
Inferring Directed Road Networks from GPS Traces by Track Alignment

 ,
, {kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Related Work
- Methods operating on a binary image created from GPS traces: These methods first divide the the geographical area covered by GPS traces into a two-dimensional grid of cells and estimate the kernel densities (KD) of the tracking data points for each cell [1,3,5,22]. A binary representation of all tracks is then produced by applying a threshold on the KD estimation. These methods differ in how the road centerlines are extracted from the resulting binary image. Davies et al. apply a contour follower to the binary image to extract a set of closed polygons, which describe the road regions’ outline, and then compute the road centerlines by producing a Voronoi graph of the contours describing the road edges [3]. Chen et al. use an image-processing approach to extract the road map from the binary image [22]. First, morphological dilation and closing operations are used to merge the discrete data points of GPS traces. A thinning operation is then used to produce the skeleton along the road centerlines. Shi et al. propose a very similar method to Chen’s approach [22], but they try to extract the crossings of the roads from the road network skeleton [5]. Biagioni and Eriksson do not produce a binary map image by applying a simple threshold to the KDE, because a single threshold cannot achieve both high accuracy and high coverage of the road map. To solve this problem, they apply a gray-scale skeletonization technique to extract a threshold-free skeleton from the KDE [16].
- Methods based on KDE suffer from thresholding, since a higher threshold will produce spurious edges. However, a lower threshold will ignore the tracks in sparse areas as noise, leading to unsuccessful detection of the roads that are not traversed frequently. Although the geometry of the road network is built using the geographical locations along the road centerlines, the topology of the road network, formed by the interconnections between roads, is not analyzed thoroughly in the previously-mentioned binary image-based road analysis. Road network topology is essential to path optimization and route planning. In this paper, we operate on the trajectories (spatial positions as a function of time) directly in order to extract road intersections and to analyze their connectivity using GPS traces.
- Methods operating on the data points of GPS traces: Most researchers segment the GPS traces into track pieces for each road segment and infer the representation of each road segment from the track pieces that correspond to it. In these methods, intersections are detected before road segment generation, and the connectivity between intersections is helpful to partition the GPS traces into each road segment. Given a set of track pieces, a variety of approaches, ranging from curve fitting to graph segmentation, have been proposed for extracting a representative road segment from its corresponding track pieces. These approaches can be divided into three categories by their algorithmic foundations.
- -
- Curve fitting methods: Edelkamp and Schroedl employ a K-means algorithm to cluster the data points of raw GPS traces of both road segments and intersections based on a distance measure. Road centerlines are generated using a spline fitting approach for each road segment from the GPS data points corresponding to it [2,18].
- -
- Topological methods: Morris et al. [23] build a topological graph to represent the physical network of the GPS traces. An initial graph is generated from the interaction points and connection lines among all tracks. Those connection lines are reduced to extract a single representation for each road segment using a graph algorithm, such as parallel reduction, face reduction, serial reduction and edge contraction.
- -
- Trace merging methods: Karagiorgou and Pfoser detect the intersections by clustering the turns according to their locations and turn type and bundle the trajectories between the intersections to merge them into road segments [24].
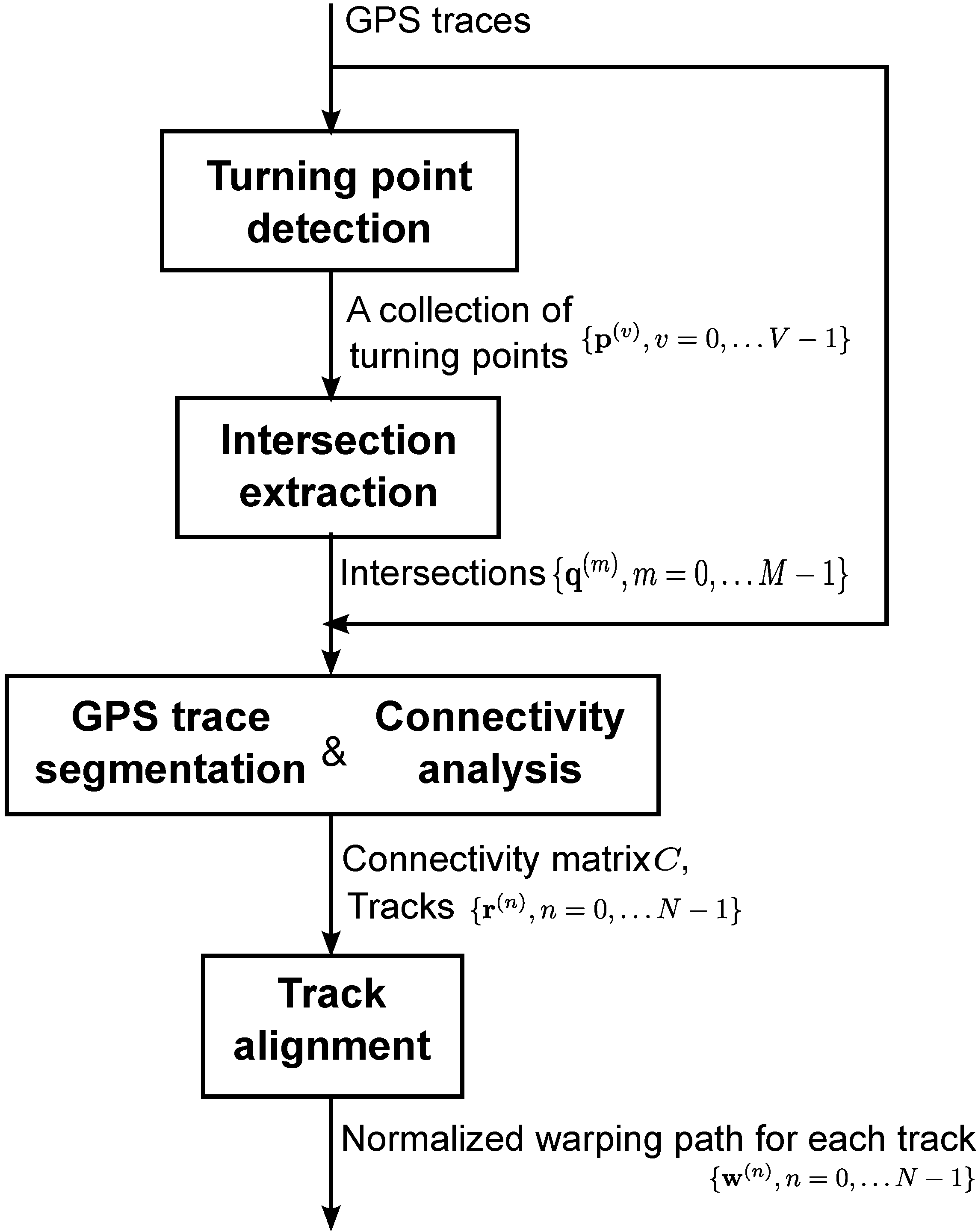
3. Road Network Inference
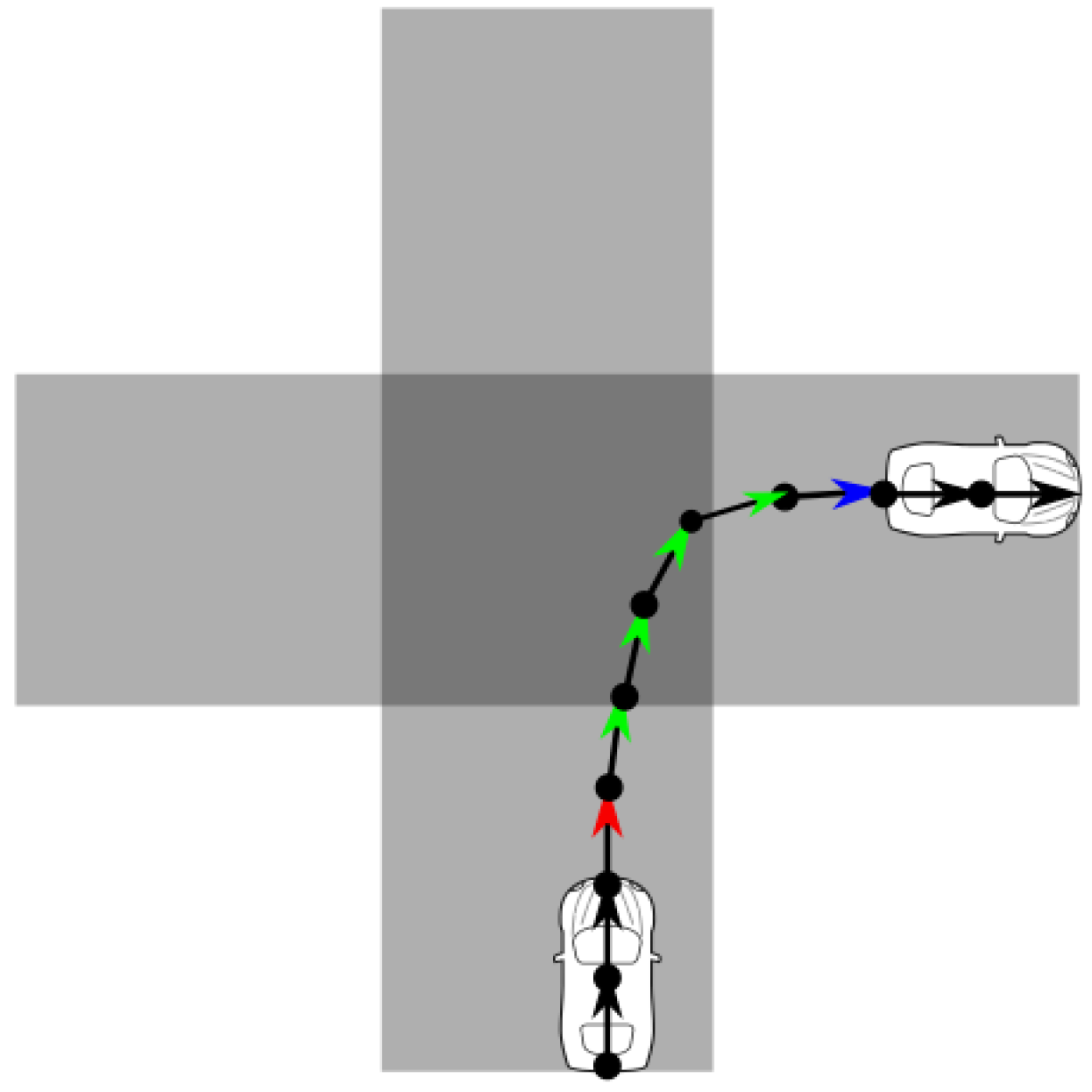
- Intersections: Road intersections are represented by their geographic position , where x and y are coordinates in latitude and longitude. An intersection can be defined as a location where the users can change directions in multiple ways, regardless of the number of road segments meeting at a particular intersection. Intersections are unique from the bends in roads, which only allow the users to make a single change in direction.
- Connectivity graph: Road connectivity graphs encode if a pair of intersections are directly connected by a road segment containing no other intersections. These graphs are represented by a binary connectivity matrix C, with M the number of intersections. By definition, if intersections i and j are directly connected by a single road segment. In our paper, C is asymmetric, i.e., can differ from due to one-way traffic. Moreover, we assume that the main diagonal elements of C are zero, i.e., an intersection is not connected to itself.
- Road segments: The directed road segments R connect pairs of intersections. The geometry of each road segment is represented using a sequence of geographical locations. In this paper, the average speed and speed variance along each road segment will be analyzed using the GPS traces. However, the type of the road and the number of lanes on the road will not be analyzed.
3.1. Turning Point Detection


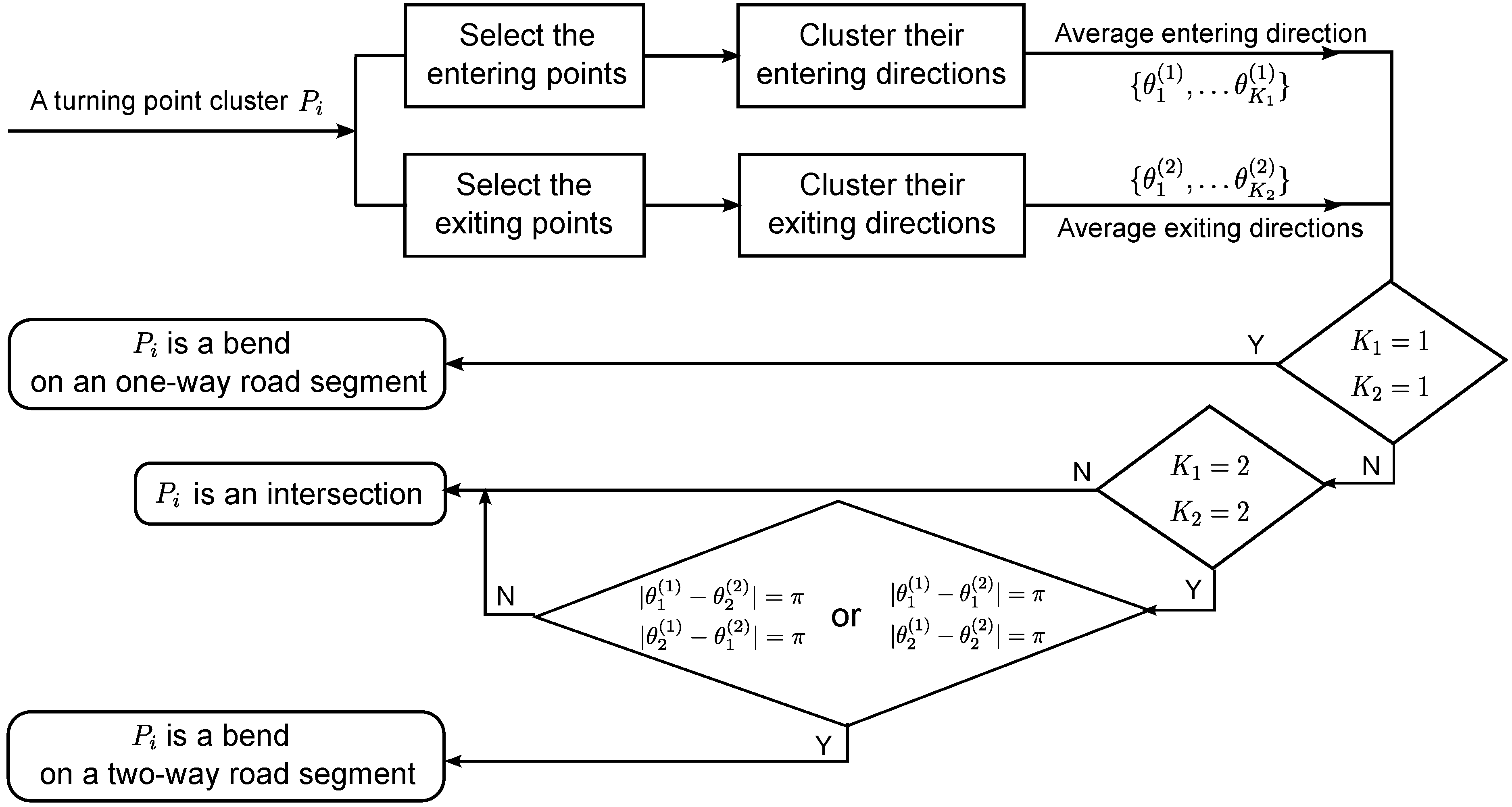
3.2. Intersection Extraction
| Algorithm 1 Cluster turning points. |
| Input: , |
| Output: |
| 1: Initialization , |
| 2: for each do |
| 3: , , |
| 4: for each do |
| 5: if then is the predefined threshold for the average Euclidean distance. |
| 6: |
| 7: end if |
| 8: end for |
| 9: |
| 10: end for |
3.3. Connectivity Analysis and GPS Trace Segmentation

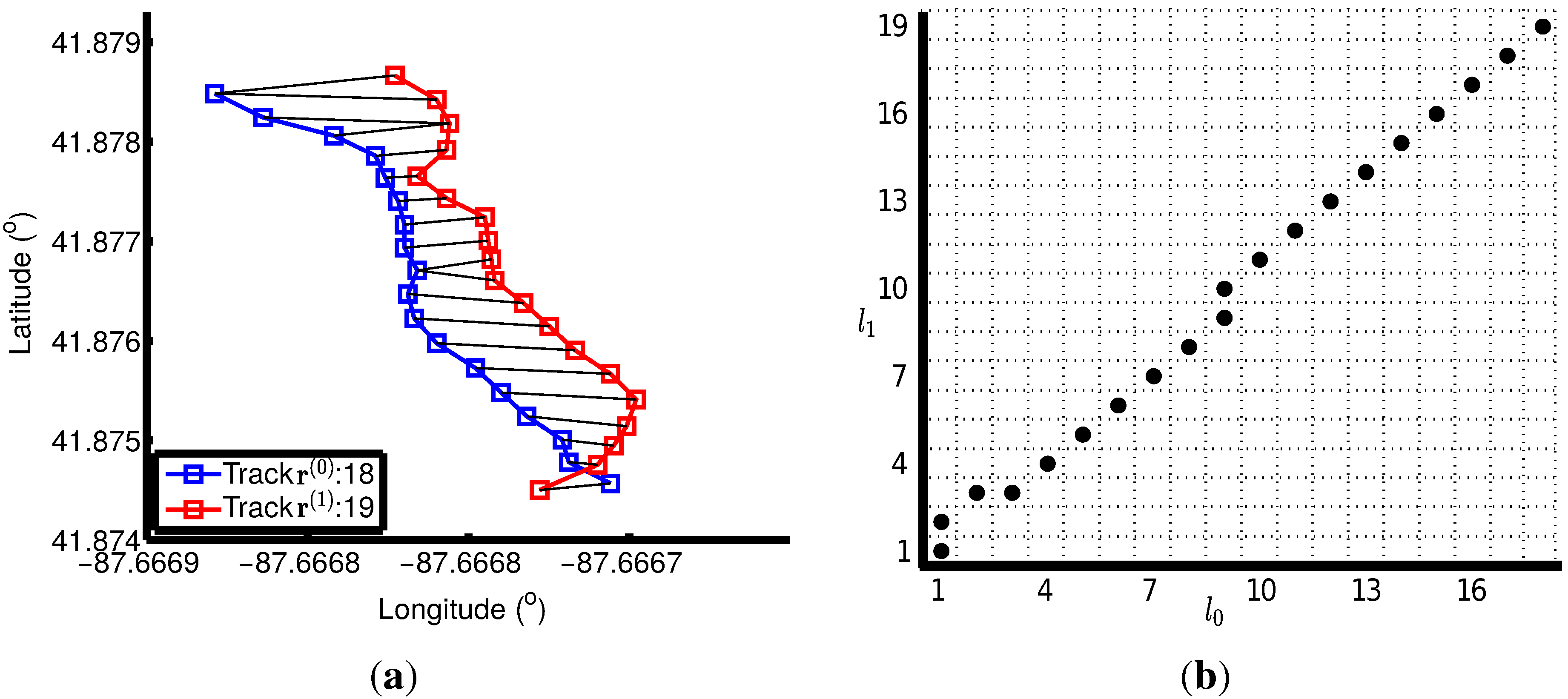
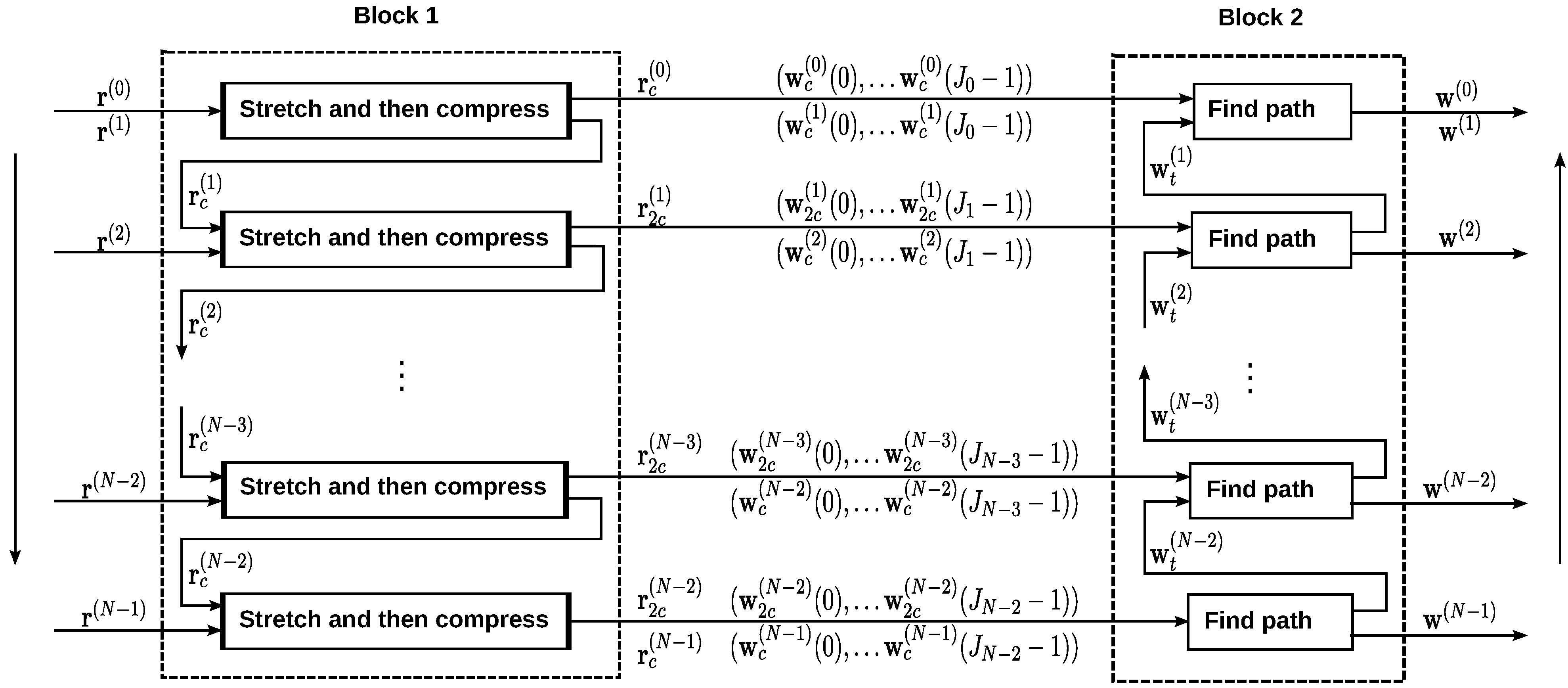
3.4. Track Alignment
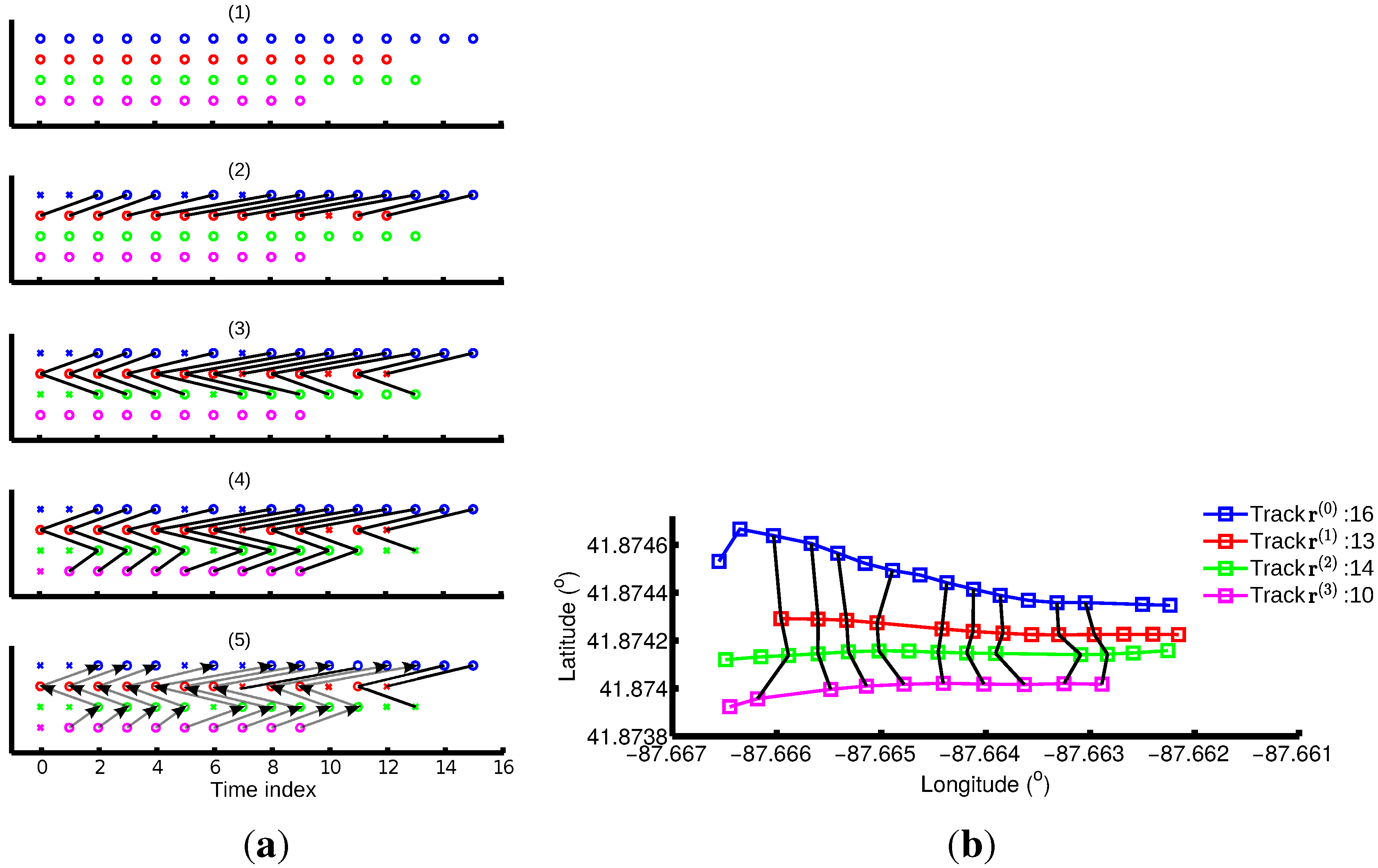
3.4.1. Two-Track Alignment Using DTW
- Boundary conditions: The warp path must start at the beginning of each time series and end at the end of each time series: , , and .
- Monotonicity: The warp path must be monotonically nondecreasing along both time axes: and .
- Continuity: Any two adjacent steps of the warp paths follow the . With this constraint, the warp path for each track moves at most one point at a time.

3.4.2. “Stretch and then Compress” Strategy
3.4.3. Multiple Track Alignment


3.5. Statistical Analysis
4. Evaluation of Algorithm Performance
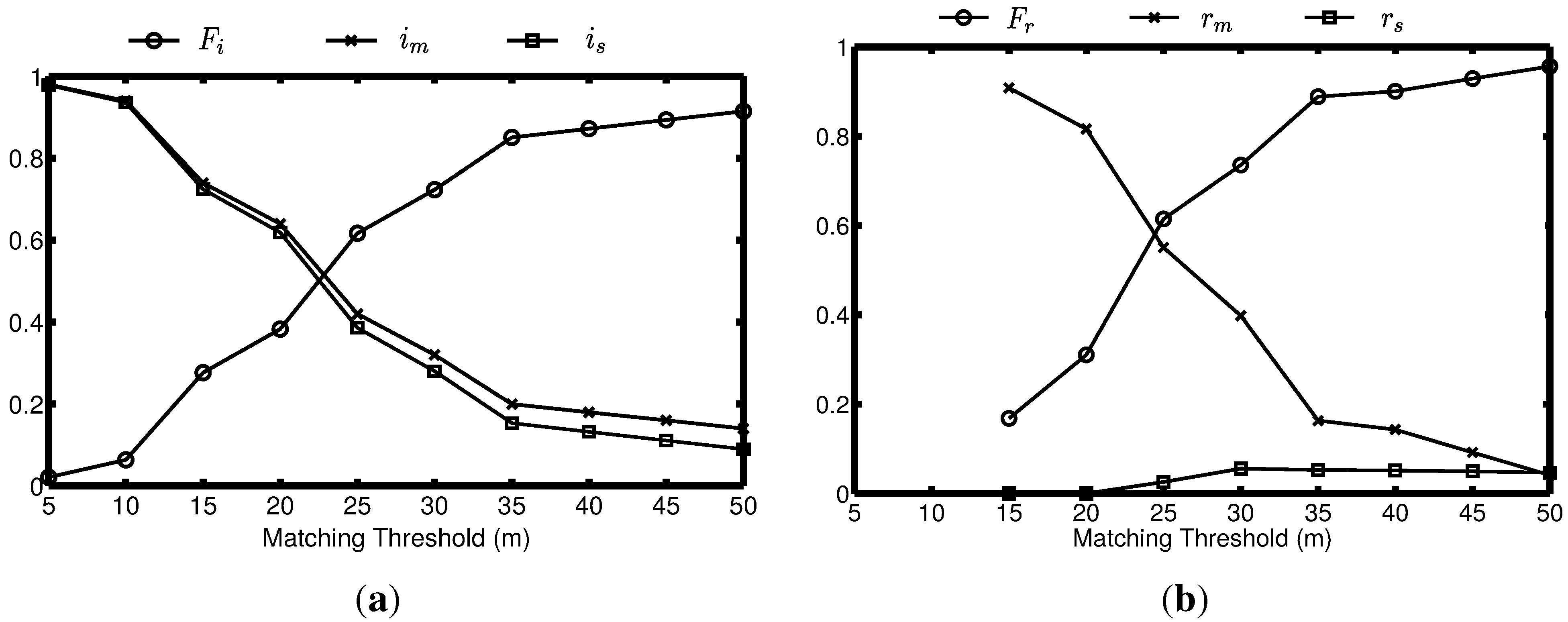
4.1. Topological Accuracy Calculation
4.2. Geographical Accuracy Evaluation

5. Experiments


5.1. Results Using Our Method
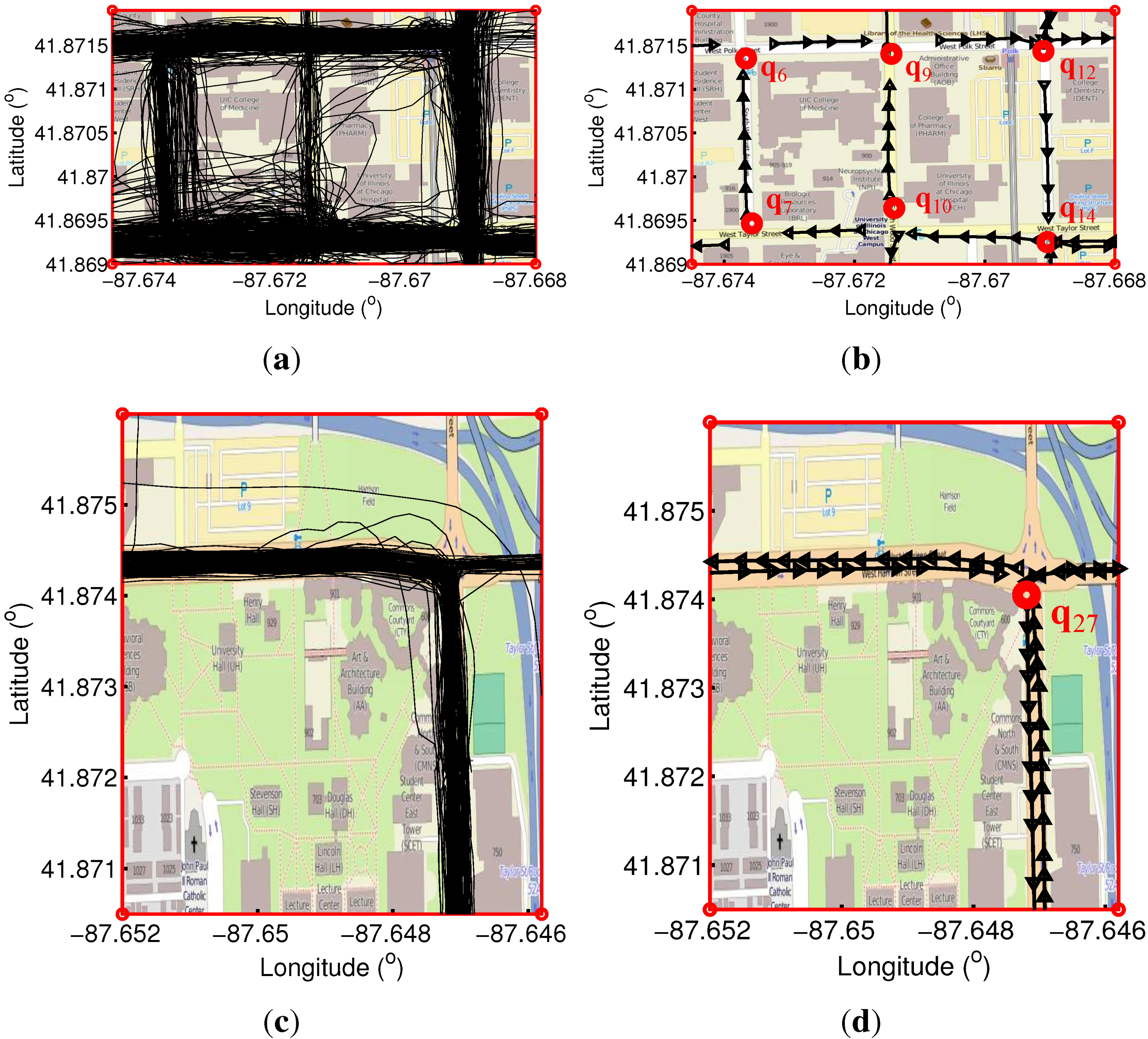
5.1.1. Inferred Turning Points and Intersections

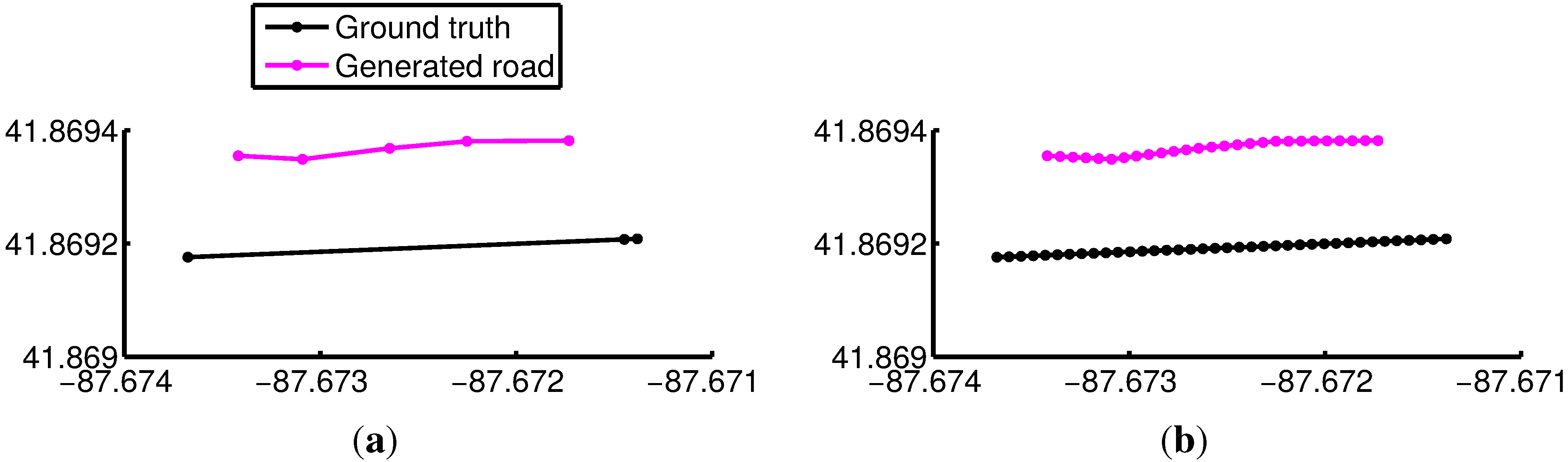
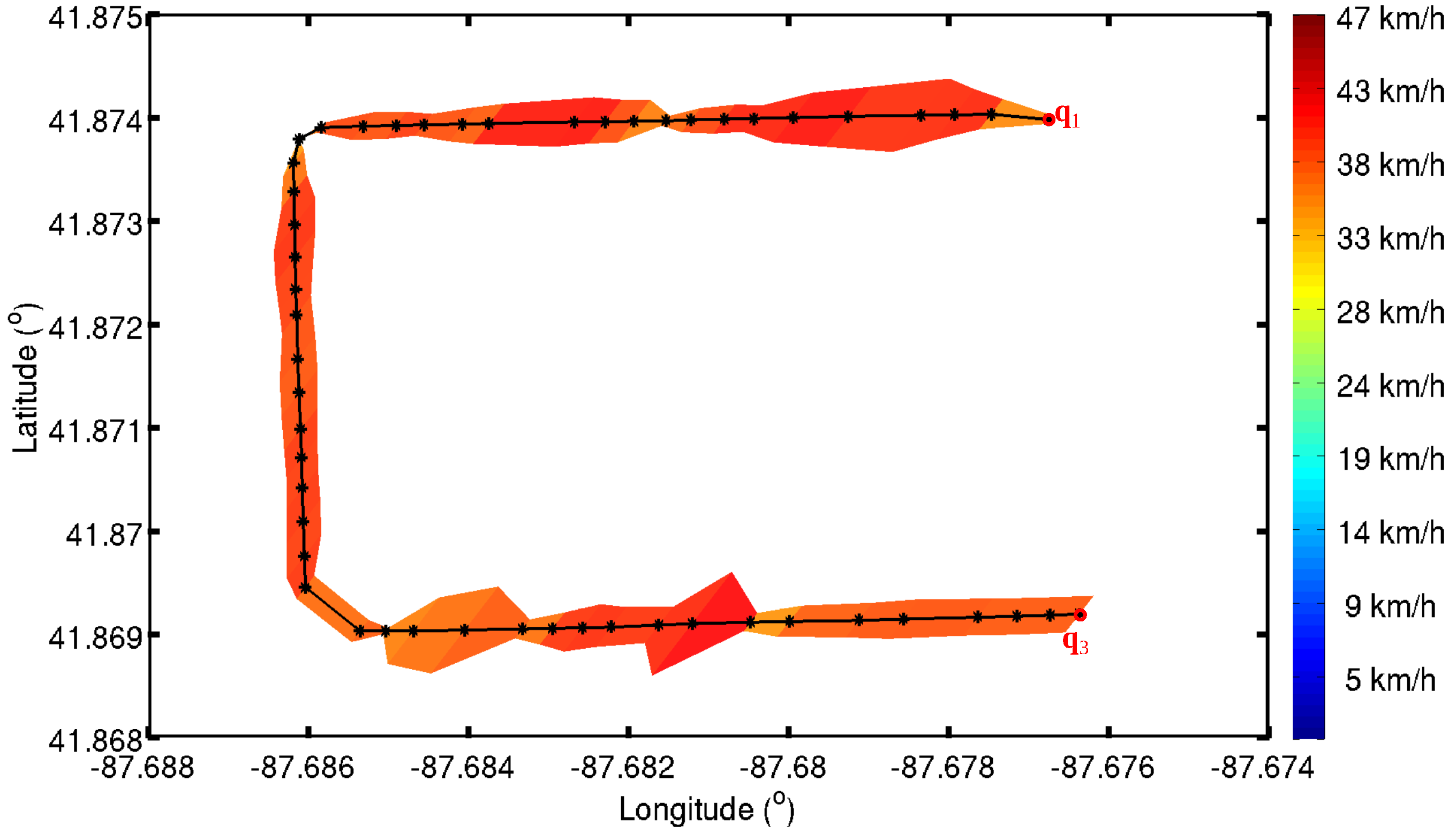
5.1.2. Inferred Roads
5.1.3. Results Evaluation


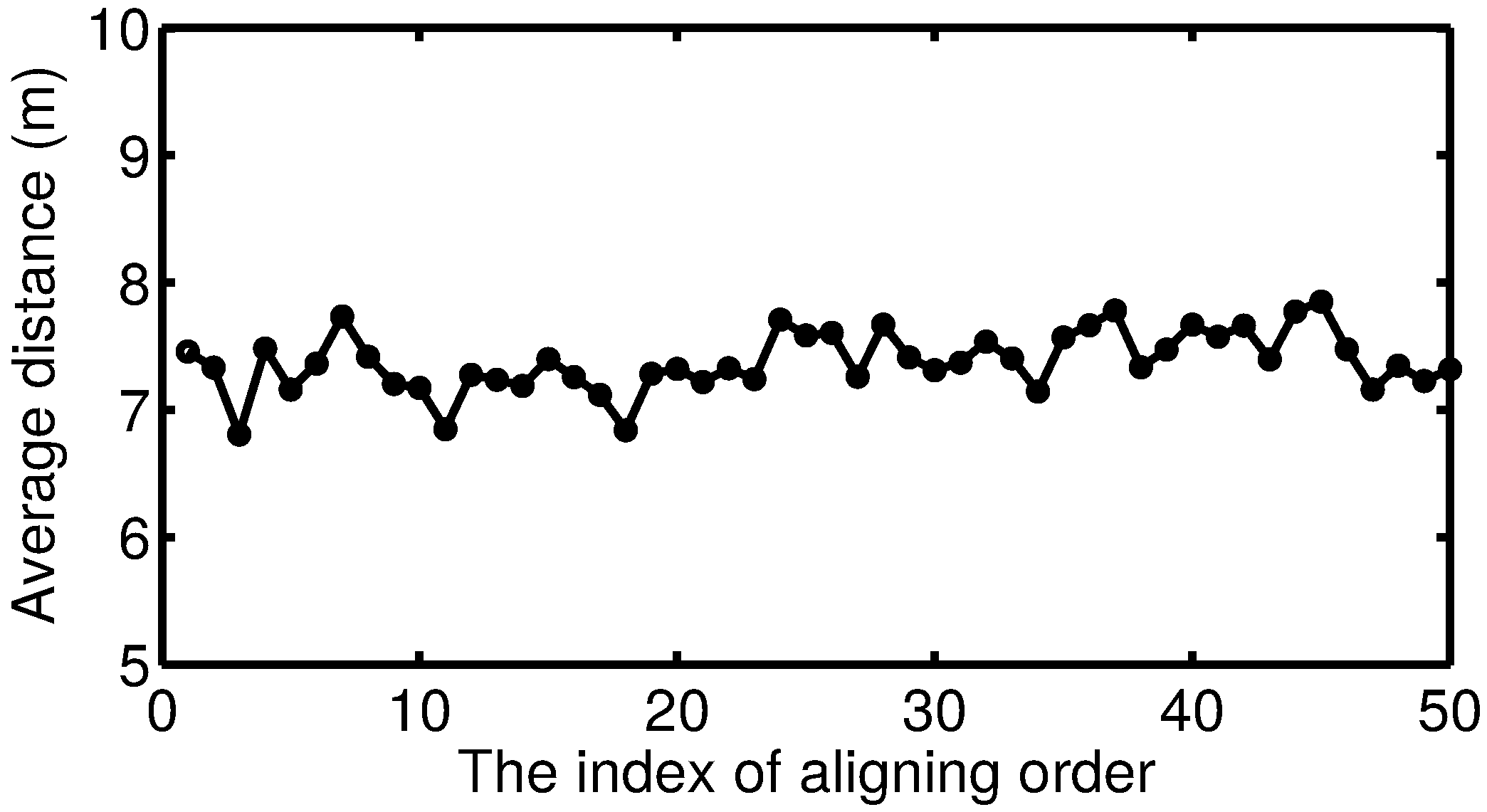
5.1.4. Discussion of How the Aligning Order Affects the Results

5.2. Comparison with Other Methods

6. Conclusions and Future Work
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Biagioni, J.; Eriksson, J. Map inference in the face of noise and disparity. In Proceedings of the 20th International Conference on Advances in Geographic Information Systems, Redondo Beach, CA, USA, 7–9 November 2012; ACM: New York, NY, USA, 2012; pp. 79–88. [Google Scholar]
- Schroedl, S.; Wagstaff, K.; Rogers, S.; Langley, P.; Wilson, C. Mining GPS traces for map refinement. Data Min. Knowl. Discov. 2004, 9, 59–87. [Google Scholar] [CrossRef]
- Davics, J.; Beresford, A.R.; Hopper, A. Scalable, distributed, real-time map generation. IEEE Pervasive Comput. 2006, 5, 47–54. [Google Scholar]
- Cao, L.; Krumm, J. From GPS traces to a routable road map. In Proceedings of the 17th ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems, Seattle, WA, USA, 4–6 November 2009.
- Shi, W.; Shen, S.; Liu, Y. Automatic generation of road network map from massive GPS, vehicle trajectories. In Proceedings of the IEEE 12th International Conference on Intelligent Transportation Systems, St. Louis, MO, USA, 4–7 October 2009.
- Sato, J.; Takahashi, T.; Ide, I.; Murase, H. Change detection in streetscapes from GPS coordinated omni-directional image sequences. In Proceedings of the IEEE 18th International Conference on Pattern Recognition, Hong Kong, China, 20–24 August 2006.
- Vlahogianni, E.I.; Karlaftis, M.G.; Golias, J.C. Optimized and meta-optimized neural networks for short-term traffic flow prediction: A genetic approach. Transp. Res. Part C Emerg. Technol. 2005, 13, 211–234. [Google Scholar] [CrossRef]
- Syberfeldt, A.; Persson, L. Using Heuristic Search for Initiating the Genetic Population in Simulation-Based Optimization of Vehicle Routing Problems. In Proceedings of the Industrial Simulation Conference, EUROSIS-ETI, Loughborough, UK, 1–3 June 2009.
- Schultes, D. Route Planning in Road Networks. Ph.D. Thesis, Karlsruhe Institute of Technology, Karlsruhe, Germany, 2008. [Google Scholar]
- Niehoefer, B.; Burda, R.; Wietfeld, C.; Bauer, F.; Lueert, O. GPS community map generation for enhanced routing methods based on trace-collection by mobile phones. In Proceedings of the IEEE 1st International Conference on Advances in Satellite and Space Communications, Colmar, France, 20–25 July 2009.
- Kukko, A.; Andrei, C.O.; Salminen, V.M.; Kaartinen, H.; Chen, Y.; Rönnholm, P.; Hyyppä, H.; Hyyppä, J.; Chen, R.; Haggrén, H.; et al. Road environment mapping system of the Finnish Geodetic InstituteâĂŤFGI Roamer. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2007, 36, 241–247. [Google Scholar]
- Bellens, R.; Vlassenroot, S.; Gautama, S. Collection and analyses of crowd travel behaviour data by using smartphones. In Proceedings of the BIVEC-GIBET 5th Transport Research Day, Namur, Belgium, 25 May 2011.
- Lee, D.; Hahn, M. Bicycle safety map system based on smartphone aided sensor network. Adv. Sci. Technol. Lett. 2013, 42, 38–43. [Google Scholar]
- Haklay, M.; Weber, P. Openstreetmap: User-generated street maps. IEEE Pervasive Comput. 2008, 7, 12–18. [Google Scholar] [CrossRef]
- Haklay, M. How good is volunteered geographical information? A comparative study of OpenStreetMap and Ordnance Survey datasets. Environ. Plan. B Plan. Des. 2010, 37, 682–703. [Google Scholar] [CrossRef]
- Biagioni, J.; Eriksson, J. Inferring road maps from global positioning system traces. Transp. Res. Rec. J. Transp. Res. Board 2012, 2291, 61–71. [Google Scholar] [CrossRef]
- Zheng, Y.; Li, Q.; Chen, Y.; Xie, X.; Ma, W.Y. Understanding mobility based on GPS data. In Proceedings of the 10th International Conference on Ubiquitous Computing, Seoul, Korea, 21–24 September 2008.
- Edelkamp, S.; Schrödl, S. Route planning and map inference with global positioning traces. In Computer Science in Perspective; Springer: Berlin, Germany; Heidelberg, Germany, 2003; pp. 128–151. [Google Scholar]
- You, Q.; Krumm, J. Transit tomography using probabilistic time geography: Planning routes without a road map. J. Locat. Based Serv. 2014, 8, 211–228. [Google Scholar] [CrossRef]
- Xie, X.; Philips, W.; Veelaert, P.; Aghajan, H. Road network inference from GPS traces using DTW algorithm. In Proceedings of the IEEE 17th International Conference on Intelligent Transportation Systems (ITSC), Qingdao, China, 8–11 October 2014; pp. 906–911.
- Liu, B. Web Data Mining; Springer: Berlin, Germany; Heidelberg, Germany, 2007. [Google Scholar]
- Chen, C.; Cheng, Y. Roads digital map generation with multi-track gps data. In Proceedings of the IEEE InternationalWorkshop on Education Technology and Training, 2008. and 2008 International Workshop on Geoscience and Remote Sensing, Shanghai, China, 21–22 December 2008.
- Morris, S.; Morris, A.; Barnard, K. Digital trail libraries. In Proceedings of the 4th ACM/IEEE-CS Joint Conference on Digital Libraries, Tucson, AZ, USA, 7–11 June 2004; ACM: New York, NY, USA, 2004. [Google Scholar]
- Karagiorgou, S.; Pfoser, D. On vehicle tracking data-based road network generation. In Proceedings of the 20th International Conference on Advances in Geographic Information Systems, Redondo Beach, CA, USA, 7–9 November 2012.
- Berndt, D.J.; Clifford, J. Using Dynamic Time Warping to Find Patterns in Time Series; KDD: Seattle, WA, USA, 1994. [Google Scholar]
- Greenfeld, J.S. Matching GPS observations to locations on a digital map. In Proceedings of the Transportation Research Board 81st Annual Meeting, Washington, DC, USA, 13–17 January 2002.
- Calcagno, P.; Chilès, J.P.; Courrioux, G.; Guillen, A. Geological modelling from field data and geological knowledge: Part I. Modelling method coupling 3D potential-field interpolation and geological rules. Phys. Earth Planet. Inter. 2008, 171, 147–157. [Google Scholar] [CrossRef]
- BITS Networked Systems Laboratory. Available online: http://bits.cs.uic.edu/ (accessed on 24 August 2015).
- OpenStreetMap. Available online: http://www.openstreetmap.org/ (accessed on 24 August 2015).
© 2015 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xie, X.; Bing-YungWong, K.; Aghajan, H.; Veelaert, P.; Philips, W. Inferring Directed Road Networks from GPS Traces by Track Alignment. ISPRS Int. J. Geo-Inf. 2015, 4, 2446-2471. https://0-doi-org.brum.beds.ac.uk/10.3390/ijgi4042446
Xie X, Bing-YungWong K, Aghajan H, Veelaert P, Philips W. Inferring Directed Road Networks from GPS Traces by Track Alignment. ISPRS International Journal of Geo-Information. 2015; 4(4):2446-2471. https://0-doi-org.brum.beds.ac.uk/10.3390/ijgi4042446
Chicago/Turabian StyleXie, Xingzhe, Kevin Bing-YungWong, Hamid Aghajan, Peter Veelaert, and Wilfried Philips. 2015. "Inferring Directed Road Networks from GPS Traces by Track Alignment" ISPRS International Journal of Geo-Information 4, no. 4: 2446-2471. https://0-doi-org.brum.beds.ac.uk/10.3390/ijgi4042446