
Filtering Link Outliers in Vehicle Trajectories by Spatial Reasoning

 , , ,
, , ,
Abstract
:1. Introduction
2. Materials and Methods
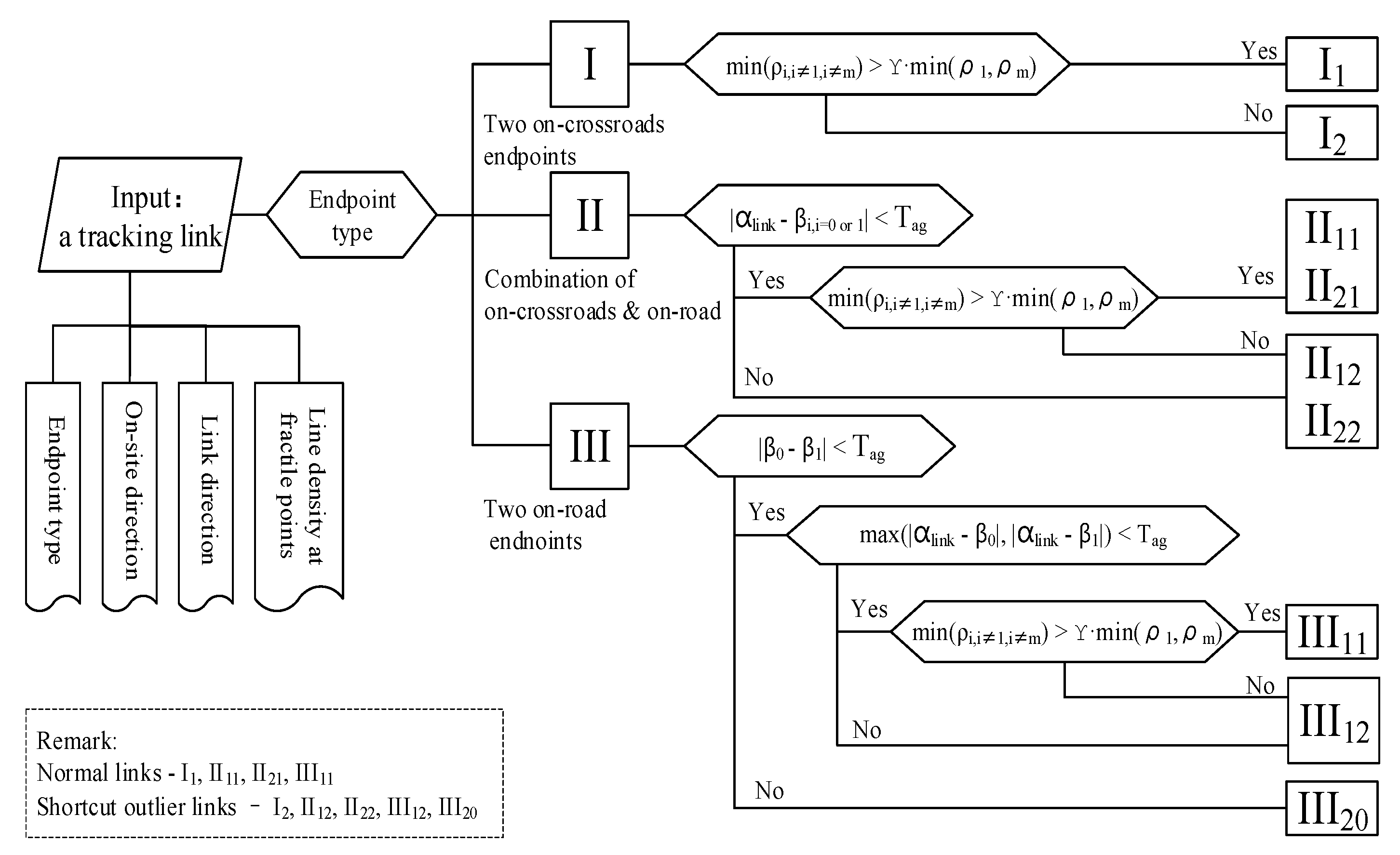
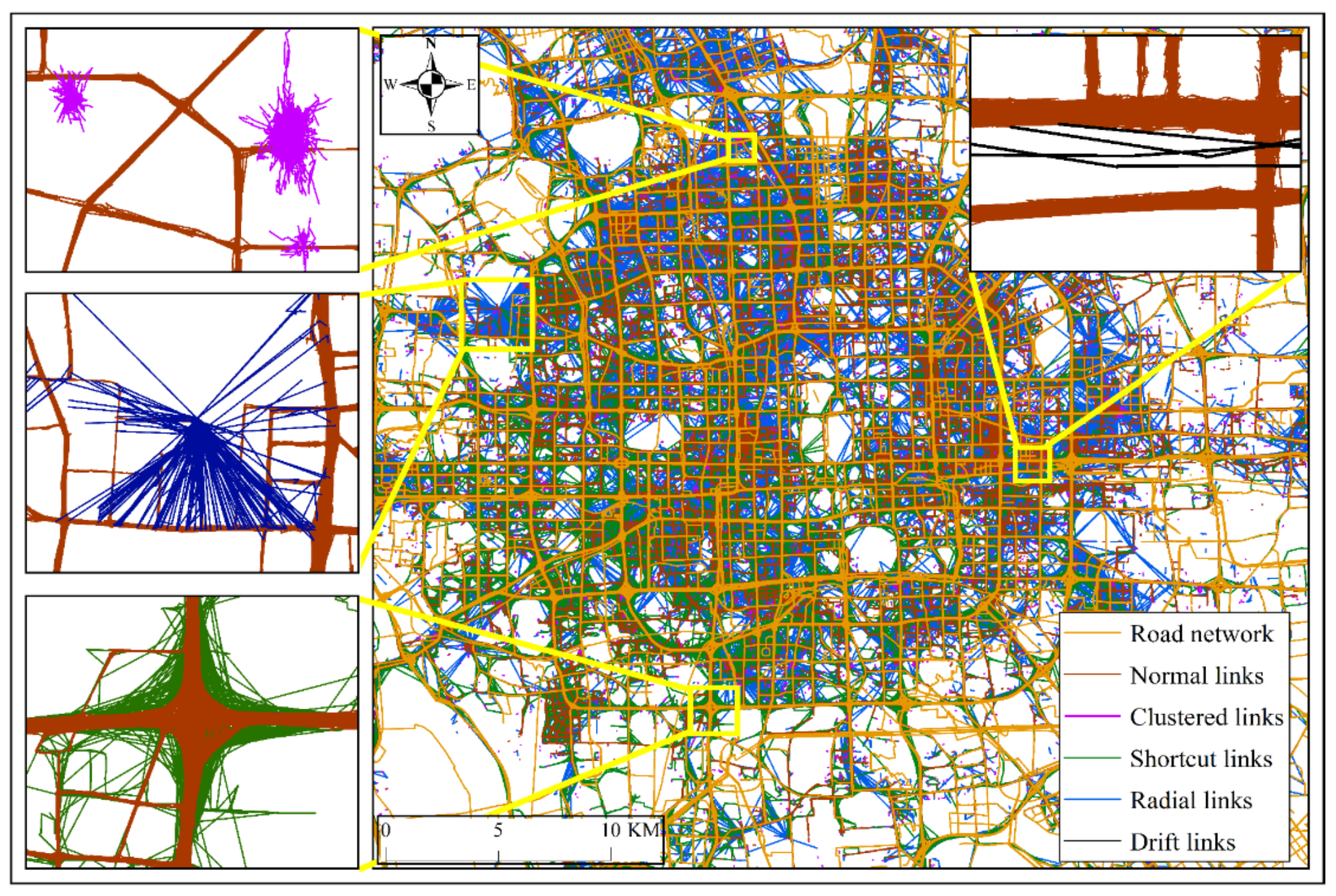
2.1. Definition of Outlier Tracking Links
- (1)
- Radial outliers (Figure 1c) radiate illumination in which the center represents the initial location to which a GNSS logger returns in case it cannot acquire a positional fix. These outliers may be due to abnormal conditions causing temporary disturbances in the GNSS;
- (2)
- Drift outliers (Figure 1d) refer to tracking links with endpoints departing from road networks due to poor-quality positioning. These outliers may be caused by ionospheric disturbances, the atmospheric layer, or multipath interference;
- (3)
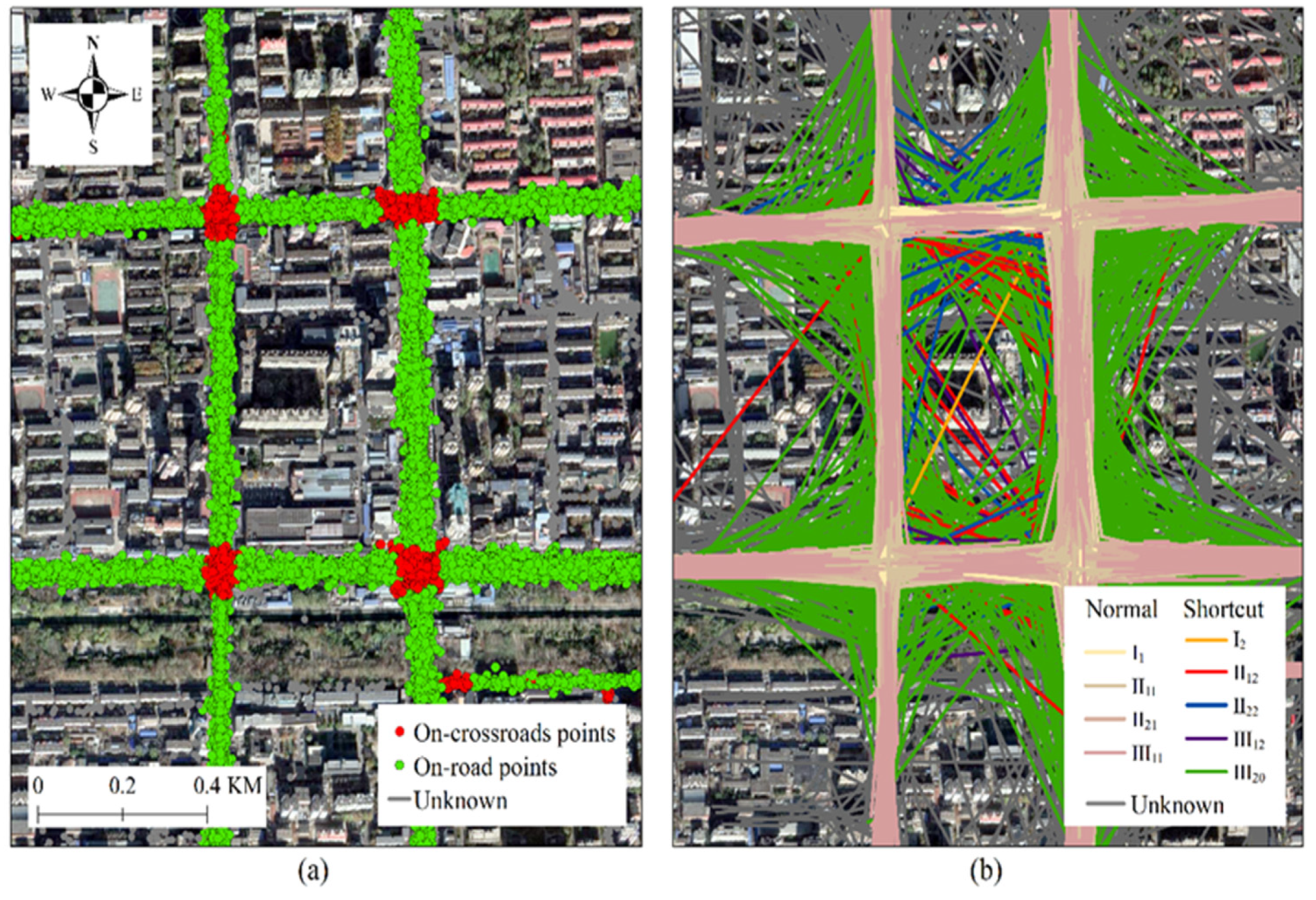
- Clustered outliers (Figure 1e) present intertwined threads in which a large number of positioned points diverge and, consequently, the links cross each other. The accuracy of these tracking points is acceptable, and they mostly appear at crossroads, parking lots, or roadsides when a vehicle stops at a traffic signal or temporarily parks;
- (4)
- Shortcut outliers (Figure 1f) often occur at crossroads. A shortcut tracking link denotes a vehicle turning path on which few tracking points were logged when a vehicle passed an intersection. The shortcut links cause a significant mismatch between the actual trajectory and the road because only two endpoints of the link lie on roads.
2.2. Tracking Link Modeling
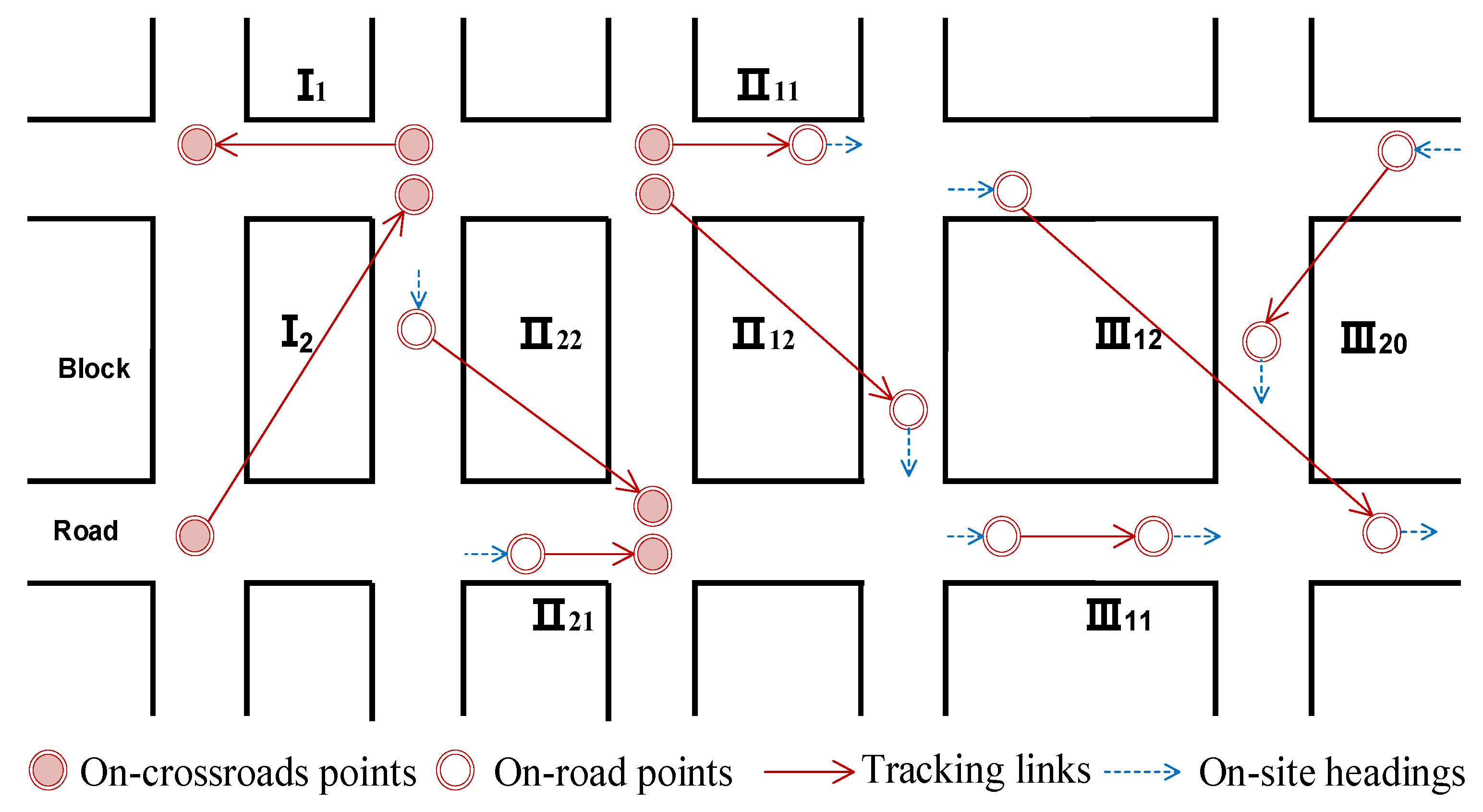
2.2.1. Geometric and Motion Measures of a Tracking Link
- (1)
- Link coordinates denote the geolocations of the link endpoints. The coordinate is represented as (xi, yi, ti), where ti is the timestamp;
- (2)
- The endpoint type refers to the location of an endpoint, i.e., on the road or at a crossroads. An innovative endpoint-type determination algorithm is proposed in this study to divide the tracking points into two types (“on-road” vs. “on-crossroads”);
- (3)
- The “on-site” heading of a tracking point denotes the true moving direction of a vehicle in a road network. This is estimated using the number of nearby tracking link directions, without requiring ancillary datasets (e.g., road networks);
- (4)
- Link direction is the link heading that can be easily calculated using the coordinates and timestamps of two endpoints. In a shortcut link case, this direction is actually not the headings of vehicles;
- (5)
- The fractile line density of a link is the spatial density of tracking links that lie within a search window centered at a fractile position along the processed tracking link. For a shortcut link, two ending points are sitting on road-network, while most fractile points depart from roads. By default, we calculated three density values, i.e., at the start-, middle-, and end-points of the link.
2.2.2. Determining the Location of Tracking Points in the Road Network without Utilizing Ancillary Road Databases
- (1)
- Measuring the information entropy at a tracking point
- (2)
- Measuring the line density gradient at a tracking point
- (3)
- Labeling tracking points by logistic regression
2.2.3. Estimating “On-Site” Headings at Two Endpoints of a Link
2.2.4. Calculation of the Line Density at a Fractile Position of a Tracking Link
2.3. Shortcut Tracking Link Detection Algorithm
2.3.1. Spatial Patterns of Tracking Links
2.3.2. Detecting Shortcut Outliers by Spatial Reasoning
3. Results
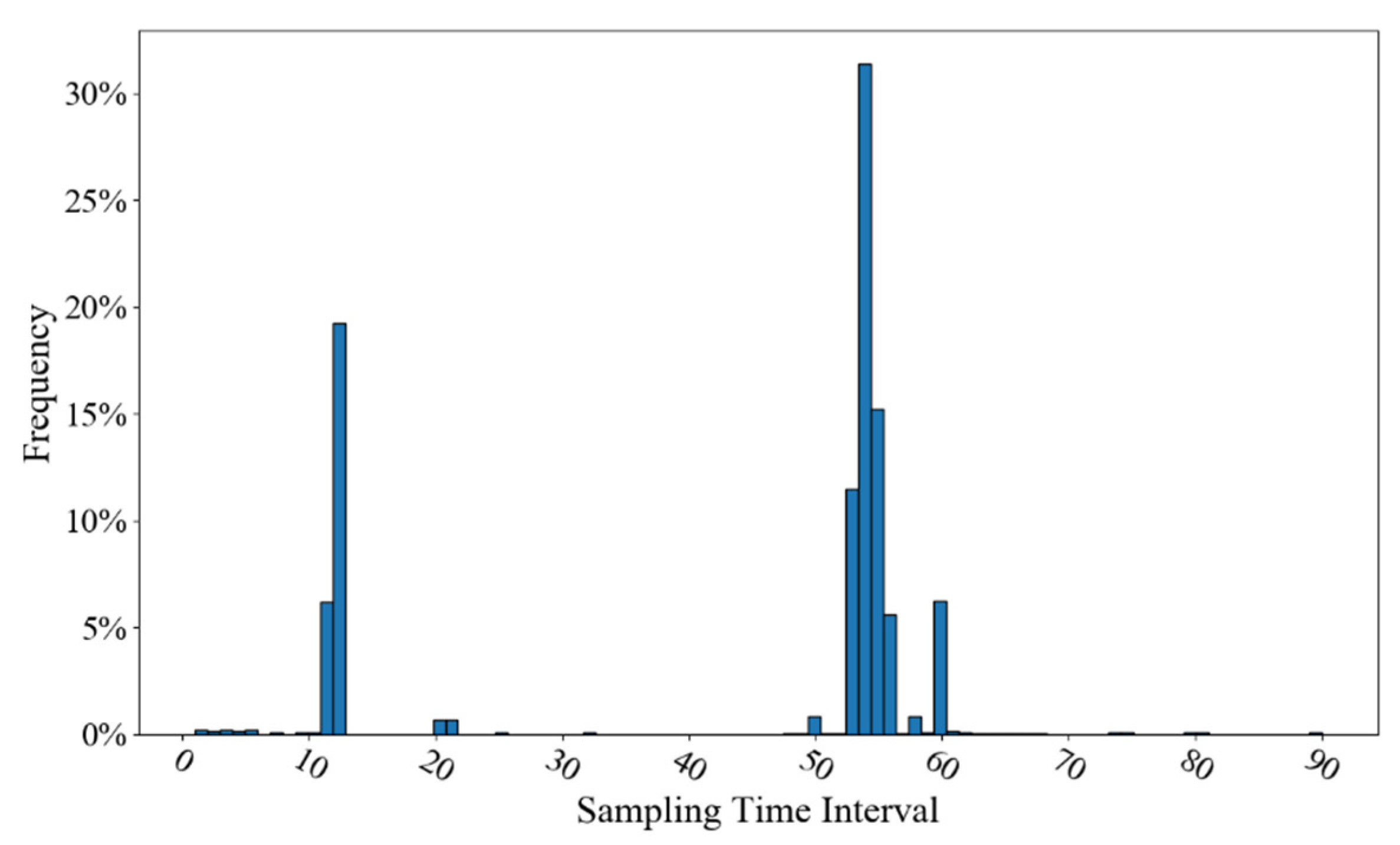
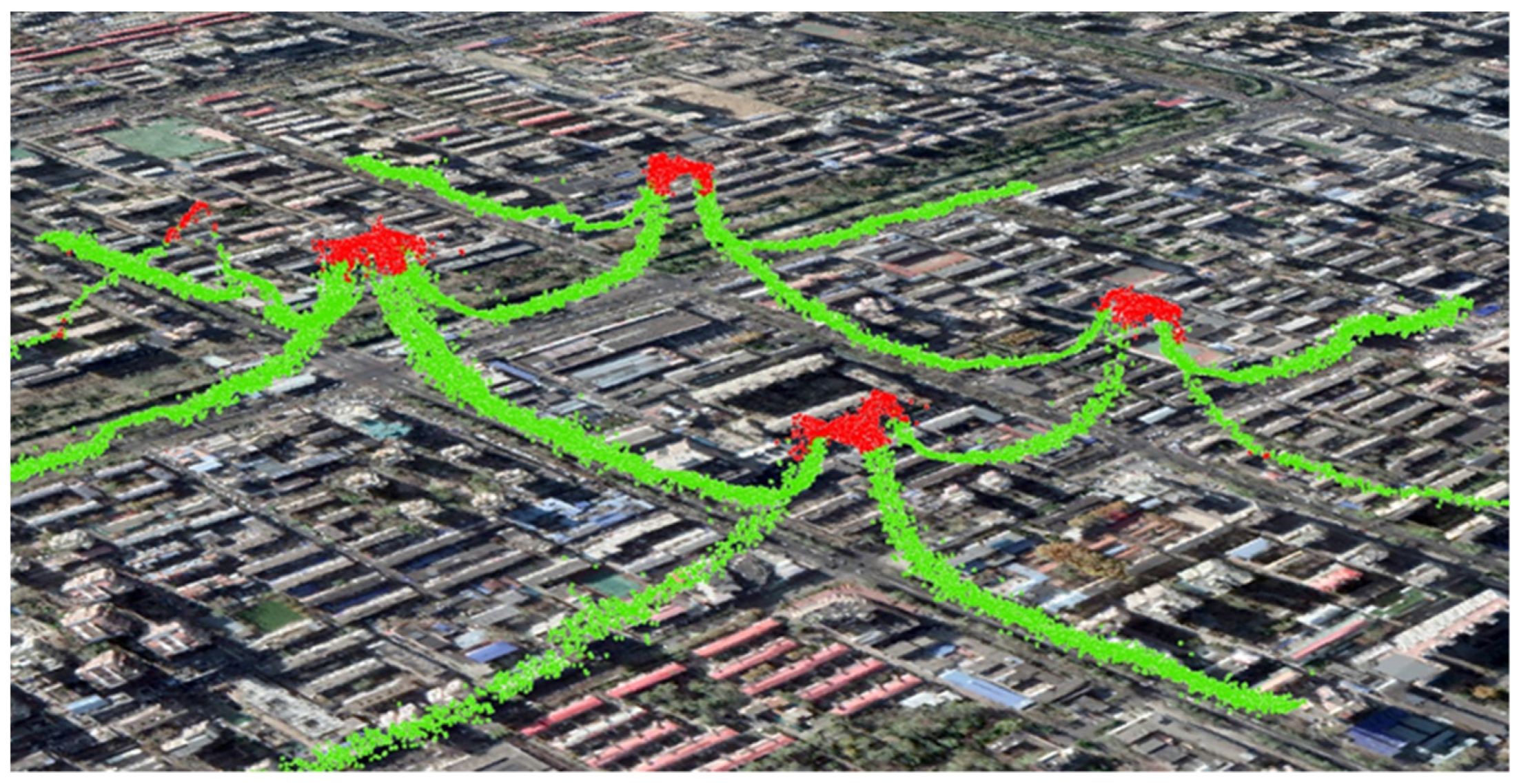
3.1. Study Area and Dataset
3.2. General Information on Detected Link Outliers
3.3. Detailed Illustration of Shortcut Link Outliers
4. Discussion
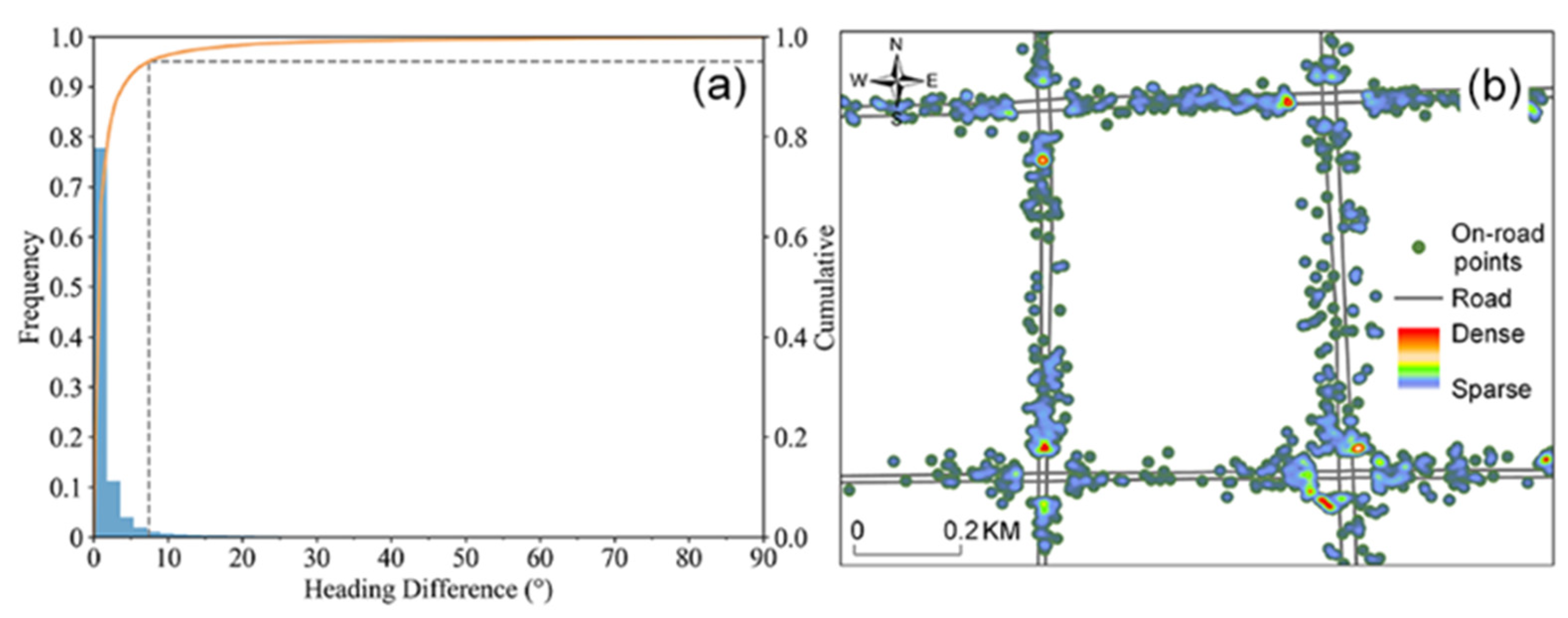
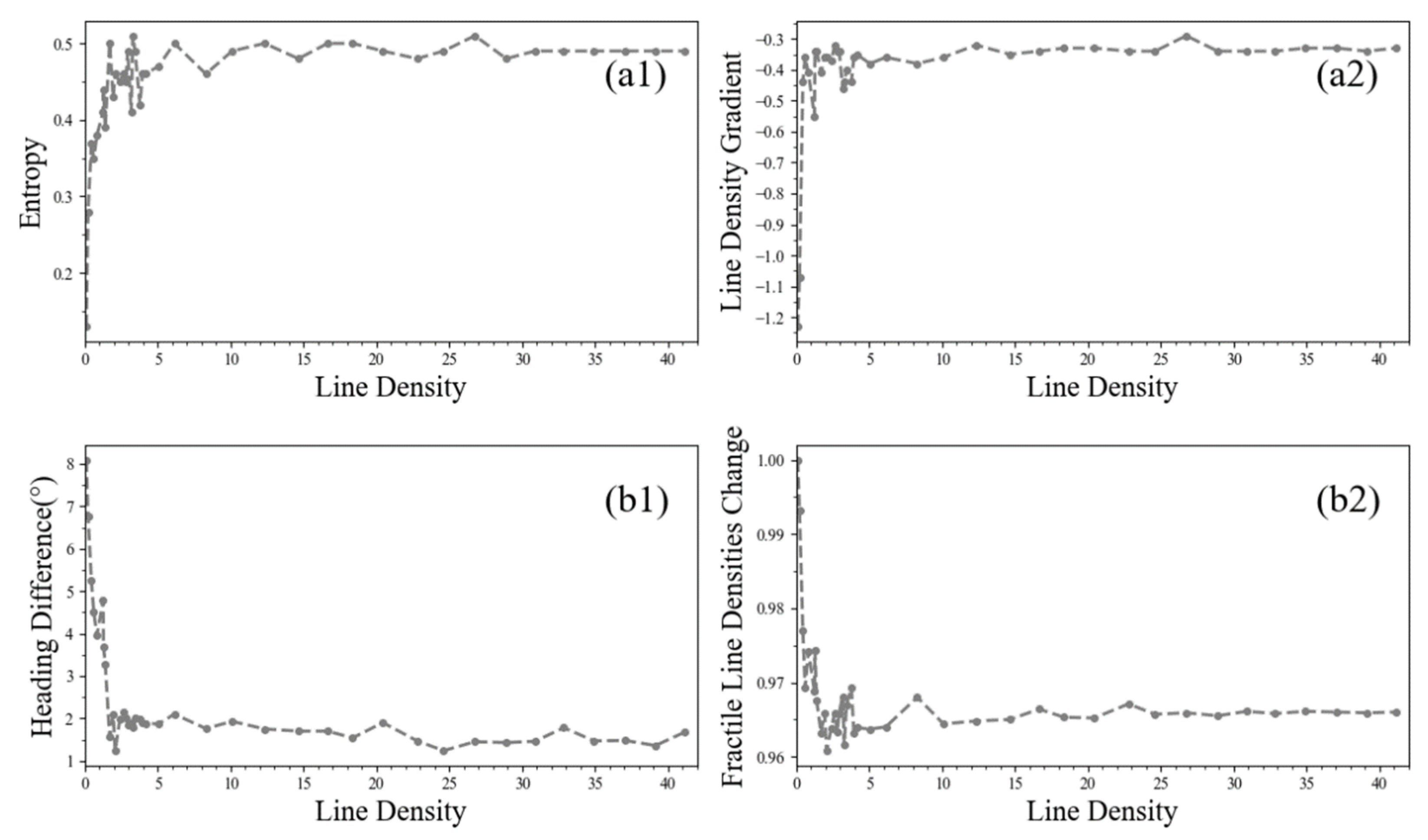
4.1. Does the Information Entropy Effectively Describe the Separation of the Location of Tracking Points in a Road Network?
4.2. Can the On-Site Heading Be a Replacement for a Vehicle Heading on a Roadway?
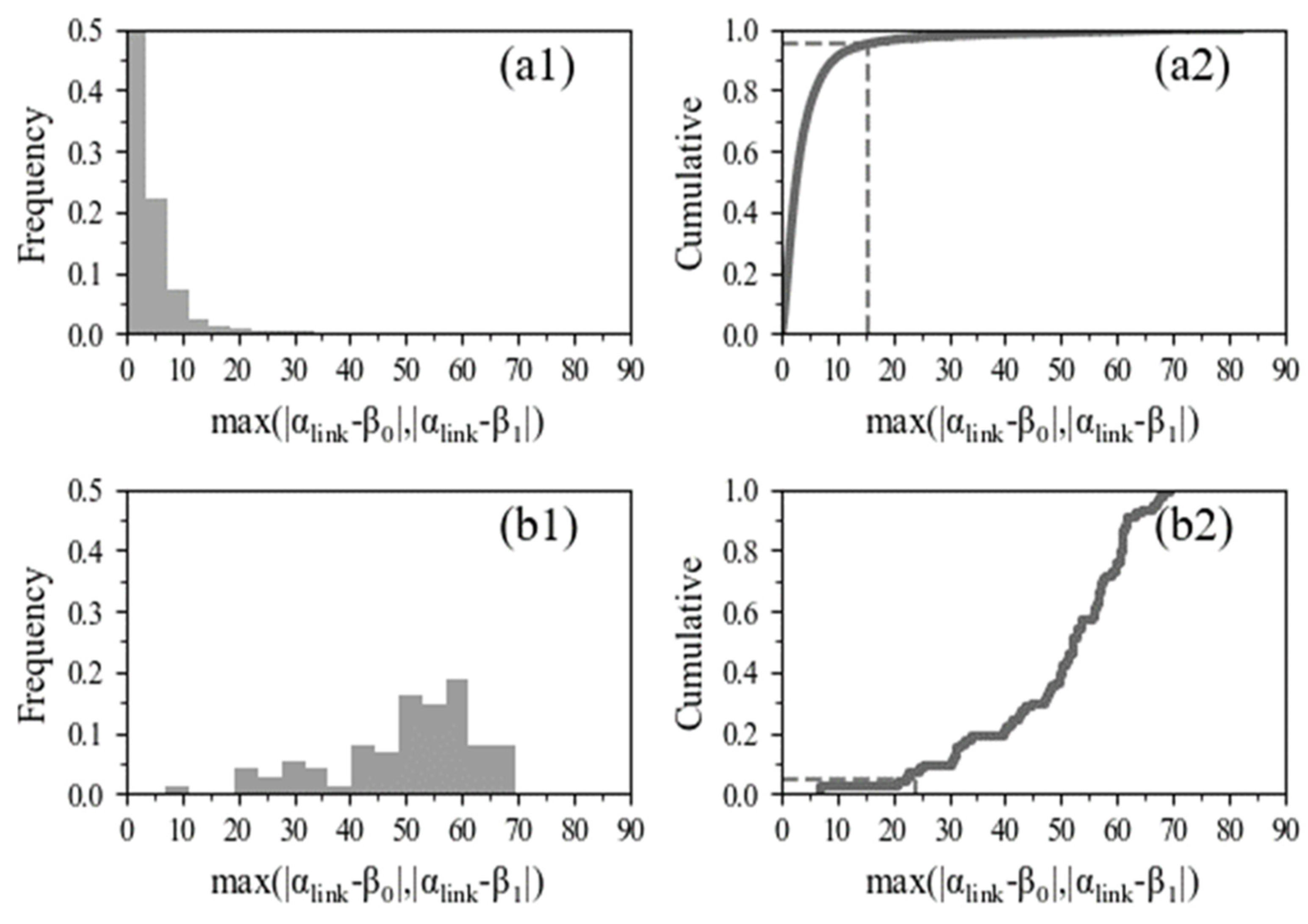
4.3. When Are On-Site Headings and Link Directions of the Same Link Considered Identical?
4.4. When Is the Change in the Fractile Line Densities along a Link Considered a Normal or Shortcut Link Case?
4.5. How Many Trajectories Are Necessary in Order to Make the Entropy- and Density-Based Approaches Work?
4.6. How Much Curvature of Urban Roads the Method Can Take without Leading to Errors?
5. Conclusions
- The proposed outlier detection method, which is based on a tracking link conceptual framework, can be used to process vehicle trajectory datasets without relying on road-network datasets. This is because the type of tracking points are determined by those density-and entropy-based features from trajectory dataset itself, and it can also be definitely recognized by matching open-access datasets i.e., OpenStreetMap.
- The shortcut link detection is based on spatial reasoning. A set of spatial patterns defining normal and shortcut links are identified and, correspondingly, several key geometric measures of a tracking link are proposed by understanding trajectory characteristics. Default threshold values of these measures are also determined by subjective sampling design and analysis.
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Liu, J.; Han, K.; Chen, X.; Ong, G.P. Spatial-temporal inference of urban traffic emissions based on taxi trajectories and multi-source urban data. Transp. Res. Part C Emerg. Technol. 2019, 106, 145–165. [Google Scholar] [CrossRef] [Green Version]
- Yang, G.; Song, C.; Shu, H.; Zhang, J.; Pei, T.; Zhou, C. Assessing Patient bypass Behavior Using Taxi Trip Origin–Destination (OD) Data. ISPRS Int. J. Geo-Inf. 2016, 5, 157. [Google Scholar] [CrossRef] [Green Version]
- Zhu, D.; Wang, N.; Wu, L.; Liu, Y. Street as a big geo-data assembly and analysis unit in urban studies: A case study using Beijing taxi data. Appl. Geogr. 2017, 86, 152–164. [Google Scholar] [CrossRef]
- Guo, J.; Huang, W.; Williams, B.M. Real time traffic flow outlier detection using short-term traffic conditional variance prediction. Transp. Res. Part C Emerg. Technol. 2015, 50, 160–172. [Google Scholar] [CrossRef]
- Lin, I.-C.; Cheng, C.-Y.; Lin, Y.-T. Improved location filtering using a context-aware approach. J. Ambient Intell. Smart Environ. 2021, 13, 1–18. [Google Scholar] [CrossRef]
- Araki, M.; Kanamori, R.; Gong, L.; Morikawa, T. Impacts of Seasonal Factors on Travel Behavior: Basic Analysis of GPS Trajectory Data for 8 Months; Springer: Tokyo, Japan, 2017. [Google Scholar] [CrossRef]
- Fu, Z.; Tian, Z.; Xu, Y.; Qiao, C. A Two-Step Clustering Approach to Extract Locations from Individual GPS Trajectory Data. ISPRS Int. J. Geo-Inf. 2016, 5, 166. [Google Scholar] [CrossRef]
- Tanimoto, J.; Sagara, H. Social Diffusive Impact Analysis Based on Evolutionary Computations for a Novel Car Navigation System Sharing Individual Information in Urban Traffic Systems. J. Navig. 2011, 64, 711–725. [Google Scholar] [CrossRef]
- Gong, S.; Cartlidge, J.; Bai, R.; Yue, Y.; Li, Q.; Qiu, G. Extracting activity patterns from taxi trajectory data: A two-layer framework using spatio-temporal clustering, Bayesian probability and Monte Carlo simulation. Int. J. Geogr. Inf. Sci. 2019, 34, 1210–1234. [Google Scholar] [CrossRef] [Green Version]
- Zheng, Y. Trajectory Data Mining: An Overview. Acm Trans. Intell. Syst. Technol. 2015, 6, 1–41. [Google Scholar] [CrossRef]
- Zheng, K.; Zheng, Y.; Xie, X.; Zhou, X. Reducing Uncertainty of Low-Sampling-Rate Trajectories. Proceedings of 2012 IEEE 28th International Conference on Data Engineering, Arlington, VA, USA, 1–5 April 2012; pp. 1144–1155. [Google Scholar]
- Deng, M.; Huang, J.; Zhang, Y.; Liu, H.; Tang, L.; Tang, J.; Yang, X. Generating urban road intersection models from low-frequency GPS trajectory data. Int. J. Geogr. Inf. Sci. 2018, 32, 2337–2361. [Google Scholar] [CrossRef]
- Ruan, S.; Long, C.; Bao, J.; Li, C.; Yu, Z.; Li, R.; Liang, Y.; He, T.; Zheng, Y. Learning to generate maps from trajectories. Proceedings of AAAI, Hilton New York Midtown, New York, NY, USA, 7–12 February 2020. [Google Scholar]
- Djenouri, Y.; Belhadi, A.; Lin, J.C.-W.; Djenouri, D.; Cano, A. A Survey on Urban Traffic Anomalies Detection Algorithms. IEEE Access 2019, 7, 12192–12205. [Google Scholar] [CrossRef]
- Knorr, E.M.; Ng, R.T.; Tucakov, V. Distance-based outliers: Algorithms and applications. VLDB J. 2000, 8, 237–253. [Google Scholar] [CrossRef]
- Wang, J.; Rui, X.; Song, X.; Tan, X.; Wang, C.; Raghavan, V. A novel approach for generating routable road maps from vehicle GPS traces. Int. J. Geogr. Inf. Sci. 2015, 29, 69–91. [Google Scholar] [CrossRef]
- Yan, Z.; Parent, C.; Spaccapietra, S.; Chakraborty, D. A Hybrid Model and Computing Platform for Spatio-semantic Trajectories. In The Semantic Web: Research and Applications, Proceedings of the 7th Extended Semantic Web Conference, ESWC 2010, Heraklion, Greece, 30 May–3 June 2010; Springer: Berlin/Heidelberg, Germany, 2010; pp. 60–75. [Google Scholar]
- Wang, J.; Wang, C.; Song, X.; Raghavan, V. Automatic intersection and traffic rule detection by mining motor-vehicle GPS trajectories. Comput. Environ. Urban Syst. 2017, 64, 19–29. [Google Scholar] [CrossRef]
- Zhao, S.; Li, W.; Cao, J. A user-adaptive algorithm for activity recognition based on k-means clustering, local outlier factor, and multivariate gaussian distribution. Sensors 2018, 18, 1850. [Google Scholar] [CrossRef] [Green Version]
- Han, S.; Wang, J. Integrated GPS/INS navigation system with dual-rate Kalman Filter. GPS Solut. 2012, 16, 389–404. [Google Scholar] [CrossRef]
- Vasiliev, K.; Saverkin, O. Comparative Evaluation of Algorithms for Trajectory Filtering. In Computer Vision in Control Systems; Springer: Cham, Switzerland, 2020; pp. 53–62. [Google Scholar] [CrossRef]
- Maiz, C.S.; Molanes-Lopez, E.M.; Miguez, J.; Djuric, P.M. A Particle Filtering Scheme for Processing Time Series Corrupted by Outliers. IEEE Trans. Signal Process. 2012, 60, 4611–4627. [Google Scholar] [CrossRef]
- Lee, J.-G.; Han, J.; Li, X.; Gonzalez, H. Traclass: Trajectory Classification Using Hierarchical Region-Based and Trajectory-Based Clustering. Proc. VLDB Endow. 2008, 1, 1081–1094. [Google Scholar] [CrossRef]
- Liu, Z.; Pi, D.; Jiang, J. Density-based trajectory outlier detection algorithm. J. Syst. Eng. Electron. 2013, 24, 335–340. [Google Scholar] [CrossRef]
- Yang, W.; Ai, T.; Lu, W. A Method for Extracting Road Boundary Information from Crowdsourcing Vehicle GPS Trajectories. Sensors 2018, 18, 1261. [Google Scholar] [CrossRef] [Green Version]
- Hadjieleftheriou, M.; Kollios, G.; Tsotras, V.J.; Gunopulos, D. Efficient Indexing of Spatiotemporal Objects. In Proceedings of the 8th International Conference on Extending Database Technology: Advances in Database Technology, Prague, Czech Republic, 25–27 March 2002; Springer: Berlin/Heidelberg, Germany, 2002; pp. 251–268. [Google Scholar]
- Mamoulis, N.; Cao, H.; Kollios, G.; Hadjieleftheriou, M.; Tao, Y.; Cheung, D. Mining, indexing, and querying historical spatiotemporal data. In Proceedings of the Tenth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Seattle, WA, USA, 22–25 August 2004; Volume 236, pp. 236–245. [Google Scholar]
- Hunter, T.; Abbeel, P.; Bayen, A. The Path Inference Filter: Model-Based Low-Latency Map Matching of Probe Vehicle Data. IEEE Trans. Intell. Transp. Syst. 2014, 15, 507–529. [Google Scholar] [CrossRef] [Green Version]
- Rahmani, M.; Koutsopoulos, H.N. Path inference of low-frequency GPS probes for urban networks. In Proceedings of the 15th International IEEE Conference on Intelligent Transportation Systems, Anchorage, AK, USA, 16–19 September 2012. [Google Scholar]
- Jenelius, E.; Koutsopoulos, H.N. Travel time estimation for urban road networks using low frequency probe vehicle data. Transp. Res. Part B Methodol. 2013, 53, 64–81. [Google Scholar] [CrossRef] [Green Version]
- Meng, F.; Guan, Y.; Lv, S.; Wang, Z.; Xia, S. An overview on trajectory outlier detection. Artif. Intell. Rev. 2018. [Google Scholar] [CrossRef]
- Guan, Y.; Xia, S.; Lei, Z.; Yong, Z.; Cheng, J. Trajectory Outlier Detection Algorithm Based on Structural Features. J. Comput. Inf. Syst. 2011, 7, 4137–4144. [Google Scholar]
- Yang, X.; Tang, L.; Li, Q. Generating Lane-based Intersection Maps from Crowdsourcing Big Trace Data. Transp. Res. Part C Emerg. Technol. 2018, 89, 168–187. [Google Scholar] [CrossRef]
- Binh, H.; Ling, L.; Omiecinski, E. Road-Network Aware Trajectory Clustering: Integrating Locality, Flow, and Density. IEEE Trans. Mob. Comput. 2015, 14, 416–429. [Google Scholar] [CrossRef] [Green Version]
- Xu, Z.; Cui, G.; Zhong, M.; Wang, X. Anomalous Urban Mobility Pattern Detection Based on GPS Trajectories and POI Data. ISPRS Int. J. Geo-Inf. 2019, 8, 308. [Google Scholar] [CrossRef] [Green Version]
- Hawkins, D.M. Identification of Outliers. Biometrics 1980, 37, 860. [Google Scholar] [CrossRef]
- Liu, W.; Li, J.; Zeng, Q.; Guo, F.; Wu, R.; Zhang, X. An improved robust Kalman filtering strategy for GNSS kinematic positioning considering small cycle slips. Adv. Space Res. 2019, 63, 2724–2734. [Google Scholar] [CrossRef]
- Xiang, L.; Gao, M.; Wu, T. Extracting Stops from Noisy Trajectories: A Sequence Oriented Clustering Approach. ISPRS Int. J. Geo-Inf. 2016, 5, 29. [Google Scholar] [CrossRef] [Green Version]
- Wehrl, A. General properties of entropy. Rev. Mod. Phys. 1978, 50, 221–260. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Link Outliers | Normal Links | Total | |||
|---|---|---|---|---|---|
| Radial | Drift | Clustered | Shortcut | ||
| 1,285,827 | 203,891 | 8,925,152 | 2,147,429 | 20,323,301 | 32,885,600 |
| 3.91% | 0.62% | 27.14% | 6.53% | 61.80% | 100% |
| Link Type | Count | (%) | Remarks |
|---|---|---|---|
| I1 | 8351 | 3.436 | Normal |
| I2 | 1 | 0.004 | Shortcut |
| II11 | 2442 | 10.049 | Normal |
| II12 | 50 | 0.206 | Shortcut |
| II21 | 2321 | 9.551 | Normal |
| II22 | 50 | 0.206 | Shortcut |
| III11 | 17,283 | 71.123 | Normal |
| III12 | 13 | 0.053 | Shortcut |
| III20 | 1305 | 5.370 | Shortcut |
| Unknown | 1008 | 4.148 | Sparse or near boundary |
| “On-Road” | “On-Crossroads” | Recall (%) | Kappa | ||
|---|---|---|---|---|---|
| Test 1 | “on-road” | 1679 | 8 | 99.53 | 98.63 |
| “on-crossroads” | 4 | 583 | 99.32 | ||
| Precision (%) | 99.76 | 98.65 | - | ||
| Test 2 | “on-road” | 1685 | 10 | 99.41 | 98.50 |
| “on-crossroads” | 3 | 576 | 99.48 | ||
| Precision (%) | 99.76 | 98.29 | - | ||
| Test 3 | “on-road” | 1714 | 10 | 99.41 | 98.21 |
| “on-crossroads” | 5 | 545 | 99.09 | ||
| Precision (%) | 99.71 | 98.20 | - | ||
| Test 4 | “on-road” | 1704 | 15 | 99.13 | 97.63 |
| “on-crossroads” | 5 | 550 | 99.10 | ||
| Precision (%) | 99.71 | 97.35 | - | ||
| Test 5 | “on-road” | 1691 | 14 | 99.18 | 97.55 |
| “on-crossroads” | 7 | 562 | 98.77 | ||
| Precision (%) | 99.59 | 97.57 | - |
| Curvature (m−1) | p-Value | Curvature (m−1) | p-Value | Curvature (m−1) | p-Value |
|---|---|---|---|---|---|
| 0.001 | 0 | 0.0064 | 0.0055 | 0.0073 | 0.7638 |
| 0.002 | 0 | 0.0065 | 0.0060 | 0.0074 | 0.9993 |
| 0.003 | 0 | 0.0066 | 0.0100 | 0.0075 | 0.9964 |
| 0.004 | 0 | 0.0067 | 0.0177 | 0.0076 | 0.994 |
| 0.005 | 0 | 0.0068 | 0.0667 | 0.0077 | 0.9994 |
| 0.006 | 0 | 0.0069 | 0.0887 | 0.0078 | 1 |
| 0.0061 | 0 | 0.007 | 0.0939 | 0.0079 | 1 |
| 0.0062 | 0.0003 | 0.0071 | 0.3718 | 0.008 | 1 |
| 0.0063 | 0.0035 | 0.0072 | 0.5679 | 0.009 | 1 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, J.; Pan, M.; Song, X.; Wang, J.; Zhu, K.; Li, R.; Rui, X.; Wang, W.; Hu, J.; Raghavan, V. Filtering Link Outliers in Vehicle Trajectories by Spatial Reasoning. ISPRS Int. J. Geo-Inf. 2021, 10, 333. https://0-doi-org.brum.beds.ac.uk/10.3390/ijgi10050333
Liu J, Pan M, Song X, Wang J, Zhu K, Li R, Rui X, Wang W, Hu J, Raghavan V. Filtering Link Outliers in Vehicle Trajectories by Spatial Reasoning. ISPRS International Journal of Geo-Information. 2021; 10(5):333. https://0-doi-org.brum.beds.ac.uk/10.3390/ijgi10050333
Chicago/Turabian StyleLiu, Junli, Miaomiao Pan, Xianfeng Song, Jing Wang, Kemin Zhu, Runkui Li, Xiaoping Rui, Weifeng Wang, Jinghao Hu, and Venkatesh Raghavan. 2021. "Filtering Link Outliers in Vehicle Trajectories by Spatial Reasoning" ISPRS International Journal of Geo-Information 10, no. 5: 333. https://0-doi-org.brum.beds.ac.uk/10.3390/ijgi10050333