The following sections detail the fusion of ORB-SLAM2 with the semantic segmentation model, the GPS integration feature, and the Fast-SCNN training details.
4.1. Fusion of SLAM and Neural Network
To enrich the ORB-SLAM2 3D map with semantic knowledge, Fast-SCNN needs to be integrated in it. Since the goal was to run the system on a mobile device, the implementation was designed to maximize the speed. It followed these two principles:
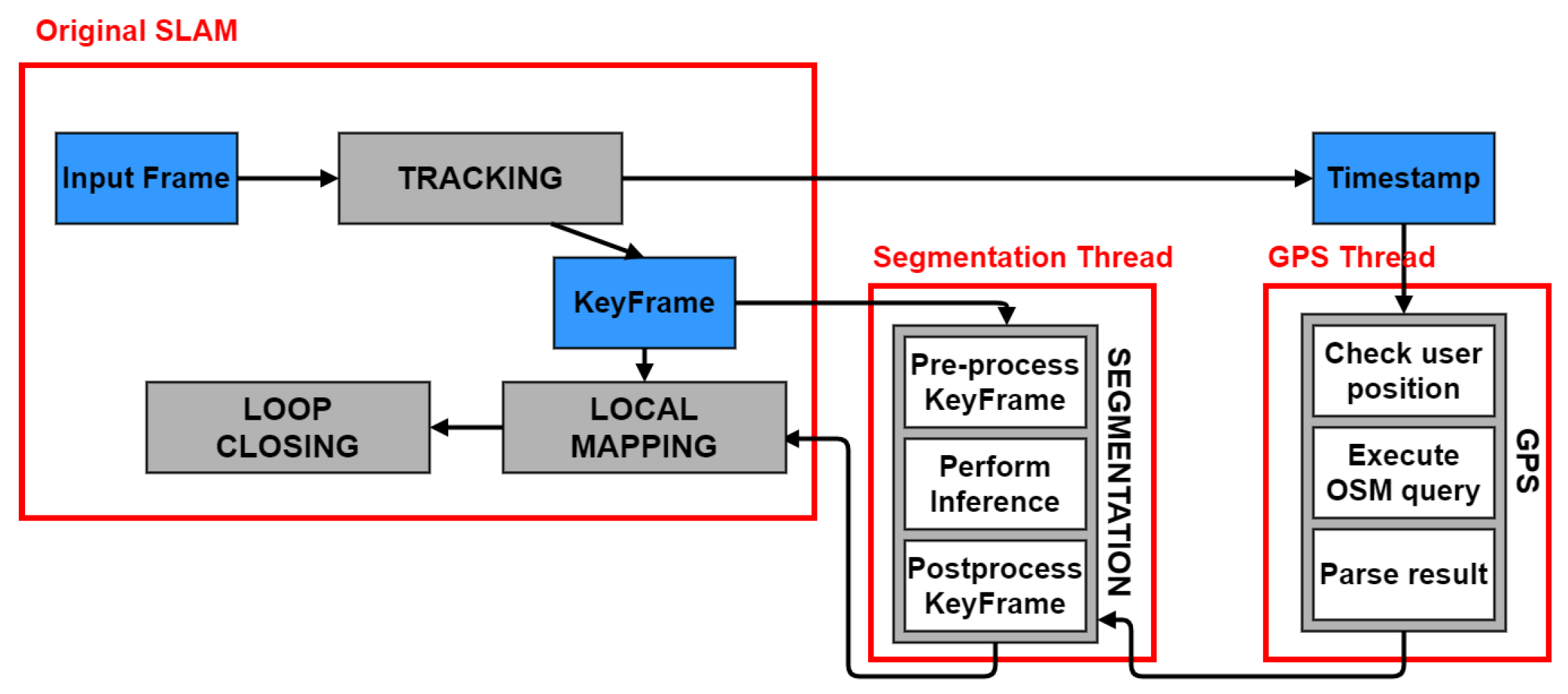
The goal is to minimize the time penalty and computational overhead caused by the neural network introduction, with respect to the original ORB-SLAM2. These rules dictate the design of the system workflow, shown in
Figure 1. As can be seen, to follow rule (1) the neural network is employed only on keyframes and not on every input image, as they are the only ones which contribute to the insertion of new points in the map. The creation of a new thread, in comparison to a sequential insertion of the network in the local mapping thread, is justified by the rule (2): minimize the time that the local mapping spends waiting for the segmentation result. In this way, the local mapping can perform some operations in parallel with the segmentation thread before having to wait for its result.
Implementation Details: Compared to the original ORB-SLAM2, a new thread is introduced: the segmentation thread. Its main function is to perform a forward pass on an image using a pre-trained network. Moreover, it takes care of the images pre- and postprocessing and of the visualization of the result. While ORB-SLAM2 runs on the CPU in real-time, the network inference is performed on the GPU. In addition, the design of this thread is highly modular, as a different network can be employed without having to change the implementation.
The system extends the original C++ implementation of ORB-SLAM2 (
https://github.com/raulmur/ORB_SLAM2 (accessed on 3 March 2021)). Regarding Fast-SCNN, its training is done using the PyTorch framework, but as its interface language is Python, it needs to be converted to Torch Script with the help of LibTorch, so that it can be loaded and executed in C++. The core part of the segmentation thread is composed by the model loading in C++ and the network inference. During its start up time, the model is loaded on the GPU using the LibTorch API, that deserializes the previously serialized network.
All the subsequent operations are repeated in a loop inside the thread and they are executed as soon as a new keyframe is sent to it. First of all the keyframe is preprocessed: it is converted from BGR to RGB representation and values are normalized to the range [0, 1]. Last, the image is normalized using the mean and the standard deviation values for the COCO-Stuff dataset [
64] in order to have a zero mean and a unit variance. After the preprocessing and the network inference, two outputs are obtained: an image with the most probable class label for every pixel and one with the corresponding probability. The two are then sent to the tracking thread, when the system is not initialized, and to the local mapping, during the normal operation, in order to be used during the 3D points creation.
For every 3D point inserted in the map, its class and the corresponding probability are saved. The label is saved only if its probability is higher than a certain threshold (0.5 in our experiments), otherwise the point is considered unlabeled and has the symbolic value 255. This is done to avoid filling the map with outliers by only considering the labels predicted with high confidence. Once the class has been determined at the time of the point creation, it is no longer updated using label fusion methods [
42,
50], as this would require the reprojection of the already created map points every time a new keyframe is segmented, thus increasing the performed computation.
Interaction with the Tracking Thread: The segmentation thread interacts with the tracking thread in two ways. First, during the normal system operations, when the tracking thread chooses a new keyframe and sends it to the segmentation thread to be analyzed by the network. The second interaction happens during the initialization, when the tracking thread is trying to detect the first camera pose and to create an initial map, for whose points it needs the semantic information. To follow rules (1) and (2), a forward pass is executed during the initialization in the parallel segmentation thread only on the current reference frame, and not on all the processed images.
As the biggest interaction between the two threads happens during the initialization, the tracking thread is not slowed down by the network inference during the rest of the operations. Instead, when the tracking is lost and the relocalization is performed, no new keyframes are added, so the segmentation thread is idle, waiting for the tracking to resume.
Interaction with the Local Mapping Thread: Once the initialization is concluded, the tracking thread no longer adds new points to the map. During this stage only the local mapping expands the map with new 3D points, so the segmentation thread needs to send its result only to it, as can be seen in
Figure 1. When a new keyframe is selected in the tracking, it is sent both to the segmentation and the local mapping threads. They then work in parallel on it before the local mapping must wait for the segmentation image, that is sent from the segmentation thread as soon as it is available. After having received that, the local mapping thread can insert new map points, having information about their class and the corresponding probability.
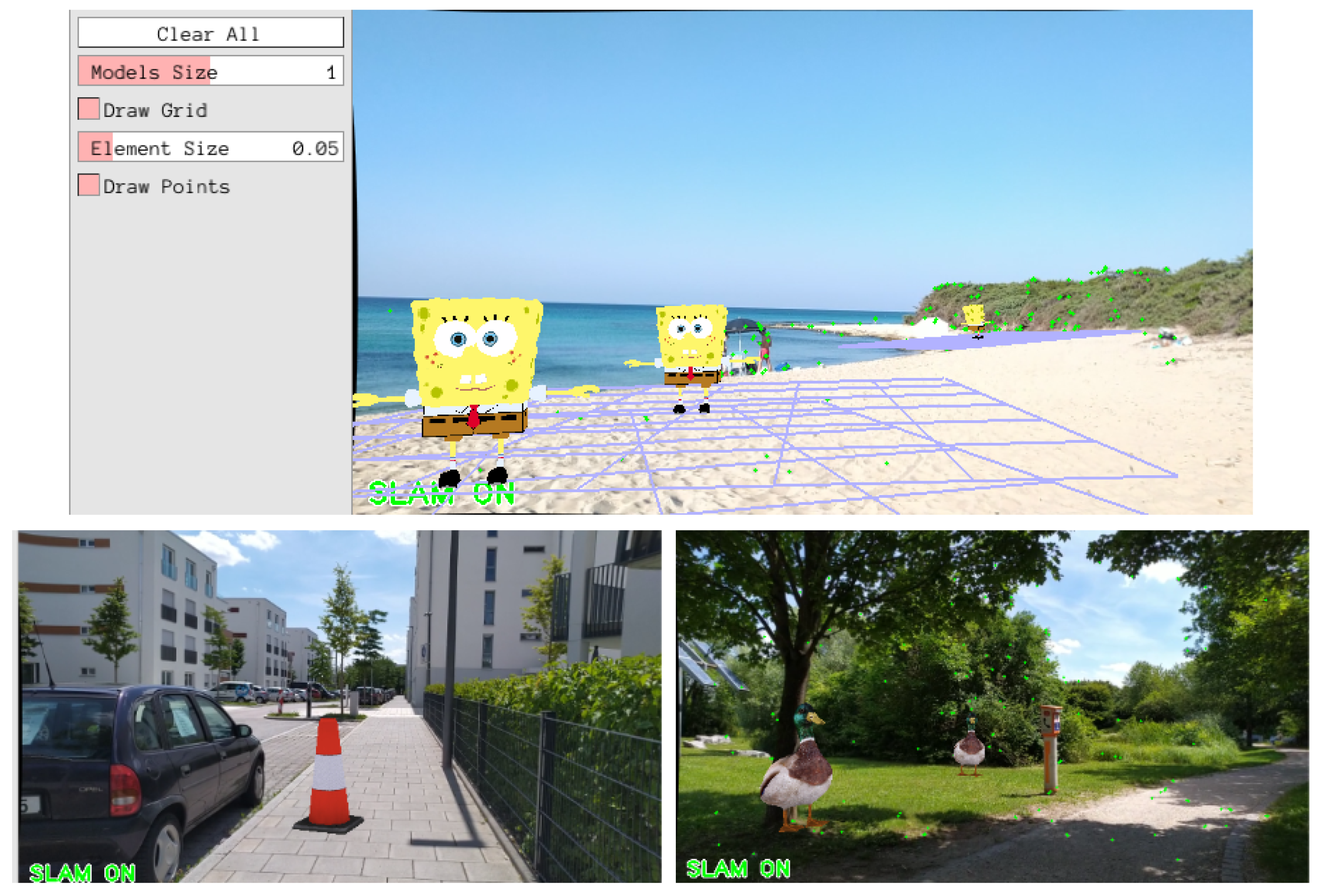
Visualization: A visualization of the created 3D semantic map can be seen in
Figure 2. In the original algorithm, the points are colored in red if they are contained in the current local map, otherwise they are black. This is modified in order to color them based on their class (if they are unlabeled, they get marked in black).
Additional Features: Two additional concepts were implemented and will be briefly discussed here.
Label Fusion: Even though a complete label fusion method is not present, we exploited the knowledge of the points’ probability to reduce the number of unlabeled points and increase the probability of the labeled ones. In fact, when duplicated points are fused by the local mapping or loop closure threads, we keep the class corresponding to the highest probability between the two.
Frame Skipping: This is a simple way to improve ORB-SLAM2 efficiency. The idea is based on the fact that it is common for an AR user to not move for some time while using the application. In these moments, the frames are similar to one another, so it is not necessary to process them at a high frequency, but some can be skipped, thus saving computations. Therefore, in the tracking thread, at the end of an iteration, the frame’s pose is inspected. If the user has not moved, the next frame is skipped. This is not performed during the initialization or the relocalization.
4.2. GPS Integration
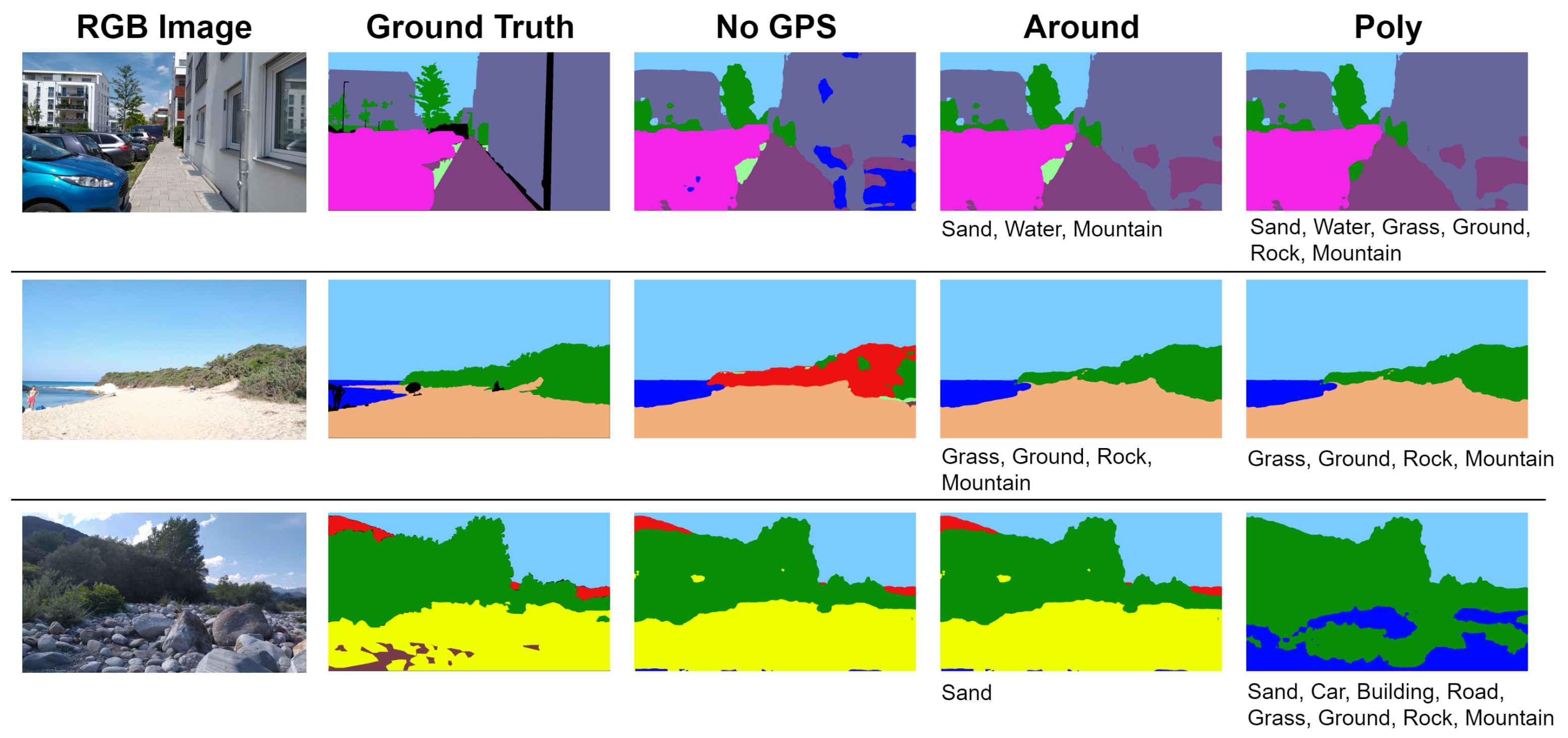
In this section, we present how the GPS information is integrated into EnvSLAM in order to improve the network predictions. We believe that, as the employed network favors efficiency over accuracy, it may be helpful to aid it with external information. Therefore, the GPS coordinates of the user position are used to understand the surrounding environment and, based on this information, limit the classes in the network output. For example, if from the GPS coordinates the system realizes to be in a park, the classes car and sand can be ignored, so that potentially misclassified pixels are filtered out.
OpenStreetMap: OpenStreetMap (OSM) is an open-source Geographic Information System (GIS), which is a framework that provides the ability to store and analyze geographic data. Its information is stored in topological data structures, associated to some attributes. Here, it was sufficient to work with the way elements, which are stored as ordered list of nodes used to represent linear features or areas. During implementation, we experimented with two different types of queries:
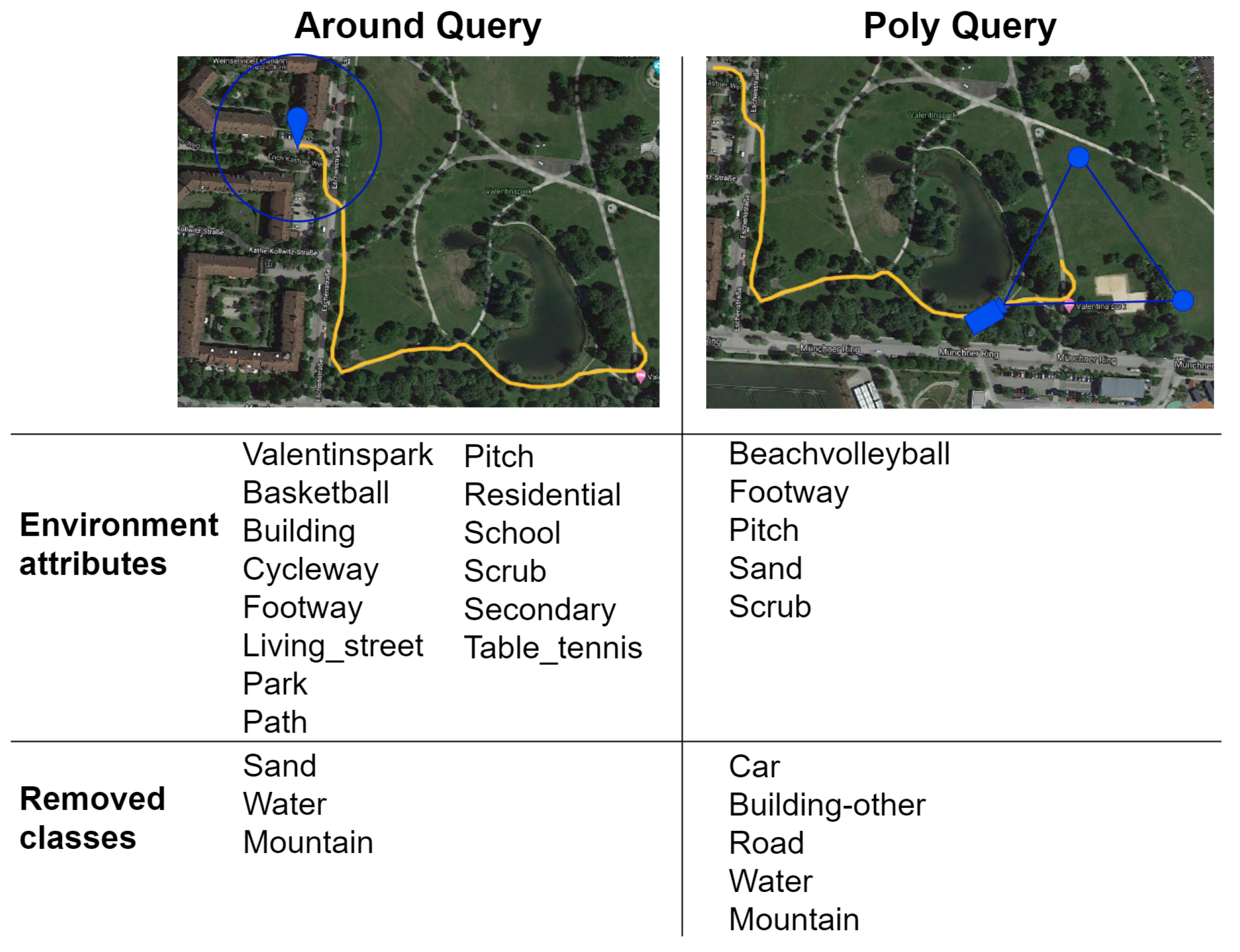
Circle around the User (around keyword): query for all the elements contained in a circle of fixed radius around the user’s current location.
Camera Field of View (poly keyword): retrieve only the features that are present in the user’s camera field of view by specifying a triangle representing it.
Functionalities and Interaction with Other Threads: First, the GPS integration takes place in a new thread. This is justified by the fact that the OSM query execution is too slow to be part of an existing thread, as the evaluation will show. Moreover, the query needs to be executed at regular intervals to always be updated about the features around the user’s current position. This new GPS thread executes the OSM queries, processes their response and takes a decision about which classes are not present in the user’s current surroundings. It does not need to be real-time as no threads directly depend on its result.
It needs to interact with the tracking and the segmentation threads, as can be seen in
Figure 1. First, the tracking thread needs to communicate the timestamp of the current tracked frame, so that a GPS position can be associated with it. After having found the classes that can be removed, they are communicated asynchronously to the segmentation thread, that will use this information to modify the network output. Note that the segmentation thread does not need to wait at any time for the GPS thread output, it just updates the classes information when it receives it. Finally, while the GPS thread is executing a query, the tracking is going on processing frames. After a query processing, the GPS thread resumes its operation from the current frame, skipping the ones processed in between.
Query Details: In order to query OSM, the Overpass API has been used. A query can be formulated using the offered Overpass QL language and then it can be sent to this API with an HTTP GET request, receiving a response in XML format.
In the GPS thread, a query is executed at the system start up, using the initial user position, the
around keyword and a radius of 200 m. After this, a new query is executed when the user has moved significantly (50 m of translation or 40 degrees of rotation) with respect to the last executed query. The difference in the two locations is computed comparing the corresponding two GPS coordinates pairs. The distance in meters can be computed using the Pythagoras’s theorem. The rotation difference is instead found by computing the difference between the bearings of the two positions, which are the angles between the north direction and the user orientation. During these computations, the user bearings are directly obtained from the rotation vector sensor’s values when using our custom dataset. This sensor, or a simple compass as an alternative, is present in all the modern smartphones. Instead, in the Málaga dataset [
66], the rotation vector data is not available; therefore, two consecutive GPS values are employed to compute the user’s current bearing. While this can lead to inaccuracies, it is not an issue when a mobile device is employed, as the rotation vector can be used instead.
Figure 3 shows two examples of OSM queries together with their GPS coordinates and their results.
The query response needs to be parsed to extract only the relevant information characterizing the user’s surroundings, by choosing the relevant tags. After the parsing, a set of environment attributes is obtained, as can be seen in
Figure 3. Based on this set, choices are made regarding which classes to keep in the neural network output and which classes to remove. As only exceptions, the classes
sky and
tree are never removed, as they can be found everywhere in an outdoor scenario. Examples of removed classes can be found in
Figure 3.
The classes that are found to be removable are communicated to the segmentation thread, that receives this information in an asynchronous way and always uses the most recent result. If the OSM queries fail, due to network delays or temporary server problems, and the last successful query is far from the current user position (150 m of translation or of rotation), no classes are removed in the segmentation thread until a new successful query is executed.
4.3. Fast-SCNN Training
Different training protocols and techniques have been compared in order to find the ones that provide the highest training accuracy.
The training was performed on a NVIDIA GeForce GTX 1650 GPU with 4GB, using PyTorch 1.4.0 and CUDA 10.1.243. Given the limited memory of the GPU, the training cycles were bounded in batch size and number of epochs. For this reason, with additional resources a more thorough hyperparameters search could be performed. The employed dataset is COCO-Stuff, reduced to 11 classes as described before.
The employed Fast-SCNN implementation is taken from the open-source version (
https://github.com/Tramac/Fast-SCNN-pytorch (accessed on 3 March 2021)). Data augmentation consists of random cropping to 321 × 321 resolution, random scaling between 0.5 and 2.0 and horizontal flipping. The training has been done with SGD optimizer, with a weight decay of 0.00004 and momentum of 0.9. The learning rate scheduler is the polynomial one, with update step of 1 and power of 0.9. We employed a batch size of 16 and two auxiliary losses, with weight of 0.4, are also present at the output of the
learning to downsample and the
global feature extractor modules.
Transfer learning has been employed using the available pre-trained weights on Cityscapes [
65]. To retain the learned features and achieve an higher accuracy, different learning rates are used: a base value of 0.01 in the new output layer and the auxiliary losses’ layers, 0.00001 in the initial
learning to downsample modules and 0.001 in the rest of the network. Moreover, the use of the OHEM (Online Hard Example Mining) loss [
67], with 0.7 as the maximum probability and 100,000 as the maximum number of considered pixels, has been found to be beneficial to address the issue of unbalanced datasets. In the end, by analyzing the network gradients and activations, the
dead ReLU issue has been identified. In order to solve it, substituting all the ReLU activation functions with LeakyReLUs has been found to be beneficial.
Following a common approach [
27,
39], the training was divided into two stages: the network has been trained completely for 194 epochs and then it has been fine-tuned for other 42 epochs freezing the batch normalization layers, for a total of 236 epochs. After the validation accuracy has reached a plateau, the training has been stopped. As a final note, the original network has been trained for 1000 epochs, so better accuracy can be achieved with more resources.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}