1. Introduction
In recent years, the field of handwriting has attracted interest from various aspects, such as biometrics [
1] and the medical field [
2]. In addition, handwritten characters can be obtained from a variety of sources such as paper documents, images, touch screens, and other devices. This makes the data easy to collect and suitable for classification. Furthermore, since handwriting is something that everyone uses every day in school, it is a method that is less stressful for people. There are few studies on handwriting classification for adults and children, and most of the studies are on the classification of face recognition [
3], age groups [
4], age, gender, and nationality [
5], gender [
6,
7], gender and handedness [
8], detection of alcohol [
9], and Parkinson’s disease (PD) [
10] based on handwriting images.
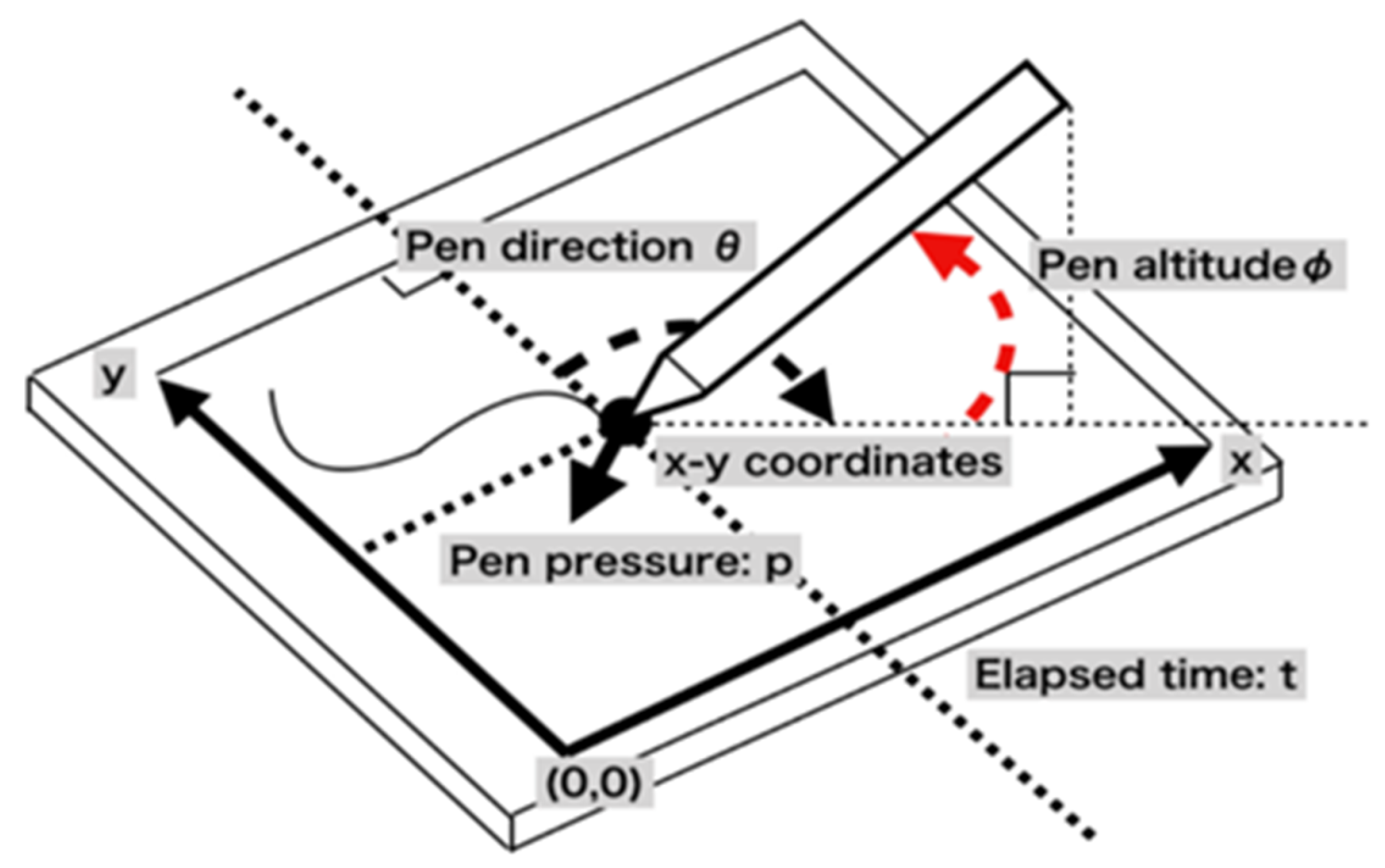
There are two types of handwriting data: offline and online. The input data collected using a scanning machine are called “offline”, whereas input data obtained using a pen tip are called “online” [
11]. In our research work, we used the online-based handwritten database. Moreover, a single writer’s handwriting may be unique or differ slightly, but the handwriting of a child and adult must always be different. Most forensic handwriting analysis is based on the inspection of specific character shapes, character ligatures, size, pen lift, pen pressure, speed, letter spacing, etc., to identify a suspected person. Age group detection will be a great solution before detecting the actual suspected person in forensic analysis. It will give additional evidence about the suspected person’s age. Currently, there are many applications of handwritten recognition, for example, signature authentication used in industrial applications [
2], authenticating of criminal investigations in a court of justice [
12,
13], document examinations [
14], and so on. The most difficult aspects of handwriting identification are distortions and pattern variations; feature extraction is of supreme importance. Handwritten forensic analysis or handwriting recognition using machine learning (ML) algorithms can be a great solution to classify adults and children based on their handwritten text and handwritten pattern.
Ahmad et al. (2004) proposed support vector machine (SVM) with some kernels for online handwritten recognition [
15]. They showed that at the character level, the SVM recognition rate was dramatically better due to the use of maximizing boundaries in the decision function. The only problem with this algorithm was storing large support vector for a huge training character that requires a larger memory size. Babu et al. (2014) proposed k-nearest neighbors (k-NN) for recognizing handwritten digits based on structural features, which does not require thinning operation and size normalization approach [
16]. Ramzan et al. (2018) implemented neural networks (NN) and their variants to recognize handwritten digits. The survey details some existing techniques implemented for handwritten digit recognition (HWDR) being carried out [
17]. Baldominos et al. (2019) [
18] also proposed convolutional neural networks (CNNs) to distinguish previous work to recognize handwritten characters using some data augmentation from works using the original dataset out-of-the-box [
19,
20]. They provided the most extensive and updated survey of the MNIIST and EMNIST datasets and achieved the lowest error rate.
Poon et al. (2019) [
2] applied logistic regression to predict PD based on handwritten recognition. They utilized the publicly available PD database and extracted secondary kinematic handwriting features from the dataset. It is being studied not only for personal identification but also in the medical field. The limitation of their proposed model was that they used small sample size of the dataset and lacked control in the study design. As for all the limitations of handwriting recognition, Japanese handwritten character recognition is complex due to the various types of writing styles, characters, and confusion among similar characters. One of the major causes of the inefficient classification of Japanese characters is a large number of letters. However, many methods have been developed to recognize Japanese handwriting as text images for several applications, but there are few studies on the classification of adults and children based on Japanese handwritten recognition.
Nisimura et al. (2004) [
21] suggested a discriminating strategy based on statistical learning and extracted linguistic features from speech or voice data to classify adults and children. They applied SVM and found that it performed with better classification accuracy than the Gaussian mixture model [
22]. The disadvantage of this strategy is that it has a trait in common with both labels. Makihara et al. (2010) [
23] proposed a method to classify gender and age using video-based gait feature analysis with a large-scale multi-view gait database. They adopted the k-NN classifier to classify gender and age. They used three databases (HumanID, Soton, and CASIA) that contained over 100 subjects. These datasets have their particular limitations, such as the small view images in the HumanID dataset; also, single view images in the Soton dataset, and maximum subjects in the CASIA dataset included in the 20’s or 30’s. Faghel-Soubeyrand classified adult and child based on faces [
24]. In this study, we propose a new approach for the classification of adults and children based on their handwritten text and pattern recognition. Our proposed method can achieve more than 89% classification accuracy, implying that classification accuracy with handwritten characters can be expected.
The organization of this paper is as follows:
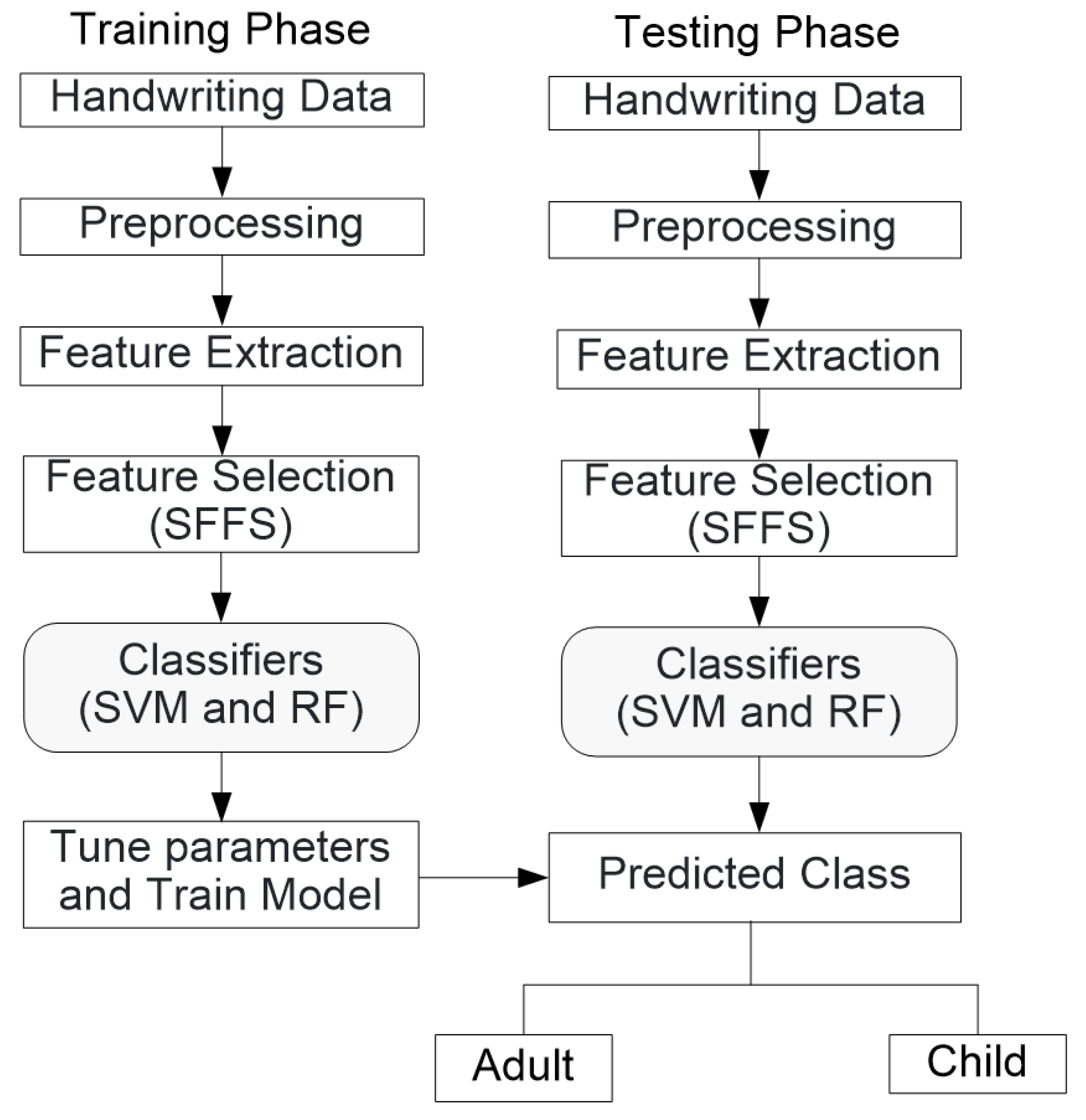
Section 2 presents materials and methods, including proposed ML-based framework; description of datasets, feature extraction, feature selection, classifiers along with their performance evaluation metrics are discussed in this section. The experimental results and discussion are discussed in
Section 3. Finally, the conclusion is discussed in
Section 4.
3. Experimental Results and Discussion
3.1. Experimental Setup
To perform the classification of adult and child, 80% of the dataset was utilized for training sets and 20% of the dataset for testing sets. For all statistical analysis, Python version 3.9 and Scikit-learn version 1.0.2 were used. We used Windows 10 21H1 (build 19043.1151) 64-bit with an Intel (R) Core (TM) i5-10400 processor and 16 GB of RAM.
3.2. Baseline Characteristics of Adult and Child
The baseline characteristics of adults and children for the handwritten text and pattern datasets are presented in
Table 4. For the handwritten text dataset, the prevalence of adult and child was 45.6% and 54.4%. Among them, 42.7% and 59.3% of adult and child were female. The average ages of adult and child for the handwritten text dataset were
and
years.
For the handwritten pattern dataset, the average ages of adult and children were and years. The overall prevalence of females was 59.3%. Approximately 64.6% and 35.4% of adult and child were female. It was observed that age and gender (except gender for handwritten text data) were significantly associated with adult and child for both handwritten text and pattern dataset (p-value < 0.05).
3.3. Hyperparameter Tuning
For the classification tasks, we set the following hyperparameters for SVM as cost (C) = [0.0001, 0.001, 0.01, 0.1, 1, 10, 100, 1000]; kernel = [“rbf”, “linear”, “poly”, “sigmoid”]; and gamma: [0.00001, 0.0001, 0.001, 0.01, 0.1, 1]. We also set the hyperparameters for RF as max_depth = [2, 3, 5, 10], n_estimators = [50, 100, 200, 300, 400], min_samples_split = [2, 3, 10], min_samples_leaf = [1, 3, 10], bootstrap = [True, False], and criterion = [“gini”, “entropy”]. We implemented grid search algorithms to tune these hyperparameters. We choose the hyperparameters that will provide the highest classification accuracy.
3.4. Experiment-1: Evaluation for Handwritten Text Dataset
In this experiment, we used different types of handwritten texts and then extracted various types of features from each image or task. We applied SVM and RF classifiers to classify adult and child and calculated the classification accuracy. We used 30 hiragana words and extracted 30 features which are clearly explained in
Table 3.
Table 5 shows the performance scores of SVM and RF for better features combination of handwritten text dataset. It was observed that SVM with RBF kernel produced the classification accuracy of 87.7% for the combination of 15 selected features out of 30 features. Moreover, SVM also produced 92.4% recall, 85.9% precision, 89.1% f1-score, and 0.919 AUC for the selected 15 features, whereas RF classifier achieved an excellent classification accuracy of 93.5% along with 95.7% recall, 92.2% precision, 93.9% f1-score, and 0.983 AUC, respectively, for the combination of 18 selected features. Therefore, RF achieved more outstanding performance than SVM.
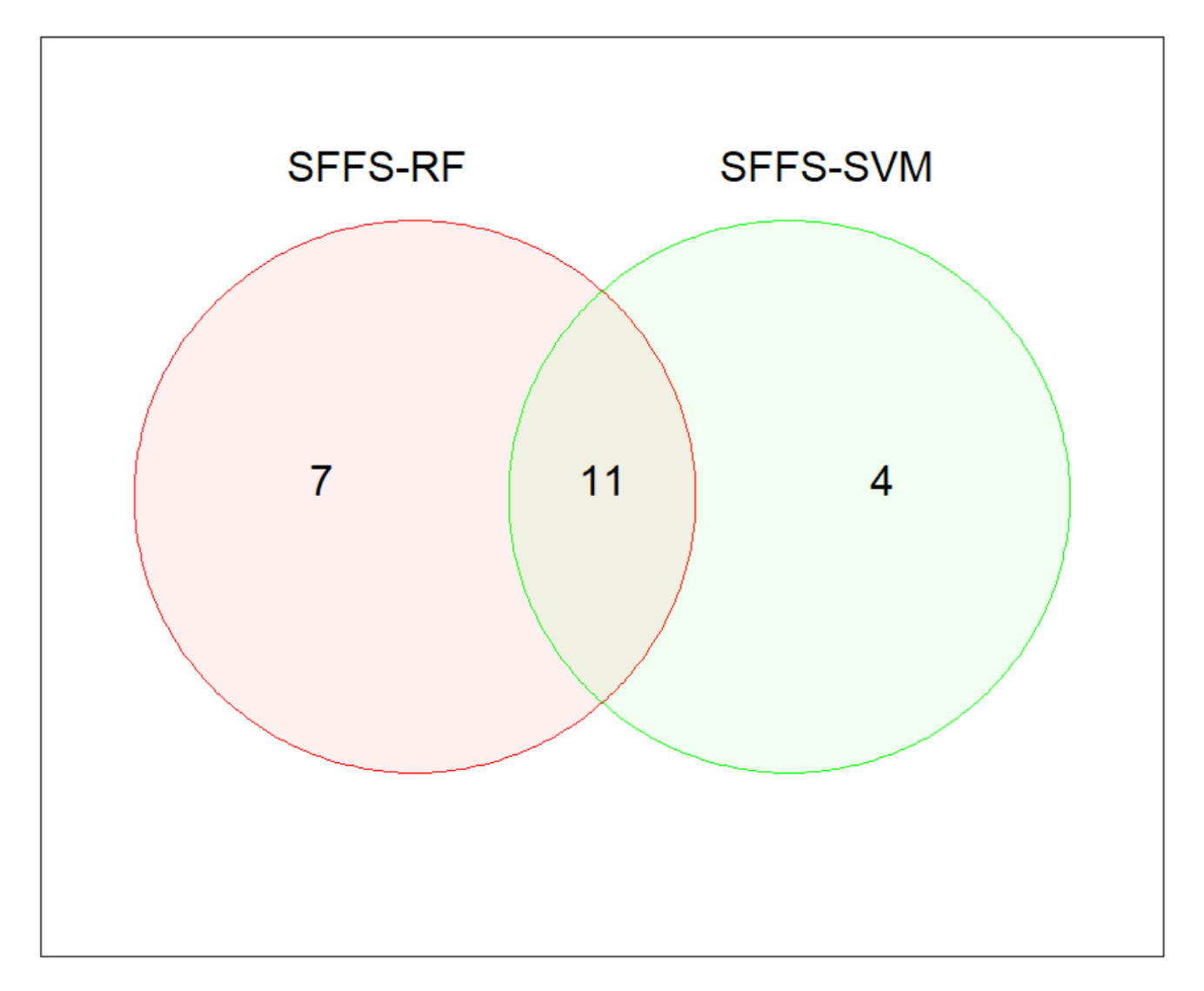
We observed that 15 and 18 features were selected by SFFS with SVM and RF classifiers. A total of 11 common features was extracted from those two methods, which are shown in
Figure 4, and the listed selected features are presented in
Table 6. These 11 common features were used as input features and then we applied SVM and RF classifiers to distinguish adults from children.
The performance scores of SVM and RF classifiers for 11 common features are shown in
Table 7. It was observed that SVM with RBF provided 87.4% accuracy, 90.8% recall, 86.6% precision, 88.7% f1-score, and 0.947 AUC, respectively, whereas RF gave 91.5% accuracy, 93.0% recall, 91.5% precision, 92.3% f1-score, and 0.967 AUC, receptively. Finally, we may conclude that RF had more outstanding performance scores than SVM for the prediction of the adult and child for handwritten text dataset.
3.5. Experiment-2: Evaluation for Handwritten Pattern Dataset
To evaluate our proposed model, we used a handwritten pattern dataset and obtained a classification accuracy of up to 89.8%. In this section, we performed two experiments. Firstly, the best combination of the features set was identified using SFFS-based RF and SVM classifiers. We chose the feature combination at which the classification model provides the highest classification accuracy. The classification accuracy of RF and SVM for the handwritten pattern dataset is presented in
Table 8. For the trace of zigzag lines, RF produced 83.3% classification accuracy for the combination of 19 selected features, whereas SVM produced 71.4% accuracy for the combination of 26 selected features. For the prediction of the zigzag, the RF classifier obtained the highest classification accuracy of 85.7% for 13 combinations of feature sets and the prediction of the zigzag line, whereas SVM provided 75.5% classification accuracy for 3 selected features. For the prediction and trace of the PL line, RF achieved 73.5% classification accuracy for the combination of 24 selected features, whereas SVM achieved 79.6% accuracy for 7 selected features and 87.7% accuracy for 12 selected features. RF classifier provided a good classification accuracy of 85.6% for the combination of all handwritten patterns, 25 features, whereas 82.1% classification accuracy was provided by SVM for the combination of all 28 features. Therefore, RF achieved better classification accuracy (89.8%) than SVM for the prediction of PL line.
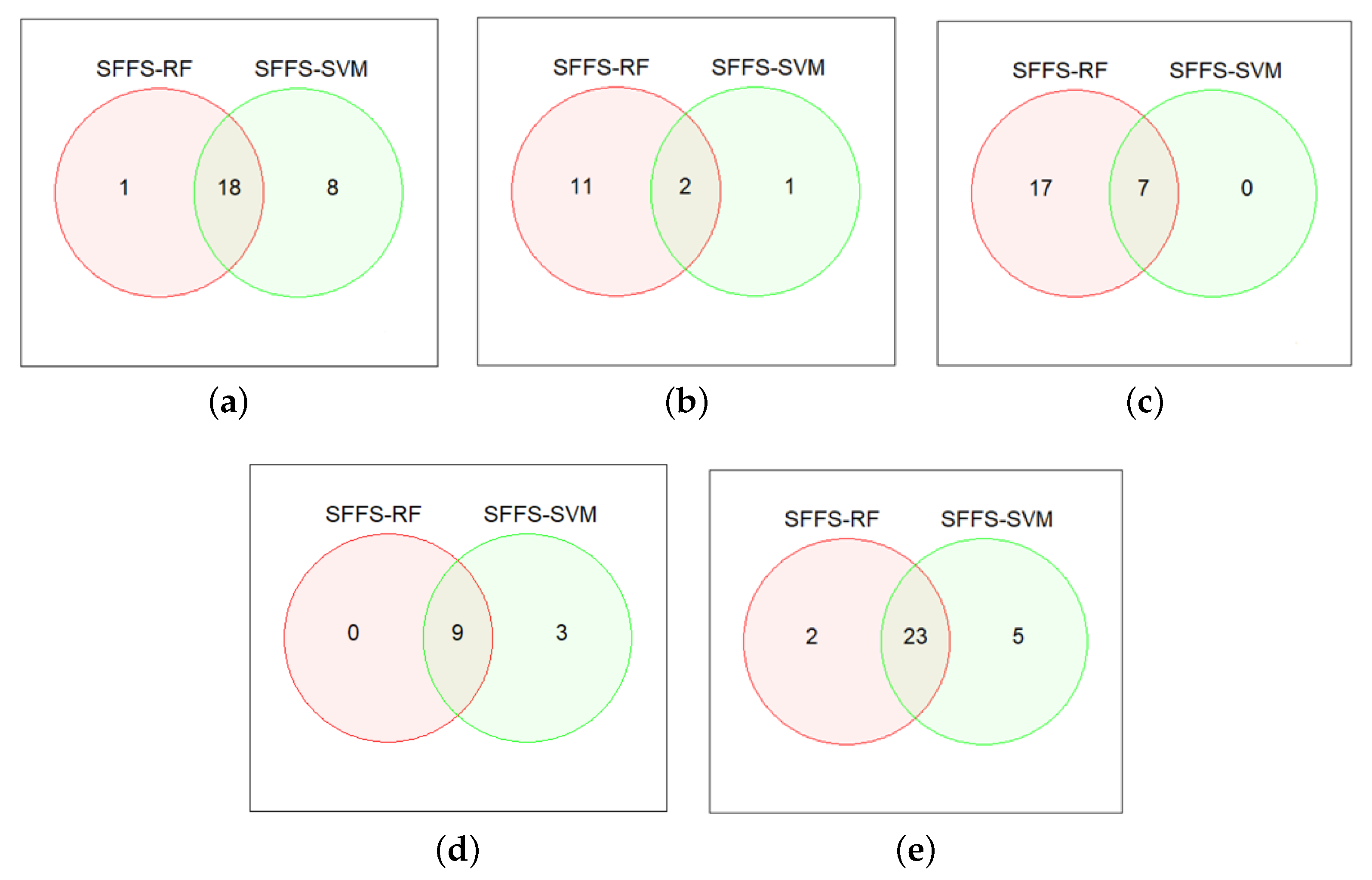
The second experiment was to take the common features from the two best combinations of feature sets and apply two classifiers for the prediction of adult and child. The number of selected common features was 18 features from the trace of zigzag line, 2 features from the prediction of zigzag line, 7 features from the trace of PL line, 9 features from the prediction of PL lines, and 23 features from all handwritten patterns (zigzag and PL lines), which are shown in
Figure 5, and the corresponding list of selected common features is presented in
Table 9.
The classification accuracies of RF and SVM for these common features are presented in
Table 10. It was observed that the RF classifier provided a higher classification accuracy of 79.5%, 73.4%, 83.6%, and 89.8% for the trace and prediction of the zigzag line than SVM for the trace and prediction of the PL line, respectively. On the other hand, the SVM classifier provided 85.1% accuracy for all handwritten patterns, whereas RF classifier gave 84.1% accuracy.
The recall, precision, f1-score, and AUC of RF and SVM for common features of the handwritten dataset are presented in
Table 11. It was observed that the RF classifier achieved comparatively better performance for all types of lines than SVM. RF classifier provided a higher recall of 87.0%, precision of 93.1%, f1-score of 90.0%, and AUC of 0.903 for the prediction of the PL line dataset, whereas SVM gave 83.8% recall, and 0.811 AUC, respectively.
Table 11 shows that the highest performance scores are achieved by RF for four types of lines with all handwritten patterns. Finally, we can say that in our experiment, RF performed better than SVM.
3.6. Comparison of Our Proposed Method with the Existing Method
The comparison of the classification accuracy of our proposed method with the existing method in the literature is presented in
Table 12. Guimaraes et al. (2017) [
4] applied different ML algorithms such as multilayer perception (MLP), deep convolutional neural network (DCNN), decision tree (DT), RF, and SVM for the classification of adult and teenager age groups based on sentences. They collected 7000 sentences for the classification of age groups (teenager vs. adult). They showed that DCNN had a better performance and obtained 95.0% precision. Rizwan et al. (2021) [
31] proposed a novel method for the classification of human age. They extracted features using interior angle formulation, anthropometric model, carnio-facial development, wrinkle detection, and heat maps. The best combination of feature sets was selected using SFS. They adopted CNN to classify human age and achieved 94.6% classification accuracy. Özkan and Turan (2018) [
32] proposed a deep learning algorithm for the classification of people based on their age. They divided the people into 12 classes using age groups and collected 18,000 images. They took 10% of the images for testing and the rest of the images for training. They showed that the DL model can correctly classify people into different groups of age and achieved 78.5% classification accuracy.
Goshvarpour (2019) [
33] proposed a novel Poincare feature set to classify age and gender based on ECG. They collected ECG data from 79 respondents. Among them, 37 were males aged 31.24 years and 42 were females aged 25.8 years. They applied SVM for the classification of age and gender and obtained the highest classification accuracy of 94.6%. Ilyas et al. (2020) [
34] investigated a novel biometric method for the classification of human age. For classification, RF, SVM, linear regression (LR), ridge regression (RR), polynomial regression (PR), and ANN were used. They collected a total of 837 subjects aged 6–60 years to evaluate the proposed biometric system. They showed that RF produced the highest classification accuracy of 92.0%. Voice is also used for user authentication and identification. Voiceprints were used in various forensic approaches to classify age, gender, and language. Reade et al. (2015) [
35] conducted a study for the classification of adult, child, and senior using face images dataset. They extracted features using HOG, local binary pattern, and active appearance model. They adopted k-NN, SVM, and GB algorithms for the classification of adult, child, and senior and achieved 82.0% classification accuracy. Tin (2012) [
36] applied PCA for the classification of age using face image and produced the highest classification accuracy of 92.5%. Our proposed SFFS with RF (SFFS-RF) model produced higher accuracy compared to SFFS with SVM (SFFS-SVM) to classify adult and child based on their handwritten text and handwritten pattern.


 ,
, 







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}