2. The Relationship between Intelligence and DT
DT describes the process of generating a variety of solutions (
Guilford 1967). In the context of the standard definition of creativity, responses are considered to be creative if they are novel/original and appropriate/effective (
Runco and Jaeger 2012). Following this reasoning, the ability to come up with various ideas (evaluated as being creative) constitutes DT ability as an indicator of creative potential (
Runco and Acar 2012). Flexible, critical, and playful thinking, as well as problem-solving ability, and the willingness to accept ambiguous situations are expected to facilitate DT (
Karwowski et al. 2016a;
Plucker and Esping 2015). In a recent review,
Plucker and Esping (
2015) outlined various points of view regarding the question of where to locate DT: as a facet of intelligence, as a result of intelligence, or as a separate construct, sharing cognitive abilities with intelligence. A fair number of intelligence researchers consider DT as a subcomponent of intelligence (
Carroll 1997;
Guilford 1967;
Jäger 1982;
Karwowski et al. 2016a). (
Carroll 1997; see also
Chrysikou 2018;
Dietrich 2015) stated that DT requires several mental abilities, such as the speed of retrieval (e.g.,
Forthmann et al. 2019), knowledge (e.g.,
Weisberg 2006), fluid intelligence (e.g.,
Beaty et al. 2014;
Nusbaum et al. 2014), and motor skills (e.g., the ability to write quickly; see:
Forthmann et al. 2017). This view emphasizes that multiple factors might moderate the strength of the association between intelligence and DT. Although DT and intelligence have been seen as somewhat different constructs in the past (
Getzels and Jackson 1962;
Wallach and Kogan 1965), some researchers have now adopted the view that the constructs might be more similar than previously thought (
Silvia 2015). To conclude, a robust empirical examination of the relationship between intelligence and DT is expected to clarify the theoretical relationship of these constructs.
Creativity research has witnessed several methodological and conceptual developments over the past two decades. First of all, today latent variable analyses provide possibilities to separate the true variance of DT from error-variance resulting from the task- or procedure-specific factors and other unknown sources. As a result, effect sizes can be estimated more accurately (
Silvia 2015). For example,
Silvia (
2008) reanalyzed the data of
Wallach and Kogan’s (
1965) study on the relationship between intelligence and DT with 151 children using a structural equation model. Compared to the negligible correlation of
r = .09 reported by
Wallach and Kogan (
1965),
Silvia (
2008) found a more substantial relationship between the latent factor intelligence and the latent factor DT (β = 0.22), demonstrating that the observed correlations deflate the true relationship between the two constructs (
Silvia 2015). Hence, increased use of appropriate corrections for unreliability—for example, employing structural equation modeling—forms one reason for the renaissance of the debate on the relationship between intelligence and DT.
Additionally, many researchers have focused on a bundle of different possible moderators of the relationship and investigated associations between these constructs’ specific facets. Some found evidence for the role of fluid intelligence (e.g.,
Beaty et al. 2014;
Nusbaum and Silvia 2011), broad retrieval ability (e.g.,
Forthmann et al. 2019;
Silvia et al. 2013), and crystallized intelligence (e.g.,
Cho et al. 2010) as factors that differentiated the intelligence–DT link. For example,
Silvia (
2015) emphasized that fluid intelligence plays a crucial role for DT. However, he and his colleagues used DT tests with explicit
be-creative instruction, evaluated ideas using subjective ratings, and statistically controlled for measurement errors (e.g.,
Nusbaum and Silvia 2011; see more details on instructions and scoring methods in
Section 3.3 below).
Silvia (
2015) concluded that contrary to the previous position that DT is closely linked to crystallized intelligence and hence depends on how much a person knows (
Mednick 1962;
Weisberg 2006), fluid intelligence (i.e., reasoning and processing of information) plays a more important role than expected and has to be taken into account. In this regard, it is especially interesting that building on a more comprehensive set of cognitive abilities,
Weiss et al. (
2020a) reported quite comparable correlations between DT and general intelligence (encompassing g
f, g
c, mental speed, and working memory) and between DT and crystallized intelligence. In this vein, it is further notable that measures of g
r (i.e., broad retrieval ability;
Carroll 1993) such as verbal fluency tasks reflect a combination of knowledge (mapping onto g
c) and strategic retrieval (mapping onto g
f). In turn, a moderate to strong relationship between g
r and DT originality/creative quality was found (
Forthmann et al. 2019;
Silvia et al. 2013). However, it is unclear whether the relationship between intelligence and DT is moderated by type of intelligence (fluid vs. crystallized intelligence), instructions used for DT assessment, scoring procedures, and time on task (
Forthmann et al. 2020a;
Preckel et al. 2011). It further remains unclear if these moderators influence the relationship between DT and intelligence independently or if specific interactions of these factors can explain differences across studies. Taken together, creativity research provides mixed results so that the question of the interrelation between the constructs has not fully been answered yet (
Batey and Furnham 2006;
Silvia 2015).
Recent works pay closer attention to more processual and cognitive mechanisms standing behind intelligence–DT links. It has been demonstrated that cognitive control (and executive functions more broadly) are involved in DT processes (
Benedek and Fink 2019;
Silvia 2015). In this context, working memory capacity and fluid intelligence are seen as necessary processes when working on DT tasks due to the ability to keep representations active and protect oneself from being distracted (e.g.,
Beaty et al. 2014;
Engle et al. 1999). Fluid intelligence and executive functions are interrelated but not identical.
Friedman et al. (
2006) found a correlation between executive function
updating (the ability to add to and delete information from the working memory) and fluid intelligence. In contrast, there was no correlation between fluid intelligence and executive functions
inhibition (the ability to control mental operations) or
shifting (the ability to switch between tasks), respectively.
Diamond (
2013) subsumed cognitive flexibility as part of the family of executive functions, which describe the ability to change perspectives and the ability to “think outside the box”. Flexibility, as assessed by DT tasks (
Ionescu 2012) and switching in verbal fluency tasks (
Nusbaum and Silvia 2011), can also be considered to reflect cognitive flexibility. Hence, it overlaps with creative thinking, task switching, and set-shifting (
Diamond 2013).
Diamond (
2013) concluded that working memory, inhibitory control, and cognitive flexibility contribute to higher-order executive functions, namely
reasoning,
problem-solving, and
planning, and that
reasoning, as well as
problem-solving, are identical with fluid intelligence. Taken together, DT might overlap with both executive functions and fluid intelligence.
Benedek et al. (
2012) specified that only certain types of intelligence are linked to certain aspects of creative thinking, and provided more differentiated insights into the relationship between these constructs. They found that
inhibition, the ability to suppress irrelevant stimuli, was positively related to
fluency (number of given responses) and
flexibility (number of categories) of idea generation, whereas
originality, reflecting the quality of ideas, was predicted by intelligence. Furthermore,
Benedek et al. (
2014b) presented evidence that while fluid intelligence and DT originality correlated moderately (
r = .34), updating predicted fluid intelligence and to a lesser extent DT originality, whereas inhibition predicted only DT originality.
The focus on executive functions has recently increased due to research with neuroimaging methods (
Silvia 2015). There is strong support for a top-down controlled view of cognitive processes in DT tasks. Idea generation appears to be a result of focused internal attention combined with controlled semantic retrieval (
Benedek et al. 2014a). In addition,
Frith et al. (
2020) found that general intelligence and creative thinking overlap not only behaviorally (
r = .63; latent variable correlation) but also in terms of functional connectivity patterns at the level of brain networks (i.e., 46% of connections were shared by networks that predicted either general intelligence or creative thinking). Importantly, this overlap of brain networks involved brain regions associated with cognitive control. It is expected that neuroscience research will pursue related lines of research to further unravel the neural basis of DT. In this vein, it seems that the interest of researchers regarding the relationship between intelligence and DT has expanded into different directions, including a more detailed view on intelligence facets and methodological considerations such as scoring methods or explicitness of instructions (
Plucker and Esping 2015;
Silvia 2015). We argue that a meta-analytical investigation of these potential moderators of the intelligence–DT correlation will help to clarify issues in the ongoing debate.
2.1. Moderators of the Relationship between Intelligence and DT
2.1.1. Intelligence Facet
The CHC model (
Carroll 1997;
Horn and Cattell 1966;
McGrew 2009) provides a useful framework to shed light on the link between DT and many cognitive abilities (
Forthmann et al. 2019;
Silvia 2015;
Silvia et al. 2013). Based on the CHC model, intelligence can be distinguished between a higher-level general intelligence (g), a middle-level of broad cognitive abilities like fluid intelligence (g
f), crystallized intelligence (g
c), and a lower-level of narrow abilities. g
f reflects the ability to solve novel problems using controlled mental operations and includes inductive and deductive reasoning. In contrast, g
c reflects the declarative (knowing what) and procedural (knowing how) knowledge acquired in academic and general life experiences. Factor-analytic studies have shown that g
f and g
c load on the higher-level factor g (
McGrew 2009). In this work, we explore the influence of intelligence facets on the intelligence–DT correlation.
2.1.2. DT Instruction
Wallach and Kogan’s (
1965) test battery includes an instruction to provide a playful environment with no time constraints to facilitate DT production. This
game-like setting is recommended to reduce the impact of test anxiety or performance stress that could occur due to a test-like setting and could lead to overestimated correlations between intelligence and DT. However, a review of the studies applying this test revealed that many researchers ignore the
game-like setting, probably for standardization and pragmatic considerations (e.g., regarding the amount of available testing time). Meanwhile, research has focused on the impact of clear and unambiguous instructions on the quality of DT production in a test-like setting (e.g.,
Forthmann et al. 2016;
Nusbaum et al. 2014; for meta-analyses see
Acar et al. 2020;
Said-Metwaly et al. 2020). Even though many DT tests traditionally instruct participants to produce many ideas, researchers have begun to modify the instructions to be more specific about the test’s intention to work towards original ideas. For example,
Forthmann et al. (
2016) found a performance advantage resulting in a higher creative quality of ideational pools when participants were instructed to
be-creative, compared to
be-fluent instructions, which is in accordance with meta-analytical findings (
Acar et al. 2020;
Said-Metwaly et al. 2020). The meta-analysis of
Kim (
2005) did not differentiate between different settings (game-like vs. test-like), which is considered a limitation. To examine the impact on the relationship between intelligence and DT, in this meta-analysis, instructions were categorized into
be-fluent,
be-original/be-creative,
hybrid-fluent-flexible,
hybrid-fluent-original,
hybrid-flexible-original, and
hybrid-fluent-flexible-original (for the logic of hybrid instructions see (
Reiter-Palmon et al. 2019)). In addition,
game-like instructions vs.
test-like settings were also coded, and it was expected that
game-like instructions weaken the relationship between intelligence and DT.
Since there is no restriction in the
be-fluent instruction, participants with a great amount of knowledge (g
c) are deemed to benefit from the possibility to list any idea that comes to mind. In contrast,
be-creative instruction requires the evaluation of whether upcoming ideas are original or not. In such conditions, participants who better control mental operations (g
f) should improve their performance on DT tasks. Hence, the kind of instruction should interact with the intelligence facet and influence the relationship between intelligence and DT. Additionally, when receiving instructions that require participants to apply certain strategies to facilitate creative thinking (e.g., decomposition of objects in the Alternate Uses Task), DT performance is expected to correlate more strongly with intelligence as compared to instructions that do not imply such strategies (e.g.,
Nusbaum et al. 2014;
Wilken et al. 2020).
2.1.3. DT Scoring
It is crucial for scoring methods of DT tasks to consider at least the
originality of responses to have a conceptual relation to the construct of creativity (e.g.,
Zeng et al. 2011), whereas, in the past,
fluency (number of ideas) and
uniqueness (frequency of occurrence in one sample) were common indicators for DT ability. It should be noted that
uniqueness in some kind reflects the quality of the idea since unique ideas are at least not common ideas. However, ideas can be assessed as unique, even though they are not necessarily unusual, clever, original, or humorous (see overview in
Silvia 2015). The confounding of
fluency and
uniqueness (more generated ideas increase the likelihood of unique ideas within the sample), the dependency of
uniqueness on the sample size, and statistical aspects regarding the assessment of infrequency required adjustments (
Silvia 2015).
Originality, assessed by subjective ratings, provides a quality evaluation of the creative product but has its own weaknesses.
Originality scorings have been critically discussed since researchers have applied varying scoring dimensions (i.e., novelty, unusualness, cleverness, overall creativity) and used different approaches (i.e., set ratings, top-scoring; for a review see
Reiter-Palmon et al. 2019). However, research has provided mixed results regarding the relationship between fluency and subjective ratings of originality/creative quality (
Forthmann et al. 2020b;
Plucker et al. 2011;
Silvia 2015).
DT outcomes can be distinguished into quantitative (
fluency,
flexibility,
elaboration) and qualitative (
originality or any other
creative quality) measures, and the type of scoring affects the relationship between intelligence and DT.
Batey and Furnham (
2006) found a smaller correlation when DT was assessed by
originality than
fluency scoring methods. However, since many researchers have recommended explicit
be-creative instruction (
Chen et al. 2005;
Nusbaum et al. 2014), the focus in this meta-analysis lies in the interactional effects of DT outcome, instruction, and intelligence facets.
Silvia (
2015) postulated that the access, manipulation, combination, and transformation (g
f) of the knowledge (g
c) is the key to DT. Hence, the involvement of g
f is supposed to have a substantial impact on the relationship between intelligence and DT. However, Silvia and colleagues conceptualized DT tests with a
be-creative instruction, used subjective scorings to evaluate the outcome, and recommended the correction for measurement errors (i.e.,
Nusbaum and Silvia 2011;
Silvia 2015). Therefore, it is hypothesized that the combination of instruction (
be-creative), DT outcome (
originality), and correction for measurement error increases the involvement of g
f in DT and, hence, the relationship between intelligence and DT.
2.1.4. Time on Task
Time on task was found by
Preckel et al. (
2011) to influence the relationship between intelligence and DT strongly. They found a stronger correlation between intelligence and DT when both were assessed under rather speeded conditions (i.e., around 2 min on task) compared to unspeeded conditions (i.e., around 8 min on task). Notably, the stronger relationship under speeded conditions was driven by shared variation of both measures with mental speed. Divergent thinking in
Preckel et al. (
2011) was assessed with be-fluent or be-fluent-be-flexible hybrid instructions and, hence, we expected a stronger correlation for these conditions when time-on-task is short (i.e., speeded conditions) for intelligence and DT (i.e., interaction of time-on-task for both measures). However, recent research by
Forthmann et al. (
2020a) suggests that such a result is not expected when DT is assessed with be-creative instructions and scored for creative quality. It is further noteworthy that timed testing implies a vital role for typing speed in DT assessment (e.g.,
Forthmann et al. 2017). For instance, participants may be able to think of more ideas than they can type when time is limited (e.g., single-finger typists) or because they type slowly, they have ideas that get blocked or are not recorded.
2.1.5. Intelligence Level
One of the aims of Kim’s meta-analysis was to find evidence for the threshold hypothesis, which states that there is a positive relationship between intelligence and DT for people with an intelligence quotient (IQ) lower than a certain threshold and vanishes or becomes statistically non-significant once the IQ exceeds the threshold (most often an IQ of 120 is assumed as a threshold; e.g.,
Jauk et al. 2013;
Karwowski et al. 2016a). Previous tests of the threshold hypothesis provided mixed results, yet several studies were plagued with inconsistent decisions regarding the criteria for support or rejection of the threshold hypothesis and concrete analytical decisions on how to test it (e.g., see
Karwowski and Gralewski 2013, for a discussion). In Kim’s meta-analysis correlations of
r = .235 and
r = .201 for IQ below and above 120, respectively, did not differ statistically. Further analyses with four IQ levels (i.e., IQ < 100, IQ ranging from 100 to 120, IQ ranging from 120 to 135, and IQ > 135) produced mixed results. Thus, the threshold hypothesis was not confirmed. It would be possible to revisit this hypothesis but treat intelligence as a continuous moderator variable to avoid choosing a certain threshold a priori (see for a discussion
Karwowski and Gralewski 2013;
Weiss et al. 2020b). However, based on average IQ in different samples, it cannot be ruled out that parts of the IQ distributions overlap, which highlights the importance to take the different level of analysis as compared to primary studies into account. That is, splitting the sample according to a predefined threshold yields groups of participants with disjunct ranges of measured IQs. However, meta-analysis operates at the level of effect sizes, and differences in sample means of IQ do not imply that participants from such studies have non-overlapping IQ ranges (i.e., average IQ is only a rough proxy). Consequently, we believe that the methodology of meta-analysis is not well suited to examine the threshold hypothesis, but such investigations require focused analytical approaches (see
Jauk et al. 2013;
Karwowski et al. 2016a;
Weiss et al. 2020b), and therefore do not reinvestigate threshold hypothesis in this meta-analysis.
2.1.6. Modality of Tasks
DT and intelligence tasks differ in terms of the modality of the item content. DT tasks are most often studied in the verbal domain, at least when older children, adolescents, and adults participate. However, figural and numerical DT tasks exist as well (e.g.,
Preckel et al. 2011). Sometimes a composite score for DT based on tasks from several modalities is derived and used. The same variety of modalities exist for intelligence measures. We explored task modality’s influence on the intelligence–DT correlation and assumed that effect sizes should be largest when DT and intelligence modality are congruent.
2.2. Aim of the Current Work
The aim of the current work is to update
Kim’s (
2005) meta-analysis by including recent work in this field and to consider additional moderators based on recent theorizing that were not taken into account in her work, such as intelligence facet, DT instruction, and time on task (all in relation to DT scoring). In addition, we aimed at correcting for attenuation (i.e., measurement error), modeling the clustering of the effect sizes (i.e., correlations are nested in articles), and examining publication bias. In relation to this, it should be noted that correcting for attenuation and correcting for measurement error within latent variable frameworks are not the same (e.g.,
Borsboom and Mellenbergh 2002). Given that latent variable modeling approaches were expected to be used far less often, we chose correction of attenuation to take measurement error into account (of course, when primary data allow for latent variable modeling, it is preferred over correction for attenuation; see
Borsboom and Mellenbergh 2002). Finally, our analysis strategy accounted for the confound of DT scores by response fluency (e.g.,
Forthmann et al. 2020b).
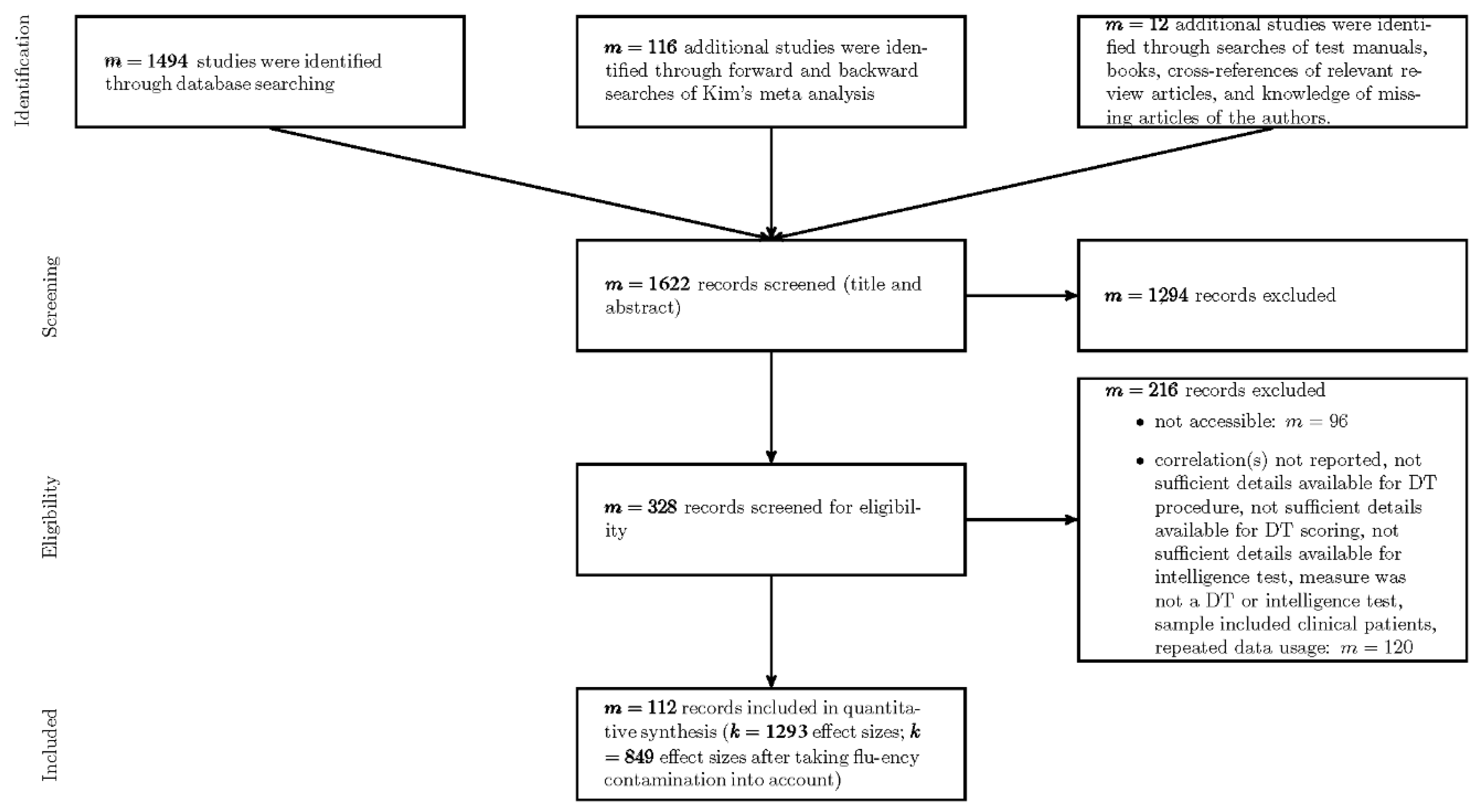
4. Results
Data involved 849 coefficients from 112 studies (N = 34,610). The age of the participants across samples ranged from 4.00 to 72.93 years (M = 20.40, SD = 12.20). Most of the samples comprised of school students (40.50%), followed by university students (34.71%), and adults (15.70%). Other sample types were preschoolers (4.13%) or mixed samples of any of the previously mentioned sample types. The average gender ratio across samples was 0.55 (SD = 0.26) with a range from 0 (only male participants) to 1 (only female participants). The average sample size was 274.68 (SD = 615.28) with sample sizes ranging from N = 10 to N = 5337 participants. Most studies were from the USA (m = 51; UK: m = 12; Germany: m = 9; Austria: m = 8; other countries contributed up to 3 studies: Australia, Canada, Chile, China, France, Hungary, India, Israel, Italy, Korea, Lebanon, Netherlands, New Zealand, Norway, Philippines, Poland, Romania, Russia, Singapore, Spain, Taiwan, and United Arab Emirates).
The most frequently used DT task was the Alternate Uses Task (33.80% of effect sizes). Next, 30.62% of the effect sizes were based on a DT test battery (e.g., TTCT, ATTA, Wallach-and-Kogan, EPoC, BIS, VKT, and so forth). Moreover, 13.66% effect sizes were based on a composite of several DT tasks (i.e., a test battery created in an ad hoc fashion for research purposes). Other DT tasks that were used for 2% to 5% of the effect sizes were Pattern Meanings, Line Meanings, Instances, Similarities, and the Consequences task. The most frequent task modality for DT was verbal (70.20% of effect sizes), 19.55% of the effect sizes were based on figural DT tasks, and only 10.25% of the effect sizes relied on several task modalities. The most frequent intelligence test was one of the variants of the Wechsler test (17.83% of the effect sizes), followed by one of the variants of the IST (9.60%; German:
Intelligenzstrukturtest; translates as Intelligence-Structure-Test) and a variant of the Raven’s (7.13%). Many other tests were used to measure intelligence and the interested reader has access to the fully coded data at the OSF repository (
https://osf.io/s4hx5). Clearly, the used intelligence measures were far more heterogeneous as compared to the used DT measures. Moreover, task modality was more evenly distributed for intelligence measures with 36.98% of the effect sizes based on verbal, 28.86% based on figural, 27.33% based on several modalities, and 6.83% based on numerical intelligence measures.
4.1. Overall Effect
The estimated overall correlation between DT and intelligence was r = .25, 95%-CI [.21, .30] (m = 112, k = 849). It was further revealed that both the variance components for between-study variation (χ2(1) = 161.00, p < .001) and within-study variation (χ2(1) = 2758.15, p < .001) of effect sizes were needed in the multi-level model. A great amount of heterogeneity (I2 = 92.07%) could be accounted for by true effect size variance, with slightly more variance within ( = 46.58%) than between studies ( = 45.49%). That is, variation of effect sizes quantifying the correlation between DT and intelligence within the studies (e.g., when correlations are based on different measures of intelligence or DT) and between-study variation (i.e., when effect sizes are aggregated at the study level) were highly comparable. As expected, obtained effects were heterogeneous, QE(848) = 9206.17, p < .001.
4.2. Publication Bias
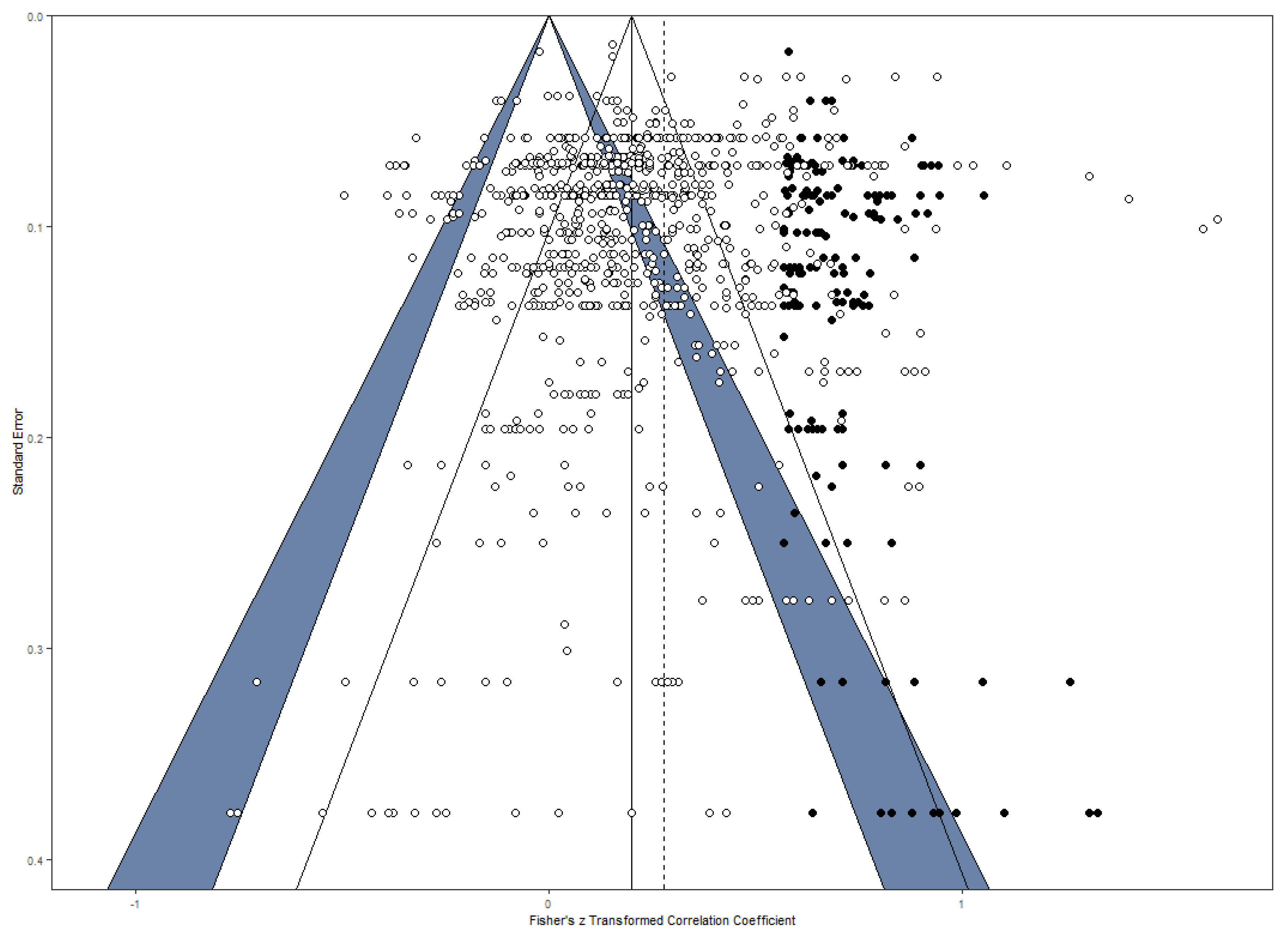
A publication bias occurs when studies reporting significant or desired results are preferred for publication, while studies reporting insignificant results are more likely to be rejected. As a result, the accessible data does not represent all results of scientific studies and might over- or underestimate certain effects (
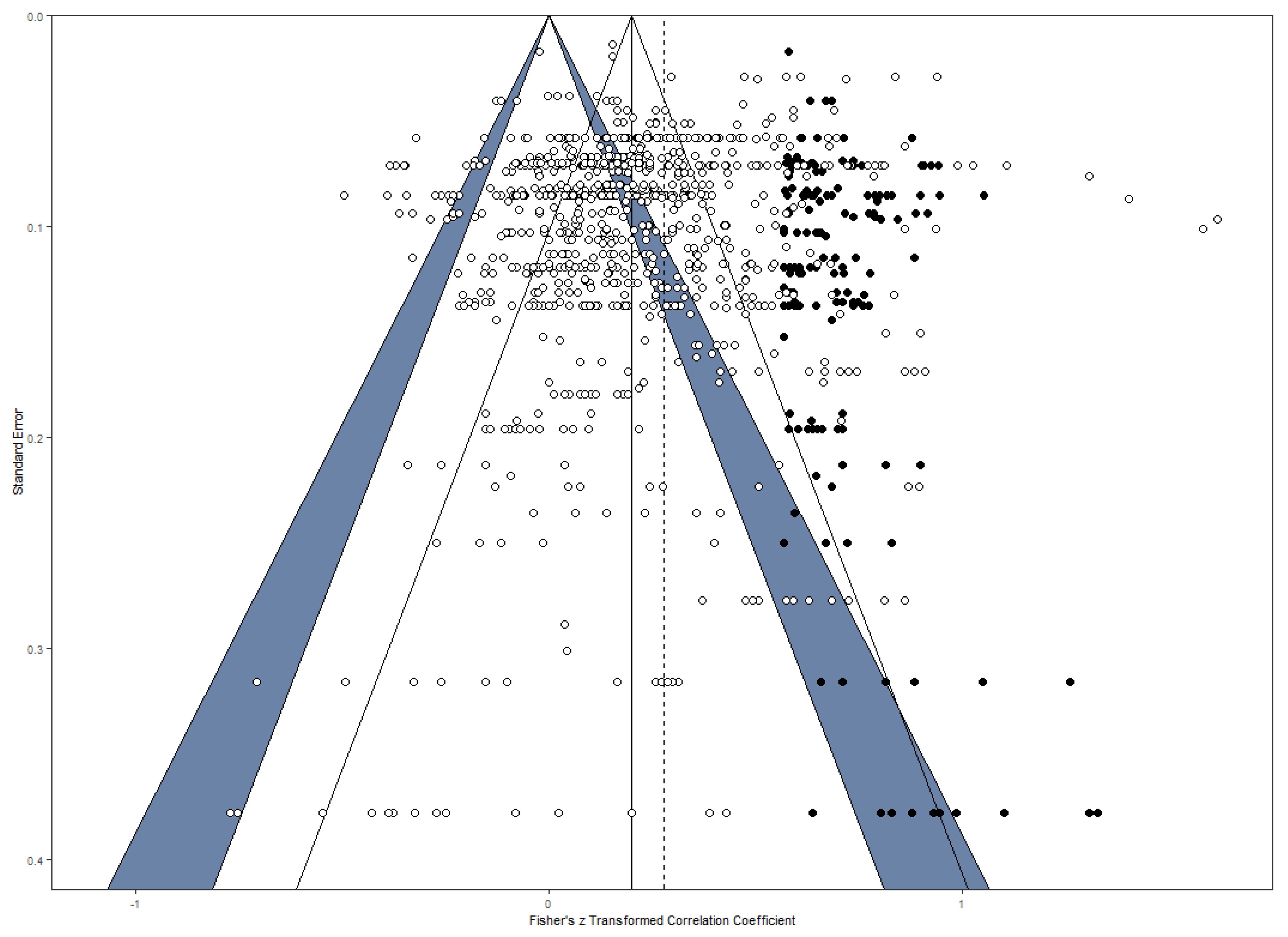
Sterling et al. 1995). To control for possible publication bias, as a first step, a funnel plot (see
Figure 2) was used as a visual method to examine the distribution of the coefficients (
Duval and Tweedie 2000). The distribution for all effect sizes appeared to be asymmetric. In the next step, the number of missing coefficients was estimated by the trim and fill method (
Duval and Tweedie 2000) and imputed 169 data points on the right side of the funnel plot (see
Figure 2). All of these imputed values were found in the region of significant or highly significant effect sizes which implies that the mechanism underlying the asymmetry was not a classical publication bias based on the publication of only significant findings (
Peters et al. 2008). Next, an Egger-type test was computed (i.e., the standard errors of the correlation coefficients were used as a moderator in the three-level model) and confirmed the publication bias (
z = −2.37,
p = .018). This publication bias suggests that the effect is underestimated. When taking the 169 imputed effect sizes into account, a significant correlation of
r = .27, 95% CI [.25, .29],
p < .001, appears, indicating that the true correlation was only slightly underestimated because of publication bias (recall that the overall estimate reported above was found to be
r = .25). However, it should be mentioned that the analysis with imputed data points did not take into account the within-study variance and was hence conducted by using a random effects model providing two sources of variance: sampling variance and true parameter variance. We repeated the publication bias analysis when aggregating effect sizes at the level of independent samples as a check of robustness. For these aggregated data, the same pattern of asymmetry was found (see OSF repository for detailed findings).
4.3. Moderator Analysis
4.3.1. Bivariate Relationships of Moderators
Prior to moderator analysis, we investigated all bivariate relationships between moderators to check for potential confounding effects between moderator variables (
Viechtbauer 2007). We calculated Pearson correlations for pairs of continuous moderators, the η coefficient for pairs of continuous and categorical moderators, and Cramer’s
V for categorical moderators. All correlations are reported in
Table 1.
As a first observation, the publication year correlated with several other moderators such as time-on-task for intelligence measures, DT instruction, DT scoring, DT time condition, and intelligence time condition. In particular, the correlations with aspects of how DT and intelligence are measured reflect changes of methodological approaches over time. Applications of be-creative instructions (vs. be-fluent instructions), originality/creative quality scoring (vs. fluency), and timed DT testing conditions (vs. untimed conditions) have increased over the years. The pattern for timed DT testing conditions was found to be reversed for intelligence testing conditions (untimed testing of intelligence increased as a function of publication year). Several other bivariate correlations were rather strong. For example, DT time-on-task correlated strongly with DT modality because of the common practice to use longer testing times when drawing is required for figural DT task as compared to verbal DT tasks. Similarly, intelligence facet and modality were strongly correlated because g
f is hard to measure in the verbal domain and relies most often on figural item content. All these observations need to be taken into account when interpreting the reported moderator analyses below. Please note further that we take confounded moderators into account in a robustness check (see
Section 4.3.12). The found bivariate associations further highlight the complexity when examining effect sizes from primary studies as the unit of measurement.
4.3.2. Intelligence Facet
The estimated correlations between DT and intelligence facets were found to be small to moderate and in the range from .23 to .28 across g, g
c, and g
f (see
Table 2). The moderator test was non-significant (
QM(2) = 5.77,
p = .056). Given the borderline significant moderator test, it was considered worthwhile to examine specific contrasts here. There was no difference between any two of the intelligence facets (all
ps > .161).
4.3.3. DT Instruction
Table 3 displays the correlation estimates between DT and intelligence as a function of the used DT instruction. The moderator test was non-significant,
QM(6) = 2.63,
p = .854. Importantly, most studies relied on be-fluent instructions (i.e., 59 studies), and only fourteen studies used be-original/creative instructions.
We further analyzed other aspects of DT instructions, such as the classical comparison between “game-like” vs. “test-like” conditions, and added concrete strategy instructions as another aspect of DT instructions. The results for this moderator analysis are displayed in
Table 4. Game-like DT instructions yielded a non-significant correlation between DT and intelligence, whereas effect sizes were small to moderate for test-like or strategy DT instructions. The moderator test was significant,
QM(2) = 25.94,
p < .001. Specific contrasts revealed that the correlation was significantly higher for test-like DT instructions (
z = −4.94,
p < .001) and strategy DT instructions (
z = −3.96,
p < .001) as compared to game-like DT instructions, respectively, whereas test-like and strategy DT instructions did not differ (
z = 1.21,
p = .226). These specific contrasts were mostly robust across both checks (see
Section 4.3.12). However, the contrast between strategy instructions and game-like instructions was only significant by trend (
p = .099) when including additional moderators in the regression model (see
Section 4.3.12).
4.3.4. DT Scoring
DT scoring was found to be a significant moderator of the relationship between DT and intelligence,
QM(2) = 22.47,
p < .001, with correlations ranging between
r = .20 (fluency) to
r = .37 (composite score; see
Table 5). Specific contrasts further revealed that DT fluency scores correlated significantly lower with intelligence as compared to originality/creative quality (
z = −3.75,
p < .001). This latter finding was robust across both checks, but the contrast found between DT fluency and composite scores was not robust across the checks (see
Section 4.3.12). Hence, the size of the correlation for DT composite scores can be partially explained by confounding with other moderators.
4.3.5. DT Instruction-Scoring-Fit
To assess instruction-scoring fit, the dataset was restricted to be-fluent and be-original/creative instructions and fluency and originality/creative quality scorings for DT. As expected, a model including the interaction between instruction and scoring showed a significantly better fit to the data, χ
2(1) = 6.70,
p = .010 (vs. a model including only main effects). As expected, the highest correlation was found for DT be-original/creative instructions when DT was scored for originality/creative quality (see
Table 6). This correlation was significantly higher as compared to the combination of be-fluent instructions and fluency scoring (
z = −3.16,
p = .008), and the combination of be-original/creative instructions and fluency scoring (
z = −4.88,
p < .001). Interestingly, under be-fluent instructions, the correlations of intelligence with DT fluency and DT originality did not differ (
z = −0.94,
p = .697). All other contrasts were non-significant (all
ps > .052). These findings were robust across the checks (see
Section 4.3.12). It should further be noted that the contrast between be-fluent-originality vs. be-creative-originality was at least significant by trend across robustness checks.
4.3.6. Interaction of DT Instruction-Scoring-Fit and Intelligence Facet
Next, intelligence facet was added to the examination of instruction-scoring fit. A model including the three-way interaction between instruction, scoring, and intelligence facet did not improve model fit beyond a model, including the Instruction × Scoring interaction and the main effect of intelligence facet, χ2(6) = 2.78, p = .836.
4.3.7. Time on Task
As an initial step, we compared if testing was timed or not. We proposed an interaction effect between the timing of DT and timing of intelligence when a be-fluent instruction and scoring for fluency was used for DT measures. This interaction was not straightforwardly testable because we did not find any studies in the literature in which both DT and intelligence were tested in untimed conditions. Hence, we aimed at examining all correlation coefficients available when crossing the moderators: instruction (restricted to be-fluent and be-original/creative instructions) and DT scoring (restricted to fluency and originality/creative quality). However, there were not enough effect sizes available for the cells of the targeted interaction effect involving untimed tasks and, hence, the proposed interaction could not be tested in a reasonable way.
Next, we focused on time-on-task in minutes (i.e., effect sizes based on untimed assessment conditions were excluded) and tested the interaction between time-on-task for DT and intelligence (be-fluent and fluency: k = 45, m = 15; be-creative and originality/creative quality: k = 109, m = 8) and found it to be non-significant (both ps > .674). Moreover, for both combinations of instruction and scoring none of the main effects of time-on-task was significant (all ps > .405).
4.3.8. Task Modality
Task modality varied at the level of DT tasks and intelligence tasks. First, we checked if an interaction between DT modality and intelligence modality improved model fit beyond a simple main effect model, which was not the case (χ
2(6) = 1.68,
p =.947). However, it was found that figural DT measures correlated significantly less strong with intelligence measures as compared to verbal DT measures (β = −0.10,
z = −4.20,
p < .001). However, this observation was not robust across all checks (see
Section 4.3.12) and should be interpreted with caution. Given the theoretical and empirical relationship between intelligence task-modality and intelligence facet (i.e., g
c will most likely be measured by verbal tasks, whereas g
f will most likely be measured by figural tasks), the same models were tested when substituting intelligence task-modality by intelligence facet (e.g., g
c measures should correlate strongest with verbal DT). However, also for this slightly different combination of variables no interaction was found (χ
2(4) = 2.02,
p =.732). To further test the proposed modality-congruency effect, a variable was constructed to contrast correlations based on non-congruent modalities (
k = 507,
m = 83,
N = 25,131) with correlations based on congruent modalities (
k = 342,
m = 67,
N = 17,610). The intelligence–DT correlation was not found to be stronger for congruent modalities of measures (β = 0.03,
z = 1.58,
p = .115). For completeness, we report all estimated correlation coefficients for all combinations of DT modality and intelligence modality in
Table 7.
4.3.9. DT Task-Type
DT task-type was found to be a significant moderator of the intelligence–DT correlation,
QM(8) = 23.96,
p < .001 (see
Table 8). However, none of the specific contrasts reached statistical significance (all
ps > .052). Additionally, robustness checks did not suggest any differences between DT task-types.
4.3.10. Comparison of Pre-Kim and Post-Kim Effect Sizes
Publication time was taken into account by coding if studies were published in 2004 or earlier (i.e., the search scope of Kim’s meta-analysis) vs. published later than 2004. Given that Kim did not correct for attenuation of correlations, we first compared pre-Kim and post-Kim effect sizes at an uncorrected level. This contrast was non-significant (β = 0.00, z = 0.10, p = .921). The uncorrected correlation for the time period of Kim’s meta-analysis was r = .19, 95%-CI: [.14, .23], which nicely covers Kim’s estimate of r = .17. The sample size for coefficients included from 2004 or earlier was N = 9581 (k = 483, m = 45) and coefficients taken from research published later than 2004 were based on N = 25,029 (k = 366, m = 67). The same contrast for the analysis corrected for unreliability was also non-significant (β = −0.01, z = −0.30, p = .766). The correlation for Kim’s time period corrected for attenuation was r = .26, 95%-CI: [.20, .32].
4.3.11. Sample Characteristics
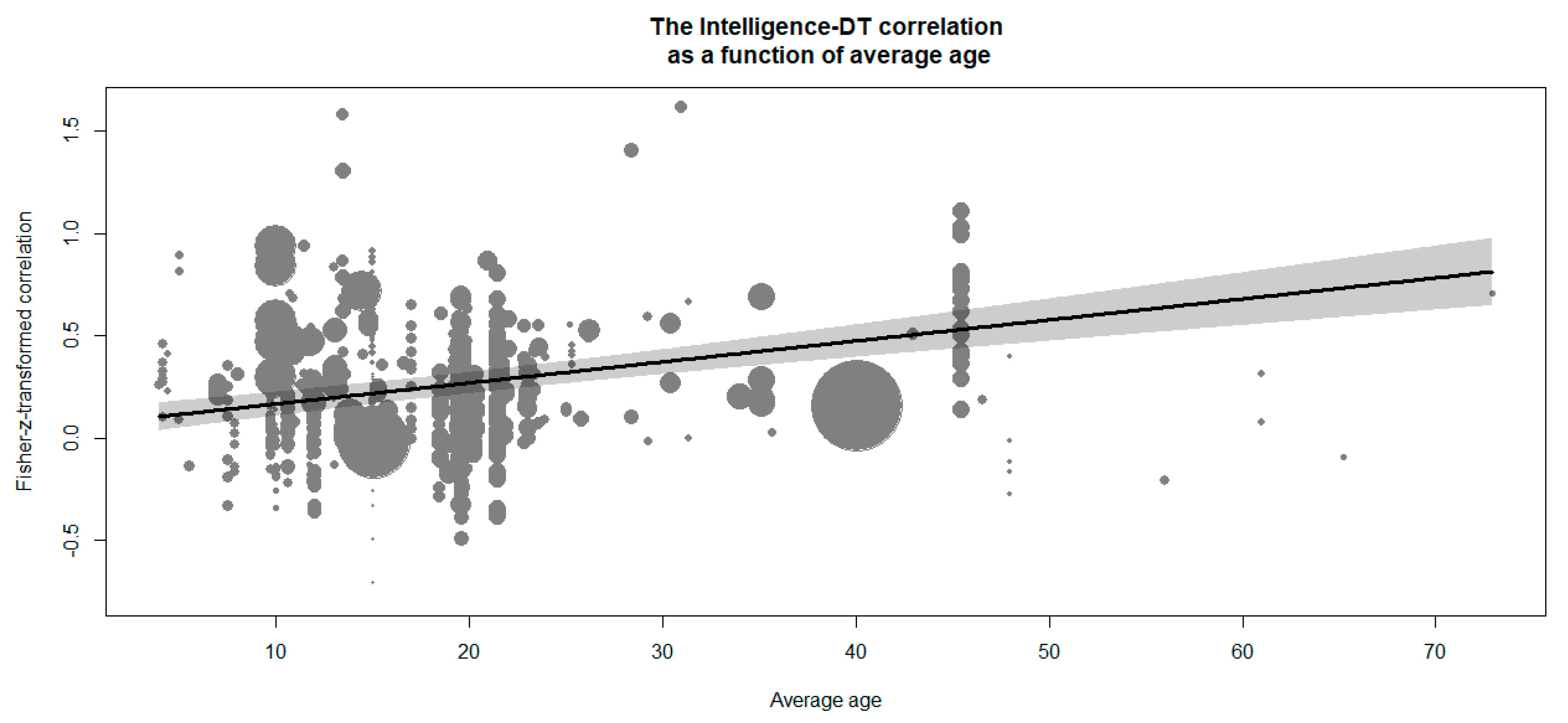
Finally, we tested the mean age and gender ratio as the most common sample characteristics. The average sample age had a positive relationship with the intelligence–DT correlation,
β = 0.01,
z = 6.93,
p < .001. This effect implies that a 10-year difference in average sample age yields a difference of .10 in the Fisher-z-transformed intelligence–DT correlation. This effect is visualized in
Figure 3. Importantly, a quadratic relationship of average age and transformed intelligence–DT correlations did not improve model fit, Δχ
2(1) = 0.09,
p = .762, and the linear effect was robust across both checks (see
Section 4.3.12).
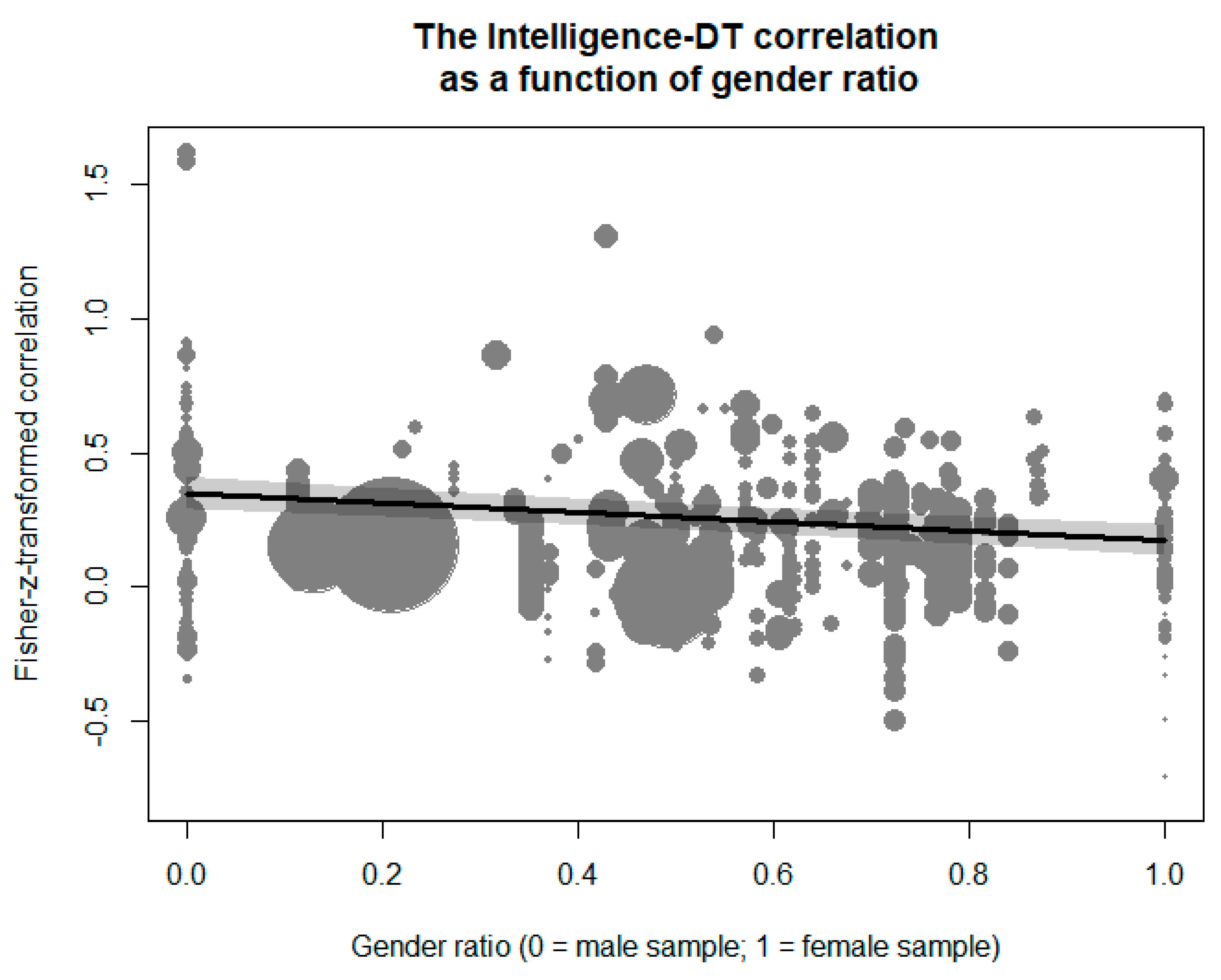
In addition, gender ratio had a negative effect on the transformed intelligence–DT correlation (see
Figure 4),
β = −0.17,
z = −5.09,
p < .001. The meta-regression implied that the correlation for samples comprising completely of males was
r = .34, 95%-CI: [.28, .39], whereas a sample comprising completely of females would yield a correlation of
r = .17, 95%-CI: [.12, .23]. A sample with a uniform distribution of gender would further imply a correlation of
r = .26, 95%-CI: [.21, .30]. Notably, gender ratio was not found to be strongly confounded by any of the other moderators (i.e., none of the bivariate correlations with gender ratio was >.40; see
Table 1), and the robustness check in which all other moderators correlating >.20 with gender ratio were added to the meta-regression revealed a highly comparable pattern.
4.3.12. Robustness Check
We applied robustness checks to further test the dependability of the above reported moderation results. In a first step, we re-examined each moderator effect that reached significance in a meta-regression model that additionally included all other moderators that correlated > .40 with the moderators under consideration (see
Table 1). In a second step, we reran the analysis now including all moderators that correlated > .20 in the confounding check. Results of the robustness checks are presented in
Table 9. It shows that most but not all moderation effects provided to be at least fairly robust. For better readability of the results section, we refer above only to those effects that passed the robustness checks and also explain non-robust findings along with the findings from separate moderator analyses. Complete results for all checks can be found in the OSF repository (
https://osf.io/s4hx5).
5. Discussion
The aim of this meta-analysis was to provide an update on the relationship between intelligence and DT by investigating the role of different DT scoring methods, task instruction, and a more specific view on intelligence facets beyond other previously established moderators. The overall effect indicates that the relationship is small to moderate (r = .25, 95%-CI: .21, .30) and, hence, slightly (but significantly) larger as compared to prior findings of Kim´s meta-analysis (2005; r = .17, 95%-CI: .17, .18). This difference for the overall correlation can be fully attributed to corrections for attenuation because a difference between pre-Kim and post-Kim effect sizes was not found regardless of whether correction for attenuation was applied or not. Nevertheless, it can be observed that studies published after 2004 report reliability measures more frequently (and corrected for measurement error more often). Hence, the studies’ methodological quality might have increased in recent years, but not necessarily the overall relationship between various measures of intelligence and DT. Moreover, moderation analyses showed that the intelligence–DT relationship is, however, somewhat higher (up to r = .31–.37) for specific test conditions such as when employing test-like, timed assessments, using be-creative instructions, and considering DT originality scores.
Following recent propositions and empirical findings (
Silvia 2015), we expected that g
f correlates stronger with DT as compared to the correlation between g
c and DT. This contrast was particularly expected for be-creative instructions and originality/creative quality scorings. However, when participants are instructed to
be-creative, the correlation between DT and g
c and DT and g
f was quite similar. Notably, the usually high correlation between g
f and g
c (
r ≈ .60–.70; e.g.,
Bryan and Mayer 2020) could preclude finding a differential pattern for these intelligence facets. Hence, it seems that g
c, namely knowledge, is required as a basic prerequisite and that g
f is required to form and evaluate ideas when participants are explicitly instructed to be creative. In addition, the fact that g
c and DT are correlated indicates that knowledge is required for DT, which supports the historical view of
Mednick (
1962). This knowledge could be used to simply recall relevant solutions (e.g.,
Miroshnik and Shcherbakova 2019), or provide the conceptual elements to be combined to original ideas. It must not be overlooked that by asking participants to produce many ideas, a DT test resembles verbal fluency tasks (
Nusbaum et al. 2014).
Beauducel and Kersting’s (
2002) view that verbal fluency tasks are markers for g
c would have suggested that DT and g
c correlate more strongly (as compared to the DT–g or DT–g
f correlations) when be-fluent instruction and fluency scoring are used to assess DT. However, this specific proposition was not supported in this study.
The correlations did not generally differ whether a
be-fluent or a
be-creative instruction (or any other variant of a hybrid instruction) is given (i.e., we did not find a main effect of instruction). However, correlations increased for the
be-creative instruction when DT responses were scored for
originality (i.e., in case of instruction-scoring fit) compared to
fluency scorings when be-fluent instructions were used. This pattern has been expected by
Silvia (
2015). Be creative instructions are thought to induce more cognitively demanding strategies and thus increase the relevance of intelligence and executive control. In addition, the intelligence–DT correlation was also found to be stronger for the combination of be-creative instructions and originality scoring as compared to be-creative instructions and fluency scoring. Clearly, the interaction of instruction and DT outcome has an impact on the relationship between intelligence and DT. Instructing participants to
be-creative leads to more sophisticated responses, whereas instructing participants to
be-fluent influences the number of responses. Hence, researchers get what they ask for (
Acar et al. 2020). Since DT is considered to be a marker of creative potential (
Runco and Acar 2012), the assessment of the
originality of the responses seems required (e.g.,
Zeng et al. 2011) and, as a matter of fact, is provided in most of the recent studies. All scoring methods have their weaknesses, and the development of new methods (e.g., based on corpus semantics;
Beaty and Johnson 2020;
Dumas et al. 2020) continues, and we can be curious about how the weaknesses of the current methods will be mitigated.
Correlations in
game-like instructions dropped to a small effect size that was non-significant. Compared to the test-like settings (or strategy instructions), it seems that under
game-like instructions, the relationship between intelligence and DT diminishes. However, it remains unclear to what extent the testing situation influences the relationship between intelligence and DT. Affective/conative factors like current motivation, time pressure, or test anxiety may play a major role when assessing DT. For example,
Byron et al. (
2010) ran a meta-analysis on the relationship between stressors and creativity and found that when participants expect an evaluation, their creative performance is influenced in an inverted U-shaped manner. Strong evaluative stress or the absence of an evaluation of the performance hinders creative performance, whereas minor levels of evaluative stress support creative performance. Test situations imply the evaluation of the outcome and might be responsible for better performance. Since a considerable part of the participants are students, it can be assumed that they are familiar with test settings and that the expected evaluation of their results may have motivated them to give their best. On the other hand, the evaluative component is absent in a
game-like setting and may hinder creative performance. In fact, playing a game does not necessarily stimulate the motivation to perform well. Furthermore, there were no time-constraints for the tasks in the
game-like setting. What is more, game-like conditions can also drastically vary from study to study. Thus, not all studies with game-like conditions rely on the same approach (see
Said-Metwaly et al. 2017). In a study with adolescents,
Preckel et al. (
2011) found stronger correlations between reasoning tasks and DT, when DT was assessed with time constraints compared to the test without time limits. Further,
Beaty and Silvia (
2012) found that more ideas are generated at the beginning of a DT task, whereas originality increased with time. Hence, the allowed time to work on a task might play a crucial role in creative performance. However, whether the game-like setting or accompanying aspects can solely account for the missing relationship between intelligence and DT remains an open issue. Future research projects should consider that the relationship between intelligence and DT may be biased due to the environmental influence of the test setting.
It was studied if modalities of DT and intelligence measures and their interplay affected the relationship between DT and intelligence. However, tests of this moderator were rather inconclusive (i.e., findings were not robust), and future primary studies are clearly needed to shed more light into the issue. As a more general point, it should be noted that common definitions of DT task modality just refer to the content modality of task items and responses, which does not necessarily define the modality of cognitive processes involved in task processing (
Benedek and Fink 2019). Especially verbal DT tasks appear to be a quite heterogeneous group, encompassing tasks that require to work creatively with words (e.g., metaphor tasks) or objects (e.g., Alternate Uses Task). Neuroscientific investigations have shown that divergent thinking commonly implicates visual and motor activity, pointing to the involvement of mental simulations (e.g., object manipulations) and visually guided search processes even for verbal material (
Benedek et al. 2020;
Matheson and Kenett 2020). Future research thus may aim to reconsider established classifications of DT tasks (please note that in the current work also DT task-type did not reveal a differential pattern with respect to the intelligence–DT correlation) with respect to their cognitive demands and eventually concede that few tasks involve only a single modality.
Two aspects of studies’ characteristics moderated the correlations between intelligence and DT: the average age of participants and the gender composition. The links were stronger among older than younger participants and more pronounced in studies composed predominantly by males than females. Although none of these effects was predicted a priori, both seem consistent with the literature.
First, the observed increasing correlations between intelligence and DT with participants’ age are in line with recent studies (e.g.,
Breit et al. 2020) that found that correlations between different abilities increase with participants’ age. This pattern should be read in light of the long-standing discussion of differentiation-versus-dedifferentiation of cognitive abilities (see, e.g.,
Hartung et al. 2018). While our findings seem to support the dedifferentiation hypothesis, we acknowledge that meta-analysis is not the best approach to resolve this issue (e.g., ecological fallacy;
Viechtbauer 2007). Given that our analyses used the average age of participants and the overlap in age between samples is natural, future studies are needed to more precisely estimate the links between DT and intelligence across different age cohorts. Please note further that for related reasons we even refrained from an analysis of average sample IQ as a moderator. However, the “measurement” of sample age as compared to the measurement of intelligence (see
Weiss et al. 2020b) poses fewer challenges in this regard and average sample age can be considered as one of the pertinent sample characteristics used in meta-regression. Hence, while we see problems related to sample age as a moderator and recommend refraining from any straightforward interpretations that generalize from the aggregation level of a meta-analysis to the level of individuals, the found pattern might have heuristic value for the planning of future studies.
The second significant moderation we observed was related to a higher correlation between intelligence and DT in samples composed of males than in samples composed of females. One possible explanation of this pattern refers to the classic “greater male variability hypothesis” (
Ellis 1894). Men are characterized by higher variability than women on almost all biological and psychological traits (e.g.,
Ritchie et al. 2018). Previous studies demonstrated that the males’ variance in intelligence tests is higher than females’ variability (see
Wai et al. 2010 or
Johnson et al. 2008, for an overview). The same pattern was found in creativity tests, both among children (
Karwowski et al. 2016b) and adults (
He and Wong 2011). As higher variability strengthens correlations between variables, lower links in predominantly female samples might stem from the restricted variance of intelligence and creativity scores among females. This explanation, however, is tentative and should be directly tested in future studies (i.e., again one should be cautious and not simply generalize from the aggregation level of meta-analysis to the level of individuals).
Interestingly, the observed funnel plot asymmetry was in the opposite direction than one would expect. The observed distribution of coefficients lacked high effect sizes (mostly in the range of highly significant effect sizes) to become symmetrical, indicating that the true relationship between intelligence and DT may be underestimated. The unusual publication bias makes the interpretation difficult. It is possible that changing theoretical assumptions about the relationship between intelligence and DT have influenced what outcomes are desirable. In the 60s of the last century, the prevailing view was that DT and intelligence are virtually unrelated, whereas, at the beginning of the 21st century, the view has shifted to the assumption that DT and intelligence have much more in common than previously thought. Hence, one might conclude that the overall relationship between intelligence and DT is underestimated based on a publication bias that is grounded in a non-significance mechanism, but after correction of the publication bias, the correlation remains moderate (
Cohen 1988). In relation to this, it should be further noted that the trim-and-fill method does not work under all conditions (
Peters et al. 2007). Hence, given that the Egger-type test revealed a funnel plot asymmetry and the very small increase of the effect size estimate based on the trim-and-fill method, it might also be possible that the corrected estimate is not accurate and caution is needed here. Moreover, beyond a possible publication bias based on non-significance, attention should be paid to the fact that imputed effect sizes on the right sight were all found to be in the region of significant or highly significant correlation coefficients.
Peters et al. (
2008) suggest that in such situations other factors related to study quality can also cause funnel plot asymmetry. For example, reliability was imputed by means of average reliability across all available estimates, but some studies may have had even lower reliability associated with the used measures. However, without a careful coding and examination of study quality, this issue is not expected to be solved. The found asymmetry could be attributable to a non-significance publication bias, a hidden study quality factor, or a combination of both.
5.1. Limitations
Even though this meta-analysis has been prepared carefully in view of the current theories of DT and intelligence research, some limitations must be noted. Several studies did not report sufficient information on DT and intelligence tests, which made the coding procedure difficult. As a result, many intelligence tests were coded with g since there was no other information available. Sometimes it remained unclear which instruction was given in DT tests and, more importantly, how DT outcomes were scored. Consequently, coding might have been more detailed if more information had been provided.
With regard to DT outcomes, a fully differentiated coding was not possible. All subjective scorings were subsumed under the DT outcome
originality. However, the procedures were not similar in all studies. Splitting up subjective scorings into smaller categories might have provided more insight into the different scoring methods (i.e., top-scoring, snapshot scoring) that are currently being discussed (
Reiter-Palmon et al. 2019). It should further be mentioned that explicit instructions to focus on an aspect of creativity (e.g., “be creative”, “be original”) vary in terms of their exact wording (
Acar et al. 2020;
Runco et al. 2005). In the current work, we did not further distinguish between these subtleties. The main difference between be-creative and be-original instructions, for example, is the wording and while theoretically “creative” does not mean the same thing as “original”, it is far less clear if participants’ understanding of these words reflects the theoretical understanding of creativity researchers. Hence, it is an open question if these nuances in the instructions lead to a different understanding of the task. Indeed,
Acar et al. (
2020) found different patterns between be-creative and be-original instructions in moderator analyses when effect sizes for mean differences were compared in a meta-analysis on explicit instruction effects. However, how these varying explicit instructions might affect the correlation between DT and intelligence is rather unclear. More intelligent participants might have it easier to adapt to any type of explicit instruction, but then it will depend on the participants’ understanding of the instructions if the intelligence–DT correlation would be affected. Another issue that adds to the complexity of this discussion is instruction-scoring fit (
Reiter-Palmon et al. 2019). To conclude, we argue that these types of instructions share a conceptual relation to the most common definitions of creativity, and based on this observation a combined analysis represents a reasonable choice for the context of the current work.
We further did not examine the intelligence–DT correlation as a function of mean IQ because of several methodological problems that could arise from studying it at the level of effect sizes (e.g.,
Karwowski and Gralewski 2013;
Weiss et al. 2020b). The question of a non-linear relationship between creative thinking and intelligence can be better studied by means of complex statistical approaches that are applied in appropriately designed primary studies (e.g.,
Breit et al. 2020,
2021;
Weiss et al. 2020b). Relatedly, other complex interactive effects could be investigated. For example,
Harris et al. (
2019) proposed that the relationship between creative achievement and intelligence would be moderated by openness to experience. Hence, openness could also be considered as a moderator of the correlation between DT and intelligence. However, measures of openness differ across studies and are unlikely to be on the same scale which in combination with the problems associated with a meta-analytical examination of the threshold hypothesis prevents such a moderator analysis.
As another limitation, we acknowledge that in some instances, moderator analyses relied on a small number of studies. These reported findings should be treated with caution and highlight another goal of meta-analysis, namely the identification of gaps in the empirical study base. Such cells in the moderator analysis design that revealed only few available studies call for further research to strengthen our knowledge on the relationship between DT and intelligence. For example, the proposed interaction between timed vs. untimed testing of DT and intelligence measures was not testable at the level of effect sizes because both measures were never assessed together under untimed conditions. Moreover, with respect to task modality, it was only rarely found that DT assessment involved numerical task content (i.e., only as part of a composite based on measures designed in accordance with the Berlin Structure of Intelligence model; e.g.,
Preckel et al. 2011), but also pure numerical intelligence measures were only used in very few studies. These observations may pave the way for related future research.
Finally, as mentioned by one anonymous reviewer, under some circumstances (e.g., only categorical moderators are available) it could be a helpful approach to code missing values of moderators as
other category. However, in most of our meta-regression models mean age and gender ratio were included as moderators and these two variables had the highest proportions of missing values. These two moderators are continuous and such an approach is not applicable without accepting any loss of information in the data (i.e., because of artificially creating categories for these variables). Clearly, complete meta-regression models are desirable to prevent type-I-error associated with separate moderator tests (see
Viechtbauer 2007). We agree that this can pose a problem because standard errors in separate moderator tests do not account for the correlational structure among moderators (i.e., moderator confounding) which in turn might yield too liberal statistical inference (i.e., standard errors are underestimated). We argue that our approach to create meta-regressions according to two levels of moderator confounding addresses this issue in a careful way. In addition, our conclusions are quite cautious as it is required for meta-regression which is an approach that has often been criticized (see
Viechtbauer 2007). Hence, we are quite confident that for the context of our work moderator analyses are carried out in an appropriate manner.
5.2. Recommendations for Future Research
Using the CHC model (
Carroll 1997) as a framework for embedding the research efforts about the relationship between intelligence and DT, other subordinate factors must not be overseen. The facet g
r (i.e., broad retrieval ability), for instance, reflects the ability to store and later retrieve information fluently through associative processes. Underlying narrow cognitive abilities are (amongst others) ideational fluency, figural flexibility, originality/creativity, and thus abilities that can be accounted to DT as well (
McGrew 2009). The first steps investigating the relationship between DT and g
r have been made and show substantial associations (e.g.,
Forthmann et al. 2019;
Silvia et al. 2013). Interestingly, recent research suggested that although g
r is strongly concerned with verbal fluency, it predicts DT originality at least as strongly as DT fluency (
Benedek et al. 2017;
Forthmann et al. 2019;
Silvia et al. 2013), which may deserve further investigation. Furthermore, g
r may benefit from g
c and g
f, and may be a connecting factor when investigating the intelligence–DT relationship, but much more needs to be learned about the inter-relations of the broad cognitive abilities of the CHC model (
Carroll 1997). Relatedly, but not discussed in more detail here, the research on executive functions (which has a conceptual overlap with g
r) and the overlaps with intelligence should be pushed forward. Considering that cognitive flexibility and DT overlap to a certain extent, the impact of working memory and inhibitory control may provide further insight into the underlying cognitive processes. Untangling the theories of intelligence and executive functions might help to locate DT within these constructs. Furthermore, it would be interesting to understand how executive functions and broad cognitive abilities of the CHC model (
Carroll 1997) interact and what role g
c and g
r play within the framework of executive functions.

 ,
, 

{kind=link}
{kind=link}
{kind=link}
{kind=link}