
SC-Political ResNet: Hashtag Recommendation from Tweets Using Hybrid Optimization-Based Deep Residual Network



School of Computer Science and Technology, Dalian University of Technology, Ganjingzi District, Dalian 116024, China
*
Author to whom correspondence should be addressed.
Information 2021, 12(10), 389; https://0-doi-org.brum.beds.ac.uk/10.3390/info12100389
Submission received: 23 July 2021
/
Revised: 7 September 2021
/
Accepted: 9 September 2021
/
Published: 22 September 2021
(This article belongs to the Special Issue Recommendation Algorithms and Web Mining)
Abstract
:Hashtags are considered important in various real-world applications, including tweet mining, query expansion, and sentiment analysis. Hence, recommending hashtags from tagged tweets has been considered significant by the research community. However, while many hashtag recommendation methods have been developed, finding the features from dictionary and thematic words has not yet been effectively achieved. Therefore, we developed an effective method to perform hashtag recommendations, using the proposed Sine Cosine Political Optimization-based Deep Residual Network (SC-Political ResNet) classifier. The developed SCPO is designed by integrating the Sine Cosine Algorithm (SCA) with the Political Optimizer (PO) algorithm. Employing the parametric features from both, optimization can enable the acquisition of the global best solution, by training the weights of classifier. The hybrid features acquired from the keyword set can effectively find the information of words associated with dictionary, thematic, and more relevant keywords. Extensive experiments are conducted on the Apple Twitter Sentiment and Twitter datasets. Our empirical results demonstrate that the proposed model can significantly outperform state-of-the-art methods in hashtag recommendation tasks.
1. Introduction
The micro-blogging platform Twitter has become one of the best-known social networks on the internet. Twitter offers a platform wherein users can create a set of follower connections, in order to share their views, and subscribe to subjects posted by their followers. Twitter is considered among the first social networking sites to use the hashtag concept [1]. Due to the proliferation of micro-blogging services, there is an ongoing expansion of short-text over the Internet. Due to the production of huge micro-posts, there exists a requirement for effectual categorization and data searching. Twitter is one of the highly rated micro-blogging sites that permits users to exploit hashtags to classify day-to-day posts. However, some tweets do not comprise tags, thus obstructing the search quality [2]. In twitter, users are liberally permitted to allocate hashtags to their tweets, which are nothing but a string whose prefix is the hash symbol, and are used to catalog their posts and highlight certain content. The hashtag is considered a community-driven principle that adds extra context to tweets. This method assists in searching, rapidly propagates the topic from millions of users, and allows users to link into specific discussions [3]. Since its introduction, twitter has become a popular standard for commencing electronic communications. Twitter utilizes post tweets that reflect an enormous variety of topics, including news, personal ideas, political affairs, events, technologies, and celebrities. Furthermore, Twitter permits its users to pursue other users, in order to track their attention [4].
Twitter possesses in-depth reach, due to the utilization of mobile applications such as smartphones. Tweets are communal in nature, and are explicitly available to every person when posted using Twitter [2]. The culture of tagging is extensive; thereby, the hashtag recommendation model has acquired the interest of researchers. Recent literary works have been devised to recommend specific hashtags or infer topics hidden in the tweets. Even though such systems help motivate and assist users in acquiring tagging habits, it is not adequate for the information seeker who desires to discover promising hashtags. The recommendation of well-known hashtags imitates timely topics, but may involve deeply utilized universal hashtags, in which the suggestions are not personalized [5]. Hashtag recommendation addresses the suggestion that one or more hashtags should be used to tag a post made on the social platform. Hashtag users, who tend to allocate posts to a certain social network, rely on the message’s key facets [6]. Hashtags are the major unit of Twitter, operating as a tagging method for grouping messages related to similar topics. The dynamic aspects of hashtags have led to the proposal of various research issues in recent years, involving topics such as semantic hashtag classification and hashtag recommendation-based discovery of events. As users generate hashtags, there is a possibility of excessive hashtags being created in a similar topic. In addition, it is a complex and lengthy process for the user to search associated hashtags. In this circumstance, the recommendation of pertinent hashtags to a user, based on their attention and preference, is complex [7].
Hashtag recommendation for Twitter has acquired huge interest amongst researchers in the natural language processing (NLP) field. Literary works have focused on the content similarity of tweets [8] and modeled topics using Latent Dirichlet Allocation (LDA) [9]. Various techniques [10] have been devised based on deep learning [11], which are considered promising methods. However, the majority of techniques have been devised for hashtag recommendation using micro-blogging platforms. These are mostly devised based on a syntactic criterion or conventional tagging methodologies. They range from probabilistic models to the utilization of classification to perform collaborative filtering. Thus, these techniques present a common shabbiness, wherein they utilize sparse lexical features, such as bag-of-words (BoW), to indicate tweets, while ignoring the semantic behind tweets with an equivalent illustration of multiple NLP tasks. Popular techniques which have been adapted for hashtag recommendation are Recurrent Neural Networks (RNNs) and Long Short-Term Memory (LSTM), which have good ability for learning sequence representations [12,13,14,15]. The classical methods of hashtag recommendation range from collaborative filtering to classification and probabilistic models, including topic models and Naïve Bayes. In addition, the majority of techniques rely on sparse lexical features that involve BoW models and delicately devise patterns. However, feature engineering is labor-intensive, as sparse and discrete features encode syntactic data from words. Meanwhile, neural techniques have been shown to have the ability to learn effectual representations and have presented improved performance in different NLP tasks [16]. The LSTM and modified RNN have been extensively employed in this respect, due to their ability to capture long-term dependencies [17].
This research was designed by employing a Deep Residual Network for recommending hashtags from twitter data. The proposed SCPO consists of the integration of the SCA and the PO algorithm. The SCA creates multiple initial random candidate solutions and requires them to fluctuate outwards or towards the best solution, using a mathematical model based on sine and cosine functions. This algorithm can explore different regions of a search space, avoid local optima, converge towards the global optimum, and exploit promising regions of a search space effectively during optimization. It can be highly effective in solving real problems with constrained and unknown search spaces. The PO consists of the mathematical mapping of all of the major phases of politics, including constituency allocation, party switching, election campaigns, inter-party elections, and parliamentary affairs. This algorithm assigns each solution a dual role, by logically dividing the population into political parties and constituencies, facilitating each candidate to update its position concerning the party leader and the constituency winner. The PO algorithm has excellent convergence speed, with good exploration capability in early iterations. This algorithm is invariant to function shifting and performs consistently in very high-dimensional search spaces. We integrate the PO algorithm with the SCA, in order to attain the global best solution.
The input data considered are twitter data, called tweets. Input tweets are processed more effectively, in order to remove the stop words. The process of stop word removal from the input data increases the quality of data for further processing. After removing stop words, the keyword set is computed by finding dictionary words, thematic words, and more relevant words. The dictionary words are the unique keywords retrieved from all the tweets in the training data. Thematic words are extracted based on the co-occurring frequency words, whereas more relevant words repeatedly occur among the tweets. After forming the keyword set, the features associated with the keyword sets are extracted by considering the dictionary Term frequency (TF), document Inverse document frequency (IDF), thematic words, and the more relevant word features. For each tweet, the document TF, document IDF, thematic words, and the more relevant features are extracted, and their respective variance measures are computed more effectively. The input to the Deep LSTM consists of the features and their variance measures, such that the Deep LSTM can compute the hashing score by considering all the features to generate the feature vector. The Deep Residual network takes the feature vector as input. It processes the features more effectively, in order to recommend the hashtag. The SCPO algorithm carries out the training of the deep learning classifier.
The major contributions of this research are as follows:
- We model an effective Hashtag Recommendation system using a Deep Residual Network Classifier, trained by the SCPO algorithm, which is derived by integrating the SCA and the PO algorithm;
- The incorporation of features in the optimization algorithm pushes the solution towards the global optimum rather than local optima;
- We conduct extensive experiments on different datasets, in which the proposed method is shown to outperform state-of-the-art methods in the Hashtag Recommendation task.
The remainder of this paper is organized as follows: Section 2 provides a review of different Hashtag Recommendation methods. Section 3 briefly introduces the architecture of the proposed framework. The system implementation and evaluation are described in Section 4, and the results and discussions are given in Section 5. Finally, Section 6 concludes the overall work and provides recommendations for future research.
2. Related Work
Some traditional hashtag recommendation methods are reviewed in this section. Nada Ben-Lhachemi and El Habib Nfaoui [18] introduced a DBSCAN clustering technique for partitioning tweets into clusters consisting of semantically and syntactically relevant tweets. This method has the potential to recommend pertinent hashtags syntactically and semantically from a given tweet; however, it failed to involve deep architectures on various semantic knowledge bases, in order to enhance the accuracy. Yang Li et al. [17] introduced a Topical Co-Attention Network (TCAN) to guide content and topic attention. This method was shown to be useful in determining structures from large documents; however, the framework failed to involve temporal information. Nada Ben-Lhachemiet al. [15] introduced an LSTM network for encoding the tweet vector concerning the representation. The skip-gram model was employed to generate the tweet embeddings, considering the vector-based representation. It was capable of recommending suitable hashtags, but failed to utilize semantic knowledge bases to improve the accuracy. Asma Belhadi et al. [19] introduced the PM-HRec model to address the issues of hashtag recommendation with two stages; namely, offline and online processing. Offline processing was used to transform the tweet corpus to a transnational database based on temporal information, whereas online processing was used to extract related hashtags. This method works effectively on huge data, but failed to include parallel GPUs to handle large data. Areej Alsini et al. [20] introduced a community-based hashtag recommendation model by applying a tweet similarity process. This method makes it easy to understand the different factors influencing hashtag recommendation, but it involves a lengthy process.
Qi Yang et al. [21] developed an AMNN to learn a representation of multimodal micro-blogging and to recommend related hashtags. The features from both images and text were extracted using a hybrid neural network model. However, it improved performance with multimodal micro-blogs but failed to adapt to external knowledge, such as comments and user information, for the purpose of recommendation. Renfeng Ma et al. [22] developed a Co-attention memory network for the recommendation of hashtags, in which the users were allowed to introduce some new hashtags dynamically. This method can manage a huge number of hashtags; however, the generation of high-quality candidate sets is complex. Da Cao et al. [23] developed a Neural Network-based LOGO model for recommending hashtags by considering multiple modalities. It assists in capturing sequential and considerate features simultaneously, but fails to include a recommendation on micro-videos. Can Li et al. [24] developed a tag recommendation technique—the Tag recommendation method with Deep learning and Collaborative filtering (TagDC)—which was developed with two different modules: initially, word learning is employed using an enhanced CNN; then, collaborative filtering is employed for tag recommendation on software sites. The performance was evaluated based on the F-Measure, recall, and precision. However, they failed to consider unpopular tags. Sahraoui et al. [25] developed a hybrid filtering technique for mining the data in a social network. In this, Big Five personality traits were devised for the mining; then, the user’s interest is represented in the graph and predicted using the meta path discovery method. Its efficiency was evaluated using the precision, recall, and F-Measure. However, they failed to evaluate its performance in signed networks. A community-based hashtag recommendation model [20] was presented for performing recommendations with tweets. However, it involves a complex and lengthy process for searching related hashtags. Moreover, the classical techniques of hashtag recommendation utilize probabilistic models, such as topic models and Naïve Bayes. In addition, the majority of techniques rely on sparse lexical features involving the Bag-of-Words (BoW) model and devised structures. However, the associated feature engineering is challenging, and these methods cannot encode semantic and syntactic information [17]. Table 1 depicts the literature review in detail.
3. Proposed Framework
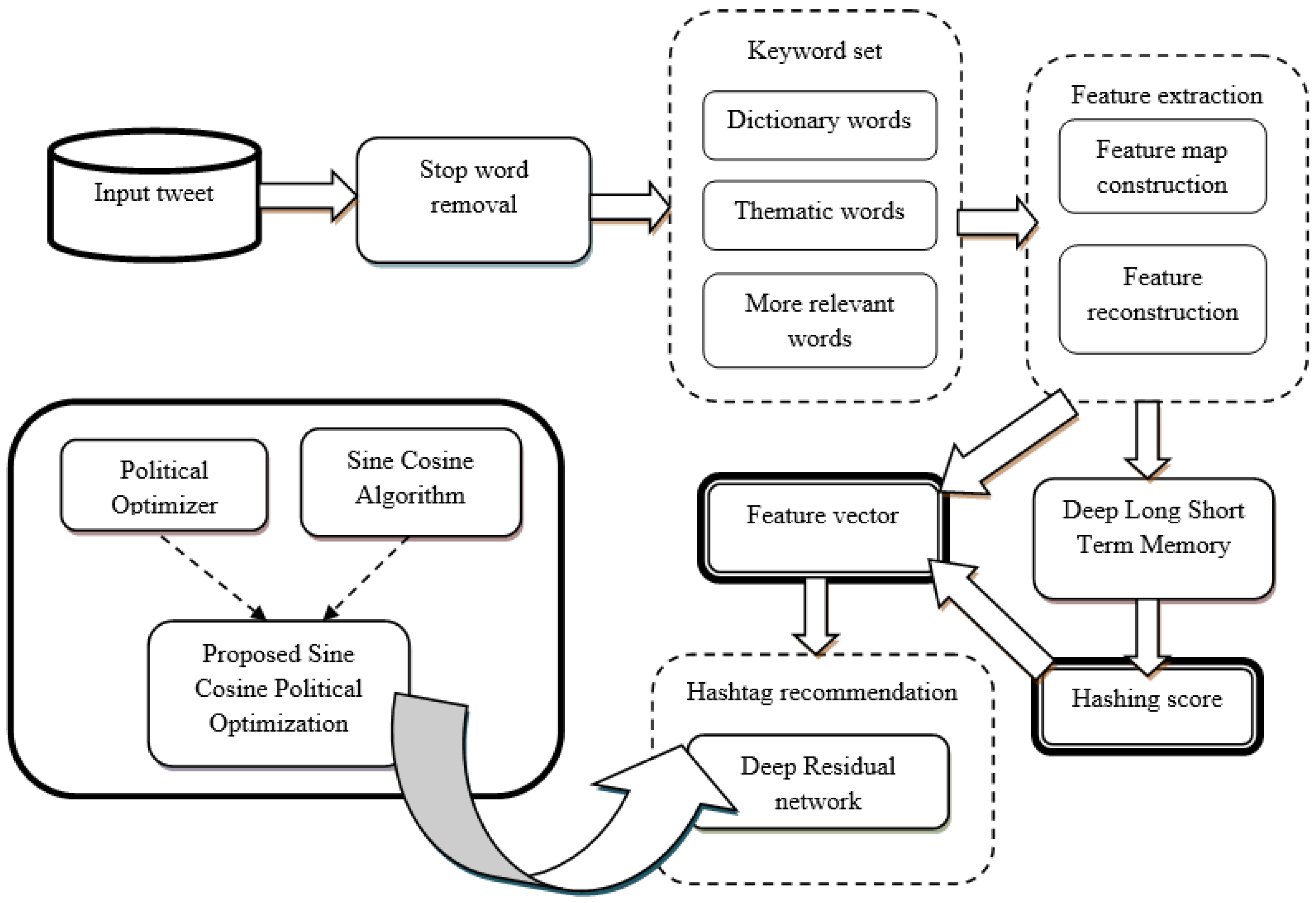
The overall architecture of the SCPO-based Deep Residual Network for Hashtag Recommendation is illustrated in Figure 1, comprising several components. The details of each component are presented in the following.
A user uses a hashtag by inserting a hash symbol (#) in front of a word, in order to access the data more easily. Due to the growth of information being shared among social services, such as Flicker and Instagram, a number of micro-blogs focused on certain the hashtags are available. Existing hashtag recommendation methods have been designed solely considering textual data. Hence, in this research, we focus on designing a model using an SCPO-based Deep Residual Network for recommending hashtags. Here, the input tweet is passed through a stop word removal phase, in order to eliminate the stop words associated with the input tweet data. The keyword set is computed based on dictionary words, thematic words, and more relevant words. The features extracted from the keyword set and hashing score computed from the Deep LSTM are passed as input to the Deep Residual Network, which performs the recommendation process.
3.1. Removal of Stop Words from Input Tweet
Informal languages are commonly used in tweets, which are restricted to 140 characters. However, this restriction forces the user to be imaginative, in terms of shortening words, writing abbreviations, and using symbols and emoticons. Moreover, the tweet may contain special components, such as URLs, media, user mentions, and hashtags. Let us consider a dataset comprised of a number of tweets, represented as
where denotes the database, indicates the tweet located at index of the dataset, and n represents the total number of tweets.
The words associated with tweet are expressed as
where denotes the total number of words in the tweet.
A stop word is the word that appears often and does not contain any meaning. Stop word removal is the process of removing these words, including ’the’, ’a’, ’is’, ’an’, and so on. As the stop word does not have any sentiment, it is very significant to remove these words from the tweet. The stop word removal process increases the performance of hashtag recommendation by reducing the dimensionality rate. After removing the stop words from tweet , the resulting output tweet is represented as .
3.2. Keyword Set: Dictionary, Thematic and More Relevant Words
In the keyword set process, the extraction of dictionary words, thematic words, and more relevant words is carried out on the tweet.
Dictionary words: The words that have a unique keyword set from all the reviews of training data are termed as dictionary words. A tweet contains a number of words, whereas the dataset contains a number of tweets. Here, the dictionary words associated with the entire dataset are selected by individually processing each tweet , and the selected dictionary words are included into the dictionary word set, denoted by .
Thematic words: These are words which are closely associated with the theme of the text. Thematic words can be easily incorporated in the summarizing statement of text, by expressing the meaning of the text. The words having co-occurring frequencies in a set of words are selected from each tweet of the entire dataset , in order to find the thematic words. The dataset may contain a few words with co-occurring frequency; among those the top N words with co-occurring frequency set are selected as thematic words. The set of thematic words selected from the dataset is termed the thematic word set, denoted by .
More relevant words: Each tweet may contain few relevant words while, when processing the entire dataset, there may exist several relevant words while individually processing each tweet . By selecting the more relevant words from each tweet, the more relevant word set can be formed, which is denoted by .
The keyword set comprises three subsets—namely, , , and —such that the keyword set can be written as .
3.3. Feature Extraction Based on Keyword Set
After finding the keyword set, the features associated with the keyword set are selected by constructing the feature map. This section explains the construction of feature maps, feature reconstruction, and the computation of hashing scores.
3.3.1. Feature Map Construction
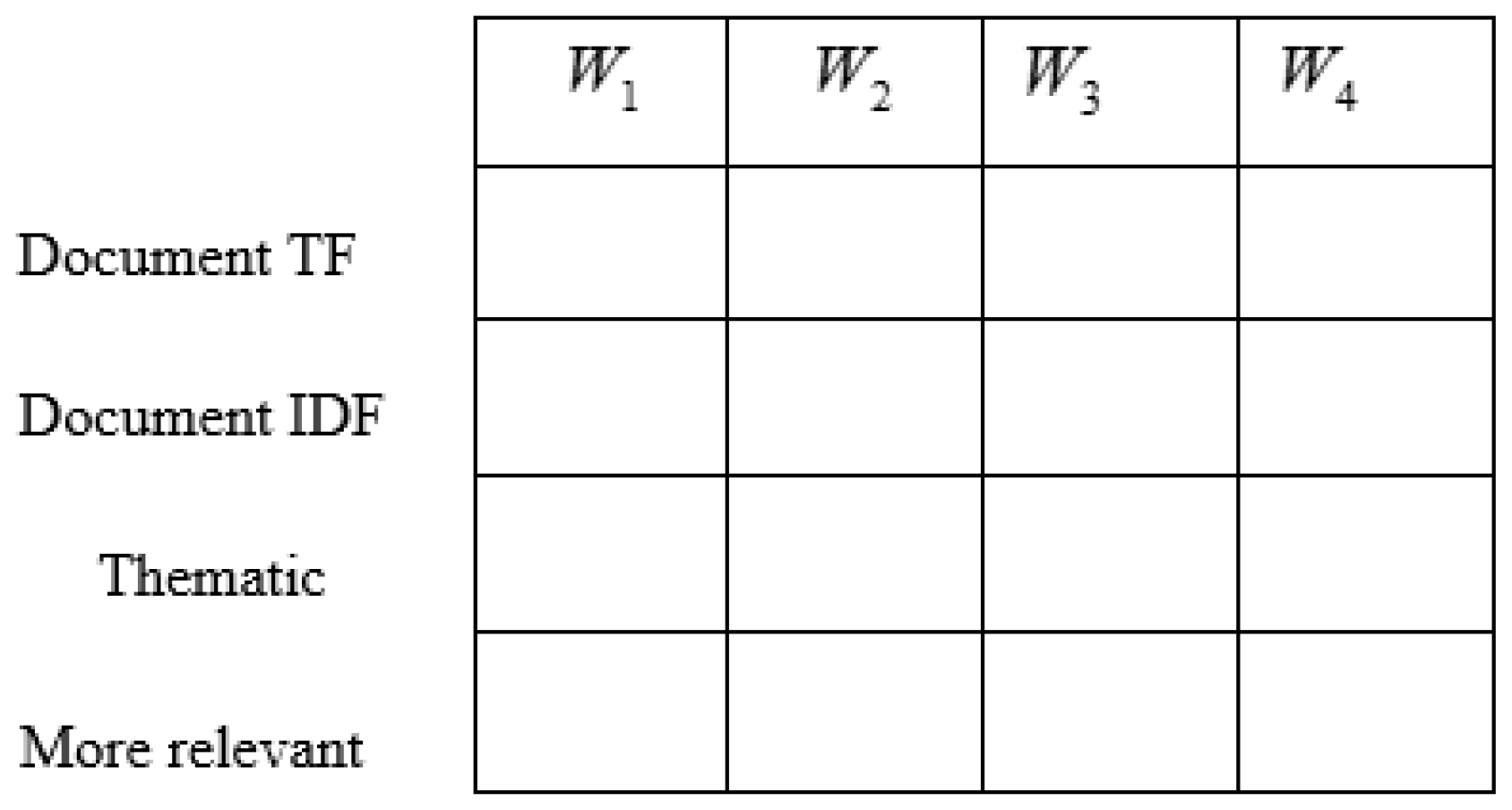
The feature map is constructed for the keyword set by considering each tweet word in the dataset. For an individual word in a tweet, the feature map is constructed based on dictionary keywords, thematic keywords, and more relevant keywords. However, the dictionary feature is constructed using the and for each word of the tweet. Figure 2 represents the schematic view of feature map construction. is the number of times each word is present in the tweet, while indicates word of the tweet. The is computed based on the ratio of the total number of tweets to the number of tweets that contain the word , measured as
Let us consider the number of words in a tweet to be four; hence, the document computed for the four words of the tweet is represented as , document measured for the same words of the tweet is represented as , and thematic and more relevant keywords measured for the four words of the tweet are denoted by and , respectively.
3.3.2. Feature Reconstruction
After constructing the feature map, the features obtained from the keyword set using the dictionary , dictionary , thematic keyword, and the non-relevant keywords are represented as , , , and , respectively, indicating the keyword set’s mean value, where
where denotes the features acquired using dictionary and the variance measure of respective is represented as .
The features acquired from the keyword set based on the dictionary are denoted as , and their respective variance is indicated as .
The feature is acquired from the keyword set, based on thematic words, and the variance measure of the respective feature is represented as .
The features acquired based on more relevant words are represented as , and their corresponding variance measure is represented as . Here, L indicates the total number of words in the tweet, and features , , , and denote the variances of the corresponding features , , , and , respectively. The features acquired from the keyword set have the dimension of .
3.3.3. Hashing Score Prediction by Deep LSTM
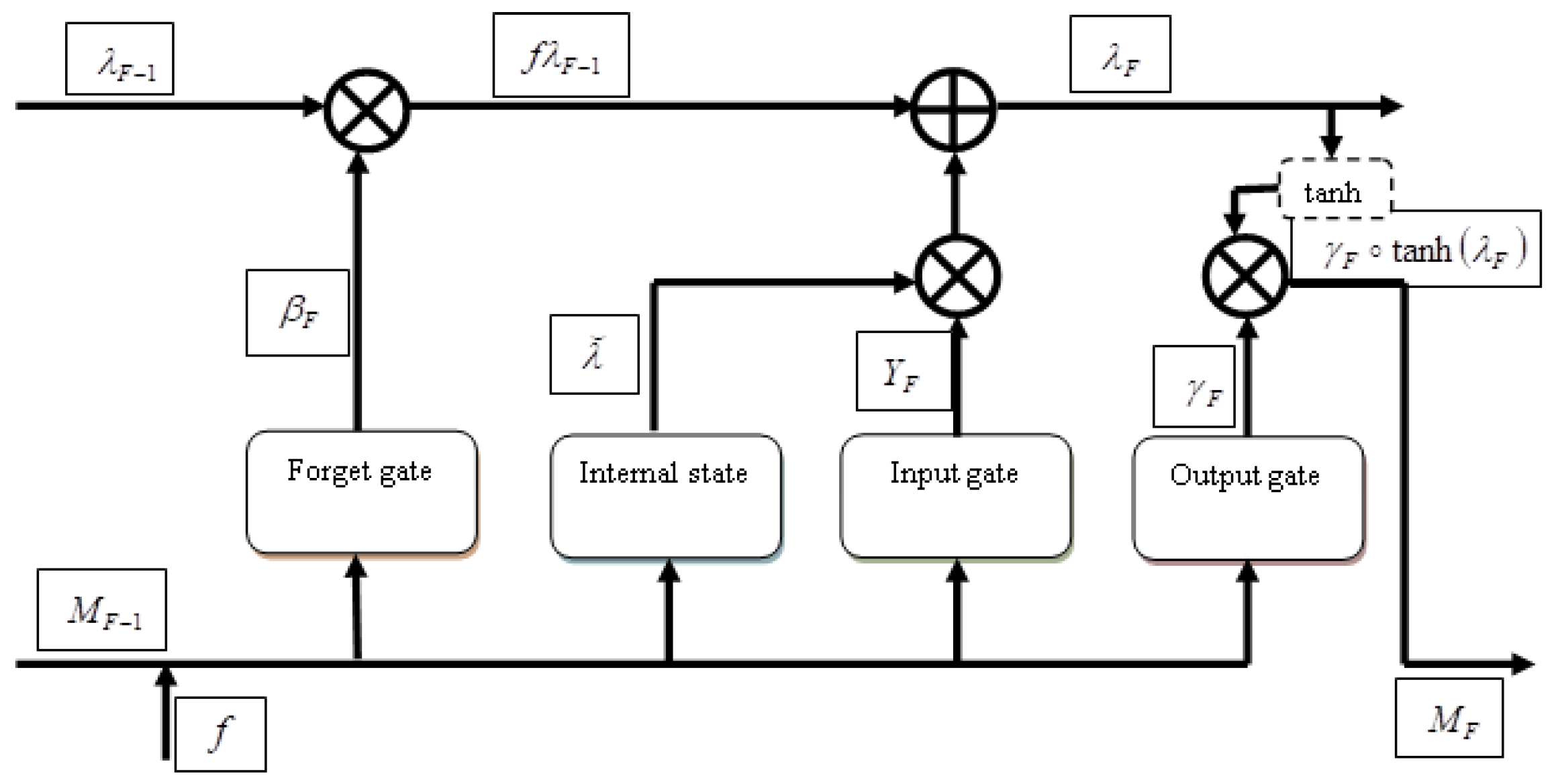
Deep LSTM [26] is employed to determine the hashing score, considering the keyword set features as input. A deep neural Network constructed by using a number of layers within the LSTM framework is called a Deep LSTM. It takes advantages of the benefits of both deep neural Networks and LSTM Networks to obtain the hashing score. It consists of internal state cells, which act as memory cells. The output of the Deep LSTM is the hashing score, which is computed based on the cell states. The working process of this Network solely depends on the memory cells.
The input node receives the input feature f, where , at the input layer.
where denotes the hyperbolic tangent function, denotes the input node at time F, f denotes the input feature, indicates the weights among the input layer and input nodes of the memory cell, represents the input of the hidden state, denotes weight matrix for the hidden state, and indicates the bias of input node.
The input gate, , is equivalent to that of the input node, and it receives the input feature f. The input gate blocks information flow between the nodes. The input gate is represented as
where denotes the input gate, denotes the bias of the input gate, and X specifies the sigmoid activation function.
The internal state, , is a node with a self-loop recurrent edge consisting of a linear activation function and a unit weight, such that the internal state can be represented as
where denotes the internal state at time F.
The forget gate is the sub-unit used for re-initiating the internal state of the memory cell, which is computed as
where denotes the forget gate, denotes weights among the forget gate and the hidden states, and represents the weights among the forget gate and the input layer.
Finally, the output gate, , is expressed as
where denotes the weights among the output gate and the input layer, represents the weights among the output gate and the hidden states, and denotes the bias of the output gate. The output of memory cell is calculated as
where and ⨀ denotes the operator. The score computed using the Deep LSTM is termed the hashing score, and is represented as with the dimension of . It is used to perform the hashtag recommendation, by passing it as an input to the Deep Residual Network, in addition to the features of the keyword set. Figure 3 shows the structure of the Deep LSTM classifier.
3.3.4. Computation of Feature Vector
The feature vector is computed by considering the features of the keyword set, along with the hashing score. The feature vector used to perform the process of hashtag recommendation is represented as
where denotes the feature vector, with the dimension of .
3.4. Hashtag Recommendation Using Proposed SC-Political ResNet
To make the tweet searching process easy, twitter users use hashtags for classifying their tweets. In this paper, the process of hashtag recommendation is carried out using a Deep Residual Network, in such a way that the training process of deep learning classifier is carried out using the SCPO algorithm.
3.4.1. Architecture of Deep Residual Network
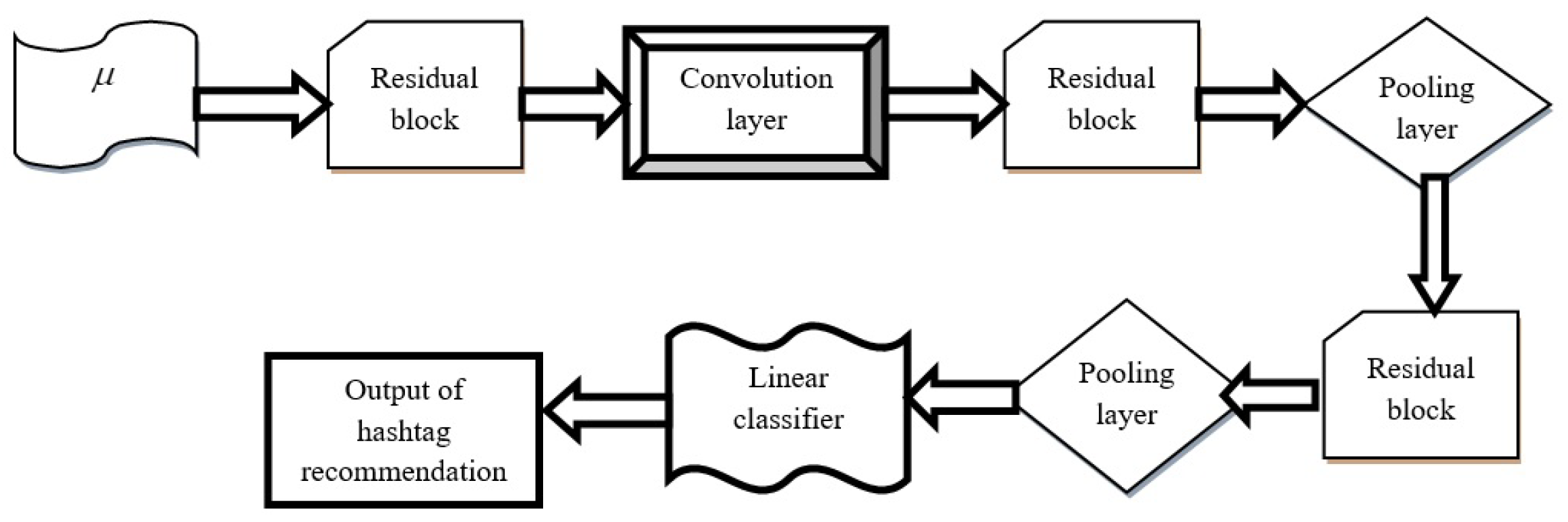
The process of hashtag recommendation is carried out by a Deep Residual Network, while the training process of the classifier is done using the proposed SCPO algorithm. The structure of a Deep Residual Network [27] is composed of different layers; namely, residual blocks, Convolutional (conv) layers, average pooling layers, and linear classifiers. Figure 4 represents the structure of the Deep Residual Network.
Convolutional layer: The two-dimensional conv layer (conv2d) is used to significantly reduce the number of free parameters in the training procedure and to ensure performance improvement by utilizing the advantages of weight sharing and the local receptive field. This layer processes the input data using a series of filters based on local connections. The series of filters used in this layer is termed the convolution kernel. The computation process of convolution layer involves the mathematical operation used for sliding the individual filter over input matrix, calculating the dot product in the kernel. The calculation process for the convolutional layer can be expressed as
where denotes the feature vector, u and v are utilized to observe the coordinates in the input, A indicates a kernel matrix (which is learned in the training process), z and c indicates the position indices of the kernel matrix, indicates kernel size for the input, and ∗ denotes the cross-correlation operator.
Pooling layer: This layer is present between the conv layers, and is generally used to minimize the spatial dimension of the feature vector and to control overfitting.
where denotes the width of the input two-dimensional matrix, denotes the height of the two-dimensional matrix, and and represent the width and height of the output two-dimensional matrix. Moreover, denotes the width of the kernel, and represents the height of the kernel.
Activation function: This function is employed to learn the nonlinear and complicated features, thus enhancing the nonlinearity of features. Here, the Rectified Linear Unit (ReLU) is used for the activation function, which is expressed as
where indicates the input feature vector.
Batch normalization: The training set is divided into different small sets called mini-batches. This can effectively train the model to achieve a better trade-off between convergence and computational complexity. However, as the mini-batch model suffers from the internal co-variate shift, the stability and training speed may be reduced. To overcome this issue, batch normalization has been designed to minimize the internal co-variate shift, using input layer normalization by adjusting and scaling the activation functions. Hence, the reliability and training speed can be improved by alleviating gradient explosion and overfitting issues, along with a better learning rate.
Residual blocks: A shortcut connection is made from the input to the output and, through this connection, the inputs are directly attached to output only if the input and output have the same dimension. For various dimensions, the dimension matching factor is employed for matching input, as well as the output dimensions, which is expressed as
where denotes the input to the residual blocks, C indicates the output, g specifies the mapping relationship between the input and output, and indicates the dimension matching factor.
Linear classifier: Hashtag recognition is carried out by a linear classifier. Here, the linear classifier contains a soft-max function and a fully connected layer. The , with dot product, is calculated as
where W denotes the weight matrix of size , indicates the input feature vector of size , and D denotes the bias. The softmax function is employed to normalize the input vector to a probability vector corresponding to each class, such that class with highest probability is selected as the output result.
3.4.2. Training Process of Deep Residual Network Using SCPO
The Deep Residual Network training process is carried out using the proposed SCPO, which was derived through the integration of the SCA [28] and PO [29] algorithms. The SCA generates a number of candidate solutions randomly and fluctuates them towards an optimal solution using mathematical functions consisting of sine and cosine functions. Adaptive parameters are used to emphasize the exploitation and exploration of the search space. It considers test cases that move the solution towards global optima and offer better convergence. Meanwhile, the PO algorithm considers two perspectives, where each solution optimizes the goodwill to win the election, whereas each party tries to maximize their number of seats in parliament, in order to form a government. Here, the party members are considered as the candidate solution and the position of the candidate in the solution space is termed as their goodwill. However, the goodwill of a political member is defined based on performance-related factors, mimicking the components or variables of the candidate solution. The PO involves five phases; namely, party formation, election campaign, party-switching, inter-party election, and parliamentary phases. The algorithmic procedure involved in the proposed SCPO is elaborated in the following:
Initialization: Let us initialize a population E with q of political parties, party members, and number of constituencies. The total number of iterations is represented as , while denotes the upper limit of party switching. The political parties are initialized as
Each party contains q members or candidates in the solution space, and is represented as
Each member, , is assumed to be a potential solution, and each solution is a p-dimensional vector, given as
where p denotes the number of input variables and denotes the dimension of .
Compute fitness measure: The best fitness value is evaluated using the fitness measure, such that training the weights using the optimal value of fitness results in higher performance. The fitness measure is represented as
where F denotes the fitness measure, C is the classifier output, Q denotes the target value, and N denotes the total number of samples.
Compute party leader : The potential solution can act as the election candidate in this phase. The q constituencies are listed as , and member of individual party from constituency is given as . The party member is the fittest member, selected after the inter-party election. The party leader is selected using the following equation:
where represents the leader of the party. The set of all party leaders is expressed as
Compute constituency winners : In the reallocation of roles in the constituency, the winner is represented as
Update solution: The standard equation of PO is represented as
and the standard equation of SCA is given as
The equation that satisfies the condition is selected for training the weights.
Let us assume that . Thus, will be removed, and
Hence, the update solution of proposed SCPO algorithm can be expressed as
where denotes the position of the current solution in dimension at the iteration; r, , , and are random numbers; indicates the position of the destination point in the dimension; and specifies the absolute value.
Termination: The above steps are repeated until the global best solution is obtained.
Algorithm 1 provides the pseudo-code for the proposed SCPO-based Deep Residual Network.
| Algorithm 1: Pseudo-code of proposed SCPO-based Deep Residual network. |
| 1 Input: |
| 2 Output: |
| 3 |
| 4 Compute fitness measure |
| 5 |
| 6 |
| 7 |
| 8 |
| 9 |
| 10 |
| 11 |
| 12 Do |
| 13 |
| 14 |
| 15 |
| 16 Do |
| 17 |
| 18 Do |
| 19 |
| 20 End |
| 21 End |
| 22 |
| 23 |
| 24 |
| 25 |
| 26 |
| 27 |
| 28 |
| 29 End |
4. System Implementation and Evaluation
In this section, we first present the used datasets and then describe the experimental setup and baseline benchmarks. Finally, the evaluation metrics are detailed.
4.1. Description of Datasets
In order to evaluate our system, we used the Apple Twitter Sentiment Dataset https://data.world/crowdflower/apple-twitter-sentiment/workspace/file?filename=Apple-Twitter-Sentiment-DFE.csv (accessed on 15 April 2021) and Twitter dataset https://www.kaggle.com/kavita5/twitter-dataset-avengersendgame?select=tweets.csv (accessed on 15 April 2021). These datasets are explained in detail below.
- Apple Twitter Sentiment Dataset: This dataset contains 12 columns and 3886 rows, including a number of fields; namely, id, sentiment, query, text, and so on. The size of the dataset is 798.47 KB. However, the text contains hashtags with positive, negative, or neutral tweet sentiments.
- Twitter Dataset: This dataset contains 10,000 records acquired from the twitter of the trending domain “AvengersEndgame”. These data can be used for sentiment analysis. It contains 17 columns with the 8 string-type variables, 4 Boolean-type variables, 3 Integer-type variables, and two other types of variables.
4.2. Experimental Setup
The method we proposed was implemented in Python Programming Language, with the Neural Network library of Tensorflow/Pytorch. Our Networks were trained on an NVIDIA GTX 1080 in a 64-bit computer with Intel(R) Core(TM) i7-6700 [email protected] GHz, 16 GB RAM, and the Ubuntu 16.04 operating system.
4.3. Evaluation Metrics
The performance of the developed scheme was analyzed by considering the metrics of Precision, Recall, and F1-Score.
Precision: The precision was used to quantify the number of hashtags that are actually classified as belonging to the positive class. It is computed as
where denotes the true positive rate, denotes the false positive rate, and is the precision.
Recall: Recall is the measure that detects the number of positive predictions achieved by considering all the positive results. It is calculated as
where denotes the false negative rate and denotes the recall.
F1-Score: The F1-score offers a single score that is a balance between precision and recall. It is computed as
where denotes F1-score.
4.4. Baseline Methods
In order to evaluate the effectiveness of the proposed framework, our method was compared with several existing algorithms, including:
- LSTM-RNN Network [15]: For this, the hashtag recommendation was designed by encoding the tweet vector using the LSTM-RNN technique;
- Pattern Mining for Hashtag Recommendation (PMHRec) [19]: PMHRec was designed using the top k high-average utility patterns for temporal transformation tweets, from which the hashtag recommendation was devised;
- Attention-based multimodal neural network model (AMNN) [21]: The AMNN was designed to extract the features from text and images, after which correlations are captured for hashtag recommendation;
- Deep LSTM [26]: Deep-LSTM was designed to evaluate the daily pan evaporation;
- Emhash [30]: For this method, the hashtag recommendation was developed using a neural network-based BERT embedding;
- Community-based hashtag recommendation [20]: For this, the hashtag recommendation was designed using the communities extracted from social Networks.
5. Results and Discussion
The performance results of our proposed model are presented in this section. The results are compared with previously introduced methods, which were tested on the same datasets.
5.1. Results Based on Apple Twitter Sentiment Dataset
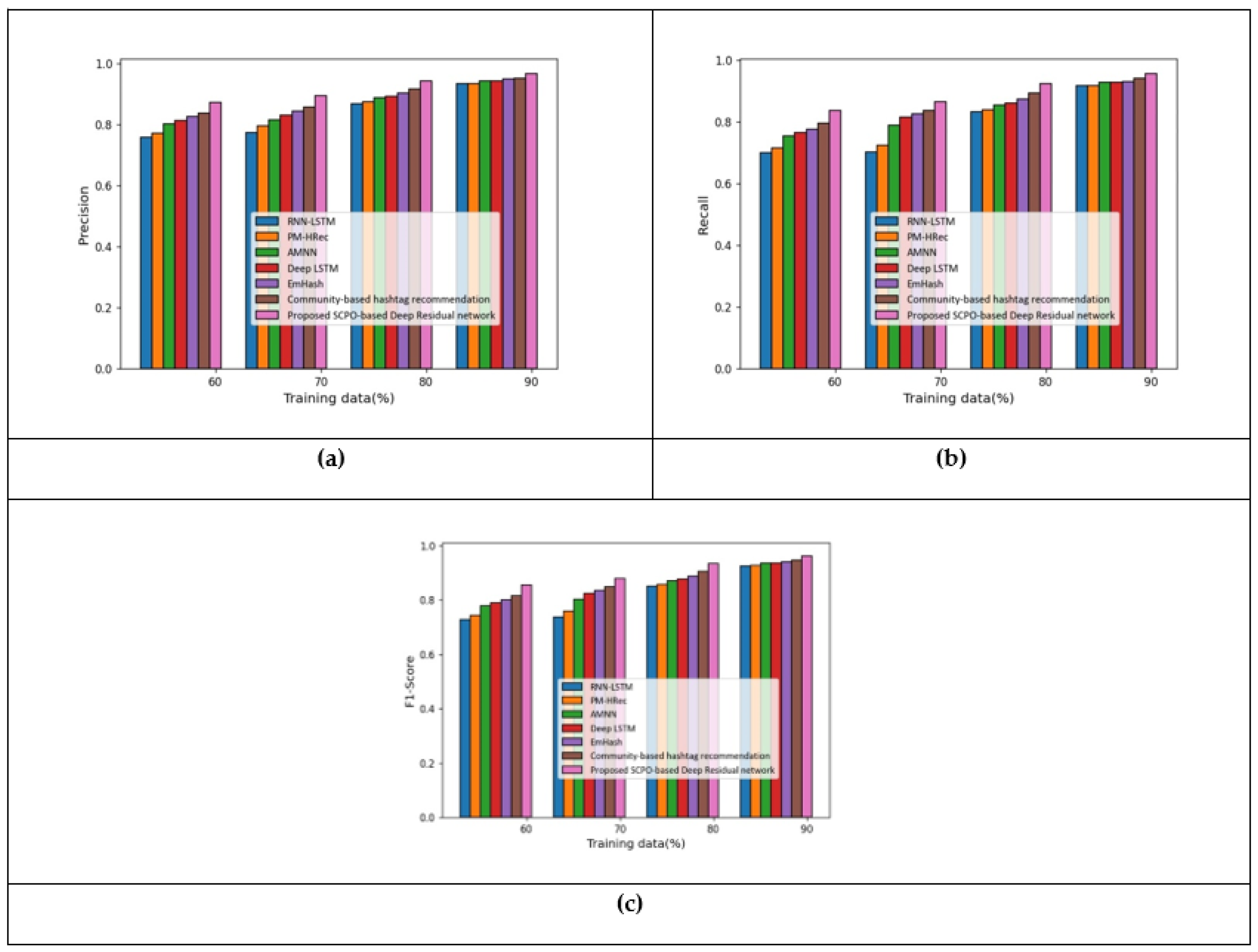
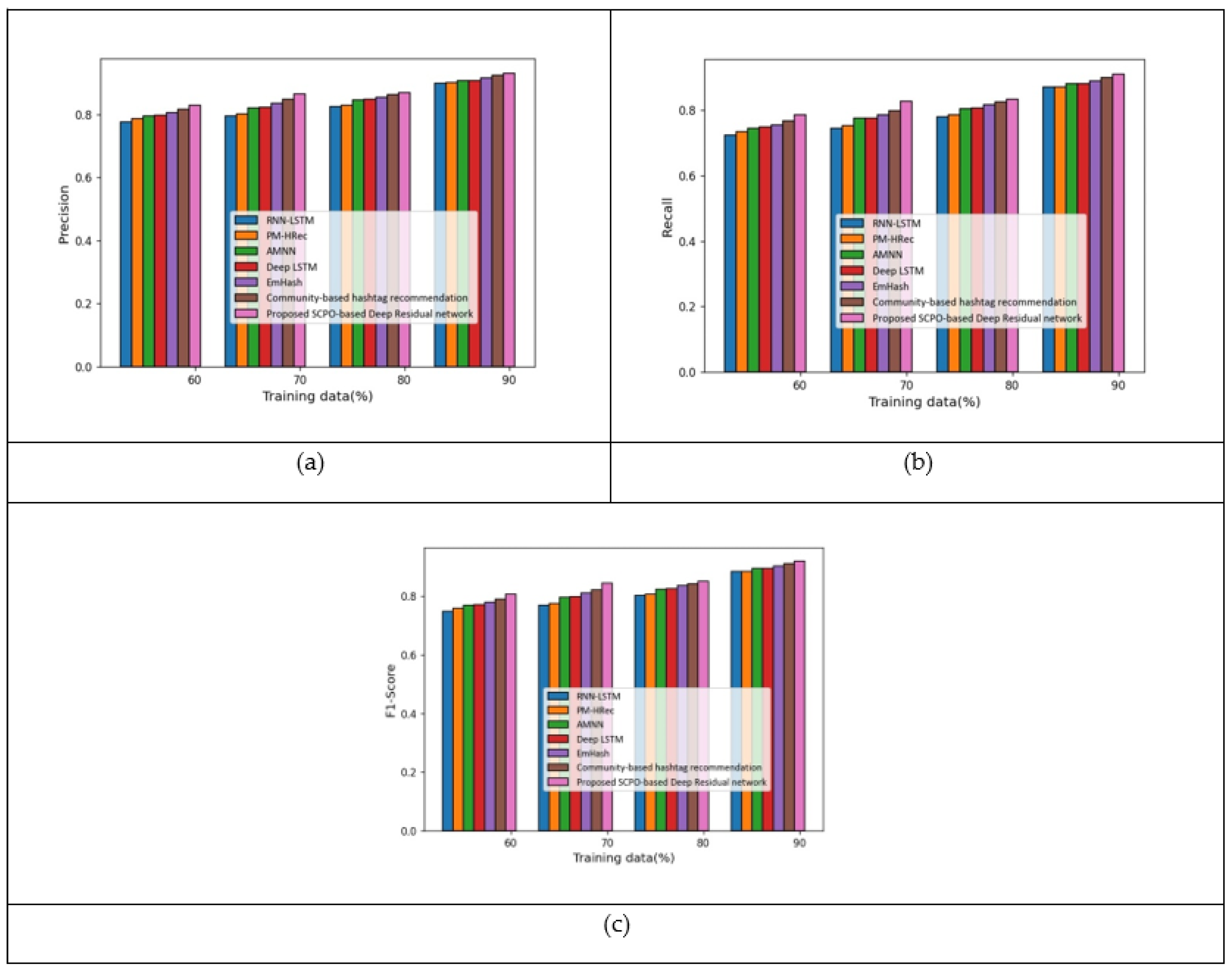
This section describes the analysis on the Apple twitter sentiment dataset. Figure 5 shows the analysis of the proposed model when using features –. Figure 5a shows the precision measure. With 70% of the training data, the precision measured by the proposed SCPO-based Deep Residual network was 0.88, making it 14.27%, 13.01%, 7.85%, 7.48%, 5.31%, and 4.30% superior to RNN-LSTM, PM-HRec, AMNN, Deep LSTM, Emhash, and Community-based hashtag recommendation, respectively. The analysis of the recall measure is presented in Figure 5b. With 80% of the training data, the recall measured by the proposed SCPO-based Deep Residual network was 0.91, making it 8.64%, 7.98%, 5.98%, 5.36%, 3.81%, and 3.02% superior to RNN-LSTM, PM-HRec, AMNN, Deep LSTM, Emhash, and Community-based hashtag recommendation, respectively. The analysis of the F1-score measure of the proposed method in presented in Figure 5c. With 70% of the training data, the F1-score measured by the proposed SCPO-based Deep Residual network was 0.87, making it 16.01%, 14.62%, 8.89%, 8.47%, 6.63%, and 5.36% superior to RNN-LSTM, PM-HRec, AMNN, Deep LSTM, Emhash, and Community-based hashtag recommendation, respectively.
The analysis of the developed approach, considering the feature f, is illustrated in Figure 6. Figure 6a portrays the precision metric. With 70% of the training data, the precision measured by the proposed SCPO-based Deep Residual network was 0.90, making it 13.56%, 11.16%, 8.82%, 7.15%, 5.66%, and 4.13% superior to RNN-LSTM, PM-HRec, AMNN, Deep LSTM, Emhash, and Community-based hashtag recommendation, respectively. The analysis of the recall measure is presented in Figure 6b. With 80% of the training data, the recall measured by the proposed SCPO-based Deep Residual network was 0.92, making it 9.89%, 9.23%, 7.44%, 6.83%, 5.42%, and 3.37% superior to RNN-LSTM, PM-HRec, AMNN, Deep LSTM, Emhash, and Community-based hashtag recommendation, respectively. The analysis of the F1-score measure is presented in Figure 6c. With 70% of the training data, the F1-score measured by the proposed SCPO-based Deep Residual network was 0.88, making it 16.31%, 13.82%, 8.73%, 6.36%, 5.00%, and 3.61% superior to RNN-LSTM, PM-HRec, AMNN, Deep LSTM, Emhash, and Community-based hashtag recommendation, respectively.
5.2. Results Based on Twitter Dataset
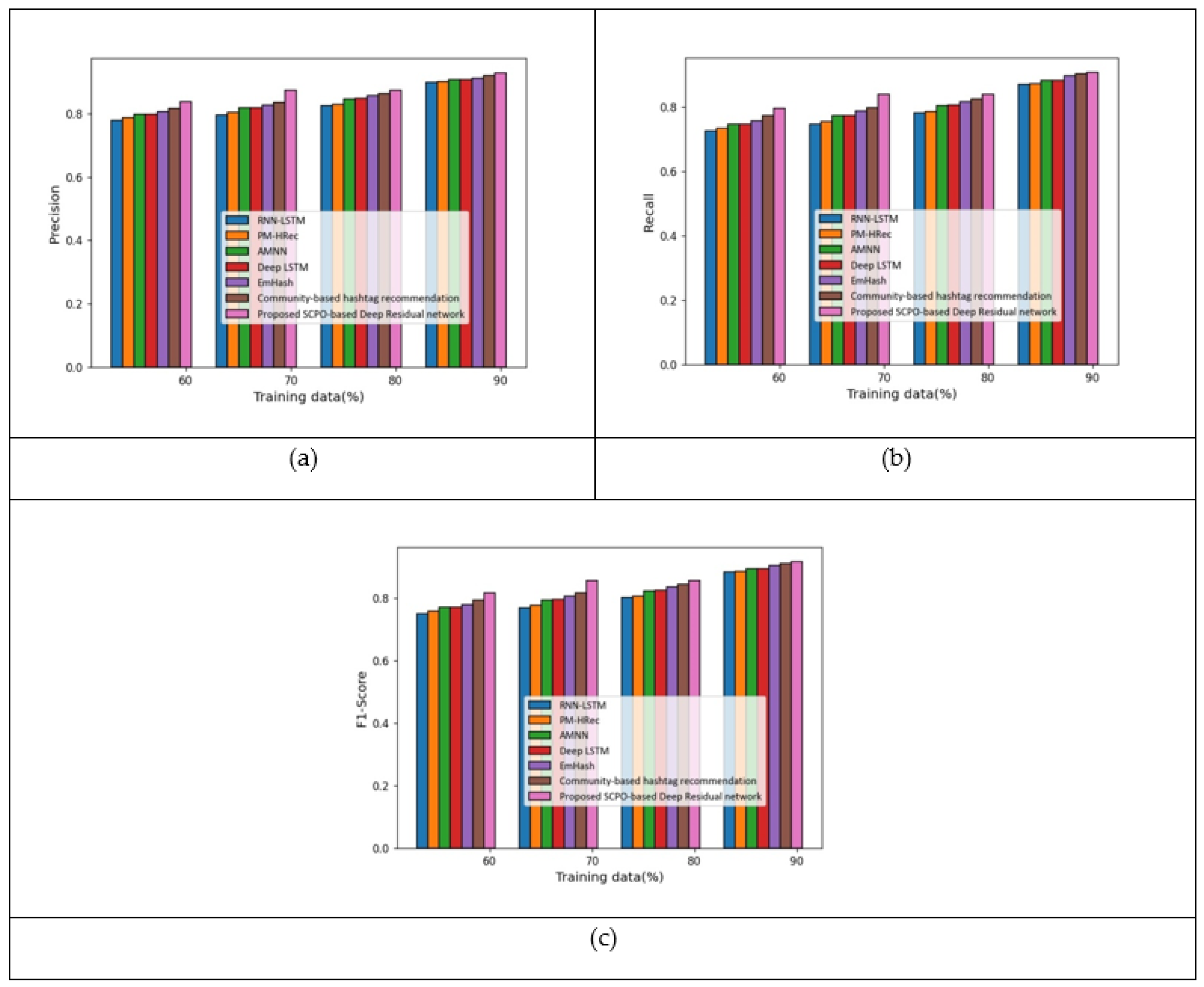
The comparative analysis carried out considering the Twitter dataset is detailed in this section. Figure 7 presents the analysis when considering the features –. Figure 7a presents the analysis with respect to the precision measure. With 80% of the training data, the precision measured by the proposed SCPO-based Deep Residual network was 0.87, making it 5.14%, 4.65%, 2.81%, 2.60%, 1.79%, and 0.76% superior to RNN-LSTM, PM-HRec, AMNN, Deep LSTM, Emhash, and Community-based hashtag recommendation, respectively. The analysis of the recall measure is presented in Figure 7b. With 60% of the training data, the recall measured by the proposed SCPO-based Deep Residual network was 0.78, making it 7.94%, 6.54%, 5.24%, 4.74%, 3.80%, and 2.26% superior to RNN-LSTM, PM-HRec, AMNN, Deep LSTM, Emhash, and Community-based hashtag recommendation, respectively. The analysis of the F1-score measure is presented in Figure 7c. With 70% of the training data, the F1-score measured by the proposed SCPO-based Deep Residual network was 0.85, making it 9.05%, 8.23%, 5.66%, 5.51%, 4.10%, and 2.80% superior to RNN-LSTM, PM-HRec, AMNN, Deep LSTM, Emhash, and Community-based hashtag recommendation, respectively.
Figure 8 indicates the comparative analysis of the proposed scheme using the feature f. Figure 8a portrays the analysis based on the precision measure. With 80% of the training data, the precision measured by the proposed SCPO-based Deep Residual network was 0.87, making it 5.56%, 5.18%, 3.29%, 3.05%, 1.94%, and 1.23% superior to RNN-LSTM, PM-HRec, AMNN, Deep LSTM, Emhash, and Community-based hashtag recommendation, respectively. The analysis of the recall measure is presented in Figure 8b. With 60% of the training data, the recall measured by the proposed SCPO-based Deep Residual network was 0.87, making it 8.92%, 7.68%, 6.21%, 6.12%, 5.04%, and 2.78% superior to RNN-LSTM, PM-HRec, AMNN, Deep LSTM, Emhash, and Community-based hashtag recommendation, respectively. The analysis of the F1-score measure is presented in Figure 8c. With 70% of the training data, the F1-score measured by the proposed SCPO-based Deep Residual network was 0.86, making it 10.09%, 9.04%, 7.08%, 7.04%, 5.81%, and 4.59% superior to RNN-LSTM, PM-HRec, AMNN, Deep LSTM, Emhash, and Community-based hashtag recommendation, respectively.
5.3. Comparative Discussion
Table 2 presents a comparison of the results of the tested methods, showing the values obtained when considering all of the features of the dataset and 90% of the training data. For the Apple twitter sentiment dataset, the precision achieved by the proposed SCPO-based Deep Residual Network was 0.958, making it 3.51%, 3.31%, 2.58%, 2.48%, 1.86%, and 1.55% superior to RNN-LSTM, PM-HRec, AMNN, Deep LSTM, Emhash, and Community-based hashtag recommendation, respectively. The recall achieved by the proposed SCPO-based Deep Residual Network was 0.958, making it 4.28%, 4.07%, 3.03%, 2.92%, 2.71%, and 1.57%, superior to RNN-LSTM, PM-HRec, AMNN, Deep LSTM, Emhash, and Community-based hashtag recommendation, respectively. Likewise, the F1-score obtained by the proposed SCPO-based Deep Residual Network was 0.963, making it 3.84%, 3.74%, 2.80%, 2.70%, 2.28%, and 1.56% better than RNN-LSTM, PM-HRec, AMNN, Deep LSTM, Emhash, and Community-based hashtag recommendation, respectively. Similarly, the proposed SCPO-based Deep Residual Network had the maximum precision, recall, and F1-score values on the Twitter dataset, compared to the considered state-of-the-art methods.
The proposed method outperformed all of the other comparative methods, in terms of precision, recall, and F1-score. This performance enhancement was achieved through the use of population diversity in the proposed algorithm, which improves the search space, thus achieving better performance enhancement. Furthermore, it is helpful to carry out the optimization of complex problems in parallel, in order to enhance the efficiency and accuracy. The proposed algorithm also has a fast convergence rate and obtained the best solution by avoiding local optima. Overall, the proposed method had improved performance, compared to the other conventional techniques.
6. Conclusions and Future Work
In this research, we developed a Hashtag Recommendation model by employing the SCPO-based Deep Residual Network method, in which a deep learning classifier—that is, the Deep Residual Network—is trained by the proposed SCPO algorithm. The proposed method performs the hashtag recommendation process by considering the features of the keyword set. The input tweet is subjected to stop word removal, effectively removing the stop words associated with the tweet. The keyword set is then computed by finding the dictionary words, thematic words, and more relevant words in the tweet data. The features of the keyword sets are passed to the Deep LSTM classifier, in order to find the hashing score. In addition to the features of the keyword set, the hashing score is also employed as an input to the Deep Residual Network which recommends the hashtags. Empirical results demonstrated that the proposed model can outperform state-of-the-art models on the Apple Twitter Sentiment dataset and Twitter dataset. In the future, the dimensionality of features can be further reduced by employing a feature selection model. Moreover, the training process may be further enhanced by testing the application of other optimization algorithms.
Author Contributions
S.K.B. designed and wrote the paper; H.L. (Hongfei Lin) supervised the work; S.K.B. performed the experiments with an advise from B.X. and H.L. (Haifeng Liu) organized and proofread the paper. All authors have read and agreed to the published version of the manuscript.
Funding
This research was supported by the National Natural Science Foundation of China No. 61572102.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Conflicts of Interest
The authors declare no conflict of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| AMNN | Attention-based Multi-model Neural Network |
| BoW | Bag of Words |
| CNN | Convolutional Neural Network |
| DNN | Deep Neural Networks |
| LSTM | Long Short-Term Memory |
| NB | Naive Bayes |
| NLP | Natural Language Processing |
| PO | Political Optimizer |
| RNN | Recurrent Neural Network |
| SCA | Sine Cosine Algorithm |
References
- Kowald, D.; Pujari, S.C.; Lex, E. Temporal effects on hashtag reuse in twitter: A cognitive-inspired hashtag recommendation approach. In Proceedings of the 26th International Conference on World Wide Web, Perth, Australia, 3–7 April 2017; pp. 1401–1410. [Google Scholar]
- Godin, F.; Slavkovikj, V.; De Neve, W.; Schrauwen, B.; Van de Walle, R. Using topic models for twitter hashtag recommendation. In Proceedings of the 22nd International Conference on World Wide Web, Rio de Janeiro, Brazil, 13–17 May 2013; pp. 593–596. [Google Scholar]
- Alvari, H. Twitter hashtag recommendation using matrix factorization. arXiv 2017, arXiv:1705.10453. [Google Scholar]
- Kabakus, A.T.; Kara, R. “TwitterSpamDetector”: A Spam Detection Framework for Twitter. Int. J. Knowl. Syst. Sci. (IJKSS) 2019, 10, 1–14. [Google Scholar] [CrossRef]
- Otsuka, E.; Wallace, S.A.; Chiu, D. A hashtag recommendation system for twitter data streams. Comput. Soc. Netw. 2016, 3, 1–26. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Dey, K.; Shrivastava, R.; Kaushik, S.; Subramaniam, L.V. Emtagger: A word embedding based novel method for hashtag recommendation on twitter. In Proceedings of the 2017 IEEE International Conference on Data Mining Workshops (ICDMW), New Orleans, LA, USA, 18–21 November 2017; pp. 1025–1032. [Google Scholar]
- Cui, A.; Zhang, M.; Liu, Y.; Ma, S.; Zhang, K. Discover breaking events with popular hashtags in twitter. In Proceedings of the 21st ACM international conference on Information and Knowledge Management, Maui, HI, USA, 29 October–2 November 2012; pp. 1794–1798. [Google Scholar]
- Li, T.; Wu, Y.; Zhang, Y. Twitter hash tag prediction algorithm. In Proceedings of the International Conference on Internet Computing (ICOMP), Las Vegas, NV, USA, 18–21 July 2011. [Google Scholar]
- Krestel, R.; Fankhauser, P.; Nejdl, W. Latent dirichlet allocation for tag recommendation. In Proceedings of the Third ACM Conference on Recommender Systems, New York, NY, USA, 23–25 October 2009; pp. 61–68. [Google Scholar]
- Khabiri, E.; Caverlee, J.; Kamath, K.Y. Predicting semantic annotations on the real-time web. In Proceedings of the 23rd ACM Conference on Hypertext and Social Media, Milwaukee, WI, USA, 25–28 June 2012; pp. 219–228. [Google Scholar]
- Weston, J.; Chopra, S.; Adams, K. # tagspace: Semantic embeddings from hashtags. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1822–1827. [Google Scholar]
- Cristin, R.; Cyril Raj, V.; Marimuthu, R. Face image forgery detection by weight optimized neural network model. Multimed. Res. 2019, 2, 19–27. [Google Scholar]
- Gangappa, M.; Mai, C.; Sammulal, P. Enhanced Crow Search Optimization Algorithm and Hybrid NN-CNN Classifiers for Classification of Land Cover Images. Multimed. Res. 2019, 2, 12–22. [Google Scholar]
- Vidyadhari, C.; Sandhya, N.; Premchand, P. A semantic word processing using enhanced cat swarm optimization algorithm for automatic text clustering. Multimed. Res. 2019, 2, 23–32. [Google Scholar]
- Ben-Lhachemi, N.; Boumhidi, J. Hashtag Recommender System Based on LSTM Neural Reccurent Network. In Proceedings of the 2019 Third International Conference on Intelligent Computing in Data Sciences (ICDS), Marrakech, Morocco, 28–30 October 2019; pp. 1–6. [Google Scholar]
- Gers, F.A.; Schmidhuber, J.; Cummins, F. Learning to forget: Continual prediction with LSTM. Neural Comput. 2000, 12, 2451–2471. [Google Scholar] [CrossRef] [PubMed]
- Li, Y.; Liu, T.; Hu, J.; Jiang, J. Topical co-attention networks for hashtag recommendation on microblogs. Neurocomputing 2019, 331, 356–365. [Google Scholar] [CrossRef] [Green Version]
- Ben-Lhachemi, N. Using tweets embeddings for hashtag recommendation in Twitter. Procedia Comput. Sci. 2018, 127, 7–15. [Google Scholar] [CrossRef]
- Belhadi, A.; Djenouri, Y.; Lin, J.C.W.; Cano, A. A data-driven approach for Twitter hashtag recommendation. IEEE Access 2020, 8, 79182–79191. [Google Scholar] [CrossRef]
- Alsini, A.; Datta, A.; Huynh, D.Q. On utilizing communities detected from social networks in hashtag recommendation. IEEE Trans. Comput. Soc. Syst. 2020, 7, 971–982. [Google Scholar] [CrossRef]
- Yang, Q.; Wu, G.; Li, Y.; Li, R.; Gu, X.; Deng, H.; Wu, J. AMNN: Attention-Based Multimodal Neural Network Model for Hashtag Recommendation. IEEE Trans. Comput. Soc. Syst. 2020, 7, 768–779. [Google Scholar] [CrossRef]
- Ma, R.; Qiu, X.; Zhang, Q.; Hu, X.; Jiang, Y.G.; Huang, X. Co-attention Memory Network for Multimodal Microblog’s Hashtag Recommendation. IEEE Trans. Knowl. Data Eng. 2019, 33, 388–400. [Google Scholar] [CrossRef]
- Cao, D.; Miao, L.; Rong, H.; Qin, Z.; Nie, L. Hashtag our stories: Hashtag recommendation for micro-videos via harnessing multiple modalities. Knowl. Based Syst. 2020, 203, 106114. [Google Scholar] [CrossRef]
- Li, C.; Xu, L.; Yan, M.; Lei, Y. TagDC: A tag recommendation method for software information sites with a combination of deep learning and collaborative filtering. J. Syst. Softw. 2020, 170, 110783. [Google Scholar] [CrossRef]
- Dhelim, S.; Aung, N.; Ning, H. Mining user interest based on personality-aware hybrid filtering in social networks. Knowl.-Based Syst. 2020, 206, 106227. [Google Scholar] [CrossRef]
- Majhi, B.; Naidu, D.; Mishra, A.P.; Satapathy, S.C. Improved prediction of daily pan evaporation using Deep-LSTM model. Neural Comput. Appl. 2020, 32, 7823–7838. [Google Scholar] [CrossRef]
- Chen, Z.; Chen, Y.; Wu, L.; Cheng, S.; Lin, P. Deep residual network based fault detection and diagnosis of photovoltaic arrays using current-voltage curves and ambient conditions. Energy Convers. Manag. 2019, 198, 111793. [Google Scholar] [CrossRef]
- Mirjalili, S. SCA: A sine cosine algorithm for solving optimization problems. Knowl. Based Syst. 2016, 96, 120–133. [Google Scholar] [CrossRef]
- Askari, Q.; Younas, I.; Saeed, M. Political optimizer: A novel socio-inspired meta-heuristic for global optimization. Knowl. Based Syst. 2020, 195, 105709. [Google Scholar] [CrossRef]
- Kaviani, M.; Rahmani, H. Emhash: Hashtag recommendation using neural network based on bert embedding. In Proceedings of the 2020 6th International Conference on Web Research (ICWR), Tehran, Iran, 22–23 April 2020; pp. 113–118. [Google Scholar]
Figure 1.
An illustration of the proposed SCPO-based Deep Residual Network for Hashtag Recommendation.
Figure 1.
An illustration of the proposed SCPO-based Deep Residual Network for Hashtag Recommendation.
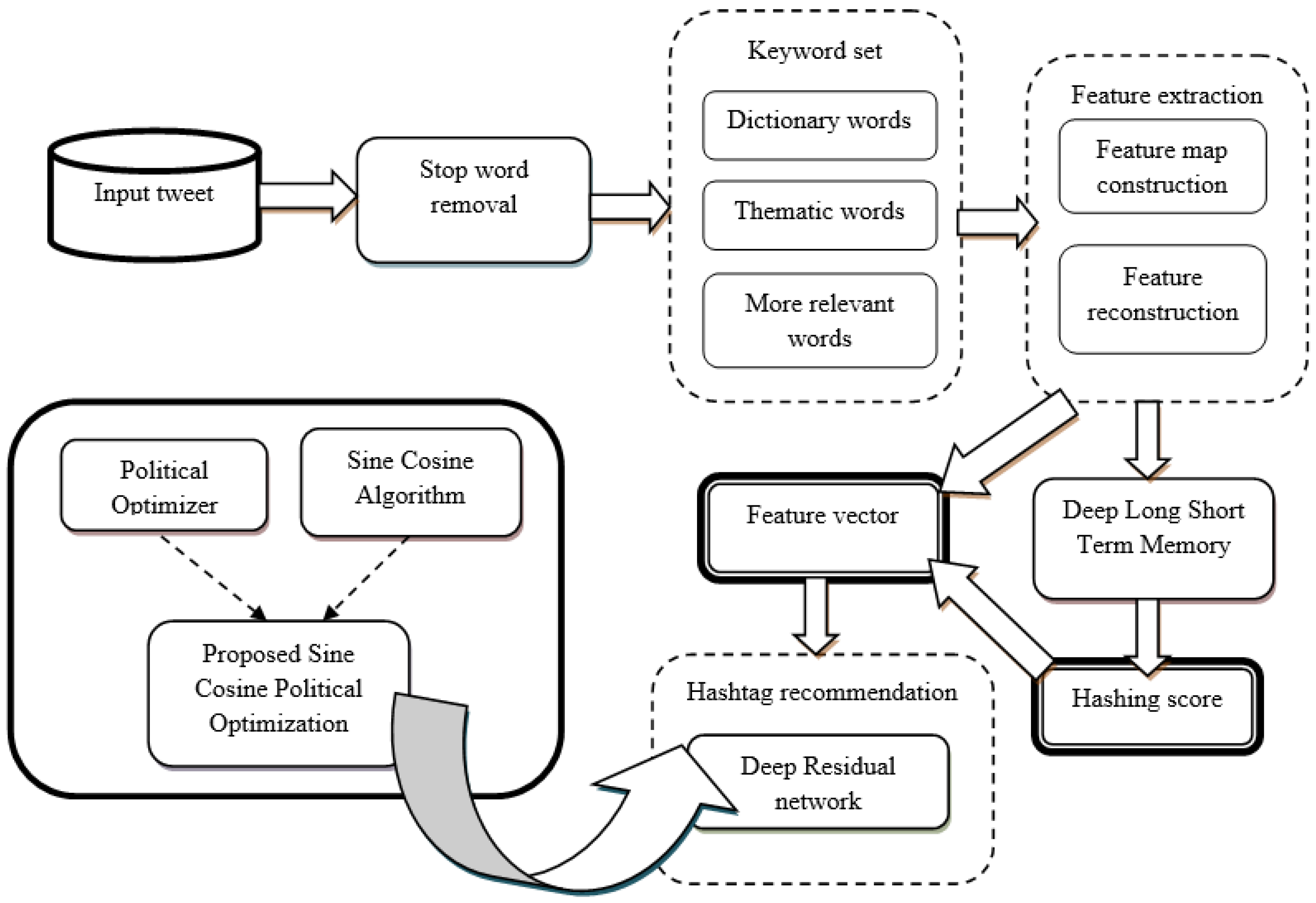
Figure 2.
Schematic view of feature map construction.

Figure 3.
Structure of Deep LSTM classifier.
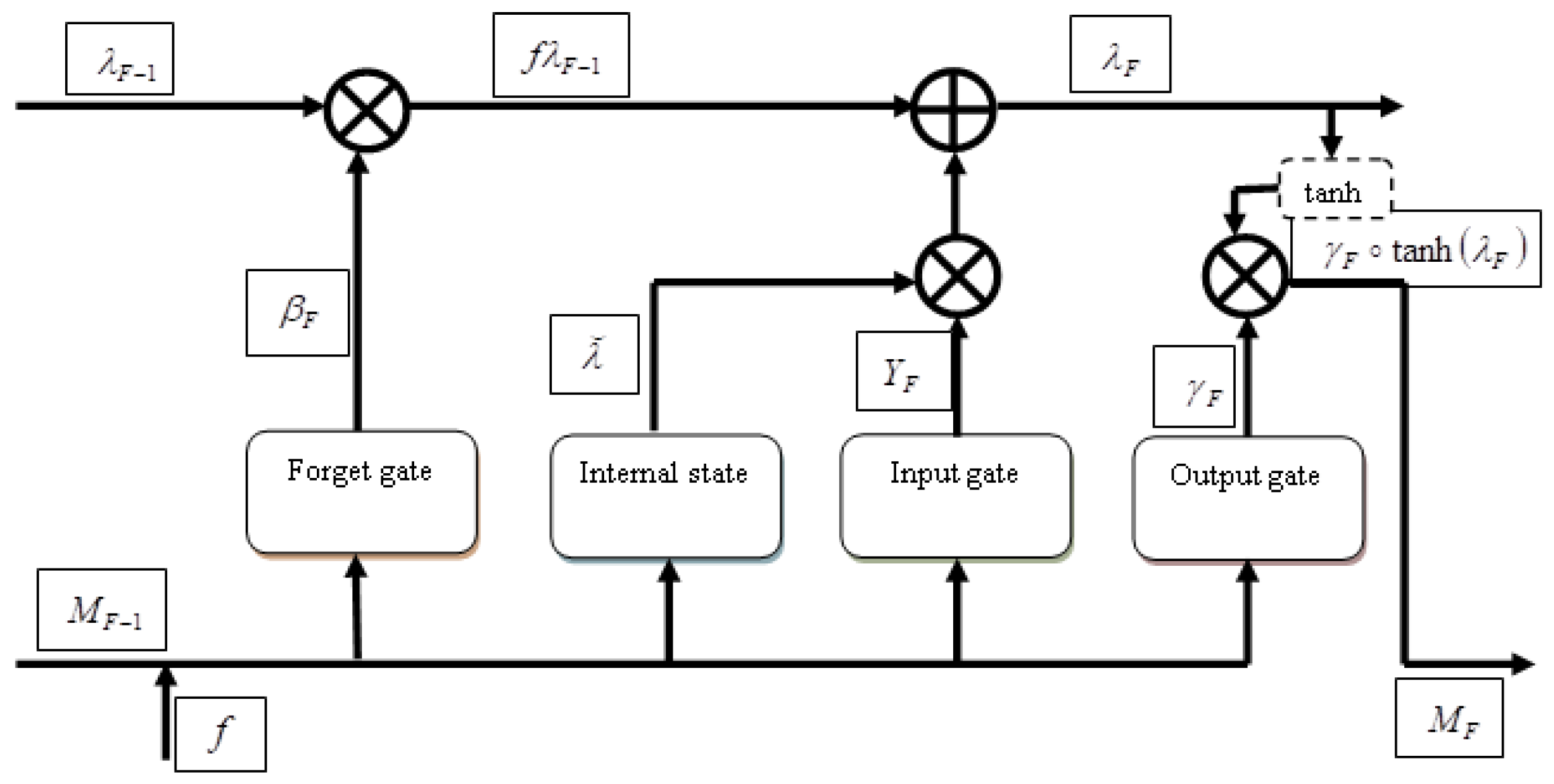
Figure 4.
Architecture of Deep Residual Network.

Figure 5.
Analysis using features – based on Apple twitter sentiment dataset: (a) Precision; (b) Recall; and (c) F1-score.
Figure 5.
Analysis using features – based on Apple twitter sentiment dataset: (a) Precision; (b) Recall; and (c) F1-score.

Figure 6.
Analysis with f features based on the Apple twitter sentiment dataset: (a) Precision; (b) Recall; and (c) F1-score.
Figure 6.
Analysis with f features based on the Apple twitter sentiment dataset: (a) Precision; (b) Recall; and (c) F1-score.
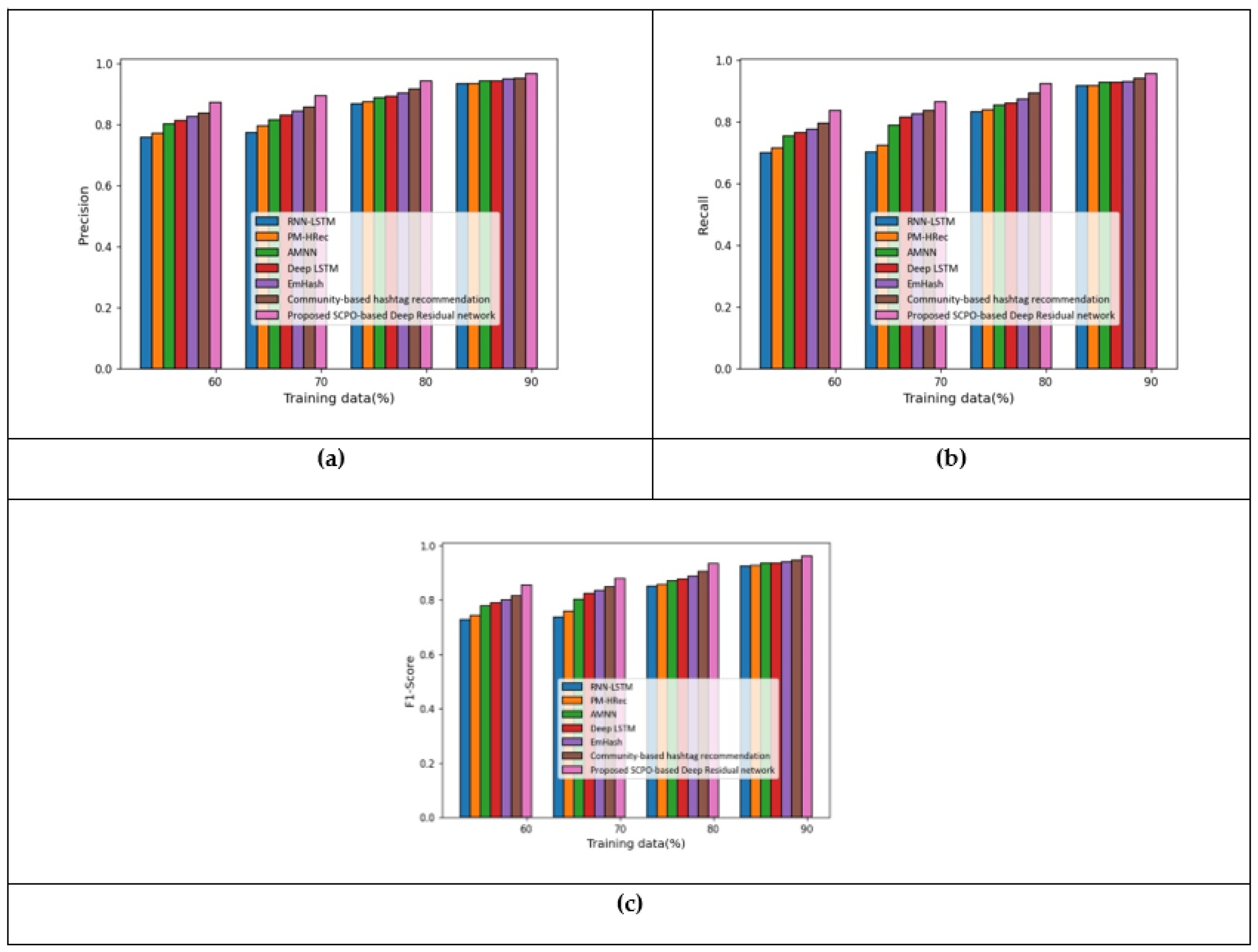
Figure 7.
Analysis with features – based on Twitter dataset: (a) Precision; (b) Recall; and (c) F1-score.
Figure 7.
Analysis with features – based on Twitter dataset: (a) Precision; (b) Recall; and (c) F1-score.

Figure 8.
Analysis with f features based on Twitter dataset: (a) Precision; (b) Recall; and (c) F1-score.
Figure 8.
Analysis with f features based on Twitter dataset: (a) Precision; (b) Recall; and (c) F1-score.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
Literature review.
| Authors | Methods | Advantages | Disadvantages |
|---|---|---|---|
| Ben-Lhachemi, N. et al. [18] | DBSCAN clustering technique. | Has the potential to recommend pertinent hashtags syntactically and semantically from a given tweet. | Fails to involve deep architectures on various semantic knowledge bases to enhance accuracy. |
| Li, Y. et al. [17] | Topical Co-Attention Network (TCAN). | Useful for determining structures from large documents. | Fails to involve temporal information. |
| Ben-Lhachemi, N. and Boumhidi, J. [15] | Long Short-Term Memory Recurrent Neural Network. | Capable of recommending suitable hashtags. | Fails to utilize semantic knowledge bases to improve accuracy. |
| Belhadi, A. et al. [19] | Pattern Mining for Hashtag Recommendation (PM-HRec). | Works effectively on huge data. | Fails to include parallel methods (e.g., GPUs) to handle large data. |
| Alsini, A. et al. [20] | Community-based hashtag recommendation model. | Easy to understand different factors that influence hashtag recommendation. | Lengthy process. |
| Yang, Q. et al. [21] | Attention-based multimodal neural network model (AMNN). | Able to attain improved performance with multimodal micro-blogs. | Fails to adapt external knowledge, such as comments and user information, for recommendation. |
| Ma, R. et al. [22] | Co-attention memory network. | Can manage a huge number of hashtags. | The generation of high-quality candidate sets is complex. |
| Cao, D. et al. [23] | Neural network-based LOGO. | Assists in capturing sequential and considerate features at the same time. | Fails to include recommendation on micro-videos. |
| Can Li et al. [24] | Tag recommendation method with Deep learning and Collaborative filtering (TagDC) | Helps to locate similar software. | Fails to consider unpopular tags. |
| Sahraoui et al. [25] | Hybrid filtering technique in a social network for data mining. | Predicts the user’s interest in a social network. | Fails to evaluate the performance in the signed Network. |
Table 2.
Comparison of existing methods and the proposed SCPO-DRN using Apple twitter sentiment dataset and Twitter dataset, in terms of Precision, Recall, and F1-Score.
Table 2.
Comparison of existing methods and the proposed SCPO-DRN using Apple twitter sentiment dataset and Twitter dataset, in terms of Precision, Recall, and F1-Score.
| Metrics/Method | RNN-LSTM | PM-HRec | AMNN | Deep LSTM | Emhash | Commu. Based | Proposed SCPO-DRN | |
|---|---|---|---|---|---|---|---|---|
| Apple | Precision | 0.934 | 0.936 | 0.943 | 0.944 | 0.950 | 0.953 | 0.968 |
| Recall | 0.917 | 0.919 | 0.929 | 0.930 | 0.932 | 0.943 | 0.958 | |
| F1-score | 0.926 | 0.927 | 0.936 | 0.937 | 0.941 | 0.948 | 0.963 | |
| Precision | 0.899 | 0.900 | 0.908 | 0.909 | 0.913 | 0.921 | 0.929 | |
| Recall | 0.870 | 0.871 | 0.882 | 0.882 | 0.898 | 0.904 | 0.907 | |
| F1-score | 0.884 | 0.886 | 0.895 | 0.895 | 0.905 | 0.912 | 0.918 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Banbhrani, S.K.; Xu, B.; Liu, H.; Lin, H. SC-Political ResNet: Hashtag Recommendation from Tweets Using Hybrid Optimization-Based Deep Residual Network. Information 2021, 12, 389. https://0-doi-org.brum.beds.ac.uk/10.3390/info12100389
AMA Style
Banbhrani SK, Xu B, Liu H, Lin H. SC-Political ResNet: Hashtag Recommendation from Tweets Using Hybrid Optimization-Based Deep Residual Network. Information. 2021; 12(10):389. https://0-doi-org.brum.beds.ac.uk/10.3390/info12100389
Chicago/Turabian StyleBanbhrani, Santosh Kumar, Bo Xu, Haifeng Liu, and Hongfei Lin. 2021. "SC-Political ResNet: Hashtag Recommendation from Tweets Using Hybrid Optimization-Based Deep Residual Network" Information 12, no. 10: 389. https://0-doi-org.brum.beds.ac.uk/10.3390/info12100389
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.