
High-Resolution Remote Sensing Image Segmentation Framework Based on Attention Mechanism and Adaptive Weighting

Abstract
:1. Introduction
- (1)
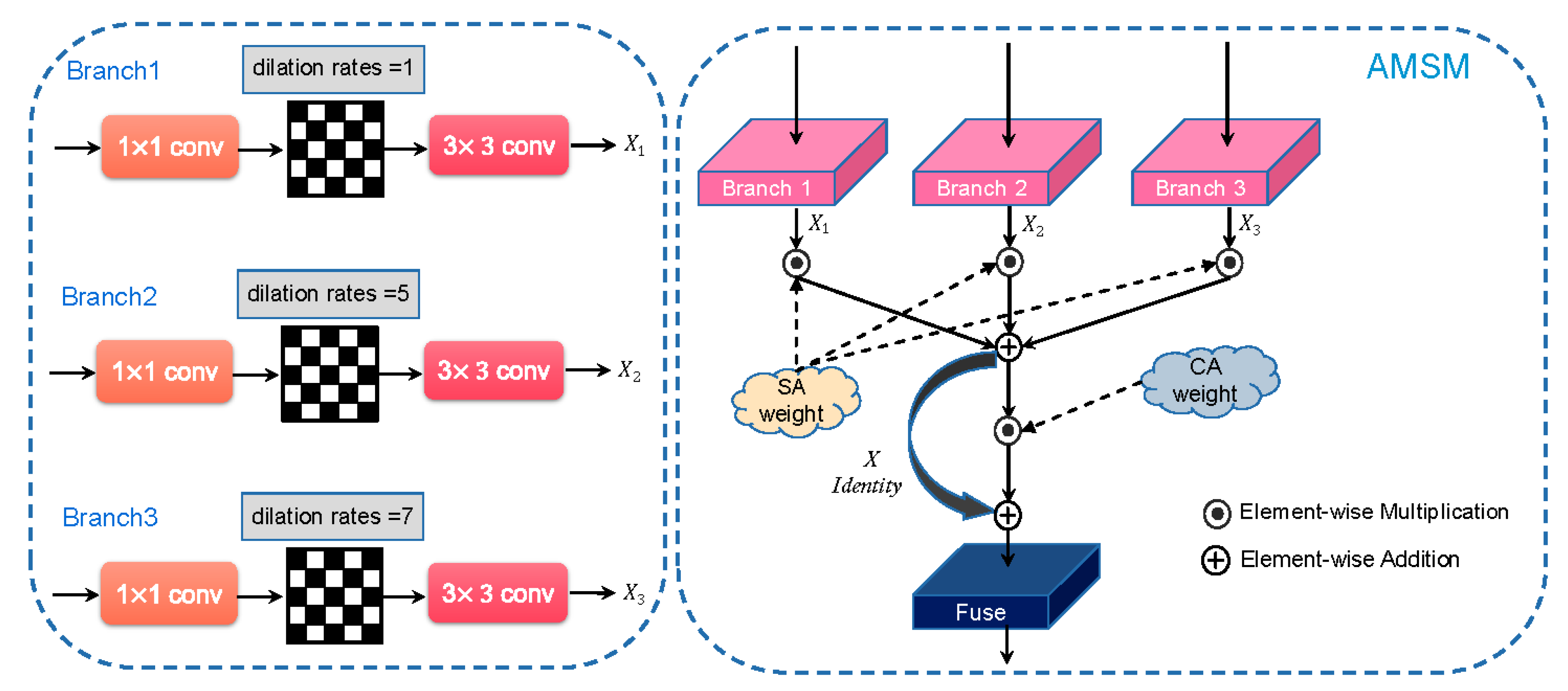
- A novel multi-scale fusion module—ASMS (Adaptive Multi-Scale Module) module is proposed, which can adaptively fuse multi-scale features from different branches according to the size characteristics of remote sensing images and has a better segmentation effect in the data sets with complex and variable object sizes.
- (2)
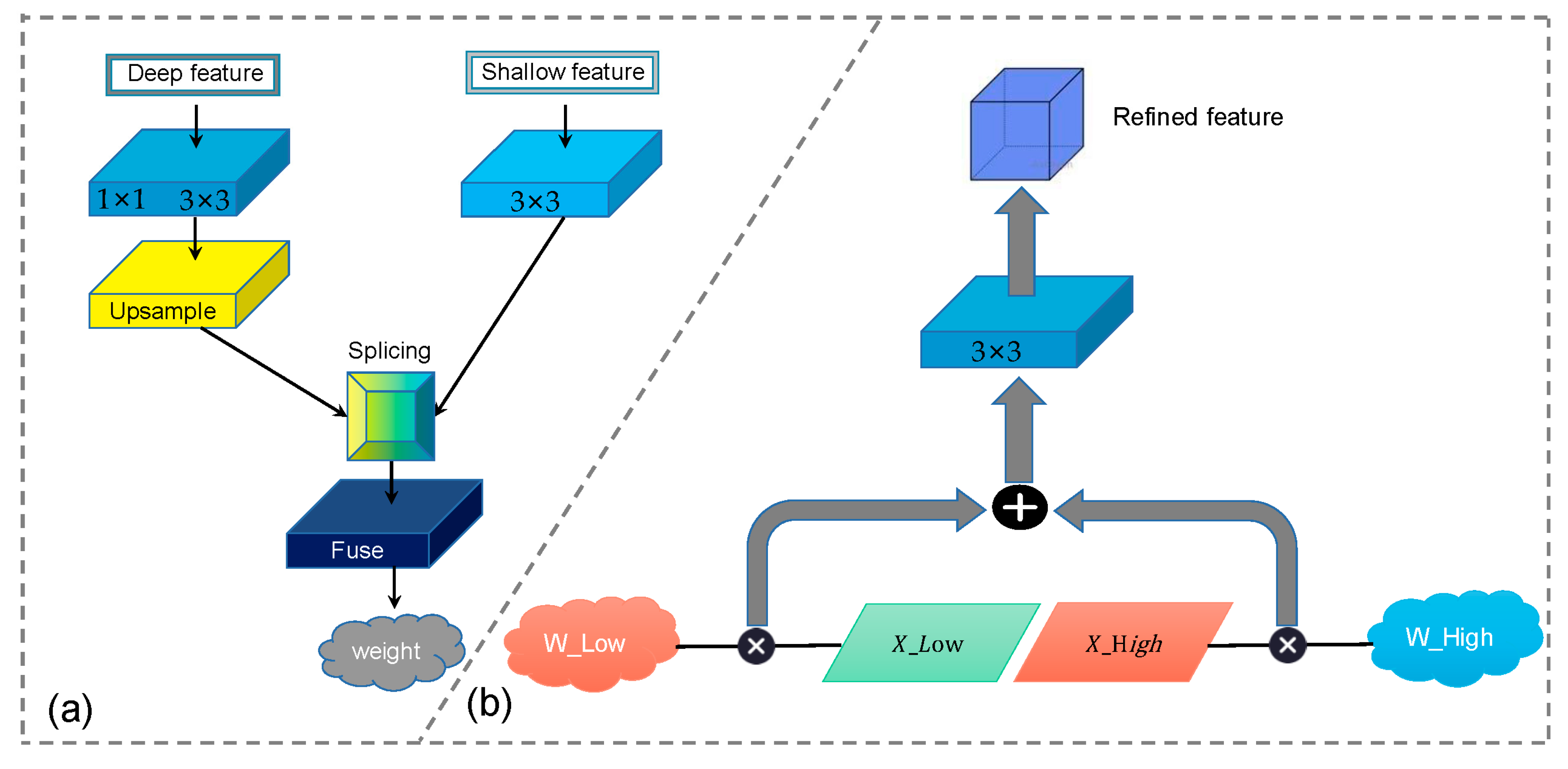
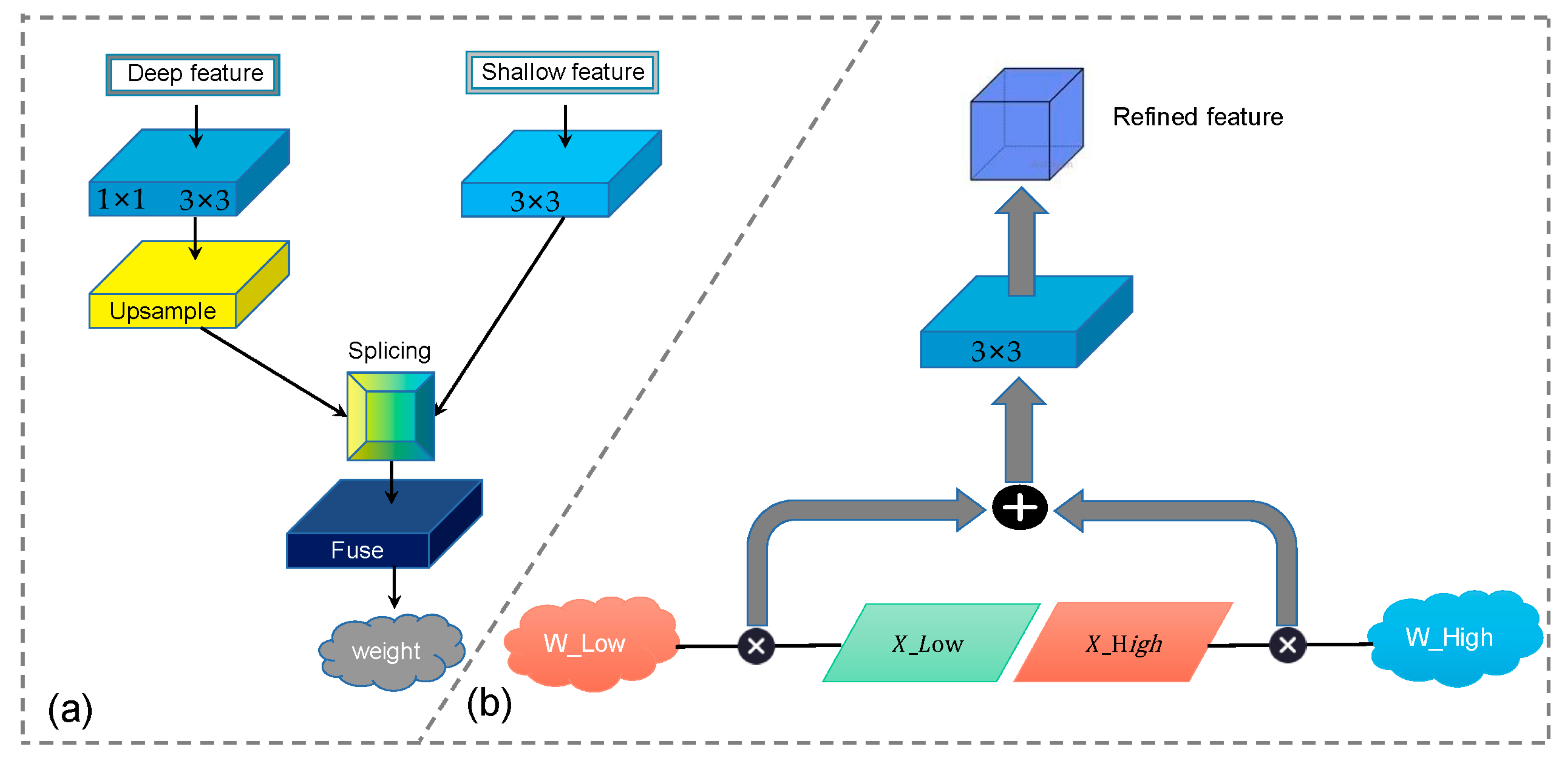
- We designed an AFM (Adaptive Fuse Module) that can filter and extract shallow information of remote sensing images. This module can combine the shallow and deep feature information effectively. After obtaining the weights of shallow and deep layers, these weights are multiplied by the original weight of the feature map to emphasize the useful information in the shallow feature map and suppress useless noise. So that the deep feature map can obtain more accurate detailed information.
- (3)
- A new type of network structure-Adaptive Weighted Network (AWNet) is proposed, which is a network structure embedded with AMSM and AFM. AWNet achieved one of the best accuracies on the ISPRS Vaigingen data set, reaching an overall accuracy of 88.35%.
2. Related work
2.1. Semantic Segmentation
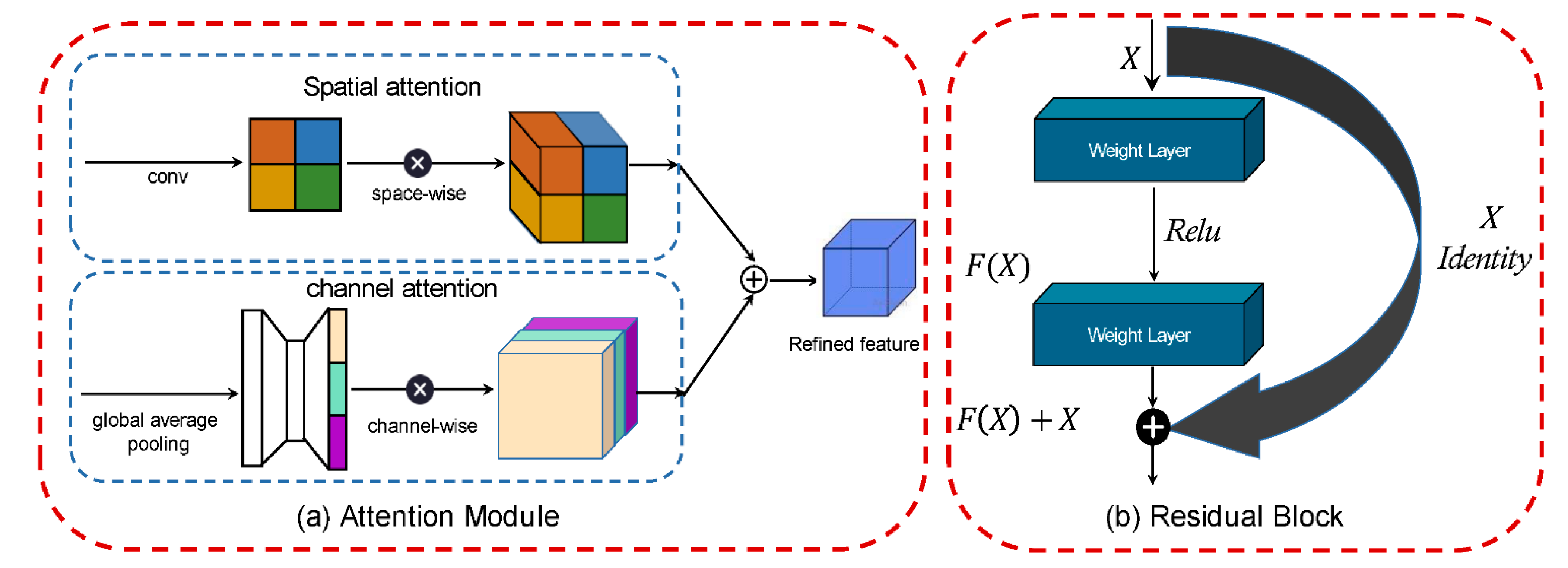
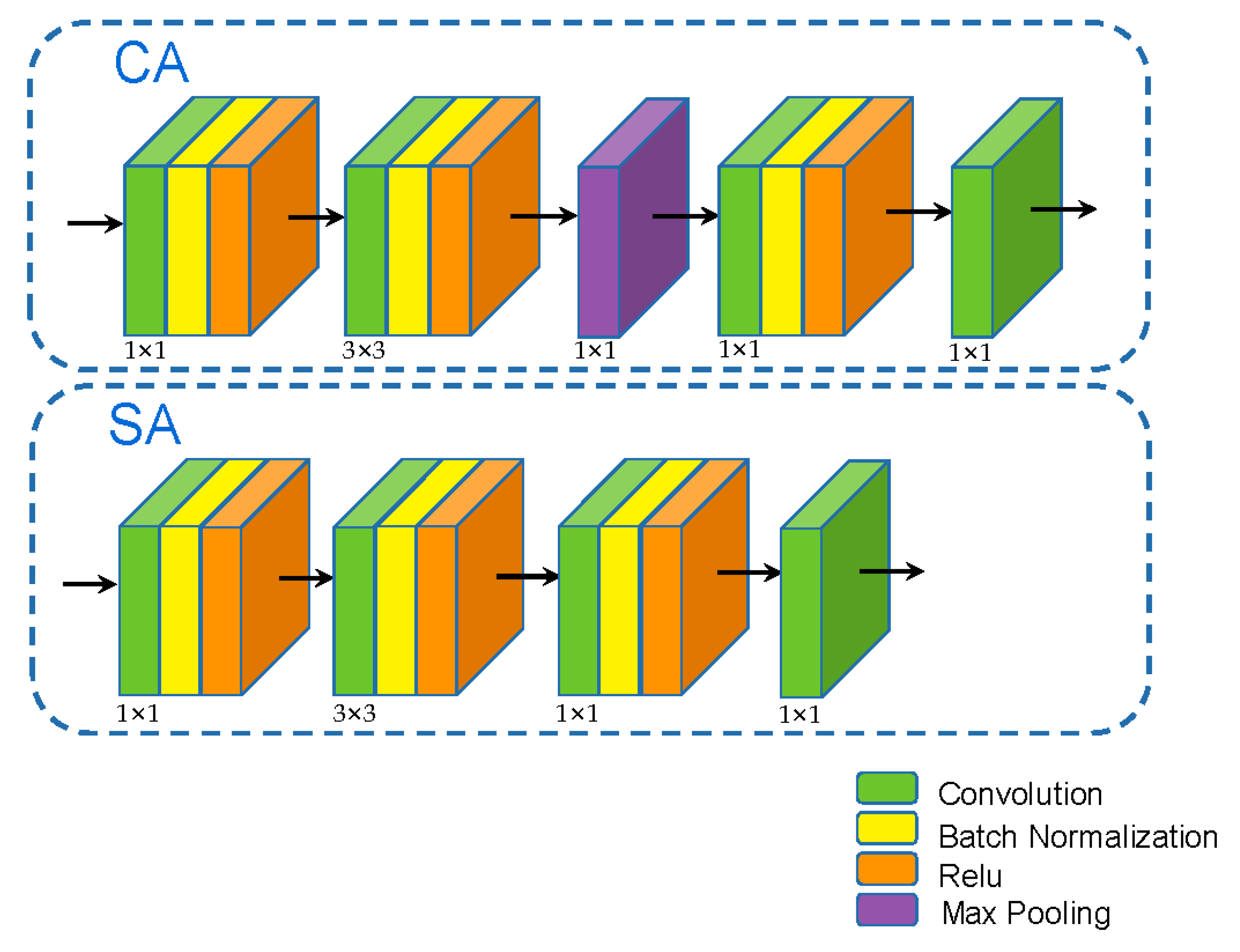
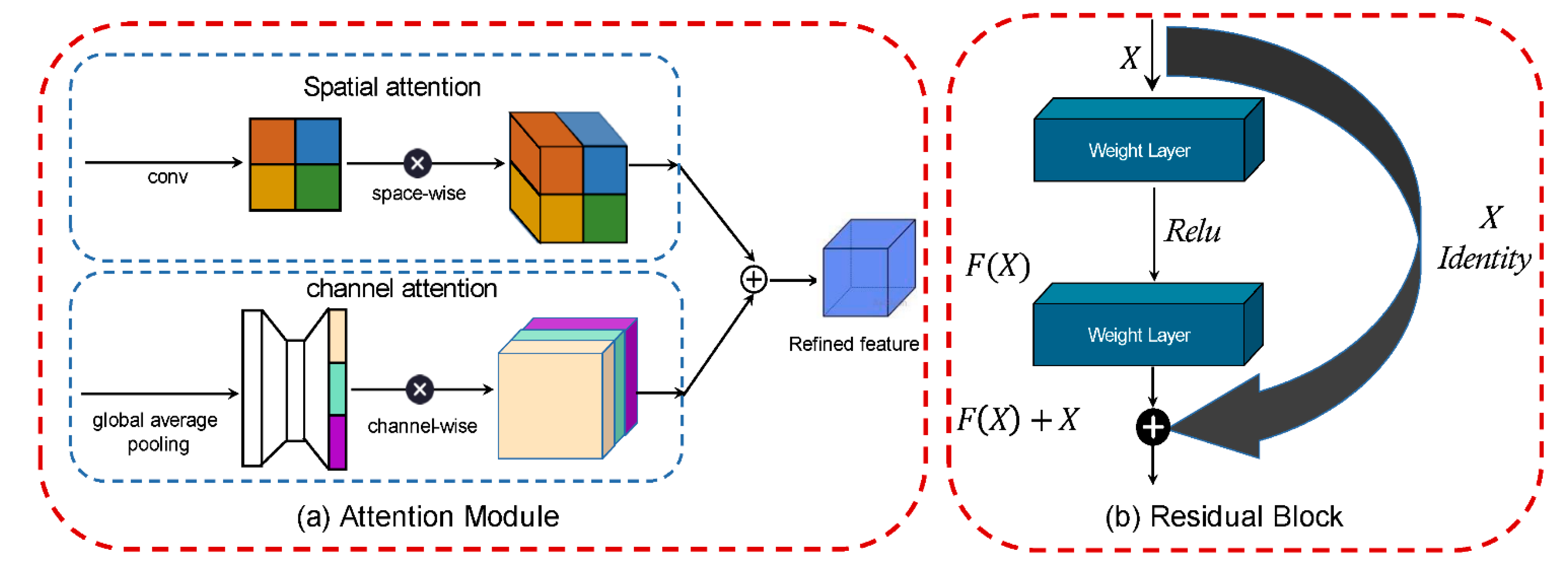
2.2. Attention Module
2.3. Spatial Pyramid Pooling and Atrous Convolution
3. Materials and Methods
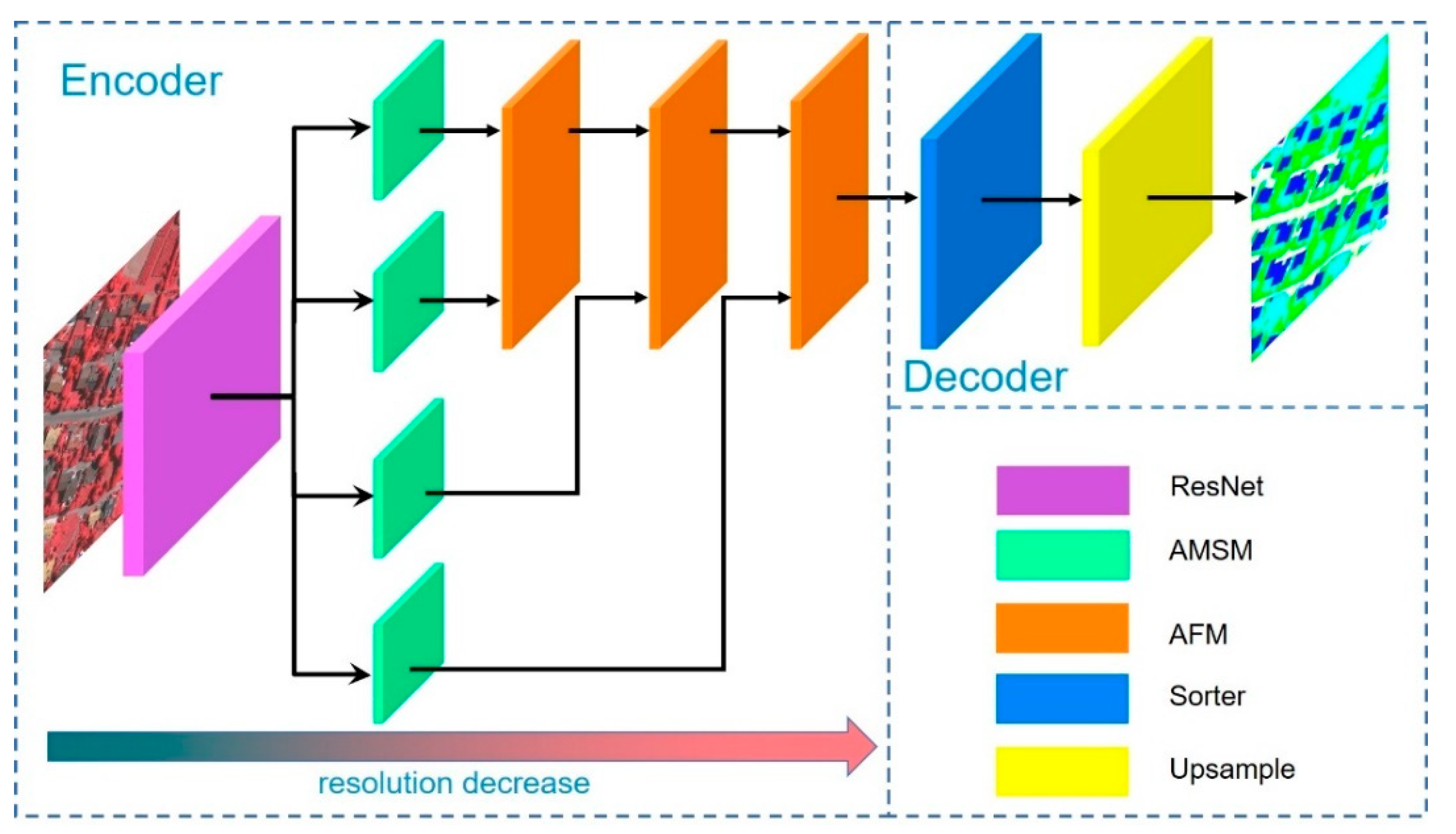
3.1. Overview
3.2. Pretreatment
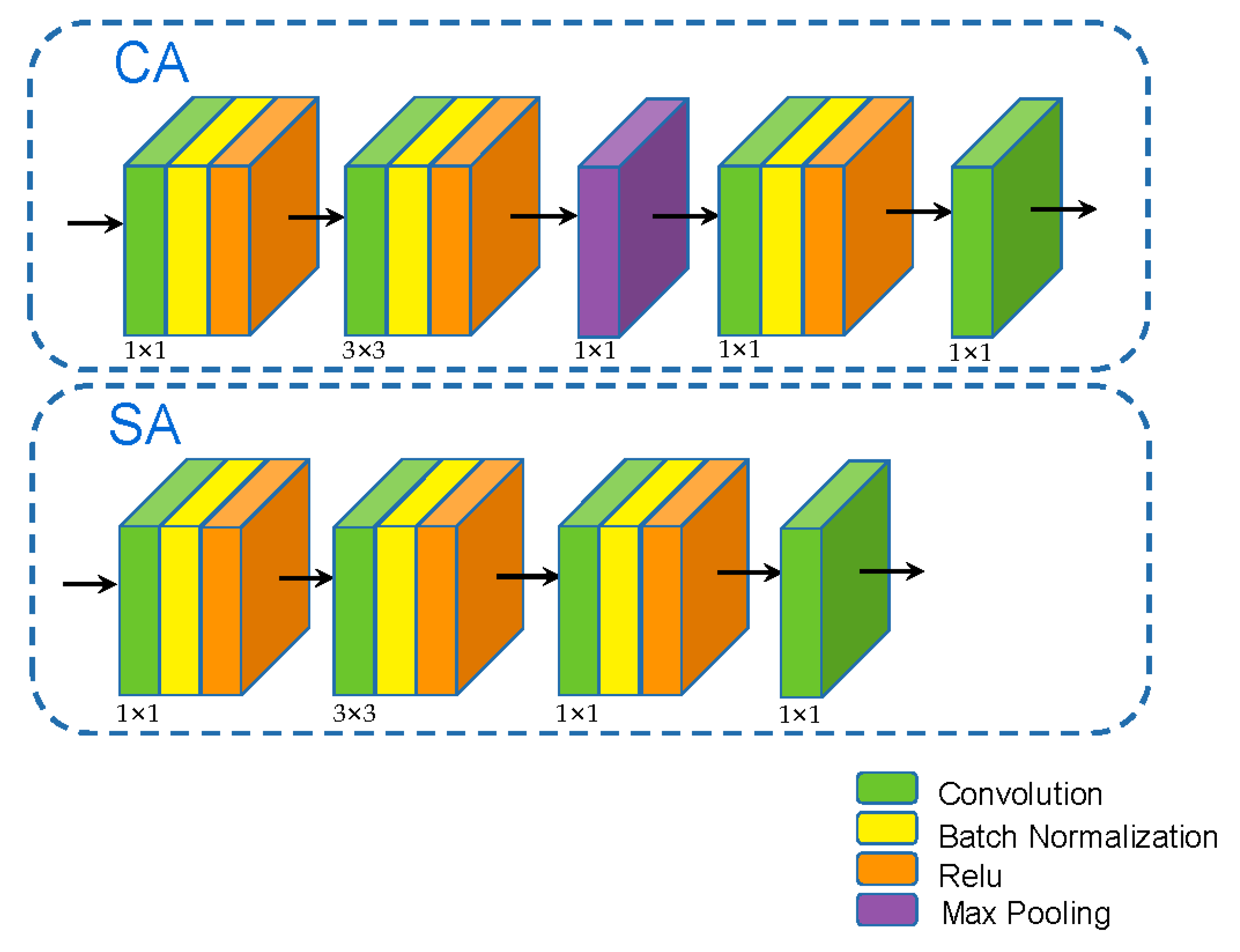
3.3. Adaptive Multi-Scale Module (AMSM)
3.4. Adaptive Fuse Module (AFM)
4. Experiments
4.1. Experiments Sets
4.2. Data Set Preprocessing
4.3. Implementation
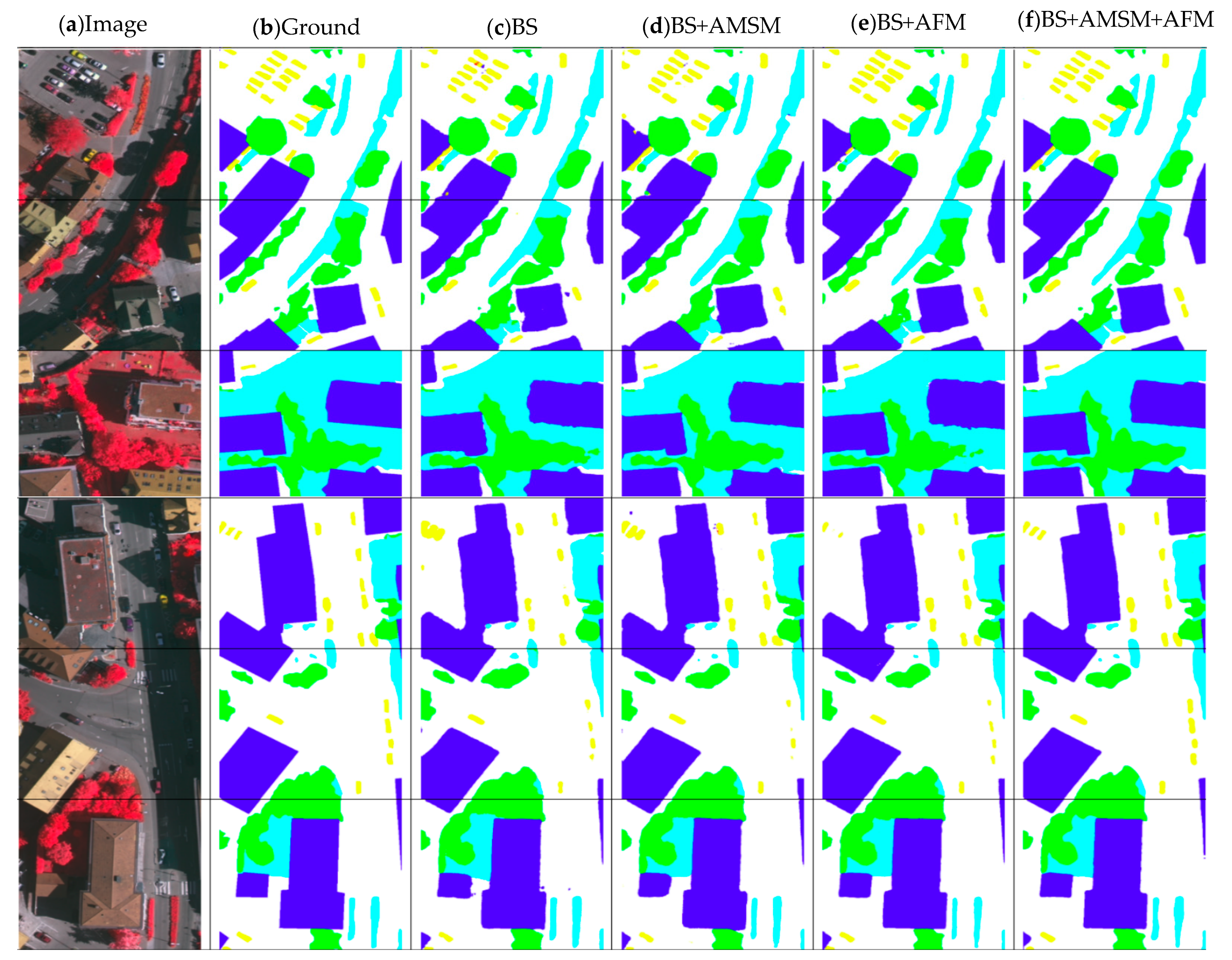
4.4. Ablation Study for Relation Modules
4.5. Comparing with Existing Works
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| AMSM | Adaptive Multi-Scale Module |
| AFM | Adaptive Fuse Module |
| AWNet | Adaptive Weighted Network |
| ASPP | Atrous Spatial Pyramid Pooling |
| BS | BaseLine |
| RGB | Red–Green–Blue |
| CNN | Convolutional Neural Network |
| OA | Overall Accuracy |
References
- Wen, D.; Huang, X.; Liu, H.; Liao, W.; Zhang, L. Semantic Classification of Urban Trees Using Very High Resolution Satellite Imagery. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2017, 10, 1413–1424. [Google Scholar] [CrossRef]
- Shi, Y.; Qi, Z.; Liu, X.; Niu, N.; Zhang, H. Urban Land Use and Land Cover Classification Using Multisource Remote Sensing Images and Social Media Data. Remote Sens. 2019, 11, 2719. [Google Scholar] [CrossRef] [Green Version]
- Matikainen, L.; Karila, K. Segment-Based Land Cover Mapping of a Suburban Area—Comparison of High-Resolution Remotely Sensed Datasets Using Classification Trees and Test Field Points. Remote Sens. 2011, 3, 1777–1804. [Google Scholar] [CrossRef] [Green Version]
- Xu, S.; Pan, X.; Li, E.; Wu, B.; Bu, S.; Dong, W.; Xiang, S.; Zhang, X. Automatic Building Rooftop Extraction from Aerial Images via Hierarchical RGB-D Priors. IEEE Trans. Geosci. Remote Sens. 2018, 56, 7369–7387. [Google Scholar] [CrossRef]
- Liu, W.; Yang, M.; Xie, M.; Guo, Z.; Li, E.; Zhang, L.; Pei, T.; Wang, D. Accurate Building Extraction from Fused DSM and UAV Images Using a Chain Fully Convolutional Neural Network. Remote Sens. 2019, 11, 2912. [Google Scholar] [CrossRef] [Green Version]
- Long, J.; Shelhamer, E.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Zhou, J.; Hao, M.; Zhang, D.; Zou, P.; Zhang, W. Fusion PSPnet Image Segmentation Based Method for Multi-Focus Image Fusion. IEEE Photon. J. 2019, 11, 1–12. [Google Scholar] [CrossRef]
- Chen, L.-C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef]
- Chen, L.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Pan, X.; Gao, L.; Zhang, B.; Yang, F.; Liao, W. High-Resolution Aerial Imagery Semantic Labeling with Dense Pyramid Network. Sensors 2018, 18, 3774. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Yang, F.; Fan, H.; Chu, P.; Blasch, E.; Ling, H. Clustered Object Detection in Aerial Images. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 8310–8319. [Google Scholar]
- Woo, S.; Kim, D.; Cho, D.; Kweon, I.S. LinkNet: Relational Embedding for Scene Graph. arXiv 2018, arXiv:1811.06410. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking Atrous Convolution for Semantic Image Segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef]
- Mnih, V.; Heess, N.; Graves, A.; Kavukcuoglu, K. Recurrent Models of Visual Attention. arXiv 2014, arXiv:1406.6247. [Google Scholar]
- Lin, D.; Ji, Y.; Lischinski, D.; Cohen-Or, D.; Huang, H. Multi-scale Context Intertwining for Semantic Segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Cheng, B.; Chen, L.-C.; Wei, Y.; Zhu, Y.; Huang, Z.; Xiong, J.; Huang, T.; Hwu, W.-M.; Shi, H.; Uiuc, U. SPGNet: Semantic Prediction Guidance for Scene Parsing. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 5217–5227. [Google Scholar]
- Lin, G.; Milan, A.; Shen, C.; Reid, I. RefineNet: Multi-path refinement networks for high-resolution semantic segmentation. In Proceedings of the 30th IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 22–25 July 2017; Volume 2017, pp. 5168–5177. [Google Scholar]
- Yu, C.; Wang, J.; Peng, C.; Gao, C.; Yu, G.; Sang, N. Learning a Discriminative Feature Network for Semantic Segmentation. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 1857–1866. [Google Scholar]
- Kumar, B.V.; Carneiro, G.; Reid, I. Learning Local Image Descriptors with Deep Siamese and Triplet Convolutional Networks by Minimizing Global Loss Functions. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 5385–5394. [Google Scholar]
- Dai, J.; Qi, H.; Xiong, Y.; Li, Y.; Zhang, G.; Hu, H.; Wei, Y. Deformable convolutional networks. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22 October 2017; pp. 764–773. [Google Scholar]
- Zhang, R.; Tang, S.; Zhang, Y.; Li, J.; Yan, S. Scale-Adaptive Convolutions for Scene Parsing. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22 October 2017; pp. 2050–2058. [Google Scholar]
- Cheng, J.; Sun, Y.; Meng, M.Q.-H. A dense semantic mapping system based on CRF-RNN network. In Proceedings of the 2017 18th International Conference on Advanced Robotics (ICAR), Hong Kong, China, 10–12 July 2017; pp. 589–594. [Google Scholar]
- Liu, Z.; Li, X.; Luo, P.; Loy, C.-C.; Tang, X. Semantic Image Segmentation via Deep Parsing Network. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1377–1385. [Google Scholar]
- Ke, T.W.; Hwang, J.J.; Liu, Z.; Yu, S.X. Adaptive affinity field for semantic segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Yu, C.; Wang, J.; Peng, C.; Gao, C.; Yu, G.; Sang, N. BiSeNet: Bilateral Segmentation Network for Real-Time Semantic Segmentation. Trans. Petri Nets Other Models Concurr. 2018, 334–349. [Google Scholar] [CrossRef] [Green Version]
- Ruan, T.; Liu, T.; Huang, Z.; Wei, Y.; Wei, S.; Zhao, Y. Devil in the Details: Towards Accurate Single and Multiple Human Parsing. Proc. Conf. AAAI Artif. Intell. 2019, 33, 4814–4821. [Google Scholar] [CrossRef]
- Bilinski, P.; Prisacariu, V. Dense Decoder Shortcut Connections for Single-Pass Semantic Segmentation. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6596–6605. [Google Scholar]
- Guo, H.; Zheng, K.; Fan, X.; Yu, H.; Wang, S. Visual Attention Consistency Under Image Transforms for Multi-Label Image Classification. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 729–739. [Google Scholar]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-CAM: Visual Explanations from Deep Networks via Gradient-Based Localization. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 618–626. [Google Scholar]
- Li, B.; Sun, Z.; Li, Q.; Wu, Y.; Anqi, H. Group-Wise Deep Object Co-Segmentation with Co-Attention Recurrent Neural Network. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Long Beach, CA, USA, 16–20 June 2019; pp. 8518–8527. [Google Scholar]
- Liu, S.; Johns, E.; Davison, A.J. End-To-End Multi-Task Learning with Attention. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 1871–1880. [Google Scholar]
- Lu, X.; Wang, W.; Ma, C.; Shen, J.; Shao, L.; Porikli, F. See More, Know More: Unsupervised Video Object Segmentation with Co-Attention Siamese Networks. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 3618–3627. [Google Scholar]
- Zheng, H.; Fu, J.; Zha, Z.-J.; Luo, J. Looking for the Devil in the Details: Learning Trilinear Attention Sampling Network for Fine-Grained Image Recognition. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 5007–5016. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. arXiv 2015, arXiv:1512.03385. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module. In Proceedings of the Lecture Notes in Computer Science; Springer Science and Business Media LLC: Berlin/Heidelberg, Germany, 2018; pp. 3–19. [Google Scholar]
- Nassar, A.S.; Lefèvre, S.; Wegner, J.D. Multi-View Instance Matching with Learned Geometric Soft-Constraints. ISPRS Int. J. Geo-Inf. 2020, 9, 687. [Google Scholar] [CrossRef]
- Pan, X.; Shi, J.; Luo, P.; Wang, X.; Tang, X. Spatial as Deep: Spatial CNN for Traffic Scene Understanding. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Maggiori, E.; Tarabalka, Y.; Charpiat, G.; Alliez, P. High-Resolution Aerial Image Labeling with Convolutional Neural Networks. IEEE Trans. Geosci. Remote Sens. 2017, 55, 7092–7103. [Google Scholar] [CrossRef] [Green Version]
- Volpi, M.; Tuia, D. Dense Semantic Labeling of Subdecimeter Resolution Images with Convolutional Neural Networks. IEEE Trans. Geosci. Remote Sens. 2017, 55, 881–893. [Google Scholar] [CrossRef] [Green Version]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid Scene Parsing Network. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1063–6919. [Google Scholar]
- Zhou, K.; Xie, Y.; Gao, Z.; Miao, F.; Zhang, L. FuNet: A Novel Road Extraction Network with Fusion of Location Data and Remote Sensing Imagery. ISPRS Int. J. Geo-Inf. 2021, 10, 39. [Google Scholar] [CrossRef]
- Song, A.; Kim, Y. Semantic Segmentation of Remote-Sensing Imagery Using Heterogeneous Big Data: International Society for Photogrammetry and Remote Sensing Potsdam and Cityscape Datasets. ISPRS Int. J. Geo-Inf. 2020, 9, 601. [Google Scholar] [CrossRef]
- Liu, Y.F. Research on video emotion analysis algorithm based on deep learning. In Basic & Clinical Pharmacology & Toxicology; Wiley: Hoboken, NJ, USA, 2021; pp. 183–184. [Google Scholar]
- Kan, K.; Yang, Z.; Lyu, P.; Zheng, Y.; Shene, L. Numerical Study of Turbulent Flow past a Rotating Axial-Flow Pump Based on a Level-set Immersed Boundary Method. Renew. Energy 2021, 168, 960–971. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
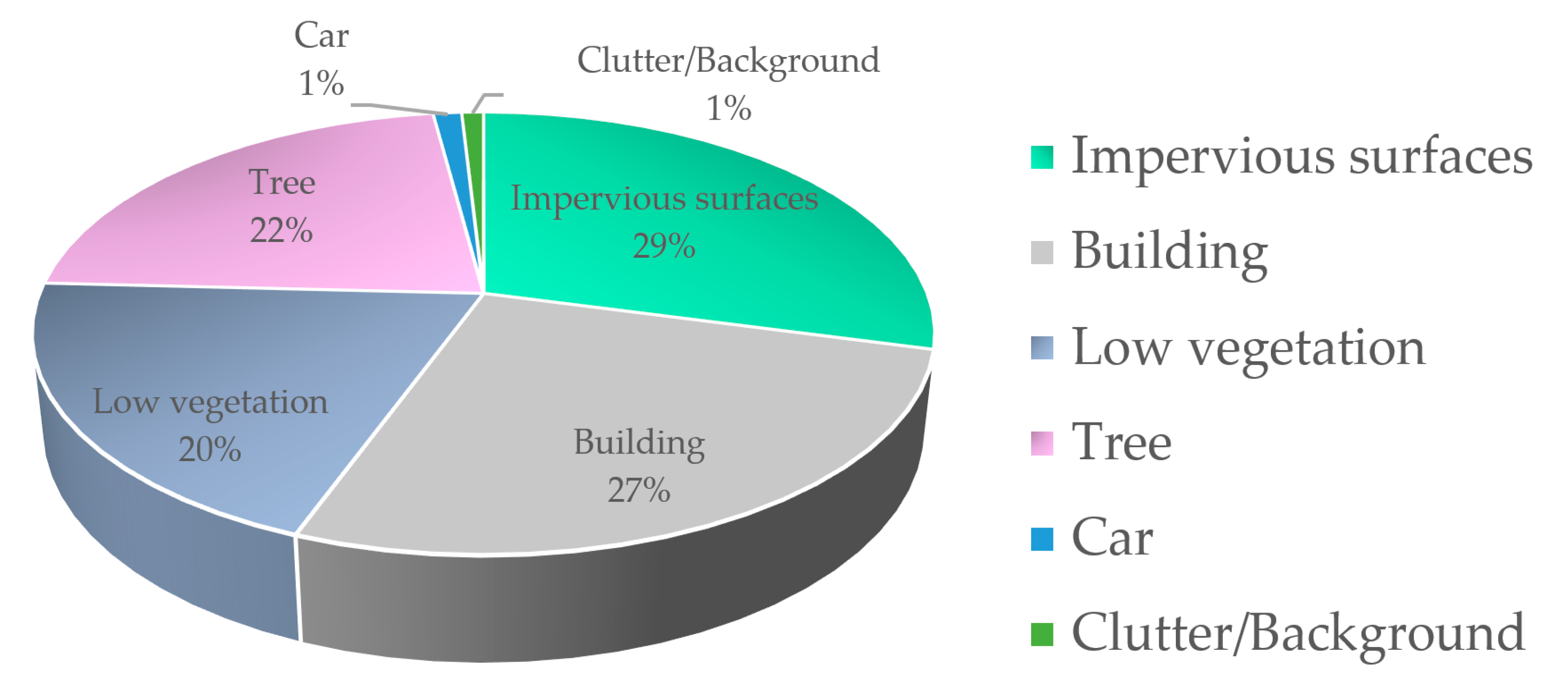
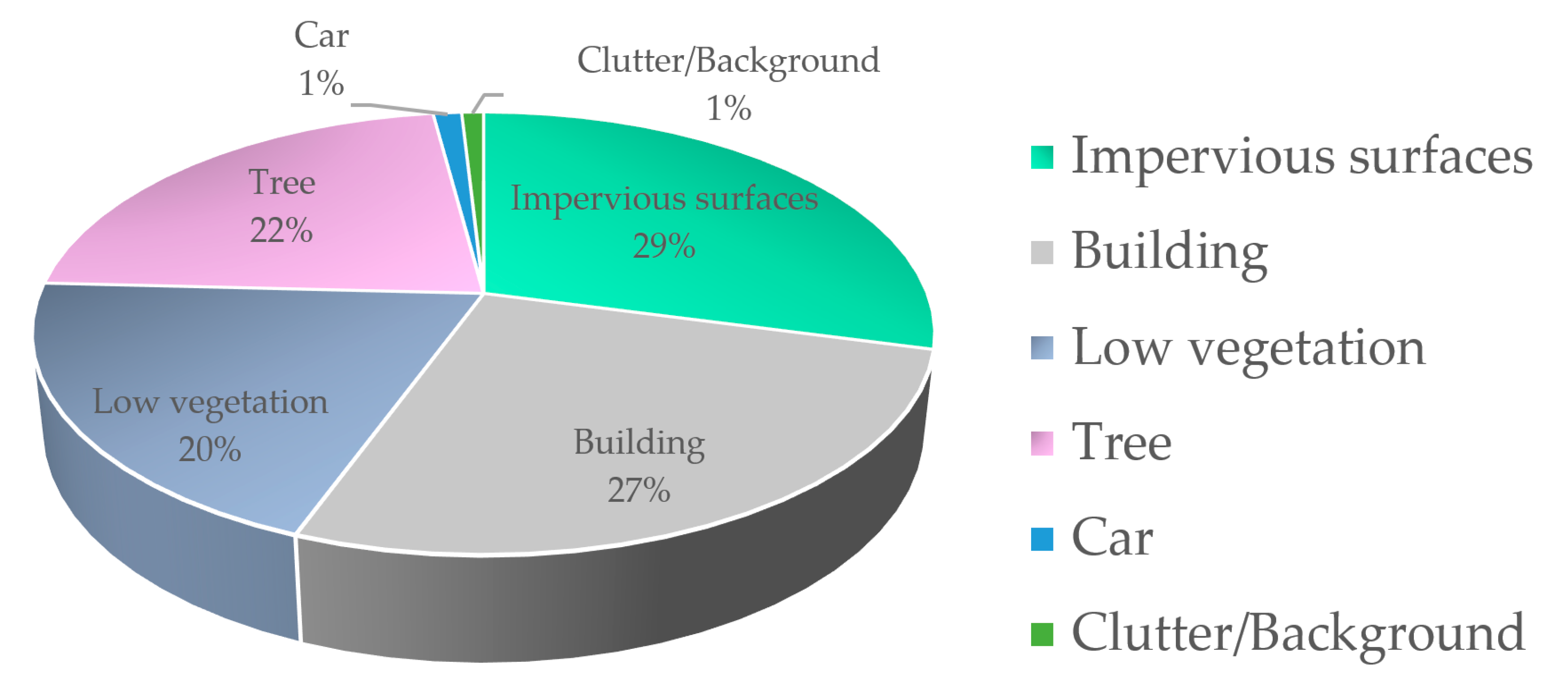
| Class. | Impervious Surfaces | Building | Low Vegetation | Tree | Car | Clutter/Background |
|---|---|---|---|---|---|---|
| Pixels Number | 15,932,837 | 14,647,182 | 11,008,085 | 12,118,796 | 666,618 | 510,494 |
| ID | Experiment | OA | Accuracy Improvement Ratio Compared with Baseline |
|---|---|---|---|
| 1 | Baseline | 86.92% | - |
| 2 | Baseline + AMSM | 87.84% | 0.92% |
| 3 | Baseline + AFM | 87.51% | 0.59% |
| 4 | Baseline + AMSM + AFM | 88.35% | 1.43% |
| Model | The F1 Value of Each Class | Mean F1 Score | OA | ||||
|---|---|---|---|---|---|---|---|
| Imp Surf | Build | Low Veg | Tree | Car | |||
| FCN | 88.67 | 92.83 | 76.32 | 86.67 | 74.21 | 83.74 | 86.51 |
| U-net | 79.05 | 79.95 | 68.10 | 70.50 | 15.72 | 62.66 | 75.60 |
| Deeplab-v3 | 66.18 | 83.74 | 64.52 | 78.78 | 36.31 | 65.91 | 73.86 |
| SegNet | 80.21 | 85.97 | 70.36 | 79.24 | 26.72 | 68.50 | 79.87 |
| DCCN | 86.43 | 92.07 | 79.36 | 82.54 | 66.40 | 81.36 | 85.31 |
| AWNet(ours) | 90.32 | 94.11 | 80.25 | 87.05 | 82.22 | 86.79 | 88.35 |
| Model | The F1 Value of Each Class | Mean F1 Score | OA | ||||
|---|---|---|---|---|---|---|---|
| Imp Surf | Build | Low Veg | Tree | Car | |||
| FCN-dCRF | 88.8 | 92.99 | 76.58 | 86.78 | 71.75 | 83.38 | 86.65 |
| SCNN | 88.21 | 91.8 | 77.17 | 87.23 | 78.6 | 84.4 | 86.43 |
| Dilated FCN | 90.19 | 94.49 | 77.69 | 87.24 | 76.77 | 85.28 | 87.7 |
| CNN-FPL | - | - | - | - | - | 83.58 | 87.83 |
| PSPNet | 89.92 | 94.36 | 78.19 | 87.12 | 72.97 | 84.51 | 87.62 |
| Deeplab v3+ | 89.92 | 94.21 | 78.31 | 87.01 | 71.43 | 84.18 | 87.51 |
| DANet | 89.31 | 93.99 | 78.25 | 86.74 | 71.26 | 83.91 | 87.44 |
| AWNet(ours) | 90.32 | 94.11 | 80.25 | 87.05 | 82.22 | 86.79 | 88.35 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, Y.; Zhu, Q.; Cao, F.; Chen, J.; Lu, G. High-Resolution Remote Sensing Image Segmentation Framework Based on Attention Mechanism and Adaptive Weighting. ISPRS Int. J. Geo-Inf. 2021, 10, 241. https://0-doi-org.brum.beds.ac.uk/10.3390/ijgi10040241
Liu Y, Zhu Q, Cao F, Chen J, Lu G. High-Resolution Remote Sensing Image Segmentation Framework Based on Attention Mechanism and Adaptive Weighting. ISPRS International Journal of Geo-Information. 2021; 10(4):241. https://0-doi-org.brum.beds.ac.uk/10.3390/ijgi10040241
Chicago/Turabian StyleLiu, Yifan, Qigang Zhu, Feng Cao, Junke Chen, and Gang Lu. 2021. "High-Resolution Remote Sensing Image Segmentation Framework Based on Attention Mechanism and Adaptive Weighting" ISPRS International Journal of Geo-Information 10, no. 4: 241. https://0-doi-org.brum.beds.ac.uk/10.3390/ijgi10040241