1. Introduction
When the National Aeronautics and Space Administration (NASA) launched the Moderate Resolution Imaging Spectroradiometer (MODIS) sensor aboard the Terra satellite on December of 1999, its products were envisioned to contribute to the long-term monitoring and global scale research of Earth’s land and oceans [
1,
2], a mission that NASA complemented in 2002 by orbiting the Aqua sensor. Since then, the 36 spectral bands of MODIS distributed at 250, 500 and 1000 m spatial resolutions have been applied in numerous projects. For instance, at the regional level, the MODIS LST product has been used to establish drought monitoring systems [
3,
4], and MODIS products have also proven useful for coastal monitoring of oil spills that are assessed based on total radiance measurements [
5]. As argued by Jin et al. [
6], the surface spectral albedo and emissivity derived from MODIS have also contributed to assessments of the effects of urbanization on the climate. The combination of MODIS products with those from other emerging higher resolution sensors made it possible to generate consistent long-term time series with information about burned area with an adequate quantification of error and uncertainty [
7,
8,
9]; some of these products are instrumental for determining the unexpected global decline of burned area [
10].
The National Oceanic and Atmospheric Administration (NOAA) Visible Infrared Imaging Radiometer Suite (VIIRS) sensor, the successor of MODIS, has undergone an interesting process of sensor calibration and accuracy improvement to meet MODIS datasets’ standards [
11]. This proper calibration allows, for example, that some phenological studies carried out with either VIIRS or MODIS would produce quantitatively similar results [
12]. Other VIIRS products, such as NPP nighttime light data, are potentially useful as economical proxies of gross domestic product [
13], and the over 20 Environmental Data Records offered by VIIRS are expected to provide continuous support to the wide range of projects currently utilizing MODIS Earth Observation data [
14,
15,
16].
Like MODIS and VIIRS, the Landsat and Sentinel missions are sources of free Earth Observation (EO) time series imagery which, although not providing data on a daily basis, offer moderate spatial resolution between 10 to 60 m, allowing a more accurate representation of Earth’s land and water conditions. These datasets are available to remote sensing experts through several platforms. Data discovery and download, or access to these platforms, however, is not always straightforward, which adds to EO data being presented in a wide range of data formats (NetCDF, HDF, GeoTiff, among others). Unlike data acquisition, pre-processing, including cloud detection, detection of cloud shadows and detection of any artifacts using quality assessment (QA) flags, often requires some coding experience, and a gap-filling method may be needed to ameliorate the lack of information resulting from pre-processing. Focusing only on simple gap-filling approaches, some interpolating or smoothing techniques are required to take into account data variability due to the different acquisition geometries (viewing and illumination conditions). Only after these steps, can EO time series be construed as reliable data sources for scientific research.
Like the successful Landsat Ecosystem Disturbance Adaptive Processing System (LEDAPS) project [
17], in the last 40 years, and with different purposes in mind, several EO time series have been produced—for example, the NPP-VIIRS nighttime light data and Gupta et al.’s [
18] high resolution aerosol optical data. In parallel with the provision of scientific data from orbiting sensors, developers have released free and highly specialized software to enable the analysis of these data in personal computers [
19,
20,
21,
22]. Another effective means to conduct scientific research based on satellite imagery is through powerful user-friendly web-based applications, such as Ferrán et al.’s [
23] application, the MODIS Reprojection Tool (MRT), OpenData Cube, GeoNode and the Google Earth Engine (GEE) [
24], among many others.
Although some researchers have acknowledged the importance of proper data quality assessments [
25], only a few of the freely-distributed open-source platforms have incorporated the analysis of quality flags during the generation and subsequent analysis of EO time series in their workflows. Colditz et al. [
26], and the references therein, provide a thorough treatment of MODIS quality flags; this paper also includes a summary of similar studies for MODIS’s predecessor, the Advanced Very High Resolution Radiometer (AVHRR) project. Busetto and Ranghetti [
27] provided a compelling summary of the advances made by the R Project for the statistical computing community [
28] to process, and in some cases, also generate QA-based time series for MODIS images. Militino et al. [
29] introduced RGISTools, a QA-enabled R package for handling diverse types of satellite images.
To address this shortcoming for EO time series generation and analysis by freely-distributed software, we present in this paper Tools for Analyzing Time Series of Satellite Imagery (TATSSI), an open-source platform written in Python that provides routines for downloading, generating, gap-filling, smoothing, analyzing and exporting EO time series. We extensively tested the TATSSI platform in Linux (Ubuntu 18.04 and 20.04), but it can also be executed on any Windows machine through the WSL-Ubuntu interpreter. Instructions for TATSSI’s installation can be found at this
GitHub repository (accessed on 16 April 2021) along with a user’s manual and related materials presented in several scientific meetings. As TATSSI integrates the quality flags of the input products when generating time series, data quality analysis is the backbone of any analysis performed with the platform. TATSSI allows users to easily generate MODIS and VIIRS time series through the straightforward access to these scientific datasets (SDS). For fully handling with TATSSI products having different SDS, such as those from the Landsat and Sentinel missions, the users need to add some metadata, for which we provide detailed instructions in
Section 2.5. By default, TATSSI produces data in the Cloud Optimized GeoTiff (COG) format, but one of its submodules enables users to generate output files in most of the formats supported by the GDAL library [
30], including standard GeoTiff, NetCDF and generic binary. By developing TATSSI in Python—a complete computational language, which according to the
TIOBE index (accessed on 16 April 2021) has acquired great popularity across the sciences—and by distributing it under a GNU Affero General Public License, we expect that software developers will expand its functionalities in the near future, as has been the case for Zambelli et al.’s [
31] PyGRASS and the PySAL open-source Python library [
32].
TATSSI can be construed as a set of tools for handling spatial data infrastructures (SDI) [
33]. As argued by Gomes et al. [
34], cloud computing and distributed systems have shown to be appropriate building blocks for the development of the next generation of SDIs. In TATSSI, we rely on the DASK library [
35] for the efficient administration of parallel computing, a vital resource when dealing with time series within a large data cube; TATSSI can be attached to a virtual machine (VM) at a cloud computing facility, which in principle, allows one to execute any of the TATSSI modules but also any Python script developed by the users. Thus, with almost no effort or advanced technical skills, the interested user can take advantage of TATSSI’s applications and explode the resources provided by a server; the details of these claims can be found in
Section 2.6. Thus, although TATSSI is not based on cloud computing, it is somehow compatible with principles required in the development of the next generation of SDIs, such as moving code and the approach to process data at the site where the data is stored.
The main goal of this paper is to present TATSSI and its capabilities to allow users to overcome common barriers when using EO data for scientific purposes, focusing mainly on getting access to different datasets, using the quality information associated with each dataset and performing statistical analysis of time series. In
Section 2, we introduce TATSSI and discuss its architecture, input/output data formats, data handling and quality assessment, as well as its three application programming interfaces—a graphical user interface (GUI), an application through the
Jupyter Notebooks (accessed on 16 April 2021) and the Python command line. In
Section 3, we present three illustrative examples of using TATSSI with MODIS data to: (1) assess spatio-temporal changes within an irrigation area, (2) perform a trend analysis of a moisture index in a wetland ecosystem and (3) monitor vegetation in a burned area.
Section 4 provides a summary of some of TATSSI’s methods for handling and analyzing EO time series,
Section 5 discusses the results of our applications, and finally,
Section 6 presents a conclusion and an outlook for future research.
2. TATSSI: Tools for Analyzing Time Series of Satellite Imagery
In this section we discuss TATSSI’s architecture, design and allowed file formats, as well as how a quality assessment can be carried out, and why by allowing three application programmed interfaces (APIs), this EO data platform is exceptionally user-friendly.
2.1. Architecture and Design
The first stage of any scientific software development project must include gathering user requirements. The main goal of the National Council of Science and Technology (CONACYT, in Spanish) funded project “Statistical Analysis of Time Series of Satellite Imagery with respect to Desertification Processes in Mexico” was to provide a software tool that would allow for monitoring desertification processes by analyzing time series of satellite images. However, providing these kinds of capabilities can be seen as a requirement for a generic toolbox. The toolbox should provide users the functionalities to create and analyze EO products with some insights into remote sensing and statistical analysis. The initial user requirements provided useful insights about the main goals that needed to be addressed within the scope of the project. Five key elements were identified: (i) data discovery and the downloading of coarse and high resolution data; (ii) generation of time series, wherein quality assessment and quality control are taken into account; (iii) interpolation and smoothing of time series; (iv) time series analysis to identify and quantify trends and changes over time; and (v) the use of different interfaces. TATSSI’s design aims at a modular structure in which each component has specific objectives.
Figure 1 graphically shows the three main components we identified to create a simple 3-layered architecture. All components will be described in the following subsections.
2.2. Data Handling
TATSSI aims to provide data discovery and the ability to download coarse resolution data from multiple online Earth Observation (EO) data discovery portals, for which we selected the Application for Extracting and Exploring Analysis Ready Samples (A
EEARS) [
36] application programming interface (API), which allows submitting and downloading A
EEARS requests using the command line or within programming languages such as Python and R. The A
EEARS API complies with representational state transfer (REST) principles, and therefore has predictable resource-oriented URLs and uses HTTP response codes showing the status of the corresponding API call. TATSSI uses the product search capability within A
EEARS API; this requires user authentication that is stored as a TATSSI config file. When TATSSI is started for the very first time, the A
EEARS API is used to create a data catalog containing all MODIS and VIIRS data products available for download from the NASA EOSDIS Land Processes Distributed Active Archive Center (LP DAAC). The catalog is stored in a Python pickle for further use. If there are any changes in the product availability, metadata or versions, the catalog can be rebuilt at any time. TATSSI uses the default MODIS Sinusoidal Grid to get the data by tiles. Additionally to the LP DAAC, TATSSI allows acquiring data from GEE, in which case the data can be acquired for a user-defined area of interest. To obtain the data, the user must have valid Google credentials. In
Section 2.4 we provide an example of how this task can be carried out.
Initially, TATSSI rely on a data processing approach through downloaded data stored in local resources, such as network area storage (NAS), local hard drives or storage attached to a VM. This approach allows full customization of the processing flow to create time series that are fit for purpose in terms of scientific applications. Once the data are downloaded, time series can be created. TATSSI can generate a time series for any MODIS and VIIRS dataset obtained from the LP DAAC, but it is possible to use some of TATSSI functionalities for time series not created with TATSSI. As an example, in
Section 2.5 we showed how to integrate some Landsat data into TATSSI’s workflow. The metadata in those files allow access to each scientific dataset (SDS) and their corresponding quality assessment (QA) and quality control (QC) flags. The QA/QC flags are only decoded during the time series generation process, their further processing being detailed in
Section 3. TATSSI uses Cloud Optimized GeoTIFF (COG) as its internal data format. A COG is a regular GeoTIFF file that can be hosted on an HTTP file server and has an internal organization by chunks, which allows an efficient workflow since a request will ask for just the parts of the needed file. The default behavior when generating a time series is:
For every file in the data directory that matches the product and version selected by the user:
- ‒
Each band or SDS is imported in the internal TATSSI format (COG).
For each QA layer associated with the product:
- ‒
Import data into the internal TATSSI format and perform the QA decoding for each flag.
For each SDS and associated QA/QC:
- ‒
Generate GDAL VRT layer stacks
MODIS and VIIRS data acquired on the LP DAAC are distributed in two different Hierarchical Data Format (HDF) modalities: HDF4 (4.
x and previous releases) and HDF5. These formats are not compatible with each other because of their intrinsic differences. TATSSI uses the Geospatial Data Abstraction Library (GDAL) [
30] to process data from both sensors. NASA’s Earth Observing System (EOS) maintains its own HDF modification named HDF-EOS. This modification is adequate for use with remote sensing data and fully compatible with underlying HDF. TATSSI uses the GDAL HDF driver to handle all MODIS data. For handling VIIRS data distributed in the HDF5, TATSSI uses the GDAL HDF5 driver; however, geolocation information is not read by default by GDAL (version 2.03.030), for which additional functionality was required to obtain the spatial reference system and geographical extent. In terms of data products generated by TATSSI, the default format is COG, but it is possible to generate output files in several of the formats supported by GDAL, including standard GeoTiff, NetCDF and generic binary.
2.3. Engine
The TATSSI engine component, as shown in
Figure 1, consists of several sub-components, allowing us to: (i) perform an exhaustive analysis of the quality information and creation of an interpolated time series that incorporates the knowledge of the QA/QC, (ii) smooth time series and (iii) apply various methods to analyze time series. A thorough analysis of the characteristics of any EO data product is required to make a consistent interpretation of the data. This analysis can start with the data type and bit depth that can be associated with radiometric resolution. The analysis can continue with the corresponding scaling and offset factors, followed by the identification of the per-pixel QA/QC flags. Some datasets provide quantitative data on top of the QA/QC information in the form of per-pixel uncertainties, or even full variance-covariance matrices, as in the the GlobAlbedo dataset [
37]. MODIS and VIIRS land datasets use a consistent QA framework developed by the MODIS Land (MODLAND) Science Team (ST) [
38]. The MODLAND QA products provide product-specific QA flags together with metadata that allow traceability along the processing chain. Per-pixel QA data can differ considerably among products, processing levels and collections. Additionally, some products provide different ancillary datasets used during QA generation, which might include atmospheric state, surface type, acquisition geometries, and whether a priori or dynamic atmospheric estimates were used during the biophysical retrieval. In this regard, TATSSI’s main challenge was to be able to access all QA related information for any product distributed by the LP DAAC. TATSSI takes advantage of the per-product quality information distributed on the A
EEARS API (
https://lpdaacsvc.cr.usgs.gov/services/appeears-api/) (accessed on 16 April 2021) to create a catalog with all products and associated QA/QC definitions (parameters, description, bit fields and values). MODIS and VIIRS QA information is stored as an integer value that needs to be decoded into binary strings. QA/QC decoding takes place by interpreting the binary string, extracting bit words for different bit fields and mapping that unique combination to quality attributes associated with each field.
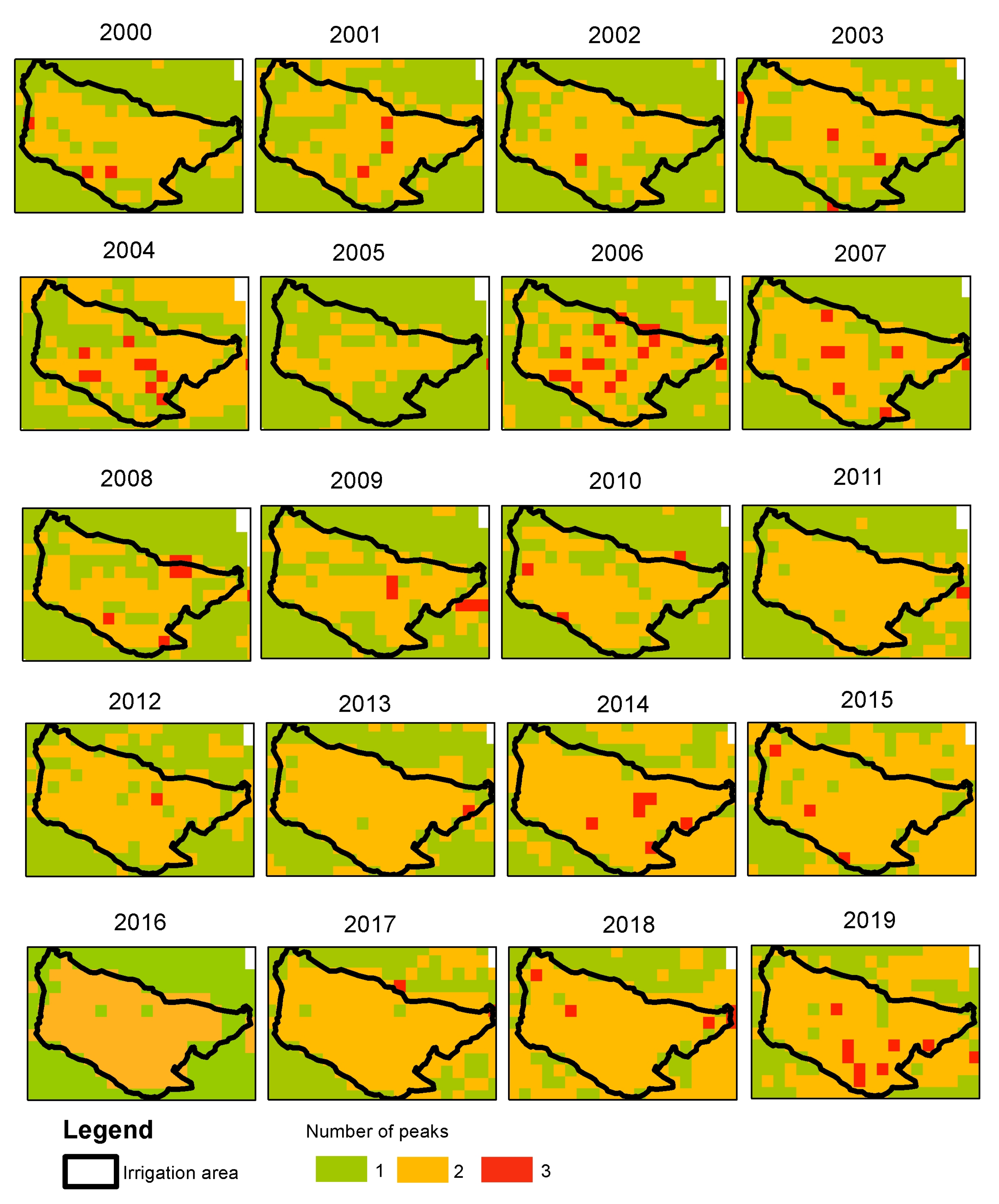
Table 1 shows an example of the first two-bit fields [0–1] from the MOD13A2 "1_km_16_days_VI_Quality” product. The integer value is converted into binary, and then bit fields 0 and 1 are extracted to create a bit word which afterwards is converted into decimal. TATSSI will create a layer for each QA parameter associated with that QA SDS in a way that the user can simply select which QA parameters and values will be selected and flagged as valid for further processing.
Once the user has selected potential QA parameters and values for a specific SDS, TATSSI will apply that selection to the whole time series to create a mask of valid pixels. The impact of the selection in terms of (i) the percentage of data kept for further processing and (ii) the maximum gap length, can be quantified as the number of missing observations. These metrics can be used to assess the impacts of using different QA settings.
Figure 2 shows an example of using the best data with high confidence or some more lenient QA values. The metrics were generated for the MODLAND parameters on the “1_km_16_days_pixel_reliability” layer from the MOD13A2 product. The metrics for the “Good data, use with confidence” QA values in the bottom row in
Figure 2 show that the proportion of data available for the eastern region of Lake Nicaragua was below 20%, and the maximum gap length was greater than 20. Since the MOD13A2 provides observations every 16 days, 23 observations fall within one calendar year, meaning that there were almost no observations left after applying the most strict QA value. When using the “Marginal data. Useful but look at other QA information” QA value, the increases in the percentage of data available and the maximum gap length became evident. The TATSSI
QA Analytics module allows us to assess different QA settings in a systematic way, so users can select the most adequate set according to their particular needs. The trade-off will be always to keep the best quality data while still fully characterizing the environmental processes of interest. Stricter QA selection results in less availability. If the data gaps produced due to this strict selection occur during a key moment during the seasonality of the studied variable, this may lead to potential misunderstandings or spurious findings, for example, the start and peak of the vegetation season. A more lenient QA selection could easily lead to lack of data to the point where it becomes impossible to understand the environmental variable of interest, as is shown in
Figure 2 for Southern Nicaragua. The worst case scenario is applying no QA at all and drawing conclusions based on potential low quality retrievals or observations, as shown by Schaaf et al. [
25].
The mask generated during the
QA Analyticsprocess is used in the next stage, where different interpolation methods can be applied to generate a gap-free time series, and finally, if required, the user can apply a smoothing function to the time series. The interpolation and smoothing methods are detailed in
Section 4. It is important to note though that the TATSSI smoothing process performs a robust outlier detection that could minimize the use of more lenient QA settings, allowing more low-quality observations to be included in the time series, but removing them during the process. By having a gap-free time series, obtained either by interpolation or smoothing, it is possible to subsequently use the TATSSI
Time Series module to apply a wide range of statistical techniques and time series operations to extract information and metrics from the time series. These operations and analysis vary from the derivation of the so-called climatology curve and the calculation of per-time-step anomalies, to performing statistical trend analysis, time series decomposition and change point detection. Products for every analysis are stored in COG format. Details about algorithms and techniques used are described in
Section 4. If the user needs to ingest a time series that was not generated using the TATSSI processing chain, additional metadata are required to allow the
Analysis module to read dates and fill values; we present such an example in the next section.
2.4. Interfaces
Access to TATSSI functionalities can be chosen depending on the complexity of the task, the amount of data to process and the software development expertise. TATSSI provides three APIs: (i) native GUI, (ii) Jupyter Notebooks and (iii) command line and Python scripting. The GUI was developed using PyQT5, which allows a seamless use of native Python and Matplotlib [
39] to generate interactive plots, a key functionality within the TATSSI GUI.
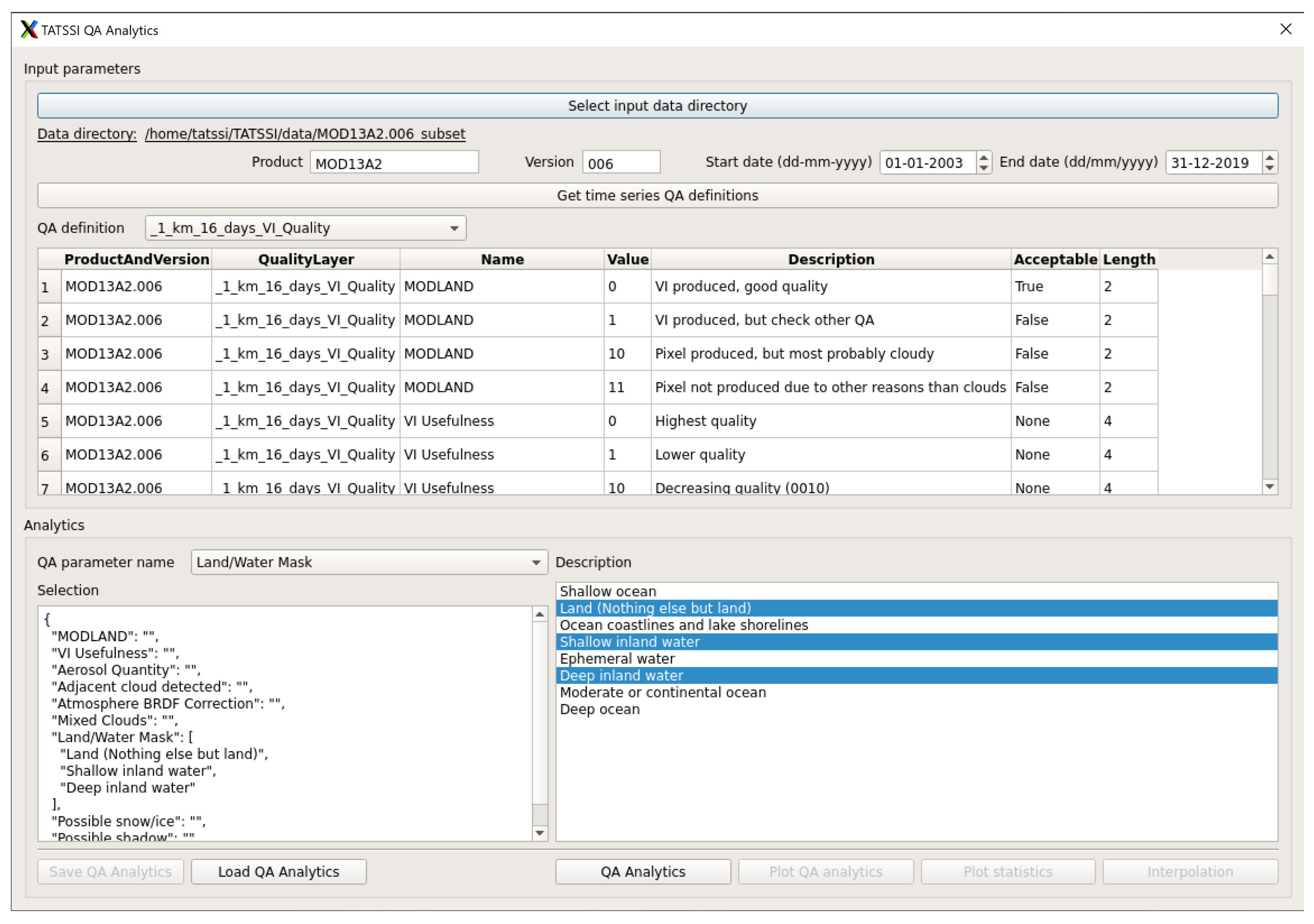
Figure 3 illustrates an example of the TATSSI GUI
QA Analytics module. The dialog allows us to perform
QA Analytics, as described in
Section 2.3. We used a combination of multiple PyQT5 elements to allow the user to open a command dialog to select the location of a time series; write text for products and version; and select dates and QA definitions. Additionally, for every QA parameter, the application of PyQT5 elements allows us to select and unselect desired QA values. We also provided PyQT5 push buttons for the user to access different dialogue boxes.
Jupyter Notebook [
40] is an open-source web application that allows the creation of interactive documents that contain live code, visualizations and narrative text. TATSSI provides several Notebooks as a step-by-step guide to understand the different TATSSI functionalities in a similar fashion as when using the GUI, but executed from a web browser. TATSSI supports JupyterLab, the next-generation version of the web-based interface. The main advantage of this interface is that there is no need to install any software on the client side. The Jupyter Notebooks can be executed either locally, for example, on a local workstation, or remotely, for example, on a cloud computing VM. When the Jupyter Notebooks are executed remotely, as in a cloud environment, the data processing can be executed as a background process. This means that the user does not need an active connection to the cloud environment. This feature provides an alternative to launching jobs and retrieving the results afterwards.
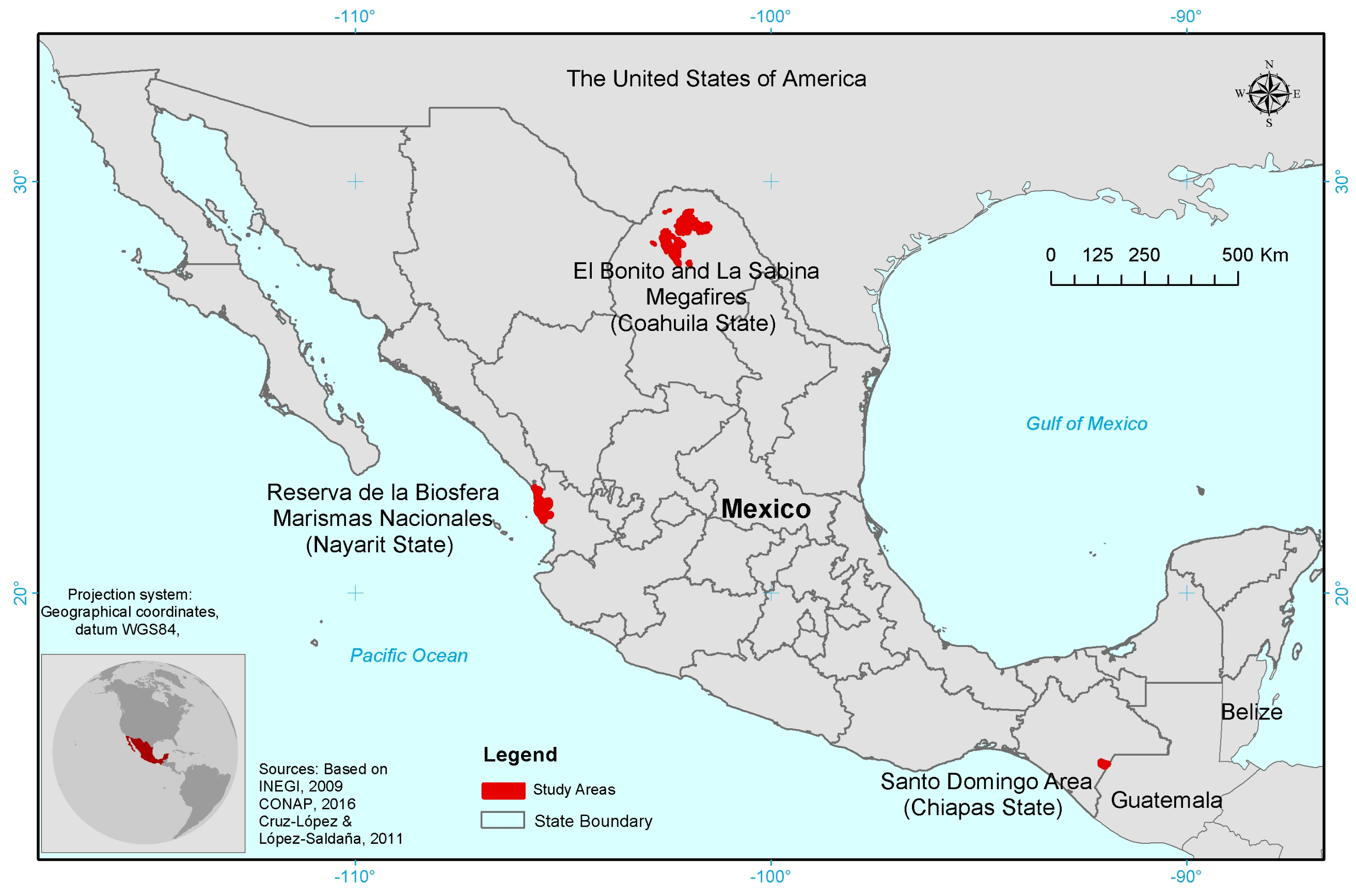
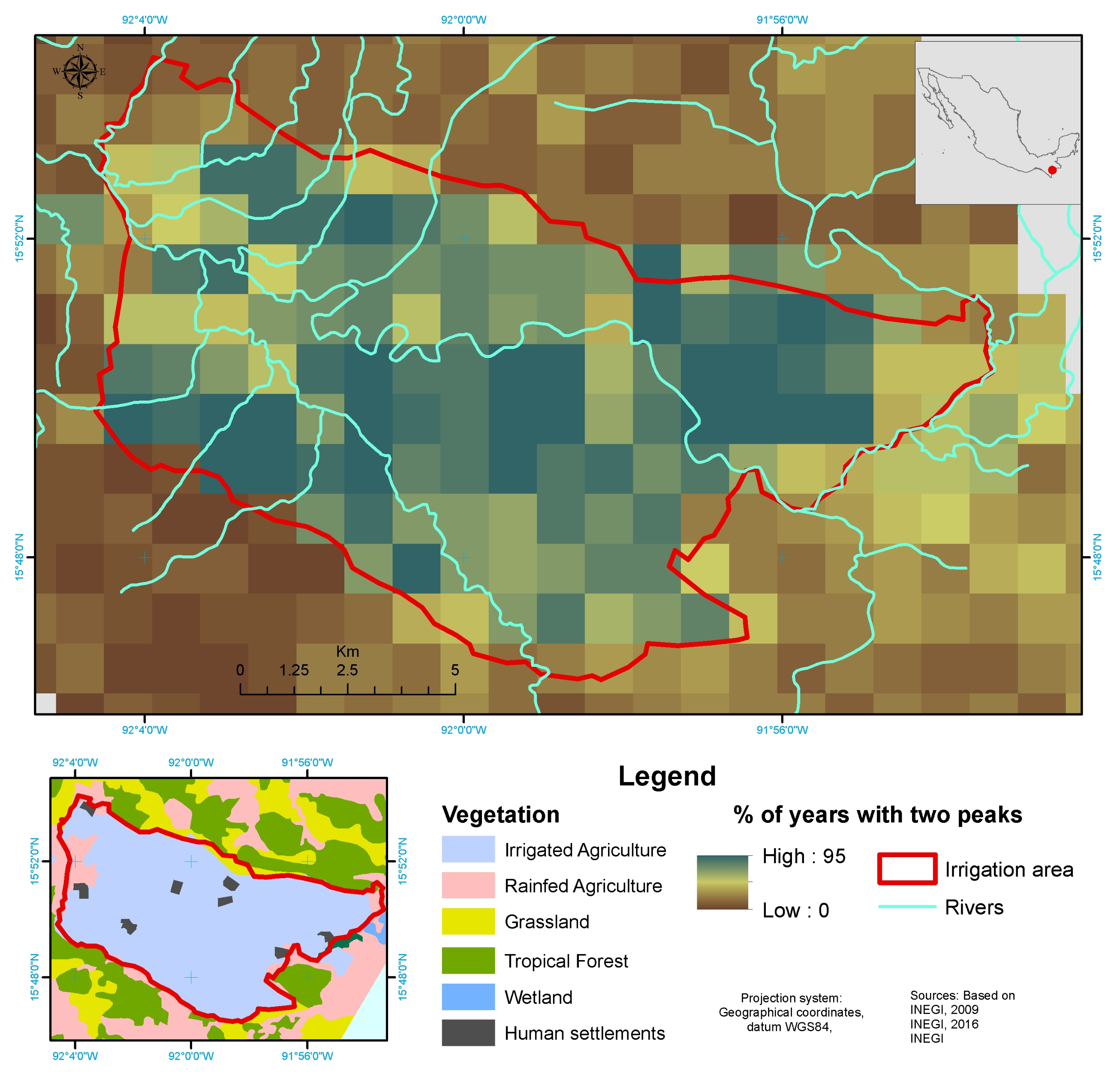
Figure 4 illustrates an example of the use of a Jupyter Notebook in TATSSI, a particularly useful feature when the area of interest (AOI) is divided amongst two or more MODIS tiles. The first step is setting Google Earth Engine (GEE) authentication and importing the required TATSSI libraries, as in
Figure 4a, after which the user must define an AOI as a bounding box that is subsequently saved into a GeoJSON file.
Figure 4b shows the AOI defined for one of our study sites in northern Mexico (see
Section 3.3 for further details). An important step is to match the SDS names from the GEE and the ones from MODIS datasets. The product layers names for some of the products available within the GEE must be modified to apply the corresponding QA flags using the metadata available from the TATSSI catalog, as we show in
Figure 4c. The final step is downloading the data and generating the time series (
Figure 4d). The time series thus generated can afterward be used for further processing in the TATSSI modules of interest.
For users familiarized with Python, TATSSI provides modules that can be called from a script, as is shown in the following example to generate a time series. The user needs to import the corresponding TATSSI module in Python (e.g., Generator); set input parameters such as source directory, product and version and input data format; create the time series Generator object; and finally, call the generate_time_series() method, see Listings 1.
| Listing 1. Python script used by TATSSI to generate time series. |
# Import TATSSI modules
from TATSSI.time_series.generator import Generator
# Set downloading parameters
source_dir = ‘/data/MCD43A4_h08v06’
product = ‘MCD43A4’
version = ‘006’
data_format = ‘hdf’
# Create TATSSI the~time series generator object
tsg = Generator(source_dir=source_dir,
product=product, version=version,
data_format=data_format)
# Generate the~time series
tsg.generate_time_series()
|
As mentioned above, TATSSI stores all geospatial raster data as COGs. To perform any time series operation and analysis, TATSSI loads the time series as xarrays [
41]. xarray is a Python package that works by accessing multi-dimensional arrays in a very efficient way by introducing labels on top of raw NumPy [
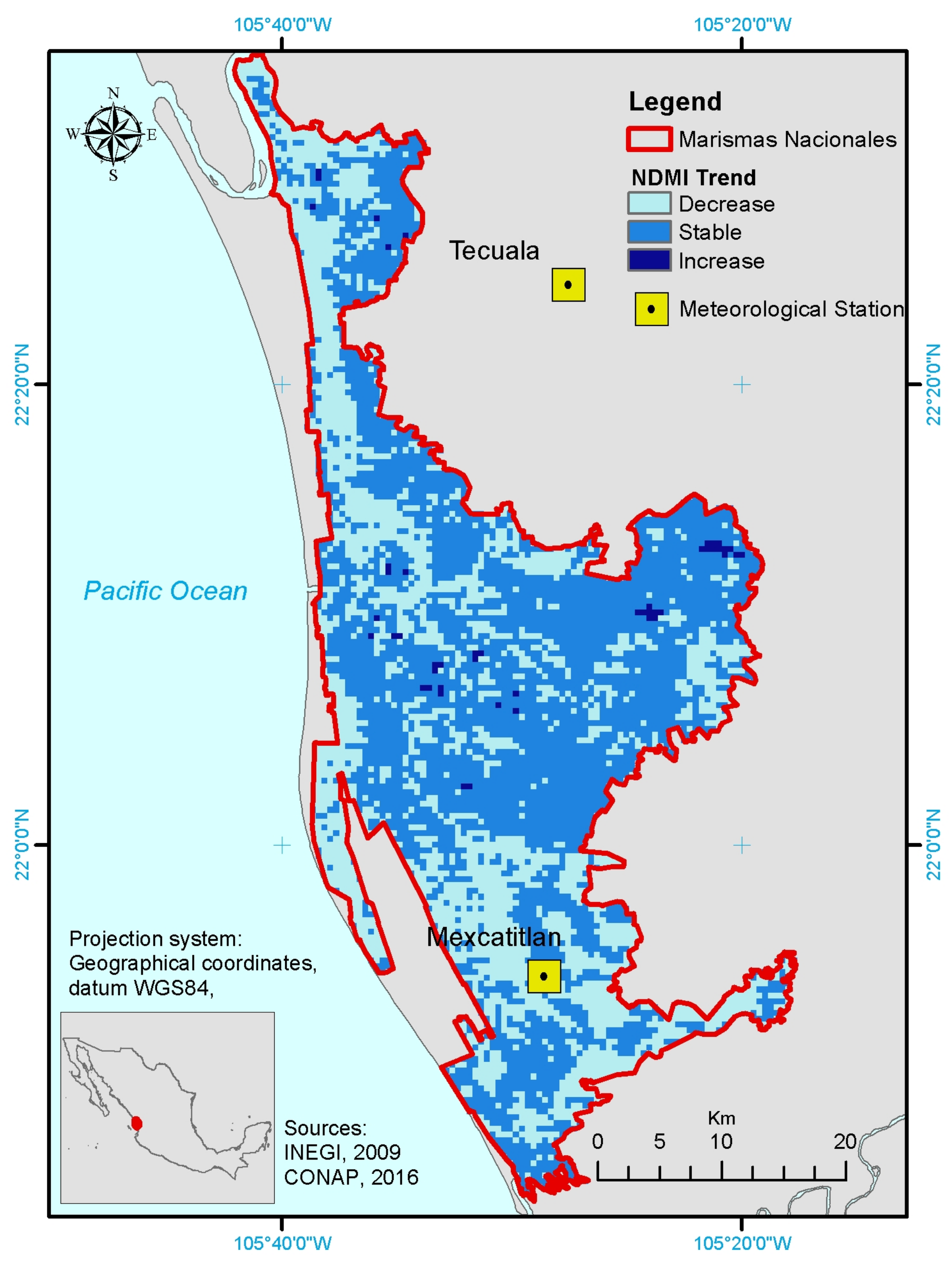
42] arrays in the form of dimensions, coordinates and attributes. Additionally, xarray provides full integration with DASK for parallel computing. By applying the code above to the MCD43A4 time series generated from the MODIS tile h08v06, it is then possible to load the TATSSI time series object as an xarray for further processing. Listings 2 provides an example of computing and storing the normalized difference moisture index (NDMI), utilized in
Section 3.2:
| Listing 2. Calculation of Normalized Difference Moisture Index based on the MCD43A4 product taken on tile h08v06. |
import os
import sys
# TATSSI modules
from TATSSI.time_series.analysis import Analysis
from TATSSI.input_output.utils import save_dask_array
# TATSSI time series object for band 2
fname = (f‘/data/MCD43A4_h08v06/Nadir_Reflectance_Band2/’
f‘interpolated/MCD43A4.006._Nadir_Reflectance_Band2.linear.tif’)
ts_b2 = Analysis(fname=fname)
# Get DataArray from {\tatssi} time series object
b2 = ts_b2.data._Nadir_Reflectance_Band2
# TATSSI time series object for band 6
fname = (f‘/data/MCD43A4_h08v06/Nadir_Reflectance_Band6/’
f‘interpolated/MCD43A4.006._Nadir_Reflectance_Band6.linear.tif’)
ts_b6 = Analysis(fname=fname)
# Get DataArray from {\tatssi} time series object
b6 = ts_b6.data._Nadir_Reflectance_Band6
# Compute normalized difference moisture index (NDMI)
ndmi = ((b2-b6) / (b2+b6)).astype(np.float32)
# Copy metadata attributes from band 2
ndmi.attrs = b2.attrs
# Change fill value to 0
ndmi.attrs[‘nodatavals’] = tuple(np.zeros(len(ndmi.time)))
# Save data
fname = ‘/data/marismas_NDMI.tif’
data_var=‘NDMI’
save_dask_array(fname=fname, data=ndmi, data_var=data_var)
|
2.5. Adding Metadata to EO Time Series Not Generated by TATSSI
One of the main purposes of using TATSSI is to genere a time series utilizing the associated QA/QC information provided. However, if the user already has a time series generated using other time series tools but still wants to use TATSSI for further analysis, date, variable description and fill value metadata must be added to every band in the time series, which will allow the different TATSSI interfaces to read the time series, and for example, perform smoothing or use the Analysis module. Listings 3 shows how to add metadata to Landsat 7 surface reflectance:
| Listing 3. Python script to add metadata to Landsat 7 images. |
import os
import sys
import gdal
from glob import glob
import datetime as dt
DataDir = ’/data/Landsat7’
def add_metadata(fname, str_date, data_var, fill_value):
"""
Adds date to metadata as follows:
RANGEBEGINNINGDATE=YYYY-MM-DD
:param fname: Full path of files to add date to its metadata
:param str_date: date in string format, layout: YYYY-MM-DD
:param data_var: Variable name, e.g. surface_reflectance
:param fill_value: Fill value
"""
# Open the file for update
d = gdal.Open(fname, gdal.GA_Update)
# Open band and get existing metadata
md = d.GetMetadata()
# Add date
md[’RANGEBEGINNINGDATE’] = str_date
# Add variable description
md[’data_var’] = data_var
# Add fill value
md[’_FillValue’] = fill_value
# Set metadata
d.SetMetadata(md)
d = None
if __name__ == "__main__":
# Get all file from data directory for Landsat band 4, for instance
# /data/Landsat7/LE70290462004017EDC01/LE70290462004017EDC01_sr_band4.tif
fnames = glob(os.path.join(DataDir, ‘*’, ‘*_sr_band4.tif’))
fnames.sort()
for fname in fnames:
# Extract date from filename
# LE7PPPRRRYYYYDDDEDC01_sr_band4.tif
# YYYY = year
# DDD = julian day
year_julian_day = os.path.basename(fname)[9:16]
# Convert string YYYYDDD into a datetime object
_date = dt.datetime.strptime(year_julian_day, ‘%Y%j’)
# Convert datetime object to string YYYY-MM-DD
str_date = _date.strftime(‘%Y-%m-%d’)
# Set data variable to a descriptive ’L7_SurfaceReflectance_B4’
data_var = ‘L7_SurfaceReflectance_B4’
# Add metadata
add_metadata(fname=fname, str_date=str_date,
data_var=data_var, fill_value=‘-9999’)
|
Once the metadata have been stored in every file and band, it is possible to create a GDAL virtual raster that TATSSI can read, see Listings 4.
| Listing 4. Creating a GDAL Virtual Raster from files modified through Listings 3’s code. |
gdalbuildvrt -separate LE70290462004.vrt /data/Landsat7/*/*_sr_band4.tif
0...10...20...30...40...50...60...70...80...90...100 - done.
|
After that, it is possible to open the Landsat 7 VRT with any TATSSI interface, as
Figure 5 shows for the
Smoothing module for the Landsat 7 near-infrared (NIR) band time series during 2004.
2.6. Cloud Computing Environments
The previous section presented TATSSI’s capabilities regarding data being downloaded and subsequently used to generate a time series. Nevertheless, the paradigm of processing EO data using local resources may not be computationally efficient for all use-cases, e.g., a data server with attached storage or high-end workstations where vast amounts of data need to be transferred from a data provider. Gomes et al. [
34] defined “Platforms for big EO Data Management and Analysis" as computational solutions that provide functionalities for big EO data management, storage and access that provide certain level of data and processing abstractions. In this context, TATSSI provides some features that can be exploited in cloud computing and high-performance computing environments.
TATSSI can be used on a cloud environment where one or more VM can be created and multiple users can access the resources. This can be seen as a hybrid paradigm because the EO data have to be downloaded to local storage within the VM, allowing different users to create time series without using local resources; thus, data are processed and stored on the server side.
The TATSSI approach encourages users to fully understand the limitations and constraints of each dataset, including the associated QA and QC flags. This understanding might require to download and analyze the data. It is expected that some abstraction is required to maximize the use and exploitation of EO data. This hybrid cloud computing approach can be attractive to users with some existing knowledge of EO data but requires some data abstraction; e.g., details about how raw data are stored, compression algorithms and metadata are not necessarily relevant.
When some processing abstraction is required and a processing chain is well-defined, downloading data, even to cloud storage, is not viable. TATSSI takes advantage of the GDAL Virtual File Systems where files stored on a network (either publicly accessible, or in private buckets of commercial cloud storage services) can be accessed. For instance, MODIS product MCD43A4 v006 Nadir Bidirectional Reflectance Distribution Function (BRDF)-Adjusted Reflectance (NBAR) for 3 March 2021 in COG format stored on a commercial cloud storage that does not require signed authentication can be accessed from the command line, see Listings 5.
| Listing 5. Accessing to MCD43A4 products stored on a cloud facility. |
gdalinfo-nomd/vsicurl/https://modis-pds.s3.amazonaws.com/MCD43A4.006/18/17/2021062/MCD43A4.A2021062.h18v17.006.2021071072416_B02.TIF
Driver: GTiff/GeoTIFF
Files: /vsicurl/https://modis-pds.s3.amazonaws.com/MCD43A4.006/18/17/2021062/MCD43A4.A2021062.h18v17.006.2021071072416_B02.TIF
/vsicurl/https://modis-pds.s3.amazonaws.com/MCD43A4.006/18/17/2021062/MCD43A4.A2021062.h18v17.006.2021071072416_B02.TIF.ovr
Size is 2400, 2400
Coordinate System is:
PROJCS["unnamed",
GEOGCS["Unknown datum based upon~the~custom spheroid",
DATUM["Not_specified_based_on_custom_spheroid",
SPHEROID["Custom spheroid",6371007.181,0]],
PRIMEM["Greenwich",0],
UNIT["degree",0.0174532925199433]],
PROJECTION["Sinusoidal"],
PARAMETER["longitude_of_center",0],
PARAMETER["false_easting",0],
PARAMETER["false_northing",0],
UNIT["metre",1,
AUTHORITY["EPSG","9001"]]]
Origin = (0.000000000000000,-8895604.157332999631763)
Pixel Size = (463.312716527916677,-463.312716527916507)
Corner Coordinates:
Upper Left ( 0.000,-8895604.157) ( 0d 0‘ 0.01"E, 80d 0’ 0.00"S)
Lower Left ( 0.000,-10007554.677) ( 0d 0’ 0.01"E, 90d 0’ 0.00"S)
Upper Right ( 1111950.520,-8895604.157) ( 57d35’15.74"E, 80d 0’ 0.00"S)
Lower Right ( 1111950.520,-10007554.677) ( 46d55‘34.78"E, 90d 0’ 0.00"S)
Center ( 555975.260,-9451579.417) ( 57d22’ 6.84"E, 85d 0’ 0.00"S)
Band 1 Block=512x512 Type=Int16, ColorInterp=Gray
Description = Nadir_Reflectance_Band2
NoData Value=32767
Overviews: 1200x1200, 600x600, 300x300
Offset: 0, Scale:0.0001
|
This allows TATSSI to access files stored on cloud storage and generate time series using the approaches and interfaces mentioned in this section.
6. Conclusions
Beyond the large commercial GIS and remote sensing software packages, so far there have been few software developments containing all the components (specially, quality data assessment) for EO time series analysis in a single homogeneous software environment. TATSSI’s 3-layered architecture enables the import of standard satellite data and products, their further processing into time series, and the analysis of the generated time series.
In particular, TATSSI uses AEEARS API to simplify the downloading of most MODIS and VIIRS products (including their QA/QC definitions) available on NASA’s LP DAAC. TATSSI’s QA Analytics module allows one to quantify the impact of the selection of QA/QC definitions over the number of missing observations in a systematic fashion; thus, users can select the most adequate sets according to their scientific needs. Having a gap-free time series, obtained either by interpolation or smoothing from the corresponding TATSSI module, it is possible to apply a wide range of statistical methods for the analysis of time series at the pixel level. Since TATSSI handles time series as xarrays, all these methods are applied efficiently through parallel computing due to the integration of the DASK library. TATSSI has the capability to perform cloud-based processing in high performance computing environments by using DASK and GDAL virtual rasters; that is, TATSSI has the basic infrastructure to cope with the demands of the modern paradigm of cloud computing, in addition to allowing download data to local storage. Despite MODIS and VIIRS products being distributed in intrinsically different formats, TATSSI uses GDAL to process data from both sensors. A further application of GDAL allows for TATSSI to generate output files in popular formats, such as GeoTiff, NetCDF, generic binary and COG (TATSSI’s default format), among many others. TATSSI also allows one to integrate time series of satellite data generated by external sources and platforms, such as Landsat data and GEE, within its main workflow. Access to TATSSI functionalities can be chosen depending on the complexity of the task, the amount of data to process and the software development expertise. TATSSI GUI was developed using PyQT5 whose push buttons and integrated elements make all of TATSSI’s routines available to non-expert users, whereas for users familiarized with Python, TATSSI provides modules that can be called from a script. By supporting the JupyterLab (and several Jupyter Notebook), TATSSI functions can be executed remotely and as background processes.
TATSSI thus has a high potential for versatile applications that require monitoring of time series. TATSSI is freely scalable and can potentially also handle large amounts of data to cover large regions, for example, for monitoring large ecoregions or an entire country. This makes TATSSI attractive for use in a variety of terrestrial and maritime applications and processes, such as deforestation monitoring; and the monitoring of insect infestation and defoliation processes, vegetation degradation and regeneration, urbanization trends, geophysical long-term changes (e.g., terrestrial or maritime temperature changes or trends), burned area impacts, anthropogenic changes and hydrology, to name just a few.
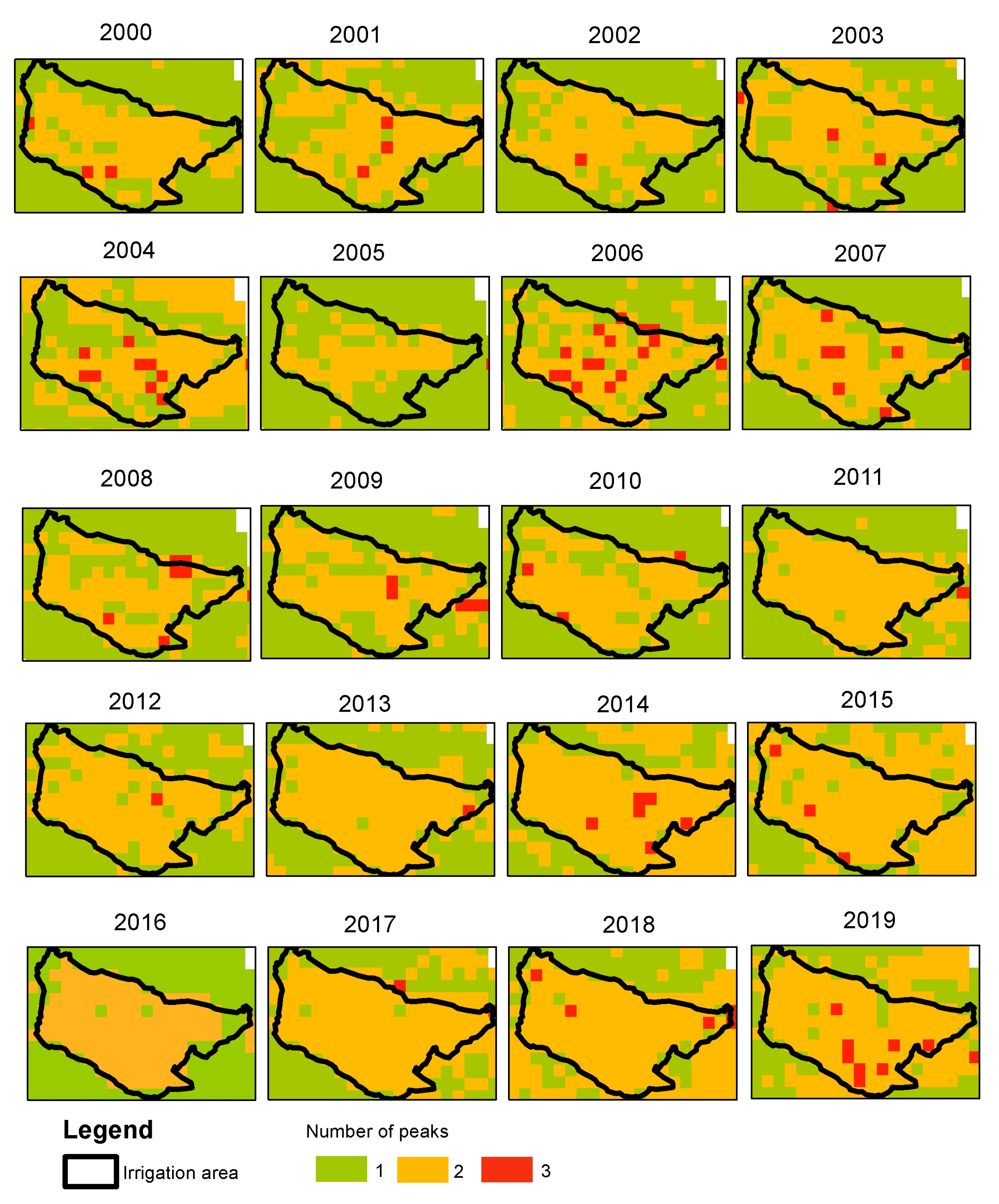
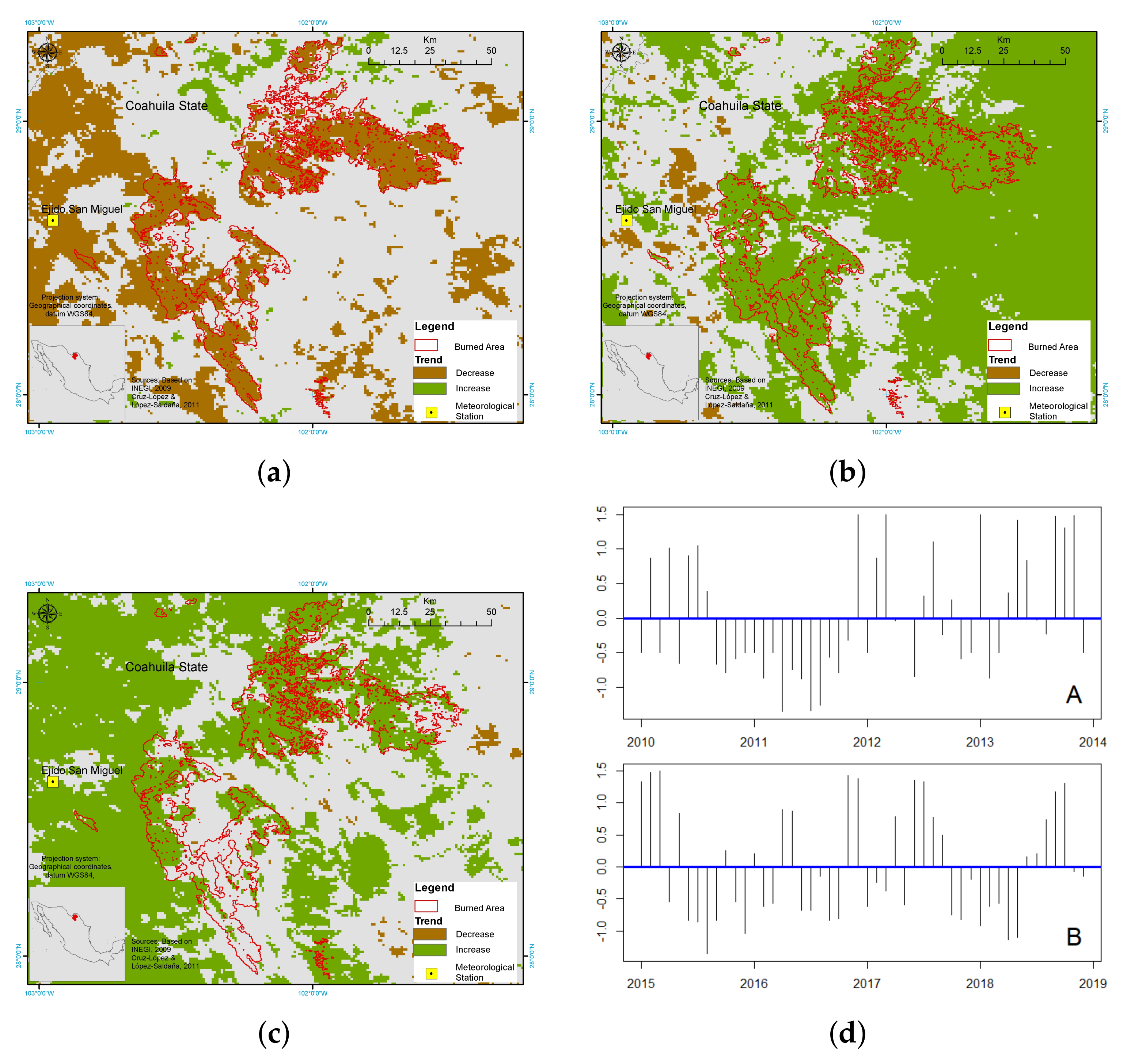
In this paper we showed the application potential of TATSSI for three examples covering very different applications—vegetation monitoring (vegetation dynamics and burned area at El Bonito), agricultural monitoring (irrigation changes at Santo Domingo), and hydrology monitoring (moisture changes in Marismas Nacionales). Future developments and improvements can include additional components, such as adaptations of the import functions for a larger range of existing and future EO platforms besides those of the existing satellites, and more interestingly, an extension to the spatio-temporal analysis of EO data and products comprising the statistical inclusion of object and texture information of the data.
In conclusion, we envision a high potential of TATSSI for the EO user community, on the one hand, through direct application of the current developed version, and on the other hand, through further development of its open-source code.


 ,
, 









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}