Building a Cardiovascular Disease Prediction Model for Smartwatch Users Using Machine Learning: Based on the Korea National Health and Nutrition Examination Survey

Abstract
:1. Introduction
2. Review of Literature
3. Research Methodology
3.1. Data Source
3.2. Variables
3.3. Research Procedure
4. Results
4.1. Performance Evaluation Index
4.2. Performance Comparison of Models
4.3. Support Vector Machine
4.3.1. Optimal Model of Support Vector Machine
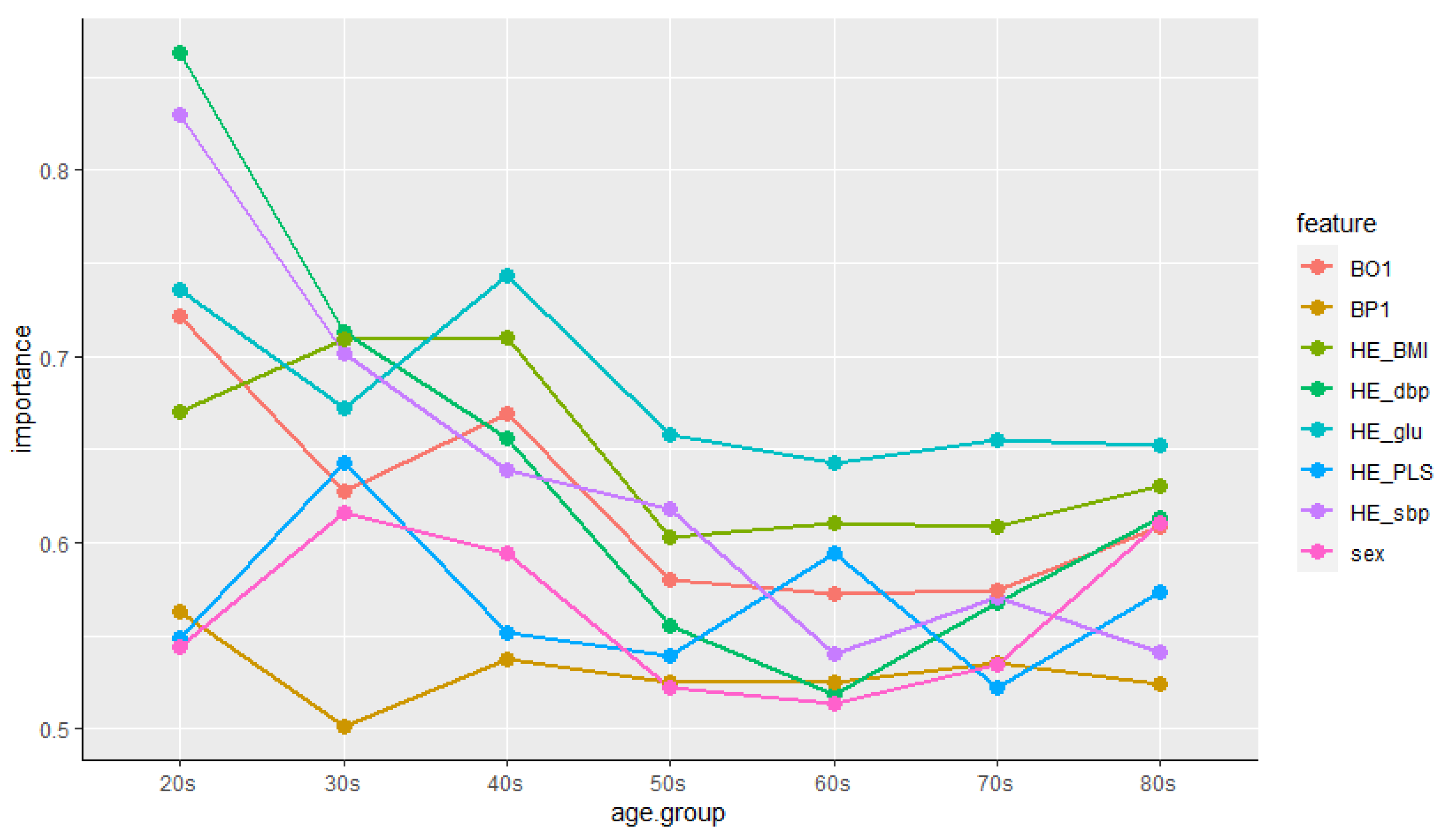
4.3.2. Features’ Importance
5. Discussion
6. Conclusions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Statistics Korea. Results of the Cause of Death Statistics in 2019. Available online: http://kostat.go.kr/portal/korea/kor_nw/1/1/index.board?bmode=read&aSeq=385219 (accessed on 12 May 2021).
- Grundy, S.M.; Pasternak, R.; Greenland, P.; Smith, S.; Fuster, V. Assessment of cardiovascular risk by use of multiple-risk-factor assessment equations. Circulation 1999, 100, 1481–1492. [Google Scholar] [CrossRef] [Green Version]
- Park, K.; Hwang, S.Y. 10-year risk for cardiovascular disease among male workers in small-sized industries. J. Cardiovasc. Nurs. 2015, 30, 267–273. [Google Scholar] [CrossRef]
- Palaniappan, S.; Awang, R. Intelligent heart disease prediction system using data mining techniques. In Proceedings of the 2008 IEEE/ACS International Conference on Computer Systems and Applications, Doha, Qatar, 31 March–4 April 2008. [Google Scholar] [CrossRef] [Green Version]
- Jung, I.-Y.; Kim, S.-K.; Lee, D.E.; Lee, Y.H. Emerging Healthcare Innovations Driven by Data and Its Policy Implications; Science and Technology Policy Institute: Sejong, Korea, 2016. [Google Scholar]
- Wu, R.; Peters, W.; Morgan, M.W. The next generation of clinical decision support: Linking evidence to best practice. J. Healthc. Inf. Manag. 2002, 16, 50–55. [Google Scholar]
- Reeder, B.; David, A. Health at hand: A systematic review of smart watch uses for health and wellness. J. Biomed. Inform. 2016, 63, 269–276. [Google Scholar] [CrossRef]
- Samsung Newsroom. Electrocardiogram Monitoring Cleared for Galaxy Watch Active2 by South Korea’s Ministry of Food and Drug Safety. Available online: https://news.samsung.com/global/electrocardiogram-monitoring-cleared-for-galaxy-watch-active2-by-south-koreas-ministry-of-food-and-drug-safety (accessed on 13 May 2021).
- Samsung Newsroom. Samsung Expands Vital Blood Pressure and Electrocardiogram Tracking to Galaxy Watch3 and Galaxy Watch Active2 in 31 More Countries. Available online: https://news.samsung.com/global/samsung-expands-vital-blood-pressure-and-electrocardiogram-tracking-to-galaxy-watch3-and-galaxy-watch-active2-in-31-more-countries (accessed on 13 May 2021).
- Korea IT News. Samsung Electronics’ Galaxy Watch 4 to Be Applied with an Ability to Monitor Blood Glucose Level. Available online: https://english.etnews.com/20210125200002 (accessed on 13 May 2021).
- Wilson, P.W.F.; D’Agostino, R.B.; Levy, D.; Belanger, A.M.; Silbershatz, H.; Kannel, W.B. Prediction of coronary heart disease using risk factor categories. Circulation 1998, 97, 1837–1847. [Google Scholar] [CrossRef] [Green Version]
- Kim, H.-C. CVD risk prediction in high-risk versus low-risk populations. J. Hypertens. 2016, 34, e16. [Google Scholar] [CrossRef]
- Ahn, K.A.; Yun, J.E.; Cho, E.R.; Nam, C.M.; Jang, Y.-S.; Jee, S.H. Framingham equation model overestimates risk of ischemic heart disease in Korean men and women. Korean J. Epidemiol. 2006, 28, 162–170. [Google Scholar]
- Cho, Y.G. Cardiovascular risk prediction in Korean adults. Korean J. Fam. Med. 2018, 39, 135–136. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Yoo, A.-R.; Shin, S.-R. The relationship between serum triglyceride/HDL cholesterol, total cholesterol/HDL cholesterol, LDL cholesterol/HDL cholesterol ratios and cardiovascular disease risk factors in Korean adults: Using the 2016 Korea National Health and Nutrition Examination Survey Data. J. Korean Soc. Integr. Med. 2019, 7, 127–139. [Google Scholar]
- Park, K.-O. Convergence exploration for predictors of the cardiovascular disease risk. J. Digit. Converg. 2018, 16, 251–259. [Google Scholar] [CrossRef]
- Kim, Y.-E.; Kim, I.-W.; Moon, A.-J.; Kim, N.-K.; Lee, S.-G.; Lee, K.-S. A study on using EAV (MERIDIAN) by analysis of cerebrovascular disease risk factors. J. Korean Med. 2010, 31, 136–145. [Google Scholar]
- Anand, T.; Pal, R.; Dubey, S.K. Data mining in healthcare informatics: Techniques and applications. In Proceedings of the 2016 3rd International Conference on Computing for Sustainable Global Development, New Delhi, India, 16–18 March 2016. [Google Scholar]
- Quentin-Trautvetter, J.; Devos, P.; Duhamel, A.; Beuscart, R. Assessing association rules and decision trees on analysis of diabetes data from the DiabCare program in France. Stud. Health Technol. Inform. 2002, 90, 557–561. [Google Scholar]
- Firouzi, F.; Rashidi, M.; Hashemi, S.; Kangavari, M.; Bahari, A.; Daryani, N.E.; Emam, M.M.; Naderi, N.; Shalmani, H.M.; Farnood, A.; et al. A decision tree-based approach for determining low bone mineral density in inflammatory bowel disease using PWEKA software. Eur. J. Gastroenterol. Hepatol. 2007, 19, 1075–1081. [Google Scholar] [CrossRef] [PubMed]
- De Edelenyi, F.S.; Goumidi, L.; Bertrais, S.; Phillips, C.; MacManus, R.; Roche, H.; Planells, R.; Lairon, D. Prediction of the metabolic syndrome status based on dietary and genetic parameters, using Random Forest. Genes Nutr. 2008, 3, 173–176. [Google Scholar] [CrossRef] [Green Version]
- Kim, K.-R.; Kim, J.-K.; Lee, J.-S. Optimized Feature Selection using Feature Subset IG-MLP Evaluation based Machine Learning Model for Disease Prediction. J. Korea Soc. Simul. 2020, 29, 11–21. [Google Scholar] [CrossRef]
- Wilmot, E.G.; Edwardson, C.L.; Achana, F.A.; Davies, M.J.; Gorely, T.; Gray, L.J.; Khunti, K.; Yates, T.; Biddle, S.J.H. Sedentary time in adults and the association with diabetes, cardiovascular disease and death: Systematic review and meta-analysis. Diabetologia 2012, 55, 2895–2905. [Google Scholar] [CrossRef] [PubMed]
- Kostis, J.-B. The Importance of Managing Hypertension and Dyslipidemia to Decrease Cardiovascular Disease. Cardiovasc. Drugs Ther. 2007, 21, 297–309. [Google Scholar] [CrossRef]
- Song, M.-J.; Kim, M.-Y.; Sim, I.-S.; Kim, W.-S. Evaluation of Horticultural Therapy on the Emotional Improvement of Depressed Patients by Using Heart Rate Variability. Korean J. Hortic. Sci. Technol. 2010, 28, 1066–1071. [Google Scholar]
- Menard, S. Logistic Regression: From Introductory to Advanced Concepts and Applications, 1st ed.; SAGE Publications, Inc.: Sauzend Oaks, CA, USA, 2009. [Google Scholar]
- Shahid, N.; Rappon, T.; Berta, W. Applications of artificial neural networks in health care organizational decision-making: A scoping review. PLoS ONE 2019, 14, e0212356. [Google Scholar] [CrossRef]
- Son, Y.-J.; Kim, H.-G.; Kim, E.-H.; Choi, S.S.; Lee, S.-K. Application of Support Vector Machine for Prediction of Medication Adherence in Heart Failure Patients. Healthc. Inform. Res. 2010, 16, 253–259. [Google Scholar] [CrossRef]
- Maglogiannis, I.; Loukis, E.; Zafiropoulos, E.; Stasis, A. Support vectors machine-based identification of heart valve diseases using heart sounds. Comput. Methods Programs Biomed. 2009, 95, 47–61. [Google Scholar] [CrossRef]
- Thurston, R.C.; Matthews, K.A.; Hernandez, J.; De La Torre, F. Improving the performance of physiologic hot flash measures with support vector machines. Psychophysiology 2009, 46, 285–292. [Google Scholar] [CrossRef]
- Chu, A.; Ahn, H.S.; Halwan, B.; Kalmin, B.; Artifon, E.L.A.; Barkun, A.; Lagoudakis, M.G.; Kumar, A. A decision support system to facilitate management of patients with acute gastrointestinal bleeding. Artif. Intell. Med. 2008, 42, 247–259. [Google Scholar] [CrossRef]
- Package ‘Caret’. Available online: https://cran.r-project.org/web/packages/caret/caret.pdf (accessed on 19 June 2021).
- Package ‘Neuralnet’. Available online: https://cran.r-project.org/web/packages/neuralnet/neuralnet.pdf (accessed on 1 April 2021).
- Package ‘e1071′. Available online: https://cran.r-project.org/web/packages/e1071/e1071.pdf (accessed on 13 April 2021).
- Al-Mejibli, I.S.; Alwan, J.K.; Abd, D.H. The effect of gamma value on support vector machine performance with different kernels. Int. J. Electr. Comput. Eng. 2020, 10, 5497–5506. [Google Scholar] [CrossRef]
- Rakotomamonjy, A. Optimizing Area under Roc Curve with SVMs. In Proceedings of the ROC Analysis in Artificial Intelligence, 1st International Workshop, Valencia, Spain, 22 August 2004. [Google Scholar]
- Cook, N.R. Statistical evaluation of prognostic versus diagnostic models: Beyond the ROC curve. Clin. Chem. 2008, 54, 17–23. [Google Scholar] [CrossRef] [Green Version]
- Flint, A.C.; Conell, C.; Ren, X.; Banki, N.M.; Chan, S.L.; Rao, V.A.; Melles, R.B.; Bhatt, D.L. Effect of Systolic and Diastolic Blood Pressure on Cardiovascular Outcomes. N. Engl. J. Med. 2019, 381, 243–251. [Google Scholar] [CrossRef] [PubMed]
- Jeong, S.-W.; Kim, S.-H.; Kang, S.-H.; Kim, H.-J.; Yoon, C.-H.; Youn, T.-J.; Chae, I.-H. Mortality reduction with physical activity in patients with and without cardiovascular disease. Eur. Heart J. 2019, 40, 3547–3555. [Google Scholar] [CrossRef]
- Halter, J.B.; Musi, N.; Horne, F.M.; Crandall, J.P.; Goldberg, A.; Harkless, L.; Hazzard, W.R.; Huang, E.S.; Kirkman, M.S.; Plutzky, J.; et al. Diabetes and Cardiovascular Disease in Older Adults: Current Status and Future Directions. Diabetes 2014, 63, 2578–2589. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Dimsdale, J.E. Psychological Stress and Cardiovascular Disease. J. Am. Coll. Cardiol. 2008, 51, 1237–1246. [Google Scholar] [CrossRef] [Green Version]
- Roemmich, J.N.; Lambiase, M.J.; Balantekin, K.N.; Feda, D.M.; Dorn, J. Stress, Behavior, and Biology: Risk Factors for Cardiovascular Diseases in Youth. Exerc. Sport Sci. Rev. 2014, 42, 145–152. [Google Scholar] [CrossRef] [PubMed]
- Oh, M.-S.; Jeong, M.-H. Sex Differences in Cardiovascular Disease Risk Factors among Korean Adults. Korean J. Med. 2020, 95, 266–275. [Google Scholar] [CrossRef]
- Park, Y.; Helms, V. On the derivation of propensity scales for predicting exposed transmembrane residues of helical membrane proteins. Bioinformatics 2007, 23, 701–708. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhang, W.; Zou, S.; Song, J. Term-tissue specific models for prediction of gene ontology biological processes using transcriptional profiles of aging in drosophila melanogaster. BMC Bioinform. 2008, 9, 129. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lee, J.-R.; Kwon, K.-N. The Critical Research of Healthcare Focused on Smartwatch Users. Korean J. Sociol. Sport 2019, 32, 92–109. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variables | Variable Names | Description | Variable Types | Values of Measures {Min, Max} | Descriptive Statistics (Mean, SD) |
|---|---|---|---|---|---|
| target variable | chd_risk | prevalence of cardiovascular disease | nominal | 0: no, 1: yes | no (4380), yes (1790) |
| input variables | sex | gender | nominal | 1: male, 2: female | male (2722), female (3448) |
| age | age | continuous | {10, 80} | (47.33, 19.45) | |
| HE_sbp | systolic blood pressure | continuous | {76, 215} | (118.21,16.08) | |
| HE_dbp | diastolic blood pressure | continuous | {34, 124} | (74.97, 10.09) | |
| HE_glu | fasting blood glucose | continuous | {35, 356} | (100.61, 22.97) | |
| HE_PLS | pulse rate for 15 s | continuous | {15, 29} | (17.80, 2.26) | |
| BP1 | perceived stress | nominal | {1, 4} | (3.03, 1.24) | |
| BO1 | self-awareness of body shape | nominal | {1, 5} | (3.36, 1.09) | |
| HE_BMI | body mass index | continuos | {13.50, 50.29} | (23.64, 3.78) |
| Variable Names | Training Data Set | Test Data Set | ||
|---|---|---|---|---|
| Mean, SD | 1st qu., 3rd qu. | Mean, SD | 1st qu., 3rd qu. | |
| chd_risk | no (3099), yes (1220) | no (1281), yes (570) | ||
| sex | male (1899), female (2420) | male (823), female (1028) | ||
| age | (47.23, 19.47) | (33, 63) | (47.57, 19.42) | (33, 63) |
| HE_sbp | (118.1,16.03) | (106, 127) | (118.4,16.20) | (106, 128) |
| HE_dbp | (74.96, 10.10) | (69, 81) | (75, 10.07) | (69, 82) |
| HE_glu | (100.4, 22.45) | (89, 103) | (101.1, 24.13) | (90, 104) |
| HE_PLS | (17.79, 2.24) | (16, 19) | (17.82, 2.29) | (16, 19) |
| BP1 | (3.04, 1.26) | (2, 3) | (3.02, 1.18) | (2, 3) |
| BO1 | (3.37, 1.11) | (3, 4) | (3.35, 1.04) | (3, 4) |
| HE_BMI | (23.62, 3.78) | (21.07, 25.79) | (23.69, 3.76) | (21.04, 25.86) |
| Methods | Accuracy | Recall | Precision | F1 Score |
|---|---|---|---|---|
| logistic regression | 82.55 | 85.59 | 89.93 | 87.70 |
| artificial neural network | 82.60 | 89.77 | 85.76 | 87.72 |
| support vector machine | 83.04 | 91.96 | 84.81 | 88.24 |
| Kernel Functions | C | Gamma | Accuracy | AUC |
|---|---|---|---|---|
| Linear | 1 | 82.55 | 0.781 | |
| Polynomial | 1 | 0.111 | 80.93 | 0.727 |
| RBF | 1 | 0.111 | 83.04 | 0.775 |
| Sigmoid | 1 | 0.111 | 76.12 | 0.708 |
| Kernel Functions | C | Gamma | Accuracy | AUC |
|---|---|---|---|---|
| Linear | 1 | 82.55 | 0.781 | |
| Polynomial | 100 | 0.1 | 81.96 | 0.761 |
| RBF | 10 | 0.01 | 83.20 | 0.778 |
| Sigmoid | 1 | 0.01 | 82.66 | 0.777 |
| Male Features | Importance | Female Features | Importance |
|---|---|---|---|
| Age | 0.8522 | Age | 0.8774 |
| HE_glu | 0.7336 | HE_sbp | 0.7897 |
| HE_sbp | 0.6648 | HE_glu | 0.7441 |
| HE_BMI | 0.6054 | HE_BMI | 0.6689 |
| BO1 | 0.5495 | HE_dbp | 0.5801 |
| BP1 | 0.5308 | BO1 | 0.5368 |
| HE_PLS | 0.5218 | BP1 | 0.5229 |
| HE_dbp | 0.5008 | HE_PLS | 0.5143 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, M.-J. Building a Cardiovascular Disease Prediction Model for Smartwatch Users Using Machine Learning: Based on the Korea National Health and Nutrition Examination Survey. Biosensors 2021, 11, 228. https://0-doi-org.brum.beds.ac.uk/10.3390/bios11070228
Kim M-J. Building a Cardiovascular Disease Prediction Model for Smartwatch Users Using Machine Learning: Based on the Korea National Health and Nutrition Examination Survey. Biosensors. 2021; 11(7):228. https://0-doi-org.brum.beds.ac.uk/10.3390/bios11070228
Chicago/Turabian StyleKim, Min-Jeong. 2021. "Building a Cardiovascular Disease Prediction Model for Smartwatch Users Using Machine Learning: Based on the Korea National Health and Nutrition Examination Survey" Biosensors 11, no. 7: 228. https://0-doi-org.brum.beds.ac.uk/10.3390/bios11070228