
Minimization of the Line Resistance Impact on Memdiode-Based Simulations of Multilayer Perceptron Arrays Applied to Pattern Recognition

 ,
, 
Abstract
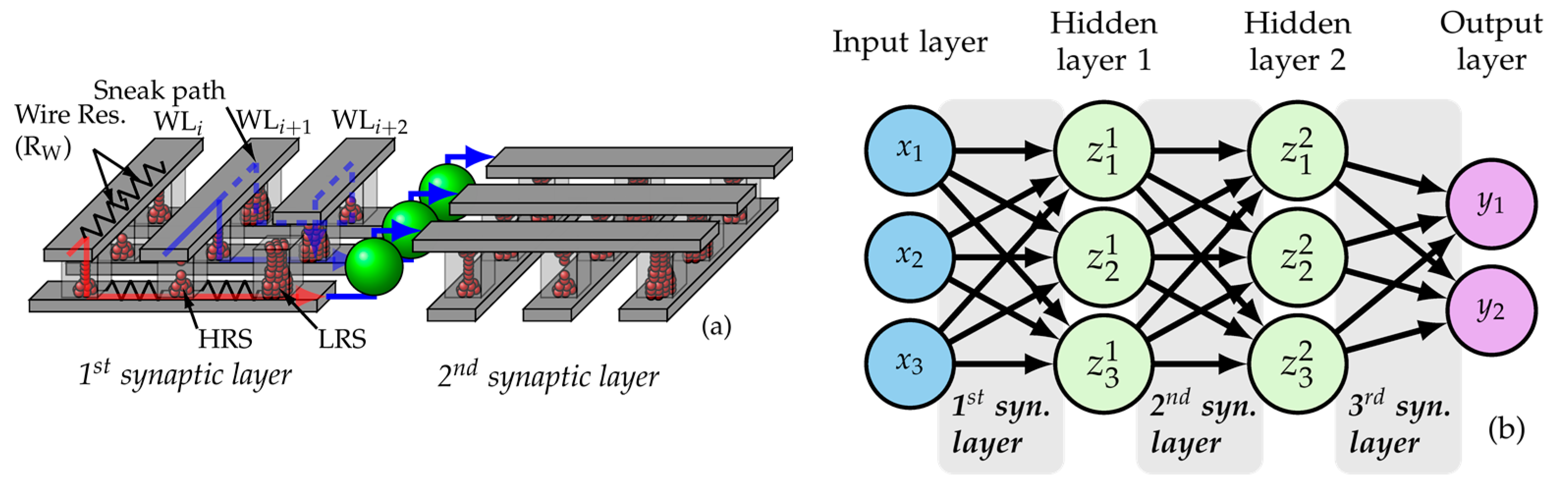
:1. Introduction
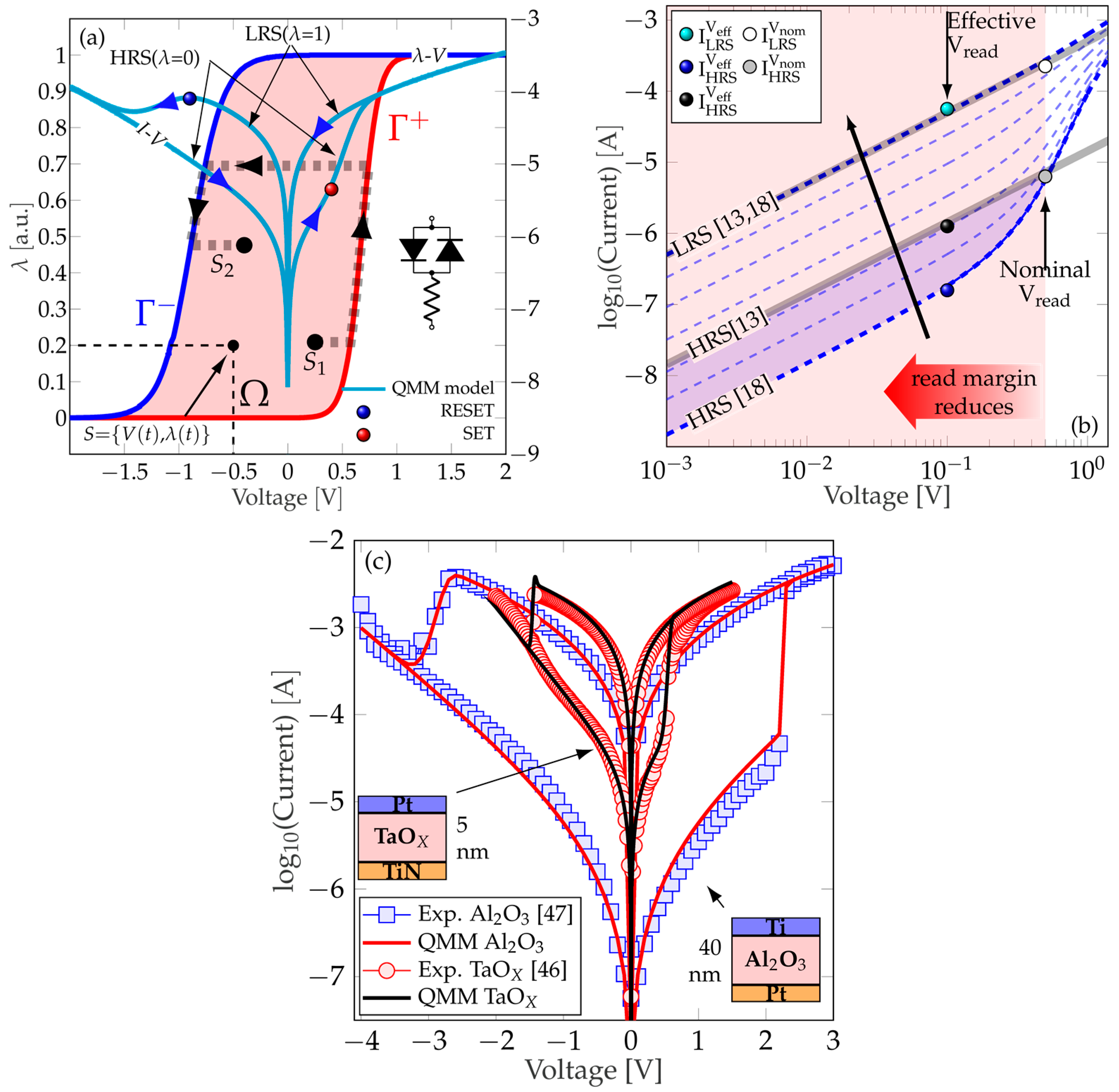
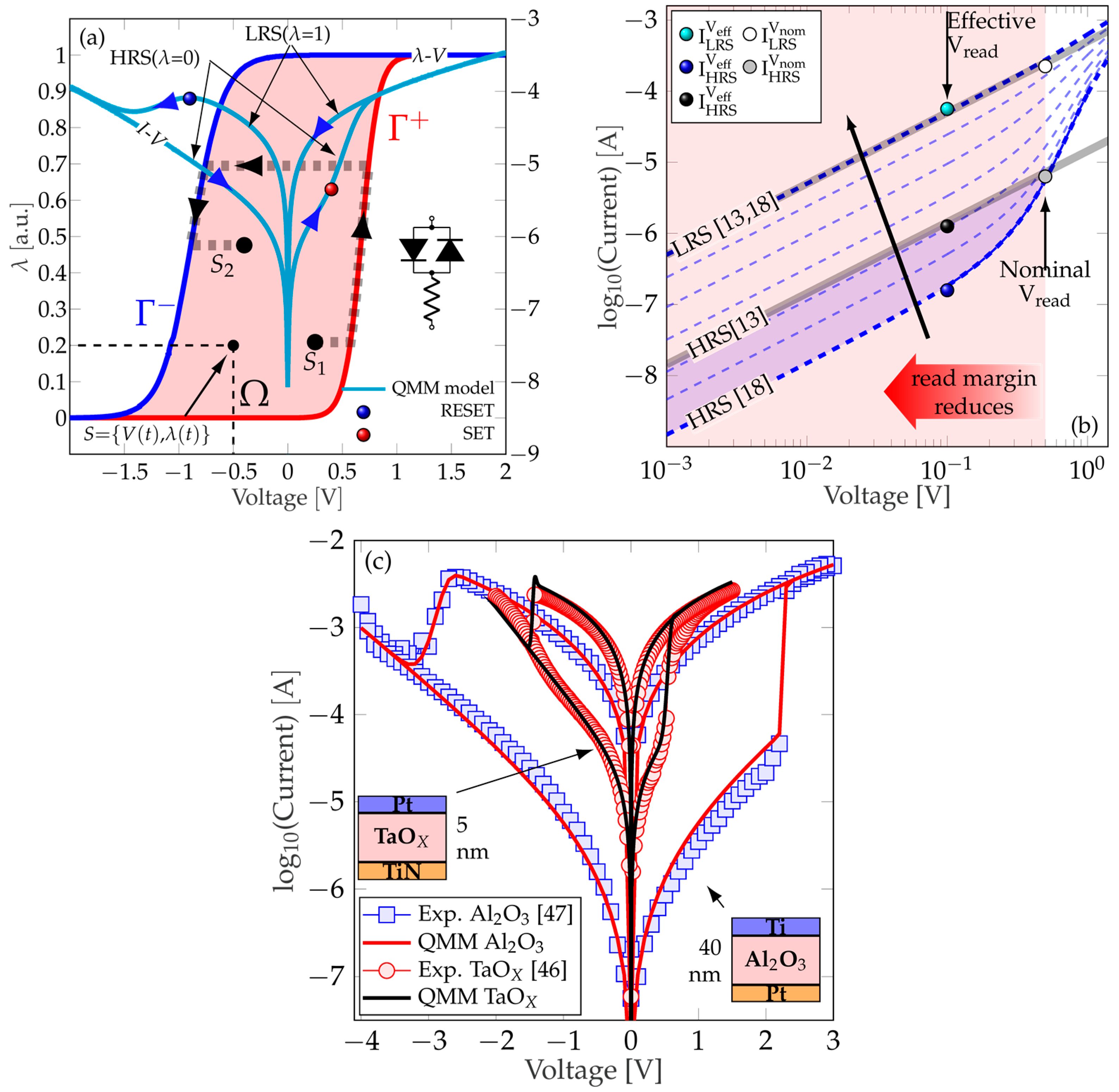
2. Quasi-Static Memdiode Model
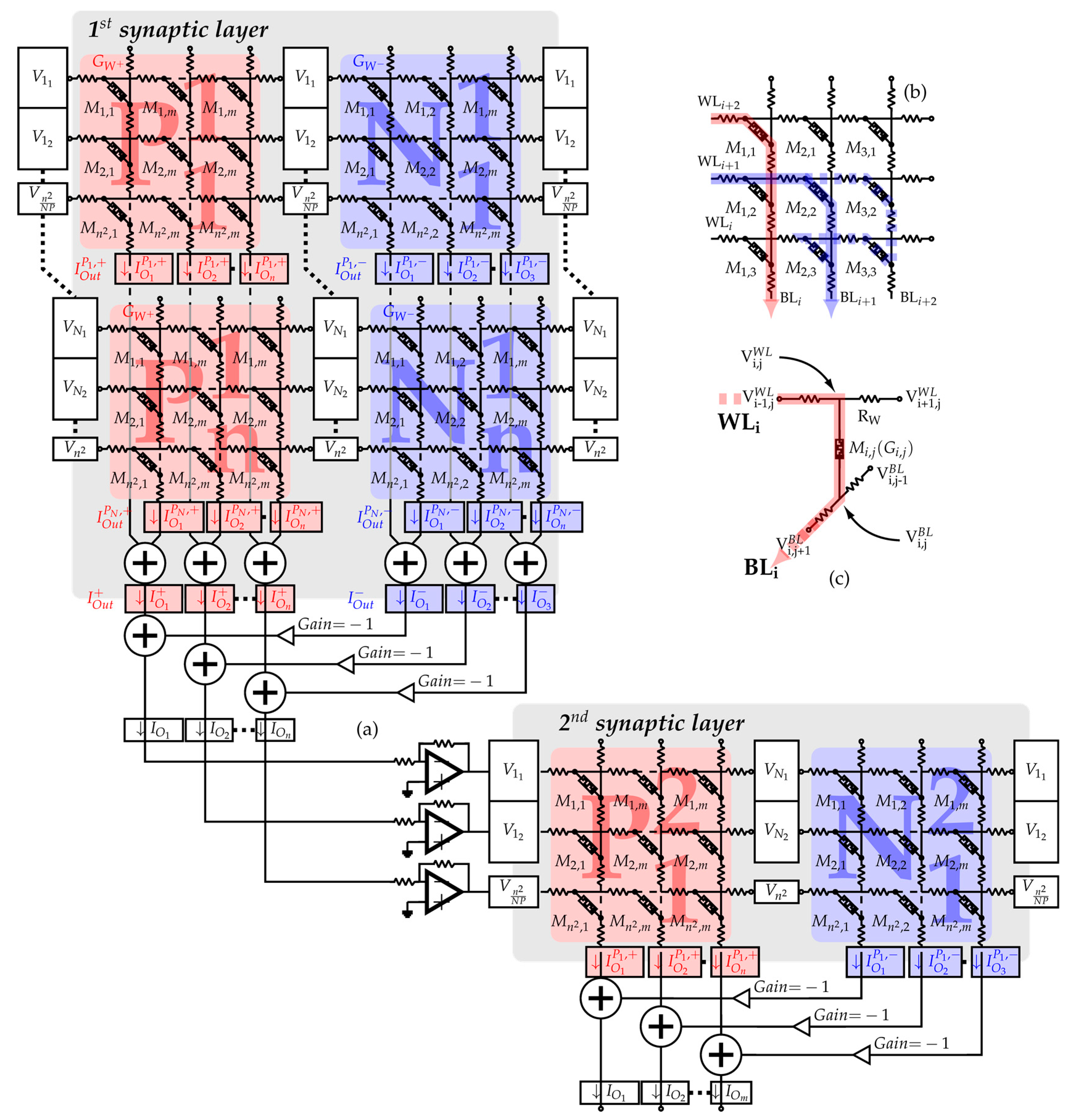
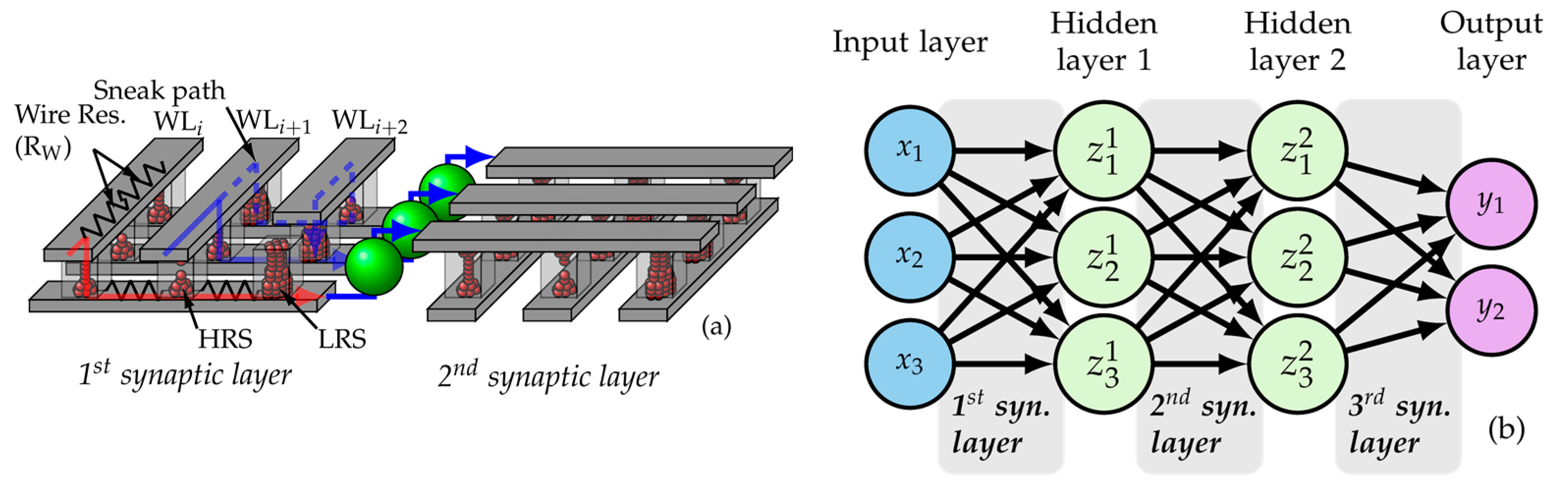
3. MCA-Based MLP Modeling and RL Calibration
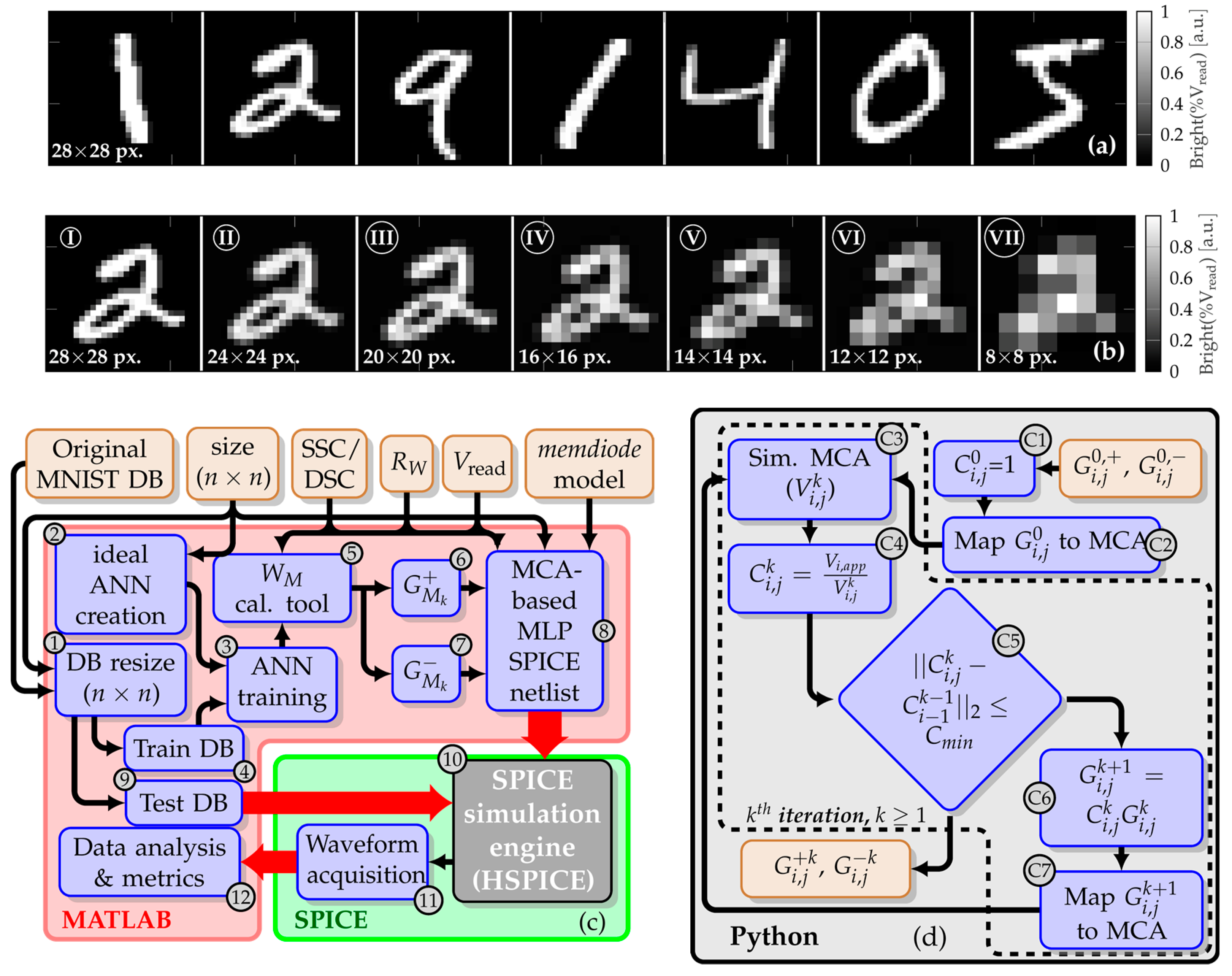
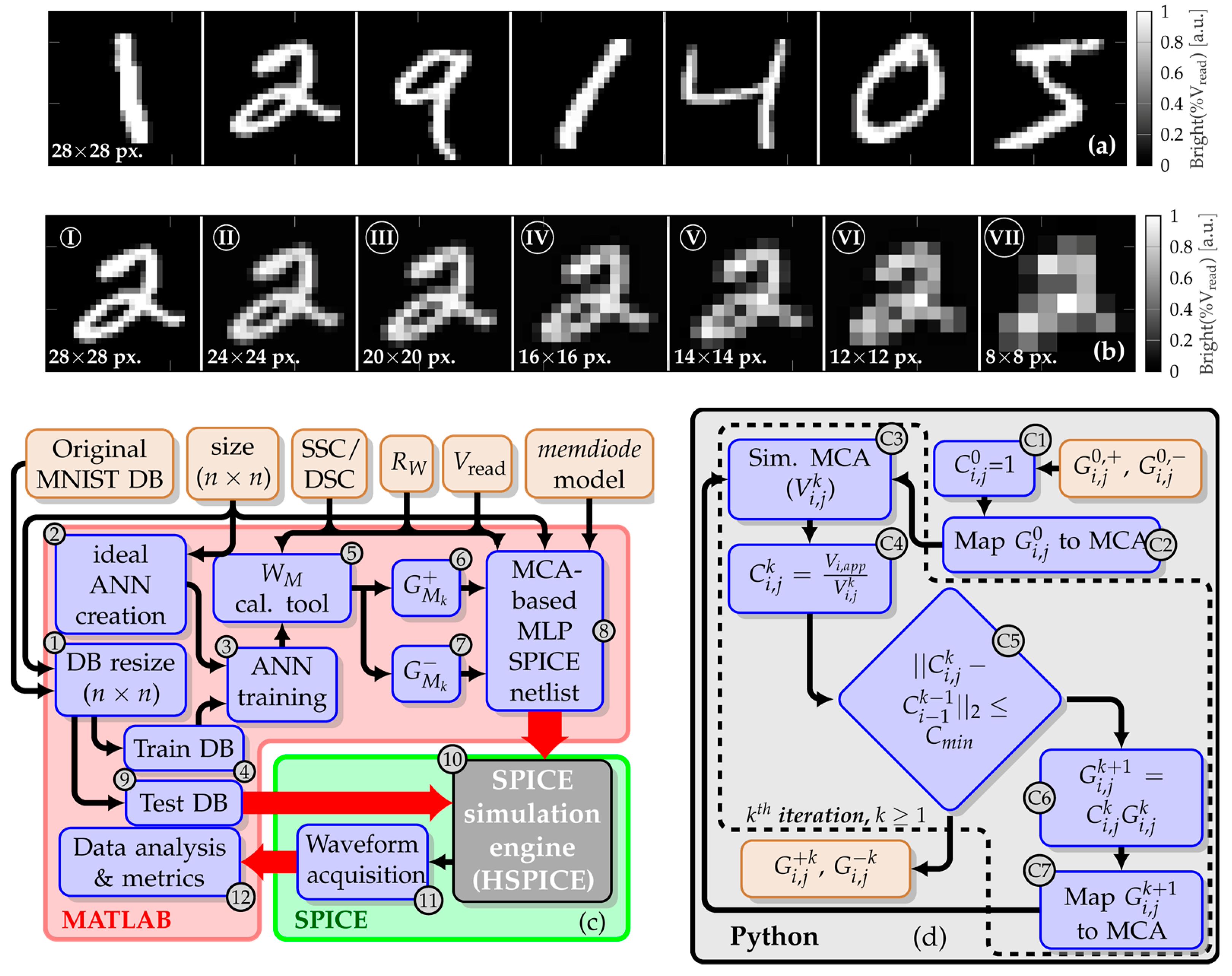
3.1. Simulation Flow
3.2. Calibration Tool Workflow
| Algorithm 1: Iterative calibration algorithm |
 |
4. Simulation Results and Discussion
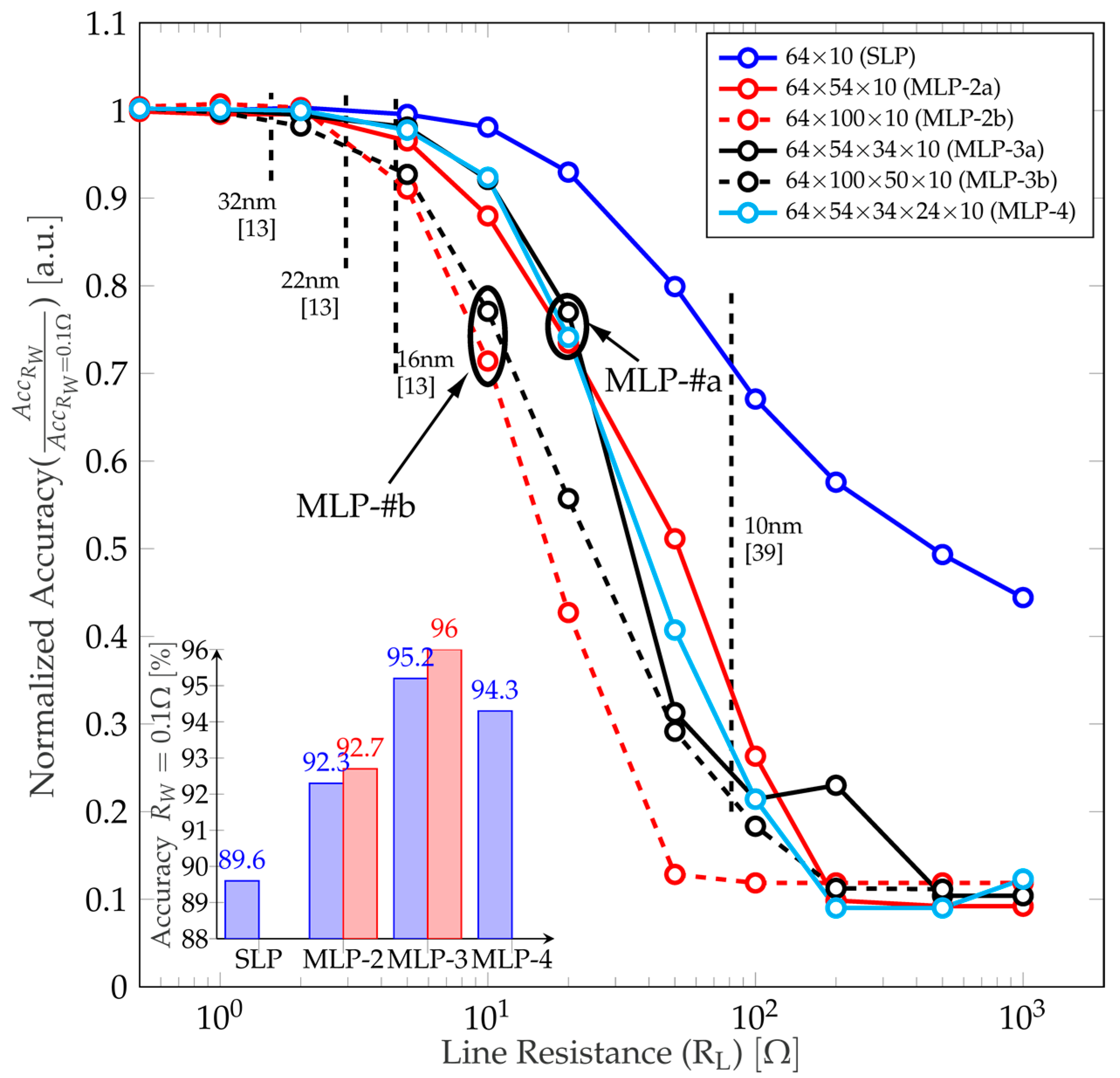
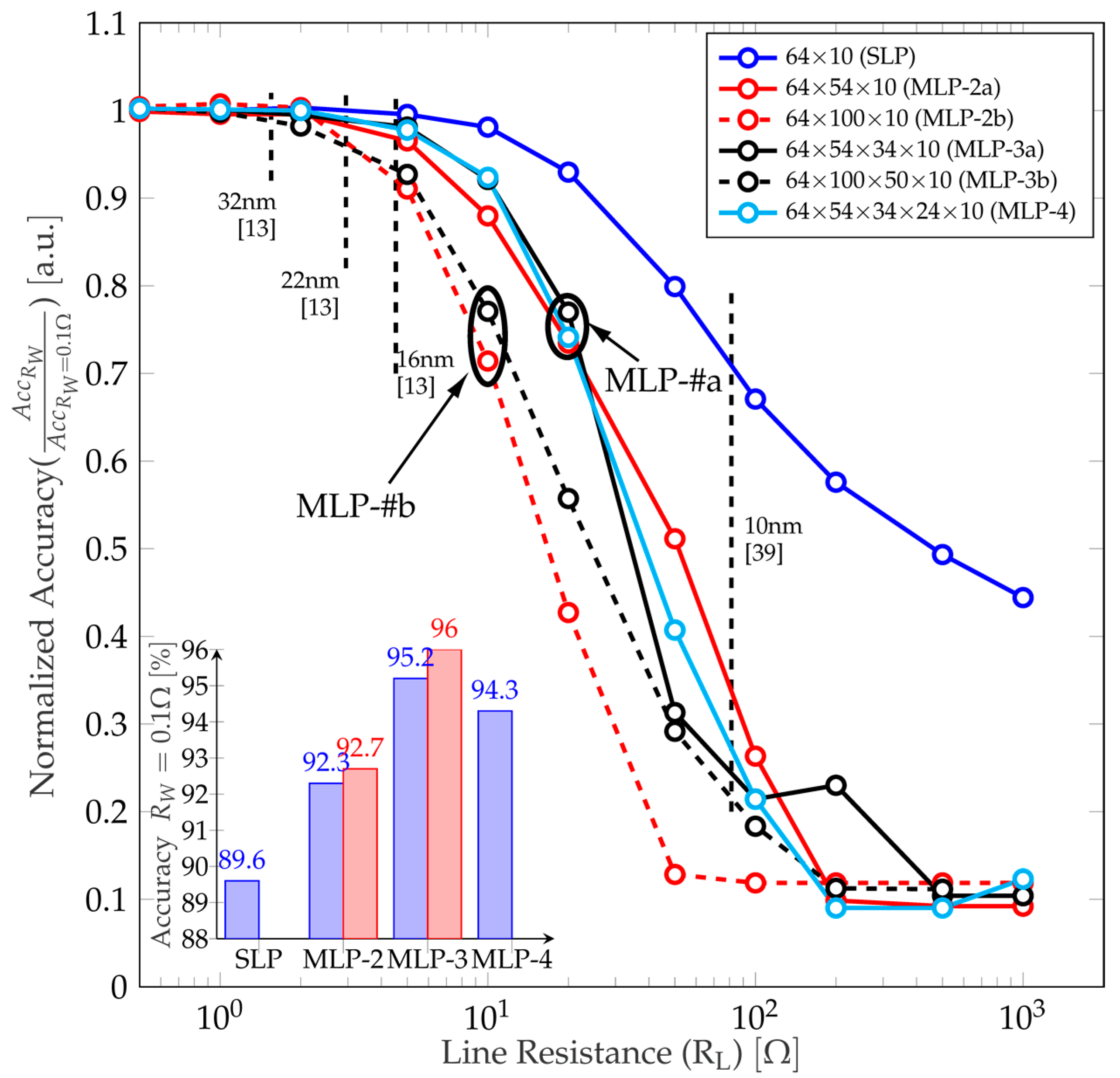
4.1. Influence of the Number of Hidden Layers
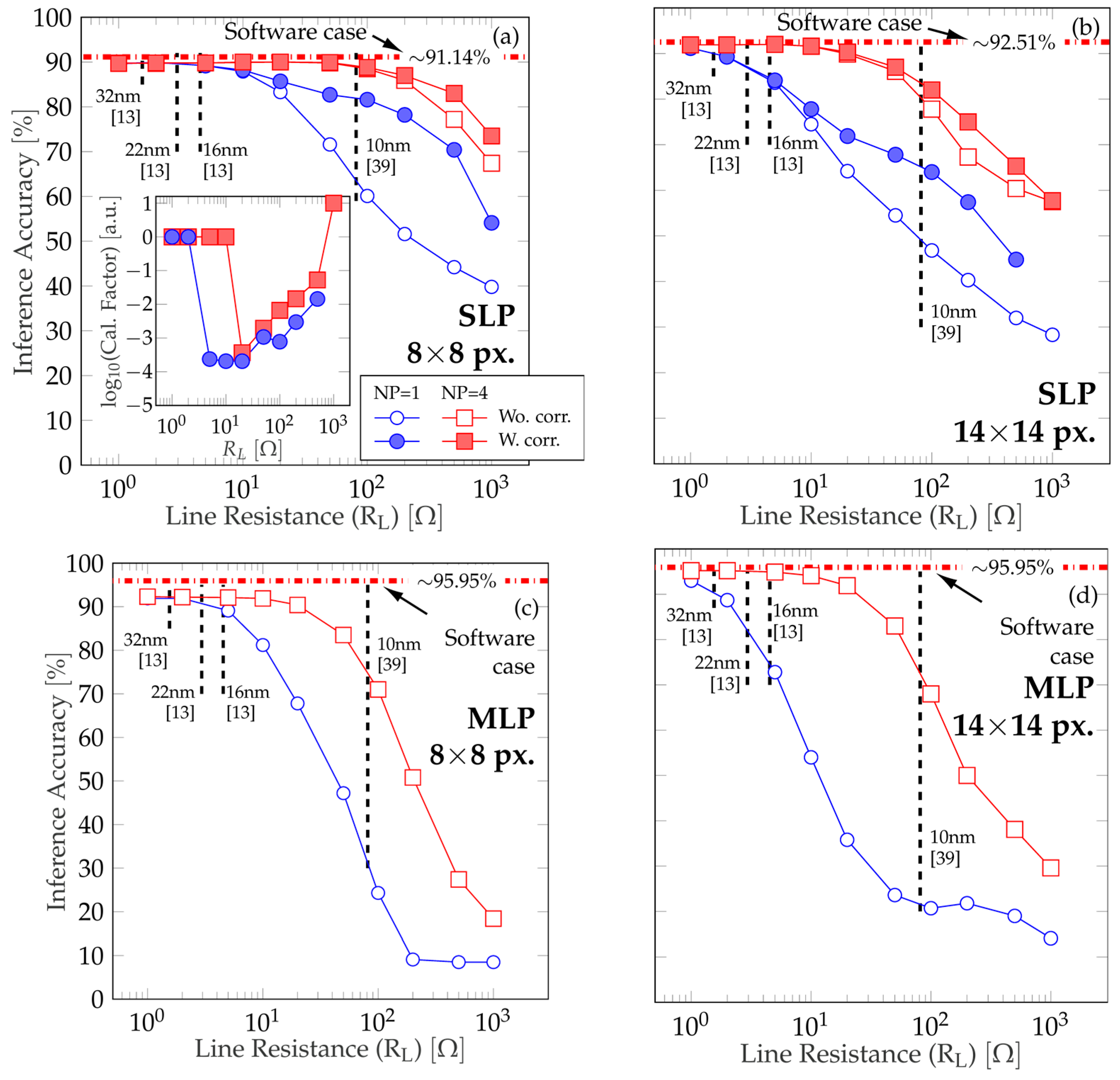
4.2. Techniques to Minimize the Impact of the Line Resistance (RL)
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
Appendix A
References
- Li, C.; Belkin, D.; Li, Y.; Yan, P.; Hu, M.; Ge, N.; Jiang, H.; Montgomery, E.; Lin, P.; Wang, Z.; et al. In-Memory Computing with Memristor Arrays. In Proceedings of the 2018 IEEE International Memory Workshop (IMW), Kyoto, Japan, 13–16 May 2018; pp. 1–4. [Google Scholar]
- Upadhyay, N.K.; Joshi, S.; Yang, J.J. Synaptic electronics and neuromorphic computing. Sci. China Inf. Sci. 2016, 59, 1–26. [Google Scholar] [CrossRef] [Green Version]
- Sasago, Y.; Kinoshita, M.; Morikawa, T.; Kurotsuchi, K.; Hanzawa, S.; Mine, T.; Shima, A.; Fujisaki, Y.; Kume, H.; Moriya, H.; et al. Cross-Point Phase Change Memory with 4F2 Cell Size Driven by Low-Contact-Resistivity Poly-Si Diode. In Proceedings of the Digest of Technical Papers-Symposium on VLSI Technology, Kyoto, Japan, 16–18 June 2009; pp. 24–25. [Google Scholar]
- Truong, S.N.; Ham, S.-J.; Min, K.-S. Neuromorphic crossbar circuit with nanoscale filamentary-switching binary memristors for speech recognition. Nanoscale Res. Lett. 2014, 9, 629. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Truong, S.N.; Min, K.-S. New Memristor-Based Crossbar Array Architecture with 50-% Area Reduction and 48-% Power Saving for Matrix-Vector Multiplication of Analog Neuromorphic Computing. J. Semicond. Technol. Sci. 2014, 14, 356–363. [Google Scholar] [CrossRef]
- Truong, S.N.; Shin, S.; Byeon, S.-D.; Song, J.; Min, K.-S. New Twin Crossbar Architecture of Binary Memristors for Low-Power Image Recognition with Discrete Cosine Transform. IEEE Trans. Nanotechnol. 2015, 14, 1104–1111. [Google Scholar] [CrossRef]
- Hu, M.; Li, H.; Chen, Y.; Wu, Q.; Rose, G.S.; Linderman, R.W. Memristor Crossbar-Based Neuromorphic Computing System: A Case Study. IEEE Trans. Neural Netw. Learn. Syst. 2014, 25, 1864–1878. [Google Scholar] [CrossRef]
- Liu, B.; Li, H.; Chen, Y.; Li, X.; Huang, T.; Wu, Q.; Barnell, M. Reduction and IR-drop compensations techniques for reliable neuromorphic computing systems. In Proceedings of the 2014 IEEE/ACM International Conference on Computer-Aided Design (ICCAD), San Jose, CA, USA, 2–6 November 2014; pp. 63–70. [Google Scholar] [CrossRef]
- Li, C.; Belkin, D.; Li, Y.; Yan, P.; Hu, M.; Ge, N.; Jiang, H.; Montgomery, E.; Lin, P.; Wang, Z.; et al. Efficient and self-adaptive in-situ learning in multilayer memristor neural networks. Nat. Commun. 2018, 9, 1–8. [Google Scholar] [CrossRef] [Green Version]
- Chen, A. A Comprehensive Crossbar Array Model with Solutions for Line Resistance and Nonlinear Device Characteristics. IEEE Trans. Electron Devices 2013, 60, 1318–1326. [Google Scholar] [CrossRef]
- Park, S.; Kim, H.; Choo, M.; Noh, J.; Sheri, A.; Jung, S.; Seo, K.; Park, J.; Kim, S.; Lee, W.; et al. RRAM-based synapse for neuromorphic system with pattern recognition function. In Proceedings of the 2012 International Electron Devices Meeting, San Francisco, CL, USA, 10–13 December 2012; Institute of Electrical and Electronics Engineers (IEEE): New York, NY, USA, 2012; pp. 10.2.1–10.2.4. [Google Scholar]
- Ham, S.-J.; Mo, H.-S.; Min, K.-S. Low-Power VDD/3 Write Scheme with Inversion Coding Circuit for Complementary Memristor Array. IEEE Trans. Nanotechnol. 2013, 12, 851–857. [Google Scholar] [CrossRef]
- Lee, Y.K.; Jeon, J.W.; Park, E.-S.; Yoo, C.; Kim, W.; Ha, M.; Hwang, C.S. Matrix Mapping on Crossbar Memory Arrays with Resistive Interconnects and Its Use in In-Memory Compression of Biosignals. Micromachines 2019, 10, 306. [Google Scholar] [CrossRef] [Green Version]
- Han, R.; Huang, P.; Zhao, Y.; Cui, X.; Liu, X.; Jin-Feng, K. Efficient evaluation model including interconnect resistance effect for large scale RRAM crossbar array matrix computing. Sci. China Inf. Sci. 2018, 62, 22401. [Google Scholar] [CrossRef] [Green Version]
- Yakopcic, C.; Taha, T.M.; Subramanyam, G.; Pino, R.E. Memristor SPICE Modeling. In Advances in Neuromorphic Memristor Science and Applications; Springer Nature: London, UK, 2012; pp. 211–244. [Google Scholar]
- Yakopcic, C.; Hasan, R.; Taha, T.; McLean, M.; Palmer, D. Memristor-based neuron circuit and method for applying learning algorithm in SPICE. Electron. Lett. 2014, 50, 492–494. [Google Scholar] [CrossRef] [Green Version]
- Aguirre, F.L.; Pazos, S.M.; Palumbo, F.; Sune, J.; Miranda, E. Application of the Quasi-Static Memdiode Model in Cross-Point Arrays for Large Dataset Pattern Recognition. IEEE Access 2020, 8, 202174–202193. [Google Scholar] [CrossRef]
- Miranda, E. Compact Model for the Major and Minor Hysteretic I–V Loops in Nonlinear Memristive Devices. IEEE Trans. Nanotechnol. 2015, 14, 787–789. [Google Scholar] [CrossRef]
- Patterson, G.; Sune, J.; Miranda, E. Voltage-Driven Hysteresis Model for Resistive Switching: SPICE Modeling and Circuit Applications. IEEE Trans. Comput. Des. Integr. Circuits Syst. 2017, 36, 2044–2051. [Google Scholar] [CrossRef] [Green Version]
- Yakopcic, C.; Taha, T.M.; Subramanyam, G.; Pino, R.E. Generalized Memristive Device SPICE Model and its Application in Circuit Design. IEEE Trans. Comput. Des. Integr. Circuits Syst. 2013, 32, 1201–1214. [Google Scholar] [CrossRef]
- Kvatinsky, S.; Friedman, E.G.; Kolodny, A.; Weiser, U.C. TEAM: ThrEshold Adaptive Memristor Model. IEEE Trans. Circuits Syst. I Regul. Pap. 2013, 60, 211–221. [Google Scholar] [CrossRef]
- Kvatinsky, S.; Ramadan, M.; Friedman, E.G.; Kolodny, A. VTEAM: A General Model for Voltage-Controlled Memristors. IEEE Trans. Circuits Syst. II Express Briefs 2015, 62, 786–790. [Google Scholar] [CrossRef]
- Eshraghian, K.; Kavehei, O.; Cho, K.R.; Chappell, J.M.; Iqbal, A.; Al-Sarawi, S.F.; Abbott, D. Memristive device fundamentals and modeling: Applications to circuits and systems simulation. Proc. IEEE 2012, 100, 1991–2007. [Google Scholar] [CrossRef] [Green Version]
- Biolek, D.; Biolek, Z.; Biolková, V.; Kolka, Z. Modeling of TiO2 memristor: From analytic to numerical analyses. Semicond. Sci. Technol. 2014, 29, 125008. [Google Scholar] [CrossRef]
- Biolek, Z.; Biolek, D.; Biolkova, V.; Kolka, Z. Reliable Modeling of Ideal Generic Memristors via State-Space Transformation. Radioengineering 2015, 24, 393–407. [Google Scholar] [CrossRef]
- Kim, T.; Kim, H.; Kim, J.; Kim, J.-J. Input Voltage Mapping Optimized for Resistive Memory-Based Deep Neural Network Hardware. IEEE Electron Device Lett. 2017, 38, 1228–1231. [Google Scholar] [CrossRef]
- Choi, S.; Lee, J.; Kim, S.; Lu, W.D. Retention failure analysis of metal-oxide based resistive memory. Appl. Phys. Lett. 2014, 105, 113510. [Google Scholar] [CrossRef]
- Raghavan, N.; Frey, D.D.; Bosman, M.; Pey, K.L. Statistics of retention failure in the low resistance state for hafnium oxide RRAM using a Kinetic Monte Carlo approach. Microelectron. Reliab. 2015, 55, 1422–1426. [Google Scholar] [CrossRef]
- Lin, Y.-D.; Chen, P.S.; Lee, H.-Y.; Chen, Y.-S.; Rahaman, S.Z.; Tsai, K.-H.; Hsu, C.-H.; Chen, W.-S.; Wang, P.-H.; King, Y.-C.; et al. Retention Model of TaO/HfOX and TaO/AlOX RRAM with Self-Rectifying Switch Characteristics. Nanoscale Res. Lett. 2017, 12, 407. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wong, H.S.P.; Lee, H.Y.; Yu, S.; Chen, Y.S.; Wu, Y.; Chen, P.S.; Lee, B.; Chen, F.T.; Tsai, M.J. Metal–oxide RRAM. Proc. IEEE 2012, 100, 1951–1970. [Google Scholar] [CrossRef]
- Wu, W.; Wu, H.; Gao, B.; Yao, P.; Zhang, X.; Peng, X.; Yu, S.; Qian, H. A methodology to improve linearity of analog RRAM for neuromorphic computing. In Proceedings of the IEEE Symposium on VLSI Technology, Honolulu, HI, USA, 18–22 June 2018; pp. 103–104. [Google Scholar]
- Kim, S.; Park, B.-G. Nonlinear and multilevel resistive switching memory in Ni/Si3N4/Al2O3/TiN structures. Appl. Phys. Lett. 2016, 108, 212103. [Google Scholar] [CrossRef]
- Ciprut, A.; Friedman, E.G. Energy-Efficient Write Scheme for Nonvolatile Resistive Crossbar Arrays with Selectors. IEEE Trans. Very Large Scale Integr. (VLSI) Syst. 2018, 26, 711–719. [Google Scholar] [CrossRef]
- Yao, P.; Wu, H.; Gao, B.; Tang, J.; Zhang, Q.; Zhang, W.; Yang, J.J.; Qian, H. Fully hardware-implemented memristor convolutional neural network. Nat. Cell Biol. 2020, 577, 641–646. [Google Scholar] [CrossRef]
- Wang, C.; Feng, D.; Tong, W.; Liu, J.; Li, Z.; Chang, J.; Zhang, Y.; Wu, B.; Xu, J.; Zhao, W.; et al. Cross-point Resistive Memory. ACM Trans. Des. Autom. Electron. Syst. 2019, 24, 1–37. [Google Scholar] [CrossRef]
- Chang, C.-C.; Chen, P.-C.; Chou, T.; Wang, I.-T.; Hudec, B.; Chang, C.-C.; Tsai, C.-M.; Chang, T.-S.; Hou, T.-H. Mitigating Asymmetric Nonlinear Weight Update Effects in Hardware Neural Network Based on Analog Resistive Synapse. IEEE J. Emerg. Sel. Top. Circuits Syst. 2018, 8, 116–124. [Google Scholar] [CrossRef]
- Wang, W.; Song, W.; Yao, P.; Li, Y.; Van Nostrand, J.; Qiu, Q.; Ielmini, D.; Yang, J.J. Integration and Co-design of Memristive Devices and Algorithms for Artificial Intelligence. iScience 2020, 23, 101809. [Google Scholar] [CrossRef]
- Milo, V.; Zambelli, C.; Olivo, P.; Perez, E.; Mahadevaiah, M.K.; Ossorio, O.G.; Wenger, C.; Ielmini, D. Multilevel HfO2-based RRAM devices for low-power neuromorphic networks. APL Mater. 2019, 7, 081120. [Google Scholar] [CrossRef] [Green Version]
- Tuli, S.; Rios, M.; Levisse, A.; Esl, D.A.; Tuli, S.; Rios, M.; Levisse, A. Rram-vac: A variability-aware controller for rram-based memory architectures. In Proceedings of the 25th Asia and South Pacific Design Automation Conference (ASP-DAC), Beijing, China, 13–16 January 2020; pp. 181–186. [Google Scholar]
- LeCun, Y.; Cortes, C.; Burges, C.J.C. MNIST Handwritten Digit Database. Available online: http://yann.lecun.com/exdb/mnist/ (accessed on 28 January 2021).
- Lee, A.R.; Bae, Y.C.; Im, H.S.; Hong, J.P. Complementary resistive switching mechanism in Ti-based triple TiOX/TiN/TiOX and TiOx/TiOxNy/TiOx matrix. Appl. Surf. Sci. 2013, 274, 85–88. [Google Scholar] [CrossRef]
- Duan, W.J.; Song, H.; Li, B.; Wang, J.-B.; Zhong, X. Complementary resistive switching in single sandwich structure for crossbar memory arrays. J. Appl. Phys. 2016, 120, 084502. [Google Scholar] [CrossRef]
- Yang, M.; Wang, H.; Ma, X.; Gao, H.; Hao, Y. Voltage-amplitude-controlled complementary and self-compliance bipolar resistive switching of slender filaments in Pt/HfO2/HfOx/Pt memory devices. J. Vac. Sci. Technol. B 2017, 35, 032203. [Google Scholar] [CrossRef]
- Chen, C.; Gao, S.; Tang, G.; Fu, H.; Wang, G.; Song, C.; Zeng, F.; Pan, F. Effect of Electrode Materials on AlN-Based Bipolar and Complementary Resistive Switching. ACS Appl. Mater. Interfaces 2013, 5, 1793–1799. [Google Scholar] [CrossRef]
- Aguirre, F.; Rodriguez, A.; Pazos, S.; Sune, J.; Miranda, E.; Palumbo, F. Study on the Connection Between the Set Transient in RRAMs and the Progressive Breakdown of Thin Oxides. IEEE Trans. Electron Devices 2019, 66, 3349–3355. [Google Scholar] [CrossRef]
- Frohlich, K.; Kundrata, I.; Blaho, M.; Precner, M.; Ťapajna, M.; Klimo, M.; Šuch, O.; Skvarek, O. Hafnium oxide and tantalum oxide based resistive switching structures for realization of minimum and maximum functions. J. Appl. Phys. 2018, 124, 152109. [Google Scholar] [CrossRef]
- Lin, C.-Y.; Wu, C.-Y.; Wu, C.-Y.; Hu, C.; Tseng, T.-Y. Bistable Resistive Switching in Al2O3 Memory Thin Films. J. Electrochem. Soc. 2007, 154, G189–G192. [Google Scholar] [CrossRef]
- Møller, M.F. A scaled conjugate gradient algorithm for fast supervised learning. Neural Netw. 1993, 6, 525–533. [Google Scholar] [CrossRef]
- Prezioso, M.; Merrikh-Bayat, F.; Hoskins, B.D.; Adam, G.C.; Likharev, K.K.; Strukov, D.B. Training and operation of an integrated neuromorphic network based on metal-oxide memristors. Nat. Cell Biol. 2015, 521, 61–64. [Google Scholar] [CrossRef] [Green Version]
- Hu, M.; Li, H.; Wu, Q.; Rose, G.S.; Chen, Y. Memristor Crossbar Based Hardware Realization of BSB Recall Function. In Proceedings of the 2012 International Joint Conference on Neural Networks (IJCNN), Brisbane, Australia, 10–15 June 2012; pp. 1–7. [Google Scholar]
- Fouda, M.E.; Lee, S.; Lee, J.; Eltawi, A.M.; Kurdahi, F. Mask Technique for Fast and Efficient Training of Binary Resistive Crossbar Arrays. IEEE Trans. Nanotechnol. 2019, 18, 704–716. [Google Scholar] [CrossRef]
- Hu, M.; Strachan, J.P.; Li, Z.; Grafals, E.M.; Davila, N.; Graves, C.; Lam, S.; Ge, N.; Yang, J.J.; Williams, R.S. Dot-Product Engine for Neuromorphic Computing. In Proceedings of the 53rd Annual Design Automation Conference, Austin, TX, USA, 5–9 June 2016; pp. 1–6. [Google Scholar]
- Liang, J.; Yeh, S.; Wong, S.S.; Wong, H.-S.P. Effect of Wordline/Bitline Scaling on the Performance, Energy Consumption, and Reliability of Cross-Point Memory Array. ACM J. Emerg. Technol. Comput. Syst. 2013, 9, 1–14. [Google Scholar] [CrossRef]
- Hagan, M.; Demuth, H.; Beale, M.; De Jesús, O. Neural Network Design, 2nd ed.; Hagan, M., Ed.; Oklahoma State University: Stillwater, OK, USA, 2014; ISBN 978-0971732117, 0971732116. [Google Scholar]
- Truong, S.N. Compensating Circuit to Reduce the Impact of Wire Resistance in a Memristor Crossbar-Based Perceptron Neural Network. Micromachines 2019, 10, 671. [Google Scholar] [CrossRef] [PubMed] [Green Version]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Hidden Layers | Code | Network Structure | Number of Memristive Sys. | Accuracy at RL→0 Ω | Accuracy (Soft. Case) |
|---|---|---|---|---|---|
| 0 | SLP | 64 × 10 | 1280 sys. | 89.6% | 91.14% |
| 1 | MLP-2a | 64 × 54 × 10 | 7992 sys. | 92.3% | 95.95% |
| MLP-2b | 64 × 100 × 10 | 14,800 sys. | 92.7% | 96.89% | |
| 2 | MLP-3a | 64 × 54 × 34 × 10 | 11,263 sys. | 95.2% | 96.30% |
| MLP-3b | 64 × 100 × 50 × 10 | 23,800 sys. | 96% | 96.92% | |
| 3 | MLP-4 | 64 × 54 × 34 × 24 × 10 | 12,696 sys. | 94.3% | 95.81% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Aguirre, F.L.; Gomez, N.M.; Pazos, S.M.; Palumbo, F.; Suñé, J.; Miranda, E. Minimization of the Line Resistance Impact on Memdiode-Based Simulations of Multilayer Perceptron Arrays Applied to Pattern Recognition. J. Low Power Electron. Appl. 2021, 11, 9. https://0-doi-org.brum.beds.ac.uk/10.3390/jlpea11010009
Aguirre FL, Gomez NM, Pazos SM, Palumbo F, Suñé J, Miranda E. Minimization of the Line Resistance Impact on Memdiode-Based Simulations of Multilayer Perceptron Arrays Applied to Pattern Recognition. Journal of Low Power Electronics and Applications. 2021; 11(1):9. https://0-doi-org.brum.beds.ac.uk/10.3390/jlpea11010009
Chicago/Turabian StyleAguirre, Fernando Leonel, Nicolás M. Gomez, Sebastián Matías Pazos, Félix Palumbo, Jordi Suñé, and Enrique Miranda. 2021. "Minimization of the Line Resistance Impact on Memdiode-Based Simulations of Multilayer Perceptron Arrays Applied to Pattern Recognition" Journal of Low Power Electronics and Applications 11, no. 1: 9. https://0-doi-org.brum.beds.ac.uk/10.3390/jlpea11010009