1. Introduction
According to the Gartner report [
1], the analysts forecast there are 5.8 billion Internet of Things (IoT) endpoints in 2020, which is increasing by 21% since 2019. The larger number of IoT devices generates a huge amount of data to the cloud. An efficient big data processing platform for the data streaming application is getting more attentions. Apache Hadoop [
2] and Apache Spark [
3] are two popular solutions to deal with the big data processing. Hadoop is an open-source implementation for MapReduce framework [
4] while Spark is an in-memory processing framework for performance efficiency. The literature [
5,
6] studied the performance of Hadoop and Spark to demonstrate that the speedup of Spark is better than that of using Hadoop.
On the other hand, with the advancement of virtualization technology, most hardware resources such as CPU, memory, disk, and network I/O can be virtualized and shared in a modern cloud infrastructure. These virtualized resources function as a resource-provisioning pool and are dynamically provisioned according to the application demands. From the viewpoint of users, the allocation and management of virtualized resources is provided by cloud services. However, the physical resources in the cloud infrastructure have to be administrated by the system. Therefore, the allocation of virtualized resources among physical servers is a crucial research topic in cloud computing. This paper focuses on tackling the essential problem of resource allocation and attempts to reduce the amount of available but unused resources in the cloud infrastructure.
Yousafzai et al. [
7] address the overlapping concept among resource provisioning, resource allocation, and resource scheduling. In general, resource provisioning is the allocation process of resources in service-providers to customers. Resource allocation is the process of distributing resources efficiently to competing jobs. Resource scheduling is to obtain the time-schedule of resources to schedule computational events on shared resources in available time. The same description also could be found in the previous work [
8].
A resource-allocation mechanism [
9,
10] plays a crucial role in determining an efficient strategy for allocating resources to satisfy application demands. However, the resource demand for various applications can be heterogeneous in cloud computing. For example, computing-intensive applications require more CPU resources for the computation task, whereas memory-intensive applications require more memory resources for the data cache. The effectiveness of a resource-allocation mechanism affects system performance. Over-provisioning and under-provisioning are two common problems for resource allocation in cloud computing [
11]. Over-provisioning with excessive resources for application demands leads to lower resource utilization and higher capital expenditure. However, under-provisioning with fewer resources results in a lower resource capacity and a higher response time, which result in loss of users and revenue. Accordingly, a trade-off exists between the provision of resource capacities and the consumption of application demands. An efficient resource-allocation mechanism can optimize the allocation of resource capacities to satisfy application demands and improve overall resource utilization.
Many resource-allocation algorithms [
12,
13,
14,
15,
16,
17,
18,
19] have been proposed to investigate the resource-allocation problem on cloud computing. Some well-known resource management systems, such as Yarn [
20] and Mesos [
21], have been developed. Previous studies have focused on the computing environment with homogeneous resources. However, the development of a practical cloud computing environment with heterogeneous computing resources has received limited attention [
22]. Resource heterogeneity is a common occurrence in a practical cloud system because various computing servers have different resource capacities. Some servers have more CPU resources and some of them may have more capacities of memory. In addition, resource heterogeneity in a hybrid cloud is significant because hardware equipment and resource capacity are heterogeneous between private and public clouds. Edge computing [
23,
24,
25,
26] is an ongoing paradigm shift in which resource types are more heterogeneous among geographical edge locations. The experimental results of our study indicate that the heterogeneity of resource capacities should be considered in the design of heterogeneous resource allocation as it reduces the amount of available but unused resources.
Compared to the literature, our contribution is to facilitate appropriate utilization of heterogeneous resources in cloud computing. A novel resource-allocation mechanism, named minimizing resource gap (MRG) algorithm, was proposed for solving the resource wastage problem for the available but unused resources. A resource gap is a phenomenon in which some resource capacities are exhausted, whereas other resources on the same server are still available. In this case, the computing server may not be able to satisfy the resource capacity demands from an application, which leads to a low resource utilization and resource wastage for the available but unused resources. In addition, the resource gap is more apparent when the computing resources are more heterogeneous. Therefore, the MRG algorithm was proposed in this study for reducing the resource gap by considering distinct resource demands in each application. For example, some applications require more CPU resources for computing-intensive tasks, whereas others require more memory capacity for memory-intensive processing. When a new application is submitted to the computing system, MRG calculates the resource gap among servers and discovers the server with a minimal resource gap for allocating the application to the server. Thus, by reducing the resource gap in servers, the MRG algorithm can improve the resource utilization of computing servers for heterogeneous resource allocation.
MRG was implemented in Apache Spark for performance evaluation. Spark [
27] is an open-source distributed computing framework written using Scala and has been a popular cloud computing platform adopted by many companies for big data [
28]. Apache Spark allocates multiple servers in a cluster to solve the resource gap problem with large amounts of data volumes and computations for parallel and distributed processing. The default resource-allocation algorithm in Apache Spark can result in resource wastage because of a large resource gap in case of servers with heterogeneous resource capacities. To evaluate the performance of the proposed MRG approach, the performance of the default algorithm in Apache Spark is compared with our approach.
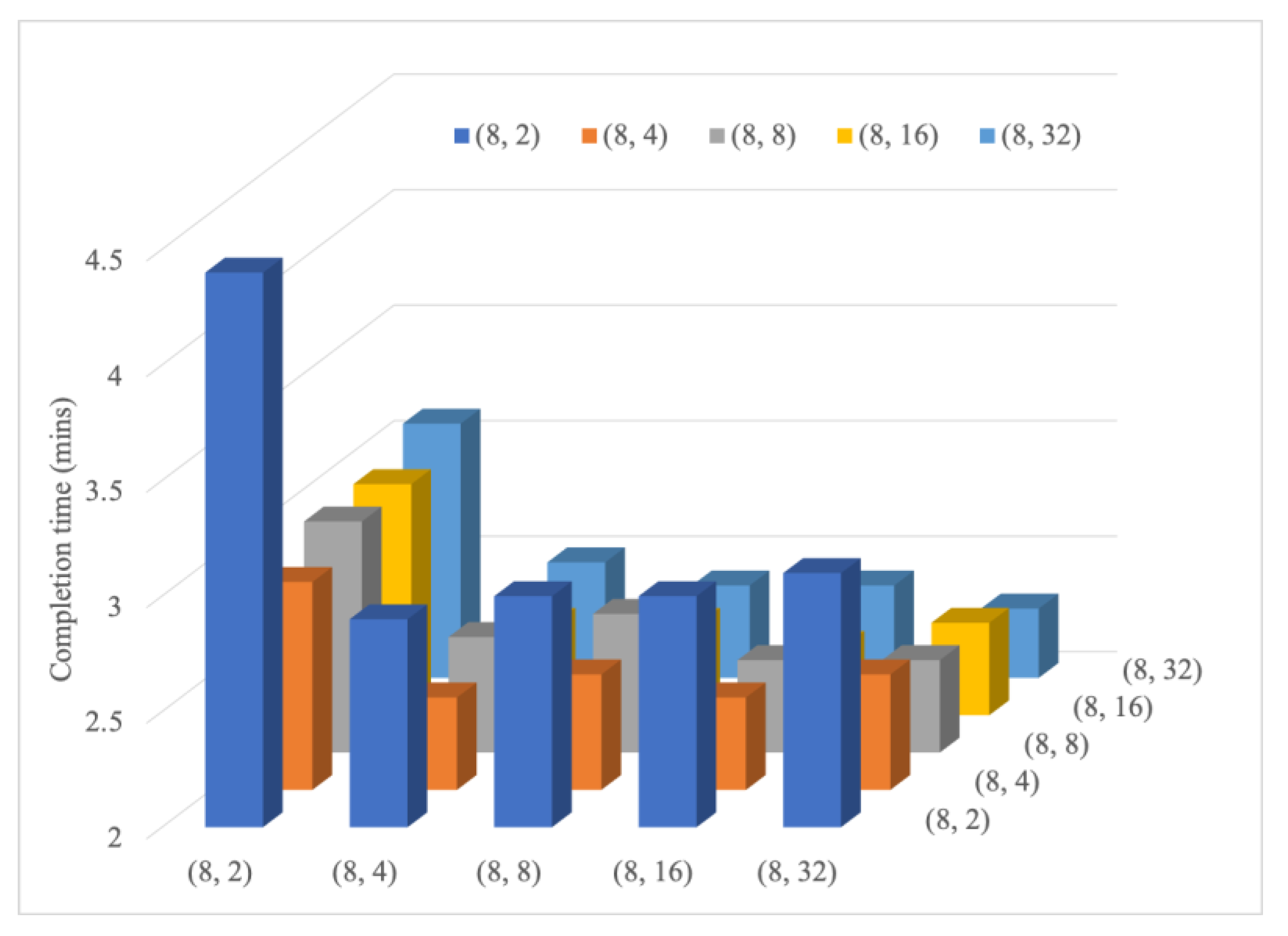
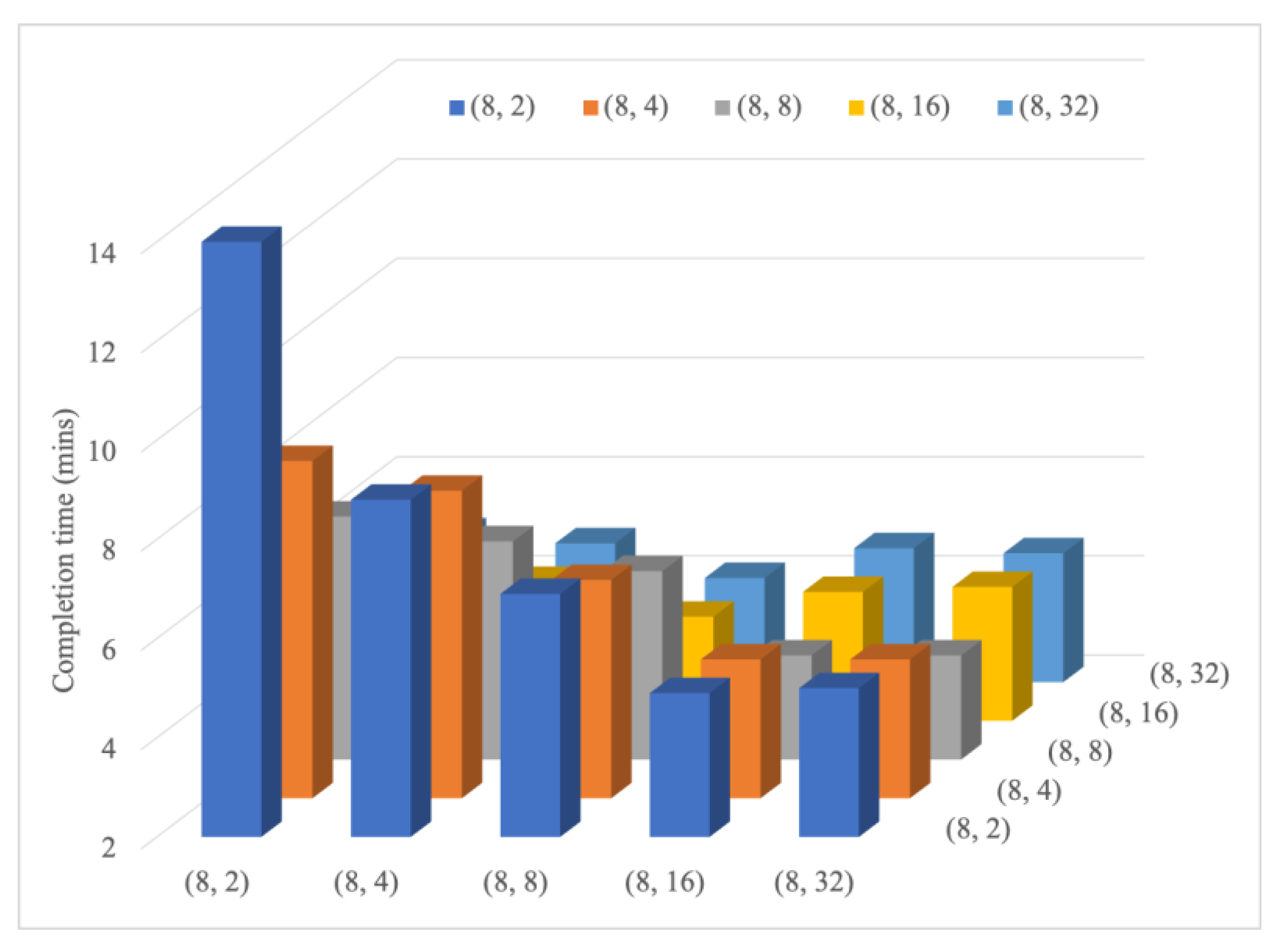
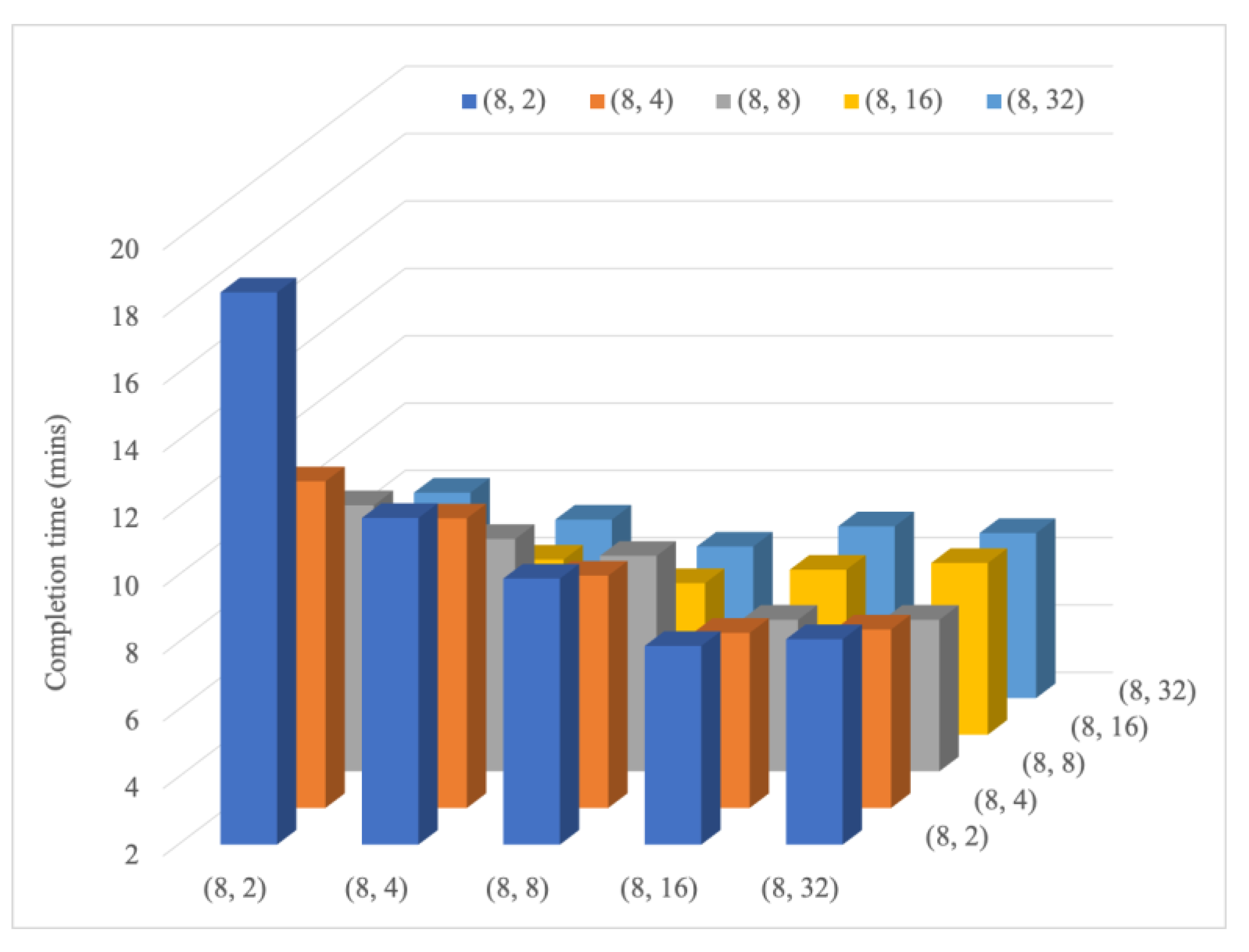
Two experiments were conducted in this study. In the first experiment, the improvement in resource allocation with the use of MRG in case of homogenous resource demands of applications was evaluated. The experimental results revealed that when the homogeneity of resource demand of applications was close to the homogeneity of server resources, the completion time of jobs by the MRG algorithm was considerably lower than that by the default algorithm in Spark. In the second experiment, the improvement by MRG was confirmed. The results revealed that when the homogeneity of server resources was lower than that of the application demand, MRG improved resource utilization and reduced the job completion time. Therefore, experimental results demonstrated that the proposed MRG approach outperforms default resource allocation in Apache Spark when resources are heterogeneous.
The rest of this study is organized as follows. The most relevant studies are discussed in
Section 2. The system framework and algorithm are proposed in
Section 3. Performance evaluations and experimental results are presented in
Section 4. Finally, conclusion remarks and future studies are presented in
Section 5.
2. Related Works
An efficient resource-allocation strategy to satisfy application demands is a vital topic in cloud computing. Shakarami et al. [
29] proposed a systematic and detailed survey on stochastic-based offloading mechanisms. Arun and Prabu [
30] presented a survey of resource-allocation approaches in mobile cloud computing. Yousafzai et al. [
7] introduced a thematic taxonomy of the resource-allocation approaches and provided their strengths and weaknesses. Manvi and Shyam [
8] introduced a survey of the resource management problem and focused on some of the important resource management techniques, which include resource allocation, resource provisioning, resource mapping, resource scheduling, and resource adaptation.
Morshedlou and Meybodi [
31] proposed a proactive resource-allocation mechanism to reduce the SLA violations. This work also provided the detail control flow of the resource-allocation mechanism. In general, processing a job in clouds can be divided into different phases: Job Submission, Job Placement, Job Execution, Job Migration (if necessary), and Job Complete. Once a job is submitted to the cloud infrastructure, the cloud resource provider has to discover available resources and assign the job to the available resources. This process is known as the initial phase for the job placement. The key mission of this phase is to control the overall resource allocation for each physical server to complete the amount of submitted jobs in an efficient way. Furthermore, when a job is under execution, the job may be transferred from its current assigned resource to a new one. This phase is known as the migration and is usually applied after the job placement phase. In our work, we aim at the initial phase for the job placement and resource-allocation problem rather than the migration phase.
The effect of resource allocation on system performance in terms of static and dynamic control has been examined in studies [
12]. Static allocation approaches include the round robin, optimization, and overbooking, whereas dynamic allocation approaches include reactive and proactive controls. In the round robin approach, virtual machines (VMs) are allocated to one server after another. Therefore, implementation of this mechanism is easy. Each server can have balanced loads when the application demands and resource capacities are homogeneous.
The effectiveness of round robin and the shortest job first (SJF) [
13] algorithms for resource allocation in cloud computing has been discussed. In the SJF algorithm, the execution time is assumed to be predefined for each application, which is not practical in cloud computing. Therefore, a modified round robin approach was proposed to improve the resource-allocation efficiency. The resource-allocation problem was addressed using the static server allocation problem (SSAPv) [
14]. The overbooking approach can be used to improve the resource utilization. In previous work [
15], the authors proposed a novel approach using truncated singular value decomposition to solve the SSAPv problem. These static approaches perform favorably when the number of required VMs and the resource demands are well-defined before allocating the resources.
Some previous works also focused on the task-scheduling problem. Gawali et al. [
32] proposed a heuristic approach to improve the turnaround time and response time of tasks in workflow fashion by adopting the modified analytic hierarchy process, bandwidth-aware divisible scheduling, and longest expected processing time preemption approaches. Zhang et al. [
33] introduced a two-level asynchronous scheduling model for cloud federation. The proposed model prioritizes the tasks sent by the federation scheduler with two multi-resource fair scheduling algorithms for cloud and federation. In addition, Shukla et al. [
34] proposed a mechanism for migrating running streaming dataflow across VMs. Tan et al. [
35] proposed a Cooperative Coevolution Genetic Programming (CCGP) hyper-heuristic approach. The proposed approach allocates resources on a two-level architecture that addresses the allocation of containers to VMs and the allocation of VMs to physical machines. Compared to these works, this paper focuses on tackling the essential problem of resource allocation and attempts to reduce the amount of available but unused resources for physical machines.
In another work [
16], a reactive control for dynamic resource allocation was proposed. When the loading of a server is higher than a predefined threshold, the reactive control migrates the VM from the server with higher loads to another server with lower loads. Furthermore, if the server load is too low, the reactive approach consolidates the VMs and shuts down the server with low loads. Another approach is to proactively predict the load of servers and allocate resources accordingly rather than waiting for the overloading condition to occur. In previous work [
17], the double exponential smoothing method was proposed to predict server loads based on histogram data. Sultan et al. [
36] developed an intelligent usage prediction model according to historical resource usage. Authors apply the proposed prediction model to allocate resources dynamically. Tang et al. [
37] introduced a dynamical load-balanced scheduling (DLBS) approach to improve the network throughput while balancing workload of data transmissions dynamically. Souravlas [
38] addressed the problem of the balanced data flow among data centers. Tantalaki et al. [
39] introduced a pipeline-based linear scheduling approach for big data streams. Lattuada et al. [
40] presented a resource-allocation approach for big data analytics. The proposed approach adopts a set of run-time optimization-based resource management policies to address the minimum resource requirements with the deadline and to balance the load to avoid the tardiness without enough resources. These works focused on load prediction and data transmissions that are out of the scope in this paper.
Apache Mesos [
21] was developed by University of Berkeley Labs and subsequently donated to the Apache Software Foundation. Mesos is a resource managing platform that can be used to not only manage all resources in the distributed system but also allocate resources such as CPU, memory, and storage to applications. In Mesos, a two-level resource-allocation architecture is presented, which uses the dominant resource fairness (DRF) [
18] algorithm. The DRF algorithm is a max–min fairness approach for the first phase of resource scheduling. In DRF, the dominant resources of frameworks are determined, and subsequently, priorities are assigned to frameworks based on the amount of dominant resources. When resources are allocated to frameworks, the scheduler in each framework schedules these resources for executing jobs. However, the heterogeneity of resources disrupts the fairness in DRF. In previous study [
19], the dominant resource fairness for heterogeneous (DRFH) was proposed to improve DRF for heterogeneous resource allocation. In DRFH, the share ratio of dominant resources in the server with heterogeneous resources is determined. In the scheduling phase, the number of jobs with dominant resources is calculated. In the allocating phase, DRFH allocates a similar proportion of the dominant resource share ratio among application demands and available resources on each server to reduce the amount of unused resources. Hamzeh et al. [
41] proposed a Multi-level Fair Dominant Resource Scheduling (MLF-DRS) algorithm to guarantee the fairness of resource demands based on dominant shares. However, previous approaches were too complicated and are not proposed for the data streaming application in Spark which mainly focuses on the in-memory processing.
Spark utilizes resilient distributed datasets (RDD) [
42] to develop a decentralized computational framework. RDD is a data structure for improving Hadoop I/O operations in the MapReduce phase. In RDD, a coarse-grained approach is adopted to record data logs. Two operations occur in RDD, namely transmission and action. Only the action operations could write data into storage for reducing the I/O access time. Two job scheduling algorithms are applied in Spark, namely the FAIR and first-in-first-out algorithms. For the resource-allocation phase, the load-balanced algorithms are used to balance the CPU utilization among cloud servers. When an application is launched, Spark allocates the application to the server with maximum number of available CPU resources. However, the load-balanced algorithm in Spark may result in resource wastage for the available but unused resources when resources are more heterogeneous in clouds.
Allocation of various application demands to heterogeneous resources has received limited attention. The heterogeneity of server capacities affects the resource utilization. For example, when the CPU resources of one Spark server are exhausted, the memory capacity of the same server are still available. In this case, the server cannot afford any application because of insufficient CPU capacity. Consequently, resource wastage leads to low utilization and high execution time in the system. The more heterogeneous the computing resources are, the more amount of available but unused resources influences the system. Therefore, a novel resource-allocation approach was proposed for enhancing the Spark system with the consideration of heterogeneous resources. The proposed algorithm can avoid the amount of available unused resources for each server to enhance the resource utilization and reduce the overall completion time for Spark applications.
3. Minimizing Resource Gap
In this section, details about the proposed MRG approach are described. The concept of resource gap is introduced first and then the MRG algorithm is presented.
3.1. Resource Gap
Assume two servers S1 and S2, with two kinds of resources, Rx and Ry. The quantity of Rx and Ry in S1 is (4,2), and the quantity of Rx and Ry in S2 is (2,4). Suppose two applications, AP1 and AP2, with different resource demands, the resource demand of AP1 is (2,1) and resource demand of AP2 is (1,2). Given an algorithm to allocate resources of S1 to AP2, the remaining resource of S1 is (3,0). Thus, in this allocation, three available but unused resources of the Rx are wasted. When the algorithm allocates resources of S2 to AP1, the three available but unused resources of Ry are wasted because of the remaining resource of S2 is (0,3). After the previous resource allocation, the system cannot afford more resource requests of other applications even though the overall system remains available Rx and Ry resources as (3,3). Accordingly, the higher heterogeneous the resource demand is, the more resource gap will be. As a result, the more available but unused resources are wasted in the system.
To solve the resource wastage problem for the available but unused resources, the MRG algorithm was proposed to calculate the degree of resource wastage and improve resource utilization. The difference between the quantities of exhausted resources and remaining resources is termed as the
resource gap. When a resource is exhausted and the quantity of remaining resources is the smallest, resource wastage for the available but unused resources is reduced.
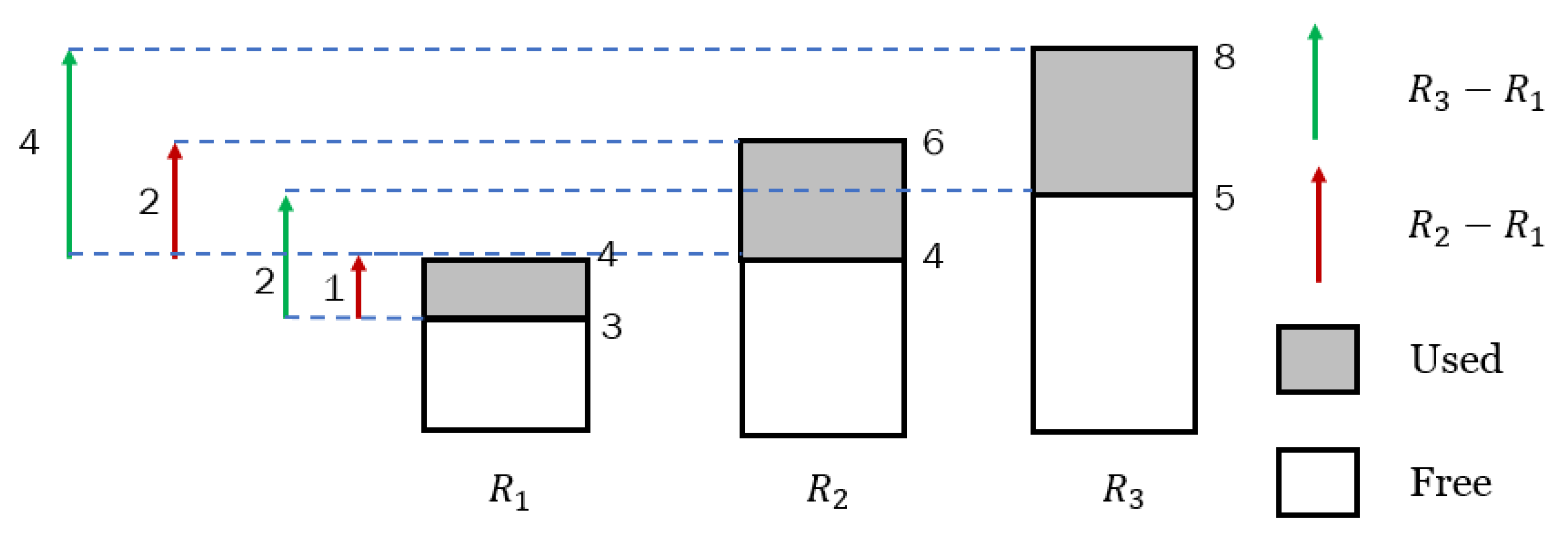
Figure 1 depicts an example to illustrate the resource gap. Assume three resources
R1,
R2, and
R3 in the system. The initial quantities of
R2 and
R3 were considerably higher than that of
R1. That is, before resource allocation, the original resource gap was two between
R1 and
R2 and four between
R1 and
R3. After resource allocation, the resource gap among remaining resources was one between
R1 and
R2 and two between
R1 and
R3. Accordingly, the resource gap between heterogeneous resources could be minimized after an efficient resource-allocation policy. Thus, all three resources are well utilized to prevent resource wastage.
3.2. MRG Algorithm
To minimize the resource gap among the heterogeneity of resources, the MRG mechanism was proposed in this study. Initially, the possible resource wastage is calculated in the MRG algorithm when an application is launched. Then, the server with the smallest resource gap is determined to allocate resources to this application. Therefore, each server has a low resource wastage for the available but unused resources and the system utilization is enhanced. In this study, the set S of servers was , and the set R of resources was . Available resources of the server K (K ∈ S) are . The application demand for resources is presented as the vector .
The MRG algorithm is invoked when the application demand is submitted for allocating available resources. First, the following is calculated in MGR:
This parameter is determined for calculating the remaining amount of resources if the algorithm allocates the candidate server
K to the application. Then, the smallest
with
is determined, which indicates that the resource
Rm in server
K is going to be depleted. All resource gaps in server
K are then calculated in the MRG algorithm for determining the accumulated resource gap, denoted by
, as follows:
Finally, the target server
TS with the smallest
is determined and this server is allocated to the application. The pseudo codes for the proposed MRG algorithm are shown in
Figure 2.
The following examples
were applied to demonstrate the effectiveness of the proposed algorithm. When only two resources are available, Equation (2) is simplified to the following expression:
Table 1 and
Table 2 list the examples to illustrate allocation steps when allocating resources for
and
. When the resource is allocated to
, the
of
is | (4 − 2) − (2 − 1) | = 1 and the
of
is | (2 − 2) − (4 − 1) | = 3. Because
has a smaller
, the MRG algorithm allocates
to be on
. When allocating resources for
, the
of
is | (4 − 1) − (2 − 2) | = 3, whereas the
of
is | (2 − 1) − (4 − 2) | = 1. Because
has a smaller
,
is allocated to
. These examples show that the proposed algorithm can allocate resources effectively to prevent a high resource gap.
To further demonstrate that MRG can reduce resource wastage for the available but unused resources, the proposed algorithm was compared with the default load-balanced algorithm in Apache Spark. In the default algorithm, the servers are allocated with the maximal free CPU cores to the application. Assume that
has resources
,
, and
with values of (4, 6, 8) and
has resources of
,
, and
with values of (8, 6, 4), respectively. The resource demands of
is (1, 2, 3) and that of
is (4, 3, 2). Suppose that these two applications are allocated one after another. Therefore, two cases are possible for the resource-allocation policy. The first case starts with the allocation step for
and the other case starts with the allocation step for
.
Table 3 and
Table 4 illustrate allocation steps for Case 1, applying the default algorithm in Apache Spark and the proposed MRG algorithm, respectively.
Table 5 and
Table 6 illustrate allocation steps for Case 2.
In Case 1, the load-balanced algorithm and the proposed MRG algorithm could allocate resources to satisfy the application demands for and . However, in Case 2, the load-balanced algorithm can only satisfy two application demands for one and one . Resource wastage for the available but unused resources is higher for the load-balanced algorithm in this case. The proposed MRG algorithm can satisfy all the resource demands for and . This is because MRG minimizes the resource gap for reducing the amount of available but unused resources.
The aforementioned cases indicate that the MRG algorithm can not only reduce the resource gap in the heterogeneous resource environment but also improve resource utilization. The load-balanced algorithm performs satisfactorily in the environment with homogeneous resources but results in poor resource utilization in the environment with heterogeneous resources. The time complexity of our MRG algorithm depends on the factors of S servers and R kinds of resource capacities. For each server S, the proposed algorithm calculates the ARG by Equation (2). for determining the accumulated resource gap. Then, the proposed algorithm finds out the target server Ts with the smallest ARG and allocate the resource of this server to the application. So, the most time consuming of the proposed algorithm is to find out the Ts. Therefore, the time complexity of the proposed algorithm is O(S × R).
5. Conclusions and Future Work
On-demand and dynamic resource provisioning plays a crucial role in improving the resource utilization in cloud computing. The efficiency of the resource-allocation mechanism affects system performance, particularly in the system with heterogeneous resources. When designing effective resource allocation for heterogeneous resources, the heterogeneity of resource capacities should be considered to avoid resource wastage. Resource gap is a phenomenon in which some resource capacities are exhausted, whereas other resources on the same server are still available. The more heterogeneous the computing resources are, the more influence the resource gap has on the system. A computing server may not satisfy all the demands of resource capacities from an application. Therefore, the system exhibits low resource utilization and resource wastage for the available but unused resources.
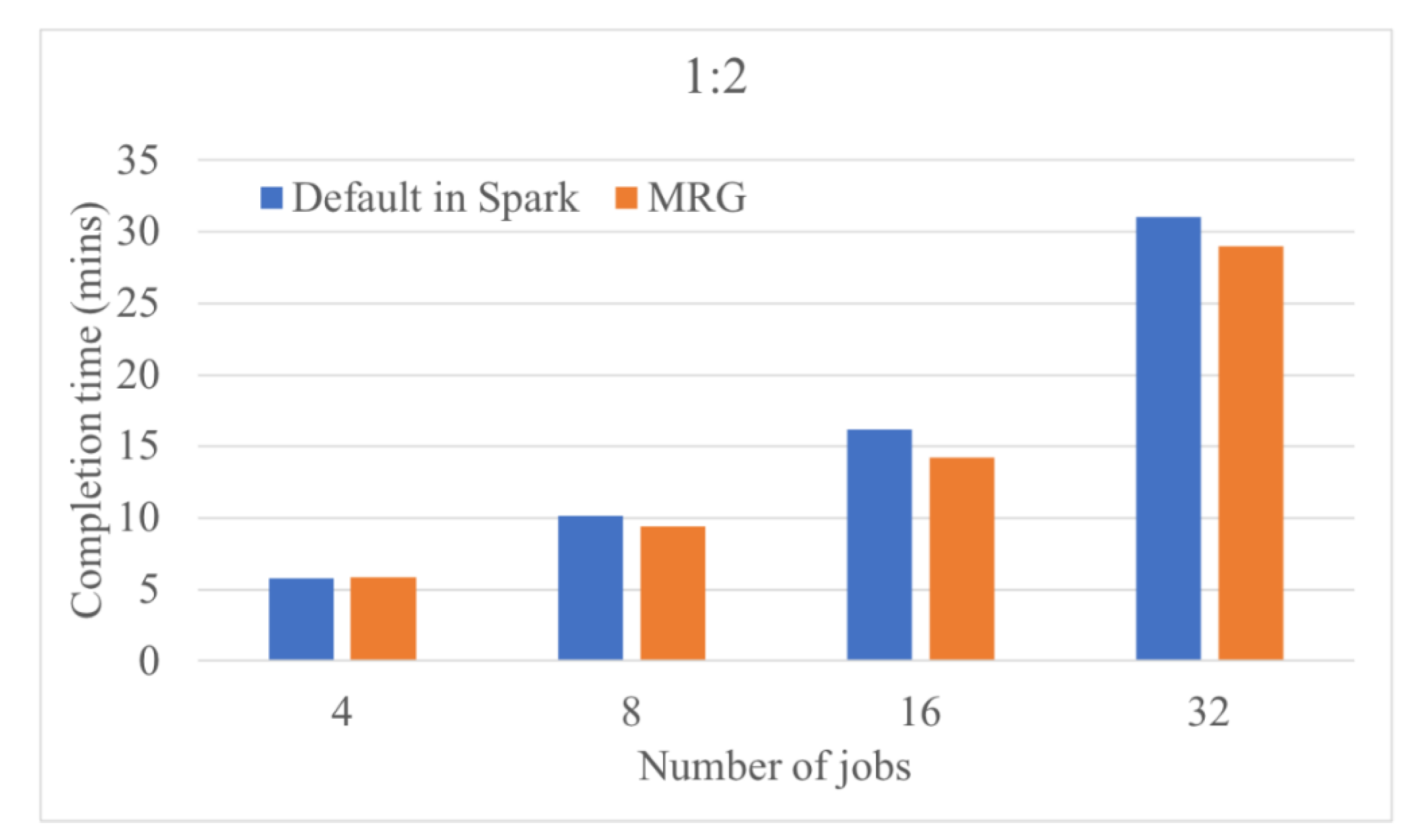
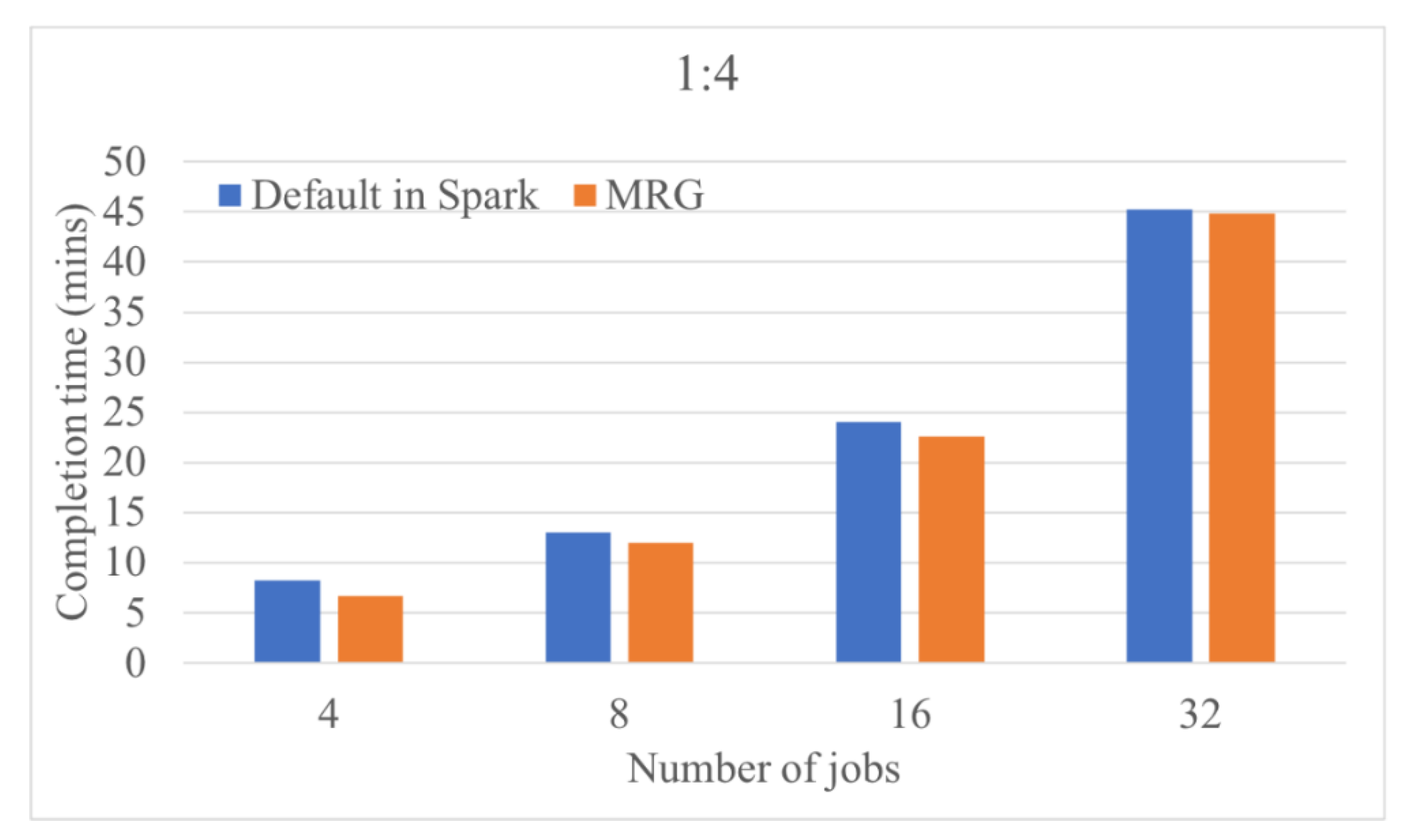
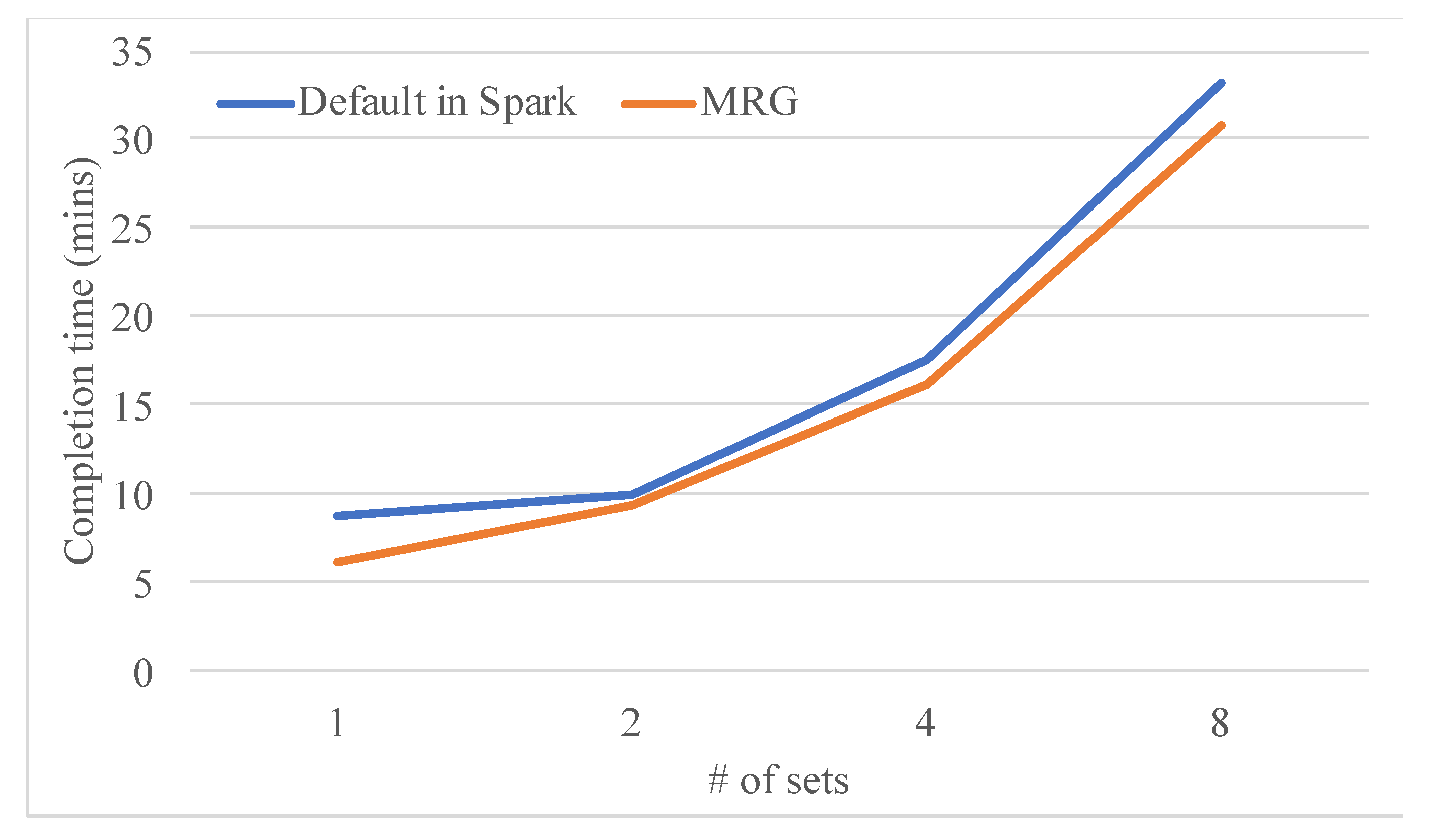
In this study, a novel resource-allocation approach, MRG, was proposed to solve the resource wastage problem. In MRG, resource demands among different applications, for example, CPU-intensive and memory-intensive applications, are considered for enhancing resource usage. When applications are submitted to the system, MRG calculates the possible resource wastage and determines the server with the smallest resource gap to allocate resources to each application. Therefore, each server can avoid the amount of available but unused resources to enhance system utilization by up to 24.7% in terms of the overall completion time.
MRG was implemented in Apache Spark to demonstrate MRG performance. Two applications with different resource demands (Spark Pi and Spark PageRank) were applied. The performance metric of overall complete time was measured under the various combination sets of different application resource demands and server capacities. Experimental results indicated the superiority of the proposed MRG approach over the load-balanced approach in Apache Spark. Furthermore, MRG can considerably reduce the overall execution time as more servers can allocate resources for both CPU- and memory-intensive applications. The performance gain can be achieved by up to 64.7% when applying the MRG approach.
In the future, we will extend the MRG approach for improving system utilization with more dimensions of resource heterogeneities. Resource allocation is also one of the important issues in mobile cloud computing [
29,
30]. After the offloaded task moving from the mobile device into the cloud, the cloud provider has to allocate enough resources to this task. In this case, task migration could be a further finetuned mechanism to enhance the job processing. Applying machine learning to enhance the MRG algorithm is vital as well for future studies.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}