
A Discriminative-Based Geometric Deep Learning Model for Cross Domain Recommender Systems



Abstract
:1. Introduction
- We modelled and implemented a novel cross-domain recommendation network capable of learning from complex data representations effectively by incorporating a sparce local sensitivity mechanism into a geometric deep learning algorithm to resolve the problem of sparsity.
- We introduce a local sensitive adaptor to enforce discriminability by capturing fully the essential local geometric information, which maybe hidden in the structure of recommender systems, for efficient and effective recognition results.
2. Review of Related Works
2.1. The Conception of Geometric Deep Learning
2.2. Deep Learning Technology in the Euclidean Domain
2.3. Data Representation in the Non-Euclidean Domain
2.4. Convolutional Neural Network (CNN)
3. Proposed Method
4. Experimental Setup and Results Analysis
4.1. Database Selection and Experiment Evaluation
4.2. Evaluation Scheme and Settings
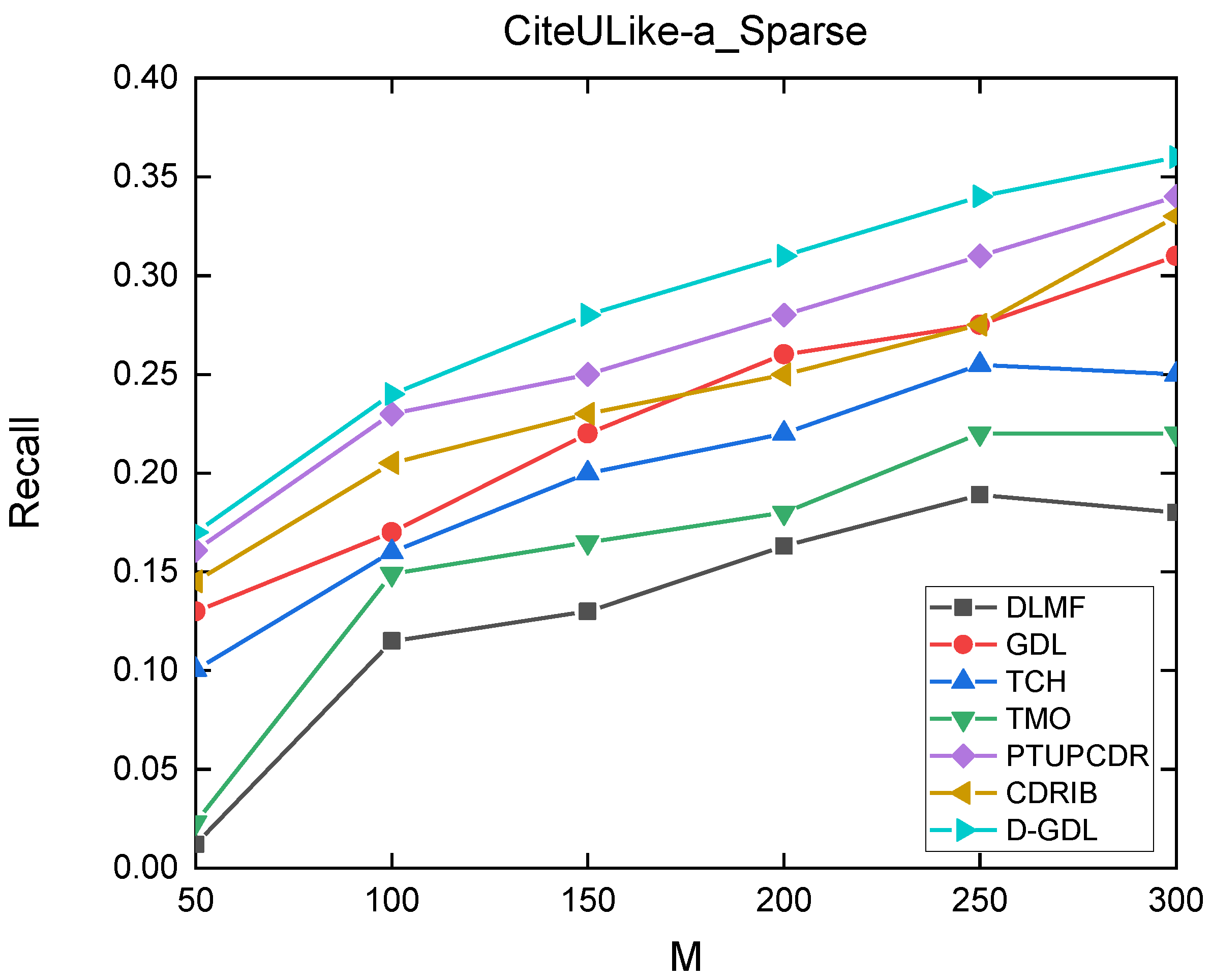
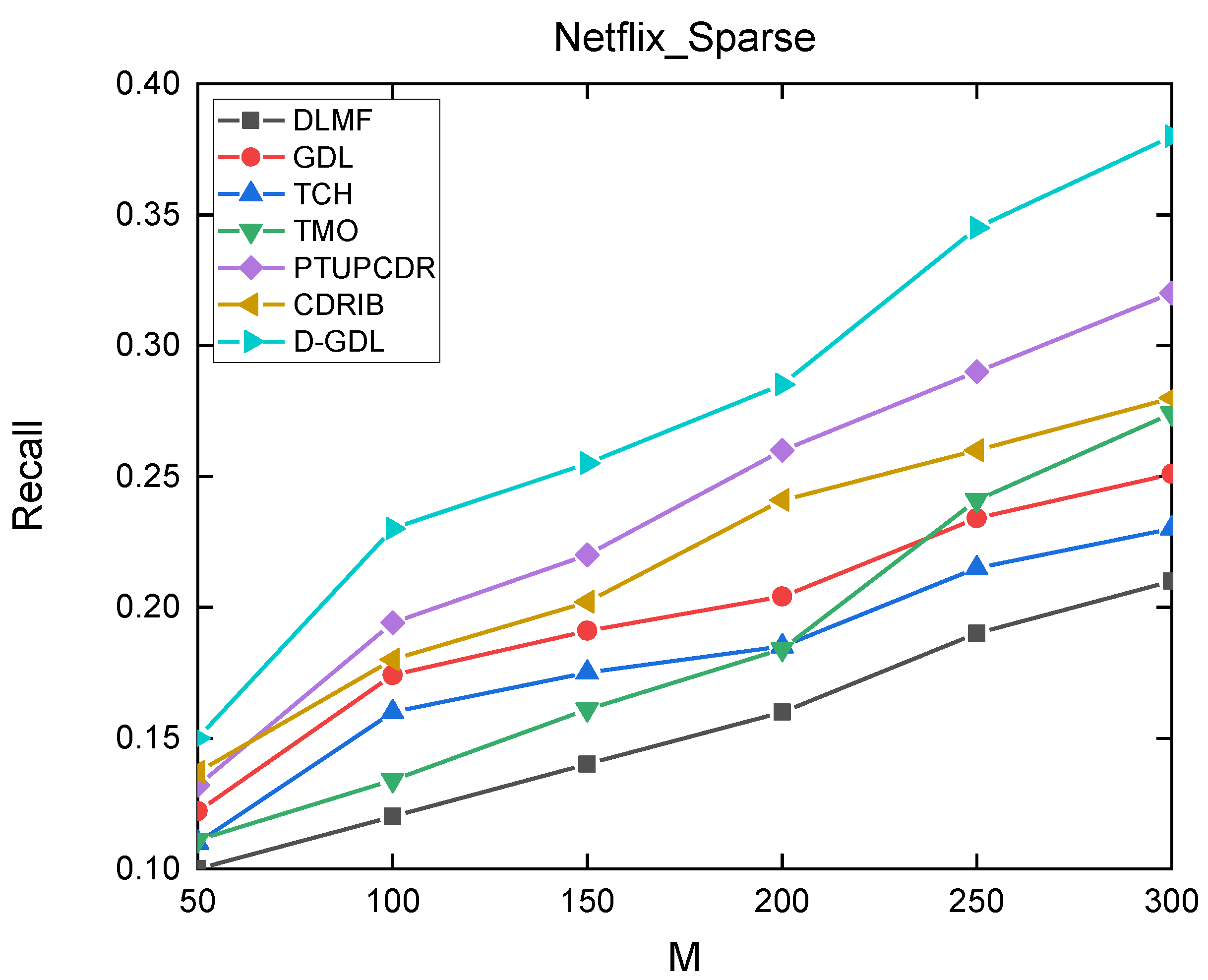
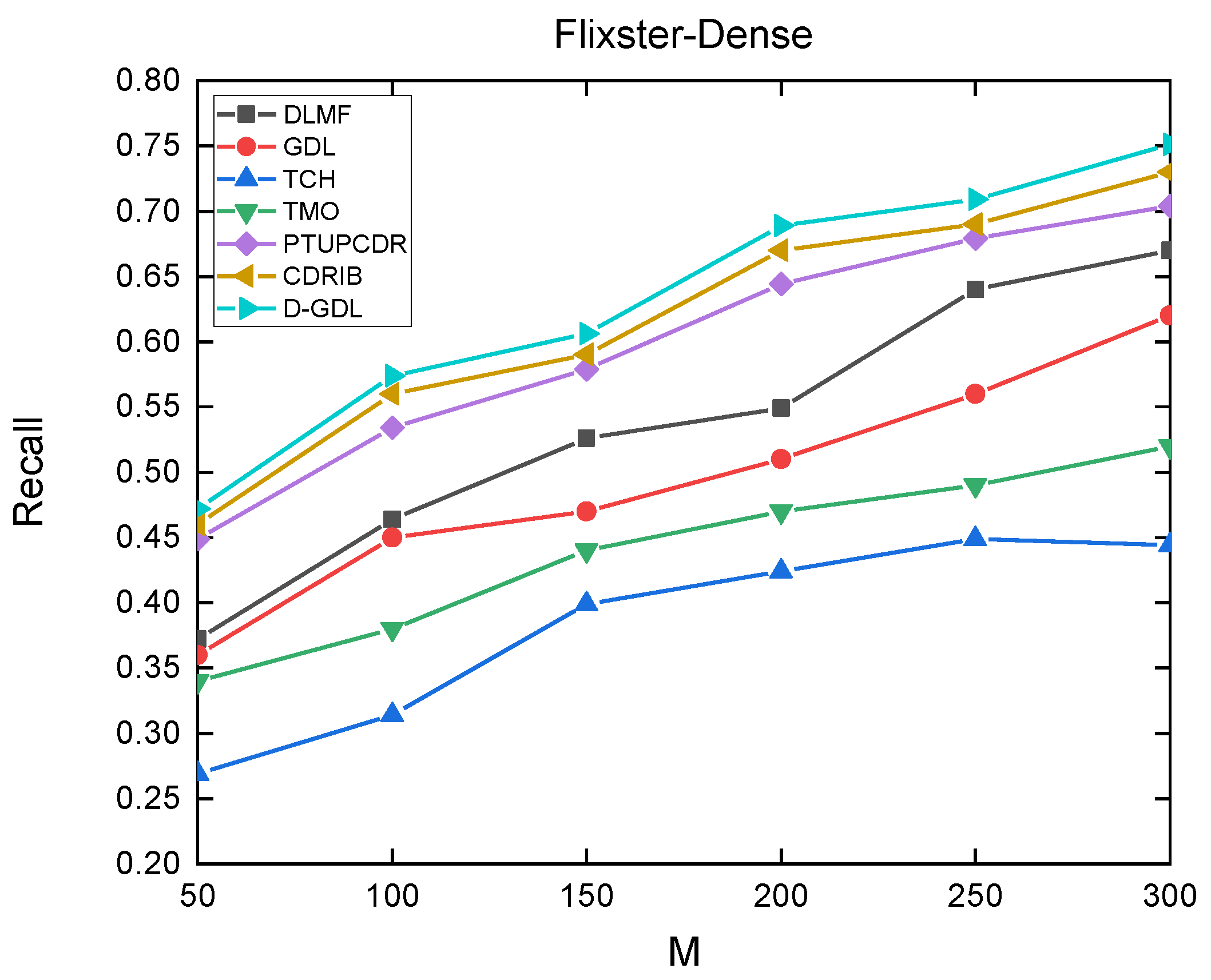
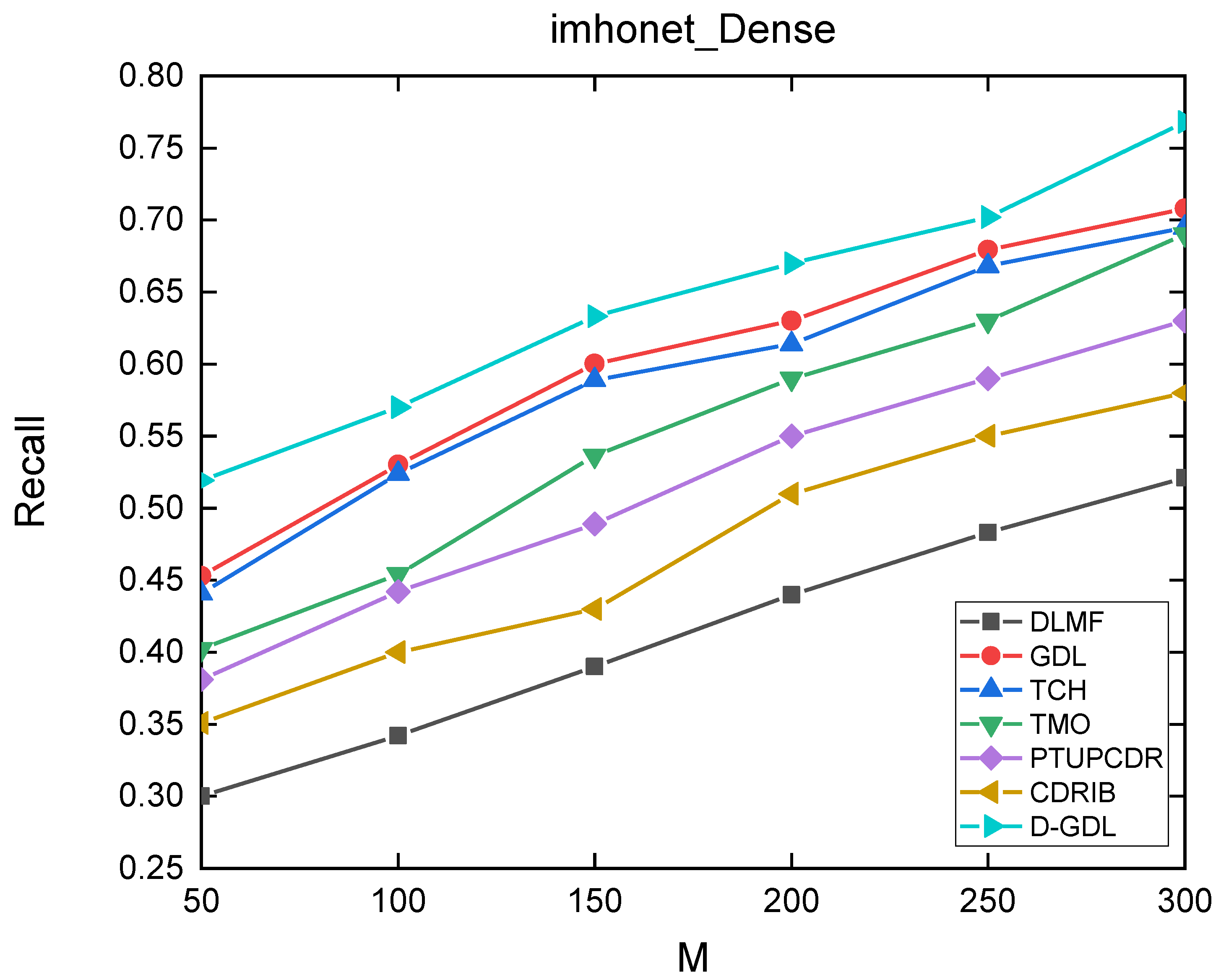
4.3. Experimental Results and Discussions
5. Conclusions and Recommendations for Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A













References
- Li, X.; She, J. Collaborative variational autoencoder for recommender systems. In Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Halifax, NS, Canada, 13–17 August 2017. [Google Scholar]
- Veeramachaneni, S.D.; Pujari, A.K.; Padmanabhan, V.; Kumar, V. A hinge-loss based codebook transfer for cross-domain recommendation with non-overlapping data. Inf. Syst. 2022, 107, 102002. [Google Scholar] [CrossRef]
- Wang, Z.; Dong, Q.; Guo, W.; Li, D.; Zhang, J.; Du, W. Geometric imbalanced deep learning with feature scaling and boundary sample mining. Pattern Recognit. 2022, 126, 108564. [Google Scholar] [CrossRef]
- Stärk, H.; Ganea, O.E.; Pattanaik, L.; Barzilay, R.; Jaakkola, T. Equibind: Geometric deep learning for drug binding structure prediction. arXiv 2022, arXiv:2202.05146. [Google Scholar]
- Powers, A.; Yu, H.; Suriana, P.; Dror, R. Fragment-Based Ligand Generation Guided by Geometric Deep Learning on Protein-Ligand Structure. bioRxiv 2022. [Google Scholar] [CrossRef]
- Monti, F.; Bronstein, M.M.; Bresson, X. Deep geometric matrix completion: A new way for recommender systems. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018. [Google Scholar]
- Candès, E.J.; Recht, B. Exact matrix completion via. convex optimization. Found. Comput. Math. 2009, 9, 717–772. [Google Scholar] [CrossRef] [Green Version]
- Kalofolias, V.; Bresson, X.; Bronstein, M.; Vandergheynst, P. Matrix completion on graphs. arXiv 2014, arXiv:1408.1717. [Google Scholar]
- Levie, R.; Monti, F.; Bresson, X.; Bronstein, M.M. Cayleynets: Graph convolutional neural networks with complex rational spectral filters. IEEE Trans. Signal Process. 2018, 67, 97–109. [Google Scholar] [CrossRef] [Green Version]
- Berg, R.V.D.; Kipf, T.N.; Welling, M. Graph convolutional matrix completion. arXiv 2017, arXiv:1706.02263. [Google Scholar]
- Bronstein, M.M.; Bruna, J.; LeCun, Y.; Szlam, A.; VanderGheynst, P. Geometric Deep Learning: Going beyond Euclidean data. IEEE Signal Process. Mag. 2017, 34, 18–42. [Google Scholar] [CrossRef] [Green Version]
- Monti, F.; Boscaini, D.; Masci, J.; Rodolà, E.; Svoboda, J.; Bronstein, M.M. Geometric deep learning on graphs and manifolds using mixture model cnns. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Gajamannage, K.; Paffenroth, R.; Bollt, E.M. A nonlinear dimensionality reduction framework using smooth geodesics. Pattern Recognit. 2019, 87, 226–236. [Google Scholar] [CrossRef] [Green Version]
- Luciano, L.; Ben Hamza, A. A global geometric framework for 3D shape retrieval using deep learning. Comput. Graph. 2019, 79, 14–23. [Google Scholar] [CrossRef]
- Arnaudon, A.; Holm, D.D.; Sommer, S. A Geometric Framework for Stochastic Shape Analysis. Math. Ann. 2019, 19, 653–701. [Google Scholar] [CrossRef] [Green Version]
- Chu, Y.; Feng, C.; Guo, C. Social-guided representation learning for images via deep heterogeneous hypergraph embedding. In Proceedings of the 2018 IEEE International Conference on Multimedia and Expo (ICME), San Diego, CA, USA, 23–27 July 2018. [Google Scholar]
- Xu, Y. An Empirical Study of Locally Updated Large-Scale Information Network Embedding (Line); UCLA: Los Angeles, CA, USA, 2017. [Google Scholar]
- Zhang, J.; Zhang, H.; Xia, C.; Sun, L. Graph-Bert: Only Attention is Needed for Learning Graph Representations. arXiv 2020, arXiv:2001.05140. [Google Scholar]
- Felmlee, D.; McMillan, C.; Towsley, D.; Whitaker, R. Social network motifs: A comparison of building blocks across multiple social networks. In Proceedings of the Annual Meetings of the American Sociological Association, Philadelphia, PA, USA, 11–14 August 2018. [Google Scholar]
- Souravlas, S.; Anastasiadou, S.; Katsavounis, S. A Survey on the Recent Advances of Deep Community Detection. Appl. Sci. 2021, 11, 7179. [Google Scholar] [CrossRef]
- Chan, J.; Wang, Z.; Xie, Y.; Meisel, C.; Meisel, J.; Solano, P.; Murillo, H. Identifying Potential Managerial Personnel Using PageRank and Social Network Analysis: The Case Study of a European IT Company. Appl. Sci. 2021, 11, 6985. [Google Scholar] [CrossRef]
- Ying, R.; He, R.; Chen, K.; Eksombatchai, P.; Hamilton, W.L.; Leskovec, J. Graph convolutional neural networks for web-scale recommender systems. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, London, UK, 19–23 August 2018. [Google Scholar]
- Lee, C.; Han, D.; Han, K.; Yi, M. Improving Graph-Based Movie Recommender System Using Cinematic Experience. Appl. Sci. 2022, 12, 1493. [Google Scholar] [CrossRef]
- AlBadani, B.; Shi, R.; Dong, J.; Al-Sabri, R.; Moctard, O.B. Transformer-Based Graph Convolutional Network for Sentiment Analysis. Appl. Sci. 2022, 12, 1316. [Google Scholar] [CrossRef]
- Boscaini, D.; Masci, J.; Rodolà, E.; Bronstein, M. Learning shape correspondence with anisotropic convolutional neural networks. In Advances in Neural Information Processing Systems. 2016. Available online: https://proceedings.neurips.cc/paper/2016/hash/228499b55310264a8ea0e27b6e7c6ab6-Abstract.html (accessed on 1 April 2022).
- Atwood, J.; Towsley, D. Diffusion-convolutional neural networks. In Advances in Neural Information Processing Systems. 2016. Available online: https://proceedings.neurips.cc/paper/2016/hash/390e982518a50e280d8e2b535462ec1f-Abstract.html (accessed on 1 April 2022).
- Beck, D.; Haffari, G.; Cohn, T. Graph-to-Sequence Learning using Gated Graph Neural Networks. arXiv 2018, arXiv:1806.09835. [Google Scholar]
- Khademi, M.; Schulte, O. Dynamic gated graph neural networks for scene graph generation. In Asian Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2018. [Google Scholar]
- Sukhbaatar, S.; Fergus, R. Learning multiagent communication with backpropagation. In Advances in Neural Information Processing Systems. 2016. Available online: https://proceedings.neurips.cc/paper/2016/hash/55b1927fdafef39c48e5b73b5d61ea60-Abstract.html (accessed on 1 April 2022).
- Bruna, J.; Zaremba, W.; Szlam, A.; LeCun, Y. Spectral networks and locally connected networks on graphs. arXiv 2013, arXiv:1312.6203. [Google Scholar]
- Defferrard, M.; Bresson, X.; Vandergheynst, P. Convolutional neural networks on graphs with fast localized spectral filtering. Advances in Neural information Processing Systems. arXiv 2016, arXiv:1606.09375. [Google Scholar]
- Henaff, M.; Bruna, J.; Lecun, Y. Deep convolutional networks on graph-structured data. arXiv 2015, arXiv:1506.05163. [Google Scholar]
- Masci, J.; Boscaini, D.; Bronstein, M.M.; Vandergheynst, P. Geodesic convolutional neural networks on riemannian manifolds. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Su, H.; Maji, S.; Kalogerakis, E.; Learned-Miller, E. Multi-view convolutional neural networks for 3D shape recognition. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Liu, B.; Shen, M. Some Geometrical and Topological Properties of DNNs’ Decision Boundaries. arXiv 2020, arXiv:2003.03687. [Google Scholar]
- Freeman, C.D.; Bruna, J. Topology and geometry of half-rectified network optimization. arXiv 2016, arXiv:1611.01540. [Google Scholar]
- Chen, T.; Goodfellow, I.; Shlens, J. Net2net: Accelerating learning via knowledge transfer. arXiv 2015, arXiv:1511.05641, 2015. [Google Scholar]
- Kawaguchi, K. Deep learning without poor local minima. In Advances in Neural Information Processing Systems. 2016. Available online: https://proceedings.neurips.cc/paper/2016/hash/f2fc990265c712c49d51a18a32b39f0c-Abstract.html (accessed on 1 April 2022).
- Cao, W.; Yan, Z.; He, Z.; He, Z. A Comprehensive Survey on Geometric Deep Learning. IEEE Access 2020, 8, 35929–35949. [Google Scholar] [CrossRef]
- Khan, M.M.; Ibrahim, R.; Ghani, I. Cross domain recommender systems: A systematic literature review. ACM Comput. Surv. (CSUR) 2017, 50, 1–34. [Google Scholar] [CrossRef]
- Zhang, S.; Yao, L.; Sun, A.; Tay, Y. Deep learning based recommender system: A survey and new perspectives. ACM Comput. Surv. (CSUR) 2019, 52, 1–38. [Google Scholar] [CrossRef] [Green Version]
- Xu, B.; Yu, Y. A personalized assistant in 3D virtual shopping environment. In 2010 Second International Conference on Intelligent Human-Machine Systems and Cybernetics, Nanjing, China, 26–28 August 2010; IEEE: Washington, DC, USA, 2010. [Google Scholar]
- Guo, G.; Elgendi, M. A New Recommender System for 3D E-Commerce: An EEG Based Approach. J. Adv. Manag. Sci. 2013, 1, 61–65. [Google Scholar] [CrossRef]
- Bu, S.; Wang, L.; Han, P.; Liu, Z.; Li, K. 3D shape recognition and retrieval based on multi-modality deep learning. Neurocomputing 2017, 259, 183–193. [Google Scholar] [CrossRef]
- Ma, X.; Wang, X. Average Contrastive Divergence for Training Restricted Boltzmann Machines. Entropy 2016, 18, 35. [Google Scholar] [CrossRef] [Green Version]
- Jang, H.; Choi, H.; Yi, Y.; Shin, J. Adiabatic persistent contrastive divergence learning. In Proceedings of the 2017 IEEE International Symposium on Information Theory (ISIT), Aachen, Germany, 25–30 June 2017. [Google Scholar]
- Tyagi, B.; Kumar, V.; Sharma, P. Cross-Domain Recommendation Approach Based on Topic Modeling and Ontology. In Soft Computing: Theories and Applications; Springer: Berlin/Heidelberg, Germany, 2022; pp. 397–406. [Google Scholar]
- Zhu, Y.; Tang, Z.; Liu, Y.; Zhuang, F.; Xie, R.; Zhang, X.; Lin, L.; He, Q. Personalized transfer of user preferences for cross-domain recommendation. In Proceedings of the Fifteenth ACM International Conference on Web Search and Data Mining, Tempe, AZ, USA, 21–25 February 2022. [Google Scholar]
- Cao, J.; Sheng, J.; Cong, X.; Liu, T.; Wang, B. Cross-Domain Recommendation to Cold-Start Users via Variational Information Bottleneck. arXiv 2022, arXiv:2203.16863. [Google Scholar]
- Deng, S.; Huang, L.; Xu, G.; Wu, X.; Wu, Z. On Deep Learning for Trust-Aware Recommendations in Social Networks. IEEE Trans. Neural Netw. Learn. Syst. 2016, 28, 1164–1177. [Google Scholar] [CrossRef] [PubMed]
- Liao, W.; Zhang, Q.; Yuan, B.; Zhang, G.; Lu, J. Heterogeneous Multidomain Recommender System Through Adversarial Learning. IEEE Trans. Neural Netw. Learn. Syst. 2022. [Google Scholar] [CrossRef] [PubMed]
- Wang, H.; Chen, B.; Li, W.-J. Collaborative topic regression with social regularization for tag recommendation. In Proceedings of the Twenty-Third International Joint Conference on Artificial Intelligence, Beijing, China, 3–9 August 2013. [Google Scholar]
- Wang, C.; Blei, D.M. Collaborative topic modeling for recommending scientific articles. In Proceedings of the 17th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Diego, CA, USA, 21–24 August 2011. [Google Scholar]
- Kanagawa, H.; Kobayashi, H.; Shimizu, N.; Tagami, Y.; Suzuki, T. Cross-domain recommendation via deep domain adaptation. In European Conference on Information Retrieval; Springer: Berlin/Heidelberg, Germany, 2019. [Google Scholar]
- Sahebi, S.; Brusilovsky, P.; Bobrokov, V. Cross-domain recommendation for large-scale data. In Proceedings of the CEUR Workshop Proceedings, 1 January 2017; Available online: http://d-scholarship.pitt.edu/id/eprint/35050 (accessed on 1 April 2022).
- Hong, W.; Zheng, N.; Xiong, Z.; Hu, Z. A Parallel Deep Neural Network Using Reviews and Item Metadata for Cross-Domain Recommendation. IEEE Access 2020, 8, 41774–41783. [Google Scholar] [CrossRef]
- Liu, B.; Shen, M. Some geometrical and topological properties of DNNs’ decision boundaries. Theor. Comput. Sci. 2022, 908, 64–75. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Netflix | Flixster | CiteULike-a | CiteULike-t | |
|---|---|---|---|---|
| Users | 407,261 | 1,049,445 | 5551 | 7947 |
| Items | 9228 | 492,359 | 16,980 | 25,975 |
| Ratings | 15,348,808 | 8,238,597 | 0.22% | 0.07% |
| Statistics | Movies | Books | Games | Perfumes |
|---|---|---|---|---|
| Users | 426,897 | 3,622,448 | 72,307 | 19,717 |
| Items | 90,793 | 167,384 | 12,768 | 3640 |
| Density | 0.00073 | 0.00022 | 0.00140 | 0.00350 |
| Number of records | 28,281,946 | 13,438,520 | 1,324,945 | 253,948 |
| Average no. of ratings per user | 66.30 | 37.0771 | 18.2339 | 12.8796 |
| Average no. of ratings per item | 311.4992 | 80.2856 | 103.7708 | 69.7659 |
| Statistics | Movie | Book |
|---|---|---|
| Users | 9043 | 38,032 |
| Items | 30,279 | 105,651 |
| Ratings | 1,264,244 | 3,637,313 |
| CiteULike-a | CiteULike-t | Netflix | Flixster | |
|---|---|---|---|---|
| D-GDL | 0.0714 | 0.0651 | 0.0531 | 0.0492 |
| CVAE | 0.0662 | 0.0545 | 0.0454 | 0.0334 |
| CDL | 0.0526 | 0.0465 | 0.0326 | 0.0375 |
| DLMF | 0.0312 | 0.0267 | 0.0189 | 0.0249 |
| DMF | 0.0159 | 0.0176 | 0.0167 | 0.0183 |
| GDL | 0.0274 | 0.0104 | 0.0158 | 0.0273 |
| DeepMusic | 0.0160 | 0.0103 | 0.0187 | 0.0157 |
| Models | Movies | Books | Games | Perfumes | ||||
|---|---|---|---|---|---|---|---|---|
| 70% | 95% | 70% | 95% | 70% | 95% | 70% | 95% | |
| DMF | 0.5883 | 0.5354 | 0.9735 | 0.9612 | 0.5895 | 0.5456 | 0.5515 | 0.5425 |
| DLMF | 0.5698 | 0.5215 | 0.9674 | 0.9554 | 0.5745 | 0.5318 | 0.5342 | |
| DeepMusic | 0.5989 | 0.5673 | 0.9845 | 0.9786 | 0.5992 | 0.5693 | 0.5772 | 0.5682 |
| GDL | 0.5982 | 0.5513 | 0.9834 | 0.9765 | 0.6024 | 0.5623 | 0.5579 | 0.5496 |
| CDL | 0.5668 | 0.5198 | 0.9664 | 0.9478 | 0.5782 | 0.5298 | 0.5467 | 0.5335 |
| CVAE | 0.5435 | 0.5136 | 0.9579 | 0.9448 | 0.5535 | 0.5212 | 0.5367 | 0.5232 |
| D-GDL | 0.5212 | 0.5057 | 0.9244 | 0.8979 | 0.5323 | 0.5176 | 0.5136 | 0.5011 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Arthur, J.K.; Zhou, C.; Mantey, E.A.; Osei-Kwakye, J.; Chen, Y. A Discriminative-Based Geometric Deep Learning Model for Cross Domain Recommender Systems. Appl. Sci. 2022, 12, 5202. https://0-doi-org.brum.beds.ac.uk/10.3390/app12105202
Arthur JK, Zhou C, Mantey EA, Osei-Kwakye J, Chen Y. A Discriminative-Based Geometric Deep Learning Model for Cross Domain Recommender Systems. Applied Sciences. 2022; 12(10):5202. https://0-doi-org.brum.beds.ac.uk/10.3390/app12105202
Chicago/Turabian StyleArthur, John Kingsley, Conghua Zhou, Eric Appiah Mantey, Jeremiah Osei-Kwakye, and Yaru Chen. 2022. "A Discriminative-Based Geometric Deep Learning Model for Cross Domain Recommender Systems" Applied Sciences 12, no. 10: 5202. https://0-doi-org.brum.beds.ac.uk/10.3390/app12105202