A Neural-Network-Based Approach to Chinese–Uyghur Organization Name Translation

 ,
,
Abstract
:1. Introduction
2. Related Works
3. Methodology
3.1. Chinese–Uyghur Organization Name Translation
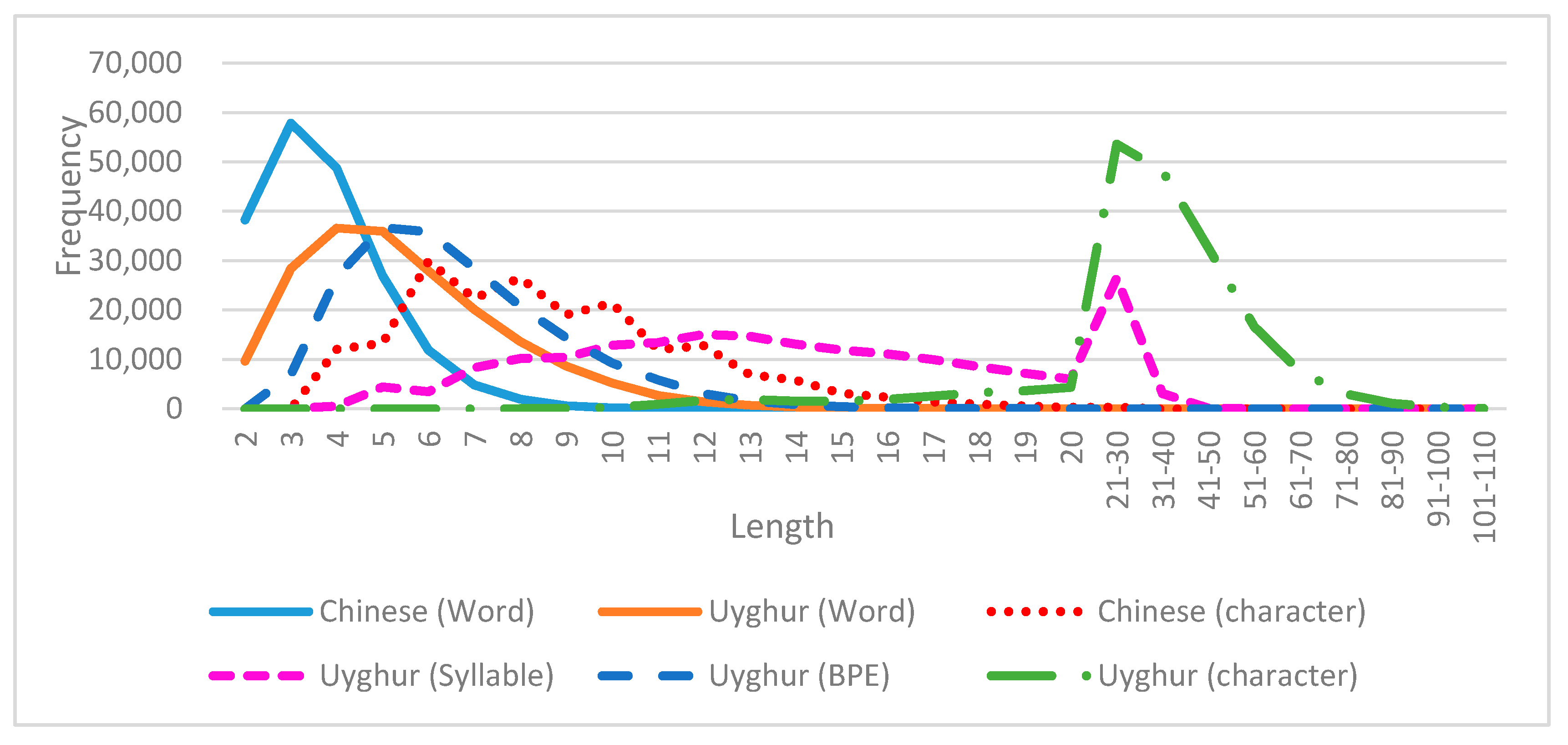
3.2. Word Segmenting
3.2.1. Characterization and Tagged Characterization
3.2.2. Byte Pair Encoding
3.2.3. Uyghur Syllabification
3.3. Neural Network Frameworks
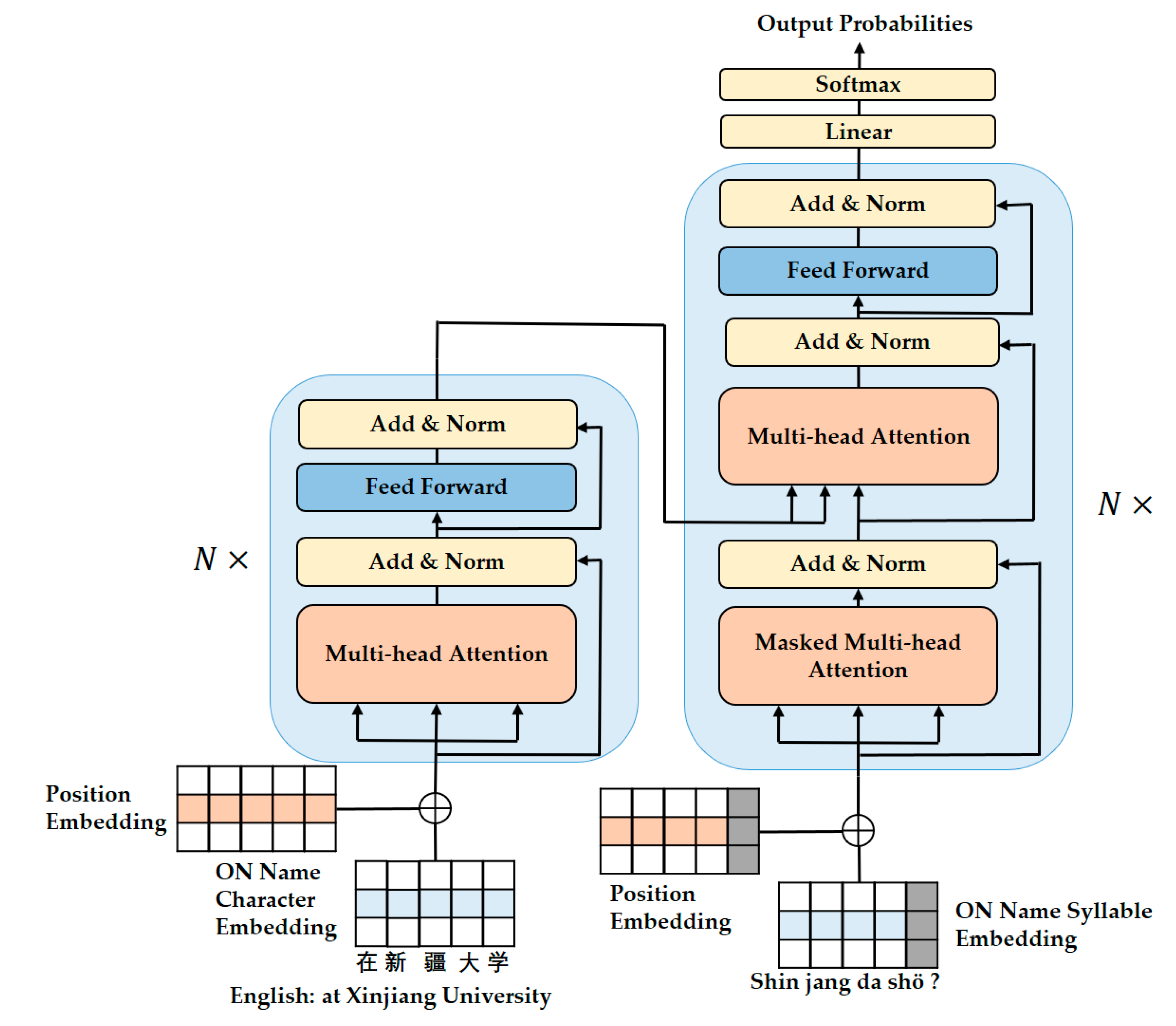
3.3.1. The RNN-Based Attention Framework
3.3.2. The Transformer
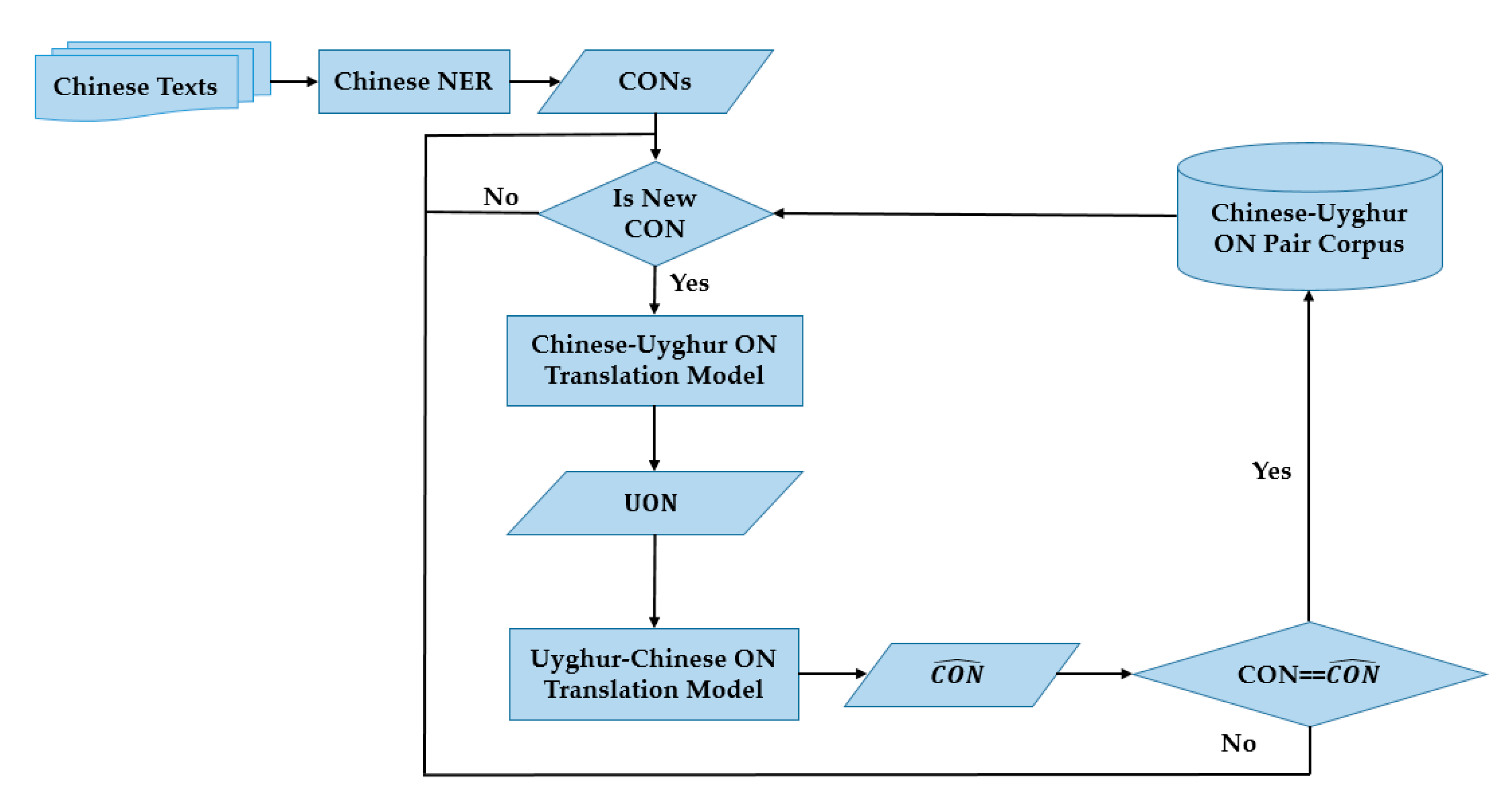
3.4. Chinese–Uyghur ON Translation Pair Generating System
4. Experimental Results and Discussion
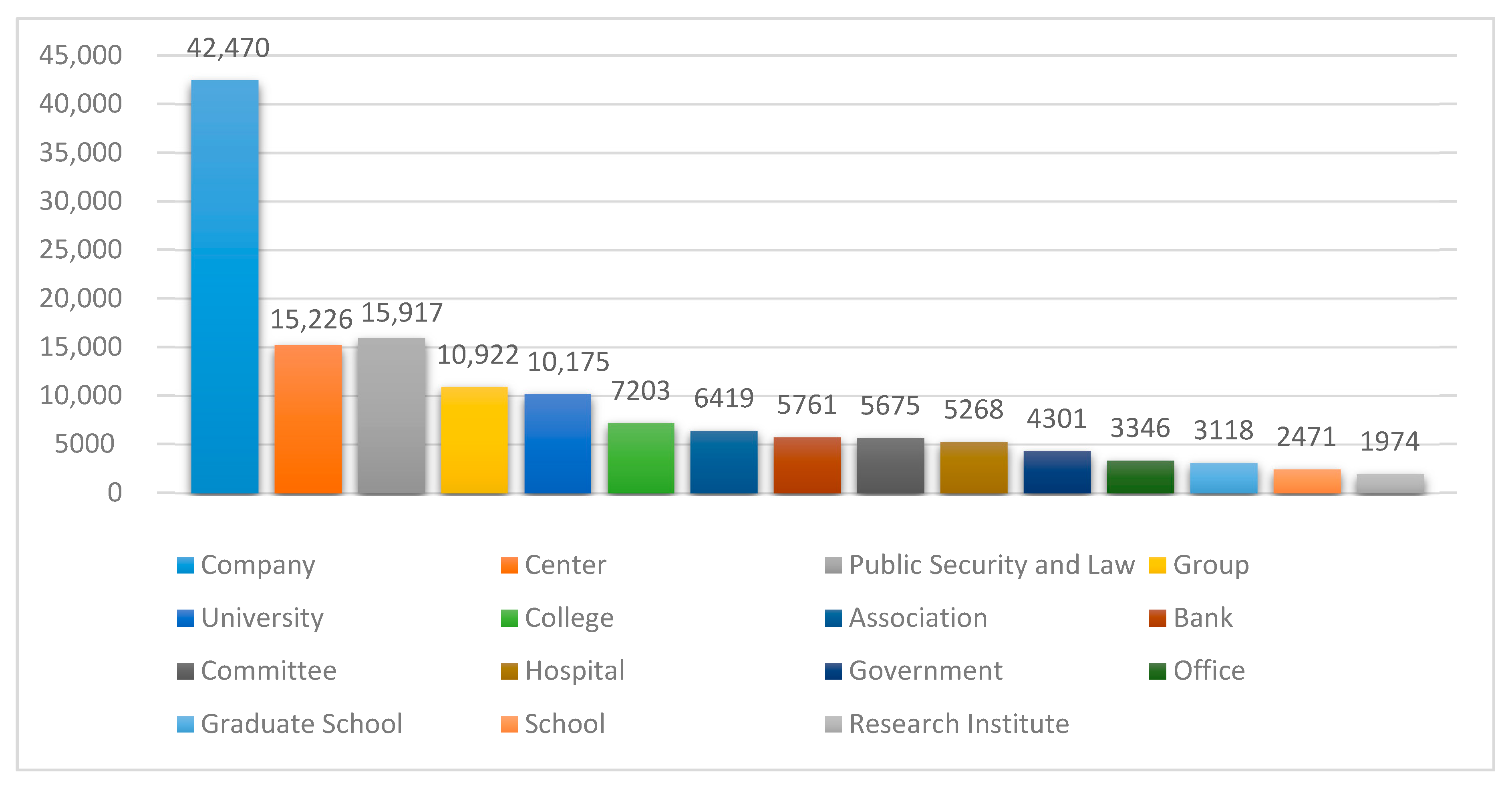
4.1. Chinese–Uyghur Organization Name Translation Corpus Construction
4.2. Evaluation Metrics
4.3. Experimental Settings
- GNMT [36] was used as an RNN-based attention training system. The dimensions of both the input and output sequence vectors, with different granularities, as well as the hidden state, were set to 512. Four hidden layers were used in both the encoder and decoder and a stochastic gradient descent (SGD) algorithm was included as an optimizer. The learning rate was set to 1.0 and the dropout rate was 0.2. The decoder used beam search decoding, with a beam size of 3 and a batch size of 128 and the default settings were used for all other hyperparameters.
- OpenNMT [37], an open-source ecosystem for neural machine translation and neural sequence learning, was used for transformer-based model training. Six encoder and decoder layers were included, in which both the input and output sequence vector dimensions were set to 512. The encoder and decoder included 16 attention heads, the feed-forward inner-layer dimension was set to 4096 and the dropout rate was set to 0.3. The Adam algorithm was included as an optimizer, with adam_beta1 = 0.9 and adam_beta2 = 0.998 and the default settings were used for all other hyperparameters.
4.4. Results and Discussion for Chinese–Uyghur ON Translation
4.5. Results and Discussion for Uyghur–Chinese ON Translation
4.6. Results and Discussion for the Chinese–Uyghur Organization Name Translation System
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Conflicts of Interest
References
- Hassan, H.; Aue, A.; Chen, C.; Chowdhary, V.; Clark, J.; Federmann, C.; Huang, X.; Junczys-Dowmunt, M.; Lewis, W.; Li, M.; et al. Achieving Human Parity on Automatic Chinese to English News Translation. arXiv 2018, arXiv:1803.05567. [Google Scholar]
- Chen, N.; Banchs, R.E.; Zhang, M.; Duan, X.; Li, H. Report of NEWS 2018 Named Entity Transliteration Shared Task. In Proceedings of the Seventh Named Entities Workshop, Melbourne, Australia, 15–20 July 2018; pp. 74–78. [Google Scholar]
- Ngo, G.H.; Nguyen, M.; Chen, N.F. Phonology-Augmented Statistical Framework for Machine Transliteration using Limited Linguistic Resources. Trans. Audio Speech Lang. Process 2019, 27, 199–211. [Google Scholar] [CrossRef]
- Bhargava, A.; Kondrak, G. How do you pronounce your name?: Improving g2p with transliterations. In Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics, Portland, Oregon, 19–24 June 2011; pp. 399–408. [Google Scholar]
- Chen, Y.F.; Zong, C.; Su, K. Interactive method of Chinese-English Bilingual Named Entity Recognition and Alignment. Chin. J. Comput. 2011, 34, 1688–1696. [Google Scholar] [CrossRef]
- Li, H.; Zhang, M.; Su, J. A joint source-channel model for machine transliteration. In Proceedings of the 42nd Annual Meeting on Association for Computational Linguistics, Barcelona, Spain, 21–26 July 2004; pp. 159–166. [Google Scholar]
- Knight, K.; Graehl, J. Machine transliteration. Comput. Linguist. 1998, 24, 599–612. [Google Scholar]
- Chen, H.; Huang, S.; Ding, Y.; Tsai, S. Proper name translation in cross-language information retrieval. In Proceedings of the 36th Annual Meeting of the Association for Computational Linguistics and 17th International Conference on Computational Linguistics, Montreal, QC, Canada, 10–14 August 1998; pp. 232–236. [Google Scholar]
- Al-Onaizan, Y.; Knight, K. Translating named entities using monolingual and bilingual resources. In Proceedings of the 40th Annual Meeting on Association for Computational Linguistics, Philadelphia, PA, USA, 7–12 July 2002; pp. 400–408. [Google Scholar]
- Ekbal, A.; Naskar, S.K.; Bandyopadhyay, S. A modified joint source-channel model for transliteration. In Proceedings of the COLING/ACL on Main Conference Poster Sessions, Sydney, Australia, 17–18 July 2006; pp. 191–198. [Google Scholar]
- Li, X.; Yan, J.; Zhang, J.; Zong, C. Neural name translation improves neural machine translation. In China Workshop on Machine Translation; Springer: Singapore, 2018; pp. 93–100. [Google Scholar]
- Li, Z.W.; Chng, E.S.; Li, H.Z. Named entity transliteration with sequence-to-sequence neural network. In Proceedings of the International Conference on Asian Language Processing, Singapore, 5–7 December 2017; pp. 374–378. [Google Scholar]
- Li, T.; Zhao, T.; Zhang, C. Recognition and translation of Japanese names based on statistics. Intell. Comput. Appl. 2012, 2, 4–7. [Google Scholar]
- Wang, D.; Xu, J.; Chen, Y.; ZHANG, Y. Japanese-Chinese name translation pair extraction method for Japanese kana based on monolingual corpus. J. Chin. Inf. Process 2015, 29, 84–91. [Google Scholar]
- Zhang, M.; Li, H.; Su, J.; Setiawan, H. A phrase-based context-dependent joint probability model for named entity translation. In International Conference on Natural Language Processing; Springer: Berlin, Germany, 2005; pp. 600–611. [Google Scholar]
- Ping, Y.; Hongxu, H.; Yupeng, J.; Zhipeng, S.; Jian, D. Chinese-New Mongolian named entity translation based on bilingual alignment. J. Peking Univ. Nat. Sci. Ed. 2016, 52, 148–154. [Google Scholar]
- Yan, J.H.; Zhang, J.J.; Xu, J.A.; Zong, C. The impact of named entity translation for neural machine translation. In China Workshop on Machine Translation; Springer: Singapore, 2018; pp. 63–73. [Google Scholar]
- Kundu, S.; Paul, S.; Pal, S. A Deep Learning Based Approach to Transliteration. In Proceedings of the Seventh Named Entities Workshop at ACL 2018, Melbourne, Australia, 15–20 July 2018; pp. 79–83. [Google Scholar]
- Najafi, H.B.; Riyadh, R.R.; Yu, L.; Kondrak, G. Comparison of Assorted Models of Transliteration. In Proceedings of the Seventh Named Entities Workshop at ACL 2018, Melbourne, Australia, 15–20 July 2018; pp. 84–88. [Google Scholar]
- Abdulikemu, Y.; Toheti, T.; Aimdula, E. Research on the Algorithm of Chinese Machine Translation of Uyghur Names Based on Rules. Comput. Appl. Softw. 2010, 27, 86–87. [Google Scholar]
- Li, J.; Liu, K.; Mairehaba, A.; Lv, Y.; Liu, Q. Recognition and Translation for Chinese Names in Uighur Language. Chin. Inf. J. 2011, 25, 82–88. [Google Scholar]
- Ayiguli, H.; Aishan, W.; Turgen, I.; Kahaerjiang, A.; Maihemuti, M. Research on the recognition and translation of Chinese and Uyghur time numbers and quantifiers. Chin. Inf. J. 2016, 30, 190–200. [Google Scholar]
- Lulu, W.; Silajiaihemaiti, R.; Aishan, W.; Turgen, I.; Maihemuti, M.; Kahaerjiang, A. Design and implementation of Chinese-Uyghur machine translation system for character resumes. Mod. Electron. Technol. 2018, 41, 111–115. [Google Scholar]
- Lei, Z.; Yating, Y.; Chenggang, M.; Xiao, L. Recognition and Translation of Uyghur named entities in numerals class. Comput. Appl. Softw. 2015, 32, 64–67+109. [Google Scholar]
- Liu, C.L.; Yin, F.; Wang, D.H.; Wang, Q.F. CASIA Online and Offline Chinese Handwriting Databases. In Proceedings of the 11th Int. Conf. Document Analysis Recognition (ICDAR 2011), Beijing, China, 18–21 September 2011; pp. 37–41. [Google Scholar]
- Abliz, W.; Wu, H.; Maimaiti, M.; Wushouer, J.; Abiderexiti, K.; Yibulayin, T.; Wumaier, A. A Syllable-Based Technique for Uyghur Text Compression. Information 2020, 11, 172. [Google Scholar] [CrossRef] [Green Version]
- Sennrich, R.; Haddow, B.; Birch, A. Neural machine translation of rare words with subword units. In Proceedings of the 2016 Conference of the Association for Computational Linguistics, Berlin, Germany, 7–12 August 2016; pp. 1715–1725. [Google Scholar]
- BPE Segmenting Toolkit. Available online: https://github.com/rsennrich/subword-nmt (accessed on 10 October 2018).
- Wayit, A.; Jamila, W.; Turgun, I. Modern Uyghur Automatic Syllable Segmentation Method and its Implementation. China Sci. 2015, 10, 957–961. [Google Scholar]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural machine translation by jointly learning to align and translate. arXiv 2014, arXiv:1409.0473. [Google Scholar]
- Wu, Y.; Schuster, M.; Chen, Z.; Le, Q.C.; Norouzi, M.; Macherey, W.; Krikun, M.; Cao, Y.; Gao, Q.; Macherey, K.; et al. Google’s neural machine translation system: Bridging the gap between human and machine translation. arXiv 2016, arXiv:1609.08144. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł. Attention is all you need. arXiv 2017, arXiv:1706.03762. [Google Scholar]
- Vaswani, A.; Bengio, S.; Brevdo, E.; Chollet, F.; Gomez, A.N.; Gouws, S.; Jones, L.; Kaiser, Ł.; Kalchbrenner, N.; Parmar, N.; et al. Tensor2Tensor for Neural Machine Translation. arXiv 2018, arXiv:1803.07416. [Google Scholar]
- Che, W.; Li, Z.; Liu, T. LTP: A Chinese Language Technology Platform. In Proceedings of the Coling 2010: Demonstrations, Beijing, China, 23–27 August 2010; pp. 13–16. [Google Scholar]
- Papineni, K.; Roukos, S.; Ward, T.; Zhu, W. BLEU: A Method for Automatic Evaluation of Machine Translation. In Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics (ACL), Philadelphia, PA, USA, 7–12 July 2002; pp. 311–318. [Google Scholar]
- GNMT System. Available online: https://github.com/tensorflow/nmt (accessed on 10 October 2018).
- OpenNMT Toolkit. Available online: https://opennmt.net/ (accessed on 1 October 2019).
- NLTK 3.5. Available online: https://www.nltk.org/_modules/nltk/translate/bleu_score.html (accessed on 10 October 2018).







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Chinese (CPA) | Uyghur (Latin Script) | English |
|---|---|---|
| 在新疆大学 (zài xīn jiāng dà xué) | Shinjang dashödE | At Xinjiang University |
| 从新疆大学 (cóng xīn jiāng dà xué) | Shinjang dashödin | From Xinjiang University |
| 红旗镇黑木耳种植合作社 (hóng qí zhèn hēi mù ěr zhòng zhí hé zuò shè) | Qizil bayraq baziri qara mor terish hEmkarliq kopratiwi | Hongqi Town Black Fungus Planting Cooperative |
| 阿勒泰地区文化体育广播电视和旅游局 (a lè tài dì qū wén huà tǐ yù guǎng bō diàn shì hé lǚ yóu jú) | Altay wilayEtlik mEdEnyEt tEntErbiyE radiyo telewiziyE wE sayahEt idarisi | Aletai Regional Bureau of Culture, Sports, Radio, Television and Tourism |
| Segment Granularity | Chinese | Uyghur (Latin Script) |
|---|---|---|
| Word | 德拉蒙德公司 | delamond shirkti |
| Character | 德拉蒙德公司 | d e l a m o n d s h i r k t i |
| Tagged Character | - | d_B e_M l_M a_M m_M o_M n_M d_E s_B h_M i_M r_M k_M t_M i_E |
| BPE | 德拉@@ 蒙@@ 德公司 | de@@ lam@@ on@@ d shirkti |
| Syllable | - | de la mond shir kti |
| Dataset | Size |
|---|---|
| train | 181,924 |
| dev | 2000 |
| test | 7717 |
| Granularity | Chinese | Uyghur |
|---|---|---|
| Word | 39,554 | 25,509 |
| Character | 3007 | 87 (55 symbols) |
| Uyghur tagged character | - | 283 |
| Uyghur syllable | - | 6995 |
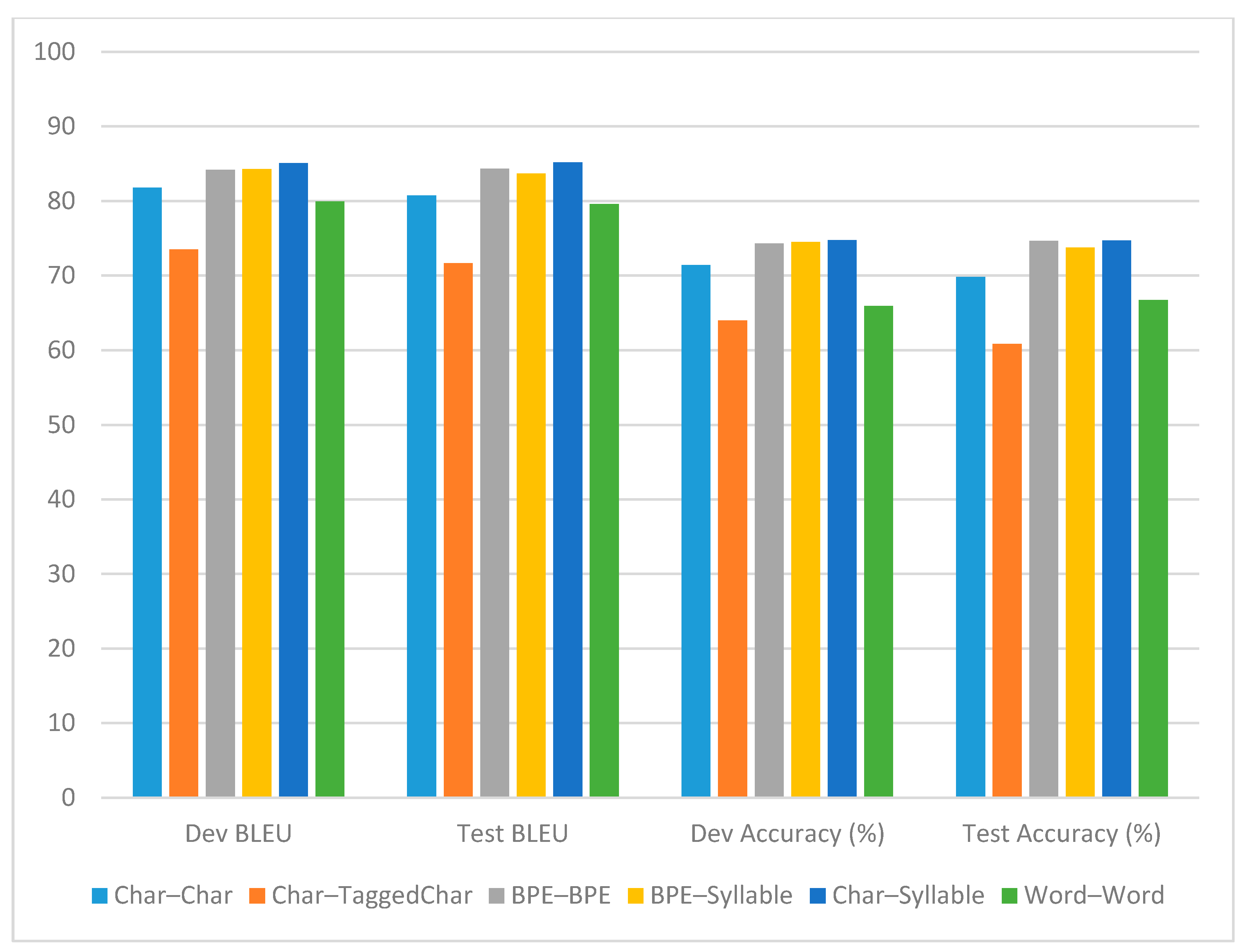
| Input Granularity | Method | BLEU | Accuracy (%) | ||
|---|---|---|---|---|---|
| Dev | Test | Dev | Test | ||
| Char–Char | GNMT | 47.34 | 43.46 | 32.20 | 27.00 |
| Transformer | 81.78 | 80.74 | 71.40 | 69.83 | |
| Char–TaggedChar | GNMT | 45.67 | 42.05 | 33.80 | 28.78 |
| Transformer | 73.49 | 71.64 | 63.95 | 60.87 | |
| BPE–BPE | GNMT | 79.01 | 77.72 | 66.80 | 65.06 |
| Transformer | 84.16 | 84.35 | 74.30 | 74.67 | |
| BPE–Syllable | GNMT | 75.87 | 74.91 | 63.20 | 61.90 |
| Transformer | 84.30 | 83.69 | 74.50 | 73.75 | |
| Char–Syllable | GNMT | 76.67 | 75.47 | 64.15 | 62.01 |
| Transformer | 85.06 | 85.17 | 74.75 | 74.71 | |
| Word–Word | GNMT | 70.98 | 70.88 | 55.90 | 56.20 |
| Transformer | 79.96 | 79.59 | 65.90 | 66.72 | |
| Error Category | Error ON (Latin Script) | Correct ON (Latin Script) | English |
|---|---|---|---|
| Character insertion | Filorida ishtati hokvmiti | Filorida shitati hokvmiti | Florida Government |
| Character missing | XuEy’En shEhiri muhit asrash idarisi | XuEy’En shEhErlik muhit asrash idarisi | Huaian Environmental Protection Bureau |
| Synonym replacement | Xuayi qërindashlar mEdEniyEt tarqitish pay chEklik shirkiti | Xuayi aka—uka mEdEniyEt tarqitish pay chEklik shirkiti | Huayi Brothers Media Group |
| Word insertion | Da guangming soda chEklik mEsuliyEt shirkiti | Da guangming soda chEklik shirkiti | Daguangming Commerce co., Ltd. |
| Wrong translation | Kongo altun hvkvmeti | Kongo kinsasha hvkvmeti | Kongo Kinsasha Goverment |
| Polyphonic translation | Sheriq desey mEktipi | Dongfang desey mEktipi | Dongfang Decai School |
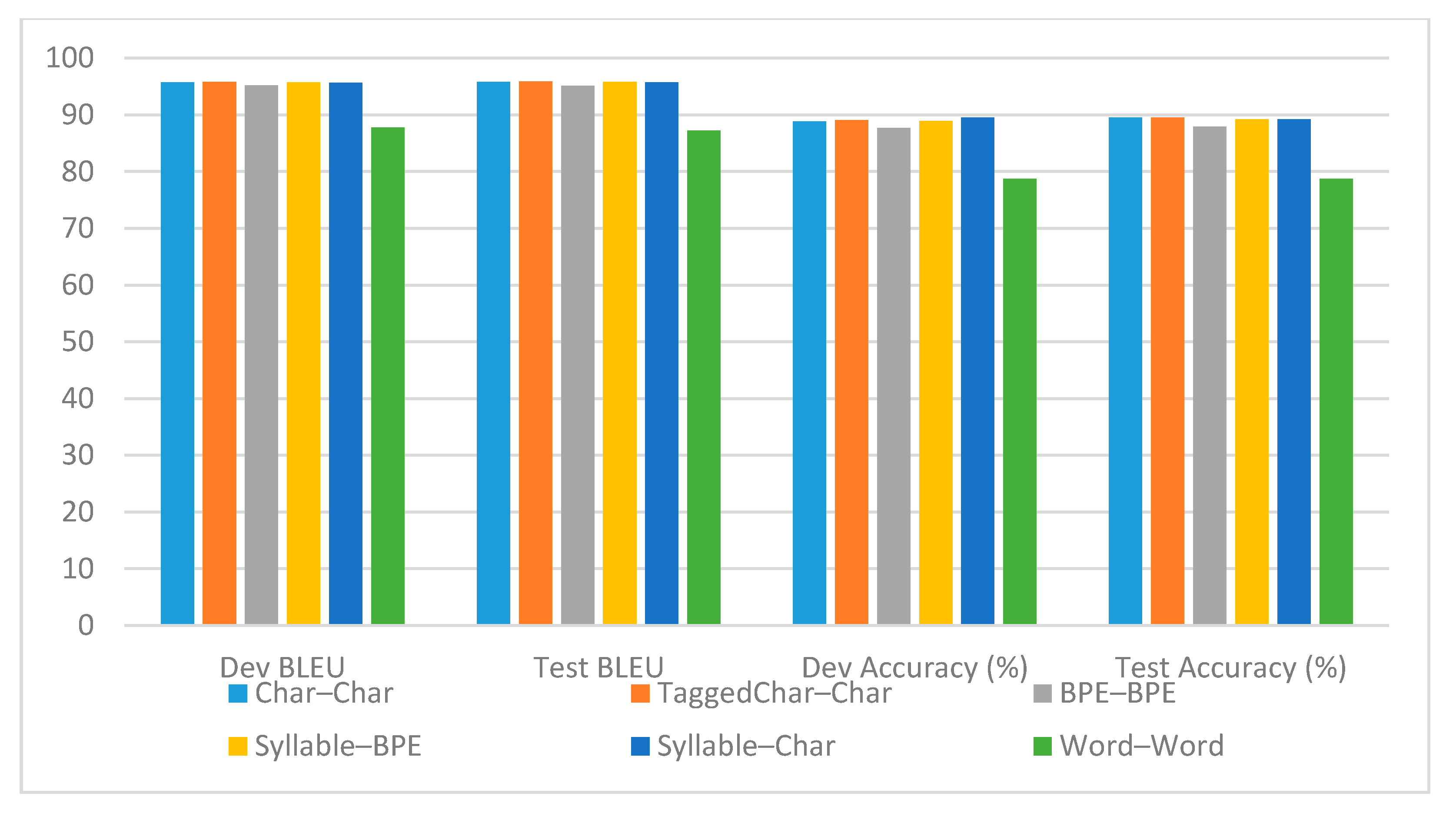
| Input Unit | Method | BLEU | Accuracy | ||
|---|---|---|---|---|---|
| Dev | Test | Dev | Test | ||
| Char–Char | GNMT | 91.64 | 91.41 | 80.02 | 80.01 |
| Transformer | 95.73 | 95.83 | 88.85 | 89.51 | |
| TaggedChar–Char | GNMT | 93.34 | 92.97 | 83.85 | 83.16 |
| Transformer | 95.78 | 95.90 | 89.10 | 89.56 | |
| BPE–BPE | GNMT | 87.50 | 87.45 | 74.55 | 74.12 |
| Transformer | 95.22 | 95.13 | 87.70 | 87.91 | |
| Syllable–BPE | GNMT | 85.14 | 84.90 | 65.20 | 65.60 |
| Transformer | 95.75 | 95.79 | 88.90 | 89.22 | |
| Syllable–Char | GNMT | 88.28 | 87.68 | 75.10 | 74.73 |
| Transformer | 95.69 | 95.74 | 89.50 | 89.24 | |
| Word–Word | GNMT | 82.72 | 83.7 | 66.75 | 67.12 |
| Transformer | 87.80 | 87.27 | 78.75 | 78.72 | |
| Error Category | Error ON (CPA) | Correct ON (CPA) | English |
|---|---|---|---|
| Character insertion | 上海网络游戏公司(shàng hǎi wǎng luò yóu xì gōng sī) | 上海网游公司(shàng hǎi wǎng yóu gōng sī) | Shanghai Online Game Company |
| Character missing | 中沙高级联合委员会(zhōng shā gāo jí lián hé wěi yuán huì) | 中沙高级别联合委员会(zhōng shā gāo jí bié lián hé wěi yuán huì) | China-Saudi Arabia High-level Joint Committee |
| Synonym | 雪歌服装有限公司(xuě gē fú zhuāng yǒu xiàn gōng sī) | 雪歌服饰有限公司(xuě gē fú shì yǒu xiàn gōng sī) | Xuege Clothing Co., Ltd. |
| Word insertion | 美国公共选举竞争基金会(měi guó gōng gòng xuǎn jǔ jìng zhēng jī jīn huì) | 美国公共竞选基金会(měi guó gōng gòng jìng xuǎn jī jīn huì) | American Public Campaign Foundation |
| Word translation | 昆明报价中心(kūn míng bào jià zhōng xīn) | 昆明价格举报中心(kūn míng jià gé jǔ bào zhōng xīn) | Kunming Price Report Center |
| Abbreviation | 北京社会科学院经济研究所(běi jīng shè huì kē xué yuàn jīng jì yán jiū suǒ) | 北京社科院经济研究所(běi jīng shè kē yuàn jīng jì yán jiū suǒ) | Institute of Economics of Beijing Academy of Social Sciences |
| Homophone | 马里基政府(mǎ lǐ jī zhèng fǔ) | 马利基政府(mǎ lì jī zhèng fǔ) | Maliki Government |
| Processing Step | Count |
|---|---|
| CON recognized by LTP | 265,930 |
| CON not in corpus | 224,239 |
| After filtering | 180,822 |
| Final ON translation pair | 102,626 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wumaier, A.; Xu, C.; Kadeer, Z.; Liu, W.; Wang, Y.; Haierla, X.; Maimaiti, M.; Tian, S.; Saimaiti, A. A Neural-Network-Based Approach to Chinese–Uyghur Organization Name Translation. Information 2020, 11, 492. https://0-doi-org.brum.beds.ac.uk/10.3390/info11100492
Wumaier A, Xu C, Kadeer Z, Liu W, Wang Y, Haierla X, Maimaiti M, Tian S, Saimaiti A. A Neural-Network-Based Approach to Chinese–Uyghur Organization Name Translation. Information. 2020; 11(10):492. https://0-doi-org.brum.beds.ac.uk/10.3390/info11100492
Chicago/Turabian StyleWumaier, Aishan, Cuiyun Xu, Zaokere Kadeer, Wenqi Liu, Yingbo Wang, Xireaili Haierla, Maihemuti Maimaiti, ShengWei Tian, and Alimu Saimaiti. 2020. "A Neural-Network-Based Approach to Chinese–Uyghur Organization Name Translation" Information 11, no. 10: 492. https://0-doi-org.brum.beds.ac.uk/10.3390/info11100492