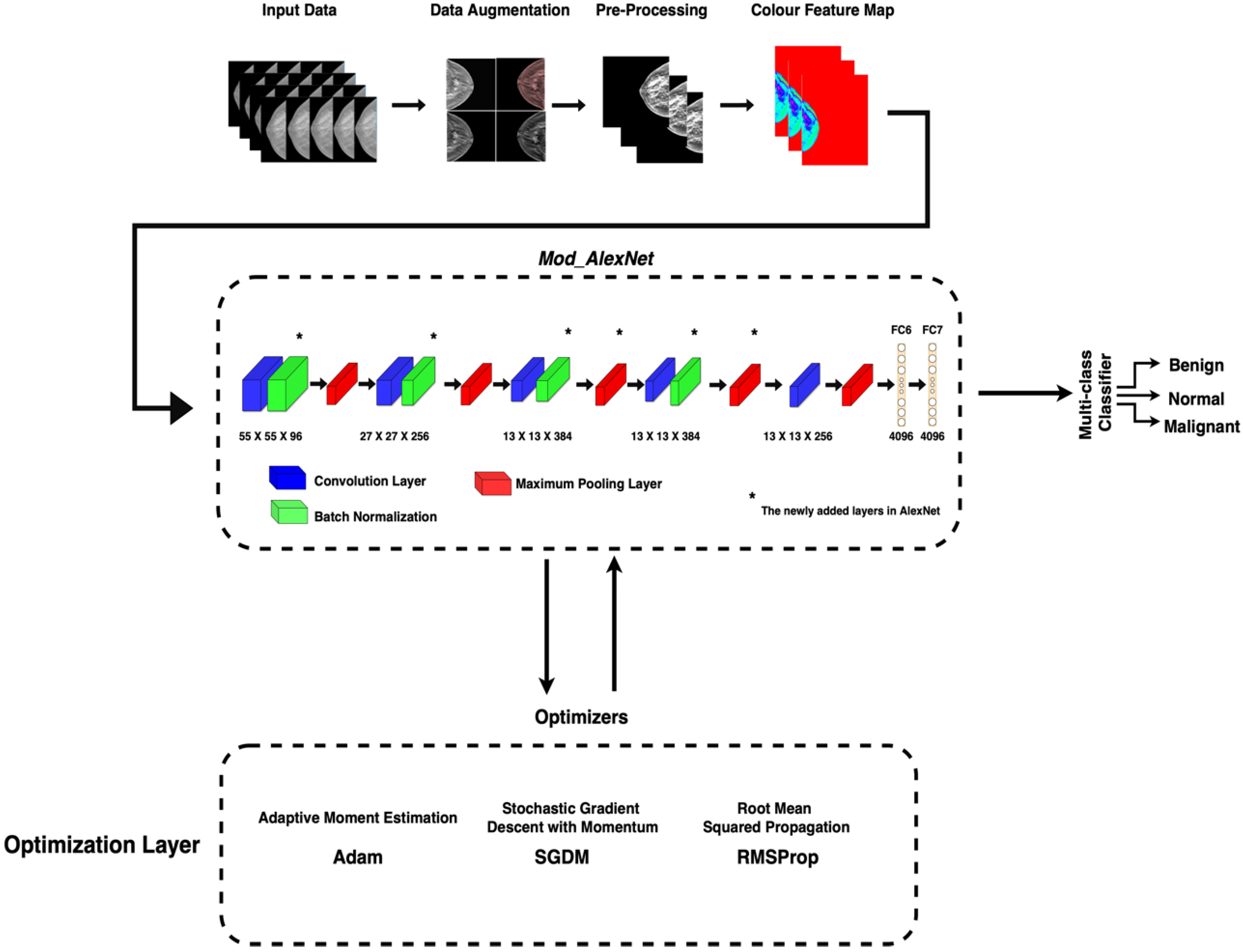
Several scenarios and experiments have taken place. Six deep learning models were deployed in the first scenario to extract features from three datasets, and their performance was compared. This experimental analysis was carried out to identify the deep learning model with the best performance. The first scenario’s results were used to determine which deep learning model performed best and to create the modified architecture for improved performance.
In the second scenario, an optimization layer was deployed with different optimizers and batch sizes. The performance of the modified architecture was compared to that of AlexNet using different performance measures such as training accuracy, training loss, and testing accuracy. The implementation in the second scenario was performed on three different optimizers, each with three different batch sizes.
3.1. First Scenario
The experimental analysis was conducted by passing the extracted features from each DL model to SVM for classification. The performance metrics were calculated for each DL model in every dataset. For each dataset and deep learning model, data were divided into 80% training and 20% testing for each class.
Three datasets have been used in this study to compare the performance of the six deep learning models in the feature extraction phase. The six deep learning models that were implemented are:
ResNet-18
AlexNet
GoogleNet
VGG-16
MobileNetV2
DenseNet-201
A comparative study has been conducted on Dataset 1 to evaluate the performance of the image enhancement techniques on the DL models. Dataset 1 featured multiple scans for patients from the following classes:
- 7.
Normal: 99 patients
- 8.
Benign: 62 patients
- 9.
Malignant: 39 patients
The performance of six deep learning models was compared twice for Dataset 1. In the first trial, after the augmentation stage, the images were passed to the colour feature map layer without using the image enhancement techniques mentioned in the pre-processing stage. In the second trial, DBT slices were augmented, then enhanced and a colour feature map was applied before being passed to the DL models. This was performed to check whether the image enhancement techniques proposed in the pre-processing stages improved the DBT classification performance or otherwise.
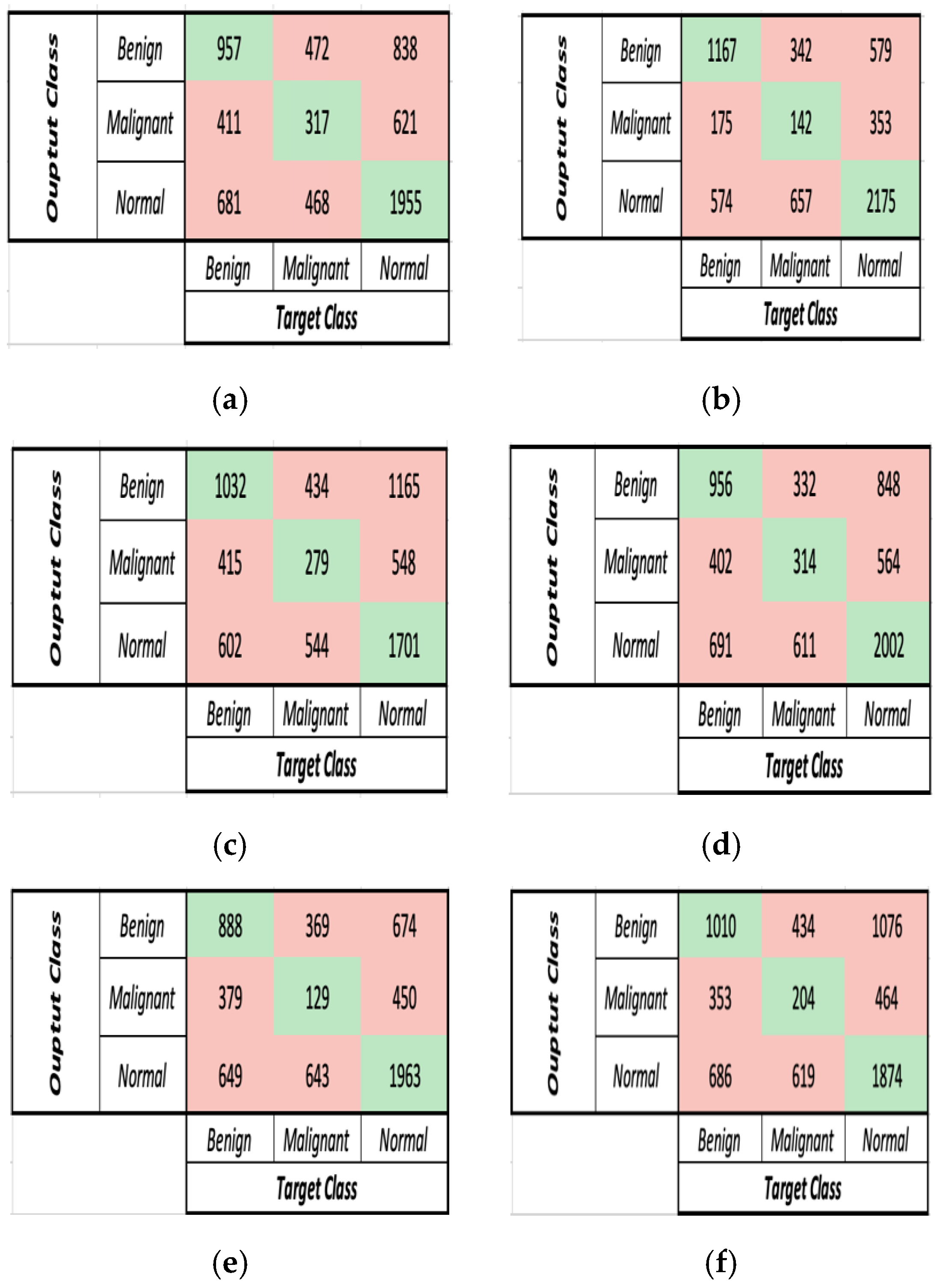
Figure 5 demonstrates the confusion matrices of the six deep learning models before applying the image and contrast enhancement techniques. The comparison between the DL models in terms of accuracy and run-time before pre-processing stage is presented in
Table 4.
Table 4 and
Figure 5 demonstrate that AlexNet obtained the highest accuracy and runtime, with an accuracy of 56.52% and a runtime of 706 s. With runtimes of 737, 4301, and 842 s, ResNet-18, VGG-16, and MobileNetV2 achieved accuracies of 48.05%, 48.69%, and 48.67%, respectively. Finally, GoogleNet and DenseNet-201 yielded the lowest accuracies of 44.82% and 45.95%, respectively, with runtimes of 916 and 4123 s.
Figure 6 features the confusion matrices of the six deep learning models after implementing the pre-processing phase before the feature extraction phase. The comparison between the DL models in terms of accuracy and run-time after pre-processing is presented in
Table S5.
Based on
Table 4 and
Table S5, it is concluded that the accuracy has improved in all DL models after applying the pre-processing stage. As for the run-time, AlexNet, ResNet-18, and MobileNetV2 needed less time to extract features from the enhanced images, thus reducing the run-time. Despite the insignificant increase in the run-time for GoogleNet, DenseNet-201, and VGG-16 there was an obvious increase in the accuracy of classification.
In terms of accuracy, after applying the image enhancement techniques, MobileNetV2 and GoogleNet managed to achieve the highest improvement of 2.86% and 2.78%, respectively. ResNet-18 and GoogleNet achieved an 0.6% and 2.78% accuracy improvement. Finally, AlexNet and DenseNet-201 recorded an improvement of 0.34% and 0.16%, respectively. In terms of runtime, ResNet-18, AlexNet and MobileNetV2 reduced their runtime by 11.9%, 7.68% and 7.36%, respectively. GoogleNet, VGG-16 and DenseNet-201, on the other hand, recorded an increase in their runtime by 24.5%, 10.6% and 8.63%, respectively.
- B.
Dataset 2
More scans from patients with no findings (normal) were added to analyse the performance of the proposed model when adding more data for training and testing. Moreover, the performance of the deep learning models on Dataset 1 and Dataset 2 was compared in terms of accuracy and run-time after adding the pre-processing stage for both datasets. Dataset 2 featured multiple scans for patients from the following classes:
- 10.
Normal: 199 patients
- 11.
Benign: 62 patients
- 12.
Malignant: 39 patients
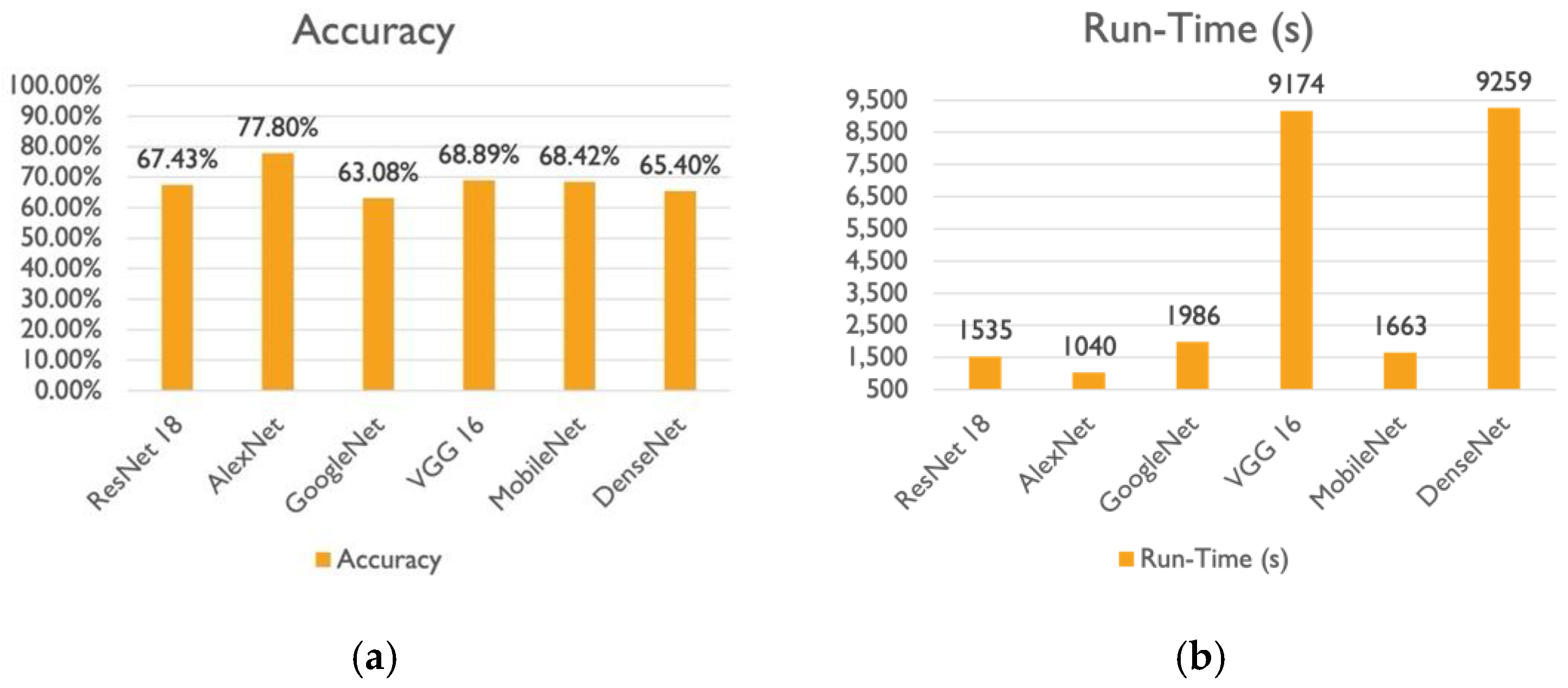
The comparison between the performance of the DL models on Dataset 2 in terms of accuracy and run-time (s) is documented in
Table S6 and
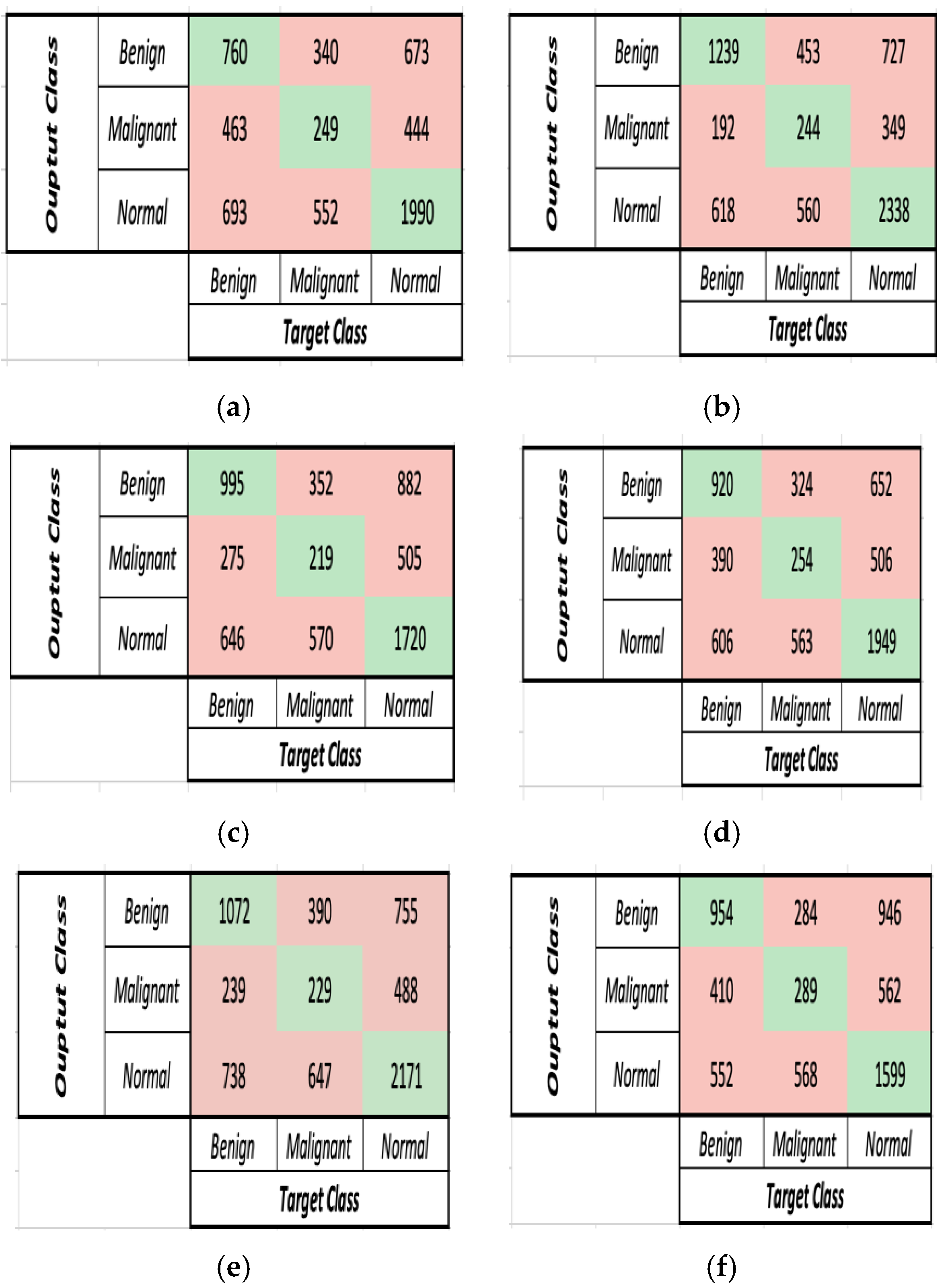
Figure 7a,b.
The comparison between the performance of the DL models on Dataset 2 in terms of accuracy and run-time (s) is documented in
Table S6 and
Figure 7a,b. Based on
Table S6 and
Figure 7a,b, it is proven that extracting features using AlexNet resulted in the best accuracy, and performance and less time was needed for training and testing, with an accuracy of 77.8% and runtime of 1040 s. Although MobileNetV2 and VGG-16 concluded with the approximately same accuracy, there is a noticeable difference in the computation time. VGG-16 took almost five times as long as MobileNetV2 to extract features. Following the three previously mentioned models, DenseNet-201 recorded the least accuracy of 65.40%, despite taking six times longer to extract features than ResNet-18. ResNet-18 achieved an accuracy of 67.43% with a runtime of 1535 s. Finally, in comparison to AlexNet, which performed the best, GoogleNet experienced a 14% drop in the model’s accuracy and a runtime of 1986 s.
A comparison between the performance of the DL models using Dataset 1 and Dataset 2 is provided in
Table S7. Based on
Table S7 using Dataset 2, AlexNet provided the best accuracy and run-time results, with a 21% gain in accuracy and the least percentage increase in runtime. On the other hand, the worst percentage increase in run-time was recorded with a 19% improvement in accuracy for ResNet-18. Moreover, VGG-16 and DenseNet-201 recorded the same percentage increase in run-time along with an accuracy increase of 18.22% and 19.29%, respectively. Finally, the least accuracy gain was observed when GoogleNet and MobileNetV2 were implemented to extract features, which increased the classification accuracy by 15.48% and 16.89%, respectively.
- C.
Dataset 3
Finally, Dataset 3 was generated by adding extra data for training and testing, as well as new scans from patients who had no findings (normal) to analyse performance and compare it to Dataset 2 and Dataset 1 outcomes. Dataset 3 featured multiple scans for patients from the following classes:
- 13.
Normal: 499 patients
- 14.
Benign: 62 patients
- 15.
Malignant: 39 patients
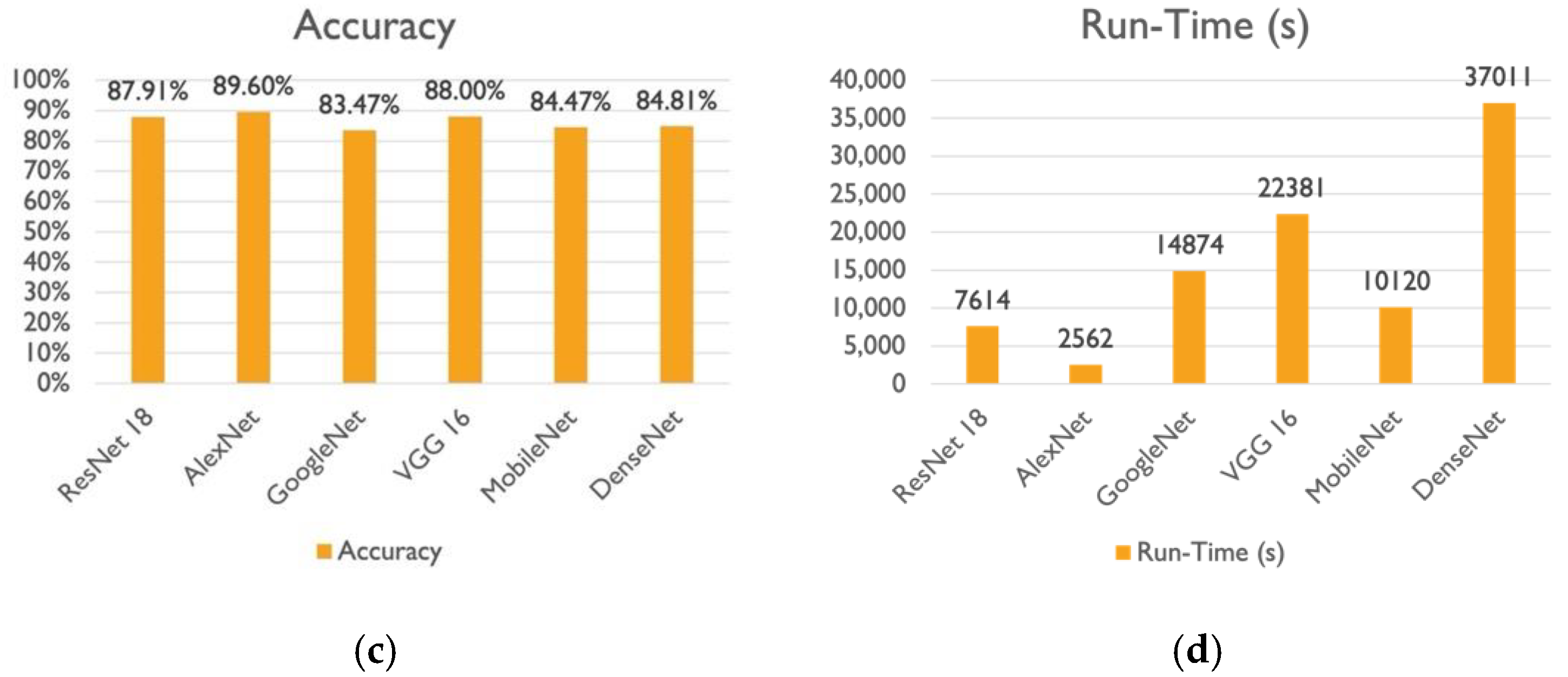
Table S8 and
Figure 7c,d compare the accuracy and run-time (s) of the DL models on Dataset 3, respectively. According to
Table S8 and
Figure 7c,d, AlexNet recorded the highest classification accuracy of 89.6%, while GoogleNet recorded the lowest classification accuracy of 83.47%, and VGG-16 and ResNet-18 both achieved an 88% classification accuracy, but VGG-16 took nearly three times as long as ResNet-18 to achieve it. Finally, DenseNet-201 achieved the same accuracy as MobileNetV2 at 85%, but it took three times as long.
A comparison between the performance of the DL models using Dataset 2 and Dataset 3 is provided in
Table S8.
Table S8 demonstrated that Dataset 3 resulted in higher classification accuracy in all six DL models. VGG-16 and AlexNet exhibited the lowest increase in elapsed time, with accuracy gains of 19% and 12%, respectively. Additionally,
Table S8 indicates that GoogleNet and ResNet-18 recorded the maximum improvement in accuracy, with a 20% increase. When compared to ResNet-18, GoogleNet experienced a considerable increase in computation time.
3.2. Second Scenario
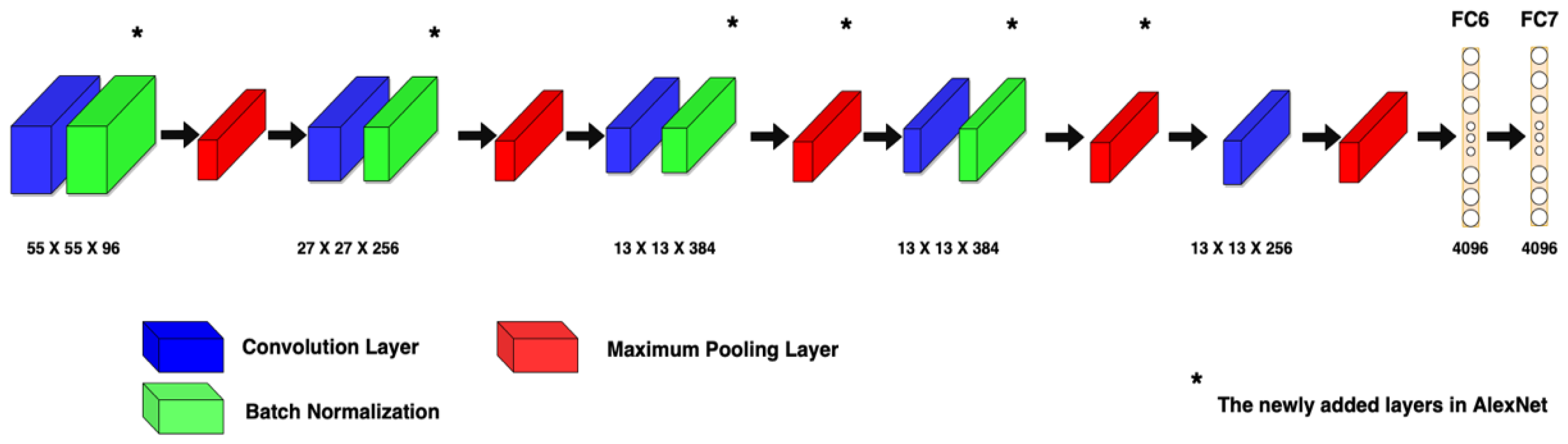
The first scenario concluded that AlexNet outperformed the other five DL models in DBT classification. As a result, a modified architecture (Mod_AlexNet) was developed to improve AlexNet’s performance.
The performance and accuracy of AlexNet and Mod_AlexNet were measured and compared using the metrics of accuracy, and loss. Due to the large size of the dataset, each training was performed for three epochs with batch sizes of 32, 64, and 512. The models were trained using a variety of optimisers, including adaptive moment estimation (Adam), root mean squared propagation (RMSProp), and stochastic gradient descent with momentum (SGDM).
A comparison between the performance of Mod_AlexNet and AlexNet in terms of training accuracy, training loss, and testing accuracy using different optimizers is shown in the following sections. The analysis was carried out on the 600 patients mentioned in Dataset 3.
The comparison between the performance of Mod_AlexNet and AlexNet in terms of training accuracy, training loss, and testing accuracy using SGDM optimizer with different batch sizes is shown in
Table 5 and
Figure S1.
Based on
Figure S1, it is concluded that for a batch size of 32, AlexNet achieved a training accuracy of 98.50% and a training loss value of 0.05, while Mod_AlexNet achieved a lower training accuracy of 97.67% and a training loss value of 0.08 for the same batch size. Moreover, AlexNet achieved 97.94% training accuracy with a training loss value of 0.07, while Mod_AlexNet achieved 96.74% training accuracy with a training loss value of 0.11 for a batch size of 64. Finally, for a batch size of 512, AlexNet obtained 93.33% training accuracy with a training loss value of 0.2, while Mod_AlexNet achieved 91% training accuracy with a training loss value of 0.26.
Table 5 demonstrated that using the SGDM optimization technique, Mod_AlexNet outperformed AlexNet in terms of testing accuracy on different batch sizes. Mod_AlexNet recorded a 2.87% testing accuracy increase when compared to AlexNet with a batch size of 32. When training the models on 64 and 512 batch sizes, Mod_AlexNet exhibited a 2.1% and 0.38% increase in test accuracy when compared to AlexNet, respectively. The highest test accuracy was achieved on a batch size of 32 by Mod_AlexNet, with an accuracy of 91.61%.
- B.
Adam Optimizer
The comparison between the performance of Mod_AlexNet and AlexNet in terms of training accuracy, training loss, and testing accuracy using Adam optimizer with different batch sizes is shown in
Table 6 and
Figure S2.
According to
Figure S2, for a batch size of 32, Mod_AlexNet achieved a training accuracy of 89.94% and a training loss value of 0.39, whereas AlexNet achieved a lower training accuracy of 89.52% and a training loss value of 0.4. Furthermore, Mod_AlexNet achieved 94.01% training accuracy with a training loss value of 0.18 for a batch size of 64, whereas AlexNet achieved 89.50% training accuracy with a training loss value of 0.4. Finally, with a batch size of 512, Mod_AlexNet achieved 90.09% training accuracy with a training loss of 0.28, while AlexNet achieved 86.70% training accuracy with a training loss of 0.48.
Based on
Table 6, Mod_AlexNet outperformed AlexNet in terms of testing accuracy on different batch sizes, according to the Adam optimization technique. When compared to AlexNet with a batch size of 32, Mod_AlexNet improved testing accuracy by 1.59%. Mod_AlexNet demonstrated a 0.43% and 1.1% increase in test accuracy when trained on 64 and 512 batch sizes, respectively, when compared to AlexNet. The highest test accuracy of 90.36% was achieved by Mod_AlexNet on a batch size of 512.
- C.
RMSProp Optimizer
The comparison between the performance of Mod_AlexNet and AlexNet in terms of training accuracy, training loss, and testing accuracy using RMSProp optimizer with different batch sizes is shown in
Table 7 and
Figure S3.
Based on
Figure S3, Mod_AlexNet outperformed AlexNet for a batch size of 32, with training accuracies of 93.18% and 87.21%, and training loss values of 0.25 and 0.72, respectively. Furthermore, for a batch size of 64, Mod_AlexNet achieved 93.49% training accuracy with a training loss value of 0.25, whereas AlexNet achieved 87.20% training accuracy with a training loss value of 0.69. Finally, with a batch size of 512, AlexNet achieved a higher training accuracy of 86.69% and a training loss of 0.50, while Mod_AlexNet achieved a lower training accuracy of 84.17% and a training loss of 0.52.
Table 7 demonstrates that according to the RMSProp optimization technique, Mod_AlexNet outperformed AlexNet in terms of testing accuracy on different batch sizes. Mod_AlexNet improved testing accuracy by 1.02% when compared to AlexNet with a batch size of 32. When trained on 64 and 512 batch sizes, Mod_AlexNet demonstrated a 1.19% and 0.34% increase in test accuracy, respectively, when compared to AlexNet. Mod_AlexNet achieved the highest test accuracy of 90.60% on a batch size of 512.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}