
Big Data-Driven Pedestrian Analytics: Unsupervised Clustering and Relational Query Based on Tencent Street View Photographs



Abstract
:1. Introduction
2. Background
2.1. Urban Big Data and Street View Photography
2.2. Deep Learning-Based Urban Semantic Features
3. Research Methods
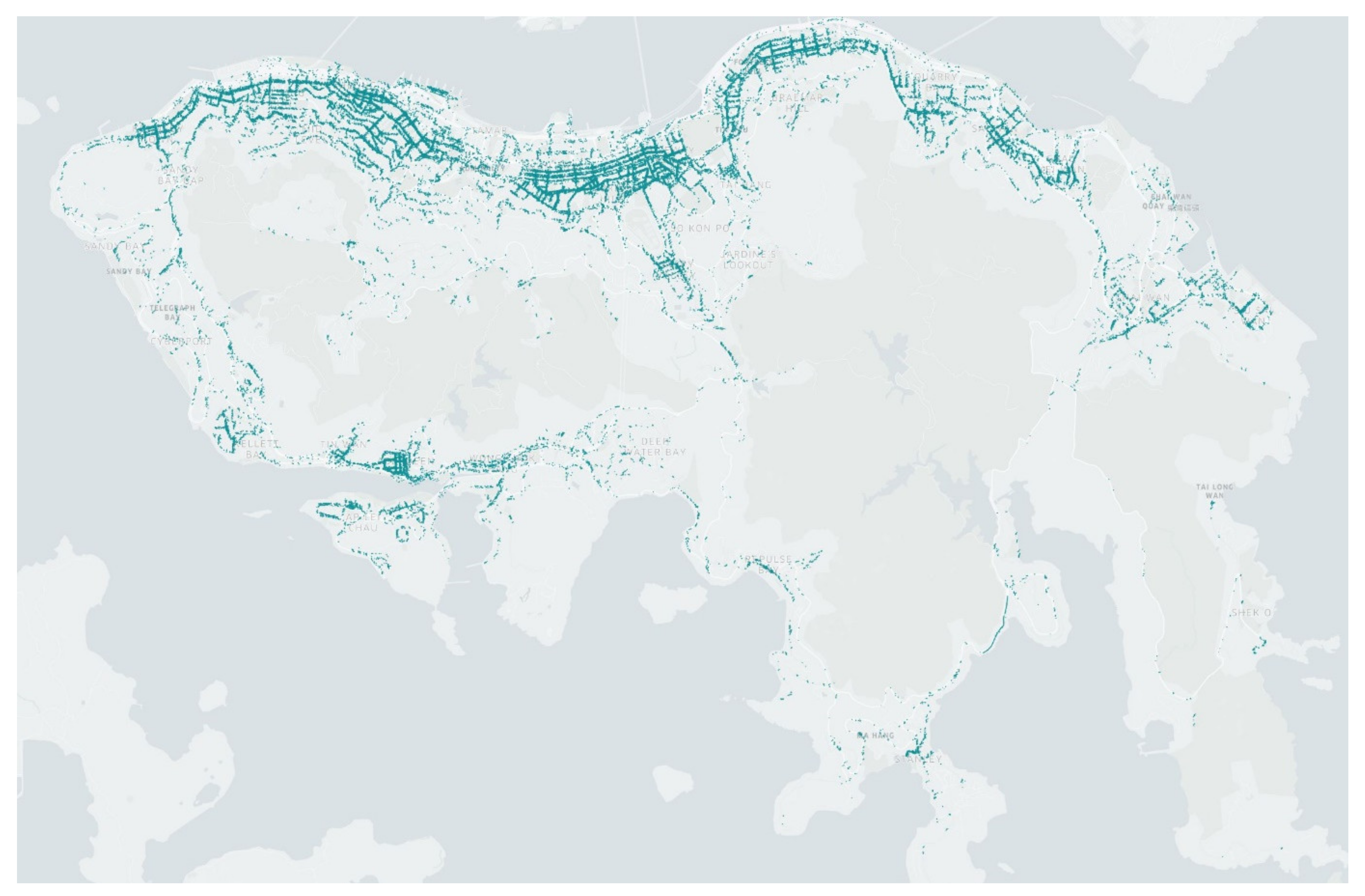
3.1. Study Area and Data Collection
3.2. The VUCCA Approach
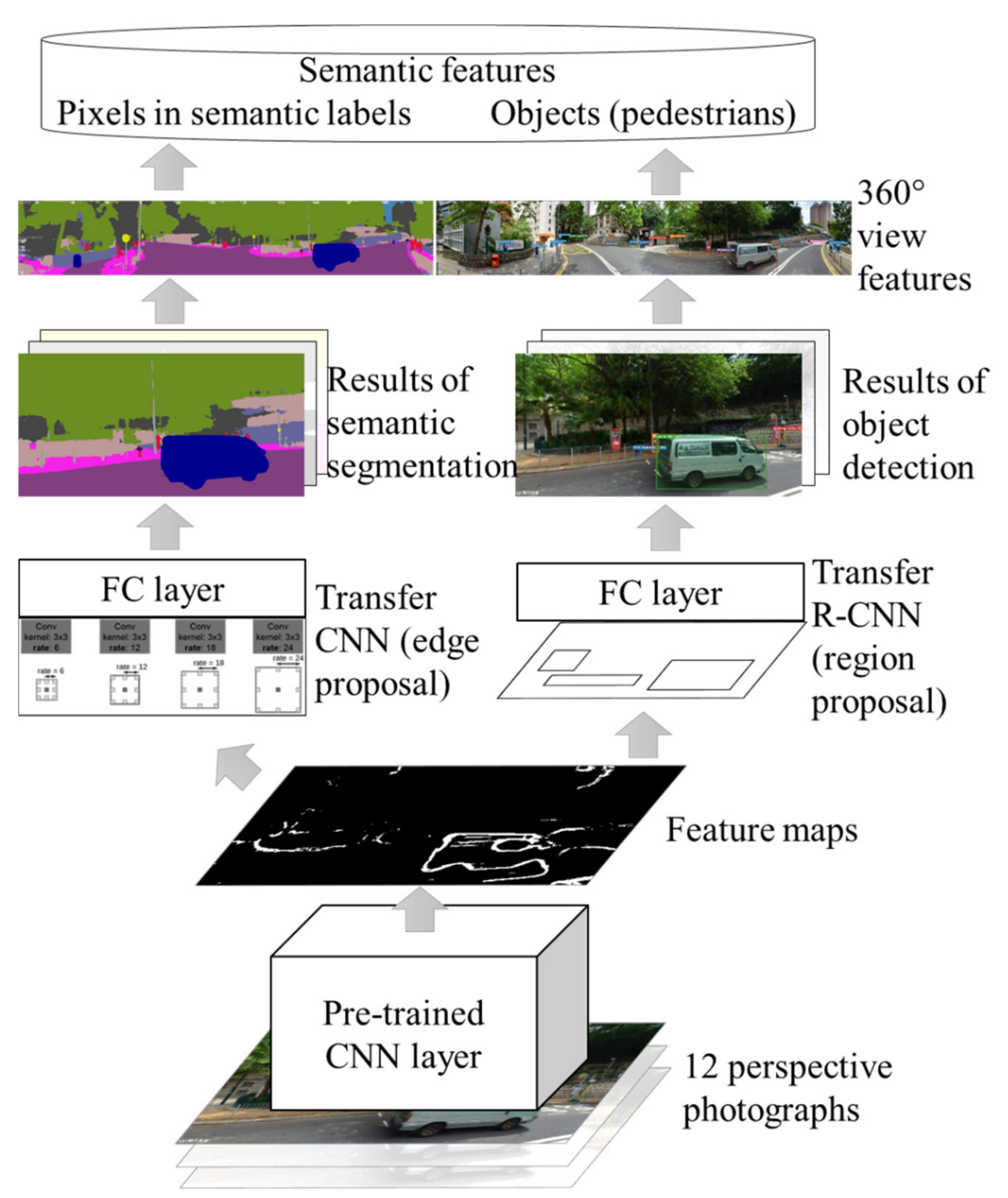
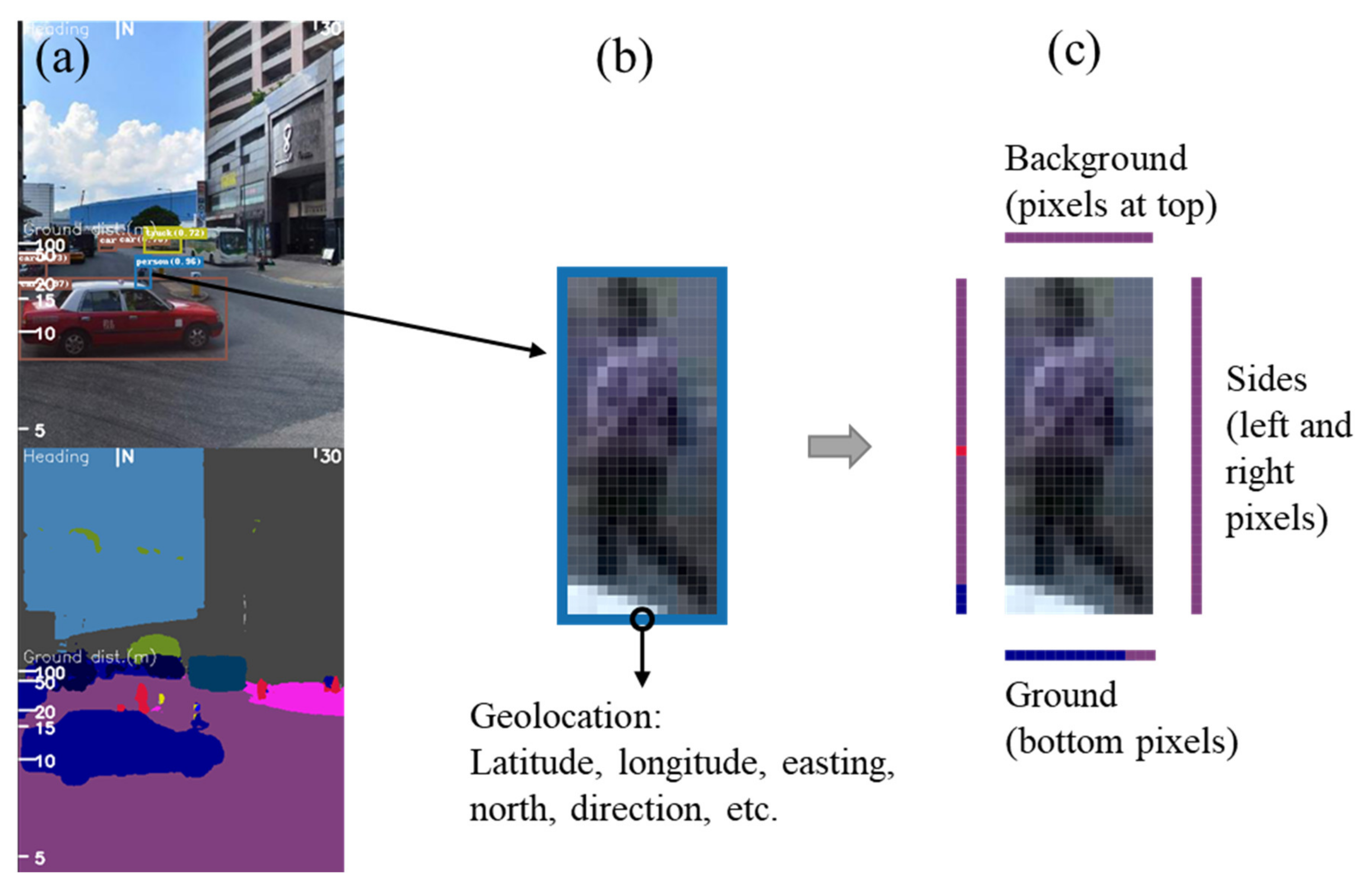
3.2.1. Semantic Feature Detection
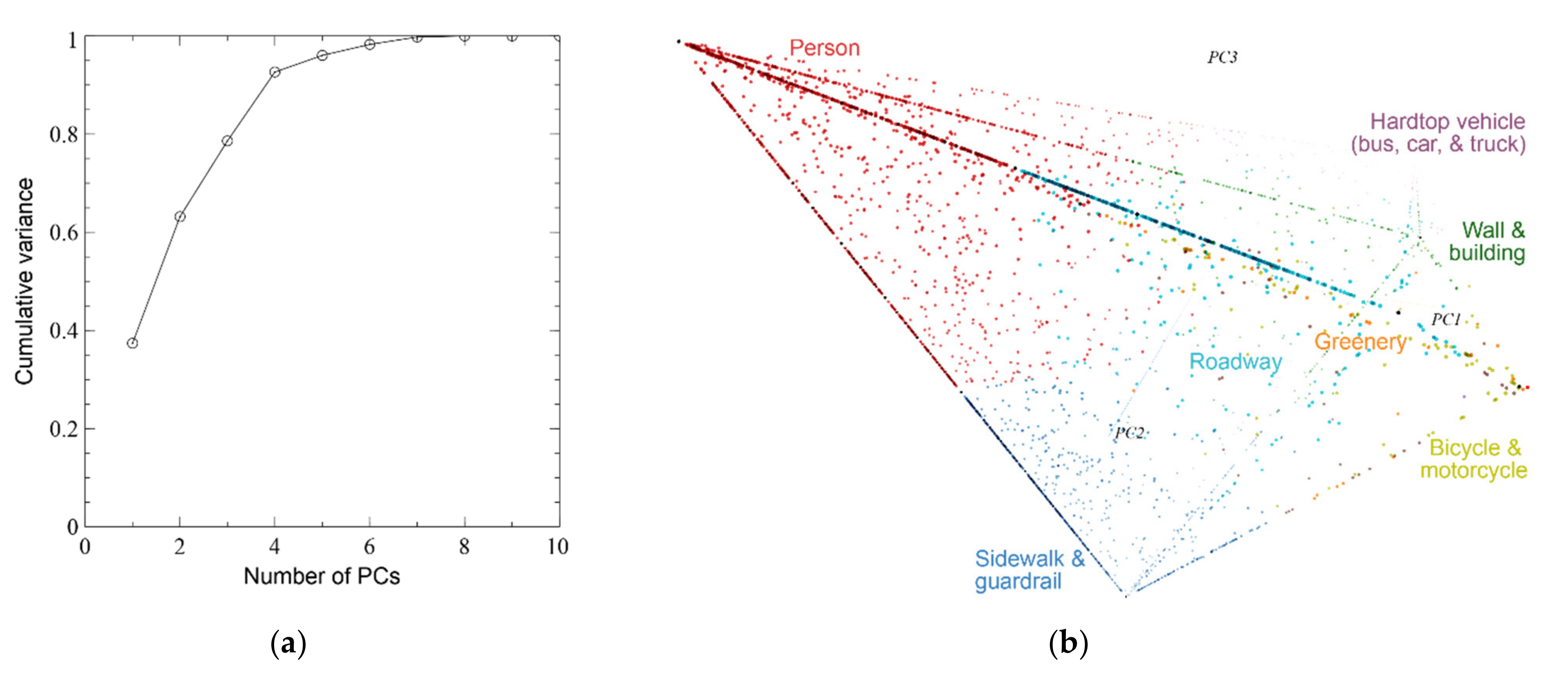
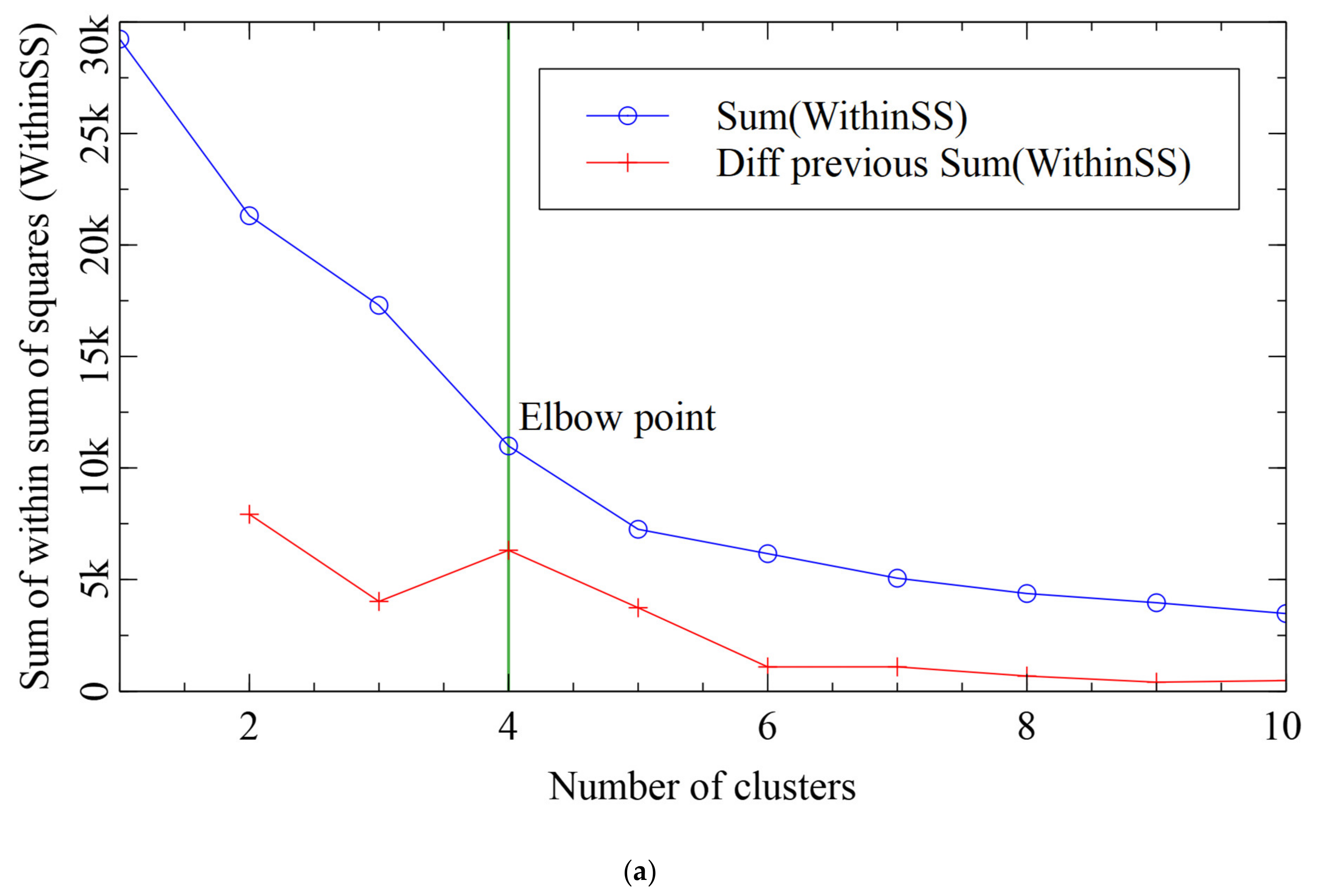
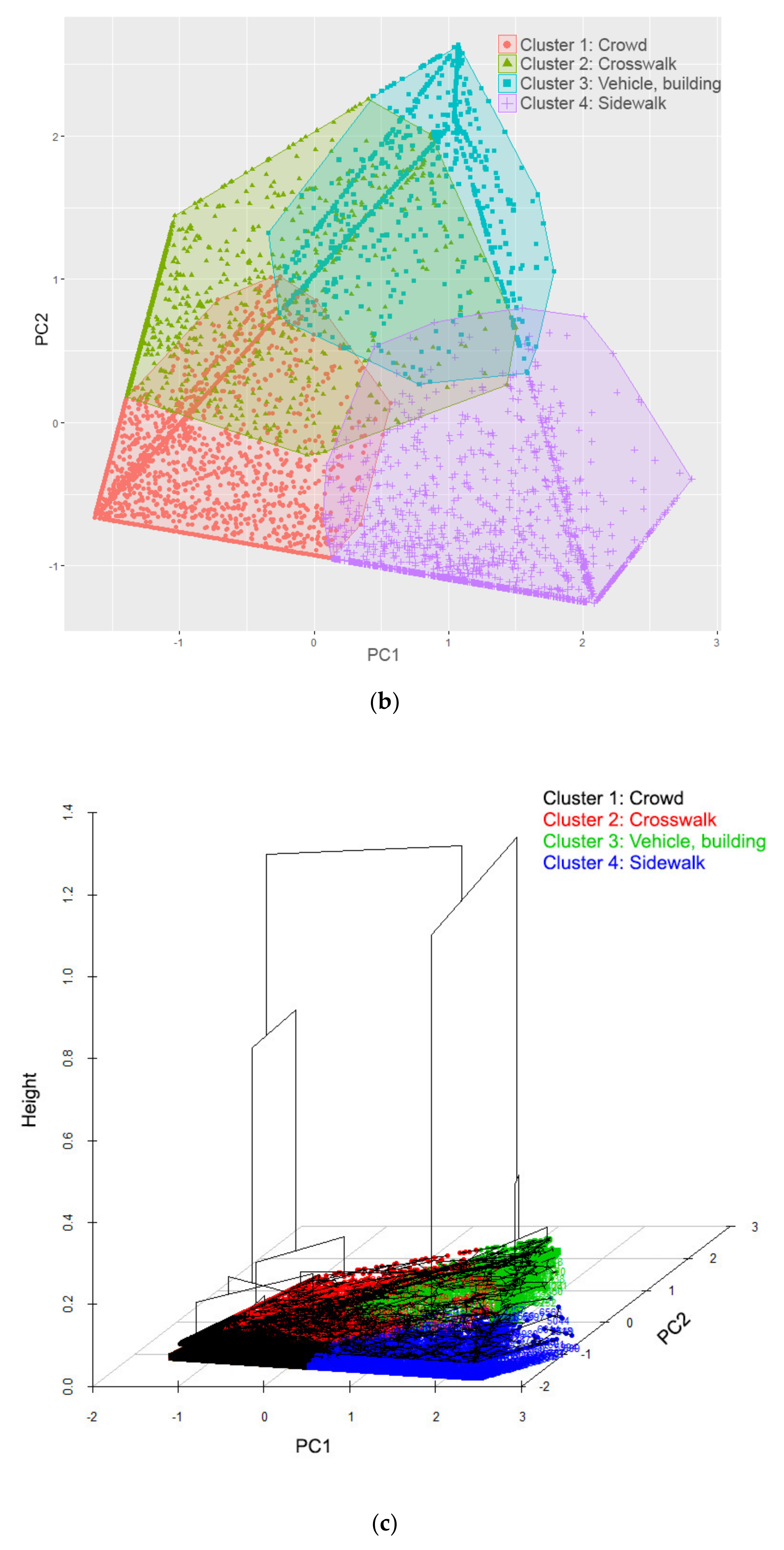
3.2.2. Unsupervised Clustering
3.2.3. Analytical Functions
4. Results
4.1. Semantic Pedestrian Detection
4.2. Pedestrian Clustering by Where They Stood
4.3. Pedestrian Query by Instance and Natural Language
4.4. Semantic Enrichment for OpenStreetMap
5. Discussion
- To begin with, pedestrians and other urban objects in unstructured big data of street view photographs are computable, analyzable, and queryable through the VUCCA approach. The vectors of semantic features enable not only unsupervised clustering and unstructured query of pedestrians in photographs, but more importantly structure information useful for applying more comprehensive vector-based concept computing for pedestrians and other key urban objects, e.g., buses, streetscapes, and urban areas. The results of unstructured, instance-based, natural language-based queries, and other semantic vector-based concept computing validated a new approach of urban computing for pedestrians.
- Secondly, CNN and R-CNN serve as positive contributors to fulfill the semantic segmentation and label uncountable or countable objects. It was successfully adopted to classify several types of features (see Table 1); with greater precision in view classification achievable by adding to the number of input network layers. In addition, VUCCA is inexpensive to reuse transfer deep learning models to publicly available street view photographs. This suggests a productive research agenda in creating high quality deep learning pre-processors for specific smart-city application domains.
- Furthermore, building computational models from static big data is exhausting, let alone for dynamic data (e.g., moving pedestrians or vehicles), which readily fluctuate in space and time. Accordingly, by leveraging unsupervised clustering algorithms, our research proposes an approach to automatically cluster the detected samples by comparing and processing resemblances through similar targets in nearby distances.
- Finally, street view data has the capacity to play a small but vital role in smart city informatics. Big-data-driven multi-faceted semantic approaches can help maximize the potential of these otherwise purely visual data sources.
- First, our query application considers specified semantic features, such as background and sides. However, the derived analytics may suffer from low reliability and detection rate due to blurred and insufficient 2D pixels, e.g., pedestrians in the distance. In addition, searchable semantic features are limited by the predicted classes of the pre-trained deep transfer learning and more dynamic pedestrian analytics within a certain time period will be more accurate in query. Thus, 3D LIDAR data [65,66], photorealistic 3D models [67], high-resolution images, and re-training of the transfer learning models with local data and enriched semantic labels [68] are prioritized among the future research directions.
- The VUCCA presented in this paper, e.g., clustering and searching, is theoretical. A future direction is to implement value-added application software systems, which utilize processes pedestrians-of-interest in uploaded images. Example results are those with similar behaviors, such as the jogging persons in the morning and higher-risk pedestrians around accident blackspots.
- Despite spending ten days applying transfer learning to over 500,000 photographs to prepare for analytics of 61,788 pedestrians, more processing time would give better results. It is always beneficial for deep learning models to acquire more abundant training data, which can allow for further training iterations and lead to better classification ability (i.e., precision, recall, and F1 score), particularly when probing the full richness of eye-level urban features.
- While we have shown that our method has potential for relational queries of urban photographic data, nevertheless, further studies are encouraged to explore latent inconsistency and indeterminacy in different data sets. Our method is clearly limited to cities with coverage of street view imaging services. More variance in street scene might be helpful to find a more robust semantic segmentation approach.
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zanella, A.; Bui, N.; Castellani, A.; Vangelista, L.; Zorzi, M. Internet of Things for Smart Cities. IEEE Internet Things J. 2014, 1, 22–32. [Google Scholar] [CrossRef]
- Barns, S. Smart cities and urban data platforms: Designing interfaces for smart governance. City Cult. Soc. 2018, 12, 5–12. [Google Scholar] [CrossRef]
- Neirotti, P.; Marco, A.D.; Cagliano, A.C.; Mangano, G.; Scorrano, F. Current trends in Smart City initiatives: Some stylised facts. Cities 2014, 38, 25–36. [Google Scholar] [CrossRef] [Green Version]
- Xue, F.; Lu, W.; Chen, Z.; Webster, C.J. From LiDAR point cloud towards digital twin city: Clustering city objects based on Gestalt principles. ISPRS J. Photogramm. Remote Sens. 2020, 167, 418–431. [Google Scholar] [CrossRef]
- Glaeser, E.L.; Kominers, S.D.; Luca, M.; Naik, N. Big data and big cities: The promises and limitations of improved measures of urban life. Econ. Inq. 2016, 56, 114–137. [Google Scholar] [CrossRef]
- McAfee, A.; Brynjolfsson, E. Big data: The management revolution. Harv. Bus. Rev. 2012, 90, 60–68, Retrieved 1 September 2020. Available online: https://hbr.org/2012/10/big-data-the-management-revolution (accessed on 15 August 2021).
- Batty, M.; Axhausen, K.W.; Giannotti, F.; Pozdnoukhov, A.; Bazzani, A.; Wachowicz, M.; Portugali, G.O. Smart cities of the future. Eur. Phys. J. Spec. Top. 2014, 1, 481–518. [Google Scholar] [CrossRef] [Green Version]
- Dubey, A.; Naik, N.; Parikh, D.; Raskar, R.; Hidalgo, C.A. Deep learning the city: Quantifying urban perception at a global scale. In Computer Vision—ECCV 2016; Springer: Cham, Switzerland, 2016; pp. 196–212. [Google Scholar] [CrossRef] [Green Version]
- Zhang, P.; Zhao, Q.; Gao, J.; Lu, W.L. Urban Street Cleanliness Assessment Using Mobile Edge Computing and Deep Learning. IEEE Access 2019, 7, 63550–63563. [Google Scholar] [CrossRef]
- Essien, A.; Petrounias, I.; Sampaio, P.; Sampaio, S. Improving Urban Traffic Speed Prediction Using Data Source Fusion and Deep Learning. In Proceedings of the IEEE International Conference on Big Data and Smart Computing, Kyoto, Japan, 27 February–2 March 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1–8. [Google Scholar] [CrossRef] [Green Version]
- Jiang, D.; Zhang, P.; Lv, Z.; Song, H. Energy-efficient multi-constraint routing algorithm with load balancing for smart city applications. IEEE Internet Things J. 2016, 3, 1437–1447. [Google Scholar] [CrossRef]
- Chen, C.; Jiao, S.; Zhang, S.; Liu, W.; Wang, L.F. TripImputor: Real-time imputing taxi trip purpose leveraging multi-sourced urban data. IEEE Trans. Intell. Transp. Syst. 2018, 19, 3292–3304. [Google Scholar] [CrossRef]
- Xue, F.; Lu, W.; Chen, K. Automatic generation of semantically rich as-built Building Information Models using 2D images: A Derivative-Free Optimization approach. Comput. Aided Civ. Infrastruct. Eng. 2018, 33, 926–942. [Google Scholar] [CrossRef]
- Zhou, L.; Pan, S.; Wang, J.; Vasilakos, A.V. Machine learning on big data: Opportunities and challenges. Neurocomputing 2017, 237, 350–361. [Google Scholar] [CrossRef] [Green Version]
- Gebru, T.; Krause, J.; Wang, Y.; Chen, D.; Deng, J.; Aiden, E.L.; Li, F.F. Using deep learning and Google Street View to estimate the demographic makeup of neighborhoods across the United States. Proc. Natl. Acad. Sci. USA 2017, 114, 13108–13113. [Google Scholar] [CrossRef] [Green Version]
- Gong, F.Y.; Zhang, F.; Li, X.; Ng, E.; Norford, L.K. Mapping sky, tree, and building view factors of street canyons in a high-density urban environment. Build. Environ. 2018, 134, 155–167. [Google Scholar] [CrossRef]
- Zhang, F.; Zhou, B.; Liu, L.; Liu, Y.; Fung, H.H.; Lin, H.; Ratti, C. Measuring human perceptions of a large-scale urban region using machine learning. Landsc. Urban Plan. 2018, 180, 148–160. [Google Scholar] [CrossRef]
- Wang, R.; Liu, Y.; Lu, Y.; Zhang, J.; Liu, P.; Yao, Y.; Grekousis, G. Perceptions of built environment and health outcomes for older Chinese in Beijing: A big data approach with street view images and deep learning technique. Comput. Environ. Urban Syst. 2019, 78, 101386. [Google Scholar] [CrossRef]
- Yang, L.; Ao, Y.; Ke, J.; Lu, Y.; Liang, Y. To walk or not to walk? Examining non-linear effects of streetscape greenery on walking propensity of older adults. J. Transp. Geogr. 2021, 94, 103099. [Google Scholar] [CrossRef]
- Lu, Y. The association of urban greenness and walking behavior: Using google street view and deep learning techniques to estimate residents’ exposure to urban greenness. Int. J. Environ. Res. Public Health 2018, 15, 1576. [Google Scholar] [CrossRef] [Green Version]
- Helbich, M.; Yao, Y.; Liu, Y.; Zhang, J.; Liu, P.; Wang, R. Using deep learning to examine street view green and blue spaces and their associations with geriatric depression in Beijing, China. Environ. Int. 2019, 126, 107–117. [Google Scholar] [CrossRef]
- Chen, J.; Zhou, C.; Li, F. Quantifying the green view indicator for assessing urban greening quality: An analysis based on Internet-crawling street view data. Ecol. Indic. 2020, 113. [Google Scholar] [CrossRef]
- Wan, L.; Gao, S.; Wu, C.; Jin, Y.; Mao, M.; Yang, L. Big data and urban system model—Substitutes or complements? A case study of modelling commuting patterns in Beijing. Comput. Environ. Urban Syst. 2018, 68, 64–77. [Google Scholar] [CrossRef]
- Pan, Y.; Tian, Y.; Liu, X.; Gu, D.; Hua, G. Urban big data and the development of city intelligence. Engineering 2016, 2, 171–178. [Google Scholar] [CrossRef] [Green Version]
- Witten, K.; Kearns, R.; Carroll, P. Urban inclusion as wellbeing: Exploring children’s accounts of confronting diversity on inner city streets. Soc. Sci. Med. 2015, 133, 349–357. [Google Scholar] [CrossRef] [PubMed]
- Middel, A.; Lukasczyk, J.; Zakrzewski, S.; Arnold, M.; Maciejewski, R. Urban form and composition of street canyons: A human-centric big data and deep learning approach. Landsc. Urban Plan. 2019, 183, 122–132. [Google Scholar] [CrossRef]
- Neilson, A.; Indratmo, D.B.; Tjandra, S. Systematic Review of the Literature on Big Data in the Transportation Domain: Concepts and Applications. Big Data Res. 2019, 17, 35–44. [Google Scholar] [CrossRef]
- Richards, D.; Wang, J.W. Fusing street level photographs and satellite remote sensing to map leaf area index. Ecol. Indic. 2020, 115, 106342. [Google Scholar] [CrossRef]
- Griew, P.; Hillsdon, M.; Foster, C.; Coombes, E.; Wilkinson, A.J. Developing and testing a street audit tool using Google Street View to measure environmental supportiveness for physical activity. J. Behav. Nutr. Phys. Act. 2013, 10. [Google Scholar] [CrossRef] [Green Version]
- Zhai, W.; Peng, Z.R. Damage assessment using Google Street View: Evidence from Hurricane Michael in Mexico Beach, Florida. Appl. Geogr. 2020, 123, 102252. [Google Scholar] [CrossRef]
- Nguyen, Q.C.; Khanna, S.; Dwivedi, P.; Huang, D.; Huang, Y.; Tasdizen, T.; Brunisholz, K.D.; Li, F.; Gorman, W.; Nguyen, T.T.; et al. Using Google Street View to examine associations between built environment characteristics and U.S. health outcomes. Prev. Med. Rep. 2019, 14, 100859. [Google Scholar] [CrossRef]
- Kang, J.; Körner, M.; Wang, Y.; Taubenböck, H.; Zhu, X.X. Building instance classification using street view images. ISPRS J. Photogramm. Remote Sens. 2018, 145, 44–59. [Google Scholar] [CrossRef]
- LeCun, Y.B. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Cireşan, D.C.; Meier, U.; Gambardella, L.M. Deep, big, simple neural nets for handwritten digit recognition. Neural Comput. 2010, 3207–3220. [Google Scholar] [CrossRef] [Green Version]
- Pan, S.J.; Yang, Q. A Survey on Transfer Learning. IEEE Trans. Knowl. Data Eng. 2010, 22, 1345–1359. [Google Scholar] [CrossRef]
- Wurm, M.; Stark, T.; Zhu, X.X.; Weigand, M.; Taubenböck, H. Semantic segmentation of slums in satellite images using transfer learning on fully convolutional neural networks. ISPRS J. Photogramm. Remote Sens. 2019, 150, 59–69. [Google Scholar] [CrossRef]
- Chang, J.; Yu, J.; Han, T.; Chang, H.-j.; Park, E. A method for classifying medical images using transfer learning: A pilot study on histopathology of breast cancer. In Proceedings of the 19th International Conference on e-Health Networking, Applications and Services (Healthcom), Dalian, China, 12–15 October 2017; pp. 1–4. [Google Scholar] [CrossRef]
- Cira, C.; Alcarria, R.; Manso-Callejo, M.Á.; Serradilla, F. A deep learning-based solution for large-scale extraction of the secondary road network from high-resolution aerial orthoimagery. Appl. Sci. 2020, 10, 7272. [Google Scholar] [CrossRef]
- Kang, Y.; Cho, N.; Yoon, J.; Park, S.; Kim, J. Transfer learning of a deep learning model for exploring tourists’ urban image using geotagged photos. ISPRS Int. J. Geo-Inf. 2021, 10, 137. [Google Scholar] [CrossRef]
- Šerić, L.; Pinjušić, T.; Topić, K.; Blažević, T. Lost person search area prediction based on regression and transfer learning models. ISPRS Int. J. Geo-Inf. 2021, 10, 80. [Google Scholar] [CrossRef]
- Bowman, S.R.; Angeli, G.; Potts, C.; Manning, C.D. A large annotated corpus for learning natural language inference. arXiv 2015, arXiv:1508.05326v1. Available online: https://arxiv.org/abs/1508.05326 (accessed on 15 August 2021).
- Zhong, B.; Xing, X.; Love, P.; Wang, X.; Luo, H. Convolutional neural network: Deep learning-based classification of building quality problems. Adv. Eng. Inform. 2019, 40, 46–57. [Google Scholar] [CrossRef]
- Fu, X.; Jia, T.; Zhang, X.; Li, S.; Zhang, Y. Do street-level scene perceptions affect housing prices in Chinese megacities? An analysis using open access datasets and deep learning. PLoS ONE 2019, 5, 14. [Google Scholar] [CrossRef]
- Chen, L.; Lu, Y.; Sheng, Q.; Ye, Y.; Wang, R.; Liu, Y. Estimating pedestrian volume using Street View images: A large-scale validation test. Comput. Environ. Urban Syst. 2020, 81. [Google Scholar] [CrossRef]
- Zhang, F.; Wu, L.; Zhu, D.; Liu, Y. Social sensing from street-level imagery: A case study in learning spatio-temporal urban mobility patterns. ISPRS J. Photogramm. Remote Sens. 2019, 153, 48–58. [Google Scholar] [CrossRef]
- Srivastava, S.; Vargas-Muñoz, J.E.; Tuia, D. Understanding urban landuse from the above and ground perspectives: A deep learning, multimodal solution. Remote Sens. Environ. 2019, 228, 129–143. [Google Scholar] [CrossRef] [Green Version]
- Salvador, A.; Bellver, M.; Campos, V.; Baradad, M.; Marques, F.; Torres, J.; Giro-i-Nieto, X. Recurrent Neural Networks for Semantic Instance Segmentation. arXiv 2017, arXiv:1712.00617. [Google Scholar]
- Liu, X.; Zhao, H.; Tian, M.; Sheng, L.; Shao, J.; Yi, S.; Yan, J.; Wang, X. HydraPlus-Net: Attentive Deep Features for Pedestrian Analysis. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; IEEE: Piscataway, NJ, USA, 2017. [Google Scholar] [CrossRef] [Green Version]
- Li, S.; Xiao, T.; Li, H.; Zhou, B.; Yue, D.; Wang, X. Person Search with Natural Language Description. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 1970–1979. [Google Scholar] [CrossRef] [Green Version]
- Branson, S.; Wegner, J.D.; Hall, D.; Lang, N.; Schindler, K.; Perona, P. From Google Maps to a fine-grained catalog of street trees. ISPRS J. Photogramm. Remote Sens. 2018, 135, 13–30. [Google Scholar] [CrossRef] [Green Version]
- Lin, Y.; Zheng, L.; Zheng, Z.; Wu, Y.; Hu, Z.; Yan, C.; Yang, Y. Improving person re-identification by attribute and identity learning. Pattern Recognit. 2019, 95, 151–161. [Google Scholar] [CrossRef] [Green Version]
- Chen, Y.-H.; Chen, W.-Y.; Chen, Y.-T.; Tsai, B.-C.; Wang, Y.-C.F.; Sun, M. No more discrimination: Cross city adaptation of road scene segmenters. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 1992–2001. [Google Scholar] [CrossRef] [Green Version]
- Cordts, M.; Omran, M.; Ramos, S.; Rehfeld, T.; Enzweiler, M.; Benenson, R.; Franke, U.; Roth, S.; Schiele, B. The cityscapes dataset for semantic urban scene understanding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 3213–3223. [Google Scholar] [CrossRef] [Green Version]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767v1. [Google Scholar]
- Lin, T.-Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common Objects in Context. In European Conference on Computer Vision; Springer: Berlin, Germany, 2014; pp. 740–755. [Google Scholar] [CrossRef]
- Wang, R.; Lu, Y.; Zhang, J.; Liu, P.; Yao, Y.; Liu, Y. The relationship between visual enclosure for neighbourhood street walkability and elders’ mental health in China: Using street view images. J. Transp. Health 2019, 13, 90–102. [Google Scholar] [CrossRef]
- Bennett, J. OpenStreetMap; Packt Publishing Ltd: Birmingham, UK, 2010. [Google Scholar]
- Raifer, M. Overpass API. 2018. Available online: http://overpass-turbo.eu/ (accessed on 15 August 2021).
- Hoyer, L.; Kesper, P.; Khoreva, A.; Fischer, V. Short-Term Prediction and Multi-Camera Fusion on Semantic Grids. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 813–821. [Google Scholar] [CrossRef] [Green Version]
- Zhang, C.; Lin, G.; Liu, F.; Yao, R.; Shen, C. CANet: Class-Agnostic Segmentation Networks with Iterative Refinement and Attentive Few-Shot Learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 5217–5226. [Google Scholar] [CrossRef] [Green Version]
- Zhao, R.; Zhan, L.; Yao, M.; Yang, L. A geographically weighted regression model augmented by Geodetector analysis and principal component analysis for the spatial distribution of PM2.5. Sustain. Cities Soc. 2020, 56, 102106. [Google Scholar] [CrossRef]
- Li, X.; Liu, X.; Li, C.Z.; Hu, Z.; Shen, G.Q.; Huang, Z. Foundation pit displacement monitoring and prediction using least squares support vector machines based on multi-point measurement. Struct. Health Monit. 2019, 18, 715–724. [Google Scholar] [CrossRef]
- Wold, S.; Esbensen, K.; Geladi, P. Principal component analysis. Chemom. Intell. Lab. Syst. 1987, 2, 37–52. [Google Scholar] [CrossRef]
- Hartigan, J.A.; Wong, M.A. Algorithm AS 136: A K-Means Clustering Algorithm. J. R. Stat. Soc. Ser. C 1979, 28, 100–108. [Google Scholar] [CrossRef]
- Babahajiani, P.; Fan, L.; Kämäräinen, J.K.; Gabbouj, M. Urban 3D segmentation and modelling from street view images and LiDAR point clouds. Mach. Vis. Appl. 2017, 28, 679–694. [Google Scholar] [CrossRef]
- Xue, F.; Lu, W.; Webster, C.J.; Chen, K. A derivative-free optimization-based approach for detecting architectural symmetries from 3D point clouds. ISPRS J. Photogramm. Remote Sens. 2019, 148, 32–40. [Google Scholar] [CrossRef]
- Wu, Y.; Shang, J.; Xue, F. RegARD: Symmetry-based coarse registration of smartphone’s colorful point clouds with CAD drawings for low-cost Digital Twin Buildings. Remote Sens. 2021, 13, 1882. [Google Scholar] [CrossRef]
- Xue, F.; Wu, L.; Lu, W. Semantic enrichment of building and city information models: A ten-year review. Adv. Eng. Inform. 2021, 47, 101245. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Id | Category of Features | Pixel Labels in the Results of CNN |
|---|---|---|
| F1 | Greenery | Vegetation |
| F2 | Roadway | Road |
| F3 | Sidewalk | Sidewalk and guardrail |
| F4 | Construction | Building and wall |
| F5 | Sky and terrain | Sky and terrain |
| F6 | Vehicle (hardtop) | Car, bus, truck, and train |
| F7 | Vehicle (bike) | Motorcycle and bicycle |
| F8 | Street furniture | Pole, traffic light, and traffic sign |
| F9 | Pedestrian | Person and rider |
| F10 | Others | Others (pets, aircrafts, etc.) |
| Category | Object | Precision | Recall | F1 | Satisfactory? |
|---|---|---|---|---|---|
| Uncountable | Vegetation | 0.87 | 0.99 | 0.93 | Yes |
| (As pixels) | Construction | 0.97 | 0.94 | 0.95 | Yes |
| Roadway | 0.95 | 0.98 | 0.97 | Yes | |
| Countable | Vehicle | 0.95 | 0.77 | 0.85 | Yes |
| Person | 0.84 | 0.87 | 0.85 | Yes | |
| Stop sign | 0.89 | 0.22 | 0.35 | No |
| Id | F1 | F2 | F3 | F4 | F5 | F6 | F7 | F8 | F9 | F10 |
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 2 | 0.00917 | 0 | 0.00917 | 0.37615 | 0 | 0.57798 | 0 | 0 | 0.02752 | 0 |
| 3 | 0 | 0 | 0.61290 | 0 | 0 | 0 | 0 | 0.16129 | 0.22581 | 0 |
| ⋮ | ⋮ | ⋮ | ⋮ | |||||||
| 61,788 | 0 | 0.26316 | 0 | 0 | 0 | 0 | 0 | 0 | 0.73684 | 0 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xue, F.; Li, X.; Lu, W.; Webster, C.J.; Chen, Z.; Lin, L. Big Data-Driven Pedestrian Analytics: Unsupervised Clustering and Relational Query Based on Tencent Street View Photographs. ISPRS Int. J. Geo-Inf. 2021, 10, 561. https://0-doi-org.brum.beds.ac.uk/10.3390/ijgi10080561
Xue F, Li X, Lu W, Webster CJ, Chen Z, Lin L. Big Data-Driven Pedestrian Analytics: Unsupervised Clustering and Relational Query Based on Tencent Street View Photographs. ISPRS International Journal of Geo-Information. 2021; 10(8):561. https://0-doi-org.brum.beds.ac.uk/10.3390/ijgi10080561
Chicago/Turabian StyleXue, Fan, Xiao Li, Weisheng Lu, Christopher J. Webster, Zhe Chen, and Lvwen Lin. 2021. "Big Data-Driven Pedestrian Analytics: Unsupervised Clustering and Relational Query Based on Tencent Street View Photographs" ISPRS International Journal of Geo-Information 10, no. 8: 561. https://0-doi-org.brum.beds.ac.uk/10.3390/ijgi10080561