
An Extended Semi-Supervised Regression Approach with Co-Training and Geographical Weighted Regression: A Case Study of Housing Prices in Beijing

Abstract
:1. Introduction
2. Literature Review
3. Data and Methods
3.1. Data Used in the Experiments

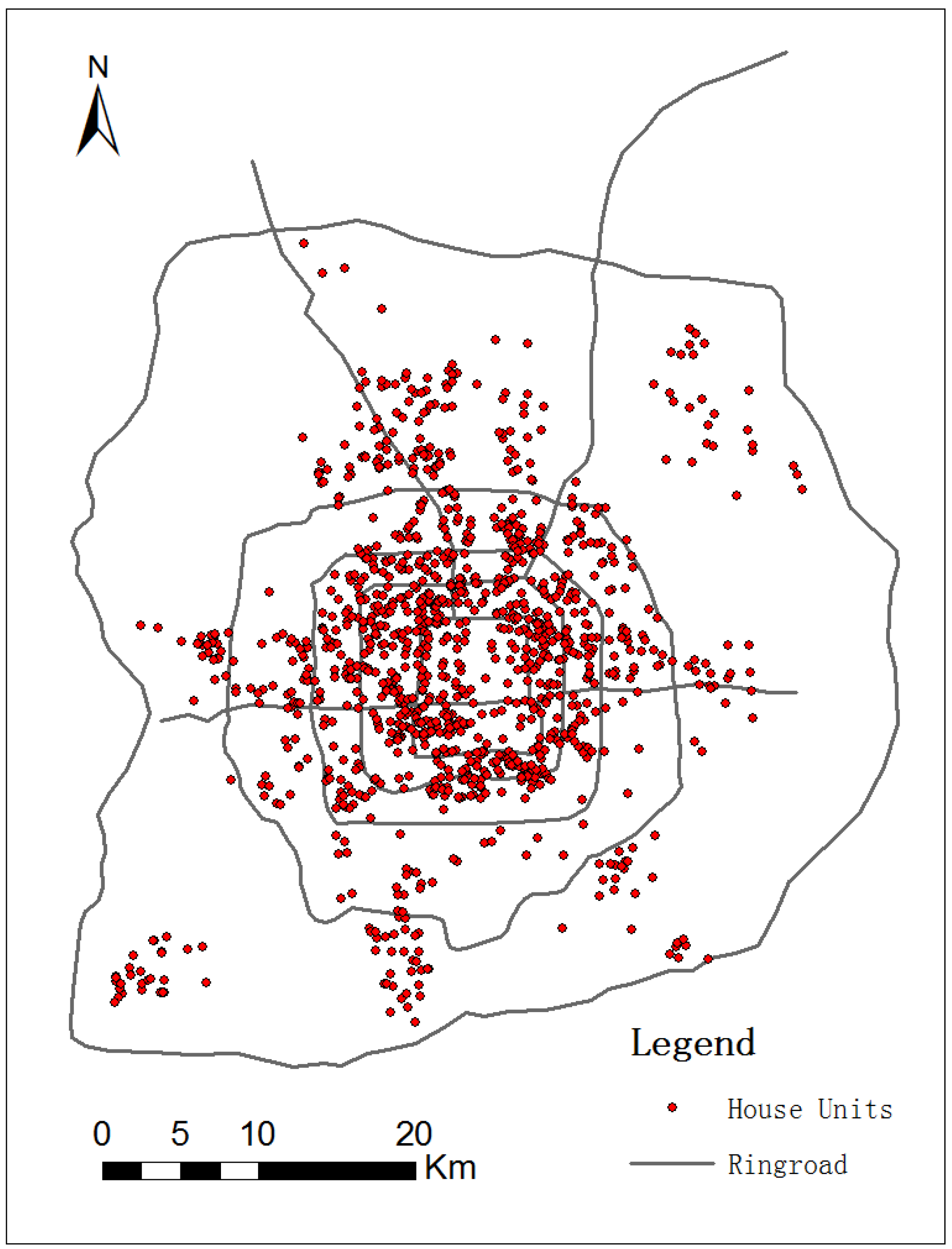{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Abbreviation | Description | Minimum | Mean | Maximum |
|---|---|---|---|---|
| lnp | Log sales transactions price of the house | 12.468 | 14.897 | 17.990 |
| Structural covariates | ||||
| lnarea_total | Log of total floor area | 2.303 | 4.317 | 6.385 |
| nbath | Number of bath rooms | 0 | 1 | 3 |
| lnpfee | Log fee of property management | −1.513 | 0.470 | 6.534 |
| lnplotratio | Log plot ratio of houses | −1.323 | 0.693 | 3.401 |
| lngratio | Log green ratio | −4.605 | 3.401 | 4.443 |
| Temporal covariates | ||||
| age | Age of building at time of sale (1996–2015) | 1 | 9 | 20 |
| Neighborhood covariates | ||||
| ringroad | Within the major road ring | 2 | 4 | 6 |

3.2. Methods
3.2.1. Geographically-Weighted Regression Model
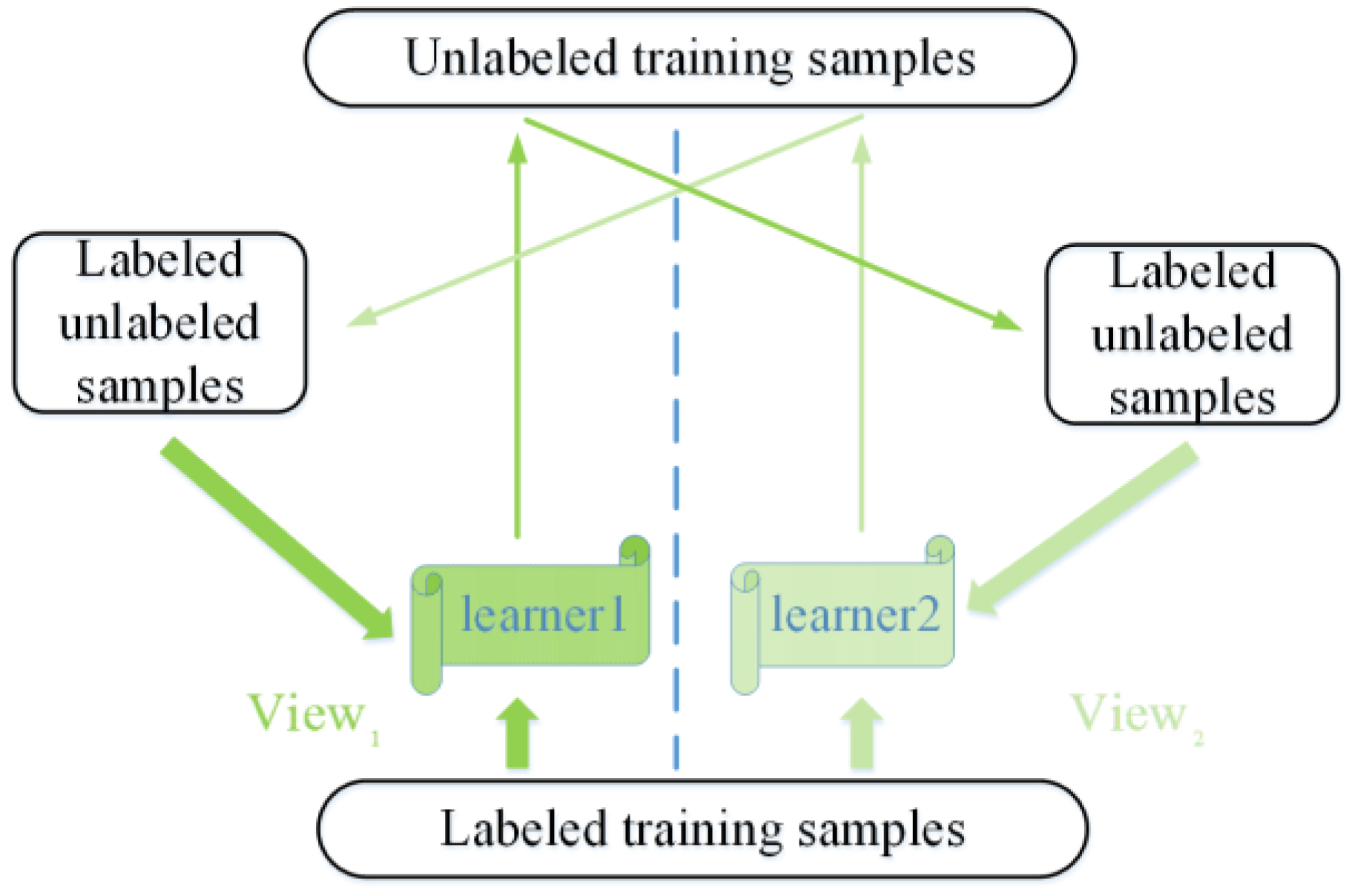
3.2.2. Co-Training Learning Paradigm

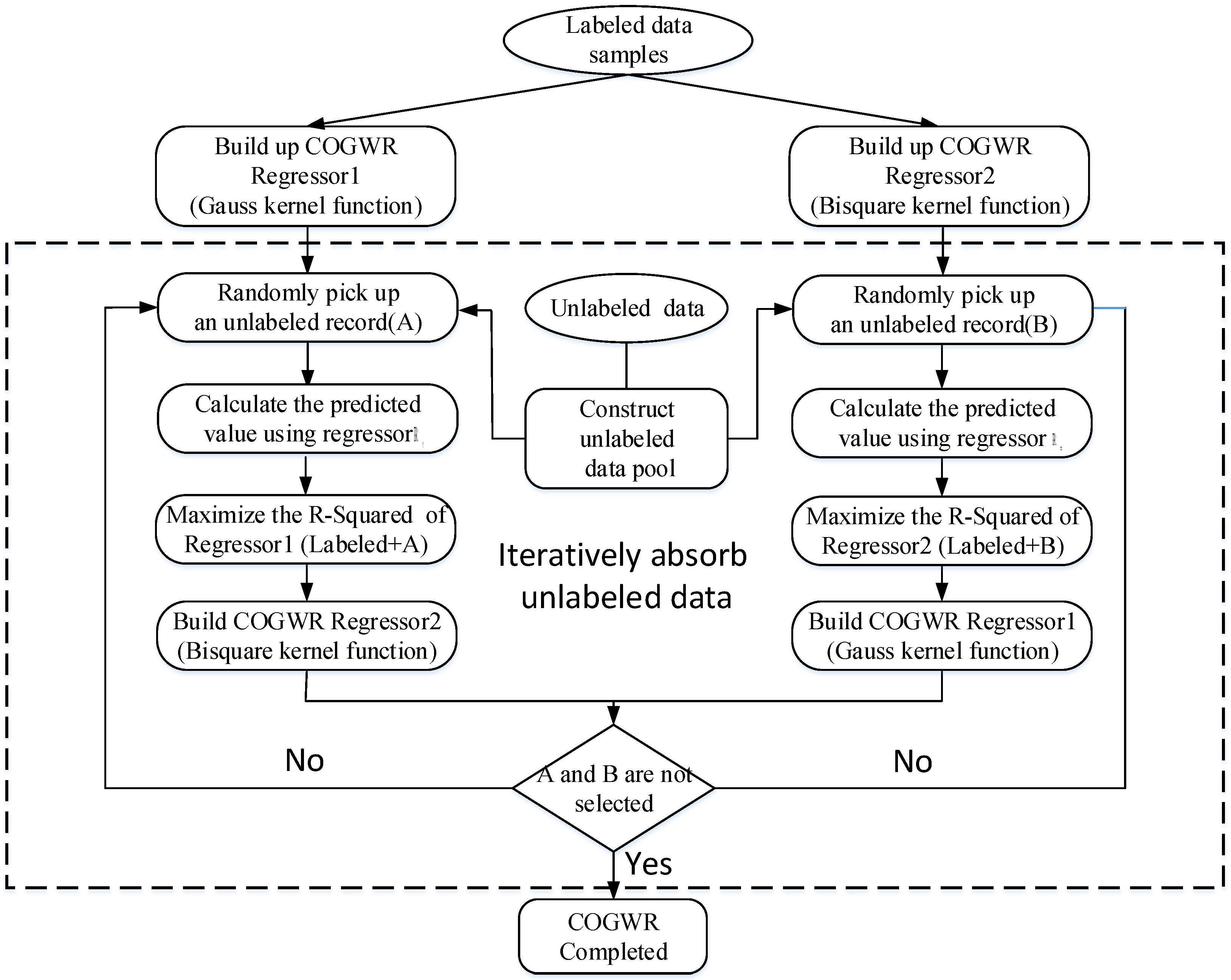
3.2.3. Co-Training Geographically-Weighted Regression Approach
- (1)
- Assign the predicted value of the no real value record using COGWR regressor and add the record to the COGWR regressor . If the of decreases in relation to the original using Equation (2), this record will be absorbed by regressor .
- (2)
- Otherwise, assign the predicted value of the no real value record using the COGWR regressor and add the record to the COGWR regressor . If the of decreases in relation to the original, this record will be absorbed by the regressor.
- (3)
- If the unlabeled record is absorbed by neither regressor nor regressor, then end the iteration.

4. Experimental Results and Comparisons
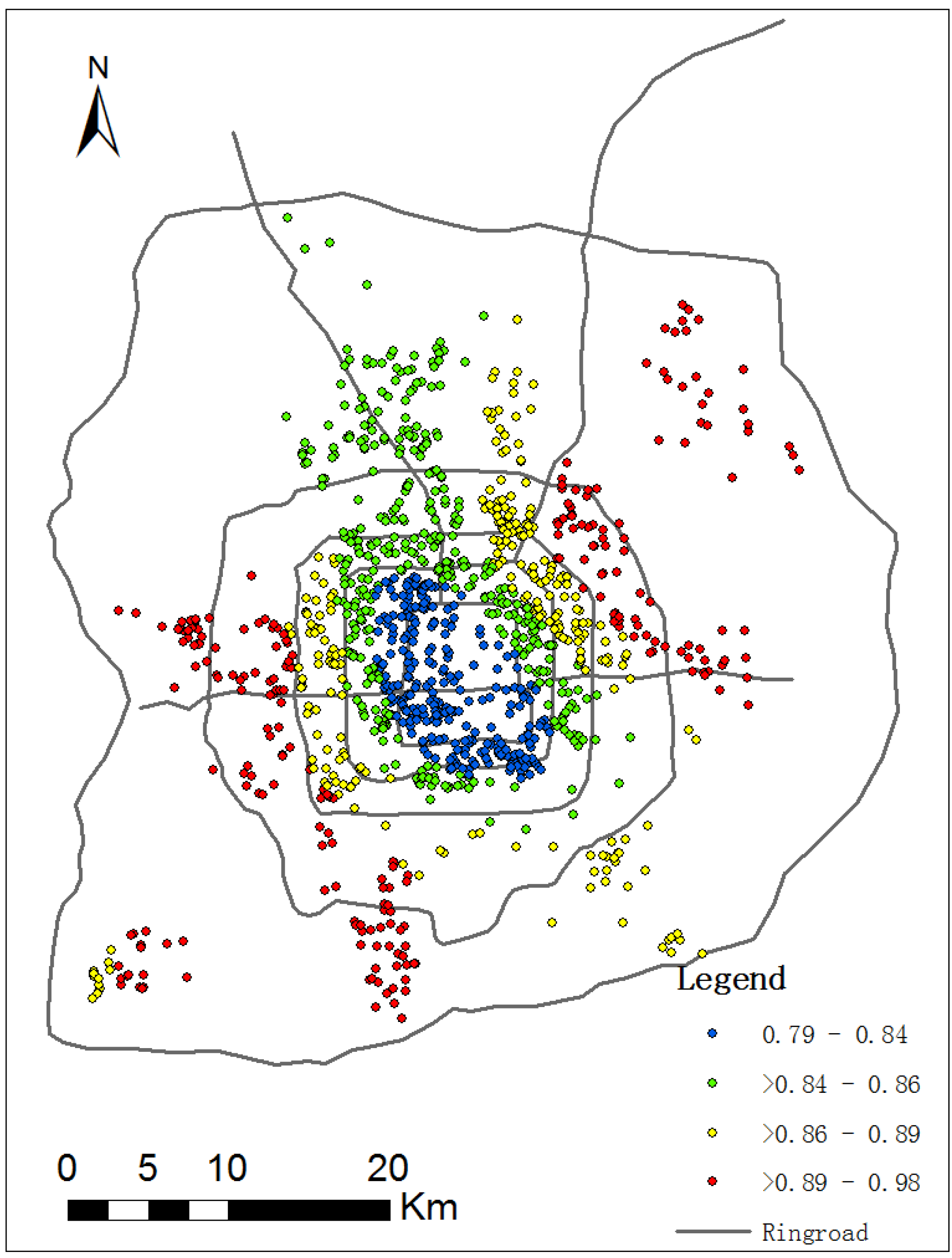
4.1. The Results of GWR Model
| Parameter | Min | LQ | Med | UQ | Max |
|---|---|---|---|---|---|
| constant | 11.29 | 11.59 | 11.70 | 11.86 | 12.24 |
| lnarea_total | 0.79 | 0.84 | 0.86 | 0.89 | 0.98 |
| nbath | 0.02 | 0.08 | 0.10 | 0.13 | 0.17 |
| lnpfee | −0.01 | 0.00 | 0.00 | 0.01 | 0.01 |
| lnplotratio | −0.23 | −0.19 | −0.16 | −0.13 | −0.07 |
| lngratio | −0.01 | 0.00 | 0.00 | 0.01 | 0.03 |
| age | 0.01 | 0.02 | 0.02 | 0.02 | 0.04 |
| ringroad | −0.03 | −0.01 | 0.00 | 0.01 | 0.02 |
| Diagnostic information | |||||
| R2 | 0.701 | ||||
| AdjustedR2 | 0.677 | ||||
| AIC | 846.410 | ||||
| Parameter | Variance | F-statistic | p-Value |
|---|---|---|---|
| constant | 7.221 | 37.620 | <0.001 * |
| lnarea_total | 0.029 | 2.417 | <0.001 * |
| nbath | 0.024 | 1.241 | 0.185 |
| lnpfee | 0.005 | 6.564 | <0.001 * |
| lnplotratio | 0.001 | 2.767 | <0.001 * |
| lngratio | 0.011 | 4.572 | <0.001 * |
| age | 0.000 | 3.956 | <0.001 * |
| ringroad | 0.624 | 149.913 | <0.001 * |

4.2. Comparison of the COGWR with the GWR Model
| Comparison between Different Models | The Labeling Ratio of Housing Price Data | |||||
|---|---|---|---|---|---|---|
| 10% | 20% | 30% | 40% | 50% | ||
| COGWR (Gauss kernel function) regressor/GWR Improvement | RSS | 3.242 | 3.375 | 3.551 | −0.144 | −0.314 |
| MSE | 0.010 | 0.010 | 0.011 | 0.000 | −0.001 | |
| AIC | 23.716 | 36.479 | 41.921 | −2.892 | −4.812 | |
| COGWR (bi-square kernel function) regressor/GWR Improvement | RSS | 2.216 | 2.801 | 2.909 | 0.101 | −1.633 |
| MSE | 0.007 | 0.008 | 0.009 | 0.000 | −0.005 | |
| AIC | 18.645 | 21.328 | 22.899 | 2.204 | −16.641 | |
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Kim, K.; Park, J. Segmentation of the housing market and its determinants: Seoul and its neighbouring new towns in Korea. J. Aust. Geogr. 2005, 36, 221–232. [Google Scholar] [CrossRef]
- Selim, S. Determinants of house prices in Turkey: A hedonic regression model. J. Doğuş Üniv. Dergisi. 2011, 9, 65–76. [Google Scholar]
- Harris, R.; Dong, G.; Zhang, W. Using contextualized geographically weighted regression to model the spatial heterogeneity of land prices in Beijing, China. Trans. GIS 2013, 17, 901–919. [Google Scholar] [CrossRef]
- Lu, B.; Charlton, M.; Harris, P.; Fotheringham, A.S. Geographically weighted regression with a non-euclidean distance metric: A case study using hedonic house price data. Int. J. Geogr. Inf. Sci. 2014, 28, 660–681. [Google Scholar] [CrossRef]
- Wu, B.; Li, R.; Huang, B. A geographically and temporally weighted autoregressive model with application to housing prices. Int. J. Geogr. Inf. Sci. 2014, 28, 1186–1204. [Google Scholar] [CrossRef]
- Brunsdon, C.; Fotheringham, A.S.; Charlton, M. Some notes on parametric significance tests for geographically weighted regression. J. Reg. Sci. 1999, 39, 497–524. [Google Scholar] [CrossRef]
- Brunsdon, C.; Fotheringham, A.S.; Charlton, M.E. Geographically weighted regression: A method for exploring spatial nonstationarity. Geogr. Anal. 1996, 28, 281–298. [Google Scholar] [CrossRef]
- Huang, Y.; Leung, Y. Analysing regional industrialisation in Jiangsu province using geographically weighted regression. J. Geogr. Syst. 2002, 4, 233–249. [Google Scholar] [CrossRef]
- Bourassa, S.; Cantoni, E.; Hoesli, M. Predicting house prices with spatial dependence: A comparison of alternative methods. J. Real. Estate Ers 2010, 32, 139–159. [Google Scholar]
- Dubin, R.A. Spatial autocorrelation: A primer. J. Hous. Econ. 1998, 7, 304–327. [Google Scholar] [CrossRef]
- Redfearn, C.L. How informative are average effects? Hedonic regression and amenity capitalization in complex urban housing markets. Reg. Sci. Urban Econ. 2009, 39, 297–306. [Google Scholar]
- Helbich, M.; Brunauer, W.; Caz, E.; Nijkamp, P. Spatial heterogeneity in hedonic house price models—The case of Austria. Urban Stud. 2014, 51, 390–411. [Google Scholar] [CrossRef]
- LeSage, J.P. An introduction to spatial econometrics. Rev. Econ. Ind. 2008, 123, 19–44. [Google Scholar] [CrossRef]
- Pace, R.K.; Gilley, O.W. Generalizing the OLS and grid estimators. R. Estate Econ. 1998, 26, 331–347. [Google Scholar] [CrossRef]
- Goodman, A.C.; Thibodeau, T.G. Housing market segmentation and hedonic prediction accuracy. J. Hous. Econ. 2003, 12, 181–201. [Google Scholar] [CrossRef]
- Blum, A.; Mitchell, T. Combining labeled and unlabeled data with co-training. In Proceedings of the 11th Annual Conference on Computational Learning Theory (ACM), Madison, WI, USA, 24–26 July 1998.
- Brefeld, U.; Gärtner, T.; Scheffer, T.; Wrobel, S. (Eds.) Efficient co-regularised least squares regression. In Proceedings of the 23rd International Conference on Machine Learning (ACM), Pittsburgh, PA, USA, 25–29 June 2006.
- Zhou, Z.H.; Li, M. Semi-supervised regression with co-training. In Proceedings of 2005 International Joint Conferences on Artificial Intelligence, Edinburgh, Scotland, 30 July–5 August 2005.
- Zhou, Z.H.; Li, M. Semisupervised regression with cotraining-style algorithms. IEEE Trans. Knowl. Data Eng. 2007, 19, 1479–1493. [Google Scholar] [CrossRef]
- Tan, K.; Li, E.; Du, Q.; Du, P. An efficient semi-supervised classification approach for hyperspectral imagery. ISPRS J. Photogram. Remote Sens. 2014, 97, 36–45. [Google Scholar] [CrossRef]
- Huang, B.; Wu, B.; Barry, M. Geographically and temporally weighted regression for modeling spatio-temporal variation in house prices. Int. J. Geogr. Inf. Sci. 2010, 24, 383–401. [Google Scholar] [CrossRef]
- Goodman, A.C. Andrew Court and the invention of hedonic price analysis. J. Urban Econ. 1998, 44, 291–298. [Google Scholar] [CrossRef]
- Yu, D.; Wei, Y.D.; Wu, C. Modeling spatial dimensions of housing prices in Milwaukee, WI. Environ. Plan. B 2007, 34, 1085–1102. [Google Scholar] [CrossRef]
- Ustaoğlu, E. Hedonic Price Analysis of Office Rents: A Case Study of the Office Market in Ankara. Master Thesis, Middle East Technical University, Ankara, Turkey, 2003. [Google Scholar]
- Rosen, S. Hedonic prices and implicit markets: Product differentiation in pure competition. J. Polit. Econ. 1974, 82, 34–55. [Google Scholar] [CrossRef]
- Farber, S.; Yeates, M. A comparison of localized regression models in a hedonic house price context. Can. J. Reg. Sci. 2006, 29, 405–420. [Google Scholar]
- McMillen, D.P.; Redfearn, C.L. Estimation and hypothesis testing for nonparametric hedonic house price functions. J. Reg. Sci. 2010, 50, 712–733. [Google Scholar] [CrossRef]
- Helbich, M.; Brunauer, W.; Hagenauer, J.; Leitner, M. Data-driven regionalization of housing markets. Ann. Assoc. Am. Geogr. 2013, 103, 871–889. [Google Scholar] [CrossRef]
- Guan, J.; Zurada, J. An adaptive neuro-fuzzy inference system based approach to real estate property assessment. J. Real Estate Res. 2008, 30, 395–421. [Google Scholar]
- Peterson, S.; Flanagan, A. Neural network hedonic pricing models in mass real estate appraisal. J. Real Estate Res. 2009, 31, 147–164. [Google Scholar]
- Kuşan, H.; Aytekin, O.; Özdemir, İ. The use of fuzzy logic in predicting house selling price. Expert Syst. Appl. 2010, 37, 1808–1813. [Google Scholar] [CrossRef]
- Kestens, Y.; Thériault, M.; Des Rosiers, F. Heterogeneity in hedonic modelling of house prices: Looking at buyers’ household profiles. J. Geogr. Syst. 2006, 8, 61–96. [Google Scholar] [CrossRef]
- Zheng, S.; Kahn, M.E. Land and residential property markets in a booming economy: New evidence from Beijing. J. Urban Econ. 2008, 63, 743–757. [Google Scholar] [CrossRef]
- Zhou, Z.; Li, M. Semi-supervised learning by disagreement. Knowl. Inf. Syst. 2010, 24, 415–439. [Google Scholar] [CrossRef]
- Páez, A.; Long, F.; Farber, S. Moving window approaches for hedonic price estimation: An empirical comparison of modelling techniques. Urban Stud. 2008, 45, 1565–1581. [Google Scholar] [CrossRef]
- Goldman, S.; Zhou, Y. Enhancing supervised learning with unlabeled data. In Proceedings of the Seventeenth International Conference on Machine Learning, Stanford, CA, USA, 21–23 June 1990.
- Zhou, Z.; Li, M. Tri-training: Exploiting unlabeled data using three classifiers. IEEE Trans. Knowl. Data Eng. 2005, 17, 1529–1541. [Google Scholar] [CrossRef]
- Li, M.; Zhou, Z. Improve computer-aided diagnosis with machine learning techniques using undiagnosed samples. IEEE Trans. Syst. Man Cybern. A 2007, 37, 1088–1098. [Google Scholar] [CrossRef]
- Wheeler, D.C. Diagnostic tools and a remedial method for collinearity in geographically weighted regression. Environ. Plan. A 2007, 39, 2464. [Google Scholar] [CrossRef]
- Wheeler, D.; Tiefelsdorf, M. Multicollinearity and correlation among local regression coefficients in geographically weighted regression. J. Geogr. Syst. 2005, 7, 161–187. [Google Scholar] [CrossRef]
- David, B. Conditioning Diagnostics, Collinearity and Weak Data in Regression; John Wiley & Sons: Hobokon, NJ, USA, 1991. [Google Scholar]
- Leung, Y.; Mei, C.; Zhang, W. Statistical tests for spatial nonstationarity based on the geographically weighted regression model. Environ. Plan. A 2000, 32, 9–32. [Google Scholar] [CrossRef]
- Zhao, N.; Yang, Y.; Zhou, X. Application of geographically weighted regression in estimating the effect of climate and site conditions on vegetation distribution in Haihe catchment, China. Plant Ecol. 2010, 209, 349–359. [Google Scholar] [CrossRef]
- Fotheringham, A.S.; Brunsdon, C.; Charlton, M. Geographically Weighted Regression: The Analysis of Spatially Varying Relationship; Wiley: Chichester, UK, 2003. [Google Scholar]
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons by Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, Y.; Liu, J.; Xu, S.; Zhao, Y. An Extended Semi-Supervised Regression Approach with Co-Training and Geographical Weighted Regression: A Case Study of Housing Prices in Beijing. ISPRS Int. J. Geo-Inf. 2016, 5, 4. https://0-doi-org.brum.beds.ac.uk/10.3390/ijgi5010004
Yang Y, Liu J, Xu S, Zhao Y. An Extended Semi-Supervised Regression Approach with Co-Training and Geographical Weighted Regression: A Case Study of Housing Prices in Beijing. ISPRS International Journal of Geo-Information. 2016; 5(1):4. https://0-doi-org.brum.beds.ac.uk/10.3390/ijgi5010004
Chicago/Turabian StyleYang, Yi, Jiping Liu, Shenghua Xu, and Yangyang Zhao. 2016. "An Extended Semi-Supervised Regression Approach with Co-Training and Geographical Weighted Regression: A Case Study of Housing Prices in Beijing" ISPRS International Journal of Geo-Information 5, no. 1: 4. https://0-doi-org.brum.beds.ac.uk/10.3390/ijgi5010004