
A Neural Network-Based Interval Pattern Matcher

Abstract
:1. Introduction
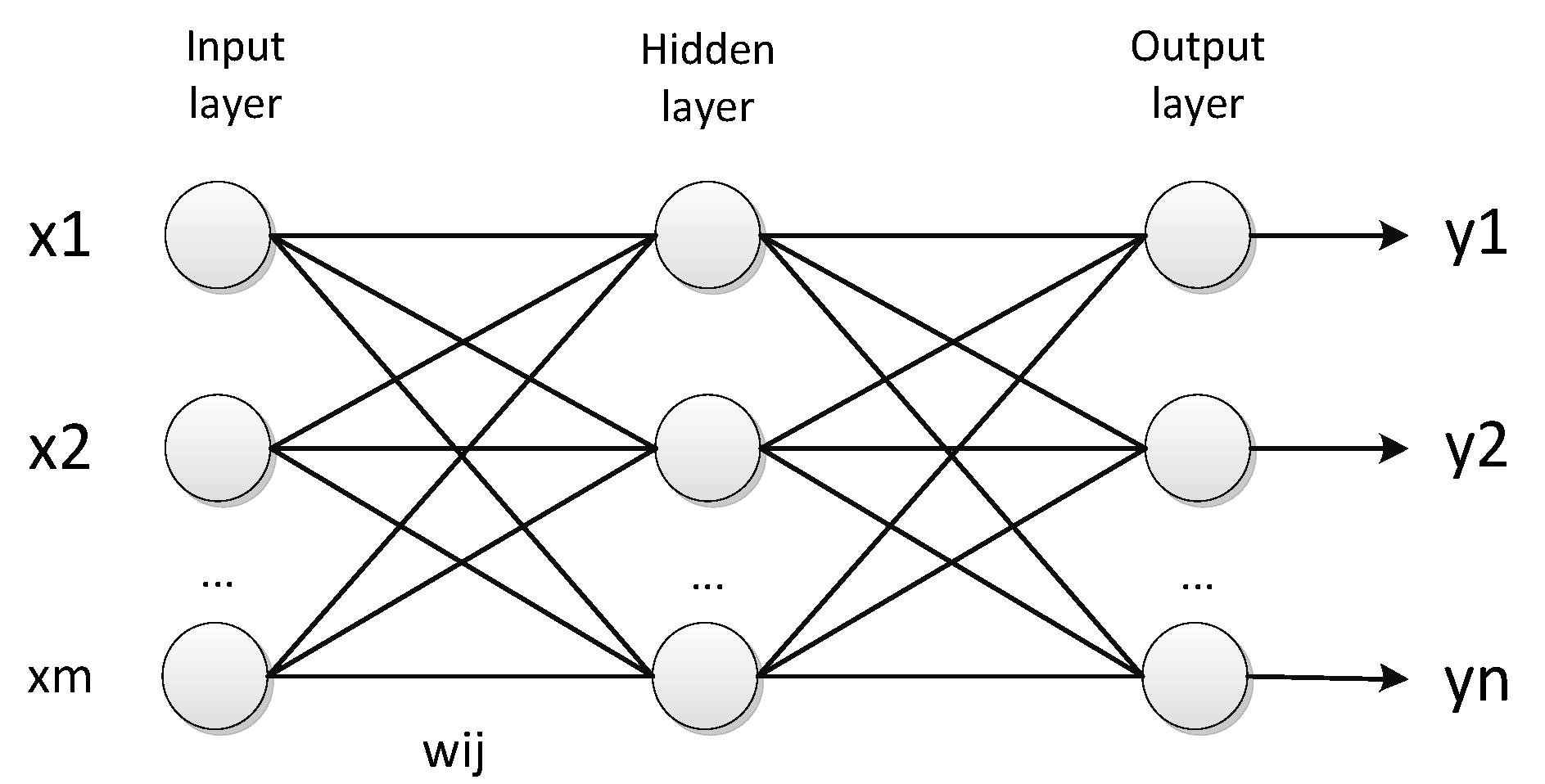
2. Preliminaries: Neural Networks

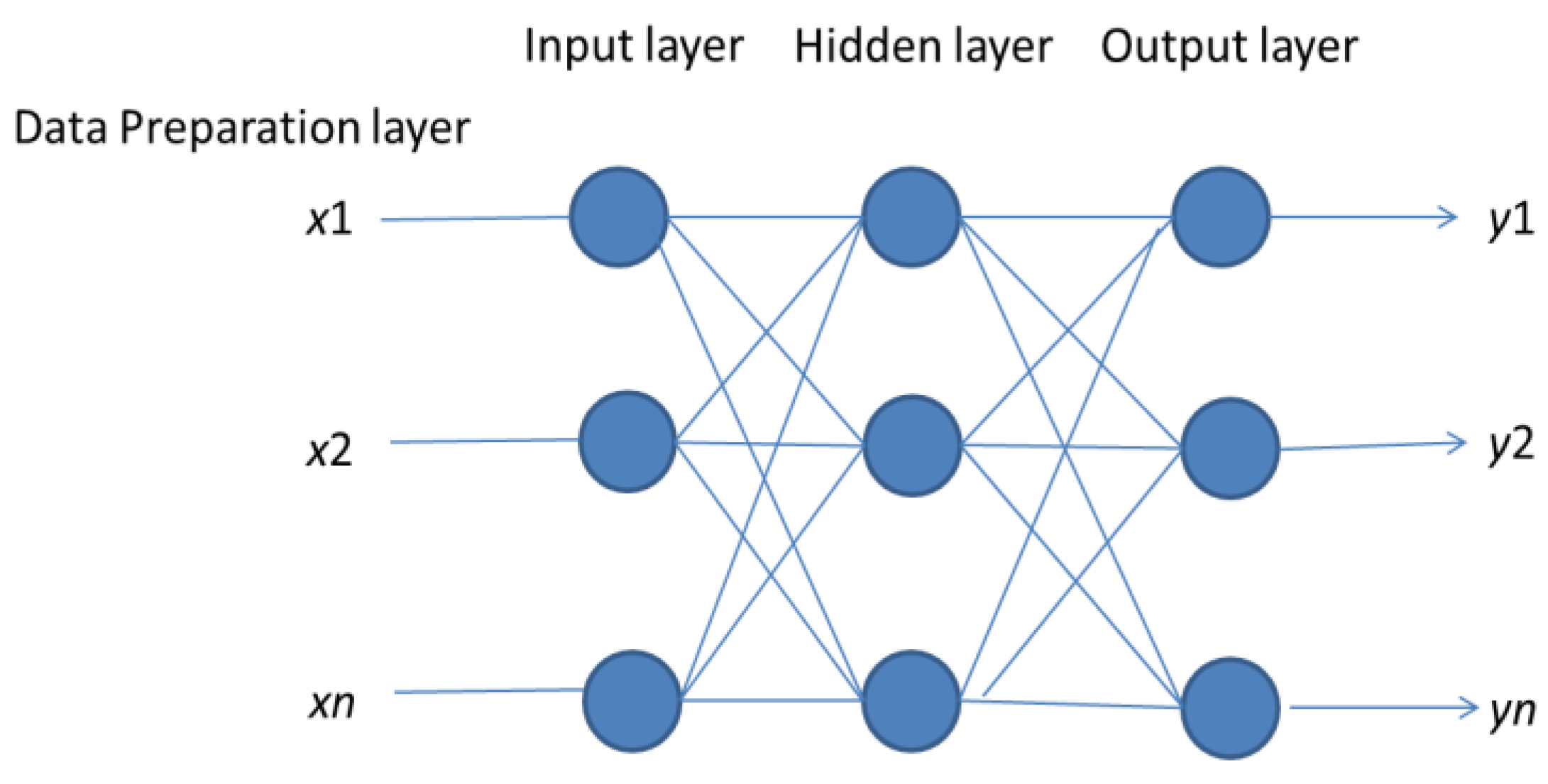
3. Neural Network-Based Interval Classifier

4. Experiments
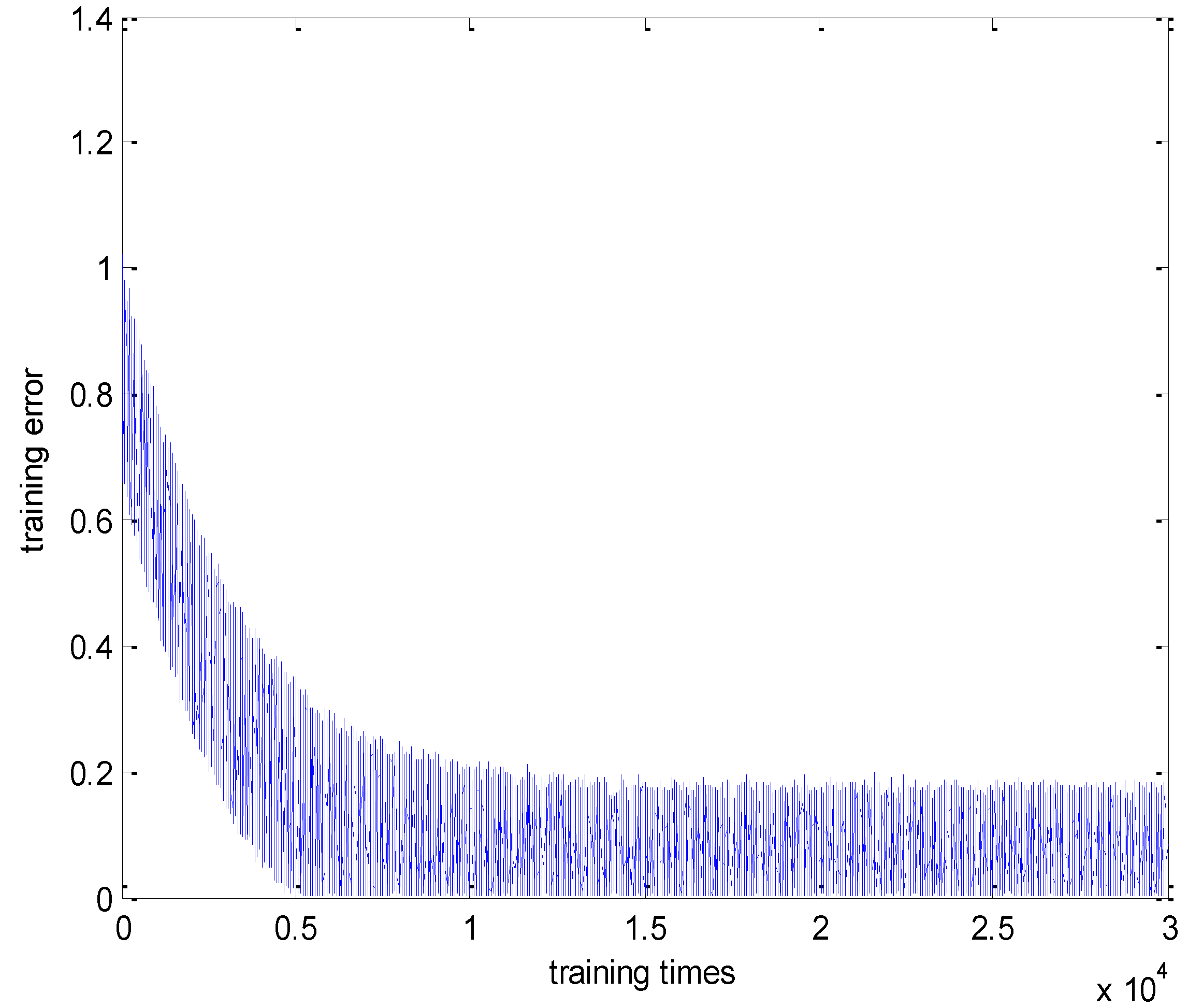
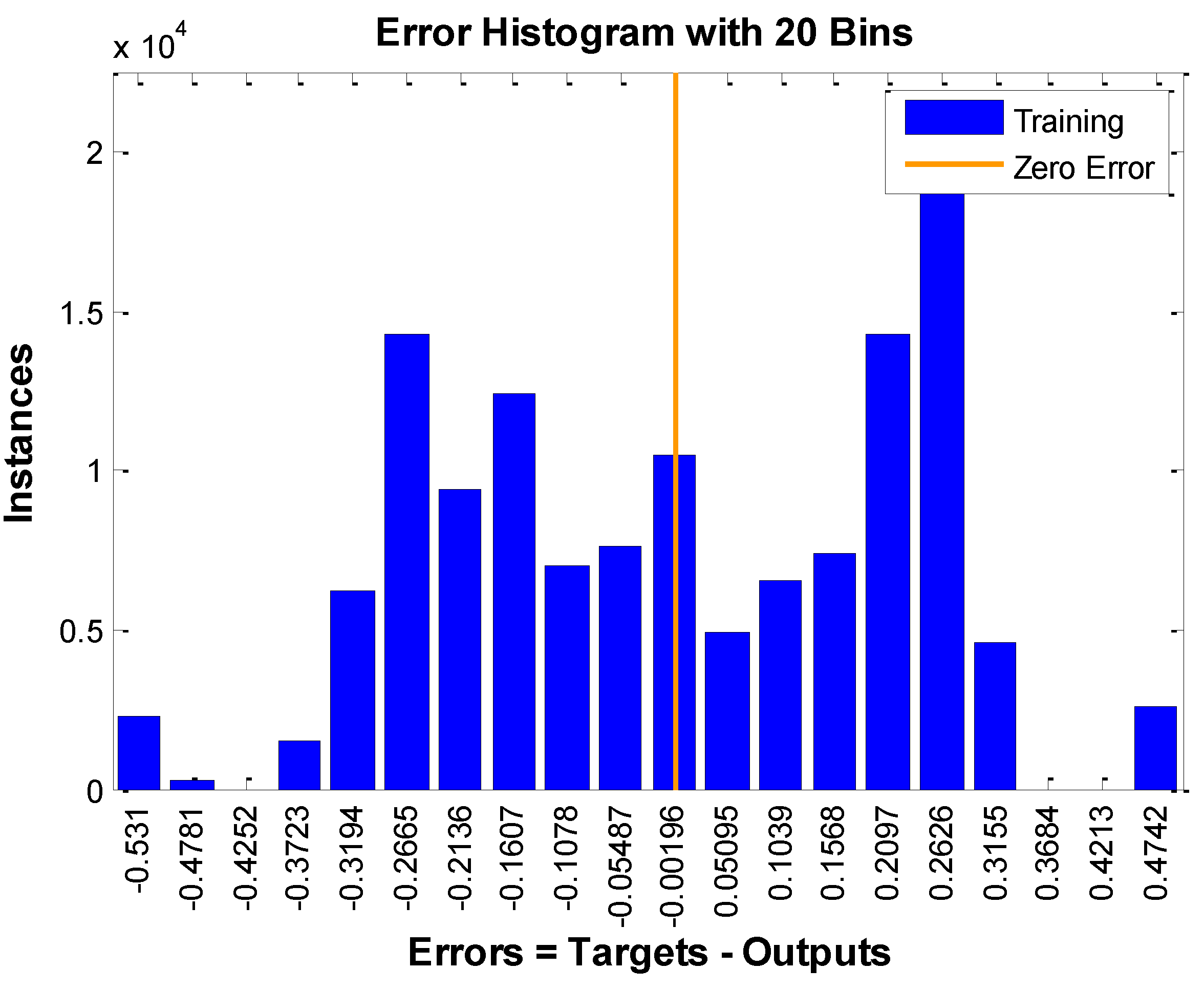
4.1. Simple Test
4.1.1. Comparison Between Two Rules Using Our Program

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
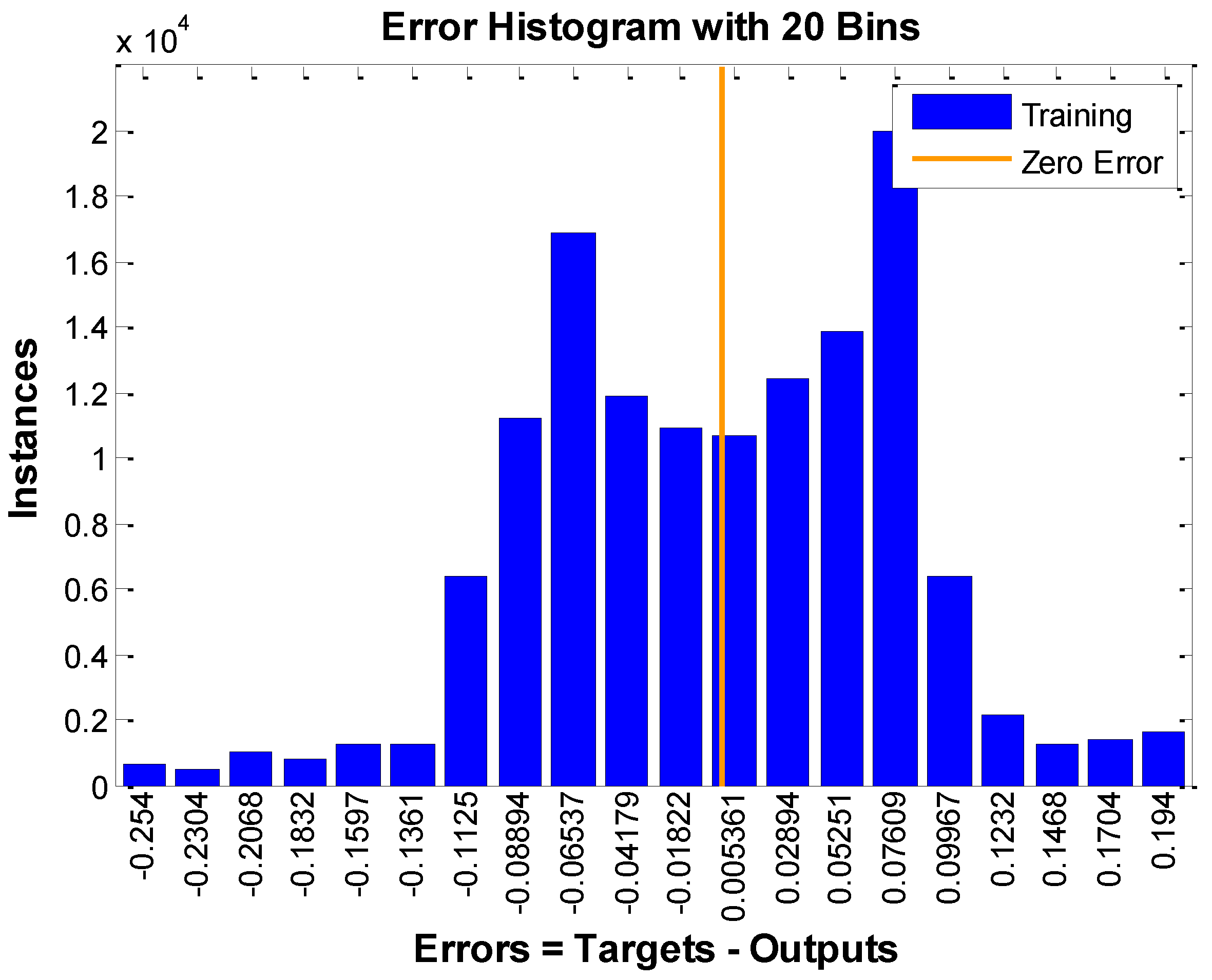{kind=link}
| Algorithm to train the neural network | Back Propagation (BP) Algorithm |
| Neural network structure | 4 layers having 3, 3, 3, and 1 neurons |
| Experiment tool | Matlab |




4.1.2. Comparison Between Two Rules Using Matlab Toolbox
| Algorithm to train the neural network | Gradient descent with momentum and adaptive learning rate backpropagation algorithm (traingdx) |
| Neural network structure | 4 layers having 3, 3, 3, and 1 neurons |
| Experiment tool | Matlab neural network tool box |
4.2. Practical Test
| Atmospheric pressure | Dry and wet bulb temperature | Relative humidity | Wind speed | ||||
|---|---|---|---|---|---|---|---|
| Rating | Value (hPa) | Rating | Value (°C) | Rating | Value (%) | Rating | Value (MPH) |
| Moderate | >940 | Lowest | <−10 | Dry | [0, 30) | Calm | (0, 2) |
| Lower slightly | [930, 940) | Lower | [−10, 5) | Less dry | [30, 50) | Light Air | [2, 4) |
| Moderate | [5, 30) | Less humid | [50, 70) | Light Breeze | [4, 7) | ||
| Lower | [920,930) | Higher | [30, 45) | Gentle Breeze | [7, 11) | ||
| Lowest | <920 | Highest | >45 | Humid | [70, 100] | Moderate Breeze | [11, 17) |
| Precipitation rating | Precipitation value (mm) |
|---|---|
| Light rain | (0, 10.0) |
| Moderate rain | [10.0, 24.9) |
| Heavy rain | [24.9, 49.9) |
| Rainstorm | [49.9, 99.9) |
| Heavy rainstorm | [99.9, 249.0) |
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References and Notes
- Kawai, T.; Akira, S. The role of pattern-recognition receptors in innate immunity: Update on Toll-like receptors. Nat. Immunol. 2010, 11, 373–384. [Google Scholar] [CrossRef] [PubMed]
- Takeuchi, O.; Akira, S. Pattern recognition receptors and inflammation. Cell 2010, 140, 805–820. [Google Scholar] [CrossRef] [PubMed]
- Bunke, H.; Riesen, K. Recent advances in graph-based pattern recognition with applications in document analysis. Pattern Recognit. 2011, 44, 1057–1067. [Google Scholar] [CrossRef]
- Wright, J.; Yi, M.; Mairal, J.; Sapiro, G.; Huang, T.S.; Yan, S. Sparse Representation for Computer Vision and Pattern Recognition. Proceed. IEEE 2010, 98, 1031–1044. [Google Scholar] [CrossRef]
- Prest, A.; Schmid, C.; Ferrari, V. Weakly supervised learning of interactions between humans and objects. Pattern Anal. Mach. Intell. 2012, 34, 601–614. [Google Scholar] [CrossRef] [PubMed]
- Gureckis, T.M.; Love, B.C. Towards a unified account of supervised and unsupervised category learning. J. Exp. Theor. Artif. Intell. 2003, 15, 1–24. [Google Scholar] [CrossRef]
- Ulbricht, C.; Dorffner, G.; Lee, A. Neural networks for recognizing patterns in cardiotocograms. Artif. Intell. Med. 1998, 12, 271–284. [Google Scholar] [CrossRef]
- Saba, T.; Rehman, A. Effects of artificially intelligent tools on pattern recognition. Int. J. Mach. Learn. Cybern. 2013, 4, 155–162. [Google Scholar] [CrossRef]
- Pedro, J.; García-Laencina, J.S.; Figueiras-Vidal, A.R. Pattern classification with missing data: A review. Neural Comput. Appl. 2010, 19, 263–282. [Google Scholar]
- Santos, A.; Powell, J.A.; Hinks, J. Using pattern matching for the international benchmarking of production practices. Benchmarking: Int. J. 2001, 8, 35–47. [Google Scholar] [CrossRef]
- Ficara, D.; Di Pietro, A.; Giordano, S.; Procissi, G.; Vitucci, F.; Antichi, G. Differential encoding of DFAs for fast regular expression matching. IEEE/ACM Trans. Netw. 2011, 19, 683–694. [Google Scholar] [CrossRef]
- Huang, J.; Berger, T. Delay analysis of interval-searching contention resolution algorithms. IEEE Trans. Inf. Theoy. 1985, 31, 264–273. [Google Scholar] [CrossRef]
- Lin, C.; Chang, S. Efficient pattern matching algorithm for memory architecture. IEEE Trans. Very Larg. Scale Integr. Syst. 2011, 19, 33–41. [Google Scholar] [CrossRef]
- Yuan, H.; Wiele, C.F.V.D.; Khorram, S. An Automated Artificial Neural Network System for Land Use/Land Cover Classification from Landsat TM Imagery. Remote Sens. 2009, 1, 243–265. [Google Scholar] [CrossRef]
- Levine, E.R.; Kimes, D.S.; Sigillito, V.G. Classifying soil structure using neural networks. Ecol. Model. 1996, 92, 101–108. [Google Scholar] [CrossRef]
- Liu, H.; Chen, Y.; Peng, X.; Xie, J. A classification method of glass defect based on multiresolution and information fusion. Int. J. Adv. Manuf. Technol. 2011, 56, 1079–1090. [Google Scholar] [CrossRef]
- Chao, W.; Lai, H.; Shih, Y.I.; Chen, Y.; Lo, Y.; Line, S.; Tsang, S.; Wu, R.; Jaw, F. Correction of inhomogeneous magnetic resonance images using multiscale retinex for segmentation accuracy improvement. Biomed. Signal Process. Control 2012, 7, 129–140. [Google Scholar] [CrossRef]
- Özbay, Y.; Ceylan, R.; Karlik, B. Integration of type-2 fuzzy clustering and wavelet transform in a neural network based ECG classifier. Expert Syst. Appl. 2011, 38, 1004–1010. [Google Scholar] [CrossRef]
- Orhan, U.; Hekim, M.; Ozer, M. EEG signals classification using the K-means clustering and a multilayer perceptron neural network model. Expert Syst. Appl. 2011, 38, 13475–13481. [Google Scholar] [CrossRef]
- Chen, L.; Liu, C.; Chiu, H. A neural network based approach for sentiment classification in the blogosphere. J. Informetr. 2011, 5, 313–322. [Google Scholar] [CrossRef]
- Mohamed, A.; Dahl, G.E.; Hinton, G. Acoustic modeling using deep belief networks. IEEE Trans. Audio Speech Lang. Process. 2012, 20, 14–22. [Google Scholar] [CrossRef]
- Feuring, T.; Lippe, W. The fuzzy neural network approximation lemma. Fuzzy Sets Syst. 1999, 102, 227–236. [Google Scholar] [CrossRef]
- Karlik, B.; Olgac, A.V. Performance analysis of various activation functions in generalized MLP architectures of neural networks. Int. J. Artif. Intell. Expert Syst. 2011, 1, 111–122. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 1, 1097–1105. [Google Scholar]
- Hasiewicz, Z. Modular neural networks for non-linearity recovering by the Haar approximation. Neural Netw. 2000, 13, 1107–1133. [Google Scholar] [CrossRef]
- Lee, H.K.H. Consistency of posterior distributions for neural networks. Neural Netw. 2000, 13, 1107–1133. [Google Scholar] [CrossRef]
- Erhan, D.; Bengio, Y.; Courville, A. Why does unsupervised pre-training help deep learning? J. Mach. Learn. Res. 2010, 11, 625–660. [Google Scholar]
- Shao, Y.; Lunetta, R.S. Comparison of support vector machine, neural network, and CART algorithms for the land-cover classification using limited training data points. ISPRS J. Photogramm. Remote Sens. 2012, 70, 78–87. [Google Scholar] [CrossRef]
- McCormack, L.; Dutkowski, P.; El-Badry, A.M. Liver transplantation using fatty livers: Always feasible? J. Hepatol. 2011, 54, 1055–1062. [Google Scholar] [CrossRef] [PubMed]
- Cortes, M.; Pareja, E.; García-Cañaveras, J.C. Metabolomics discloses donor liver biomarkers associated with early allograft dysfunction. J. Hepatol. 2014, 61, 564–574. [Google Scholar] [CrossRef] [PubMed]
- Lloyd, C.; Grossman, A. The AIP (aryl hydrocarbon receptor-interacting protein) gene and its relation to the pathogenesis of pituitary adenomas. Endocrine 2014, 46, 387–396. [Google Scholar] [CrossRef] [PubMed]
© 2015 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lu, J.; Xue, S.; Zhang, X.; Han, Y. A Neural Network-Based Interval Pattern Matcher. Information 2015, 6, 388-398. https://0-doi-org.brum.beds.ac.uk/10.3390/info6030388
Lu J, Xue S, Zhang X, Han Y. A Neural Network-Based Interval Pattern Matcher. Information. 2015; 6(3):388-398. https://0-doi-org.brum.beds.ac.uk/10.3390/info6030388
Chicago/Turabian StyleLu, Jing, Shengjun Xue, Xiakun Zhang, and Yang Han. 2015. "A Neural Network-Based Interval Pattern Matcher" Information 6, no. 3: 388-398. https://0-doi-org.brum.beds.ac.uk/10.3390/info6030388