
Mapping Transformation Enabled High-Performance and Low-Energy Memristor-Based DNNs

 ,
,  ,
,  , ,
, ,
Abstract
:1. Introduction
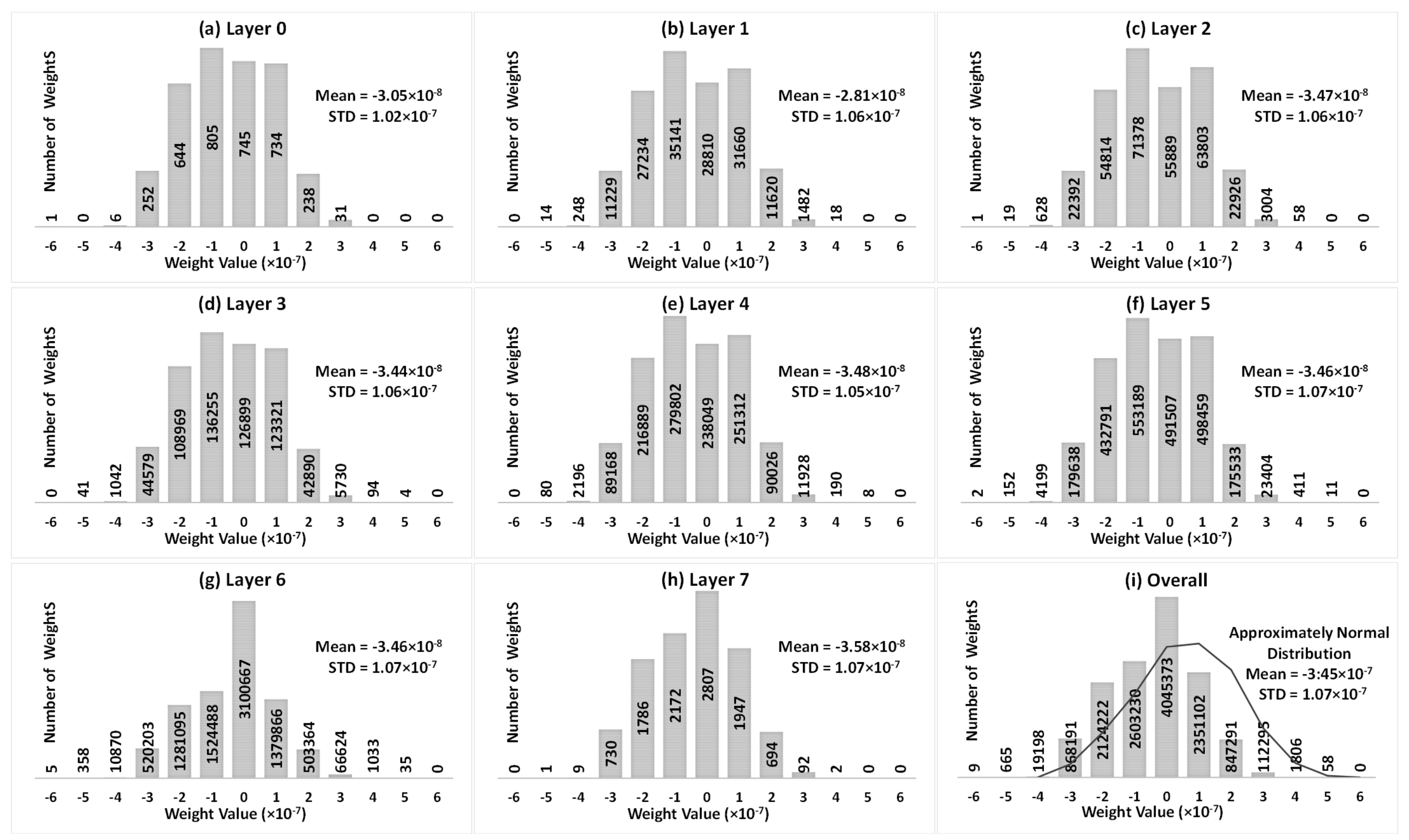
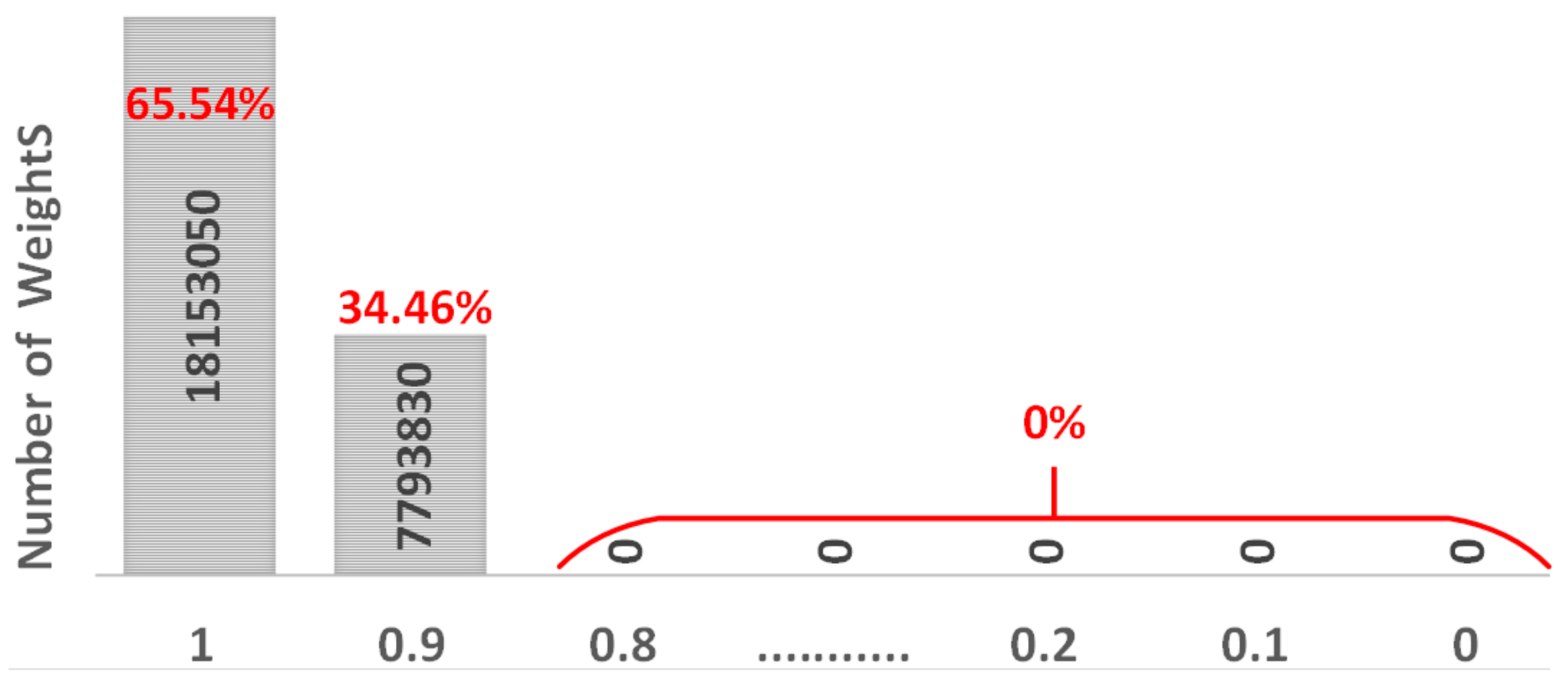
- In order to investigate the inference accuracy drop in memristor-based DNNs due to SAFs, the weight distribution for the VGG8 model is presented and analyzed.
- As the SAF defects are immensely random and vary from device to device, the accuracy drop of a DNN is listed for different SAF ratios from 0.1% to 50% with SA1:SA0 = 5:1 and 1:5, respectively.
- A MT method is proposed to achieve outstanding accuracy recovery even in extremely high SAF cases.
- The MT method for the accuracy improvement, energy saving, and latency reduction is validated on the VGG8 model with the CIFAR10 dataset.
- It is also verified that even with the significant non-linear properties, the MT technology is still effective to recover the accuracy, save energy, and decrease latency in memristor-based DNNs under various SAF conditions.
- Finally, the proposed MT method is compared with the state-of-the-art.
2. Methodology
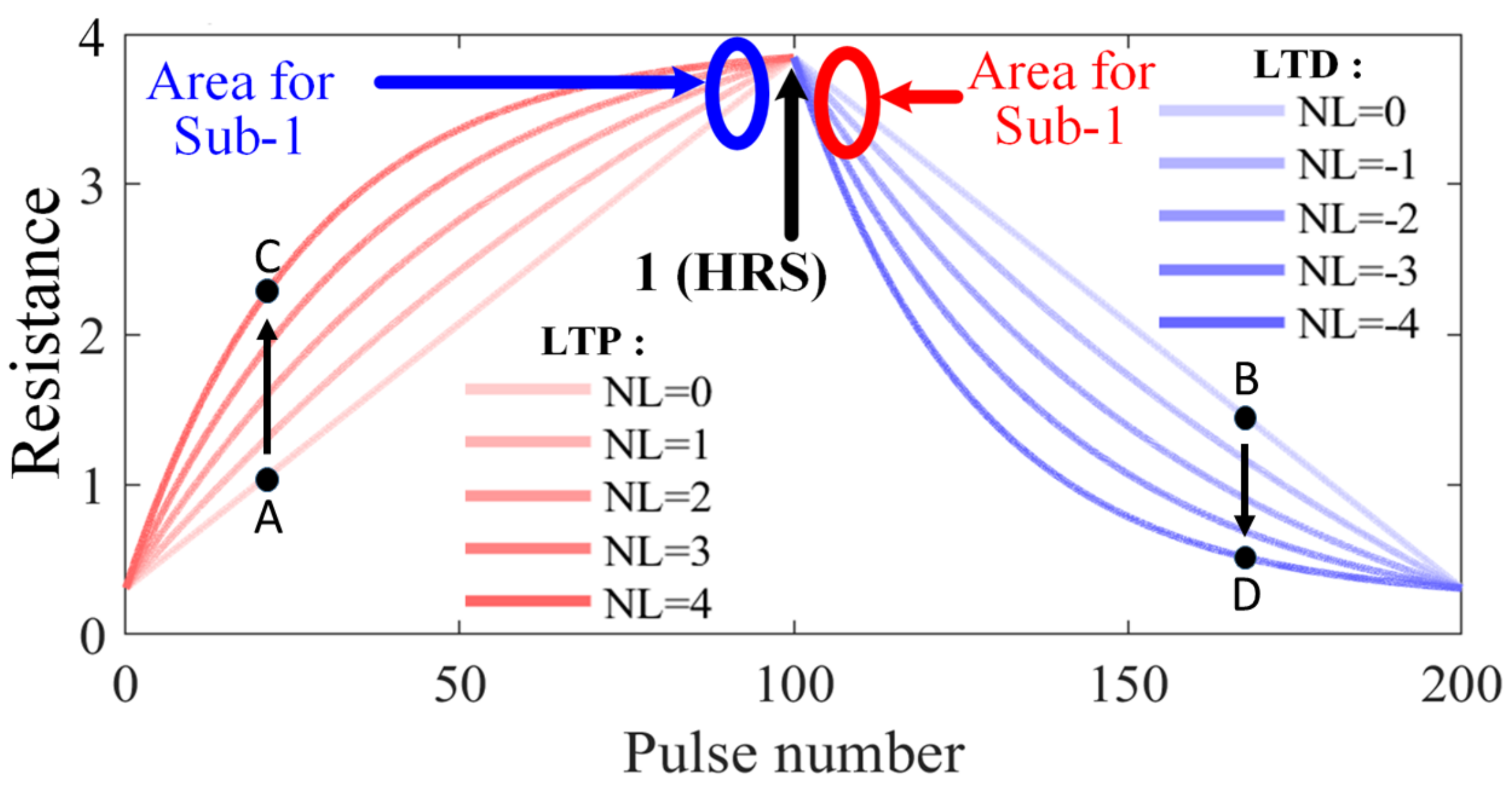
2.1. Stuck-At-Fault (SAF)
2.2. Weight Distribution
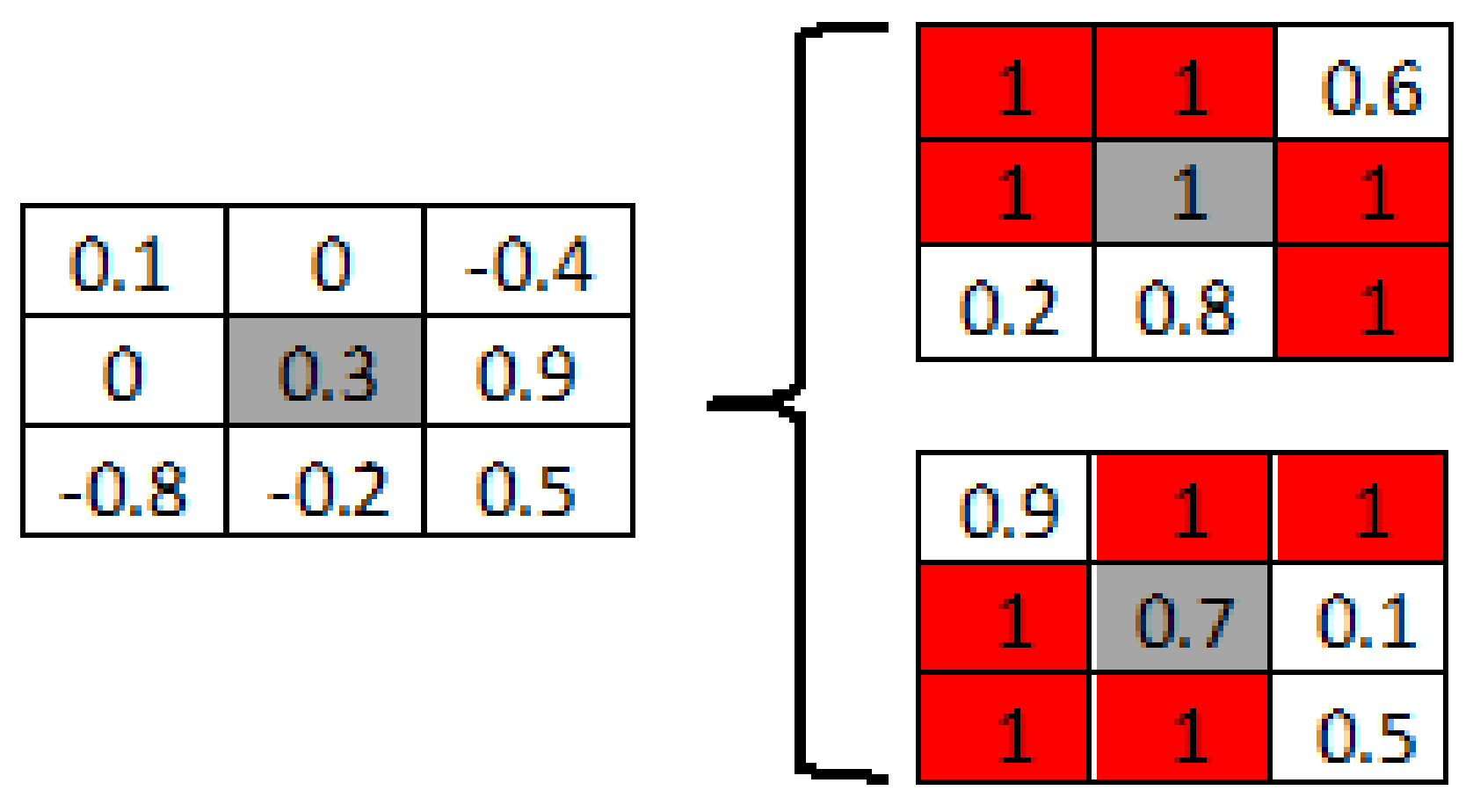
2.3. Mapping Transformation (MT)
3. Result and Discussion
3.1. Weight Distribution with MT
| Alogirithm 1. Mapping Transformation |
 |
3.2. Impact of MT Method
3.2.1. Accuracy
3.2.2. Energy
3.2.3. Latency
3.3. Immunity of Mapping Transformation Method against Non-Linearity
3.3.1. Accuracy
3.3.2. Energy and Latency
4. Comparison
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| CMOS | Complementary Metal Oxide Semiconductor |
| DNN | Deep Neural Network |
| MT | Mapping Transformation |
| IoT | Internet of Things |
| AI | Artificial Intelligence |
| SAF | Stuck-at-Fault |
References
- Shi, W.; Dustdar, S. The promise of edge computing. Computer 2016, 49, 78–81. [Google Scholar] [CrossRef]
- Fu, J.; Liao, Z.; Liu, J.; Smith, S.C.; Wang, J. Memristor-Based Variation-Enabled Differentially Private Learning Systems for Edge Computing in IoT. IEEE Internet Things J. 2020, 8, 9672–9682. [Google Scholar] [CrossRef]
- Liu, F.; Ju, X.; Wang, N.; Wang, L.; Lee, W.J. Wind farm macro-siting optimization with insightful bi-criteria identification and relocation mechanism in genetic algorithm. Energy Convers. Manag. 2020, 217, 186–198. [Google Scholar] [CrossRef]
- Williams, R.S. What’s Next? [The end of Moore’s law]. Comput. Sci. Eng. 2017, 19, 7–13. [Google Scholar] [CrossRef]
- Waldrop, M.M. The chips are down for Moore’s law. Nat. News 2016, 530, 144–147. [Google Scholar] [CrossRef] [Green Version]
- Chua, L. Memristor-the missing circuit element. IEEE Trans. Circuit Theory 1971, 18, 507–519. [Google Scholar] [CrossRef]
- Strukov, D.B.; Snider, G.S.; Stewart, D.R.; Williams, R.S. The missing memristor found. Nature 2008, 453, 80–83. [Google Scholar] [CrossRef]
- Jo, S.H.; Chang, T.; Ebong, I.; Bhadviya, B.B.; Mazumder, P.; Lu, W. Nanoscale memristor device as synapse in neuromorphic systems. Nano Lett. 2010, 10, 1297–1301. [Google Scholar] [CrossRef]
- Jo, S.H.; Lu, W. CMOS compatible nanoscale nonvolatile resistance switching memory. Nano Lett. 2008, 8, 392–397. [Google Scholar] [CrossRef]
- Oblea, A.S.; Timilsina, A.; Moore, D.; Campbell, K.A. Silver chalcogenide based memristor devices. In Proceedings of the International Joint Conference on Neural Networks (IJCNN), Barcelona, Spain, 18–23 July 2010; pp. 1–3. [Google Scholar]
- Prodromakis, T.; Michelakis, K.; Toumazou, C. Fabrication and electrical characteristics of memristors with TiO2/TiO2+x active layers. In Proceedings of the IEEE International Symposium on Circuits and Systems, Paris, France, 30 May–2 June 2010; pp. 1520–1522. [Google Scholar]
- Chen, C.Y.; Shih, H.C.; Wu, C.W.; Lin, C.H.; Chiu, P.F.; Sheu, S.S.; Chen, F.T. RRAM defect modeling and failure analysis based on march test and a novel squeeze-search scheme. IEEE Trans. Comput. 2014, 64, 180–190. [Google Scholar] [CrossRef]
- Kvatinsky, S.; Friedman, E.G.; Kolodny, A.; Weiser, U.C. TEAM: Threshold adaptive memristor model. IEEE Trans. Circuits Syst. I Regul. Pap. 2012, 60, 211–221. [Google Scholar] [CrossRef]
- Pickett, M.D.; Williams, R.S. Sub-100 fJ and sub-nanosecond thermally driven threshold switching in niobium oxide crosspoint nanodevices. Nanotechnology 2012, 23, 1–7. [Google Scholar] [CrossRef] [PubMed]
- Torrezan, A.C.; Strachan, J.P.; Medeiros-Ribeiro, G.; Williams, R.S. Sub-nanosecond switching of a tantalum oxide memristor. Nanotechnology 2011, 22, 485203. [Google Scholar] [CrossRef] [PubMed]
- Lee, M.J.; Lee, C.B.; Lee, D.; Lee, S.R.; Chang, M.; Hur, J.H.; Kim, Y.B.; Kim, C.J.; Seo, D.H.; Seo, S.; et al. A fast, high-endurance and scalable non-volatile memory device made from asymmetric Ta2O5-x/TaO2-x bilayer structures. Nat. Mater. 2011, 10, 625–630. [Google Scholar] [CrossRef]
- Pi, S.; Lin, P.; Xia, Q. Cross point arrays of 8 nm × 8 nm memristive devices fabricated with nanoimprint lithography. J. Vac. Sci. Technol. B Nanotechnol. Microelectron. Mater. Process. Meas. Phenom. 2013, 31, 06FA02. [Google Scholar] [CrossRef]
- Xia, Q.; Robinett, W.; Cumbie, M.W.; Banerjee, N.; Cardinali, T.J.; Yang, J.J.; Wu, W.; Li, X.; Tong, W.M.; Strukov, D.B.; et al. Memristor- CMOS hybrid integrated circuits for reconfigurable logic. Nano Lett. 2009, 9, 3640–3645. [Google Scholar] [CrossRef]
- Fu, J.; Liao, Z.; Gong, N.; Wang, J. Mitigating nonlinear effect of memristive synaptic device for neuromorphic computing. IEEE J. Emerg. Sel. Top. Circuits Syst. 2019, 9, 377–387. [Google Scholar] [CrossRef]
- Liu, C.; Hu, M.; Strachan, J.P.; Li, H. Rescuing memristor-based neuromorphic design with high defects. In Proceedings of the 54th ACM/EDAC/IEEE Design Automation Conference (DAC), Austin, TX, USA, 18–22 June 2017; pp. 1–6. [Google Scholar]
- Chen, L.; Li, J.; Chen, Y.; Deng, Q.; Shen, J.; Liang, X.; Jiang, L. Accelerator-friendly neural-network training: Learning variations and defects in RRAM crossbar. In Proceedings of the Design, Automation & Test in Europe Conference & Exhibition (DATE), Lausanne, Switzerland, 27–31 March 2017; pp. 19–24. [Google Scholar]
- Zhang, B.; Uysal, N.; Fan, D.; Ewetz, R. Handling stuck-at-fault defects using matrix transformation for robust inference of dnns. IEEE Trans. Comput.-Aided Des. Integr. Circuits Syst. 2019, 39, 2448–2460. [Google Scholar] [CrossRef]
- Xia, L.; Huangfu, W.; Tang, T.; Yin, X.; Chakrabarty, K.; Xie, Y.; Wang, Y.; Yang, H. Stuck-at fault tolerance in RRAM computing systems. IEEE J. Emerg. Sel. Top. Circuits Syst. 2017, 8, 102–115. [Google Scholar] [CrossRef]
- Xia, L.; Liu, M.; Ning, X.; Chakrabarty, K.; Wang, Y. Fault-tolerant training with on-line fault detection for RRAM-based neural computing systems. In Proceedings of the 54th Annual Design Automation Conference, Austin, TX, USA, 18–22 June 2017; pp. 1–6. [Google Scholar]
- Yeo, I.; Chu, M.; Gi, S.G.; Hwang, H.; Lee, B.G. Stuck-at-fault tolerant schemes for memristor crossbar array-based neural networks. IEEE Trans. Electron Devices 2019, 66, 2937–2945. [Google Scholar] [CrossRef]
- Chen, P.Y.; Peng, X.; Yu, S. NeuroSim: A circuit-level macro model for benchmarking neuro-inspired architectures in online learning. IEEE Trans. Comput.-Aided Des. Integr. Circuits Syst. 2018, 37, 3067–3080. [Google Scholar] [CrossRef]
- Krestinskaya, O.; James, A.P.; Chua, L.O. Neuromemristive circuits for edge computing: A review. IEEE Trans. Neural Netw. Learn. Syst. 2019, 31, 4–23. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Peng, X.; Huang, S.; Jiang, H.; Lu, A.; Yu, S. DNN+ NeuroSim V2. 0: An end-to-end benchmarking framework for compute-in-memory accelerators for on-chip training. IEEE Trans. Comput.-Aided Des. Integr. Circuits Syst. 2020, 40, 2306–2319. [Google Scholar] [CrossRef]
- Liao, Z.; Fu, J.; Wang, J. Ameliorate Performance of Memristor Based ANNs in Edge Computing. IEEE Trans. Comput. 2021, 70, 1299–1310. [Google Scholar] [CrossRef]
- QueryNet: Querying neural networks for lightweight specialized models. Inf. Sci. 2022, 589, 186–198. [CrossRef]
- Gaudet, V. A survey and tutorial on contemporary aspects of multiple-valued logic and its application to microelectronic circuits. IEEE J. Emerg. Sel. Top. Circuits Syst. 2016, 6, 5–12. [Google Scholar] [CrossRef]
- Chen, P.Y.; Lin, B.; Wang, I.T.; Hou, T.H.; Ye, J.; Vrudhula, S.; Seo, J.S.; Cao, Y.; Yu, S. Mitigating effects of non-ideal synaptic device characteristics for on-chip learning. In Proceedings of the IEEE/ACM International Conference on Computer-Aided Design (ICCAD), Austin, TX, USA, 2–6 November 2015; pp. 194–199. [Google Scholar]
- Jung, G.; Fouda, M.; Lee, S.; Lee, J.; Eltawil, A.; Kurdahi, F. Cost- and Dataset-free Stuck-at Fault Mitigation for ReRAM-based Deep Learning Accelerators. In Proceedings of the Design, Automation, Test in Europe Conference Exhibition (DATE), Grenoble, France, 1–5 February 2021; pp. 1733–1738. [Google Scholar]
- Zhang, J.; Kline, D.; Fang, L.; Melhem, R.; Jones, A.K. Dynamic partitioning to mitigate stuck-at faults in emerging memories. In Proceedings of the IEEE/ACM International Conference on Computer-Aided Design (ICCAD), Irvine, CA, USA, 13–16 November 2017; pp. 651–658. [Google Scholar]
- Charan, G.; Mohanty, A.; Du, X.; Krishnan, G.; Joshi, R.V.; Cao, Y. Accurate Inference With Inaccurate RRAM Devices: A Joint Algorithm-Design Solution. IEEE J. Explor.-Solid-State Comput. Devices Circuits 2020, 6, 27–35. [Google Scholar] [CrossRef]
- He, Z.; Lin, J.; Ewetz, R.; Yuan, J.S.; Fan, D. Noise Injection Adaption: End-to-End ReRAM Crossbar Non-ideal Effect Adaption for Neural Network Mapping. In Proceedings of the 56th ACM/IEEE Design Automation Conference (DAC), Las Vegas, NV, USA, 2–6 June 2019; pp. 1–6. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| SAF (SA1 & SA0) | Before MT | After MT | ||||
|---|---|---|---|---|---|---|
| Energy (J) | Latency (s) | Accuracy | Energy (J) | Latency (s) | Accuracy | |
| 0.1% | 2.550 × | 66.490 × | 90% | 2.334 × | 66.395 × | 90% |
| 1.0% | 2.550 × | 66.499 × | 42% | 2.335 × | 66.401 × | 90% |
| 2.5% | 2.550 × | 66.479 × | 10% | 2.335 × | 66.398 × | 90% |
| 20% | 7.130 × | 12.019 × | 10% | 2.330 × | 66.397 × | 88% |
| 50% | 7.127 × | 12.019 × | 10% | 2.311 × | 66.397 × | 80% |
| SAF (SA1 & SA0) | Before MT | After MT | ||||
|---|---|---|---|---|---|---|
| Energy (J) | Latency (s) | Accuracy | Energy (J) | Latency (s) | Accuracy | |
| 0.1% | 2.542 × | 66.465 × | 88% | 2.335 × | 66.397 × | 90% |
| 1.0% | 9.542 × | 12.019 × | 10% | 2.336 × | 66.401 × | 90% |
| 2.5% | 9.517 × | 12.019 × | 10% | 2.332 × | 66.397 × | 89% |
| 20% | 9.035 × | 12.019 × | 10% | 2.274 × | 66.387 × | 63% |
| 50% | 9.029 × | 12.019 × | 10% | 2.226 × | 66.388 × | 21% |
| SAF | Before MT LTP = 4, LTD = −4 | After MT LTP = 4, LTD = −4 | ||||
|---|---|---|---|---|---|---|
| Energy (J) | Latency (s) | Accuracy | Energy (J) | Latency (s) | Accuracy | |
| 0.1% | 2.494 × | 66.445 × | 65% | 2.287 × | 66.354 × | 71% |
| 1.0% | 2.090 × | 66.396 × | 10% | 2.292 × | 66.357 × | 71% |
| 2.5% | 2.187 × | 66.421 × | 10% | 2.286 × | 66.358 × | 70% |
| 20% | 7.127 × | 12.019 × | 10% | 2.319 × | 66.359 × | 62% |
| 50% | 7.126 × | 12.019 × | 10% | 2.322 × | 66.365 × | 50% |
| SAF | Before MT LTP = 4, LTD = −4 | After MT LTP = 4, LTD = −4 | ||||
|---|---|---|---|---|---|---|
| Energy (J) | Latency (s) | Accuracy | Energy (J) | Latency (s) | Accuracy | |
| 0.1% | 2.499 × | 66.431 × | 53% | 2.289 × | 66.365 × | 70% |
| 1.0% | 9.327 × | 12.019 × | 10% | 2.298 × | 66.359 × | 69% |
| 2.5% | 9.205 × | 12.019 × | 10% | 2.305 × | 66.358 × | 68% |
| 20% | 9.031 × | 12.018 × | 10% | 2.309 × | 66.366 × | 30% |
| 50% | 9.030 × | 12.018 × | 10% | 2.285 × | 66.398 × | 14% |
| Items | [33] | [34] | [35] | [21] | [20] | [24] | [23] | [22] | [36] | [25] | This Work |
|---|---|---|---|---|---|---|---|---|---|---|---|
| No Additional Algorithm | × | × | × | × | × | × | × | × | × | √ | √ |
| No Individual Optimization | √ | × | × | × | × | × | × | × | × | √ | √ |
| No Complex Control Circuit | √ | √ | √ | × | × | × | × | √ | √ | × | √ |
| Extreme SAF Considerations (50%) | × | × | × | × | × | × | × | √ | × | × | √ |
| Energy Analysis | × | × | × | × | × | × | × | × | × | × | √ |
| Latency Analysis | × | × | × | × | × | × | × | × | × | × | √ |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Oli-Uz-Zaman, M.; Khan, S.A.; Yuan, G.; Liao, Z.; Fu, J.; Ding, C.; Wang, Y.; Wang, J. Mapping Transformation Enabled High-Performance and Low-Energy Memristor-Based DNNs. J. Low Power Electron. Appl. 2022, 12, 10. https://0-doi-org.brum.beds.ac.uk/10.3390/jlpea12010010
Oli-Uz-Zaman M, Khan SA, Yuan G, Liao Z, Fu J, Ding C, Wang Y, Wang J. Mapping Transformation Enabled High-Performance and Low-Energy Memristor-Based DNNs. Journal of Low Power Electronics and Applications. 2022; 12(1):10. https://0-doi-org.brum.beds.ac.uk/10.3390/jlpea12010010
Chicago/Turabian StyleOli-Uz-Zaman, Md., Saleh Ahmad Khan, Geng Yuan, Zhiheng Liao, Jingyan Fu, Caiwen Ding, Yanzhi Wang, and Jinhui Wang. 2022. "Mapping Transformation Enabled High-Performance and Low-Energy Memristor-Based DNNs" Journal of Low Power Electronics and Applications 12, no. 1: 10. https://0-doi-org.brum.beds.ac.uk/10.3390/jlpea12010010