A Ranking-Based Hashing Algorithm Based on the Distributed Spark Platform

Faculty of Electrical Engineering and Computer Science, Ningbo University, Ningbo 315211, China
*
Author to whom correspondence should be addressed.
Information 2020, 11(3), 148; https://0-doi-org.brum.beds.ac.uk/10.3390/info11030148
Submission received: 23 January 2020
/
Revised: 2 March 2020
/
Accepted: 5 March 2020
/
Published: 9 March 2020
Abstract
:With the rapid development of modern society, generated data has increased exponentially. Finding required data from this huge data pool is an urgent problem that needs to be solved. Hashing technology is widely used in similarity searches of large-scale data. Among them, the ranking-based hashing algorithm has been widely studied due to its accuracy and speed regarding the search results. At present, most ranking-based hashing algorithms construct loss functions by comparing the rank consistency of data in Euclidean and Hamming spaces. However, most of them have high time complexity and long training times, meaning they cannot meet requirements. In order to solve these problems, this paper introduces a distributed Spark framework and implements the ranking-based hashing algorithm in a parallel environment on multiple machines. The experimental results show that the Spark-RLSH (Ranking Listwise Supervision Hashing) can greatly reduce the training time and improve the training efficiency compared with other ranking-based hashing algorithms.
1. Introduction
With the continuous development of computing technology and digital media technology in recent years, data generation is increasing every day. This data exists in many forms, including text, images, audio, video, and other forms. Obtaining the information that people need from these massive and high-dimensional data quickly and accurately is an important technical problem [1,2].
At present, there are mainly two ways to solve such problems. One is a tree-based spatial partitioning method, which mainly represents red-black trees, kd-tree, and R-trees [3,4]. However, the disadvantages of this method is that it is only applicable to low-dimensional data. When the dimension rises sharply, it will produce problems such as “dimension disaster”, and its search efficiency is close to a linear search function. The other method is a hashing-based search method. This method is also divided into two categories, with one being the data-independent method and the other being locality-sensitive hashing (LSH) [5,6]. This second method employs data dependence. It is also a popular machine learning-based approach that encodes the relevant characteristics of the learning data, thereby improving the retrieval speed and reducing the storage cost [6]. However, some hashing algorithms are currently taking too long to meet the search requirements of the current big data environment.
On the other hand, as the data scale is ever-increasing, the storage and processing requirements of data cannot be met in a stand-alone environment. Therefore, distributed processing systems have emerged for big data, mainly including Hadoop, Storm, and Spark. These distributed systems can process data quickly and in parallel by storing data on multiple computer nodes. By combining the advantages of learning with hashing and distributed systems, this paper designs and implements a distributed learning and hashing method based on the Spark computing platform, which can reduce training time greatly and improve training efficiency.
Section 2 of this paper introduces some of the main learning points for hashing and ranking-based hashing methods. Section 3 introduces the ranking-based hashing algorithm and the resilient distributed dataset model in Spark. Section 4 describes the distributed ranking-based hashing algorithm, along with its design and implementation in the Spark platform. Section 5 analyzes the experimental results of the distributed ranking-based hashing algorithm on several data sets and compares it with several other algorithms. Section 6 is the conclusion.
2. Related Work
In recent years, the learning methods for hashing have been researched extensively due to the faster retrieval speed and lower storage cost, and the core idea is to convert high-dimensional data into compact binary codes by using various machine learning algorithms. By setting a reasonable learning goal, the obtained Hamming codes can maintain the similarity of the original data. The convenient calculation of the Hamming distance also improves the retrieval efficiency of large-scale data.
Currently, the hashing learning methods are mainly divided into two types based on the presence or absence of tag information: unsupervised hashing and supervised hashing (including semi-supervised hashing). Representative unsupervised hashing methods include locality-sensitive hashing (LSH) [7], spectral hashing (SH) [8], self-taught hashing (STH) [9], iterative quantization (ITQ) [10], unsupervised deep video hashing (UDVH) [11], and principal component analysis hashing (PCAH) [12]. The current classical methods of supervised hashing are minimal loss hashing (MLH) [13], supervised hashing with kernels (KSH) [14], supervised discrete hashing (SDH) [15], discrete semantic alignment hashing (DSAH) [16], and linear discriminant analysis hashing (LDAH) [17].
Although the above hashing learning methods have achieved good results, they rarely consider the ranking information in the actual search task. This is because, in general, in the process of searching through the search engine, the returned query results are arranged from top to bottom according to the degree of relevance to the query point.
Based on this, some ranking-based hashing methods have appeared in recent years [18,19,20,21,22,23,24], which preserve information by retaining triples (such as learning hash functions using column generation (CGH) [25], Hamming distance metric learning (HDML) [26], etc.) or listwise supervision information (listwise supervision hashing (RSH) [27], ranking preserving hashing (RPH) [28], deep semantic ranking-based hashing (DSRH) [29], discrete semantic ranking hashing (DSeRH) [30], etc.) to learn to generate hashing codes. The triplet supervision method is used to establish a triple , where represents the query point, represents data similar to the query point, and represents the data that is not similar to the query point. The code is created by establishing the loss function to make more similar to , and less similar to . The listwise supervision method is used to rank all the points in the database in the Euclidean and Hamming spaces, according to the similarity between the query points and data points, and so that the ranking of each point is as consistent as possible in the two spaces.
3. Basic Knowledge
Ranking-Based Hashing Algorithm
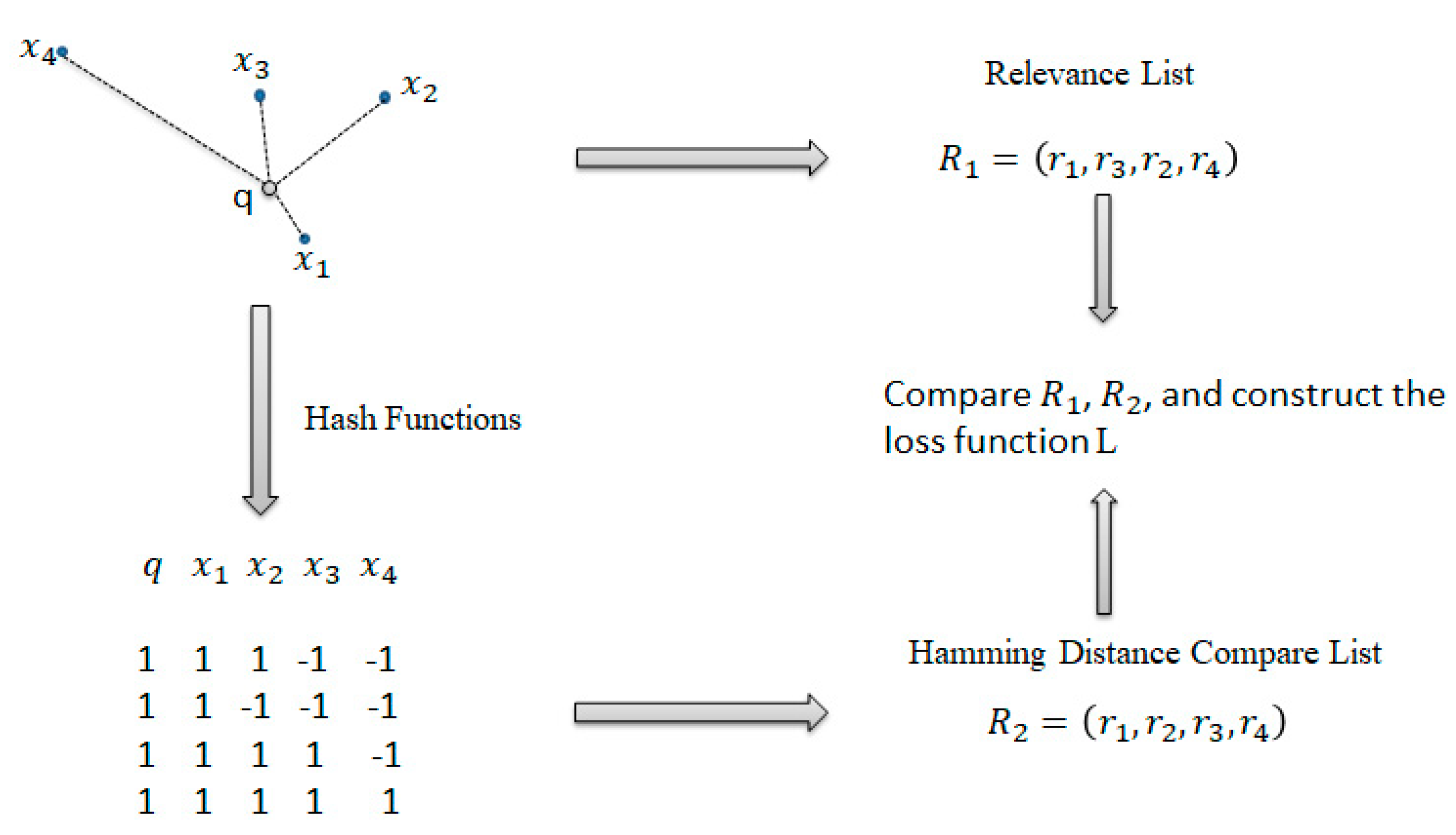
The ranking hashing algorithm is one of the supervised learning methods used for hashing algorithms, which better satisfies the search task requirements faced by people in real life. This paper adopts a ranking-based hashing algorithm based on listwise supervision. The basic idea is shown in Figure 1. Here, , , , and represent four data points in the datasets, and represents the query point. By calculating the distance between and four data points in the Euclidean space and then ranking the four points according to the distance, the ranking list is obtained, where represent the relevance ranking of and query point , respectively. At the same time, by encoding all the data points and calculating the distance between and the four data points in the Hamming space, the ranking list is also obtained. Finally, we compare and , then construct the loss function to keep and as consistent as possible.
4. Distributed Ranking-Based Hashing Algorithm
4.1. Overall Description of the Algorithm
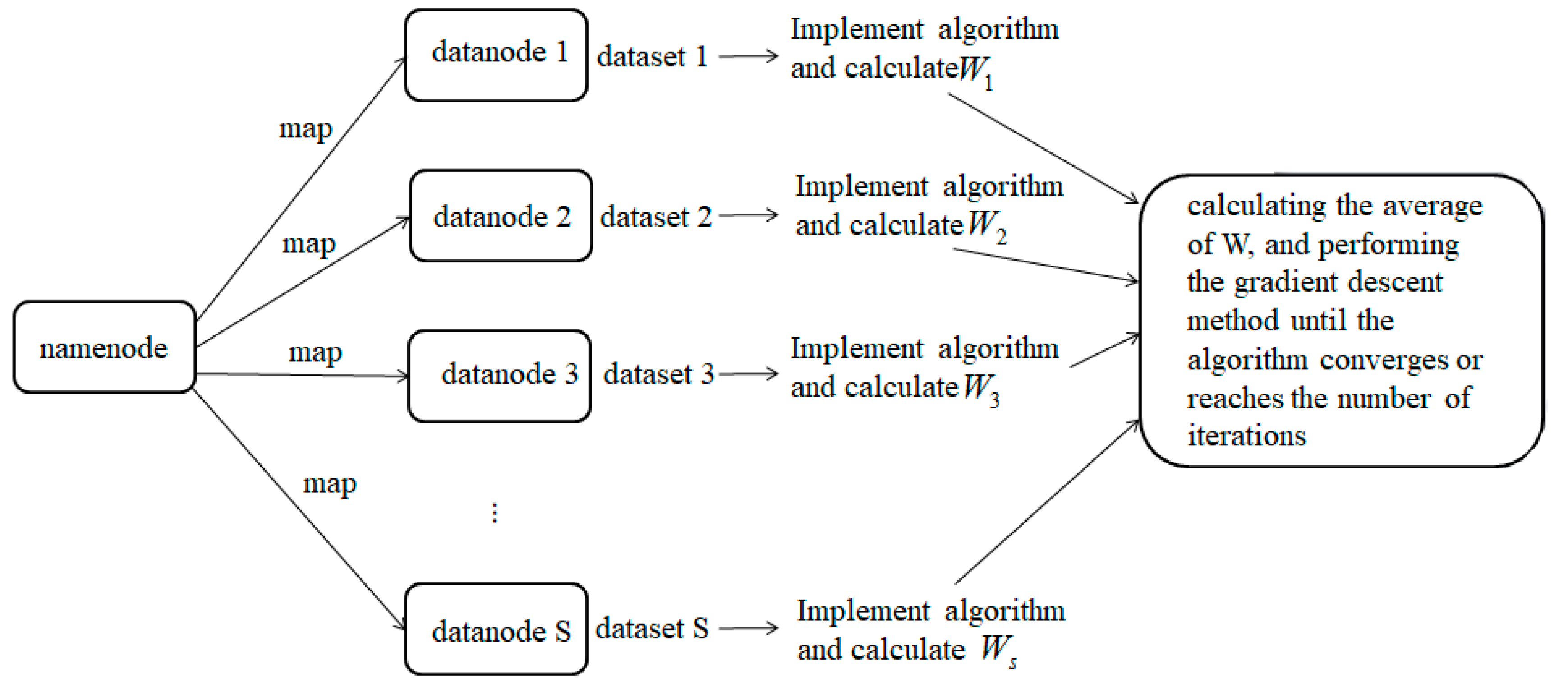
At present, the complexity of most of the ranking-based hashing algorithms is too high to meet the existing training requirements, while the distributed Spark platform can execute the algorithm flow in parallel and shorten the training time. Therefore, this paper proposes a ranking-based hashing based on the distributed Spark platform. The algorithm is described as follows:
- In the distributed Spark environment, all the data in the datasets are mapped to different averaged working nodes. The Euclidean distances between the query points in the query set and all the data points in the datasets in each working node are calculated, and then the distance is ranked. The actual ranking of each point is obtained.
- Similarly, the query points and all the data points are converted into binary codes on each working node, and the Hamming distance is calculated to obtain the ranking in the Hamming space.
- According to the loss function, minimize the inconsistency of the data points in the two spaces is minimized. The data transformation matrix on each working node is calculated, and then all the nodes are summed and the average values are calculated using the gradient descent method until the algorithm converges or the number of iterations is reached.
4.2. The Details of the Algorithm
Suppose there are data points in the dataset that expressed as , where represents the characteristic dimension of the data and there is also a query set . The number of nodes in the distributed Spark cluster is . For any of the working nodes, the dataset ( and ) is assigned, along with the query set . For any query point in the query set , we can calculate the distance from each of the datasets directly based on the distance formula of the two points, then ranking the points according to the distance, obtaining the relevance ranking list (we believe that the smaller the Euclidean distance from the query point, the greater the correlation, thus the smaller the ranking), which is recorded as:
where , which represents the similarity ranking between the data sample and the query point . If , this means that is more similar to the query point than . Our goal is to obtain the hashing function ƒ(∙) to generate the binary codes and to define the hashing function mapping as follows:
where , represents the length of the codes, and we define the following formula to calculate the Hamming distance after the query points and the training data points are encoded:
Based on the above formula, we divide the codes into several subspaces of the same length, where the parameter represents the length of each subspace. Here, is the number of subspaces that are divided, and then according to the above Hamming distance calculation formula, the ranking of each point in the datasets is obtained. The ranking information of point is:
Finally, we compare the sizes of and to construct the loss function, so that the two are as consistent as possible.
For any worker node in a spark cluster, we define the loss function as:
where represents the ranking weight of the data points; obviously, the greater the weight of the real ranking in the Euclidean space, the smaller the value. Therefore, for all nodes, the total loss function is defined as:
where represents the balance factor and represents a regularization term to prevent overfitting during training. Finally, we derive the above loss function:
The gradient on each working node can be obtained by the updated rule of the gradient descent method:
where represents the learning factor, the total of which can be calculated as:
The entire algorithm execution architecture is shown in Figure 2.
5. Experiments
5.1. Experimental Platform Construction
The cluster system of the experimental platform is mainly composed of ten hosts, one of which has a master node (name node) and nine computer nodes (data nodes). The CPU for all hosts is an Intel Core i5-3470, and the memory is 8GB DDR3. In addition, the software environment plays a vital role as a prerequisite for building Hadoop and Spark distributed cluster environments. The specific configuration of the software environment of each machine is shown in Table 1.
5.2. Experimental Datasets
This paper mainly experiments with two public datasets, which are the CIFAR-10 dataset and MNIST dataset, and compares these with other ranking-based hashing algorithms (RSH [27], RPH [28]). In the experiment, the data is subjected to pre-processing, such as zero-meanization, and then the image dataset is converted into matrix form by feature extraction and transformation to facilitate the operation.
CIFAR-10 dataset: This contains 60,000 1024-dimensional image data points and includes a total of 10 categories. In this experiment, 320-dimensional gist features were extracted from each photo in the CIFAR-10 dataset, 2000 images were randomly selected as a test dataset, another 2000 images were used as a training dataset, and 200 images were used as a query dataset.
MNIST dataset: This is a handwritten digital image dataset (0–9) containing 60,000 use cases. We also extracted 520-dimensional GIST features for each photo, and randomly selected 2000 images as test datasets. Here, 2000 images are used as a training dataset and 200 images are used as a query dataset.
5.3. Experimental Result
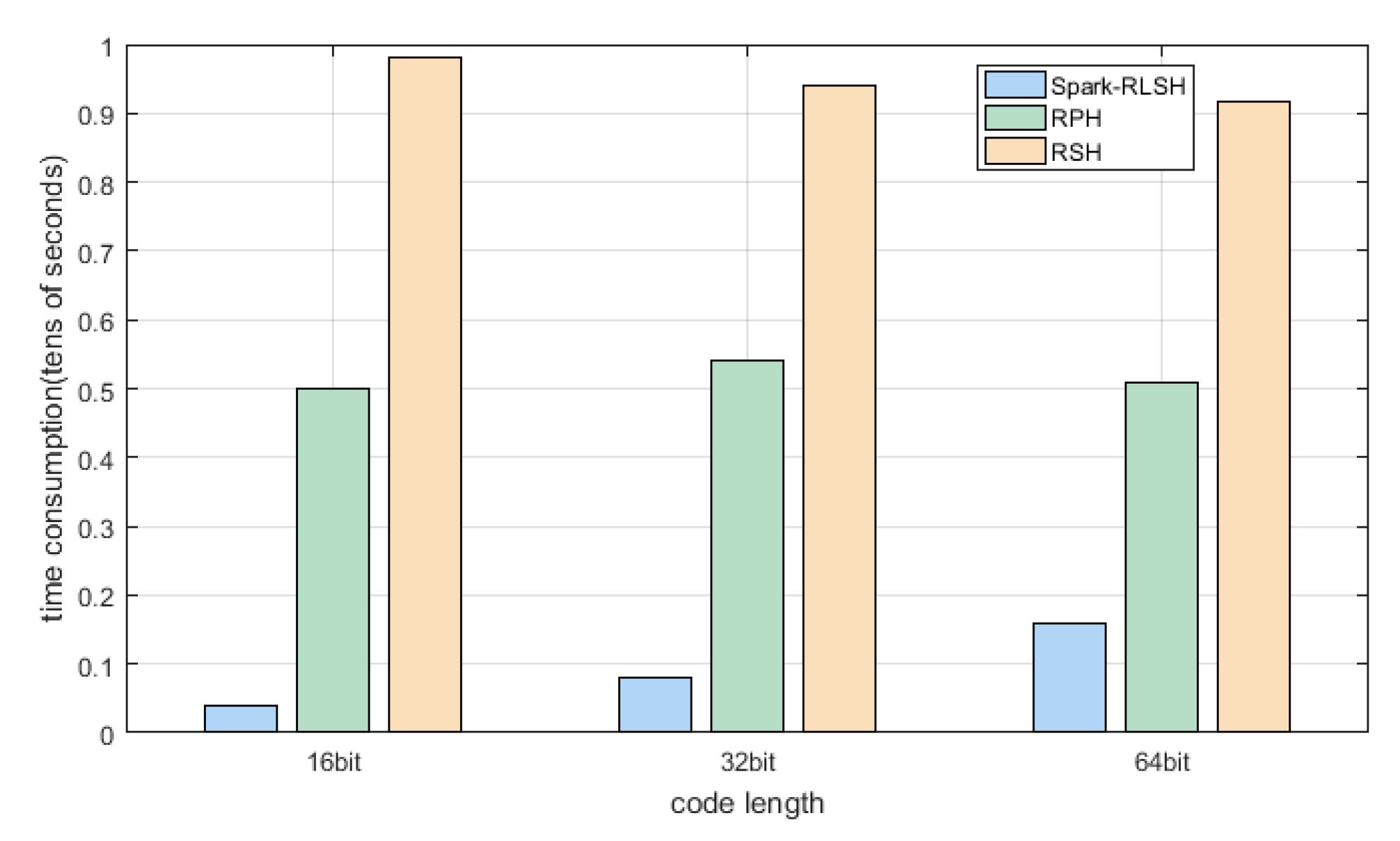
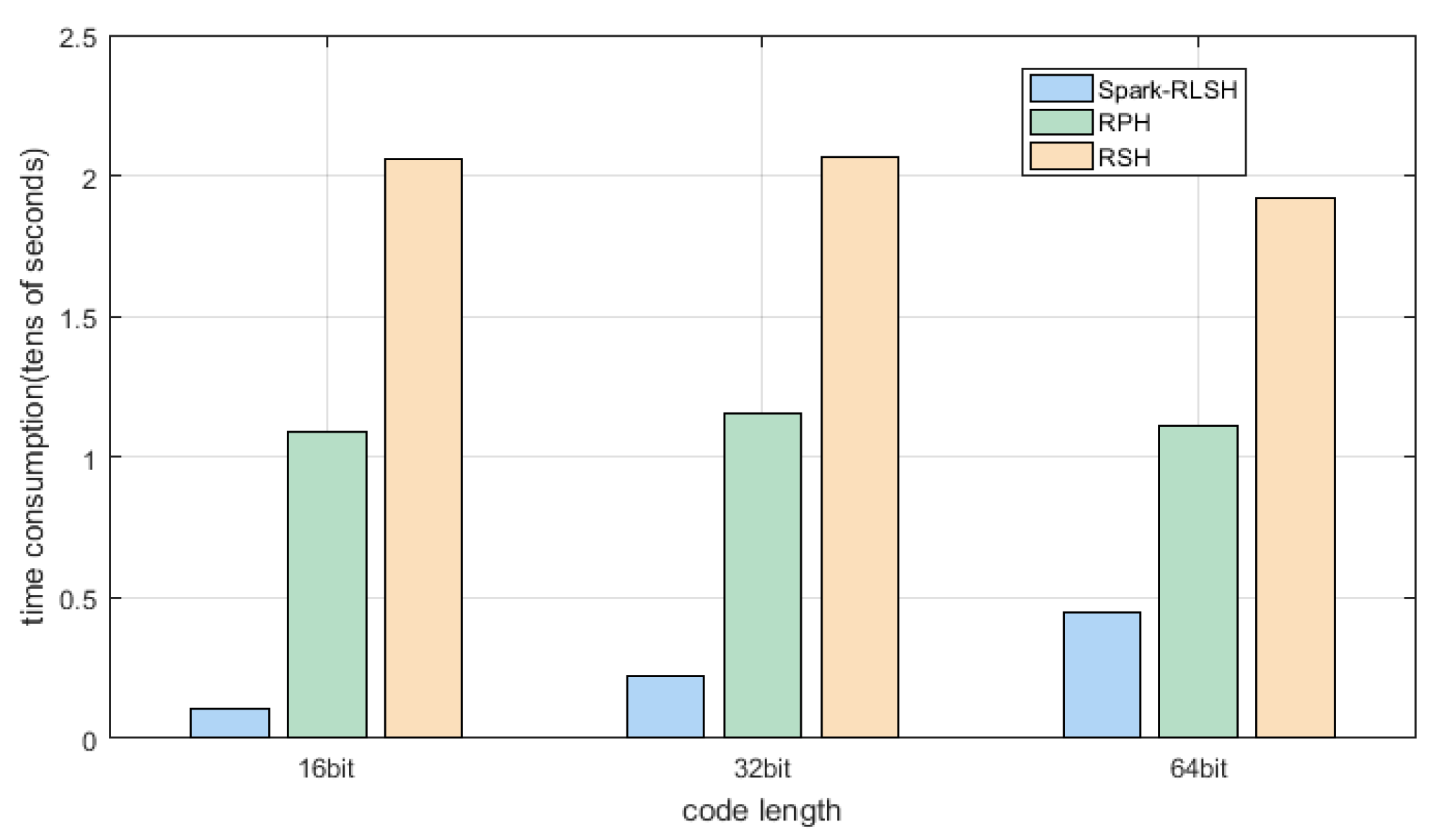
Experiments compare the time required for several hashing algorithms to iterate once when encoding lengths are 16, 32, and 64 bits in two data sets. It can be seen from Figure 3 and Figure 4 and Table 2 and Table 3 that both Spark-RLSH datasets have the shortest training times and the fastest running speeds. RSH and RPH have the longest training times due to their operation in the stand-alone environment. At the same time, with the linear increase of the coding length, the training time for Spark-RLSH also grows linearly, while for RSH and RPH, the two ranking-based hashing algorithms, the training time has nothing to do with the length of the code basically remains unchanged.
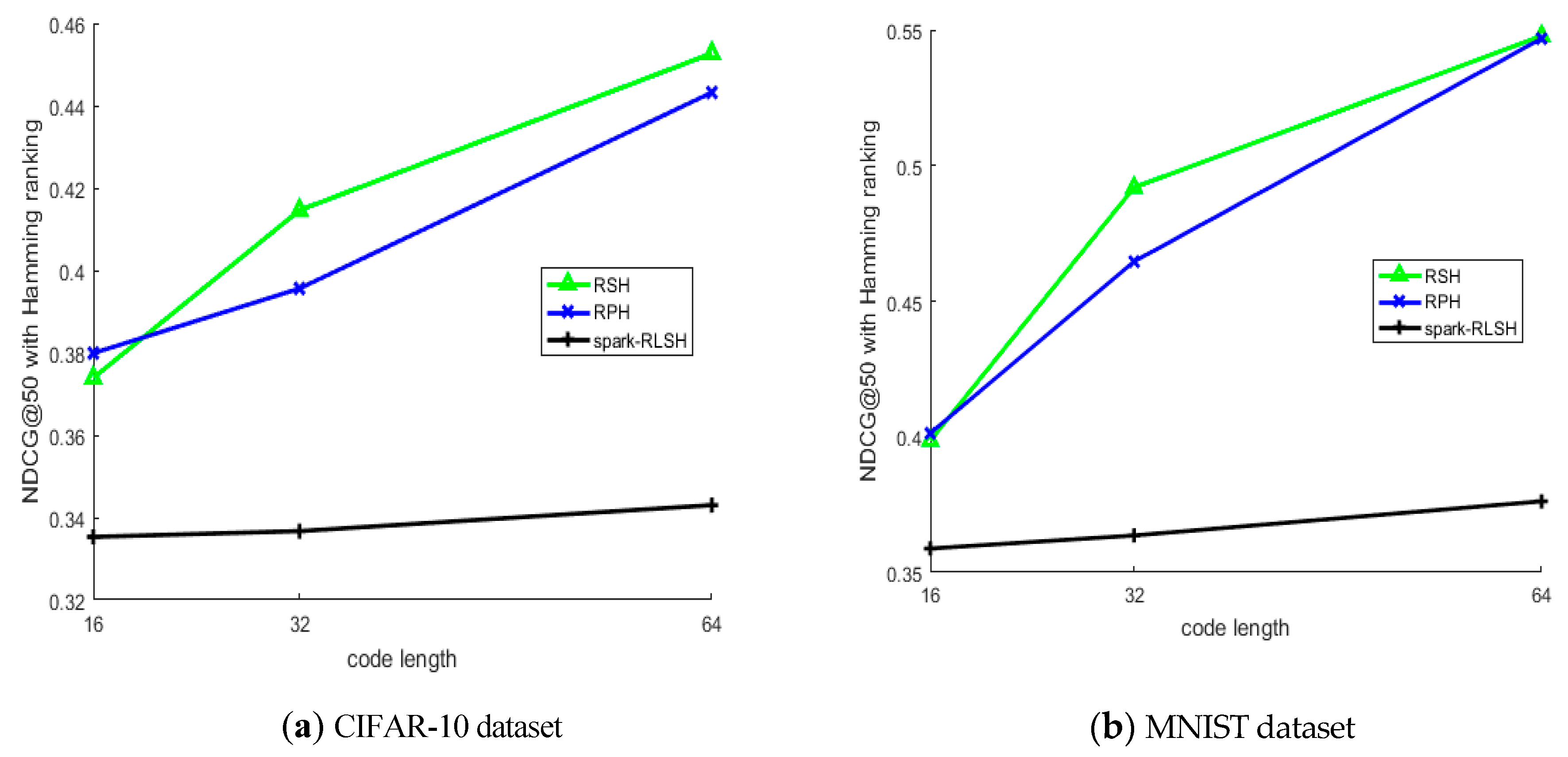
At the same time, Figure 5a,b also compares the top 50 normalized discounted cumulative gain (NDCG) values returned by the three ranking-based hashing algorithms for the two datasets. Although the NDCG value for Spark-RLSH is slightly lower than for RSH and RPH, considering the training time cost, this result is acceptable when the code length is short.
It can be seen from this result that the ranking-based hashing algorithm implemented on the Spark distributed platform can greatly shorten the training time of the algorithm and improve the training efficiency.
6. Conclusion
This paper introduces the running architecture and working principle of Spark in detail, and proposes the basic principle and algorithm-specific flow of the ranking-based hashing algorithm implemented on the distributed Spark platform. Here, we divide large datasets into small datasets with the same number of working nodes, and compare the ranking of the query set and the small dataset in the Euclidean space and the Hamming space for each working node. Finally, we construct the loss function and run the gradient descent method until the function converges or reaches the number of iterations that minimizes total loss.
Experiments show that the Spark distributed platform can effectively reduce the training time of the model and greatly improve the training efficiency. In the future, we can consider the following points to improve the existing ranking-based hashing algorithm:
- Improvements in the ranking formula. After converting the data points into binary codes, all the data needs to be ranked according to Hamming distance, and then the ranking list can be constructed. This requires comparison between every two points, so that the time complexity of the designed ranking algorithm is too high, which can seriously affect the training efficiency. Later, we can consider redesigning the ranking formula to run the algorithm model with the lowest cost.
- The gradient descent method is implemented as a whole on the distributed platform. This paper considers the complexity of the algorithm in the ranking process. Each working node runs the algorithm model and implements the gradient descent method independently. Although this method can reduce the training time of the model effectively, there is no overall calculation gradient, and there is a certain training error. In the future, the overall comparison of the Hamming distance between the query set and the dataset can be considered, which can improve the accuracy of the search and reduce the training time simultaneously.
Author Contributions
Formal analysis, A.Y. and J.Q.; Funding acquisition, J.Q. and Y.D.; Methodology, J.Q. and H.C.; Software, A.Y; Writing—original draft, A.Y.; Writing—review and editing, A.Y. and J.Q. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by ZHEJIANG NSF(National Science Foundation), grant number LZ20F020001 and LY20F020009, CHINA NSF grant number 61472194 and 61572266, as well as programs sponsored by K.C. Wong Magna Fund in Ningbo University.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Indyk, P. Nearest Neighbors in High-Dimensional Spaces. Discrete Math. Its Appl. 2004, 20042571. [Google Scholar]
- Arya, S.; Mount, D.M.; Netanyahu, N.S.; Silverman, R.; Wu, A.Y. An Optimal Algorithm for Approximate Nearest Neighbor Searching. J. ACM 1998, 45, 91–923. [Google Scholar] [CrossRef] [Green Version]
- Guttman, A. R-trees: A Dynamic Index Structure for Spatial Searching. In ACM SIGMOD International Conference on Management of Data; SIGMOD: New York, NY, USA, 1984; pp. 47–57. [Google Scholar]
- Bentley, J.L. K-d trees for semidynamic point sets. Annu. Symp. 1990, 187–197. [Google Scholar]
- Datar, M.; Immorlica, N.; Indyk, P.; Mirrokni, V. Locality-sensitive hashing scheme based on p-stable distributions. Annu. Symp. 2004, 253–262. [Google Scholar]
- Wangb, J.; Zhang, T.; Song, J.; Sebe, N.; Shen, H.T. A Survey on Learning to Hash. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 769–790. [Google Scholar] [CrossRef] [PubMed]
- Kulis, B.; Grauman, K. Kernelized Locality-Sensitive Hashing. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 34, 1092–1104. [Google Scholar] [CrossRef] [PubMed]
- Weiss, Y.; Torralba, A.; Fergus, R. Spectral Hashing. Available online: https://people.csail.mit.edu/torralba/publications/spectralhashing.pdf (accessed on 7 March 2020).
- Zhang, D.; Wang, J.; Cai, D.; Lu, J. Self-taught hashing for fast similarity search. In Proceedings of the 33rd international ACM SIGIR conference, New York, NY, USA, 19 July 2010; pp. 18–25. [Google Scholar]
- Fu, H.; Kong, X.; Lu, J. Large-scale image retrieval based on boosting iterative quantization hashing with query-adaptive reranking. Neurocomputing 2013, 122, 480–489. [Google Scholar] [CrossRef]
- Wu, G.; Han, J.; Guo, Y.; Liu, L.; Ding, G.; Ni, Q.; Shao, L. Unsupervised Deep Video Hashing via Balanced Code for Large-Scale Video Retrieval. IEEE Trans. Image Process. 2018, 28, 1993–2007. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lin, R.-S.; Ross, D.A.; Yagnik, J. SPEC Hashing: Similarity Preserving Algorithm for Entropy-Based Coding; In Proceedings of the 2010 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), San Francisco, CA, USA2010; pp. 848–854. [Google Scholar]
- Norouzi, M.; Blei, D.M. Minimal Loss Hashing for Compact Binary Codes; In Proceedings of the International Machine Learning Society (IMLS), 28 June–2 July 2011; pp. 353–360. [Google Scholar]
- Liu, W.; Wang, J.; Ji, R.; Jiang, Y.-G.; Chang, S.-F. Supervised hashing with kernels. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 2074–2081. [Google Scholar]
- Shen, F.; Shen, C.; Liu, W.; Shen, H.T. Supervised Discrete Hashing. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 37–45. [Google Scholar]
- Yao, T.; Kong, X.; Fu, H.; Tian, Q. Discrete Semantic Alignment Hashing for Cross-Media Retrieval. IEEE Trans. Cybern. 2019, 1–12. [Google Scholar] [CrossRef] [PubMed]
- Strecha, C.; Bronstein, A.M.; Bronstein, M.M.; Fua, P. LDAHash: Improved Matching with Smaller Descriptors. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 34, 66–78. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lin, G.; Shen, C.; Wu, J. Optimizing Ranking Measures for Compact Binary Code Learning. In Proceedings of the 13th European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; Volume 8691, pp. 613–627. [Google Scholar]
- Wang, J.; Wangb, J.; Yu, N.; Li, S. Order preserving hashing for approximate nearest neighbor search. In Proceedings of the 21st ACM international conference on Multimedia—MM’13, Nara, Japan, 21 October 2013; pp. 133–142. [Google Scholar]
- Ji, T.; Liu, X.; Deng, C.; Huang, L.; Lang, B. Query-Adaptive Hash Code Ranking for Fast Nearest Neighbor Search. In Proceedings of the ACM International Conference on Interactive Experiences for TV and Online Video—TVX’16; Association for Computing Machinery (ACM), Newcastle, UK, 3 November 2014; pp. 1005–1008. [Google Scholar]
- Song, D.; Liu, W.; Ji, R.; Meyer, D.; Smith, J.R. Top Rank Supervised Binary Coding for Visual Search. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1922–1930. [Google Scholar]
- Song, D.; Liu, W.; Meyer, D.; Tao, D.; Ji, R.D.A.M. Rank Preserving Hashing for Rapid Image Search. In Proceedings of the 2015 Data Compression Conference. In Proceedings of the Institute of Electrical and Electronics Engineers (IEEE), Snowbird, UT, USA, 7–9 April 2015; pp. 353–362. [Google Scholar]
- Jiang, Y.-G.; Wang, J.; Xue, X.; Chang, S.-F. Query-Adaptive Image Search with Hash Codes. IEEE Trans. Multimedia 2012, 15, 442–453. [Google Scholar] [CrossRef]
- Zhang, X.; Zhang, L.; Heung-Yeung, S. QsRank:Query-sensitive Hash Code Ranking for Efficient ε-nighbor Search. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Providence, RI, USA, 16–21 June 2012. [Google Scholar]
- Li, X.; Lin, G.; Shen, C.; Hengel, A.V.D.; Dick, A. Learning Hash Functions Using Column Generation. arXiv 2013, arXiv:1303.0339. [Google Scholar]
- Norouzi, M.; Fleet, D.J.; Salakhutdinov, R. Hamming Distance Metric Learning. In Proceedings of the Twenty-sixth Conference on Neural Information Processing Systems, Lake Tahoe, NA, USA, 3–8 December 2012. [Google Scholar]
- Wang, J.; Liu, W.; Sun, A.X.; Jiang, Y.-G. Learning Hash Codes with Listwise Supervision. In Proceedings of the 2013 IEEE International Conference on Computer Vision, Sydney, Australia, 2–3 June 2013; pp. 3032–3039. [Google Scholar]
- Wang, Q.; Zhang, Z.; Si, L. Ranking Preserving Hashing for Fast Similiarity Search. In Proceedings of the Twenty-Fourth International Joint Conference on Artificial Intelligence, Buenos Aires, Argentina, 27 June 2015. [Google Scholar]
- Yao, T.; Long, F.; Mei, T.; Rui, Y. Deep Semantic Preserving and Ranking-based Hashing for Image Retrieval. In Proceedings of the Twenty-Fourth International Joint Conference on Artificial Intelligence, Buenos Aires, Argentina, 9 July 2016. [Google Scholar]
- Liu, L.; Shao, L.; Shen, F.; Yu, M. Discretely Coding Semantic Rank Orders for Supervised Image Hashing. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 5140–5149. [Google Scholar]
Figure 1.
Conceptual diagram of listwise supervised ranking-based hashing algorithm.

Figure 2.
The running framework of Spark-RLSH.

Figure 3.
The training time diagram of different length codes for CIFAR-10 datasets.

Figure 4.
The training time diagram of different length codes for MNIST datasets.

Figure 5.
Top 50 normalized discounted cumulative gain (NDCG) values from different datasets. (a) CIFAR-10 dataset, (b) MNIST dataset.
Figure 5.
Top 50 normalized discounted cumulative gain (NDCG) values from different datasets. (a) CIFAR-10 dataset, (b) MNIST dataset.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
Configuration of software environment for experimental clusters.
| Software Environment | Configuration |
|---|---|
| Operation System | Ubuntu 14.04 |
| Hadoop | Hadoop 2.7.6 |
| Spark | Spark 2.3.0 |
| Java | jdk-8u172 |
| Python | Python 3.5.2 |
Table 2.
Comparison of training times of different algorithms for CIFAR-10 datasets.
| 16 bit | 32 bit | 64 bit | |
|---|---|---|---|
| RPH | 5000.68 | 5420.92 | 5087.96 |
| RSH | 9803.62 | 9388.89 | 9162.93 |
| RLSH | 26478.66 | 51835.27 | 104892.85 |
| Spark-RLSH | 395.77 | 796.71 | 1602.98 |
Table 3.
Comparison of training times of different algorithms for MNIST datasets.
| 16 bit | 32 bit | 64 bit | |
|---|---|---|---|
| RPH | 10889.39 | 11542.78 | 11095.41 |
| RSH | 20577.43 | 20629.58 | 19171.19 |
| RLSH | 46302.18 | 93483.59 | 191638.21 |
| Spark-RLSH | 1073.69 | 2204.01 | 4495.96 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Yang, A.; Qian, J.; Chen, H.; Dong, Y. A Ranking-Based Hashing Algorithm Based on the Distributed Spark Platform. Information 2020, 11, 148. https://0-doi-org.brum.beds.ac.uk/10.3390/info11030148
AMA Style
Yang A, Qian J, Chen H, Dong Y. A Ranking-Based Hashing Algorithm Based on the Distributed Spark Platform. Information. 2020; 11(3):148. https://0-doi-org.brum.beds.ac.uk/10.3390/info11030148
Chicago/Turabian StyleYang, Anbang, Jiangbo Qian, Huahui Chen, and Yihong Dong. 2020. "A Ranking-Based Hashing Algorithm Based on the Distributed Spark Platform" Information 11, no. 3: 148. https://0-doi-org.brum.beds.ac.uk/10.3390/info11030148
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.