1. Introduction
Urban human mobility modeling is the prerequisite for traffic demand modeling [
1], tourist behavior analysis [
2,
3], functional urban structure exploration [
4,
5], spatial allocation of service facilities [
6], etc. With the rapid development of ICT (Information and Communication Technology), the emergence of massive, passive, and positive human tracking data makes it possible to model and analyze urban activities [
7,
8]. Data-driven analysis of human activities and urban dynamics has become a hot topic in academia [
9,
10,
11,
12]. However, related studies mostly assess the distribution of human activity intensity without distinguishing the content of human activities, which greatly reduces the understanding of human behaviors and urban dynamics. Furthermore, it also weakened its ability to support urban planning, travel needs, and public resource allocation. This paper aims to propose an effective technique to build human activity chains with massive urban sensing data.
In recent years, various positive and passive human footprints have been organized to uncover human movement patterns within the city [
13,
14,
15,
16,
17]. Travel surveys and geotagged social media data (geotagged tweets or social media check-in data) are typically used to characterize tourist flow [
18], detect events [
19], model traffic demands [
20,
21,
22], and explore human mobility patterns [
23]. Although these data provide activity purposes and precise locations, the population bias [
24] and sparse sample [
25] constrains its reliability in modeling continuous, large-scale human activities. Mobile phone signaling (MPS) data has gradually been recognized as a promising data source for estimating the population’s spatial distribution [
26,
27,
28], monitoring urban dynamics [
29,
30,
31,
32], and understanding human behaviors [
33,
34,
35]. Though MPS data do not provide the spatiotemporal precise personal traces as traditional travel survey data or geotagged social media data do, it can be obtained at a much lower cost and on a greater scale [
36]. Related literature coincidentally uses mobile phone location data to build activity-based trips [
37,
38,
39]. Scholars generally agree that the spatial-temporal uncertainty of mobile phone location becomes a big challenge for inferring the types of human activities (e.g., home, work, shopping, etc.).
So far, researchers have proposed two types of approaches to implement MPS data-based activities inference: prior knowledge rules-based methods and machine learning related algorithms, respectively.
Usually, people’s destination choices are closely related to the types/purpose of activities. Therefore, semantically rich geospatial data provide a direct basis for activity type inference. Several studies have examined the characteristics of home-centered urban mobility patterns based on where people most often visit [
36]. Another part of the study inferred the possible purpose of human activities based on the land-use status [
37,
40]. However, such studies ignore the diverse complexity and spatiotemporal dynamics of human activities, limiting the value of the method for generalization.
The development of machine learning techniques has produced a large number of excellent classification models. More and more researchers use machine learning classification algorithms to infer urban activity types [
41]. Depending on whether they need a given training sample, the relevant methods include supervised learning-based and unsupervised learning-based activity inference.
The supervised learning-based activity inference method [
42,
43] uses many spatiotemporal stays with activity annotations as supervised samples to infer activity types for mobile phone users. For example, Tu et al. (2017) proposed a hidden Markov activity type recognition model by combining the social media check-in data and mobile phone data [
43]. Based on the learned knowledge of human social activities as supervision, their work inferred seven types of activities, including In-home, Working, Shopping, Transportation, Schooling, Recreation, and Entertainment. However, it is difficult to obtain such effective supervision samples, and the quality of social media data is often difficult to control.
Unsupervised learning-based activity inference method [
38,
44] infer the types of human activities based on statistical probability, e.g., a round-trip in the same place in a day is considered a home activity with high probability. Widhalm et al. (2015) used Probability Graphical Models (PGM) to cluster activities by modeling the dependencies between activity type, arrival time, duration of stays, and land use types via a Relational Markov Network (RMNs) [
38]. Essentially, they tried to construct a joint posterior distribution of land use characteristics and human activity types to implement urban activity types labeling and inferring. Since the potential functions of RMNs need to be defined manually, their ability to characterize complex human spatiotemporal behavior is greatly reduced. Besides, due to the high spatiotemporal complexity of the association patterns between the stay objects, the posterior distribution of these activity labels is difficult to converge.
Aiming at the shortcomings of the above urban activity type recognition methods, we define an individual daily activity chains model and propose an effective method to construct user activity chains by annotating their activity purposes semantically, based on semi-supervised learning. The advantage of this method includes: (1) it does not need to collect a large number of supervised learning samples as input for classification; (2) it can achieve high type inference accuracy supported by easily accessible data. The technique could provide reliable data models and methodologies for human movement pattern mining, urban crowd spatiotemporal hotspot detection, dynamic urban monitoring, etc. In turn, it provides decision support for smart city management and services such as traffic demand analysis, travel behavior analysis, and service resource allocation.
We use the MPS data of a communication operator in Nanjing from April 1 to 14 as the experimental data source to verify the proposed urban activity chain and type inference method. This paper realizes the inference of seven urban activity types: Home, Work, Shopping and Catering, Leisure and recreation, Medical, Sports and Others. The classification of these activity types regards the travel purpose classification of urban travel survey. Since the real activity types of mobile phone users are not available, we verify the superiority and reliability of this method in two aspects: (1) to explore the advantages in activity recognition accuracy by comparing with the methods of RMNs-based model; (2) to analyze the spatial and temporal characteristics of human activities obtained in this paper against the real urban land use status and universal pattern of human activity behavior.
2. Methodology
Our tasks of this method are to build user’s daily trips based on MPS data and infer the type of activity for each stay during trips. Before elaborating on the detailed methodology, it is necessary to give some essential definitions.
Definition 1. Urban activities are activities that people do in a specific spatiotemporal context within the urban scene, such as working, fitness, school, etc. It contains both the time and place where the activity takes place as well as the subject and category information of the activity.
At present, the classification of urban activities has not formed a unified standard. Different studies of activity-based human mobility patterns using MPS data also vary in their classification of activity types [
36,
43,
44]. The spatiotemporal uncertainty of mobile phone location data makes it difficult to distinguish between types of urban activities finely. Regarding urban residents’ travel questionnaire survey [
45,
46] and activity classification of related studies, this paper classifies urban activity types into seven categories: Medical, Shopping and catering, Home, Work, Leisure and recreation, Sports, and Others. The specific activity contents of each activity category are shown in
Table A1.
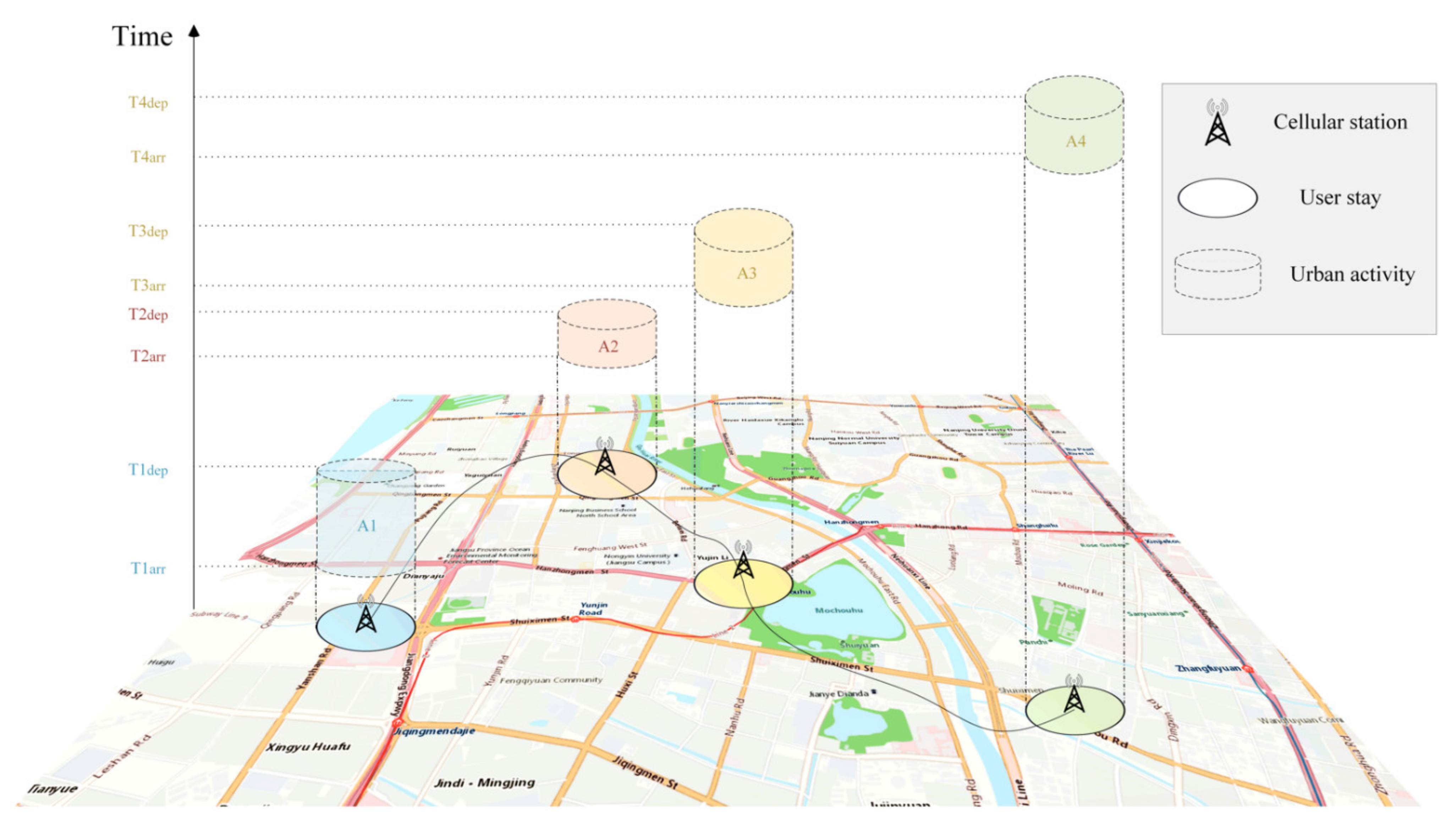
Definition 2. The daily activity semantic stay chain is an activity-based chain that portrays urban user mobility with labeled activity purposes. It is a chronological group of user stays, as shown in Figure 1. A stay is composed of the location, start and end time, and the purpose of the stay (type of activity). 2.1. Recognition of Stay and Construction of User Daily Activity Semantic Stay Chain
The MPS data continuously and uninterruptedly records the moments and base stations of communication activities such as user calls, sending and receiving SMS, accessing the Internet, switching base stations, and periodic reporting in standby (usually reporting every half an hour). Compared with GPS and travel survey data, the spatial measurement accuracy and the temporal sampling rate of MPS data are low [
39]. Ulm, Widhalm, and Brandle (2015) analyzed the spatial distribution of errors in the cellular positioning method by comparing cellular positioning data with collected GPS location data [
47]. They found that the median of antenna positioning inaccuracy in Vienna was 507.6 m. Moreover, the density of the base station is positively correlated with the positioning inaccuracy. The Voronoi polygons take the urban ground as a homogeneous surface, and that is not a desirable method for base stations’ coverage areas acquisition. Considering the spatiotemporal uncertainty characteristics of the cellular location, we propose the following steps to construct a personal daily activity chain by combing the research mentioned above on cellular positioning errors.
(1) In chronological order, original signaling records of successive same cell ID are merged into user stays to construct an initial user daily activity chain. This data can be described as:
in which,
represents the user’s daily activity chain, and
is a unique identity. A stay
consists of base station ID, arrival time, departure time, and duration of stay.
(2) Due to the spatial uncertainty of cellular positioning, we create a buffer of a certain size for each base station, which is called “potential active area”. The size of the “potential active area” varies with the density of the base stations. Furthermore, the initial activity chain of step (1) is transformed into “user daily activity region chain”:
(3) Cell phone signal propagation is often affected by the physical environment, dynamic load balancing, and other factors. The MPS data will suddenly jump to a remote base station and then turn back in a short time. This is called “drift data” [
48]. Besides, mobile phone location data can also swing back and forth in two or more adjacent areas, which is called the “ping-pong” effect [
49].
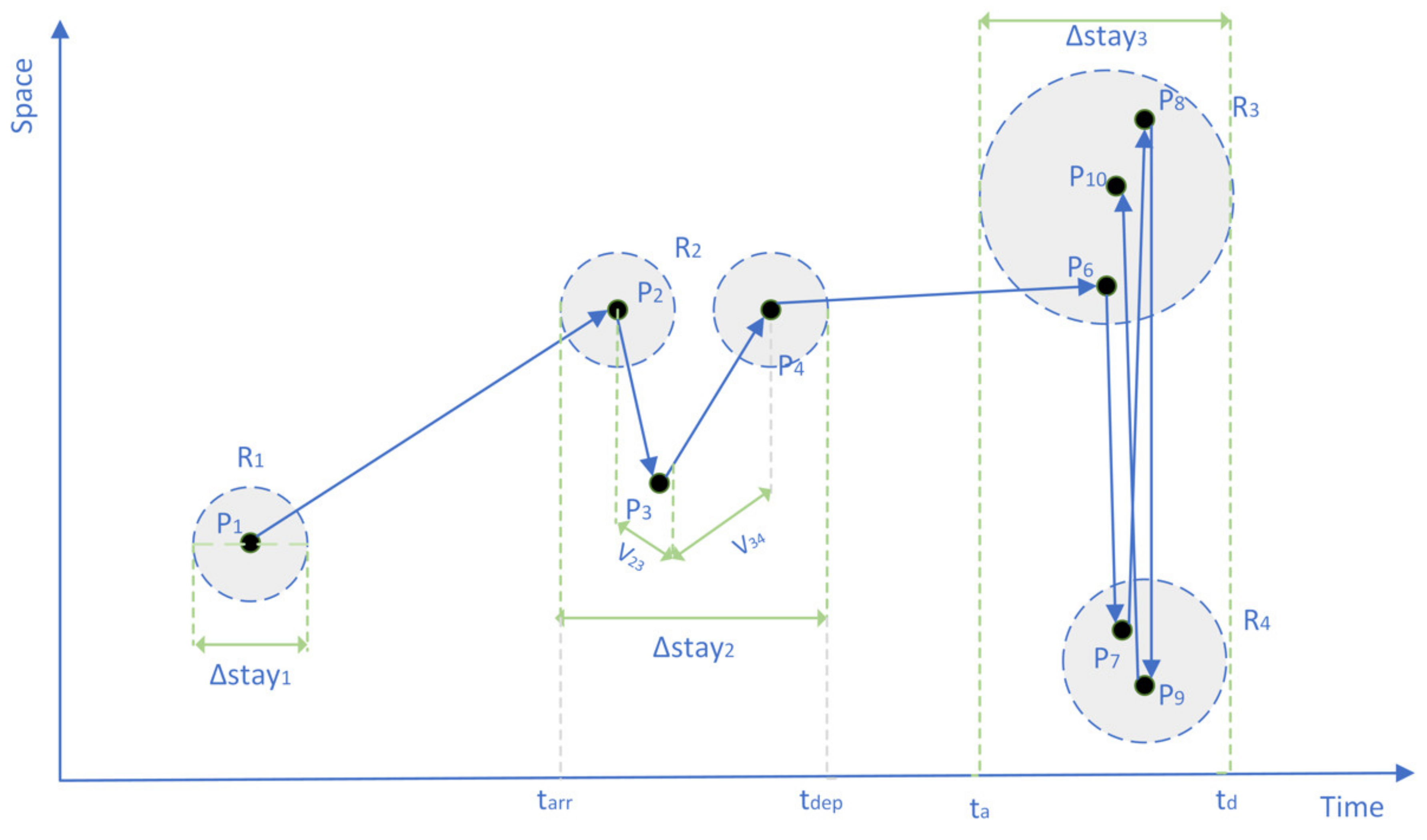
As shown in
Figure 2,
show the drift phenomenon, and
is the drift point. Speed from
to
and
to
is faster than normal human walking speed (
), thus the activities between
are combined into one stay
, the time of arrival is
, the time of departure is
, the duration of stay is
.
show the “ping-pong switch” phenomenon. The user jumps back and forth between multiple base stations in adjacent locations, which takes a very short time. The speed of movement is much higher than
, therefore the region
with more occurrence times of dots will be regarded as the potential active area, and the duration of stay is
. When the number of occurrences is the same, the possible active area could be randomly selected.
(4) The recursive look-ahead filter method, which achieved the best performance compared to the recursive naïve filter and Kalman filter [
50], combined with low-pass filtering, is used to filter users’ outliers. Calculate the user’s movement speed
based on the distance between adjacent stops (
,
) and the travel time. If the speed does not exceed
, the user is considered to have a visit in the zone, and the two stops are combined into one stay. Otherwise,
is identified as the crossing point and is removed from the activity region chain.
2.2. Annotating Home and Work Activities for Different User Groups
In probabilistic inference based on Graph Neural Networks, providing the labels of some nodes as known information helps improve the prediction accuracy of network learning [
51]. Home and work are the most important two activities in people’s daily urban life [
35,
52], and they have a strong regularity. This paper realizes the identification of Home and Work activities by constructing knowledge rules. Labeling some nodes in the user’s daily activity chain with Home or Work can reduce the uncertainty of activity type inference and support building a semi-supervised activity type inference model.
The behavior of different groups varies widely. We divide the urban population into locals and visitors and then identify their homes and work separately. Locals generally live in residential areas or dormitories, while visitors tend to live in hotels. Locals typically have a relatively fixed place of work, whereas visitors do not. Therefore, this study proposes the following rules to recognize Home and Work, taking into account the behavioral differences for different groups (which has not been considered in the existing literature):
(1) User group segmentation. Benefitting from the long-term observation of MPS data, we use the number of days people appeared in the same city during two weeks as the basis for user group segmentation. The total number of days of appearance () and the average total duration per day () are used as parameters for the determination. It is considered that the users whose days exceed and daily activity duration exceeds are residents. Otherwise, they are visitors.
(2) Home (H) and Work (W) recognition. Based on population division, this paper makes the following strategies to detect people’s homes and workplaces to distinguish family and work activities.
The total length of stay in each activity region during the daytime (09:00~17:00) and late-night (00:00~07:00) for each person were counted, respectively.
Places with the longest cumulative duration of stay are identified as locals’ workplaces or residences.
The surrounding land is used to determine the above places’ activity type with the longest cumulative stay (refer to
Table A2). If the main land use in the area is residential, it is determined to be the user’s home location. Otherwise, it is the user’s workplace.
Places with the longest cumulative duration of stay are identified as visitors’ residences (hotels or friends’ residences).
Label the user’s daily activity chain with the corresponding activity type for stays occurring at home and workplace. Due to the existence of night shift or no workgroups, all possible combinations of day and night activity types are limited to “H-W”, “W-H”, or “H-H”.
2.3. Urban Activity Inference Model (UAIM) for Annotating Urban Activities
Type labeling of mobile phone activity chains using machine learning algorithms has gained wide acceptance for its higher scientific validity and accuracy than methods that rely only on prior knowledge [
38,
41,
43,
44]. Many supervised and unsupervised learning methods, such as support vector machines, decision trees, hidden Markov network models, are applied to annotate MPS data with activity types. The supervised learning methods require long-term individual tracking data as the basis for probabilistic inference. The unsupervised learning approach requires manual construction of relational functions and cannot express complex characteristics of human activities. This paper uses a semi-supervised learning technique to annotate urban activities.
GMNN (Graph Markov Neural Networks) model is a deep learning model that combines advantages of statistical relational learning (SRL) and graph neural network (GNN). It learns the network nodes’ characteristics through GNN and simultaneously models the conditional distribution between node labels to implement object classification [
53]. It is a graph relational dataset classification algorithm with high recognition accuracy from comparison results on public datasets such as Cora and Citeseer.
Urban activities tend to follow certain rules, and most revolve around the family-centered diet and living and the work-centered business office. There is a potential connection between each stay. For example, people usually choose to go home after work in the evening, go home after eating, or shopping outside. Thus, we use this widespread potential association of human spatiotemporal movement behavior (activity transfer) to construct graph datasets. Combined with the annotation of Home and Work in the activity chain in
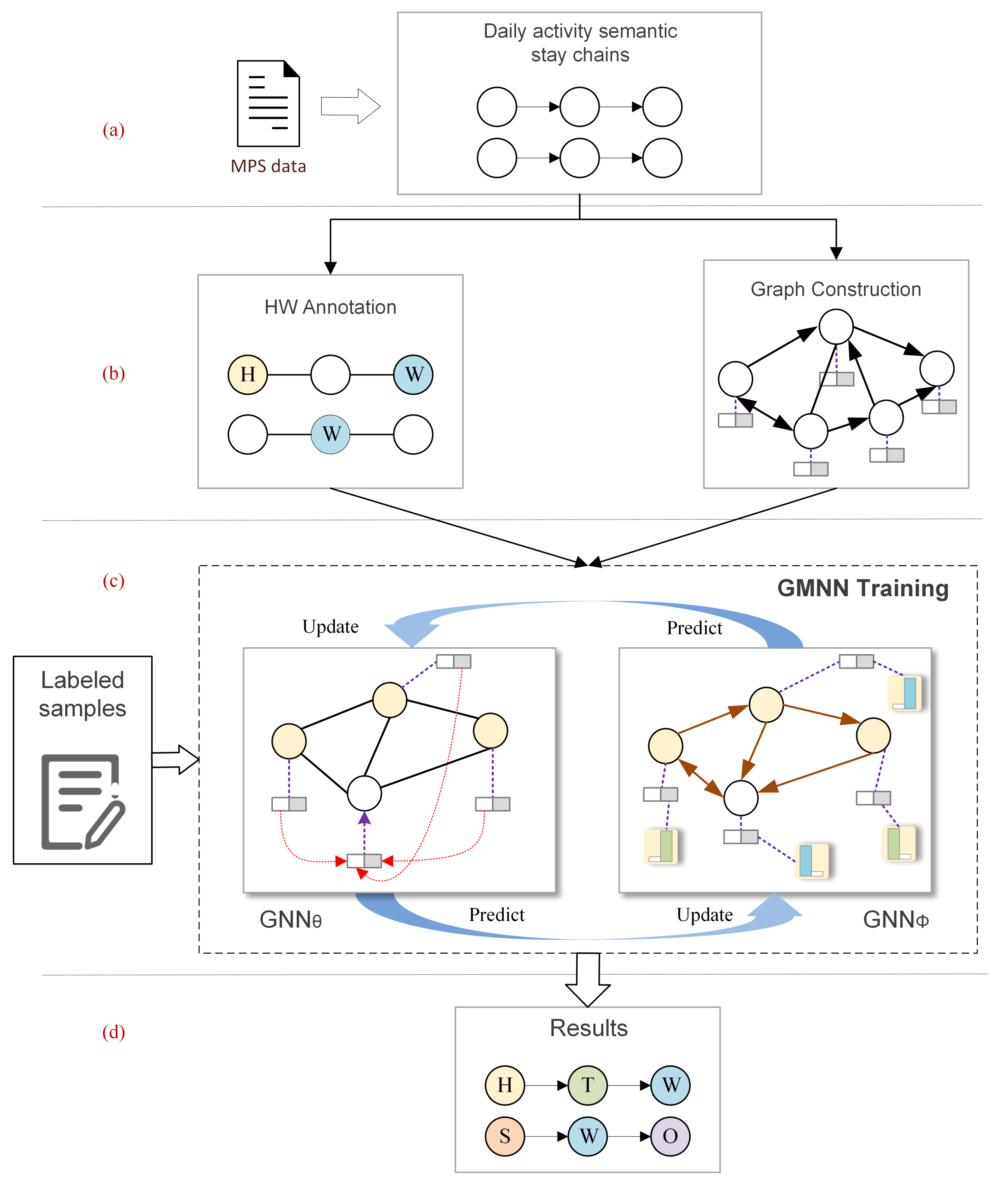
Section 2.2, we propose a semi-supervised learning framework based on GMNN to classify the unlabeled types of stays in the user’s daily activity chain. The framework of the Urban Activity Inference Model (UAIM) is shown in
Figure 3.
Since the relationship pattern between activity stays is very complex, the GMNN model realizes the fusion of feature learning and statistical relationship learning by constructing two GNN models. It introduces alternate training for two GCN models to approximate the target distribution, and here the two GNNs are denoted as () and (). On the one hand, taking the attributes of network nodes and their neighbor nodes as input constructs a model can be used to learn abstract features of user stays and predict the urban activity type of each node. On the other hand, taking the node labels predicted in as input, builds a model to model the correlation between node labels and constructs their joint posterior distribution. GMNN makes the probability distribution obtained from approximate to the distribution as much as possible, prompting the two models to constrain each other and accelerate model convergence. This model uses the pseudo-likelihood variational inference EM algorithm to achieve the above mutual approximation process.
Below, we describe how to construct the graph and the feature vectors of nodes (user stays) based on daily human activity stay chains. In addition, to efficiently build the posterior distribution among activity features, network relationships, and node labels, it needs to label some nodes for semi-supervised learning manually.
(1) Graph construction
In graph neural networks, the graph connection of common social networks and paper citation networks can be directly built based on the data’s subscription and citation relationships. These relationships represent the potential consistency of interest, topic, and field [
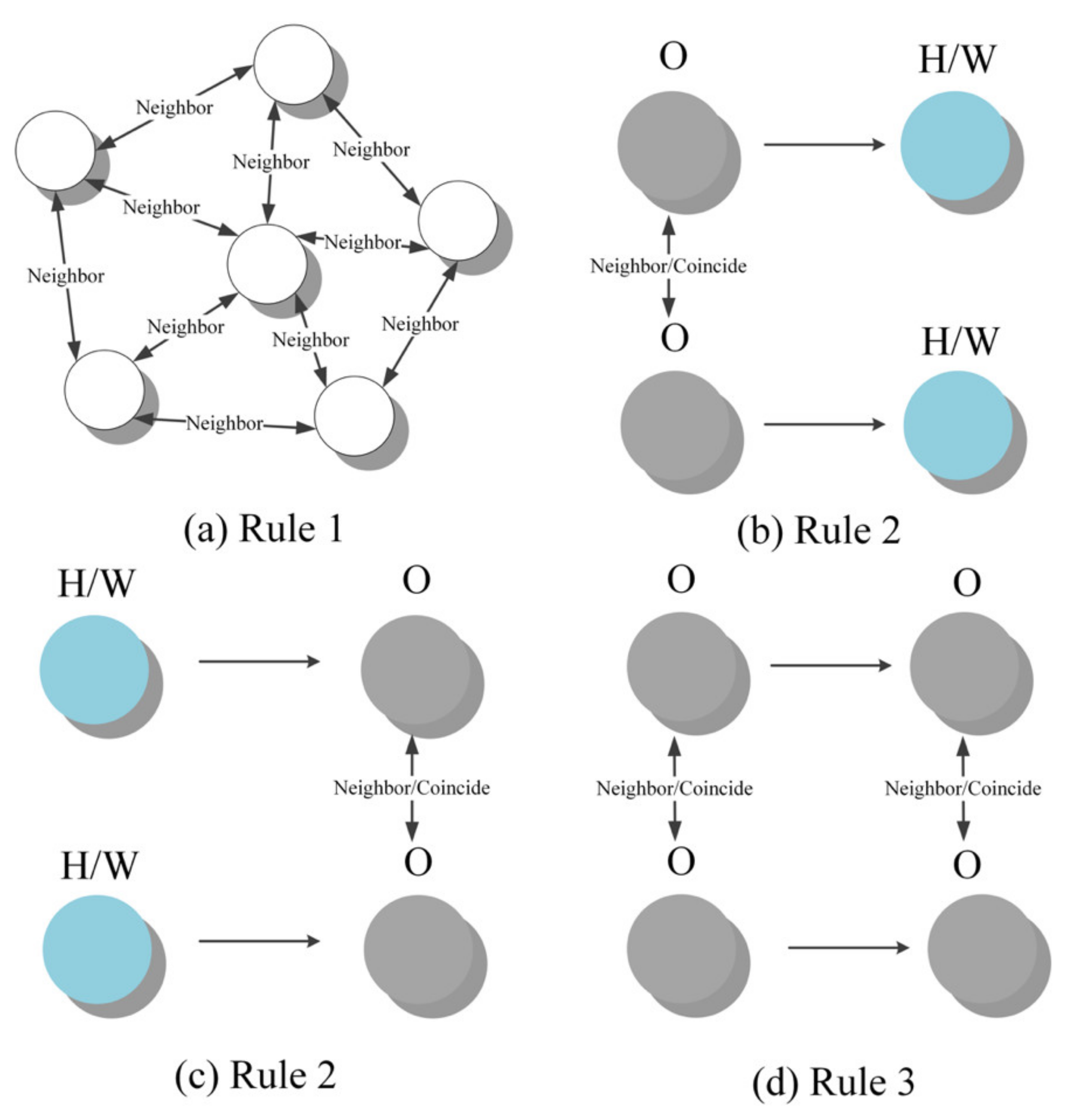
54]. However, for human activities, this connection is more abstract. The following rules are proposed to construct the network graph for activity nodes (user stays):
Firstly, we believe that human activities largely conform to the “First Law of Geography” [
55]: activities adjacent to space will be more similar. Therefore, this article uses the adjacent spatial relationship as the premise of establishing a connection between the activity stays, as shown in
Figure 4a.
Secondly, the choice of the next activity from the same activity has a high probability of being the same (for example, the next destination that people start from home is often the place of work), especially when the destination location is close. In the same way, the previous activity of the same type of activity also has a high probability of convergence. Based on the identified Home and Work, we establish net connections for the nodes that are spatially adjacent to the target location of the next activity and the nodes that are spatially adjacent to the previous activity location, as shown in
Figure 4b,c.
Thirdly, similar to the previous rule, two consecutive unlabeled activities are considered to have a similar activity type transfer relationship if there is a spatial proximity relationship between them. A net connection is established between them, as shown in
Figure 4d.
(2) Activity feature vectors
The feature variables of objects are the key input data for UAIM learning and training. The purpose of the activities is usually closely related to time and place. In this study, user activity feature vectors are used as the input of graph neural network nodes. The feature vectors of each node are expressed as:
where
and
represent land use and activity time characteristics, respectively.
(1) Temporal dimensional feature vector construction. We use a time-segmentation strategy to quantify the time-dimensional vectors to prevent over-fitting training and accelerate model convergence. Here, a day is divided into 144 periods with intervals of 10 min, and the binarization method is adopted to characterize the time feature of user activities. Let the value of the part where the 144 time periods overlap with the user’s stay be 1; otherwise, it is 0. Thus, the time feature vector of each stay node is represented as 144 binary sequences composed of 0 and 1.
(2) Spatial dimension feature vector construction. The urban land-use status depicts the spatial characteristics of user activities. Specifically, it uses the proportion of land use types covering each stay’s “potential active area” to characterize the spatial features. This paper divides land use types into eight categories, as shown in
Table A2 in the
Appendix B.
(3) Manually label the training data set
According to the basic principles of training sample screening in machine learning, the manual labeling training set selects 1% of samples from personal daily activity chains. In order to make the data cover the diverse characteristics of people’s activities and behaviors as much as possible, the following strategies are used to filter the data set.
Excludes users with only contain ‘H’ and ‘W’ activities.
The activity chains covering various areas of the city are randomly selected.
All urban land types should be covered within the selected activity areas.
The activity chain data of 2, 3, 4, 5, and more than five stays were selected at a ratio of about 20%.
On this basis, several volunteers were selected to annotate the activity types of these selected samples, and cross-verification was carried out to ensure that the labeled activity types were as close to the real situation as possible.
4. Results and Discussion
We get the final urban activity chains with seven activity types based on the above experimental parameters and methods.
Table 4 shows the statistical results of various human activities (not include “Others”). According to
Table 4, we can find that: (1) In addition to Others (the number of other activities is 4670.37 thousand), Home and Work account for the highest proportions. People often go home many times in a day, so the ratio of Home is higher than that of Work. (2) Among the “Shopping and catering”, “Leisure and recreation” and “Medical” activities, “Shopping and catering” occupies an absolute leading position, while the other two have close proportions. (3) Sports are the least in the number of various activities on that day (a normal working day).
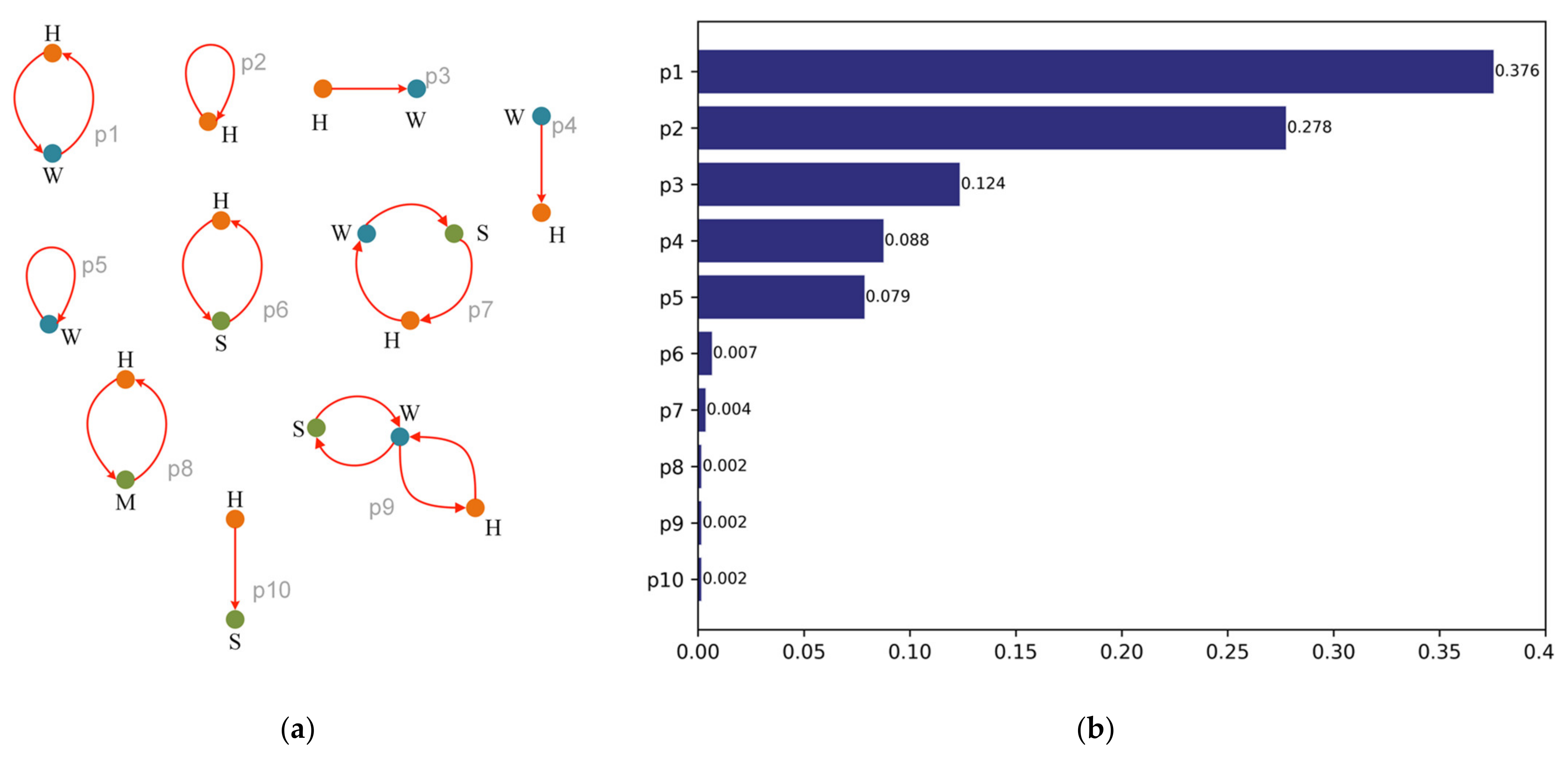
This article extracts major daily activity mobility patterns (“Others” are excluded) by filtering the top 10 daily movements with the highest proportion, as shown in
Figure 6. According to
Figure 6a,b, the mobility pattern of “H-W-H” is the most frequent, and the top five mobility patterns center on Home and Work. It exactly reflects the laws of people’s daily life. Patterns “p6” and “p7” show that shopping and catering venues are the third main space of people’s daily life. Overall, a two-point lifestyle is dominant among the major mobility patterns, while three or more activities are relatively rare. The activities that people are most likely to undertake centered around Home are: Work, Shopping and catering, and Medical.
To further explore the reliability of the UAIM method, we present an in-depth discussion from both the temporal dynamics and spatial distribution of urban activities.
4.1. Temporal Dynamics of Urban Activities
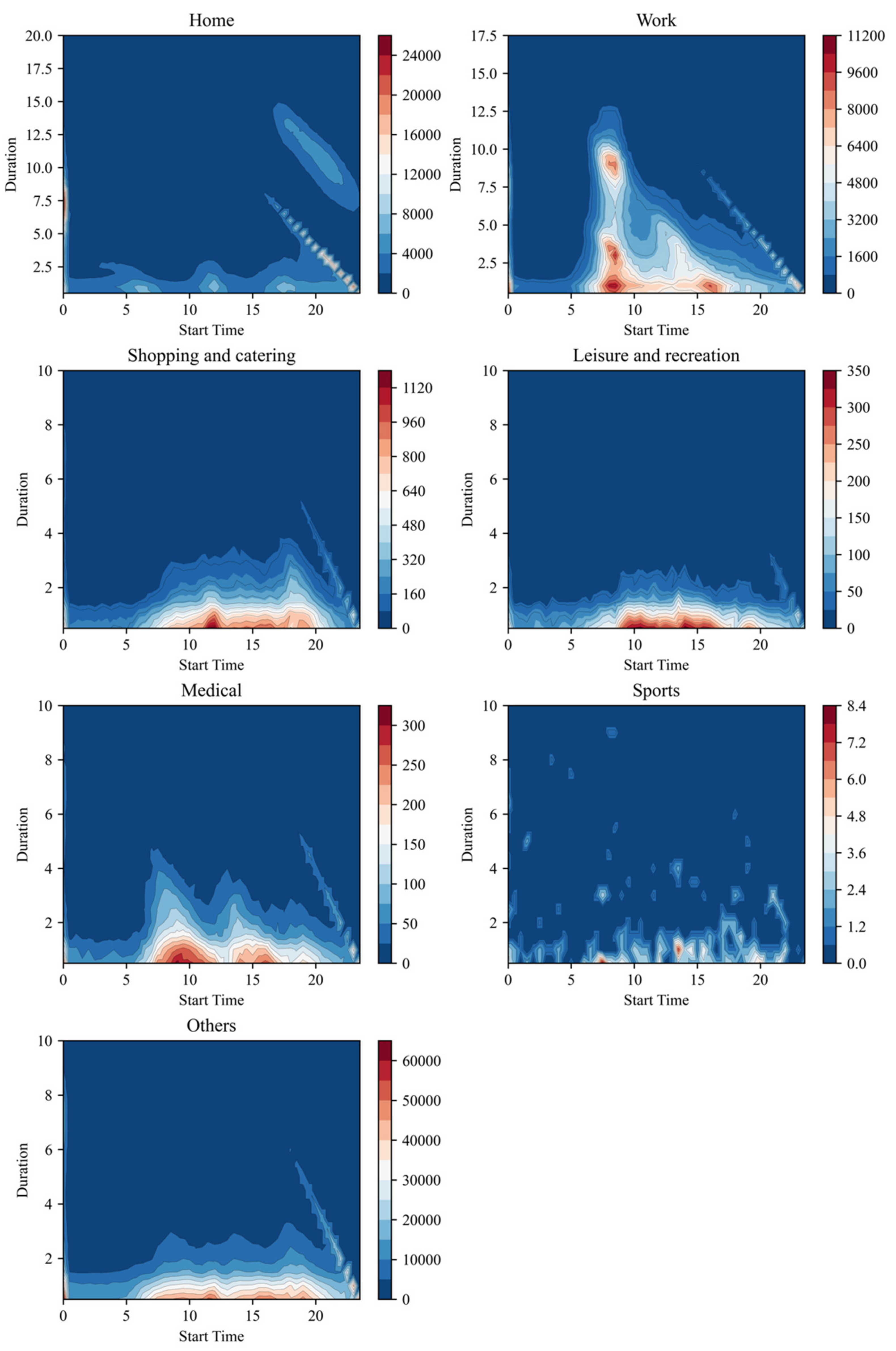
Here, half an hour is used as the statistical unit to explore the temporal dynamic pattern of various urban activities. The contour heat map shows the time dynamic distribution of all recognized activities, and the results are shown in
Figure 7.
Figure 7 clearly shows that Home and Work concentrate on the opposite time. The main Working hours are between 6 o’clock and 18 o’clock, and the duration is about 4 to 10 h. Nine o’clock is the peak time to start work, and there are two groups: One group works for up to 8–10 h, while the others work for about 2 h in the morning and then carry out other activities (e.g., go home at lunchtime) and return to work in the afternoon. The two most active times for Home are between 0:00 and 1:00 and after 17:00. The duration time of Home is mostly 5–10 h. The duration of people at home from 18 to 24 pm is about 8 to 13 h (sleeping time). The above time distribution characteristics fit perfectly with people’s work and rest patterns on weekdays.
Except for Home and Work, the main temporal characteristics of the remaining activities are as follows: “Shopping and Catering” are mainly distributed from 10:00 to 20:00, and the two concentrated periods are around 12 noon and 7 pm. The hottest period of “Leisure and recreation” is from 9 to 16 o’clock with a relatively short duration. Compared to the above two types of activities, the characteristics of the bimodal distribution of “Medical” activity are more prominent, and its duration is relatively longer. Sports activities have no obvious regularity, the distribution is relatively scattered, and the number of people is small. Others have the widest distribution time, and the amount of this activity is large. It has a greater relationship with the spatiotemporal sampling uncertainty of mobile phone positioning data.
Based on the above analysis, the temporal dynamic patterns of people’s various urban activities estimated based on the UAIM method in this paper are consistent with the regularity and rhythm of urban human life on working days [
52,
57]. This well confirms the reliability of the activity type inference results of this method.
4.2. Verification of Urban Activity Spatial Distribution with Ground Truth
It has been widely proved that a strong correlation exists between urban land use and human activities [
17,
58,
59,
60]. Here, we chose to compare the spatial distribution of “Home” and “Shopping and Catering” with the ground truth of the corresponding urban land use. To better show the detailed features, we take the main urban area of Nanjing with diverse and complex human activities as the spatial scope of analysis here. Using ESRI’s ArcGIS spatial analysis tools, we estimate the population distribution for “Home” and “Shopping and Catering” activities with 200 m grid unit based on IDW interpolation and zonal statistical methods (as shown in
Figure 8a and
Figure 9a).
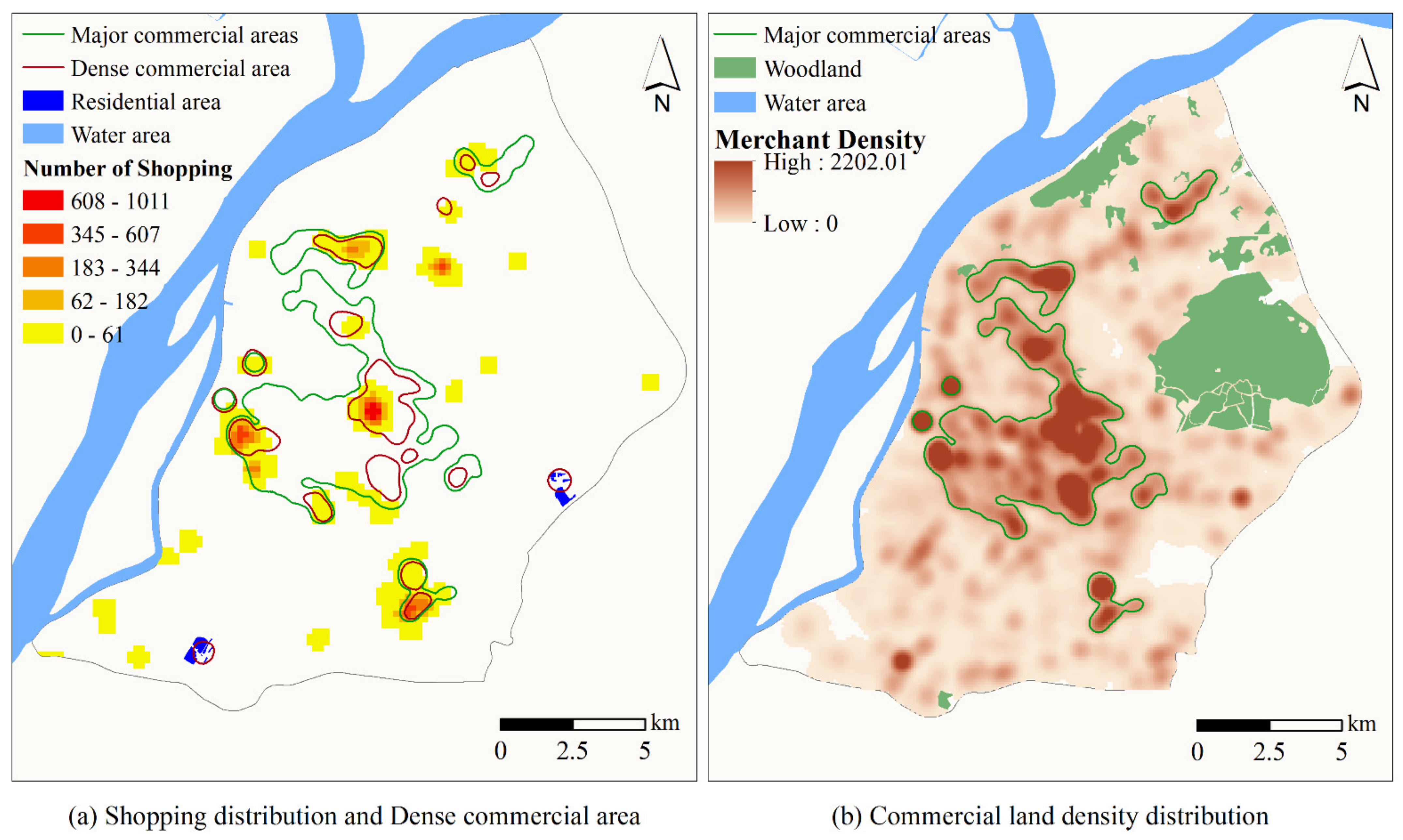
Figure 8a overlays the main contours of the residential area and the distribution of “Home” activity. The outer shape of the “Residential Area” recognized in
Figure 8a is added in
Figure 8b to help us compare the activity identification results with the land use ground truth. On the one hand, the areas that cannot host “Home” activity are effectively-identified here, e.g., the woodland and the large water area has a fairly small amount of family activities. On the other hand, the areas where “Home” activity is active are highly compatible with the scopes of residential areas.
We extracted the areas with dense commercial service facilities from
Figure 9b and overlaid them in
Figure 9a. The distribution pattern of areas with high-intensity commercial activities identified by the UAIM method is consistent with the distribution pattern of high-density commercial facilities. Due to the uncertainty of the spatial location of MPS data, some shopping and catering activities that stay briefly near office or residential areas are difficult to identify. As a result, few dense commercial areas exist with no shopping activities, such as the red circles on the right and bottom left in
Figure 9a.
5. Conclusions and Future Research
With the development and maturity of big data and ubiquitous sensing technologies, urban dynamics and human spatiotemporal behavior analysis based on massive data have become research hotspots in smart cities, spatial big data mining, and environmental protection. However, mostly these researches focus on modeling and analyzing crowd activity intensity but pay little attention to people’s activity purposes. Only a few studies have proposed technologies for inferring the urban activity types based on mobile phone data. However, there are still problems such as relying on massive effective supervision samples, using limited prior knowledge for modeling, and lacking the ability to characterize complex human activities.
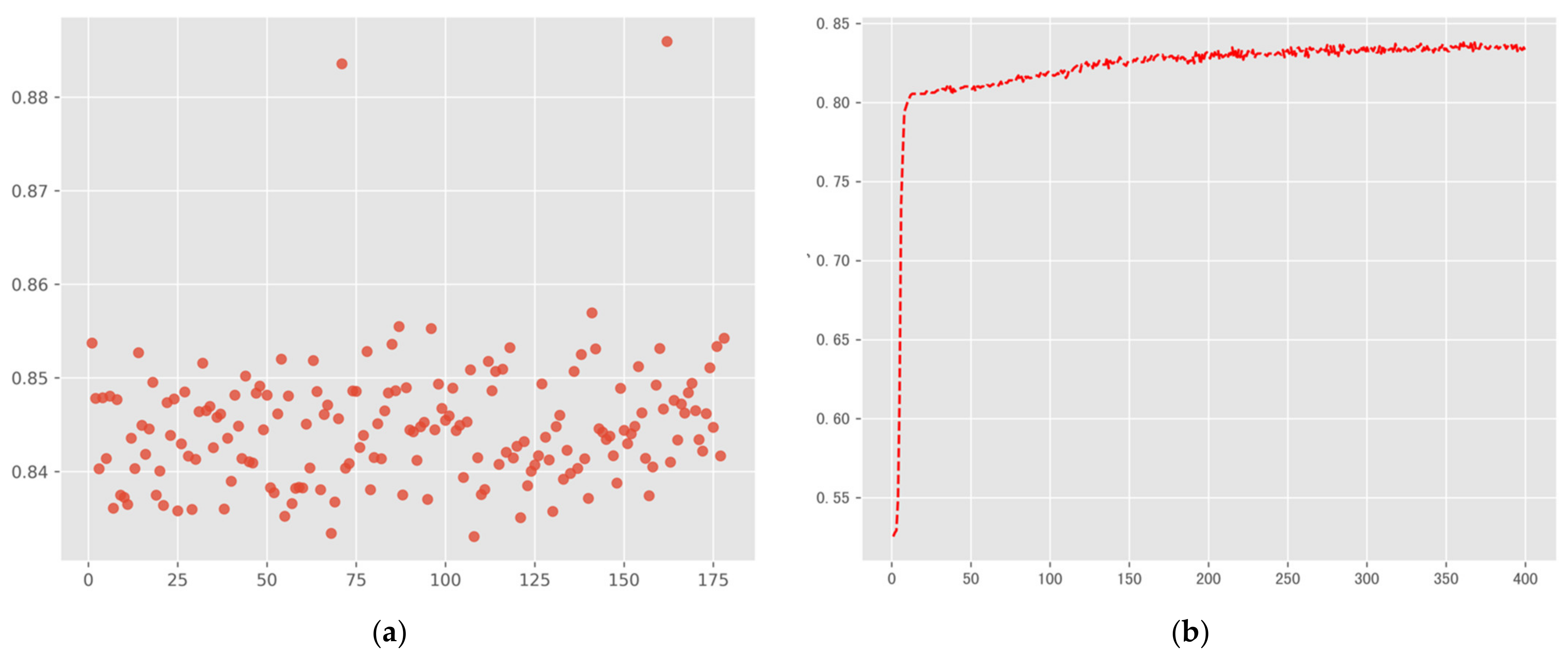
In this context, this paper proposes constructing the “Daily activity semantic stay chain” based on MPS data, which aims to organize and speculate on people’s urban life trajectories effectively. Therefore, we design the UAIM framework to implement the modeling and type annotating of human activity chains. In conclusion, our work contributes in the following two aspects: (1) We propose a generic mobile phone data-oriented daily activity semantic stay chain model and its construction technique, which is a development of a human trajectory data model. Based on this, the model can deepen our knowledge of human dynamic patterns in cities. (2) The UAIM approach achieves higher recognition accuracy and recall than the existing literature on activity type inference. Our average accuracy of activity type recognition can reach 84.47%, and the highest accuracy is about 88.5%. Meanwhile, the recognition accuracy and recall are better than the RMNs-based method [
38] through comparison experiments. Our activity type inference method does not need to depend on a large number of supervised samples. It also overcomes weakened feature learning ability caused by the manual construction of potential functions for the statistical relational learning model.
We analyzed the characteristics and reliability of the urban activities modeling results from multiple perspectives by investigating the human movement patterns, the temporal dynamics of human activities, and comparing the spatial distribution of “Home” and “Shopping and catering” with the ground land use. Nevertheless, our approach inevitably has some limitations, which leads to a large scale of “Others” being identified. We believe that people’s social-demographic attributes such as occupations and the correctness of manual labeling have a crucial impact on the accuracy of the activity labeling. Besides, the GMNN learning model adopts a spectrum-based network construction and learning method. It needs to add the graph structure and feature vector to the memory for calculation simultaneously, which greatly improves the computational complexity and the computation time. In the future, we can optimize the activity modeling and inference algorithm in the following aspects:
Firstly, the different ages and occupations of users have different behavior patterns, which greatly affects the inference of the purpose of the activity. We do not have access to this data due to the constraints of personal privacy protection. We propose to realize the category segmentation of the urban population by analyzing the long-term personal movement trajectory, designing diverse behavior recognition strategies for different user groups (students, senior citizens, taxi drivers, office workers, etc.) to circumvent the influence of this factor on urban activity type labeling.
Secondly, the manually annotated samples in this paper are manually discriminated by combining the user’s before-and-after position and activity trajectory of multiple consecutive days as the basic knowledge. The inability to compare the manual annotation results of activities with the real activity purpose of users makes it difficult to obtain an accurate and high-quality sample. In the future, we will sign a confidentiality agreement to obtain the real MPS data and GPS tracks of a certain number of volunteers. We will design a more accurate activity purpose inference method by analyzing the impact of the mobile phone positioning error on human activity labeling.
Thirdly, the behavior analysis would be extended more than the spatial and temporal distributions. The characteristics of individual trajectories, such as the daily range of travel, movement radius, and movement entropy [
61], will be further discussed. The exploration results will enrich our knowledge of individual behavior and provide reliable decision support for rational allocation of urban services and facilities, traffic planning, etc.
Finally, a space-based method will be considered to realize the convolution operation of adjacent networks in subsequent studies to improve computational efficiency.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}








