Main Concept, Sequencing, and Story Grammar Analyses of Cinderella Narratives in a Large Sample of Persons with Aphasia

 , ,
, ,
Abstract
:1. Introduction
1.1. Main Concept Analysis
1.2. Story Grammar Analysis
1.3. Linking Main Concept and Story Grammar Analyses
1.4. Sequencing
1.5. Main Concept, Sequencing, and Story Grammar Analyses
1.6. Study Purpose
2. Materials and Methods
2.1. Participants
2.2. Transcripts
2.3. Scoring
2.3.1. Main Concepts
2.3.2. Sequencing
2.3.3. Main Concept + Sequencing
2.3.4. Essential Story Grammar Components
2.3.5. Total Episodic Components
2.3.6. Episodic Complexity
2.4. Fidelity and Reliability
2.4.1. Assessment Fidelity
2.4.2. Inter-Rater Reliability
2.5. Data Analysis
2.5.1. Normative Data
2.5.2. Comparisons between PNBIs and PWAs
2.5.3. Secondary Analysis
3. Results
3.1. Comparisons between PNBIs and PWAs
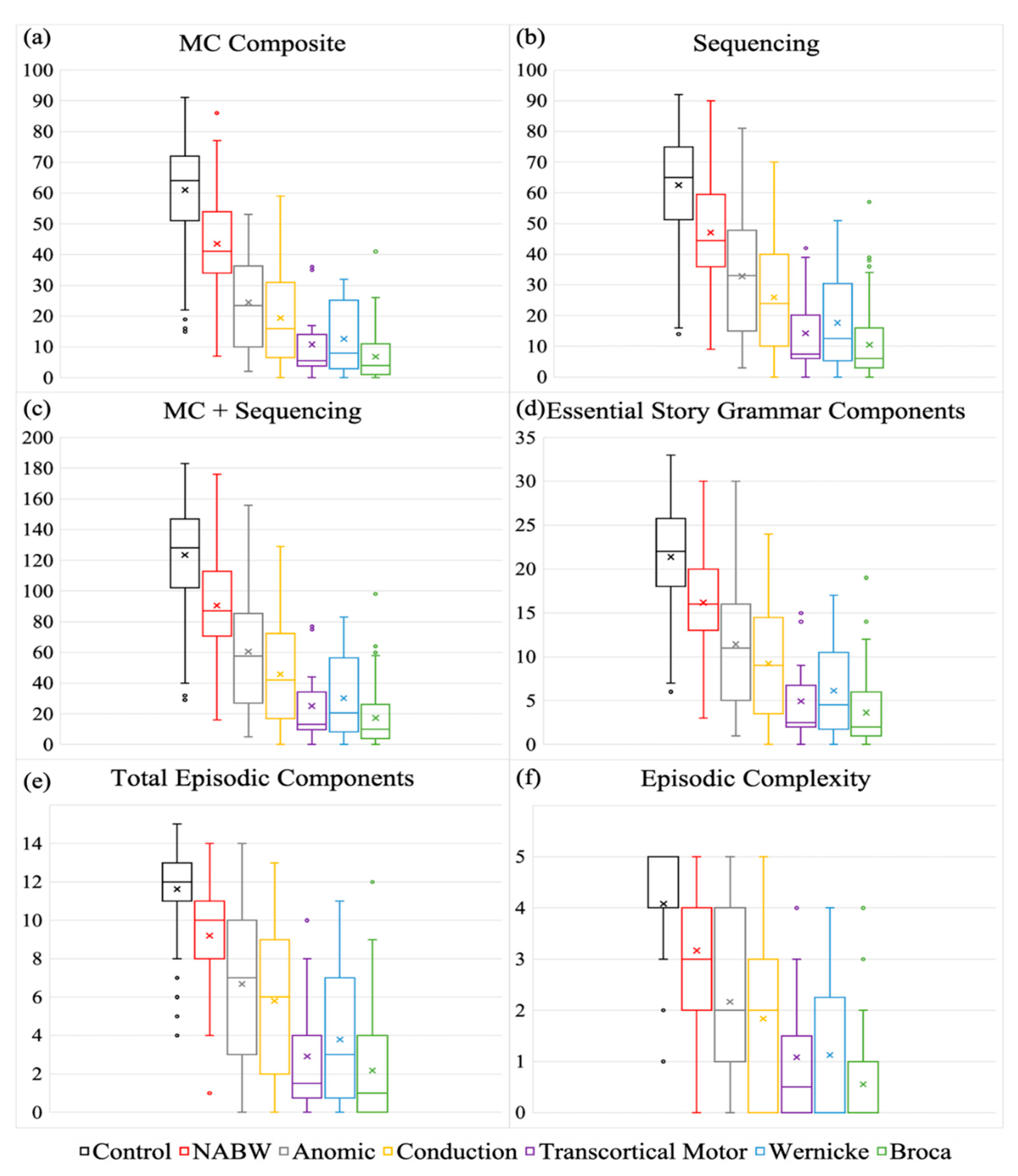
3.1.1. Main Concept Composite
3.1.2. Sequencing
3.1.3. Main Concept+Sequencing
3.1.4. Essential Story Grammar Components
3.1.5. Total Episodic Components
3.1.6. Episodic Complexity
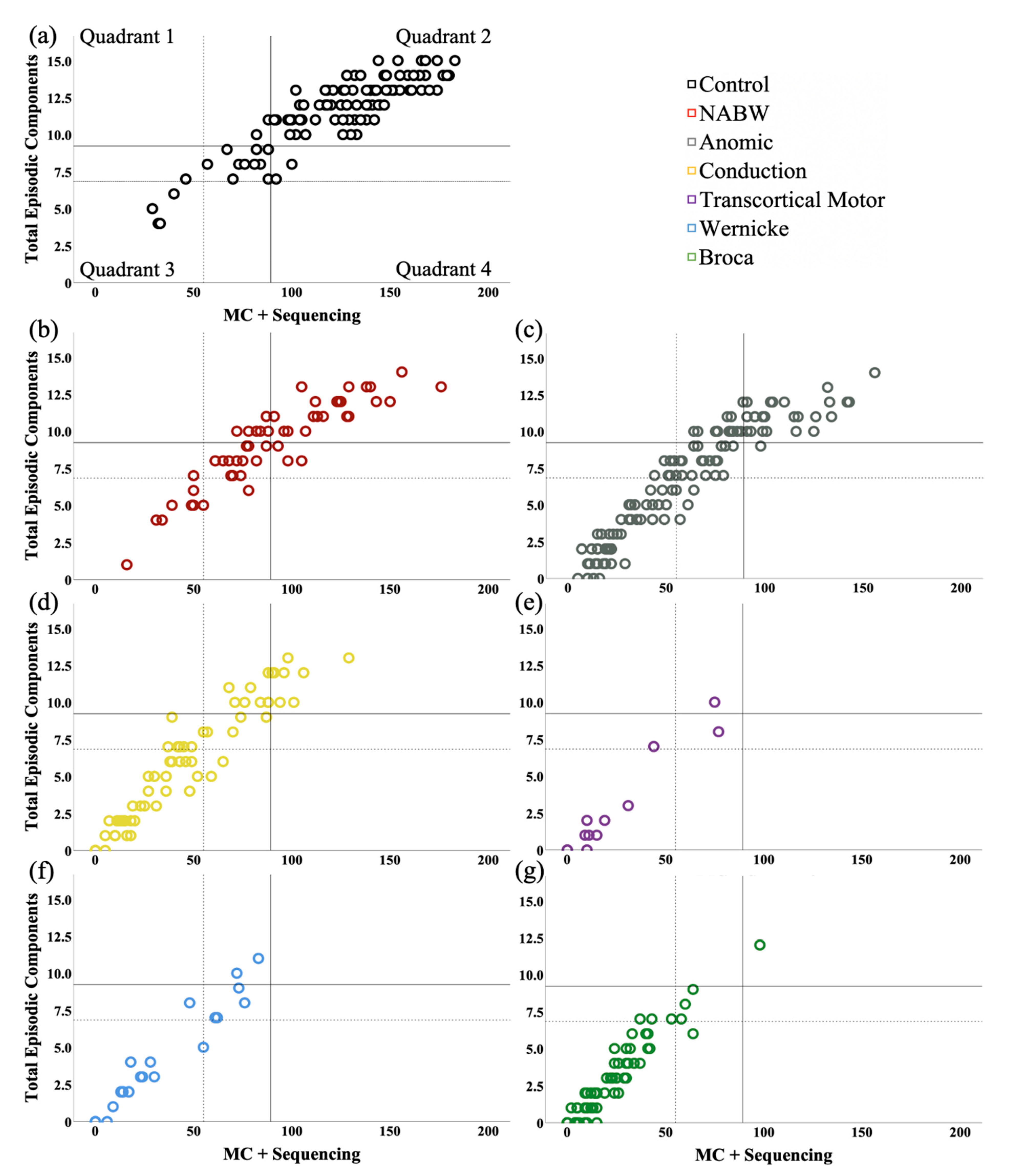
3.1.7. MSSG Classification
3.2. Secondary Analysis
4. Discussion
4.1. Spotlight on PWAs-NABW
4.2. Limitations and Future Directions
4.2.1. The Timing May be the Thing
4.2.2. Errors and Macrostructure and Timing (Again), Oh My
4.2.3. Non-Essential Workers
4.2.4. Discourse Research and Diversity
4.2.5. Happily Ever … after Cinderella
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Nicholas, L.E.; Brookshire, R.H. A system for scoring main concepts in the discourse of non-brain-damaged and aphasic speakers. In Proceedings of the Clinical Aphasiology Conference, Sandestin, FL, USA, June 1991; Volume 21, pp. 87–99. [Google Scholar]
- Nicholas, L.E.; Brookshire, R.H. Presence, completeness, and accuracy of main concepts in the connected speech of non-brain-damaged adults and adults with aphasia. J. Speech Lang. Hear. Res. 1995, 38, 145–156. [Google Scholar] [CrossRef] [PubMed]
- Kong, A.P.H. The use of main concept analysis to measure discourse production in Cantonese-speaking persons with aphasia: A preliminary report. J. Commun. Disord. 2009, 42, 442–464. [Google Scholar] [CrossRef] [PubMed]
- Richardson, J.D.; Dalton, S.G. Main concepts for three different discourse tasks in a large non-clinical sample. Aphasiology 2016, 30, 45–73. [Google Scholar] [CrossRef]
- Richardson, J.D.; Dalton, S.G.H. Main concepts for two picture description tasks: An addition to Richardson and Dalton, 2016. Aphasiology 2020, 34, 119–136. [Google Scholar] [CrossRef] [PubMed]
- Pritchard, M.; Hilari, K.; Cocks, N.; Dipper, L. Reviewing the quality of discourse information measures in aphasia. Int. J. Lang. Commun. Disord. 2017, 52, 689–732. [Google Scholar] [CrossRef]
- Kong, A.P.H. The main concept analysis in Cantonese aphasic oral discourse: External validation and monitoring chronic aphasia. J. Speech Lang. Hear. Res. 2011, 42, 442–464. [Google Scholar]
- Kong, A.P.H.; Whiteside, J.; Bargmann, P. The main concept analysis: Validation and sensitivity in differentiating discourse produced by unimpaired English speakers from individuals with aphasia and dementia of Alzheimer type. Logop. Phoniatr. Vocology 2016, 41, 129–141. [Google Scholar] [CrossRef]
- Boyle, M. Test–retest stability of word retrieval in aphasic discourse. J. Speech Lang. Hear. Res. 2014, 57, 966–978. [Google Scholar] [CrossRef]
- Greenslade, K.J.; Stuart, J.E.; Richardson, J.D.; Dalton, S.G.; Ramage, A.E. Macrostructural analyses of Cinderella narratives in a large nonclinical sample. Am. J. Speech Lang. Pathol. 2020, 29, 1923–1936. [Google Scholar] [CrossRef]
- Dalton, S.G.; Richardson, J.D. Core-lexicon and main-concept production during picture-sequence description in adults without brain damage and adults with aphasia. Am. J. Speech Lang. Pathol. 2015, 24, S923–S938. [Google Scholar] [CrossRef] [Green Version]
- Fromm, D.; Forbes, M.; Holland, A.; Dalton, S.G.; Richardson, J.; MacWhinney, B. Discourse characteristics in aphasia beyond the Western Aphasia Battery cutoff. Am. J. Speech Lang. Pathol. 2017, 26, 762–768. [Google Scholar] [CrossRef] [PubMed]
- Dalton, S.G.H.; Richardson, J.D. A large-scale comparison of main concept production between persons with aphasia and persons without brain injury. Am. J. Speech Lang. Pathol. 2019, 28, 293–320. [Google Scholar] [CrossRef] [PubMed]
- Dalton, S.G.H.; Hubbard, H.I.; Richardson, J.D. Moving toward non-transcription based discourse analysis in stable and progressive aphasia. Semin. Speech Lang. 2020, 41, 32. [Google Scholar] [CrossRef] [PubMed]
- Richardson, J.D.; Hudspeth Dalton, S.G.; Fromm, D.; Forbes, M.; Holland, A.; MacWhinney, B. The relationship between confrontation naming and story gist production in aphasia. Am. J. Speech Lang. Pathol. 2018, 27, 406–422. [Google Scholar] [CrossRef] [PubMed]
- Cupit, J.; Rochon, E.; Leonard, C.; Laird, L. Social validation as a measure of improvement after aphasia treatment: Its usefulness and influencing factors. Aphasiology 2010, 24, 1486–1500. [Google Scholar] [CrossRef]
- Ross, K.B.; Wertz, R.T. Comparison of impairment and disability measures for assessing severity of, and improvement in, aphasia. Aphasiology 1999, 13, 113–124. [Google Scholar] [CrossRef]
- Doyle, P.J.; Goda, A.J.; Spencer, K.A. The communicative informativeness and efficiency of connected discourse by adults with aphasia under structured and conversational sampling conditions. Am. J. Speech Lang. Pathol. 1995, 4, 130–134. [Google Scholar] [CrossRef] [Green Version]
- Armes, E.; Richardson, J.; Arenas, R.; Nelson, L. The Relationship between Narrative Informativeness and Psychosocial Outcomes in Chronic Stroke-Induced Aphasia. Master’s Thesis, University of New Mexico, Albuquerque, NM, USA, 2020. [Google Scholar]
- Stein, N.L.; Glenn, C.G. An analysis of story comprehension in elementary school children. In New Directions in Discourse Processing; Freedle, R.O., Ed.; Ablex: Norwood, NJ, USA, 1979; pp. 53–120. [Google Scholar]
- Roth, F.P.; Spekman, N.J. Narrative discourse: Spontaneously generated stories of learning-disabled and normally achieving students. J. Speech Hear. Disord. 1986, 51, 8–23. [Google Scholar] [CrossRef]
- Coelho, C.A.; Liles, B.Z.; Duffy, R.J.; Clarkson, J.V.; Elia, D. Longitudinal assessment of narrative discourse in a mildly aphasic adult. Clin. Aphasiol. 1994, 22, 145–155. [Google Scholar]
- Ulatowska, H.K.; North, A.J.; Macaluso-Haynes, S. Production of narrative and procedural discourse in aphasia. Brain Lang. 1981, 13, 345–371. [Google Scholar] [CrossRef] [Green Version]
- Ulatowska, H.K.; Freedman-Stern, R.; Doyel, A.W.; Macaluso-Haynes, S. Production of narrative discourse in aphasia. Brain Lang. 1983, 19, 317–334. [Google Scholar] [CrossRef]
- Lê, K.; Coelho, C.; Mozeiko, J.; Grafman, J. Measuring goodness of story narratives. J. Speech Lang. Hear. Res. 2011, 54, 118–126. [Google Scholar] [CrossRef]
- Cairns, D.; Marshall, J.; Cairns, P.; Dipper, L. Event processing through naming: Investigating event focus in two people with aphasia. Lang. Cogn. Process. 2007, 22, 201–233. [Google Scholar] [CrossRef]
- Hameister, I.; Nickels, L. The cat in the tree–using picture descriptions to inform our understanding of conceptualisation in aphasia. Lang. Cogn. Neurosci. 2018, 33, 1296–1314. [Google Scholar] [CrossRef]
- Bottenberg, D.; Lemme, M.; Hedberg, N. Analysis of oral narratives of normal and aphasic adults. Clin. Aphasiol. 1985, 15, 241–247. [Google Scholar]
- Lemme, M.L.; Hedberg, N.L.; Bottenberg, D.E. Cohesion in narratives of aphasic adults. In Proceedings of the Clinical Aphasiology Conference, Seabrook Island, SC, USA, 20–24 May 1984; pp. 215–222. [Google Scholar]
- Applebee, A.N. The Child’s Concept of Story: Ages Two to Seventeen; University of Chicago Press: Chicago, IL, USA, 1978. [Google Scholar]
- Bottenberg, D.; Lemme, M.; Hedberg, N. Effect of story content on narrative discourse of aphasic adults. Clin. Aphasiol. 1987, 17, 202–209. [Google Scholar]
- Hedberg, N.L.; Stoel-Gammon, C. Narrative analysis: Clinical procedures. Top. Lang. Disord. 1986, 7, 58–69. [Google Scholar] [CrossRef]
- Whitworth, A. Using narrative as a bridge: Linking language processing models with real-life communication. Semin. Speech Lang. 2010, 31, 64–75. [Google Scholar] [CrossRef]
- Whitworth, A.; Leitao, S.; Cartwright, J.; Webster, J.; Hankey, G.J.; Zach, J.; Wolz, V. NARNIA: A new twist to an old tale. A pilot RCT to evaluate a multilevel approach to improving discourse in aphasia. Aphasiology 2015, 29, 1345–1382. [Google Scholar] [CrossRef]
- Miller, J.F.; Iglesias, A. Systematic Analysis of Language Transcripts (SALT Softwar); University of Wisconsin-Madison, Waisman Centre, Language Analysis Laboratory: Madison, WI, USA, 2008. [Google Scholar]
- Pritchard, M.; Hilari, K.; Cocks, N.; Dipper, L. Psychometric properties of discourse measures in aphasia: Acceptability, reliability, and validity. Int. J. Lang. Commun. Disord. 2018, 53, 1078–1093. [Google Scholar] [CrossRef]
- Stark, J.A. Content analysis of the fairy tale Cinderella—A longitudinal single-case study of narrative production: “From rags to riches”. Aphasiology 2010, 24, 709–724. [Google Scholar] [CrossRef]
- Le, K.; Coelho, C.; Mozeiko, J.; Grafman, J. Quantifying goodness of story narratives. In Proceedings of the Clinical Aphasiology Conference, Jackson Hole, WY, USA, 27 May–1 June 2008. [Google Scholar]
- Hunt, K. Differences in Grammatical Structures Written at Three Grade Levels (NCTE Research Report No. 3); National Council of Teachers of English: Urbana, IL, USA, 1965. [Google Scholar]
- Le, K.; Coelho, C.; Mozeiko, J.; Krueger, F.; Grafman, J. Measuring goodness of story narratives: Implications for traumatic brain injury. Aphasiology 2011, 25, 748–760. [Google Scholar] [CrossRef] [Green Version]
- Coelho, C.; Lê, K.; Mozeiko, J.; Hamilton, M.; Tyler, E.; Krueger, F.; Grafman, J. Characterizing discourse deficits following penetrating head injury: A preliminary model. Am. J. Speech Lang. Pathol. 2013, 22, S438–S448. [Google Scholar] [CrossRef]
- Lindsey, A.; Mozeiko, J.; Krueger, F.; Grafman, J.; Coelho, C. Changes in discourse structure over time following traumatic brain injury. Neuropsychologia 2018, 119, 308–319. [Google Scholar] [CrossRef] [PubMed]
- Lindsey, A.; Hurley, E.; Mozeiko, J.; Coelho, C. Follow-up on the story goodness index for characterizing discourse deficits following traumatic brain injury. Am. J. Speech Lang. Pathol. 2019, 28, 330–340. [Google Scholar] [CrossRef]
- Power, E.; Weir, S.; Richardson, J.; Fromm, D.; Forbes, M.; MacWhinney, B.; Togher, L. Patterns of narrative discourse in early recovery following severe Traumatic Brain Injury. Brain Inj. 2020, 34, 98–109. [Google Scholar] [CrossRef]
- Kertesz, A. Western Aphasia Battery-Revised (WAB-R); Pro-Ed: Austin, TX, USA, 2006. [Google Scholar]
- Grimes, N. Walt Disney’s Cinderella; Random House: New York, NY, USA, 2005. [Google Scholar]
- Kazdin, A.E. Single-Case Research Designs: Methods for Clinical and Applied Setting; Oxford University Press: New York, NY, USA, 1982. [Google Scholar]
- Fabrigar, L.R.; Wegener, D.T.; MacCallum, R.C.; Strahan, E.J. Evaluating the use of exploratory factor analysis in psychological research. Psychol. Methods 1999, 4, 272. [Google Scholar] [CrossRef]
- West, S.G.; Finch, J.F.; Curran, P.J. Structural equation models with nonnormal variables: Problems and remedies. In Structural Equation Modeling: Concepts, Issues, and Applications; Hoyle, R.H., Ed.; Sage Publications: Thousand Oaks, CA, USA, 1995; pp. 56–75. [Google Scholar]
- Bothe, A.K.; Richardson, J.D. Statistical, practical, clinical, and personal significance: Definitions and applications in speech-language pathology. Am. J. Speech Lang. Pathol. 2011, 20, 233–242. [Google Scholar] [CrossRef]
- Fritz, C.O.; Morris, P.E.; Richler, J.J. Effect size estimates: Current use, calculations, and interpretation. J. Exp. Psychol. Gen. 2012, 141, 2–18. [Google Scholar] [CrossRef] [Green Version]
- McNeil, M.R.; Doyle, P.J.; Fossett, T.R.; Park, G.H.; Goda, A.J. Reliability and concurrent validity of the information unit scoring metric for the story retelling procedure. Aphasiology 2001, 15, 991–1006. [Google Scholar] [CrossRef]
- Kintz, S.; Fergadiotis, G.; Wright, H.H. Aging effects on discourse production. In Cognition, Language and Aging; John Benjamins: Amsterdam, The Netherlands, 2016; pp. 81–106. [Google Scholar]
- Fromm, D.; MacWhinney, B.; Forbes, M.; Holland, A. Is the Cinderella task biased for age or gender? Montréal Can. Acad. Aphasia 2011, 23, 122–123. [Google Scholar]
- Portet, S. A primer on model selection using the Akaike information criterion. Infect. Dis. Model. 2020, 5, 111–128. [Google Scholar] [CrossRef] [PubMed]
- Gill, J.; Gill, J.M.; Torres, M.; Pacheco, S.M.T. Generalized Linear Models: A Unified Approach; Sage Publications: Thousand Oaks, CA, USA, 2019; Volume 134. [Google Scholar]
- Olsen, T.S.; Bruhn, P.; Öberg, R.G.E. Cortical hypoperfusion as a possible cause of ‘subcortical aphasia’. Brain 1986, 109, 393–410. [Google Scholar] [CrossRef] [PubMed]
- DeDe, G.; Salis, C. Temporal and episodic analyses of the story of cinderella in latent aphasia. Am. J. Speech Lang. Pathol. 2020, 29, 449–462. [Google Scholar] [CrossRef] [PubMed]
- Silkes, J.P.; Zimmerman, R.M.; Greenspan, W.; Reinert, L.; Kendall, D.; Martin, N. Identifying verbal short-term memory and working memory impairments in individuals with latent aphasia. Am. J. Speech Lang. Pathol. 2020, 1–16. [Google Scholar] [CrossRef]
- Cunningham, K.T.; Haley, K.L. Measuring lexical diversity for discourse analysis in aphasia: Moving-average type–token ratio and word information measure. J. Speech Lang. Hear. Res. 2020, 63, 710–721. [Google Scholar] [CrossRef]
- Cavanaugh, R.; Haley, K.L. Subjective communication difficulties in very mild aphasia. Am. J. Speech Lang. Pathol. 2020, 29, 437–448. [Google Scholar] [CrossRef]
- Rosen, K.; Murdoch, B.; Folker, J.; Vogel, A.; Cahill, L.; Delatycki, M.; Corben, L. Automatic method of pause measurement for normal and dysarthric speech. Clin. Linguist. Phon. 2010, 24, 141–154. [Google Scholar] [CrossRef]
- Jacks, A.; Haley, K.L.; Bishop, G.; Harmon, T.G. Automated speech recognition in adult stroke survivors: Comparing human and computer transcriptions. Folia Phoniatr. Et Logop. 2019, 71, 282–292. [Google Scholar] [CrossRef]
- Andreetta, S.; Marini, A. The effect of lexical deficits on narrative disturbances in fluent aphasia. Aphasiology 2015, 29, 705–723. [Google Scholar] [CrossRef]
- Lazar, R.M.; Speizer, A.E.; Festa, J.R.; Krakauer, J.W.; Marshall, R.S. Variability in language recovery after first-time stroke. J. Neurol. Neurosurg. Psychiatry 2008, 79, 530–534. [Google Scholar] [CrossRef] [PubMed]
- Hillis, A.E.; Tippett, D.C. Stroke recovery: Surprising influences and residual consequences. Adv. Med. 2014, 2014. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Gargano, J.W.; Reeves, M.J. Sex differences in stroke recovery and stroke-specific quality of life: Results from a statewide stroke registry. Stroke 2007, 38, 2541–2548. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Petrea, R.E.; Beiser, A.S.; Seshadri, S.; Kelly-Hayes, M.; Kase, C.S.; Wolf, P.A. Gender differences in stroke incidence and poststroke disability in the Framingham heart study. Stroke 2009, 40, 1032–1037. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Rosenich, E.; Hordacre, B.; Paquet, C.; Koblar, S.A.; Hillier, S.L. Cognitive reserve as an emerging concept in stroke recovery. Neurorehabilit. Neural Repair 2020, 34, 187–199. [Google Scholar] [CrossRef] [PubMed]
- Bryant, L.; Ferguson, A.; Spencer, E. Linguistic analysis of discourse in aphasia: A review of the literature. Clin. Linguist. Phon. 2016, 30, 489–518. [Google Scholar] [CrossRef]
- Dalton, S.G.; Kim, H.; Richardson, J.D.; Wright, H.H. A compendium of core lexicon checklists. Semin. Speech Lang. 2020, 41, 45–60. [Google Scholar] [CrossRef]
- Labov, W. Some principles of linguistic methodology. Lang. Soc. 1972, 1, 97–120. [Google Scholar] [CrossRef] [Green Version]
- Heilmann, J.; Malone, T.O. The rules of the game: Properties of a database of expository language samples. Lang. Speech Hear. Serv. Sch. 2014, 45, 277–290. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
| PNBI (n = 110) | PWA (n = 370) | Anomic (n = 122) | Broca’s (n = 85) | Conduction (n = 67) | NABW (n = 54) | Transcortical Motor (n = 12) | Wernicke’s (n = 24) | |
|---|---|---|---|---|---|---|---|---|
| Age (years) † | 58.3 (±20.8) 20.0–89.5 | 62 (±12.6) 25–90.7 | 63 (±12.1) 32.7–85.7 | 58.3 (±12.9) 25.6–85.4 | 64.3 (±12.1) 30.9–90.7 | 60.7 (±13.7) 25–88 | 65 (±10.6) 47–83.6 | 67.3 (±10.8) 42.6–81.3 |
| WAB Aphasia Quotient †† | N/A | 72.8 (±19.8) 10.8–100 | 85.2 (±6.6) 63.4–93.5 | 51.2 (±15.1) 10.8–77.6 | 69.3 (±9.1) 47.8–90 | 96.6 (±1.8) 93.8–100 | 71.8 (±6.1) 59.8–80.3 | 52.2 (±14) 28.2–74.4 |
| Sex | 65 Female 45 Male | 151 Female 219 Male | 52 Female 70 Male | 29 Female 56 Male | 27 Female 40 Male | 29 Female 25 Male | 5 Female 7 Male | 7 Female 17 Male |
| Education (years) ††† | 15.8 (±2.5) 11–23 | 15.4 (±2.8) 7–25 | 15.7 (±2.8) 11–23 | 14.8 (±2.7) 8–23 | 15.2 (±3.1) 7–25 | 15.9 (±2.7) 12–21 | 14.1 (±2.3) 12–20 | 15.8 (±2.4) 12–20 |
| Race/Ethnicity | 92 Caucasian 3 African-American 3 Hispanic/Latino -- 12 Unknown | 311 Caucasian 35 African-American 15 Hispanic/Latino 7 Other 2 Unknown | 110 Caucasian 9 African-American 2 Hispanic/Latino -- 1 Unknown | 65 Caucasian 12 African-American 5 Hispanic/Latino 3 Other -- | 58 Caucasian 5 African-American 1 Hispanic/Latino 3 Other -- | 44 Caucasian 2 African-American 7 Hispanic/Latino 1 Other -- | 9 Caucasian 3 African-American -- -- -- | 20 Caucasian 3 African-American -- -- 1 Unknown |
| Statistic | Participant Groups | |||||||
|---|---|---|---|---|---|---|---|---|
| PNBI | PWA | ANO | BRO | CON | NABW | TCM | WER | |
| MC Composite | ||||||||
| Mean | 61.0 | 21.8 | 27.7 | 6.8 | 19.4 | 43.5 | 10.8 | 12.6 |
| SD | 17.1 | 18.8 | 17.5 | 7.7 | 14.6 | 16.6 | 12.5 | 11.9 |
| Median | 64 | 16 | 26 | 4 | 16 | 41 | 5.5 | 8 |
| Range | 15–91 | 0–86 | 2–75 | 0–41 | 0–59 | 7–86 | 0–36 | 0–32 |
| Skew | −0.630 | 0.810 | 0.496 | 1.763 | 0.621 | 0.250 | 1.464 | 0.582 |
| Kurtosis | 0.209 | −0.099 | −0.468 | 4.064 | −0.486 | −0.076 | 0.992 | −1.325 |
| Sequencing | ||||||||
| Mean | 62.5 | 26.5 | 32.8 | 10.5 | 25.9 | 47.1 | 14.3 | 17.6 |
| SD | 17.2 | 20.7 | 19.3 | 11.3 | 18.2 | 17.5 | 14.4 | 16.3 |
| Median | 65 | 24 | 33 | 6 | 24 | 44.5 | 7.5 | 12.5 |
| Range | 14–92 | 0–90 | 3–81 | 0–57 | 0–70 | 9–90 | 0–42 | 0–51 |
| Skew | −0.706 | 0.563 | 0.284 | 1.544 | 0.407 | 0.202 | 1.121 | 0.688 |
| Kurtosis | 0.263 | −0.605 | −0.800 | 2.806 | −0.924 | −0.257 | 0.024 | −0.837 |
| MC Composite + Sequencing | ||||||||
| Mean | 123.5 | 48.3 | 60.5 | 17.3 | 45.8 | 90.6 | 25.1 | 30.3 |
| SD | 34.2 | 39.3 | 36.7 | 18.9 | 32.7 | 34.0 | 26.8 | 28.1 |
| Median | 128 | 41 | 57.5 | 10 | 42 | 87 | 13 | 20.5 |
| Range | 29–183 | 0–176 | 5–156 | 0–98 | 0–129 | 16–176 | 0–77 | 0–83 |
| Skew | −0.680 | 0.668 | 0.378 | 1.630 | 0.455 | 0.226 | 1.276 | 0.628 |
| Kurtosis | 0.252 | −0.390 | −0.654 | 3.341 | −0.818 | −0.172 | 0.444 | −1.096 |
| Essential Story Grammar Components | ||||||||
| Mean | 21.4 | 9.2 | 11.4 | 3.6 | 9.2 | 16.2 | 4.9 | 6.1 |
| SD | 5.9 | 7.1 | 6.7 | 3.8 | 6.2 | 5.8 | 5.1 | 5.6 |
| Median | 22 | 8 | 11 | 2 | 9 | 16 | 2.5 | 4.5 |
| Range | 6–33 | 0–30 | 1–30 | 0–19 | 0–24 | 3–30 | 0–15 | 0–17 |
| Skew | −0.591 | 0.537 | 0.321 | 1.468 | 0.343 | 0.160 | 1.215 | 0.664 |
| Kurtosis | 0.203 | −0.617 | −0.642 | 2.468 | −0.914 | −0.232 | 0.283 | −0.871 |
| Total Episodic Components | ||||||||
| Mean | 11.6 | 5.5 | 6.7 | 2.2 | 5.8 | 9.2 | 2.9 | 3.8 |
| SD | 2.4 | 4.2 | 3.9 | 2.6 | 3.9 | 2.8 | 3.4 | 3.5 |
| Median | 12 | 5 | 7 | 1 | 6 | 10 | 1.5 | 3 |
| Range | 4–15 | 0–14 | 0–14 | 0–12 | 0–13 | 1–14 | 0–10 | 0–11 |
| Skew | −1.088 | 0.198 | −0.205 | 1.375 | 0.168 | −0.611 | 1.216 | 0.655 |
| Kurtosis | 1.056 | −1.314 | −1.257 | 1.706 | −1.198 | 0.099 | 0.107 | −0.803 |
| Episodic Complexity | ||||||||
| Mean | 4.1 | 1.7 | 2.2 | 0.6 | 1.8 | 3.2 | 1.1 | 1.1 |
| SD | 1.0 | 1.7 | 1.6 | 0.9 | 1.7 | 1.3 | 1.4 | 1.5 |
| Median | 4 | 1 | 2 | 0 | 2 | 3 | 0.5 | 0 |
| Range | 1–5 | 0–5 | 0–5 | 0–4 | 0–5 | 0–5 | 0–4 | 0–4 |
| Skew | −1.293 | 0.397 | −0.049 | 1.633 | 0.451 | −0.631 | 1.134 | 0.875 |
| Kurtosis | 1.520 | −1.216 | −1.308 | 2.253 | −0.990 | −0.240 | −0.126 | −0.806 |
| MC Composite | Sequencing | MC+Sequencing | Essential SG Components | Total Episodic Components | Episodic Complexity | |
|---|---|---|---|---|---|---|
| PNBI overlap anomic | 81% | 87% | 85% | 96% | 95% | 100% |
| PNBI overlap Broca’s | 13% | 33% | 20% | 34% | 56% | 60% |
| PNBI overlap conduction | 39% | 64% | 52% | 70% | 78% | 100% |
| PNBI overlap NABW | 96% | 98% | 96% | 96% | 95% | 100% |
| PNBI overlap transcortical motor | 8% | 14% | 9% | 16% | 24% | 60% |
| PNBI overlap Wernicke’s | 5% | 25% | 13% | 25% | 40% | 60% |
| Anomic overlap PNBI | 70% | 76% | 74% | 74% | 74% | 76% |
| Broca’s overlap PNBI | 14% | 31% | 25%% | 27% | 26% | 34% |
| Conduction overlap PNBI | 57% | 67% | 63% | 67% | 64% | 69% |
| NABW overlap PNBI | 98% | 98% | 98% | 98% | 98% | 96% |
| Transcortical motor overlap PNBI | 25% | 33% | 33% | 33% | 25% | 50% |
| Wernicke’s overlap PNBI | 33% | 46% | 38% | 42% | 42% | 46% |
| PNBI Predictors | PWA Predictors | |||
|---|---|---|---|---|
| MC Composite | Tweedie+Identity link | Gamma+Identity link | ||
| Age | χ2 = 24.8 p < 0.001 β = −0.387 | Education | χ2 = 7.5 p = 0.006 β = 1.0 | |
| Gender | χ2 = 10.0 p = 0.002 βFemale = 10.1 | Gender | χ2 = 14.8 p < 0.001 βFemale = 9.2 | |
| Sequencing | Tweedie+Identity link | Gamma+Identity link | ||
| Age | χ2 = 20.0 p < 0.001 β = −0.355 | Education | χ2 = 6.6 p = 0.10 β = 1.0 | |
| Gender | χ2 = 10.266 p = 0.001 βFemale = 10.4 | Gender | χ2 = 11.7 p = 0.001 βFemale = 8.9 | |
| MC+Sequencing | Tweedie+Identity link | Gamma+Identity link | ||
| Age | χ2 = 22.4 p < 0.001 β = −0.742 | Education | χ2 = 7.0 p = 0.008 β = 2.0 | |
| Gender | χ2 = 10.2 p = 0.001 βFemale = 20.5 | Gender | χ2 = 13.6 p < 0.001 βFemale = 18.3 | |
| Essential Story Grammar Components | Poisson+Identity link | Gamma+Identity link | ||
| Age | χ2 = 29.6 p < 0.001 β = −0.118 | Education | χ2 = 7.2 p = 0.007 β = 0.4 | |
| Gender | χ2 = 14.6 p < 0.001 βFemale = 3.5 | Gender | χ2 = 13.1 p < 0.001 βFemale = 3.2 | |
| Total Episodic Components | Poisson+Identity link | Tweedie+Identity link | ||
| Age | χ2 = 10.2 p = 0.001 β = −0.051 | Education | χ2 = 6.4 p = 0.012 β = 0.2 | |
| Gender | χ2 = 10.9 p = 0.001 βFemale = 1.9 | |||
| Episodic Complexity | Multinomial+Cumulative logit link | |||
| Age | χ2 = 16.0 p < 0.001 β = −0.038 | Education | χ2 = 7.2 p = 0.007 β = 0.1 | |
| Gender | χ2 = 7.2 p = 0.007 βFemale = 1.1 | Gender | χ2 = 20.3 p < 0.001 βFemale = 0.9 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Richardson, J.D.; Dalton, S.G.; Greenslade, K.J.; Jacks, A.; Haley, K.L.; Adams, J. Main Concept, Sequencing, and Story Grammar Analyses of Cinderella Narratives in a Large Sample of Persons with Aphasia. Brain Sci. 2021, 11, 110. https://0-doi-org.brum.beds.ac.uk/10.3390/brainsci11010110
Richardson JD, Dalton SG, Greenslade KJ, Jacks A, Haley KL, Adams J. Main Concept, Sequencing, and Story Grammar Analyses of Cinderella Narratives in a Large Sample of Persons with Aphasia. Brain Sciences. 2021; 11(1):110. https://0-doi-org.brum.beds.ac.uk/10.3390/brainsci11010110
Chicago/Turabian StyleRichardson, Jessica D., Sarah Grace Dalton, Kathryn J. Greenslade, Adam Jacks, Katarina L. Haley, and Janet Adams. 2021. "Main Concept, Sequencing, and Story Grammar Analyses of Cinderella Narratives in a Large Sample of Persons with Aphasia" Brain Sciences 11, no. 1: 110. https://0-doi-org.brum.beds.ac.uk/10.3390/brainsci11010110