Towards Improved Classification Accuracy on Highly Imbalanced Text Dataset Using Deep Neural Language Models




Abstract
:1. Introduction
- teacher next time sir litt time improvement
- well buarning hanse
- sir try concersent subject subject
- method teacher good
- teacher good teacher time properly experienced
- Proposed an LSTM-based sentence-level text generation model to address high data imbalance issues in common NLP related classification tasks.
- Evaluated the performance of the proposed LSTM and GPT-2 model for document-level sequence generation on three highly imbalanced datasets from two different domains.
- Showed an improved overall classification accuracy of up to 17% for all three datasets.
2. Related Work
3. Methodology
3.1. Text Generation
3.1.1. LSTM Based Text Generation
- Check the language of each of the instance and remove all instances with non-English language.
- Remove special characters like hashtag, comma, semicolon, etc.
- Remove stop words like ’is’, ’am’, ’are’, ’the’, etc.
- Convert all the input characters to lowercase
- Lemmatize all the words to retain only root words
3.1.2. GPT-2 Text Generation
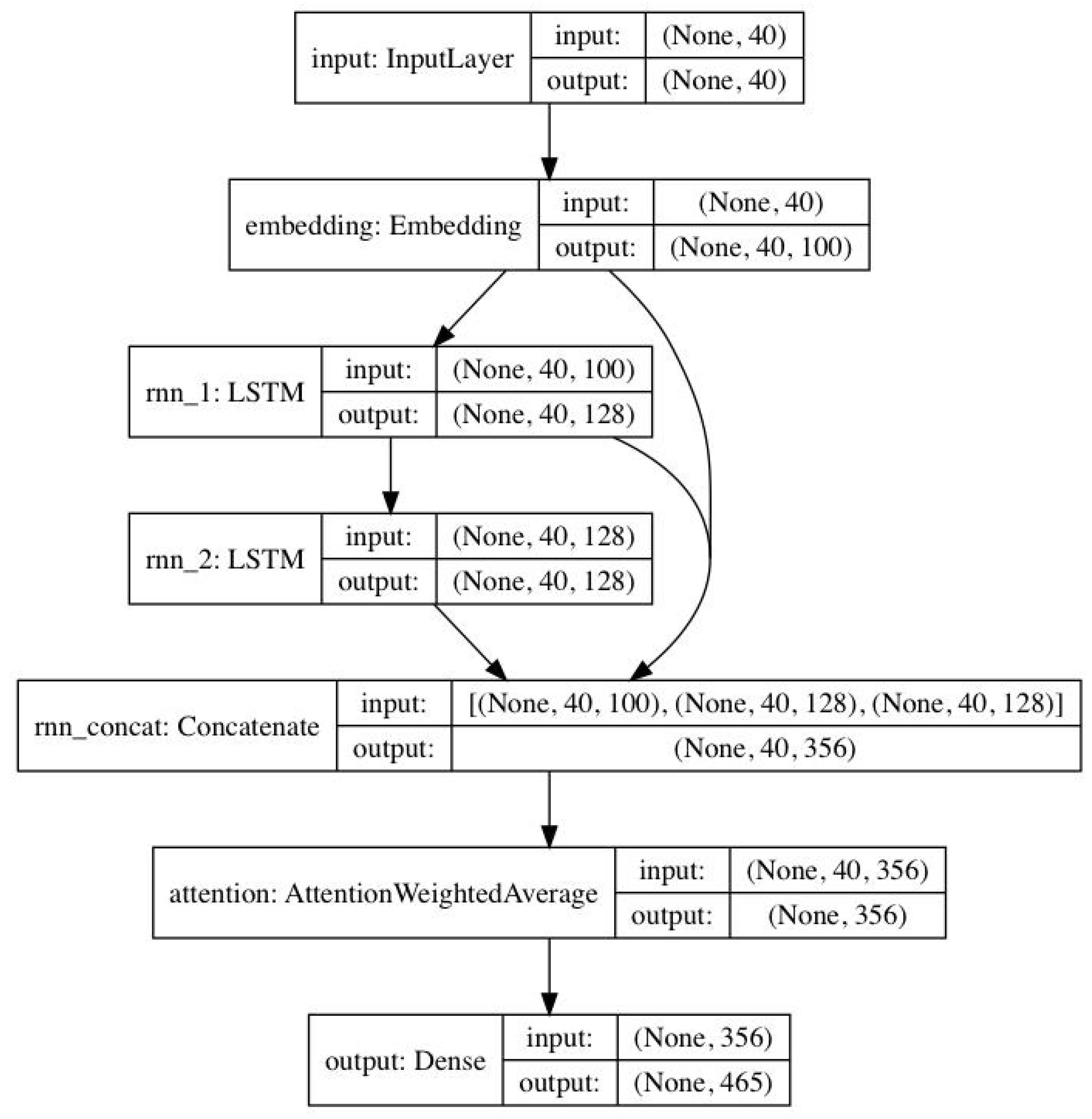
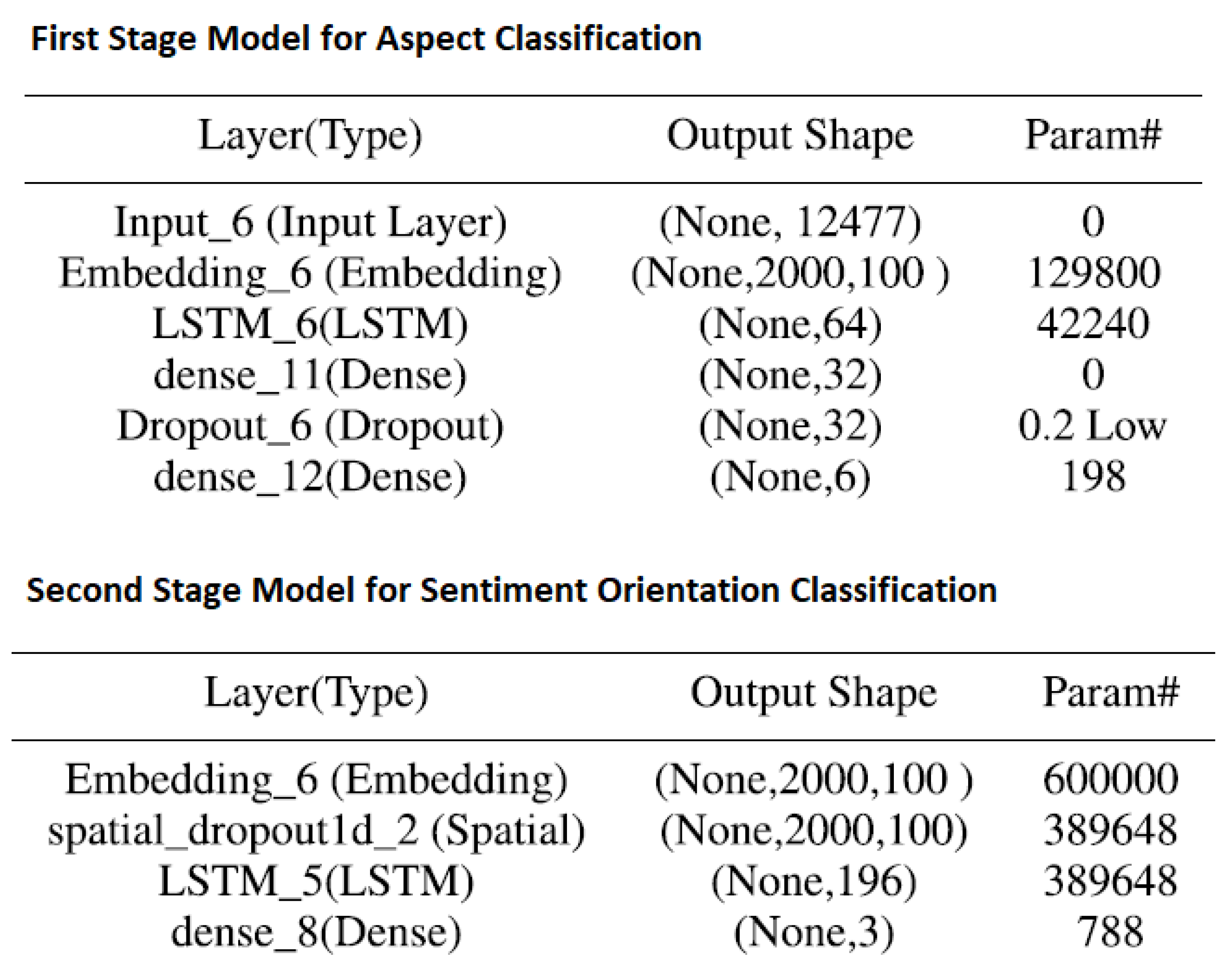
3.2. Deep Neural Network Based Classification
4. Results
4.1. Dataset-1: Students’ Reviews
4.2. Dataset-2: Tweet Emotion Dataset
4.3. Dataset-3: MOOCs Lectures Dataset
4.4. Evaluating Generated Text
4.4.1. Word-Overlap Metrics
- BLEUThe BLEU metric [4] performs n-grams comparison between the generated texts and original/reference texts. In our work, we have applied this metric at corpus level for the evaluation of generated texts. The BLEU score calculation is mathematically defined as below:where N is the maximum length for n-grams (in this paper, we have used BLEU-3) because implicitly it contains the BLEU-1 and BLUE-2, w is a uniform weighting and is the brevity penalty. In the next sections, BLEU score implicitly refers to BLEU-3.
- METEORThe METEOR metric [28] is used to correlate human evaluation more better for the generated texts. This score first create unigram alignment by assigning 0 or 1 to the unigram in the generated texts to the unigram in reference/original texts. This alignment not only considers the exact matches but also stemming, synonyms and paraphrase matching. The precision and recall for unigrams are calculated based on this alignment. The METEOR score calculation is mathematically defined as below:where is the harmonic mean of recall and precision and p is a penalty.
- ROUGE-LThe ROUGE-L metric [5] is a F-measure based calculation defined on the Longest Common Subsequence (LCS) between the generated and original texts.
4.4.2. Embedding-Based Metrics
- Skip-Thought Cosine SimilarityThe Skip-Thought model [31] is a combination of multiple recurrent networks which performs encoding of generated and original/reference texts into embeddings and then measure the cosine similarity of those embeddings. For this study, we have used the pre-trained Skip-Thought network provided by [21].
- Embedding-AverageThis metric calculates the sentence-level embedding scores by calculating average embeddings of all the words composing the text. This metric perform this calculation for all generated and reference/original texts and at the end calculates the cosine similarity. The formula for calculating average embeddings is defined as:where and represent the embeddings for words w and x in the sentence C.
4.5. Discussion Related to Evaluation Metrics
5. Conclusions and Future Directions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
Abbreviations
| SMOTE | Synthetic Minority Oversampling Technique |
| AdaSyn | Adaptive Synthetic |
| GANs | Generative Adversial Networks |
| LSTM | Long Short Term Memory |
| GPT-2 | Generative Pre-trained Transformer 2 |
| BLEU | Bilingual Evaluation Understudy |
| ROUGE | Recall-Oriented Understudy for Gisting Evaluation |
| NLP | Natural Language Processing |
| RNN | Recurrent Neural Network |
| BERT | Bidirectional Encoder Representations from Transformers |
| GRU | Gated Recurrent Unit |
| CS-GAN | Cyclic-Synthesized Generative Adversarial Networks |
| MOOC | Massive Open Online Course |
| AI | Artificial Intelligence |
| Glove | Global Vectors for Word Representation |
| METEOR | Metric for Evaluation of Translation with Explicit ORdering |
| CIDEr | Consensus-based Image De-scription Evaluation |
| ELMo | Embeddings from Language Models |
References
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic minority over-sampling technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- He, H.; Bai, Y.; Garcia, E.A.; Li, S. ADASYN: Adaptive synthetic sampling approach for imbalanced learning. In Proceedings of the IEEE International Joint Conference on Neural Networks (IEEE World Congress on Computational Intelligence), Hong Kong, China, 1–8 June 2008; pp. 1322–1328. [Google Scholar]
- Almahairi, A.; Rajeswar, S.; Sordoni, A.; Bachman, P.; Courville, A. Augmented cyclegan: Learning many-to-many mappings from unpaired data. arXiv 2018, arXiv:1802.10151. [Google Scholar]
- Papineni, K.; Roukos, S.; Ward, T.; Zhu, W.J. BLEU: A method for automatic evaluation of machine translation. In Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics, Philadelphia, PA, USA, 7–12 July 2002; pp. 311–318. [Google Scholar]
- Lin, C.Y. Rouge: A package for automatic evaluation of summaries. In Text Summarization Branches Out; Association for Computational Linguistics: Stroudsburg, PA, USA, 2004; pp. 74–81. [Google Scholar]
- Lee, J.S.; Hsiang, J. Patent claim generation by fine-tuning OpenAI GPT-2. World Pat. Inf. 2020, 62, 101983. [Google Scholar] [CrossRef]
- Qu, Y.; Liu, P.; Song, W.; Liu, L.; Cheng, M. A Text Generation and Prediction System: Pre-training on New Corpora Using BERT and GPT-2. In Proceedings of the IEEE 10th International Conference on Electronics Information and Emergency Communication (ICEIEC), Beijing, China, 17–19 July 2020; pp. 323–326. [Google Scholar]
- Islam, M.S.; Sharmin Mousumi, S.S.; Abujar, S.; Hossain, S.A. Sequence-to-sequence Bangla Sentence Generation with LSTM Recurrent Neural Networks. Procedia Comput. Sci. 2019, 152, 51–58. [Google Scholar] [CrossRef]
- Santhanam, S. Context based Text-generation using LSTM networks. arXiv 2020, arXiv:cs.CL/2005.00048. [Google Scholar]
- Mangal, S.; Joshi, P.; Modak, R. LSTM vs. GRU vs. Bidirectional RNN for script generation. arXiv 2019, arXiv:cs.CL/1908.04332. [Google Scholar]
- Chen, J.; Wu, Y.; Jia, C.; Zheng, H.; Huang, G. Customizable text generation via conditional text generative adversarial network. Neurocomputing 2020, 416, 125–135. [Google Scholar] [CrossRef]
- Zhang, R.; Chen, C.; Gan, Z.; Wang, W.; Shen, D.; Wang, G.; Wen, Z.; Carin, L. Improving Adversarial Text Generation by Modeling the Distant Future. arXiv 2020, arXiv:cs.CL/2005.01279. [Google Scholar]
- Li, Y.; Pan, Q.; Wang, S.; Yang, T.; Cambria, E. A Generative Model for category text generation. Inf. Sci. 2018, 450, 301–315. [Google Scholar] [CrossRef]
- Akkaradamrongrat, S.; Kachamas, P.; Sinthupinyo, S. Text Generation for Imbalanced Text Classification. In Proceedings of the 16th International Joint Conference on Computer Science and Software Engineering (JCSSE), Pataya, Thailand, 10–12 July 2019; pp. 181–186. [Google Scholar] [CrossRef]
- Sindhu, I.; Daudpota, S.M.; Badar, K.; Bakhtyar, M.; Baber, J.; Nurunnabi, M. Aspect-based opinion mining on student’s feedback for faculty teaching performance evaluation. IEEE Access 2019, 7, 108729–108741. [Google Scholar] [CrossRef]
- Mohammad, S.M.; Bravo-Marquez, F. WASSA-2017 Shared Task on Emotion Intensity. In Proceedings of the Workshop on Computational Approaches to Subjectivity, Sentiment and Social Media Analysis (WASSA), Copenhagen, Denmark, 7–11 September 2017; pp. 34–39. [Google Scholar]
- Kastrati, Z.; Kurti, A.; Imran, A.S. WET: Word embedding-topic distribution vectors for MOOC video lectures dataset. Data Brief 2020, 28, 105090. [Google Scholar] [CrossRef] [PubMed]
- Pawade, D.; Sakhapara, A.; Jain, M.; Jain, N.; Gada, K. Story scrambler-automatic text generation using word level rnn-lstm. Int. J. Inf. Technol. Comput. Sci. (IJITCS) 2018, 10, 44–53. [Google Scholar] [CrossRef] [Green Version]
- Chakraborty, S.; Banik, J.; Addhya, S.; Chatterjee, D. Study of Dependency on number of LSTM units for Character based Text Generation models. In Proceedings of the International Conference on Computer Science, Engineering and Applications (ICCSEA), Sydney, Australia, 19–20 December 2020; pp. 1–5. [Google Scholar]
- Park, D.; Ahn, C.W. LSTM encoder-decoder with adversarial network for text generation from keyword. In Theories and Applications, Proceedings of the International Conference on Bio-Inspired Computing, Qingdao, China, 23–25 October 2018; Springer: Cham, Switzerland, 2018; pp. 388–396. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Radford, A.; Wu, J.; Child, R.; Luan, D.; Amodei, D.; Sutskever, I. Language models are unsupervised multitask learners. OpenAI Blog 2019, 1, 9. [Google Scholar]
- Tetko, I.V.; Karpov, P.; Van Deursen, R.; Godin, G. State-of-the-art augmented NLP transformer models for direct and single-step retrosynthesis. Nat. Commun. 2020, 11, 1–11. [Google Scholar] [CrossRef] [PubMed]
- Bostrom, K.; Durrett, G. Byte pair encoding is suboptimal for language model pretraining. arXiv 2020, arXiv:2004.03720. [Google Scholar]
- Imran, A.S.; Daudpota, S.M.; Kastrati, Z.; Bhatra, R. Cross-Cultural Polarity and Emotion Detection Using Sentiment Analysis and Deep Learning on COVID-19 Related Tweets. IEEE Access 2020. [Google Scholar] [CrossRef]
- Kastrati, Z.; Imran, A.S.; Kurti, A. Integrating word embeddings and document topics with deep learning in a video classification framework. Pattern Recognit. Lett. 2019, 128, 85–92. [Google Scholar] [CrossRef]
- Sharma, S.; Asri, L.E.; Schulz, H.; Zumer, J. Relevance of unsupervised metrics in task-oriented dialogue for evaluating natural language generation. arXiv 2017, arXiv:1706.09799. [Google Scholar]
- Banerjee, S.; Lavie, A. METEOR: An automatic metric for MT evaluation with improved correlation with human judgments. In Proceedings of the Acl Workshop on Intrinsic and Extrinsic Evaluation Measures for Machine Translation and/or Summarization, Ann Arbor, MI, USA, June 2005; pp. 65–72. [Google Scholar]
- Huang, A. Similarity measures for text document clustering. In Proceedings of the Sixth New Zealand Computer Science Research Student Conference (NZCSRSC2008), Christchurch, New Zealand, 28–29 April 2008; Volume 4, pp. 9–56. [Google Scholar]
- Pennington, J.; Socher, R.; Manning, C.D. Glove: Global vectors for word representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1532–1543. [Google Scholar]
- Kiros, R.; Zhu, Y.; Salakhutdinov, R.R.; Zemel, R.; Urtasun, R.; Torralba, A.; Fidler, S. Skip-thought vectors. In Advances in Neural Information Processing Systems; Bradford Books: London, UK, 2015; pp. 3294–3302. [Google Scholar]
- Fagni, T.; Falchi, F.; Gambini, M.; Martella, A.; Tesconi, M. TweepFake: About Detecting Deepfake Tweets. arXiv 2020, arXiv:2008.00036. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset-1 | Students’ Reviews [15] | A sentence-level students’ feedback dataset about faculty. |
| Dataset-2 | Tweet Emotion Dataset [16] | A tweets’ dataset labeled in six emotions. |
| Dataset-3 | MOOCs Lecture Transcripts [17] | Long text of transcripts of video lectures from Coursera. |
| Original | Generated | |||
|---|---|---|---|---|
| # | Text | Class Label | Text | Class Label |
| 1 | he is very well experienced | Experience | well-experienced | Experience |
| 2 | give result on time | Assessment | sir still hasn’t given result of 1st | Assessment |
| 3 | sir is very kind | Behavior | always pay respect to students | Behavior |
| 4 | sir is very slow in carry out course | Knowledge | he is very good teacher for case study especially | Knowledge |
| 5 | he improves teaching style | Teaching Skills | he is very fast! | Teaching Skills |
| Original | Generated | |||
|---|---|---|---|---|
| # | Text | Class Label | Text | Class Label |
| 1 | Thinks that @melbahughes had a great 50th birthday party :) | Surprise | My dad just got a guest cell of my be | Surprise |
| 2 | My heart and soul @Jay_Babe is leaving me and I can’t even see here | Sadness | I miss the fact that I was so much to be the dog.. | Sadness |
| 3 | @CarolineHirons Buddy the elf, what’s your favourite colour? | Disgust | I hate the kids that the crup that they tweet me | Disgust |
| 4 | God im so mad its burning my fuckin stomach! | Anger | Sometimes I feel if w/ I want to sleep on and it was a shit | Anger |
| 5 | ...and guess what song just popped in my head. | Fear | A weak is on the floor in my hearts of the world. | Fear |
| Original | Generated | |||
|---|---|---|---|---|
| # | Text | Class Label | Text | Class Label |
| 1 | In the last video, you learned how to use a convolutional implementation of sliding windows. That’s more computationally efficient, but it still has a problem of not quite outputting the most accurate bounding boxes. In this video, let’s see how you can get your bounding box predictions to be more accurate. With sliding windows, you take this three sets of locations and run the crossfire through it. | Data Science | In the previous video, we talked. about how you can gain an intuitive understanding, of vectorization, how you can take these convolutional. functions and apply them to your models, and try to gain an intuitive understanding, of how these supervised learning algorithms work, understanding perhaps eveniving. knowledge from intuitive cues in the neural network. Let’s see what that might mean,. let’s go into the next video | Data Science |
| Aspect | Count |
|---|---|
| General | 1867 |
| Teaching Skills | 1656 |
| Knowledge | 1186 |
| Behavior | 844 |
| Experience | 297 |
| Assessment | 139 |
| Sentiment Orientation | Count |
| Positive | 4250 |
| Negative | 1489 |
| Aspect | Count |
|---|---|
| General | 1867 |
| Teaching Skills | 1867 |
| Knowledge | 1867 |
| Behavior | 1867 |
| Experience | 1867 |
| Assessment | 1867 |
| Sentiment Orientation | Count |
| Positive | 4250 |
| Negative | 4250 |
| Imbalanced Dataset [15] | Balanced Dataset | |||||
|---|---|---|---|---|---|---|
| Aspect | Precision | Recall | F1-Score | Precision | Recall | F1-Score |
| General | 0.95 | 0.90 | 0.92 | 0.92 | 0.90 | 0.91 |
| Teaching Skills | 0.89 | 0.83 | 0.85 | 0.87 | 0.86 | 0.87 |
| Knowledge | 0.87 | 0.88 | 0.87 | 0.94 | 0.92 | 0.93 |
| Behavior | 0.82 | 0.85 | 0.83 | 0.94 | 0.93 | 0.94 |
| Experience | 0.93 | 0.90 | 0.91 | 0.97 | 0.97 | 0.97 |
| Assessment | 0.90 | 0.62 | 0.73 | 0.98 | 0.99 | 0.99 |
| Overall | 0.89 | 0.83 | 0.85 | 0.93 | 0.93 | 0.93 |
| Aspect | Count |
|---|---|
| Teaching Skills | 1296 |
| Knowledge | 915 |
| General | 806 |
| Behavior | 669 |
| Experience | 239 |
| Assessment | 88 |
| Sentiment Orientation | Count |
| Positive | 4250 |
| Negative | 1489 |
| Aspect | Count |
|---|---|
| Teaching Skills | 1296 |
| Knowledge | 1296 |
| General | 1296 |
| Behavior | 1296 |
| Experience | 1296 |
| Assessment | 1296 |
| Sentiment Orientation | Count |
| Positive | 4250 |
| Negative | 1489 |
| Imbalanced Dataset [15] | Balanced Dataset | |||||
|---|---|---|---|---|---|---|
| Aspect | Precision | Recall | F1-Score | Precision | Recall | F1-Score |
| General | 0.85 | 0.86 | 0.85 | 0.86 | 0.91 | 0.89 |
| Teaching Skills | 0.82 | 0.89 | 0.85 | 0.83 | 0.81 | 0.82 |
| Knowledge | 0.92 | 0.88 | 0.90 | 0.89 | 0.88 | 0.89 |
| Behavior | 0.89 | 0.80 | 0.84 | 0.89 | 0.88 | 0.88 |
| Experience | 0.80 | 0.81 | 0.80 | 0.93 | 0.91 | 0.92 |
| Assessment | 0.83 | 0.62 | 0.71 | 0.97 | 0.95 | 0.96 |
| Overall | 0.86 | 0.86 | 0.86 | 0.89 | 0.89 | 0.89 |
| Class Label | Count |
|---|---|
| Joy | 8240 |
| Surprise | 3849 |
| Sadness | 3830 |
| Fear | 2816 |
| Anger | 1555 |
| Disgust | 761 |
| Class Label | Count |
|---|---|
| Joy | 8240 |
| Surprise | 8240 |
| Sadness | 8240 |
| Fear | 8240 |
| Anger | 8240 |
| Disgust | 8240 |
| Number of class Labels | Accuracy on Imbalanced Dataset | Accuracy on Balanced Dataset |
|---|---|---|
| 6 (joy, surprise, sadness, anger, fear, disgust) | 59% | 73% |
| 2 (joy, surprise) | 81.9% | 84% |
| 4 (sadness, anger, fear, disgust) | 69% | 86.5% |
| Metrics | Anger | Disgust | Fear | Sadness | Surprise |
|---|---|---|---|---|---|
| BLEU | 0.004 | 0.000 | 0.008 | 0.005 | 0.003 |
| METEOR | 0.039 | 0.037 | 0.039 | 0.039 | 0.032 |
| ROUGE_L | 0.066 | 0.066 | 0.061 | 0.066 | 0.048 |
| Skip-Thought | 0.312 | 0.284 | 0.304 | 0.295 | 0.294 |
| Embedding-Average | 0.691 | 0.716 | 0.649 | 0.726 | 0.548 |
| Metrics | Assessment | Behavior | Experience | Knowledge | Teaching Skills |
|---|---|---|---|---|---|
| BLEU | 0.011 | 0.000 | 0.015 | 0.013 | 0.000 |
| METEOR | 0.046 | 0.030 | 0.059 | 0.073 | 0.058 |
| ROUGE_L | 0.091 | 0.052 | 0.091 | 0.104 | 0.081 |
| Skip-Thought | 0.359 | 0.320 | 0.318 | 0.355 | 0.366 |
| Embedding-Average | 0.696 | 0.465 | 0.539 | 0.633 | 0.646 |
| Metrics | Arts and Humanities | Business | Computer Science | Data Science | Health | Information Technology | Social Sciences |
|---|---|---|---|---|---|---|---|
| BLEU | 0.029 | 0.046 | 0.034 | 0.035 | 0.028 | 0.041 | 0.022 |
| METEOR | 0.128 | 0.151 | 0.114 | 0.128 | 0.107 | 0.147 | 0.105 |
| ROUGE_L | 0.124 | 0.125 | 0.124 | 0.126 | 0.116 | 0.126 | 0.113 |
| Skip-Thought | 0.435 | 0.481 | 0.461 | 0.473 | 0.468 | 0.472 | 0.439 |
| Embedding-Average | 0.964 | 0.982 | 0.983 | 0.977 | 0.961 | 0.975 | 0.964 |
| # | Original Text | Generated Text | Class Label |
|---|---|---|---|
| 1 | I just absolutely lost my mind.. :( | I want to complain to the rest of my since people and walk by the times again. What is your face that so I don’t understand or lost my mind down | anger |
| 2 | The fact that @KimKardashian wedding makes headlines and provides that pathetic excuse of a celebrity with more money makes me sick | I hate the worst time when you live picture the stomarting cover her poppet time with the more money or an thing like a go me | digust |
| 3 | Don’t believe the lies look me In the eyes, please don’t be scared of me | I don’t wanna stay a trust I feel a combinations/hardest for me | fear |
| 4 | I miss hanging out with AM, Lee and Jay. Those were good times. | i hate good times to be able to throw a depression :( | sadness |
| 5 | You would think by now they would of controlled the smoke problem in the bathrooms. Butttt, they haven’t. | I just found out that we are taking a card for bathrooms and a surprise in a surprise birthday | surprise |
| # | Original Text | Generated Text | Class Label |
|---|---|---|---|
| 1 | evaluation is unjustified | evaluated us more than our level | assessment |
| 2 | Always showing respect towards the students | showed respect to students | behavior |
| 3 | he just has not experience of how to handle class | sir is not able to handle class because of which effective learning does not take place | experience |
| 4 | have good knowledge about subject | He has great knowledge about the course | knowledge |
| 5 | cooperative teacher | he is very cooperative | teaching skills |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shaikh, S.; Daudpota, S.M.; Imran, A.S.; Kastrati, Z. Towards Improved Classification Accuracy on Highly Imbalanced Text Dataset Using Deep Neural Language Models. Appl. Sci. 2021, 11, 869. https://0-doi-org.brum.beds.ac.uk/10.3390/app11020869
Shaikh S, Daudpota SM, Imran AS, Kastrati Z. Towards Improved Classification Accuracy on Highly Imbalanced Text Dataset Using Deep Neural Language Models. Applied Sciences. 2021; 11(2):869. https://0-doi-org.brum.beds.ac.uk/10.3390/app11020869
Chicago/Turabian StyleShaikh, Sarang, Sher Muhammad Daudpota, Ali Shariq Imran, and Zenun Kastrati. 2021. "Towards Improved Classification Accuracy on Highly Imbalanced Text Dataset Using Deep Neural Language Models" Applied Sciences 11, no. 2: 869. https://0-doi-org.brum.beds.ac.uk/10.3390/app11020869