1. Introduction
The relationship between the concept of traceability and the tourist contributes to the improvement of the methodological approaches used in studies because it provides us with the precision and validity of the data obtained, especially from ubiquitous environments [
1]. Traceability constitutes an advance for the collection of tourist mobility data in spatial–temporal relationships. Traditionally, in the fields of production, logistics, and software, traceability has been considered as the set of actions, metrics, and technical procedures to identify and record each product from the beginning to the end of the supply chain [
2]. Furthermore, the ISO defines the traceability concept “as the ability to trace the history, application, or location of that which is under consideration.” [
3]. Furthermore, the GS1 defines tracing as “the ability to identify the origin, attributes, or history of a particular traceable item” and tracking as “the ability to follow the path of a traceable item” [
4].
In this sense, through a TTS, the DMO can identify the routes of the tourists and the degree of interest that the attractions of the destination arouse in them. Furthermore, TTS can use sociodemographic metrics and statistics reports to identify tourist profiles, to prepare and adapt both the tourist destination and the tourism management system. Hence, with the accelerated technological advance that characterizes ubiquitous computing, now DMOs have at their disposal various data sources. These sources provide input data for the TTS, such as social networks, cloud platforms, the web, the IoT, traditional databases, public or private datasets, and linked data, among other data sources.
On the other hand, these data sources typically are extensive volume datasets and reach high speed (in real time or almost in real time). Furthermore, variety is another characteristic of these data (some have a format; the vast majority do not). Big Data can process and store this type of data and constitute a knowledge base through ontological systems. In this way, the DMO can make decisions based on the information processed.
Currently, in most cases, the DMO makes decisions based on paper surveys applied to some tourists. Furthermore, government reports and those of the tourism sector actors serve as data for this decision-making process. These strategies have drawbacks, such as the subjectivity and predisposition of tourists to answer surveys. Many of them prefer not to answer them for time or data privacy reasons, and government reports are generated in extended periods, and in some cases, they arrive late. For this reason, the research gap of this study arises, which takes advantage of data from ubiquitous sources to provide information related to the traceability of tourists to a given destination. In this way, with the processing of these characteristic Big Data, precisely due to the volume, velocity, and variety, to constitute a knowledge base, the research question arises: How can we develop a tourist traceability ontology based on obtaining data and ubiquitous data processing, using Big Data analytics techniques?
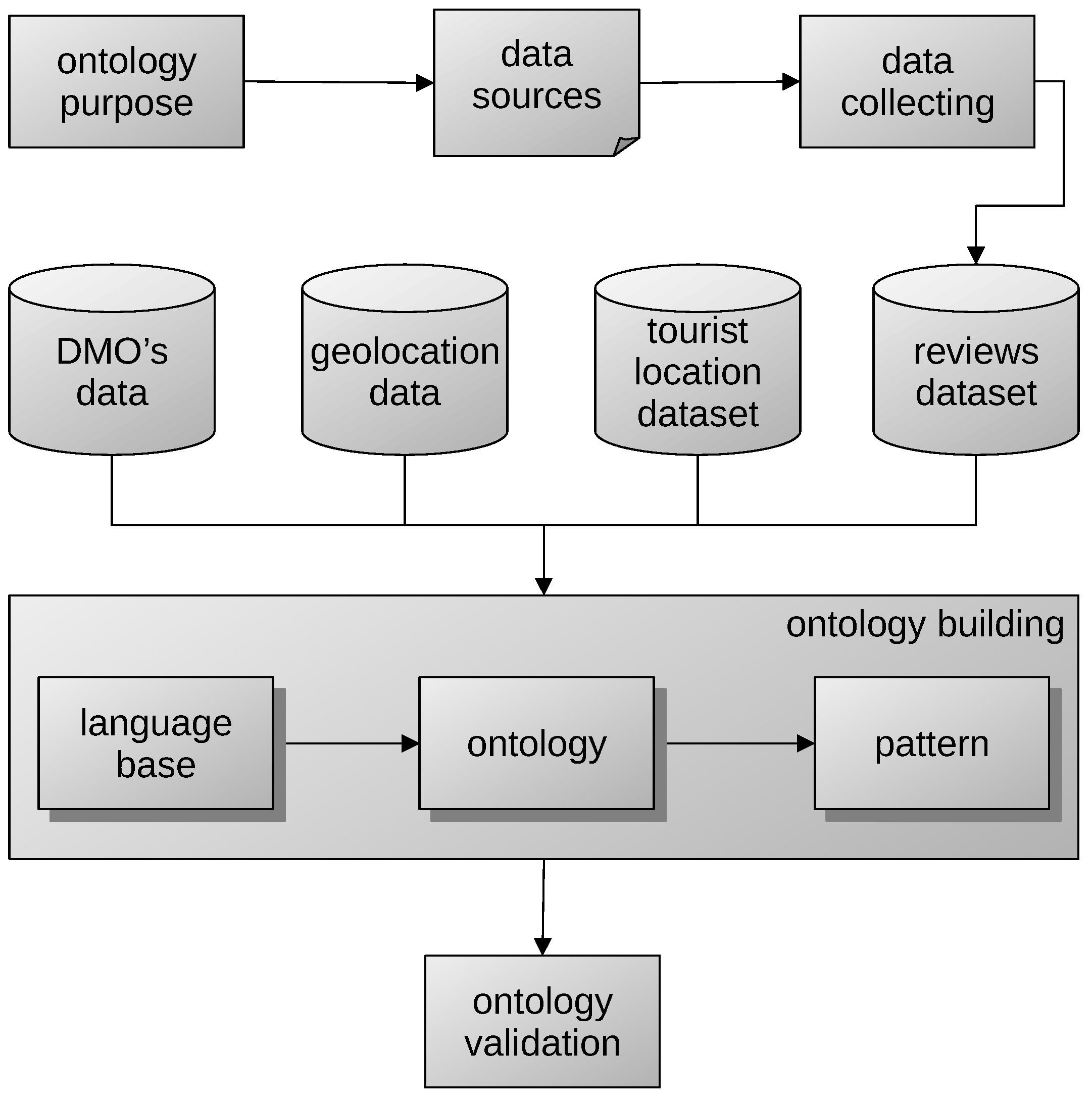
It is worth mentioning that the purpose of this study is to constitute an ontology based on data previously generated in a massive way, not on data from tourists in particular. Initially, we considered the data from three types of ubiquitous sources: reviews of tourists in OTAs, data from sensors located in the POIs of the destination, and data from tourist guide applications installed on the tourist’s mobile devices, which have prior permission for further processing. A tourist traceability ontology allows the DMO to make decisions regarding the management of the destination according to the flow and track of tourists, determine their preferred POIs, intelligently dispose of the infrastructure for adequate attention, and foresee improvements in services, as well as design tourist experiences according to the interests of the tourist in a space–time causality.
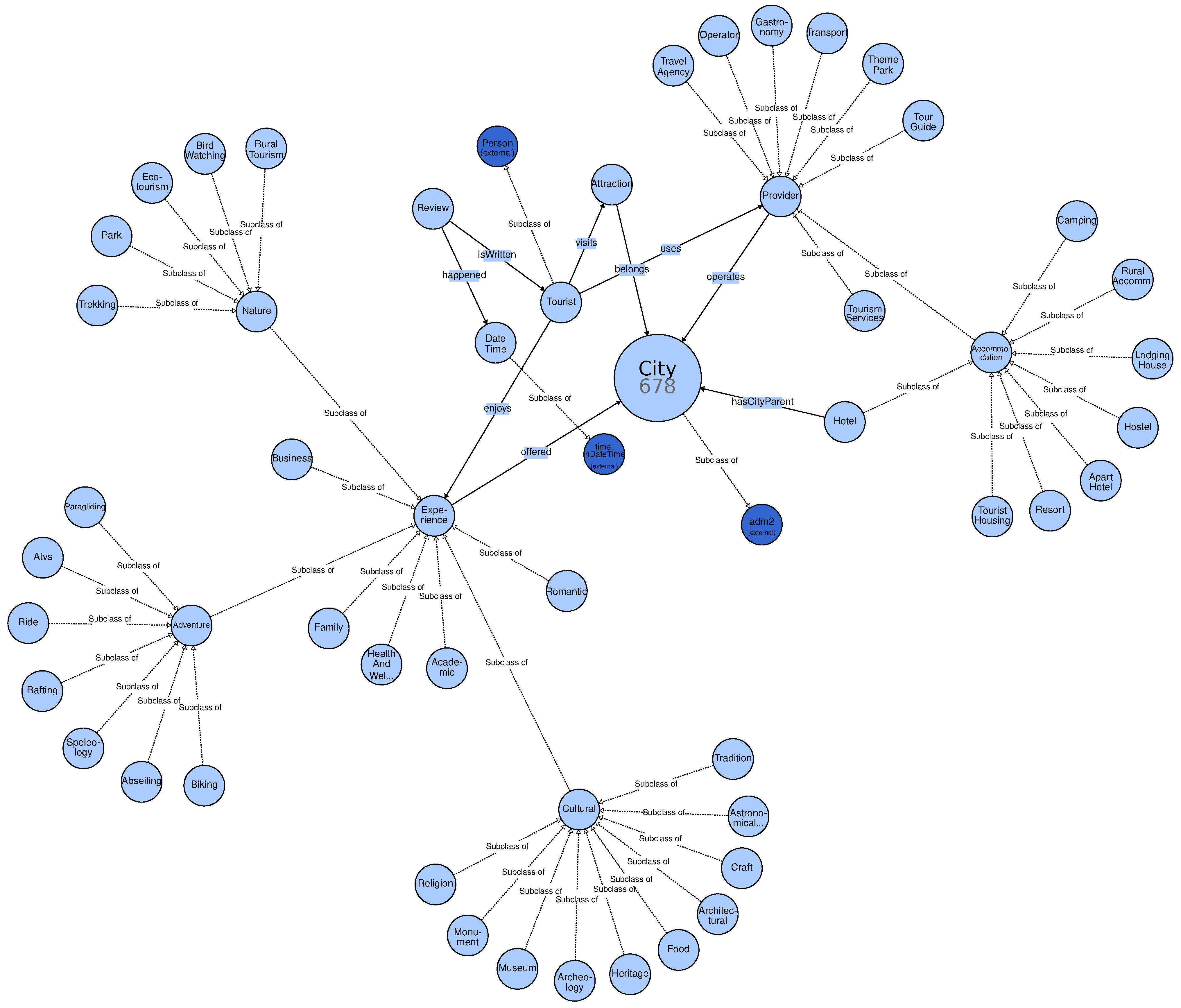
OntoTouTra is an ontology that explains the structure of knowledge, whose domain is the tourist traceability system, based on data collected from ubiquitous systems. OntoTouTra shares this knowledge through the conceptual design of this domain, enabling the reuse of knowledge. This paper shows the development of the OntoTouTra ontology. The ontology input data are from pervasive data sources. OntoTouTra is useful for making decisions on the destination, and its ontological goal [
5] is the integration of homogenous or heterogeneous data sources and search engines and building knowledge systems.
The paper is organized as follows:
Section 2 reviews the development of tourism ontologies related to this research. In
Section 3, we explain the ontology structure. Then, in
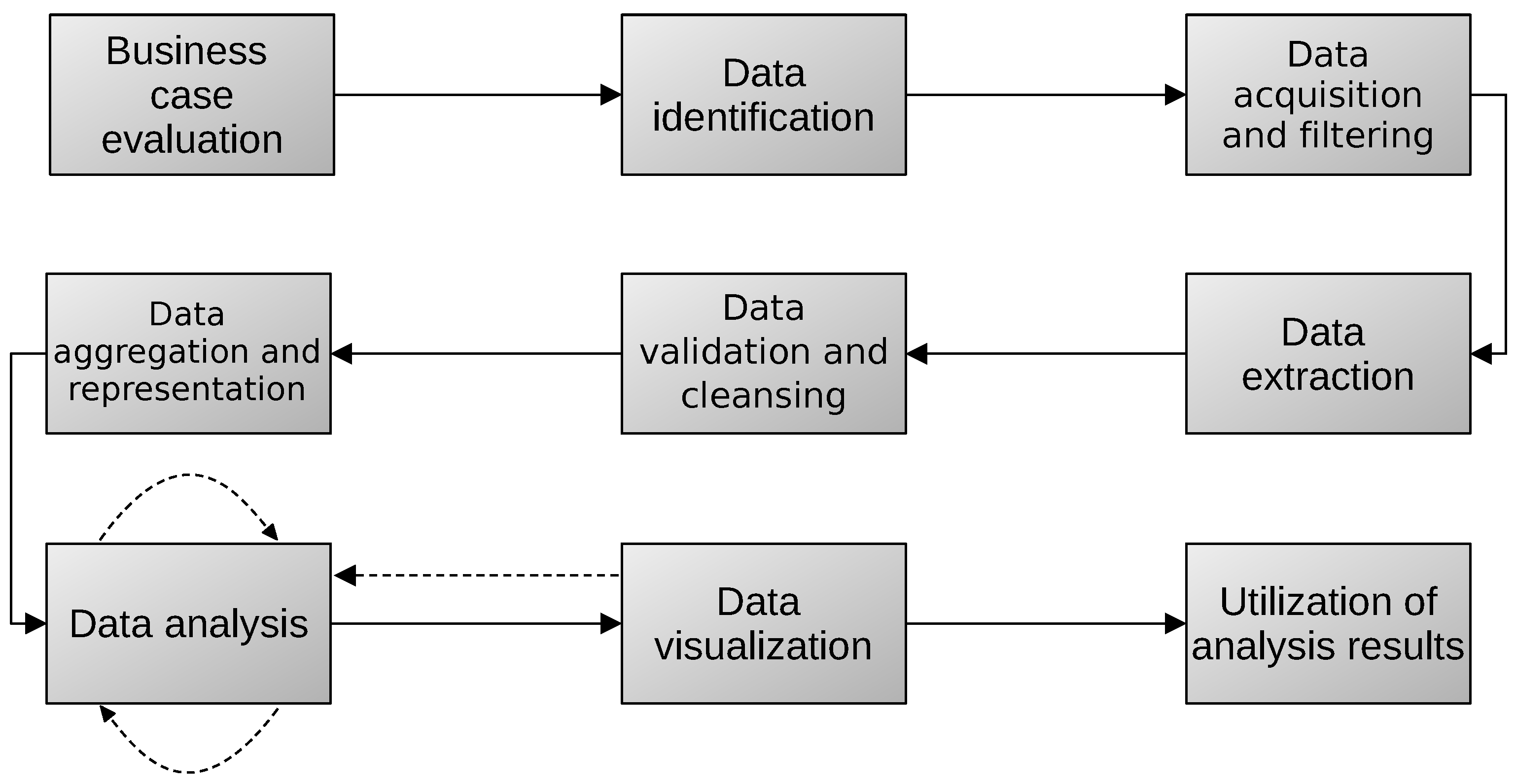
Section 4, we describe the methodology of the Big Data analytics used to build the ontology.
Section 5 provides the details for the implementation of the ontology with the chosen tourist destination. In
Section 6, we show the results obtained from the experiment. Furthermore,
Section 6 shows the knowledge base for the tourist traceability system, and
Section 7 describes the data treatment for OntoTouTra. Then,
Section 8 highlights the conclusions of the study and future work. Finally, this paper has
Supplementary Material, which is an ontology implementation document. There are lists and figures that illustrate the process of creating OntoTouTra and the different possibilities of queries according to the requirements for decision-making in the management of a tourist destination in the domain of the TTS.
2. Related Work
Some research on the semantic representation of the tourism domain uses information gathered from tourism websites for different applications. Xiang et al. [
6] concluded that tourism websites can incorporate tools (such as reviews, tagging, and excavation) to allow travelers to interact directly with these sites. This way, the knowledge of travelers’ perceptions and experiences can be collected and learned. Therefore, these tools offer promising avenues for tourist destination specialists to better understand and interact with potential visitors. Hence, the ontology is “the language of tourism” between the traveler and the industry. OTAs have communication channels with tourists to interact between them and the operators. Mainly, these channels are based on reviews that tourists give about their experience; in general, OTAs tag these reviews.
Concerning the knowledge domain of tourism, research such as that of Tribe and Liburd [
7] “reconceptualizes” its system, taking into account three cores: disciplinary knowledge, problem-centered knowledge, and value-based knowledge. The domain of the TTS refers to the disciplinary knowledge of the ontology of this research. It denotes the importance of understanding that tourism is a multidisciplinary field and an extradisciplinary one and considers the person, position, ideology, government, and global capital as elements of expertise. The “problem-centered knowledge” lies in the fact that DMOs need to have a knowledge base for decision-making, especially statistical information obtained from the traceability of the tourist at the destination. The decision-making by the DMO enables the improvement of the destination infrastructure and the feedback of the tourism management system; in this way, we obtain value-based knowledge.
Mouhim et al. [
8] highlighted the importance of KM in tourism: share knowledge, facilitate the development of new products and services, develop the ability to learn, acquire tacit knowledge to transform it into explicit knowledge, satisfy customers, and exploit the market. Based on [
9], these researchers analyzed existing ontologies such as the Harmonize Ontology [
10], for the exchange of data between organizations; the Mondeca Ontology [
11] for profiling tourist and cultural objects, tourist packages, and multimedia content for tourism; and the OnTour project [
12], which describes the domain of tourism focused on accommodation and activities. Seeing that none of these ontologies met the particular needs of their destination city, the researchers created their ontology (the Moroccan Tourism Ontology), taking advantage of the thesaurus of UNESCO and the UNWTO. Its ontology has the main classes: accommodation, transportation, attractions, activities, services, restaurants, and cultural heritage. As a study preceding their OnTourism project, Prantner et al. [
13] analyzed, in addition to the ontologies above, the OTA specification, the Tourism Ontology of the University of Karlsruhe, and the traveling ontologies EON and TAGA. They also reviewed the main ontology management tools for the domain of tourism, identifying the following: DIP Ontology Management Suite, WSMT, WebOnto, and Ontolingua [
14]. They complement the previous state-of-the-art because they feature a summary of ontologies in the travel industry, adding to the Comprehensive Ontology for the Tourism Industry, the LA_DMS project for destinations, the SWAP project, the Tiscover platform, and the Hi-Touch project, for the domain of intra-European sustainable tourism. The ontology proposed in this document has as its domain the tourist traceability system in a specific destination. In contrast to the ontologies described above, we used Big Data analysis for the building of OntoTouTra. We collected data from ubiquitous computer sources, especially from social networks.
Subsequently, in the process of building a domain ontology for African tourism areas, Zhao et al. [
15] reviewed new ontologies such as the e-tourism ontology, Tourism ProtegeEsportOWL, and the botanical ontology of the National Knowledge Infrastructure of the Chinese Academy of Sciences. In this way, they proposed a method for the construction of ontologies in seven steps: determine the field and the scope; examine existing ontologies; summarize essential concepts; define the classes and their hierarchy; define the attributes; define the properties; and finally, establish the individuals. We analyzed the Big Data analytical methodology proposed by Erl et al. [
16], in addition to contemplating the steps of the previous methods, as being ideal for the collection and processing of large volumes of data at high transfer rates.
To unify the tourism terminology, we need a central authority that promotes standards for tourists and suppliers to understand tourism-related ontologies. Huang and Bian [
17] recognized the UNWTO’s effort in defining the thesaurus about tourism and leisure activities, but believed that it is not enough due to the complex character of tourist data. They proposed their research to integrate both types of ontologies through the formal concept analysis and Bayesian approaches. These approaches are mathematical tools for data analysis, knowledge representation, and information management, using triples with binary relations among the concepts.
More recent studies, such as Valls et al. [
18], entrusted their research to word ontologies, such as WordNet [
19], applying clustering based on ontologies, determining the motivations of tourists when visiting a destination. OnTraNetBD [
20] also used WordNet for mapping the key concepts to build the ontology using the Domain, Entity Classes, Relations, and Attributes (DERA) methodology [
21] in six phases: identify atomic concepts, analysis, synthesis, standardization, ordering, and formalization. From WordNet and Wikipedia were derived Yet Another Great Ontology (YAGO) [
22], which uses a logical model, capable of representing n-ary relations maintaining compatibility with the RDFS. In this sense, Reference [
23] developed a system that supports different types of document formats, including the essential structures of textual documents and native forms of the web. In the paper, the authors compared the results of the semantic annotation approach with other popular methods (Armadillo, CERNO, CREAM, EVONTO, GoNTogle, KIM, MnM, Onto-Mat, and S-CREAM). Ontologies based on words use relations between elements, for instance, Llorens et al. [
24] called the words “terms” and established the relationships among the terms as the entity relationship model of the UML diagrams in software engineering.
The tourism sector has highlighted the need to develop personalized applications using knowledge bases. Currently, researchers focus their interest on the development of applications based on ontologies. Such is the case of the scientometric review that we preliminarily carried out on the frameworks of tourist recommendation systems [
25] that use heterogeneous data sources extracted from wearable devices, the IoT, social networks, and ontologies. A specific application we found is the TRSO [
26] recommendation system for tourists to know the attractions they can see and the activities they can do. The recommender system uses collaborative filtering techniques based on information from attraction ontologies. Investigations such as SocioOntoProcess [
27] draw from social networks to build ontologies and take advantage of user interactions to develop the models, in this case for consulting a consensual vocabulary. The ontology’s construction is collaborative through web tools, such as wikis.
SigTur/E-Destination [
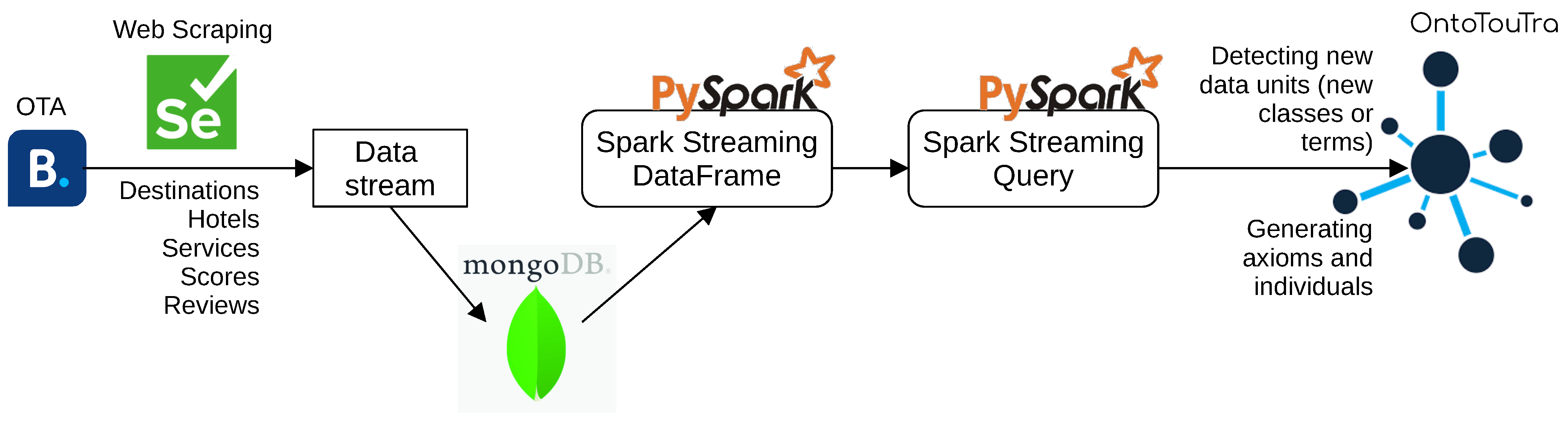
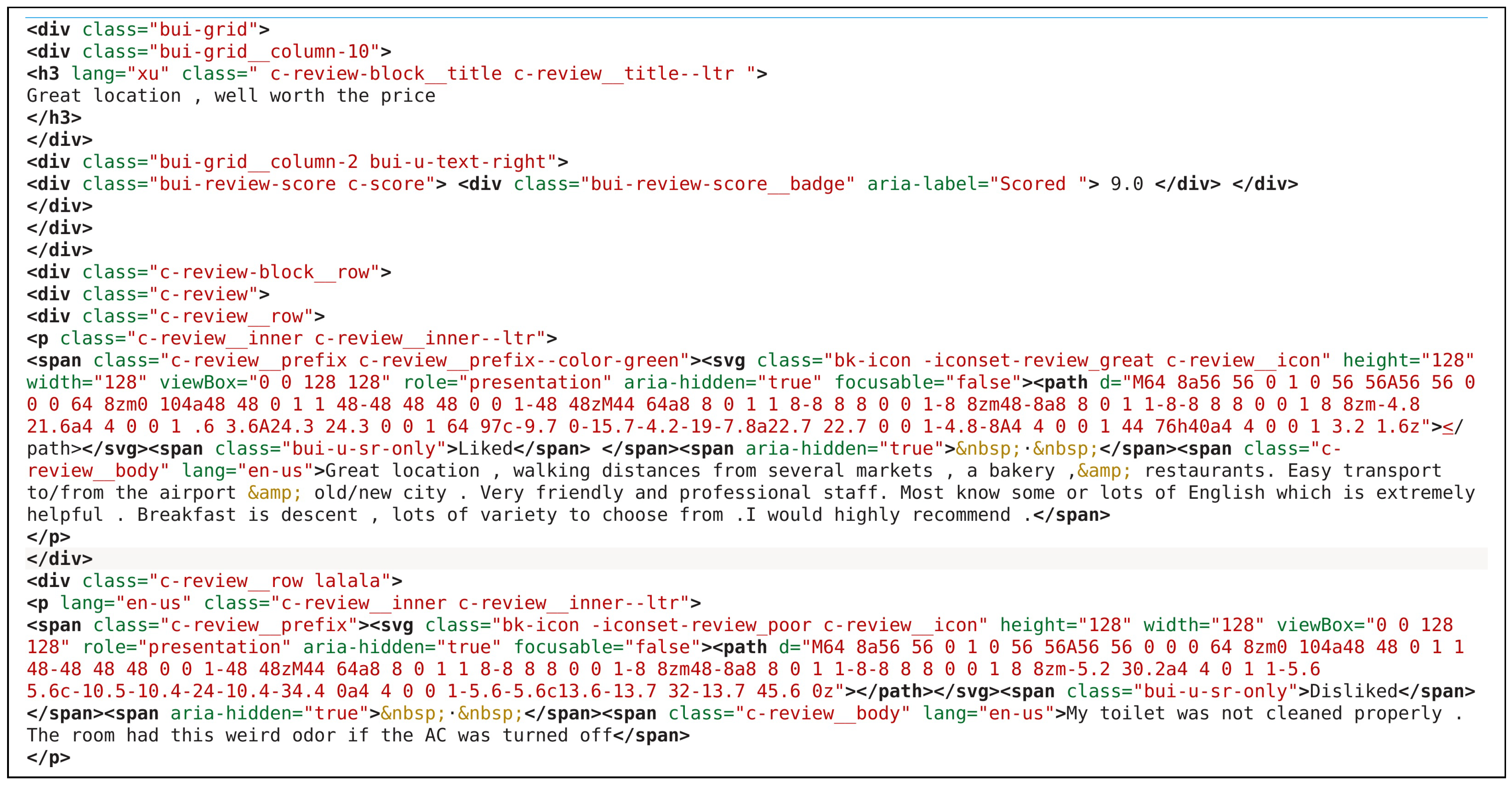
28] is a project that, from the knowledge management point of view, through a specific domain ontology, provides information on activities and guides aimed at the user and for employees. The system considers as much information as possible (demography, spatial, travel, motives, user stereotypes) to make the recommendations. We were also motivated to gather data from social networks, especially from OTAs or eWOMs, because they tagged tourist reviews. Some OTAs offer an API to consult these reviews, but it is necessary to develop tools that can collect those public reviews for others. For this purpose, we created a web scraping tool.
From the perspective of the software industry, in particular the reuse of information, arose the RSHP meta-model [
24]; the authors looked for a general model capable of representing the information of software artifacts, without dependence on their internal structure. They found that the data of all the artifacts form a representation of a particular domain. The authors concluded that the field could be created automatically by indexing the artifacts through a fundamental and simple idea: “the information is related facts.” Therefore, the central element of an artifact is the relationship. The semantics of the RSHP qualifies the existing relationship and its type; its components are artifact, term, relationship, information element, and property.
During the last decade, Shoval and Ahas [
29] reviewed the literature on the use of tracking technologies for tourism, finding forty-five articles (40% of the articles were published in the three leading tourism journals). This review found that tracking data occur in three generations: The first generation deals with methodological research and analyzes the potential of tracking data. The second generation is related to spatial and temporal data. The third generation is interested in new data sources. The researchers concluded that the movement of tourists has implications for infrastructure, transport, products, marketing, the commercial viability of the industry, and the management of the social, environmental, and cultural impact of the destination. They also detected the current research gaps in this area: a large amount of data for processing, personal data, and tourist data protection. Using new techniques is necessary to know the tourist traceability since some theorists think that the tourist can change the activity or behavior when being followed or studied.
Girardin et al. [
30] proposed a challenge for social science research since large volumes of data from ubiquitous sources are available. With these data, we can understand the dynamics of the population and customize the services, among other essential activities for tourism management. They named the tourist tracks “digital footprints”, which are of two types: active and passive. The passive traces are data left with the interaction of infrastructure, and the active traces are the location data exposed by the users, especially in social networks. They worked with Flickr data (actives) and the call records of a telephone company (passives). The data used in Flickr are explicitly public data by the user. They carried out the process and the visualization of the large volumes of data through geo-visualization. Concerning data privacy, the authors handled the number of users instead of individual data. For this research, the expression “digital footprints” is similar to the data sources of ubiquitous computing, which are the input of the traceability system.
Mariani and Borghi [
31] conducted a review of research literature on hospitality and tourism with Big Data and Business Intelligence to identify future research and development gaps. They found that the research that applied analytical techniques is limited in scope and methodologies. Besides, conceptual frameworks are missing to identify critical business problems that link Business Intelligence and Big Data to tourism management. They evidenced epistemological dilemmas for the development of knowledge theories conducted using Big Data. They concluded with their study that further research on tourism should be stimulated and systematized by leveraging Big Data and Business Intelligence and providing information bases aimed at companies and stakeholders in tourism.
As a synthesis of this review of the related work,
Table 1 depicts the highlighted ontologies and their respective objectives.
In
Table 1, we see that all ontologies meet a particular objective, which is why their domain of knowledge is well defined. We show that none of the ontologies listed in this table have tourist traceability as their domain.
Chantre et al. [
1] established two thematic cores of the movement of tourists and the tracking methodologies in the relationship of traceability and the tourist. In this sense, they considered tourist traceability as the set of actions, measures, and technical procedures to identify and record the activity of tourists in a given destination. For the above, to keep this record, it is necessary to build a spatiotemporal causality. Through a tourist traceability system, we gather information on the activities of interest to tourists, the most frequented POIs, the timing of visits, tourist satisfaction with their experience, visitor profiling, and a portfolio of tourist experiences, among others. In turn, a TTS allows decision-making by the DMO, establishing KPIs that determine the level of service offered to improve destination management. With the above considerations, it is essential to have a knowledge base of the TTS domain, with updated, accessible, actionable, and reliable data.
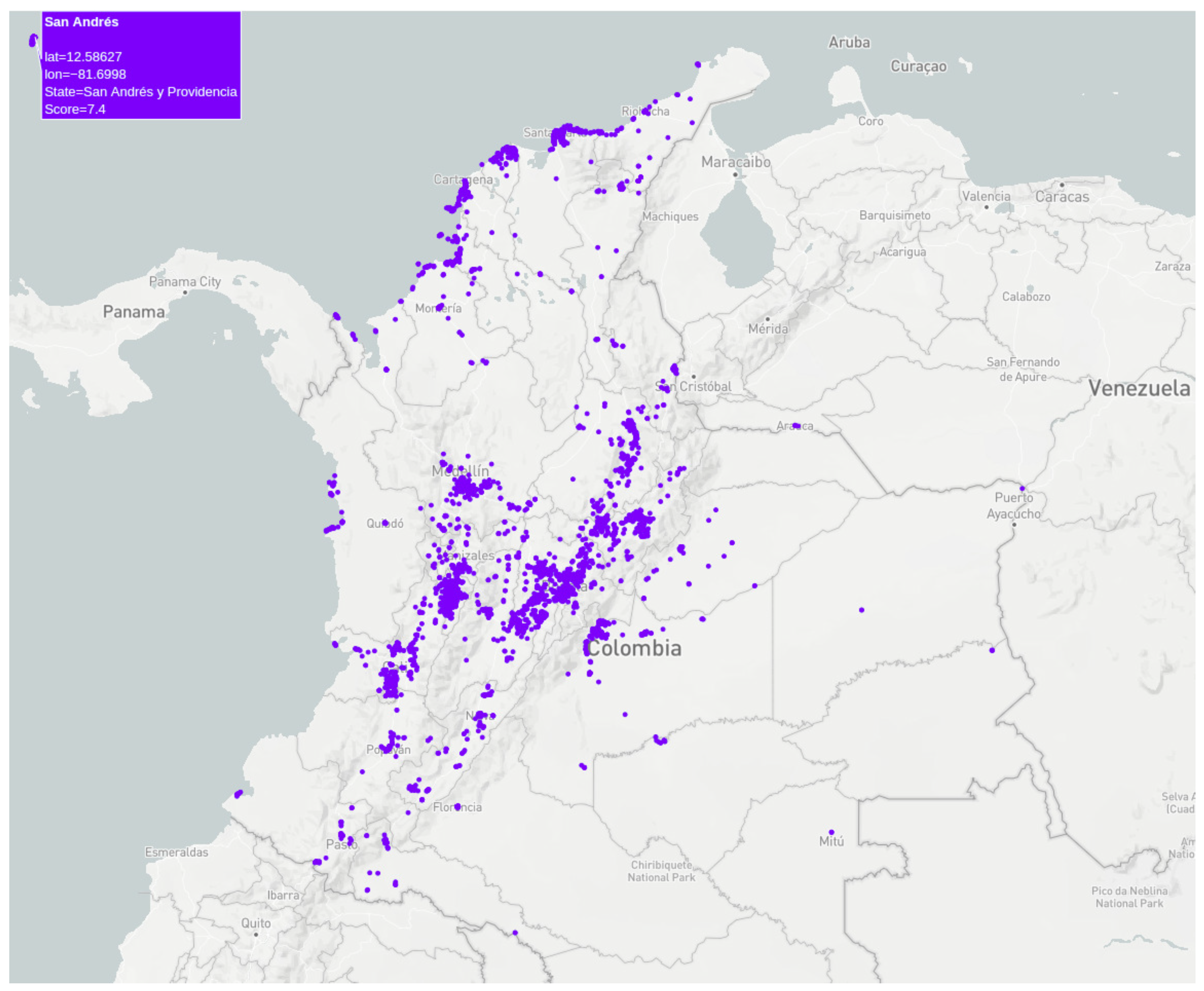
This study took advantage of data from ubiquitous sources, especially from OTAs, because these satisfy the above requirements, especially tourist reviews. Furthermore, these allow identifying, among others, data on spatiality, temporality, satisfaction, feelings, preferences, and experiences. The analysis of these data is boosted through link data, for instance, with georeferenced data from tourist reviews, we reach more location levels, establishing a relationship between the review location and the hotel, destination, POI, or service reviewed. We move up the geographical level, passing through the state or region and reaching a particular country. Linking data with GeoNames provides complementary geographic information, which we did not obtain directly from the ubiquitous data source. Similarly, complementary temporal information is collected from linking data with the Time Ontology.
The GeoNames ontology [
37] allows adding semantic data to the World Wide Web. It has more than 11 million toponyms with a single URL (RDF web service). The ontology of GeoNames is available in OWL as a database dump and also as open data linked in RDF [
38]. Geographic levels in GeoNames [
39] vary according to the country, for example, Germany has six levels, France five, and Colombia four. Therefore, it was necessary to resort to national data providers; for the Colombian case, the National Administrative Department of Statistics (DANE) provides the DIVIPOLA system [
40]. Thus, we can provide more data about the location of a person, hotel, or tourist attraction (POI).
The other aspect of the spatiotemporal relationship of tourist traceability is based on temporal concepts; the OntoTouTra data link is the Time Ontology [
41]. We took advantage of the vocabulary from this ontology to express the facts of relations between instants and intervals. We can establish temporal reference systems (time: DateTimeDescription), position in time (time: TemporalPosition), intervals (time: DateTimeInterval), and duration (time: duration time: DurationDescription).
OntoTouTra does not have a data link with any tourism management ontology. However, for its construction, open data repositories were taken into account by the International Open Data Charter [
42], for instance, we used Colombia’s Open Data [
43] and SITUR [
44].
8. Discussion and Conclusions
In this study, we proposed a model for building an ontology of a TTS, answering the research question “How can we develop a tourist traceability ontology based on gathering and processing ubiquitous data, using Big Data techniques?” The gap demonstrated in the state-of-the-art showed us the lack of an ontology whose domain was tourist traceability. Therefore, we proposed a model for the creation of the OntoTouTra ontology. In turn, we adapted the lifecycle of Big Data analytics presented by Erl et al. [
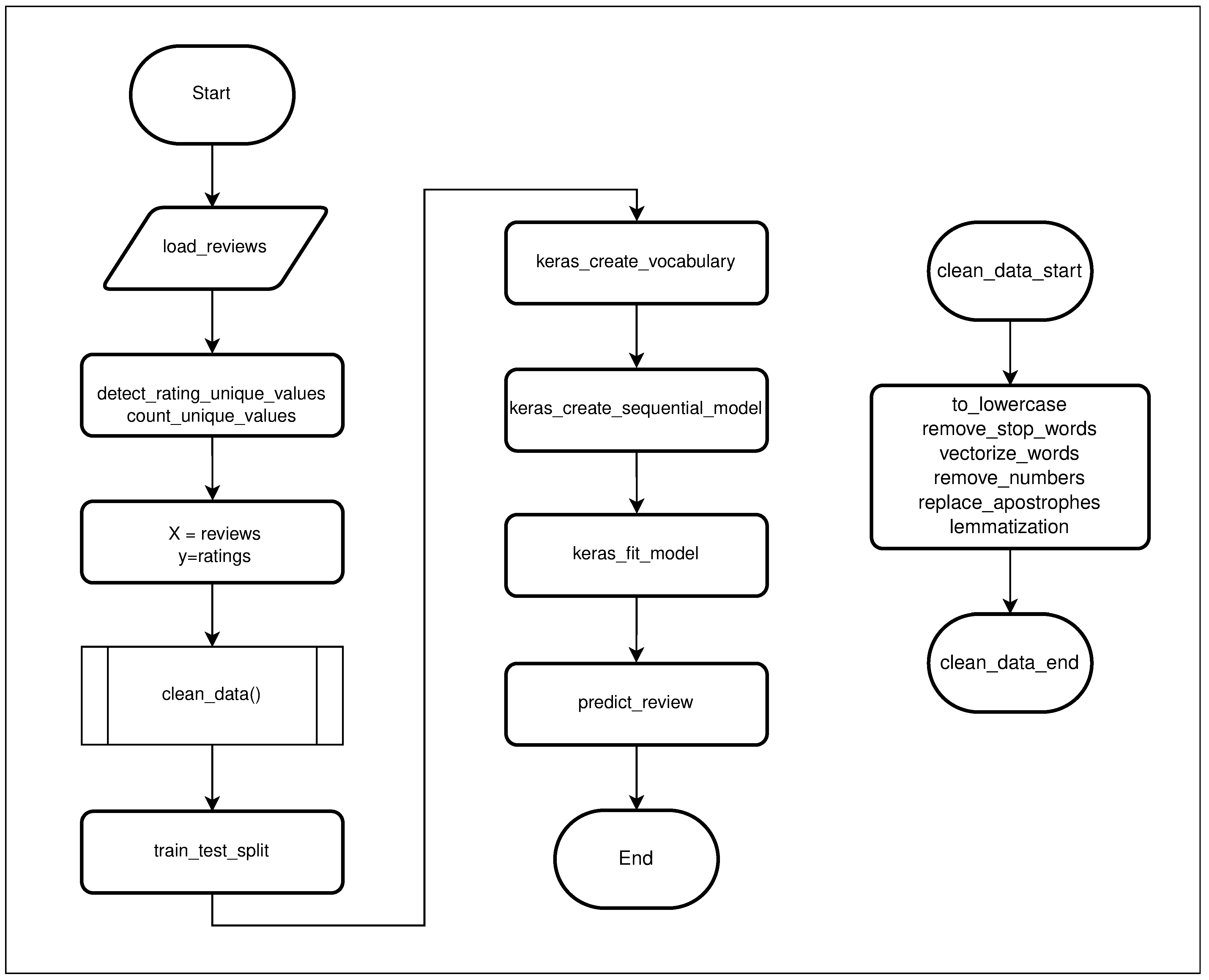
16] to deal with the volume, variety, and velocity of data coming from ubiquitous sources, in particular from an OTA.
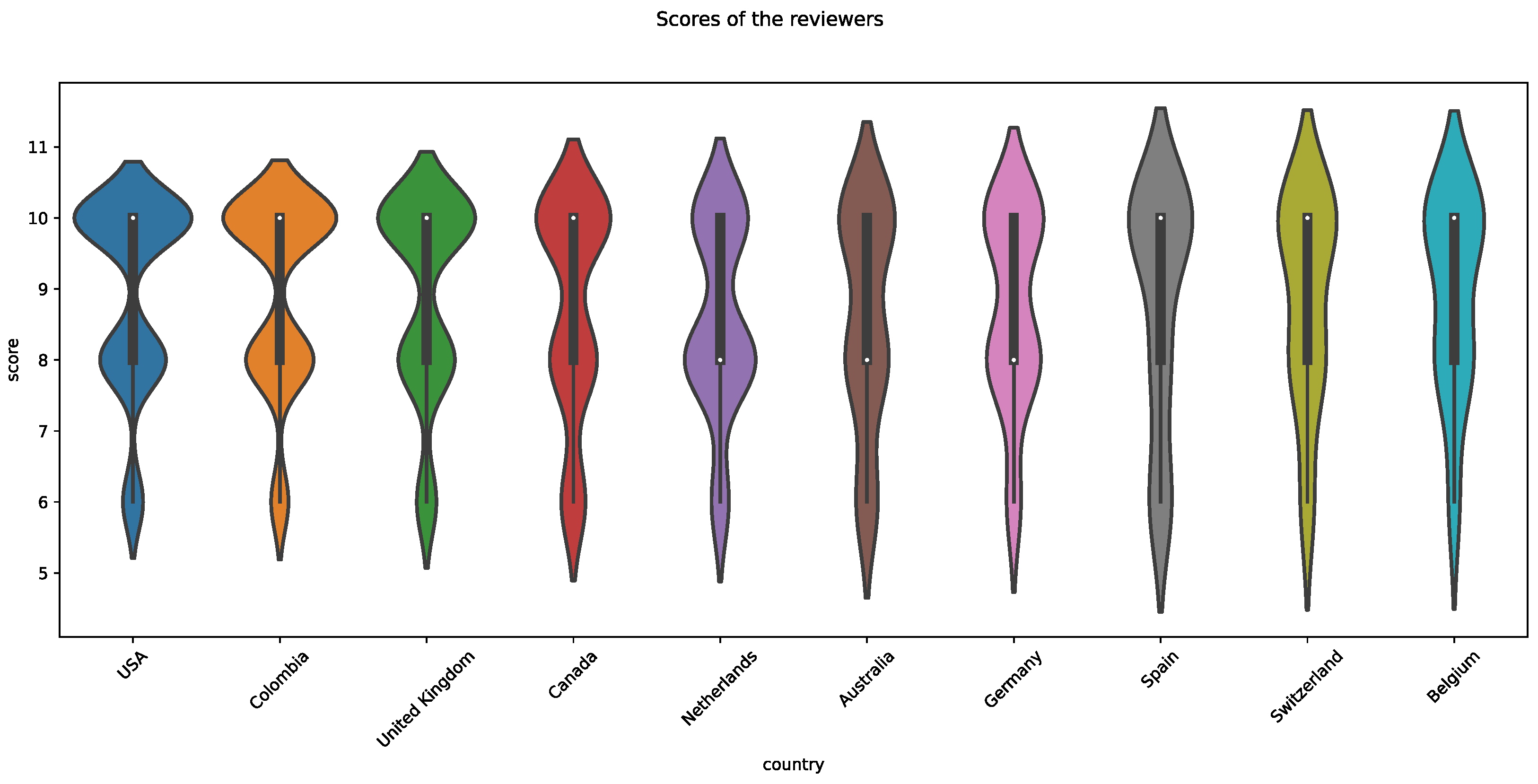
We applied the GQM approach of the FOCA methodology to validate the OntoTouTra ontology and achieved a score of 99.77% of the total quality of the ontology. We used HermiT, Protégé, and OOPS! as evaluation tools. However, the number of individuals in the ontology, especially tourist reviews, required enormous computational resources. For instance, we used HermiT as a Protégé [
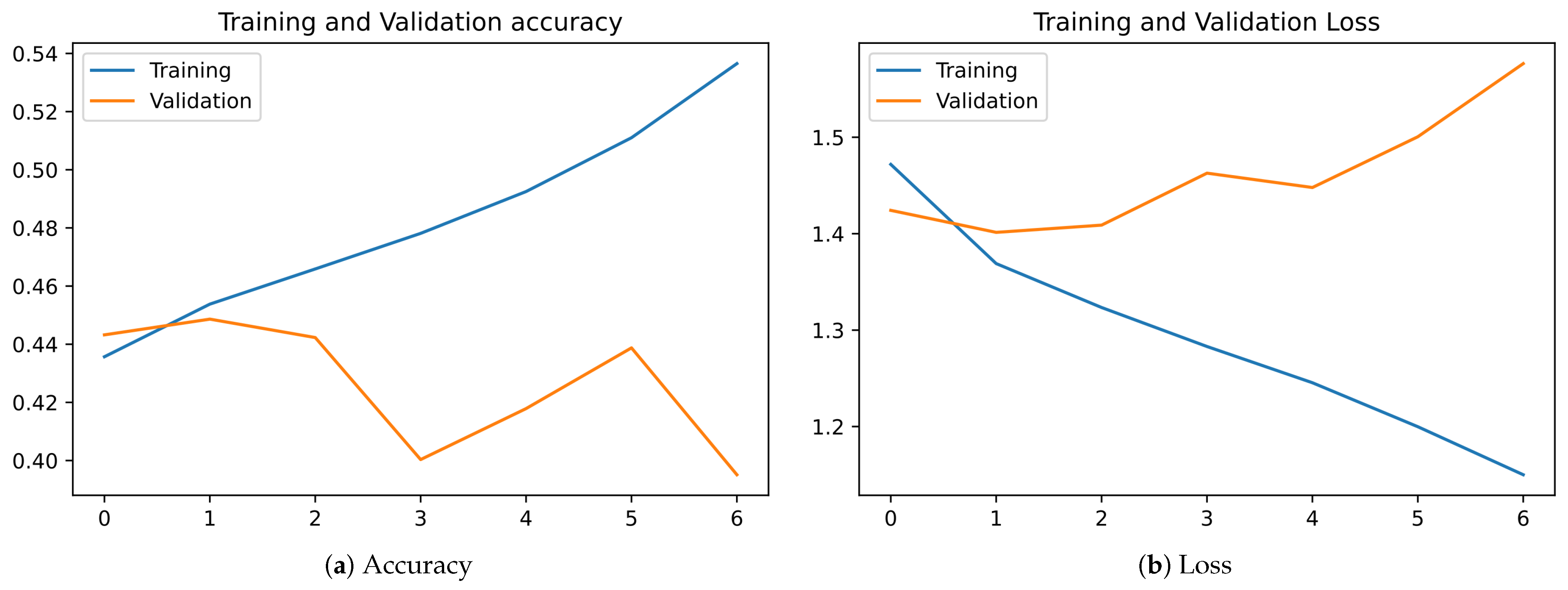
56] plugin, and the capacity of this tool restricted its execution. For the evaluation tests, we had to ignore the individuals of the tourist reviews. A new research challenge arises to adapt this type of ontological tool to Big Data environments. The amount of knowledge affects the quality of the ontology’s testing processes, which is imperative in this environment. The analysis of the ontology validation results demonstrated its functionality. The validation was conceptual, whose aim was to evaluate the purpose and functionality of the ontology. This goal was achieved by executing SPARQL queries for 10 KPIs representative of a TTS.
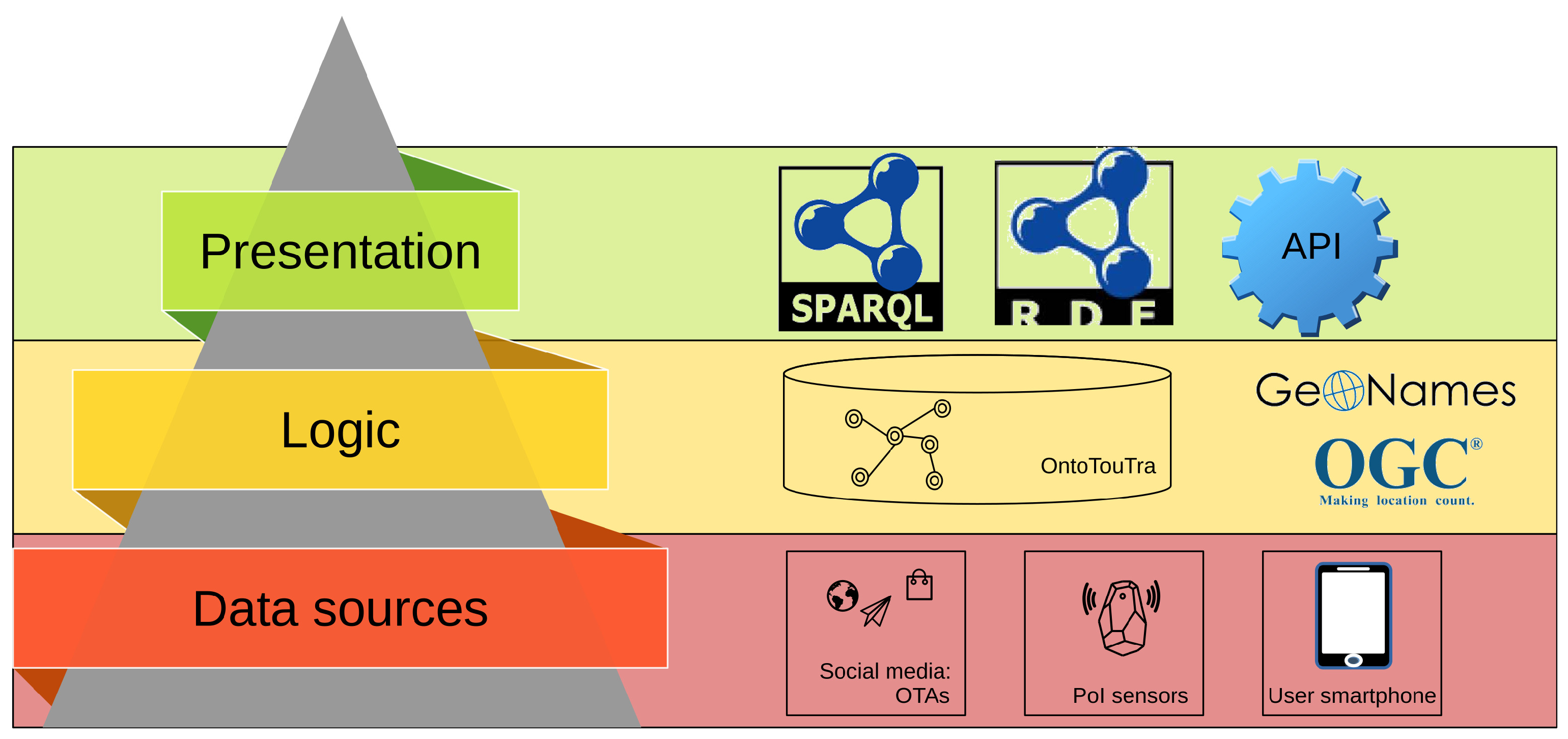
As contributions of this study, we highlight the construction model of the ontology, the adaptation of the lifecycle of Big Data analytics so that the ontology works with ubiquitous data sources in Big Data contexts, and the interoperability of the ontology with open systems, since it allows SPARQL queries and RESTFUL API. The source code allowed the creation, access, and use of the ontology in Big Data environments, using PySpark, and the provision of the ontology for open link data, in particular with GeoNames and Time Ontology. The results of this study are a meaningful contribution to the scientific community and to DMOs looking for a knowledge base to support decision-making regarding destination management.
The practical application of the developed ontology is extensive: it serves as a knowledge base to support decision-making in the destination, recommendation systems for tourist experiences, monitoring of the management of the DMO, the design or improvement of tourist experiences, the benchmarking of tourist experiences, tourist service providers, and web portals on destination tourist information, among others.
Through the OntoTouTra ontology, we plan to consolidate the knowledge base for DMOs. As future work, we will include other ubiquitous computing sources, such as data from tourist mobile devices and sensors from POIs. Besides, we will offer a portfolio of tourist experiences of the destination.


 ,
, 


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}



















