1. Introduction
Knowledge graphs (KGs) are widely used in question answering and dialogue systems. Minimizing the error rate in these graphs without sacrificing coverage of entities and relationships is essential for improving the quality of these systems. In this paper, we focus on the problem of identifying relations among entities found in a large corpus with the goal of populating a pre-existing KG [
1,
2]. Relation extraction (RE) from text is described as inducing new relationships between pre-identified entities belonging to a predefined schema. Expanding the size and coverage of a knowledge graph with relation extraction is a challenging process as it introduces noise and oftentimes requires a manual process to clean it.
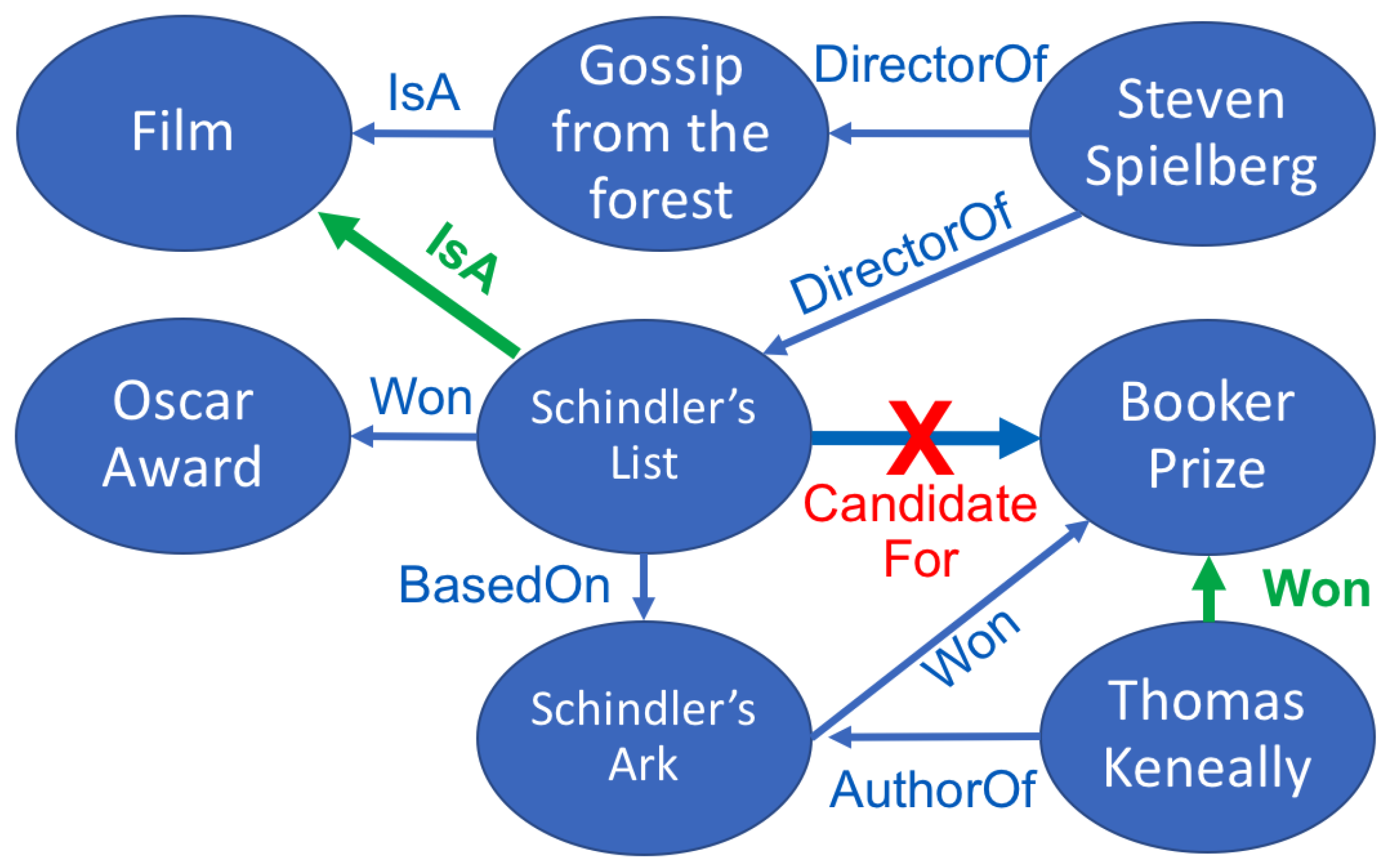
For example, an automatic system might have reasonably high confidence in the relationship
“Schindler’s List -
candidateFor -
Booker Prize” from the text
“Thomas Keneally has been shortlisted for Booker Prize in four different occasions, in 1972 for The Chant of Jimmie Blacksmith, Gossip from the Forest in 1975, and Confederates in 1979, before winning the prize in 1982 with Schindler’s Ark, later turned into the Oscar Award winning film Schindler’s List directed by Steven Spielberg.” However, as illustrated in
Figure 1, other extracted relationships might contradict this, such as the fact that because
Steven Spielberg directed
Schindler’s list, it follows that
Schindler’s list isA Film and therefore it cannot be
candidateFor the
Booker Prize, which is a literary award. The first type of inference is equivalent to identifying a new relation in a KG, and it is typically referred to as
link prediction, as illustrated by
Figure 1. The second inference step is equivalent to assessing the confidence of an existing relation in the KG, and it is typically referred to as knowledge base validation (KBV). Both processes are very intimately related and interfere with each other. In the example before, we needed to infer that
Schindler’s List isA Film from the explicit information in order to detect the fact that
Schindler’s List cannot be a candidate for the
Booker prize.
Humans are able to reconcile inconsistencies such as these at an almost subconscious level, resulting in improved perception capabilities. Unfortunately, this is not the case for most AI systems, and this is one of the main reasons why pure NLP-based approaches, whether pattern-based or deep-learning-based, typically perform poorly on this task.
In this paper, we present an approach that overcomes the aforementioned problem while offering a scalable solution to extend large knowledge graphs from web-scale corpora. It consists of two main components: relation extraction, a deep-learning-based distantly supervised system to detect relations from text, and relation validation, a deep-learning-based knowledge base validation component able to spot inconsistencies in the acquired graphs and improve the global quality. In order to operate these components, the only required input is a partially populated KG and a large scale document corpus. In our experiments, we used DBpedia and Freebase for the KG and Common Crawl web text and New York Times news articles for the document corpora.
To implement the
RE component, we applied a state-of-the-art distantly supervised relation extraction system that is capable of recognizing relations among pre-identified entities using a deep neural network approach [
3].
Entity recognition is simply achieved by using a dictionary matching approach in a large corpus without requiring an
entity detection and linking system. As for the
relation validation (RV) component, we used a deep neural network approach trained from the same KG as well as from the relations identified from text, adopting knowledge base completion (KBC) strategies.
The main contribution of this paper is that we show how combining distantly supervised solutions for RE with KBC techniques trained on top of their output can largely boost the overall RE accuracy, providing a scalable yet effective solution to extend their coverage. We describe a system combining those two approaches in a single framework, and we apply it to the problem of extending KG from web-scale corpora. Previously, KBC has been applied to hand-crafted knowledge bases and not to the result of the information extraction system. We empirically show how this combination improves the quality of the induced knowledge by a large margin, improving the state of the art in a scalable manner.
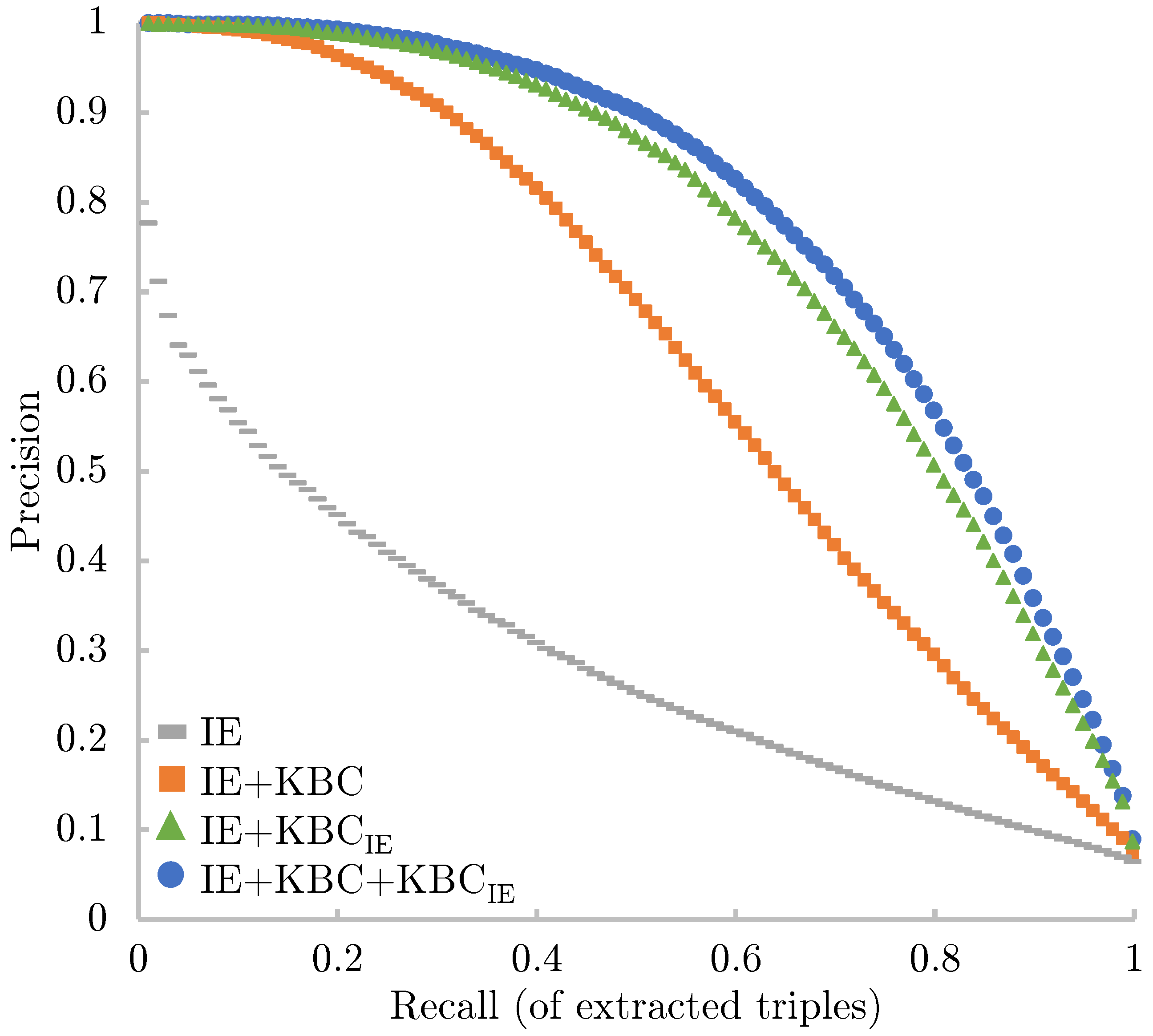
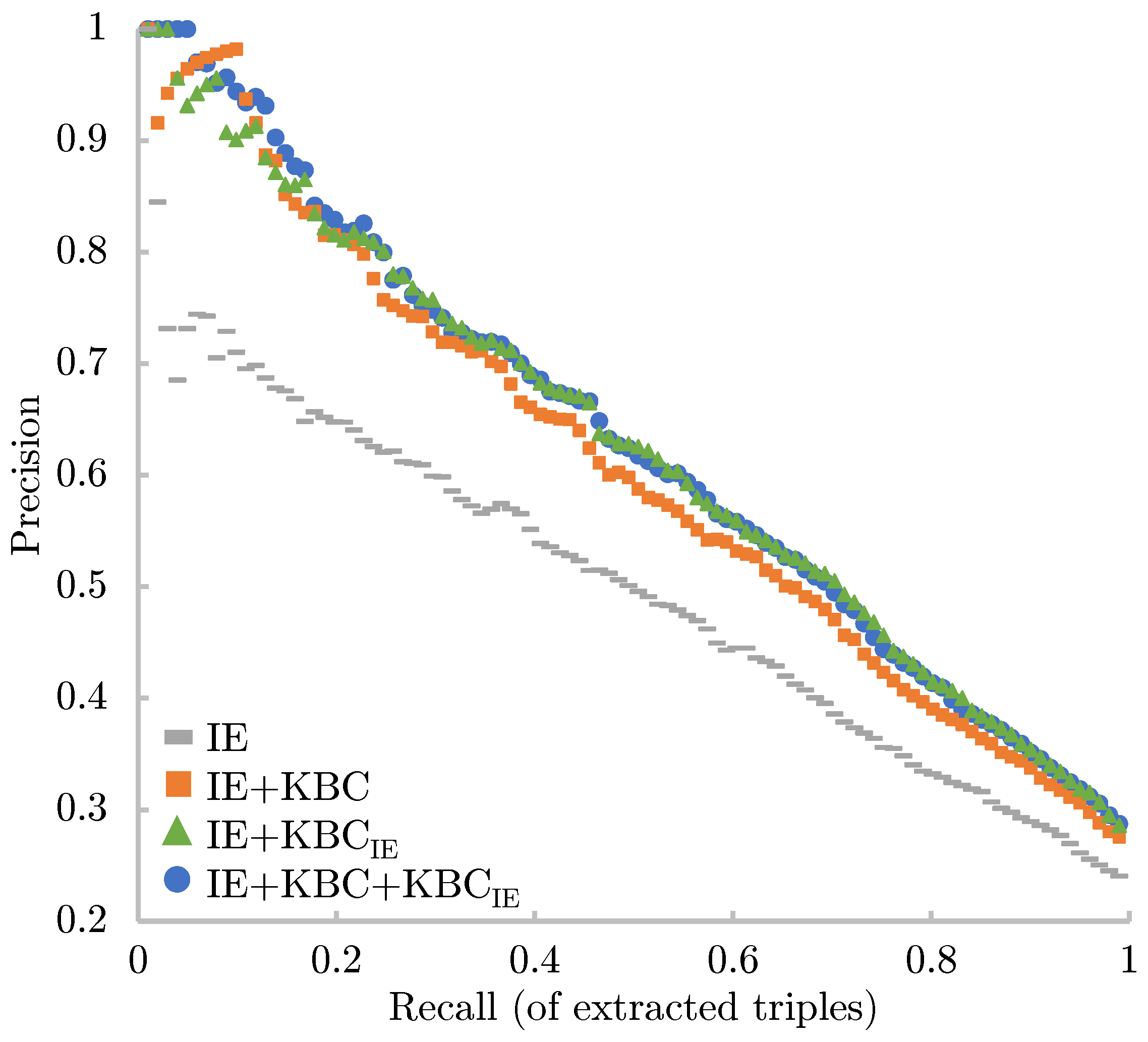
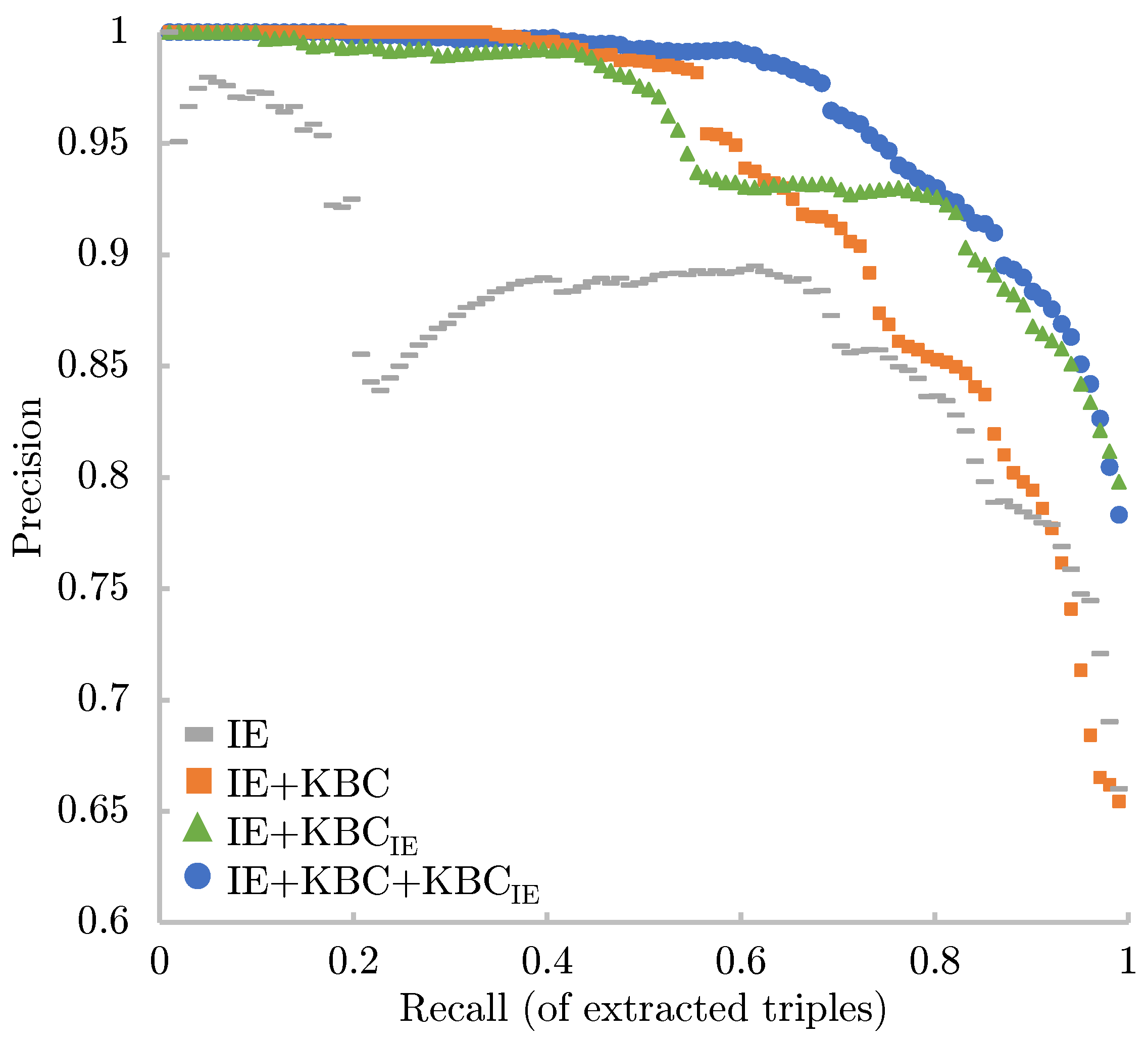
We tested our approach on three different KBP benchmarks: extending Freebase with knowledge coming from the NYT, extending DBpedia with knowledge coming from Common Crawl, and refining the result of pattern-based information extraction systems used for the never-ending language learning (NELL) task. Our experiments show that the validation step boosts the performance of RE by a wide margin, reporting error reductions of 50%, sometimes resulting in a relative improvement of up to 100%.
The rest of the paper is structured as follows. The related work section describes the background in the area of RE and KBC, as well as alternative approaches such as the application of probabilistic logic to the validation of KBs. We then introduce our approach and provide a description of the RE system we use for our experiments. The evaluation section describes the benchmarks and provides an extensive evaluation of our framework, followed by an analysis of the reasoning behind its effectiveness. Finally, we summarize the main research result and highlight possible directions for future work.
3. Distantly Supervised Relation Extraction and Validation
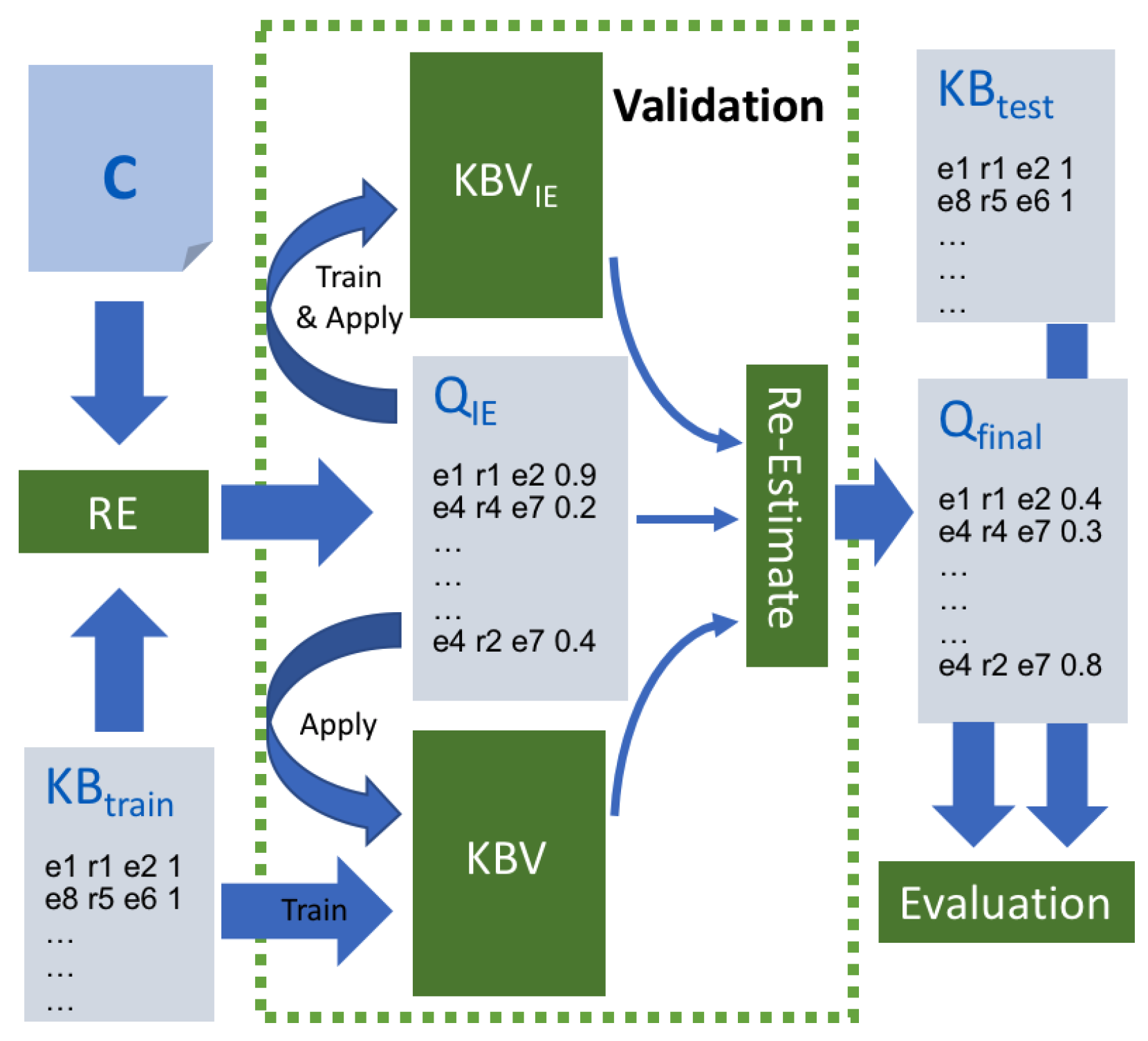
In this section, we describe the architecture of our solution for knowledge base population (KBP). KBP is the task of identifying entities and relations from a corpus, according to a predefined schema. It is illustrated by
Figure 2, representing the architecture of our final KBP solution. It is composed by a distantly supervised information extraction system that takes a pre-existing KB and a corpus as an input and generates a list of quads representing induced relations with their associated confidence scores. Its output is then merged with the triples in the pre-existing KG and fed into a KBC deep net to train a KBV system whose goal is to re-assess the generated assertions, providing new confidence scores for each of them. Finally, the scores are aggregated by a logistic regression layer that provides the final confidence score for each triple. For all these steps, the same KB is always used for training.
More formally, the information extraction component of KBP generates a set of quads (triples with confidence) from a corpora of text documents . Here, each text document c is represented in the form of a sequence of words containing two entity mentions and . Quads have the form , where are entities found in the corpus, is a finite set of relations, and is a confidence score. We define the function to ignore the confidence of a quad, forming a triple. Since is typically the Abox of a handcrafted ontology, we assume all the confidence scores of quads in being equal to 1.
For each context , the entity detection and linking (EDL) function returns the two entities contained in it. In our current implementation, EDL is implemented by a simple string match with regard to the entities in the KB; however, it could also be replaced with more advanced EDL solutions if available. For each entity , the function returns all possible contexts where the entity e appears in the corpus, and returns all contexts containing both. The RE process consists of applying a deep net to the context returned by for every pair of entities that co-occur in the corpus. The result of the application of RE to a context is a list of quads , where represents the confidence of the system on the detection of the relation in one or more contexts in , where the two entities co-occur in the corpus. Obviously, most of the relations will have very low scores since all the relations are explored and returned for each pair.
The RE step takes into account mostly information coming from the corpus for each entity pair to predict the relations, if any, between them. It does not take into account global information provided by the structure of the KG. The relation validation component is designed to overcome this problem. It is formally described as a function . For any triple produced by IE (), KBV returns a confidence score.
The KBV system is to be trained from a knowledge graph consisting of a set of quads. In this paper, we experimented with two different ways of training, producing two-component systems: (a) , using the ground truth from the knowledge graph , and (b) , using the output of information extraction . The result is two different functions returning different confidence scores when applied to the same triple.
The three confidence scores generated from IE and by applying and to every triple from are then aggregated using a confidence re-estimation layer trained on a validation set to provide a final confidence score, generating the final output . In the following subsection, we will describe the distantly supervised RE approach and the knowledge base validation step in detail.
3.2. Relation Validation
We implement using a deep network inspired by a state-of-the-art KBC approach where we modified the loss function in order to take into account the fuzzy truth values provided by the output of IE. This network considers a set of quads as the probabilistic knowledge graph for training and learns a function that returns a confidence score s for the triple at hand. This score is informed by the global analysis of the knowledge graph Q differently from the that uses the evidence from the corpus for the same purpose.
KBC algorithms are trained from a set of triples T, usually produced manually, wherein each entry comprises two entities and a relation r. The KBC system assigns tensors to the entities and relations and trains them by exploiting a local closed world assumption.
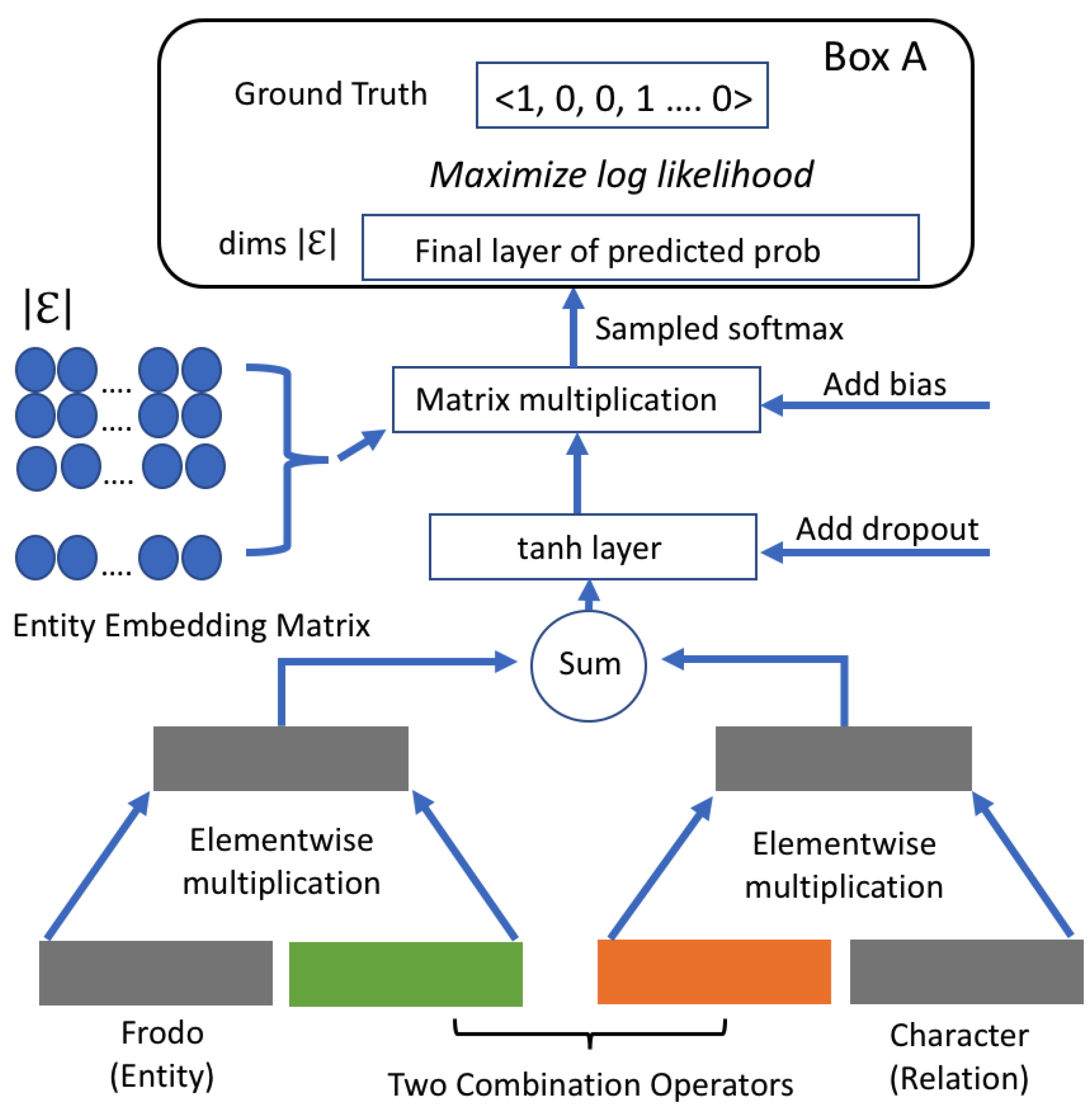
In this work, we use a state-of-the-art model for KBC, called ProjE softmax [
21]. A block diagram architecture of such a model is shown in
Figure 3. The network is trained for each triple
t in the training data by providing an input vector representation for the subject and the relation, while the output of the network exploits a one-hot representation encoding the probability for each possible object in
. Negative examples are provided by a random sampling of the objects.
However, this approach cannot be directly applied to implement
because many triples extracted by IE are actually not true. This is usually reflected by a lower confidence score associated with the triple. To overcome this issue, we modified the loss function described in
Figure 3 (Box A) to use confidence scores, rather than labels, following an approach proposed for computer vision in [
22].
Let us assume that the inputs are
and
r, and the system needs to predict appropriate
. Let
(of dimensions
—number of entities in vocabulary) represent the final layer of predicted probabilities corresponding to input entity
and input relation
r. Define a vector
of dimensions
that uses the input confidence scores as follows:
Recall that
s represents the confidence score for the quad
. The modified loss function is now the cross-entropy between the confidence vector and the prediction vector.
In Equation (
2), the
vector is now a vector of confidence scores (rather than a one-hot encoding).
After the network is trained, it can be used for both link prediction (i.e., generating the object from a subject and relation input) or validation (i.e., assessing the validity of a new triple composed of known entities and relations). In this paper, we explore the second option.
The predictions of and make use of the embeddings of entities that are determined by the training set. Embeddings for an entity can be effectively trained only when the number of triples in which the entity appears meets some minimum threshold: three in our work. The KBC system cannot provide a confidence estimate for triples involving entities that do not occur in the training set or occur more rarely than the minimum threshold. This is a critical limitation of typical KBC systems, which can only predict new relations between existing entities in the knowledge base. solves this issue by using the output of the IE system for training, which can include new entities.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}