
Reliable Identification of Oolong Tea Species: Nondestructive Testing Classification Based on Fluorescence Hyperspectral Technology and Machine Learning


Abstract
:1. Introduction
2. Materials and Methods
2.1. Sample
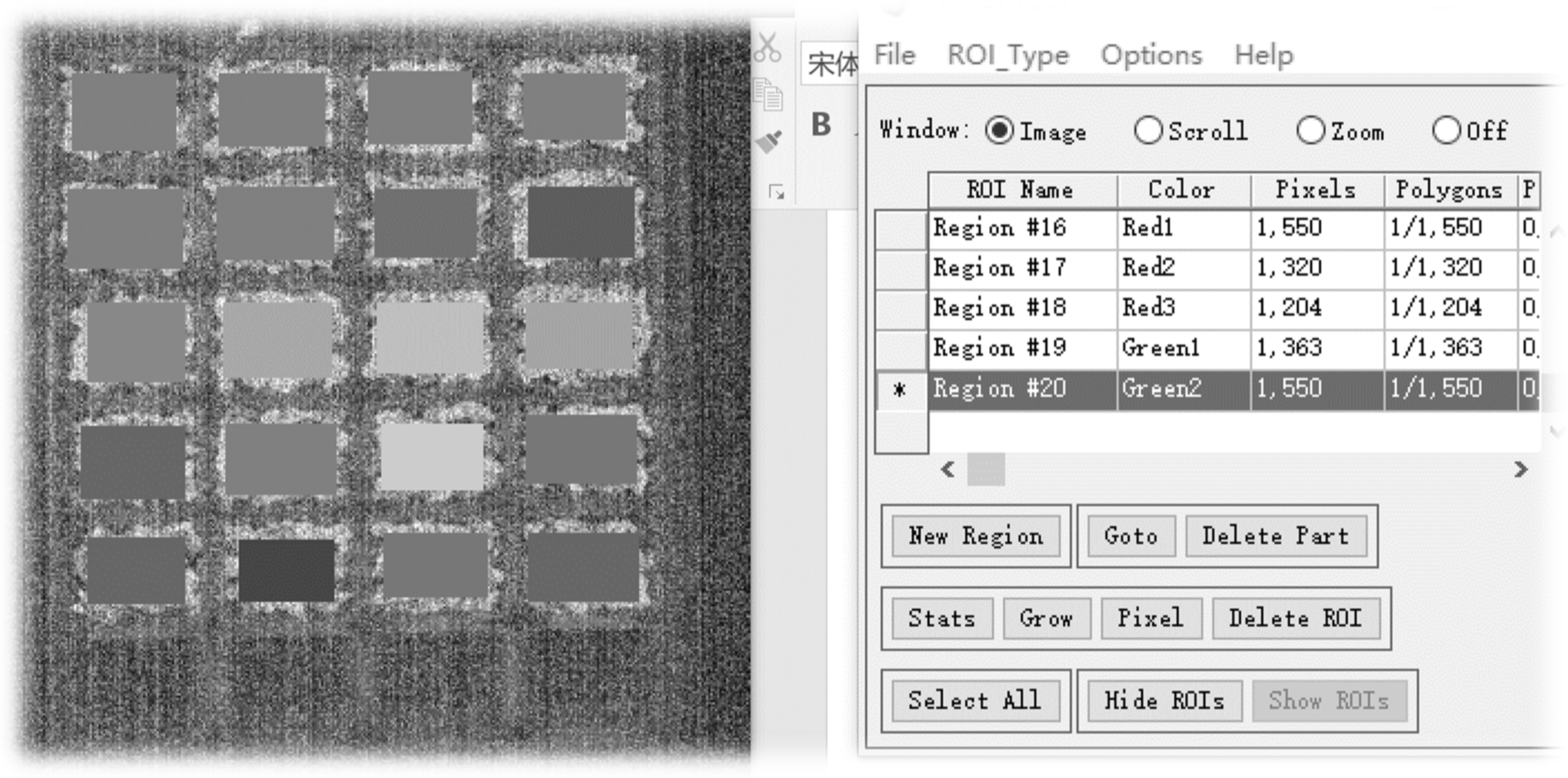
2.2. Fluorescence Hyperspectral Image Acquisition
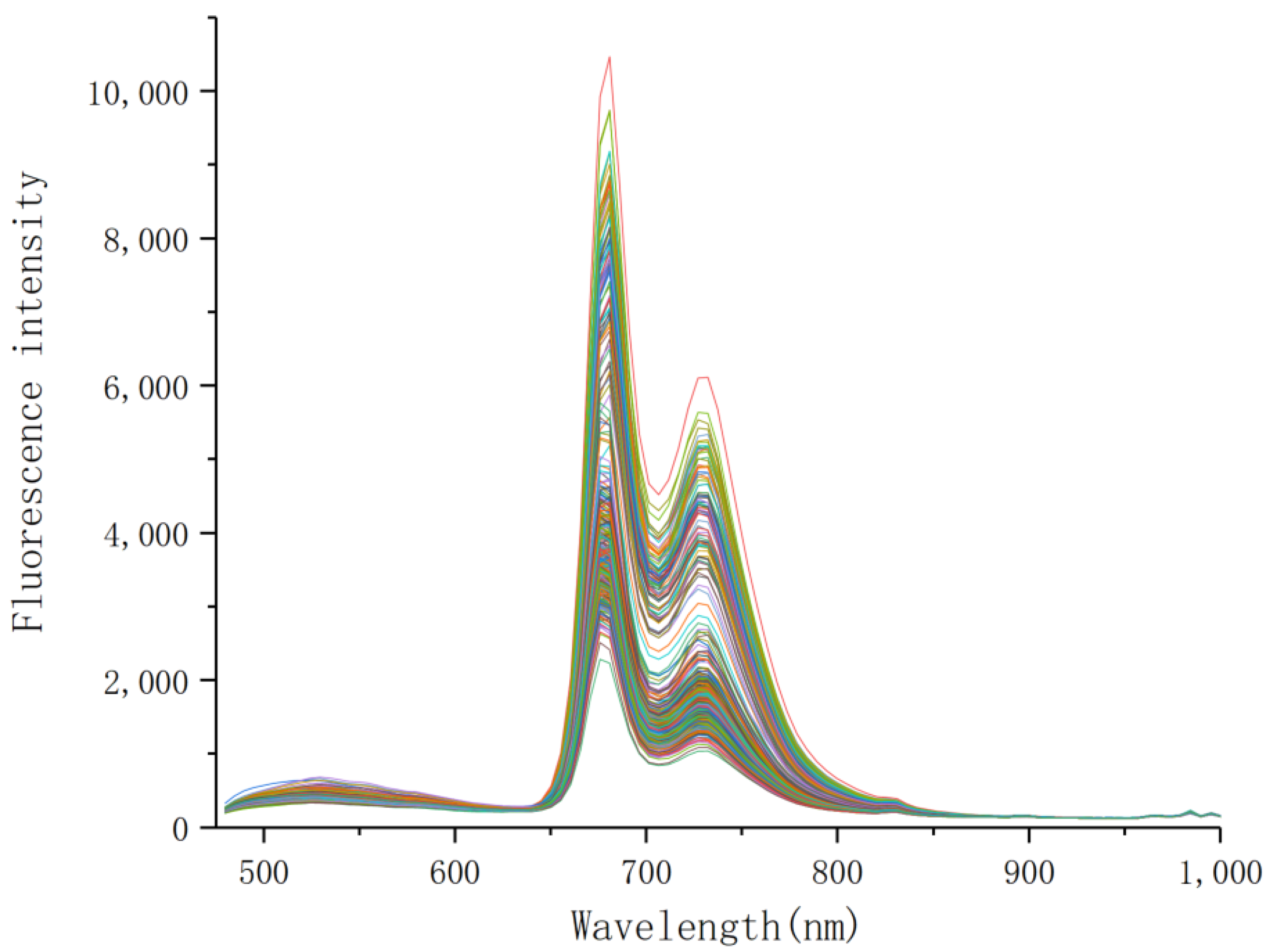
2.3. Fluorescence Hyperspectral Data Extraction
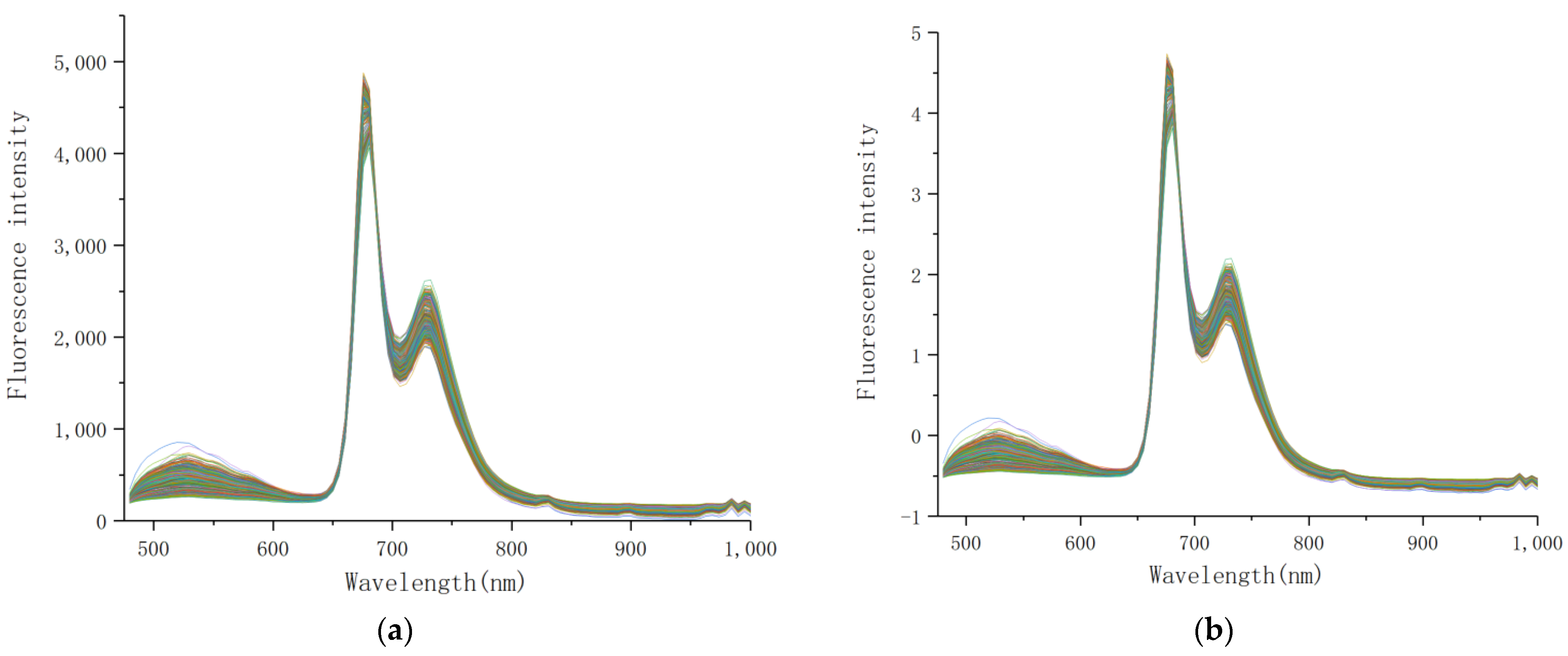
2.4. Spectral Preprocessing
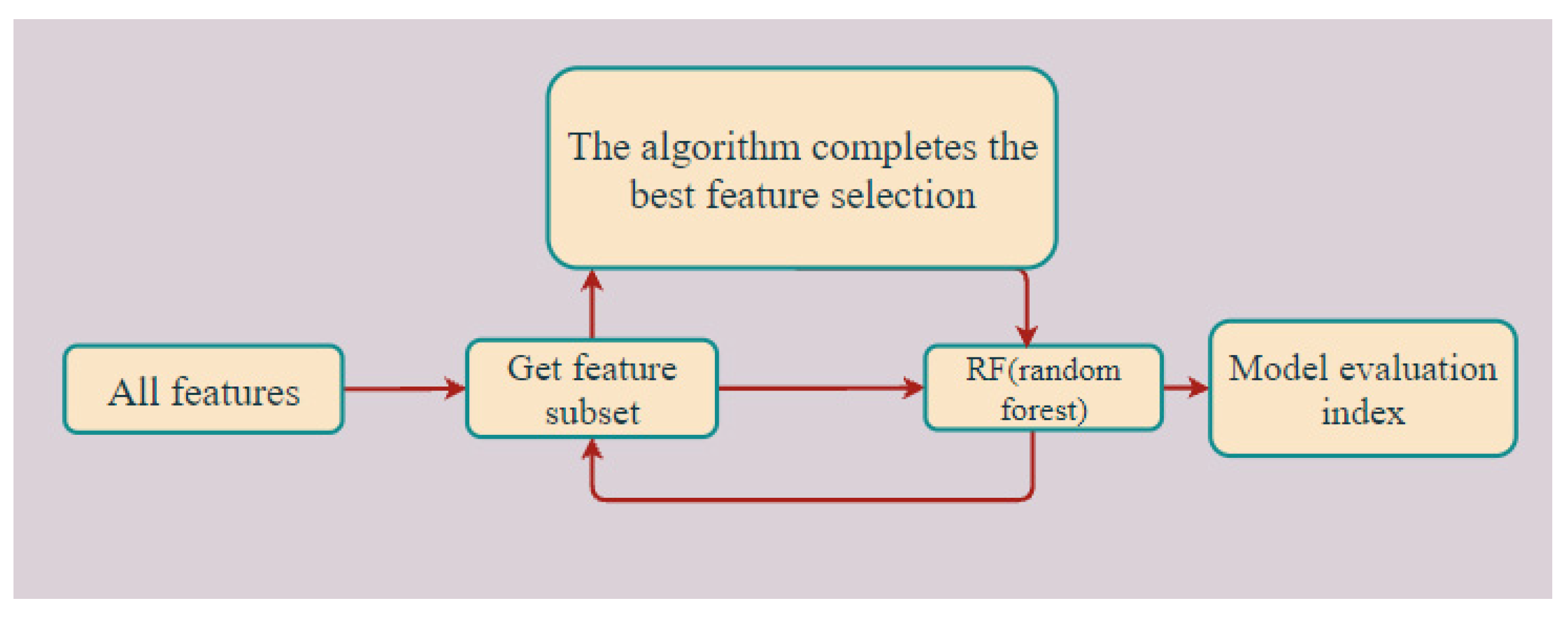
2.5. Feature Selection
2.5.1. Feature Dimensionality Reduction and Data Visualization
- (1)
- Joint probability distribution function for measuring the similarity of high dimensional spatial data points.
- (2)
- Joint probability distribution function for measuring the similarity of low dimensional spatial data points.
- (3)
- Computational low dimensional embedding
2.5.2. Feature Selection
2.6. Classification Model
2.6.1. Decision Tree (DT)
2.6.2. Random Forest Classification (RFC)
2.6.3. K-Nearest Neighbor (KNN)
2.6.4. Support Vector Machine (SVM)
2.7. Evaluation Index
3. Results
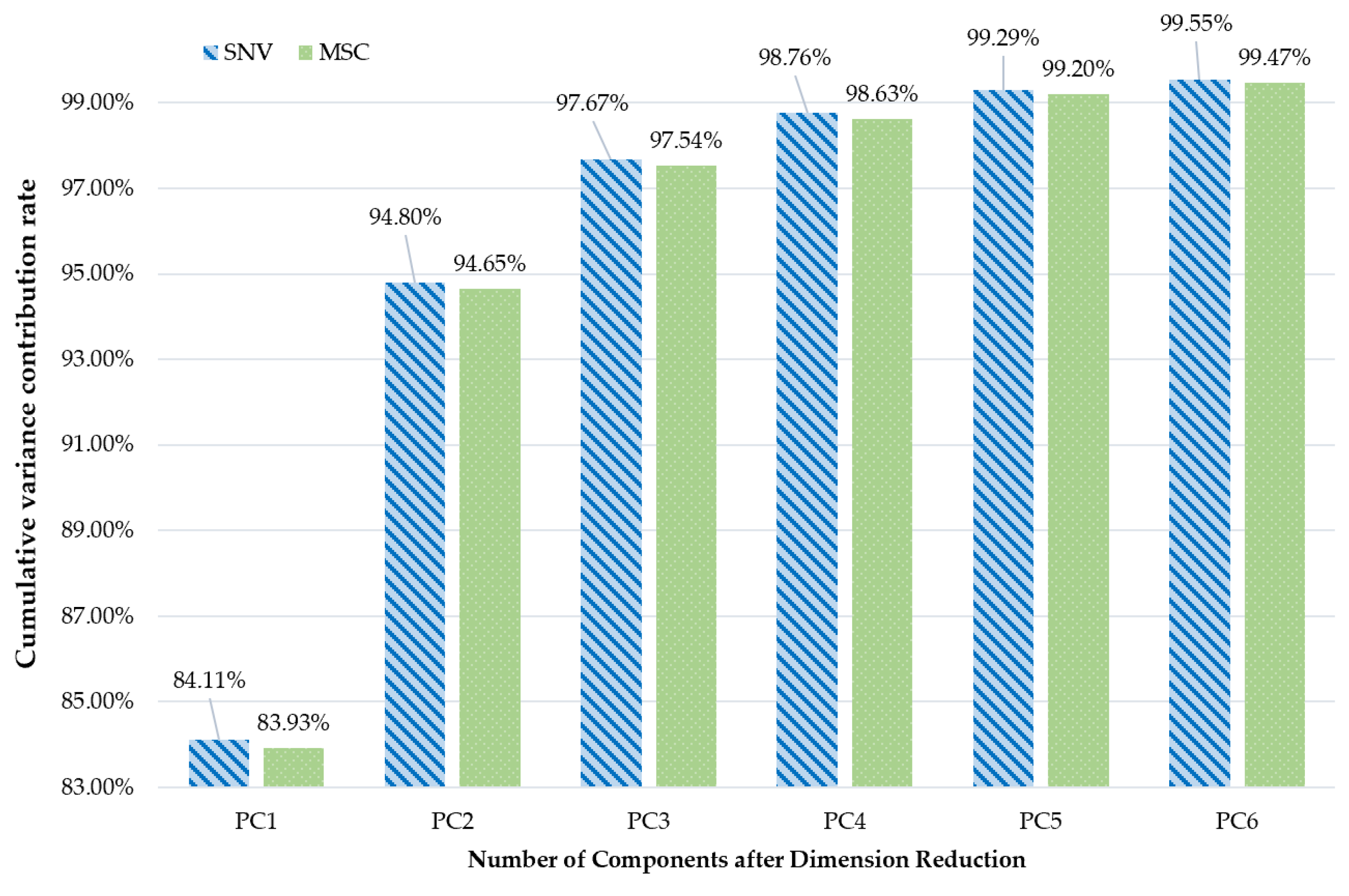
3.1. Spectral Preprocessing
3.2. Characteristic Wavelength Selection
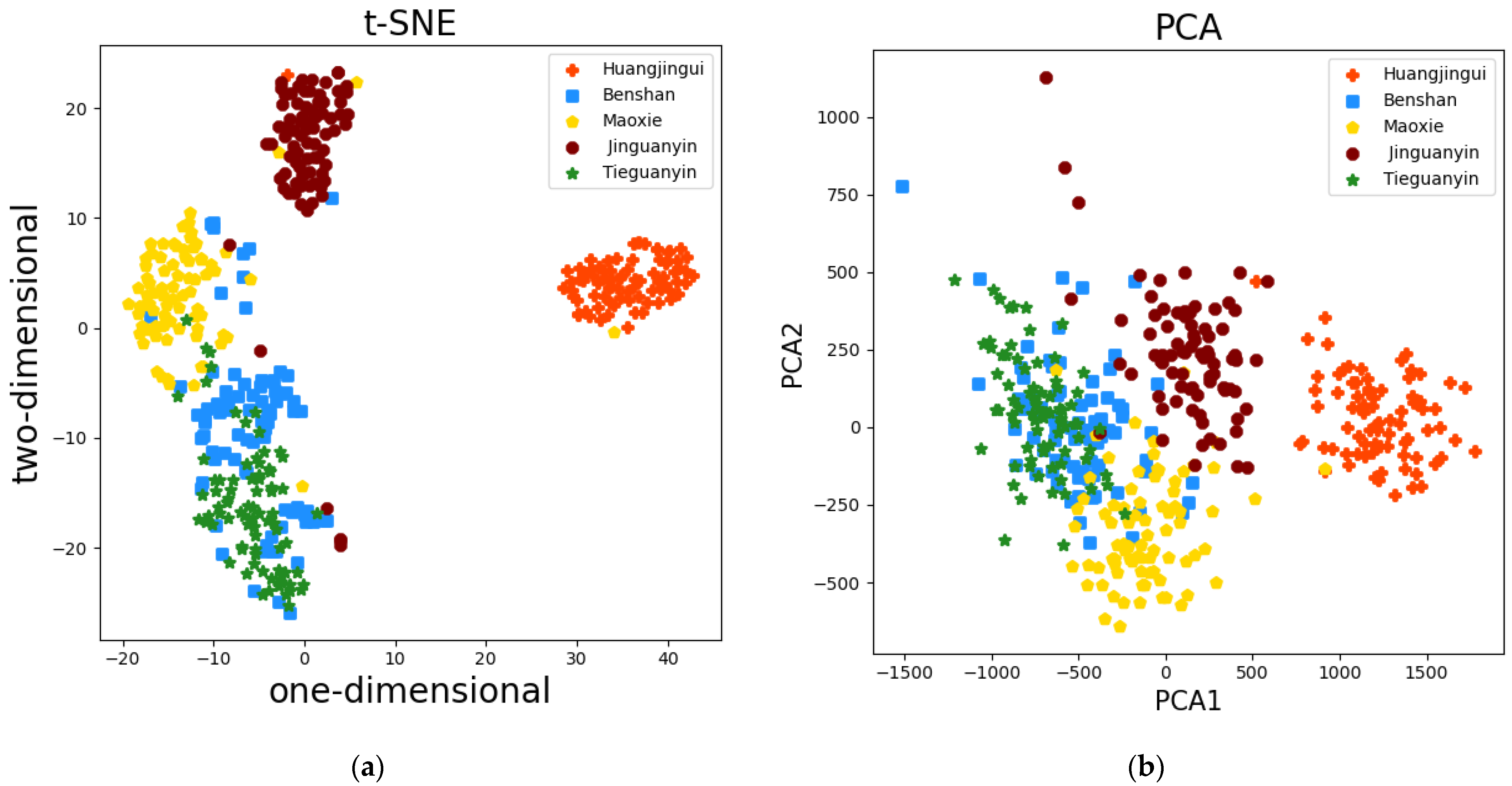
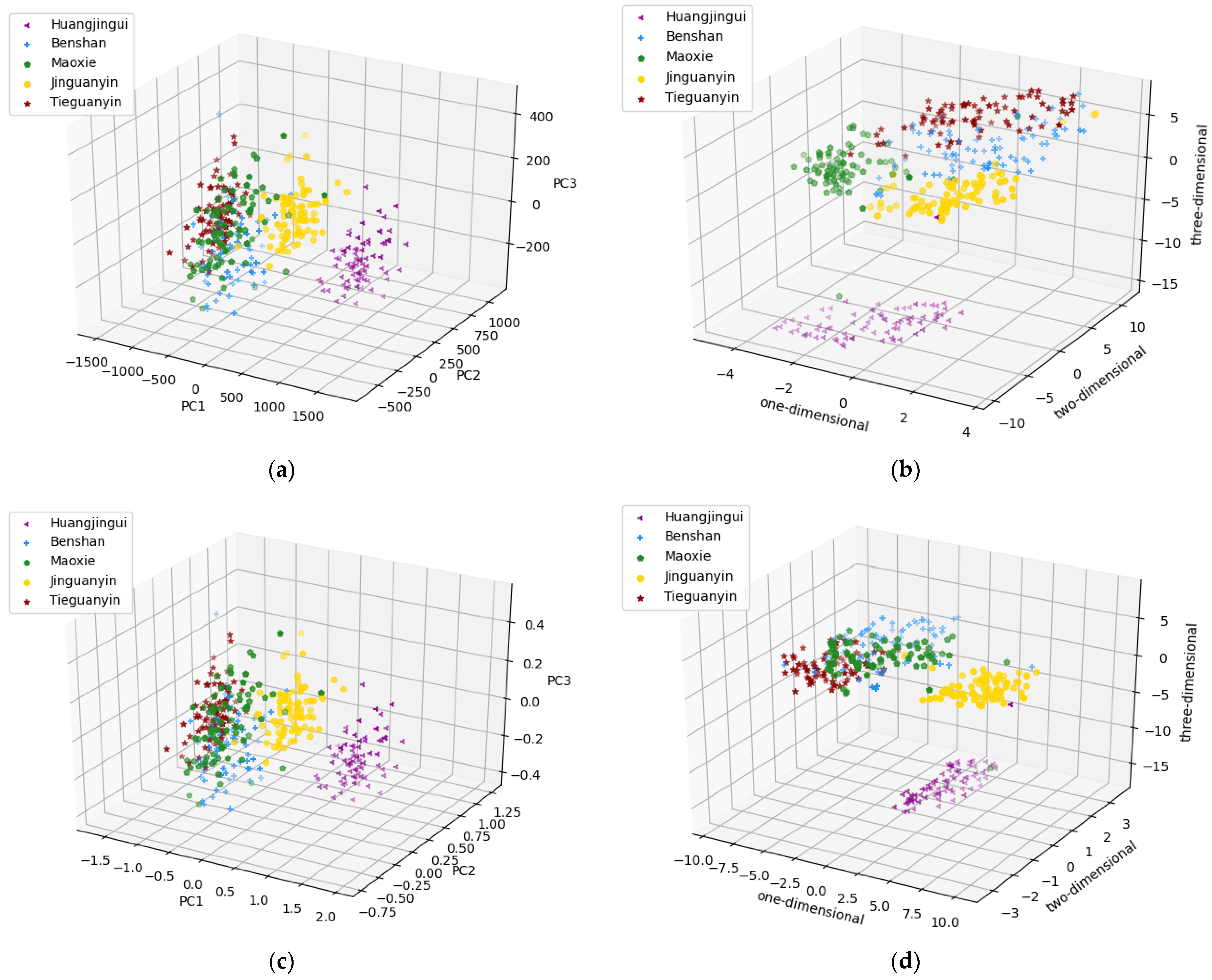
3.2.1. PCA and t-SNE Dimensionality Reduction Algorithm
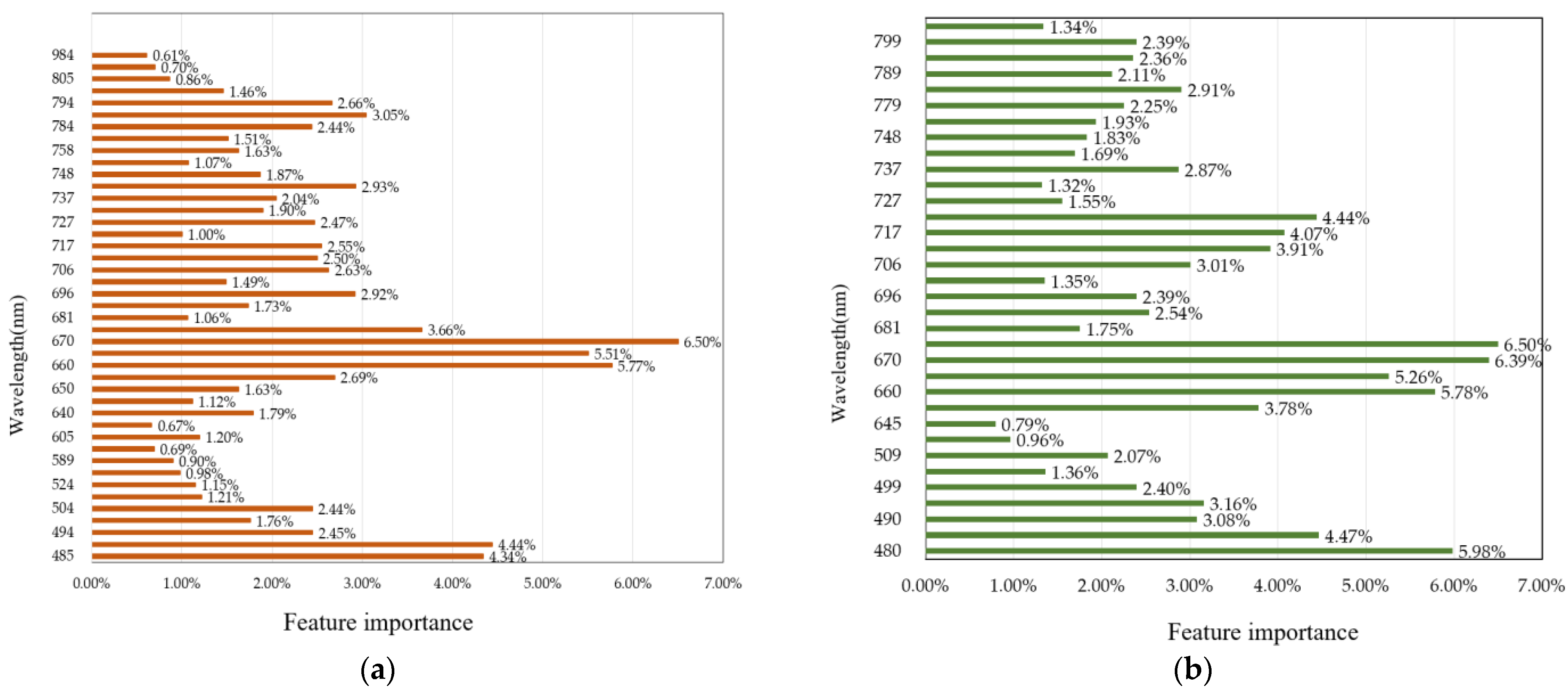
3.2.2. RF-RFE Feature Selection Method
3.3. Original Band Classification Results
3.4. Modeling Analysis after Preprocessing and Feature Processing
4. Conclusions
- SNV and MSC can reduce the impact of spectral baseline drift and tilt, and improve the accuracy of the model.
- Feature dimensionality reduction and feature selection can reduce the degree of data redundancy and improve the predictive accuracy and robustness of the model. In the comparison of two feature dimensionality reduction methods and one feature selection method, PCA < t-SNE < RF-RFE.
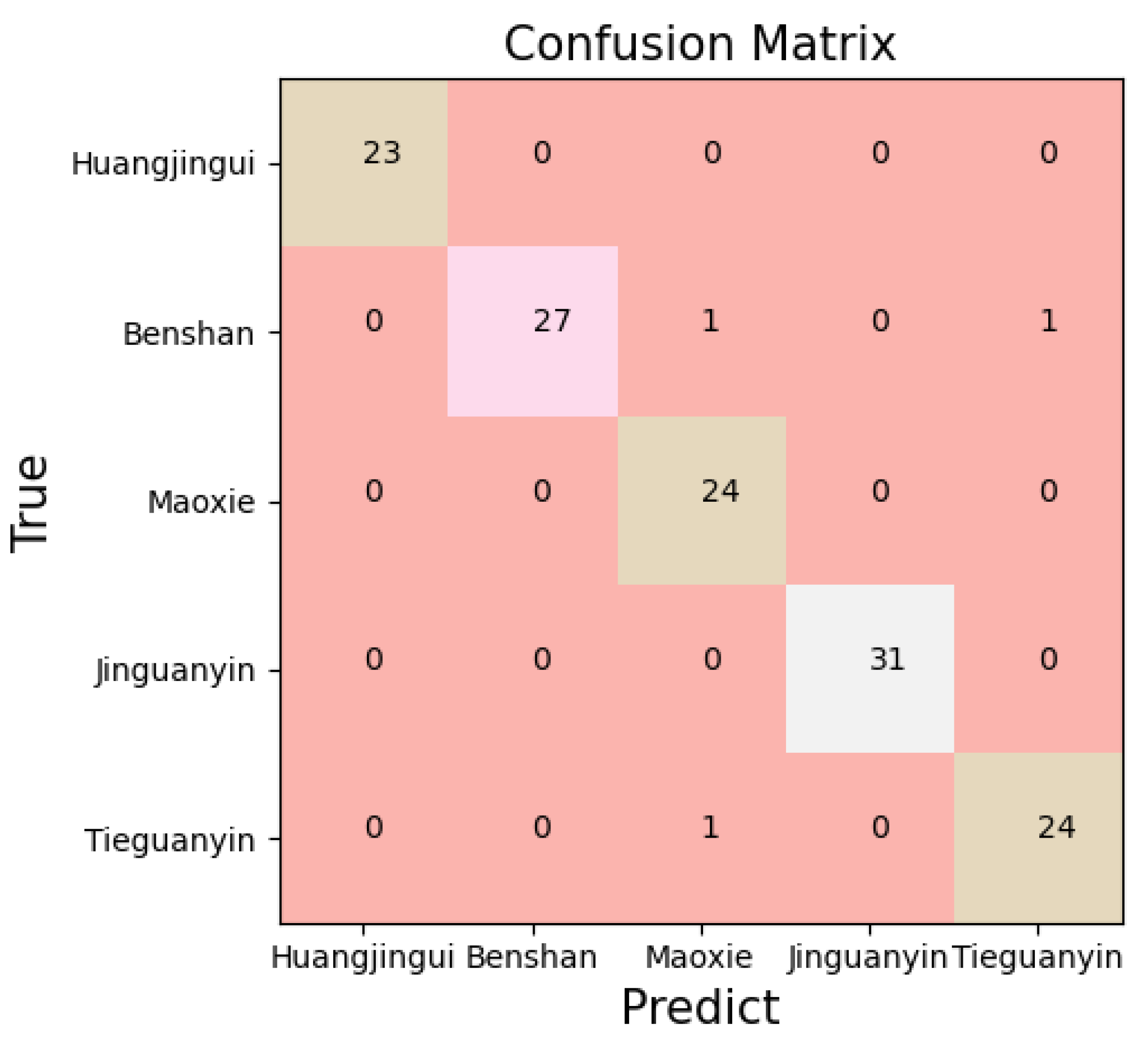
- Among the four classification models, the effect of SVM is the best. SVM combined with preprocessing and feature processing offers the best performance. MSC-RF-RFE-SVM is the best method. The accuracy of the training set and test set reaches 100% and 98.73%, respectively. The accuracy is greater than other spectroscopy and chemical methods.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| Tie | Tieguanyin |
| Jin | Jinguanyin |
| Mao | Maoxie |
| Ben | Benshan |
| Huang | Huangjingui |
| MSC | Multivariate Scattering Correction |
| SNV | Standard Normal Variate |
| FD | First Derivative |
| SD | Second Derivative |
| WT | Wavelet Transform |
| PCA | Principal Component Analysis |
| t-SNE | t-distributed stochastic neighbor embedding |
| RF-RFE | Random Forest Recursive Feature Elimination Method |
| DT | Decision Tree |
| RFC | Random Forest Classification |
| KNN | K-Nearest Neighbor |
| SVM | Support Vector Machine |
References
- Luo, X.; Xu, L.; Huang, P.; Wang, Y.; Liu, J.; Hu, Y.; Wang, P.; Kang, Z. Nondestructive Testing Model of Tea Polyphenols Based on Hyperspectral Technology Combined with Chemometric Methods. Agriculture 2021, 11, 673. [Google Scholar] [CrossRef]
- Ahmad, H.; Sun, J.; Nirere, A.; Shaheen, N.; Zhou, X.; Yao, K. Classification of tea varieties based on fluorescence hyperspectral image technology and ABC-SVM algorithm. J. Food Process. Preserv. 2021, 45, e15241. [Google Scholar] [CrossRef]
- Ning, J.M.; Sun, J.J.; Li, S.H.; Sheng, M.G.; Zhang, Z.Z. Classification of five Chinese tea categories with different fermentation degrees using visible and near-infrared hyperspectral imaging. Int. J. Food Prop. 2017, 20, 1515–1522. [Google Scholar] [CrossRef] [Green Version]
- Chen, G.; Zhang, X.; Wu, Z.; Su, J.; Cai, G. An efficient tea quality classification algorithm based on near infrared spectroscopy and random Forest. J. Food Process Eng. 2020, 44, e13604. [Google Scholar] [CrossRef]
- Ren, G.; Liu, Y.; Ning, J.; Zhang, Z. Assessing black tea quality based on visible–near infrared spectra and kernel-based methods. J. Food Compos. Anal. 2021, 98, 103810. [Google Scholar] [CrossRef]
- Li, M.; Pan, T.; Chen, Q. Estimation of tea quality grade using statistical identification of key variables. Food Control 2021, 119, 107485. [Google Scholar] [CrossRef]
- Yu, X.-L.; He, Y. Fast nondestructive identification of steamed green tea powder adulterations in matcha by visible spectroscopy combined with chemometrics. Spectrosc. Lett. 2018, 51, 112–117. [Google Scholar] [CrossRef]
- Wang, Y.; Li, M.; Li, L.; Ning, J.; Zhang, Z. Green analytical assay for the quality assessment of tea by using pocket-sized NIR spectrometer. Food Chem. 2021, 345, 128816. [Google Scholar] [CrossRef]
- Yang, J.; Wang, J.; Lu, G.; Fei, S.; Yan, T.; Zhang, C.; Lu, X.; Yu, Z.; Li, W.; Tang, X. TeaNet: Deep learning on Near-Infrared Spectroscopy (NIR) data for the assurance of tea quality. Comput. Electron. Agric. 2021, 190, 106431. [Google Scholar] [CrossRef]
- Wang, P.; Liu, J.; Xu, L.; Huang, P.; Luo, X.; Hu, Y.; Kang, Z. Classification of Amanita Species Based on Bilinear Networks with Attention Mechanism. Agriculture 2021, 11, 393. [Google Scholar] [CrossRef]
- Dong, C.; Ye, Y.; Yang, C.; An, T.; Jiang, Y.; Ye, Y.; Li, Y.; Yang, Y. Rapid detection of catechins during black tea fermentation based on electrical properties and chemometrics. Food Biosci. 2021, 40, 100855. [Google Scholar] [CrossRef]
- Wang, Y.; Li, L.; Liu, Y.; Cui, Q.; Ning, J.; Zhang, Z. Enhanced quality monitoring during black tea processing by the fusion of NIRS and computer vision. J. Food Eng. 2021, 304, 110599. [Google Scholar] [CrossRef]
- Yuan, L.M.; Mao, F.; Huang, G.; Chen, X.; Wu, D.; Li, S.; Zhou, X.; Jiang, Q.; Lin, D.; He, R. Models fused with successive CARS-PLS for measurement of the soluble solids content of Chinese bayberry by vis-NIRS technology. Postharvest Biol. Technol. 2020, 169, 111308. [Google Scholar] [CrossRef]
- Li, X.; Li, Z.; Yang, X.; He, Y. Boosting the generalization ability of Vis-NIR-spectroscopy-based regression models through dimension reduction and transfer learning. Comput. Electron. Agric. 2021, 186, 106157. [Google Scholar] [CrossRef]
- Li, L.; Huang, J.; Wang, Y.; Jin, S.; Li, M.; Sun, Y.; Ning, J.; Chen, Q.; Zhang, Z. Intelligent evaluation of storage period of green tea based on VNIR hyperspectral imaging combined with chemometric analysis. Infrared Phys. Technol. 2020, 110, 103450. [Google Scholar] [CrossRef]
- Cardoso, V.G.K.; Poppi, R.J. Non-invasive identification of commercial green tea blends using NIR spectroscopy and support vector machine. Microchem. J. 2021, 164, 106052. [Google Scholar] [CrossRef]
- Zhao, J.W.; Chen, Q.S.; Cai, J.R.; Ouyang, Q. Automated tea quality classification by hyperspectral imaging. Appl. Opt. 2009, 48, 3557–3564. [Google Scholar] [CrossRef] [PubMed]
- Zhang, X.; Sun, J.; Li, P.; Zeng, F.; Wang, H. Hyperspectral detection of salted sea cucumber adulteration using different spectral preprocessing techniques and SVM method. LWT 2021, 152, 112295. [Google Scholar] [CrossRef]
- Hong, Z.; Zhang, C.; Kong, D.; Qi, Z.; He, Y. Identification of storage years of black tea using near-infrared hyperspectral imaging with deep learning methods. Infrared Phys. Technol. 2021, 114, 103666. [Google Scholar] [CrossRef]
- Sun, J.; Zhang, Y.; Mao, H.; Cong, S.; Wu, X.; Wang, P. Research of moldy tea identification based on RF-RFE-Softmax model and hyperspectra. Opt.-Int. J. Light Electron. Opt. 2018, 153, 156–163. [Google Scholar] [CrossRef]
- Wang, H.; Wan, X. Effect of chlorophyll fluorescence quenching on quantitative analysis of adulteration in extra virgin olive oil. Spectrochim. Acta A Mol. Biomol. Spectrosc. 2021, 248, 119183. [Google Scholar] [CrossRef]
- Liu, Y.; Zou, J.; Luo, B.; Yu, H.; Zhao, Z.; Xia, H. Ivy extract-assisted photochemical vapor generation for sensitive determination of mercury by atomic fluorescence spectrometry. Microchem. J. 2021, 169, 106547. [Google Scholar] [CrossRef]
- Guo, X.J.; He, X.S.; Li, C.W.; Li, N.X. The binding properties of copper and lead onto compost-derived DOM using Fourier-transform infrared, UV-vis and fluorescence spectra combined with two-dimensional correlation analysis. J. Hazard. Mater. 2019, 365, 457–466. [Google Scholar] [CrossRef]
- Li, G.; Liao, Y.; Wang, X.; Sheng, S.; Yin, D. In situ estimation of the entire color and spectra of age pigment-like materials: Application of a front-surface 3D-fluorescence technique. Exp. Gerontol. 2006, 41, 328–336. [Google Scholar] [CrossRef]
- Hu, Y.; Zhang, H.; Zhao, D. Transform method in three-dimensional fluorescence spectra for direct reflection of internal molecular properties in rapid water contaminant analysis. Spectrochim. Acta A Mol. Biomol. Spectrosc. 2021, 250, 119376. [Google Scholar] [CrossRef]
- Sunuwar, S.; Manzanares, C.E. Excitation, emission, and synchronous fluorescence for astrochemical applications: Experiments and computer simulations of synchronous spectra of polycyclic aromatic hydrocarbons and their mixtures. Icarus 2021, 370, 114689. [Google Scholar] [CrossRef]
- Zhou, X.; Sun, J.; Tian, Y.; Yao, K.; Xu, M. Detection of heavy metal lead in lettuce leaves based on fluorescence hyperspectral technology combined with deep learning algorithm. Spectrochim. Acta A Mol. Biomol. Spectrosc. 2021, 266, 120460. [Google Scholar] [CrossRef] [PubMed]
- Yu, Y.; Qu, Y.; Zhang, M.; Guo, X.; Zhang, H. Fluorescence detection of paclobutrazol pesticide residues in apple juice. Optik 2020, 224, 165542. [Google Scholar] [CrossRef]
- Lim, C.M.; Carey, M.; Williams, P.N.; Koidis, A. Rapid classification of commercial teas according to their origin and type using elemental content with X-ray fluorescence (XRF) spectroscopy. Curr. Res. Food Sci. 2021, 4, 45–52. [Google Scholar] [CrossRef]
- Wang, Y.-J.; Jin, G.; Li, L.-Q.; Liu, Y.; Kalkhajeh, Y.K.; Ning, J.-M.; Zhang, Z.-Z. NIR hyperspectral imaging coupled with chemometrics for nondestructive assessment of phosphorus and potassium contents in tea leaves. Infrared Phys. Technol. 2020, 108, 103365. [Google Scholar] [CrossRef]
- Wei, X.; He, J.; Zheng, S.; Ye, D. Modeling for SSC and firmness detection of persimmon based on NIR hyperspectral imaging by sample partitioning and variables selection. Infrared Phys. Technol. 2020, 105, 103099. [Google Scholar] [CrossRef]
- Zhao, Y.; Zhang, C.; Zhu, S.; Li, Y.; He, Y.; Liu, F. Shape induced reflectance correction for non-destructive determination and visualization of soluble solids content in winter jujubes using hyperspectral imaging in two different spectral ranges. Postharvest Biol. Technol. 2020, 161, 111080. [Google Scholar] [CrossRef]
- Zhu, X.; Li, W.; Wu, R.; Liu, P.; Hu, X.; Xu, L.; Xiong, Z.; Wen, Y.; Ai, S. Rapid detection of chlorpyrifos pesticide residue in tea using surface-enhanced Raman spectroscopy combined with chemometrics. Spectrochim. Acta A Mol. Biomol. Spectrosc. 2021, 250, 119366. [Google Scholar] [CrossRef] [PubMed]
- Song, Y.; Wang, X.; Xie, H.; Li, L.; Ning, J.; Zhang, Z. Quality evaluation of Keemun black tea by fusing data obtained from near-infrared reflectance spectroscopy and computer vision sensors. Spectrochim. Acta A Mol. Biomol. Spectrosc. 2021, 252, 119522. [Google Scholar] [CrossRef]
- Zhang, D.; Zhao, Z.; Zhang, S.; Chen, F.; Sheng, Z.; Deng, F.; Zeng, Q.; Guo, L. Accurate identification of soluble solid content in citrus by indirect laser-induced breakdown spectroscopy with its leaves. Microchem. J. 2021, 169, 106530. [Google Scholar] [CrossRef]
- Xia, Y.; Fan, S.; Tian, X.; Huang, W.; Li, J. Multi-factor fusion models for soluble solid content detection in pear (Pyrus bretschneideri ‘Ya’) using Vis/NIR online half-transmittance technique. Infrared Phys. Technol. 2020, 110, 103443. [Google Scholar] [CrossRef]
- Jamwal, R.; Amit; Kumari, S.; Sharma, S.; Kelly, S.; Cannavan, A.; Singh, D.K. Recent trends in the use of FTIR spectroscopy integrated with chemometrics for the detection of edible oil adulteration. Vib. Spectrosc. 2021, 113, 103222. [Google Scholar] [CrossRef]
- Huang, Y.; Dong, W.; Sanaeifar, A.; Wang, X.; Luo, W.; Zhan, B.; Liu, X.; Li, R.; Zhang, H.; Li, X. Development of simple identification models for four main catechins and caffeine in fresh green tea leaf based on visible and near-infrared spectroscopy. Comput. Electron. Agric. 2020, 173, 105388. [Google Scholar] [CrossRef]
- Bunaciu, A.A.; Aboul-Enein, H.Y. Adulterated drug analysis using FTIR spectroscopy. Appl. Spectrosc. Rev. 2020, 56, 423–437. [Google Scholar] [CrossRef]
- Wang, S.; Liu, S.; Yuan, Y.; Zhang, J.; Wang, Z.; Che, X. A novel CC-tSNE-SVR model for rapid determination of diesel fuel quality by near infrared spectroscopy. Infrared Phys. Technol. 2020, 106, 103276. [Google Scholar] [CrossRef]
- Ndlovu, P.F.; Magwaza, L.S.; Tesfay, S.Z.; Mphahlele, R.R. Rapid spectroscopic method for quantifying gluten concentration as a potential biomarker to test adulteration of green banana flour. Spectrochim. Acta A Mol. Biomol. Spectrosc. 2021, 262, 120081. [Google Scholar] [CrossRef] [PubMed]
- Xie, C.; Lee, W.S. Detection of citrus black spot symptoms using spectral reflectance. Postharvest Biol. Technol. 2021, 180, 111627. [Google Scholar] [CrossRef]
- Yao, M.; Fu, G.; Chen, T.; Liu, M.; Xu, J.; Zhou, H.; He, X.; Huang, L. A modified genetic algorithm optimized SVM for rapid classification of tea leaves using laser-induced breakdown spectroscopy. J. Anal. At. Spectrom. 2021, 36, 361–367. [Google Scholar] [CrossRef]
- Wei, X.; He, J.-C.; Ye, D.-P.; Jie, D.-F. Navel Orange Maturity Classification by Multispectral Indexes Based on Hyperspectral Diffuse Transmittance Imaging. J. Food Qual. 2017, 2017, 1023498. [Google Scholar] [CrossRef] [Green Version]
- Firmani, P.; De Luca, S.; Bucci, R.; Marini, F.; Biancolillo, A. Near infrared (NIR) spectroscopy-based classification for the authentication of Darjeeling black tea. Food Control 2019, 100, 292–299. [Google Scholar] [CrossRef]
- Huang, Y.; Dong, W.; Chen, Y.; Wang, X.; Luo, W.; Zhan, B.; Liu, X.; Zhang, H. Online detection of soluble solids content and maturity of tomatoes using Vis/NIR full transmittance spectra. Chemom. Intell. Lab. Syst. 2021, 210, 104243. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | Models of Classification | |||
|---|---|---|---|---|
| DT | RFC | KNN (5) | SVM | |
| RAW | 81.82% | 78.03% | 81.82% | 93.18% |
| MSC | 82.58% | 88.64% | 90.15% | 95.45% |
| SNV | 81.82% | 87.88% | 90.15% | 96.21% |
| FD | 84.85% | 85.61% | 87.12% | 92.48% |
| SD | 76.52% | 79.55% | 86.36% | 91.48% |
| WT | 81.82% | 75.76% | 81.82% | 91.67% |
| Methods | Number | Selected Wavelengths (nm) | |
|---|---|---|---|
| RF-RFE | MSC | 44 | 479, 484, 489, 494, 499, 504, 509, 524, 574, 589, 594, 604, 624, 639, 645, 650, 655, 660, 665, 670, 675, 680, 690, 696, 701, 706, 711, 716, 721, 726, 732, 737, 742, 747, 752, 757, 778, 783, 788, 794, 799, 804, 809, 984 |
| SNV | 34 | 479, 484, 489, 494, 499, 504, 509, 609, 645, 655, 660, 665, 670, 675, 680, 690, 696, 701, 706, 711, 716, 721, 726, 732, 737, 742, 747, 752, 778, 783, 788, 794, 799, 804 |
| Model | Method | Train-Accuracy | Test-Accuracy | Time (s) |
|---|---|---|---|---|
| DT | RAW | 87.68% | 83.21% | 0.0120 |
| RFC | RAW | 89.00% | 83.33% | 0.0898 |
| KNN-7 | RAW | 89.92% | 81.06% | 0.0140 |
| SVM | RAW | 96.26% | 92.42% | 0.0050 |
| Models | Methods | Train-Accuracy | Test-Accuracy | Time (s) |
|---|---|---|---|---|
| DT | MSC | 88.06% | 82.58% | 0.0030 |
| SNV | 91.79% | 84.09% | 0.0020 | |
| MSC-RF-RFE (44) | 91.04% | 89.39% | 0.0020 | |
| SNV-RF-RFE (34) | 91.79% | 87.88% | 0.0020 | |
| RFC | MSC-PCA | 91.79% | 85.61% | 0.0379 |
| SNV-PCA | 92.16% | 86.36% | 0.0339 | |
| MSC-TSNE | 93.28% | 86.36% | 0.1606 | |
| SNV-TSNE | 93.66% | 92.39% | 0.1366 | |
| MSC-RF-RFE (44) | 93.28% | 92.42% | 0.0688 | |
| SNV-RF-RFE (34) | 91.04% | 87.12% | 0.0738 | |
| KNN (9) | MSC-PCA | 85.45% | 84.85% | 0.0160 |
| SNV-PCA | 85.45% | 84.85% | 0.0140 | |
| MSC-TSNE | 89.93% | 87.12% | 0.0160 | |
| SNV-TSNE | 88.06% | 87.12% | 0.0160 | |
| MSC-RF-RFE (44) | 94.03% | 92.42% | 0.0205 | |
| SNV-RF-RFE (34) | 94.40% | 93.94% | 0.0160 | |
| SVM (poly) | MSC-PCA | 97.01% | 98.48% | 0.0050 |
| SNV-PCA | 97.76% | 98.48% | 0.0060 | |
| MSC-TSNE | 97.31% | 96.36% | 0.0110 | |
| SNV-TSNE | 98.81% | 95.09% | 0.0110 | |
| MSC-RF-RFE (44) | 100.00% | 98.73% | 0.0040 | |
| SNV-RF-RFE (34) | 100.00% | 98.21% | 0.0030 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hu, Y.; Xu, L.; Huang, P.; Luo, X.; Wang, P.; Kang, Z. Reliable Identification of Oolong Tea Species: Nondestructive Testing Classification Based on Fluorescence Hyperspectral Technology and Machine Learning. Agriculture 2021, 11, 1106. https://0-doi-org.brum.beds.ac.uk/10.3390/agriculture11111106
Hu Y, Xu L, Huang P, Luo X, Wang P, Kang Z. Reliable Identification of Oolong Tea Species: Nondestructive Testing Classification Based on Fluorescence Hyperspectral Technology and Machine Learning. Agriculture. 2021; 11(11):1106. https://0-doi-org.brum.beds.ac.uk/10.3390/agriculture11111106
Chicago/Turabian StyleHu, Yan, Lijia Xu, Peng Huang, Xiong Luo, Peng Wang, and Zhiliang Kang. 2021. "Reliable Identification of Oolong Tea Species: Nondestructive Testing Classification Based on Fluorescence Hyperspectral Technology and Machine Learning" Agriculture 11, no. 11: 1106. https://0-doi-org.brum.beds.ac.uk/10.3390/agriculture11111106