
A Semi-Automated Workflow Solution for Data Set Publication

 , ,
, ,
Abstract
:1. Introduction
2. ORNL DAAC
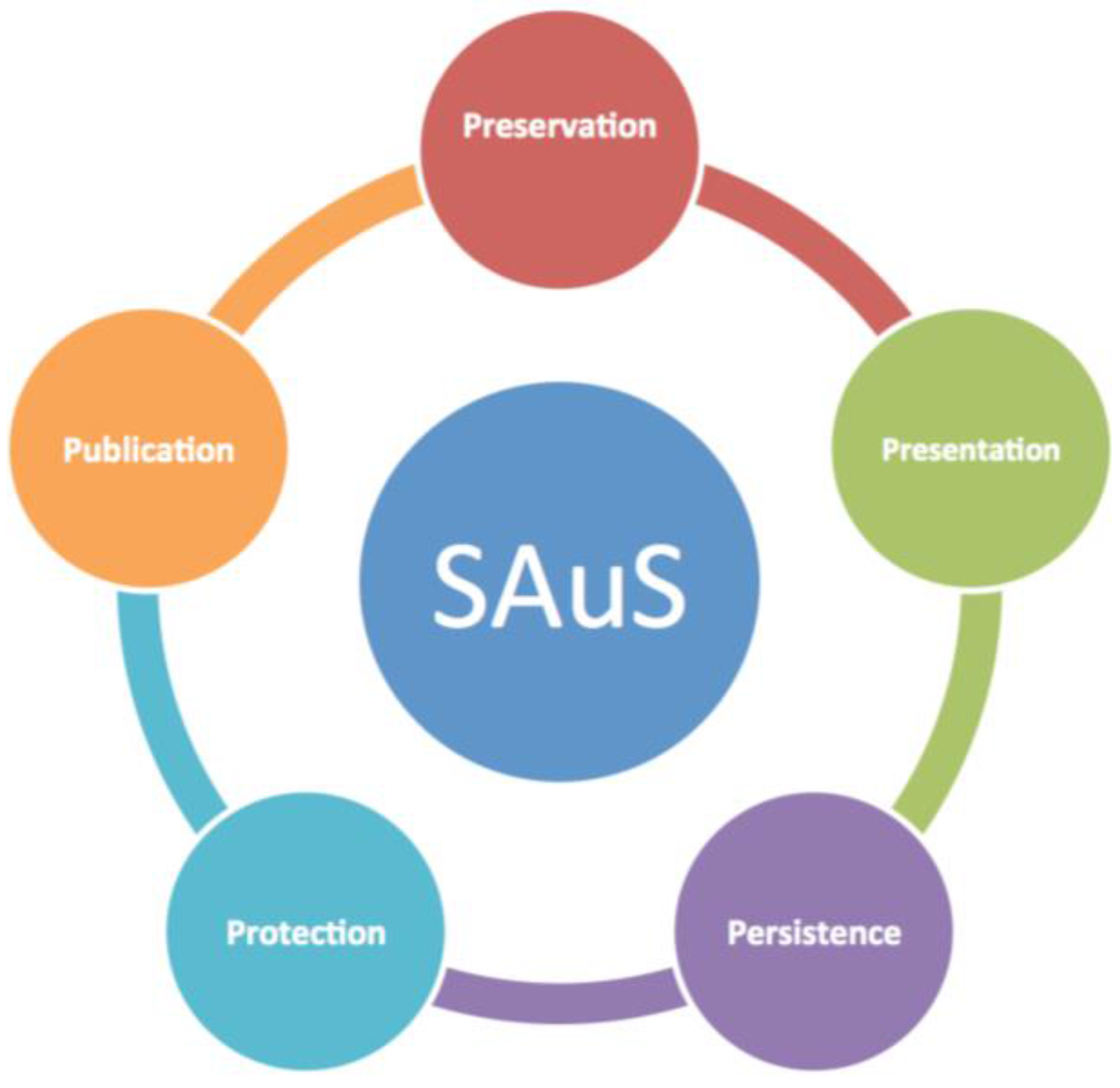
3. Data Ingest—Essential 5Ps
- (1)
- Accepting the data package from the data providers, ensuring the full integrity of the transferred data files (through checksums, file counts etc.);
- (2)
- Identifying and fixing data quality issues;
- (3)
- Assembling detailed metadata and documentation, including file-level details, processing methodology, and characteristics of data files;
- (4)
- Developing a discovery tool that allows users to search metadata for the data sets needed;
- (5)
- Setting up data access mechanisms;
- (6)
- Re-packaging data files to better suit the end user’s research/application needs (optional);
- (7)
- Setup of the data in data tools and services for improved data discovery and dissemination (optional);
- (8)
- Registering the data set in online search and discovery catalogues;
- (9)
- Provide a permanent identifier through Digital Object Identifiers (DOI).
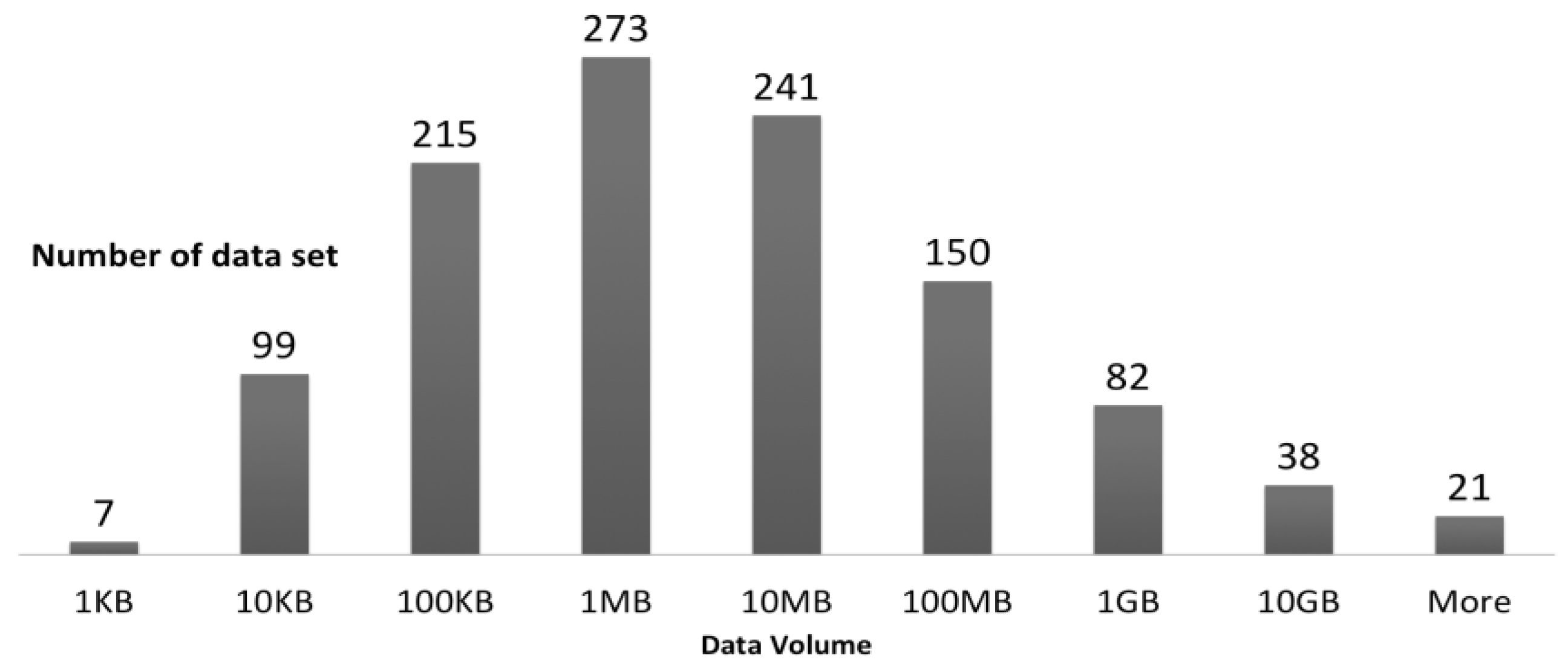
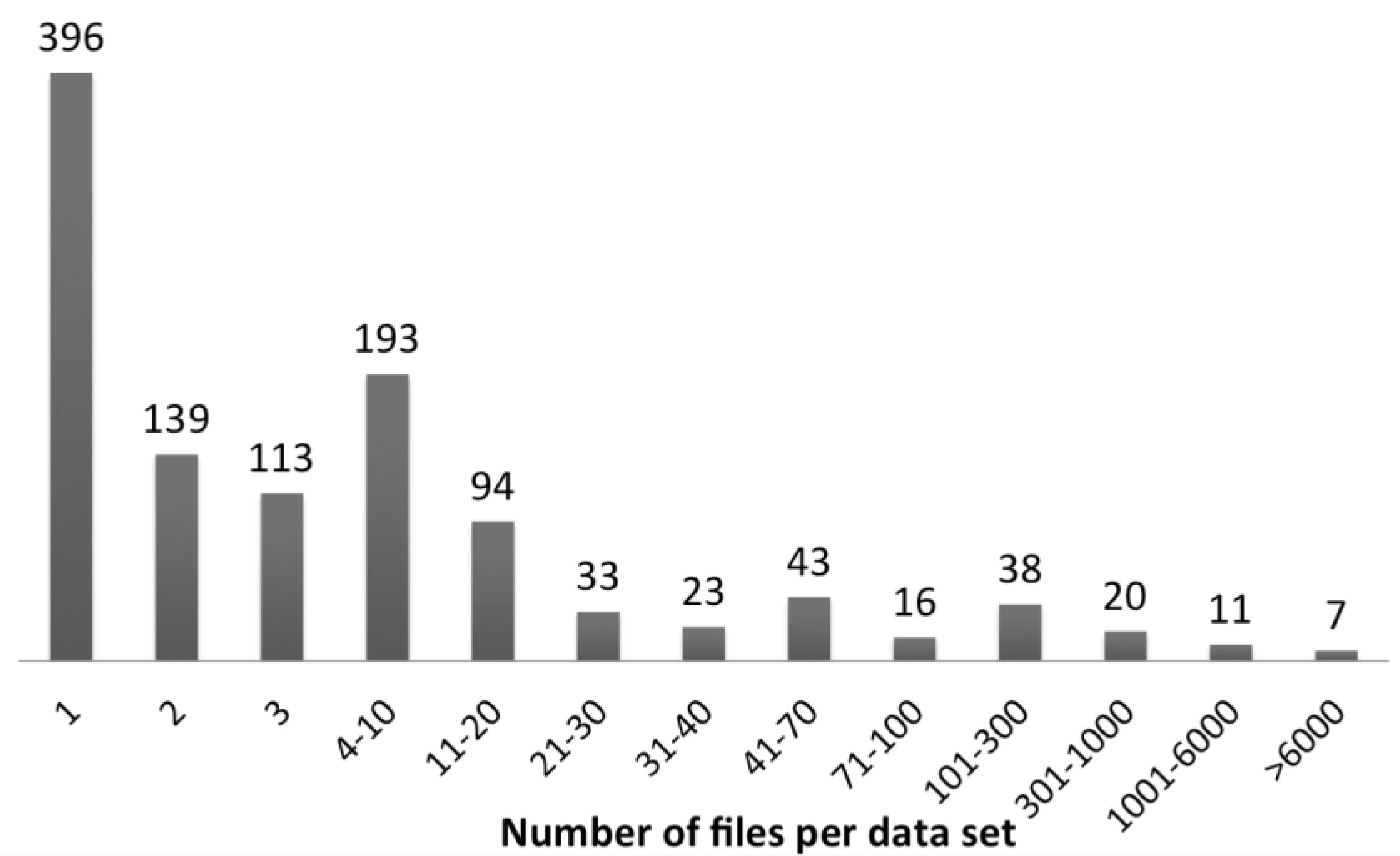
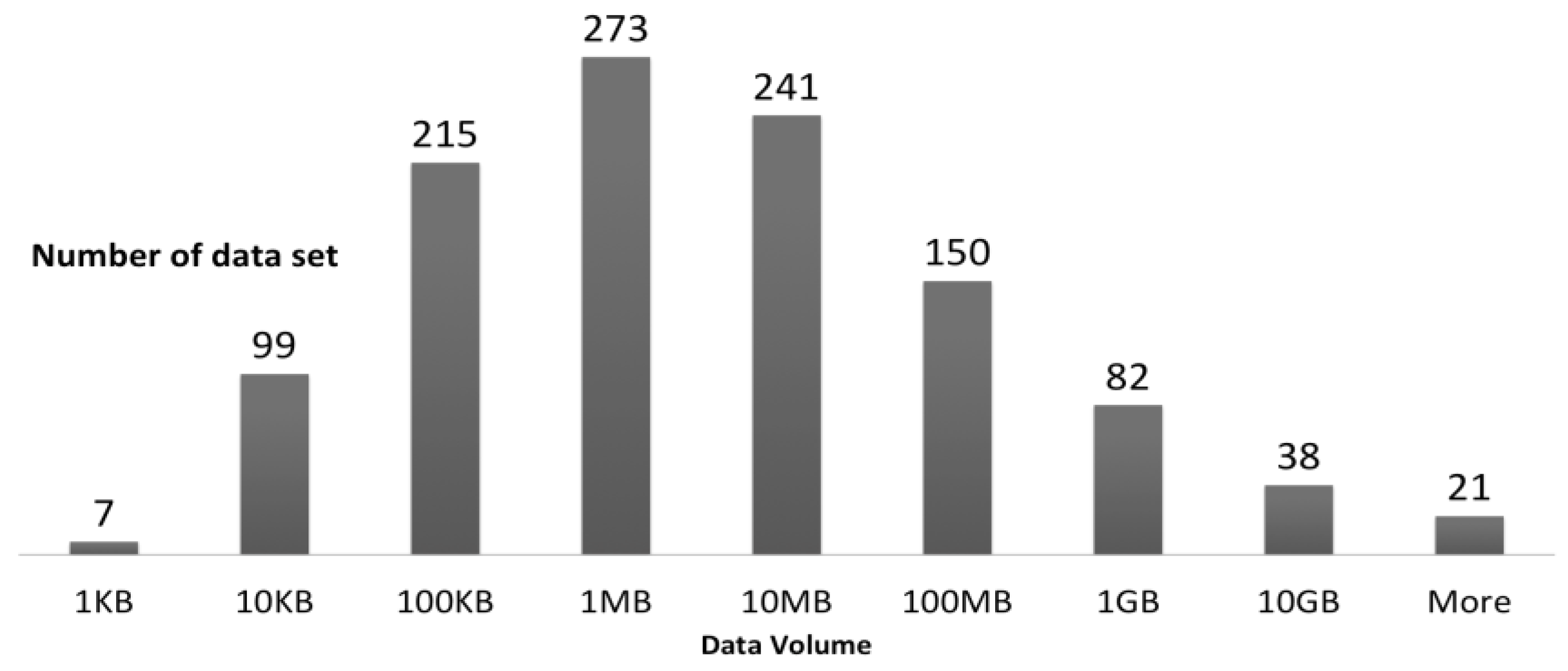
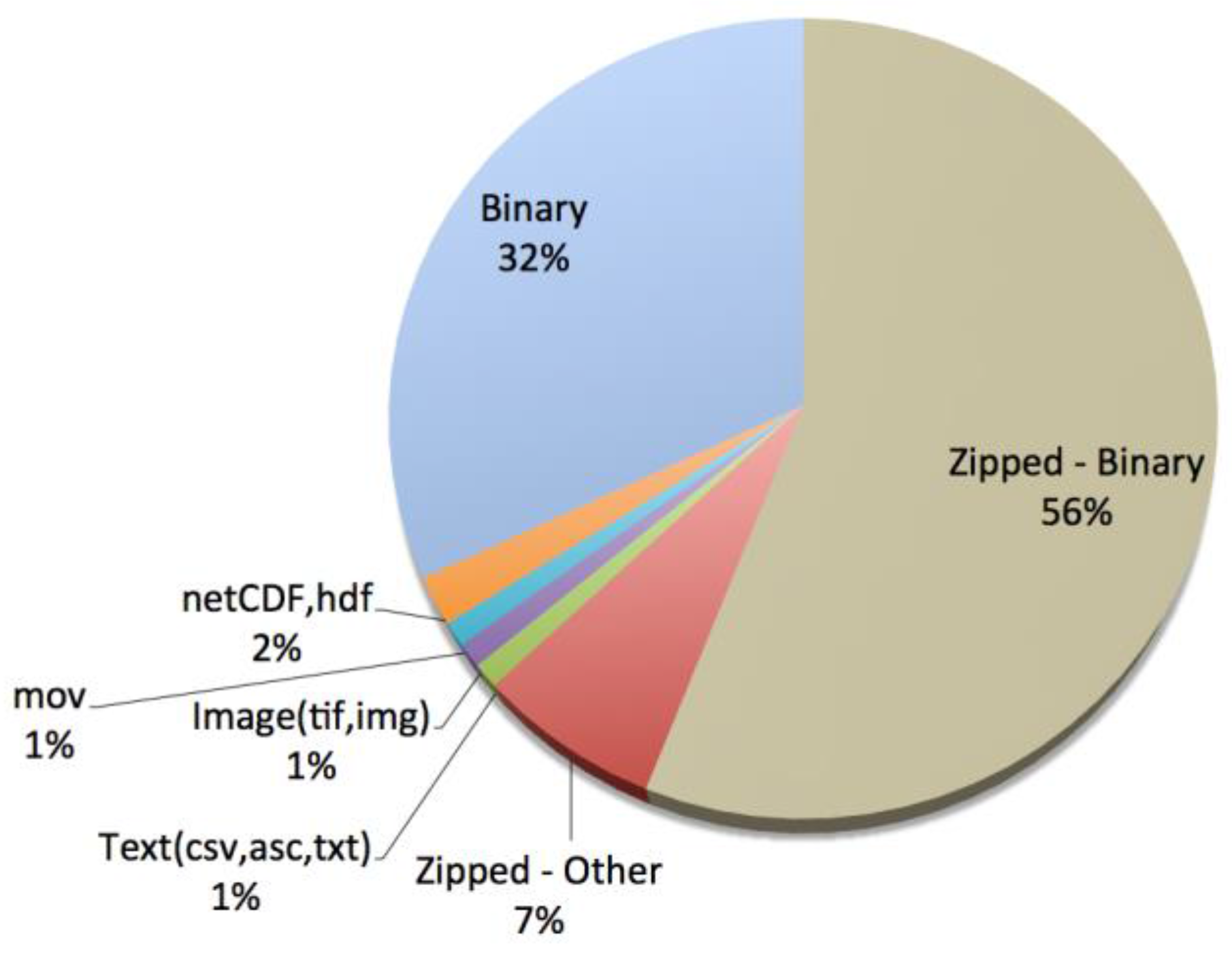
4. Data “Deluge” and Diversity—ORNL DAAC Case Study
- 2583 keywords
- 1364 investigators
- 343 variables
- 282 sensors
- 125 sources (satellites, flux towers, airplanes, etc.)
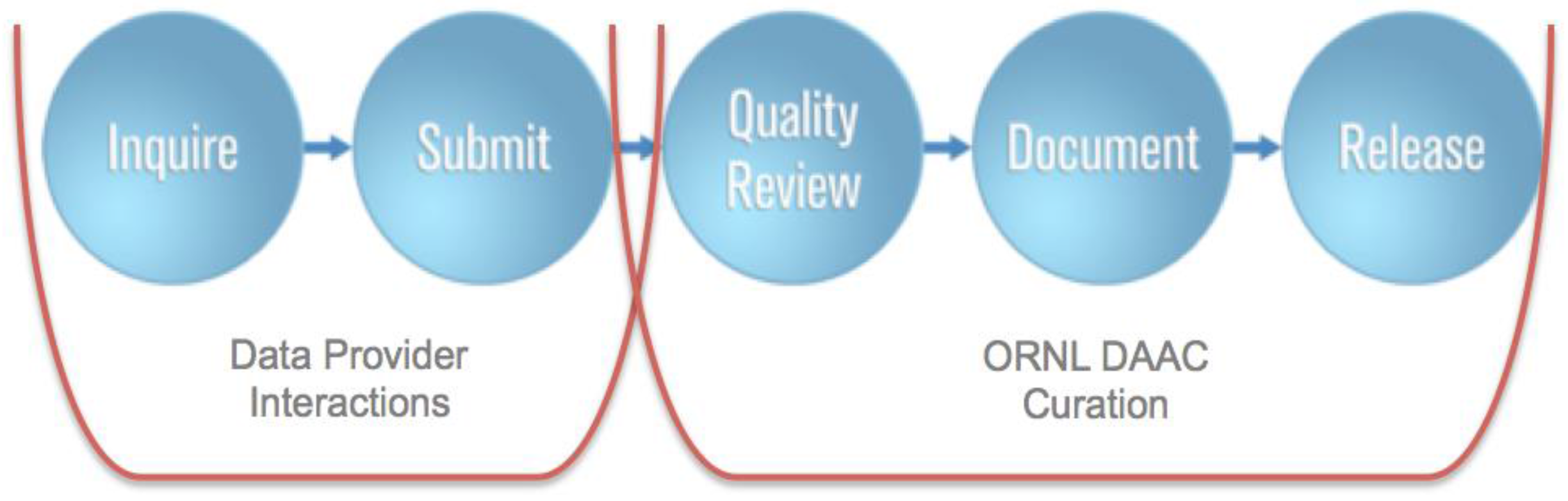
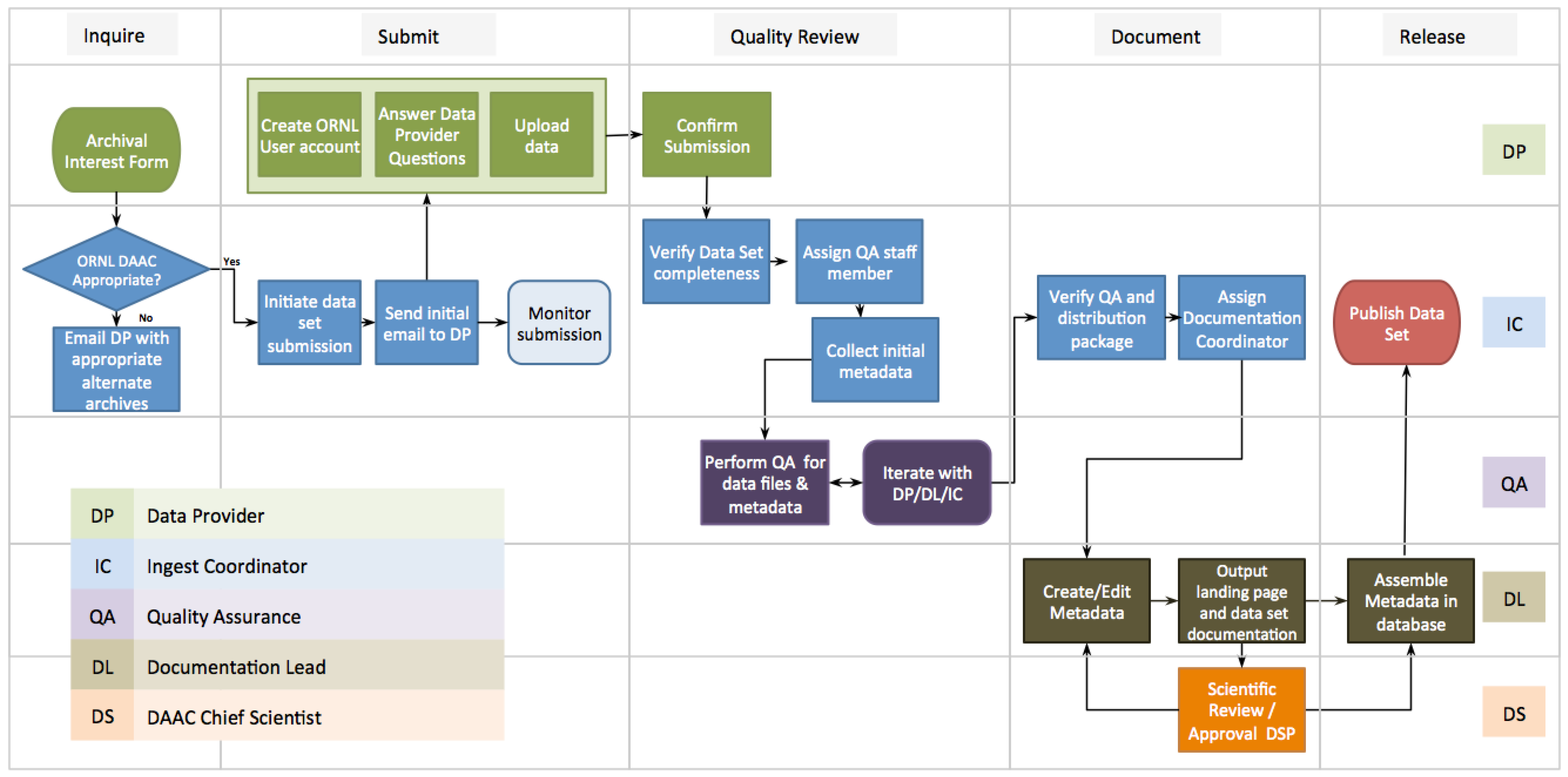
5. Semi-Automated ingest System (SAuS)
5.1. Workflow Architecture
5.2. Data Provider Interactions
- (1)
- Information to get an user account on the ORNL DAAC data publication system;
- (2)
- Link to answer a short questionnaire about the data set;
- (3)
- Link to upload data files;
- (4)
- Link to notify the ORNL DAAC system that all the above steps are complete.
5.3. ORNL DAAC Curation
Thornton, P.E., M.M. Thornton, B.W. Mayer, N. Wilhelmi, Y. Wei, R. Devarakonda, and R.B. Cook. 2014. Daymet: Daily Surface Weather Data on a 1-km Grid for North America, Version 2. ORNL DAAC, Oak Ridge, Tennessee, USA. Accessed August 25, 2015. Time Period: 1980-01-01 to 1985-12-31. Spatial range: N=35.05, S=32.50, W=-101.80, E=-85.20. http://0-dx-doi-org.brum.beds.ac.uk/10.3334/ORNLDAAC/1219.
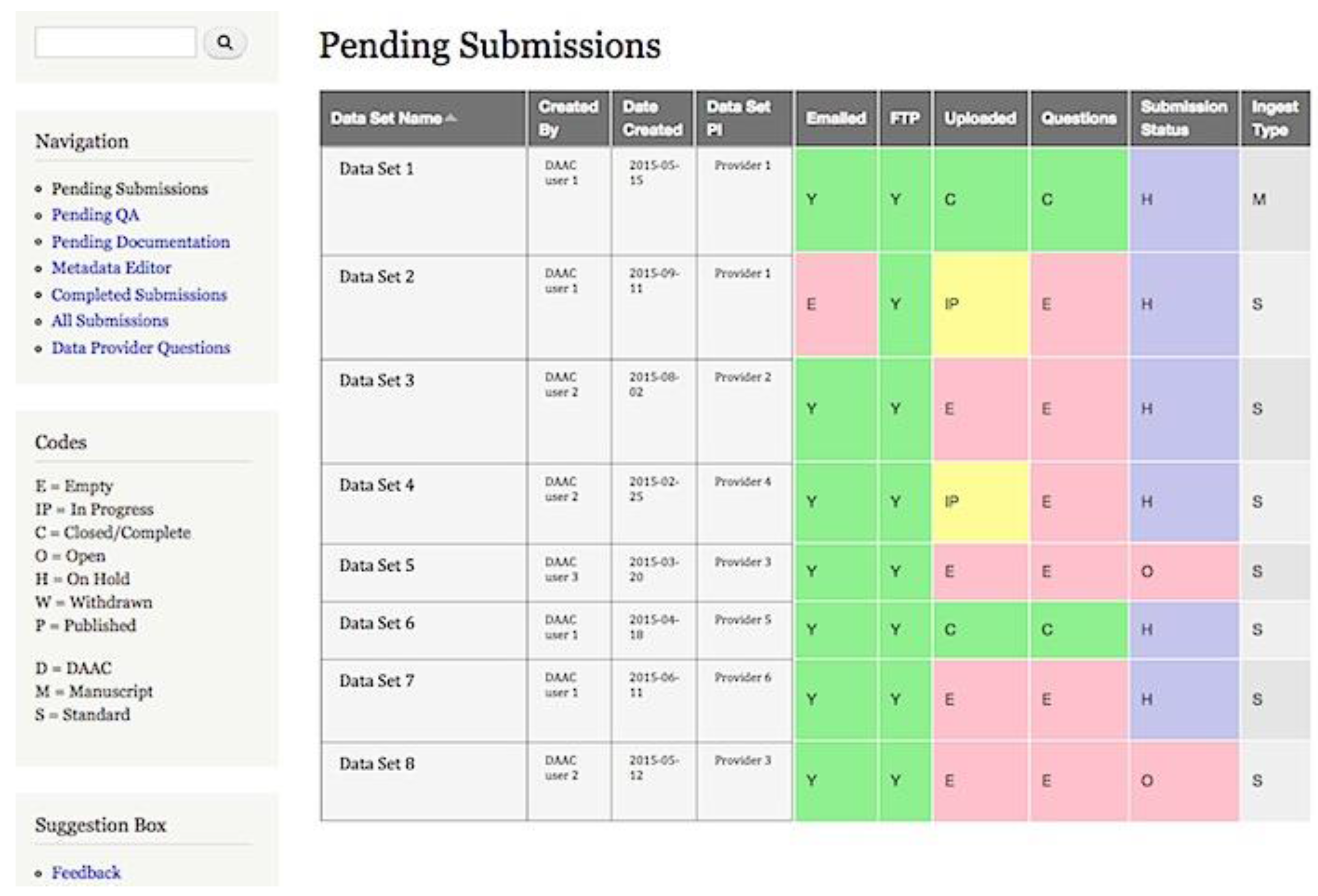
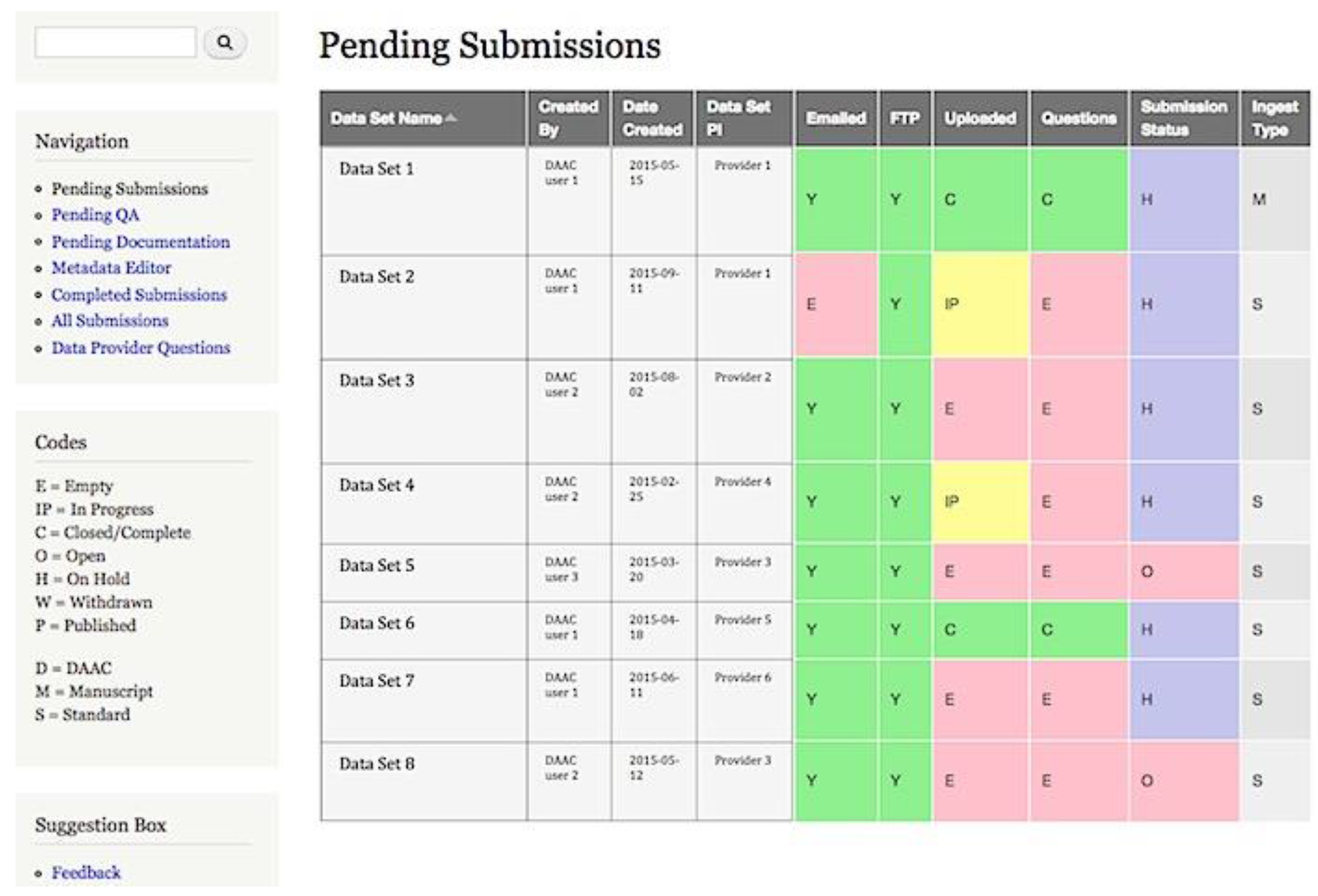
5.4. Ingest Dashboard
5.5. Stage 3 (Publish): Publication and Post-Publication Activities
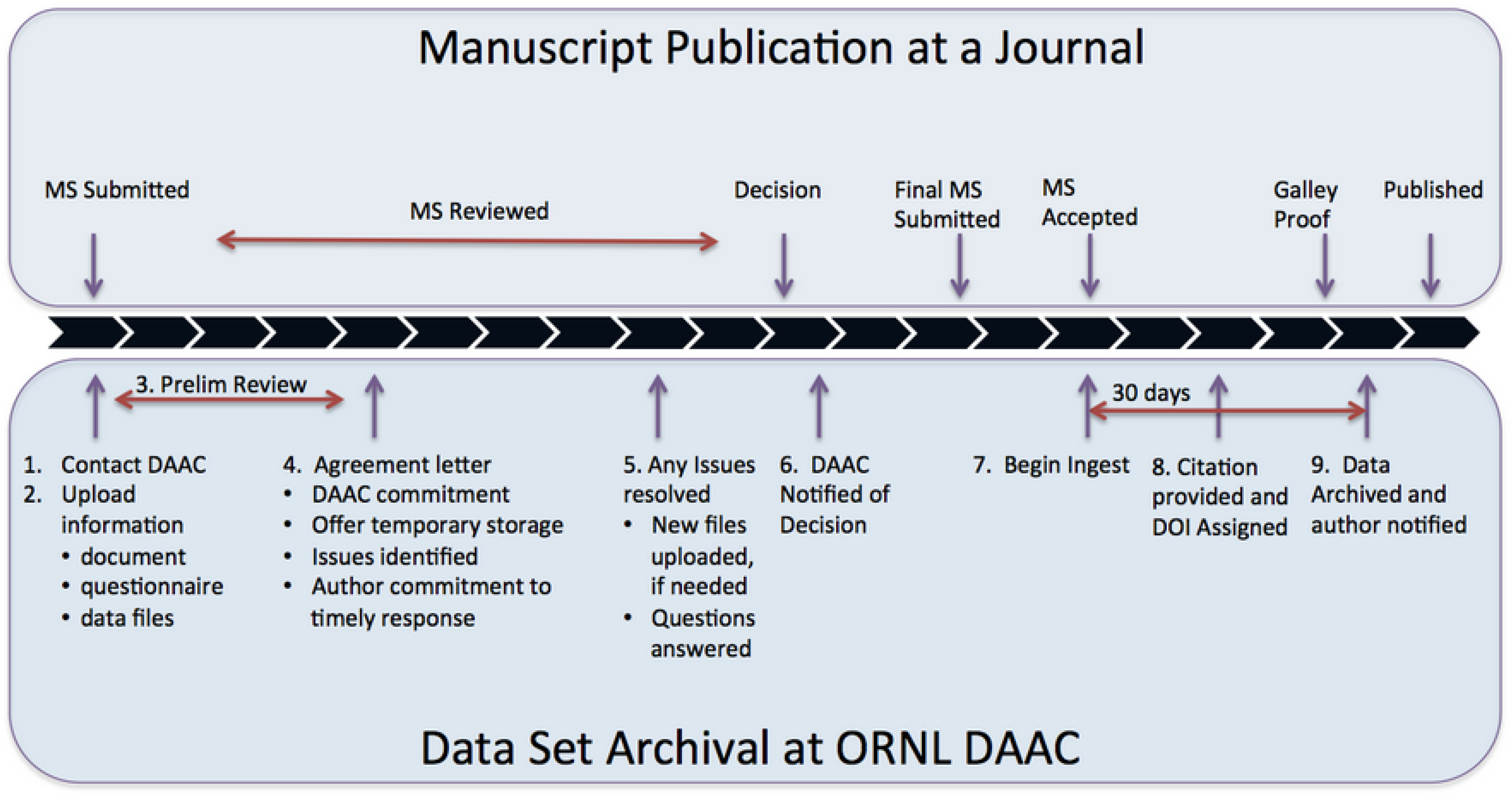
6. Manuscript Publication Process
7. Benefits of the SAuS Workflow
8. Lessons Learned in using the SAuS Workflow
Case 1: Updated Data Files
Case 2: Data Set Versions
Case 3: Data Provider Question Participation
Case 4: Unresponsive Data Provider
Case 5: Citation Correction after Publication
Case 6: Approval of the Data Prior to Publication
9. Conclusion
Acknowledgements
Author Contributions
Conflicts of Interest
References
- Kobler, B.; Berbert, J.; Caulk, P.; Hariharan, P. Architecture and design of storage and data management for the NASA Earth observing system Data and Information System (EOSDIS). In Proceedings of the 14th IEEE Symposium on Mass Storage Systems, Monterey, CA, USA, 11–14 September 1995; pp. 65–76.
- Committee on Geophysical and Environmental Data; Commission on Geosciences, Environment and Resources; Division on Earth and Life Studies; National Research Council. Review of NASA's Distributed Active Archive Centers; National Academy Press: Washington, D.C., USA, 1998. [Google Scholar]
- Baker, K.S.; Yarmey, L. Data stewardship: Environmental data curation and a web-of-repositories. Int. J. Digit. Curation 2009, 4, 12–27. [Google Scholar] [CrossRef]
- Ball, A. Briefing Paper: The OAIS Reference Model. Available online: http://www.ukoln.ac.uk/projects/grand-challenge/papers/oaisBriefing.pdf (accessed on 20 January 2016).
- Data Management for Data Providers. Available online: http://daac.ornl.gov/PI/pi_info.shtml (accessed on 3 March 2016).
- UK Data Archive. Managing and Sharing Data. Available online: http://www.data-archive.ac.uk/media/2894/managingsharing.pdf (accessed on 20 January 2016).
- Send2NCEI. Available online: https://www.nodc.noaa.gov/s2n/ (accessed on 20 January 2016).
- National Science Board. Long-Lived Digital Data Collections: Enabling Research and Education in the 21st Century. Available online: www.nsf.gov/pubs/2005/nsb0540/nsb0540.pdf (accessed on 20 January 2016).
- Memorandum for the Heads of Executive Departments and Agencies. Available online: https://www.whitehouse.gov/sites/default/files/microsites/ostp/ostp_public_access_memo_2013.pdf (accessed on 20 January 2016).
- Hanson, B.; Lehnert, K.L.K.; Cutcher-Gershenfeld, J. Committing to publishing data in the earth and space sciences. Eos 2015, 96. [Google Scholar] [CrossRef]
- Nature Editorial. Announcement: Reducing our irreproducibility. Nature 2013, 496, 398–398. [Google Scholar]
- Cook, R.B.; Olson, R.J.; Kanciruk, P.; Hook, L.A. Best practices for preparing ecological and ground-based data sets to share and archive. Bulletin of ESA 2001, 82, 138–141. [Google Scholar]
- Hook, L.A.; Vannan, S.K.S.; Beaty, T.W.; Cook, R.B.; Wilson, B.E. Best Practices for Preparing Environmental Data Sets to Share and Archive. Oak Ridge National Laboratory Distributed Active Archive. Available online: http://daac.ornl.gov/PI/BestPractices-2010.pdf (accessed on 3 March 2016 ).
- ORNL DAAC 2016 Archival Priority. Available online: http://daac.ornl.gov/PI/archival_priority.html (accessed on 3 March 2016).
- Data Provider Questions. Available online: http://daac.ornl.gov/PI/questions.shtml (accessed on 4 March 2016).
- Data Quality Review Checklist. Available online: https://daac.ornl.gov/PI/qa_checklist.html (accessed on 20 January 2016).
- Committee on Geophysical Data; Commission on Geosciences, Environment, and Resources; National Research Council. Solving The Global Change Puzzle: A U.S. Strategy for Managing Data and Information; National Academy Press: Washington, D.C., USA, 1991. [Google Scholar]
- Starr, J.; Willett, P.; Federer, L.; Horning, C.; Bergstrom, M.L. A collaborative framework for data management services: The experience of the University of California. J. eSci. Librariansh. 2012, 1. [Google Scholar] [CrossRef]
- Drupal. Available online: https://www.drupal.org/ (accessed on 20 January 2016).
- Randerson, J.T.; van der Werf, G.R.; Giglio, L.; Collatz, G.J.; Kasibhatla, P.S. Global Fire Emissions Database (GFED); Version 4; Oak Ridge National Laboratory: Oak Ridge, TN, USA, 2015. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Information About Your Data Set |
|---|
| Have you looked at our recommendations for the preparation of data files and documentation? |
| Who produced this data set? |
| What agency and program funded the project? |
| What awards funded this project? (comma separate multiple awards) |
| Data Set Description |
| Provide a title for your data set. |
| What type of data does your data set contain? |
| What does the data set describe? |
| What parameters did you measure, derive, or generate? |
| Have you analyzed the uncertainty in your data? |
| Briefly describe your uncertainty analysis. |
| Will the uncertainty estimates be included with your data set? |
| Temporal and Spatial Characteristics |
| What date range does the data cover? (YYYY-MM-DD) |
| What is a representative sampling frequency or temporal resolution for your data? |
| Where were the data collected/generated? |
| Which of the following best describes the spatial nature of your data? (single point, multiple points, transect, grid, polygon, n/a) |
| What is a representative spatial resolution for these data? |
| Provide a bounding box around your data. |
| Data Preparation and Delivery |
| What are the formats of your data files? |
| How many data files does your product contain? |
| What is the total disk volume of your data set? (MB) |
| Is this data set final, unrestricted, and available for release? |
| What are the reasons to restrict access to the data set? |
| Has this data set been described and used in a published paper? If so, provide a DOI or upload a digital copy of the manuscript with the data set. |
| Are the data and documentation posted on a public server? If so, provide the URL. |
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons by Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Vannan, S.; Beaty, T.W.; Cook, R.B.; Wright, D.M.; Devarakonda, R.; Wei, Y.; Hook, L.A.; McMurry, B.F. A Semi-Automated Workflow Solution for Data Set Publication. ISPRS Int. J. Geo-Inf. 2016, 5, 30. https://0-doi-org.brum.beds.ac.uk/10.3390/ijgi5030030
Vannan S, Beaty TW, Cook RB, Wright DM, Devarakonda R, Wei Y, Hook LA, McMurry BF. A Semi-Automated Workflow Solution for Data Set Publication. ISPRS International Journal of Geo-Information. 2016; 5(3):30. https://0-doi-org.brum.beds.ac.uk/10.3390/ijgi5030030
Chicago/Turabian StyleVannan, Suresh, Tammy W. Beaty, Robert B. Cook, Daine M. Wright, Ranjeet Devarakonda, Yaxing Wei, Les A. Hook, and Benjamin F. McMurry. 2016. "A Semi-Automated Workflow Solution for Data Set Publication" ISPRS International Journal of Geo-Information 5, no. 3: 30. https://0-doi-org.brum.beds.ac.uk/10.3390/ijgi5030030