
Detection of Small Size Traffic Signs Using Regressive Anchor Box Selection and DBL Layer Tweaking in YOLOv3

 ,
,  ,
,  and
and
Abstract
:1. Introduction
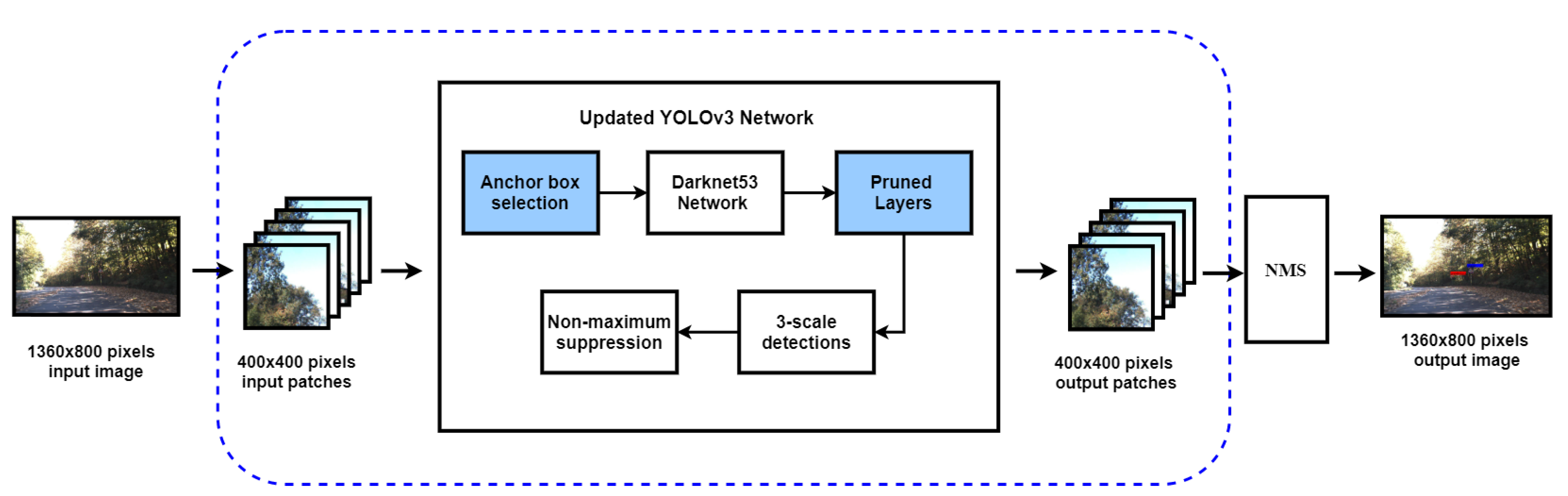
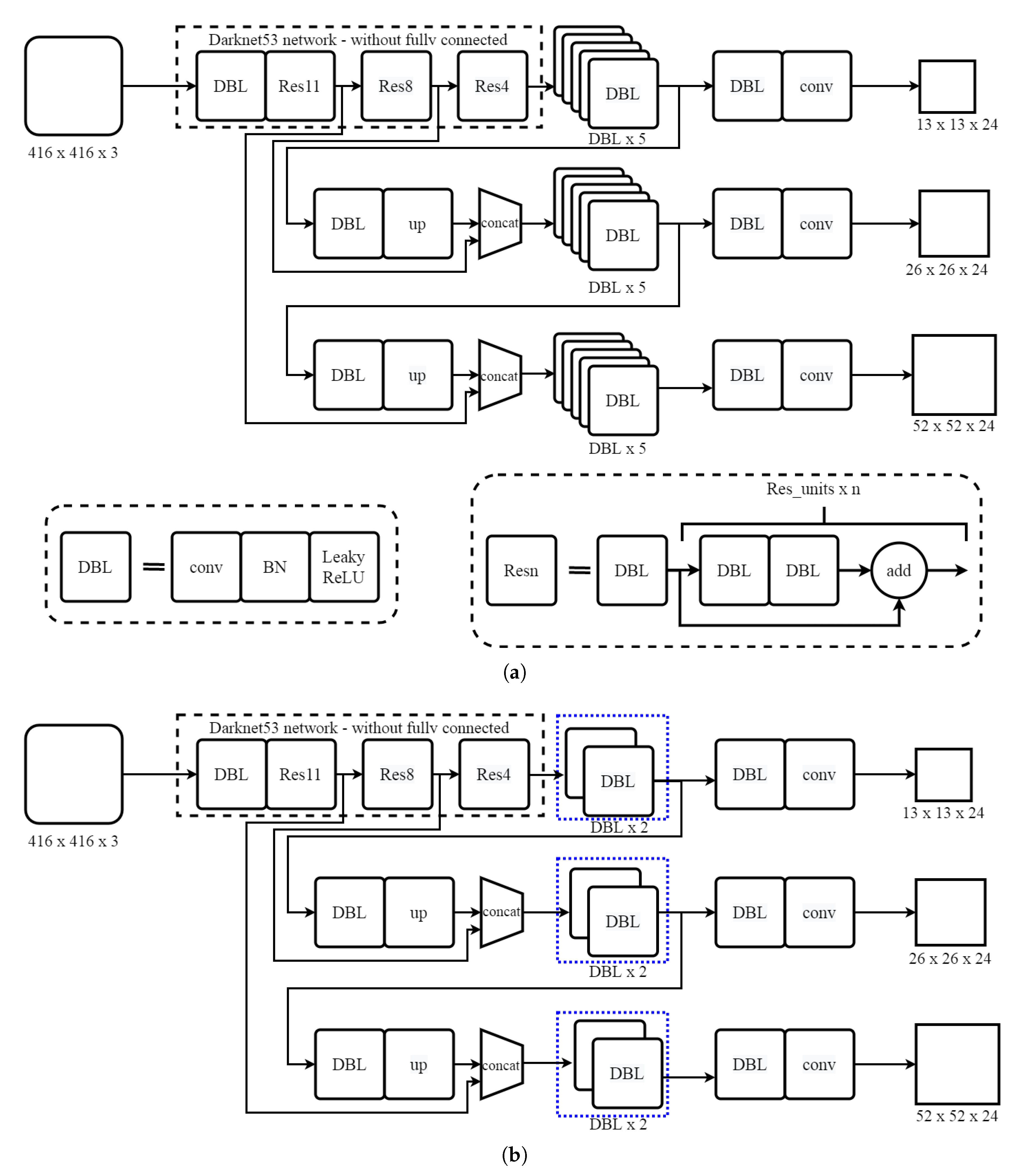
- Tweaked YOLOv3 model for smaller object detection: YOLOv3 model uses multiple DBL layers for object detection. For larger object size relative to image size, these DBL layers are sufficient however, for a smaller object such as a traffic sign, useless features are being learned. We propose pruning a few of those layers and validating the rationale on GTSDB.This improvement helped in extraction and saving fine details of traffic signs. In addition, a new strategy for training and testing is proposed. Instead of using the whole image at once, it was broken into patches and those patches were used for training and testing. We report an increased accuracy of 14% from the default YOLOv3 accuracy, fewer false detections, and log-average miss rate. We also evaluated the proposed network framework on two publicly available datasets, namely GTSDB (German Traffic Sign Detection Benchmark) and STS (Swedish Traffic Sign) dataset [9], giving 16% and 5% rise in mAP, respectively.
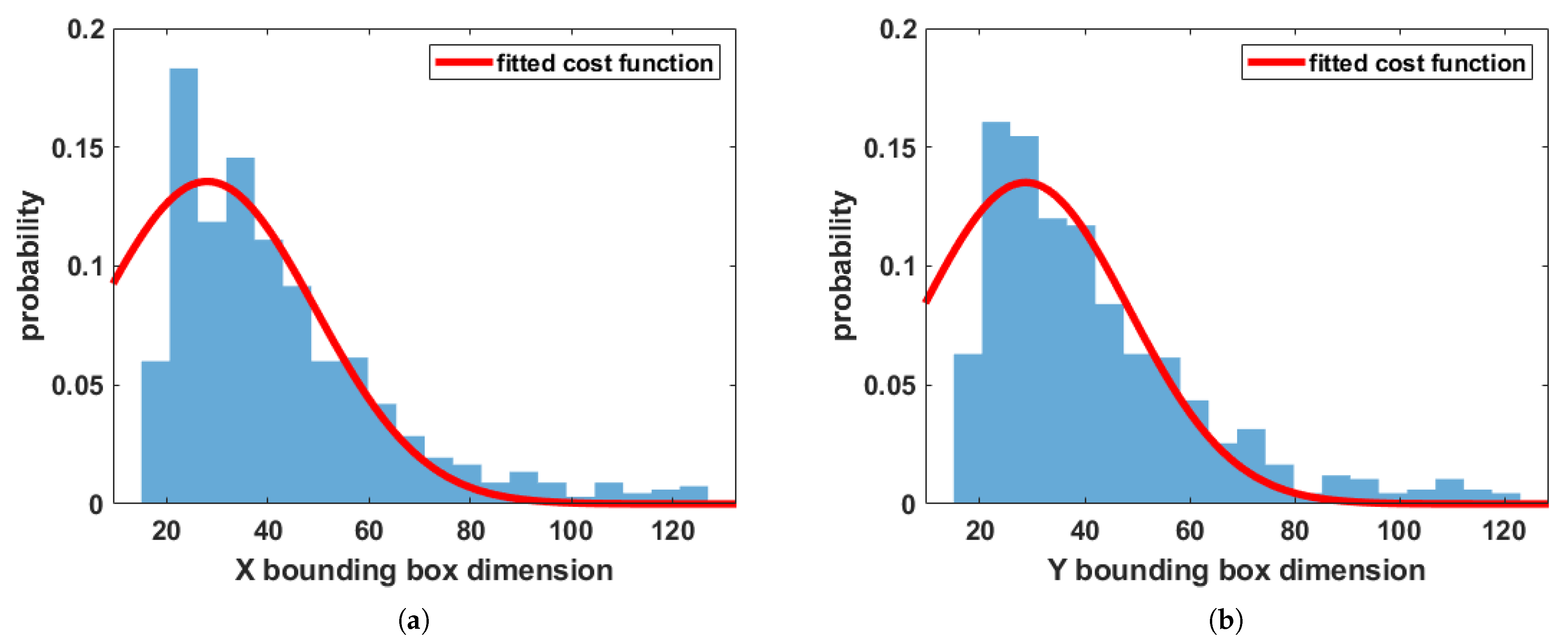
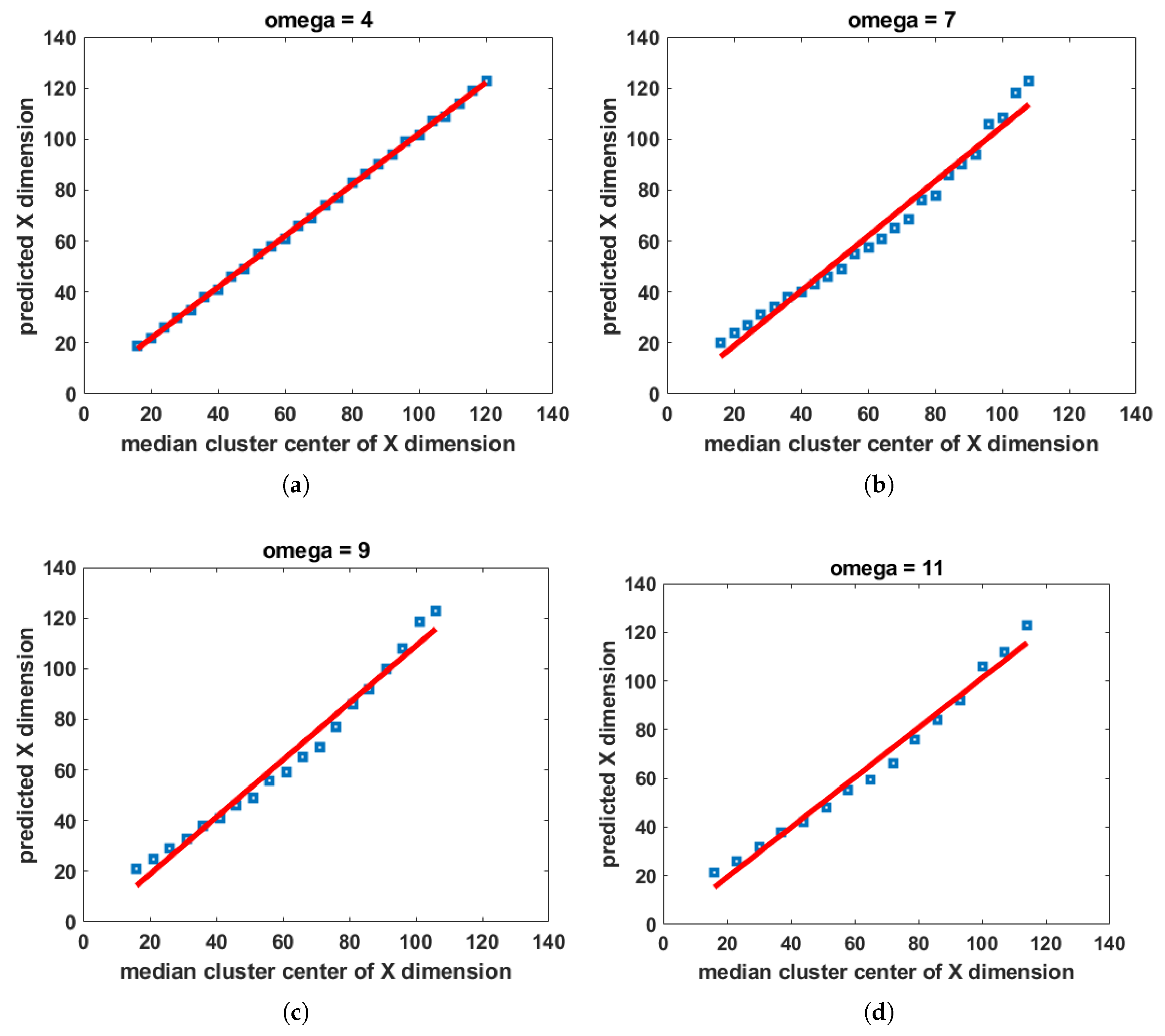
- Regressive anchor box selection: While analyzing the traffic sign size distribution in the German and Swedish traffic sign training set, we noticed that the majority of the traffic sign sizes are smaller and concentrated in the range from 20 pixels to 40 pixels. The base technique in YOLOv3 uses k-means clustering to select the anchors.We propose to make this selection adaptive using a regression model. We designed a cost function that adds more weight (by assigning higher numbers of clusters) to the bounding box size distribution where a majority of the traffic signs are concentrated. This helps us to select most of the anchors from the pixel value range that contains most of the traffic signs sizes and lesser anchors from the lesser concentration regions. The cost function helps the regression model to adapt the traffic sign sizes for any dataset. As a result, the detection accuracy of the traffic signs on GTSDB was further increased by 2% in addition to the increased accuracy achieved with the tweaked YOLOv3 detector. We noted that the increase in 2% accuracy was due to the perfect placement of anchors on test samples. The proposed model is adaptive and can be used with any object.
- Focal loss: In this research, we also investigated the effect of incorporating focal loss [10] as Objectness score. We note that the hyper-parameters in focal loss are object shape as well as size-dependent. The optimal values for alpha and gamma for traffic signs have also been determined. Our proposed method achieved higher mean Average Precision (mAP) and equal Log Average Miss Rate (LAMR) as compared with the Focal loss implemented YOLOv3 detector.
2. Related Work
3. Proposed Method
3.1. Regressive Anchor Box Selection
3.2. YOLOv3 Coupled with Patch-Wise Detection Strategy
3.3. Focal Loss as Objectiveness Score
4. Experimental Results and Discussion
4.1. Datasets
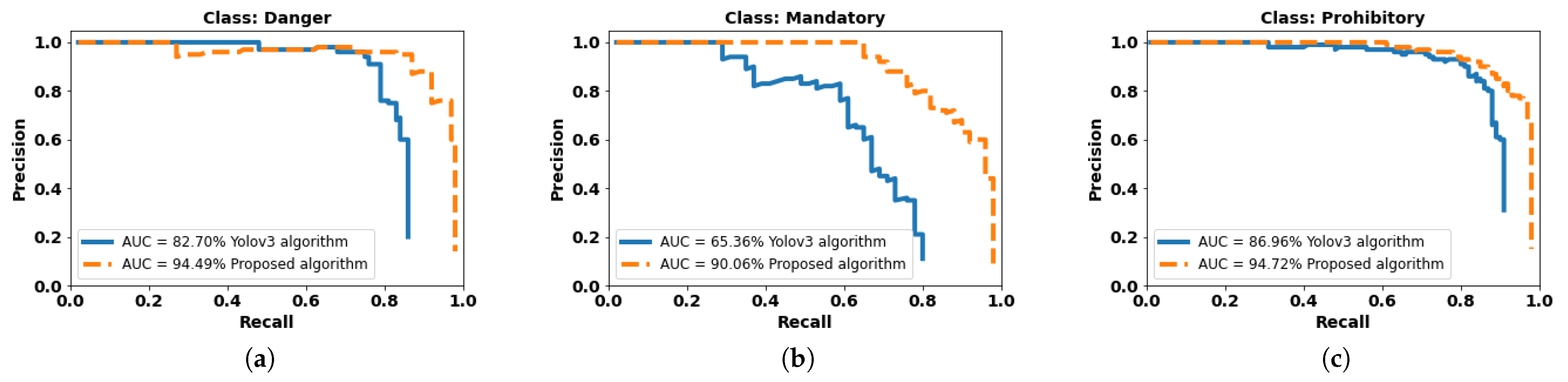
4.2. Regressive Anchor Box Selection
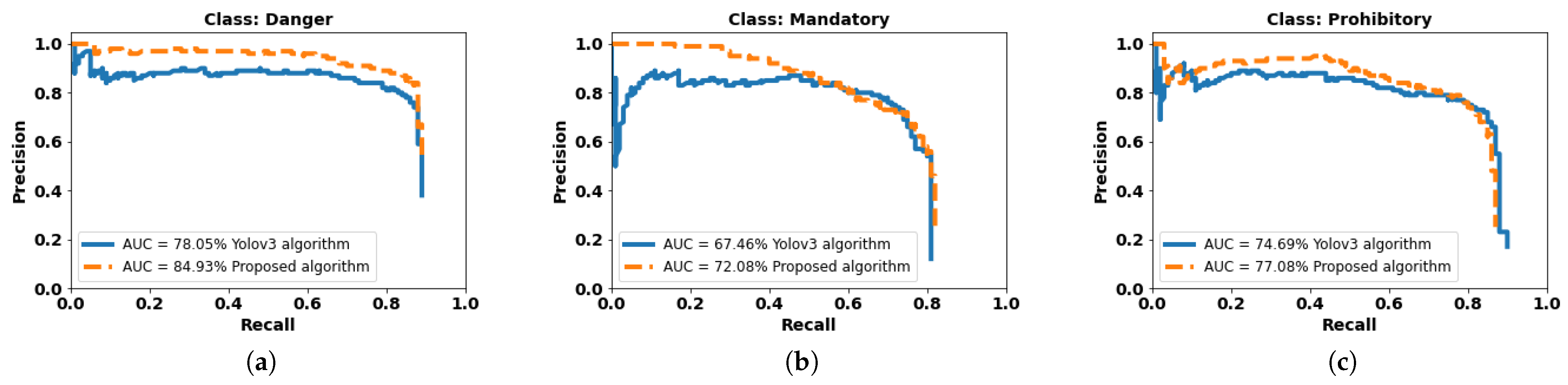
4.3. Updating Network Layers
4.4. Focal loss Implementation
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| BCE | Binary cross entropy |
| lamr | log-average miss rate |
| mAP | mean Average Precision |
| FPPI | False Positive Per Image |
References
- Serna, C.; Ruicheck, Y. Traffic signs detection and classification for European urban environments. IEEE Trans. Intell. Transp. Syst. 2020, 21, 4388–4399. [Google Scholar] [CrossRef]
- Gupta, A.; Choudhary, A. A Framework for Real-time Traffic Sign Detection and Recognition using Grassmann Manifolds. In Proceedings of the ITSC 2018: International Conference on Intelligent Transportation Systems, Maui, HI, USA, 4 November 2018. [Google Scholar]
- The German Traffic Sign Detection Benchmark. Available online: http://benchmark.ini.rub.de/?section=gtsdb&subsection=dataset (accessed on 9 July 2020).
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- He, K.; Gkioxari, G.; Girshick, R. Mask R-CNN. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D. SSD: Single shot multibox detector. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Amsterdam, The Netherlands, 11–14 October 2016; pp. 21–37. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R. You only look once: Unified, real time object detection. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 18–20 June 2016; pp. 779–788. [Google Scholar]
- Swedish Traffic Signs Dataset. Available online: https://www.cvl.isy.liu.se/research/datasets/traffic-signs-dataset/ (accessed on 27 December 2020).
- Tsung-Yi, L.; Goyal, P.; Girshick, R. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Khalid, S.; Muhammad, N.; Sharif, M. An automatic measurement of the traffic sign with digital segmentation and recognition. Inst. Eng. Technol. 2019, 13, 269–279. [Google Scholar] [CrossRef]
- Yang, Y.; Luo, H.; Xu, H. Towards real time traffic sign detection and classification. IEEE Trans. Intell. Transp. Syst. 2016, 17, 2022–2031. [Google Scholar] [CrossRef]
- Ohta, Y.; Kanade, T.; Sakae, T. Color information for region segmentation. Comput. Graph. Image Process. 1980, 13, 222–241. [Google Scholar] [CrossRef]
- Gonzalez, A.; Garrido, M.; Fernandez, D. Automatic Traffic Signs and Panels Inspection System Using Computer Vision. IEEE Trans. Intell. Transp. Syst. 2011, 12, 485–499. [Google Scholar] [CrossRef]
- Barnes, N.; Zelinsky, A.; Fletcher, L. Real-time speed sign detection using radial symmetry detector. IEEE Trans. Intell. Transp. Syst. 2008, 9, 322–332. [Google Scholar] [CrossRef]
- Yuan, Y.; Xiong, Z.; Wang, Q. An incremental framework for video-based traffic sign detection, tracking, and recognition. IEEE Trans. Intell. Transp. Syst. 2017, 18, 1918–1929. [Google Scholar] [CrossRef]
- Luo, H.; Yang, Y.; Tong, B. Traffic sign recognition using a multi-task convolutional neural network. IEEE Trans. Intell. Transp. Syst. 2018, 19, 110–1111. [Google Scholar] [CrossRef]
- Donoser, M.; Bischof, H. Efficient Maximally Stable Extremal Region (MSER) Tracking. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, New York, NY, USA, 17–22 June 2006. [Google Scholar]
- Li, J.; Wang, Z. Real time traffic sign recognition based on efficient CNNs in the wild. IEEE Trans. Intell. Transp. Syst. 2019, 20, 975–984. [Google Scholar] [CrossRef]
- Lee, H.; Kim, K. Simultaneous traffic sign detection and boundary estimation using convolutional neural network. IEEE Trans. Intell. Transp. Syst. 2018, 19, 1652–1663. [Google Scholar] [CrossRef] [Green Version]
- Chen, E.; Rothing, P.; Zeisler, J. Investigating low level features in CNN for traffic sign detection and recognition. In Proceedings of the 2019 IEEE Intelligent Transportation Systems Conference, ITSC 2019, Auckland, New Zealand, 27–30 October 2019. [Google Scholar]
- Lin, T.; Dollar, P.; Girshick, R. Feature Pyramid Networks for Object Detection. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Choi, J.; Chun, D.; Kim, H. Gaussian YOLOv3: An accurate and fast object detector using localization uncertainty for autonomous driving. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Seoul, Korea, 27–28 October 2019. [Google Scholar]
- Doval, G.; Al-Kaff, A.; Beltran, J. Traffic sign detection and 3D localization via deep convolutional neural networks and stereo vision. In Proceedings of the 2019 IEEE Intelligent Transportation Systems Conference, ITSC 2019, Auckland, New Zealand, 27–30 October 2019. [Google Scholar]
- Github Repository for LSI Traffic Sign Detection Dataset. Available online: https://github.com/lsi-uc3m/lsitsd (accessed on 1 November 2020).
- Common Objects in Context Dataset. Available online: https://cocodataset.org/#download (accessed on 27 December 2020).
- Redmon, J.; Farhadi, A. YOLOv3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Rehman, Y.; Ahmed Khan, J.; Shin, H. Efficient coarser-to-fine holistic traffic sign detection for occlusion handling. IET Image Process. 2018, 12, 2229–2237. [Google Scholar] [CrossRef]
- Fan, X.; Riaz, I.; Rehman, Y.; Shin, H. Vanishing point detection using random forest and patch-wise weighted soft voting. IET Image Process. 2016, 10, 900–907. [Google Scholar] [CrossRef]
- Github Repository for Train Your Own YOLO. Available online: https://github.com/AntonMu/TrainYourOwnYOLO (accessed on 17 October 2020).














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Anchor Box Selection Algorithm | Evaluation Metric | Default YOLOv3 Network | Proposed YOLOv3 Network |
|---|---|---|---|
| Default-Kmeans | Recall percentage | 77.23% | 96.83% |
| AUC | 75.57% | 91.82% | |
| Ours-Regressive | Recall percentage | 85.32% | 98.13% |
| AUC | 78.34% | 93.09% |
| Methods | mAP | Inference Time |
|---|---|---|
| SSD + FPN + ITA [20] | 80.30% | - |
| Faster RCNN-Mobilenets [19] | 84.50% | 0.13 s |
| Mask RCNN [1] | 96.16% | 0.32 s |
| Ours | 93.09% | 0.04 s |
| Gamma | Alpha | Danger | Mandatory | Prohibitory | mAP | Mean Lamr |
|---|---|---|---|---|---|---|
| 0 | 0.25, 0.50, 0.75 | - | - | - | - | - |
| 1.0 | 0.25 | 97.92% | 57.92% | 95.20% | 83.68% | 0.16 |
| 1.0 | 0.50 | 97.61% | 97.61% | 93.62% | 91.70% | 0.04 |
| 1.0 | 0.75 | 98.30% | 85.01% | 93.92% | 92.41% | 0.01 |
| 1.0 | 0.80 | 91.17% | 82.55% | 95.77% | 89.83% | 0.07 |
| 1.0 | 0.85 | 97.82% | 73.21% | 95.50% | 88.84% | 0.16 |
| 1.0 | 0.99 | 90.00% | 74.22% | 94.70% | 86.31% | 0.09 |
| 1.2 | 0.75 | 96.75% | 70.95% | 91.45% | 86.38% | 0.05 |
| 1.5 | 0.75 | 93.63% | 85.52% | 94.96% | 91.37% | 0.04 |
| Ours | 94.49% | 90.06% | 94.72% | 93.09% | 0.11 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rehman, Y.; Amanullah, H.; Saqib Bhatti, D.M.; Toor, W.T.; Ahmad, M.; Mazzara, M. Detection of Small Size Traffic Signs Using Regressive Anchor Box Selection and DBL Layer Tweaking in YOLOv3. Appl. Sci. 2021, 11, 11555. https://0-doi-org.brum.beds.ac.uk/10.3390/app112311555
Rehman Y, Amanullah H, Saqib Bhatti DM, Toor WT, Ahmad M, Mazzara M. Detection of Small Size Traffic Signs Using Regressive Anchor Box Selection and DBL Layer Tweaking in YOLOv3. Applied Sciences. 2021; 11(23):11555. https://0-doi-org.brum.beds.ac.uk/10.3390/app112311555
Chicago/Turabian StyleRehman, Yawar, Hafsa Amanullah, Dost Muhammad Saqib Bhatti, Waqas Tariq Toor, Muhammad Ahmad, and Manuel Mazzara. 2021. "Detection of Small Size Traffic Signs Using Regressive Anchor Box Selection and DBL Layer Tweaking in YOLOv3" Applied Sciences 11, no. 23: 11555. https://0-doi-org.brum.beds.ac.uk/10.3390/app112311555