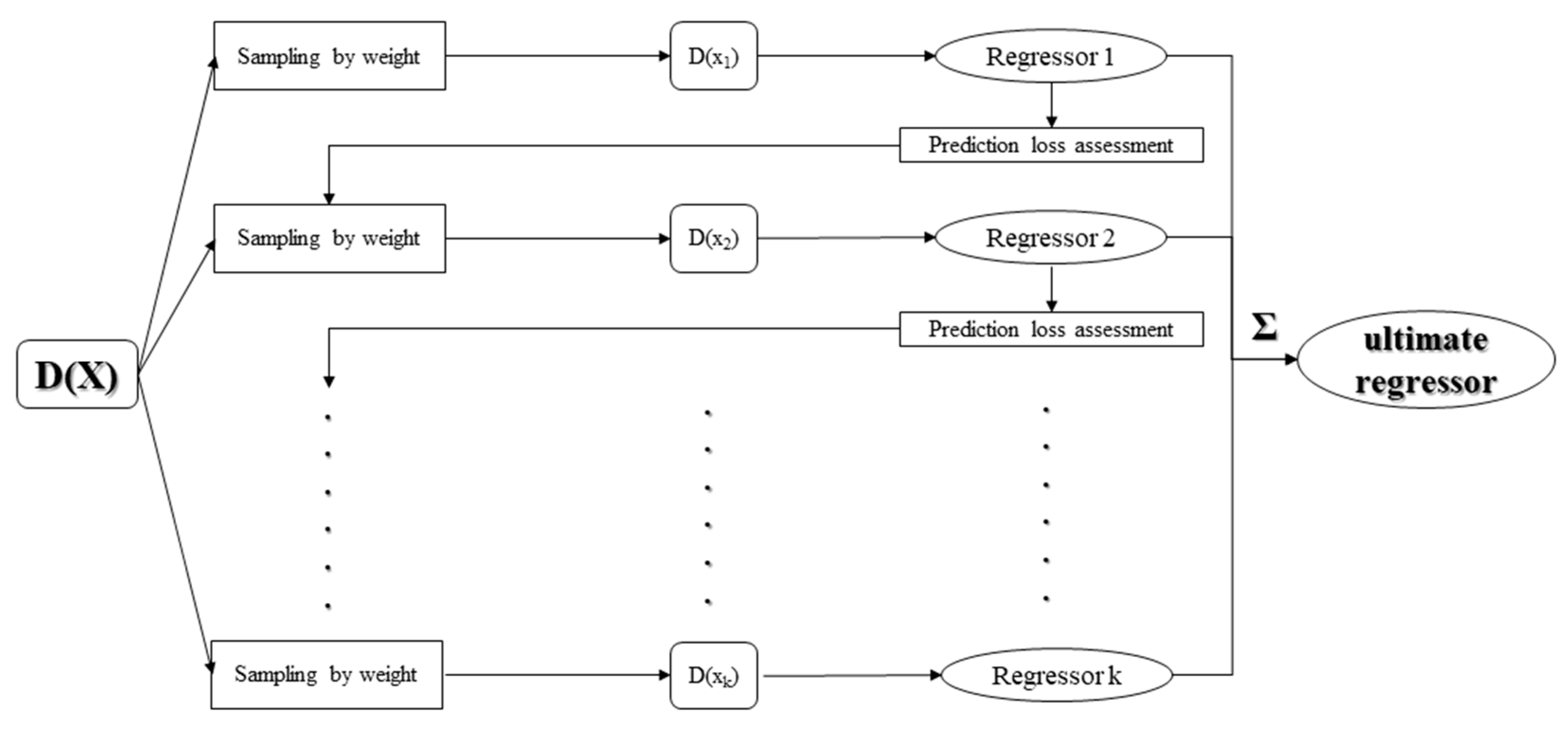
18] are widely used for the calibration of VIS-NIR spectra, but boosting regression algorithms are almost never used. GBRT and AdaBoost, which are boosting algorithms, can be effectively calibrated to predict the soil-available potassium content. Boosting is a frame algorithm that produces a predictor in the form of an ensemble of multiple weak predictors. GBRT improves the prediction accuracy by building each decision tree for the past residuals rather than the response variable [
21]. The AdaBoost algorithm trains a weak classifier step by step, and every weak classifier is trained on a different weight set of the sample subset. Then, a strong classifier is finally constructed by selecting each training iteration [
22]. GBRT calculates the gradient value to locate the deficiency of the model, but AdaBoost is based on loss assessment of the prediction to adjust the weight of the sample subset. From the above figure and table, both algorithms have better performance than other regression algorithms. GBRT and AdaBoost both exhibit the best prediction of soil-available potassium content by VIS-NIR. It is important to solve the problem of fairly comparing the models [
24,
25]. For VIS-NIR model analysis, the common evaluation metrics are the coefficient of determination, root mean square error, mean absolute error, residual predictive deviation, and the ratio of performance to IQ [
7,
8,
9,
10,
29,
30]. The accuracy of the models can be weighed by
R2, RMSE, and MAE. These models with the same RPD level represent consistent stability; therefore, the stability can be analyzed by RPD and RPIQ [
23]. Meanwhile, the sum of the ranked differences [
24,
25] was calculated for a fair comparison of models.
Table 9 summarizes these metrics of the regression models with the prediction of the concentration of soil-available potassium by VIS-NIR.
The RPDs of the four regression models were all level A. Considering the SRD,
R2, RMSE, and RPIQ shown in
Table 9, the boosting algorithms of GBRT and AdaBoost were significantly superior to SVR and PLS. GBRT is better than AdaBoost according to SRD and MAE, but AdaBoost is better than GBRT according to
R2 and RPIQ. Therefore, the two boosting algorithms had their own advantage for the prediction of VIS-NIR regression.
To yield a more robust and trustworthy model,
Figure 9 shows the prediction of two sub-ranges with boosting algorithms and all pretreatment methods. The models with low and high concentrations exhibited better performance than those with all samples but showed only minor improvement. These reasons are analyzed as follows:
- (1)
The samples were collected from two places that are far apart. Therefore, two sub-range samples both have some outliers that would affect the performance of these models.
- (2)
The number of samples with a sub-range was not enough for training. The regression algorithm is better if there are more samples.
Although the performance did not improve, the pretreatment and boosting methods have a positive influence on the quantitative model. Therefore, future studies should focus on outlier analysis methods and collect more samples to build a more robust and trustworthy model that can be used across industries for NIR quantification.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}