Accelerating Detection of Lung Pathologies with Explainable Ultrasound Image Analysis

 , , , , and
, , , , and
Abstract
:1. Introduction
1.1. Related Work
1.2. Our Contributions
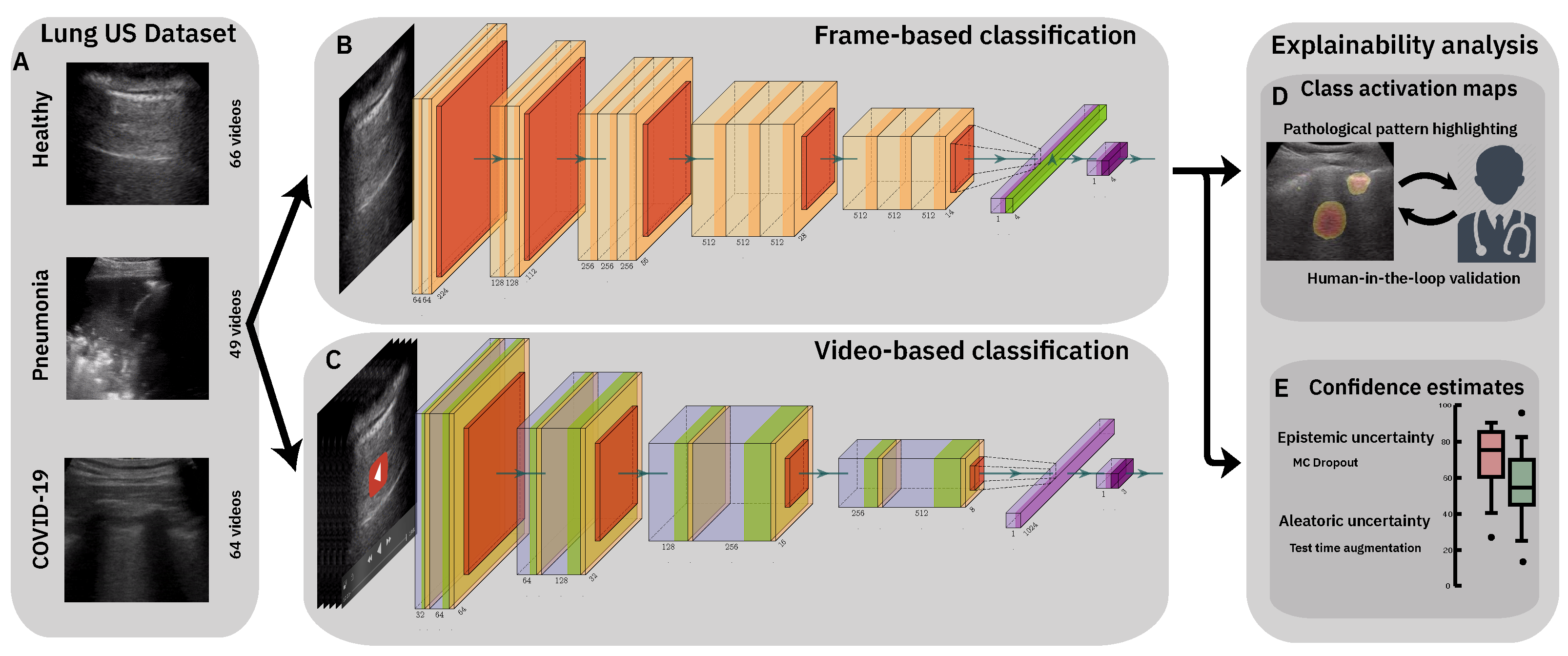
2. A Lung Ultrasound Dataset for COVID-19 Detection
2.1. Dataset Description
2.2. Data Collection
2.2.1. Northumbria Data
2.2.2. Neuruppin Data
2.3. Dataset Analysis
3. Classification of Lung Ultrasound Data
3.1. Methods
3.1.1. Data Processing
3.1.2. Frame-Based Models
3.1.3. Video-Based Model
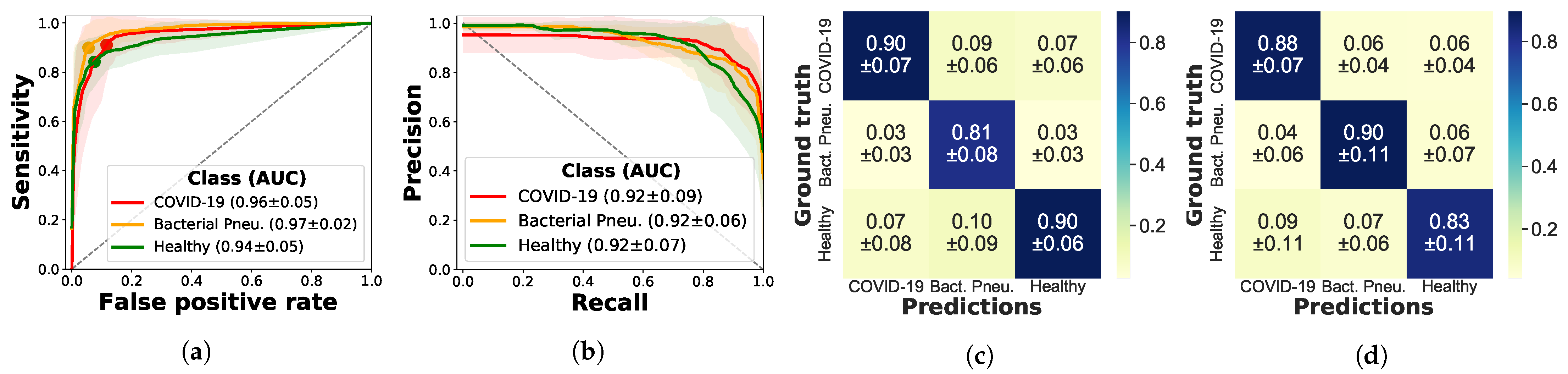
3.2. Results
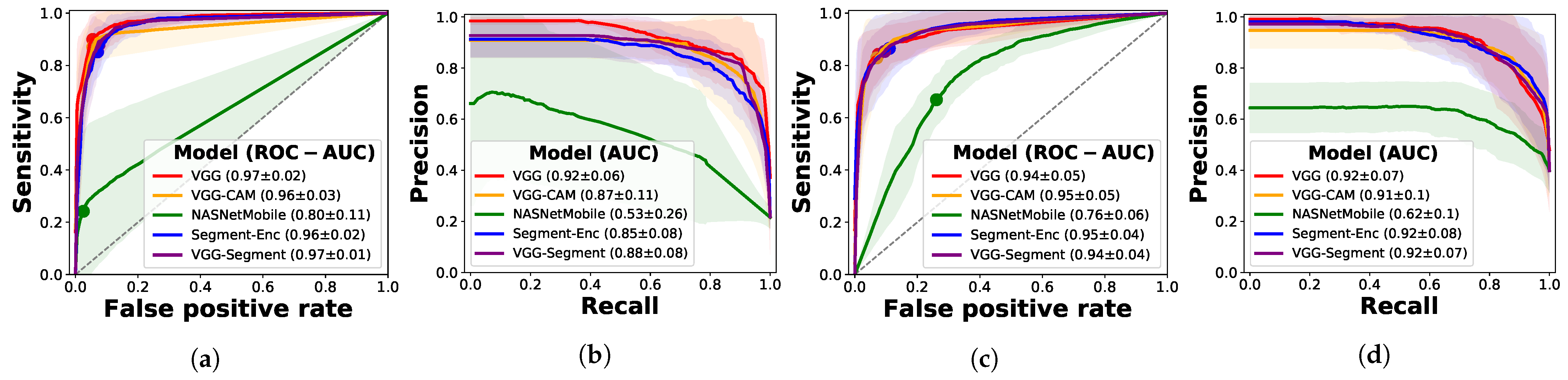
3.2.1. Frame-Based Experiments
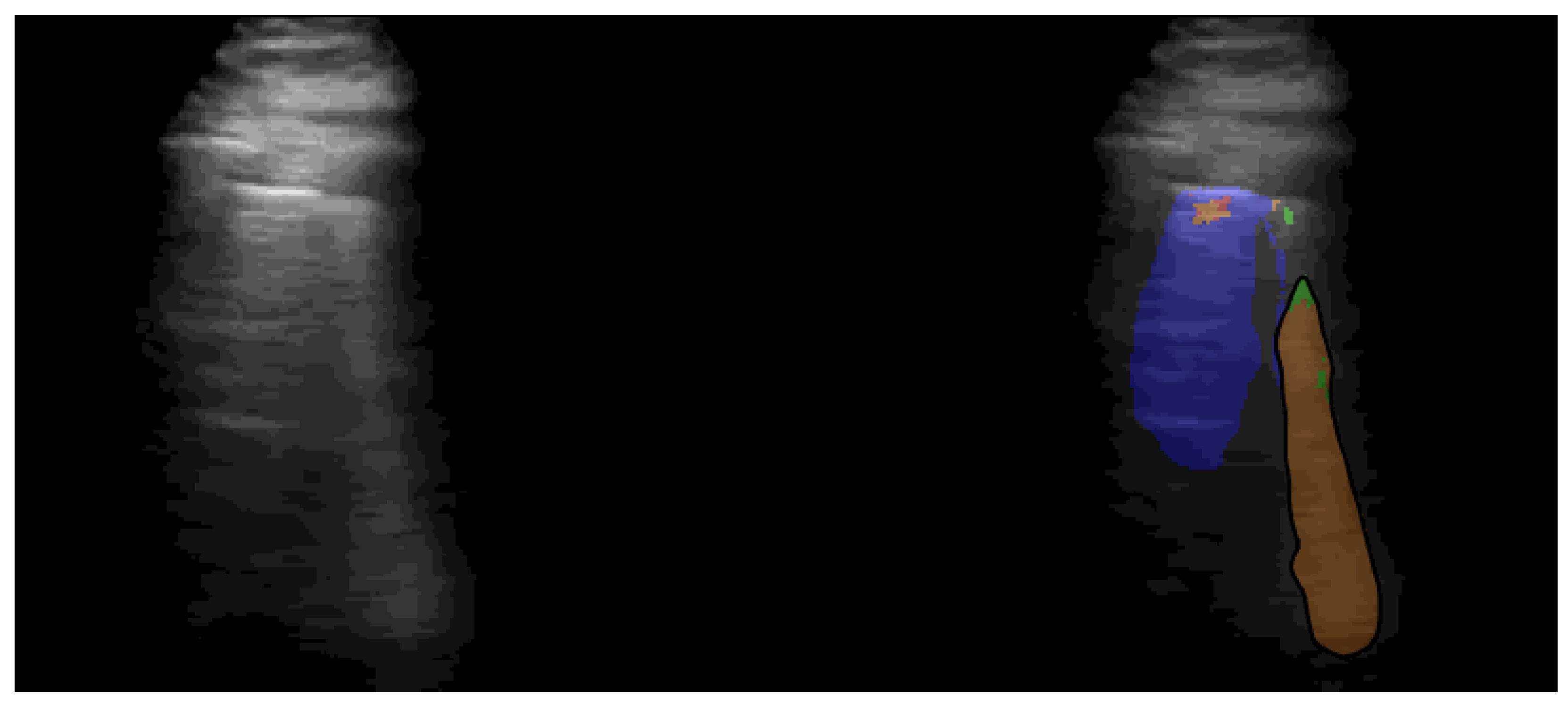
Ablation Study with Segmentation Models
Ablation Study on Other Architectures
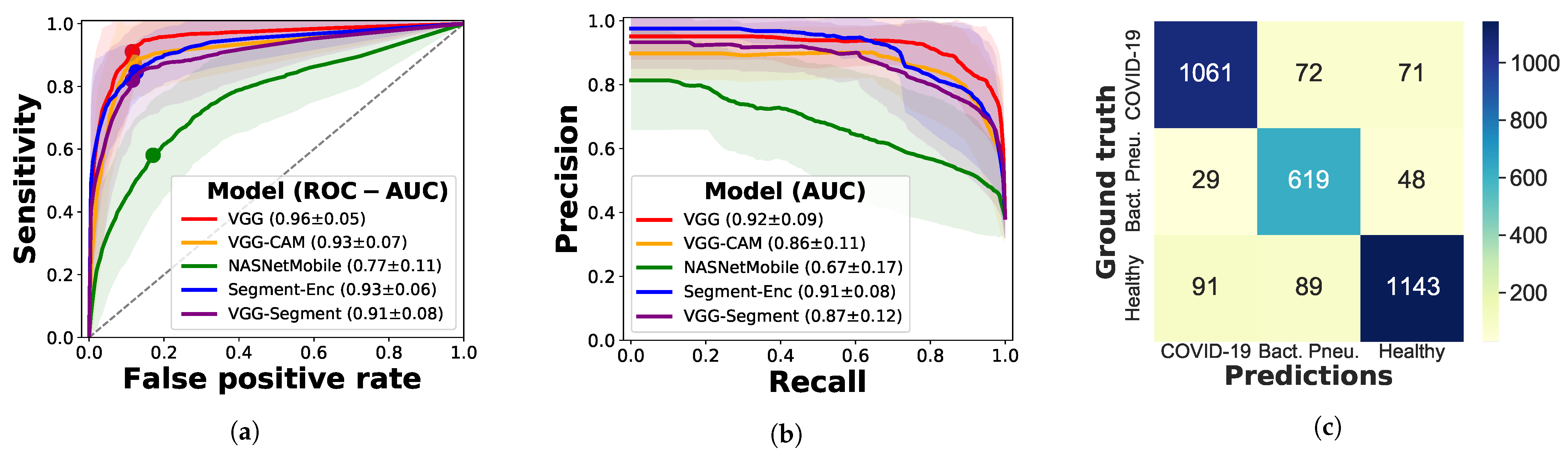
3.2.2. Video-Based Experiments
3.2.3. Evaluation on Independent Test Data
4. Model Explainability
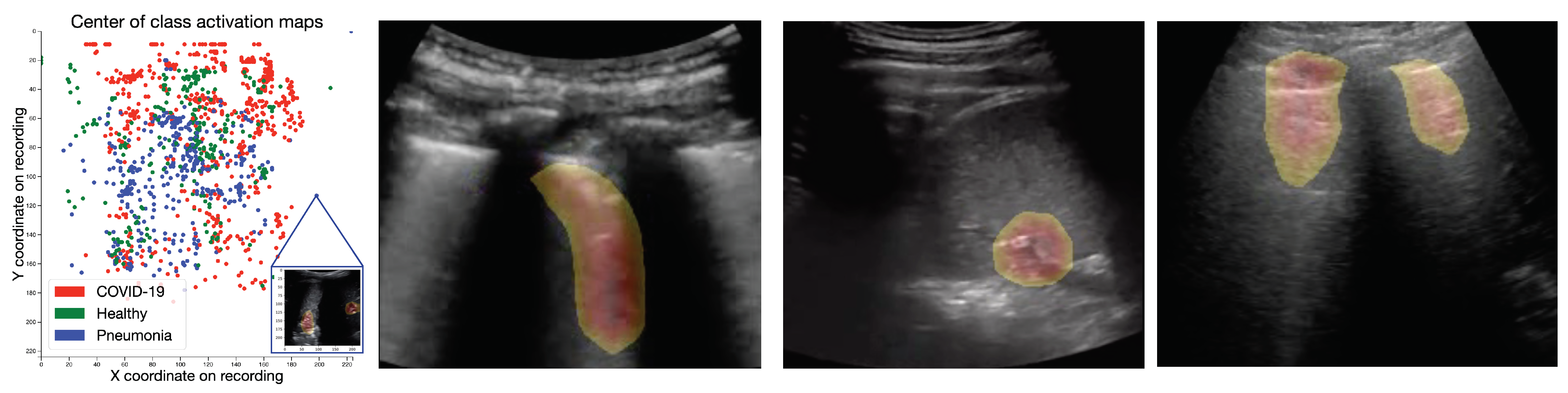
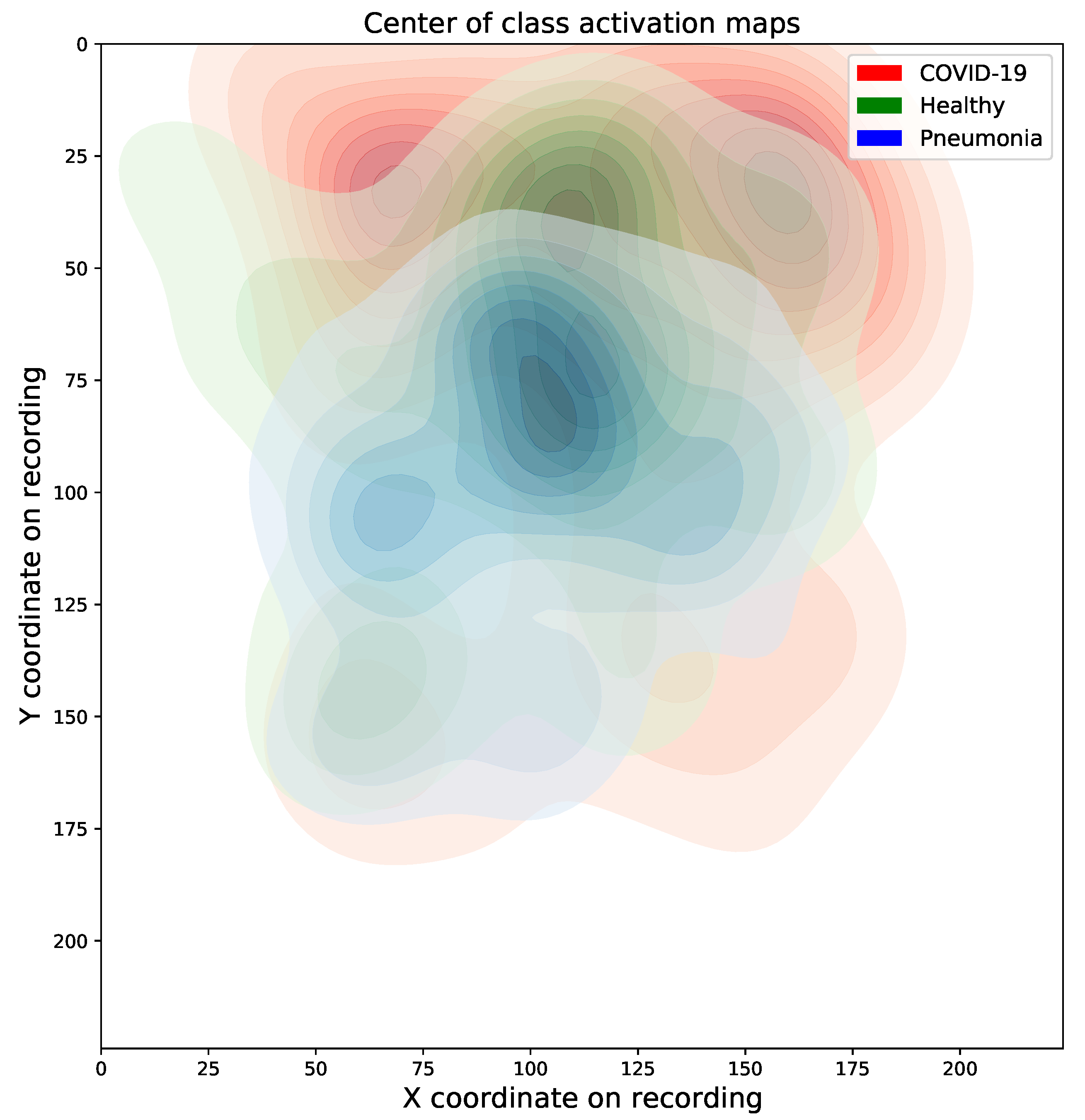
4.1. Class Activation Maps
4.1.1. Results
4.1.2. Expert Validation of CAMs for Human-in-the-Loop Settings
4.2. Confidence Estimates
5. Discussion
5.1. Prediction Performance Evaluation
5.2. Dataset Limitations
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| CAM | Class Activation Map |
| CNN | Convolutional Neural Network |
| DL | Deep Learning |
| LUS | Lung Ultrasound |
| PCR | Polymerase Chain Reaction |
| RT-PCR | Reverse Transcription Polymerase Chain Reaction |
Appendix A. Dataset

{kind=link}
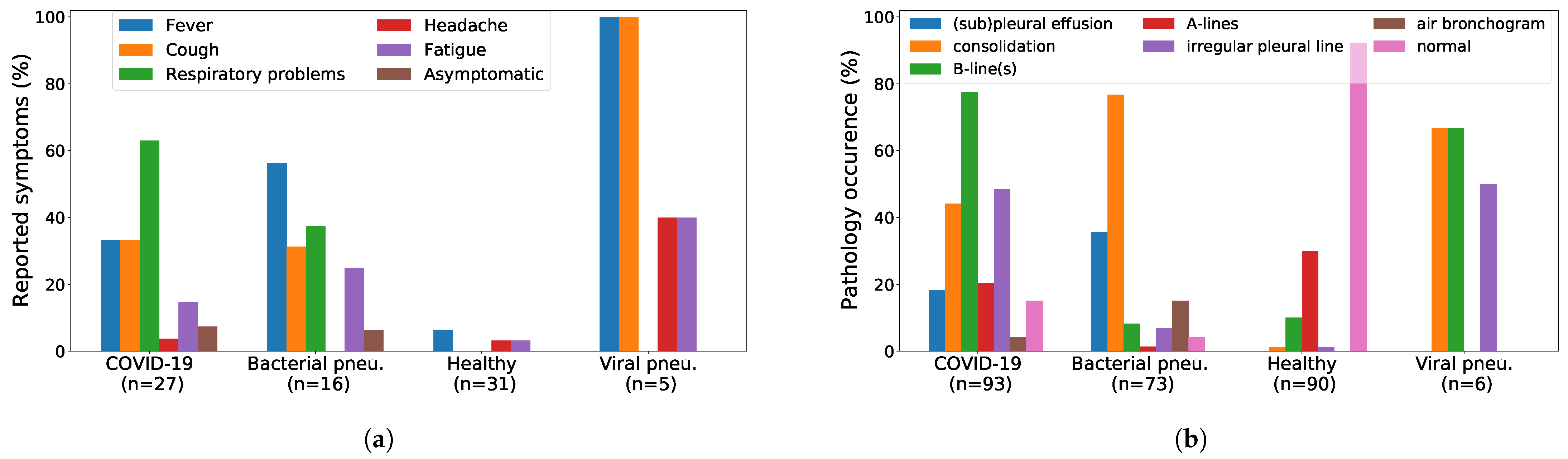{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Data Source | Data Selected | Description |
|---|---|---|
| Northumbria (NH NHS-FT) | Convex: 47 videos and 23 images (31 healthy and 39 bacterial pneumonia infected patients) | The Northumbria Healthcase NHS Foundation Trust (NH NHS-FT) contributed patient data (images and videos) to our dataset |
| Neuruppin (MHB) | Convex: 28 videos Linear: 3 videos (all healthy) | Ultrasoud course instructors from Medizinische Hochschule Brandenburg Theodor Fontane (MHB) recorded volunteers that did not show any symptoms of COVID-19 infections and were not tested positively |
| Publications | Convex: 15 images and 30 videos from all classes Linear: 4 images, 4 videos | Miscallaneous LUS videos and images were fetched from publications [19,83,84,85,86,87,88,89,90,91,92,93,94,95,96,97,98] |
| GrepMed | Convex: 9 COVID-19, 9 pneumonia and 2 healthy Linear: 3 COVID-19, 1 healthy (all videos) | GrepMed is a community-sourced, medical image repository for referencing clinically relevant medical images |
| Butterfly | Convex: 18 COVID-19 and 2 healthy videos | Butterfly is a vendor of a portable US device needing only a single probe usable on the whole body that connects to a smartphone |
| ThePocusAtlas | Convex: 8 COVID-19, 2 pneumonia and 3 healthy videos Linear: 2 COVID-19 videos | ThePocusAtlas is a Collaborative Ultrasound Education Platform |
| LITFL | Convex: 5 bacterial and 2 viral pneumonia (H1N1), 2 healthy Linear: 1 H1N1 (all videos) | Australasian critical care physicians maintain an educational platform and provide an ultrasound library with case studies |
| Web | Convex: 15 images, 15 videos Linear: 2 images, 6 videos from all classes | Remaining online sources were: https://www.stemlynsblog.org/, https://clarius.com/, https://everydayultrasound.com/, https://radiopaedia.org, https://www.acutemedicine.org, https://www.bcpocus.ca, https://www.youtube.com, www.sonographiebilder.de/ |
| Bolzano AG | 45 linear videos of probably COVID-19 infected patients | |
| (Data not used for any analysis presented herein) | Videos were recorded in spring 2020 in Piacenza (Italy) from patients suspected of COVID-19. Diagnosis was not confirmed via PCR or thorax imaging. Bolzano AG donated this data to our dataset. |
Data License
Appendix B. Model Architectures and Hyperparameter
Appendix B.1. Pretrained Segmentation Models

Appendix C. Results


Appendix C.1. Uninformative Class
| Class | Recall | Precision | F1-Score | Specificity | |
|---|---|---|---|---|---|
| VGG | COVID-19 | ||||
| Accuracy: 0.885 | Pneumonia | ||||
| Balanced: 0.903 | Healthy | ||||
| Par.: 14 747 971 | Uninformative | ||||
| VGG-CAM | COVID-19 | ||||
| Accuracy: 0.88 | Pneumonia | ||||
| Balanced: 0.894 | Healthy | ||||
| #Param.: 14 716 227 | Uninformative | ||||
| NASNetMobile | COVID-19 | ||||
| Accuracy: 0.588 | Pneumonia | ||||
| Balanced: 0.42 | Healthy | ||||
| #Param.: 4 814 487 | Uninformative | ||||
| VGG-Segment | COVID-19 | ||||
| Accuracy: 0.866 | Pneumonia | ||||
| Balanced: 0.877 | Healthy | ||||
| #Param.: 34 018 074 | Uninformative | ||||
| Segment-Enc | COVID-19 | ||||
| Accuracy: 0.873 | Pneumonia | ||||
| Balanced: 0.886 | Healthy | ||||
| Par.: 19 993 307 | Uninformative |
Appendix D. Class Activation Maps
| Consolidations | A-Lines | B-Lines | Bronchogram | Effusion | Pleural Line | |
|---|---|---|---|---|---|---|
| Specific for | Bacterial Pne. | Healthy | COVID-19 (Viral Pne.) | Bacterial Pne. | Pne. | Pne. If Irregular |
| Total visible | 18 | 13 | 12 | 2 | 7 | 20 (expert 2) |
| CAM (expert 1) | 17 | 6 | 0 | 2 | 1 | 0 |
| CAM (expert 2) | 17 | 10 | 6 | 0 | 0 | 9 |

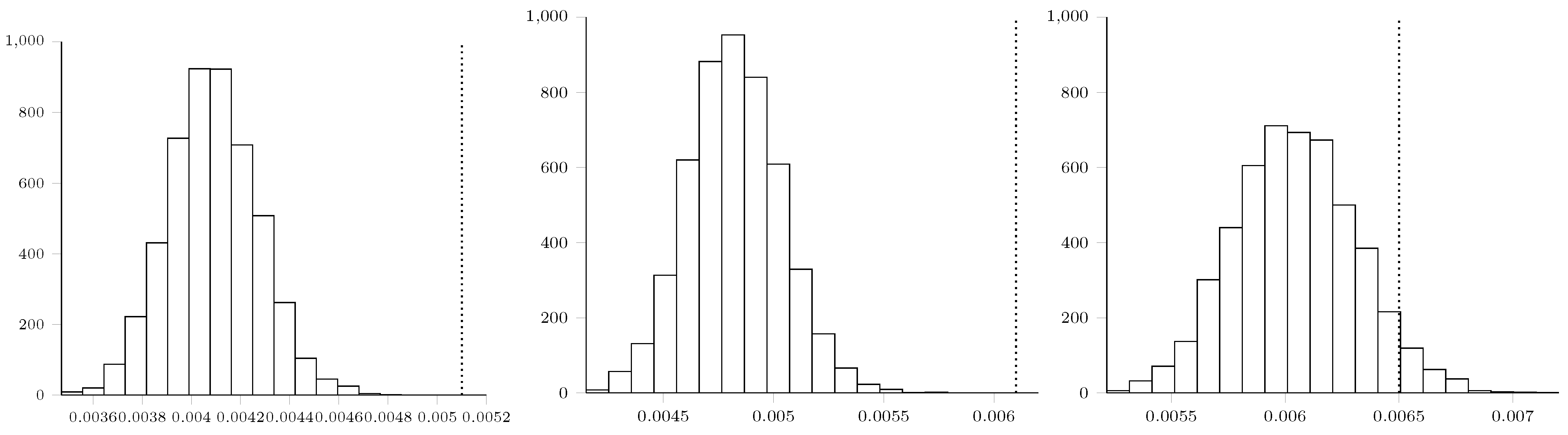
Maximum Mean Discrepancy Analysis

Appendix E. Statement of Broader Impact
Appendix E.1. Model Failure
Appendix E.2. Impact on Society
Appendix E.3. Biases and Validation
References
- Li, Q.; Guan, X.; Wu, P.; Wang, X.; Zhou, L.; Tong, Y.; Ren, R.; Leung, K.S.; Lau, E.H.; Wong, J.Y.; et al. Early transmission dynamics in Wuhan, China, of novel coronavirus–infected pneumonia. N. Engl. J. Med. 2020, 382, 1199–1207. [Google Scholar] [CrossRef]
- Mei, X.; Lee, H.C.; Diao, K.y.; Huang, M.; Lin, B.; Liu, C.; Xie, Z.; Ma, Y.; Robson, P.M.; Chung, M.; et al. Artificial intelligence–enabled rapid diagnosis of patients with COVID-19. Nat. Med. 2020, 26, 1224–1228. [Google Scholar] [CrossRef]
- Kanne, J.P.; Little, B.P.; Chung, J.H.; Elicker, B.M.; Ketai, L.H. Essentials for radiologists on COVID-19: An update—Radiology scientific expert panel. Radiology 2020, 296, E113–E114. [Google Scholar] [CrossRef] [Green Version]
- Ai, T.; Yang, Z.; Hou, H.; Zhan, C.; Chen, C.; Lv, W.; Tao, Q.; Sun, Z.; Xia, L. Correlation of chest CT and RT-PCR testing in coronavirus disease 2019 (COVID-19) in China: A report of 1014 cases. Radiology 2020, 296, E32–E40. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kucirka, L.M.; Lauer, S.A.; Laeyendecker, O.; Boon, D.; Lessler, J. Variation in False-Negative Rate of Reverse Transcriptase Polymerase Chain Reaction–Based SARS-CoV-2 Tests by Time Since Exposure. Ann. Intern. Med. 2020, 173, 262–267. [Google Scholar] [CrossRef] [PubMed]
- Dong, D.; Tang, Z.; Wang, S.; Hui, H.; Gong, L.; Lu, Y.; Xue, Z.; Liao, H.; Chen, F.; Yang, F.; et al. The role of imaging in the detection and management of COVID-19: A review. IEEE Rev. Biomed. Eng. 2020. [Google Scholar] [CrossRef] [PubMed]
- Bourcier, J.E.; Paquet, J.; Seinger, M.; Gallard, E.; Redonnet, J.P.; Cheddadi, F.; Garnier, D.; Bourgeois, J.M.; Geeraerts, T. Performance comparison of lung ultrasound and chest x-ray for the diagnosis of pneumonia in the ED. Am. J. Emerg. Med. 2014, 32, 115–118. [Google Scholar] [CrossRef] [PubMed]
- Bao, C.; Liu, X.; Zhang, H.; Li, Y.; Liu, J. COVID-19 Computed Tomography Findings: A Systematic Review and Meta-Analysis. J. Am. Coll. Radiol. 2020, 17, 701–709. [Google Scholar] [CrossRef] [PubMed]
- Fang, Y.; Zhang, H.; Xie, J.; Lin, M.; Ying, L.; Pang, P.; Ji, W. Sensitivity of chest CT for COVID-19: Comparison to RT-PCR. Radiology 2020, 296, E115–E117. [Google Scholar] [CrossRef]
- Yang, Y.; Huang, Y.; Gao, F.; Yuan, L.; Wang, Z. Lung ultrasonography versus chest CT in COVID-19 pneumonia: A two-centered retrospective comparison study from China. Intensive Care Med. 2020, 46, 1761–1763. [Google Scholar] [CrossRef]
- Mossa-Basha, M.; Meltzer, C.C.; Kim, D.C.; Tuite, M.J.; Kolli, K.P.; Tan, B.S. Radiology department preparedness for COVID-19: Radiology scientific expert panel. Radiology 2020, 296, E106–E112. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Castillo, M. The industry of CT scanning. Am. J. Neuroradiol. 2012, 33, 583–585. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Weinstock, M.; Echenique, A.; Daugherty, S.R.; Russell, J. Chest x-ray findings in 636 ambulatory patients with COVID-19 presenting to an urgent care center: A normal chest x-ray is no guarantee. J. Urgent Care Med. 2020, 14, 13–18. [Google Scholar]
- Sippel, S.; Muruganandan, K.; Levine, A.; Shah, S. Use of ultrasound in the developing world. Int. J. Emerg. Med. 2011, 4, 1–11. [Google Scholar] [CrossRef] [Green Version]
- Lichtenstein, D.; Goldstein, I.; Mourgeon, E.; Cluzel, P.; Grenier, P.; Rouby, J.J. Comparative diagnostic performances of auscultation, chest radiography, and lung ultrasonography in acute respiratory distress syndrome. Anesthesiology 2004, 100, 9–15. [Google Scholar] [CrossRef]
- Chavez, M.A.; Shams, N.; Ellington, L.E.; Naithani, N.; Gilman, R.H.; Steinhoff, M.C.; Santosham, M.; Black, R.E.; Price, C.; Gross, M.; et al. Lung ultrasound for the diagnosis of pneumonia in adults: A systematic review and meta-analysis. Respir. Res. 2014, 15, 50. [Google Scholar] [CrossRef] [Green Version]
- Pagano, A.; Numis, F.G.; Visone, G.; Pirozzi, C.; Masarone, M.; Olibet, M.; Nasti, R.; Schiraldi, F.; Paladino, F. Lung ultrasound for diagnosis of pneumonia in emergency department. Intern. Emerg. Med. 2015, 10, 851–854. [Google Scholar] [CrossRef]
- Reali, F.; Papa, G.F.S.; Carlucci, P.; Fracasso, P.; Di Marco, F.; Mandelli, M.; Soldi, S.; Riva, E.; Centanni, S. Can lung ultrasound replace chest radiography for the diagnosis of pneumonia in hospitalized children? Respiration 2014, 88, 112–115. [Google Scholar] [CrossRef]
- Claes, A.S.; Clapuyt, P.; Menten, R.; Michoux, N.; Dumitriu, D. Performance of chest ultrasound in pediatric pneumonia. Eur. J. Radiol. 2017, 88, 82–87. [Google Scholar] [CrossRef] [Green Version]
- Abdalla, W.; Elgendy, M.; Abdelaziz, A.; Ammar, M. Lung ultrasound versus chest radiography for the diagnosis of pneumothorax in critically ill patients: A prospective, single-blind study. Saudi J. Anaesth. 2016, 10, 265. [Google Scholar] [CrossRef]
- Brogi, E.; Bignami, E.; Sidoti, A.; Shawar, M.; Gargani, L.; Vetrugno, L.; Volpicelli, G.; Forfori, F. Could the use of bedside lung ultrasound reduce the number of chest X-rays in the intensive care unit? Cardiovasc. Ultrasound 2017, 15, 23. [Google Scholar] [CrossRef] [PubMed]
- Buonsenso, D.; Pata, D.; Chiaretti, A. COVID-19 outbreak: Less stethoscope, more ultrasound. Lancet Respir. Med. 2020, 8, e27. [Google Scholar] [CrossRef] [Green Version]
- Smith, M.; Hayward, S.; Innes, S.; Miller, A. Point-of-care lung ultrasound in patients with COVID-19—A narrative review. Anaesthesia 2020, 75, 1096–1104. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lepri, G.; Orlandi, M.; Lazzeri, C.; Bruni, C.; Hughes, M.; Bonizzoli, M.; Wang, Y.; Peris, A.; Matucci-Cerinic, M. The emerging role of lung ultrasound in COVID-19 pneumonia. Eur. J. Rheumatol. 2020, 7, S129–S133. [Google Scholar] [CrossRef]
- Sultan, L.R.; Sehgal, C.M. A review of early experience in lung ultrasound (LUS) in the diagnosis and management of COVID-19. Ultrasound Med. Biol. 2020, 46, 2530–2545. [Google Scholar] [CrossRef]
- Muse, E.D.; Topol, E.J. Guiding ultrasound image capture with artificial intelligence. Lancet 2020, 396, 749. [Google Scholar] [CrossRef]
- Volpicelli, G.; Lamorte, A.; Villén, T. What’s new in lung ultrasound during the COVID-19 pandemic. Intensive Care Med. 2020, 46, 1445–1448. [Google Scholar] [CrossRef]
- Pare, J.R.; Camelo, I.; Mayo, K.C.; Leo, M.M.; Dugas, J.N.; Nelson, K.P.; Baker, W.E.; Shareef, F.; Mitchell, P.M.; Schechter-Perkins, E.M. Point-of-care lung ultrasound is more sensitive than chest radiograph for evaluation of COVID-19. West. J. Emerg. Med. 2020, 21, 771. [Google Scholar] [CrossRef]
- Peng, Q.Y.; Wang, X.T.; Zhang, L.N.; Chinese Critical Care Ultrasound Study Group (CCUSG). Findings of lung ultrasonography of novel corona virus pneumonia during the 2019–2020 epidemic. Intensive Care Med. 2020, 46, 849–850. [Google Scholar] [CrossRef] [Green Version]
- Fiala, M. Ultrasound in COVID-19: A timeline of ultrasound findings in relation to CT. Clin. Radiol. 2020. [Google Scholar] [CrossRef]
- Lieveld, A.; Kok, B.; Schuit, F.; Azijli, K.; Heijmans, J.; van Laarhoven, A.; Assman, N.; Kootte, R.; Olgers, T.; Nanayakkara, P.; et al. Diagnosing COVID-19 pneumonia in a pandemic setting: Lung Ultrasound versus CT (LUVCT) A multi-centre, prospective, observational study. ERJ Open Res. 2020. [Google Scholar] [CrossRef]
- Tung-Chen, Y.; Martí de Gracia, M.; Díez-Tascón, A.; Alonso-González, R.; Agudo-Fernández, S.; Parra-Gordo, M.L.; Ossaba-Vélez, S.; Rodríguez-Fuertes, P.; Llamas-Fuentes, R. Correlation between Chest Computed Tomography and Lung Ultrasonography in Patients with Coronavirus Disease 2019 (COVID-19). Ultrasound Med. Biol. 2020, 46, 2918–2926. [Google Scholar] [CrossRef] [PubMed]
- Ellington, L.E.; Gilman, R.H.; Chavez, M.A.; Pervaiz, F.; Marin-Concha, J.; Compen-Chang, P.; Riedel, S.; Rodriguez, S.J.; Gaydos, C.; Hardick, J.; et al. Lung ultrasound as a diagnostic tool for radiographically-confirmed pneumonia in low resource settings. Respir. Med. 2017, 128, 57–64. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Amatya, Y.; Rupp, J.; Russell, F.M.; Saunders, J.; Bales, B.; House, D.R. Diagnostic use of lung ultrasound compared to chest radiograph for suspected pneumonia in a resource-limited setting. Int. J. Emerg. Med. 2018, 11, 8. [Google Scholar] [CrossRef] [Green Version]
- Stewart, K.A.; Navarro, S.M.; Kambala, S.; Tan, G.; Poondla, R.; Lederman, S.; Barbour, K.; Lavy, C. Trends in Ultrasound Use in Low and Middle Income Countries: A Systematic Review. Int. J. 2020, 9, 103–120. [Google Scholar]
- Di Serafino, M.; Notaro, M.; Rea, G.; Iacobellis, F.; Paoli, V.D.; Acampora, C.; Ianniello, S.; Brunese, L.; Romano, L.; Vallone, G. The lung ultrasound: Facts or artifacts? In the era of COVID-19 outbreak. La Radiol. Med. 2020, 125, 738–753. [Google Scholar] [CrossRef]
- Tutino, L.; Cianchi, G.; Barbani, F.; Batacchi, S.; Cammelli, R.; Peris, A. Time needed to achieve completeness and accuracy in bedside lung ultrasound reporting in intensive care unit. Scand. J. Trauma Resusc. Emerg. Med. 2010, 18, 44. [Google Scholar] [CrossRef] [Green Version]
- Ulhaq, A.; Born, J.; Khan, A.; Gomes, D.; Chakraborty, S.; Paul, M. COVID-19 Control by Computer Vision Approaches: A Survey. IEEE Access 2020, 8, 179437–179456. [Google Scholar] [CrossRef]
- Shi, F.; Wang, J.; Shi, J.; Wu, Z.; Wang, Q.; Tang, Z.; He, K.; Shi, Y.; Shen, D. Review of artificial intelligence techniques in imaging data acquisition, segmentation and diagnosis for COVID-19. IEEE Rev. Biomed. Eng. 2020. [Google Scholar] [CrossRef] [Green Version]
- Born, J.; Beymer, D.; Rajan, D.; Coy, A.; Mukherjee, V.V.; Manica, M.; Prasanna, P.; Ballah, D.; Shah, P.L.; Karteris, E.; et al. On the Role of Artificial Intelligence in Medical Imaging of COVID-19. medRxiv 2020. [Google Scholar] [CrossRef]
- Liu, S.; Wang, Y.; Yang, X.; Lei, B.; Liu, L.; Li, S.X.; Ni, D.; Wang, T. Deep learning in medical ultrasound analysis: A review. Engineering 2019, 5, 261–275. [Google Scholar] [CrossRef]
- van Sloun, R.J.; Demi, L. Localizing B-lines in lung ultrasonography by weakly-supervised deep learning, in-vivo results. IEEE J. Biomed. Health Inform. 2019, 24, 957–964. [Google Scholar] [CrossRef] [PubMed]
- Wang, X.; Burzynski, J.S.; Hamilton, J.; Rao, P.S.; Weitzel, W.F.; Bull, J.L. Quantifying lung ultrasound comets with a convolutional neural network: Initial clinical results. Comput. Biol. Med. 2019, 107, 39–46. [Google Scholar] [CrossRef] [PubMed]
- Kulhare, S.; Zheng, X.; Mehanian, C.; Gregory, C.; Zhu, M.; Gregory, K.; Xie, H.; Jones, J.M.; Wilson, B.K. Ultrasound-Based Detection of Lung Abnormalities Using Single Shot Detection Convolutional Neural Networks. In Simulation, Image Processing, and Ultrasound Systems for Assisted Diagnosis and Navigation; Springer: Berlin, Germany, 2018; Volume 11042, pp. 65–73. [Google Scholar] [CrossRef]
- Carrer, L.; Donini, E.; Marinelli, D.; Zanetti, M.; Mento, F.; Torri, E.; Smargiassi, A.; Inchingolo, R.; Soldati, G.; Demi, L.; et al. Automatic pleural line extraction and COVID-19 scoring from lung ultrasound data. IEEE Trans. Ultrason. Ferroelectr. Freq. Control 2020, 67, 2207–2217. [Google Scholar] [CrossRef] [PubMed]
- Xu, Y.; Zhang, Y.; Bi, K.; Ning, Z.; Xu, L.; Shen, M.; Deng, G.; Wang, Y. Boundary Restored Network for Subpleural Pulmonary Lesion Segmentation on Ultrasound Images at Local and Global Scales. J. Digit. Imaging 2020, 33, 1155–1166. [Google Scholar] [CrossRef] [PubMed]
- Chen, C.H.; Lee, Y.W.; Huang, Y.-S.; Lan, W.R.; Chang, R.F.; Tu, C.Y.; Chen, C.Y.; Liao, W.C. Computer-aided diagnosis of endobronchial ultrasound images using convolutional neural network. Comput. Methods Programs Biomed. 2019, 177, 175–182. [Google Scholar] [CrossRef]
- Born, J.; Brändle, G.; Cossio, M.; Disdier, M.; Goulet, J.; Roulin, J.; Wiedemann, N. POCOVID-Net: Automatic Detection of COVID-19 From a New Lung Ultrasound Imaging Dataset (POCUS). arXiv 2020, arXiv:2004.12084. [Google Scholar]
- Roberts, J.; Tsiligkaridis, T. Ultrasound Diagnosis of COVID-19: Robustness and Explainability. arXiv 2020, arXiv:2012.01145. [Google Scholar]
- Chen, Y.; Zhang, C.; Liu, L.; Feng, C.; Dong, C.; Luo, Y.; Wan, X. Effective Sample Pair Generation for Ultrasound Video Contrastive Representation Learning. arXiv 2020, arXiv:2011.13066. [Google Scholar]
- Hou, D.; Hou, R.; Hou, J. Interpretable Saab Subspace Network for COVID-19 Lung Ultrasound Screening. In Proceedings of the 2020 11th IEEE Annual Ubiquitous Computing, Electronics & Mobile Communication Conference (UEMCON), New York, NY, USA, 28–31 October 2020; pp. 0393–0398. [Google Scholar]
- Morteza, A.; Amirmazlaghani, M. A novel statistical approach for multiplicative speckle removal using t-locations scale and non-sub sampled shearlet transform. Digit. Signal Process. 2020, 107, 102857. [Google Scholar] [CrossRef]
- Baum, Z.; Bonmati, E.; Cristoni, L.; Walden, A.; Prados, F.; Kanber, B.; Barratt, D.C.; Hawkes, D.J.; Parker, G.J.; Wheeler-Kingshott, C.A.; et al. Image quality assessment for closed-loop computer-assisted lung ultrasound. arXiv 2020, arXiv:2008.08840. [Google Scholar]
- Liu, L.; Lei, W.; Luo, Y.; Feng, C.; Wan, X.; Liu, L. Semi-Supervised Active Learning for COVID-19 Lung Ultrasound Multi-symptom Classification. arXiv 2020, arXiv:2009.05436. [Google Scholar]
- Zhang, J.; Chng, C.B.; Chen, X.; Wu, C.; Zhang, M.; Xue, Y.; Jiang, J.; Chui, C.K. Detection and Classification of Pneumonia from Lung Ultrasound Images. In Proceedings of the 2020 5th International Conference on Communication, Image and Signal Processing (CCISP), Chengdu, China, 13–15 November 2020; pp. 294–298. [Google Scholar] [CrossRef]
- Arntfield, R.; VanBerlo, B.; Alaifan, T.; Phelps, N.; White, M.; Chaudhary, R.; Ho, J.; Wu, D. Development of a deep learning classifier to accurately distinguish COVID-19 from look-a-like pathology on lung ultrasound. medRxiv 2020. [Google Scholar] [CrossRef]
- Roy, S.; Menapace, W.; Oei, S.; Luijten, B.; Fini, E.; Saltori, C.; Huijben, I.; Chennakeshava, N.; Mento, F.; Sentelli, A.; et al. Deep learning for classification and localization of COVID-19 markers in point-of-care lung ultrasound. IEEE Trans. Med. Imaging 2020, 39, 2676–2687. [Google Scholar] [CrossRef]
- Bagon, S.; Galun, M.; Frank, O.; Schipper, N.; Vaturi, M.; Zalcberg, G.; Soldati, G.; Smargiassi, A.; Inchingolo, R.; Torri, E.; et al. Assessment of COVID-19 in lung ultrasound by combining anatomy and sonographic artifacts using deep learning. J. Acoust. Soc. Am. 2020, 148, 2736. [Google Scholar] [CrossRef]
- Yaron, D.; Keidar, D.; Goldstein, E.; Shachar, Y.; Blass, A.; Frank, O.; Schipper, N.; Shabshin, N.; Grubstein, A.; Suhami, D.; et al. Point of Care Image Analysis for COVID-19. arXiv 2020, arXiv:2011.01789. [Google Scholar]
- Jim, A.A.J.; Rafi, I.; Chowdhury, M.S.; Sikder, N.; Mahmud, M.P.; Rubaie, S.; Masud, M.; Bairagi, A.K.; Bhakta, K.; Nahid, A.A. An Automatic Computer-Based Method for Fast and Accurate Covid-19 Diagnosis. medRxiv 2020. [Google Scholar] [CrossRef]
- Soldati, G.; Smargiassi, A.; Inchingolo, R.; Buonsenso, D.; Perrone, T.; Briganti, D.F.; Perlini, S.; Torri, E.; Mariani, A.; Mossolani, E.E.; et al. Is there a role for lung ultrasound during the COVID-19 pandemic? J. Ultrasound Med. 2020, 39, 1459–1462. [Google Scholar] [CrossRef] [Green Version]
- Lichtenstein, D.A. Lung Ultrasound in the Critically Ill: The BLUE Protocol; Springer: Berlin, Germany, 2015. [Google Scholar]
- Jackson, K.; Butler, R.; Aujayeb, A. Lung ultrasound in the COVID-19 pandemic. Postgrad. Med J. 2020, 97. [Google Scholar] [CrossRef]
- Aujayeb, A.; Johnston, R.; Routh, C.; Wilson, P.; Mann, S. Consolidating medical ambulatory care services in the COVID-19 era. Int. J. Health Sci. 2020, 14, 1. [Google Scholar]
- Aujayeb, A. Consolidating malignant pleural and peritoneal services during the COVID-19 response. Future Healthc. J. 2020, 7, 161–162. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Altmayer, S.; Zanon, M.; Pacini, G.S.; Watte, G.; Barros, M.C.; Mohammed, T.L.; Verma, N.; Marchiori, E.; Hochhegger, B. Comparison of the Computed Tomography Findings in COVID-19 and Other Viral Pneumonia in Immunocompetent Adults: A Systematic Review and Meta-Analysis. Eur. Radiol. 2020, 30, 6485–6496. [Google Scholar] [CrossRef] [PubMed]
- Mendel, J.B.; Lee, J.T.; Rosman, D. Current Concepts Imaging in COVID-19 and the Challenges for Low and Middle Income Countries. J. Glob. Radiol. 2020, 6, 3. [Google Scholar] [CrossRef]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. Imagenet large scale visual recognition challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef] [Green Version]
- Dataset, K. Ultrasound Nerve Segmentation, 206. Data Retrieved from Kaggle. Available online: https://www.kaggle.com/c/ultrasound-nerve-segmentation (accessed on 10 May 2020).
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. In Proceedings of the 3rd International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Zoph, B.; Vasudevan, V.; Shlens, J.; Le, Q.V. Learning transferable architectures for scalable image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8697–8710. [Google Scholar]
- Zhou, B.; Khosla, A.; Lapedriza, A.; Oliva, A.; Torralba, A. Learning deep features for discriminative localization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2921–2929. [Google Scholar]
- Zhou, Z.; Sodha, V.; Rahman Siddiquee, M.M.; Feng, R.; Tajbakhsh, N.; Gotway, M.B.; Liang, J. Models Genesis: Generic Autodidactic Models for 3D Medical Image Analysis. In Medical Image Computing and Computer Assisted Intervention–MICCAI 2019; Springer International Publishing: Cham, Switzerland, 2019; pp. 384–393. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-cam: Visual explanations from deep networks via gradient-based localization. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 618–626. [Google Scholar]
- Gretton, A.; Borgwardt, K.M.; Rasch, M.J.; Schölkopf, B.; Smola, A. A kernel two-sample test. J. Mach. Learn. Res. 2012, 13, 723–773. [Google Scholar]
- Gal, Y.; Ghahramani, Z. Dropout as a bayesian approximation: Representing model uncertainty in deep learning. In Proceedings of the 33rd International Conference on Machine Learning, New York, NY, USA, 19–24 June 2016; pp. 1050–1059. [Google Scholar]
- Ayhan, M.S.; Berens, P. Test-time data augmentation for estimation of heteroscedastic aleatoric uncertainty in deep neural networks. In Proceedings of the 1st Conference on Medical Imaging with Deep Learning (MIDL 2018), Amsterdam, The Netherlands, 4 July 2018. [Google Scholar]
- Butt, C.; Gill, J.; Chun, D.; Babu, B.A. Deep learning system to screen coronavirus disease 2019 pneumonia. Appl. Intell. 2020. [Google Scholar] [CrossRef]
- Barish, M.; Bolourani, S.; Lau, L.F.; Shah, S.; Zanos, T.P. External validation demonstrates limited clinical utility of the interpretable mortality prediction model for patients with COVID-19. Nat. Mach. Intell. 2020. [Google Scholar] [CrossRef]
- Vedula, S.; Senouf, O.; Bronstein, A.M.; Michailovich, O.V.; Zibulevsky, M. Towards CT-quality Ultrasound Imaging using Deep Learning. arXiv 2017, arXiv:1710.06304. [Google Scholar]
- Zhang, L.; Vishnevskiy, V.; Goksel, O. Deep Network for Scatterer Distribution Estimation for Ultrasound Image Simulation. arXiv 2020, arXiv:2006.10166. [Google Scholar] [CrossRef]
- Abrams, E.R.; Rose, G.; Fields, J.M.; Esener, D. Clinical Review: Point-of-Care Ultrasound in the Evaluation of COVID-19. J. Emerg. Med. 2020, 59, 403–408. [Google Scholar] [CrossRef] [PubMed]
- Volpicelli, G.; Gargani, L. Sonographic signs and patterns of COVID-19 pneumonia. Ultrasound J. 2020, 12, 1–3. [Google Scholar] [CrossRef] [PubMed]
- Denault, A.Y.; Delisle, S.; Canty, D.; Royse, A.; Royse, C.; Serra, X.C.; Gebhard, C.E.; Couture, É.J.; Girard, M.; Cavayas, Y.A.; et al. A proposed lung ultrasound and phenotypic algorithm for the care of COVID-19 patients with acute respiratory failure. Can. J. Anaesth. 2020, 67, 1393–1404. [Google Scholar] [CrossRef] [PubMed]
- Inchingolo, R.; Smargiassi, A.; Moro, F.; Buonsenso, D.; Salvi, S.; Del Giacomo, P.; Scoppettuolo, G.; Demi, L.; Soldati, G.; Testa, A.C. The Diagnosis of Pneumonia in a Pregnant Woman with COVID-19 Using Maternal Lung Ultrasound. Am. J. Obstet. Gynecol. 2020, 223, 9–11. [Google Scholar] [CrossRef] [PubMed]
- Huang, Y.; Wang, S.; Liu, Y.; Zhang, Y.; Zheng, C.; Zheng, Y.; Zhang, C.; Min, W.; Zhou, H.; Yu, M.; et al. A Preliminary Study on the Ultrasonic Manifestations of Peripulmonary Lesions of Non-Critical Novel Coronavirus Pneumonia (COVID-19). 2020. Available online: https://papers.ssrn.com/sol3/papers.cfm?abstract_id=3544750 (accessed on 28 March 2020).
- Irwin, Z.; Cook, J.O. Advances in point-of-care thoracic ultrasound. Emerg. Med. Clin. N. Am. 2016, 34, 151–157. [Google Scholar] [CrossRef] [PubMed]
- Bouhemad, B.; Zhang, M.; Lu, Q.; Rouby, J.J. Clinical review: Bedside lung ultrasound in critical care practice. Crit. Care 2007, 11, 205. [Google Scholar] [CrossRef]
- Lomoro, P.; Verde, F.; Zerboni, F.; Simonetti, I.; Borghi, C.; Fachinetti, C.; Natalizi, A.; Martegani, A. COVID-19 pneumonia manifestations at the admission on chest ultrasound, radiographs, and CT: Single-center study and comprehensive radiologic literature review. Eur. J. Radiol. Open 2020, 7, 100231. [Google Scholar] [CrossRef]
- Testa, A.; Soldati, G.; Copetti, R.; Giannuzzi, R.; Portale, G.; Gentiloni-Silveri, N. Early recognition of the 2009 pandemic influenza A (H1N1) pneumonia by chest ultrasound. Crit. Care 2012, 16, R30. [Google Scholar] [CrossRef] [Green Version]
- Yassa, M.; Birol, P.; Mutlu, A.M.; Tekin, A.B.; Sandal, K.; Tug, N. Lung Ultrasound Can Influence the Clinical Treatment of Pregnant Women with COVID-19. J. Ultrasound Med. 2020, 40. [Google Scholar] [CrossRef]
- Stadler, J.A.; Andronikou, S.; Zar, H.J. Lung ultrasound for the diagnosis of community-acquired pneumonia in children. Pediatr. Radiol. 2017, 47, 1412–1419. [Google Scholar] [CrossRef] [Green Version]
- Reissig, A.; Copetti, R. Lung ultrasound in community-acquired pneumonia and in interstitial lung diseases. Respiration 2014, 87, 179–189. [Google Scholar] [CrossRef] [PubMed]
- Tsung, J.W.; Kessler, D.O.; Shah, V.P. Prospective application of clinician-performed lung ultrasonography during the 2009 H1N1 influenza A pandemic: Distinguishing viral from bacterial pneumonia. Crit. Ultrasound J. 2012, 4, 1–10. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Vieira, A.L.S.; Júnior, J.M.P.; Bastos, M.G. Role of point-of-care ultrasound during the COVID-19 pandemic: Our recommendations in the management of dialytic patients. Ultrasound J. 2020, 12, 1–9. [Google Scholar] [CrossRef] [PubMed]
- Sofia, S.; Boccatonda, A.; Montanari, M.; Spampinato, M.; D’ardes, D.; Cocco, G.; Accogli, E.; Cipollone, F.; Schiavone, C. Thoracic ultrasound and SARS-COVID-19: A pictorial essay. J. Ultrasound 2020, 23, 217–221. [Google Scholar] [CrossRef] [Green Version]
- Rogoza, K.; Kosiak, W. Usefulness of lung ultrasound in diagnosing causes of exacerbation in patients with chronic dyspnea. Adv. Respir. Med. 2016, 84, 38–46. [Google Scholar] [CrossRef] [PubMed] [Green Version]






| Convex | Linear | ||||
|---|---|---|---|---|---|
| Vid. | Img. | Vid. | Img. | Sum | |
| COVID-19 | 64 | 18 | 6 | 4 | 92 |
| Bacterial Pneu. | 49 | 20 | 2 | 2 | 73 |
| Viral Pneu. | 3 | – | 3 | – | 6 |
| Healthy | 66 | 15 | 9 | – | 90 |
| Sum | 182 | 53 | 20 | 6 | 261 |
| Class | Recall (Sens.) | Precision | F1-Score | Specificity | |
|---|---|---|---|---|---|
| VGG | |||||
| Accuracy: 87.8% | COVID-19 | ||||
| Balanced: 87.1% | Pneumonia | ||||
| #Param: 14.7 M | Healthy | ||||
| VGG-CAM | |||||
| Accuracy: 87.4% | COVID-19 | ||||
| Balanced: 86.1% | Pneumonia | ||||
| #Param: 14.7 M | Healthy | ||||
| NASNetMobile | |||||
| Accuracy: 62.5% | COVID-19 | ||||
| Balanced: 55.2% | Pneumonia | ||||
| #Param: 4.8 M | Healthy | ||||
| VGG-Segment | |||||
| Accuracy: 85.1% | COVID-19 | ||||
| Balanced: 83.9% | Pneumonia | ||||
| #Param: 34.0 M | Healthy | ||||
| Segment-Enc | |||||
| Accuracy: 85.7% | COVID-19 | ||||
| Balanced: 84.4% | Pneumonia | ||||
| #Param: 20.0 M | Healthy |
| Class | Recall | Precision | F1-Score | Specificity | |
|---|---|---|---|---|---|
| VGG | |||||
| Accuracy: 90% | COVID-19 | ||||
| Balanced: 90% | Pneumonia | ||||
| #Param.: 14.7 M | Healthy | ||||
| Models Genesis | |||||
| Accuracy: 78% | COVID-19 | ||||
| Balanced: 77% | Pneumonia | ||||
| #Param.: 7.6 M | Healthy |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Born, J.; Wiedemann, N.; Cossio, M.; Buhre, C.; Brändle, G.; Leidermann, K.; Goulet, J.; Aujayeb, A.; Moor, M.; Rieck, B.; et al. Accelerating Detection of Lung Pathologies with Explainable Ultrasound Image Analysis. Appl. Sci. 2021, 11, 672. https://0-doi-org.brum.beds.ac.uk/10.3390/app11020672
Born J, Wiedemann N, Cossio M, Buhre C, Brändle G, Leidermann K, Goulet J, Aujayeb A, Moor M, Rieck B, et al. Accelerating Detection of Lung Pathologies with Explainable Ultrasound Image Analysis. Applied Sciences. 2021; 11(2):672. https://0-doi-org.brum.beds.ac.uk/10.3390/app11020672
Chicago/Turabian StyleBorn, Jannis, Nina Wiedemann, Manuel Cossio, Charlotte Buhre, Gabriel Brändle, Konstantin Leidermann, Julie Goulet, Avinash Aujayeb, Michael Moor, Bastian Rieck, and et al. 2021. "Accelerating Detection of Lung Pathologies with Explainable Ultrasound Image Analysis" Applied Sciences 11, no. 2: 672. https://0-doi-org.brum.beds.ac.uk/10.3390/app11020672