Computer code has permeated almost every aspect of society, yet only recently have psychology researchers investigated how programmers perceive and reuse code [
1]. The advent of open-source software (OSS) for use in larger architectures has shortened the required completion time of software products. With multiple options available for code that functions similarly, developers can choose which OSS to download, test, and implement. The decision to download and use the code is analogous to relying on the code, as the user makes themselves—and their system—vulnerable when downloading the code with the expectation the code will satisfy their requirements [
2]. The
willingness (or intention) to download and use the code is analogous to trust in the code [
2]. Understanding the antecedents to trust in code would benefit developers who write code as well as those who seek out code to use in their own projects. Although prior research has examined the factors that influence the decision to use OSS in the computer science literature [
3,
4], none have approached this topic from a human factors perspective or tested these factors using an experimental design. The current study sought to remedy this gap in the research.
1.1. Trust and OSS Interactions
Trust is the positive expectation of making oneself vulnerable to a referent [
5]. Although trust is typically referenced within human–human interactions, trust also plays an important role in how people perceive non-human referents. For example, Lee and See [
6] expanded the trust literature to automation contexts—that is, human trust toward automation. They mapped Mayer and colleagues’ [
5] ability, benevolence, and integrity perceptions of human trustworthiness to performance, purpose, and process perceptions of automation trustworthiness, respectively (see [
6], p. 59). Similarly, Oleson and colleagues [
7] have explicated the factors that influence when a person trusts a robot. Lastly, Alarcon and colleagues [
1,
2] have investigated how programmers trust code [
1,
2], linking the factors of performance, transparency, and reputation to Mayer and colleagues’ [
5] ability, benevolence and integrity factors in human–human trust, respectively [
2]. These factors are antecedents to a willingness to be vulnerable to the consequences of utilizing computer code. Across the aforementioned literature, trust is related to reliance behaviors, both for human–human [
2] and human–automation interactions [
8,
9].
The widespread use of code and the need for code in a safe and timely manner has led to an increase in code reuse. Code reuse is defined as “the use of existing software or software knowledge to construct new software” [
10] (p. 529). The decision to reuse code presents some advantages but also potential risks [
2]. The reused code may contain errors or malicious code, which can hinder the new architecture [
1,
2]. Prior research has examined the relationship between OSS properties and reuse behaviors. Li and colleagues [
3] identified a lack of guaranteed, long-term technical support as a major concern associated with OSS software. Most OSS technical support is run on a volunteer basis; without a formal contract (i.e., with a vendor), it may be hard to guarantee support. Despite these difficulties, many programmers reuse OSS in their architectures, which indicates reliance on OSS [
2,
6]. Furthermore, Weber and colleagues [
4] used data mining and machine-learning techniques to ascertain and predict factors associated with popular or unpopular projects. Three key features were identified. First, popular projects were found to have larger README files. Second, popular projects used the Python WITH statement more frequently, which was designed specifically to be read easily. Finally, projects with high popularity were found to have Travis CI, a service used to test software projects, configured much more frequently than projects with low popularity.
Computer science and psychological researchers have recently examined how developers perceive and trust code. For example, in the field of computer science, Hasselbring and Reussner [
11] examined the main features associated with software trustworthiness. In this context, the researchers operationalized trust as the risk of making software available for use. The results showed that the risk of software deployment decreased through the improvement of the certification of trustworthiness. In psychology, a cognitive task analysis (CTA) found that three key factors—reputation, transparency, and performance—affect perceptions of code trustworthiness and developers’ decisions to reuse code written by another programmer [
2]. Reputation represents information cues about the source of the code such as the number of reviews, the origin (e.g., website, colleagues), or the number of users. Transparency represents the understanding of the code upon examination. Lastly, performance represents the ability of the code to meet context-specific needs. Additionally, researchers have adapted a model from the persuasion literature to explain how trustworthiness perceptions influence programmers’ interactions with computer code [
12].
1.2. Heuristic-Systematic Processing Model of Trust in Code
The heuristic-systematic processing model (HSM) of persuasion is a dual-process model that posits people are efficiency-driven and use two methods for analyzing information: heuristic and systematic processing [
13]. Heuristic processing involves the use of mental shortcuts (e.g., relying on norms and biases) to reach a decision [
13], whereas systematic processing is an effortful, deep analysis of stimuli [
14]. Heuristic processing is often faster than systematic processing but may be less accurate [
13]. In reality, cognitive processing is almost certainly not discretized into two independent systems, but nomenclature facilitates ease of communication as to how people may process information with different amounts of effort [
15]. Based on the HSM, people have a threshold that indicates the extent to which systematic processing is necessary (i.e., the sufficiency principle). If that particular threshold is unmet, people will default to the less-effortful heuristic approach. Prior research has supported the use of the HSM when investigating the effects of reputation and transparency on code trustworthiness perceptions and willingness to reuse (or trust) code [
12,
16]. For the current paper, however, we consider only reputation and performance characteristics.
Reputation is portrayed as meta-information about the source of computer code, as described in the section above. Reputation characteristics have influenced code perceptions in previous research [
17,
18,
19]. Sim and colleagues [
19], for example, found that social cues (e.g., reputation characteristics) had a greater influence on internet code reuse than the technical properties of the code did. Alarcon and colleagues [
16,
20,
21] have found that programmers dedicate more time to examining code developed from a reputable source. In accordance with the HSM, participants appeared to allot systematic processing to the code once it was established that the code was from a reputable source and also assessed the code more accurately (e.g., ensured all code in the study compiled and was functional). In the present study, it was hypothesized that reputation characteristics displayed in an online repository would be related to trustworthiness perceptions in a similar manner.
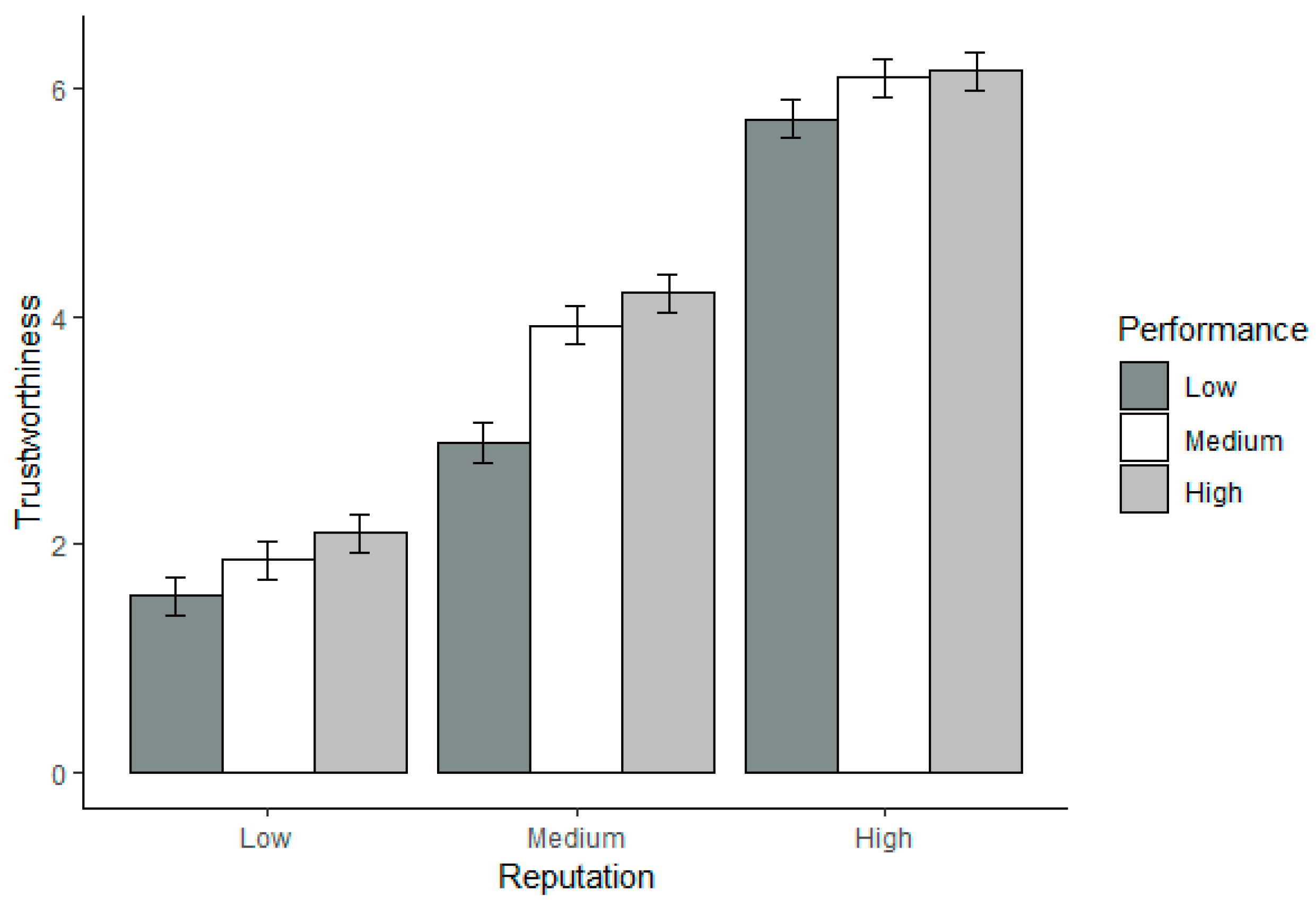
Hypothesis 1a. Code reputation is positively related to time spent on code.
Hypothesis 1b. Code reputation is positively related to code interactions.
Hypothesis 1c. Code reputation is positively related to trustworthiness perceptions.
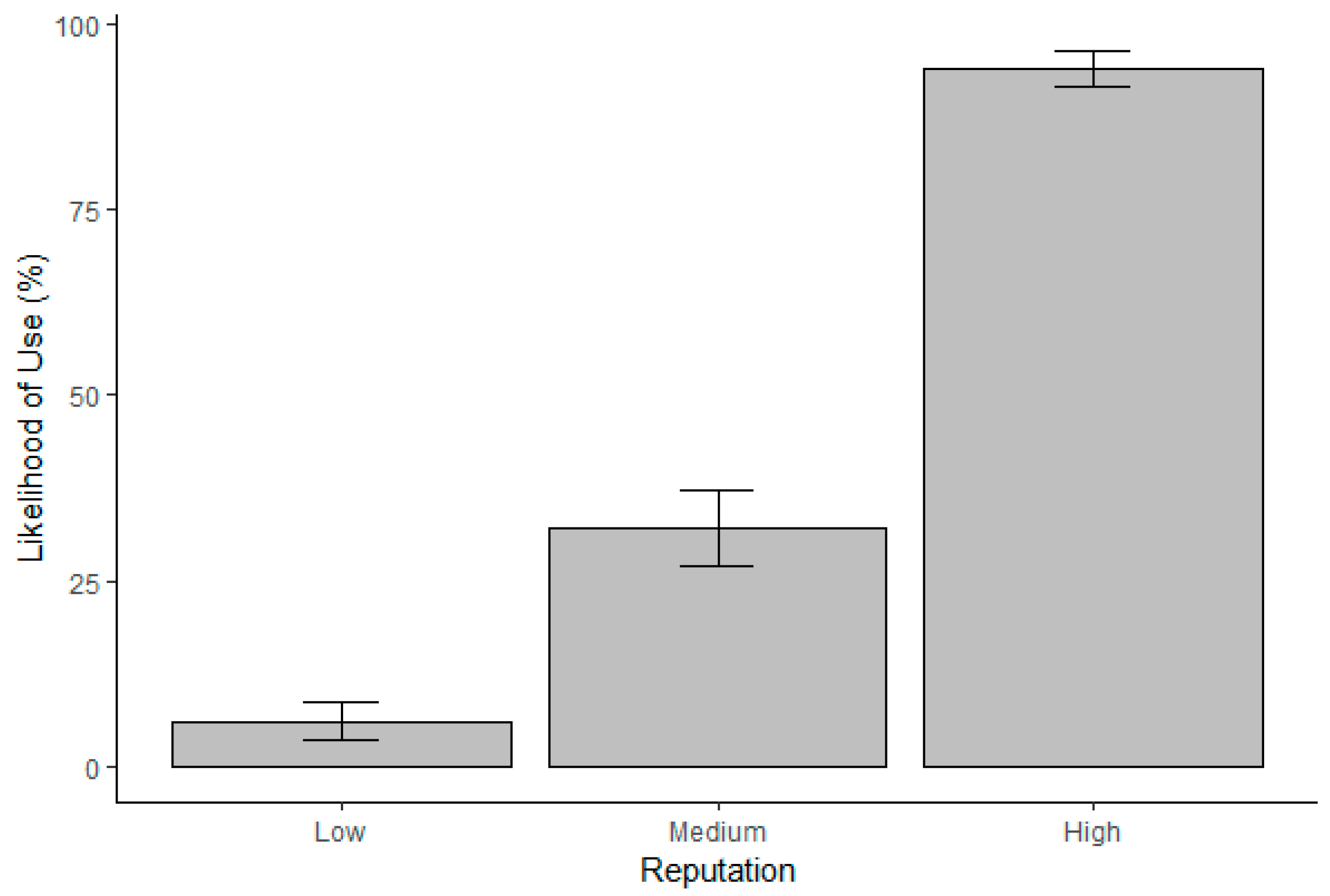
Hypothesis 1d. Code reputation is positively related to participant’s willingness to reuse code (i.e., trust).
Performance is described as the overall ability of code to complete a context-dependent task. Performance has been linked to key aspects of trust in other scenarios, such as robotics [
7] and automation [
6]. Related to computer science, Lingzi and Zhi [
22] found that performing audits on code led to increased user confidence and code usage, both of which are associated with trust. Stated simply, auditing code provides important performance-relevant information about the code [
10], while also revealing security vulnerabilities and inefficiencies in code execution. The increased transparency of the underlying processes in the code from the audit led to an increase in trustworthiness perceptions. Similarly, the most important qualities found when selecting OSS to use were compliance with user requirements, extensibility, and ease of updates [
17], all of which are possible metrics of performance. Code that meets the appropriate standards for performance will engage the use of heuristics, leading to less mental processing of the code. In contrast, code that is lower in performance will necessitate a deeper dive, ascertaining more information about the code before making a judgement (in other words, users become engaged in more systematic processing). In the present study, it was hypothesized that performance characteristics displayed in an online repository would be related to trustworthiness perceptions.
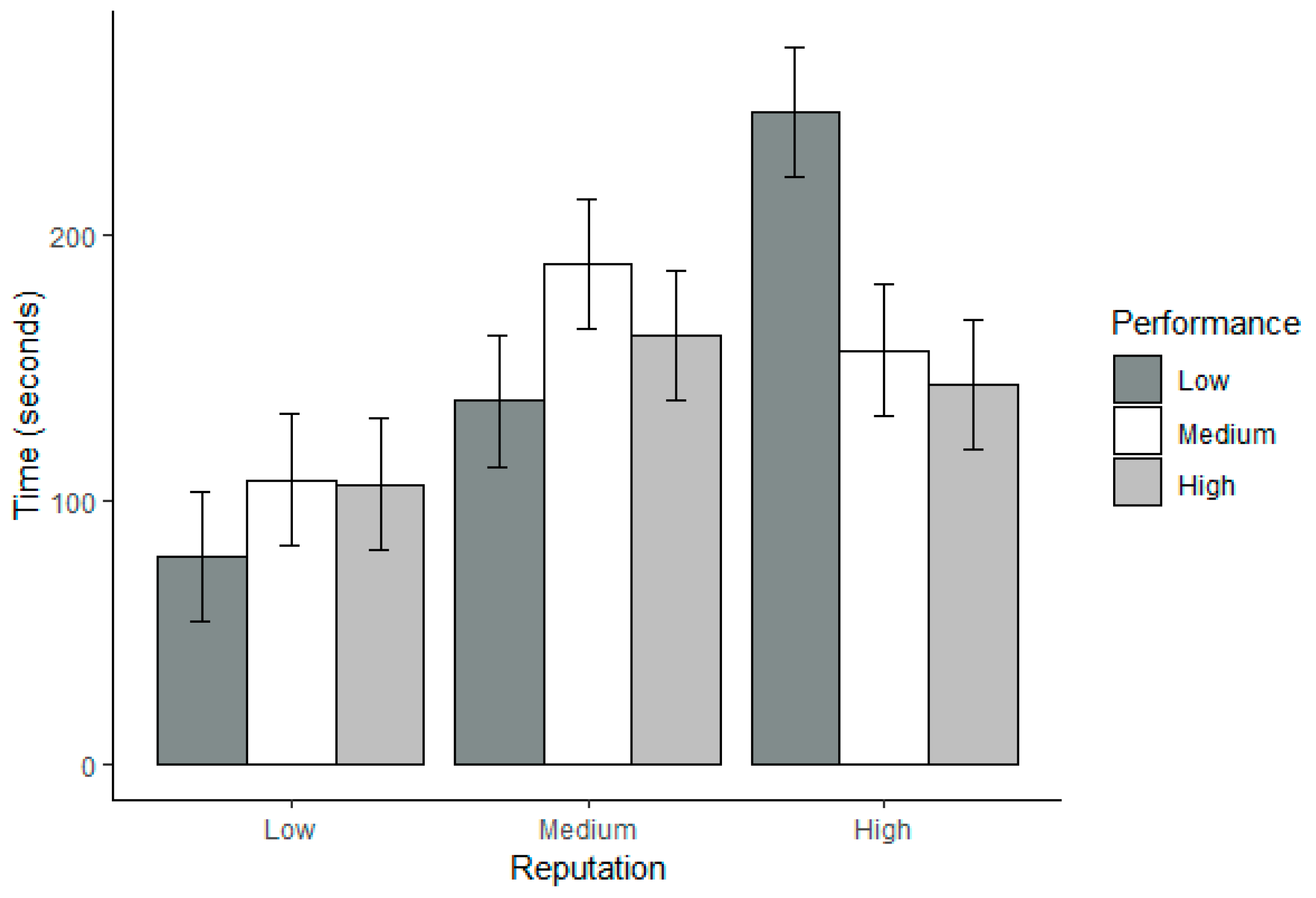
Hypothesis 2a. Code performance is negatively related to time spent on code.
Hypothesis 2b. Code performance is positively related to code interactions.
Hypothesis 2c. Code performance is positively related to trustworthiness perceptions.
Hypothesis 2d. Code performance is positively related to participants’ willingness to reuse code (i.e., trust).
Prior research, however, has shown that trust perceptions of code sometimes interact unpredictably. Interestingly, Alarcon and colleagues [
1] found that when code was organized poorly but was highly readable and reputable, programmers spent more time on and were more trusting of the code. According to the HSM, the high reputation and readability of the code may have prompted the user to perform systematic processing over code snippets that are functional and compile [
2,
12], even though the code was poorly organized. Similarly, Alarcon and colleagues [
16] investigated the effects of comments—defined as documentation that has no effect on code functionality—on trust perceptions of code. Trust assessments were found to not be solely based on the code itself but can be influenced by informational cues ascertained from outside sources, such as commenting or perhaps the repository website from which the code was obtained.
These studies indicated that the relationship between the factors found in Alarcon and colleagues’ [
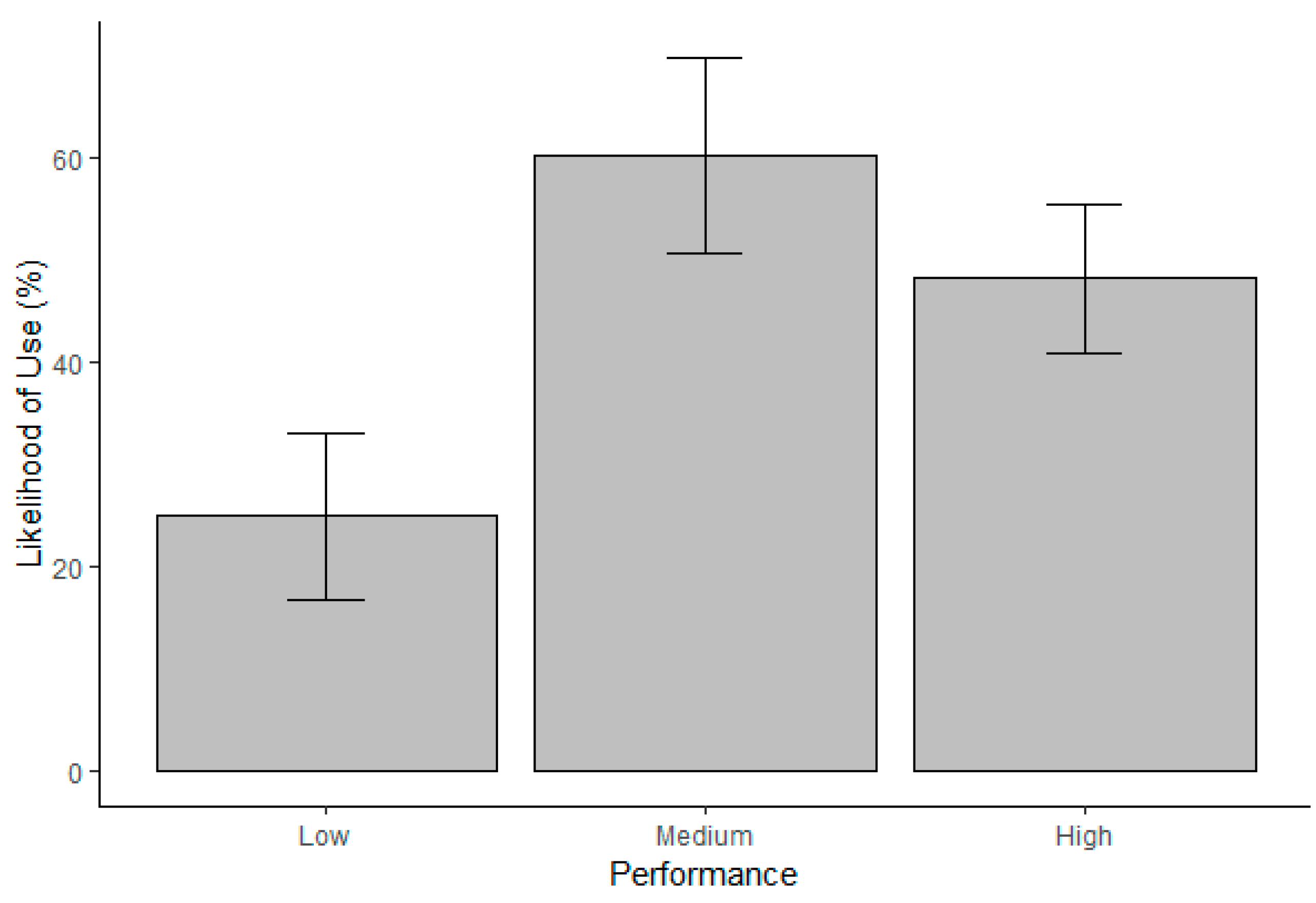
2] CTA and trustworthiness perceptions is not straightforward. Thus, we used exploratory techniques when interpreting the extent to which the reputation of the code source and perceived code performance interact to influence trustworthiness perceptions and willingness to reuse (i.e., trust) the OSS code. Specifically, in cases where we found a significant two-way interaction, we examined the bar charts and highlighted the general trends without reporting inferential statistics.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}