
The Integration of Linguistic and Geospatial Features Using Global Context Embedding for Automated Text Geocoding



Abstract
:1. Introduction
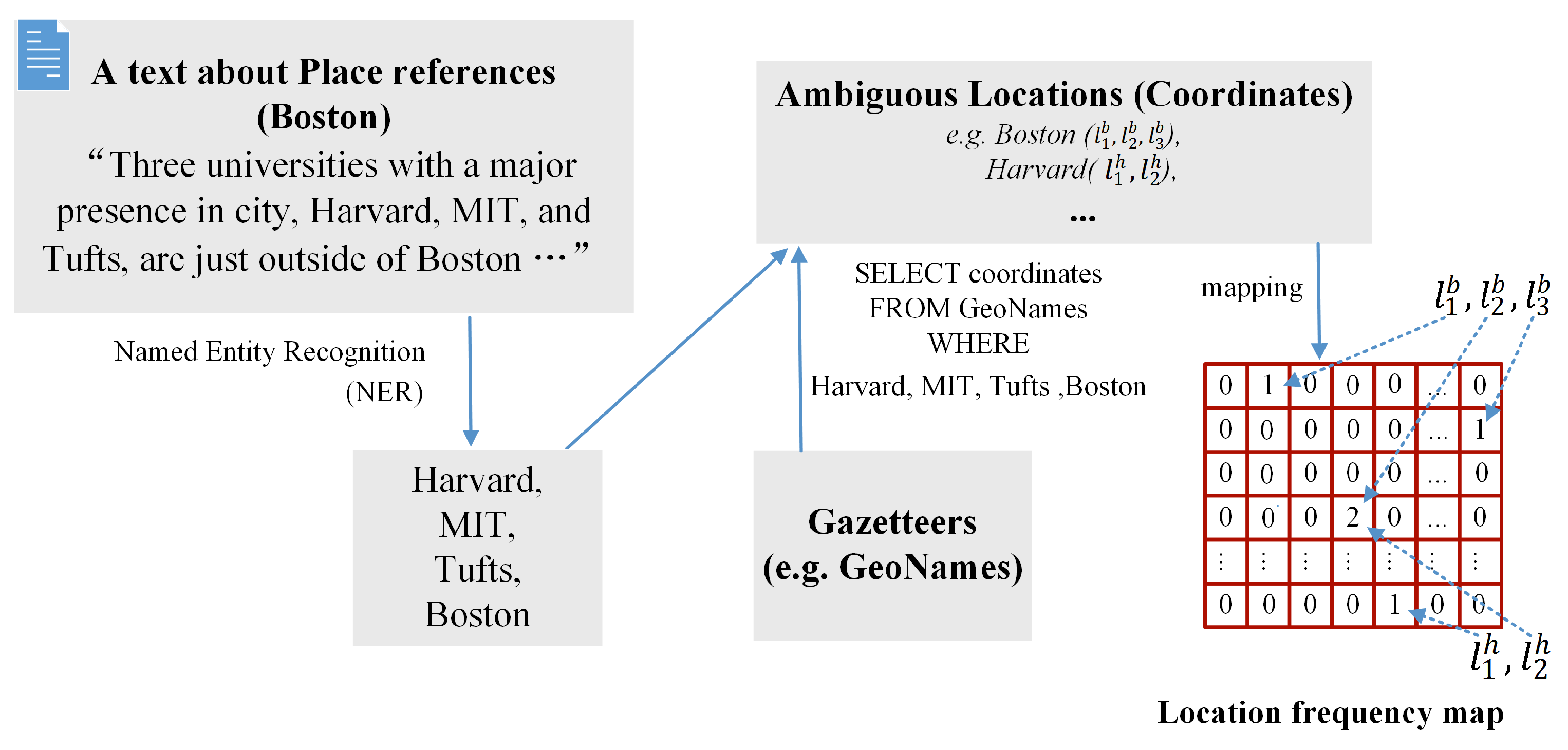
Washington is a census-designated place located in Nevada County, California.Washington is located on the bank of the South Fork of the Yuba River.
- It employs topic embedding to improve feature representation by enforcing topic modeling to transform words’ topics into low-dimensional vectors. However, traditional geocoding tasks ignore topic information and are limited to the syntax and semantics of text.
- It employs location embedding from deep learning to transform spatial distribution around the place reference into low-dimensional vectors and enrich the geospatial features vector. Since place mentions in a text are often few, the location embedding works as a priori feature aiding the generation of the geospatial feature vector to alleviate the data scarcity.
- It discovers that fusion with topic information can effectively reduce the geospatial feature vector’s noise.
2. Related Work
3. Methodology
3.1. Preliminaries
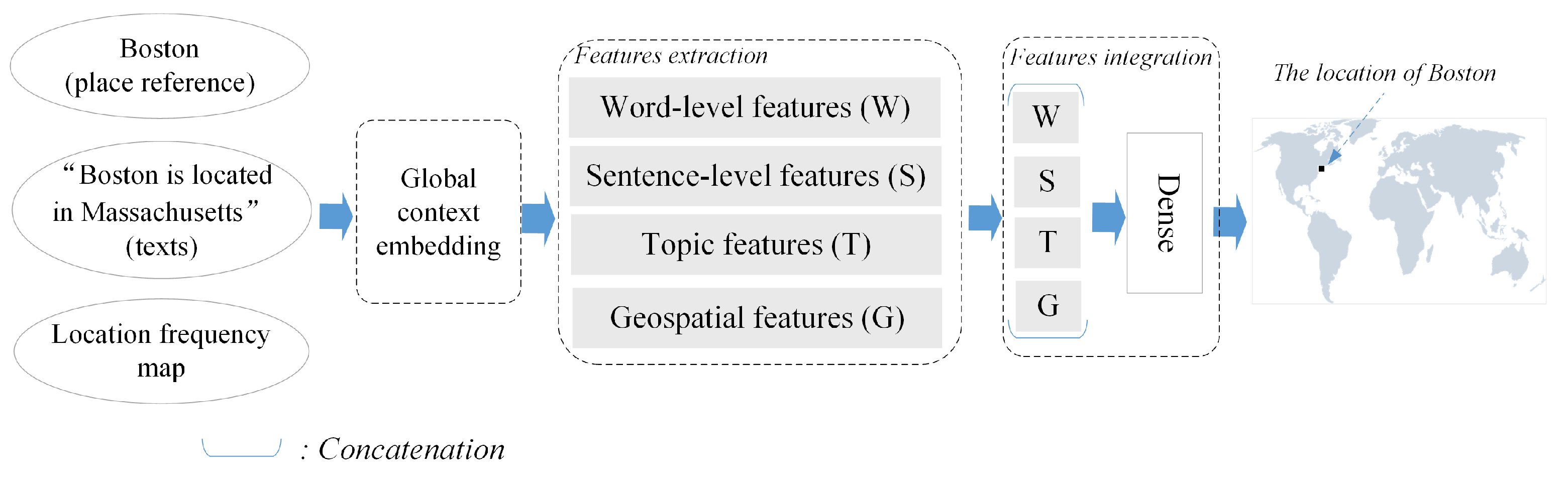
3.2. Global Context Embedding for Linguistic Features and Geospatial Features
3.2.1. Word Embedding for Linguistic Features
3.2.2. Topic Embedding for Global Linguistic Features
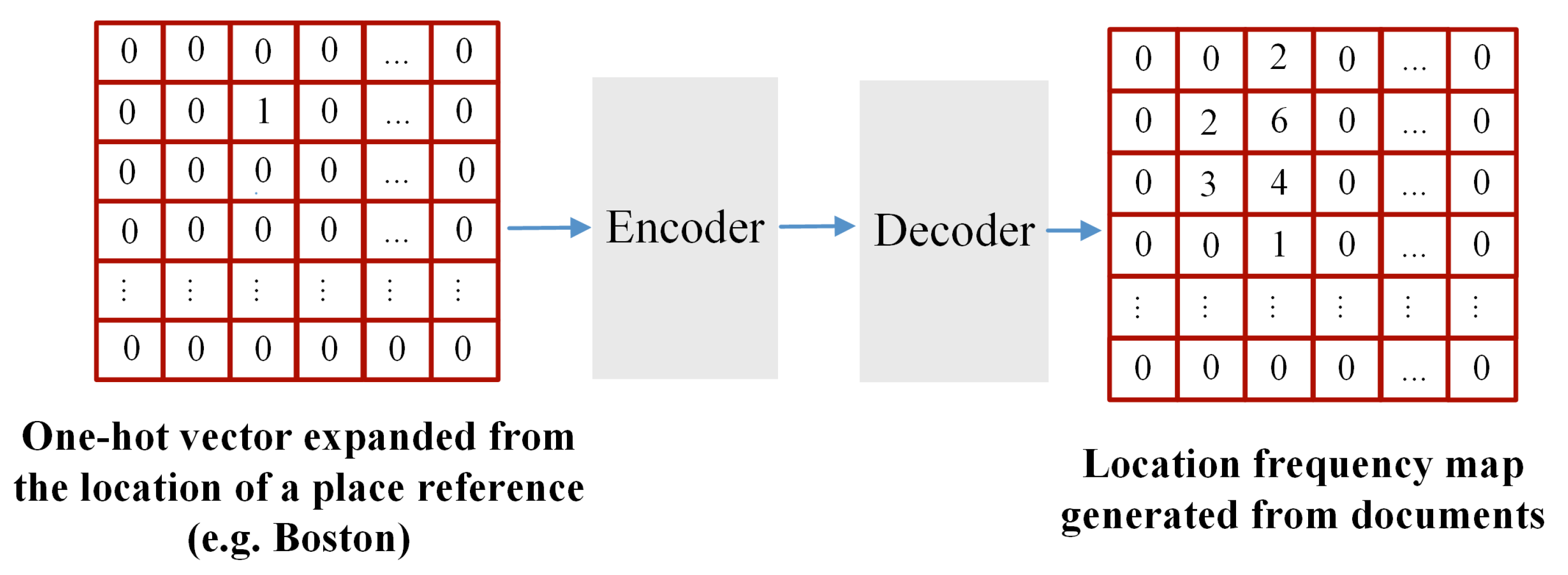
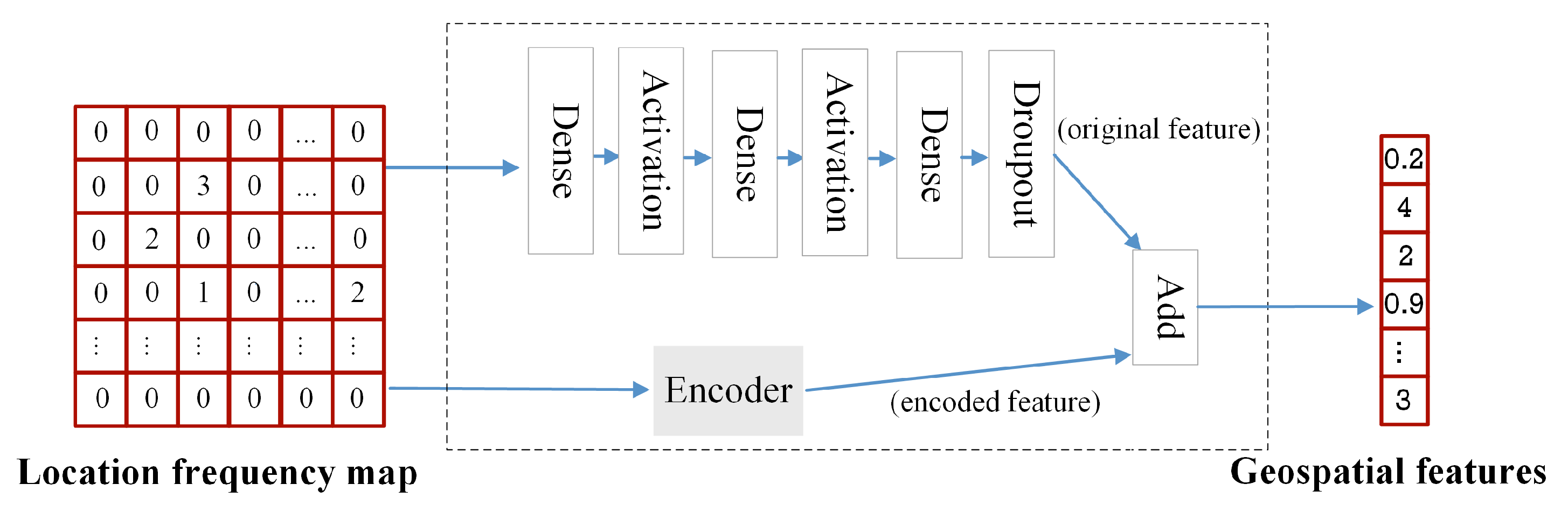
3.2.3. Location Embedding for Geospatial Features
3.2.4. Training of Embedding Model
3.3. LGGeoCoder
4. Experiments and Result Discussion
4.1. Experimental Settings
4.2. Performance Comparison
- GeoCoder: GeoCoder is a deep learning approach for geocoding based on CNN, which is use to represent word-level and sentence-level features, respectively. Glove is used in the GeoCoder to represent word vectors.
- CamCoder: CamCoder is a deep learning approach that integrates linguistic and geospatial features for geocoding based on CNN, which is used to represent word-level features, sentence-level features and geospatial features, respectively. Glove is also used in the CamCoder to represent word vectors. The main difference between the CamCoder and our method is that CamCoder does not extract topic features and uses one-hot encoding to represent location vectors. As far as we know, this is the only deep learning network that combines geospatial features and linguistic features for geocoding.
4.3. Ablation Study
- FEATURE-G: Compared with CamCoder, it enrich geospatial features using location embedding.
- FEATURE-D: Compared with CamCoder, it adds topic features through topic embedding.
Dubai zoo housed approximately 230 animal species. Endangered species include Socotra shag or cormorant, Bengal tiger, gorilla, subspecies of grey wolf and Arabian wolf, Siberian tiger, and the indigenous Gordon’s wildcat.[52]
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Purves, R.; Jones, C. Geographic information retrieval. SIGSPATIAL Spec. 2011, 3, 2–4. [Google Scholar] [CrossRef] [Green Version]
- Tsou, M.H.; Yang, J.A.; Lusher, D.; Han, S.; Spitzberg, B.; Gawron, J.M.; Gupta, D.; An, L. Mapping social activities and concepts with social media (Twitter) and web search engines (Yahoo and Bing): A case study in 2012 US Presidential Election. Cartogr. Geogr. Inf. Sci. 2013, 40, 337–348. [Google Scholar] [CrossRef]
- Hu, L.; Li, Z.; Ye, X. Delineating and modeling activity space using geotagged social media data. Cartogr. Geogr. Inf. Sci. 2020, 47, 277–288. [Google Scholar] [CrossRef]
- Campelo, C.E. Geographically-Aware Information Retrieval on the Web. In Encyclopedia of Information Science and Technology, 3rd ed.; IGI Global: Hershey, PA, USA, 2015; pp. 3893–3900. [Google Scholar]
- Gritta, M.; Pilehvar, M.; Limsopatham, N.; Collier, N. What’s missing in geographical parsing? Lang. Resour. Eval. 2018, 52, 603–623. [Google Scholar] [CrossRef] [Green Version]
- Melo, F.; Martins, B. Automated geocoding of textual documents: A survey of current approaches. Trans. GIS 2017, 21, 3–38. [Google Scholar] [CrossRef]
- Hervey, T.; Kuhn, W. Using provenance to disambiguate locational references in social network posts. Int. J. Geogr. Inf. Sci. 2019, 33, 1594–1611. [Google Scholar] [CrossRef]
- Sui, D.; Goodchild, M. The convergence of GIS and social media: Challenges for GIScience. Int. J. Geogr. Inf. Sci. 2011, 25, 1737–1748. [Google Scholar] [CrossRef]
- Wick, M. Geonames. 2011. Available online: https://www.geonames.org/ (accessed on 3 July 2018).
- DeLozier, G.; Baldridge, J.; London, L. Gazetteer-independent toponym resolution using geographic word profiles. In Proceedings of the Twenty-Ninth AAAI Conference on Artificial Intelligence, Austin, TX, USA, 25–30 January 2015. [Google Scholar]
- Santos, J.; Anastácio, I.; Martins, B. Using machine learning methods for disambiguating place references in textual documents. GeoJournal 2015, 80, 375–392. [Google Scholar] [CrossRef]
- Speriosu, M.; Baldridge, J. Text-driven toponym resolution using indirect supervision. In Proceedings of the Annual Metting of the Association for Computational Linguistics, Sofia, Bulgaria, 4–9 August 2013. [Google Scholar]
- Navigli, R. Word sense disambiguation: A survey. ACM Comput. Surv. (CSUR) 2009, 41, 1–69. [Google Scholar] [CrossRef]
- Gritta, M.; Pilehvar, M.; Collier, N. Which melbourne? Augmenting geocoding with maps. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics, Melbourne, Australia, 15–20 July 2018; pp. 1285–1296. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, MN, USA, 2–7 June 2019; pp. 4171–4186. [Google Scholar]
- Goldberg, D.; Wilson, J.; Knoblock, C. From text to geographic coordinates: The current state of geocoding. URISA J. 2007, 19, 33–46. [Google Scholar]
- Zhang, W.; Gelernter, J. Geocoding location expressions in Twitter messages: A preference learning method. J. Spat. Inf. Sci. 2014, 9, 37–70. [Google Scholar]
- Grover, C.; Tobin, R.; Byrne, K.; Woollard, M.; Reid, J.; Dunn, S.; Ball, J. Use of the Edinburgh geoparser for georeferencing digitized historical collections. Philos. Trans. R. Soc. A Math. Phys. Eng. Sci. 2010, 368, 3875–3889. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wang, X.; Zhang, Y.; Chen, M.; Lin, X.; Yu, H.; Liu, Y. An evidence-based approach for toponym disambiguation. In Proceedings of the 18th International Conference on Geoinformatics, Beijing, China, 18–20 June 2010; pp. 1–7. [Google Scholar]
- Li, H.; Srihari, R.; Niu, C.; Li, W. Location normalization for information extraction. In Proceedings of the 19th International Conference on Computational Linguistics, Taipei, Taiwan, 24 August–1 September 2002; pp. 1–7. [Google Scholar]
- Speriosu, M.; Brown, T.; Moon, T.; Baldridge, J.; Erk, K. Connecting language and geography with region-topic models. In Proceedings of the Workshop on Computational Models of Spatial Language Interpretation (COSLI), Portland, OR, USA, 15 August 2010. [Google Scholar]
- Liu, Y.; Wang, F.; Kang, C.; Gao, Y.; Lu, Y. Analyzing Relatedness by Toponym Co-O ccurrences on Web Pages. Trans. GIS 2014, 18, 89–107. [Google Scholar] [CrossRef]
- Overell, S.; Rüger, S. Using co-occurrence models for placename disambiguation. Int. J. Geogr. Inf. Sci. 2008, 22, 265–287. [Google Scholar] [CrossRef]
- Bishop, C. Pattern Recognition and Machine Learning; Springer: Berlin/Heidelberg, Germany, 2006. [Google Scholar]
- Wing, B.; Baldridge, J. Hierarchical discriminative classification for text-based geolocation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 336–348. [Google Scholar]
- Melo, F.; Martins, B. Geocoding textual documents through the usage of hierarchical classifiers. In Proceedings of the 9th Workshop on Geographic Information Retrieval, Paris, France, 26–27 November 2015; pp. 1–9. [Google Scholar]
- Liu, J.; Inkpen, D. Estimating user location in social media with stacked denoising auto-encoders. In Proceedings of the 1st Workshop on Vector Space Modeling for Natural Language Processing, Denver, CO, USA, 31 May–5 June 2015; pp. 201–210. [Google Scholar]
- Murdock, V. Dynamic location models. In Proceedings of the Thirty-Seventh International ACM SIGIR Conference on Research and Development in Information Retrieval, Queensland, Australia, 11 July 2014. [Google Scholar]
- Hulden, M.; Silfverberg, M.; Francom, J. Kernel density estimation for text-based geolocation. In Proceedings of the Twenty-Ninth AAAI Conference on Artificial Intelligence, Austin, TX, USA, 25–30 January 2015. [Google Scholar]
- Rahimi, A.; Baldwin, T.; Cohn, T. Continuous Representation of Location for Geolocation and Lexical Dialectology Using Mixture Density Networks. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, Copenhagen, Denmark, 9–11 September 2017. [Google Scholar]
- Wang, S.; Manning, C. Baselines and bigrams: Simple, good sentiment and topic classification. In Proceedings of the 50th Annual Meeting of the Association for Computational Linguistics: Short Papers-Volume 2, Jeju Island, Korea, 8–14 July 2012; pp. 90–94. [Google Scholar]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.S.; Dean, J. Distributed Representations of Words and Phrases and their Compositionality. Adv. Neural Inf. Process. Syst. 2013, 26, 3111–3119. [Google Scholar]
- Bamman, D.; Dyer, C.; Smith, N.A. Distributed representations of geographically situated language. In Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), Baltimore, MD, USA, 22–27 June 2014; pp. 828–834. [Google Scholar]
- Kejriwal, M.; Szekely, P. Neural Embeddings for Populated Geonames Locations. In Proceedings of the International Semantic Web Conference, Vienna, Austria, 21–25 October 2017; pp. 139–146. [Google Scholar]
- Liu, Y.; Liu, Z.; Chua, T.; Sun, M. Topical word embeddings. In Proceedings of the Twenty-Ninth AAAI Conference on Artificial Intelligence, Austin, TX, USA, 25 January 2015. [Google Scholar]
- Honnibal, M.; Montani, I. spacy 2: Natural language understanding with bloom embeddings. Convolut. Neural Netw. Increm. Parsing 2017, 7, 411–420. [Google Scholar]
- Chomsky, N. Systems of syntactic analysis. J. Symb. Log. 1953, 18, 242–256. [Google Scholar] [CrossRef]
- Pennington, J.; Socher, R.; Manning, C. Glove: Global vectors for word representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1532–1543. [Google Scholar]
- Blei, D.M.; Ng, A.Y.; Jordan, M.I. Latent dirichlet allocation. J. Mach. Learn. Res. 2003, 3, 993–1022. [Google Scholar]
- Vu, T.; Yang, H.; Nguyen, V.; Oh, A.; Kim, M. Multimodal learning using convolution neural network and Sparse Autoencoder. In Proceedings of the IEEE International Conference on Big Data and Smart Computing (BigComp), Jeju Island, Korea, 13–16 February 2017; pp. 309–312. [Google Scholar]
- Mao, X.J.; Shen, C.; Yang, Y.B. Image restoration using very deep convolutional encoder-decoder networks with symmetric skip connections. In Proceedings of the 30th International Conference on Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; pp. 2810–2818. [Google Scholar]
- NG, A. On discriminative vs. generative classifiers: A comparison of logistic regression and naive Bayes. Adv. Neural Inf. Process. Syst. 2002, 14, 841–848. [Google Scholar]
- Weston, J.; Ratle, F.; Mobahi, H.; Collobert, R. Deep learning via semi-supervised embedding. In Neural Networks: Tricks of the Trade; Springer: Berlin/Heidelberg, Germany, 2012; pp. 639–655. [Google Scholar]
- Lin, T.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Michalski, R.S. A theory and methodology of inductive learning. In Machine Learning; Elsevier: Amsterdam, The Netherlands, 1983; pp. 83–134. [Google Scholar]
- Phan, X.; Nguyen, C. GibbsLDA++: AC/C++ Implementation of Latent Dirichlet Allocation, 2018. Git Code. Available online: https://github.com/mrquincle/gibbs-lda (accessed on 3 July 2018).
- Zeiler, M.D. ADADELTA: An Adaptive Learning Rate Method. arXiv 2012, arXiv:1212.5701. [Google Scholar]
- Kim, Y. Convolutional Neural Networks for Sentence Classification. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1746–1751. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2015, arXiv:1412.6980. [Google Scholar]
- Li, R.; Wang, S.; Deng, H.; Wang, R.; Chang, K.C.C. Towards social user profiling: Unified and discriminative influence model for inferring home locations. In Proceedings of the 18th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Beijing, China, 12–16 August 2012; pp. 1023–1031. [Google Scholar]
- Jurgens, D.; Finethy, T.; McCorriston, J.; Xu, Y.; Ruths, D. Geolocation prediction in twitter using social networks: A critical analysis and review of current practice. In Proceedings of the International AAAI Conference on Web and Social Media, Oxford, UK, 26–29 May 2015. [Google Scholar]
- Wikipedia Contributors. ‘Plagiarism’, Wikipedia, The Free Encyclopedia. 2004. Available online: https://en.wikipedia.org/wiki/Dubai_Zoo (accessed on 5 July 2021).





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Accuracy | Median Error (km) | Mean Error (km) | AUC | |
|---|---|---|---|---|
| GeoCoder | 64.5% | 107.7 | 798.5 | 0.5180 |
| CamCoder | 68.0% | 102.6 | 882.0 | 0.5142 |
| LGGeoCoder | 72.5% | 96.9 | 651.4 | 0.4987 |
| Accuracy | AUC | |
|---|---|---|
| LGGeoCoder | 72.5% | 0.4987 |
| LGGeoCoder + proximity search | 89.6% | 0.176 |
| Accuracy | Median Error (km) | Mean Error (km) | AUC | |
|---|---|---|---|---|
| CamCoder | 68.0% | 102.6 | 882.0 | 0.5142 |
| FEATURE-G | 69.5% | 100.6 | 835.0 | 0.5100 |
| FEATURE-D | 70.2% | 99.95 | 661.4 | 0.5032 |
| LGGeoCoder | 72.5% | 96.9 | 651.4 | 0.4987 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yan, Z.; Yang, C.; Hu, L.; Zhao, J.; Jiang, L.; Gong, J. The Integration of Linguistic and Geospatial Features Using Global Context Embedding for Automated Text Geocoding. ISPRS Int. J. Geo-Inf. 2021, 10, 572. https://0-doi-org.brum.beds.ac.uk/10.3390/ijgi10090572
Yan Z, Yang C, Hu L, Zhao J, Jiang L, Gong J. The Integration of Linguistic and Geospatial Features Using Global Context Embedding for Automated Text Geocoding. ISPRS International Journal of Geo-Information. 2021; 10(9):572. https://0-doi-org.brum.beds.ac.uk/10.3390/ijgi10090572
Chicago/Turabian StyleYan, Zheren, Can Yang, Lei Hu, Jing Zhao, Liangcun Jiang, and Jianya Gong. 2021. "The Integration of Linguistic and Geospatial Features Using Global Context Embedding for Automated Text Geocoding" ISPRS International Journal of Geo-Information 10, no. 9: 572. https://0-doi-org.brum.beds.ac.uk/10.3390/ijgi10090572