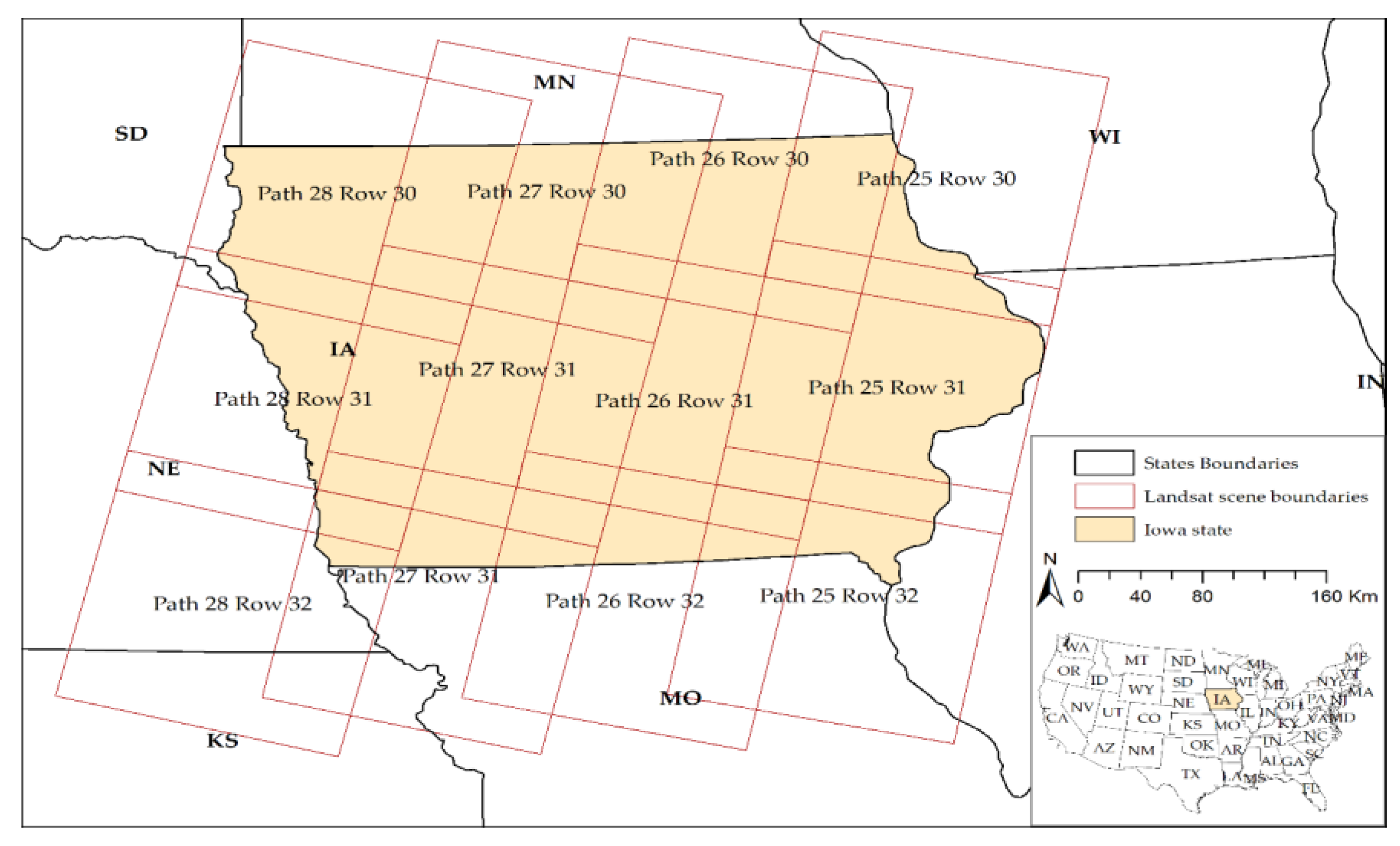
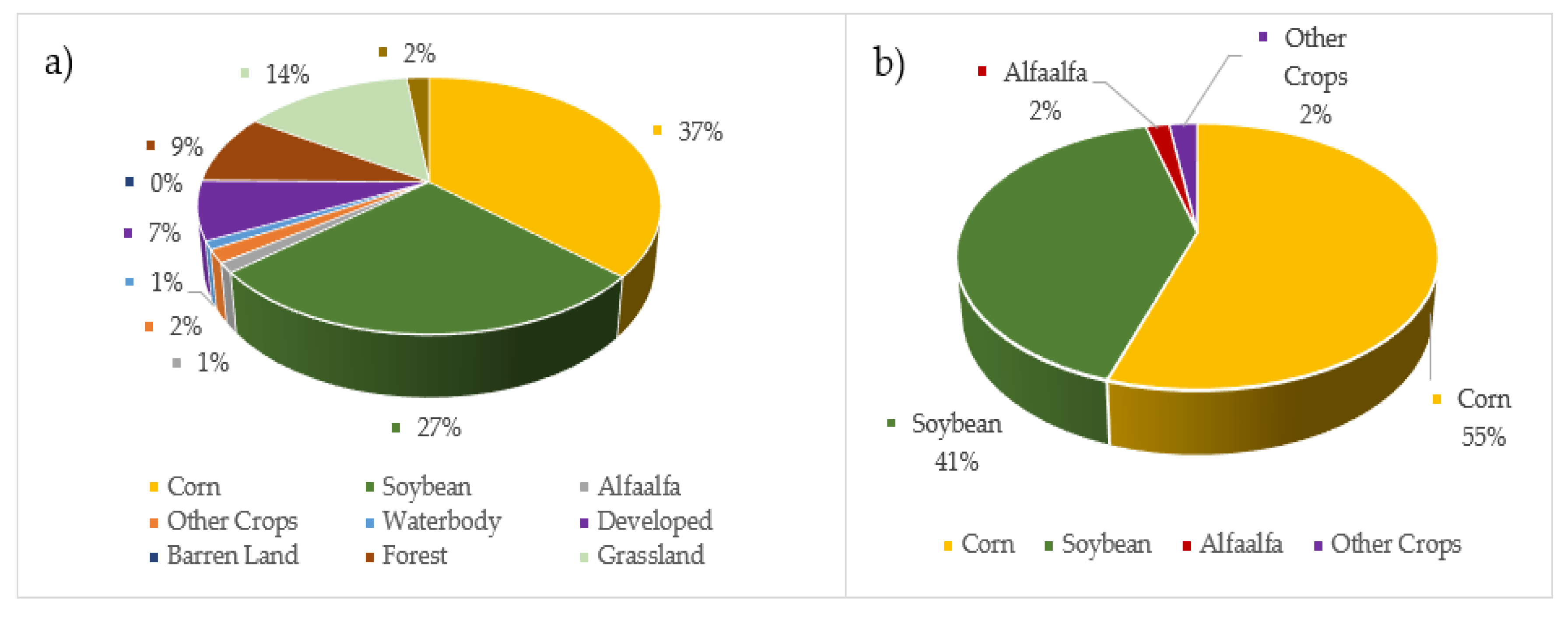
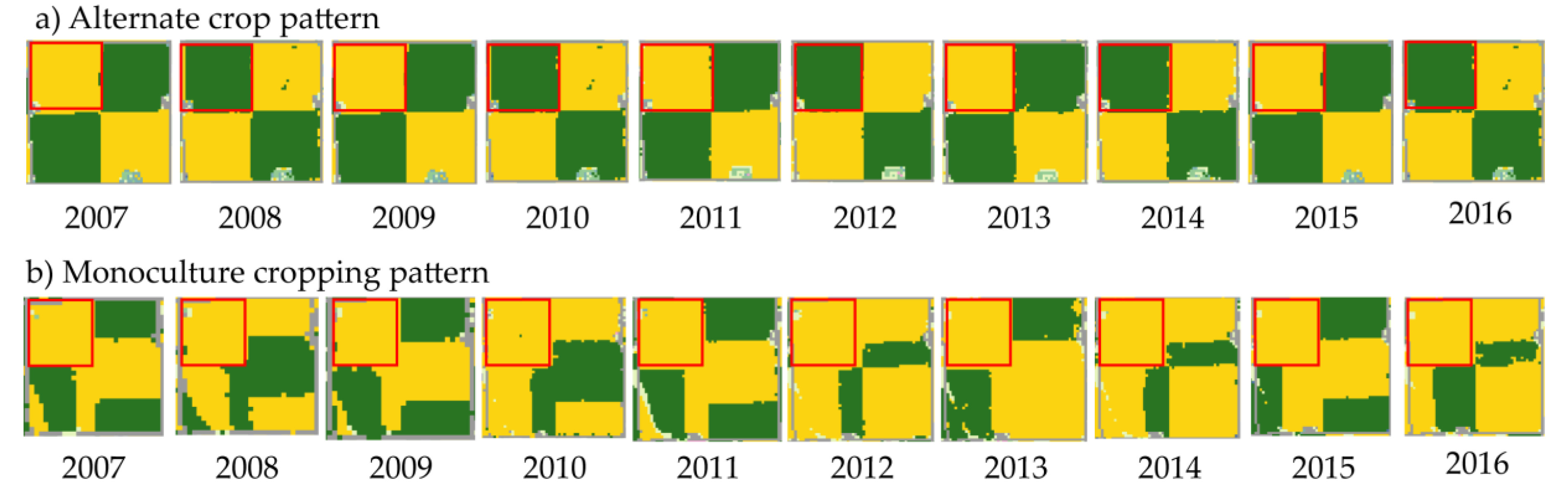
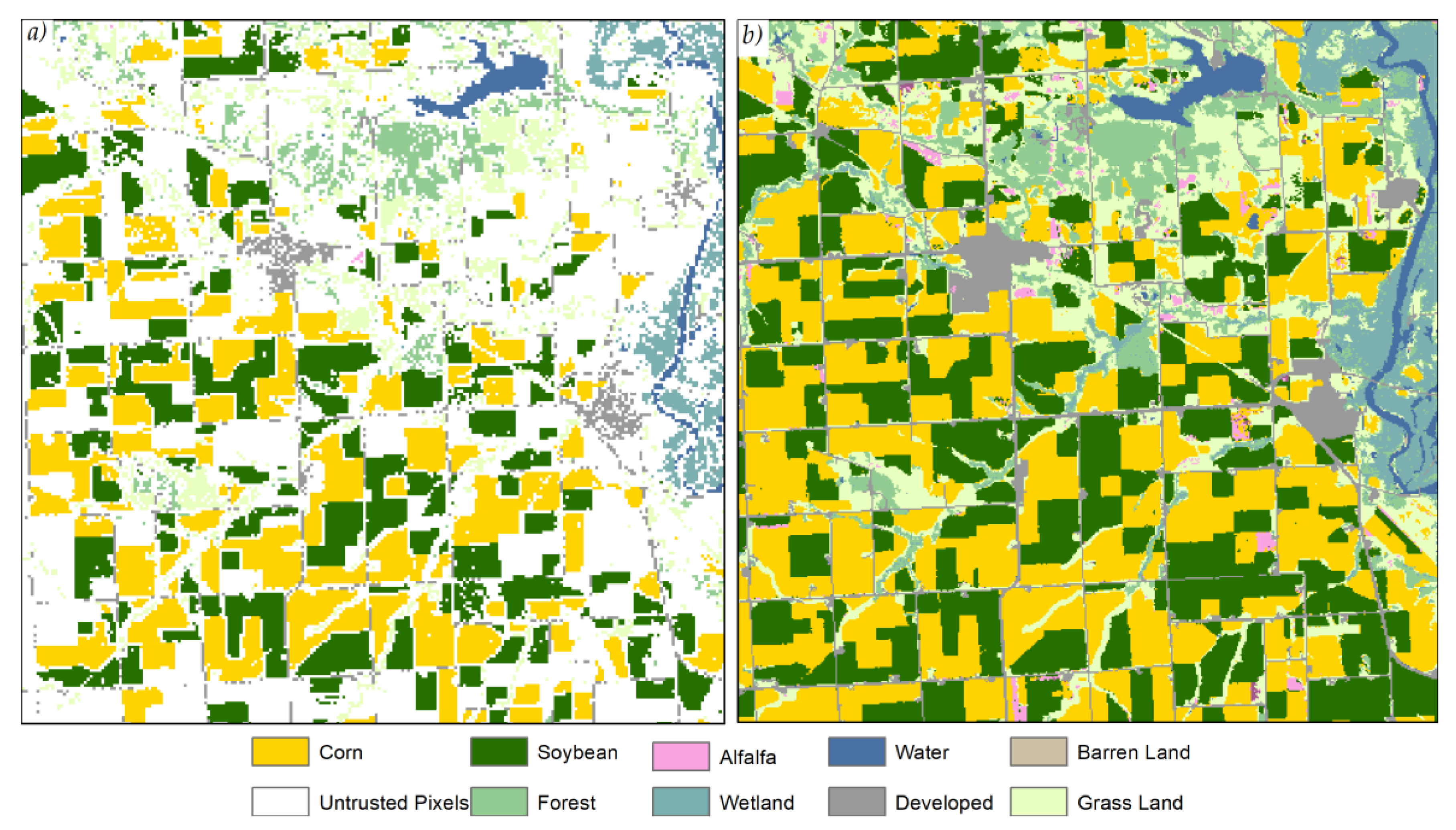
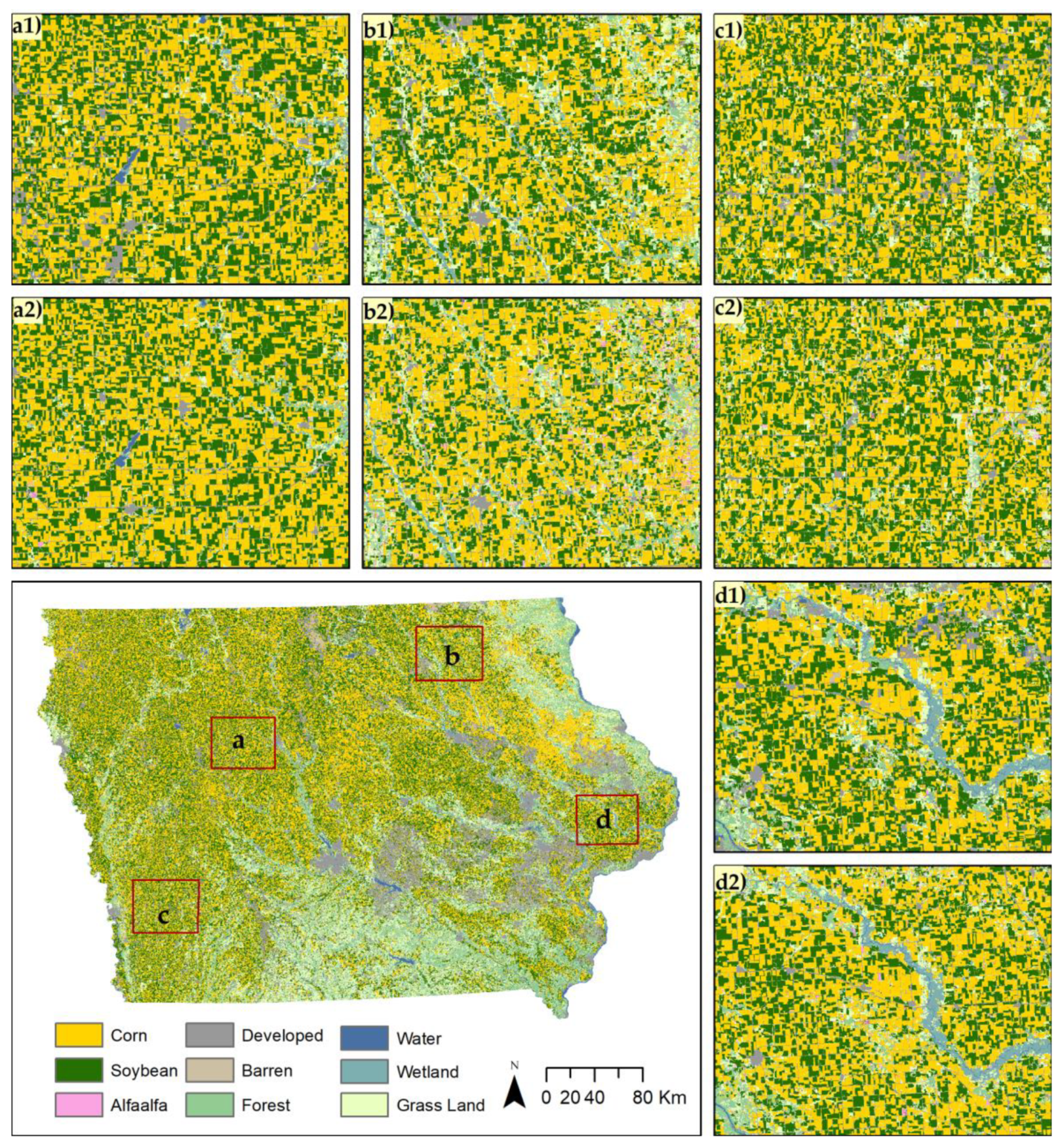
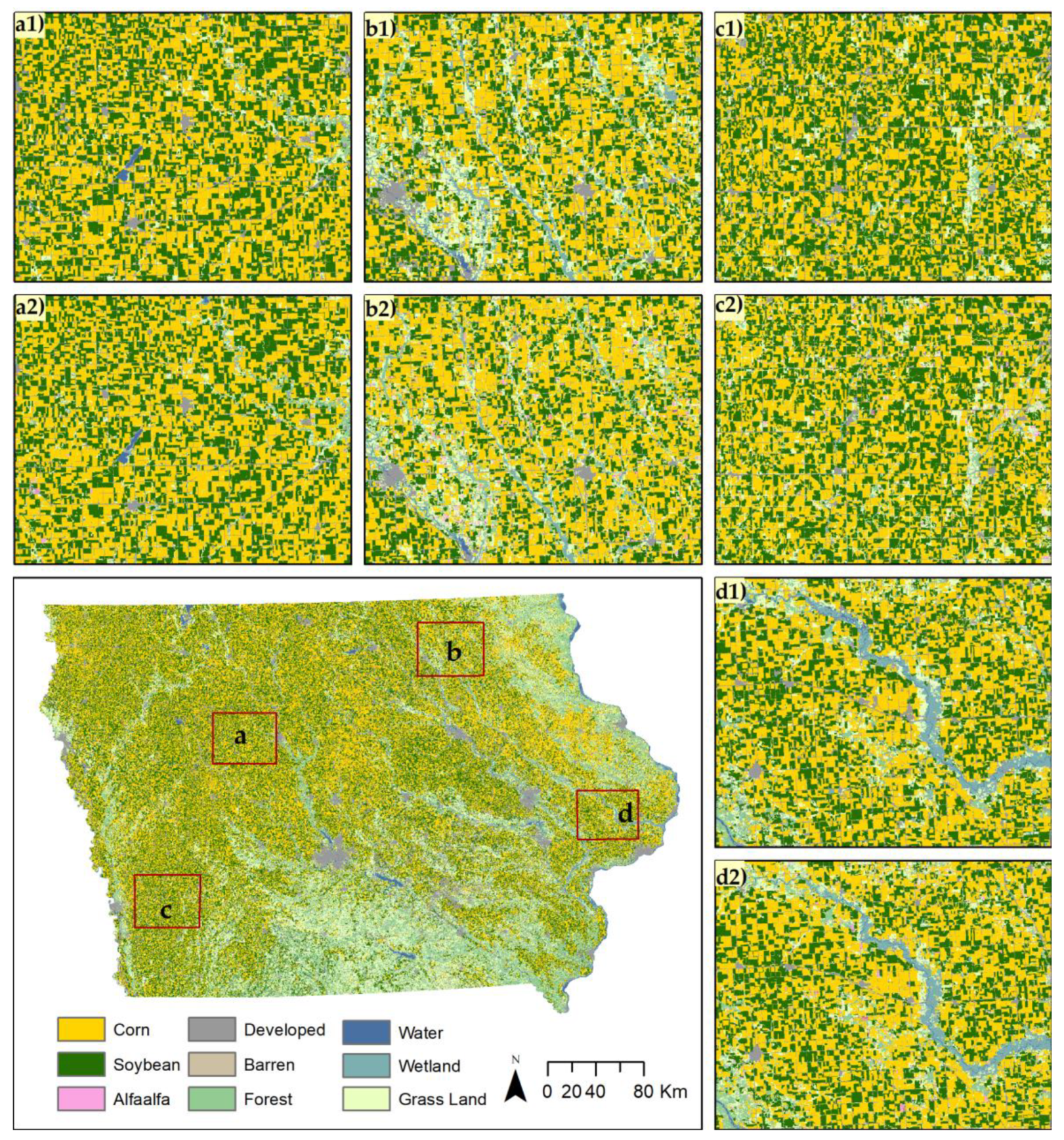
1. Introduction
Crop-specific acreage information, such as crop types with their location, is useful for crop statistics, yield estimation, change in cropland use, cropland environmental dynamics, crop loss assessment, crop pricing, decision support, and policy formulation [
1]. Generating yearly or seasonal information for each crop field at the regional scale is not a trivial task in any part of the world. Field survey-based information collection has been replaced using satellite images. Information can be extracted from satellite images multiple times within or outside of the growing season. Therefore, satellite images are useful for crop condition monitoring, growth stage monitoring, and loss assessment. Moreover, the use of satellite images in crop type identification is time and cost effective over vast areas. Worldwide, the National Agricultural Statistics Service (NASS) of the US Department of Agriculture (USDA) probably made the first attempt to produce unique crop-specific land cover products and dissemination methods annually at a national scale [
1,
2]. This crop-specific land cover product for the United States (US) is called the Cropland Data Layer (CDL), which has been produced since 1997 for more than 100 unique crop categories across the US; it is delivered annually with 85% to 95% accuracy at a 30–56 m spatial resolution [
1]. The usefulness of CDL data has already been proven in practice; for instance, mapping crop types using CDL time series data [
3], identifying agricultural production areas [
4,
5], examining the relationship between agricultural chemical exposure and disease [
6], crop specific inundation mapping [
7], yield estimation [
8,
9], crop growth monitoring [
10], pure crop pixel identification [
11], land use transformation [
12,
13,
14], agricultural rotational patterns [
15,
16], chemical/environmental studies for cropland [
17,
18], crop carbon dynamics [
19,
20], and cyberinfrastructure for agroecosystem modeling [
21]. Therefore, an accurate and timely cropland data layer can facilitate many applications and research in the agriculture sector.
Satellite remote sensing is useful for mapping both crop types and crop rotation patterns. The synoptic and repeated collection of data for vast areas is the main advantage of the application of satellite remote sensing in crop mapping [
22,
23,
24,
25]. Optical data are one of the most attractive choices for crop mapping among satellite remote sensing options because they offer vegetation indices, frequent revisit, adequate spatiotemporal resolutions, and options for free of charge data distribution [
26]. Waldhoff et al. [
24] mapped the crop rotation pattern at a catchment scale in Germany for eight consecutive years (2008–2015). At first, they identified crop types through supervised classification of images from multiple sensors (e.g., Landsat, ASTER, SPOT) for each year. They extracted crop rotation patterns at the field level for eight consecutive years from crop maps. Martínez-Casasnovas et al. [
22] mapped multi-year cropping patterns between 1993 and 2000 using Landsat images in Spain. Although their approach is not suitable to extract specific sequence of cropping patterns at the field level over the years, spatial distribution of cropping patterns in study area can be visualized. The combination of remote sensing-derived landcover and census data has also been utilized to map the cropping pattern at a half-degree grid in China [
23]. Panigrahy and Sharma utilized a similar approach of Waldhoff et al. [
24] to map three years of crop rotation patterns in west Bengal of India using the Indian Remote Sensing Satellite (IRS) LISS-I [
27]. Conrad et al. [
28] mapped crop types and crop rotation using classification and regression trees (CARTs) in central Asia. They utilized MODIS optical bands and derived products such as NDVI. Sonobe et al. [
26] mapped crop cover with very high accuracy using multi-temporal Landsat 8 images and derived products in Hokkaido, Japan. Landsat images have been one of the most attractive options due to its high spatial and temporal resolution, which is very suitable for crop mapping [
25,
26,
29,
30]. Many derived vegetation indices such as NDVI, EVI, LAI, and SAVI have been utilized along with original Landsat bands to ensure better accuracy in crop classification [
25,
29,
30,
31]. A wide range of classification algorithms such as support vector machine (SVM), random forest (RF), maximum likelihood, spectral angle mapper (SAM) has been utilized for crop mapping [
25,
26,
28,
30]. Most of the crop mapping approaches around the world utilize ground truth collected from the field to train the classification models.
Similar to the approaches for crop mapping using satellite remote sensing images, the CDL program in the US also uses moderate spatial resolution satellite images, NASS June Agriculture Survey data and other ancillary data such as National Landcover Data [
2]. NASS mainly uses in-season Landsat images to identify major crop types across the US through supervised image classification. Supervised learning requires a training dataset to train image classification models. Thus, the NASS CDL program used ground truth data collected during the June Agricultural Survey (JAS) to train the model for supervised image classification from 1997–2005 [
2]. The JAS is a field-based annual survey program of NASS which collects data for 11,000 individual one square-mile sample segments using an area sampling frame. Information on crop types and acreage of all agricultural activities occurring on the primary sampling units (PSU) is collected during field visits [
2,
32]. In this survey program, approximately 85,000 agricultural and non-agricultural land use tracts are identified within the sampled segments in a given year [
33]. The manual digitization requirement of the sampled field boundary is one of the major drawbacks of JAS segment data [
2]. Thus, this field-based ground sample collection for training data is time consuming, costly and tedious. Therefore, the Common Land Unit (CLU) data from the Farm Service Agency (FSA) replaced the JAS segment data in 2017 [
2]. The CLU data are a standardized GIS data layer generated from farmers’ reports on crop types and acreage sent to 2300 FSA county offices [
34,
35]. Since this new approach depends on farmers’ reports and construction of GIS layer from reported crop types, it may be time and cost intensive. Therefore, the current study proposed a new solution for the training dataset construction based on crop rotation patterns instead of field surveys and depending on the farmers’ reports. Usually, CDL is released after a few months of the growing season, approximately at the end of each year [
1]. Therefore, the current CDL may not be able to support many research activities which require early season crop information, such as crop-specific inundation mapping, rapid yield estimation, crop specific loss estimation, grain pricing, crop-specific irrigation need, grain supply, and flood policy. Early season crop type identification will facilitate many types of research and applications in the agriculture sector.
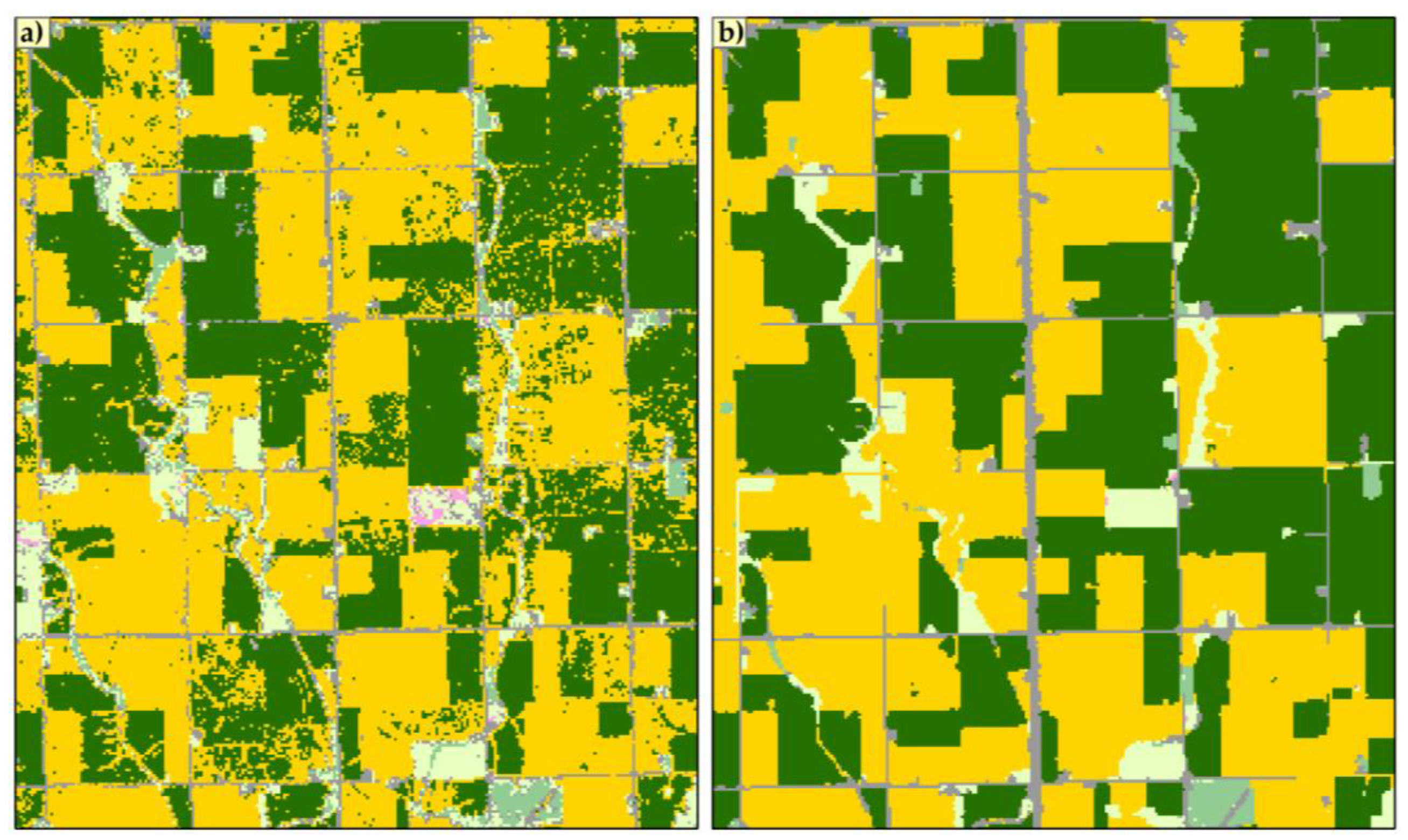
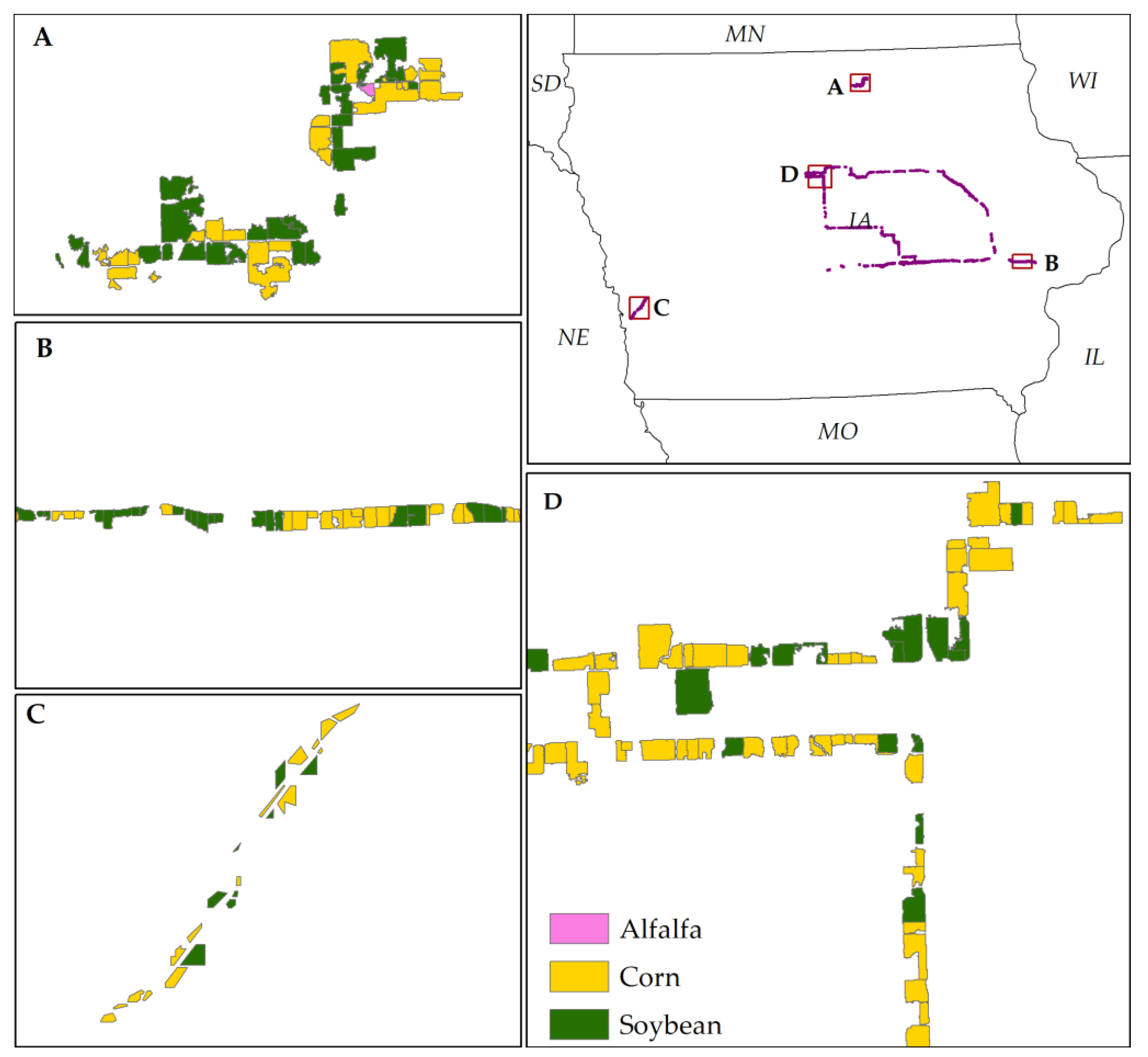
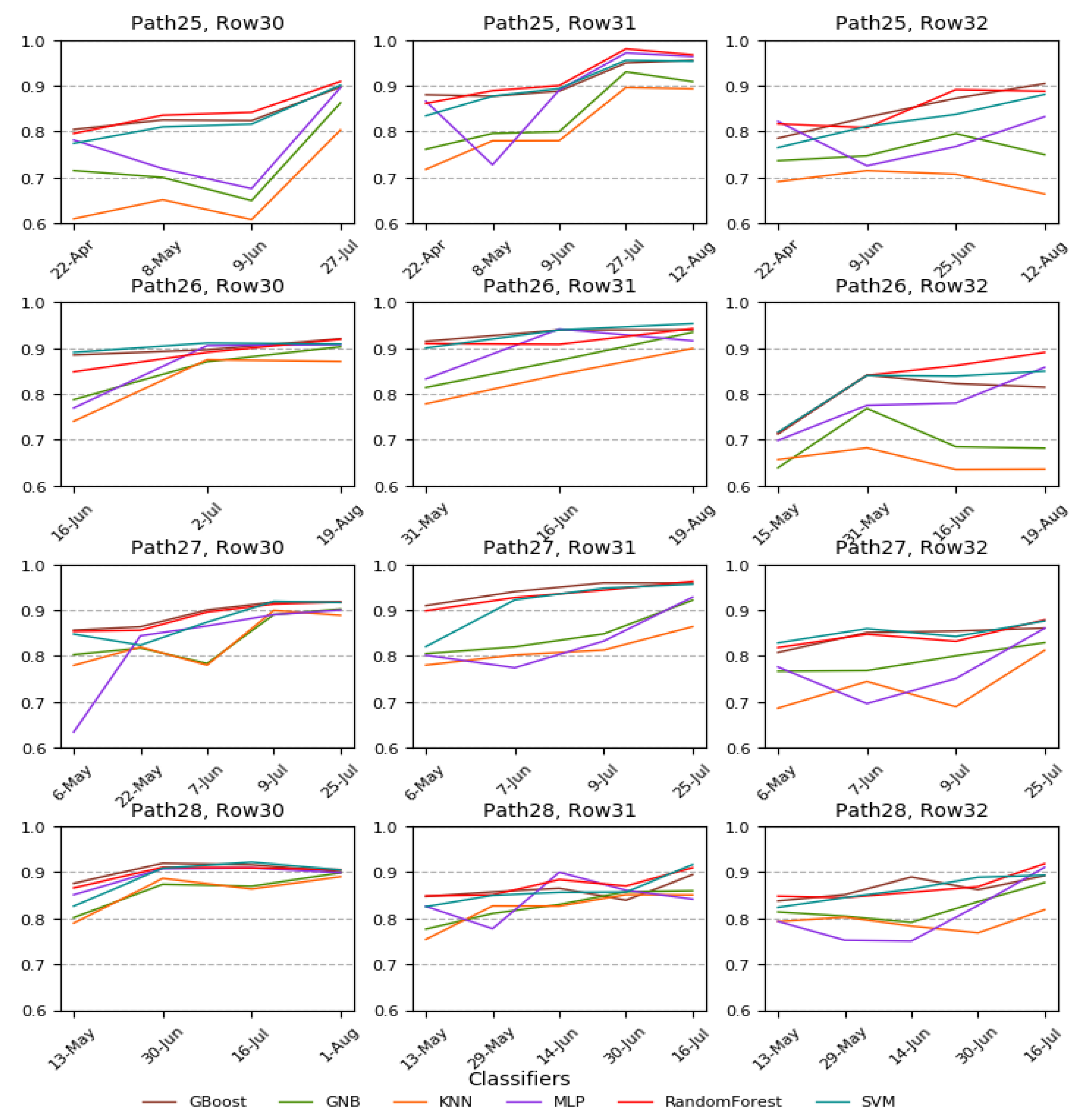
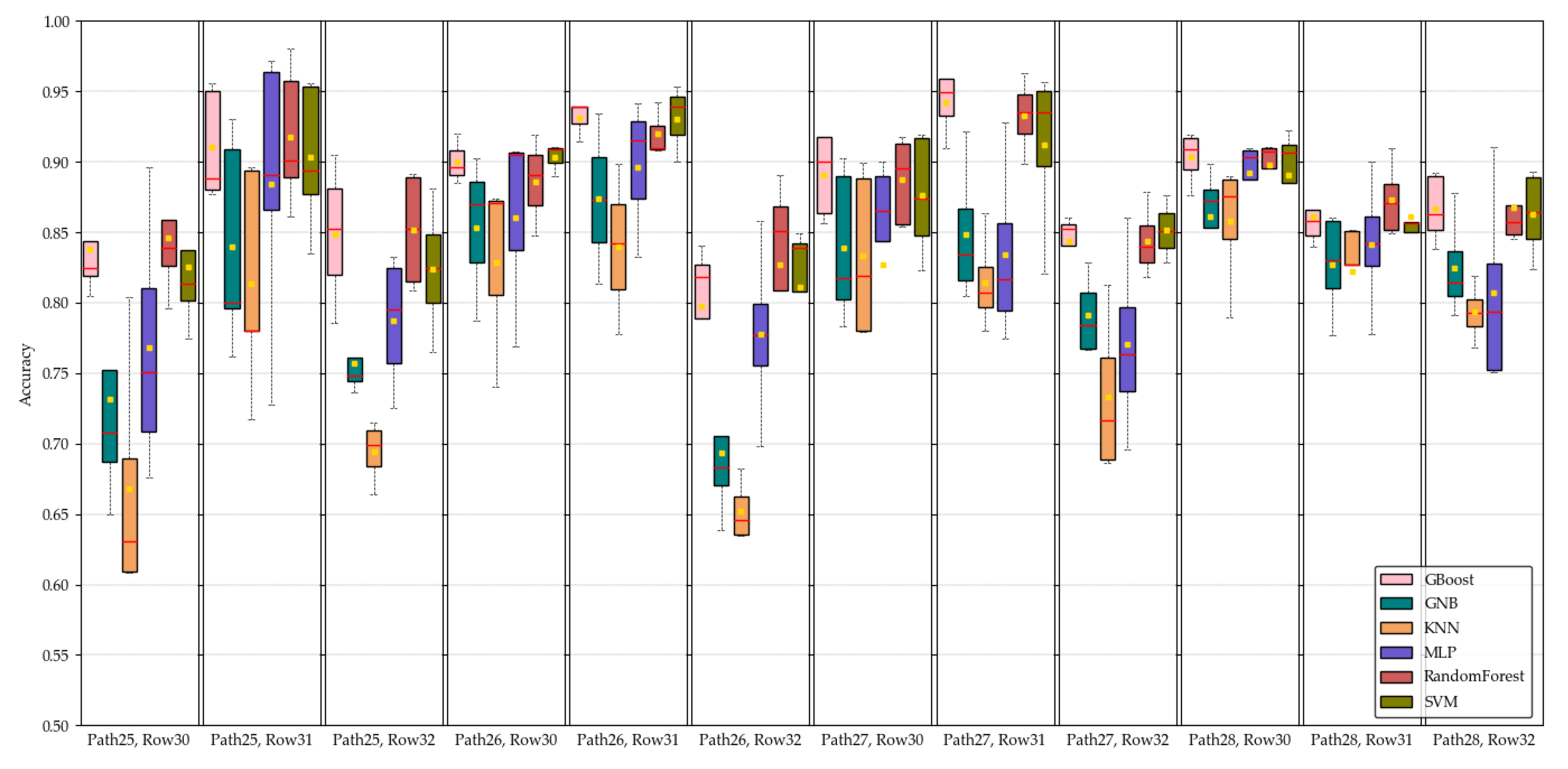
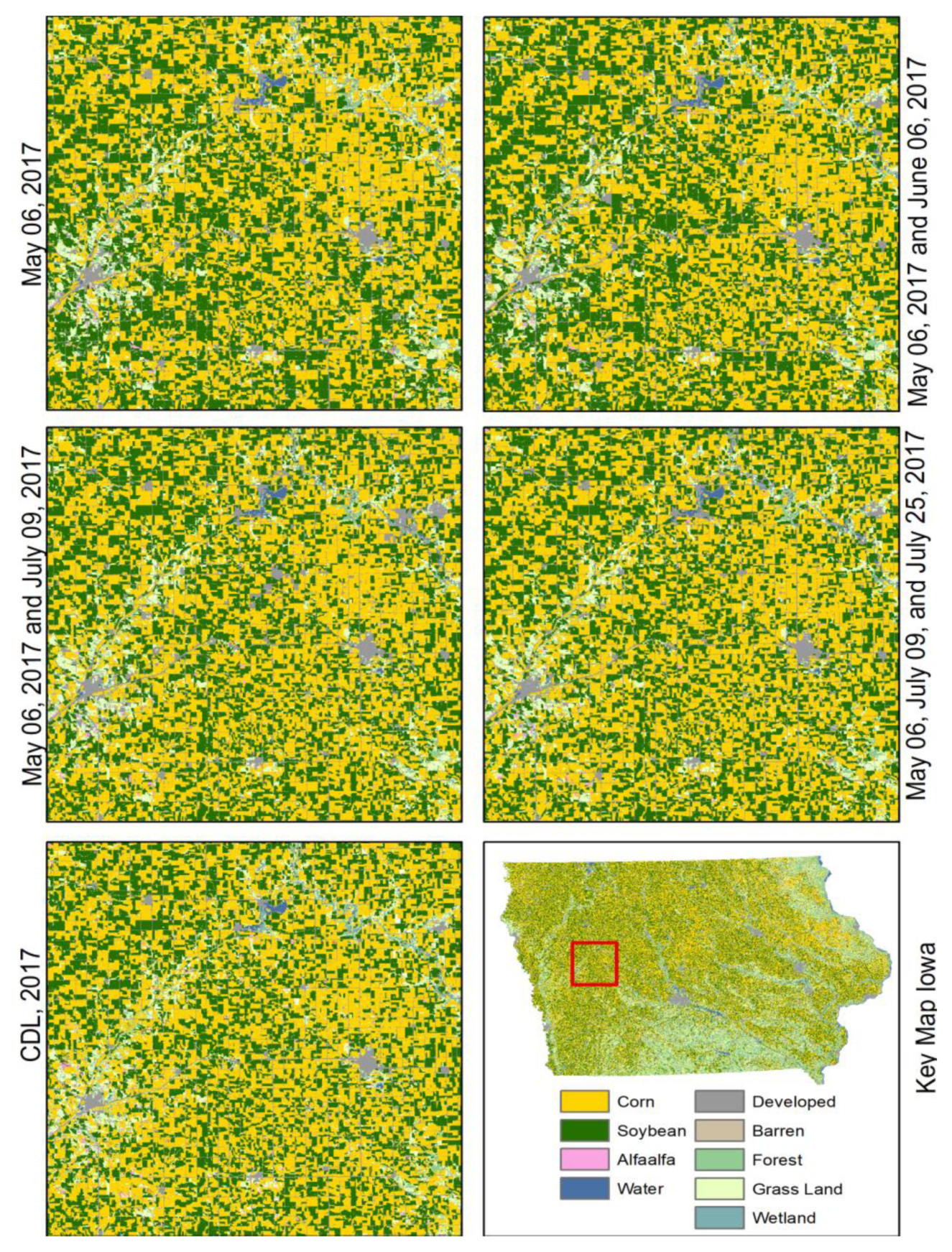
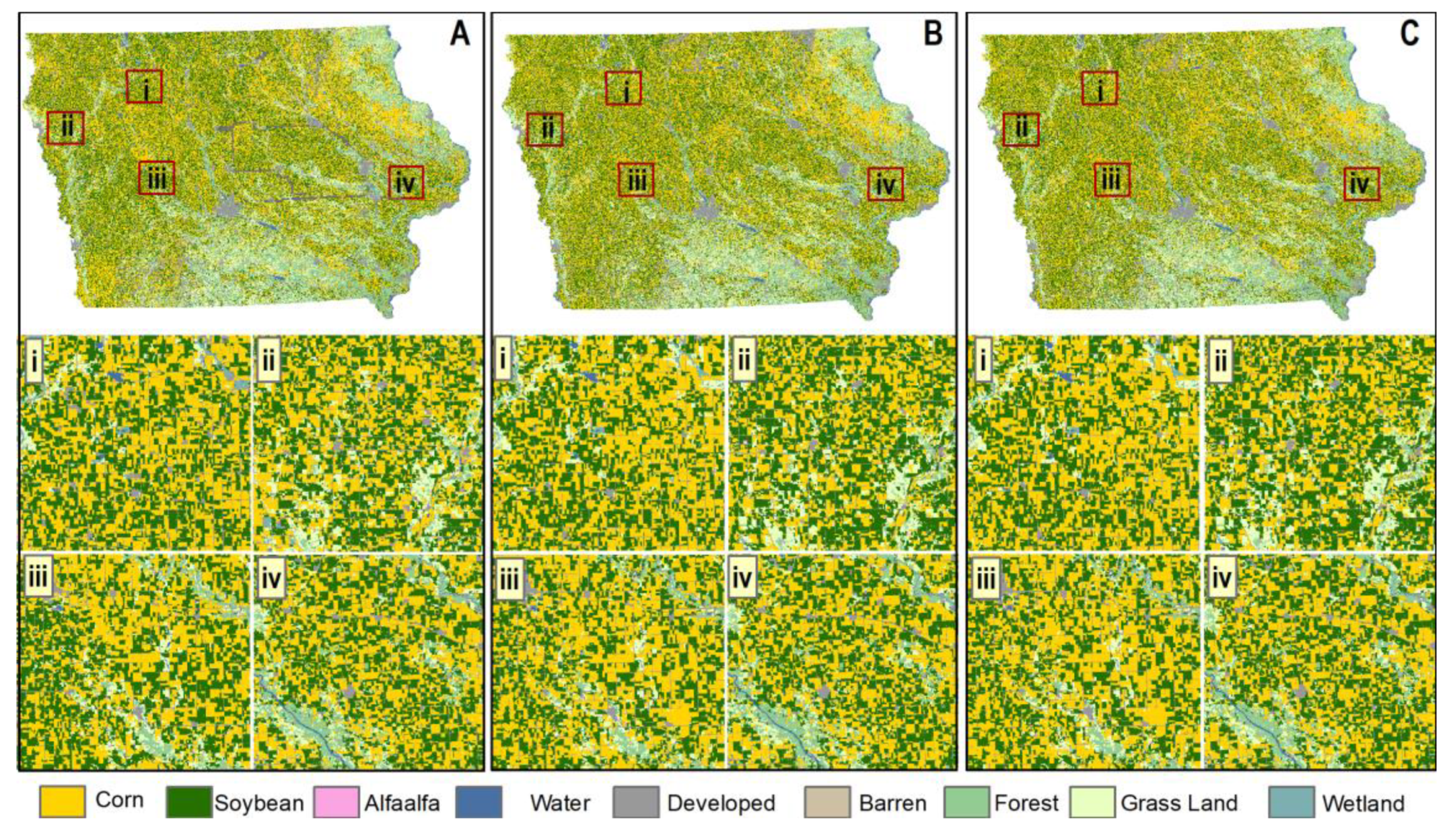
From the above discussion, it is evident that CDL is unique and very useful data on US croplands, which contributes to many research activities and applications in this field. However, there are two major drawbacks: the time and cost-extensive training sample collection and the delayed release of the data at the end of the year; these drawbacks hinder the use of CDL in in-season research. Therefore, this study specifically aims to address these two weaknesses of CDL and propose a solution to overcome them. This study aims to extract major crop rotation patterns from historic CDL instead of mapping crop rotation patterns directly from satellite images. The goal of this study is to create in-season CDL based on crop rotation patterns and Landsat image classification with similar accuracy of current CDL.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}












