
Modified Deep Reinforcement Learning with Efficient Convolution Feature for Small Target Detection in VHR Remote Sensing Imagery


Abstract
:1. Introduction
2. Related Works
3. Methods
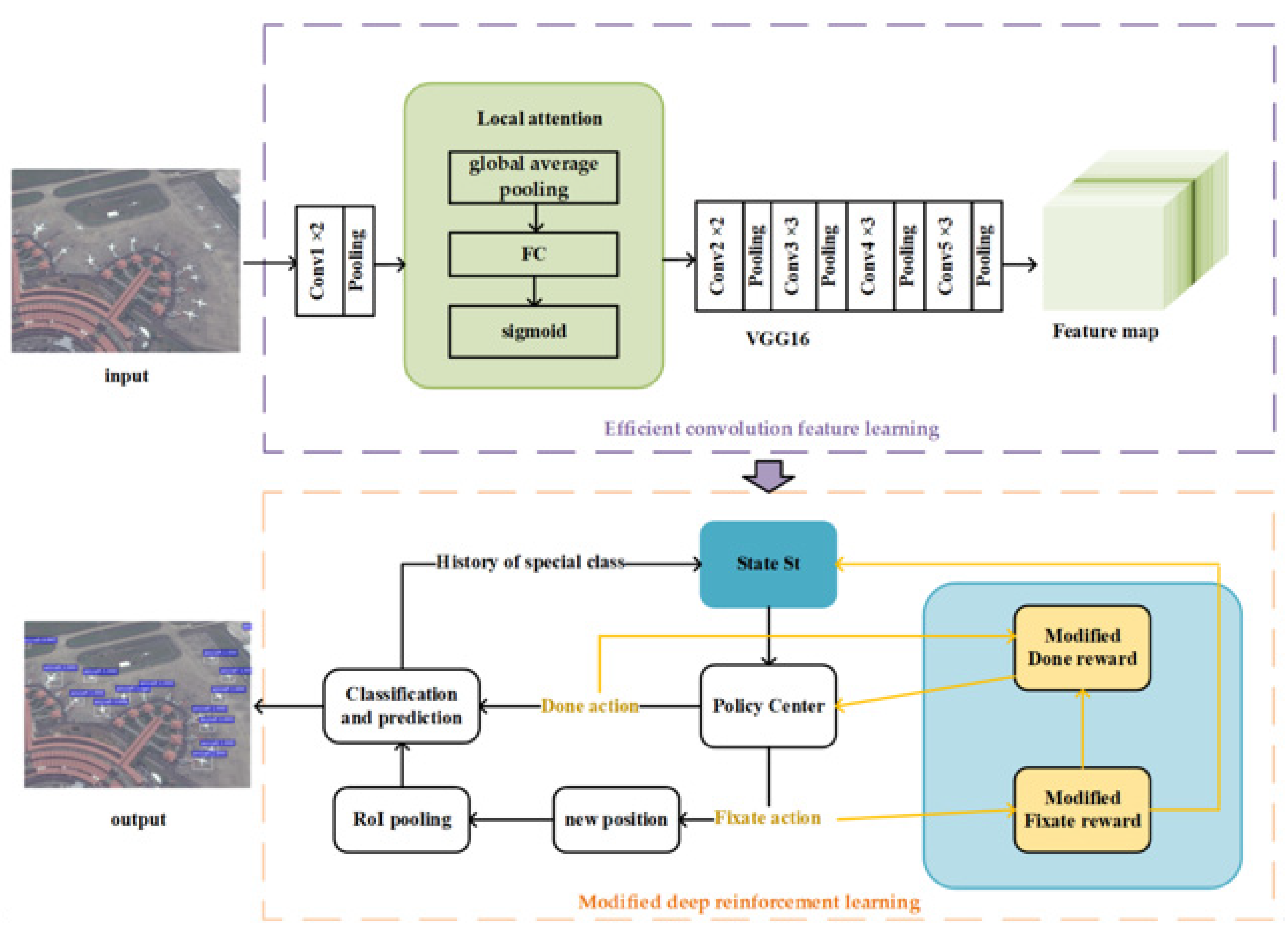
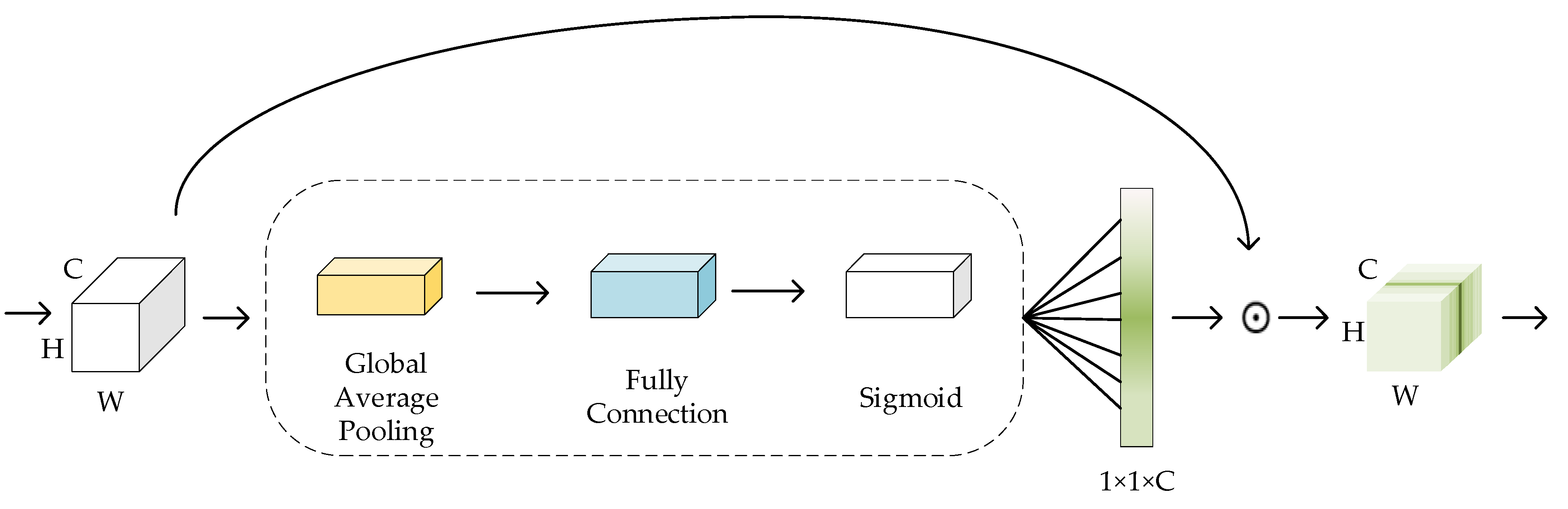
3.1. Efficient Convolution Feature Learning
3.2. Deep Reinforcement Learning with the Modified Reward Function
| Algorithm 1 Modified deep reinforcement learning | |
| Input: feature map | |
| Output: the final classification results | |
| 1: | initialize the state space and give the agent an initial state |
| 2: | for time slot : |
| 3: | derive actions based on strategy |
| 4: | IF : |
| 5: | visit new location and update RoIs |
| 6: | calculate the maximum IoU between each object instance and the ground truth at time slot 0… , denoted as |
| 7: | in each time slot t, calculate the IoU between the RoIs and the object instance, denoted as |
| 8: | IF: |
| 9: | calculate based on (3), let |
| do the classification and bounding box offset prediction of the specific class | |
| insert the prediction results into the history of specific class | |
| combine and with to form a new state | |
| 10: | Jump to Step 2 |
| 11: | ELSE IF done action is chosen |
| 12: | calculate and based on (4) |
| 13: | generate the region proposals |
| 14: | Stop the agent |
| 15: | calculate and draw the prediction boxes based on the regional proposals; obtain the classification result y. |
4. Experiments
4.1. Experimental Setup
4.2. Experimental Results and Analysis
4.2.1. Estimating Locations of the Added Local Attention
4.2.2. Quantitative Analysis
4.3. Visualization Results and Analysis
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Sharma, V.; Mir, R.N. A comprehensive and systematic look up into deep learning based object detection techniques: A review. Comput. Sci. Rev. 2020, 38, 100301. [Google Scholar] [CrossRef]
- Cheng, G.; Zhou, P.C.; Han, J.W. Leaning rotation-invariant convolutional neural networks for object detection in VHR optical remote sensing images. IEEE Trans. Geosci. Remote Sens. 2016, 54, 7405–7415. [Google Scholar] [CrossRef]
- Dong, R.; Xu, D.; Zhao, J.; Jiao, L.; An, J. Sig-NMS-Based Faster R-CNN Combining Transfer Learning for Small Target Detection in VHR Optical Remote Sensing Imagery. IEEE Trans. Geosci. Remote Sens. 2019, 57, 8534–8545. [Google Scholar] [CrossRef]
- Yang, S.; Tian, L.; Zhou, B.; Chen, D.; Zhang, D.; Xu, Z.; Liu, J. Inception Parallel Attention Network for Small Object Detection in Remote Sensing Images. In Proceedings of the 3rd Chinese Conference on Pattern Recognition and Computer Vision (PRCV), Nanjing, China, 16–18 October 2020; pp. 469–480. [Google Scholar]
- Bosquet, B.; Mucientes, M.; Brea, V.M. STDnet: Exploiting high resolution feature maps for small object detection. Eng. Appl. Artif. Intell. 2020, 91, 103615. [Google Scholar] [CrossRef]
- Deng, Z.; Sun, H.; Zhou, S.; Zhao, J.; Lei, L.; Zou, H. Multi-scale object detection in remote sensing imagery with convolutional neural networks. ISPRS J. Photogramm. Remote Sens. 2018, 145, 3–22. [Google Scholar] [CrossRef]
- Sun, C.; Ai, Y.; Wang, S.; Zhang, W. Mask-guided SSD for small-object detection. Appl. Intell. 2020, 1–12. [Google Scholar] [CrossRef]
- Agarwal, S.; Terrail, J.O.D.; Jurie, F. Recent advances in object detection in the age of deep convolutional neural networks. arXiv 2018, arXiv:1809.03193. [Google Scholar]
- Liu, L.; Yang, W.O.; Wang, X. Deep Learning for Generic Object Detection: A Survey. Int. J. Comput. 2020, 128, 261–318. [Google Scholar] [CrossRef] [Green Version]
- Zou, Z.; Shi, Z. Random Access Memories: A New Paradigm for Target Detection in High Resolution Aerial Remote Sensing Images. IEEE Trans. Image Process. 2018, 27, 1100–1111. [Google Scholar] [CrossRef] [PubMed]
- Zhu, X.X.; Tuia, D.; Mou, L.; Xia, G.S.; Zhang, L.; Xu, F.; Fraundorfer, F. Deep Learning in Remote Sensing: A Comprehensive Review and List of Resources. Remote Sens. 2017, 5, 8–36. [Google Scholar] [CrossRef] [Green Version]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the 2015 IEEE International Conference on Computer Vision, Santiago, MN, USA, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Image Process. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6517–6525. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.E.; Fu, C.-Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 21–37. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Law, H.; Deng, J. CornerNet: Detecting Objects as Paired Keypoints. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 734–750. [Google Scholar]
- Yi, Z.X.; Cheng, Z.J.; Philipp, K. Bottom-up Object Detection by Grouping Extreme and Center Points. In Proceedings of the 2019 IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 850–859. [Google Scholar]
- Zhi, T.; Chunhua, S.; Hao, C.; Tong, H. FCOS: Fully Convolutional One-Stage Object Detection. In Proceedings of the 2019 IEEE International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 9626–9635. [Google Scholar]
- Pang, J.; Chen, K.; Shi, J.; Feng, H.; Ouyang, W.; Lin, D. Libra R-CNN: Towards balanced learning for object detection. In Proceedings of the 2019 IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 821–830. [Google Scholar]
- Tong, K.; Wu, Y.; Zhou, F. Recent advances in small object detection based on deep learning: A review. Image Vis. Comput. 2020, 97, 103910. [Google Scholar] [CrossRef]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 936–944. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path aggregation network for instance segmentation. In Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8759–8768. [Google Scholar]
- Caicedo, J.C.; Lazebnik, S. Active object localization with deep reinforcement learning. In Proceedings of the IEEE International Conference on Computer Vision, Las Condes, Chile, 11–18 December 2015; pp. 2488–2496. [Google Scholar]
- Pirinen, A.; Sminchisescu, C. Deep Reinforcement Learning of Region Proposal Networks for Object Detection. In Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6945–6954. [Google Scholar]
- Al, W.A.; Yun, I.D. Partial policy-based reinforcement learning for anatomical landmark localization in 3d medical images. IEEE Trans. Med. Imaging 2019, 39, 1245–1255. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Jie, H.; Shen, L.; Sun, G. Squeeze-and-Excitation Networks. In Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. ECA-net: Efficient channel attention for deep convolutional neural networks. In Proceedings of the 2020 IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11534–11542. [Google Scholar]
- Hu, D. An Introductory Survey on Attention Mechanisms in NLP Problems. arXiv 2018, arXiv:1811.05544. [Google Scholar]
- Mnih, V.; Heess, N.; Graves, A.; Kavukcuoglu, K. Recurrent Models of Visual Attention. In Proceedings of the 27th International Conference on Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; pp. 2204–2212. [Google Scholar]
- Shan, C.; Zhang, J.; Wang, Y.; Xie, L. Attention-Based End-to-End Speech Recognition on Voice Search. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing, Calgary, AB, Canada, 15–20 April 2018; pp. 4764–4768. [Google Scholar]
- Li, Y.; Bei, Z.J.; Shan, S.; Chen, X. Occlusion Aware Facial Expression Recognition Using CNN with Attention Mechanism. IEEE Trans. Image Process 2019, 28, 2439–2450. [Google Scholar] [CrossRef]
- Bellver, M.; Giro-i-Nieto, X.; Marques, F.; Torres, J. Hierarchical object detection with deep reinforcement learning. In Proceedings of the Conference on Neural Information Processing Systems, Barcelona, Spain, 5–20 December 2016. [Google Scholar]
- Kong, X.; Xin, B.; Wang, Y.; Hua, G. Collaborative deep reinforcement learning for joint object search. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 21–26 July 2017; pp. 7072–7081. [Google Scholar]
- Uzkent, B.; Yeh, C.; Ermon, S. Efficient object detection in large images using deep reinforcement learning. In Proceedings of the 2020 IEEE Winter Conference on Applications of Computer Vision, Snowmass Village, CO, USA, 1–5 March 2020; pp. 1824–1833. [Google Scholar]
- Liu, S.; Huang, D.; Wang, Y. Pay Attention to Them: Deep Reinforcement Learning-Based Cascade Object Detection. IEEE Trans Neural Netw. Learn Syst. 2020, 31, 2544–2556. [Google Scholar] [CrossRef] [PubMed]
- Yao, Q.; Hu, X.; Lei, H. Multiscale Convolutional Neural Networks for Geospatial Object Detection in VHR Satellite Images. IEEE Geosci. Remote Sens. Lett. 2021, 18, 23–27. [Google Scholar] [CrossRef]
- Wang, Y.; Wang, C.; Zhang, H.; Dong, Y.; Wei, S. A SAR Dataset of Ship Detection for Deep Learning under Complex Backgrounds. Remote Sens. 2019, 11, 765. [Google Scholar] [CrossRef] [Green Version]
- Long, Y.; Gong, Y.; Xiao, Z.; Liu, Q. Accurate object localization in remote sensing images based on convolutional neural networks. IEEE Trans. Geosci. Remote Sens. 2017, 55, 2486–2498. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Number of Categories | Number of Pictures | Supplements |
|---|---|---|---|
| NWPU VHR-10 [38] | 10 | 800 | A 10-level geographic remote sensing dataset for space object detection. |
| SAR-Ship-Dataset [39] | 1 | 43,819 | This dataset labeled by SAR experts was created using 102 Chinese Gaofen-3 images and 108 Sentinel-1 images. |
| RSOD [40] | 4 | 976 | Spatial resolution from 0.3 m to 3 m, and contains 6950 instances |
| Module | Add Layer | Scaling Parameters | mAP |
|---|---|---|---|
| local attention | 1 | × | 0.834 |
| SE module | 1,2 | 16 | 0.670 |
| SE module | 1,2 | 32 | 0.780 |
| SE module | 1,2 | 64 | 0.748 |
| local attention | 1,2 | × | 0.810 |
| SE module | 1,2,3 | 16 | 0.608 |
| SE module | 1,2,3 | 32 | 0.663 |
| local attention | 1,2,3 | × | 0.742 |
| SE module | 2,3 | 16 | 0.588 |
| local attention | 2,3 | × | 0.809 |
| SE module | 1,2,3,4,5 | 16 | 0.527 |
| RICNN | Faster R-CNN | DRL-Fr | MDRL | MdrlEcf | SSD | YOLO | |
|---|---|---|---|---|---|---|---|
| airplane | 0.884 | 0.903 | 0.907 | 0.905 | 0.927 | 0.932 | 0.874 |
| ship | 0.773 | 0.800 | 0.814 | 0.853 | 0.844 | 0.857 | 0.847 |
| storage tank | 0.853 | 0.711 | 0.629 | 0.631 | 0.775 | 0.617 | 0.658 |
| baseball diamond | 0.881 | 0.894 | 0.897 | 0.872 | 0.922 | 0.904 | 0.931 |
| tennis court | 0.408 | 0.815 | 0.813 | 0.818 | 0.838 | 0.850 | 0.658 |
| baseball court | 0.585 | 0.808 | 0.816 | 0.823 | 0.824 | 0.870 | 0.872 |
| ground track field | 0.867 | 0.909 | 0.995 | 0.999 | 0.988 | 0.985 | 0.976 |
| harbor | 0.686 | 0.798 | 0.786 | 0.797 | 0.789 | 0.812 | 0.832 |
| bridge | 0.615 | 0.706 | 0.706 | 0.734 | 0.722 | 0.731 | 0.793 |
| vehicle | 0.711 | 0.714 | 0.704 | 0.715 | 0.715 | 0.762 | 0.742 |
| mAP | 0.726 | 0.806 | 0.807 | 0.814 | 0.834 | 0.832 | 0.818 |
| Training Time(s) | 8.77 | 0.242 | 0.267 | 0.271 | 0.264 | 0.186 | 0.182 |
| RICNN | Faster R-CNN | DRL-Fr | MDRL | MdrlEcf | SSD | YOLO | |
|---|---|---|---|---|---|---|---|
| ship | 0.803 | 0.907 | 0.900 | 0.901 | 0.917 | 0.901 | 0.746 |
| mAP | 0.803 | 0.907 | 0.900 | 0.901 | 0.917 | 0.901 | 0.746 |
| Training Time(s) | 7.13 | 0.213 | 0.225 | 0.214 | 0.198 | 0.189 | 0.196 |
| RICNN | Faster R-CNN | DRL-Fr | MDRL | MdrlEcf | SSD | YOLO | |
|---|---|---|---|---|---|---|---|
| oiltank | 0.721 | 0.901 | 0.901 | 0.906 | 0.909 | 0.692 | 0.743 |
| playground | 0.678 | 0.885 | 0.885 | 0.884 | 0.889 | 0.712 | 0.738 |
| aircraft | 0.763 | 0.804 | 0.805 | 0.806 | 0.810 | 0.702 | 0.751 |
| overpass | 0.844 | 0.732 | 0.694 | 0.692 | 0.737 | 0.823 | 0.851 |
| mAP | 0.751 | 0.831 | 0.821 | 0.822 | 0.836 | 0.732 | 0.771 |
| Training Time(s) | 8.25 | 0.236 | 0.241 | 0.231 | 0.227 | 0.214 | 0.217 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, S.; Tang, J. Modified Deep Reinforcement Learning with Efficient Convolution Feature for Small Target Detection in VHR Remote Sensing Imagery. ISPRS Int. J. Geo-Inf. 2021, 10, 170. https://0-doi-org.brum.beds.ac.uk/10.3390/ijgi10030170
Liu S, Tang J. Modified Deep Reinforcement Learning with Efficient Convolution Feature for Small Target Detection in VHR Remote Sensing Imagery. ISPRS International Journal of Geo-Information. 2021; 10(3):170. https://0-doi-org.brum.beds.ac.uk/10.3390/ijgi10030170
Chicago/Turabian StyleLiu, Shuai, and Jialan Tang. 2021. "Modified Deep Reinforcement Learning with Efficient Convolution Feature for Small Target Detection in VHR Remote Sensing Imagery" ISPRS International Journal of Geo-Information 10, no. 3: 170. https://0-doi-org.brum.beds.ac.uk/10.3390/ijgi10030170