Valence and Arousal-Infused Bi-Directional LSTM for Sentiment Analysis of Government Social Media Management



Abstract
:1. Introduction
2. Related Work
2.1. Sentiment Analysis
2.2. Valence and Arousal
3. Materials and Methods
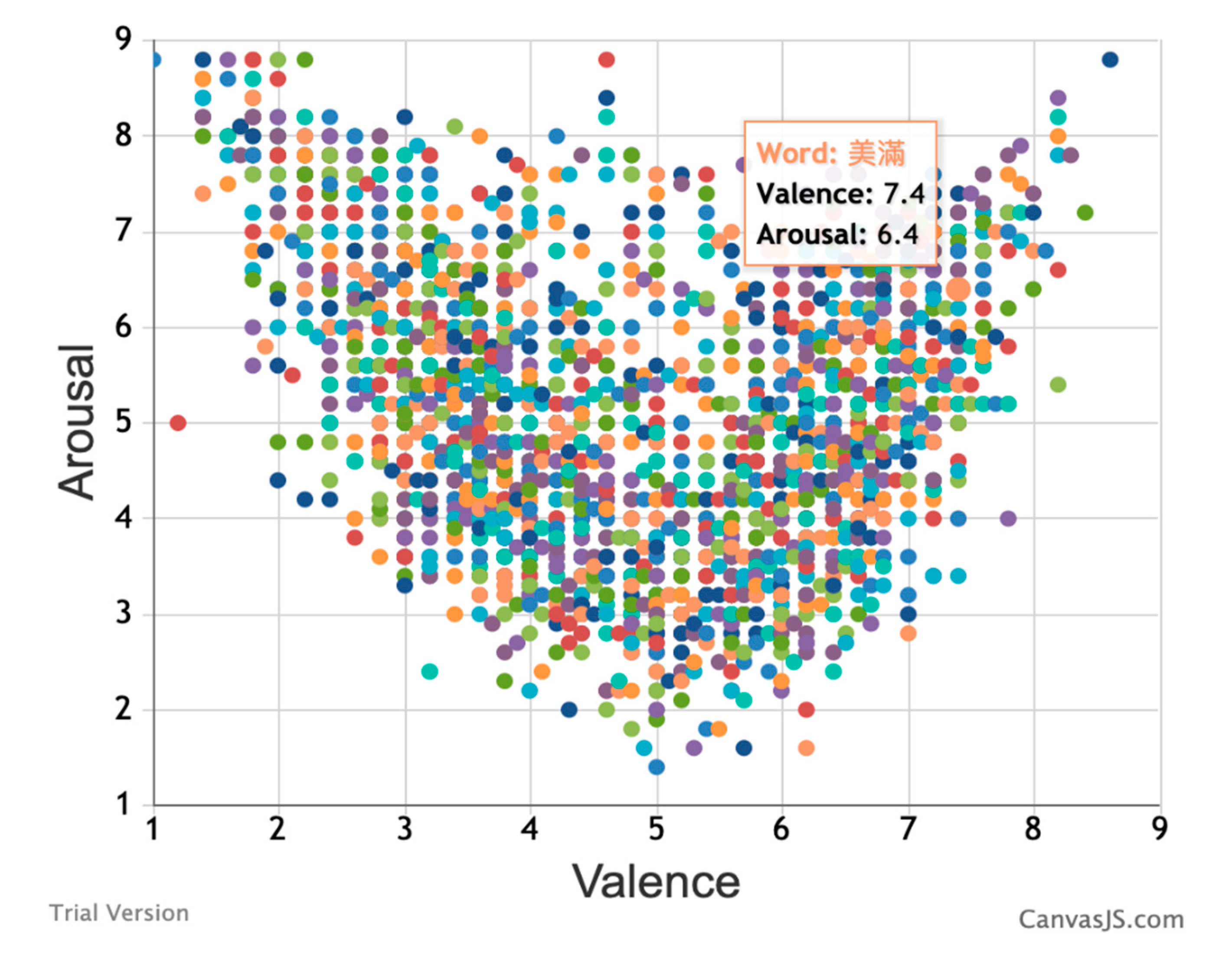
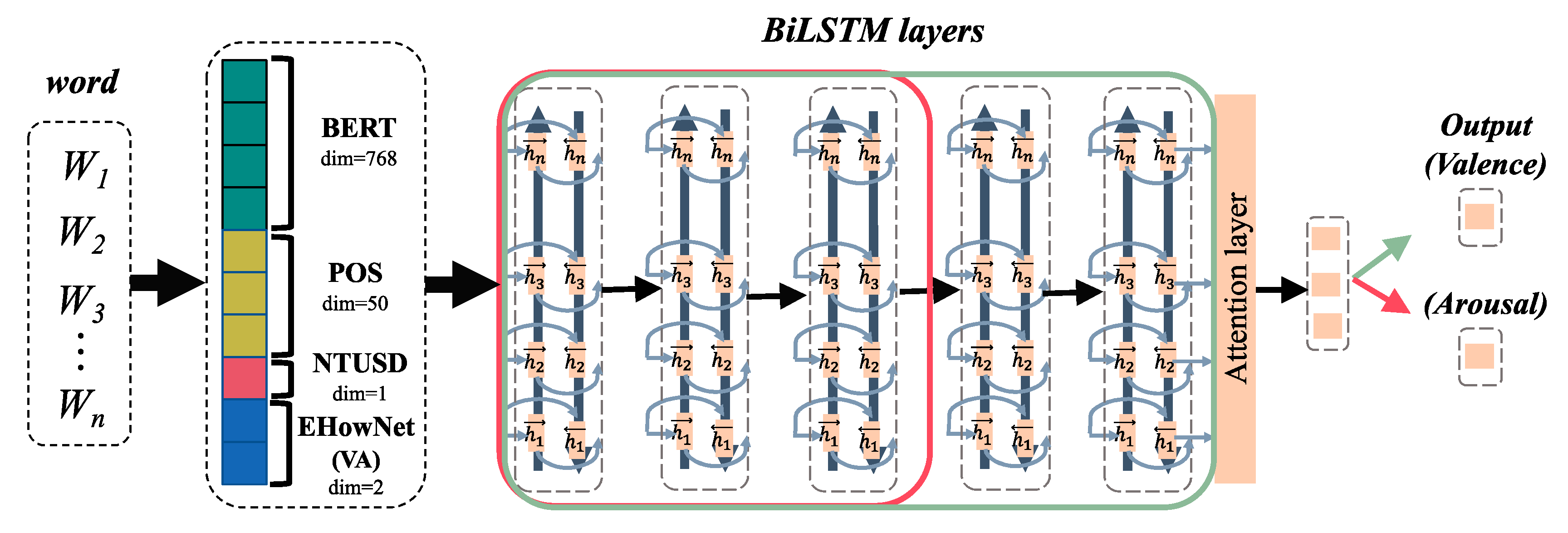
3.1. Valence-Arousal Analysis
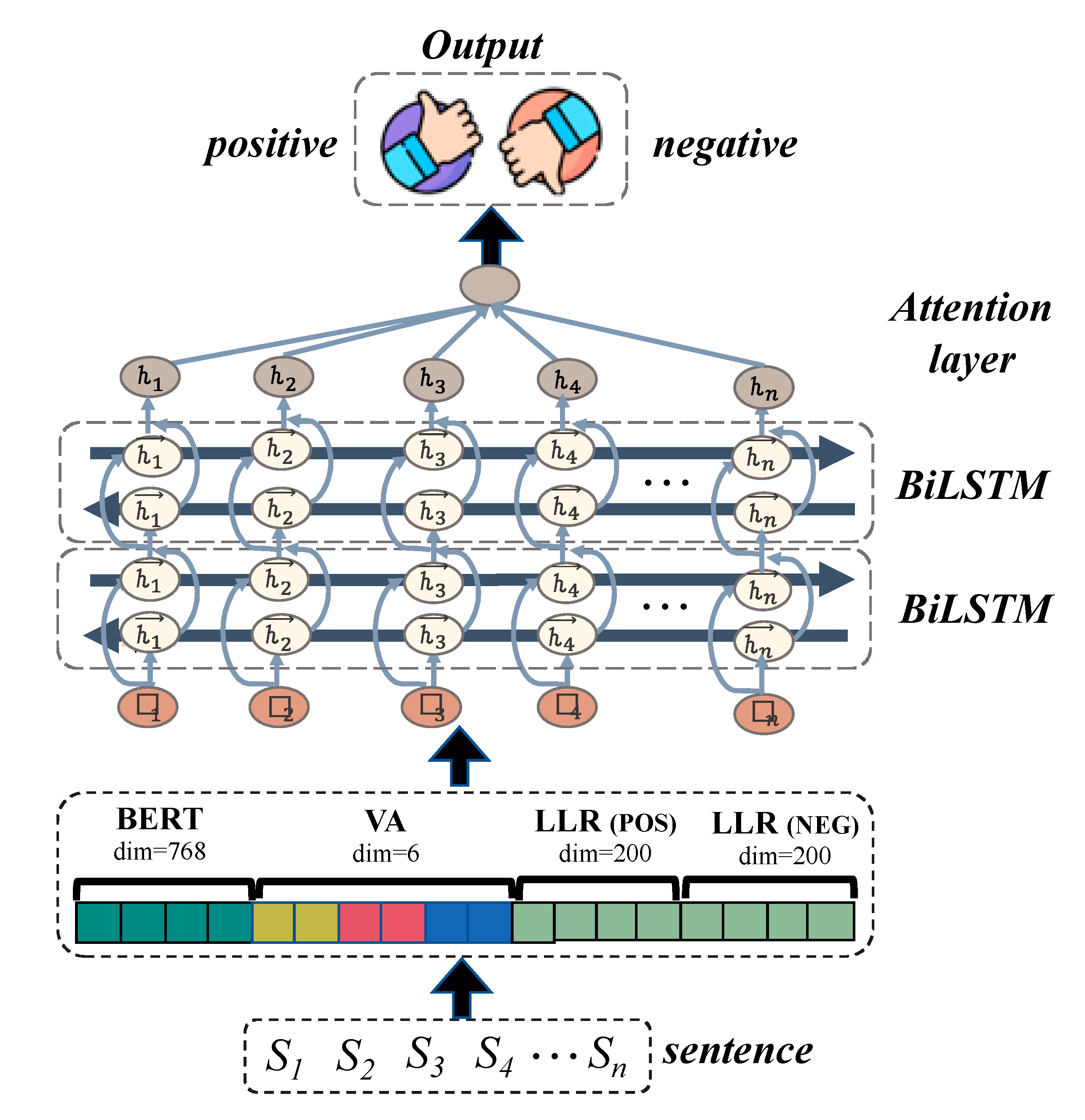
3.2. Sentiment Prediction of Social Media Comments
4. Experimental Results and Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Zavattaro, S.M.; French, P.E.; Mohanty, S.D. A sentiment analysis of US local government tweets: The connection between tone and citizen involvement. Gov. Inf. Q. 2015, 32, 333–341. [Google Scholar] [CrossRef]
- Chen, Q.; Min, C.; Zhang, W.; Wang, G.; Ma, X.; Evans, R. Unpacking the black box: How to promote citizen engagement through government social media during the COVID-19 crisis. Comput. Hum. Behav. 2020, 110, 106380. [Google Scholar] [CrossRef] [PubMed]
- Liu, B. Sentiment analysis and opinion mining. Synth. Lect. Hum. Lang. Technol. 2012, 5, 1–167. [Google Scholar] [CrossRef] [Green Version]
- Shakeel, M.H.; Karim, A. Adapting deep learning for sentiment classification of code-switched informal short text. In Proceedings of the 35th Annual ACM Symposium on Applied Computing, Brno, Czech Republic, 30 March 2020; pp. 903–906. [Google Scholar]
- Yenter, A.; Verma, A. Deep CNN-LSTM with combined kernels from multiple branches for IMDb review sentiment analysis. In Proceedings of the 2017 IEEE 8th Annual Ubiquitous Computing, Electronics and Mobile Communication Conference (UEMCON), New York, NY, USA, 19–21 October 2017; pp. 540–546. [Google Scholar]
- Singh, V.K.; Piryani, R.; Uddin, A.; Waila, P. Sentiment analysis of Movie reviews and Blog posts. In Proceedings of the 2013 3rd IEEE International Advance Computing Conference (IACC), Ghaziabad, India, 22–23 February 2013; pp. 893–898. [Google Scholar]
- Zhang, W.; Xu, H.; Wan, W. Weakness Finder: Find product weakness from Chinese reviews by using aspects-based sentiment analysis. Expert Syst. Appl. 2012, 39, 10283–10291. [Google Scholar] [CrossRef]
- Turney, P.D. Thumbs up or thumbs down? Semantic orientation applied to unsupervised classification of reviews. arXiv 2002, arXiv:cs/0212032. [Google Scholar]
- Kim, S.M.; Hovy, E. Determining the sentiment of opinions. In Proceedings of the 20th International Conference on Computational Linguistics, Geneva, Switzerland, 23–27 August 2004; pp. 1367–1373. [Google Scholar]
- Hu, M.; Liu, B. Mining and summarizing customer reviews. In Proceedings of the Tenth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Seattle, WA, USA, 22–25 August 2004; pp. 168–177. [Google Scholar]
- Wilson, T.; Wiebe, J.; Hoffmann, P. Recognizing contextual polarity in phrase-level sentiment analysis. In Proceedings of the Human Language Technology Conference and Conference on Empirical Methods in Natural Language Processing, Vancouver, BC, Canada, 6–8 October 2005; pp. 347–354. [Google Scholar]
- Agarwal, A.; Biadsy, F.; Mckeown, K. Contextual phrase-level polarity analysis using lexical affect scoring and syntactic n-grams. In Proceedings of the 12th Conference of the European Chapter of the ACL (EACL 2009), Athens, Greece, 30 March–3 April 2009; pp. 24–32. [Google Scholar]
- Sayeed, A.; Boyd-Graber, J.; Rusk, B.; Weinberg, A. Grammatical structures for word-level sentiment detection. In Proceedings of the 2012 Conference of the North American Chapter of the Association for computational Linguistics: Human Language Technologies, Montreal, QC, Canada, 3–8 June 2012; pp. 667–676. [Google Scholar]
- Yu, L.C.; Lee, L.H.; Hao, S.; Wang, J.; He, Y.; Hu, J.; Lai, K.R.; Zhang, X. Building Chinese affective resources in valence-arousal dimensions. In Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, San Diego, CA, USA, 12–17 June 2016; pp. 540–545. [Google Scholar]
- Yu, L.C.; Wang, J.; Lai, K.R.; Zhang, X.J. Predicting valence-arousal ratings of words using a weighted graph method. In Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing (Volume 2: Short Papers), Beijing, China, 26–31 July 2015; pp. 788–793. [Google Scholar]
- Wu, C.; Wu, F.; Huang, Y.; Wu, S.; Yuan, Z. Thu_ngn at ijcnlp-2017 task 2: Dimensional sentiment analysis for chinese phrases with deep lstm. In Proceedings of the IJCNLP 2017, Shared Tasks, Taipei, Taiwan, 27 November–1 December 2017; pp. 47–52. [Google Scholar]
- Zhou, X.; Wang, J.; Xie, X.; Sun, C.; Si, L. Alibaba at IJCNLP-2017 Task 2: A Boosted Deep System for Dimensional Sentiment Analysis of Chinese Phrases. In Proceedings of the IJCNLP 2017, Shared Tasks, Taipei, Taiwan, 27 November–1 December 2017; pp. 100–104. [Google Scholar]
- Li, P.H.; Ma, W.Y.; Wang, H.Y. CKIP at IJCNLP-2017 Task 2: Neural Valence-Arousal Prediction for Phrases. In Proceedings of the IJCNLP 2017, Shared Tasks, Taipei, Taiwan, 27 November–1 December 2017; pp. 89–94. [Google Scholar]
- Chang, Y.C.; Yeh, W.C.; Hsing, Y.C.; Wang, C.A. Refined distributed emotion vector representation for social media sentiment analysis. PLoS ONE 2019, 14, e0223317. [Google Scholar] [CrossRef] [PubMed]
- Wang, J.; Yu, L.C.; Lai, K.R.; Zhang, X. Tree-structured regional CNN-LSTM model for dimensional sentiment analysis. IEEE/ACM Trans. Audio Speech Lang. Process. 2019, 28, 581–591. [Google Scholar] [CrossRef]
- Ku, L.W.; Chen, H.H. Mining opinions from the Web: Beyond relevance retrieval. J. Am. Soc. Inf. Sci. Technol. 2007, 58, 1838–1850. [Google Scholar]
- Chen, W.T.; Lin, S.C.; Huang, S.L.; Chung, Y.S.; Chen, K.J. E-HowNet and automatic construction of a lexical ontology. In Proceedings of the Coling 2010: Demonstrations, Beijing, China, 23–27 August 2010; pp. 45–48. [Google Scholar]
- Hsieh, Y.L.; Chang, Y.C.; Huang, Y.J.; Yeh, S.H.; Chen, C.H.; Hsu, W.L. MONPA: Multi-objective named-entity and part-of-speech annotator for Chinese using recurrent neural network. In Proceedings of the Eighth International Joint Conference on Natural Language Processing (Volume 2: Short Papers), Taipei, Taiwan, 27 November–1 December 2017; pp. 80–85. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems, 12 June 2017; pp. 5998–6008. [Google Scholar]
- Moreno, J.G.; Boros, E.; Doucet, A. TLR at the NTCIR-15 FinNum-2 Task: Improving Text Classifiers for Numeral Attachment in Financial Social Data. In Proceedings of the 15th NTCIR Conference on Evaluation of Information Access Technologies, Tokyo Japan, 8–11 December 2020. [Google Scholar]
- Gomes, H.M.; Barddal, J.P.; Enembreck, F.; Bifet, A. A survey on ensemble learning for data stream classification. ACM Comput. Surv. (CSUR) 2017, 50, 1–36. [Google Scholar] [CrossRef]
- Dong, X.; Yu, Z.; Cao, W.; Shi, Y.; Ma, Q. A survey on ensemble learning. Front. Comput. Sci. 2020, 14, 241–258. [Google Scholar] [CrossRef]
- Yu, L.C.; Lee, L.H.; Wang, J.; Wong, K.F. IJCNLP-2017 Task 2: Dimensional Sentiment Analysis for Chinese Phrases. In Proceedings of the IJCNLP 2017, Shared Tasks, Taipei, Taiwan, 27 November–1 December 2017; pp. 9–16. [Google Scholar]
- Wang, Y.; Li, Z.; Liu, J.; He, Z.; Huang, Y.; Li, D. Word vector modeling for sentiment analysis of product reviews. In Communications in Computer and Information Science, Proceedings of the CCF International Conference on Natural Language Processing and Chinese Computing, Shenzhen, China, 5–9 December 2014; Springer: Berlin/Heidelberg, Germany, 2014; pp. 168–180. [Google Scholar]
- Manning, C.D.; Raghavan, P.; Schütze, H. Introduction to Information Retrieval; Cambridge University Press: Cambridge, MA, USA, 2008. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Group | Valence | Arousal | ||
|---|---|---|---|---|
| MAE | PCC | MAE | PCC | |
| THU_NGN | 0.509 | 0.908 | 0.864 | 0.686 |
| Our method | 0.543 | 0.887 | 0.855 | 0.689 |
| AL_I_NLP | 0.545 | 0.892 | 0.857 | 0.678 |
| CKIP | 0.602 | 0.858 | 0.949 | 0.576 |
| Dataset | Evaluation (Precision/Recall/F1) | Method | |||
|---|---|---|---|---|---|
| NNLM | EmBERT + BiLSTM_Att | EmBERT+LLR + BiLSTM_Att | EmBERT+LLR+VA + BiLSTM_Att | ||
| NLPCC 2014 | Positive Negative Macro-Avg | 0.758/0.789/0.773 | 0.723/0.771/0.746 | 0.762/0.762/0.762 | 0.771/0.815/0.792 |
| 0.780/0.748/0.764 | 0.754/0.701/0.726 | 0.764/0.763/0.764 | 0.782/0.764/0.773 | ||
| 0.769/0.769/0.769 | 0.738/0.736/0.736 | 0.763/0.763/0.763 | 0.776/0.789/0.782 | ||
| ECSR | Positive Negative Macro-Avg | - | 0.853/0.853/0.853 | 0.901/0.913/0.907 | 0.932/0.903/0.917 |
| - | 0.881/0.881/0.881 | 0.914/0.914/0.914 | 0.924/0.952/0.938 | ||
| - | 0.867/0.867/0.867 | 0.907/0.914/0.911 | 0.928/0.928/0.928 | ||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cheng, Y.-Y.; Chen, Y.-M.; Yeh, W.-C.; Chang, Y.-C. Valence and Arousal-Infused Bi-Directional LSTM for Sentiment Analysis of Government Social Media Management. Appl. Sci. 2021, 11, 880. https://0-doi-org.brum.beds.ac.uk/10.3390/app11020880
Cheng Y-Y, Chen Y-M, Yeh W-C, Chang Y-C. Valence and Arousal-Infused Bi-Directional LSTM for Sentiment Analysis of Government Social Media Management. Applied Sciences. 2021; 11(2):880. https://0-doi-org.brum.beds.ac.uk/10.3390/app11020880
Chicago/Turabian StyleCheng, Yu-Ya, Yan-Ming Chen, Wen-Chao Yeh, and Yung-Chun Chang. 2021. "Valence and Arousal-Infused Bi-Directional LSTM for Sentiment Analysis of Government Social Media Management" Applied Sciences 11, no. 2: 880. https://0-doi-org.brum.beds.ac.uk/10.3390/app11020880