Relationships between Causal Factors Affecting Future Carbon Dioxide Output from Thailand’s Transportation Sector under the Government’s Sustainability Policy: Expanding the SEM-VECM Model


Abstract
:1. Introduction
- Identify a variable framework according to Structure Equation Modeling [34], where exogenous variables and endogenous variables are extracted to be latent variables and observed variables.
- Choose variables that have a co-integration at the same level to construct a SEM-VECM Model where the relationship of causal factors is both in the short and long term, indicating the direct effect, indirect effect, and total effect of the relationship.
- Examine the developed model regarding its heteroscedasticity, multicollinearity, and autocorrelation.
- Compare the effectiveness of the SEM-VECM Model with other existing models, including Multiple Linear Regression, Gray Model (GM (1,1)), GM-ARIMA Model, Artificial Neural Natural Model (ANN), back propagation neural network (BP Model), and ARIMA Model, through the performance measures of MAPE and RMSE.
- Analyze the relationship and direction parameter estimates of the SEM-VECM Model.
- Forecast CO2 emissions for the next 30 years (2018–2047) using the SEM-VECM Model. The flowchart of the SEM-VECM Model is shown in Figure 1 below.
2. The Forecasting Model
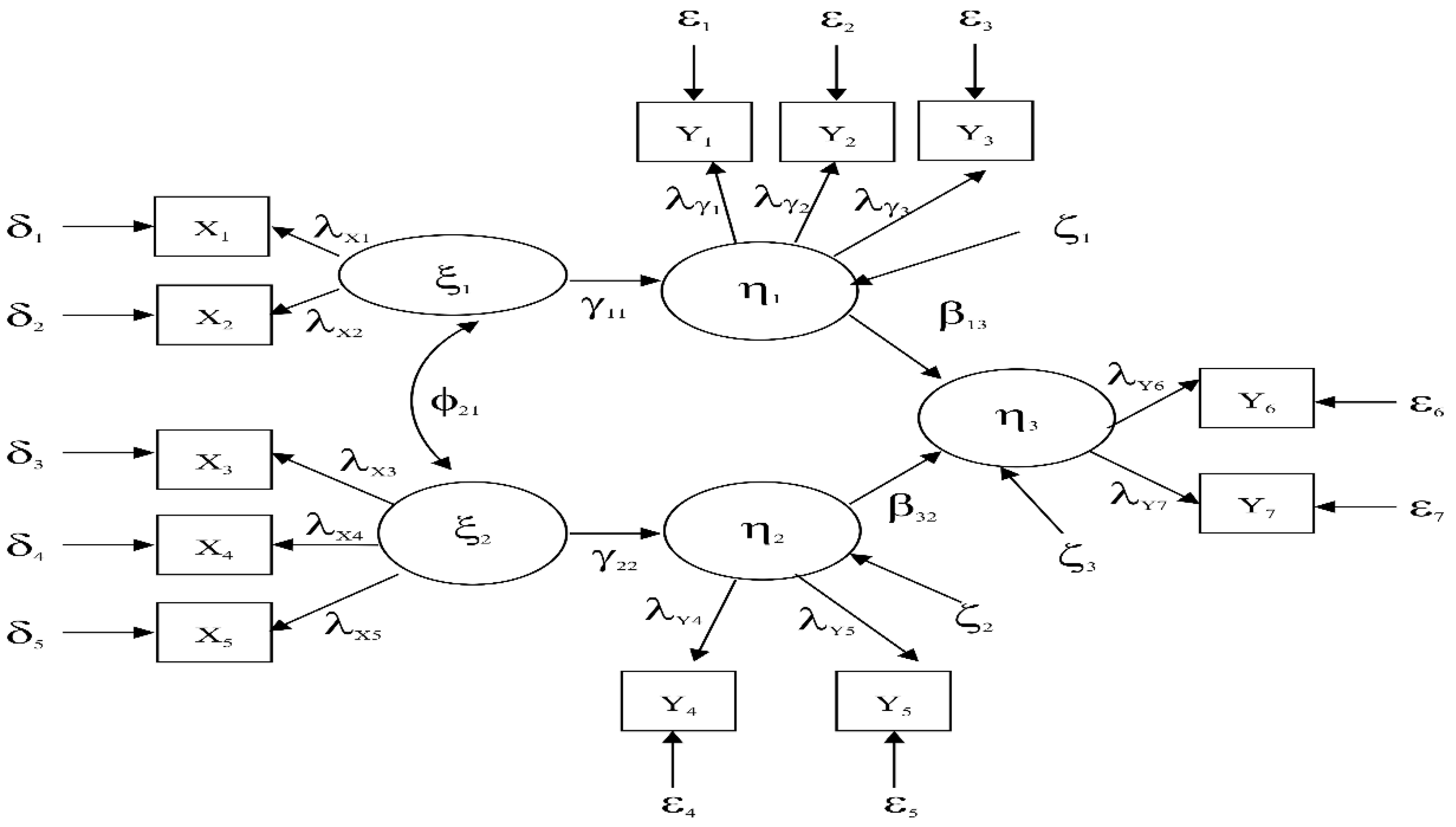
2.1. Structure Estimation Modeling-Vector Error Correction Mechanism Model (SEM-VECM Model)
2.2. Measurement of the Forecasting Performance
3. Empirical Analysis
3.1. Screening of Influencing Factors for Model Input
3.2. Analysis of Co-Integration
3.3. Formation of Analysis Modeling with the SEM-VECM Model
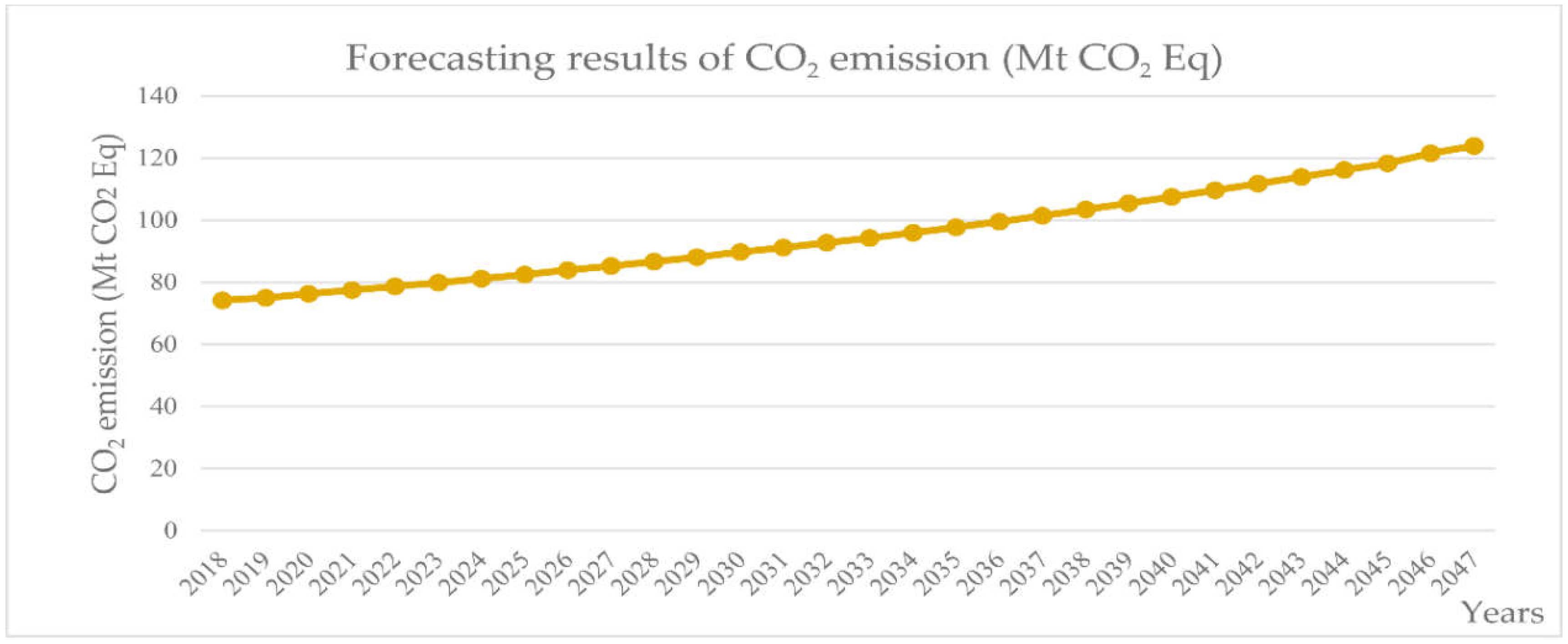
3.4. CO2 Emission Forecasting Based on the SEM-VECM Model
4. Discussion
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Achawangkul, Y. Thailand’s Alternative Energy Development Plan. Available online: http://www.unescap.org/sites/default/files/MoE%20_%20AE%20policies.pdf (accessed on 1 October 2018).
- Office of the National Economic and Social Development Board (NESDB). Available online: http://www.nesdb.go.th/nesdb_en/more_news.php?cid=154&filename=index (accessed on 1 October 2018).
- National Statistic Office Ministry of Information and Communication Technology. Available online: http://web.nso.go.th/index.htm (accessed on 2 October 2018).
- Department of Alternative Energy Development and Efficiency. Available online: http://www.dede.go.th/ewtadmin/ewt/dede_web/ewt_news.php?nid=47140 (accessed on 2 October 2018).
- Thailand Greenhouse Gas Management Organization (Public Organization). Available online: http://www.tgo.or.th/2015/thai/content.php?s1=7&s2=16&sub3=sub3 (accessed on 2 October 2018).
- Hu, Y.; Guo, D.; Wang, M.; Zhang, X.; Wang, S. The relationship between energy consumption and economic growth: Evidence from China’s industrial sectors. Energies 2015, 8, 9392–9406. [Google Scholar] [CrossRef]
- Zhao, H.; Zhao, H.; Han, X.; He, Z.; Guo, S. Economic growth, electricity consumption, labor force and capital input: A more comprehensive analysis on North China using panel data. Energies 2016, 9, 891. [Google Scholar] [CrossRef]
- Armeanu, D.S.; Vintilă, G.; Gherghina, S.C. Does renewable energy drive sustainable economic growth? Multivariate panel data evidence for EU-28 countries. Energies 2017, 10, 381. [Google Scholar] [CrossRef]
- Bandalos, D.L. Assessing sources of error in structural equation models: The effects of sample size, reliability, and model misspecification. Struct. Equ. Model. Multidiscip. J. 1997, 4, 177–192. [Google Scholar] [CrossRef]
- Gómez, M.; Ciarreta, A.; Zarraga, A. Linear and nonlinear causality between energy consumption and economic growth: The case of Mexico 1965–2014. Energies 2018, 11, 784. [Google Scholar] [CrossRef]
- Arango-Miranda, R.; Hausler, R.; Romero-Lopez, R.; Glaus, M.; Ibarra-Zavaleta, S.P. Carbon dioxide emissions, energy consumption and economic growth: A comparative empirical study of selected developed and developing countries. “The Role of Exergy”. Energies 2018, 11, 2668. [Google Scholar] [CrossRef]
- Chang, C.C. A multivariate causality test of carbon dioxide emissions, energy consumption and economic growth in China. Appl. Energy 2010, 87, 3533–3537. [Google Scholar] [CrossRef]
- Kivyiro, P.; Arminen, H. Carbon dioxide emissions, energy consumption, economic growth, and foreign direct investment: Causality analysis for Sub-Saharan Africa. Energy 2014, 74, 595–606. [Google Scholar] [CrossRef]
- Wesseh, P.K., Jr.; Zoumara, B. Causal independence between energy consumption and economic growth in Liberia: Evidence from a non-parametric bootstrapped causality test. Energy Policy 2012, 50, 518–527. [Google Scholar] [CrossRef]
- Yoo, S.H.; Ku, S.J. Causal relationship between nuclear energy consumption and economic growth: A multi-country analysis. Energy Policy 2009, 37, 1905–1913. [Google Scholar] [CrossRef]
- Chang, T.; Gatwabuyege, F.; Gupta, R.; Inglesi-Lotz, R.; Manjezi, N.C.; Simo-Kengne, B.D. Causal relationship between nuclear energy consumption and economic growth in G6 countries: Evidence from panel Granger causality tests. Nucl. Energy 2014, 77, 187–193. [Google Scholar] [CrossRef] [Green Version]
- Nasreen, S.; Anwar, S. Causal relationship between trade openness, economic growth and energy consumption: A panel data analysis of Asian countries. Energy Policy 2014, 69, 82–91. [Google Scholar] [CrossRef]
- Zhixina, Z.; Xin, R. Causal relationships between energy consumption and economic growth. Energy Procedia 2011, 5, 2065–2071. [Google Scholar] [CrossRef]
- Yu, H.; Pan, S.Y.; Tang, B.J.; Mi, Z.F.; Zhang, Y.; Wei, Y.M. Urban energy consumption and CO2 emissions in Beijing: Current and future. Energy Effic. 2015, 8, 527–543. [Google Scholar] [CrossRef] [Green Version]
- Mudarissov, B.A.; Lee, Y. The relationship between energy consumption and economic growth in Kazakhstan. Geosyst. Eng. 2014, 17, 63–68. [Google Scholar] [CrossRef]
- Li, S.; Li, R. Comparison of forecasting energy consumption in Shandong, China Using the ARIMA model, GM model, and ARIMA-GM model. Sustainability 2017, 9, 1181. [Google Scholar]
- Ozturk, S.; Ozturk, F. Forecasting energy consumption of Turkey by Arima Model. J. Asian Sci. Res. 2018, 8, 52–60. [Google Scholar] [CrossRef]
- Sun, W.; He, Y.; Chang, H. Forecasting fossil fuel energy consumption for power generation using QHSA-Based LSSVM model. Energies 2015, 8, 939–959. [Google Scholar] [CrossRef]
- Yuan, C.; Liu, S.; Fang, Z. Comparison of China’s primary energy consumption forecasting by using ARIMA (the autoregressive integrated moving average) model and GM (1,1) model. Energy 2016, 100, 384–390. [Google Scholar] [CrossRef]
- Sen, P.; Roy, M.; Pal, P. Application of ARIMA for forecasting energy consumption and GHG emission: A case study of an Indian pig iron manufacturing organization. Energy 2016, 116, 1031–1038. [Google Scholar] [CrossRef]
- Fan, G.F.; Wang, A.; Hong, W.C. Combining grey model and self-adapting intelligent grey model with genetic algorithm and annual share changes in natural gas demand forecasting. Energies 2018, 11, 1625. [Google Scholar] [CrossRef]
- Barak, S.; Sadegh, S. Forecasting energy consumption using ensemble ARIMA–ANFIS hybrid algorithm. Int. J. Electr. Power Energy Syst. 2016, 82, 92–104. [Google Scholar] [CrossRef]
- Okumus, I.; Dinler, A. Current status of wind energy forecasting and a hybrid method for hourly predictions. Energy Convers. Manag. 2016, 123, 362–371. [Google Scholar] [CrossRef]
- Zeng, B.; Zhou, M.; Zhang, J. Forecasting the energy consumption of China’s manufacturing using a homologous grey prediction model. Sustainability 2017, 9, 1975. [Google Scholar] [CrossRef]
- Dai, S.; Niu, D.; Li, Y. Forecasting of energy consumption in China based on ensemble empirical mode decomposition and least squares support vector machine optimized by improved shuffled frog leaping algorithm. Appl. Sci. 2018, 8, 678. [Google Scholar] [CrossRef]
- Liu, B.; Fu, C.; Bielefield, A.; Liu, Y.Q. Forecasting of Chinese primary energy consumption in 2021 with GRU artificial neural network. Energies 2017, 10, 1453. [Google Scholar] [CrossRef]
- Ma, M.; Su, M.; Li, S.; Jiang, F.; Li, R. Predicting coal consumption in South Africa based on linear (metabolic grey model), nonlinear (non-linear grey model), and combined (metabolic grey model-Autoregressive Integrated Moving Average Model) Models. Sustainability 2018, 10, 2552. [Google Scholar] [CrossRef]
- Ma, J.; Oppong, A.; Acheampong, K.N.; Abruquah, L.A. Forecasting Renewable Energy Consumption under Zero Assumptions. Sustainability 2018, 10, 576. [Google Scholar] [CrossRef]
- Barbara, M.B. Structural Equation Modeling with Mplus: Basic Concepts, Application, and Programming; Taylor & Francis Group: New York, NY, USA, 2012. [Google Scholar]
- Dickey, D.A.; Fuller, W.A. Likelihood ratio statistics for autoregressive time series with a unit root. Econometrica 1981, 49, 1057–1072. [Google Scholar] [CrossRef]
- MacKinnon, J. Critical Values for Cointegration Test in Long-Run Economic Relationships; Engle, R., Granger, C., Eds.; Oxford University Press: Oxford, UK, 1991. [Google Scholar]
- Johansen, S.; Juselius, K. Maximum likelihood estimation and inference on cointegration with applications to the demand for money. Oxf. Bull. Econ. Stat. 1990, 52, 169–210. [Google Scholar] [CrossRef]
- Johansen, S. Likelihood-Based Inference in Cointegrated Vector Autoregressive Models; Oxford University Press: New York, NY, USA, 1995. [Google Scholar]
- Enders, W. Applied Econometrics Time Series; Wiley Series in Probability and Statistics; University of Alabama: Tuscaloosa, AL, USA, 2010. [Google Scholar]
- Harvey, A.C. Forecasting, Structural Time Series Models and the Kalman Filter; Cambridge University Press: Cambridge, UK, 1989. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| ADF Test at First Difference I(1) | MacKinnon Critical Value | |||
|---|---|---|---|---|
| Variables | Value | 1% | 5% | 10% |
| −6.79 *** | −4.75 | −3.41 | −2.77 | |
| −5.92 *** | −4.75 | −3.41 | −2.77 | |
| −4.77 *** | −4.75 | −3.41 | −2.77 | |
| −6.51 *** | −4.75 | −3.41 | −2.77 | |
| −5.99 *** | −4.75 | −3.41 | −2.77 | |
| −6.47 *** | −4.75 | −3.41 | −2.77 | |
| −4.99 *** | −4.75 | −3.41 | −2.77 | |
| −6.54 *** | −4.75 | −3.41 | −2.77 | |
| −6.13 *** | −4.75 | −3.41 | −2.77 | |
| Variables | Hypothesized No of CE(S) | Trace Statistic Test | Max-Eigen Statistic Test | MacKinnon Critical Value | |
|---|---|---|---|---|---|
| 1% | 5% | ||||
| , , , , , , , , | None *** | 241.65 | 135.09 | 25.25 | 12.50 |
| At Most 1 *** | 89.15 | 91.50 | 5.60 | 3.50 | |
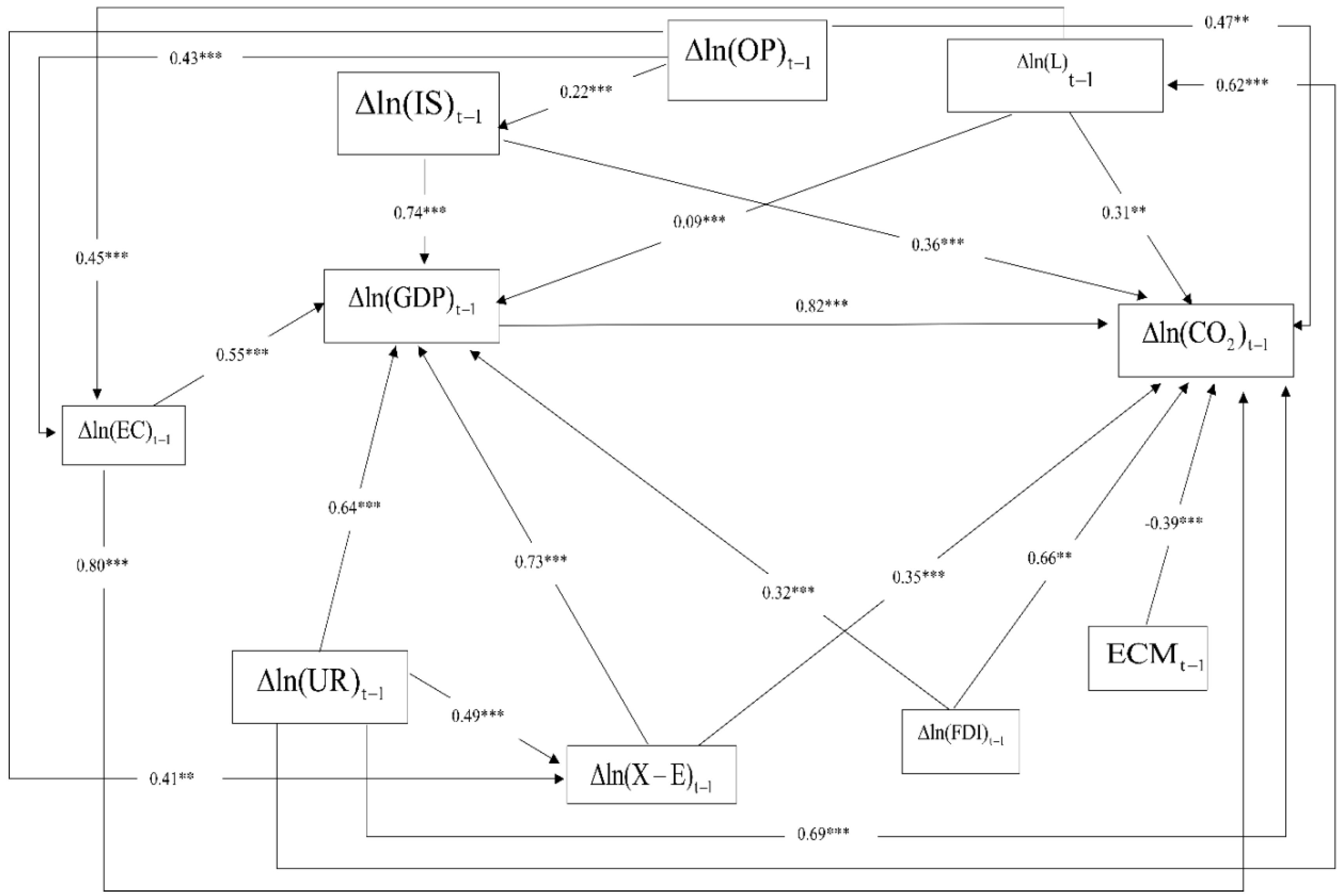
| Dependent Variables | Type of Effect | Independent Variables | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| DE | 0.82 *** | 0.31 ** | 0.69 *** | 0.74 *** | 0.80 *** | 0.66 ** | 0.47 ** | 0.35 *** | 0.39 *** | ||
| IE | 0.11 *** | 0.15 ** | 0.04 *** | 0.09 *** | 0.02 *** | 0.01 ** | 0.05 ** | 0.11 *** | - | ||
| DE | - | 0.09 *** | 0.64 *** | 0.36 *** | 0.55 *** | 0.32 *** | - | 0.73 *** | - | ||
| IE | - | - | - | - | - | - | - | - | |||
| DE | - | - | 0.62*** | - | - | - | - | - | - | ||
| IE | - | - | - | - | - | - | - | - | |||
| DE | - | - | - | - | - | - | - | - | - | ||
| IE | - | - | - | - | - | - | - | - | - | ||
| DE | - | - | - | - | - | - | 0.22 *** | - | - | ||
| IE | - | - | - | - | - | - | - | - | |||
| DE | - | 0.45 *** | - | - | - | - | 0.43 *** | - | - | ||
| IE | - | - | - | - | - | - | - | - | - | ||
| DE | - | - | - | - | - | - | - | - | - | ||
| IE | - | - | - | - | - | - | - | - | - | ||
| DE | - | - | - | - | - | - | - | - | - | ||
| IE | - | - | - | - | - | - | - | - | - | ||
| DE | - | - | 0.49 *** | - | - | - | 0.41 ** | - | - | ||
| IE | - | - | - | - | - | - | - | - | - | ||
| Forecasting Model | Mean Absolute Percentage Error (MAPE) (%) | Root Mean Square Error (RMSE) (%) |
|---|---|---|
| Multiple Linear Regression model | 23.09 | 21.39 |
| Artificial Neural Natural Model (ANN) | 15.54 | 14.22 |
| Back propagation neural network (BP model) | 10.15 | 10.03 |
| Gray model (GM (1,1)) | 8.61 | 7.98 |
| ARIMA model | 4.97 | 6.07 |
| GM-ARIMA Model | 4.63 | 4.09 |
| SEM-VECM Model | 1.21 | 1.02 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sutthichaimethee, P.; Ariyasajjakorn, D. Relationships between Causal Factors Affecting Future Carbon Dioxide Output from Thailand’s Transportation Sector under the Government’s Sustainability Policy: Expanding the SEM-VECM Model. Resources 2018, 7, 81. https://0-doi-org.brum.beds.ac.uk/10.3390/resources7040081
Sutthichaimethee P, Ariyasajjakorn D. Relationships between Causal Factors Affecting Future Carbon Dioxide Output from Thailand’s Transportation Sector under the Government’s Sustainability Policy: Expanding the SEM-VECM Model. Resources. 2018; 7(4):81. https://0-doi-org.brum.beds.ac.uk/10.3390/resources7040081
Chicago/Turabian StyleSutthichaimethee, Pruethsan, and Danupon Ariyasajjakorn. 2018. "Relationships between Causal Factors Affecting Future Carbon Dioxide Output from Thailand’s Transportation Sector under the Government’s Sustainability Policy: Expanding the SEM-VECM Model" Resources 7, no. 4: 81. https://0-doi-org.brum.beds.ac.uk/10.3390/resources7040081