
Variable Neighborhood Strategy Adaptive Search to Solve Parallel-Machine Scheduling to Minimize Energy Consumption While Considering Job Priority and Control Makespan


Abstract
:1. Introduction
2. Literature Review
3. Mathematical-Model Formulation
3.1. Problem Description
3.2. Mathematical Formulation
| Index | |
| i, j | Job indices; j, i = 1, 2,…, I when i or j = 0, 0 represents the dummy node, which is always produced first in each machine |
| m, n | Machine indices; m, n = 1, 2,…, M |
| Parameters | |
| I | Total number of jobs |
| M | Total number of machines |
| Pjm | Processing time of job j on machine m |
| Ejm | Energy consumption for producing job j on machine m |
| Dj | Due date of job j |
| aj | Penalty cost of job j (priority of job) |
| B | Cost per time units of processing with all machines. |
| Ajm | Job-machine restriction; Ajm = 1 when job j can produce on machine m. |
| LMAX | Maximal lateness that is allowed |
| TMAX | Maximal number of tardy jobs that are allowed |
| KKK | Cost conversion for used energy |
| Decision Variable | |
| Xijm | |
| Yjm | |
| Sjm | Start time of job j on machine m |
| Cjm | Completion time of job j on machine m |
| Li | Lateness of job i |
| Ti | |
4. Proposed Method
| Algorithm 1. Variable neighborhood strategy adaptive search (VaNSAS). |
| Input: number of jobs, number of machines, production time, energy consumption Output: consumed energy Begin Randomly generate predefined number of tracks (NT) While t is less than the predefined number of iterations, Perform track-touring process 1. Each track individually selects a black box 2. Each track performs a black-box searching process 2.1 Solution decompose and repair method (SDR) (optional) 2.2 Track-transition method (TTM) (optional) 2.3 Multiplier factor (MF) (optional) 3. t = t + 1; End |
4.1. Generating an Initial Solution
4.1.1. Decoding Methods
- Separately apply the rank order value (ROV) between job and machine vectors. The ROV of jobs is called the job sequence at position i (SJi), and machine sequence in position m is called SMm.
- Assign the first job in Position 1 of SJi to Machine 1 of SMm, assign the second job in Position 2 of Sji to the machine in Position 2 of SMm, and continuously assign the remaining jobs in position i + 1 to machine m + 1 until m = M, where M is the total number of machines. In the context of job or machine restrictions, job j is assigned to machine m only when job j is allowed to be produced on machine m. If job j is not allowed to be produced on machine m, job j is assigned to the next order of machine.
- Continue assigning jobs in position i + 1 to the machine that has minimal total processing time among all M machines until all jobs are assigned to a machine. While assigning a job to a machine, the maximal number of tardy jobs and maximal lateness must be controlled to be less than the maximal predefined number.
- Calculate completion time and energy used in Step 3.
4.1.2. Decoding-Method Example
- Step 1:
- Separately apply ROV to the job and machine tracks from the smallest to the largest value; results are shown in Table 3.
- Step 2:
- Apply Jobs 7, 3, and 10 to Machines B, C, and A, respectively.
- Step 3:
- Assign Job 8 to B, but it is not allowed to produce Job 8 on Machine B; thus, assign Job 8 to Machine C instead of Machine B. Since it has the lowest total processing time, Jobs 9, 8, 5, 6, 3, and 7 are assigned to Machines A, B, A, C, B, and B, respectively. The results of this assignment are shown in Table 4.
4.2. Performing the Track-Touring Process
4.2.1. Solution Decompose and Repair (SDR) Method
- a.
- Destroy MethodIn this section, the destroy method was employed to disassemble the initial solution so it would become an incomplete solution that made the solution move to other search areas, and a new solution was thereby obtained. This paper applied N-job-string removal as the destroy method, the value of the considered solution on the basis of a randomly generated job sequence before removing jobs from list I. The N-job-string removal algorithm is shown in Algorithm 2.
Algorithm 2. N-job-string removal - Randomly select a value of N that lies between 2 to I (number of jobs)
- B = I; I = {Sequence of all jobs}
- L = {}
- Randomly select job position in sequence B and name it position e
- Remove job in position e + N-1 from list B
- Insert removed job into list L
- b.
- Repair MethodAfter the destroy procedure deconstructed the initial solution, the repair procedure was performed to reconstruct the solution by randomly using one of two repair methods: (1) best insertion and (2) random insertion.
- b.1
- Best InsertionBest insertion was used to repair a solution by determining the processing time to move the job from list L into an empty machine for operating that job. The best-insertion algorithm is shown in Algorithm 3.
Algorithm 3. Best insertion. - B = L {a, b, c, d.., Z}
- While |B| > 0, do
Insert job in position a into the machine that currently has the lowest energy consumption among all M machines except for the machine from which it was removed. For instance, there was a list of jobs {2,10,8,5}. Producing Job 2 consumed 14, 41, and 39 energy units for Machines A, B, and C, respectively. Since Job 2 was removed from machine C, only two choices remained, namely machines A and B. Therefore, Job 2 was placed into Machine A due to it needing the least energy to produce Job 2. After that, Jobs 10, 8, and 5 were continuously executed with the same mechanism until all jobs in B had been reassigned. - b.2
- Random InsertionRandom insertion is a method used to repair an incomplete solution by finding a random machine to operate the job under conditions to reconstruct the solution. Algorithm 4 shows the random insertion algorithm.
Algorithm 4. Random insertion. - B = L
- While |B| > 0, do
Insert the job in list B into randomly selected machines that are not the machine from which the job was removed. For example, there was a list of jobs {2,10,8,5}, and Job 2 was removed from Machine C. Therefore, Machines A or B were the choices to operate Job 2. Algorithm 5 demonstrates the SDR procedure.Algorithm 5. SDR. Begin
Given current solution
While termination condition is not met, do
1. Perform destroy method (N-random jobs removal)
2. Randomly select repair methods
2.1 Best insertion method (optional)
2.2 Ransom insertion method (optional)
End
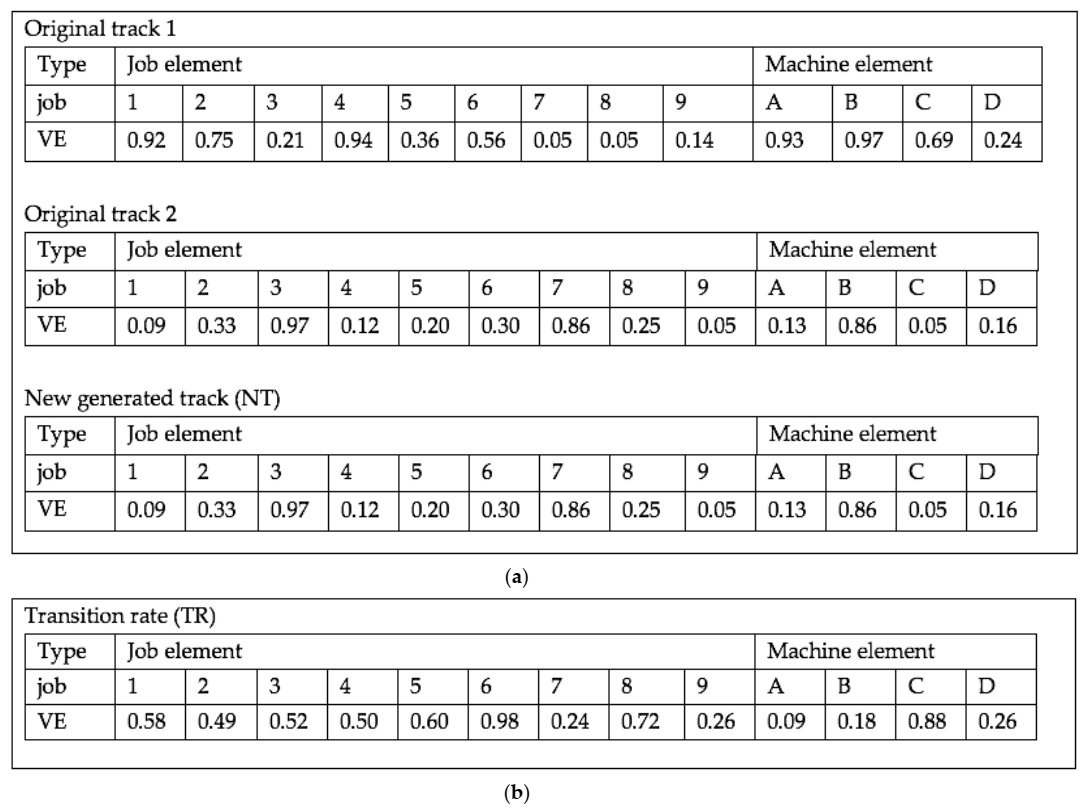
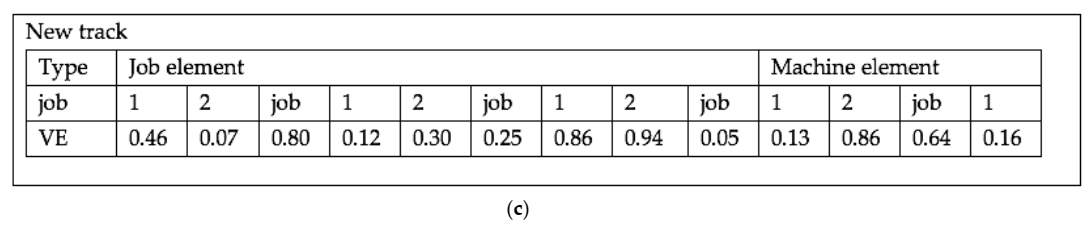
4.2.2. Track-Transition Method (TTM)
4.2.3. Multiplier Factor (MF)
| Algorithm 6. Multiplier factor. |
| Input: The value in track , number of jobs, number of machines Outputs: Track after MF Begin i = 1 While i ≤ maximal number of iterations, Randomly generate the random track Multiply by and obtain Decode to obtain solution for the problem i = i + 1; end while End |
4.3. Updating Track and Other Information
4.4. Current Practice Procedure
- Step 1.
- Sort jobs according to energy used from least to most used, and name this list job list (JL).
- Step 2.
- Calculate average number of jobs per machine and call this number AM.
- Step 3.
- Assign jobs to machines according to JL. Job j is assigned to the machine that uses the least energy. If that machine has more jobs than AM, the next machine that uses the least energy is selected and continuously performs until all jobs are assigned.
- Step 4.
- Calculate the objective function of the assignment from Step 3.
4.5. Differential Evolution Algorithm
| Algorithm 7. Differential evolution (DE) pseudocode. |
| Set NP, CR, F, NP (size of track) Generate initial solution Begin For G = 1 to Gmax when G = iterations and Gmax = Maximum iteration Randomly generates the set of initial solution (tracks) For N = 1 to NP Perform mutation process using (23) Perform the recombination process using (24) Perform selection process using formula (25) End |
5. Computational Framework and Result
6. Conclusions and Outlook
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- EIA. Available online: https://www.eia.gov/outlooks/aeo/data/browser/#/?id=37-AEO2020&cases=ref2020&sourcekey=1 (accessed on 28 March 2021).
- EIA. Available online: https://www.eia.gov/outlooks/aeo/data/browser/#/?id=22-AEO2020&cases=ref2020&sourcekey=0 (accessed on 28 March 2021).
- Fang, K.T.; Lin, B.M. Parallel-machine scheduling to minimize tardiness penalty and power cost. Comput. Ind. Eng. 2013, 64, 224–234. [Google Scholar] [CrossRef]
- Che, A.; Zhang, S.; Wu, X. Energy-conscious unrelated parallel machine scheduling under time-of-use electricity tariffs. J. Clean. Prod. 2017, 156, 688–697. [Google Scholar] [CrossRef]
- Abikarram, J.B.; McConky, K.; Proano, R. Energy Cost Minimization for Unrelated Parallel Machine Scheduling under Real Time and Demand Charge Pricing. J. Clean. Prod. 2019, 208, 232–242. [Google Scholar] [CrossRef]
- Cui, W.; Lu, B. A Bi-Objective Approach to Minimize Makespan and Energy Consumption in Flow Shops with Peak Demand Constraint. Sustainability 2020, 12, 4110. [Google Scholar] [CrossRef]
- Fang, K.; Uhan, N.; Zhao, F.; Sutherland, J.W. A New Approach to Scheduling in Manufacturing for Power Consumption and Carbon Footprint Reduction. J. Manuf. Syst. 2011, 30, 234–240. [Google Scholar] [CrossRef]
- Yin, L.; Li, X.; Lu, C.; Gao, L. Energy-Efficient Scheduling Problem Using an Effective Hybrid Multi-Objective Evolutionary Algorithm. Sustainability 2016, 8, 1268. [Google Scholar] [CrossRef] [Green Version]
- Mansouri, S.A.; Aktas, E.; Besikci, U. Green Scheduling of a Two-Machine Flowshop: Trade-off between Makespan and Energy Consumption. Eur. J. Oper. Res. 2016, 248, 772–788. [Google Scholar] [CrossRef] [Green Version]
- Liu, C.-H.; Huang, D.-H. Reduction of Power Consumption and Carbon Footprints by Applying Multi-Objective Optimisation via Genetic Algorithms. Int. J. Prod. Res. 2013, 52, 337–352. [Google Scholar] [CrossRef]
- Zhang, Z.; Wu, L.; Peng, T.; Jia, S. An Improved Scheduling Approach for Minimizing Total Energy Consumption and Makespan in a Flexible Job Shop Environment. Sustainability 2019, 11, 179. [Google Scholar] [CrossRef] [Green Version]
- Fysikopoulos, A.; Pastras, G.; Alexopoulos, T.; Chryssolouris, G. On a Generalized Approach to Manufacturing Energy Efficiency. Int. J. Adv. Manuf. Technol. 2014, 73, 1437–1452. [Google Scholar] [CrossRef] [Green Version]
- Zeng, Z.; Chen, X.; Wang, K. Energy Saving for Tissue Paper Mills by Energy-Efficiency Scheduling under Time-of-Use Electricity Tariffs. Processes 2021, 9, 274. [Google Scholar] [CrossRef]
- Liu, C.-H.; Nanthapodej, R.; Hsu, S.-Y. Scheduling Two Interfering Job Sets on Parallel Machines under Peak Power Constraint. Prod. Eng. 2018, 12, 611–619. [Google Scholar] [CrossRef]
- Lin, D.-Y.; Huang, T.-Y. A Hybrid Metaheuristic for the Unrelated Parallel Machine Scheduling Problem. Mathematics 2021, 9, 768. [Google Scholar] [CrossRef]
- Vakhania, N.; Werner, F. Branch Less, Cut More and Schedule Jobs with Release and Delivery Times on Uniform Machines. Mathematics 2021, 9, 633. [Google Scholar] [CrossRef]
- Kusoncum, C.; Sethanan, K.; Pitakaso, R.; Hartl, R.F. Heuristics with Novel Approaches for Cyclical Multiple Parallel Machine Scheduling in Sugarcane Unloading Systems. Int. J. Prod. Res. 2020, 1–19. [Google Scholar] [CrossRef]
- Lin, Y.K.; Pfund, M.E.; Fowler, J.W. Heuristics for Minimizing Regular Performance Measures in Unrelated Parallel Machine Scheduling Problems. Comput. Oper. Res. 2011, 38, 901–916. [Google Scholar] [CrossRef]
- Zhou, S.; Li, X.; Du, N.; Pang, Y.; Chen, H. A Multi-Objective Differential Evolution Algorithm for Parallel Batch Processing Machine Scheduling Considering Electricity Consumption Cost. Comput. Oper. Res. 2018, 96, 55–68. [Google Scholar] [CrossRef]
- Sethanan, K.; Jamrus, T. Hybrid Differential Evolution Algorithm and Genetic Operator for Multi-Trip Vehicle Routing Problem with Backhauls and Heterogeneous Fleet in the Beverage Logistics Industry. Comput. Ind. Eng. 2020, 146, 106571. [Google Scholar] [CrossRef]
- Theeraviriya, C.; Sirirak, W.; Praseeratasang, N. Location and Routing Planning Considering Electric Vehicles with Restricted Distance in Agriculture. World Electr. Veh. J. 2020, 11, 61. [Google Scholar] [CrossRef]
- Jirasirilerd, G.; Pitakaso, R.; Sethanan, K.; Kaewman, S.; Sirirak, W.; Kosacka-Olejnik, M. Simple Assembly Line Balancing Problem Type 2 by Variable Neighborhood Strategy Adaptive Search: A Case Study Garment Industry. J. Open Innov. Technol. Mark. Complex. 2020, 6, 21. [Google Scholar] [CrossRef] [Green Version]
- Zeng, Y.; Che, A.; Wu, X. Bi-Objective Scheduling on Uniform Parallel Machines Considering Electricity Cost. Eng. Optim. 2017, 50, 19–36. [Google Scholar] [CrossRef]
- Sethanan, K.; Wisittipanich, W.; Wisittipanit, N.; Nitisiri, K.; Moonsri, K. Integrating Scheduling with Optimal Sublot for Parallel Machine with Job Splitting and Dependent Setup Times. Comput. Ind. Eng. 2019, 137, 106095. [Google Scholar] [CrossRef]
- Li, K.; Zhang, X.; Leung, J.Y.-T.; Yang, S.-L. Parallel Machine Scheduling Problems in Green Manufacturing Industry. J. Manuf. Syst. 2016, 38, 98–106. [Google Scholar] [CrossRef]
- Al-Shayea, A.M.; Saleh, M.; Alatefi, M.; Ghaleb, M. Scheduling Two Identical Parallel Machines Subjected to Release Times, Delivery Times and Unavailability Constraints. Processes 2020, 8, 1025. [Google Scholar] [CrossRef]
- Eltaeib, T.; Mahmood, A. Differential Evolution: A Survey and Analysis. Appl. Sci. 2018, 8, 1945. [Google Scholar] [CrossRef] [Green Version]
- Storn, R.; Price, K. Differential Evolution—A Simple and Efficient Heuristic for Global Optimization over Continuous Spaces. J. Glob. Optim. 1997, 11, 341–359. [Google Scholar] [CrossRef]
- Wang, W.-L.; Wang, H.-Y.; Zhao, Y.-W.; Zhang, L.-P.; Xu, X.-L. Parallel Machine Scheduling with Splitting Jobs by a Hybrid Differential Evolution Algorithm. Comput. Oper. Res. 2013, 40, 1196–1206. [Google Scholar] [CrossRef]
- Praseeratasang, N.; Pitakaso, R.; Sethanan, K.; Kosacka-Olejnik, M.; Theeraviriya, C. Adaptive Large Neighborhood Search to Solve Multi-Level Scheduling and Assignment Problems in Broiler Farms. J. Open Innov. Technol. Mark. Complex. 2019, 5, 37. [Google Scholar] [CrossRef] [Green Version]
- Praseeratasang, N.; Pitakaso, R.; Sethanan, K.; Kaewman, S.; Golinska-Dawson, P. Adaptive Large Neighborhood Search for a Production Planning Problem Arising in Pig Farming. J. Open Innov. Technol. Mark. Complex. 2019, 5, 26. [Google Scholar] [CrossRef] [Green Version]
- Pitakaso, R.; Sethanan, K. Adaptive Large Neighborhood Search for Scheduling Sugarcane Inbound Logistics Equipment and Machinery under a Sharing Infield Resource System. Comput. Electron. Agric. 2019, 158, 313–325. [Google Scholar] [CrossRef]
- Cota, L.P.; Guimarães, F.G.; de Oliveira, F.B.; Souza, M.J.F. An Adaptive Large Neighborhood Search with Learning Automata for the Unrelated Parallel Machine Scheduling Problem. Available online: https://0-ieeexplore-ieee-org.brum.beds.ac.uk/abstract/document/7969312 (accessed on 26 February 2021).
- Khamsing, N.; Chindaprasert, K.; Pitakaso, R.; Sirirak, W.; Theeraviriya, C. Modified ALNS Algorithm for a Processing Application of Family Tourist Route Planning: A Case Study of Buriram in Thailand. Computation 2021, 9, 23. [Google Scholar] [CrossRef]
- Cota, L.P.; Guimarães, F.G.; Ribeiro, R.G.; Meneghini, I.R.; de Oliveira, F.B.; Souza, M.J.F.; Siarry, P. An Adaptive Multi-Objective Algorithm Based on Decomposition and Large Neighborhood Search for a Green Machine Scheduling Problem. Swarm Evol. Comput. 2019, 51, 100601. [Google Scholar] [CrossRef]
- Theeraviriya, C.; Pitakaso, R.; Sethanan, K.; Kaewman, S.; Kosacka-Olejnik, M. A New Optimization Technique for the Location and Routing Management in Agricultural Logistics. J. Open Innov. Technol. Mark. Complex. 2020, 6, 11. [Google Scholar] [CrossRef] [Green Version]
- Pitakaso, R.; Sethanan, K.; Theeraviriya, C. Variable Neighborhood Strategy Adaptive Search for Solving Green 2-Echelon Location Routing Problem. Comput. Electron. Agric. 2020, 173, 105406. [Google Scholar] [CrossRef]
- Pitakaso, R.; Sethanan, K.; Jirasirilerd, G.; Golinska-Dawson, P. A Novel Variable Neighborhood Strategy Adaptive Search for SALBP-2 Problem with a Limit on the Number of Machine’s Types. Ann. Oper. Res. 2021. [Google Scholar] [CrossRef]
- Liu, C.-H. Approximate Trade-off between Minimisation of Total Weighted Tardiness and Minimisation of Carbon Dioxide (CO2) Emissions in Bi-Criteria Batch Scheduling Problem. Int. J. Comput. Integr. Manuf. 2013, 27, 759–771. [Google Scholar] [CrossRef]
- Pan, Z.; Lei, D.; Zhang, Q. A New Imperialist Competitive Algorithm for Multiobjective Low Carbon Parallel Machines Scheduling. Math. Probl. Eng. 2018, 2018, 1–13. [Google Scholar] [CrossRef] [Green Version]
- Chen, B.; Potts, C.N.; Woeginger, G.J. A Review of Machine Scheduling: Complexity, Algorithms and Approximability. Handb. Comb. Optim. 1998, 1493–1641. [Google Scholar] [CrossRef]
- Pinedo, M.L. Scheduling; Springer International Publishing: Cham, Swizerland, 2016. [Google Scholar] [CrossRef]
- Behera, D.K. Complexity on Parallel Machine Scheduling: A Review. Lect. Notes Mech. Eng. 2012, 373–381. [Google Scholar] [CrossRef]
- Theeraviriya, C.; Ruamboon, K.; Praseeratasang, N. Solving the Multi-Level Location Routing Problem Considering the Environmental Impact Using a Hybrid Metaheuristic. Int. J. Eng. Bus. Manag. 2021, 13, 184797902110173. [Google Scholar] [CrossRef]
- Mouzon, G.; Yildirim, M.B.; Twomey, J. Operational Methods for Minimization of Energy Consumption of Manufacturing Equipment. Int. J. Prod. Res. 2007, 45, 4247–4271. [Google Scholar] [CrossRef] [Green Version]
- Angel, E.; Bampis, E.; Kacem, F. Energy Aware Scheduling for Unrelated Parallel Machines. Available online: https://0-ieeexplore-ieee-org.brum.beds.ac.uk/abstract/document/6468361 (accessed on 27 February 2021).
- Sobottka, T.; Kamhuber, F.; Heinzl, B. Simulation-Based Multi-Criteria Optimization of Parallel Heat Treatment Furnaces at a Casting Manufacturer. J. Manuf. Mater. Process. 2020, 4, 94. [Google Scholar] [CrossRef]
- Nanthapodej, R.; Liu, C.-H.; Nitisiri, K.; Pattanapairoj, S. Hybrid Differential Evolution Algorithm and Adaptive Large Neighborhood Search to Solve Parallel Machine Scheduling to Minimize Energy Consumption in Consideration of Machine-Load Balance Problems. Sustainability 2021, 13, 5470. [Google Scholar] [CrossRef]
- Chaudhry, I.A.; Elbadawi, I.A. Minimisation of total tardiness for identical parallel machine scheduling using genetic algorithm. Sādhanā 2017, 42, 11–21. [Google Scholar] [CrossRef] [Green Version]
- Pei, J.; Cheng, B.; Liu, X.; Pardalos, P.M.; Kong, M. Single-Machine and Parallel-Machine Serial-Batching Scheduling Problems with Position-Based Learning Effect and Linear Setup Time. Ann. Oper. Res. 2017, 272, 217–241. [Google Scholar] [CrossRef]
- Maecker, S.; Shen, L. Solving Parallel Machine Problems with Delivery Times and Tardiness Objectives. Ann. Oper. Res. 2019, 285, 315–334. [Google Scholar] [CrossRef]
- Zhou, S.; Liu, M.; Chen, H.; Li, X. An Effective Discrete Differential Evolution Algorithm for Scheduling Uniform Parallel Batch Processing Machines with Non-Identical Capacities and Arbitrary Job Sizes. Int. J. Prod. Econ. 2016, 179, 1–11. [Google Scholar] [CrossRef]
- Wu, X.; Che, A. A Memetic Differential Evolution Algorithm for Energy-Efficient Parallel Machine Scheduling. Omega 2019, 82, 155–165. [Google Scholar] [CrossRef]
- Li, D.; Wang, J.; Qiang, R.; Chiong, R. A Hybrid Differential Evolution Algorithm for Parallel Machine Scheduling of Lace Dyeing Considering Colour Families, Sequence-Dependent Setup and Machine Eligibility. Int. J. Prod. Res. 2020, 1–17. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
| Track | Position | Job Elements | Machine Elements | |||||||||||
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | A | B | C | ||
| 1 | 0.48 | 0.70 | 0.22 | 0.43 | 0.75 | 0.91 | 0.04 | 0.41 | 0.48 | 0.34 | 0.95 | 0.31 | 0.65 | |
| 2 | 0.99 | 0.06 | 0.84 | 0.63 | 0.38 | 0.87 | 0.03 | 0.94 | 0.74 | 0.41 | 0.39 | 0.26 | 0.63 | |
| 3 | 0.04 | 0.49 | 0.62 | 0.44 | 0.13 | 0.49 | 0.59 | 0.32 | 0.97 | 0.44 | 0.02 | 0.52 | 0.01 | |
| 4 | 0.94 | 0.16 | 0.34 | 0.67 | 0.17 | 0.90 | 0.26 | 0.25 | 0.93 | 0.95 | 0.59 | 0.62 | 0.37 | |
| 5 | 0.46 | 0.90 | 0.68 | 0.60 | 0.19 | 0.26 | 0.15 | 0.30 | 0.60 | 0.22 | 0.54 | 0.46 | 0.72 | |
| Job j | m | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Pjm | A | 22 | 15 | 30 | 16 | 29 | 25 | 26 | 18 | 26 | 19 |
| B | 24 | N/A | 20 | 29 | 25 | 22 | 29 | N/A | 16 | 16 | |
| C | 24 | 16 | 18 | 22 | 18 | N/A | 17 | 17 | 18 | 27 | |
| Ejm | A | 26 | 17 | 29 | 19 | 27 | 25 | 26 | 23 | 22 | 29 |
| B | 21 | N/A | 30 | 18 | 25 | 23 | 30 | N/A | 28 | 26 | |
| C | 24 | 29 | 19 | 30 | 17 | N/A | 19 | 18 | 28 | 24 | |
| Dj | 30 | 45 | 80 | 85 | 120 | 45 | 150 | 30 | 50 | 200 | |
| aj | 483 | 421 | 338 | 449 | 438 | 480 | 383 | 321 | 389 | 418 | |
| Track before ROV | Job/Machine | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | A | B | C |
| Value in position | 0.48 | 0.7 | 0.22 | 0.43 | 0.75 | 0.91 | 0.04 | 0.41 | 0.48 | 0.34 | 0.95 | 0.31 | 0.65 | |
| Track after ROV | Job/Machine | 7 | 3 | 10 | 8 | 4 | 1 | 9 | 2 | 5 | 6 | B | C | A |
| Value in position | 0.04 | 0.22 | 0.34 | 0.41 | 0.43 | 0.48 | 0.48 | 0.7 | 0.75 | 0.91 | 0.31 | 0.65 | 0.95 |
| Job | 7 | 3 | 10 | 8 | 4 | 1 | 9 | 2 | 5 | 6 |
| Machine | B | C | A | C | B | A | B | C | A | B |
| Energy used (THB) | 30 | 19 | 29 | 18 | 18 | 26 | 28 | 29 | 27 | 23 |
| Job | 10 | 1 | 5 | |||||
| Machine A | S10,A | C10,A | S1,A | C1,A | S5,A | C5,A | ||
| Sjm/Cjm | 0 | 19 | 19 | 41 | 41 | 70 | ||
| Dj | 200 | 30 | 120 | |||||
| Lj | 0 | 11 | 0 | |||||
| Tj | 0 | 1 | 0 | |||||
| Job | 7 | 4 | 9 | 6 | ||||
| Machine B | S7,B | C7,B | S4,B | C74B | S9,B | C9,B | S6,B | C6,B |
| Sjm/Cjm | 0 | 29 | 29 | 58 | 58 | 76 | 76 | 98 |
| Dj | 150 | 85 | 50 | 45 | ||||
| Lj | 0 | 0 | 26 | 53 | ||||
| Tj | 0 | 0 | 1 | 1 | ||||
| Job | 3 | 8 | 2 | |||||
| Machine C | S3,C | C3,C | S8,C | C8,C | S2,C | C2,C | ||
| Sjm/Cjm | 0 | 18 | 18 | 35 | 35 | 51 | ||
| Dj | 80 | 30 | 45 | |||||
| Lj | 0 | 5 | 6 | |||||
| Tj | 0 | 1 | 1 |
| Type | Job Element | Machine Element | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Job | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D |
| 0.58 | 0.49 | 0.52 | 0.5 | 0.6 | 0.98 | 0.24 | 0.72 | 0.26 | 0.09 | 0.18 | 0.88 | 0.26 | |
| 0.20 | 0.31 | 0.12 | 0.67 | 0.12 | 0.35 | 0.75 | 0.95 | 0.66 | 0.18 | 0.56 | 0.70 | 0.03 | |
| 0.12 | 0.15 | 0.06 | 0.33 | 0.07 | 0.34 | 0.18 | 0.68 | 0.17 | 0.02 | 0.10 | 0.62 | 0.01 | |
| Group Test Instance | Number of Test Instances | Pjm (m) | Number of Jobs | Number of Machines | Ejm (THB) | TMAX | B | LMAX |
|---|---|---|---|---|---|---|---|---|
| Small | 12 | 4–30 | 5–30 | 2–5 | 30–75 | 20–30% | 10–50 | 10–100 |
| Medium | 12 | 4–20 | 40–52 | 3–5 | 30–75 | 20–30% | 10–50 | 10–100 |
| Large | 12 | 4–20 | 80–134 | 5–8 | 30–75 | 20–30% | 10–50 | 10–100 |
| Case study | 1 | 4–20 | 201 | 11 | 30–75 | 20–30% | 10–50 | 10–100 |
| Algorithm | Detail |
|---|---|
| DE | Traditional DE |
| CU | Current practice procedure |
| VaNSAS | Variable neighborhood strategy adaptive search |
| SDR | Solution destroy and repair methods |
| TTM | Track-transition methods |
| MF | Multiplier factor |
| No | Job | m | NT | Lingo v.11 | Traditional Method (THB) | Proposed Methods | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Obj. (THB) | Com. Time (sec) | DE | CU | VaNSAS | SDR | TTM | MF | ||||||||||
| Best Sol. | Max. Error | Best Sol. | Max. Error | Best Sol. | Max. Error | Best Sol. | Max. Error | Best Sol. | Max. Error | Best Sol. | Max. Error | ||||||
| S-1 | 5 | 3 | 2 | 5150 | 872 | 5180 | 155 | 6782 | 474 | 5150 | 0 | 6718 | 268 | 6212 | 186 | 6237 | 311 |
| S-2 | 6 | 3 | 2 | 6820 | 651 | 6954 | 139 | 7428 | 371 | 6820 | 0 | 7119 | 355 | 7023 | 210 | 6988 | 209 |
| S-3 | 10 | 4 | 2 | 10,230 | 2056 | 10,230 | 102 | 13,981 | 699 | 10,230 | 0 | 12,238 | 367 | 13,148 | 657 | 13,119 | 655 |
| S-4 | 15 | 3 | 2 | 10,921 | 1843 | 11,589 | 115 | 13,879 | 555 | 10,921 | 0 | 12,239 | 611 | 12,181 | 487 | 12,033 | 481 |
| S-5 | 15 | 3 | 4 | 10,831 | 4561 | 10,831 | 108 | 14,713 | 588 | 10,831 | 0 | 12,815 | 640 | 12,219 | 366 | 12,172 | 608 |
| S-6 | 20 | 3 | 3 | 9020 | 85,625 | 9347 | 280 | 10,895 | 544 | 9020 | 0 | 10,229 | 511 | 11,296 | 564 | 10,687 | 534 |
| S-7 | 20 | 4 | 3 | 8900 | 80,371 | 9492 | 284 | 11,374 | 568 | 8900 | 0 | 11,818 | 472 | 10,722 | 428 | 10,381 | 415 |
| S-8 | 25 | 4 | 3 | 11,612 | 76,819 | 12,784 | 255 | 14,981 | 749 | 11,612 | 0 | 13,209 | 660 | 13,348 | 533 | 12,987 | 389 |
| S-9 | 25 | 4 | 2 | 12,360 | 78,371 | 12,788 | 255 | 14,582 | 583 | 12,360 | 0 | 13,371 | 401 | 13,794 | 689 | 12,984 | 649 |
| S-10 | 25 | 4 | 5 | 11,390 | 67,621 | 11,390 | 113 | 15,378 | 461 | 11,390 | 0 | 12,879 | 643 | 12,046 | 602 | 12,288 | 614 |
| S-11 | 28 | 4 | 5 | 13,705 | 84,004 | 13,794 | 137 | 17,619 | 880 | 13,705 | 0 | 14,013 | 560 | 14,237 | 569 | 14,886 | 744 |
| S-12 | 30 | 4 | 5 | 11,006 | 89,122 | 12,891 | 257 | 16,716 | 835 | 11,006 | 0 | 13,310 | 532 | 14,018 | 420 | 13,873 | 693 |
| % different from Lingo | 4.52 | 29.05 | 0.00 | 14.43 | 15.01 | 13.44 | |||||||||||
| % found optimal solution | 25% | 0% | 100% | 0% | 0% | 0% | |||||||||||
| DE | CU | VaNSAS | SDR | TTM | MF | |
|---|---|---|---|---|---|---|
| Lingo | 0.022 | 0.000 | 0.207 | 0.000 | 0.000 | 0.000 |
| DE | 0.000 | 0.007 | 0.001 | 0.000 | 0.001 | |
| CU | 0.000 | 0.000 | 0.001 | 0.001 | ||
| VaNSAS | 0.000 | 0.000 | 0.000 | |||
| SDR | 0.907 | 0.591 | ||||
| TTM | 0.247 |
| No | Job | m | NT | Exact Method | Traditional Method (THB) | Proposed Methods | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Lingo | DE | CU | VaNSAS | SDR | TTM | MF | ||||||||||
| Best Sol. | Max. Error | Best Sol. | Max. Error | Best Sol. | Max. Error | Best Sol. | Max. Error | Best Sol. | Max. Error | Best Sol. | Max. Error | |||||
| M-1 | 40 | 5 | 3 | 18,227 | 16,381 | 163 | 18,728 | 936 | 15,794 | 157 | 17,719 | 708 | 17,653 | 529 | 17,756 | 532 |
| M-2 | 40 | 4 | 4 | 18,385 | 17,288 | 518 | 21,193 | 2119 | 15,992 | 159 | 17,578 | 703 | 17,233 | 861 | 17,481 | 874 |
| M-3 | 40 | 4 | 2 | 19,371 | 16,872 | 337 | 22,371 | 1118 | 16,014 | 320 | 17,722 | 886 | 17,235 | 689 | 17,443 | 697 |
| M -4 | 45 | 4 | 4 | 19,184 | 16,880 | 506 | 20,883 | 1670 | 16,598 | 497 | 16,957 | 847 | 17,182 | 687 | 17,084 | 512 |
| M -5 | 45 | 3 | 2 | 21,827 | 17,998 | 179 | 21,059 | 1263 | 17,550 | 526 | 18,018 | 720 | 18,242 | 912 | 18,115 | 905 |
| M -6 | 45 | 3 | 5 | 21,284 | 17,094 | 170 | 22,014 | 1761 | 16,881 | 506 | 17,225 | 689 | 17,188 | 687 | 17,269 | 518 |
| M -7 | 45 | 5 | 4 | 21,189 | 16,995 | 339 | 20,913 | 2091 | 16,774 | 335 | 17,281 | 518 | 17,192 | 515 | 17,007 | 680 |
| M -8 | 45 | 5 | 2 | 21,087 | 18,047 | 180 | 22,387 | 2238 | 17,559 | 351 | 18,817 | 564 | 19,110 | 764 | 18,349 | 733 |
| M -9 | 50 | 5 | 4 | 24,871 | 20,122 | 402 | 25,881 | 2329 | 19,563 | 195 | 21,883 | 656 | 22,915 | 1145 | 23,120 | 924 |
| M -10 | 50 | 5 | 3 | 24,483 | 23,287 | 232 | 24,879 | 2239 | 22,397 | 223 | 23,589 | 1179 | 23,117 | 924 | 22,996 | 689 |
| M -11 | 50 | 3 | 5 | 25,598 | 24,448 | 733 | 26,712 | 2404 | 22,014 | 220 | 24,421 | 732 | 24,388 | 731 | 24,817 | 1240 |
| M-12 | 52 | 4 | 6 | 26,515 | 24,481 | 734 | 26,818 | 1340 | 22,456 | 673 | 25,817 | 1032 | 25,985 | 1039 | 25,671 | 1026 |
| % Improved from best objective found by Lingo | 14.59 | 4.37 | 19.55 | 11.19 | 11.04 | 11.24 | ||||||||||
| DE | CU | VaNSAS | SDR | TTM | MF | |
|---|---|---|---|---|---|---|
| Lingo | 0.000 | 0.006 | 0.000 | 0.001 | 0.000 | 0.001 |
| DE | 0.000 | 0.002 | 0.006 | 0.030 | 0.039 | |
| CU | 0.000 | 0.000 | 0.000 | 0.000 | ||
| VaNSAS | 0.000 | 0.001 | 0.001 | |||
| SDR | 0.777 | 0.962 | ||||
| TTM | 0.767 |
| No | Job | m | NT | Exact Method | Traditional Method (THB) | Proposed Methods | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Lingo | DE | CU | VaNSAS | SDR | TTM | MF | ||||||||||
| Best Sol. | Max. Error | Best Sol. | Max. Error | Best Sol. | Max. Error | Best Sol. | Max. Error | Best Sol. | Max. Error | Best Sol. | Max. Error | |||||
| L-1 | 80 | 5 | 6 | 47,968 | 45,871 | 1376 | 52,297 | 5229 | 39,917 | 1197 | 46,617 | 1864 | 46,521 | 1960 | 45,598 | 1823 |
| L-2 | 80 | 5 | 5 | 49,351 | 41,278 | 825 | 45,580 | 4102 | 40,015 | 1200 | 42,893 | 1715 | 42,886 | 1293 | 42,361 | 1270 |
| L-3 | 80 | 4 | 5 | 37,599 | 33,192 | 998 | 38,817 | 2329 | 31,108 | 311 | 34,918 | 1396 | 34,118 | 1847 | 34,287 | 1028 |
| L-4 | 80 | 3 | 5 | 41,625 | 38,185 | 381 | 41,491 | 2904 | 36,614 | 366 | 38,811 | 1164 | 38,927 | 1824 | 38,891 | 1555 |
| L-5 | 100 | 4 | 6 | 52,604 | 47,467 | 474 | 53,158 | 3721 | 44,581 | 891 | 48,819 | 2440 | 48,984 | 2275 | 48,816 | 1464 |
| L-6 | 100 | 5 | 6 | 56,497 | 49,981 | 1499 | 57,619 | 5185 | 48,819 | 1464 | 50,176 | 1505 | 51,197 | 484 | 52,348 | 1570 |
| L-7 | 100 | 6 | 6 | 55,823 | 50,187 | 1003 | 58,281 | 4079 | 47,713 | 954 | 51,810 | 1554 | 52,184 | 2216 | 52,183 | 1565 |
| L-8 | 100 | 7 | 6 | 54,891 | 49,571 | 1487 | 55,819 | 3349 | 47,289 | 1418 | 50,972 | 2548 | 50,013 | 2488 | 51,197 | 2047 |
| L-9 | 120 | 6 | 7 | 67,905 | 62,995 | 1889 | 68,913 | 6891 | 59,982 | 599 | 63,395 | 3169 | 64,512 | 1418 | 53,891 | 2155 |
| L-10 | 120 | 7 | 7 | 67,067 | 63,417 | 1268 | 68,919 | 4135 | 58,813 | 1764 | 64,992 | 1949 | 63,857 | 4384 | 64,387 | 3219 |
| L-11 | 120 | 8 | 6 | 65,596 | 60,874 | 608 | 65,817 | 5265 | 58,716 | 1174 | 59,816 | 1794 | 60,128 | 2678 | 60,016 | 3000 |
| L-12 | 134 | 8 | 7 | 72,168 | 67,617 | 676 | 73,215 | 5125 | 64,480 | 644 | 67,764 | 2710 | 67,366 | 3108 | 67,952 | 2718 |
| C-1 | 201 | 11 | 7 | 128,704 | 118,917 | 2378 | 129,814 | 11,683 | 110,172 | 2203 | 119,859 | 5992 | 119,347 | 4107 | 119,846 | 5992 |
| % Improved from best objective found by Lingo | 9.88 | 1.42 | 16.35 | 7.89 | 8.01 | 9.33 | ||||||||||
| DE | CU | VaNSAS | SDR | TTM | MF | |
|---|---|---|---|---|---|---|
| Lingo | 0.000 | 0.090 | 0.000 | 0.000 | 0.000 | 0.000 |
| DE | 0.000 | 0.000 | 0.002 | 0.003 | 0.836 | |
| CU | 0.000 | 0.000 | 0.000 | 0.000 | ||
| VaNSAS | 0.000 | 0.000 | 0.005 | |||
| SDR | 0.754 | 0.379 | ||||
| TTM | 0.468 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nanthapodej, R.; Liu, C.-H.; Nitisiri, K.; Pattanapairoj, S. Variable Neighborhood Strategy Adaptive Search to Solve Parallel-Machine Scheduling to Minimize Energy Consumption While Considering Job Priority and Control Makespan. Appl. Sci. 2021, 11, 5311. https://0-doi-org.brum.beds.ac.uk/10.3390/app11115311
Nanthapodej R, Liu C-H, Nitisiri K, Pattanapairoj S. Variable Neighborhood Strategy Adaptive Search to Solve Parallel-Machine Scheduling to Minimize Energy Consumption While Considering Job Priority and Control Makespan. Applied Sciences. 2021; 11(11):5311. https://0-doi-org.brum.beds.ac.uk/10.3390/app11115311
Chicago/Turabian StyleNanthapodej, Rujapa, Cheng-Hsiang Liu, Krisanarach Nitisiri, and Sirorat Pattanapairoj. 2021. "Variable Neighborhood Strategy Adaptive Search to Solve Parallel-Machine Scheduling to Minimize Energy Consumption While Considering Job Priority and Control Makespan" Applied Sciences 11, no. 11: 5311. https://0-doi-org.brum.beds.ac.uk/10.3390/app11115311