1. Introduction
Human-centered computing is a new area of study and application that focuses on understanding human behavior and combining users and their social backgrounds with digital technology. Human activity recognition (HAR), which attempts to recognize the behavior, features, and objectives of one or more persons from a temporal sequence of observations transmitted from one or more sensors, is required and subsumed by this [
1]. Successful recognition of human activities can be extensively useful in ambient assisted living (AAL) applications [
2] such as intelligent activity monitoring systems developed for elderly and disabled people in healthcare systems [
3], automatic interpretation of hand gestures in sports [
4], user identify verification for security systems using gait characteristics [
5], and human–robot interactions through gesture recognition [
6]. Typically, the objectives of HAR systems are to (1) determine (both online and offline) the ongoing actions/activities of an individual, a group of individuals, or even a community based on sensory observation data; (2) identify certain individual characteristics such as the identity of people in a particular frame, gender, age, and so on; and (3) increase awareness concerning the context in which observational interactions have actually been happening. The variety of sensory data used significantly influences the types of functionality, algorithms, architectures, and approaches used for research, so HAR systems can be categorized based on the modality of sensory data used [
7,
8]. In general, the following research and development types in HAR systems can be identified [
9]: (1) HAR systems based on visual information (images and videos), (2) HAR systems based on motion inertial sensors like IMUs (inertial measurement units), and (3) HAR systems based on obtained signal strength from commodity networks in the surrounding area. The second methodology, sensor-based human activity recognition (S-HAR) [
10], is the target of this ongoing study.
The concept behind an automated S-HAR design is to obtain data from a collection of sensors that are influenced by the motion characteristics of various body joints. Following this, several features are extracted based on these measurements to be used in the training of activity models, which will subsequently be used to identify these activities [
11,
12]. Activities of daily living (ADL) that individuals have the ability to do on a regular basis, such as dining, walking, washing, dressing, and so on, are good illustrations of such activities [
13]. There are a variety of methodologies and data gathering systems for recognizing these actions, all of which are based on various sensory measurements [
14]. Wearable devices are among the most effective tools in our conventional lifestyles, and they become more capable of meeting client needs and expectations as technology advances. Developers are always adding new features and components to the products to make these gadgets more practical and effective. Sensors play an important part in making wearable devices more functional and aware of their surroundings. Hence, most smart-wearable gadgets have a variety of integrated sensors, allowing for the collection of large amounts of data on the user’s simple human activities (SHA) and complex human activities (CHA). Almost all smart-wearable gadget makers use an accelerometer and a gyroscope as conventional sensors. Accelerometers are sensors that detect the acceleration of moving objects along referential axes. They are especially good at tracking simple human actions such as walking, jogging, resting, standing, and ascending since they entail repetitive body movements [
15,
16]. The data from the accelerometer can be analyzed to detect dramatic changes in motion. The gyroscope, which determines direction using gravity, is another sensor that has become common technology for smart-wearable devices. Signal data obtained by the gyroscope can be analyzed to determine the device’s position and alignment [
17]. Most of the previous studies have been conducted on SHA recognition, whereas trivial research has been carried out on CHA recognition [
18]. Many vital aspects (recognition accuracy, computational cost, energy consumption, privacy, mobility) need to be addressed in both areas to improve their viability.
HAR with wearable sensors has traditionally been viewed as a multivariant time-series classification challenge. Feature extraction is a critical step in solving the problem, and it may be done using the statistical methodology in both the time and frequency domains [
19]. Traditional machine learning algorithms such as Naïve Bayes, decision trees, and support vector machines have effectively classified various kinds of human activities [
20]. Handcrafted feature extraction, on the other hand, necessitates domain knowledge or expertise. As a result, statistical learning methods could not identify discriminative features that could appropriately differentiate complex activities. The architecture of a deep model with convolutional layers [
21] has been used to achieve automatic feature extraction in a deep learning (DL) environment. Convolutional neural networks (CNNs) were used in the early stages of DL-based HAR research to solve sensor-based HAR by automatically extracting abstract characteristics from sensor data [
22,
23]. While CNNs can capture the spatial domain of sensor data and provide adequate performance for simple activities, they are unable to capture complex activities that require analysis of the wearable sensor data’s temporal characteristics [
24]. Implementing diverse classifiers utilizing deep learning approaches to categorize complex human activities with high performance can be considered a significant challenge. As a result, in HAR [
25], recurrent neural networks (RNNs) are applied, providing significance to temporal information from wearable sensor data. The RNN, on the other hand, has a vanishing or exploding gradient problem, making it difficult to train. Long short-term memory neural networks were developed to tackle this problem (LSTM). Many recent works in HAR have used LSTMs to improve performance [
23,
26]. Hybrid deep learning models have recently been developed to address the drawbacks of both CNN and RNN neural networks.
Learning spatial representation from sensor data is a strength of the CNN, but learning temporal representation from sensor data is a strength of the RNN. As a result, a hybrid model combines these two modules to enable the model to learn a rich representation of sensor input in spatial and temporal feature representation. HAR was performed using a CNN and LSTM in [
27]. The input was entered into a CNN structure, which was then followed by LSTM modules. As a consequence, the hybrid model outperforms using only a CNN or RNN. From the sensor data provided, the model was capable of learning a detailed representation. A CNN and gated recurrent unit (GRU) model framework was presented in [
28]. We have also recently seen several deep neural network methods applied in complicated human activity recognition. Researchers have used deep neural networks to determine how to solve the complex HAR issue. The former state-of-the-art models on the complex HAR were InceptionTime [
29] and DeepCovnTCN [
30]. Furthermore, after many years, the extraction of valuable characteristics was the most challenging part of the mobile and wearable sensor-based HAR pipeline [
31]. It had an impact on categorization accuracy, computing speed, and complexity.
The literature mentioned above inspires us to learn the spatial and temporal features of each unit-level activity and then use these high-level abstract features to recognize complex human activities from both accelerometer and gyroscope data. In this research, the S-HAR framework to address CHA recognition is introduced. The proposed CNN-BiGRU model for activity recognition underwent several experiments with the UTwente dataset to determine the most effective window sizes and a DL approach that outperforms the CHA issue. With a score of 98.89%, the proposed approach surpasses previous DL models in terms of accuracy according to model validation using assessment criteria. As a result, the following are the primary contributions of this paper:
Different DL networks were implemented to analyze and classify complex human activity data.
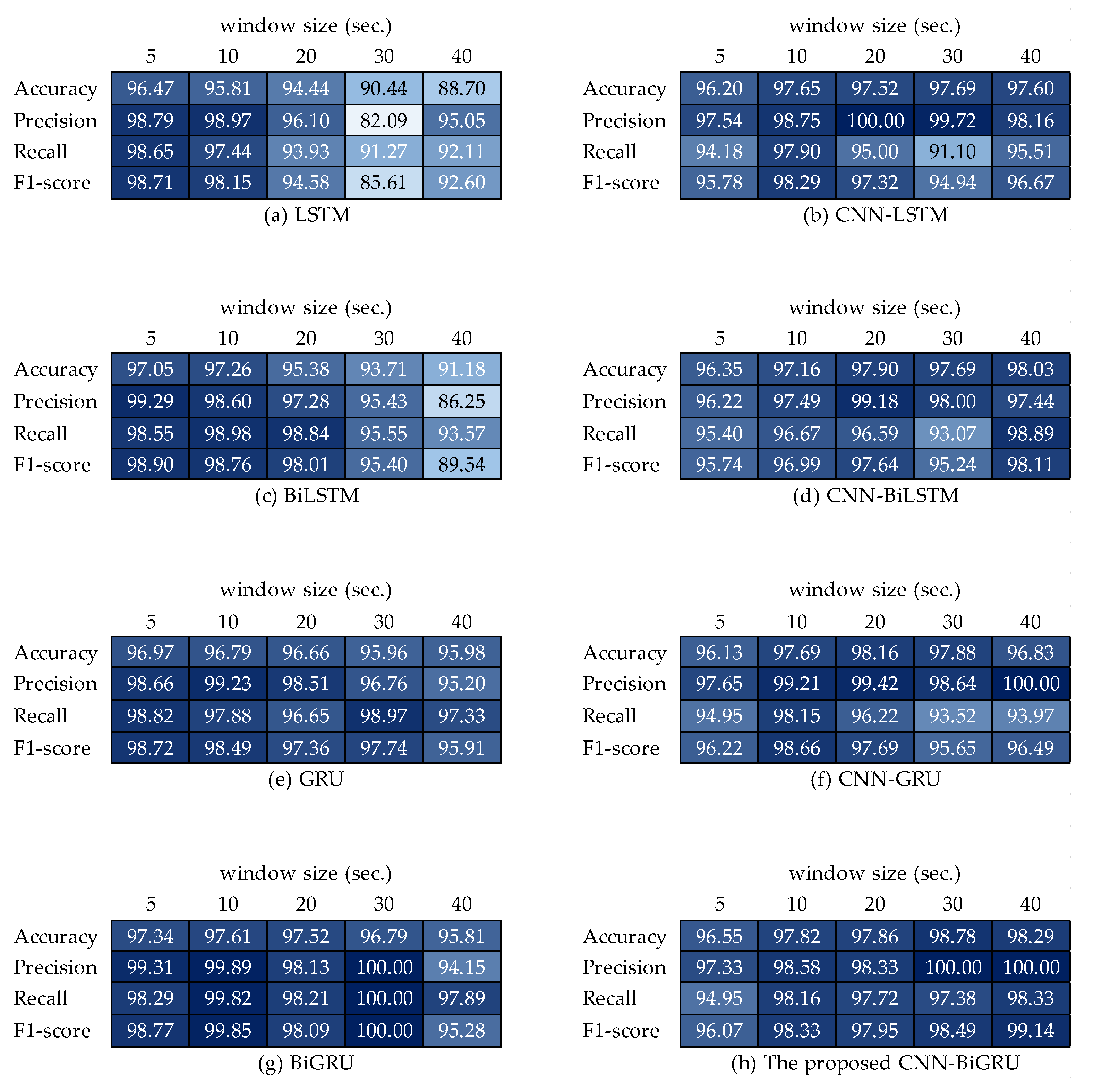
Using four baseline recurrent neural network (RNN) models (LSTMs, BiLSTMs, GRUs, and BiGRUs) and various hybrid DL models, we evaluated fundamental recognition performance indicators (accuracy, precision, recall, F1-score, and confusion matrix) for these DL models.
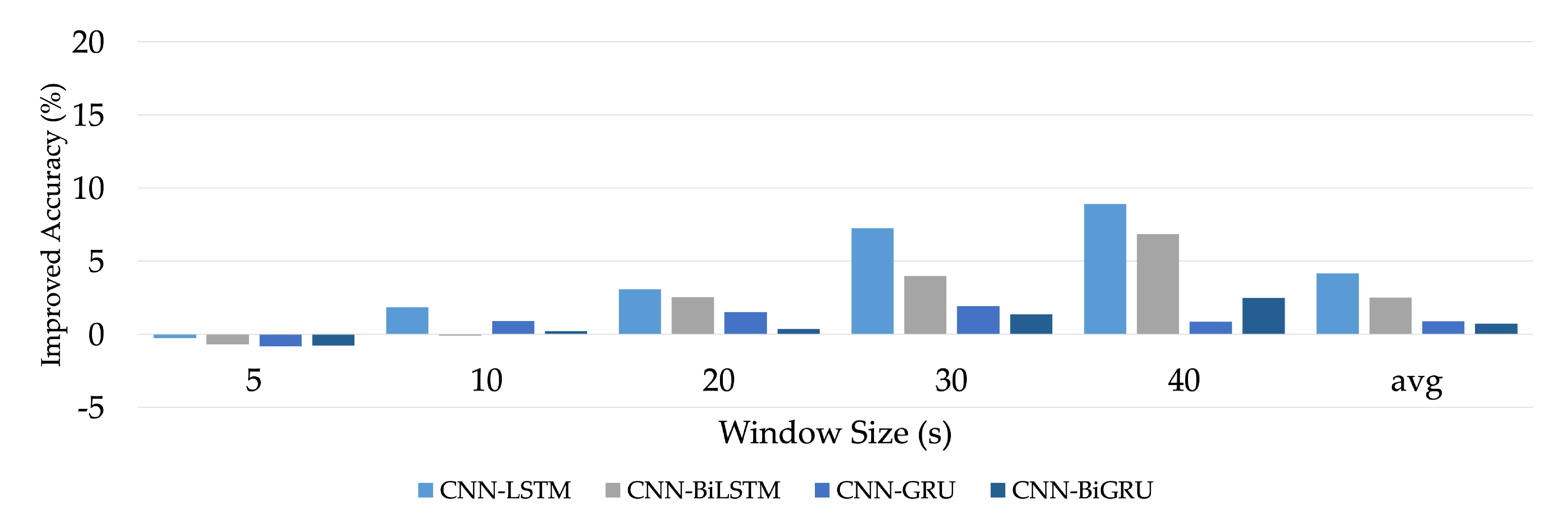
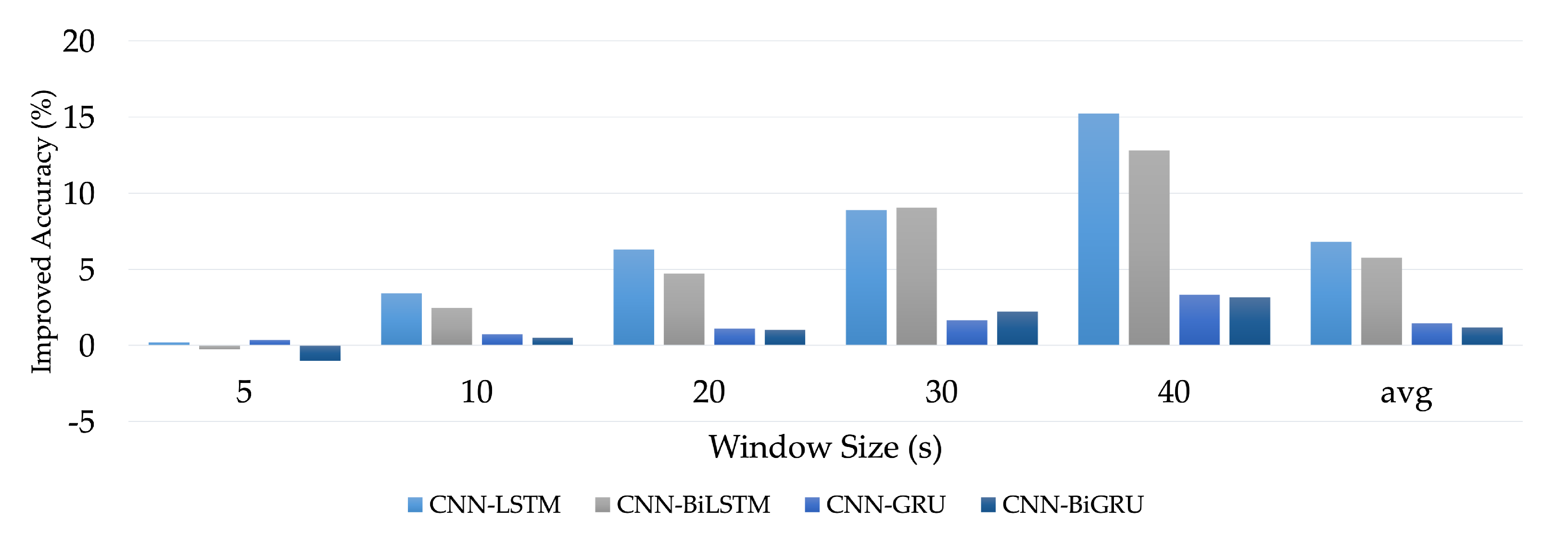
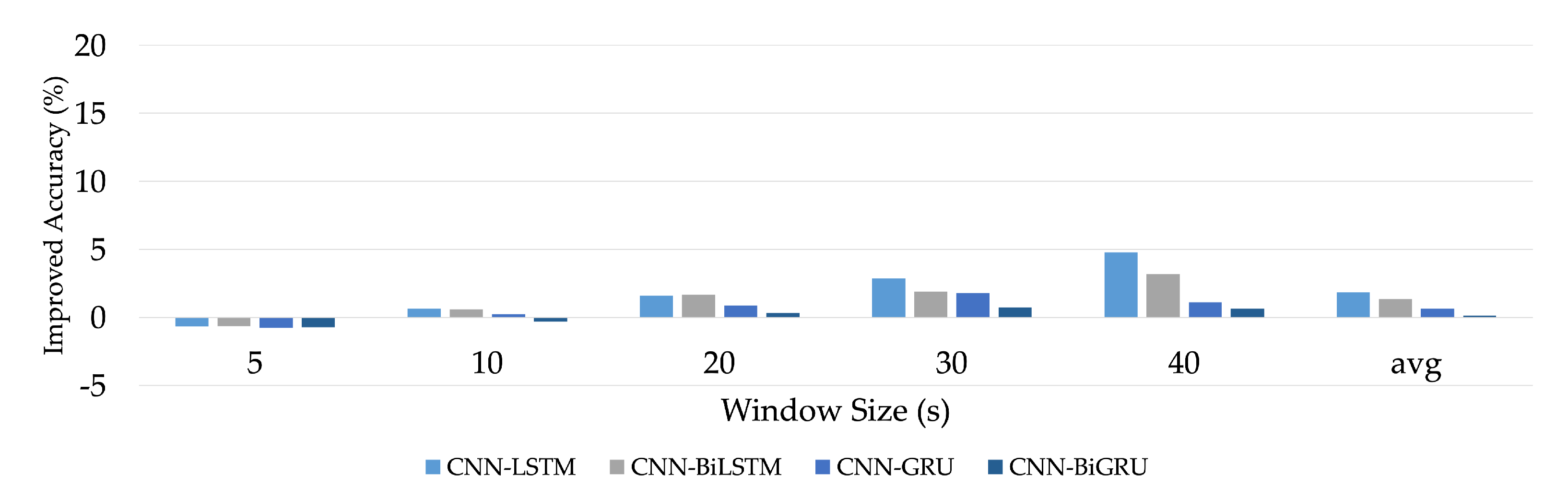
We analyzed the impacts of various aspects on the evaluation outcomes (window sizes, integrating with convolutional layers, and bidirectional method).
On the same complex human activity dataset, we compared the performance of the proposed model against that of other baseline DL methods.
The remainder of this paper is structured as follows:
Section 2 presents an overview of related HAR concepts and DL approaches.
Section 3 details the proposed S-HAR framework for complex human activity recognition.
Section 4 presents research experiments conducted on the UTwente dataset, while the derived results are discussed in
Section 5. A summary of the research study and possible future directions are concluded in
Section 6.
3. The Proposed S-HAR Framework
This section presents an S-HAR framework for addressing the study’s goal of CHA recognition. Using signal data gathered from wrist-worn sensors, the S-HAR framework developed in this research leverages DL algorithms to explore the activity conducted by the wearable device’s user.
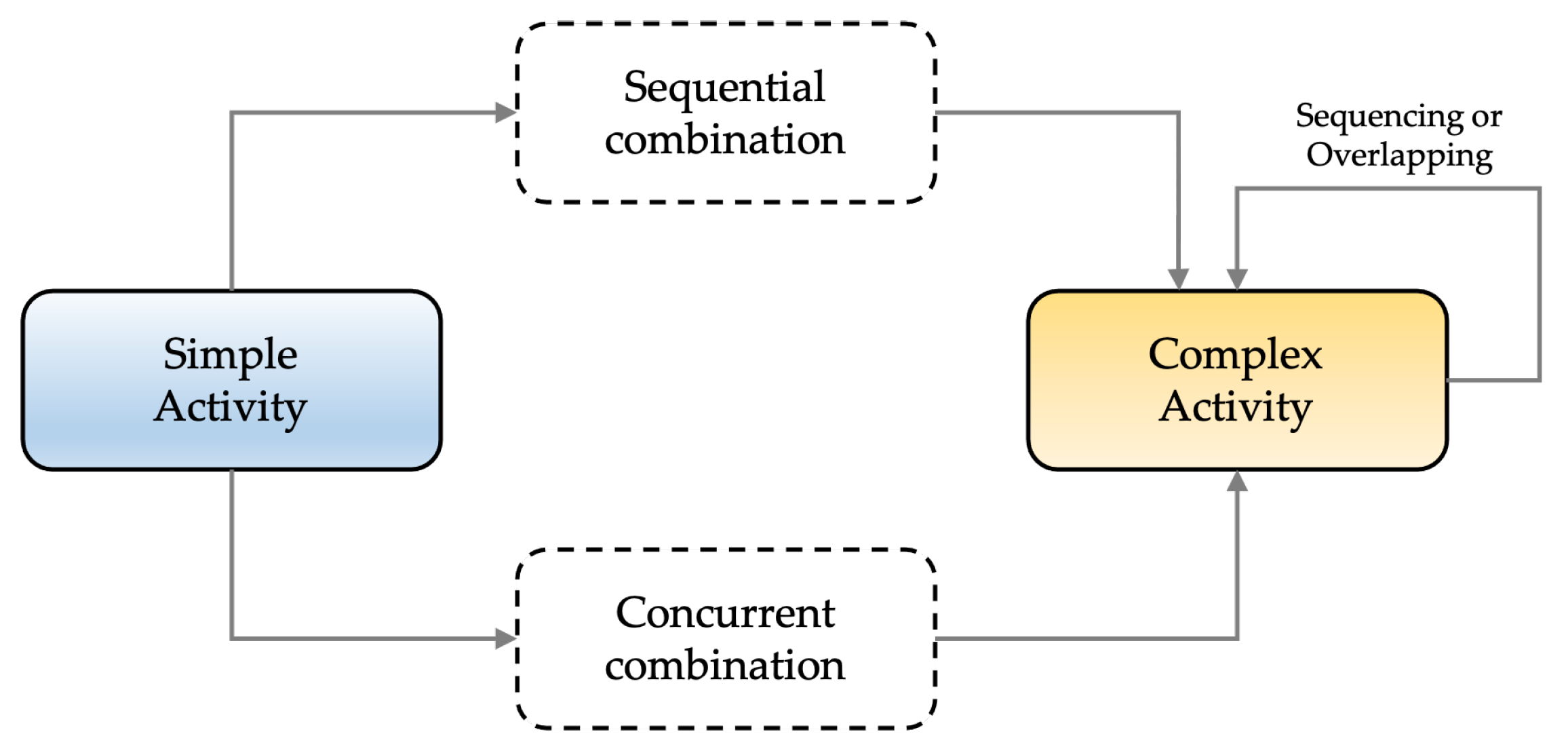
To address the problem of complex human recognition, we explored activity taxonomies [
19,
35,
64] and classified human activity into two classes, simple and complex, using the SC
taxonomy paradigm [
35] as shown in
Figure 2.
A simple activity is a unit-level human behavior that is defined by body motion or posture and cannot be further dissected. For example, “walking”, “standing”, and “sitting” can all be described as simple activities because they cannot be further deconstructed into other unit-level activities.
A complex activity is a high-level human process which involves a sequence or overlapping of simple human activities, sequential activities, or other complex activities. The recursive definition of complex activity can be used to depict a variety of complex circumstances. For example, “sitting and sipping a cup of coffee” is a simultaneous combination of two unit-level activities: “sitting” and “raising a cup to drink”.
3.1. Overview of the S-HAR Framework
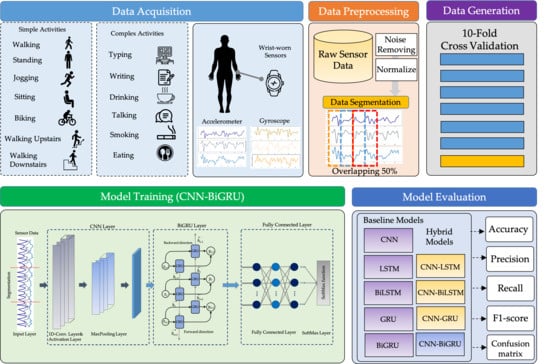
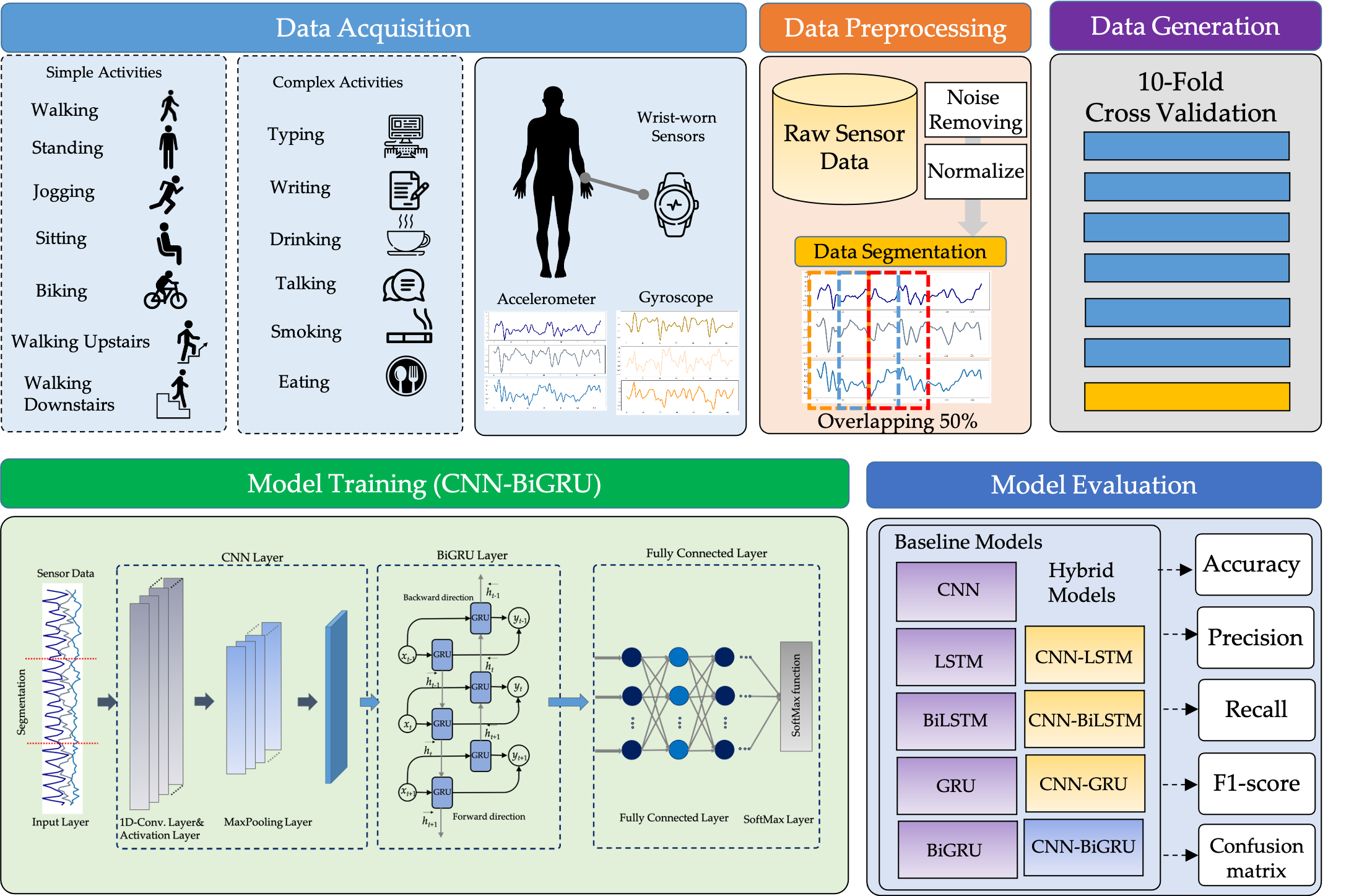
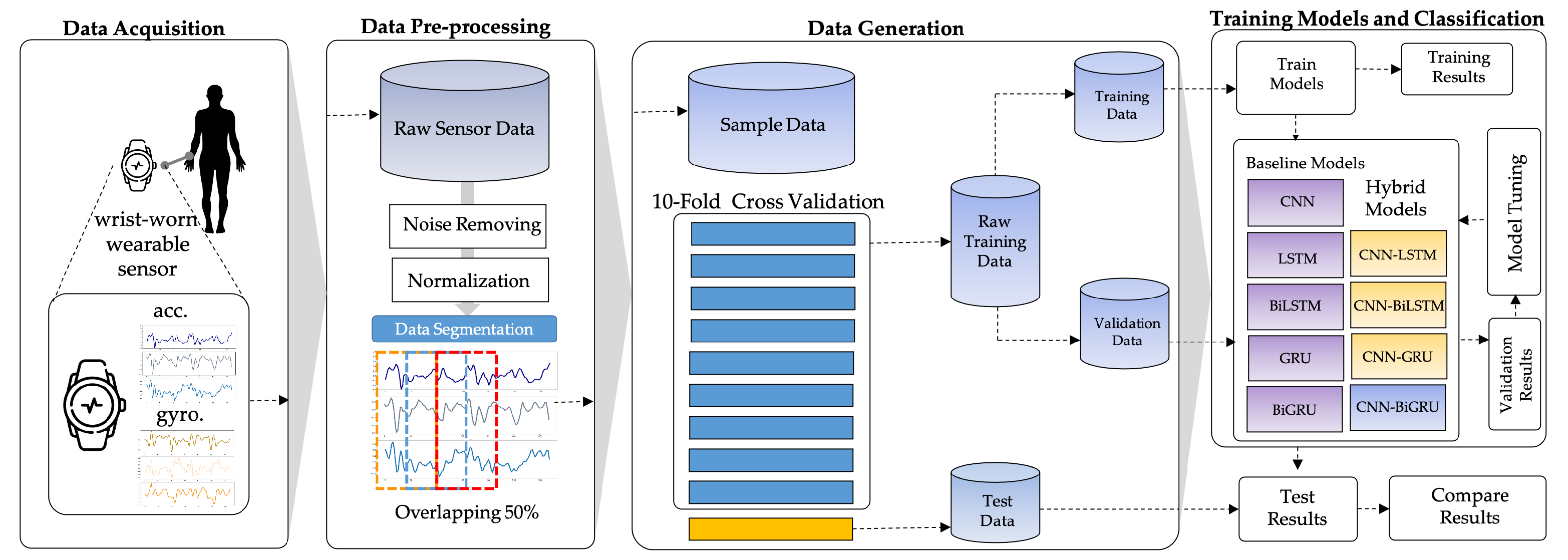
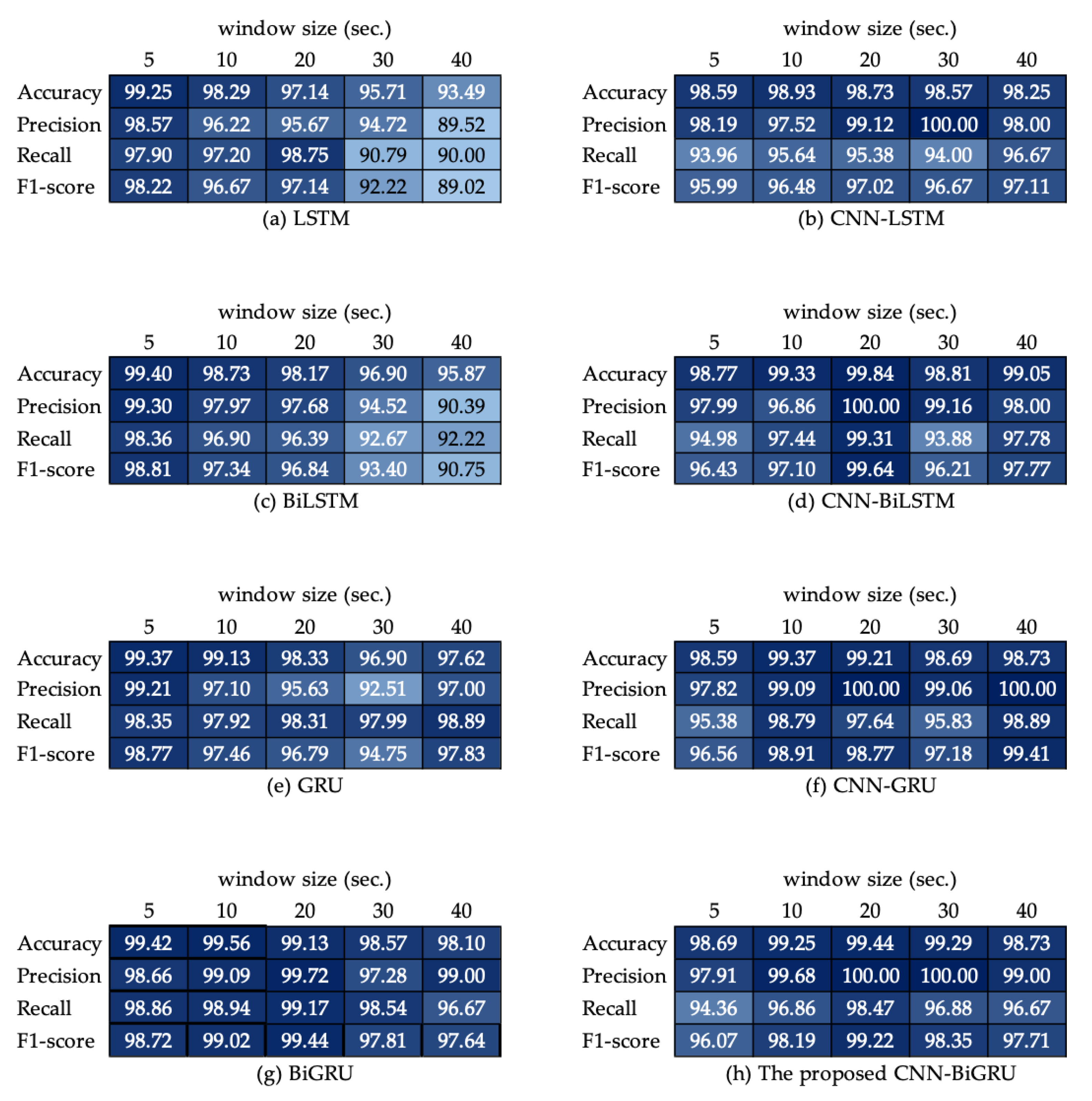
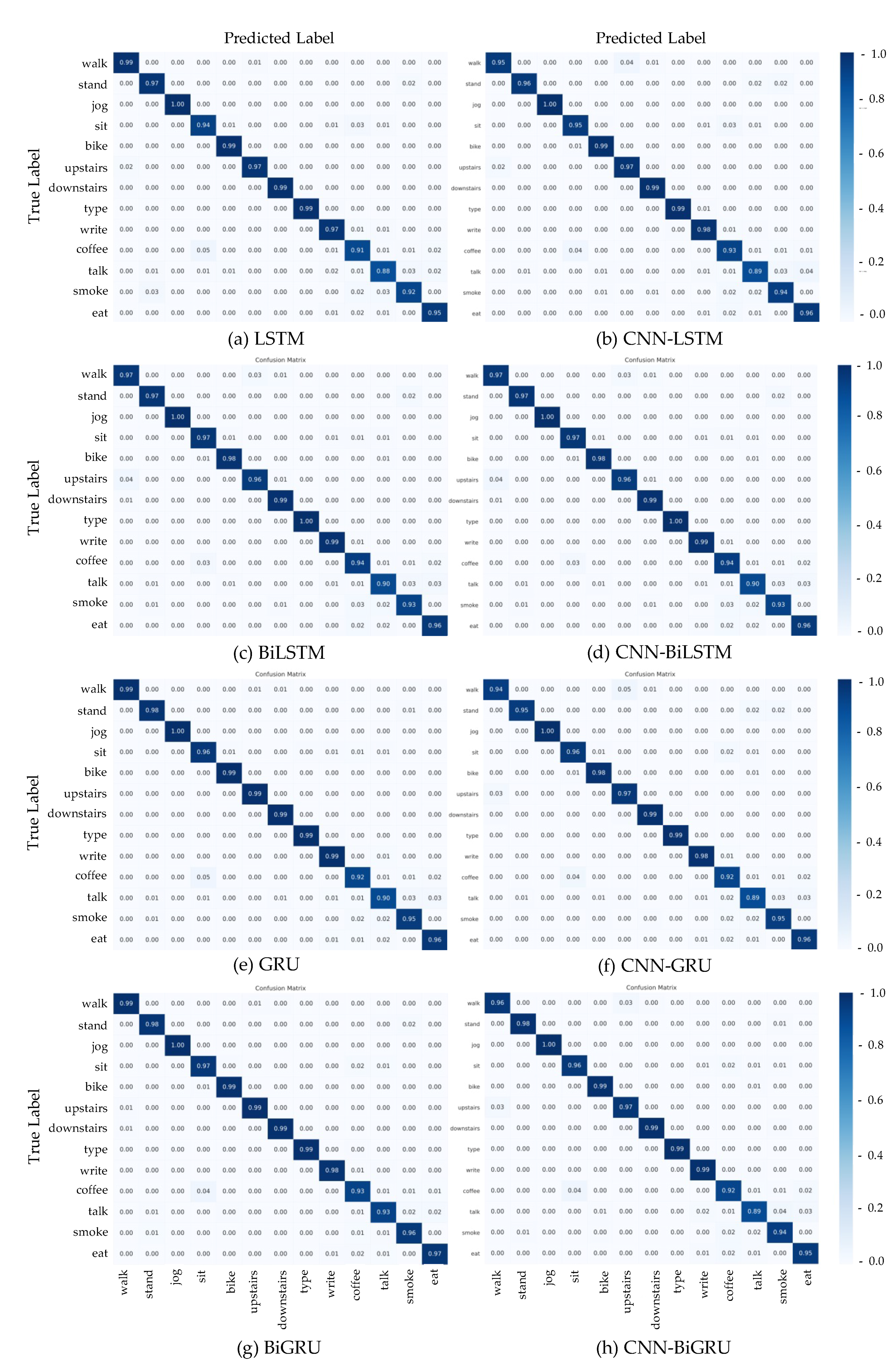
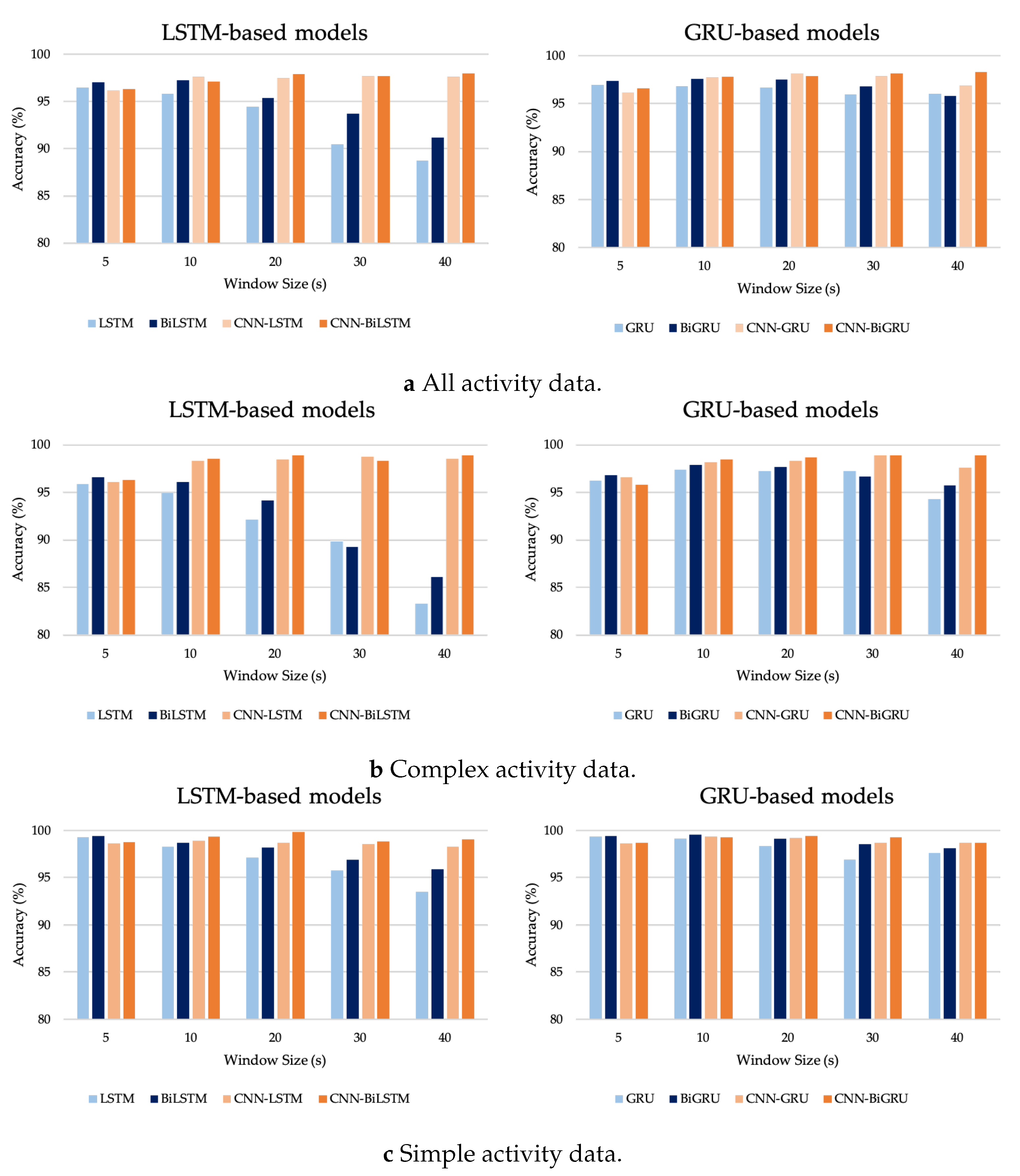
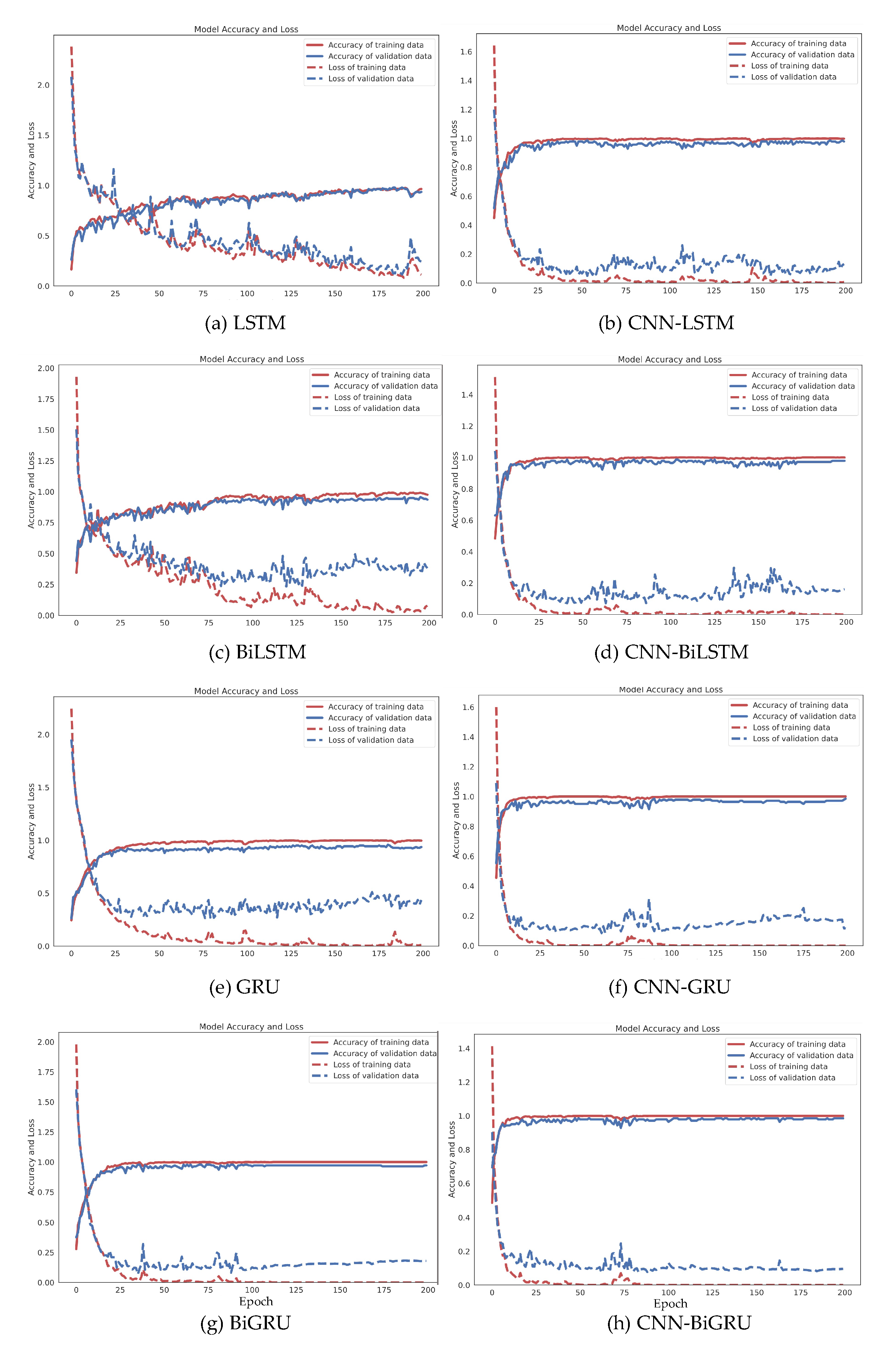
This section summarizes the entire configuration of the proposed S-HAR framework. Data acquisition, which includes data gathering from wrist-worn sensors, is the first step in the process. The next step is data pre-processing, which includes noise reduction, missing data filling, and data normalization. Data segmentation is also required in this procedure to convert multi-dimensional sensor data into sample data in suitable conditions for model training. This covers the definition of temporal windows, the overlap of temporal windows, and the class assignment and labeling. Following this, the sample data are separated into training and test data using the 10-fold cross validation approach in the data generation stage. DL model training with variations of DL models is the next step. Four RNN-based DL models (LSTM, BiLSTM, GRU, and BiGRU) and hybrid DL models are included in our proposed CNN-BiGRU model. Finally, performance evaluation criteria such as accuracy, precision, recall, F1-score, and confusion matrix are used to validate these models. As a result, a confusion matrix is used to compare the results of each DL model.
Figure 3 shows the workflow for the proposed S-HAR framework.
3.2. Data Acquisition
In this paper, we select a public wrist-worn dataset to study, which is a public benchmark dataset called “Complex Human Activities using smartphones and smartwatch sensors” (shortly, UTwente dataset) [
20]. This dataset was publicly released by a pervasive system research group, Twente University, in late 2016. They gathered a dataset for 13 human activities from 10 healthy participants, as shown in
Table 2. All 10 participants were asked to carry two Samsung Galaxy S2 mobile phones in their right pants pockets and on their right wrists, thereby emulating a smartwatch. To collect sensor-based activity data, they were asked to perform seven daily-life basic activities for three minutes. Seven of these ten participants were asked to perform additional complex activities including eating, typing, writing, drinking coffee, and talking for 5–6 min. Six of the ten participants were smokers and were asked to perform smoking one cigarette. To create a balanced class distribution, the authors used 30 min of data for each activity from each participant. The data were captured for an accelerometer, a linear acceleration sensor, a gyroscope, and a magnetometer at a rate of 50 Hz.
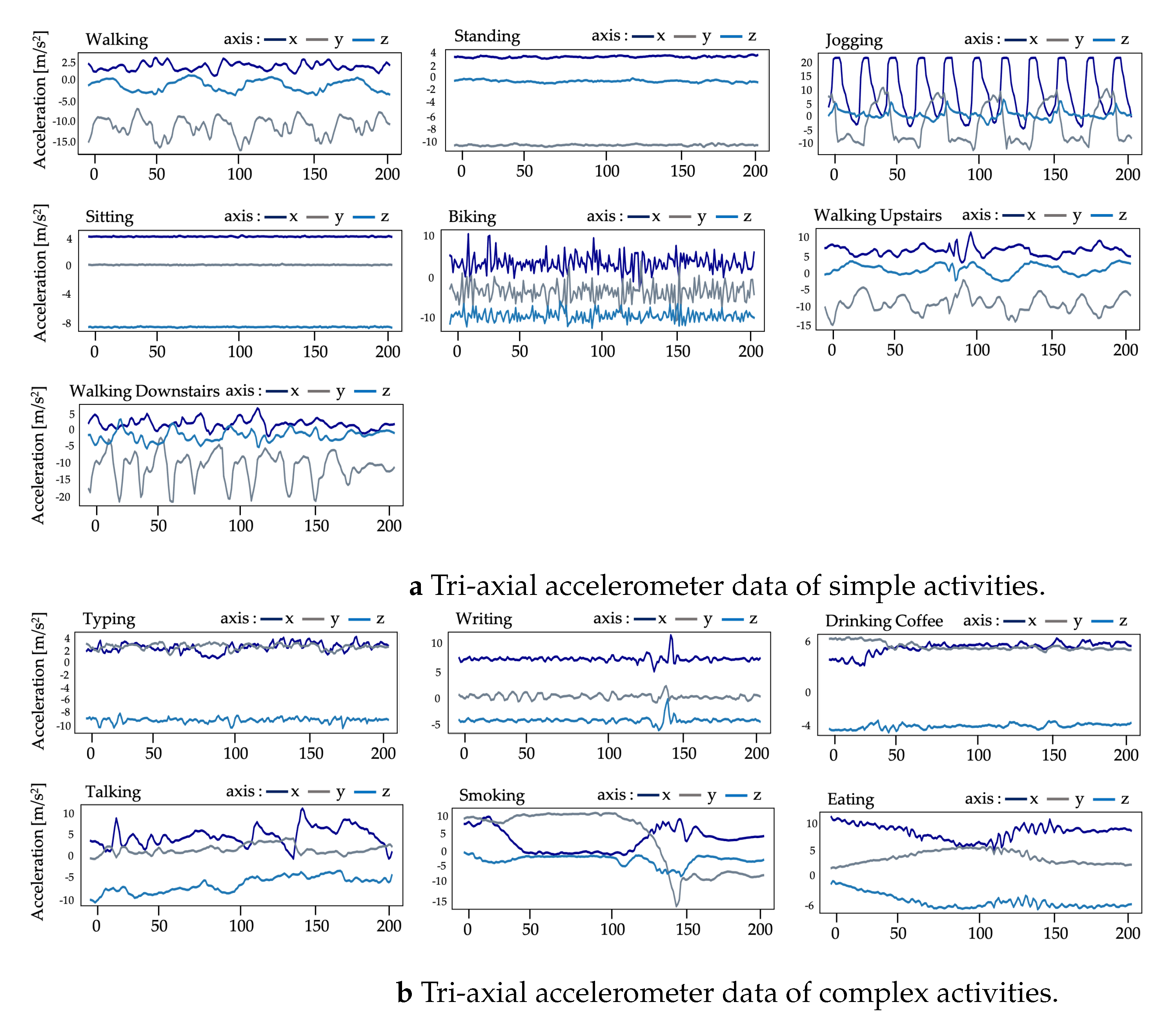
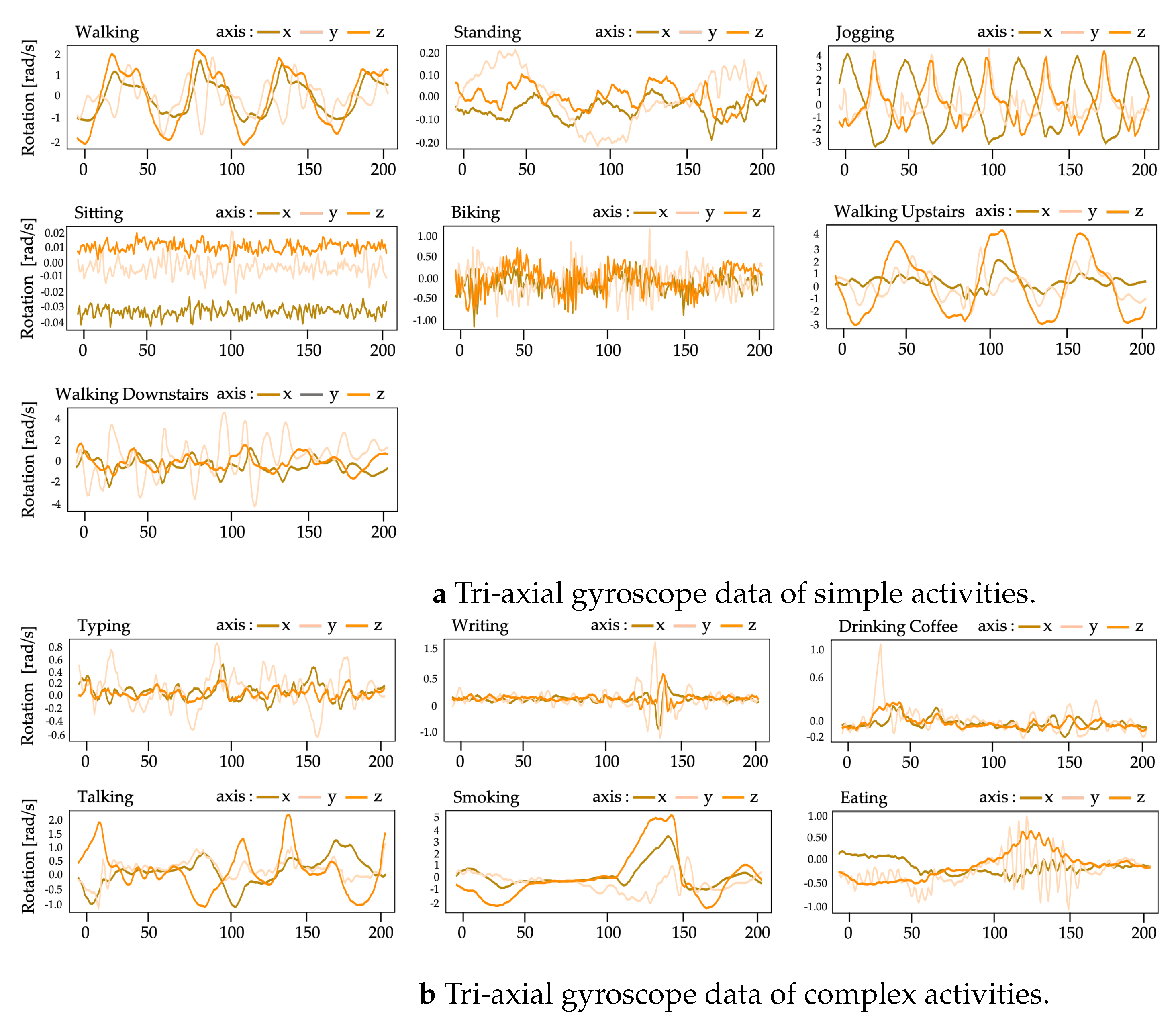
The graphical plots of accelerometer and gyroscope data from some activity samples in the UTwente dataset are demonstrated in
Figure 4 and
Figure 5, respectively.
Figure 4 shows graphical plots of the tri-axial accelerometer data for seven activities categorized as simple, including “Walking”, “Standing”, “Jogging”, “Sitting”, “Biking”, “Walking Upstairs”, and “Walking Downstairs”. We can observe that most of the sensor data are repetitive and stable. The accelerometer data are distinguishable from the six activities categorized as complex, including “Typing”, “Writing”, “Drinking Coffee”, “Talking”, “Smoking”, and “Eating”, as shown in
Figure 4b. As mentioned in
Section 2, the complex activities are hand-related. The accelerometer data of complex activities can be perceived as being non-repetitive.
Figure 5 shows graphical plots of the tri-axial gyroscope data for simple human activities (
Figure 5a) and complex human activities (
Figure 5b). The angular velocity (in radians per second) of each axis is measured by the gyroscope. The gyroscope data for the simple activities illustrated in
Figure 5a show that the majority of them are visibly repeated. The gyroscope data for complex actions, on the other hand, are non-repetitive, as seen in
Figure 5b.
3.3. Data Pre-Processing
The data collected by the wearable sensors are filtered and standardized in this step, resulting in a dataset that is consistent and suitable for training an identification model. In this method, all incomplete and outlier data values are discarded, as follows:
For the normalization procedure, a min-max technique is employed in this work to make a linear modification of the raw sensor data. The dataset that has been cleaned and normalized is the eventual input for the data generation and model training processes. The data are separated according to the method in order to train the classifier. The second set is used as a test set to evaluate the trained classifier’s performance.
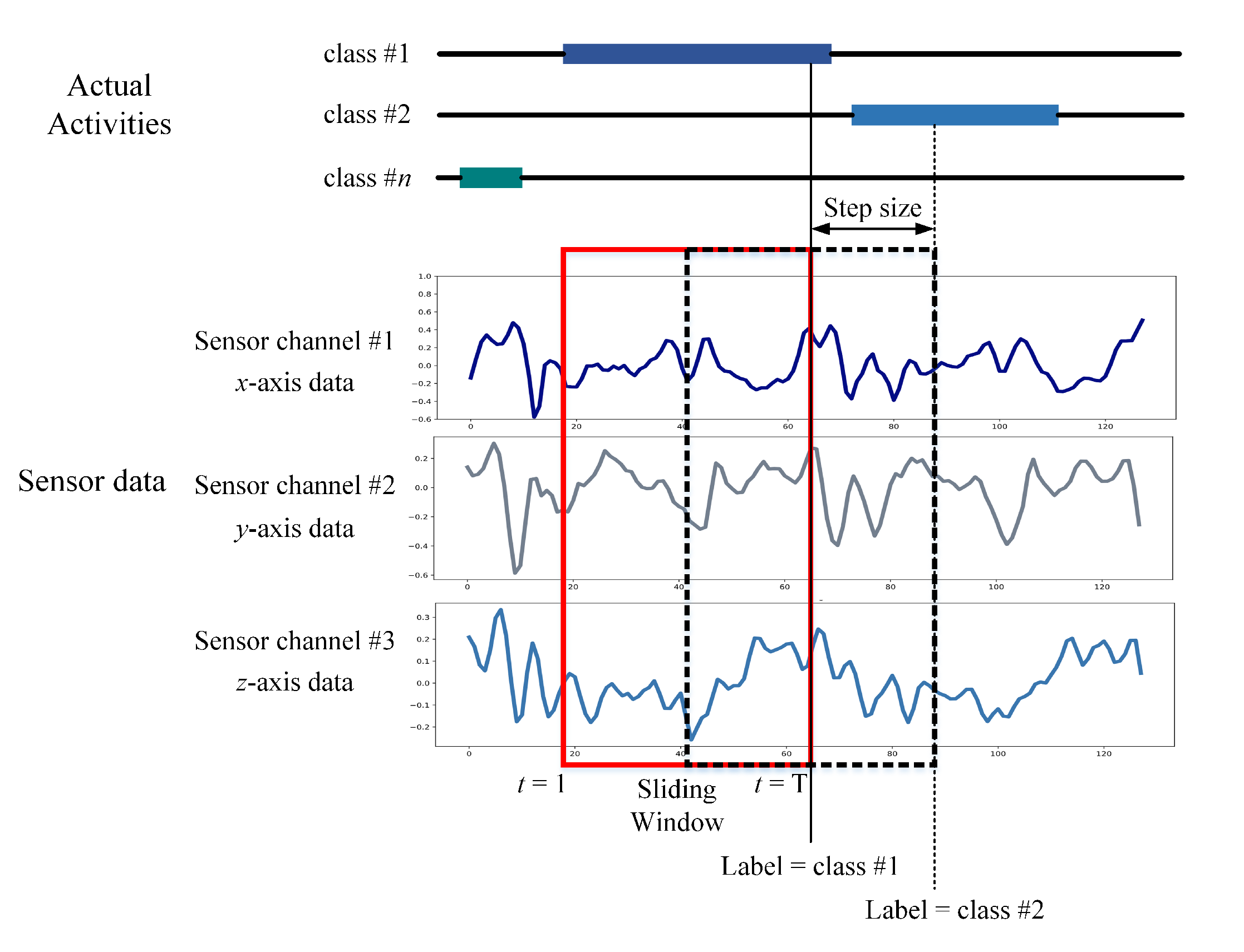
The next step of the proposed S-HAR is to create data samples from the raw sensor data. The raw data was segmented into small windows of the same size, known as temporal windows, in this method. Before training a DL model, raw time-series data recorded from wrist-worn wearable sensors are split into temporal segments. The sliding approach is frequently used and has been demonstrated to be useful for handling flowing data.
Figure 6 depicts a data segmentation scheme with an example of sensor data segmentation, where
X,
Y, and
Z represent the three components of a tri-axial wrist-worn sensor. All time intervals are the same as
t, defined as the window size. The
refers to the reading of
X,
Y, and
Z in the period [
t,
t]. The method is known as an overlapped temporal window and involves applying a fixed-size window to the sensor data sequence to generate data samples. With a 50% overlap proportion, the OW scheme is commonly utilized in S-HAR research [
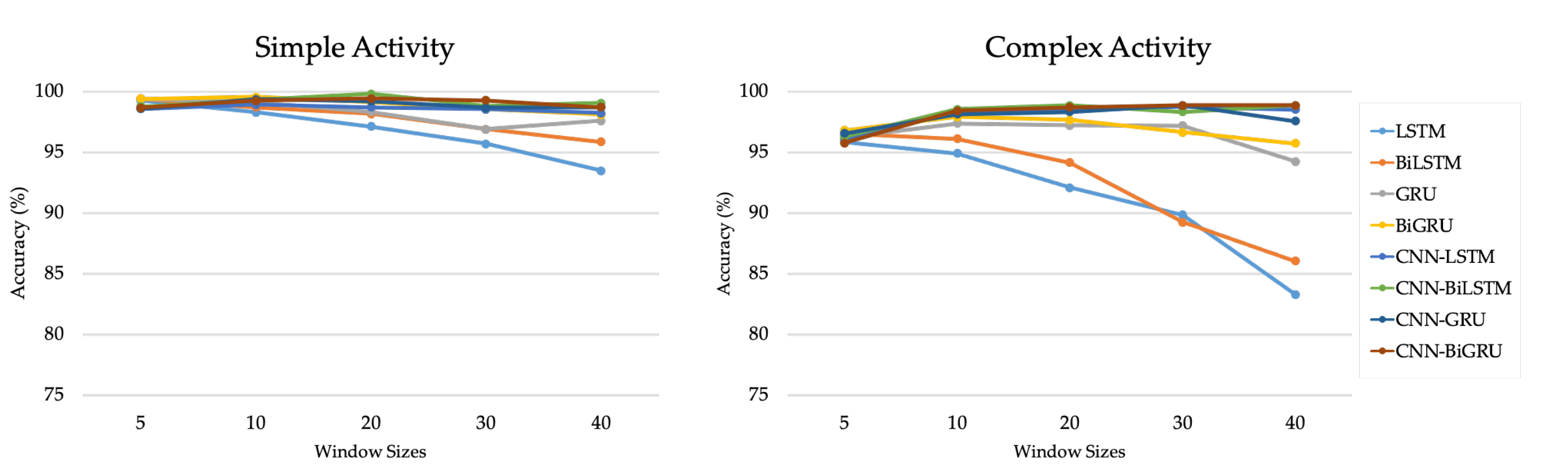
24]. In the proposed S-HAR, the wrist-worn data were segmented with window sizes of 5, 10, 20, 30, and 40 s with the overlapping of 50% in this process.
3.4. Data Generation
In this process, data samples are segmented into training data, while the temporal windows from the signals are used to learn a model and test the data to validate the learned model. Cross validation is used as the standard technique, whereby the data are separated into training and test data [
67]. To split the data for training and testing, several techniques can be utilized, such as k-fold cross validation [
68]. The goal of this step is to assess the learning algorithm’s ability to generalize new data. For this step, we employ 10-fold cross validation in the S-HAR framework.
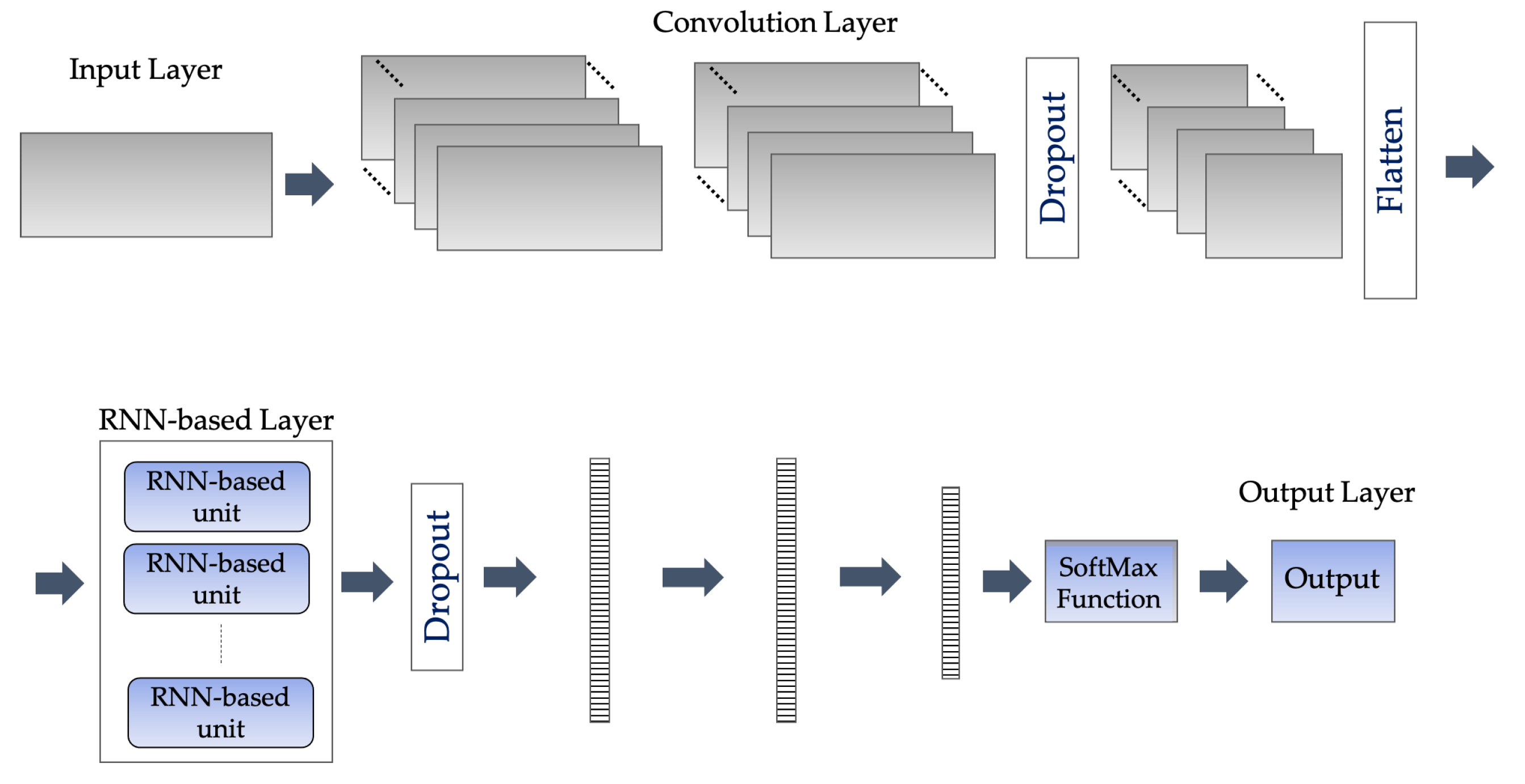
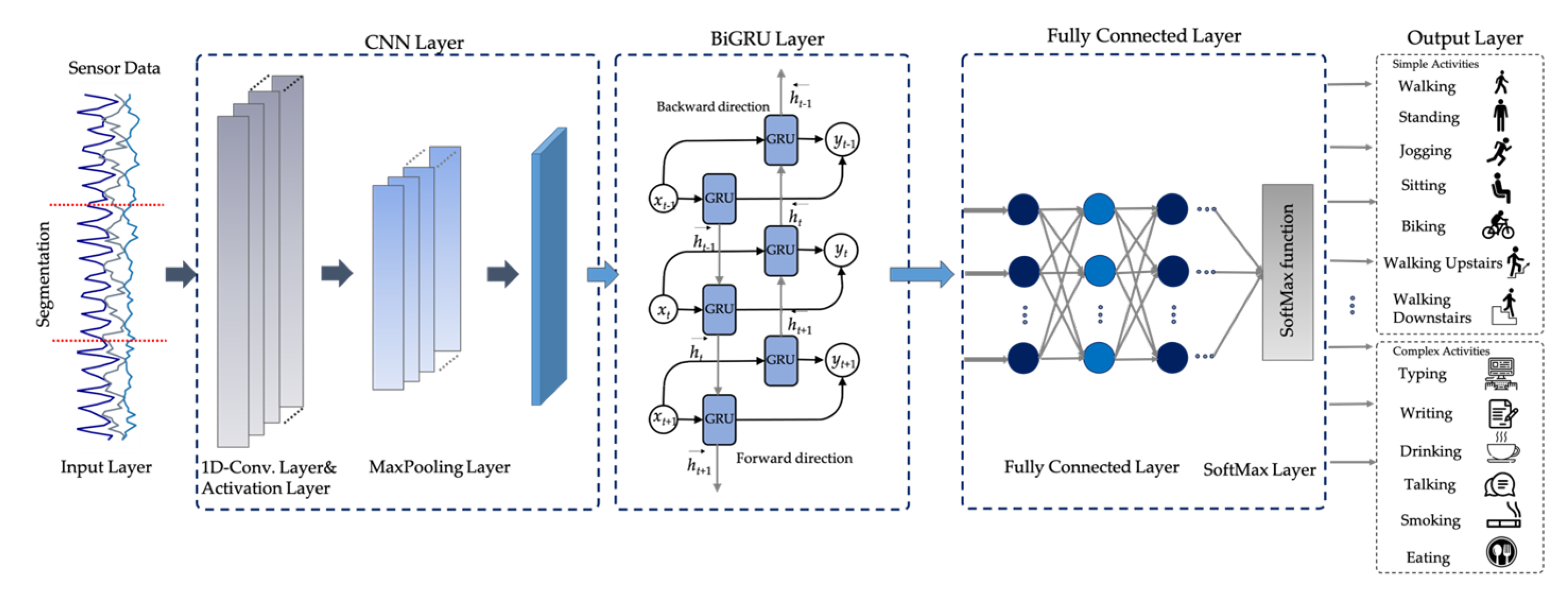
3.5. The Proposed CNN-BiGRU Model
The architecture for the proposed CNN-BiGRU model is illustrated in
Figure 7. The main design of the proposed DL model to solve the CHA problem involves employing CNN and BiGRU to automatically extract spatio-temporal features.
The input for the proposed DL model is the time-series in a time window of size T from N sensors. Let the input time series be X = {, , ,…, , ,…} where is the input at time point t. It consists of three sub-modules: (1) an embedding layer consisting of multiple one-dimensional convolutional layers to learn locally spatial features from the inputs of wearable sensors; (2) an encoder consisting of one or more bidirectional gated recurrent unit (BiGRU) layers to extract long temporal features from the abstract information in the preceding CNN layer; and (3) a fully connected module composed of hidden layers of a deep neural network. Each hidden layer is composed of neural nodes which relate to the neural nodes of the previous layer. We add a SoftMax classification layer on top of these sub-modules.
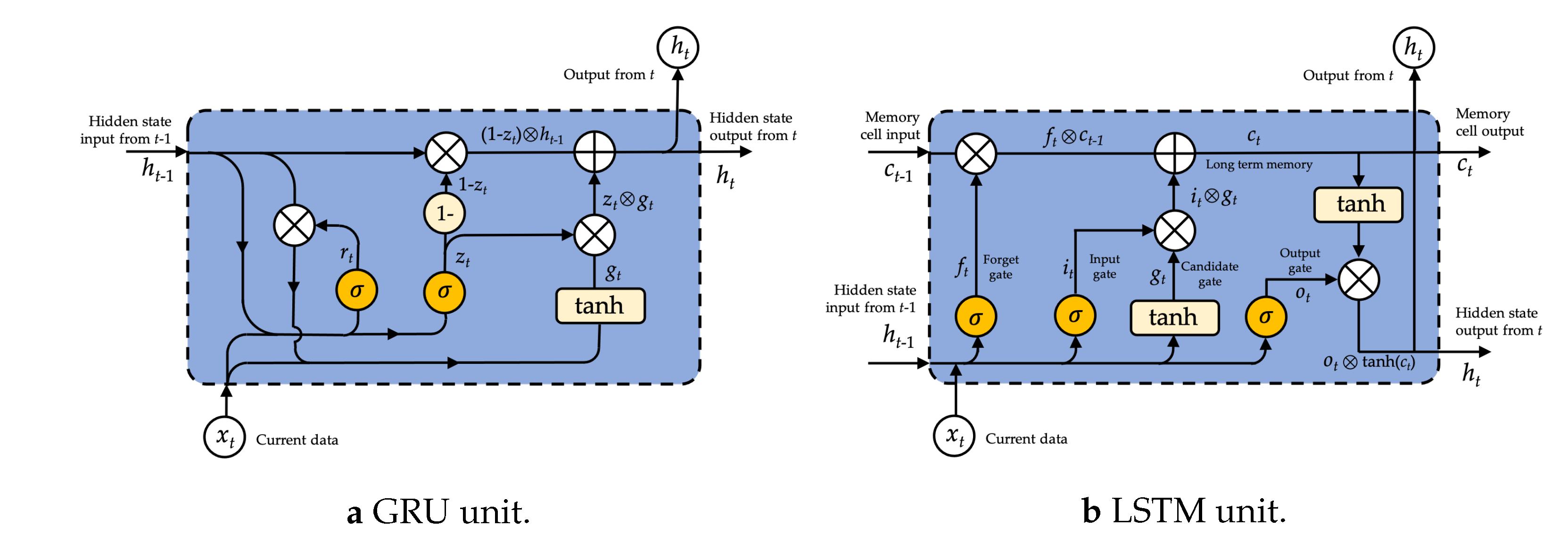
The GRU is an improved version of the LSTM that does not have a separate memory cell in its structure [
52]. In the network of a GRU, there is an update and reset gate that deals with the modification degree of each hidden state as shown in
Figure 8. That is, it determines which knowledge needs to be transferred to the next state and which does not [
53,
54]. GRU considers hidden state
at time
t from the output of the update gate
, reset gate
, current input
, and previous hidden state
, determined as
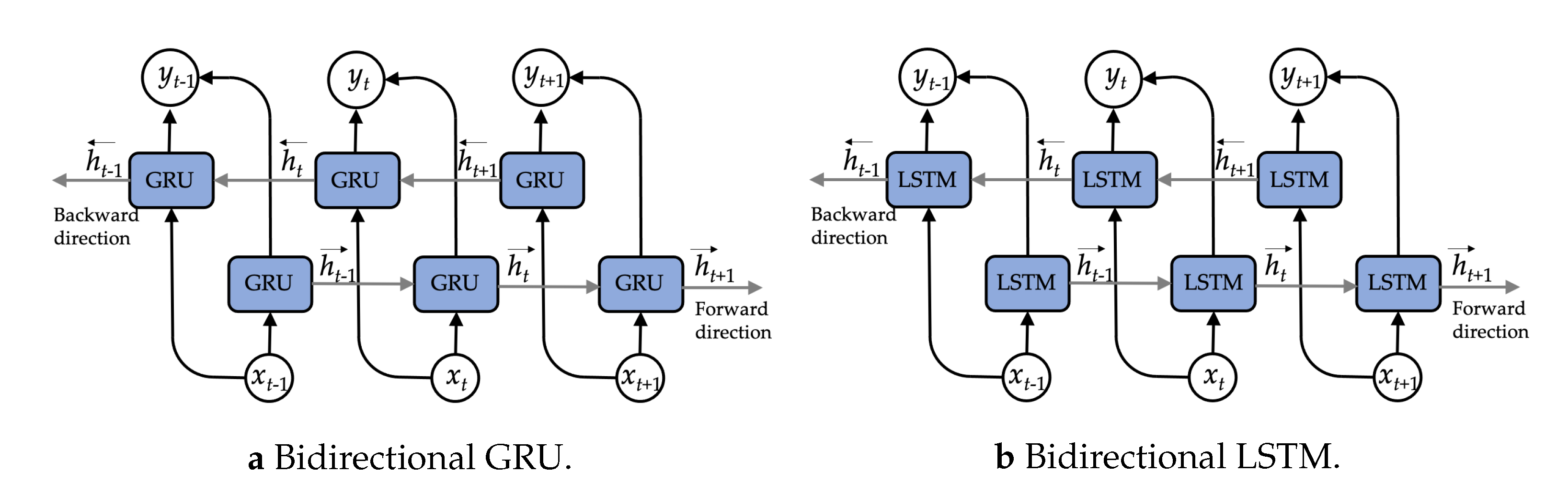
The GRU can be accomplished using a bidirectional network called a BiGRU which is presented next as shown in
Figure 9. The BiGRU is linked to two hidden layers in different directions. This structure will simultaneously acquire knowledge from the previous and subsequent sequences. The BiGRU does not need any input data reconfiguration and can enter future inputs in its present state.
Figure 9a illustrates the architecture of the BiGRU. The front of GRU networks (
) and reverse GRU networks (
) determine the features of the input data. The BiGRU network generates vector
at time phase
t. These related details are formulated as follows:
A summary of the hyperparameters for the proposed CNN-BiGRU networks in this work is presented in
Table 3.
3.6. Performance Measurement Criteria
The proposed DL model is evaluated in the 10-fold cross validation step to assess the effectiveness of activity recognition. The following equations represent the mathematical expressions for all five measures:
These are the most prominent assessment criteria used in HAR study. A true positive (TP) identification for the designated class and a true negative (TN) identification for all other classes are used to classify the recognition. It is possible that activity sensor data from one class are misclassified as data from another, resulting in a false positive (FP) identification of that class, though activity sensor data from another class may also be incorrectly identified as belonging to that class, resulting in a false negative (FN) identification of that class.
Moreover, the DL models studied in this work were evaluated for their performance with a confusion matrix. The confusion matrix is a square matrix with a k number of classes that is used to provide detailed findings from a multiclass classification issue. The confusion matrix gives a more comprehensive and fine-grained analysis of the supervised learning-based models’ properly and incorrectly categorized classes. A given element of the matrix is the number of instances belonging to class , classified as class . The confusion matrix also provides information on categorization errors.
Let
C be a confusion matrix obtained under the same procedure of experiments. In these expressions,
,
,
, …,
are the
k categories of activities in a HAR dataset, and
n =
the total number of data elements classified for the matrix
C. Moreover, diagonal elements indicate the concordant elements which are the elements classified in the same category, whereas
and
indicate the number of discordant elements that are in
but are classified as class
. The confusion matrix
C is expressed as follows:
6. Conclusions and Future Works
In this research, we introduced a framework for S-HAR to address the problem of the recognition of CHA by using wrist-worn wearable sensors. With tri-axial accelerometer and tri-axial gyroscope data, we investigated different types of DL models that are RNN-based models and hybrid DL models, including the proposed CNN-BiGRU model. We implemented these DL models and compared their predicted accuracy in terms of a publicly accessible dataset called the UTwente dataset, as well as other performance metrics including precision, recall, F1-score, and confusion matrix with 10-fold cross validation. The experimental results showed that the CNN-BiGRU model outperformed the other baseline DL models with a high accuracy of 98.78% in the combination of simple and complex activities. Moreover, the CNN-BiGRU network performs with the highest accuracy of 98.89% when using only complex human activity data. The statistical results with FAR and Finner post hoc tests based on the accuracy metric indicate that the CNN-BiGRU significantly outperformed other RNN-based models.
In the future, we plan to improve the CNN-BiGRU model and study it with various hyperparameters, such as learning rate, batch size, optimizer, and many others. We also aim to introduce our model to more complicated activities in order to address other DL models and S-HAR concerns by assessing it on other publicly available complex activity datasets (OPPORTUNITY, MHEALTH, etc.).





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}



















