
Power Electric Transformer Fault Diagnosis Based on Infrared Thermal Images Using Wasserstein Generative Adversarial Networks and Deep Learning Classifier


Abstract
:1. Introduction
- (1)
- This paper proposed a full-time online IRT fault detection system based on IRT image methods. Compared with other existing methods, the proposed system can find out earlier the overheating of fault location without the complicated installation and the professional operators.
- (2)
- Since the proposed method is based on the comparison between the real images and the reconstructed images, the fault feature can be extracted easily without any preprocessing for the ROI, image segmentation or complex computation for feature extraction.
- (3)
- A lightweight WAR-DIC network structure is proposed, which can effectively reduce the number of the model parameters and the storage size, ensuring the classification accuracy and the fast calculation speed when compared with other common method.
2. Theoretical Background
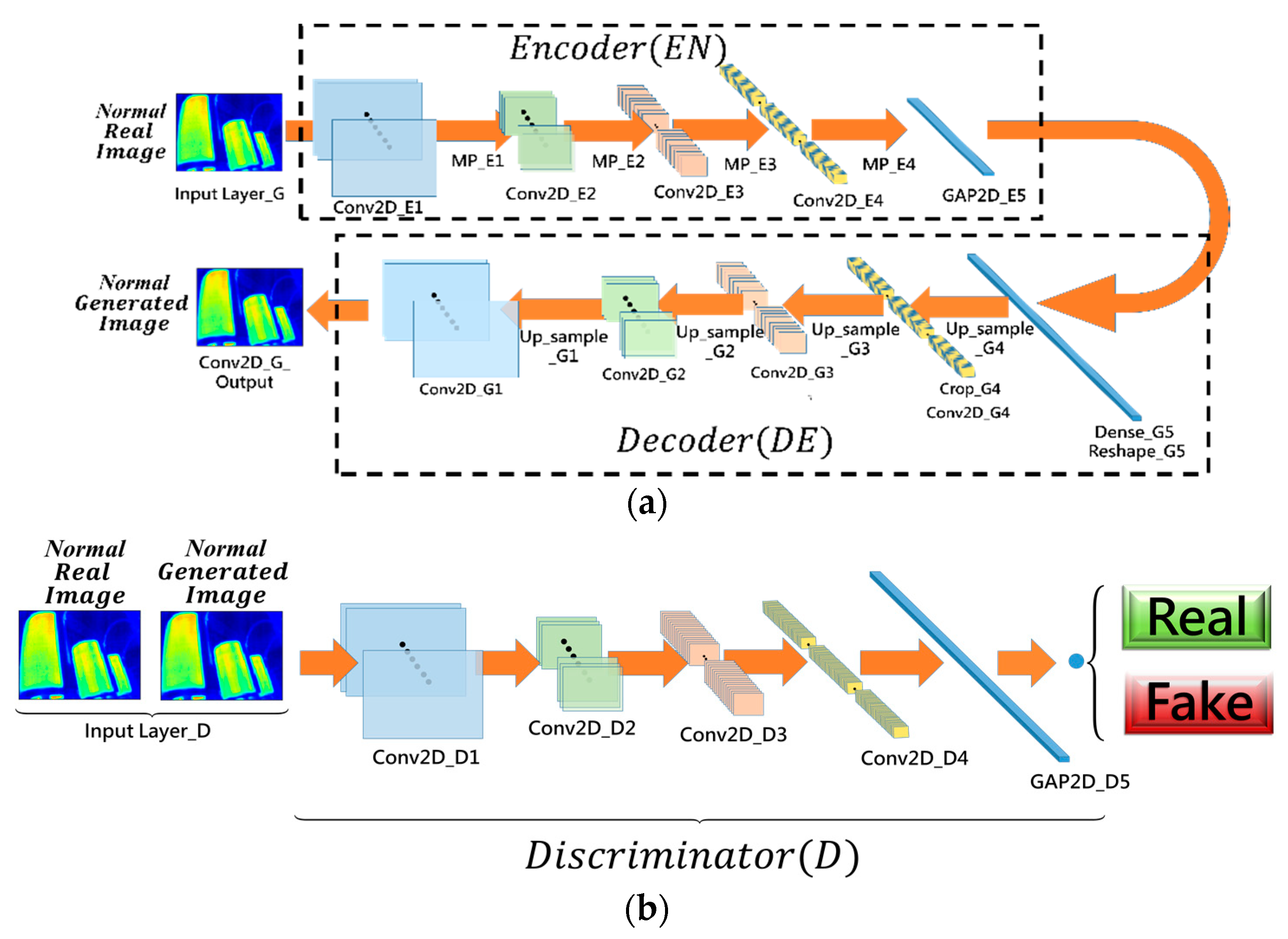
2.1. Deep Convolutional Autoencoder
2.2. Wasserstein Distance Adversarial Learning
2.3. Evaluation of GAN Generator Model
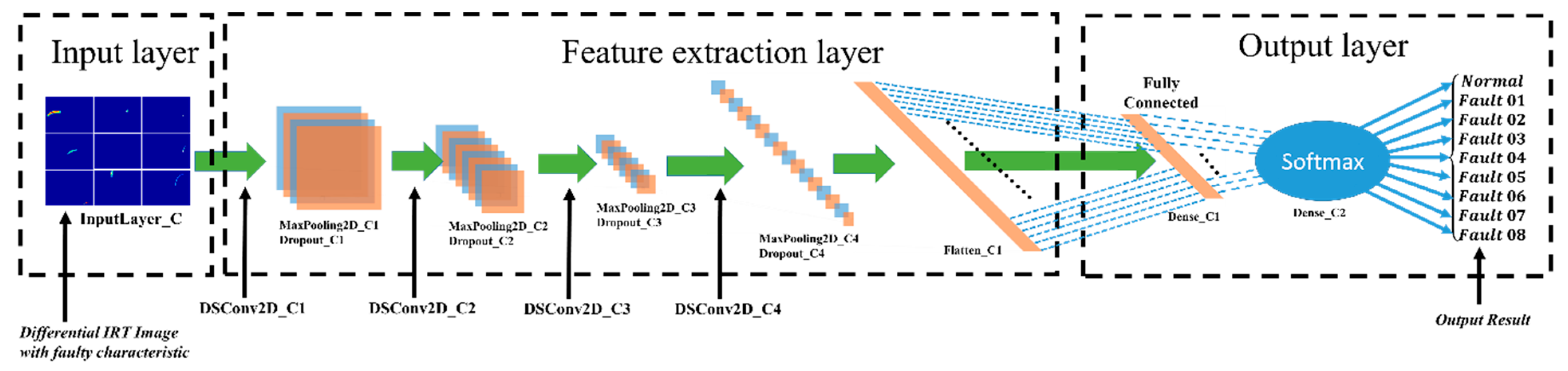
2.4. Deep Convolution Networks
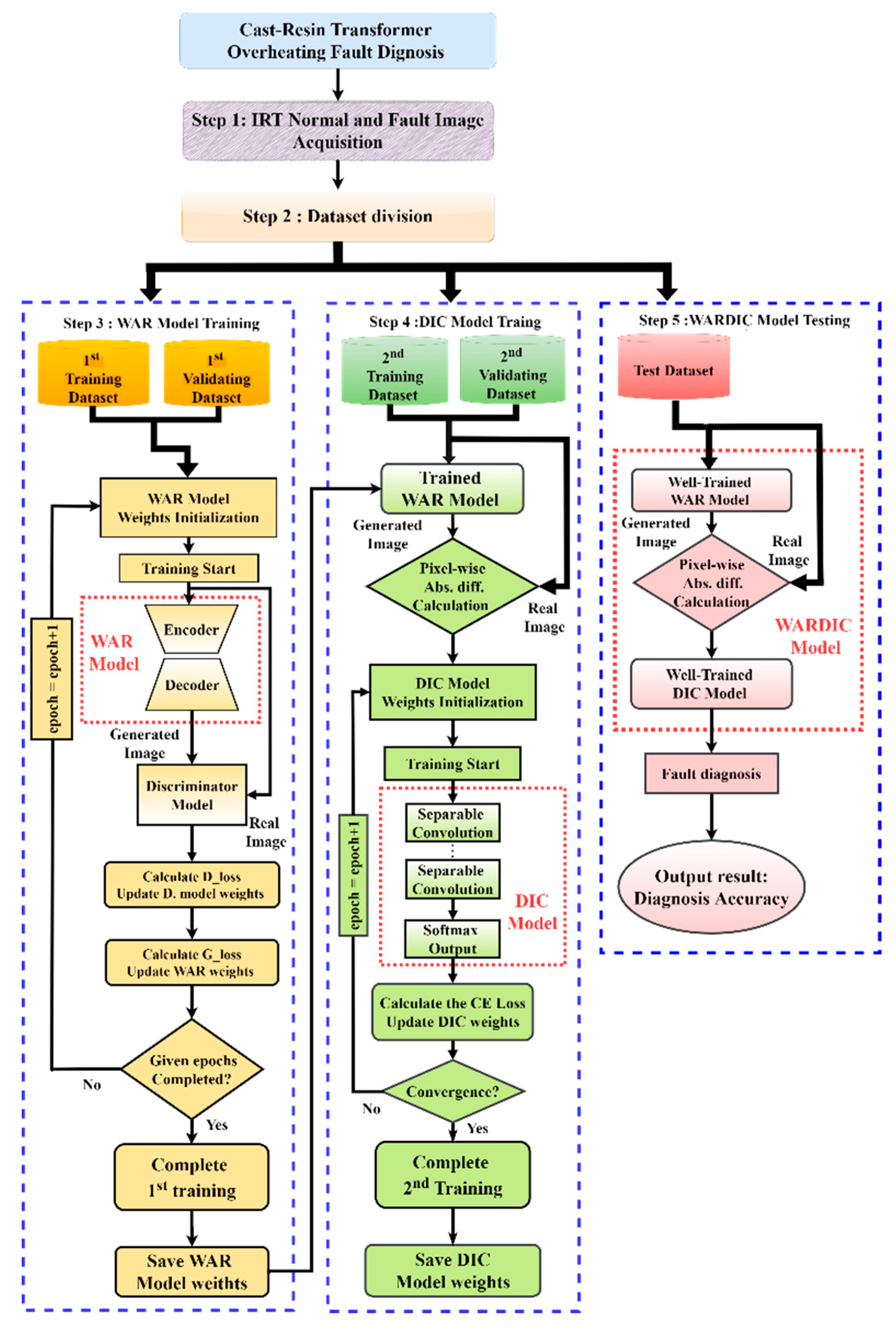
3. The Proposed Intelligent Fault Diagnosis Method
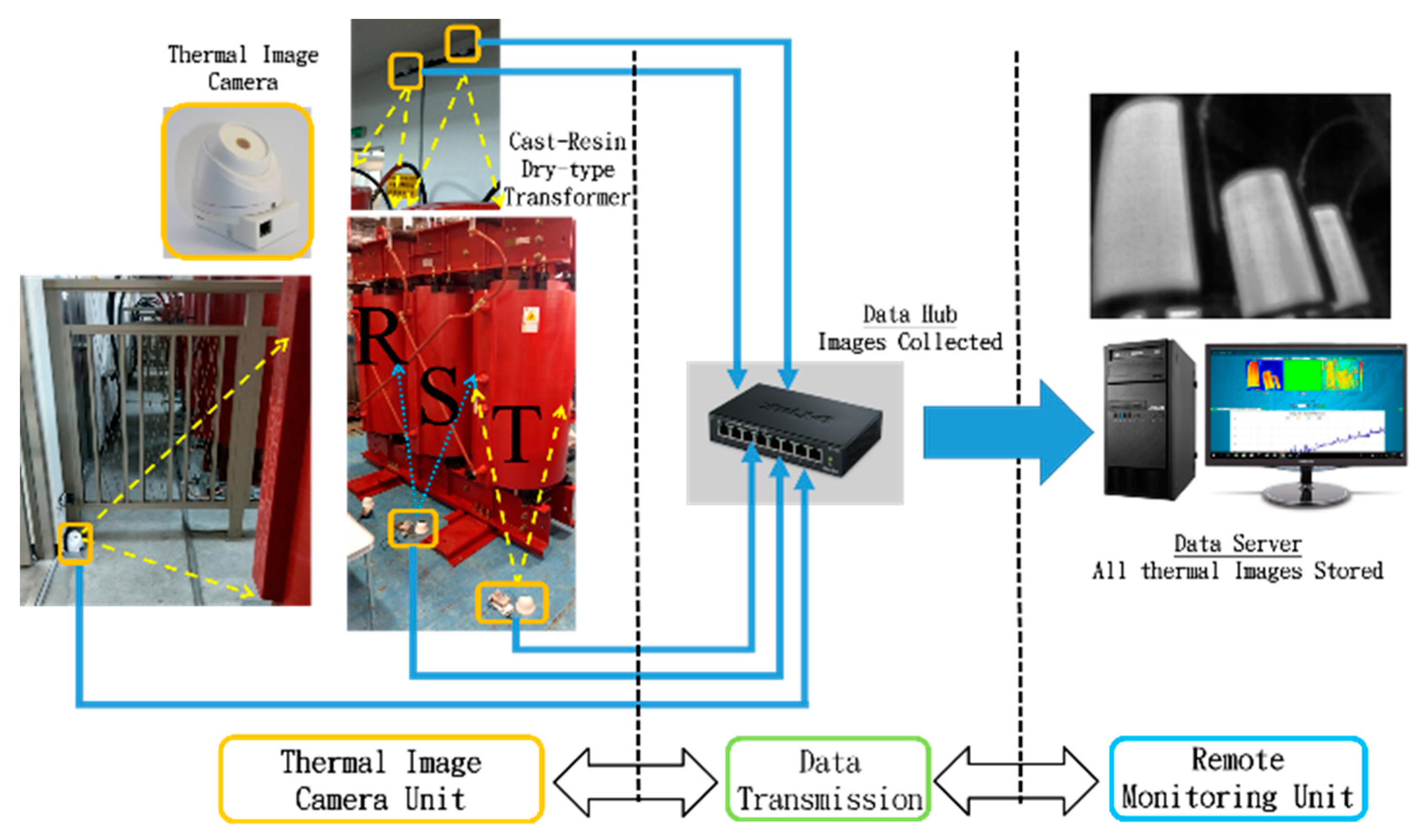
3.1. Overheating Fault Diagnosis System for Transformer-Based IRT Image
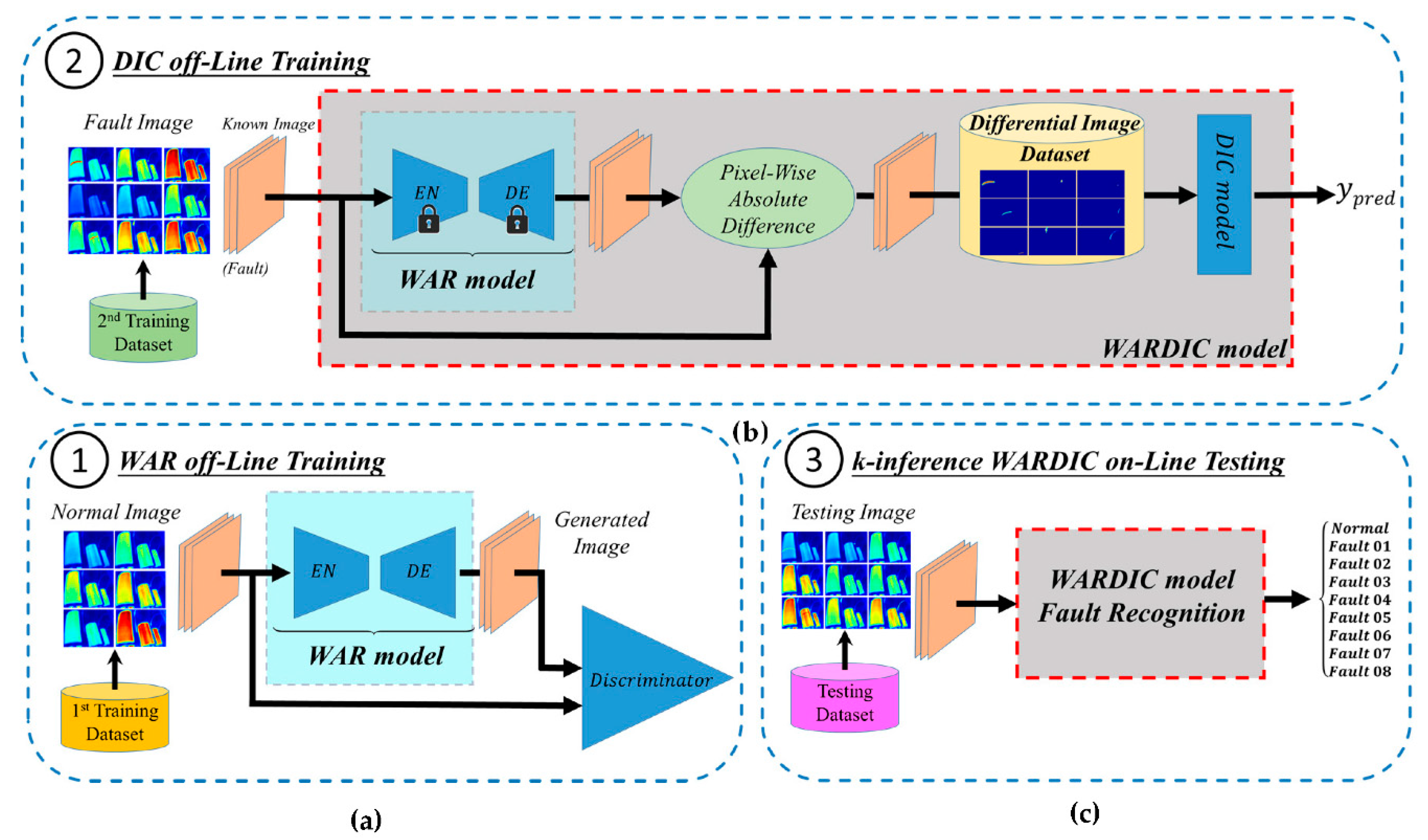
3.2. Design and Model Structure of the Proposed Networks
3.2.1. The WAR Model Off-Line Training
3.2.2. The DIC Model Off-Line Training
3.3. Diagnosis Procedure
4. Experiment Results and Comparisons
4.1. Dataset Description
4.2. Results and Discussion
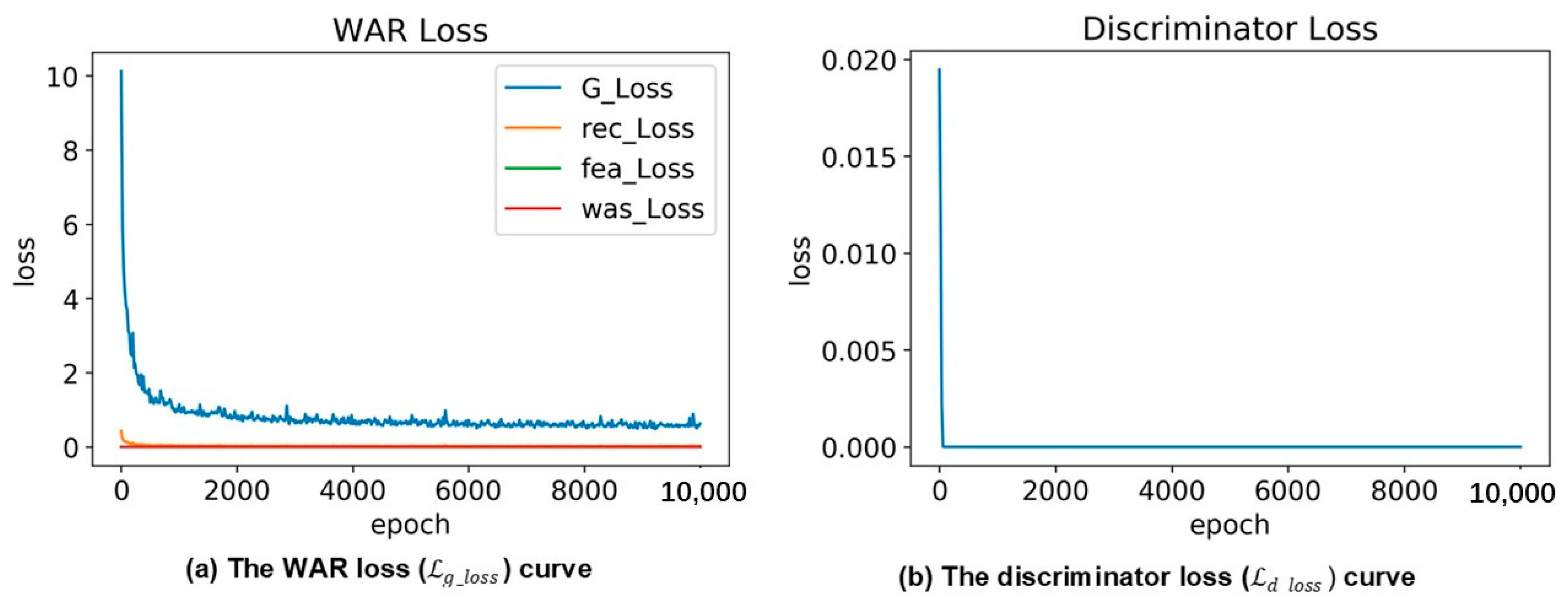
4.2.1. Evaluation Result of the WAR Model
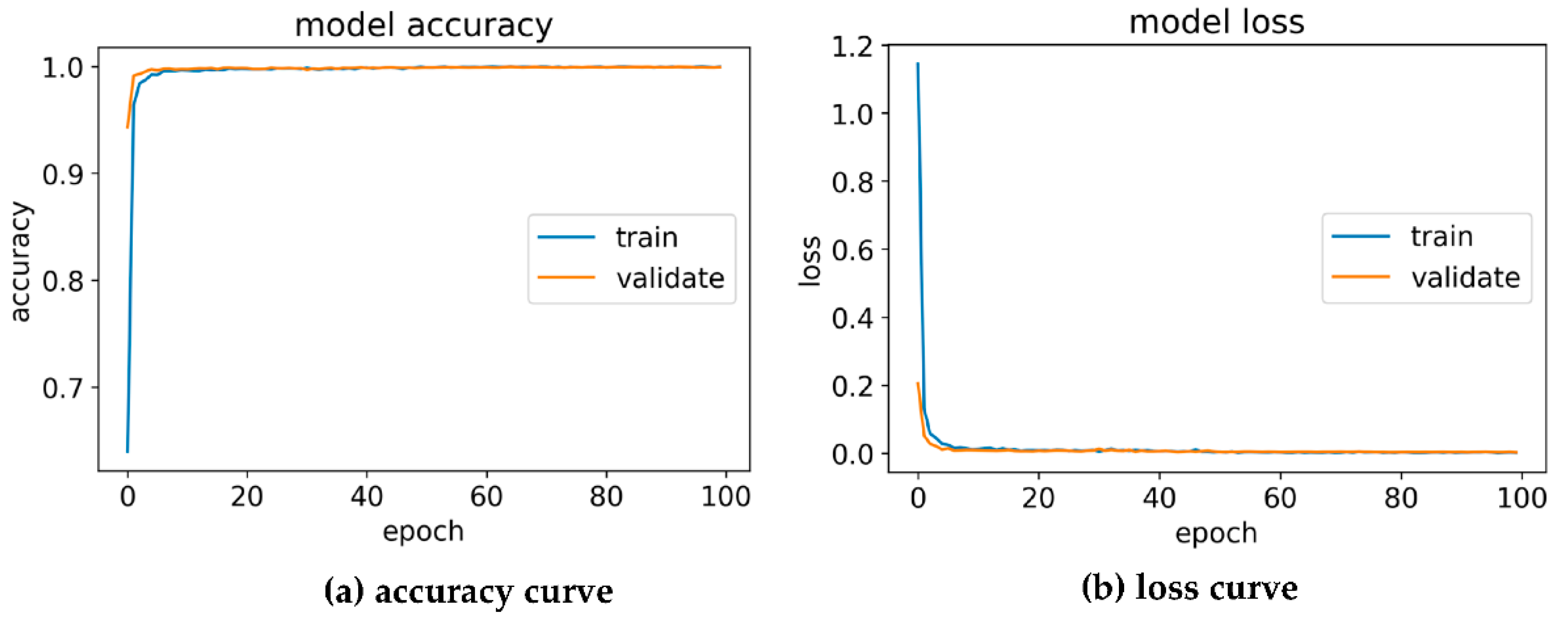
4.2.2. Evaluation Result of the DIC Model
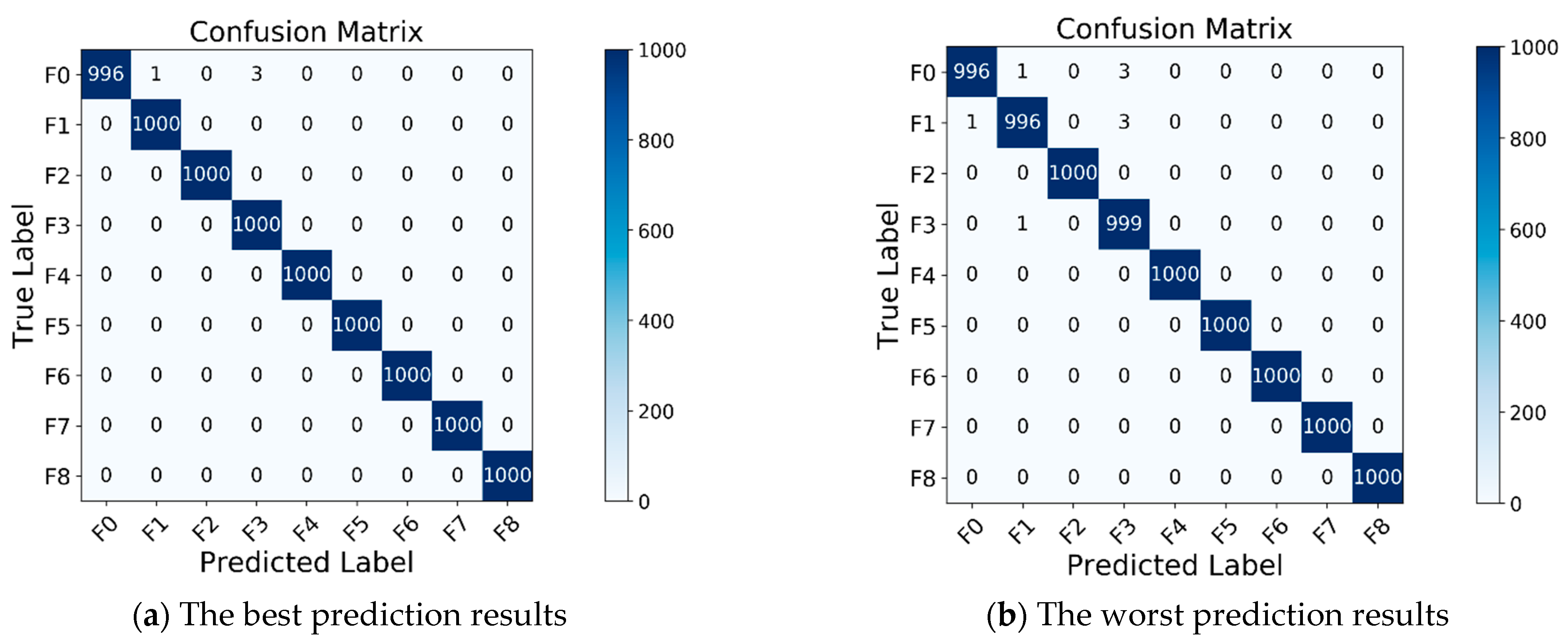
4.2.3. Testing Result of the WAR-DIC Model
4.3. Performance Analysis of the Network Parameters
4.4. Comparison with Other Methods
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Chen, P.; Huang, Y.; Zeng, F.; Jin, Y.; Zhao, X.; Wang, J. Review on insulation and reliability of dry-type transformer. In Proceedings of the 2019 IEEE Sustainable Power and Energy Conference (iSPEC), Beijing, China, 20–24 November 2019. [Google Scholar]
- Mafra, R.; Magalhães, E.; Anselmo, B.; Belchior, F.; Lima e Silva, S.M.M. Winding hottest-spot temperature analysis in dry-type transformer using numerical simulation. Energies 2018, 12, 68. [Google Scholar] [CrossRef] [Green Version]
- Duan, X.; Zhao, T.; Liu, J.; Zhang, L.; Zou, L. Analysis of Winding Vibration Characteristics of Power Transformers Based on the Finite-Element Method. Energies 2018, 11, 2404. [Google Scholar] [CrossRef] [Green Version]
- Senobari, R.K.; Sadeh, J.; Borsi, H. Frequency response analysis (FRA) of transformers as a tool for fault detection and location: A review. Electric. Power Syst. Res. 2018, 155, 172–183. [Google Scholar] [CrossRef]
- Zhang, Z.; Gao, W.; Kari, T.; Lin, H. Identification of Power Transformer Winding Fault Types by a Hierarchical Dimension Reduction Classifier. Energies 2018, 11, 2434. [Google Scholar] [CrossRef] [Green Version]
- Li, E.; Wang, L.; Song, B.; Jian, S. Improved Fuzzy C-Means Clustering for Transformer Fault Diagnosis Using Dissolved Gas Analysis Data. Energies 2018, 11, 2344. [Google Scholar] [CrossRef] [Green Version]
- Bagheri, M.; Zollanvari, A.; Nezhivenko, S. Transformer fault condition prognosis using vibration signals over cloud environment. IEEE Access 2018, 6, 9862–9874. [Google Scholar] [CrossRef]
- Sun, Y.; Hua, Y.; Wang, E.; Li, N.; Ma, S.; Zhang, L.; Hu, Y. A temperature-based fault pre-warning method for the dry-type transformer in the offshore oil platform. Int. J. Electr. Power Energy Syst. 2020, 123, 106218. [Google Scholar] [CrossRef]
- Chen, M.-K.; Chen, J.-M.; Cheng, C.-Y. Partial discharge detection in 11.4 kV cast resin power transformer. IEEE Trans. Dielectr. Electr. Insul. 2016, 23, 2223–2231. [Google Scholar] [CrossRef]
- Athikessavan, S.C.; Jeyasankar, E.; Manohar, S.S.; Panda, S.K. Inter-turn fault detection of dry-type transformers using core-leakage fluxes. IEEE Trans. Power Deliv. 2019, 34, 1230–1241. [Google Scholar] [CrossRef]
- Gockenbach, E.; Werle, P.; Borsi, H. Monitoring and diagnostic systems for dry type transformers. In Proceedings of the ICSD’01 2001 IEEE 7th International Conference on Solid Dielectrics (Cat. No.01CH37117), Eindhoven, The Netherlands, 25–29 June 2001. [Google Scholar] [CrossRef]
- Lee, C.-T.; Horng, S.-C. Abnormality detection of cast-resin transformers using the fuzzy logic clustering decision tree. Energies 2020, 13, 2546. [Google Scholar] [CrossRef]
- Tang, S.; Hale, C.; Thaker, H. Reliability modeling of power transformers with maintenance outage. Syst. Sci. Control Eng. 2014, 2, 316–324. [Google Scholar] [CrossRef]
- Tenbohlen, S.; Vahidi, F.; Jagers, J. A Worldwide Transformer Reliability Survey. In Proceedings of the VDE High Voltage Technology 2016, ETG-Symposium, Berlin, Germany, 14–16 November 2016; pp. 1–6. [Google Scholar]
- Murugan, R.; Ramasamy, R. Understanding the power transformer component failures for health index-based maintenance planning in electric utilities. Eng. Fail. Anal. 2019, 96, 274–288. [Google Scholar] [CrossRef]
- Alonso, P.E.B.; Meana-Fernández, A.; Oro, J.M.F. Thermal response and failure mode evaluation of a dry-type transformer. Appl. Therm. Eng. 2017, 120, 763–771. [Google Scholar] [CrossRef]
- Osornio-Rios, R.A.; Antonino-Daviu, J.A.; de Jesus Romero-Troncoso, R. Recent Industrial Applications of Infrared Thermography: A Review. IEEE Trans. Ind. Inform. 2019, 15, 615–625. [Google Scholar] [CrossRef]
- Zou, H.; Huang, F. A novel intelligent fault diagnosis method for electrical equipment using infrared thermography. Infrared Phys. Technol. 2015, 73, 29–35. [Google Scholar] [CrossRef]
- López-Pérez, D.; Antonino-Daviu, J. Application of Infrared Thermography to Failure Detection in Industrial Induction Motors: Case Stories. IEEE Trans. Ind. Appl. 2017, 53, 1901–1908. [Google Scholar] [CrossRef]
- Duan, J.; He, Y.; Du, B.; Ghandour, R.M.R.; Wu, W.; Zhang, H. Intelligent Localization of Transformer Internal Degradations Combining Deep Convolutional Neural Networks and Image Segmentation. IEEE Access 2019, 7, 62705–62720. [Google Scholar] [CrossRef]
- Janssens, O.; Loccufier, M.; van Hoecke, S. Thermal Imaging and Vibration-Based Multisensor Fault Detection for Rotating Machinery. IEEE Trans. Ind. Inform. 2019, 15, 434–444. [Google Scholar] [CrossRef] [Green Version]
- Siddiqui, Z.A.; Park, U.; Lee, S.-W.; Jung, N.-J.; Choi, M.; Lim, C.; Seo, J.-H. Robust Powerline Equipment Inspection System Based on a Convolutional Neural Network. Sensors 2018, 18, 3837. [Google Scholar] [CrossRef] [Green Version]
- Matuszewski, J.; Pietrow, D. Recognition of electromagnetic sources with the use of deep neural networks. In Proceedings of the XII Conference on Reconnaissance and Electronic Warfare Systems, Oltarzew, Poland, 19–21 November 2018. [Google Scholar]
- Ma, S.; Cai, W.; Liu, W.; Shang, Z.; Liu, G. A lighted deep convolutional neural network based fault diagnosis of rotating machinery. Sensors 2019, 19, 2381. [Google Scholar] [CrossRef] [Green Version]
- Kang, Q.; Zhao, H.; Yang, D.; Ahmed, H.S.; Ma, J. Lightweight convolutional neural network for vehicle recognition in thermal infrared images. Infrared Phys. Technol. 2020, 104, 103120. [Google Scholar] [CrossRef]
- Iandola, F.N.; Han, S.; Moskewicz, M.W.; Ashraf, K.; Dally, W.J.; Keutzer, K. Squeezenet: Alexnet-level accuracy with 50× fewer parameters and<1mb model size, CoRR. arXiv 2016, arXiv:1602.07360. [Google Scholar]
- Biswas, D.; Su, H.; Wang, C.; Stevanovic, A.; Wang, W. An automatic traffic density estimation using Single Shot Detection (SSD) and MobileNet-SSD. Phys. Chem. Earth 2019, 110, 176–184. [Google Scholar] [CrossRef]
- Zhang, X.; Zhou, X.; Lin, M.; Sun, J. ShuffleNet: An extremely efficient convolutional neural network for mobile devices. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar] [CrossRef] [Green Version]
- Masci, J.; Meier, U.; Cireşan, D.; Schmidhuber, J. Stacked convolutional auto-encoders for hierarchical feature extraction. In Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2011; pp. 52–59. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; pp. 2672–2680. [Google Scholar]
- Wiatrak, M.; Albrecht, S.V.; Nystrom, A. Stabilizing Generative Adversarial Networks: A Survey. arXiv 2020, arXiv:1910.00927v2. Available online: https://arxiv.org/pdf/1910.00927.pdf (accessed on 12 May 2021).
- Wang, Z.; She, Q.; Ward, T.E. Generative adversarial networks in computer vision: A survey and taxonomy. ACM Comput. Surv. 2021, 54, 1–38. [Google Scholar]
- Arjovsky, M.; Bottou, L. Towards Principled Methods for Training Generative adversarial Networks. arXiv 2017, arXiv:1701.04862. Available online: https://arxiv.org/abs/1701.04862 (accessed on 12 May 2021).
- Salimans, T.; Goodfellow, I.; Zaremba, W.; Cheung, V.; Radford, A.; Chen, X. Improved techniques for training GANs. In Proceedings of the 30th International Conference on Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; pp. 2234–2242. [Google Scholar]
- Arjovsky, M.; Chintala, S.; Bottou, L. Wasserstein Generative Adversarial Networks. In Proceedings of the 34th International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; Volume 70, pp. 214–223. [Google Scholar]
- Akcay, S.; Abarghouei, A.A.; Breckon, T.P. GANomaly: Semi-supervised Anomaly Detection via Adversarial Training. ACCV 2018, 11363, 622–637. [Google Scholar]
- Wang, Z.; Chen, J.; Hoi, S.C.H. Deep learning for image super-resolution: A survey. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 1. [Google Scholar] [CrossRef] [Green Version]
- Borji, A. Pros and cons of GAN evaluation measures. Comput. Vis. Image Underst. 2019, 179, 41–65. [Google Scholar] [CrossRef] [Green Version]
- Han, J.; Moraga, C. The influence of the sigmoid function parameters on the speed of backpropagation learning. In Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 1995; pp. 195–201. [Google Scholar]
- Agarap, A.F. Deep Learning Using Rectified Linear Units (ReLU). arXiv 2018, arXiv:1803.08375. [Google Scholar]
- Chollet, F. Xception: Deep learning with depthwise separable convolutions. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Yao, D.; Liu, H.; Yang, J.; Li, X. A lightweight neural network with strong robustness for bearing fault diagnosis. Measurement 2020, 159, 107756. [Google Scholar] [CrossRef]
- Gong, W.; Chen, H.; Zhang, Z.; Zhang, M.; Wang, R.; Guan, C.; Wang, Q. A novel deep learning method for intelligent fault diagnosis of rotating machinery based on improved CNN-SVM and multichannel data fusion. Sensors 2019, 19, 1693. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Isola, P.; Zhu, J.-Y.; Zhou, T.; Efros, A.A. Image-to-image translation with conditional adversarial networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Duchi, J.C.; Hazan, E.; Singer, Y. Adaptive Subgradient Methods for Online Learning and Stochastic Optimization. J. Mach. Learn. Res. 2011, 12, 2121–2159. [Google Scholar]
- Qian, N. On the momentum term in gradient descent learning algorithms. Neural Netw. 1999, 12, 145–151. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- LeCun, Y. LeNet-5, Convolutional Neural Networks. 2015. Available online: http://yann.lecun.com/exdb/lenet (accessed on 12 May 2021).
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NE, USA, 26 June–1 July 2016. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556v6. [Google Scholar]
- He, H.; Garcia, E.A. Learning from imbalanced data. IEEE Trans. Knowl. Data Eng. 2009, 21, 1263–1284. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Advantage | Disadvantage |
|---|---|---|
| FRA [4,5] | High sensitivity | Influenced by external noise available only for offline operating |
| Vibration sensor [7] | Easy portability Good in real-time monitoring | Influenced by external noise |
| Thermal sensor [8] | Good in real-time monitoring | Difficult to locate the fault point |
| Magnetic sensor [9] | Higher immunity against noise | Difficult to install |
| Core-Leakage Fluxes sensor [10] | Low cost to install Good in real-time monitoring | Influenced by the excitation currents Need professional knowledge Required by external protection |
| Fiber optic sensor [11] | Capable to detect and locate PD | Difficult to install |
| RF sensor [12] | High sensitivity High measurement Precision | Difficult to apply on-site measurement Need professional knowledge |
| Ours | Good in real-time monitoring Higher immunity against noise | Require GPU for real-time processing. |
| Layer Type | Number of Kernel | Size of Kernel | Activation (DR Rate) | Output Shape |
|---|---|---|---|---|
| Input Layer_G | - | - | - | 120 × 160 × 3 |
| Conv2D_E1 | 8 | 5 × 5 | ReLU/BN | 120 × 160 × 8 |
| MP_E1 | - | 2 × 2 | - | 60 × 80 × 8 |
| Conv2D_E2 | 16 | 3 × 3 | ReLU/BN | 60 × 80 × 16 |
| MP_E2 | 2 × 2 | 30 × 40 × 16 | ||
| Conv2D_E3 | 24 | 3 × 3 | ReLU/BN | 30 × 40 × 24 |
| MP_E3 | - | 2 × 2 | - | 15 × 20 × 24 |
| Conv2D_E4 | 32 | 3 × 3 | ReLU/BN | 15 × 20 × 32 |
| MP_E4 | - | 2 × 2 | - | 8 × 10 × 32 |
| GAP2D_E5 | - | - | - | 32 |
| Dense_G5 | - | - | - | 2560 |
| Reshape_G5 | - | - | - | 8 × 10 × 32 |
| Up_sample_G4 | - | - | - | 16 × 20 × 32 |
| Crop_G4 | - | - | (0, 1), (0, 0) | 15 × 20 × 32 |
| Conv2D_G4 | 32 | 3 × 3 | ReLU/BN | 15 × 20 × 32 |
| Up_sample_G3 | - | 2 × 2 | - | 30 × 40 × 32 |
| Conv2D_G3 | 24 | 3 × 3 | ReLU/BN | 30 × 40 × 24 |
| Up_sample_G2 | - | 2 × 2 | - | 60 × 80 × 24 |
| Conv2D_G2 | 16 | 3 × 3 | ReLU/BN | 60 × 80 × 16 |
| Up_sample_G1 | - | 2 × 2 | - | 120 × 160 × 16 |
| Conv2D_G1 | 8 | 3 × 3 | ReLU/BN | 120 × 160 × 8 |
| Conv2D_G_Output | 3 | 1 × 1 | Sigmoid | 120 × 160 × 3 |
| Layer Type | Number of Kernel | Size of Kernel | Activation | Output Shape |
|---|---|---|---|---|
| Input Layer_D | - | - | - | 120 × 160 × 3 |
| Conv2D_D1 | 8 | 5 × 5 | ReLU/BN | 120 × 160 × 8 |
| Conv2D_D2 | 16 | 3 × 3 | ReLU/BN | 60 × 80 × 16 |
| Conv2D_D3 | 32 | 3 × 3 | ReLU/BN | 30 × 40 × 32 |
| Conv2D_D4 | 128 | 3 × 3 | ReLU/BN | 15 × 20 × 128 |
| GAP2D_D5 | - | - | - | 128 |
| Dense_D5 | - | - | Linear | 1 |
| Layer Type | Number of Kernel | Size of Kernel | Activation | Output Shape |
|---|---|---|---|---|
| InputLayer_C | - | - | - | 120 × 160 × 3 |
| DSConv2D_C1 | 8 | 3 × 3 | ReLU | 120 × 160 × 8 |
| MP2D_C1 | - | 2 × 2 | - | 60 × 80 × 8 |
| DSConv2D_C2 | 16 | 3 × 3 | ReLU | 60 × 80 × 16 |
| MP2D_C2 | - | 2 × 2 | - | 30 × 40 × 16 |
| DSConv2D_C3 | 32 | 3 × 3 | ReLU | 30 × 40 × 32 |
| MP2D_C3 | - | 2 × 2 | - | 15 × 20 × 32 |
| DSConv2D_C4 | 64 | 3 × 3 | ReLU | 15 × 20 × 64 |
| MP2D_C4 | - | 2 × 2 | - | 7 × 10 × 64 |
| Flatten_C1 | - | - | - | 4480 |
| Dense_C1 | 16 | - | ReLU | 16 |
| OutputLayer_C | 9 | - | SoftMax | 1 |
| Cast-Resin Transformer Fault Type | Label | Number of Training Dataset | Number of Testing Datasets | |||||
|---|---|---|---|---|---|---|---|---|
| 1st Training for WAR | 2nd Training for DIC | |||||||
| Dataset 1 | Dataset 2A | Dataset 2B | Dataset 2C | Dataset 2D | ||||
| Normal | F0 | 1000 | 1000 | 1000 | 1000 | 1000 | 1000 | |
| Interturn short circuit | (R) | F1 | - | 1000 | 500 | 200 | 100 | 1000 |
| (S) | F2 | - | 1000 | 500 | 200 | 100 | 1000 | |
| (T) | F3 | - | 1000 | 500 | 200 | 100 | 1000 | |
| Connection overheating | (R) | F4 | - | 1000 | 500 | 200 | 100 | 1000 |
| (S) | F5 | - | 1000 | 500 | 200 | 100 | 1000 | |
| (T) | F6 | - | 1000 | 500 | 200 | 100 | 1000 | |
| Wire overheating | (S) | F7 | - | 1000 | 500 | 200 | 100 | 1000 |
| (T) | F8 | - | 1000 | 500 | 200 | 100 | 1000 | |
| Epoch | FID | Mean_SSIM | Mean_PSNR |
|---|---|---|---|
| 4700 | 0.447291 | 0.999919 | 76.433 |
| 5540 | 0.288334 | 0.999837 | 75.162 |
| 6420 | 0.316712 | 0.999927 | 77.061 |
| 7000 | 0.295348 | 0.999757 | 73.630 |
| 7040 | 0.299828 | 0.999765 | 74.588 |
| 8240 | 0.298133 | 0.999734 | 74.416 |
| 8320 | 0.276073 | 0.999832 | 75.667 |
| 8400 | 0.299400 | 0.999772 | 74.258 |
| 9500 | 0.256580 | 0.999874 | 76.293 |
| 9540 | 0.257940 | 0.999856 | 75.998 |
| Training Dataset | Max. Accuracy | Max. Accuracy | Mean Accuracy | Std |
|---|---|---|---|---|
| 2A | 99.95% | 99.91% | 99.92% | 0.0235% |
| 2B | 99.88% | 99.78% | 99.86% | 0.0228% |
| 2C | 99.71% | 99.65% | 99.69% | 0.0205% |
| 2D | 99.45% | 99.38% | 99.42% | 0.0219% |
| Fault Type | Precision | Sensitivity | Specificity | Accuracy |
|---|---|---|---|---|
| F0 | 100% | 99.60% | 100% | 99.95% |
| F1 | 100% | 99.90% | 99.98% | |
| F2 | 100% | 100% | 100% | |
| F3 | 99.50% | 100% | 99.96% | |
| F4 | 100% | 100% | 100% | |
| F5 | 100% | 100% | 100% | |
| F6 | 100% | 100% | 100% | |
| F7 | 100% | 100% | 100% | |
| F8 | 100% | 100% | 100% |
| Method | Number of Total Parameters (Million) | Floating-Point Computations (Million) | Weight Storage (MB) |
|---|---|---|---|
| ShuffleNet | 3.903 | 64.875 | 31.725 |
| MobileNetV1 | 3.494 | 58.697 | 27.513 |
| SqueezeNet | 0.378 | 2.27 | 3.068 |
| LeNet5 | 6.448 | 77.379 | 50.406 |
| ResNet-50 | 24.115 | 408.620 | 188.794 |
| VGG-16 | 14.849 | 252.392 | 116.103 |
| Ours | 0.223 | 1.781 | 1.837 |
| Method | Classification Accuracy | Inference Time (sec/1.8 K Images) | |||
|---|---|---|---|---|---|
| 2A | 2B | 2C | 2D | ||
| SVM | 98.56% | 97.84% | 94.50% | 87.34% | 287.59 |
| RF | 98.51% | 94.64% | 95.52% | 86.28% | 0.21 |
| DT | 97.39% | 91.87% | 84.62% | 76.86% | 0.09 |
| ShuffleNet | 99.93% | 99.78% | 99.31% | 11.13% | 90.44 |
| MobileNetV1 | 99.92% | 99.75% | 98.65% | 11.11% | 78.10 |
| SqueezeNet | 99.90% | 99.83% | 99.44% | 99.15% | 24.62 |
| LeNet5 | 99.94% | 99.63% | 99.57% | 98.82% | 26.83 |
| ResNet-50 | 99.96% | 99.90% | 99.32% | 98.94% | 86.94 |
| VGG-16 | 99.96% | 99.95% | 11.11% | 11.11% | 346.33 |
| Ours | 99.95% | 99.89% | 99.71% | 99.46% | 28.53 |
| Method | Precision | Recall | Specificity | ROC AUC |
|---|---|---|---|---|
| SVM | 88.63% | 87.34% | 98.41% | 0.982382 |
| RF | 90.99% | 85.82% | 98.23% | 0.991549 |
| DT | 78.05% | 76.87% | 97.11% | 0.869988 |
| SqueezeNet | 99.22% | 99.16% | 99.89% | 0.999951 |
| LeNet5 | 98.28% | 99.78% | 98.51% | 0.999961 |
| ResNet 50 | 99.03% | 98.94% | 99.87% | 0.999930 |
| Ours | 99.46% | 99.45% | 99.93% | 0.999971 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fanchiang, K.-H.; Huang, Y.-C.; Kuo, C.-C. Power Electric Transformer Fault Diagnosis Based on Infrared Thermal Images Using Wasserstein Generative Adversarial Networks and Deep Learning Classifier. Electronics 2021, 10, 1161. https://0-doi-org.brum.beds.ac.uk/10.3390/electronics10101161
Fanchiang K-H, Huang Y-C, Kuo C-C. Power Electric Transformer Fault Diagnosis Based on Infrared Thermal Images Using Wasserstein Generative Adversarial Networks and Deep Learning Classifier. Electronics. 2021; 10(10):1161. https://0-doi-org.brum.beds.ac.uk/10.3390/electronics10101161
Chicago/Turabian StyleFanchiang, Kuo-Hao, Yen-Chih Huang, and Cheng-Chien Kuo. 2021. "Power Electric Transformer Fault Diagnosis Based on Infrared Thermal Images Using Wasserstein Generative Adversarial Networks and Deep Learning Classifier" Electronics 10, no. 10: 1161. https://0-doi-org.brum.beds.ac.uk/10.3390/electronics10101161