
A Dynamic and Static Context-Aware Attention Network for Trajectory Prediction


Abstract
:1. Introduction
2. Literature Review
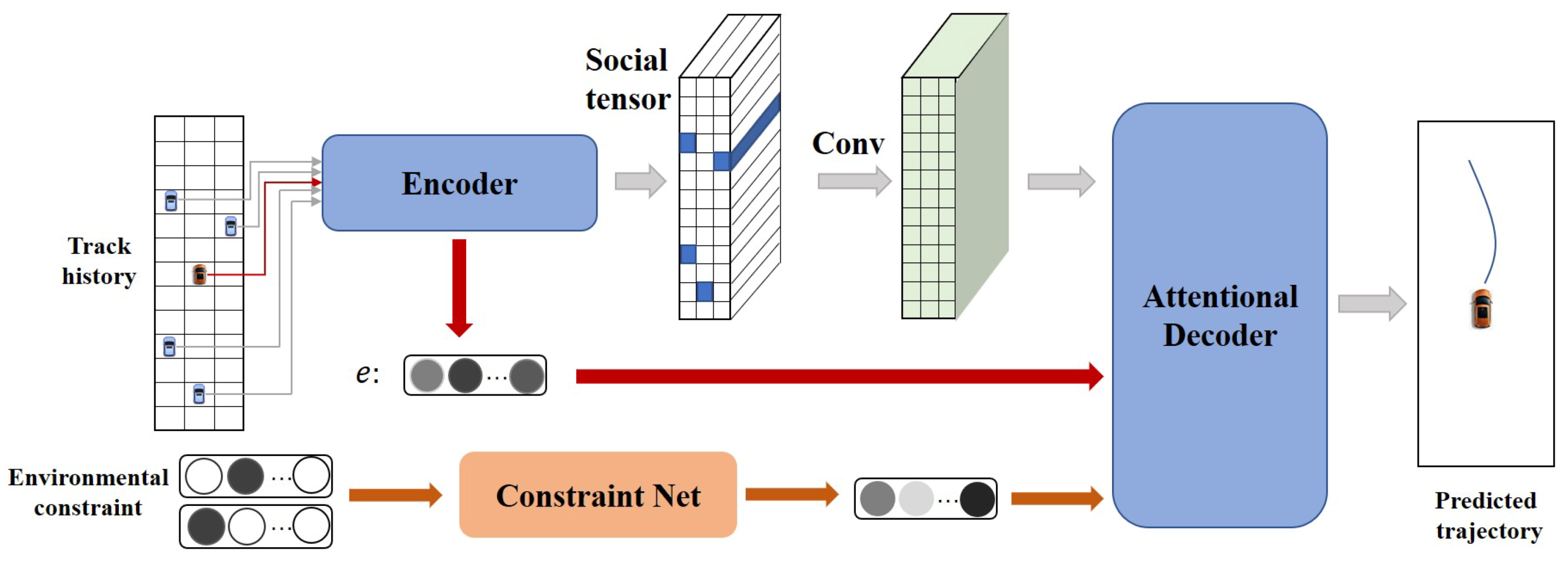
3. Methodology
3.1. Encoder
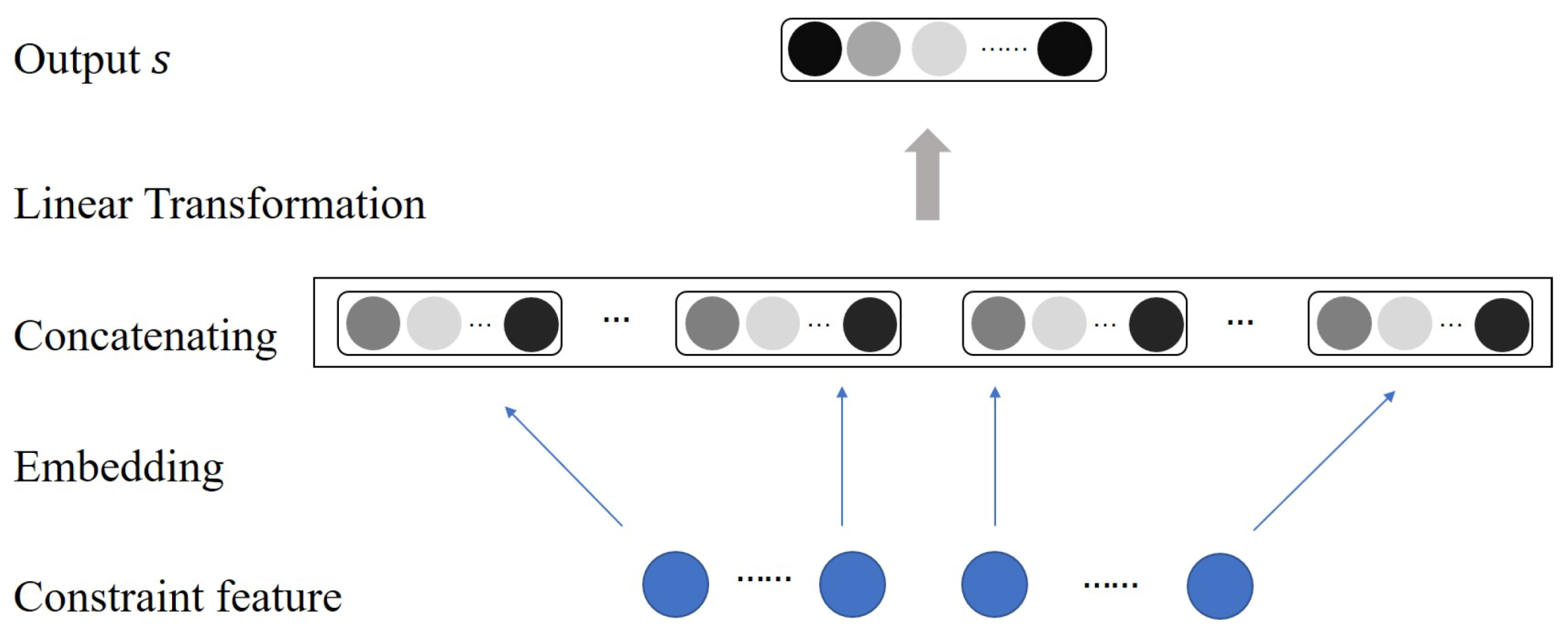
3.2. Constraint Net
3.3. Attentional Decoder
4. Experimental Evaluation
4.1. Dataset
- (i)
- Deleted outliers for which the acceleration exceeds the vehicle’s physical properties or the human endurance limit [36].
- (ii)
- Used a Lagrange quintic polynomial (Equations (8) and (9)) to interpolate outliers’ coordinates.where are the interpolation joints, is the interpolated function, is a polynomial of degree n, and is the Lagrange polynomial interpolation result.
- (iii)
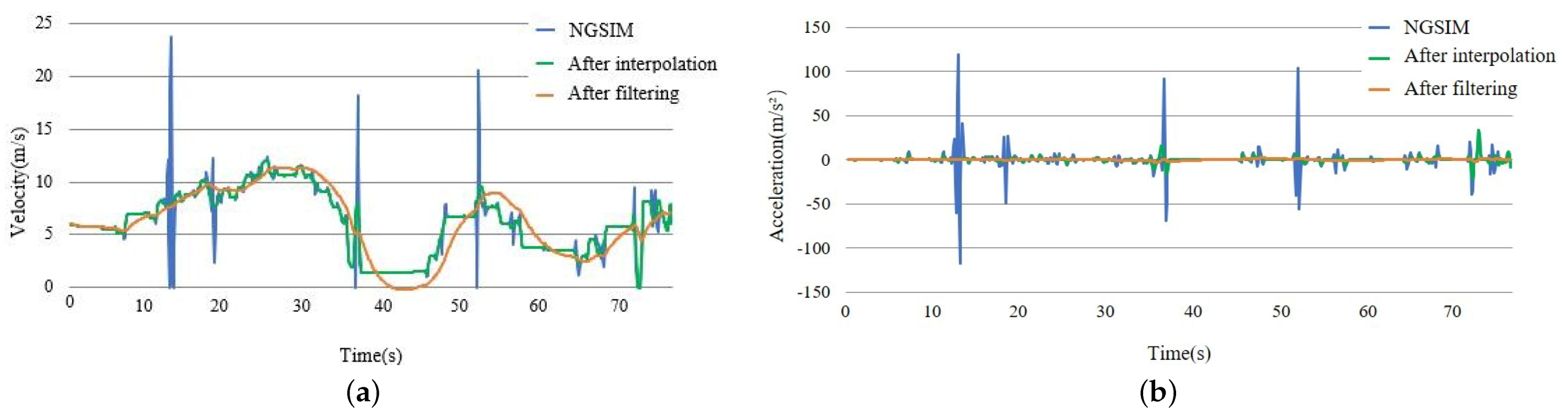
- Used Kalman filter to eliminate the errors caused by observation and interpolation. Figure 3 shows the processed data changes. After the preprocessing, these data are more stable and practical.
4.2. Parameter Settings
- (1)
- Evaluation metrics
- (2)
- Main parameters
4.3. Compared Models
- Vanilla LSTM (V-LSTM): The V-LSTM is built on the seq2seq structure with an LSTM encoder and an LSTM decoder. As a basic model, it only takes the historical trajectory of target vehicle as input without considering other factors.
- LSTM with fully connected social pooling (S-LSTM): We implement this baseline according to [5]. Different from V-LSTM, the S-LSTM also incorporates historical trajectories of surrounding vehicles. The encoded representation of target vehicle and surrounding vehicles are fused with a fully connected layer before being sent to the decoder.
- LSTM with convolutional social pooling (CS-LSTM): Similar to S-LSTM, the CS-LSTM also incorporates historical trajectories of the target vehicle and surrounding vehicles. However, the CS-LSTM utilizes convolutional neural network to learn the interaction between target vehicle and surrounding vehicles. More details about CS-LSTM can be found in [4].
- Dynamic Context-aware Attention Network (DCAN): DCAN is implemented with an LSTM encoder and an attentional decoder described in Section 3, which are the same as our proposed DSCAN. It adds the attention mechanism to assign different weights to surrounding vehicles. We set this baseline model to demonstrate the effectiveness of constraint net.
- DSCAN: This is the complete model described in this paper, which is composed of the LSTM encoder, constraint net, and attentional decoder. Different from DCAN, DSCAN considers not only historical trajectories of the target vehicle and surrounding vehicles but also environment information.
4.4. Results
5. Discussion
5.1. Attention Distribution Analysis
5.2. Scenario Analysis
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Liu, Y.; Wang, X. Differences in Driving Intention Transitions Caused by Driver’s Emotion Evolutions. Int. J. Environ. Res. Public Health 2020, 17, 6962. [Google Scholar] [CrossRef]
- Park, S.H.; Kim, B.; Kang, C.M.; Chung, C.C.; Choi, J.W. Sequence-to-sequence prediction of vehicle trajectory via LSTM encoder-decoder architecture. In Proceedings of the 2018 IEEE Intelligent Vehicles Symposium (IV), Changshu, China, 26–30 June 2018; pp. 1672–1678. [Google Scholar]
- Sakata, N.; Kinoshita, Y.; Kato, Y. Predicting a pedestrian trajectory using seq2seq for mobile robot navigation. In Proceedings of the IECON 2018-44th Annual Conference of the IEEE Industrial Electronics Society, Washington, DC, USA, 21–23 October 2018; pp. 4300–4305. [Google Scholar]
- Deo, N.; Trivedi, M.M. Convolutional social pooling for vehicle trajectory prediction. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–22 June 2018; pp. 1468–1476. [Google Scholar]
- Alahi, A.; Goel, K.; Ramanathan, V.; Robicquet, A.; Fei-Fei, L.; Savarese, S. Social lstm: Human trajectory prediction in crowded spaces. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 961–971. [Google Scholar]
- Lefèvre, S.; Vasquez, D.; Laugier, C. A survey on motion prediction and risk assessment for intelligent vehicles. Robomech J. 2014, 1, 1–14. [Google Scholar] [CrossRef] [Green Version]
- Hillenbrand, J.; Spieker, A.M.; Kroschel, K. A multilevel collision mitigation approach—Its situation assessment, decision making, and performance tradeoffs. IEEE Trans. Intell. Transp. Syst. 2006, 7, 528–540. [Google Scholar] [CrossRef]
- Polychronopoulos, A.; Tsogas, M.; Amditis, A.J.; Andreone, L. Sensor fusion for predicting vehicles’ path for collision avoidance systems. IEEE Trans. Intell. Transp. Syst. 2007, 8, 549–562. [Google Scholar] [CrossRef]
- Batz, T.; Watson, K.; Beyerer, J. Recognition of dangerous situations within a cooperative group of vehicles. In Proceedings of the 2009 IEEE Intelligent Vehicles Symposium, Xi’an, China, 3–5 June 2009; pp. 907–912. [Google Scholar]
- Ammoun, S.; Nashashibi, F. Real time trajectory prediction for collision risk estimation between vehicles. In Proceedings of the 2009 IEEE 5th International Conference on Intelligent Computer Communication and Processing, Cluj-Napoca, Romania, 27–29 August 2009; pp. 417–422. [Google Scholar]
- Althoff, M.; Mergel, A. Comparison of Markov chain abstraction and Monte Carlo simulation for the safety assessment of autonomous cars. IEEE Trans. Intell. Transp. Syst. 2011, 12, 1237–1247. [Google Scholar] [CrossRef] [Green Version]
- Atev, S.; Miller, G.; Papanikolopoulos, N.P. Clustering of vehicle trajectories. IEEE Trans. Intell. Transp. Syst. 2010, 11, 647–657. [Google Scholar] [CrossRef]
- Kumar, P.; Perrollaz, M.; Lefevre, S.; Laugier, C. Learning-based approach for online lane change intention prediction. In Proceedings of the 2013 IEEE Intelligent Vehicles Symposium (IV), Gold Coast, QLD, Australia, 23–26 June 2013; pp. 797–802. [Google Scholar]
- Qiao, S.; Shen, D.; Wang, X.; Han, N.; Zhu, W. A self-adaptive parameter selection trajectory prediction approach via hidden Markov models. IEEE Trans. Intell. Transp. Syst. 2014, 16, 284–296. [Google Scholar] [CrossRef]
- Houenou, A.; Bonnifait, P.; Cherfaoui, V.; Yao, W. Vehicle trajectory prediction based on motion model and maneuver recognition. In Proceedings of the 2013 IEEE/RSJ International Conference on Intelligent Robots and Systems, Tokyo, Japan, 3–7 November 2013; pp. 4363–4369. [Google Scholar]
- Schlechtriemen, J.; Wirthmueller, F.; Wedel, A.; Breuel, G.; Kuhnert, K.D. When will it change the lane? A probabilistic regression approach for rarely occurring events. In Proceedings of the 2015 IEEE Intelligent Vehicles Symposium (IV), Seoul, Korea, 28 June–1 July 2015; pp. 1373–1379. [Google Scholar]
- Leon, F.; Gavrilescu, M. A Review of Tracking and Trajectory Prediction Methods for Autonomous Driving. Mathematics 2021, 9, 660. [Google Scholar] [CrossRef]
- Xu, K.; Qin, Z.; Wang, G.; Huang, K.; Ye, S.; Zhang, H. Collision-free lstm for human trajectory prediction. In International Conference on Multimedia Modeling; Springer: Cham, Switzerland, 2018; pp. 106–116. [Google Scholar]
- Gupta, A.; Johnson, J.; Fei-Fei, L.; Savarese, S.; Alahi, A. Social gan: Socially acceptable trajectories with generative adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 2255–2264. [Google Scholar]
- Xu, Y.; Zhao, T.; Baker, C.; Zhao, Y.; Wu, Y.N. Learning trajectory prediction with continuous inverse optimal control via Langevin sampling of energy-based models. arXiv 2019, arXiv:1904.05453. [Google Scholar]
- Yoon, Y.; Kim, T.; Lee, H.; Park, J. Road-aware trajectory prediction for autonomous driving on highways. Sensors 2020, 20, 4703. [Google Scholar] [CrossRef]
- Staudemeyer, R.C.; Morris, E.R. Understanding LSTM—A tutorial into Long Short-Term Memory Recurrent Neural Networks. arXiv 2019, arXiv:1909.09586. [Google Scholar]
- Choi, D.; Yim, J.; Baek, M.; Lee, S. Machine Learning-Based Vehicle Trajectory Prediction Using V2V Communications and On-Board Sensors. Electronics 2021, 10, 420. [Google Scholar] [CrossRef]
- Lee, N.; Choi, W.; Vernaza, P.; Choy, C.B.; Torr, P.H.; Chandraker, M. Desire: Distant future prediction in dynamic scenes with interacting agents. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 336–345. [Google Scholar]
- Das, S.; Dutta, A.; Sun, X. Patterns of rainy weather crashes: Applying rules mining. J. Transp. Saf. Secur. 2020, 12, 1083–1105. [Google Scholar] [CrossRef]
- Zhu, D.; Shen, G.; Liu, D.; Chen, J.; Zhang, Y. FCG-aspredictor: An approach for the prediction of average speed of road segments with floating car GPS data. Sensors 2019, 19, 4967. [Google Scholar] [CrossRef] [Green Version]
- Dey, K.C.; Rayamajhi, A.; Chowdhury, M.; Bhavsar, P.; Martin, J. Vehicle-to-vehicle (V2V) and vehicle-to-infrastructure (V2I) communication in a heterogeneous wireless network–Performance evaluation. Transp. Res. Part C 2016, 68, 168–184. [Google Scholar] [CrossRef] [Green Version]
- Milanés, V.; Villagrá, J.; Godoy, J.; Simó, J.; Pérez, J.; Onieva, E. An intelligent V2I-based traffic management system. IEEE Trans. Intell. Transp. Syst. 2012, 13, 49–58. [Google Scholar] [CrossRef] [Green Version]
- Cheng, H.T.; Koc, L.; Harmsen, J.; Shaked, T.; Chandra, T.; Aradhye, H.; Shah, H. Wide & deep learning for recommender systems. In Proceedings of the 1st Workshop on Deep Learning for Recommender Systems, Boston, MA, USA, 15 September 2016; pp. 7–10. [Google Scholar]
- Guo, H.; Tang, R.; Ye, Y.; Li, Z.; He, X. DeepFM: A factorization-machine based neural network for CTR prediction. arXiv 2017, arXiv:1703.04247. [Google Scholar]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural machine translation by jointly learning to align and translate. arXiv 2014, arXiv:1409.0473. [Google Scholar]
- Xu, K.; Ba, J.; Kiros, R.; Cho, K.; Courville, A.; Salakhudinov, R.; Zemel, R.; Bengio, Y. Show, attend and tell: Neural image caption generation with visual attention. In Proceedings of the 32nd International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 2048–2057. [Google Scholar]
- Chorowski, J.; Bahdanau, D.; Serdyuk, D.; Cho, K.; Bengio, Y. Attention-based models for speech recognition. arXiv 2015, arXiv:1506.07503. [Google Scholar]
- Rush, A.M.; Chopra, S.; Weston, J. A neural attention model for abstractive sentence summarization. arXiv 2015, arXiv:1509.00685. [Google Scholar]
- Lin, L.; Gong, S.; Peeta, S.; Wu, X. Long Short-Term Memory-Based Human-Driven Vehicle Longitudinal Trajectory Prediction in a Connected and Autonomous Vehicle Environment. Transp. Res. Rec. 2021. [Google Scholar] [CrossRef]
- Montanino, M.; Punzo, V. Making NGSIM data usable for studies on traffic flow theory: Multistep method for vehicle trajectory reconstruction. Transp. Res. Rec. 2013, 2390, 99–111. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | RMSE (m) | ||||
|---|---|---|---|---|---|
| 1 s | 2 s | 3 s | 4 s | 5 s | |
| V-LSTM | 0.672 | 1.702 | 3.039 | 4.603 | 6.310 |
| S-LSTM | 0.628 | 1.365 | 2.226 | 3.249 | 4.516 |
| CS-LSTM | 0.63 | 1.366 | 2.211 | 3.244 | 4.489 |
| DCAN | 0.582 | 1.266 | 2.041 | 3.001 | 4.175 |
| DSCAN | 0.579 | 1.259 | 2.034 | 2.982 | 4.134 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yu, J.; Zhou, M.; Wang, X.; Pu, G.; Cheng, C.; Chen, B. A Dynamic and Static Context-Aware Attention Network for Trajectory Prediction. ISPRS Int. J. Geo-Inf. 2021, 10, 336. https://0-doi-org.brum.beds.ac.uk/10.3390/ijgi10050336
Yu J, Zhou M, Wang X, Pu G, Cheng C, Chen B. A Dynamic and Static Context-Aware Attention Network for Trajectory Prediction. ISPRS International Journal of Geo-Information. 2021; 10(5):336. https://0-doi-org.brum.beds.ac.uk/10.3390/ijgi10050336
Chicago/Turabian StyleYu, Jian, Meng Zhou, Xin Wang, Guoliang Pu, Chengqi Cheng, and Bo Chen. 2021. "A Dynamic and Static Context-Aware Attention Network for Trajectory Prediction" ISPRS International Journal of Geo-Information 10, no. 5: 336. https://0-doi-org.brum.beds.ac.uk/10.3390/ijgi10050336