1. Introduction
Emotions are the inner feelings of human beings and expressions are the windows of human emotions. A micro-expression on the face is a unique expression that happens spontaneously. When humans try to conceal their true emotions, the restrained feelings are shown by fast muscular movement out of a spontaneous physical reaction [
1]. Therefore, a micro-expression is one of the foundations for the judgment of human psychological status.
In contrast to normal facial expressions that usually sustained 1/2 s to 4 s [
2], the micro-expressions of humans last so short that they tend to be neglected. The duration of a micro-expression is only 1/25 s to 1/5 s with low intensity [
3]. Porter suggested that micro-expressions are generated by parts of human faces as the result of muscular movement [
4]. The micro-expression recognition is more difficult than the macro one because of its features.
Thanks to the development of artificial intelligence, the human–computer interaction better facilitates the study of micro-expression recognition. Specifically, Hinton proposed the concept of deep learning in 2006 [
5], which is an important branch of machine learning. Deep learning excelled at feature extraction and categorization in image recognition. More and more researchers made breakthroughs by combining machine learning or deep learning with micro-expression recognition [
6,
7,
8].
Different from macro-expressions, micro-expressions consist of facial muscle movement with low intensity and short duration. What is more, this facial muscle movement tends to happen in some small but specific facial regions. For example, the macro-expression of happiness will involve the movement of action unit (AU)6 and AU12 with high intensity, which results in the raise of cheeks, wrinkling of outer corner of eyes, smaller of eye region, open of mouth or raise of mouth corner. However, the micro-expression of happiness will involve low intensity of AU12 or AU6, which results in the slight raise of the mouth corner or smaller of eye area. Therefore, for the recognition of micro-expression, we may focus on the mouth corner and eye regions without paying attention to other regions of the face. The attention model is a suitable method for performing this attention mechanism. It is thus used in this research.
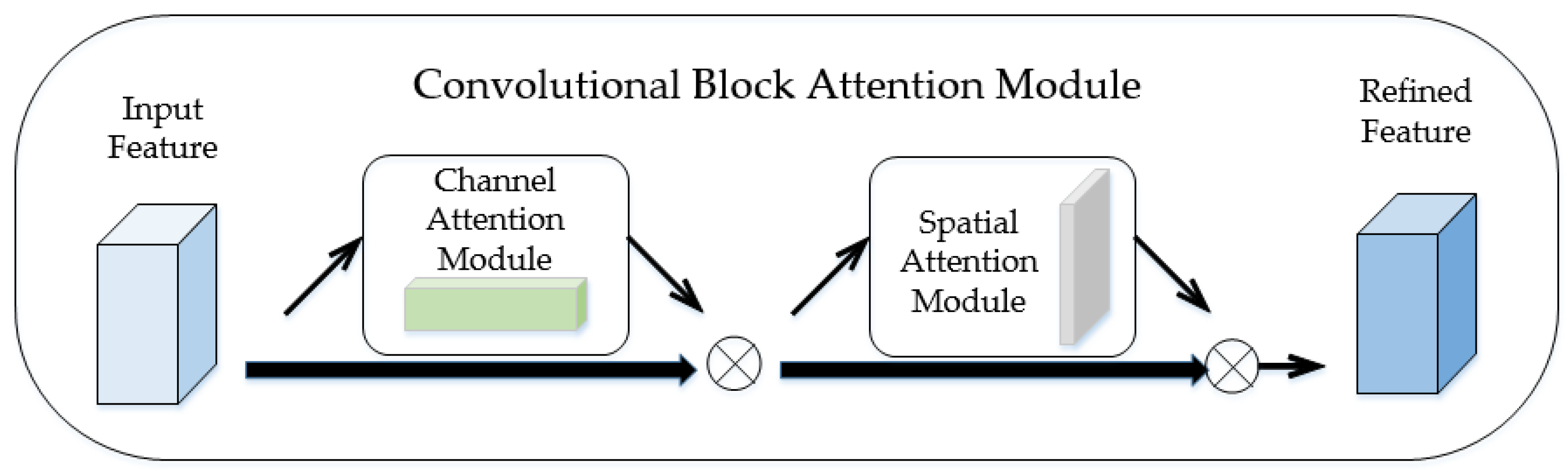
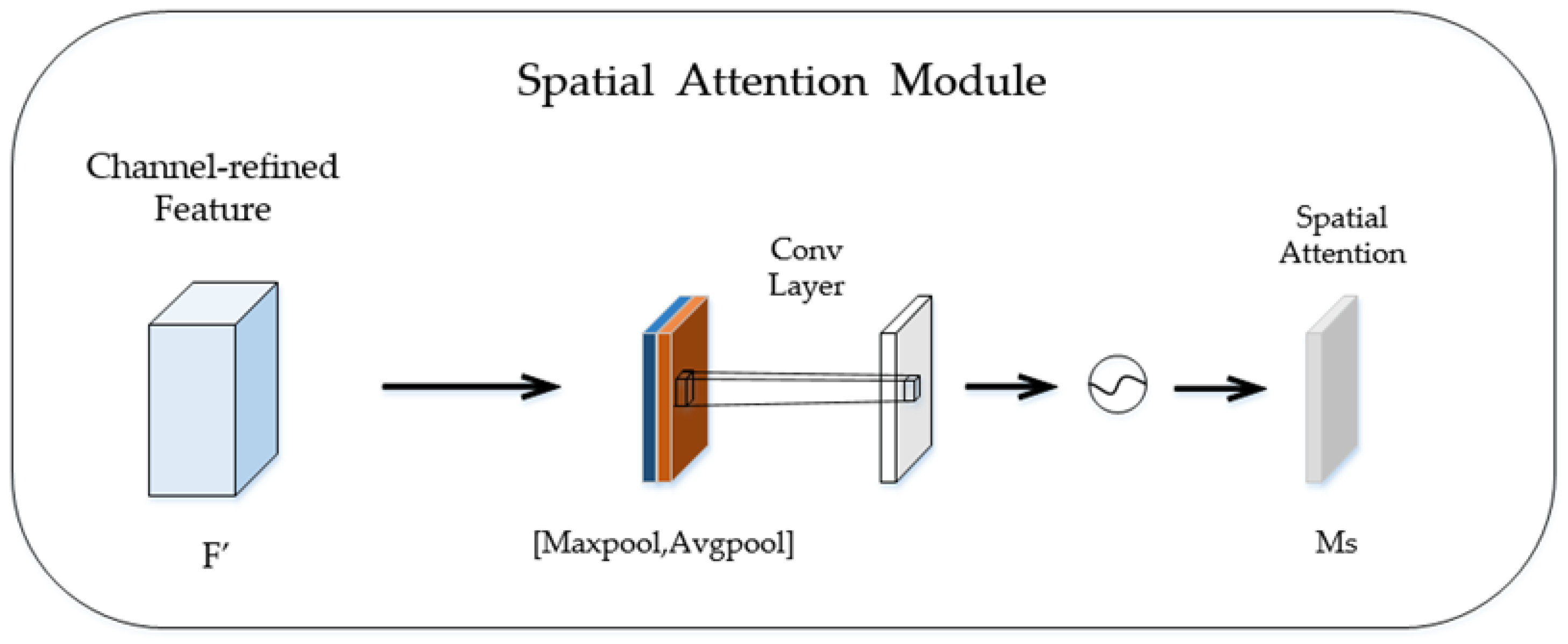
The attention mechanism was added to the designed deep convolutional neural network (CNN) for micro-expression recognition. This method can not only extract the overall features of human faces, but also concentrate on some key features. Since micro-expressions only occur in parts of the human face, the attention mechanism helps to focus on specific facial regions, learning and acquiring the important features.
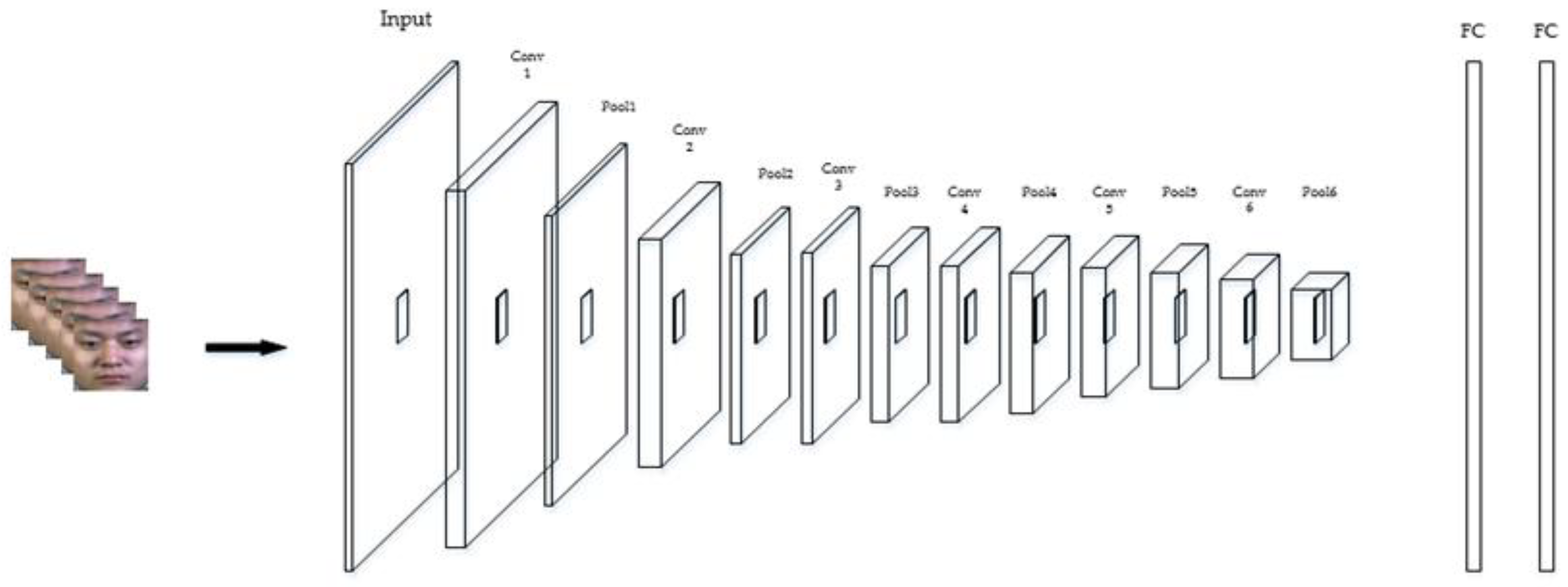
In our work, we designed a three-dimensional convolutional neural network (3D CNN) to learn spatiotemporal information, and a convolutional block attention module (CBAM) was appended after the 3D CNN. The proposed method was able to learn the information at the target domain effectively and to emphasize the features at important regions and this improved the ability of feature extraction.
The contributions of this study contain three aspects:
- (1)
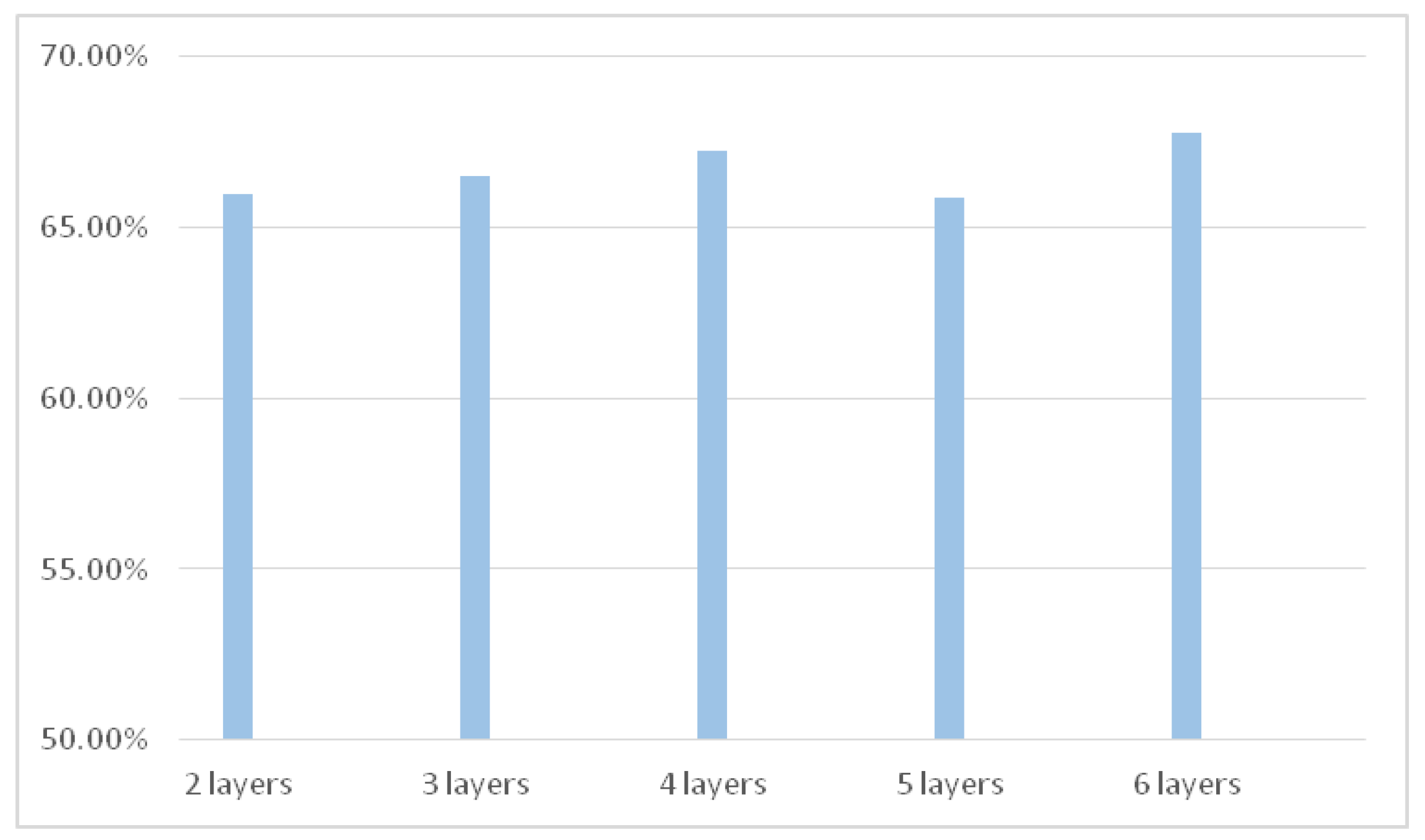
this study designed a six-layer 3D CNN and took the whole face into the network for micro-expression recognition;
- (2)
the researchers reached the optimized network structure by monitoring the recognition accuracy while decreasing the convolutional layers successively on the basis of the existed network;
- (3)
this study combined the convolutional block attention module (CBAM) with its 3D CNN to simulate visual attention mechanism and enhance the information flows in channels and spaces.
2. Related Works
Polikovsky and other researchers [
9] divided human faces into specific regions according to facial action coding system (FACS), based on which they proposed the 3D-gradient direction histogram for movement description. To extend the general texture features to the dynamic ones, Zhao et al. [
10] proposed a feature descriptor named as local binary patterns on three orthogonal planes (LBP-TOP) for micro-expression recognition. This method achieved better accuracy. Pfister et al. [
11] normalized videos of different lengths on the basis of a temporal interpolation model. Meanwhile, they extracted the image features with the help of the spatiotemporal local texture descriptors (SLTDs) in combination with multi-kernel learning (MKL) to recognize micro-expressions. Furthermore, Wang et al. [
12] proposed the method of tensor independent color space (TICS) from the perspective of color space. This model extracted the dynamic texture features from the color components with better performance. Moreover, Liu et al. [
13] proposed the method of main directional mean optical flow (MDMO), which used optical flow estimation technology to calculate the subtle motion of 36 regions of interest (ROIs). In addition, they aligned all the frames in the video clips of micro-expressions in the approach driven by optical flows.
These traditional methods for feature extraction have contributed significantly to the micro-expression researches. However, the approaches mentioned above do not achieve high accuracy in micro-expression recognition. As compensation for inefficiency, deep learning is able to advance the capability of feature presentations.
Deep learning has been gradually applied to computer vision [
14], natural language processing [
15], and other fields. In this context, a growing number of researchers have applied neural network to various tasks in the study of micro-expressions, such as detection, recognition, etc.
One of the most popular methods in the study of deep learning is CNN. Since the popularity of the LeNet [
16], designed by LeCun in 1998, various network structures have been designed (e.g., AlexNet [
17], GoogleNet [
14], VGG-Net [
18], etc.). They have been widely applied in fields of facial recognition and voice recognition. However, these models are confined to two-dimensional data processing. In recent years, researchers have utilized 3D CNN in consideration of the temporal dimension.
Peng et al. [
19] employed a 3D CNN with the dual temporal scale in micro-expression recognition. After computing the optical flow of two video clips which had different numbers of frames, the dual temporal scale network with the support vector machine (SVM) generated satisfactory results. In addition, Li et al. [
20] presented a micro-expression recognition method based on the image sequence (i.e., introducing both the gray sequence and the optical flow sequence to a 3D CNN). This 3D CNN could catch subtle motion flows, promoting recognition accuracy. On the other hand, Reddy et al. [
21] testified the feature fusion of eyes and mouth as well as features on the whole face, concluding that learning the facial features on the whole face accomplished the micro-expression recognition task better with the help of two kinds of spatiotemporal CNNs. In consideration of overfitting that might occur when using small sample data in deep network, Peng et al. [
22] applied fine-tuning on the micro-expression database after pre-training ResNet 10 on the macro-expression database from the perspective of transfer learning. Xia et al. [
7] proposed spatiotemporal recurrent convolutional networks to capture the spatiotemporal feature from micro-expression video clips. They also adopted temporal data augmentation strategies to enlarge training data and proposed a balanced loss mechanism, which showed its effectiveness on spontaneous micro-expression databases. Verma et al. [
6] utilized a dynamic imaging technique to convert the sequence into a frame of image sequences, and proposed a Lateral Accretive Hybrid Network (LEARNet) to learn the subtle features of the face area, which involves the cross decoupled relationship between convolution layers. Based on the standard micro-expression databases, the results of the proposed algorithm were improved to a certain extent compared with ResNet.
Author Contributions
Conceptualization, B.C., Z.Z. and T.C.; Methodology, B.C., and T.C.; Data curation, Z.Z. and X.L.; Formal analysis, N.L. and Y.T.; Validation, B.C.; all authors wrote the paper. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Ekman, P. Darwin, deception, and facial expression. Ann. N. Y. Acad. Sci. 2003, 1000, 205–221. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ekman, P. Emotions Revealed: Recognizing Faces and Feelings to Improve Communication and Emotional Life; Henry Holt and Company: New York, NY, USA, 2003. [Google Scholar]
- Yan, W.J.; Wu, Q.; Liang, J.; Chen, Y.H.; Fu, X. How fast are the leaked facial expressions: The duration of micro-expressions. J. Nonverbal. Behav. 2013, 37, 217–230. [Google Scholar] [CrossRef]
- Porter, S.; Brinke, L.T. Reading between the lies: Identifying concealed and falsified emotions in universal facial expressions. Psychol. Sci. 2008, 19, 508–514. [Google Scholar] [CrossRef]
- Hinton, G.E.; Osindero, S.; Teh, Y.W. A fast learning algorithm for deep belief nets. Neural. Comput. 2006, 18, 1527–1554. [Google Scholar] [CrossRef] [PubMed]
- Verma, M.; Vipparthi, S.K.; Singh, G.; Murala, S. Learnet: Dynamic imaging network for micro expression recognition. IEEE Trans. Image Process. 2020, 29, 1618–1627. [Google Scholar] [CrossRef] [Green Version]
- Xia, Z.Q.; Hong, X.P.; Gao, X.Y.; Feng, X.Y.; Zhao, G.Y. Spatiotemporal recurrent convolutional networks for recognizing spontaneous micro-expressions (vol 22, pg 626, 2020). IEEE Trans. Multimed. 2020, 22, 1111. [Google Scholar] [CrossRef]
- Wang, S.J.; Li, B.J.; Liu, Y.J.; Yan, W.J.; Ou, X.Y.; Huang, X.H.; Xu, F.; Fu, X.L. Micro-expression recognition with small sample size by transferring long-term convolutional neural network. Neurocomputing 2018, 312, 251–262. [Google Scholar] [CrossRef]
- Polikovsky, S.; Kameda, Y.; Ohta, Y. Facial micro-expressions recognition using high speed camera and 3D-gradient descriptor. In Proceedings of the 3rd International Conference on Imaging for Crime Detection and Prevention (ICDP 2009), London, UK, 3 December 2009. [Google Scholar]
- Zhao, G.Y.; Pietikainen, M. Dynamic texture recognition using local binary patterns with an application to facial expressions. IEEE Trans. Pattern Anal. 2007, 29, 915–928. [Google Scholar] [CrossRef] [Green Version]
- Pfister, T.; Li, X.; Zhao, G.; Pietikainen, M. Recognising Spontaneous Facial Micro-Expressions. In Proceedings of the International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 1449–1456. [Google Scholar]
- Wang, S.; Yan, W.; Li, X.; Zhao, G.; Fu, X. Micro-expression recognition using dynamic textures on tensor independent color space. In Proceedings of the International Conference on Pattern Recognition, Stockholm, Sweden, 24–28 August 2014; pp. 4678–4683. [Google Scholar]
- Liu, Y.J.; Zhang, J.K.; Yan, W.J.; Wang, S.J.; Zhao, G.Y.; Fu, X.L. A main directional mean optical flow feature for spontaneous micro-expression recognition. IEEE Trans. Affect. Comput. 2016, 7, 299–310. [Google Scholar] [CrossRef]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going Deeper with Convolutions. In Proceedings of the IEEE International Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Sutskever, I.; Vinyals, O.; Le, Q.V. Sequence to sequence learning with neural networks. In Advances in Neural Information Processing Systems; MIT Press: Montreal, QC, Canada, 2014. [Google Scholar]
- Lecun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef] [Green Version]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Peng, M.; Wang, C.Y.; Chen, T.; Liu, G.Y.; Fu, X.L. Dual temporal scale convolutional neural network for micro-expression recognition. Front. Psychol. 2017, 8, 1745. [Google Scholar] [CrossRef] [PubMed]
- Li, J.; Wang, Y.D.; See, J.; Liu, W.B. Micro-expression recognition based on 3D flow convolutional neural network. Pattern Anal. Appl. 2019, 22, 1331–1339. [Google Scholar] [CrossRef]
- Reddy, S.P.T.; Karri, S.T.; Dubey, S.R.; Mukherjee, S. Spontaneous facial micro-expression recognition using 3D spatiotemporal convolutional neural networks. In Proceedings of the 2019 International Joint Conference on Neural Networks, Budapest, Hungary, 14–19 July 2019; pp. 1–8. [Google Scholar]
- Peng, M.; Wu, Z.; Zhang, Z.; Chen, T. From macro to micro expression recognition: Deep learning on small datasets using transfer learning. In Proceedings of the IEEE International Conference on Automatic Face Gesture Recognition, Xi’an, China, 15–19 May 2018; pp. 657–661. [Google Scholar]
- Ji, S.W.; Xu, W.; Yang, M.; Yu, K. 3D convolutional neural networks for human action recognition. IEEE Trans. Pattern Anal. 2013, 35, 221–231. [Google Scholar] [CrossRef] [Green Version]
- Woo, S.; Park, J.; Lee, J.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the 15th European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Peng, M.; Wang, C.; Chen, T.; Liu, G. Nirfacenet: A convolutional neural network for near-infrared face identification. Inf. Int. Interdiscip. J. 2016, 7, 61. [Google Scholar] [CrossRef] [Green Version]
- Yan, W.J.; Li, X.B.; Wang, S.J.; Zhao, G.Y.; Liu, Y.J.; Chen, Y.H.; Fu, X.L. Casme ii: An improved spontaneous micro-expression database and the baseline evaluation. PLoS ONE 2014, 9, e86041. [Google Scholar] [CrossRef]
- Yan, W.; Wu, Q.; Liu, Y.; Wang, S.; Fu, X. Casme database: A dataset of spontaneous micro-expressions collected from neutralized faces. In Proceedings of the IEEE International Conference on Automatic Face Gesture Recognition, Shanghai, China, 22–26 April 2013; pp. 1–7. [Google Scholar]
- Gan, Y.S.; Liong, S.; Yau, W.; Huang, Y.; Tan, L. Off-apexnet on micro-expression recognition system. Signal Process. Image Commun. 2019, 74, 129–139. [Google Scholar] [CrossRef] [Green Version]
- Liong, S.; Gan, Y.S.; See, J.; Khor, H.; Huang, Y. Shallow triple stream three-dimensional cnn (ststnet) for micro-expression recognition. In Proceedings of the IEEE International Conference on Automatic Face Gesture Recognition, Lille, France, 14–18 May 2019; pp. 1–5. [Google Scholar]
- Li, X.; Pfister, T.; Huang, X.; Zhao, G.; Pietikainen, M. A spontaneous micro-expression database: Inducement, collection and baseline. In Proceedings of the IEEE International Conference on Automatic Face Gesture Recognition, Shanghai, China, 22–26 April 2013; pp. 1–6. [Google Scholar]
- Asthana, A.; Zafeiriou, S.; Cheng, S.; Pantic, M. Robust Discriminative Response Map Fitting with Constrained Local Models. In Proceedings of the IEEE Conference Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 3444–3451. [Google Scholar]
- Wu, H.Y.; Rubinstein, M.; Shih, E.; Guttag, J.; Durand, F.; Freeman, W. Eulerian video magnification for revealing subtle changes in the world. ACM Trans. Graph. 2012, 31, 1–48. [Google Scholar] [CrossRef]
- Smolic, A.; Muller, K.; Dix, K.; Merkle, P.; Kauff, P.; Wiegand, T. Intermediate view interpolation based on multiview video plus depth for advanced 3D video systems. In Proceedings of the International Conference on Image Processing, San Diego, CA, USA, 12–15 October 2008; pp. 2448–2451. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- ZHI, R.; XU, H.; WAN, M.; LI, T. Combining 3D convolutional neural networks with transfer learning by supervised pre-training for facial micro-expression recognition. IEICE Trans. Inf. Syst. 2019, 102, 1054–1064. [Google Scholar] [CrossRef] [Green Version]
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}