
Cloud Storage Service Architecture Providing the Eventually Consistent Totally Ordered Commit History of Distributed Key-Value Stores for Data Consistency Verification


Abstract
:1. Introduction
Contributions
- We analyze the fundamental limitation of previous proposals enabling client-side data consistency verification.
- This is the first work to explore how to provide an eventually consistent totally ordered commit history for client-side data consistency verification.
- We built a prototype system, Relief (https://github.com/Kaelus/Relief, accessed on 27 September 2021), and empirically evaluated its performance compared to previous approaches.
- We integrate a consistency oracle with our prototype and demonstrate the efficiency of the white-box consistency verification using the history provided by Relief.
2. Background
2.1. Motivation for Consistency Verification
2.2. Consistency Verification
2.3. Clocks and Ordering of Distributed Events
3. Problem Statement
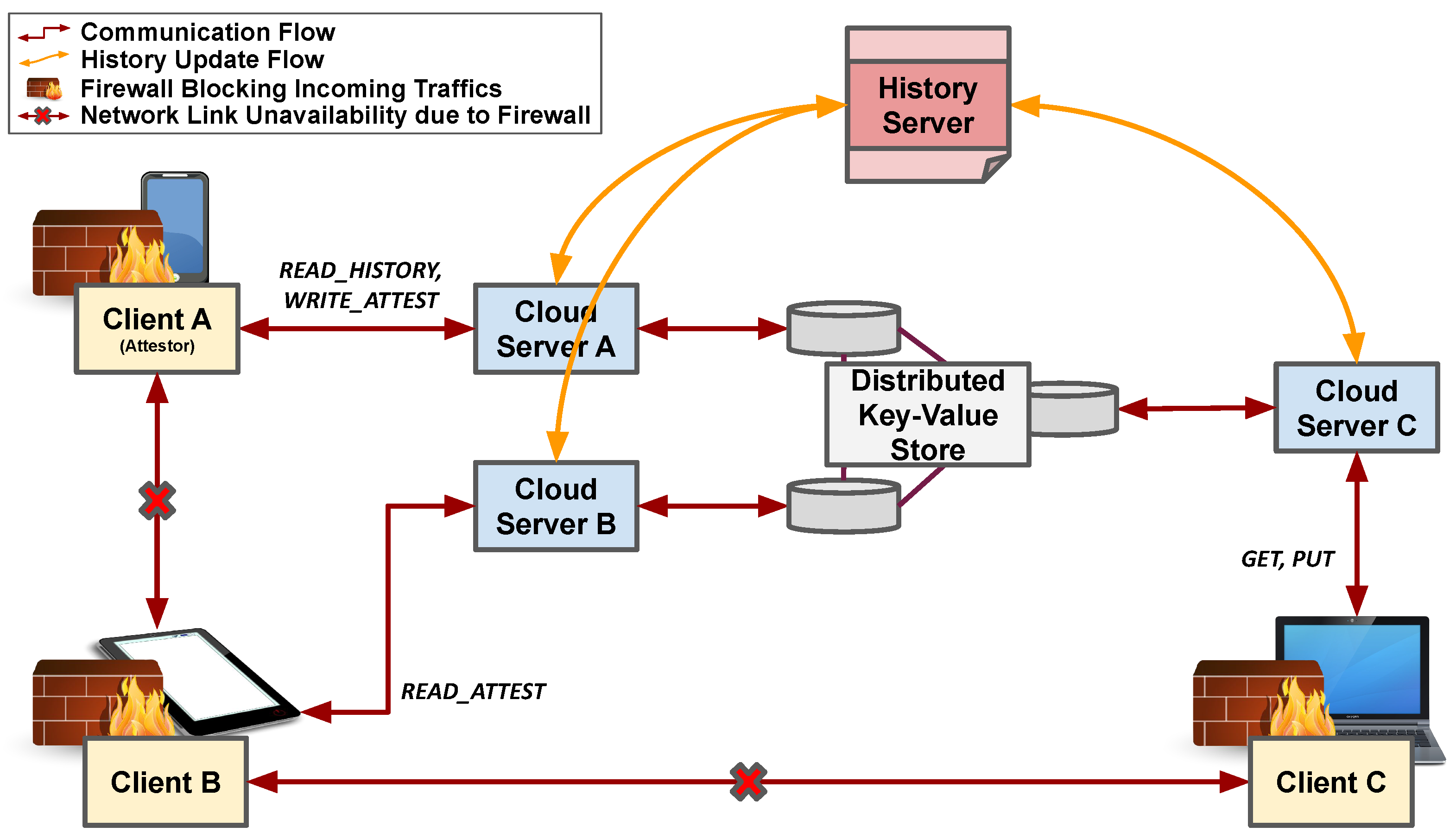
3.1. Target Environment
3.2. A History Server Using Strong Consistency
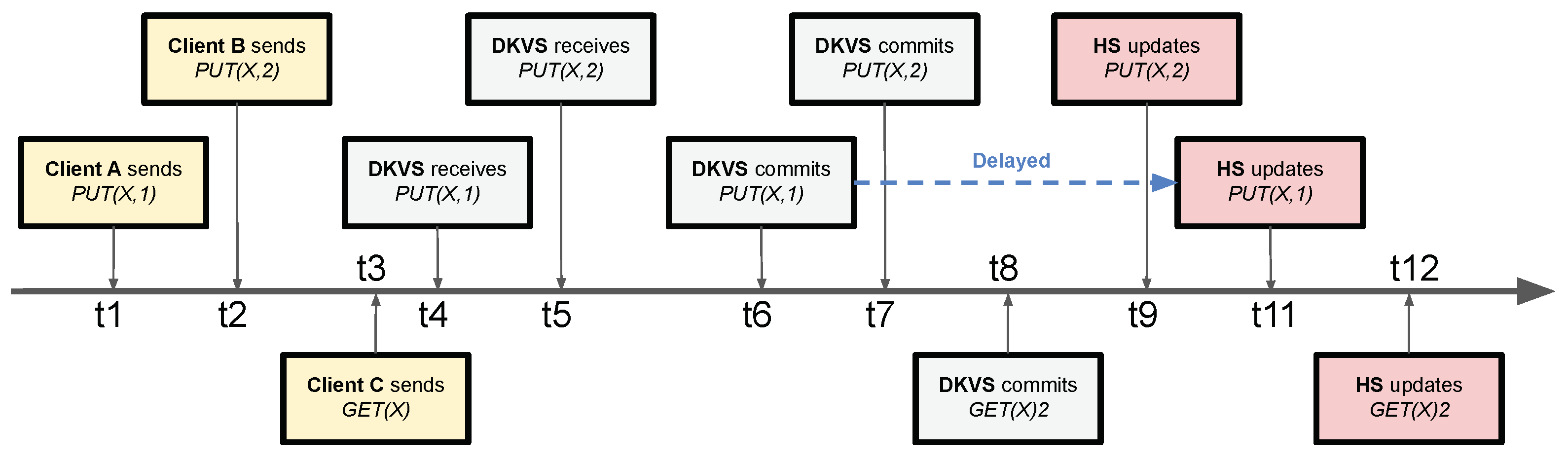
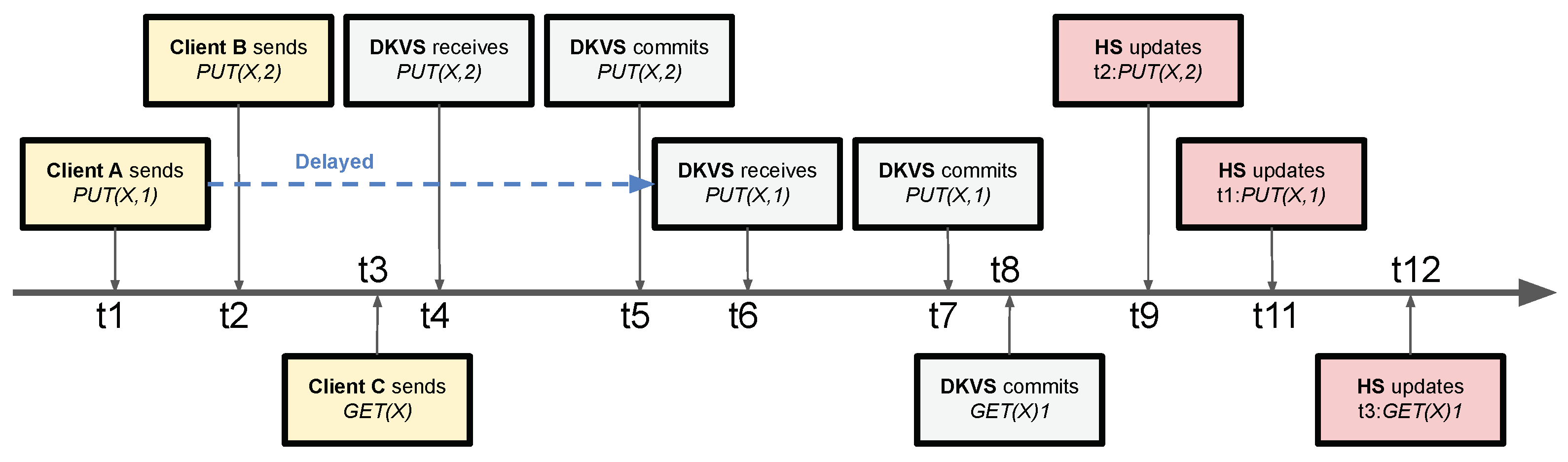
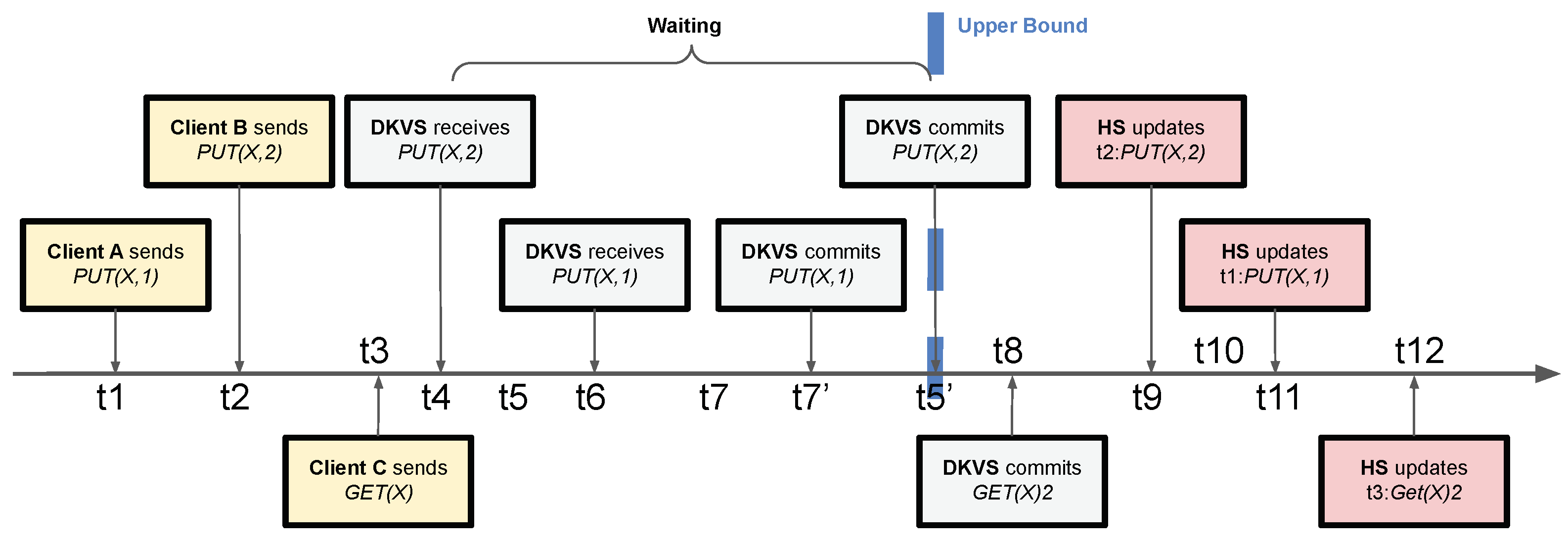
3.3. Reflecting a Commit Order in the History
4. Materials and Methods
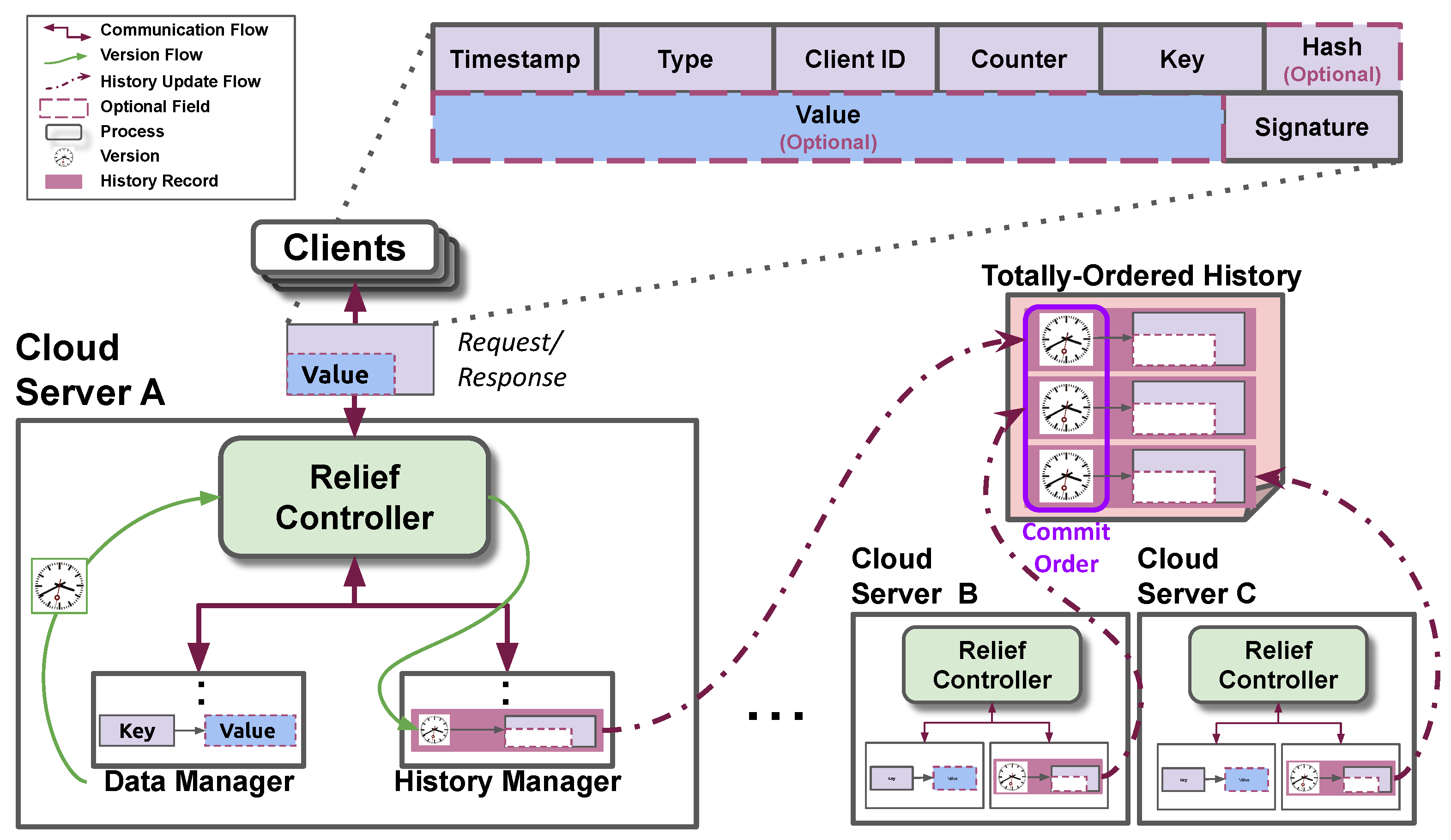
4.1. Relief Architecture
- GET(k)v: Reading a value for the key k. It is expected to return a value v. If the key k does not exist, then is returned for the value v.
- PUT(k,v): Writing a value v to the key k.
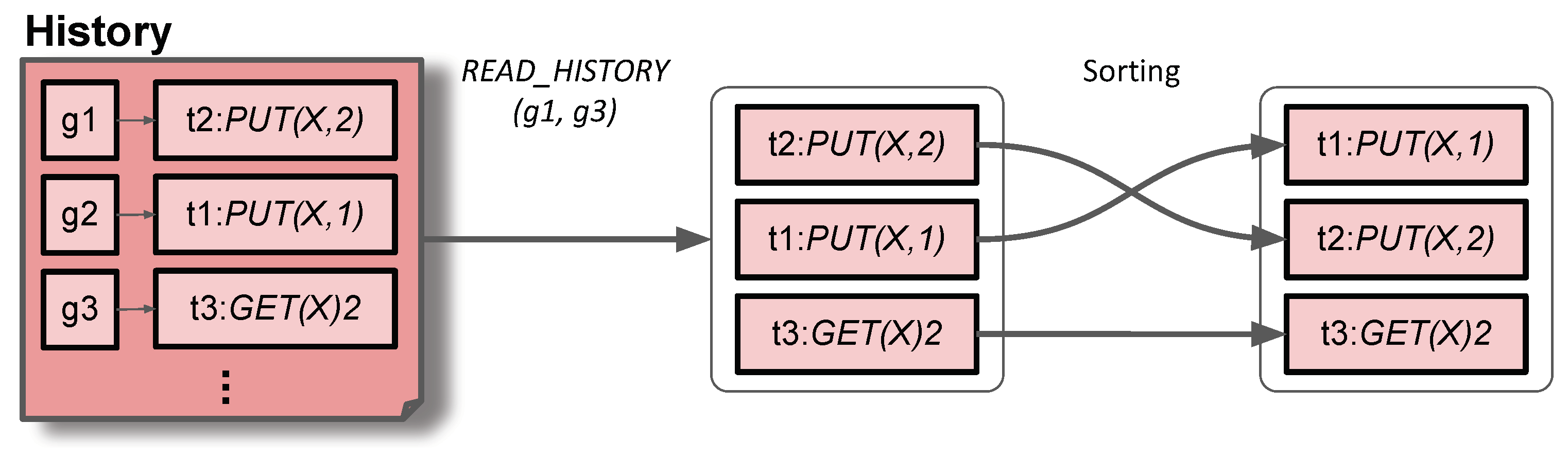
- READ_HISTORY(s,e)H: Reading a section of the history between the start version s and the end version e where . It returns H, a list of entries sorted based on the version. All entries in H are indexed by versions falling in the range between s and e. If the given e is larger than the version of the latest entry in the history, then the history returns the list of entries up to the latest entry.
- WRITE_ATTEST(s,e): Writing an attestation that attests the section of the history between the start version s and the end version e.
- READ_ATTEST(s,e)<A,H,s’,e’>: Reading attestations that attest the section of the history between the start version s and the end version e. Along with A, the list of attestations, H, the section of the history is also read and returned similar to READ_HISTORY(s,e). However, if there are attestations that attest the section between s and e and the outer range, then the entire section of the history attested by those attestations is inclusively retrieved. The response also includes the start version and to precisely specify the section of the history and attestations retrieved.
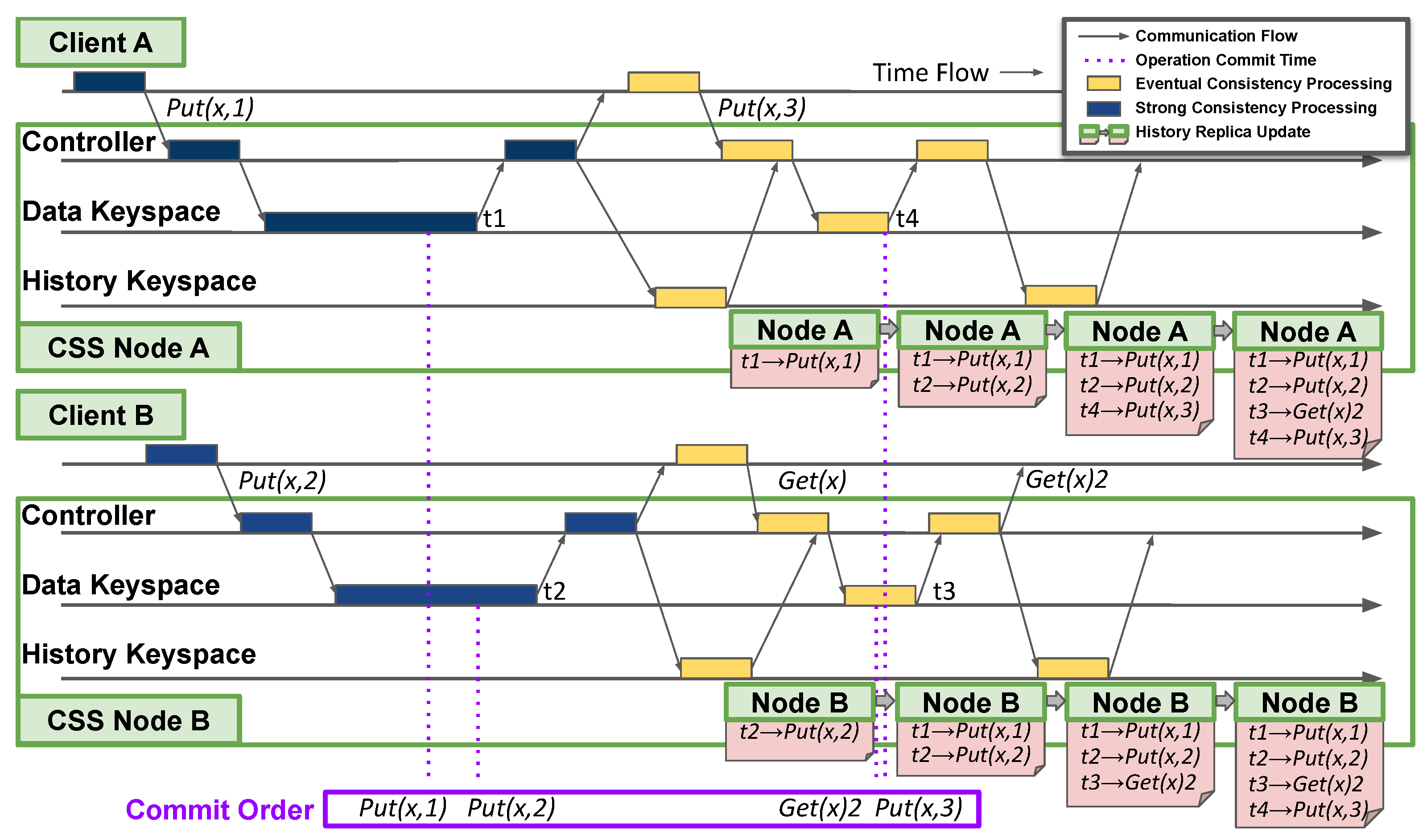
4.2. Conflict-Free Replicated History Update (CRHU)
| Algorithm 1: Relief Controller’s Request Handling Algorithm |
 |
4.3. Request/Response Format
4.4. Data Consistency Verification
5. Results
5.1. Evaluation Setup
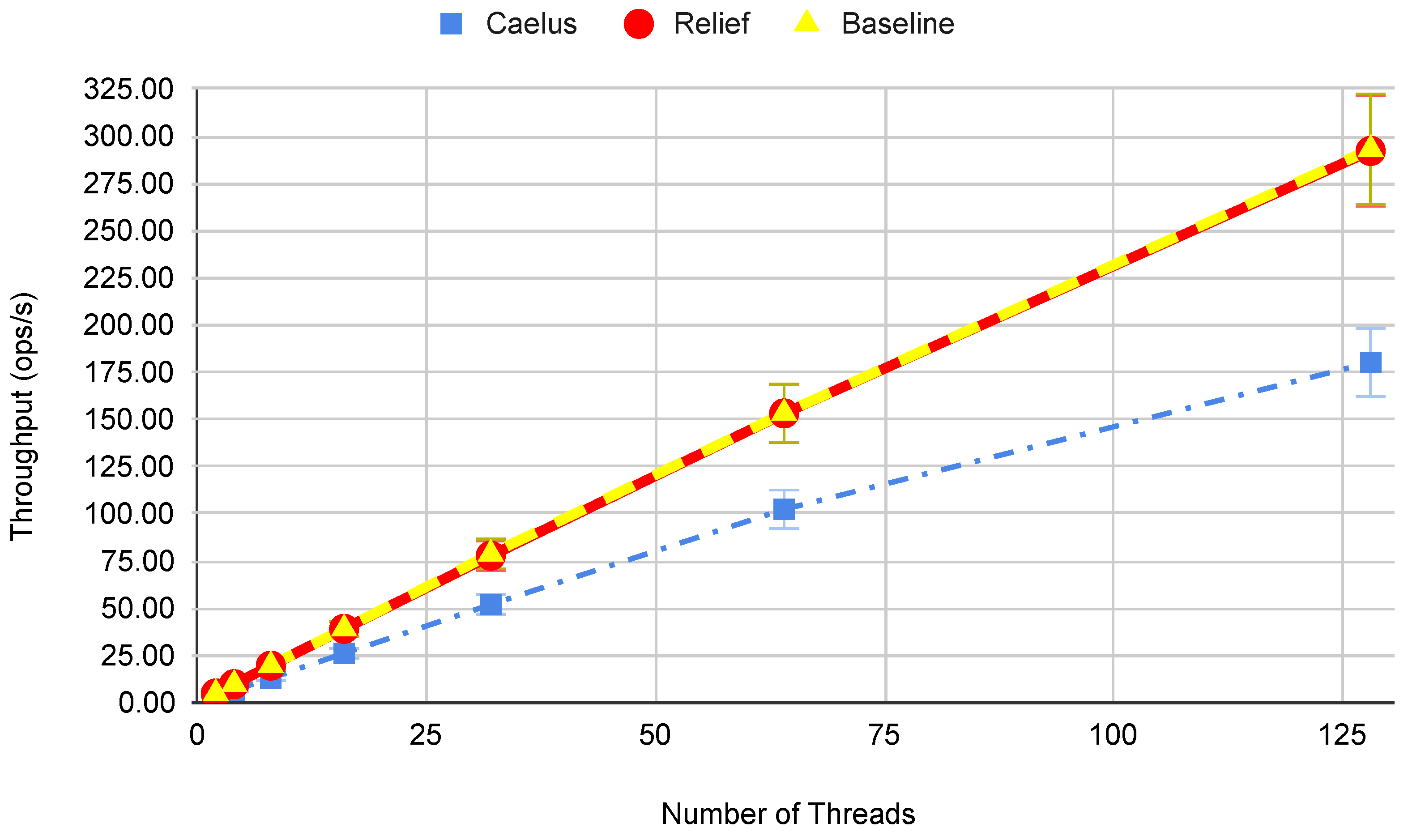
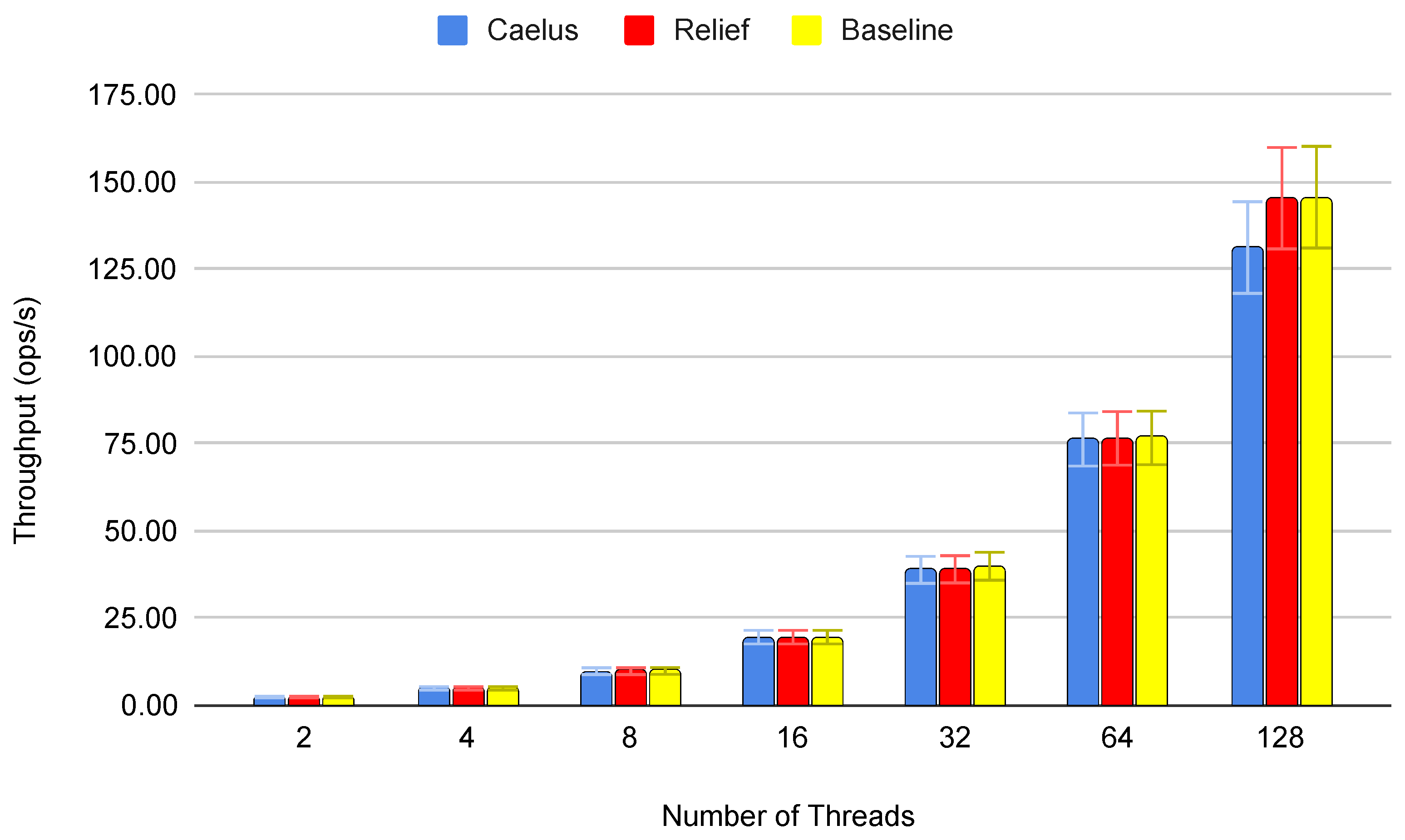
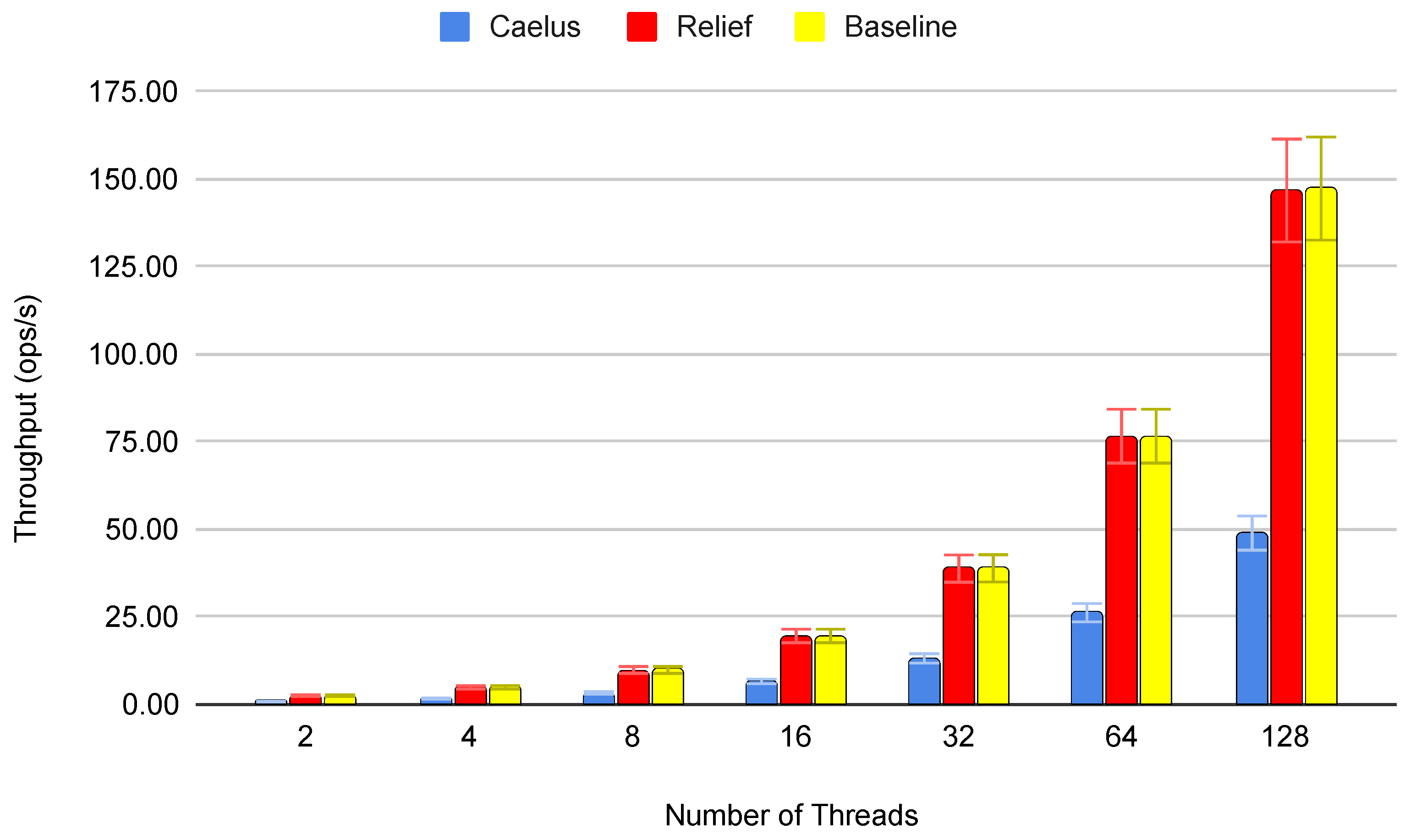
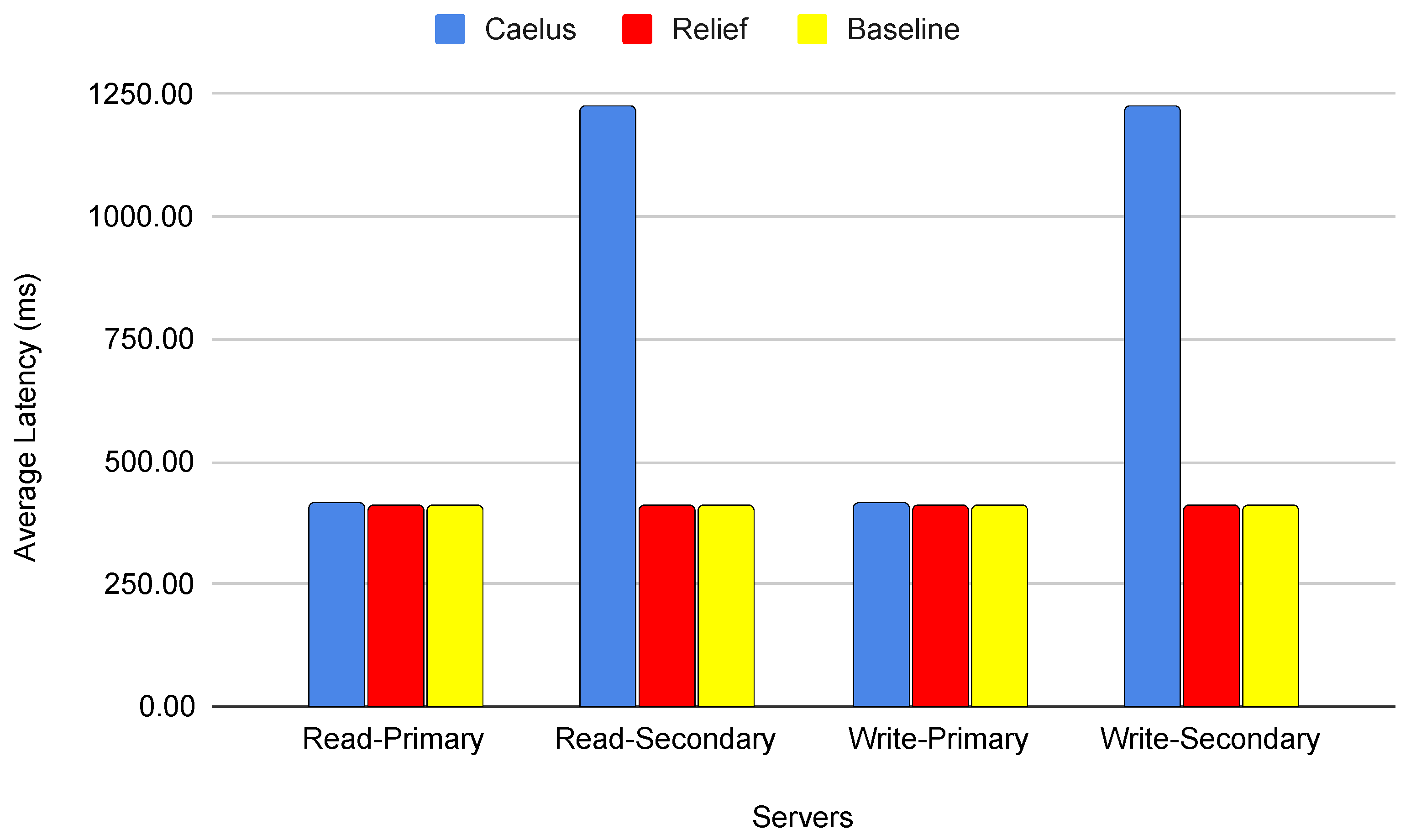
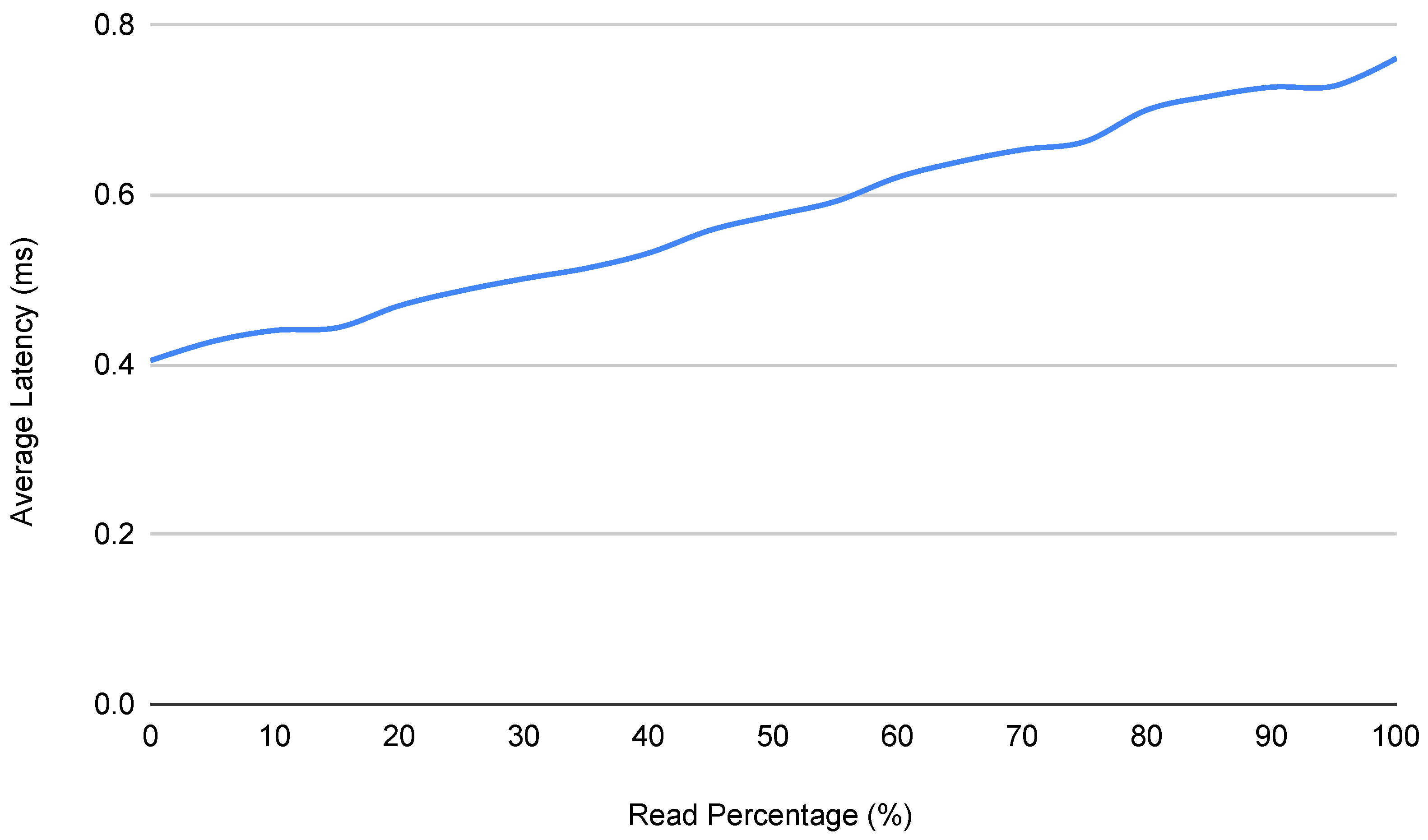
5.2. Performance
5.3. Verification Speed
6. Discussion
6.1. Related Work
6.2. Cloud Storage Service Architecture Comparison
7. Conclusions
Limitation and Future Work
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| CSS | Cloud Storage Service |
| DKVS | Distributed Key-Value Store |
| CRHU | Conflict-free Replicated History Update |
References
- Research and Markets. Global Cloud Storage Market (2020 to 2025)—Rise of Containerization Presents Opportunities. 2020. Available online: https://www.globenewswire.com/news-release/2020/10/16/2109759/0/en/Global-Cloud-Storage-Market-2020-to-2025-Rise-of-Containerization-Presents-Opportunities.html (accessed on 25 March 2021).
- Terry, D. Replicated data consistency explained through baseball. Commun. ACM 2013, 56, 82–89. [Google Scholar] [CrossRef]
- Tan, C.; Zhao, C.; Mu, S.; Walfish, M. Cobra: Making Transactional Key-Value Stores Verifiably Serializable. In Proceedings of the 14th USENIX Symposium on Operating Systems Design and Implementation, OSDI 2020, Virtual Event, 4–6 November 2020; pp. 63–80. [Google Scholar]
- Kingsbury, K. Distributed Systems Safety Research. 2016. Available online: https://jepsen.io/ (accessed on 21 March 2021).
- Li, J.; Krohn, M.N.; Mazières, D.; Shasha, D.E. Secure Untrusted Data Repository (SUNDR). In Proceedings of the 6th Symposium on Operating System Design and Implementation (OSDI 2004), San Francisco, CA, USA, 6–8 December 2004; pp. 121–136. [Google Scholar]
- Mahajan, P.; Setty, S.T.V.; Lee, S.; Clement, A.; Alvisi, L.; Dahlin, M.; Walfish, M. Depot: Cloud Storage with Minimal Trust. In Proceedings of the 9th USENIX Symposium on Operating Systems Design and Implementation, OSDI 2010, Vancouver, BC, Canada, 4–6 October 2010; pp. 307–322. [Google Scholar]
- Feldman, A.J.; Zeller, W.P.; Freedman, M.J.; Felten, E.W. SPORC: Group Collaboration using Untrusted Cloud Resources. In Proceedings of the 9th USENIX Symposium on Operating Systems Design and Implementation, OSDI 2010, Vancouver, BC, Canada, 4–6 October 2010; pp. 337–350. [Google Scholar]
- Shraer, A.; Cachin, C.; Cidon, A.; Keidar, I.; Michalevsky, Y.; Shaket, D. Venus: Verification for untrusted cloud storage. In Proceedings of the 2nd ACM Cloud Computing Security Workshop, CCSW 2010, Chicago, IL, USA, 8 October 2010; pp. 19–30. [Google Scholar]
- Kim, B.H.; Huang, W.; Lie, D. Unity: Secure and durable personal cloud storage. In Proceedings of the 2012 ACM Workshop on Cloud computing security, CCSW 2012, Raleigh, NC, USA, 19 October 2012; pp. 31–36. [Google Scholar]
- Li, J.; Mazières, D. Beyond One-Third Faulty Replicas in Byzantine Fault Tolerant Systems. In Proceedings of the 4th Symposium on Networked Systems Design and Implementation (NSDI 2007), Cambridge, MA, USA, 11–13 April 2007. [Google Scholar]
- Popa, R.A.; Lorch, J.R.; Molnar, D.; Wang, H.J.; Zhuang, L. Enabling Security in Cloud Storage SLAs with CloudProof. In Proceedings of the 2011 USENIX Annual Technical Conference, Portland, OR, USA, 15–17 June 2011. [Google Scholar]
- Tomescu, A.; Devadas, S. Catena: Efficient Non-equivocation via Bitcoin. In Proceedings of the 2017 IEEE Symposium on Security and Privacy (SP), San Jose, CA, USA, 22–26 May 2017; IEEE Computer Society: Los Alamitos, CA, USA, 2017; pp. 393–409. [Google Scholar] [CrossRef]
- Kim, B.H.; Lie, D. Caelus: Verifying the Consistency of Cloud Services with Battery-Powered Devices. In Proceedings of the 2015 IEEE Symposium on Security and Privacy, SP 2015, San Jose, CA, USA, 17–21 May 2015; pp. 880–896. [Google Scholar]
- Li, K.; Tang, Y.R.; Kim, B.H.B.; Xu, J. Secure Consistency Verification for Untrusted Cloud Storage by Public Blockchains. In Proceedings of the Security and Privacy in Communication Networks—15th EAI International Conference, SecureComm 2019, Orlando, FL, USA, 23–25 October 2019; Volume 304, pp. 39–62. [Google Scholar]
- Herlihy, M.; Wing, J.M. Linearizability: A Correctness Condition for Concurrent Objects. ACM Trans. Program. Lang. Syst. 1990, 12, 463–492. [Google Scholar] [CrossRef]
- Lamport, L. Time, clocks, and the ordering of events in a distributed system. In Concurrency: The Works of Leslie Lamport; Malkhi, D., Ed.; ACM: New York, NY, USA, 2019; pp. 179–196. [Google Scholar] [CrossRef] [Green Version]
- Liskov, B.; Ladin, R. Highly Available Distributed Services and Fault-Tolerant Distributed Garbage Collection. In Proceedings of the Fifth Annual ACM Symposium on Principles of Distributed Computing, New York, NY, USA, 11–13 August 1986; Association for Computing Machinery: New York, NY, USA; pp. 29–39. [Google Scholar] [CrossRef]
- Fidge, C.J. A Limitation of Vector Timestamps for Reconstructing Distributed Computations. Inf. Process. Lett. 1998, 68, 87–91. [Google Scholar] [CrossRef]
- Mattern, F. Efficient Algorithms for Distributed Snapshots and Global Virtual Time Approximation. J. Parallel Distrib. Comput. 1993, 18, 423–434. [Google Scholar] [CrossRef]
- DeCandia, G.; Hastorun, D.; Jampani, M.; Kakulapati, G.; Lakshman, A.; Pilchin, A.; Sivasubramanian, S.; Vosshall, P.; Vogels, W. Dynamo: Amazon’s Highly Available Key-Value Store. In Proceedings of the Twenty-First ACM SIGOPS Symposium on Operating Systems Principles; Association for Computing Machinery: New York, NY, USA, 2007; pp. 205–220. [Google Scholar] [CrossRef]
- Lakshman, A.; Malik, P. Cassandra: A decentralized structured storage system. ACM SIGOPS Oper. Syst. Rev. 2010, 44, 35–40. [Google Scholar] [CrossRef]
- Ellis, J. Why Cassandra Doesn’t Need Vector Clocks. 2013. Available online: https://www.datastax.com/blog/why-cassandra-doesnt-need-vector-clocks (accessed on 27 September 2021).
- Corbett, J.C.; Dean, J.; Epstein, M.; Fikes, A.; Frost, C.; Furman, J.J.; Ghemawat, S.; Gubarev, A.; Heiser, C.; Hochschild, P.; et al. Spanner: Google’s Globally Distributed Database. ACM Trans. Comput. Syst. 2013, 31, 1–22. [Google Scholar]
- Chang, F.; Dean, J.; Ghemawat, S.; Hsieh, W.C.; Wallach, D.A.; Burrows, M.; Chandra, T.; Fikes, A.; Gruber, R. Bigtable: A Distributed Storage System for Structured Data (Awarded Best Paper!). In Proceedings of the 7th Symposium on Operating Systems Design and Implementation (OSDI ’06), Seattle, WA, USA, 6–8 November 2006; pp. 205–218. [Google Scholar]
- Kartch, R. Best Practices for Network Border Protection. 2017. Available online: https://insights.sei.cmu.edu/sei_blog/2017/05/best-practices-for-network-border-protection.html (accessed on 18 March 2021).
- Kim, B.H.; Oh, S.; Lie, D. Consistency Oracles: Towards an Interactive and Flexible Consistency Model Specification. In Proceedings of the 16th Workshop on Hot Topics in Operating Systems; Association for Computing Machinery: New York, NY, USA, 2017; pp. 82–87. [Google Scholar] [CrossRef]
- Cooper, B.F.; Silberstein, A.; Tam, E.; Ramakrishnan, R.; Sears, R. Benchmarking cloud serving systems with YCSB. In Proceedings of the 1st ACM Symposium on Cloud Computing, SoCC 2010, Indianapolis, IN, USA, 10–11 June 2010; Hellerstein, J.M., Chaudhuri, S., Rosenblum, M., Eds.; ACM: New York, NY, USA, 2010; pp. 143–154. [Google Scholar] [CrossRef]
- Cachin, C. Integrity and Consistency for Untrusted Services - (Extended Abstract). In Proceedings of the SOFSEM 2011: Theory and Practice of Computer Science—37th Conference on Current Trends in Theory and Practice of Computer Science, Nový Smokovec, Slovakia, 22–28 January 2011; Cerná, I., Gyimóthy, T., Hromkovic, J., Jeffery, K.G., Královic, R., Vukolic, M., Wolf, S., Eds.; Springer: New York, NY, USA, 2011; Volume 6543, pp. 1–14. [Google Scholar] [CrossRef]
- Cachin, C.; Ohrimenko, O. Verifying the Consistency of Remote Untrusted Services with Commutative Operations. In Proceedings of the Principles of Distributed Systems—18th International Conference, OPODIS 2014, Cortina d’Ampezzo, Italy, 16–19 December 2014; Aguilera, M.K., Querzoni, L., Shapiro, M., Eds.; Springer: New York, NY, USA, 2014; Volume 8878, pp. 1–16. [Google Scholar] [CrossRef] [Green Version]
- Maniatis, P.; Baker, M. Secure History Preservation Through Timeline Entanglement. In Proceedings of the 11th USENIX Security Symposium, San Francisco, CA, USA, 5–9 August 2002; pp. 297–312. [Google Scholar]
- Haeberlen, A.; Aditya, P.; Rodrigues, R.; Druschel, P. Accountable Virtual Machines. In Proceedings of the 9th USENIX Symposium on Operating Systems Design and Implementation, OSDI 2010, Vancouver, BC, Canada, 4–6 October 2010; Arpaci-Dusseau, R.H., Chen, B., Eds.; USENIX Association: Berkeley, CA, USA, 2010; pp. 119–134. [Google Scholar]
- Haeberlen, A.; Kouznetsov, P.; Druschel, P. PeerReview: Practical accountability for distributed systems. In Proceedings of the 21st ACM Symposium on Operating Systems Principles 2007, SOSP 2007, Stevenson, WA, USA, 14–17 October 2007; Bressoud, T.C., Kaashoek, M.F., Eds.; ACM: New York, NY, USA, 2007; pp. 175–188. [Google Scholar] [CrossRef]
- Adya, A.; Bolosky, W.J.; Castro, M.; Cermak, G.; Chaiken, R.; Douceur, J.R.; Howell, J.; Lorch, J.R.; Theimer, M.; Wattenhofer, R. FARSITE: Federated, Available, and Reliable Storage for an Incompletely Trusted Environment. In Proceedings of the 5th Symposium on Operating System Design and Implementation (OSDI 2002), Boston, MA, USA, 9–11 December 2002; Culler, D.E., Druschel, P., Eds.; USENIX Association: Berkeley, CA, USA, 2002. [Google Scholar]
- Chun, B.; Maniatis, P.; Shenker, S.; Kubiatowicz, J. Attested append-only memory: Making adversaries stick to their word. In Proceedings of the 21st ACM Symposium on Operating Systems Principles 2007, SOSP 2007, Stevenson, WA, USA, 14–17 October 2007; Bressoud, T.C., Kaashoek, M.F., Eds.; ACM: New York, NY, USA, 2007; pp. 189–204. [Google Scholar] [CrossRef]
- Levin, D.; Douceur, J.R.; Lorch, J.R.; Moscibroda, T. TrInc: Small Trusted Hardware for Large Distributed Systems. In Proceedings of the 6th USENIX Symposium on Networked Systems Design and Implementation, NSDI 2009, Boston, MA, USA, 22–24 April 2009; Rexford, J., Sirer, E.G., Eds.; USENIX Association: Berkeley, CA, USA, 2009; pp. 1–14. [Google Scholar]
- Schiffman, J.; Sun, Y.; Vijayakumar, H.; Jaeger, T. Cloud Verifier: Verifiable Auditing Service for IaaS Clouds. In Proceedings of the IEEE Ninth World Congress on Services, SERVICES 2013, Santa Clara, CA, USA, 28 June–3 July 2013; IEEE Computer Society: Los Alamitos, CA, USA, 2013; pp. 239–246. [Google Scholar] [CrossRef] [Green Version]
- Stefanov, E.; van Dijk, M.; Juels, A.; Oprea, A. Iris: A scalable cloud file system with efficient integrity checks. In Proceedings of the 28th Annual Computer Security Applications Conference, ACSAC 2012, Orlando, FL, USA, 3–7 December 2012; Zakon, R.H., Ed.; ACM: New York, NY, USA, 2012; pp. 229–238. [Google Scholar] [CrossRef]
- Goh, E.; Shacham, H.; Modadugu, N.; Boneh, D. SiRiUS: Securing Remote Untrusted Storage. In Proceedings of the Network and Distributed System Security Symposium, NDSS 2003, San Diego, CA, USA, 24–27 February 2003; The Internet Society: Reston, VA, USA, 2003. [Google Scholar]
- Rivest, R.L.; Fu, K.; Fu, K.E. Group Sharing and Random Access in Cryptographic Storage File Systems. Master’s Thesis, Massachusetts Institute of Technology, Cambridge, MA, USA, 1999. [Google Scholar]
- Goodrich, M.T.; Papamanthou, C.; Tamassia, R.; Triandopoulos, N. Athos: Efficient Authentication of Outsourced File Systems. In Proceedings of the Information Security, 11th International Conference, ISC 2008, Taipei, Taiwan, 15–18 September 2008; Wu, T., Lei, C., Rijmen, V., Lee, D., Eds.; Springer: New York, NY, USA, 2008; Volume 5222, Lecture Notes in Computer Science. pp. 80–96. [Google Scholar] [CrossRef] [Green Version]
- Barsoum, A.F.; Hasan, M.A. Enabling Dynamic Data and Indirect Mutual Trust for Cloud Computing Storage Systems. IEEE Trans. Parallel Distrib. Syst. 2013, 24, 2375–2385. [Google Scholar] [CrossRef]
- Dobre, D.; Karame, G.; Li, W.; Majuntke, M.; Suri, N.; Vukolic, M. PoWerStore: Proofs of writing for efficient and robust storage. In Proceedings of the 2013 ACM SIGSAC Conference on Computer and Communications Security, CCS’13, Berlin, Germany, 4–8 November 2013; Sadeghi, A., Gligor, V.D., Yung, M., Eds.; ACM: New York, NY, USA, 2013; pp. 285–298. [Google Scholar] [CrossRef]
- Vrable, M.; Savage, S.; Voelker, G.M. BlueSky: A cloud-backed file system for the enterprise. In Proceedings of the 10th USENIX conference on File and Storage Technologies, FAST 2012, San Jose, CA, USA, 14–17 February 2012; Bolosky, W.J., Flinn, J., Eds.; USENIX Association: Berkeley, CA, USA, 2012; p. 19. [Google Scholar]
- Bessani, A.N.; Correia, M.P.; Quaresma, B.; André, F.; Sousa, P. DepSky: Dependable and secure storage in a cloud-of-clouds. European Conference on Computer Systems. In Proceedings of the Sixth European conference on Computer systems, EuroSys 2011, Salzburg, Austria, 10–13 April 2011; Kirsch, C.M., Heiser, G., Eds.; ACM: New York, NY, USA, 2011; pp. 31–46. [Google Scholar] [CrossRef]
- Bowers, K.D.; Juels, A.; Oprea, A. HAIL: A high-availability and integrity layer for cloud storage. In Proceedings of the 2009 ACM Conference on Computer and Communications Security, CCS 2009, Chicago, IL, USA, 9–13 November 2009; Al-Shaer, E., Jha, S., Keromytis, A.D., Eds.; ACM: New York, NY, USA, 2009; pp. 187–198. [Google Scholar] [CrossRef]
- Juels, A.; Kaliski, B.S., Jr. Pors: Proofs of retrievability for large files. In Proceedings of the 2007 ACM Conference on Computer and Communications Security, CCS 2007, Alexandria, VA, USA, 28–31 October 2007; Ning, P., di Vimercati, S.D.C., Syverson, P.F., Eds.; ACM: New York, NY, USA, 2007; pp. 584–597. [Google Scholar] [CrossRef]
- Chen, H.C.H.; Lee, P.P.C. Enabling Data Integrity Protection in Regenerating-Coding-Based Cloud Storage: Theory and Implementation. IEEE Trans. Parallel Distrib. Syst. 2014, 25, 407–416. [Google Scholar] [CrossRef]
- Ateniese, G.; Burns, R.C.; Curtmola, R.; Herring, J.; Kissner, L.; Peterson, Z.N.J.; Song, D.X. Provable data possession at untrusted stores. In Proceedings of the 2007 ACM Conference on Computer and Communications Security, CCS 2007, Alexandria, VA, USA, 28–31 October 2007; Ning, P., di Vimercati, S.D.C., Syverson, P.F., Eds.; ACM: New York, NY, USA, 2007; pp. 598–609. [Google Scholar] [CrossRef] [Green Version]
- van Dijk, M.; Juels, A.; Oprea, A.; Rivest, R.L.; Stefanov, E.; Triandopoulos, N. Hourglass schemes: How to prove that cloud files are encrypted. In Proceedings of the ACM Conference on Computer and Communications Security, CCS’12, Raleigh, NC, USA, 16–18 October 2012; Yu, T., Danezis, G., Gligor, V.D., Eds.; ACM: New York, NY, USA, 2012; pp. 265–280. [Google Scholar] [CrossRef] [Green Version]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Field | Size | Request | Response |
|---|---|---|---|
| Timestamp | 64 bits | Timestamp assigned by a client. | For GET, it is the matching PUT’s timestamp. |
| Type | 8 bits | The specifier for several operation types in Caelus. | For GET, it is the matching PUT’s type. |
| Client ID | 128 bits | The UUID of a client | For GET, it is the matching PUT’s client ID. |
| Counter | 32 bits | The monotonically increasing sequence number for each request per client. | For GET, it is the matching PUT’s counter. |
| Key | 2048 bytes | The key of values either to read or write. | For GET, it is the matching PUT’s key. |
| Value | 400 KB | Value to write for PUT. It is null for GET. | Value to read for GET. It is null for PUT. |
| Hash | 512 bits | The SHA-512 hash the field Value. For GET, it is null. | The hash of the value reading for GET. It is null for PUT. |
| Signature | 3072 bits | The RSA signature of the all meta-data fields, generated by the requesting client. | The RSA signature of the all meta-data fields, generated by the responding CSS. |
| Name | History Server | Consistency Models | Verification Method | History Update |
|---|---|---|---|---|
| SUNDR | Yes | Strong Consistency | Deterministic | Serialized |
| CloudProof | Yes | Strong Consistency | Deterministic | Serialized |
| Depot | No | Fork-Join-Causal-Consistency | Deterministic | Not serialized |
| Jepsen | No | Multiple | Non-deterministic | Not serialized |
| Cobra | No | Serializability | Non-deterministic | Not serialized |
| Caelus | Yes | Multiple | Deterministic | Serialized |
| Relief | Yes | Multiple | Deterministic | Not serialized |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, B.-H.; Yoon, Y. Cloud Storage Service Architecture Providing the Eventually Consistent Totally Ordered Commit History of Distributed Key-Value Stores for Data Consistency Verification. Electronics 2021, 10, 2702. https://0-doi-org.brum.beds.ac.uk/10.3390/electronics10212702
Kim B-H, Yoon Y. Cloud Storage Service Architecture Providing the Eventually Consistent Totally Ordered Commit History of Distributed Key-Value Stores for Data Consistency Verification. Electronics. 2021; 10(21):2702. https://0-doi-org.brum.beds.ac.uk/10.3390/electronics10212702
Chicago/Turabian StyleKim, Beom-Heyn, and Young Yoon. 2021. "Cloud Storage Service Architecture Providing the Eventually Consistent Totally Ordered Commit History of Distributed Key-Value Stores for Data Consistency Verification" Electronics 10, no. 21: 2702. https://0-doi-org.brum.beds.ac.uk/10.3390/electronics10212702