Mobile Money Fraud Prediction—A Cross-Case Analysis on the Efficiency of Support Vector Machines, Gradient Boosted Decision Trees, and Naïve Bayes Algorithms



Abstract
:1. Introduction
2. Related Work
3. The Mobile Money Ecosystem
3.1. The Case of the Unbanked in the Developing World
- In the developing world, banking is considered a prerogative for the rich in society since they can afford the regular and expensive fees that come with regular banking.
- Banking is considered to be “something” for those in urban areas where banks are easily accessible [31]
- People tend to avoid the patronage of the traditional banking system due to overcrowding, slow access to services, and the continuous excuse of “network down” so we can not serve you.
- Banks are few which translates to the fact that people have to travel long distances on deplorable roads coupled with the additional risk of being attacked by thieves.
- Cumbersome account opening requirements [20].
3.2. Regulating MMTs, the Role of Central Banks and Telecommunication Companies
- Discourage the use of physical cash for transactions and
- Enable the integration of an electronic payment system
- Limiting the spread of the COVID-19 virus by encouraging digital payments
- Easing the burden of the living cost on people who use digital payments through the following measures such as
- Waiving P-2-P transaction fees
- Support for mobile money agents
- Waiving interchange fees.
4. Machine Learning Algorithms
- Definition of an objective
- Collection of relevant data in line with the objective
- Preparing and preprocessing the data
- Selection of the relevant machine learning algorithm
- Training the selected ML algorithm with the preprocessed data from step 3
- Testing the trained ML algorithm in step 5 with the test data
- Testing the fitness of the model and adjusting where necessary
- Performing predictions or classifications with the model
- Deploying the model to solve real-world problems
- Supervised
- Unsupervised
- Reinforced machine learning.
4.1. Support Vector Machines
4.2. Decision Tree
4.3. Entropy
4.4. Information Gain
4.5. Gini Index
4.6. Gradient Boosted Decision Tree
4.7. Naïve Bayes
5. The Dataset, Experimental Setup and Methods
5.1. The Dataset
- type—CASH-IN, CASH-OUT, DEBIT, PAYMENT, and TRANSFER, which are the main types of transactions under MMT.
- amount—amount of the transaction in local currency.
- nameOrig—customer who started the transaction
- oldbalanceOrg—initial balance before the transaction
- newbalanceOrig—new balance after the transaction
- nameDest—customer who is the recipient of the transaction
- oldbalanceDest—initial balance recipient before the transaction
- newbalanceDest—new balance recipient after the transaction.
- isFraud—This is the transaction made by the fraudulent.
- isFlaggedFraud—The business model aims to control massive transfers from one account to another and flags illegal attempts. An illegal attempt in this dataset is an attempt to transfer more than 200,000 in a single transaction.
5.2. Model Construction
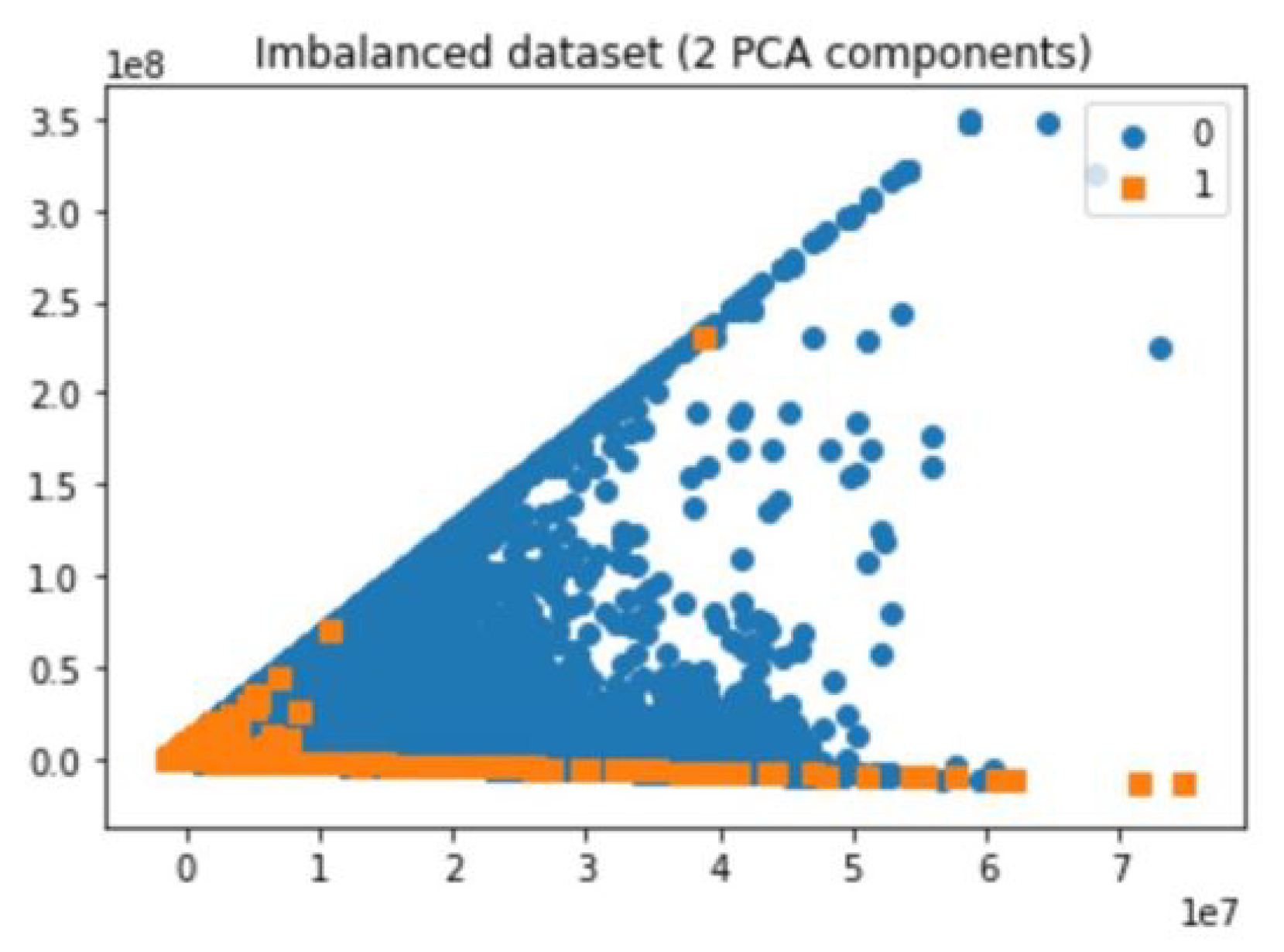
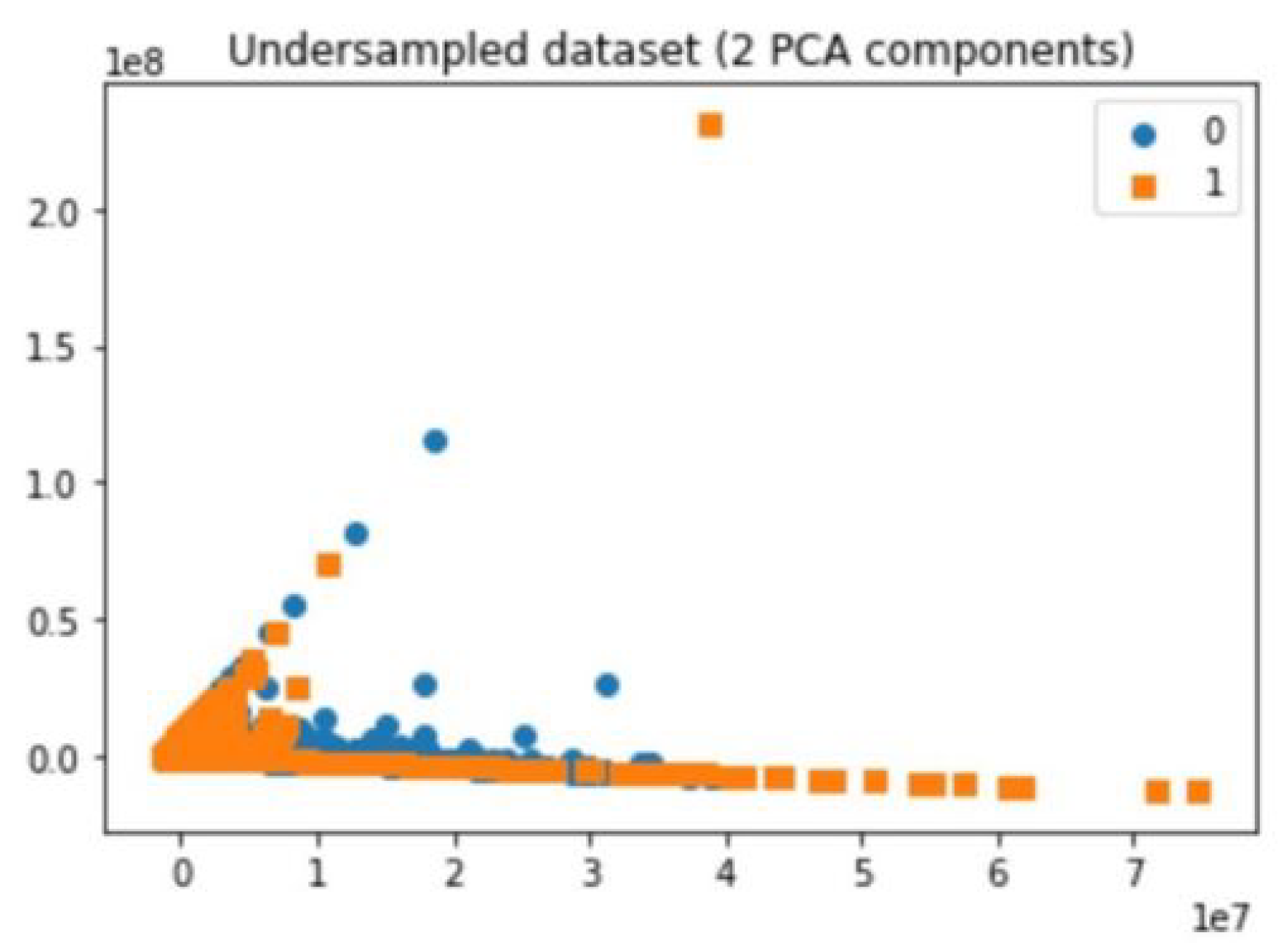
5.3. Undersampling
5.4. Random Undersampler
5.5. NearMiss
5.6. Tomek Links
5.7. Oversampling
5.8. Random Oversampler
5.9. Synthetic Minority Oversampling Technique (SMOTE)
- A minority class A is set and for each , the k-nearest neighbors of x are obtained by performing calculations to obtain the Euclidean distance between x and all other samples in that set A.
- A sampling rate N is set according to the imbalanced proportion. That is for each , N examples are randomly chosen from its k-nearest neighbor and they construct the new set .
- For each sample the formula used to generate a new sample is in which represents the random numbers between 0 and 1.
5.10. Combining Undersampling and Oversampling
5.11. SMOTETomek
6. Performance Evaluation
7. Results and Discussion
7.1. Results
7.2. Discussion
8. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| FinTech | Financial Technology |
| MMT | Mobile Money Transaction |
| SMS | Short Message Services |
| SVM | Support Vector Machine |
| RBF | Radial Basis Function |
| SMOTE | Synthetic Minority Oversampling Technique |
| ADASYN | Adaptive Synthetic Sampling |
| GI | Gini Index |
| PCA | Principal Component Analysis |
| TP | True Positive |
| FP | False Positive |
| FN | False Negative |
| TN | True Negative |
| TPR | True Positive Rate |
| FNR | False Negative Rate |
| FPR | False Positve Rate |
| TNR | True Negative Rate |
| NB | Naïve Bayes |
| BN | Bernoulli |
| GS | Gaussian |
| MN | Multinomial |
| GBDT | Gradient Boosted Decision Tree |
| NGO | Non-Governmental Organization |
| P-2-P | Peer-to-Peer |
| SMS | Short Message Services |
| NCA | National Communications Authority |
| GSMA | Global System for Mobile Communication |
References
- Guo, J.; Bouwman, H. An ecosystem view on third party mobile payment providers: A case study of Alipay wallet. Info 2016, 18, 56–78. [Google Scholar] [CrossRef] [Green Version]
- Cao, Q.; Niu, X. Integrating context-awareness and UTAUT to explain Alipay user adoption. Int. J. Ind. Ergon. 2019, 69, 9–13. [Google Scholar] [CrossRef]
- Akomea-Frimpong, I.; Andoh, C.; Akomea-Frimpong, A.; Dwomoh-Okudzeto, Y. Control of fraud on mobile money services in Ghana: An exploratory study. J. Money Laund. Control 2019, 22, 300–317. [Google Scholar] [CrossRef]
- Available online: https://www.ghanaweb.com/GhanaHomePage/NewsArchive/Momo-fraud-How-scammers-steal-your-money-791051 (accessed on 5 June 2020).
- Available online: https://www.graphic.com.gh/business/business-news/ghana-news-momo-fraud-threatens-emerging-payment-technologies.html (accessed on 5 June 2020).
- Available online: https://www.ghanabusinessnews.com/2019/09/18/mtn-ghana-tackles-mobile-money-fraud (accessed on 5 June 2020).
- de Sá, A.G.; Pereira, A.C.; Pappa, G.L. A customized classification algorithm for credit card fraud detection. Eng. Appl. Artif. Intell. 2018, 72, 21–29. [Google Scholar] [CrossRef]
- Hajek, P.; Henriques, R. Mining corporate annual reports for intelligent detection of financial statement fraud–A comparative study of machine learning methods. Knowl.-Based Syst. 2017, 128, 139–152. [Google Scholar] [CrossRef]
- Sadgali, I.; Sael, N.; Benabbou, F. Performance of machine learning techniques in the detection of financial frauds. Procedia Comput. Sci. 2019, 148, 45–54. [Google Scholar] [CrossRef]
- Singh, G.; Gupta, R.; Rastogi, A.; Chandel, M.D.; Ahmad, R. A machine learning approach for detection of fraud based on svm. Int. J. Sci. Eng. Technol. 2012, 1, 192–196. [Google Scholar]
- Jurgovsky, J.; Granitzer, M.; Ziegler, K.; Calabretto, S.; Portier, P.E.; He-Guelton, L.; Caelen, O. Sequence classification for credit-card fraud detection. Expert Syst. Appl. 2018, 100, 234–245. [Google Scholar] [CrossRef]
- Ryman-Tubb, N.F.; Krause, P.; Garn, W. How Artificial Intelligence and machine learning research impacts payment card fraud detection: A survey and industry benchmark. Eng. Appl. Artif. Intell. 2018, 76, 130–157. [Google Scholar] [CrossRef]
- Kotsiantis, S.; Koumanakos, E.; Tzelepis, D.; Tampakas, V. Forecasting fraudulent financial statements using data mining. Int. J. Comput. Intell. 2006, 3, 104–110. [Google Scholar]
- Pumsirirat, A.; Yan, L. Credit card fraud detection using deep learning based on auto-encoder and restricted boltzmann machine. Int. J. Adv. Comput. Sci. Appl. 2018, 9, 18–25. [Google Scholar] [CrossRef]
- Randhawa, K.; Loo, C.K.; Seera, M.; Lim, C.P.; Nandi, A.K. Credit card fraud detection using AdaBoost and majority voting. IEEE Access 2018, 6, 14277–14284. [Google Scholar] [CrossRef]
- Tran, P.H.; Tran, K.P.; Huong, T.T.; Heuchenne, C.; HienTran, P.; Le, T.M.H. Real time data-driven approaches for credit card fraud detection. In Proceedings of the 2018 International Conference on E-Business and Applications, Da Nang, Vietnam, 23–25 February 2018; pp. 6–9. [Google Scholar]
- Wang, C.; Wang, Y.; Ye, Z.; Yan, L.; Cai, W.; Pan, S. Credit card fraud detection based on whale algorithm optimized BP neural network. In Proceedings of the 2018 13th International Conference on Computer Science & Education (ICCSE), Colombo, Sri Lanka, 8–11 August 2018; pp. 1–4. [Google Scholar]
- Akila, S.; Reddy, U.S. Cost-sensitive Risk Induced Bayesian Inference Bagging (RIBIB) for credit card fraud detection. J. Comput. Sci. 2018, 27, 247–254. [Google Scholar] [CrossRef]
- Husejinovic, A. Credit card fraud detection using naive Bayesian and C4.5 decision tree classifiers. Period Eng. Nat. Sci. 2020, 8, 1–5. [Google Scholar]
- Adedoyin, A.; Kapetanakis, S.; Samakovitis, G.; Petridis, M. Predicting fraud in mobile money transfer using case-based reasoning. In Artificial Intelligence XXXIV: 37th SGAI International Conference on Innovative Techniques and Applications of Artificial Intelligence, AI 2017, Cambridge, UK, 12–14 December 2017; Springer: Berlin/Heidelberg, Germany, 2017; pp. 325–337. [Google Scholar]
- Fiore, U.; De Santis, A.; Perla, F.; Zanetti, P.; Palmieri, F. Using generative adversarial networks for improving classification effectiveness in credit card fraud detection. Inf. Sci. 2019, 479, 448–455. [Google Scholar] [CrossRef]
- Carcillo, F.; Le Borgne, Y.A.; Caelen, O.; Kessaci, Y.; Oblé, F.; Bontempi, G. Combining unsupervised and supervised learning in credit card fraud detection. Inf. Sci. 2019. [Google Scholar] [CrossRef]
- Awoyemi, J.O.; Adetunmbi, A.O.; Oluwadare, S.A. Credit card fraud detection using machine learning techniques: A comparative analysis. In Proceedings of the 2017 International Conference on Computing Networking and Informatics (ICCNI), Lagos, Nigeria, 29–31 October 2017; pp. 1–9. [Google Scholar]
- Varmedja, D.; Karanovic, M.; Sladojevic, S.; Arsenovic, M.; Anderla, A. Credit Card Fraud Detection-Machine Learning methods. In Proceedings of the 2019 18th International Symposium INFOTEH-JAHORINA (INFOTEH), East Sarajevo, Bosnia and Herzegovina, 20–22 March 2019; pp. 1–5. [Google Scholar]
- Vincent, P.; Larochelle, H.; Lajoie, I.; Bengio, Y.; Manzagol, P.A.; Bottou, L. Stacked denoising autoencoders: Learning useful representations in a deep network with a local denoising criterion. J. Mach. Learn. Res. 2010, 11, 3371–3408. [Google Scholar]
- Wah, Y.B.; Rahman, H.A.A.; He, H.; Bulgiba, A. Handling imbalanced dataset using SVM and k-NN approach. AIP Conf. Proc. 2016, 1750, 020023. [Google Scholar]
- Fernández, A.; Garcia, S.; Herrera, F.; Chawla, N.V. SMOTE for learning from imbalanced data: Progress and challenges, marking the 15-year anniversary. J. Artif. Intell. Res. 2018, 61, 863–905. [Google Scholar]
- Gosain, A.; Sardana, S. Handling class imbalance problem using oversampling techniques: A review. In Proceedings of the 2017 International Conference on Advances in Computing, Communications and Informatics (ICACCI), Udupi, India, 13–16 September 2017; pp. 79–85. [Google Scholar]
- Sundarkumar, G.G.; Ravi, V.; Siddeshwar, V. One-class support vector machine based undersampling: Application to churn prediction and insurance fraud detection. In Proceedings of the 2015 IEEE International Conference on Computational Intelligence and Computing Research (ICCIC), Madurai, India, 10–12 December 2015; pp. 1–7. [Google Scholar]
- Hossin, M.; Sulaiman, M. A review on evaluation metrics for data classification evaluations. Int. J. Data Min. Knowl. Manag. Process 2015, 5, 1–11. [Google Scholar]
- Available online: https://www.afi-global.org (accessed on 17 July 2020).
- Available online: https://www.gsma.com/mobilemoney (accessed on 17 July 2020).
- Payment System Statistics. Available online: https://www.bog.gov.gh (accessed on 18 July 2020).
- 2017 Findex full report_chapter2.pdf. Available online: https://globalfindex.worldbank.org (accessed on 18 July 2020).
- Hssina, B.; Merbouha, A.; Ezzikouri, H.; Erritali, M. A comparative study of decision tree ID3 and C4.5. Int. J. Adv. Comput. Sci. Appl. 2014, 4, 13–19. [Google Scholar] [CrossRef] [Green Version]
- Gokgoz, E.; Subasi, A. Comparison of decision tree algorithms for EMG signal classification using DWT. BioMed. Signal Process. Control 2015, 18, 138–144. [Google Scholar] [CrossRef]
- Farid, D.M.; Zhang, L.; Rahman, C.M.; Hossain, M.A.; Strachan, R. Hybrid decision tree and naïve Bayes classifiers for multi-class classification tasks. Expert Syst. Appl. 2014, 41, 1937–1946. [Google Scholar] [CrossRef]
- Si, S.; Zhang, H.; Keerthi, S.; Mahajan, D.; Dhillon, I.; Hsieh, C.J. Gradient boosted decision trees for high dimensional sparse output. In Proceedings of the 34th International conference on machine learning, Sydney, Australia, 6–11 August 2017. [Google Scholar]
- Martinek, P.; Krammer, O. Optimising pin-in-paste technology using gradient boosted decision trees. Solder. Surf. Mt. Technol. 2018, 30, 164–170. [Google Scholar] [CrossRef]
- Wen, Z.; He, B.; Kotagiri, R.; Lu, S.; Shi, J. Efficient gradient boosted decision tree training on GPUs. In Proceedings of the 2018 IEEE International Parallel and Distributed Processing Symposium (IPDPS), Vancouver, BC, Canada, 21–25 May 2018; pp. 234–243. [Google Scholar]
- Saritas, M.M.; Yasar, A. Performance analysis of ANN and Naive Bayes classification algorithm for data classification. Int. J. Intell. Syst. Appl. Eng. 2019, 7, 88–91. [Google Scholar] [CrossRef] [Green Version]
- Li, T.; Li, J.; Liu, Z.; Li, P.; Jia, C. Differentially private Naive Bayes learning over multiple data sources. Inf. Sci. 2018, 444, 89–104. [Google Scholar] [CrossRef]
- Lopez-Rojas, E.; Elmir, A.; Axelsson, S. PaySim: A financial mobile money simulator for fraud detection. In Proceedings of the 28th European Modeling and Simulation Symposium, EMSS, Larnaca, Cyprus, 26–28 September 2016; pp. 249–255. [Google Scholar]
- Available online: https://imbalanced-learn.readthedocs.io/en/stable/generated/imblearn.under_sampling.RandomUnderSampler.html (accessed on 5 June 2020).
- Mani, I.; Zhang, I. kNN approach to unbalanced data distributions: A case study involving information extraction. In Proceedings of the Workshop on Learning from Imbalanced Datasets, Washington, DC, USA, 21 August 2003; Volume 126. [Google Scholar]
- Devi, D.; Purkayastha, B. Redundancy-driven modified Tomek-link based undersampling: A solution to class imbalance. Pattern Recognit. Lett. 2017, 93, 3–12. [Google Scholar] [CrossRef]
- Batista, G.E.; Prati, R.C.; Monard, M.C. A study of the behavior of several methods for balancing machine learning training data. ACM SIGKDD Explor. Newsl. 2004, 6, 20–29. [Google Scholar] [CrossRef]
- Pereira, R.M.; Costa, Y.M.; Silla, C.N., Jr. MLTL: A multi-label approach for the Tomek Link undersampling algorithm. Neurocomputing 2020, 383, 95–105. [Google Scholar] [CrossRef]
- Available online: https://imbalanced-learn.readthedocs.io/en/stable/generated/imblearn.over_sampling.RandomOverSampler.html (accessed on 5 June 2020).
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic minority over-sampling technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Available online: https://www.geeksforgeeks.org/ml-handling-imbalanced-data-with-smote-and-near-miss-algorithm-in-python/ (accessed on 21 July 2020).
- de Morais, R.F.; Vasconcelos, G.C. Boosting the performance of over-sampling algorithms through under-sampling the minority class. Neurocomputing 2019, 343, 3–18. [Google Scholar] [CrossRef]
- Wang, Z.; Wu, C.; Zheng, K.; Niu, X.; Wang, X. SMOTETomek-Based Resampling for Personality Recognition. IEEE Access 2019, 7, 129678–129689. [Google Scholar] [CrossRef]
- Boardman, J.; Biron, K.; Rimbey, R. Mitigating the Effects of Class Imbalance Using SMOTE and Tomek Link Undersampling in SAS®. Available online: https://pdfs.semanticscholar.org/bf3e/68c3e9cfe50b75897d6e6296c45f5bd30f82.pdf (accessed on 31 July 2020).
- Liu, T.; Wang, S.; Wu, S.; Ma, J.; Lu, Y. Predication of wireless communication failure in grid metering automation system based on logistic regression model. In Proceedings of the 2014 China International Conference on Electricity Distribution (CICED), Shenzhen, China, 23–26 September 2014; pp. 894–897. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Registered Accounts | Active Accounts | Transaction Volume | Transaction Value (USD) | |
|---|---|---|---|---|
| Global | 1.04 Billion | 372 Million | 37.1 Billion | 690.1 Billion |
| East Asia and Pacific | 158 Million | 60 Million | 4.4 Billion | 78.9 Billion |
| Europe and Central Asia | 20 Million | 7 Million | 217 Million | 3.8 Billion |
| Latin America and Caribbean | 26 Million | 13 Million | 601 Million | 16.5 Billion |
| Middle East and North Africa | 51 Million | 19 Million | 663 Million | 9.1 Billion |
| South Asia | 315 Million | 91 Million | 7.3 Billion | 125.4 Billion |
| Sub-Saharan Africa | 469 Million | 181 Million | 23.8 Billion | 456.3 Billion |
| Registered Accounts | Active Accounts | Transaction Volume | Transaction Value (USD) | |
|---|---|---|---|---|
| East Africa | 249 Million | 102 Million | 17.1 Billion | 293.4 Billion |
| Central Africa | 48 Million | 20 Million | 1.8 Billion | 30.4 Billion |
| South Africa | 9 Million | 3 Million | 165 Million | 2.5 Billion |
| West Africa | 163 Million | 56 Million | 4.8 Billion | 130.0 Billion |
| 2016 | 2017 | 2018 | January–March 2018 | January–March 2019 | 2019 % Growth | |
|---|---|---|---|---|---|---|
| Registered MM Accounts | 19,735,098 | 23,947,437 | 32,554,346 | 25,306,085 | 29,578,169 | 16.88 |
| Active MM Accounts | 8,313,283 | 11,119,376 | 13,056,978 | 11,248,758 | 12,725,649 | 13.3 |
| Registered Agents | 136,769 | 194,688 | 396,599 | 217,974 | 355,912 | 63.28 |
| Active Agents | 107,415 | 151,745 | 180,664 | 161,317 | 182,344 | 13.03 |
| Total Volume of Transactions | 550,218,427 | 981,564,563 | 1,454,470,801 | 312,926,881 | 436,723,487 | 39.56 |
| Total Transactions( Million)Cedis | 78,508.90 | 155,844.84 | 223,207.23 | 52,352.80 | 66,356.41 | 26.75 |
| Metric | ||||
|---|---|---|---|---|
| Classifier | Accuracy (%) | Precision (%) | Recall (%) | F1-Score (%) |
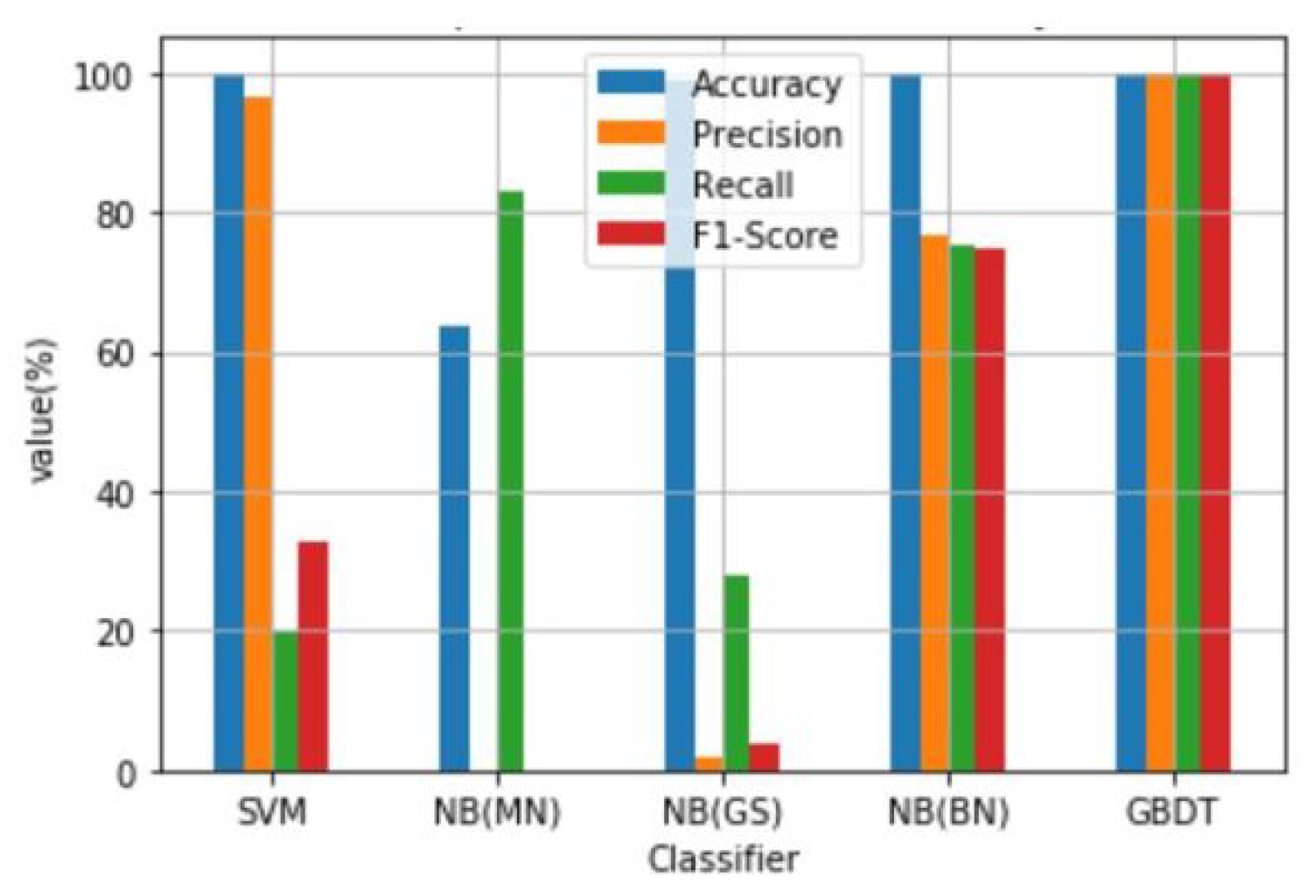
| SVM | 99.91 | 96.49 | 19.71 | 32.73 |
| NB(MN) | 63.83 | 0.00 | 83.00 | 0.00 |
| NB(GS) | 98.66 | 2.00 | 28.00 | 4.00 |
| NB(BN) | 99.90 | 76.79 | 75.31 | 74.97 |
| Metric | ||||
|---|---|---|---|---|
| Classifier | Accuracy (%) | Precision (%) | Recall (%) | F1-Score (%) |
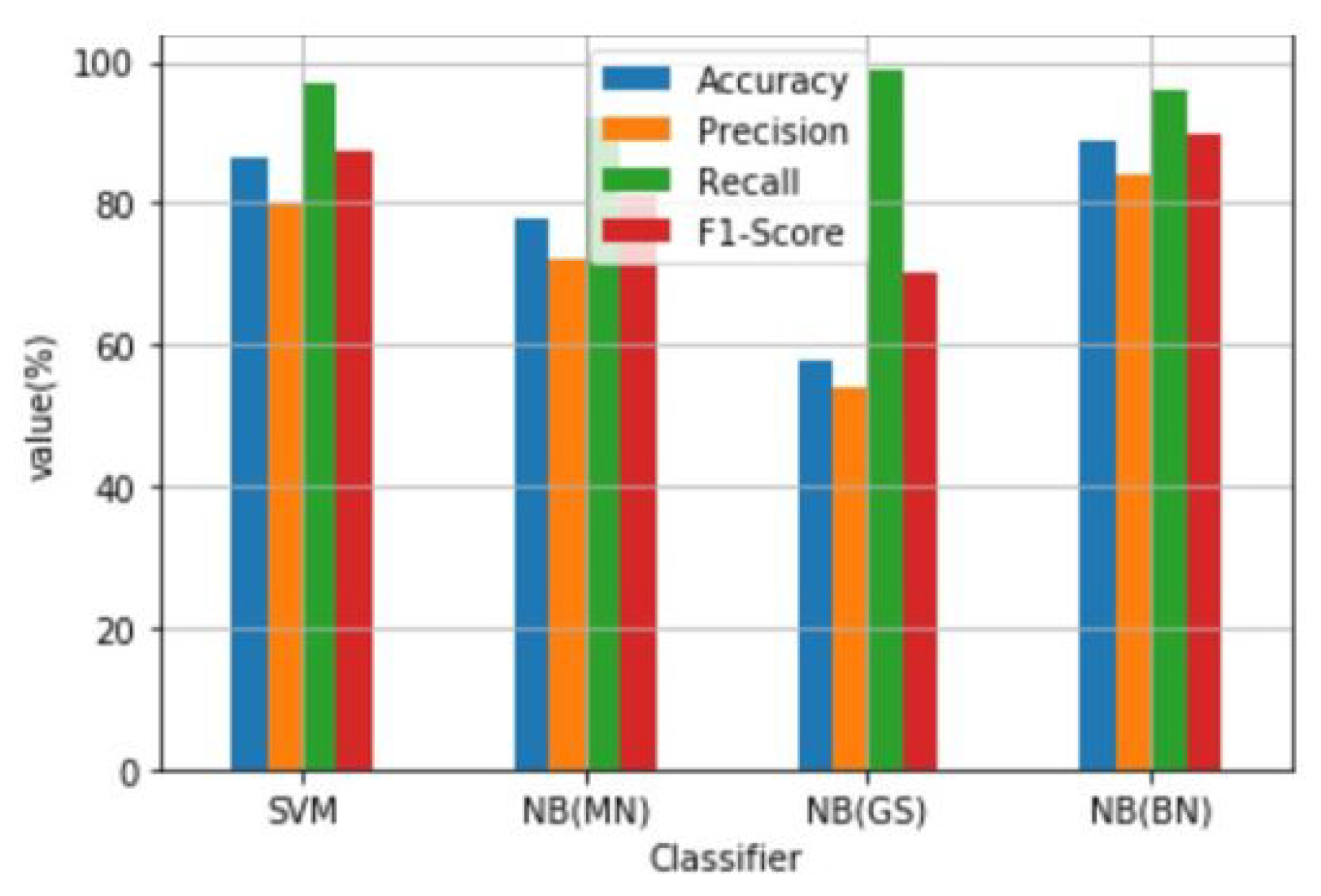
| SVM | 86.34 | 79.76 | 97.18 | 87.62 |
| NB(MN) | 77.93 | 72.00 | 92.00 | 81.00 |
| NB(GS) | 57.97 | 54.00 | 99.00 | 70.00 |
| NB(BN) | 88.97 | 84.00 | 96.00 | 90.00 |
| Metric | ||||
|---|---|---|---|---|
| Classifier | Accuracy (%) | Precision (%) | Recall (%) | F1-Score (%) |
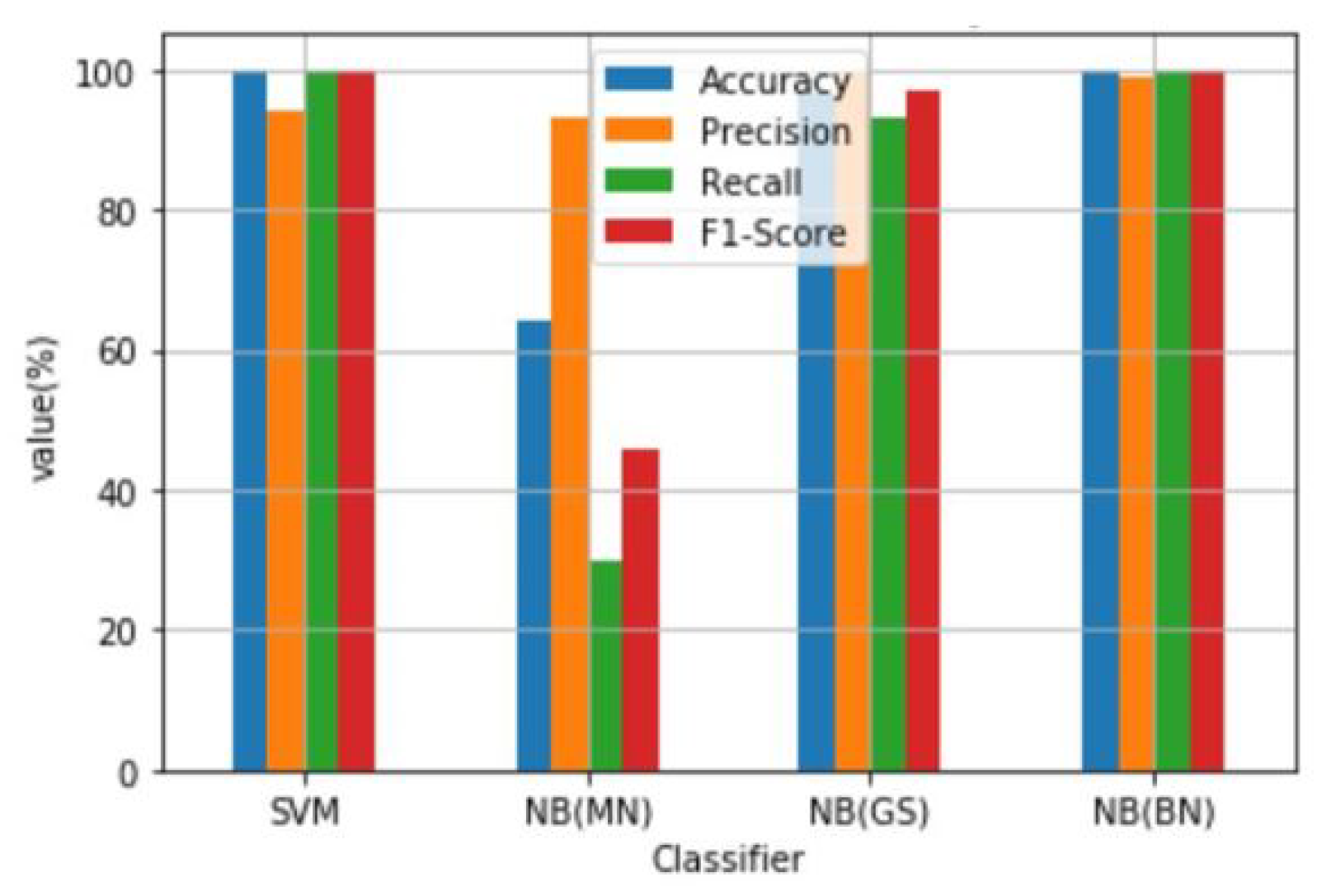
| SVM | 99.64 | 93.90 | 100.00 | 99.65 |
| NB(MN) | 64.27 | 93.00 | 30.00 | 46.00 |
| NB(GS) | 96.67 | 100.00 | 93.00 | 97.00 |
| NB(BN) | 99.65 | 99.00 | 100.00 | 100.00 |
| Metric | ||||
|---|---|---|---|---|
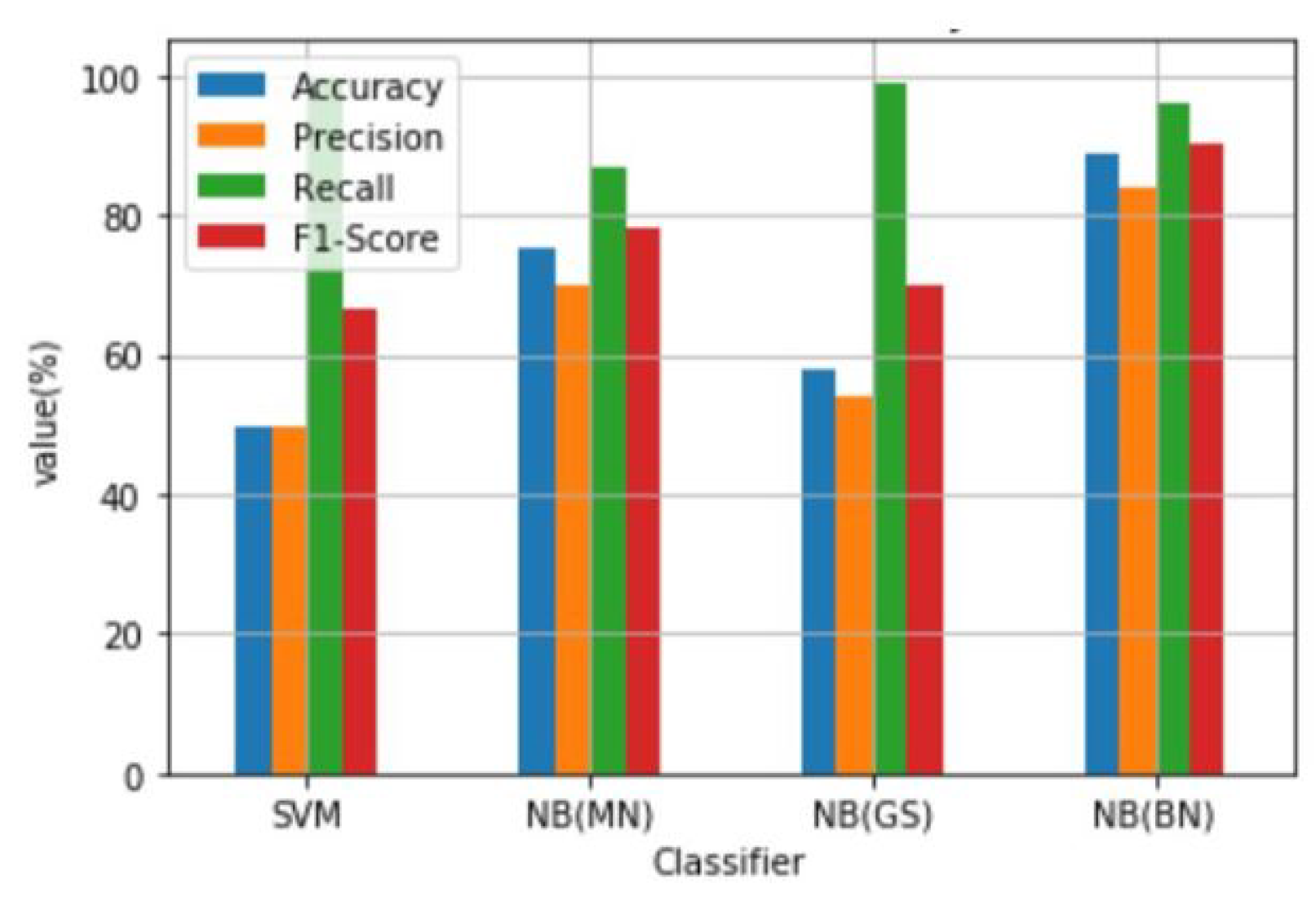
| Classifier | Accuracy (%) | Precision (%) | Recall (%) | F1-Score (%) |
| SVM | 49.87 | 49.77 | 100.00 | 66.47 |
| NB(MN) | 75.23 | 70.00 | 88.00 | 78.00 |
| NB(GS) | 57.97 | 54.00 | 99.00 | 70.00 |
| NB(BN) | 88.97 | 84.00 | 96.00 | 90.00 |
| Metric | ||||
|---|---|---|---|---|
| Classifier | Accuracy (%) | Precision (%) | Recall (%) | F1-Score (%) |
| SVM | 49.87 | 49.87 | 100.00 | 66.47 |
| NB(MN) | 75.30 | 70.00 | 87.00 | 78.00 |
| NB(GS) | 57.97 | 54.00 | 99.00 | 70.00 |
| NB(BN) | 88.97 | 84.00 | 96.00 | 90.00 |
| Metric | ||||
|---|---|---|---|---|
| Classifier | Accuracy (%) | Precision (%) | Recall (%) | F1-Score (%) |
| SVM | 49.78 | 49.78 | 100.00 | 66.47 |
| NB(MN) | 75.27 | 70.00 | 87.00 | 78.00 |
| NB(GS) | 57.97 | 54.00 | 99.00 | 70.00 |
| NB(BN) | 88.97 | 84.00 | 96.00 | 90.00 |
| Metric | ||||
|---|---|---|---|---|
| Classifier | Accuracy (%) | Precision (%) | Recall (%) | F1-Score (%) |
| GBDT | 99.90 | 99.99 | 100.00 | 99.95 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Botchey, F.E.; Qin, Z.; Hughes-Lartey, K. Mobile Money Fraud Prediction—A Cross-Case Analysis on the Efficiency of Support Vector Machines, Gradient Boosted Decision Trees, and Naïve Bayes Algorithms. Information 2020, 11, 383. https://0-doi-org.brum.beds.ac.uk/10.3390/info11080383
Botchey FE, Qin Z, Hughes-Lartey K. Mobile Money Fraud Prediction—A Cross-Case Analysis on the Efficiency of Support Vector Machines, Gradient Boosted Decision Trees, and Naïve Bayes Algorithms. Information. 2020; 11(8):383. https://0-doi-org.brum.beds.ac.uk/10.3390/info11080383
Chicago/Turabian StyleBotchey, Francis Effirim, Zhen Qin, and Kwesi Hughes-Lartey. 2020. "Mobile Money Fraud Prediction—A Cross-Case Analysis on the Efficiency of Support Vector Machines, Gradient Boosted Decision Trees, and Naïve Bayes Algorithms" Information 11, no. 8: 383. https://0-doi-org.brum.beds.ac.uk/10.3390/info11080383