
Could a Conversational AI Identify Offensive Language? †

 ,
,  , ,
, ,  , , and
, , and 
Abstract
:1. Introduction
2. Background
- Chatbots and Conversational AI can identify offensive language?
- Could ML be designed for reliability and justice?
- Do the ethical issues depend on the geographical area?
2.1. AI Ethics
- Virtue Ethics —Aristotle argues that a moral agent reaches “flowering”, seen as an action and not a state, through the constant balance of factors as the social environment, material provisions, friends, family, and yourself. In the context of A/IS, there are two immediate values of virtue ethics: a model for iterative learning and growth; a framework for A/IS developers counteracted tendencies towards excess.
- Deontological ethics—Developed by the German philosopher Immanuel Kant, it is based on moral and legal responsibility. In other words, a rule must be inherently desirable, feasible, valuable, and others must be able to understand and follow it. Rules based on personal choices cannot be universalized. In the context of A/IS, the question is whether developers are acting with the best interests of humanity and human dignity in mind.
- Utilitarian (Consequentialist) ethics—Refers to the consequences of your decisions and actions, that is, the right course of action is the one that maximizes utility (utilitarianism) or pleasure (hedonism) for the greatest number of people, but considering superficial and short-term usefulness or pleasure. In the context of ethical AI, it is the responsibility of A/IS developers to consider the long-term effects including social justice.
- Ethics of Care—This philosophy emphasizes the importance of relationships, and taking care of another human being is one of our basic attributes. That is, the relationship with another person must exist or have the potential to exist and the relationship should be one of growth and care. With regards to A/IS, if A/IS is expected to be beneficial to humans then the human will need to take care of A/IS. Moreover, if this possibility exists, then principles applicable to A/IS will be needed.
- Transparency—the basis of the decision-making process of an autonomous and intelligent system (A/IS) must be always detectable.
- Responsibility—an A/IS must be created and operated according to an unambiguous logic for all decisions taken.
- Awareness of misuse—the A/IS creators must protect themselves against all possible undue, inequitable, and risks of the A/IS in operation.
2.2. AI Bias and Discrimination
2.3. Fair ML
2.4. Language Models
2.5. Offensive Language
- Subject = I;
- Intensity = really;
- Intention = hate; and
- Target = Black People.
2.5.1. Part 1—Analysis of Occurrences from Internet
2.5.2. Part 2—Analysis of Common Expressions for Each Category
2.5.3. Part 3—Spelling Corrections
2.5.4. Part 4—Content Removal Policy
2.5.5. Limitations about the Template Dictionary
2.6. The Limitations of a Conversational AI to Identify Offensive Language
- It needs to prove that classical ethical issues have been addressed;
- It also needs to explore the ethical contributions of other systems based on religion and culture;
- It needs to adapt to cultural clusters and global preferences, and additionally to regional preferences internally in the clusters;
- It also needs to mitigate biases in real-time, and handle biases not only in the data but also in the algorithms, as well as address adjustment of their hyperparameters for a fair ML;
- It is necessary to handle data change over time and also have a way to address the impact in the long term;
- It needs to clearly identify the criteria for fairness, and what it is based on;
- It needs to identify high impact decisions based on data that can be intrinsically biased;
- Pre-training is the dominant approach in transfer learning and annotated databases is a common practice in recent years. However there is a cost and a limit to pre-training approaches to Conversational AI as it would break the flow and the possibility of mitigating and apply justice in real time;
- Furthermore, due to homogenization, the models are based on the same self-supervised learning architecture and therefore inheriting the same problems related to ethics and justice;
- Foundation models may contain an Anglocentric metric by default, which may not be beneficial in other contexts where the foundation model may apply;
- There are few studies on the religious bias of models, and therefore it is necessary more evidence that these models can deal with religious bias or ethical contributions;
- Because these models also introduce some unethical behavior, there is also a need for further studies on how this risk could be mitigated through an automation process to introduce positive associations; and
- Data creation process is complex and data can contain different types of biases. Also after deployment, those models can present undesirable behavior on sub-populations of data. They also need to adapt to dynamical nature of training data.
3. Methods
3.1. The Dictionary Creation
- The existing database was created from the number of occurrences of words in a text from a list of sites that contained content on categories considered offensive language. This database contains nouns, adjectives, adverbs, and verbs, in addition to pronouns, articles, and prepositions.
- Words that had the highest number of occurrences were grouped by category, keeping only noun, adjective and verbs. A vocabulary frequency counter was performed in a post. Moreover, the category was indicated if there was a large number of words in a post that belonged to a specific category, and there is a limitation to this approach as some offensive words can only appear a few times.
- The recommendation is that the removal of content also follow current legislation for data privacy, as well as for making data available to government agencies if necessary.
- The truth and intent of any statement generally cannot be evaluated by computers alone; therefore, efforts could depend on collaboration between humans and technology and that said once an unethical comment is identified it needs to be reviewed by a moderator before being removed. However, this approach to interaction between humans and technology would not be appropriate as it would make real-time conversational AI impossible.
- The database proposed is an initial sample. This database is not static and will need to be periodically reviewed by a moderator to evaluate new words to be inserted and existing words to be changed or removed.
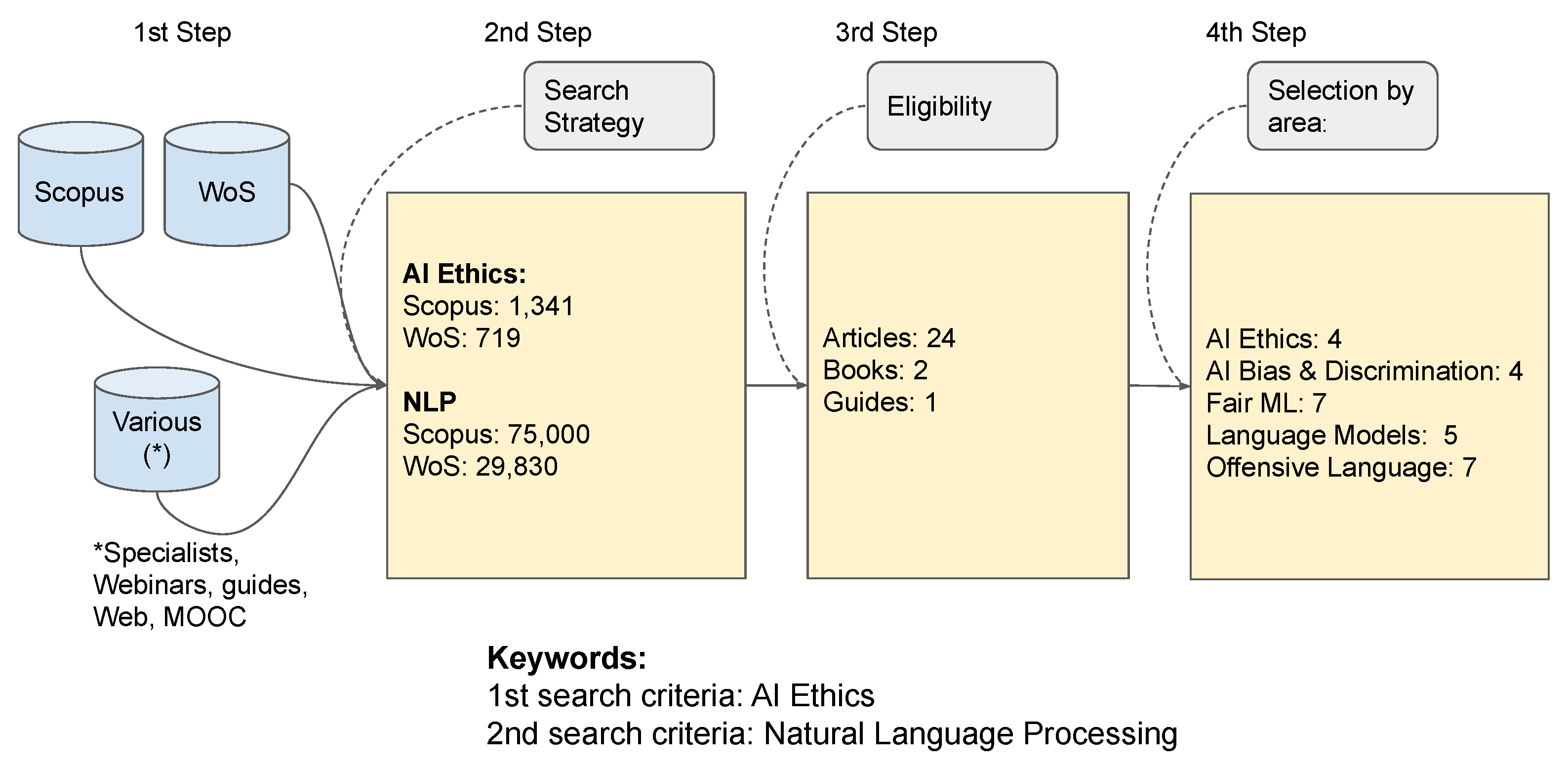
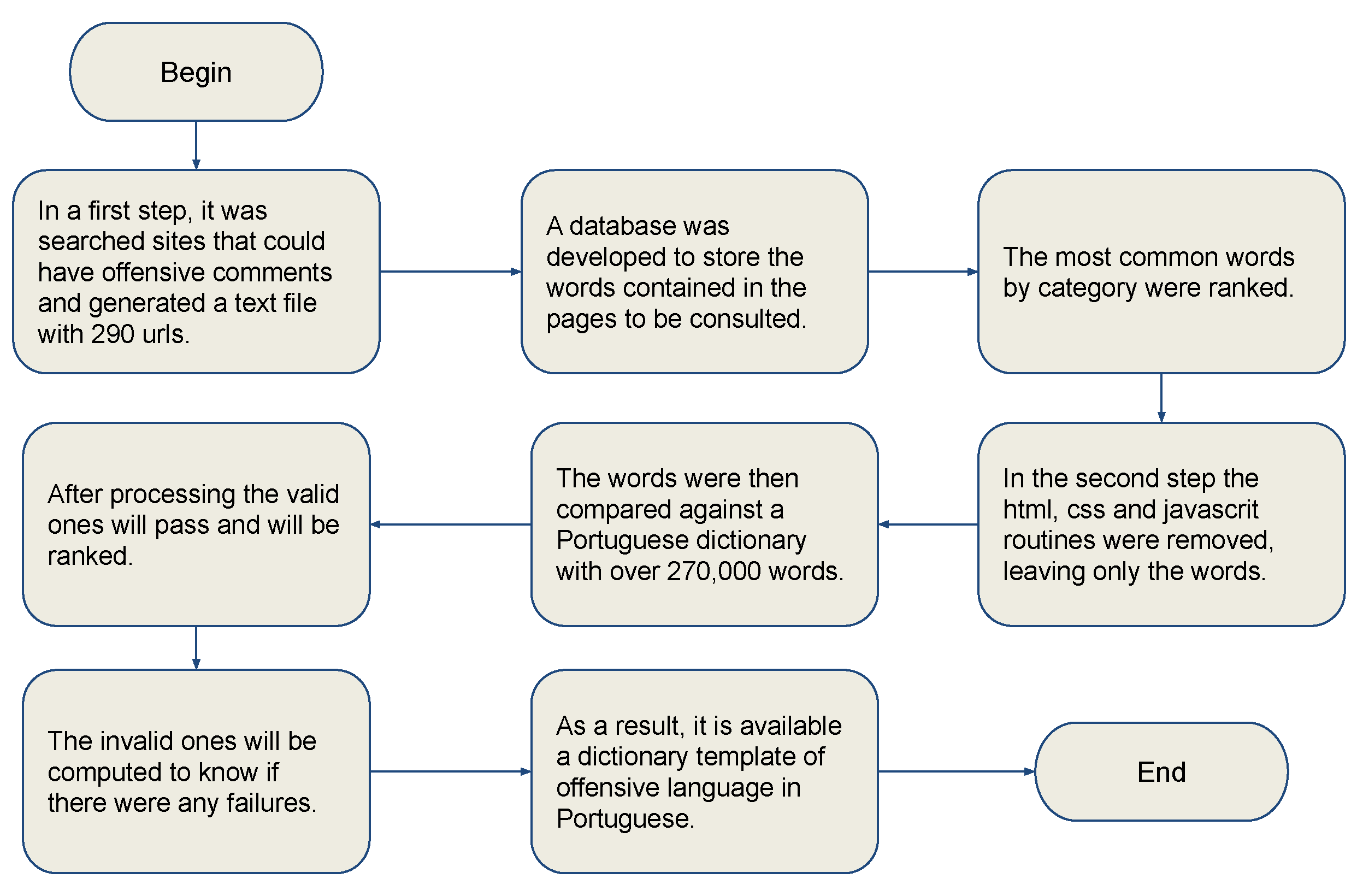
- In a first step, we identified the sites that could contain offensive language and generated a text file with 290 URLs. For the low-level proof-of-concept, some sites that could contain posts with offensive language were annotated manually. A database was developed to collect the words contained in the pages to be consulted. The most common words were ranked by category.
- In the second step, the html, css, and javascript routines were removed, leaving only the words.
- In the third step, the words were then compared to a database of a Portuguese word dictionary with more than 270,000 words.
- After processing, the valid ones will pass and will be ranked. The invalid ones will be computed to know if there was any failure.
- Definition of 12 categories on offensive content: legal drugs, illegal drugs, sex (pedophilia, rape, abuse, pornography), weapons, heinous crimes (assault, robbery, murder), smuggling, swearing, gambling, racism, homophobia, perjury, and defamation. Specifically in this low-level proof of concept carried out in Brazil, the legal drugs were included because when there is abusive use of these drugs, there may be the use of offensive language. In the case of the gambling, the verification of posts was carried out on social media in Brazil, because there are illegal games in the country. That said, the identification of categories for offensive language may depend on the country’s cultural characteristics and legislation;
- Google search for 20 random URLs that contained text on selected categories;
- Creation of a database with the tables necessary to classify the words found by category and validated by a dictionary with more than 270,000 entries;
- Creating a routine in Java that loads these URLs and tries to extract just the texts:
- (a)
- Reading a text file with searched URLs;
- (b)
- Access to each URL;
- (c)
- Removal of HTML and CSS content;
- (d)
- Removal of Javascript content;
- (e)
- Removal of special characters and numbers, keeping only letters, including those with accents and cedilla;
- (f)
- Removing more than one space between words; and
- (g)
- Removal of blank lines;
- Reading each line of text, breaking them into words;
- Discard words smaller than 3 letters;
- Dictionary search for existing or non-existing word classification;
- Classification of each word ranking them by category;
- Found 116,893 words in all texts of the chosen categories;
- Export to an Excel spreadsheet of 13,391 words of up to 50 characters, per category (there was still a lot of mess from the HTMLs);
- Manual cleaning of “dirt”, creating new table to exclude the terms not applicable in next search in URLs;
- Manual separation of words by category in the spreadsheet;
- Manual removal from the list of words that do not relate to the researched categories; and
- Final creation of a dictionary template in a spreadsheet.
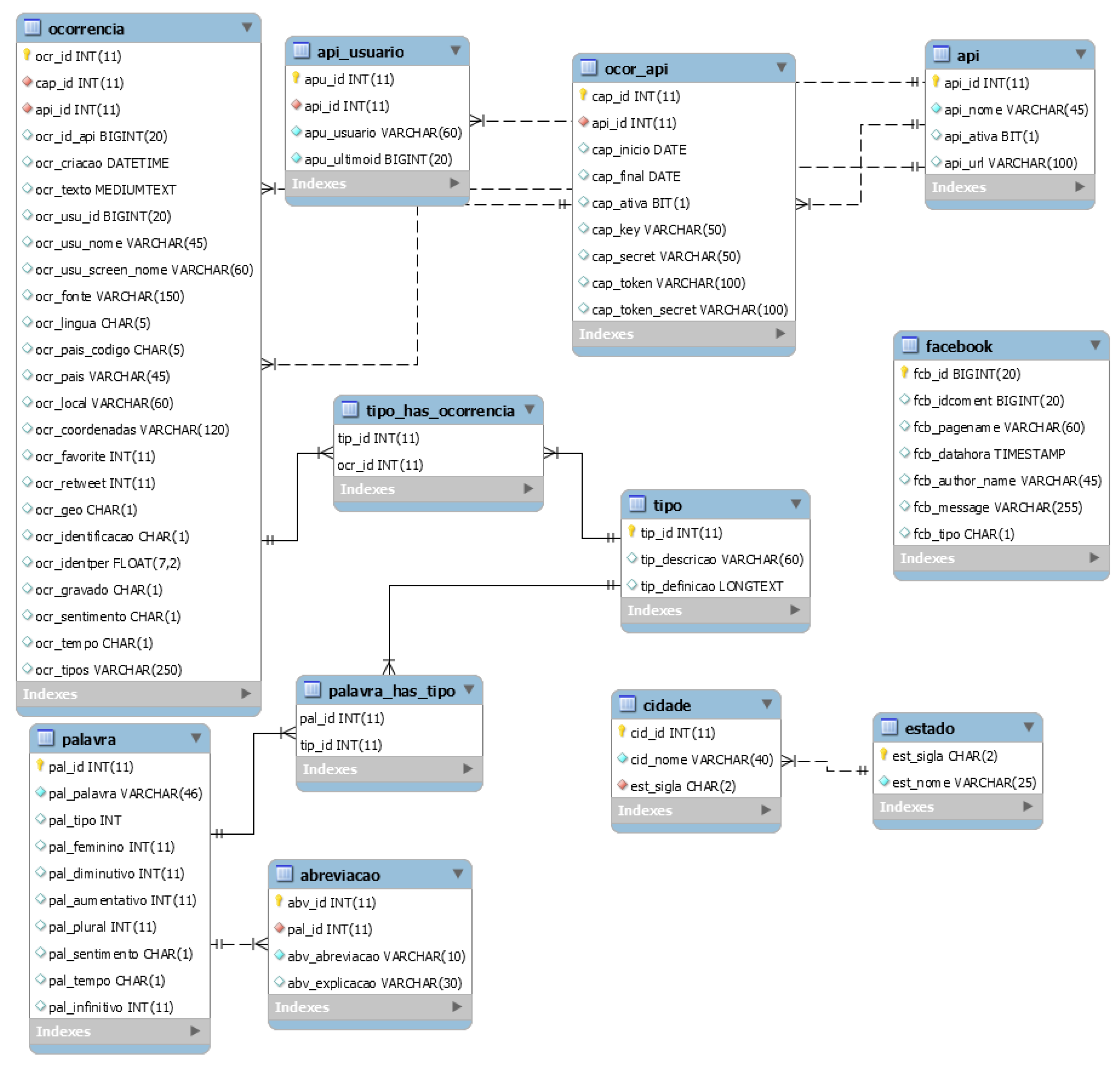
3.2. The Database
- Table Ocorrencia—it will contain the posts captured from Twitter, with all the information provided by the platform. Highlight for the fields:
- (a)
- ocr_text—message text;
- (b)
- ocr_identificacao—If the message was marked as having words from any of the categories in the dictionary;
- (c)
- ocr_identper—number of words found in the message; and
- (d)
- ocr_tipos—the subjects in which the selected words fit.
- Table Palavra—it contains 328,112 entries in the Portuguese language and serves to validate the words in the dictionary by category;
- Table Abreviação—it contains 561 most common abbreviations found in internet messages in portuguese. Serves for the routine that converts any abbreviations found in the messages into the words they mean;
- Table Tipo—it contains the types of subjects that will be the basis for the dictionary. Remember that there may be repeated words in more than one subject;
- Table PalavraHasTipo—This table is the “true” dictionary. It actually just matches the words in the Table Palavra with the subjects in the Table Tipo;
- Table TipoHasOcorrencia—This table is an auxiliary to the table Occorrencia, by making the relationship of the captured message with the possible subjects in which they fit, according to the words found in the text. As the same words can be part of different subjects, it was necessary to create this table with many-to-many relationship; and
- Other Tables—it will be used for future expansions of the routine.
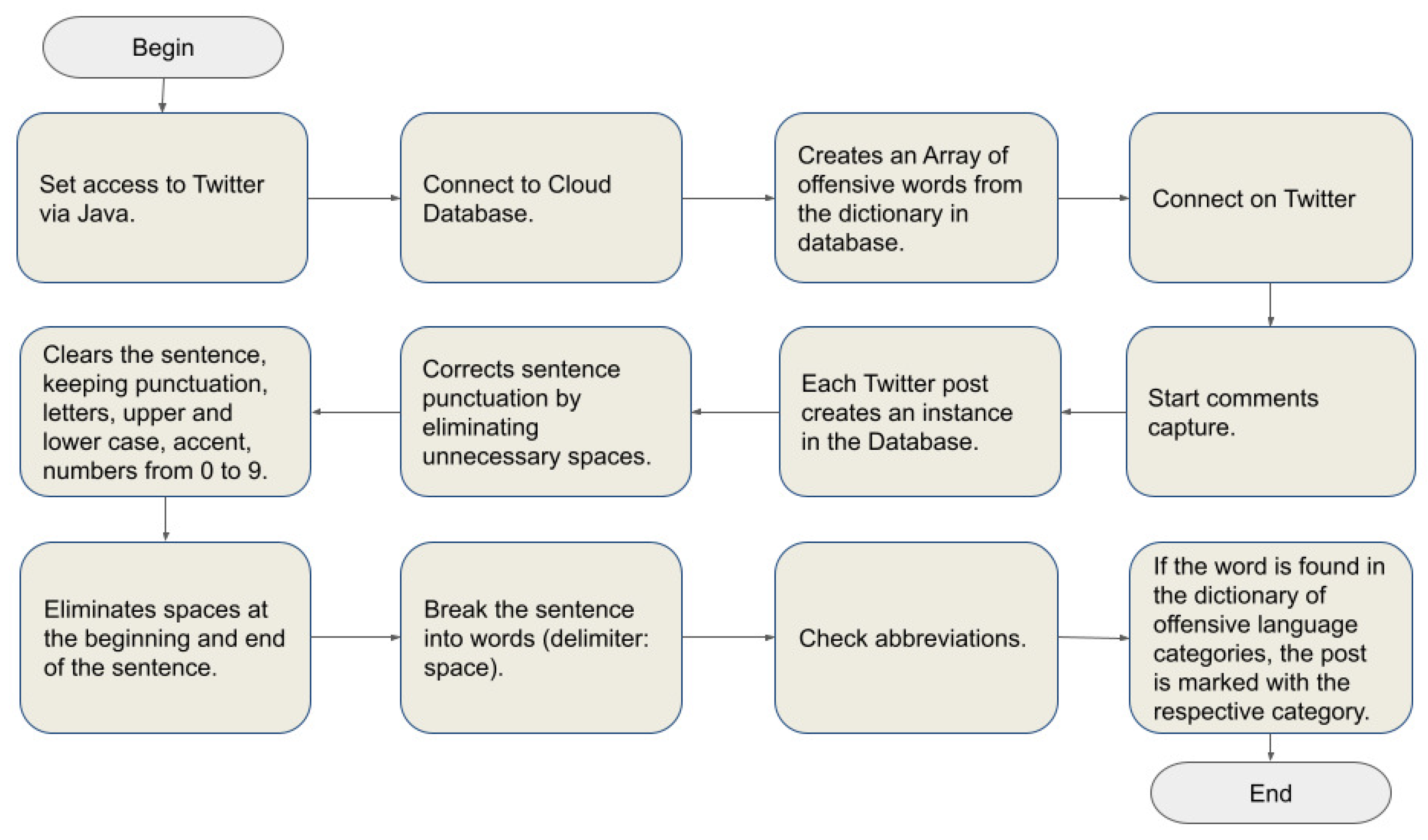
3.3. The Program to Collect Posts from Twitter
- Initialization:
- (a)
- It is used the twitter4j Java library to access twitter and its posts;
- (b)
- It was necessary to register on Twitter an app with complete information to obtain the release of keys and tokens to access the twitter API;
- (c)
- The routine starts connecting to the database created in the cloud;
- (d)
- Makes the relationship of categories with their respective words in the database, bringing the data to an ArrayList;
- (e)
- Some standard parameters are initially set to meet the criteria chosen to collect posts; and
- (f)
- Then, it tries to connect to the API with the keys and tokens provided by Twitter;
- With the connection established, post capture starts:
- (a)
- At each capture, an object called Ocorrencia is created with the information contained in the Twitter post;
- (b)
- Next, the message processing begin. First, it is checked if the message content is not empty;
- (c)
- Then a routine corrects the punctuation of the sentence, removing the spaces between the words and punctuation;
- (d)
- Afterwards a routine “clean-up” the sentence, keeping only the standard punctuation, capital, small and accented letters, cedilla and numbers from 0 to 9;
- (e)
- Then spaces at the beginning and end of the sentence are removed, if any;
- (f)
- Afterwards, the sentence is broken into words by a routine that uses the spaces between them as delimitation;
- (g)
- Another routine comes into play looking for each of the words in the dictionary of abbreviations. If found, the abbreviation is replaced by the word it represents, and is marked between the minor and major signs (diamond) to indicate that there was an abbreviation in the original sentence; and
- (h)
- Then each word is searched in the dictionary and variable is incremented to identify the multiple categories that it belongs to, and the categories will be also registered;
- To finalize the routine, the phrase containing one or more offensive categories will be classified as possible offensive language:
- (a)
- Categories related to that occurrence will be indicated in the database;
- (b)
- Posts that were not related to any category will be also stored, for later checking and statistics;
- (c)
- The entire program was prepared with error and exception handling routines so that its execution is not interrupted and it is possible to capture as much information as possible for the proof of concept; and
- (d)
- However, there is a limitation in the model as some offending words may not be captured using the word count frequency and it is also a very simple approach where a word may be out of context.
4. Results
The Experiment
5. Discussion
- Conversational AI models are based on foundation models trained on large, scaled data and can be adapted to a wide range of tasks. These models are not new and they have existed for decades; however, their use has increased in recent years and has brought discussions about what is possible when using these models and also understanding their characteristics;
- There is also a need to addresses classical ethical methodologies in algorithm design considerations for autonomous and intelligent systems (A/IS) where ML may or may not reflect ethical results considered in human decision making;
- It is also important for a Conversational AI to address cultural aspects involving preferences of individuals, among them global and individual preferences and cultural clusters in the use of systems;
- Those systems have also potential to harm historically underrepresented or disadvantaged groups of a population, because it is based on historical data often intrinsically discriminatory;
- Systems need to be improved to address individual justice, between the improvements, for example, identify how a pair of individuals could be treated similarly. In addition, even with bias, it is necessary systems that could provide accurate predictions for future decision-making, but without discriminating people into population subgroups;
- The algorithms need also to deal with changes in joint data over time, integrating an algorithm-level solution for a fair classification and an online approach to keep an accurate and up-to-date classifier to infinity data streams with non-stationary distribution and bias discrimination. It is not possible for a Conversational AI to rely on annotated data as it would break the flow of the algorithm;
- Domain experts are also required because NLP have complex tasks, such as questioning and answering and object recognition, using sentences or images as inputs, and it is necessary to write domain specific-logic to convert raw data into higher-level features;
- Foundation models may be also have a cultural-centric metric by default, which may not be beneficial in other contexts where the foundation model might be applied. Furthermore, the application of these foundation models in different domains can be a force for epistemic and cultural homogenization;
- Recent studies about NLP have been focused on gender and race bias, however there are few studies on religious bias. Therefore, it is necessary that some probes detect that those systems are not introducing any unethical behavior and/or offensive language in the areas of prompt completion, analogical reasoning, and story generation involving religious bias; and
- NLP needs to support diverse documentation, to allow data curation, identification of potential biases and, transparency on limitations of data sets. Furthermore, it needs to support mechanisms for safe maintenance and data sharing to correct undesirable behavior due to changes in the data.
- The study of feelings and emotions using text analysis, as demonstrated in the study “Linguistic Inquiry and Word Count (LIWC)” [40];
- In the study of words and expressions, as in the study conducted by the Federal University of Minas Gerais, Brazil, in the article “A Measurement Study of Hate Speech in Social Media” [29];
- In GPT-3, as it can generate hateful text, its capacity could also be used to identify and classify hate speech, such as in the study from Chiu et al. [30], “Detecting Hate Speech with GPT-3”;
- This work is an extension of a previous publication, “A Hybrid Dictionary Model for Ethical Analysis” [4], that proposes a dictionary template for sorting comments that may contain offensive language using a word filter. The dictionary template is not an NLP algorithm and there are some limitations when applying this dictionary to the task of identifying offensive language because it operates at the level of words, without any context. Breaking sentences into words, valuable semantic context, and content is lost. Additionally, offensive language can be used ironically, a common practice on the internet, where jokes, slang, and sarcasm are pervasive.
- The article seeks to show that Conversational AI cannot detect unethical behavior and/or offensive language and it is also expensive and difficult to manually identify offensive posts. Furthermore, by demonstrating the application of the dictionary to a text, in this case Twitter posts, a low-level proof-of-concept is presented to detect offensive language. However, it will be necessary to refine the study to something more relevant to Conversational AI seeking more solid results such as training an ML in examples of offensive language and/or unethical behavior and then applying it as a detector;
- For the low-level proof of concept, some sites that could contain posts with offensive language were annotated manually. Moreover, the dictionary categories were selected by checking areas that may be related to online crime, from state bodies, such as the Police, or from associations that receive reports of crime on the Internet. Furthermore, to define categories is necessary to understand cultural aspects and the law in the country or state were the template dictionary will be designed, because while some categories are clearly unethical like ”rape”, others are not, such as “legal drugs”, because an abusive consumption could lead to offensive language, and, in Brazil, where the template dictionary was applied, some types of “gambling” are illegal;
- In addition, using a labeling process for offensive language and/or unethical behavior is not acceptable to the industry as they are looking to eliminate this intervention. Furthermore, a manual process would break the flow of conversational AI; and
- Although there is a partial applicability of the dictionary model, the results propitiated identify the complexities of categorizing offensive language in Portuguese, and demonstrates the contextual complexity including the importance of addressing bias and discrimination as well. Without proper categories, for example, the automated system could erroneously consider many people to be hate speakers and the automated system could fail to differentiate between commonplace offensive language and serious hate speech. Furthermore, other categories of offensive language could be erroneously addressed.
6. Conclusions
6.1. Specific Conclusions
6.2. General Conclusions
6.3. Recommendations
6.4. Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| ACM FAT | ACM Conference on Fairness, Accountability, and Transparency |
| AGI | Artificial General Intelligence |
| AI | Artificial Intelligence |
| AAAI | Association for the Advancement of Artificial Intelligence |
| A/IS | Autonomous and Intelligent System |
| ASR | Automatic Speech Recognition |
| BERT | Bidirectional Encoder Representations for Transformers |
| EAD | IEEE Ethically Aligned Design |
| GPT | Generative Pre-trained Transformer |
| HAI | Stanford Human-Centered Artificial Intelligence Laboratory |
| NLP | Natural Language Processing |
| ICML | International Conference on Machine Learning |
| IEEE | Institute of Electrical and Electronics Engineers |
| NeurIPS | Neural Information Processing Systems |
| NLU | Natural Language Understanding |
| SLU | Spoken Language Understanding |
References
- Ertel, W. Introduction to Artificial Intelligence. In Introduction to Artificial Intelligence; Springer International Publishing: Cham, Switzerland, 2017; pp. 1–21. [Google Scholar] [CrossRef]
- Jurafsky, D.; Martin, J. Dialog systems and chatbots. Speech Lang. Proc. 2017, 3. Available online: http://www.cs.columbia.edu/~julia/courses/CS6998-2019/25.pdf (accessed on 3 July 2021).
- McKenna, J.P.; Choudhary, S.; Saxon, M.; Strimel, G.P.; Mouchtaris, A. Semantic complexity in end-to-end spoken language understanding. arXiv 2020, arXiv:2008.02858. [Google Scholar]
- da Silva, D.A.; Louro, H.D.B.; Goncalves, G.S.; Marques, J.C.; Dias, L.A.V.; da Cunha, A.M.; Tasinaffo, P.M. A Hybrid Dictionary Model for Ethical Analysis. In Advances in Intelligent Systems and Computing; Springer International Publishing: Cham, Switzerland, 2020; pp. 625–629. [Google Scholar] [CrossRef]
- Petersen, K.; Feldt, R.; Mujtaba, S.; Mattsson, M. Systematic mapping studies in software engineering. In Proceedings of the 12th International Conference on Evaluation and Assessment in Software Engineering (EASE), Bari, Italy, 26–27 June 2008; pp. 1–10. [Google Scholar]
- Karampela, M.; Isomursu, M.; Porat, T.; Maramis, C.; Mountford, N.; Giunti, G.; Chouvarda, I.; Lehocki, F. The extent and coverage of current knowledge of connected health: Systematic mapping study. J. Med. Internet Res. 2019, 21, e14394. [Google Scholar] [CrossRef]
- Saba, T. Module 1—The Concepts of Bias and Fairness in the AI Paradigm / The Notion of Diversity (MOOC Lecture). In UMontrealX and IVADO, Bias and Discrimination in AI. edX. 2021. Available online: https://learning.edx.org/course/course-v1:UMontrealX+IVADO-BIAS-220+3T2021/block-v1:UMontrealX+IVADO-BIAS-220+3T2021+type@sequential+block@4c92c4a7912e437cb114995fd817ef2e (accessed on 3 October 2021).
- Farnadi, G. Module 1—The Concepts of Bias and Fairness in the AI Paradigm/Fairness (MOOC Lecture). In UMontrealX and IVADO, Bias and Discrimination in AI. edX. 2021. Available online: https://learning.edx.org/course/course-v1:UMontrealX+IVADO-BIAS-220+3T2021/block-v1:UMontrealX+IVADO-BIAS-220+3T2021+type@sequential+block@bd20a537e32e43b8a1f694f17a9f7b44 (accessed on 3 October 2021).
- IEEE. IEEE Ethically Aligned Design. 2020. Available online: https://0-ethicsinaction-ieee-org.brum.beds.ac.uk/ (accessed on 18 November 2020).
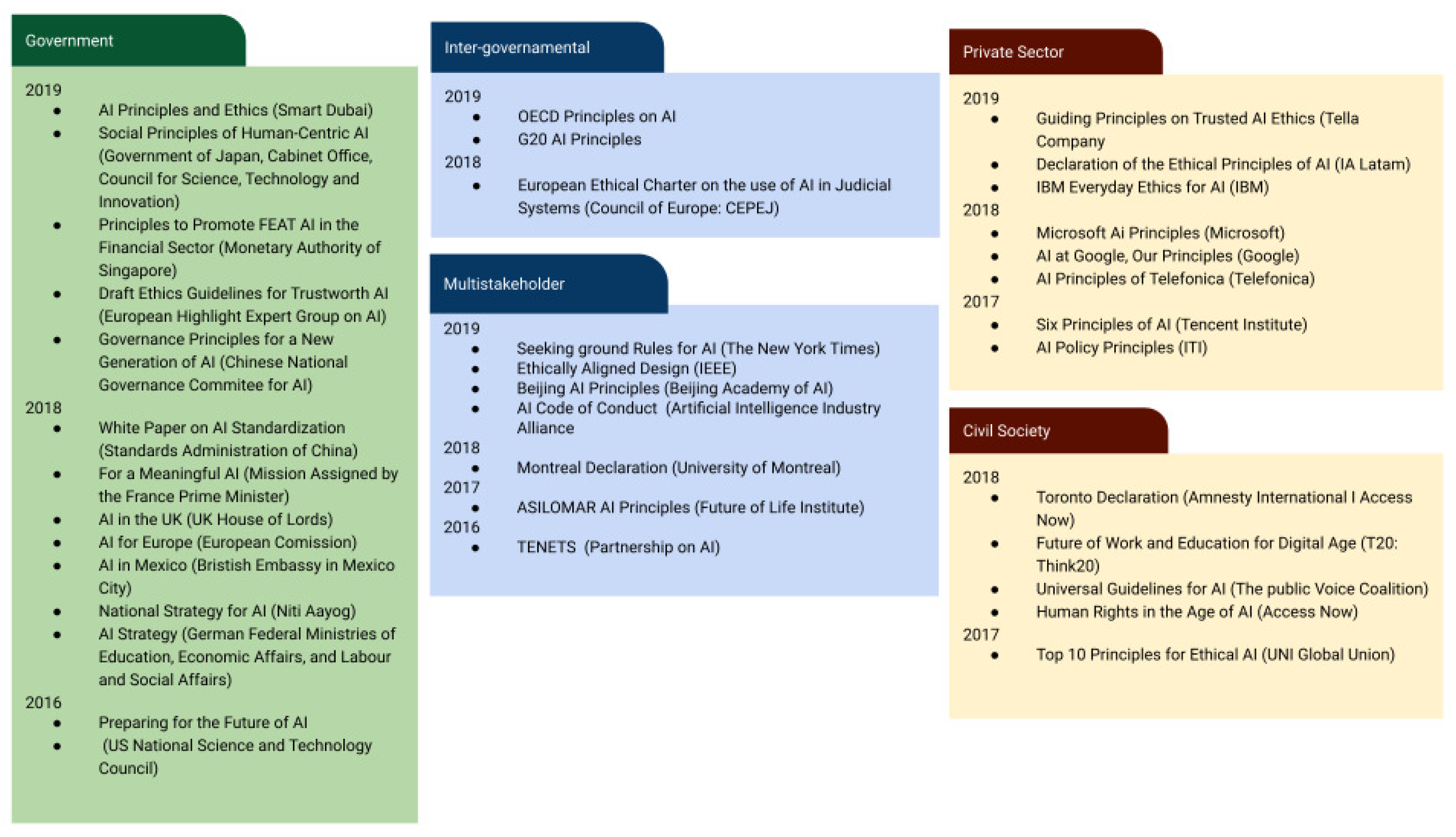
- Jobin, A.; Ienca, M.; Vayena, E. The global landscape of AI ethics guidelines. Nat. Mach. Intell. 2019, 1, 389–399. [Google Scholar] [CrossRef]
- Hutson, M. Robo-writers: The rise and risks of language-generating AI. Nature 2021, 591, 22–25. [Google Scholar] [CrossRef]
- Awad, E.; Dsouza, S.; Kim, R.; Schulz, J.; Henrich, J.; Shariff, A.; Bonnefon, J.F.; Rahwan, I. The moral machine experiment. Nature 2018, 563, 59–64. [Google Scholar] [CrossRef]
- Suresh, H.; Guttag, J.V. A framework for understanding sources of harm throughout the machine learning life cycle. arXiv 2019, arXiv:1901.10002. [Google Scholar]
- Tufekci, Z. Big questions for social media big data: Representativeness, validity and other methodological pitfalls. In Proceedings of the Eighth International AAAI Conference on Weblogs and Social Media, Ann Arbor, MI, USA, 1–4 June 2014. [Google Scholar]
- Olteanu, A.; Castillo, C.; Diaz, F.; Kıcıman, E. Social data: Biases, methodological pitfalls, and ethical boundaries. Front. Big Data 2019, 2, 13. [Google Scholar] [CrossRef] [Green Version]
- Caliskan, A.; Bryson, J.J.; Narayanan, A. Semantics derived automatically from language corpora contain human-like biases. Science 2017, 356, 183–186. [Google Scholar] [CrossRef] [Green Version]
- Hutchinson, B.; Mitchell, M. 50 years of test (un) fairness: Lessons for machine learning. In Proceedings of the Conference on Fairness, Accountability, and Transparency, Atlanta, GA, USA, 29–31 January 2019; pp. 49–58. [Google Scholar]
- Verma, S.; Rubin, J. Fairness definitions explained. In Proceedings of the 2018 IEEE/ACM International Workshop on Software Fairness (FairWare), Gothenburg, Sweden, 29 May 2018; pp. 1–7. [Google Scholar]
- Mehrabi, N.; Morstatter, F.; Saxena, N.; Lerman, K.; Galstyan, A. A survey on bias and fairness in machine learning. ACM Comput. Surv. (CSUR) 2021, 54, 1–35. [Google Scholar] [CrossRef]
- Liu, L.T.; Dean, S.; Rolf, E.; Simchowitz, M.; Hardt, M. Delayed impact of fair machine learning. In Proceedings of the International Conference on Machine Learning, Stockholmsmässan, Stockholm, Sweden, 10–15 July 2018; pp. 3150–3158. [Google Scholar]
- Zhang, W.; Ntoutsi, E. Faht: An adaptive fairness-aware decision tree classifier. arXiv 2019, arXiv:1907.07237. [Google Scholar]
- Zhang, W.; Bifet, A.; Zhang, X.; Weiss, J.C.; Nejdl, W. FARF: A Fair and Adaptive Random Forests Classifier. In Pacific-Asia Conference on Knowledge Discovery and Data Mining; Springer: Berlin/Heidelberg, Germany, 2021; pp. 245–256. [Google Scholar]
- Bechavod, Y.; Jung, C.; Wu, Z.S. Metric-free individual fairness in online learning. arXiv 2020, arXiv:2002.05474. [Google Scholar]
- Bommasani, R.; Hudson, D.A.; Adeli, E.; Altman, R.; Arora, S.; von Arx, S.; Bernstein, M.S.; Bohg, J.; Bosselut, A.; Brunskill, E.; et al. On the Opportunities and Risks of Foundation Models. arXiv 2021, arXiv:2108.07258. [Google Scholar]
- Abid, A.; Farooqi, M.; Zou, J. Persistent anti-muslim bias in large language models. arXiv 2021, arXiv:2101.05783. [Google Scholar]
- Gebru, T.; Morgenstern, J.; Vecchione, B.; Vaughan, J.W.; Wallach, H.; Daumé, H., III; Crawford, K. Datasheets for datasets. arXiv 2018, arXiv:1803.09010. [Google Scholar]
- Bender, E.M.; Friedman, B. Data statements for natural language processing: Toward mitigating system bias and enabling better science. Trans. Assoc. Comput. Linguist. 2018, 6, 587–604. [Google Scholar] [CrossRef] [Green Version]
- Tausczik, Y.R.; Pennebaker, J.W. The psychological meaning of words: LIWC and computerized text analysis methods. J. Lang. Soc. Psychol. 2010, 29, 24–54. [Google Scholar] [CrossRef]
- Mondal, M.; Silva, L.A.; Benevenuto, F. A measurement study of hate speech in social media. In Proceedings of the 28th ACM Conference on Hypertext and Social Media, Prague, Czech Republic, 4–7 July 2017; pp. 85–94. [Google Scholar]
- Chiu, K.L.; Alexander, R. Detecting Hate Speech with GPT-3. arXiv 2021, arXiv:2103.12407. [Google Scholar]
- Gordon, M.L.; Zhou, K.; Patel, K.; Hashimoto, T.; Bernstein, M.S. The disagreement deconvolution: Bringing machine learning performance metrics in line with reality. In Proceedings of the 2021 CHI Conference on Human Factors in Computing Systems, Yokohama, Japan, 8–13 May 2021; pp. 1–14. [Google Scholar]
- Sap, M.; Card, D.; Gabriel, S.; Choi, Y.; Smith, N.A. The risk of racial bias in hate speech detection. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; pp. 1668–1678. [Google Scholar]
- Davidson, T.; Warmsley, D.; Macy, M.; Weber, I. Automated hate speech detection and the problem of offensive language. In Proceedings of the International AAAI Conference on Web and Social Media, Montréal, QC, Canada, 15–18 May 2017; Volume 11. [Google Scholar]
- Davidson, T.; Bhattacharya, D.; Weber, I. Racial bias in hate speech and abusive language detection datasets. arXiv 2019, arXiv:1905.12516. [Google Scholar]
- JAIC. Explaining Artificial Intelligence and Machine Learning. 2020. Available online: https://www.youtube.com/watch?v=y_rY0ZIn5L4 (accessed on 5 January 2021).
- The World Bank. Be Data-Driven: Reimagining Human Connections Technology and Innovation in Education at the World Bank. 2020. Available online: https://www.worldbank.org/en/topic/edutech/brief/be-data-driven-reimagining-human-connections-technology-and-innovation-in-education-at-the-world-bank (accessed on 2 December 2020).
- Berkman Klein Center. Principled AI. 2020. Available online: https://cyber.harvard.edu/publication/2020/principled-ai (accessed on 18 November 2020).
- Executive Office of the President; Munoz, C.; Director, D.P.; Megan, D.J. Big Data: A Report on Algorithmic Systems, Opportunity, and Civil Rights; Executive Office of the President: Washington, DC, USA, 2016.
- Swiss Cognitive. Distinguishing between Chatbots and Conversational AI. 2021. Available online: https://swisscognitive.ch/2021/06/11/chatbots-and-conversational-ai-3/ (accessed on 22 June 2021).
- Pennebaker, J.W.; Francis, M.E.; Booth, R.J. Linguistic inquiry and word count: LIWC 2001. Mahway Lawrence Erlbaum Assoc. 2001, 71, 2001. [Google Scholar]
- Gonçalves, P.; Benevenuto, F.; Cha, M. Panas-t: A psychometric scale for measuring sentiments on twitter. arXiv 2013, arXiv:1308.1857. [Google Scholar]
- Bollen, J.; Mao, H.; Pepe, A. Modeling public mood and emotion: Twitter sentiment and socio-economic phenomena. In Proceedings of the Fifth International AAAI Conference on Weblogs and Social Media, Barcelona, Spain, 17–21 July 2011. [Google Scholar]
- HAI. Why AI Struggles To Recognize Toxic Speech on Social Media. 2021. Available online: https://hai.stanford.edu/news/why-ai-struggles-recognize-toxic-speech-social-media (accessed on 16 July 2021).
- Facebook. Update on Our Progress on AI and Hate Speech Detection. 2021. Available online: https://about.fb.com/news/2021/02/update-on-our-progress-on-ai-and-hate-speech-detection/ (accessed on 16 July 2021).
- WashingtonPost. YouTube Says It Is Getting Better at Taking Down Videos That Break Its Rules. They Still Number in the Millions. 2021. Available online: https://www.washingtonpost.com/technology/2021/04/06/youtube-video-ban-metric/ (accessed on 16 July 2021).
- Time. Twitter Penalizes Record Number of Accounts for Posting Hate Speech. 2021. Available online: https://time.com/6080324/twitter-hate-speech-penalties/ (accessed on 16 July 2021).
- SaferNet Segurança Digital. SaferNet Segurança Digital. 2021. Available online: https://new.safernet.org.br/ (accessed on 2 July 2021).
- Bosselut, A.; Rashkin, H.; Sap, M.; Malaviya, C.; Celikyilmaz, A.; Choi, Y. Comet: Commonsense transformers for automatic knowledge graph construction. arXiv 2019, arXiv:1906.05317. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Areas | Documents |
|---|---|
| AI Ethics: | IEEE [9], Jobin et al. [10], Hutson [11], Awad et al. [12] |
| AI Bias & Discrimination: | Suresh and Guttag [13], Tufekci [14], Olteanu et al. [15], Caliskan et al. [16] |
| Fair ML: | Hutchinson and Mitchell [17], Verma and Rubin [18], Mehrabi et al. [19], Liu et al. [20], Zhang and Ntoutsi [21], Zhang et al. [22], Bechavod et al. [23] |
| Language Models: | Jurafsky and Martin [2], Bommasani et al. [24], Abid et al. [25], Gebru et al. [26], Bender and Friedman [27] |
| Offensive Language: | Tausczik and Pennebaker [28], Mondal et al. [29], Chiu and Alexander [30], Gordon et al. [31], Sap et al. [32], Davidson et al. [33], Davidson et al. [34] |
| Category | Words | Percentage |
|---|---|---|
| Pedophilia | 143 | 10.2% |
| Legal Drugs | 137 | 9.8% |
| Illicit Drugs | 131 | 9.3% |
| Sex | 116 | 8.3% |
| Contraband | 108 | 7.7% |
| Rape | 108 | 7.7% |
| Heinous Crimes | 98 | 7.0% |
| Weapons and Armaments | 91 | 6.5% |
| Racism | 83 | 5.9% |
| Defamation | 76 | 5.4% |
| Homophobia | 70 | 5.0% |
| Gambling | 69 | 4.9% |
| Porn | 63 | 4.5% |
| Perjury | 62 | 4.4% |
| Bad Lanquage | 49 | 3.5% |
| Category | Posts | Percentage |
|---|---|---|
| Sex | 2076 | 25.96% |
| Bad Language | 1272 | 15.91% |
| Legal Drugs | 869 | 10.87% |
| Pedophilia | 752 | 9.4% |
| Illicit Drugs | 643 | 8.04% |
| Gambling | 434 | 5.43% |
| Racism | 387 | 4.83% |
| Heinous Crimes | 369 | 4.61% |
| Rape | 342 | 4.28% |
| Perjury | 275 | 3.44% |
| Weapons and Armaments | 274 | 3.43% |
| Contraband | 117 | 1.46% |
| Homophobia | 94 | 1.18% |
| Defamation | 82 | 1.03% |
| Porn | 11 | 0.14% |
| Concept | Relation | Behaviours | Category | Comments |
|---|---|---|---|---|
| X threats disclosing intimate images from Y | xIntent | threat, indemnity, insult | Sexting | To compel the victim to do something against his or her will; |
| X is bulling Y as joke | xIntent | insult, humiliation, psychological violence, intimidation, embarrassment | Bullying | Bullying is no joke; |
| X is quoting information from Y | xIntent | bonding, disturb, alarm, terrify, threaten | Stalking | Online pursuit is more than mere curiosity about the other; |
| X is exhibiting information from Y | xVisibility | tragedies, emergencies, urgencies, embarrassment | Selfie | The most popular word on the internet, not always a good behavior; |
| X is exposing Y | xRevenge | nudes, embarrassment, shame, financial benefit | Revenge pornography | Exposure of others on the web for revenge; |
| X is glorifying attacks on Y | xRevenge, xVisibility | violence, pursuit, revenge, tragedies, attacks, weapon obssession | Massacres | Exhibition of violence to promote attacks; |
| X is glorifying superiority on Y | xRevenge, xVisibility | aggression, humiliation, intimidation, superiority, symbols, badges, ornaments, nazi thought | Neonazism | Spread of nazism ideology on the web; |
| X is asking intimate information from Y’s children | xIntent | explicit sex, children, teenagers, sex organs | Child Pornography | Inapropriate sexual images and information for children and teenagers; |
| X repudiates sexual orientation from Y’s | xIntent | offense, repudiation, discrimination | Homophobia | Discrimination, offense, repudiation regarding sexual orientation. |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
da Silva, D.A.; Louro, H.D.B.; Goncalves, G.S.; Marques, J.C.; Dias, L.A.V.; da Cunha, A.M.; Tasinaffo, P.M. Could a Conversational AI Identify Offensive Language? Information 2021, 12, 418. https://0-doi-org.brum.beds.ac.uk/10.3390/info12100418
da Silva DA, Louro HDB, Goncalves GS, Marques JC, Dias LAV, da Cunha AM, Tasinaffo PM. Could a Conversational AI Identify Offensive Language? Information. 2021; 12(10):418. https://0-doi-org.brum.beds.ac.uk/10.3390/info12100418
Chicago/Turabian Styleda Silva, Daniela America, Henrique Duarte Borges Louro, Gildarcio Sousa Goncalves, Johnny Cardoso Marques, Luiz Alberto Vieira Dias, Adilson Marques da Cunha, and Paulo Marcelo Tasinaffo. 2021. "Could a Conversational AI Identify Offensive Language?" Information 12, no. 10: 418. https://0-doi-org.brum.beds.ac.uk/10.3390/info12100418