
Parallel Landscape Driven Data Reduction & Spatial Interpolation Algorithm for Big LiDAR Data

Abstract
:1. Introduction
1.1. Overview
1.2. Related Work
1.2.1. Approaches to Data Reduction
1.2.2. Approaches to Spatial Interpolation
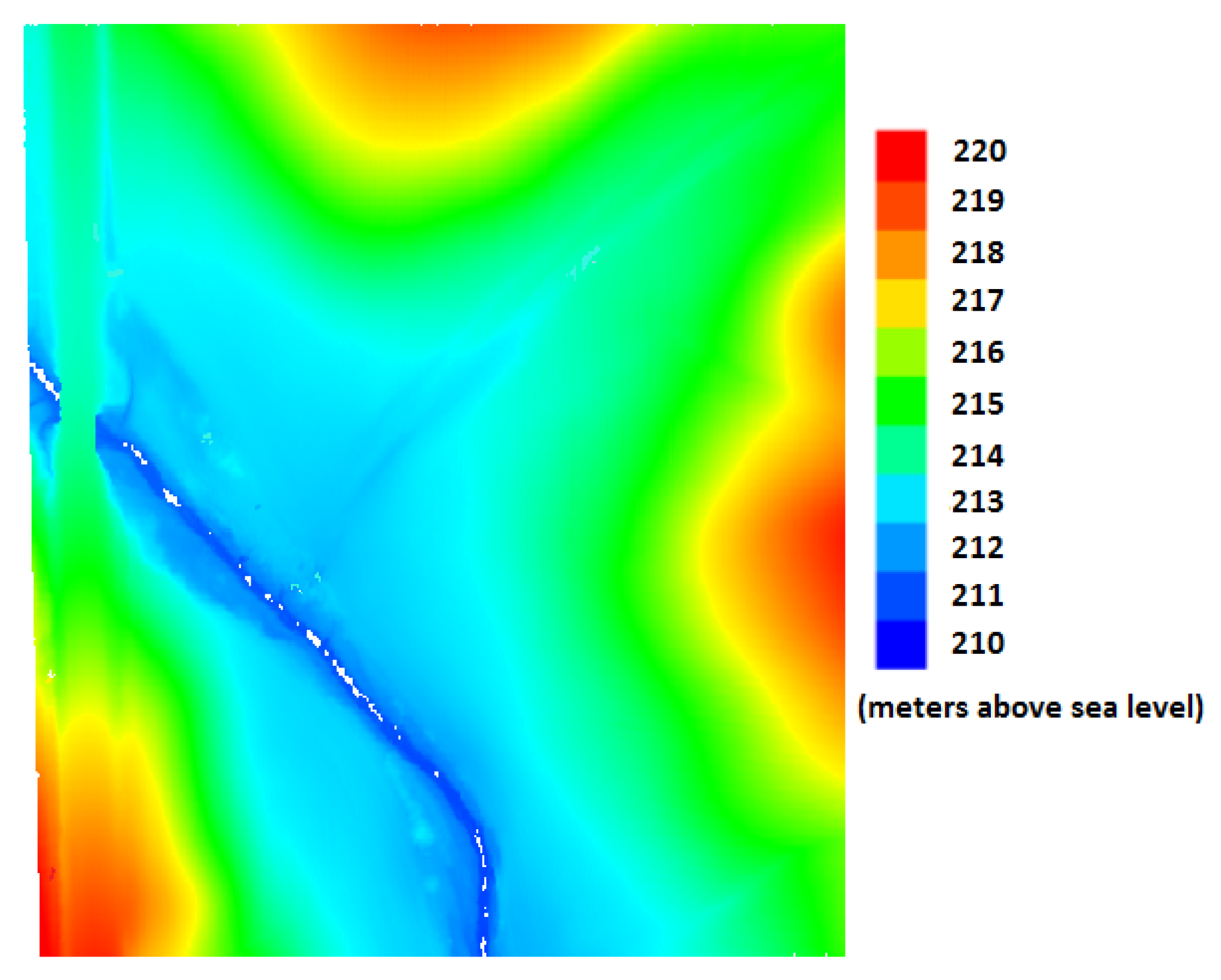
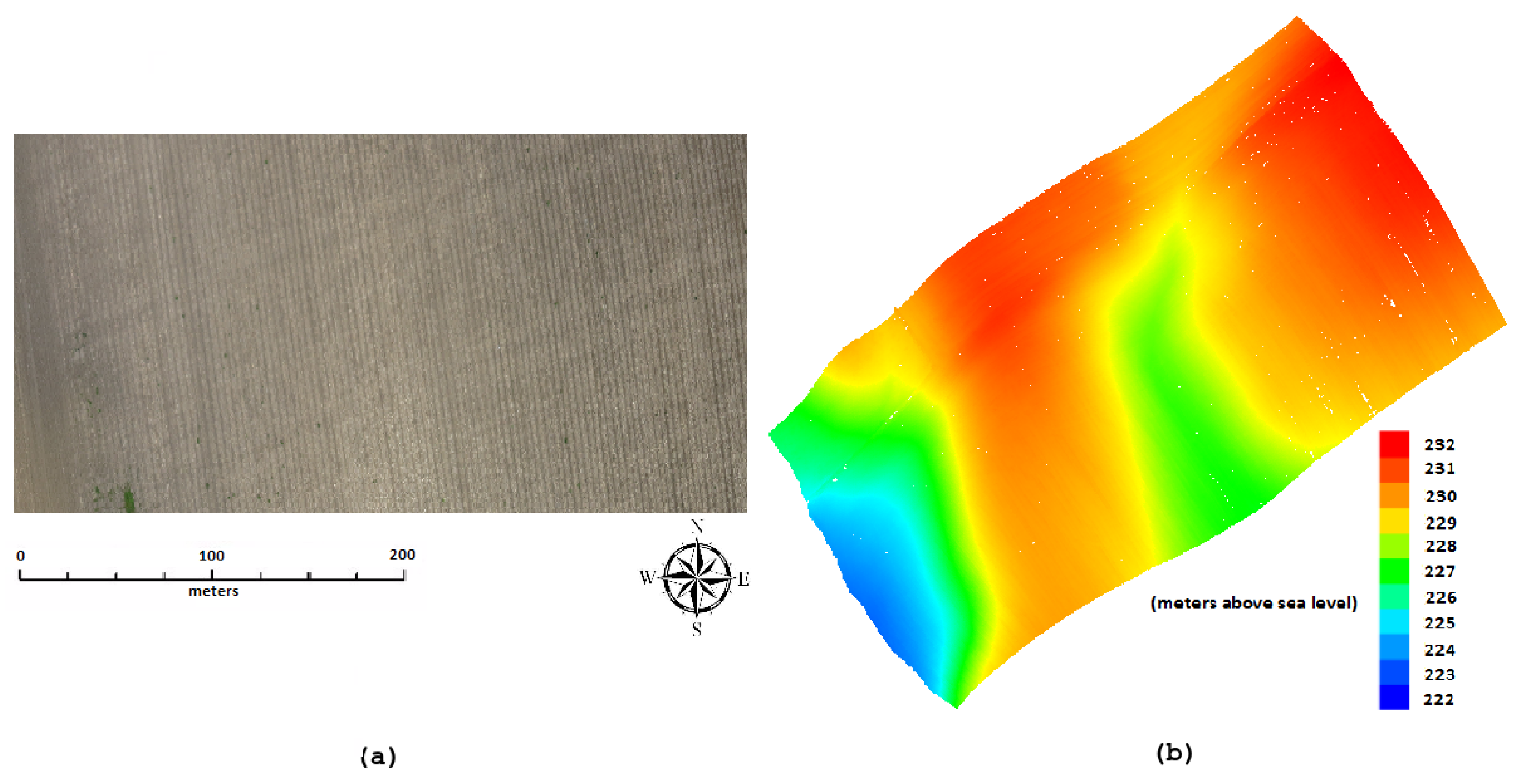
2. Dataset
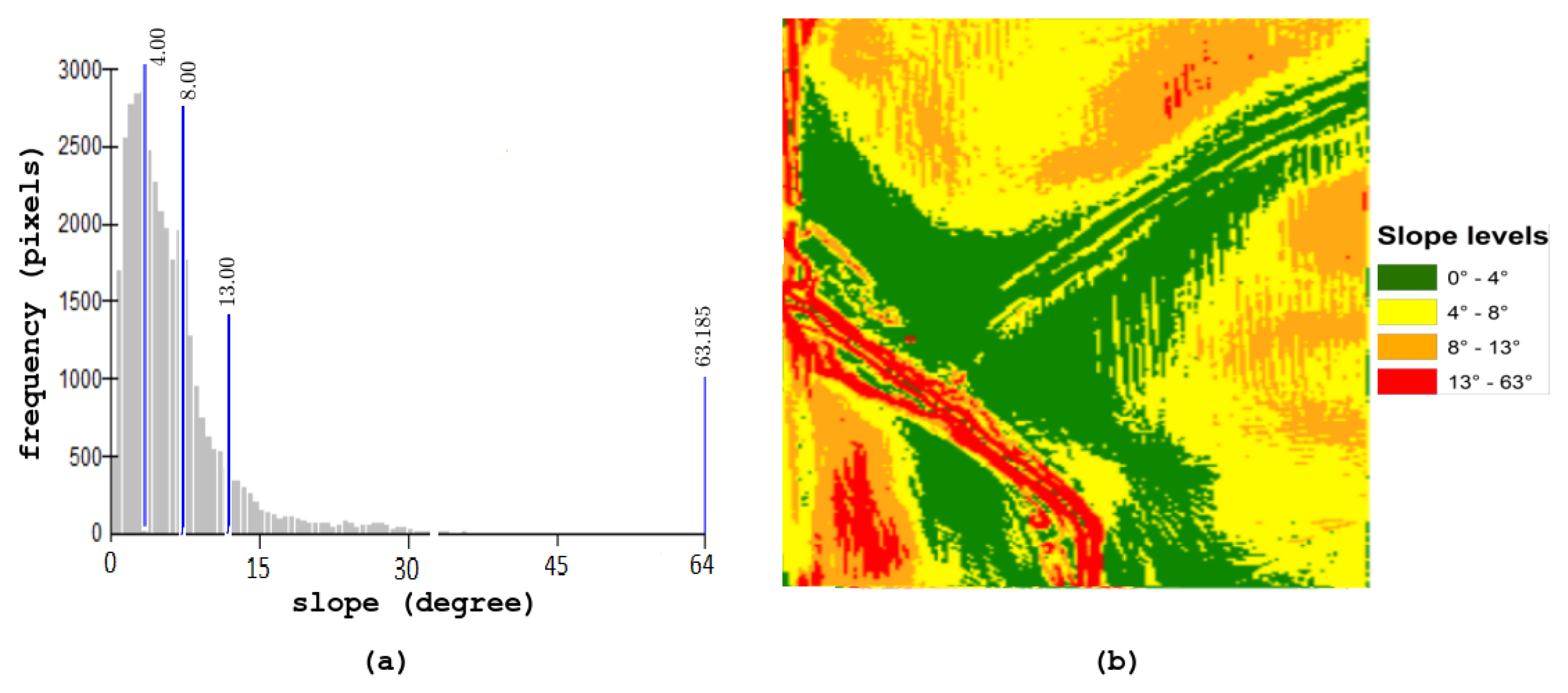
3. Data Reduction Method
3.1. Data Preparation
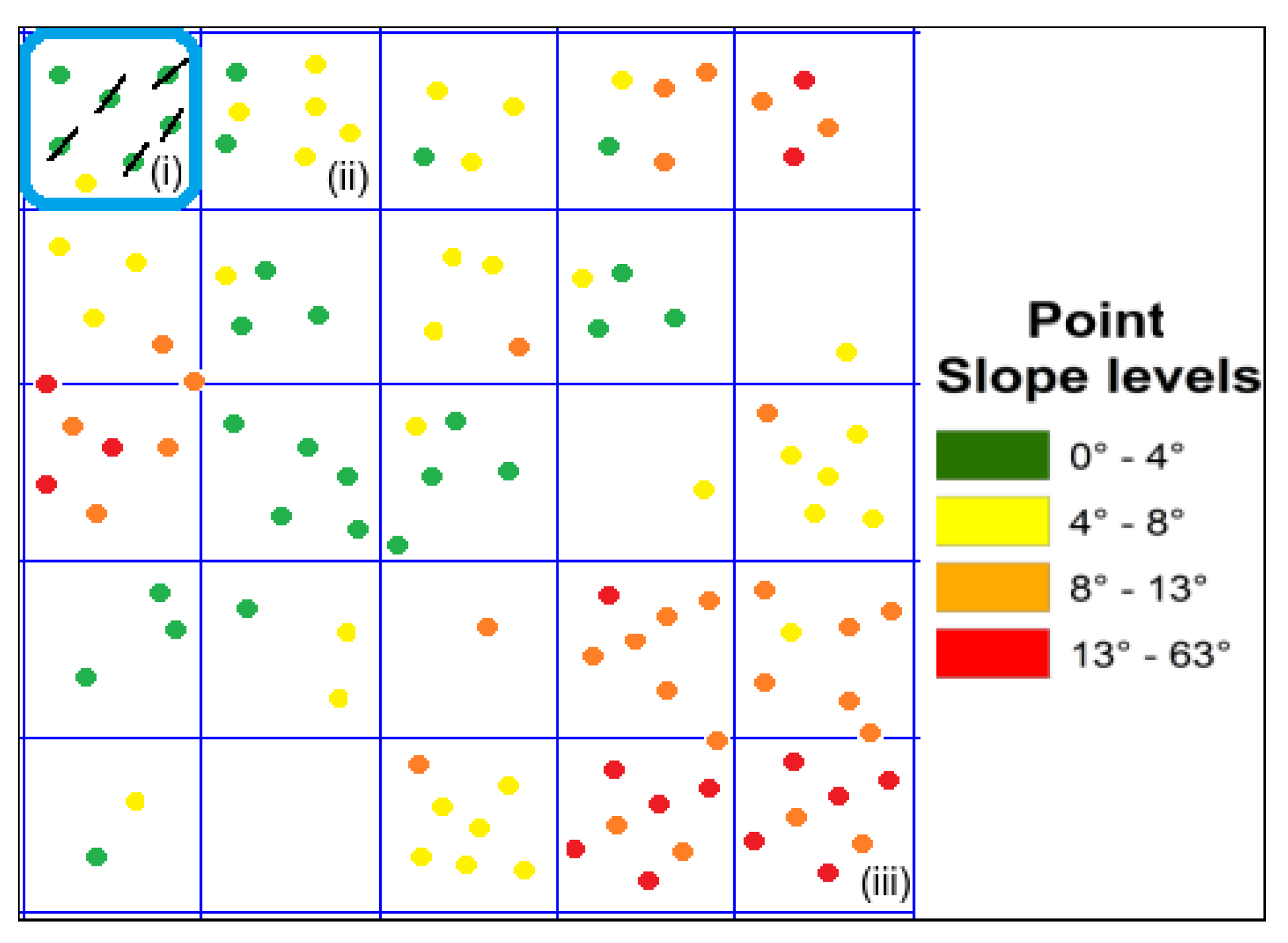
3.2. Algorithm
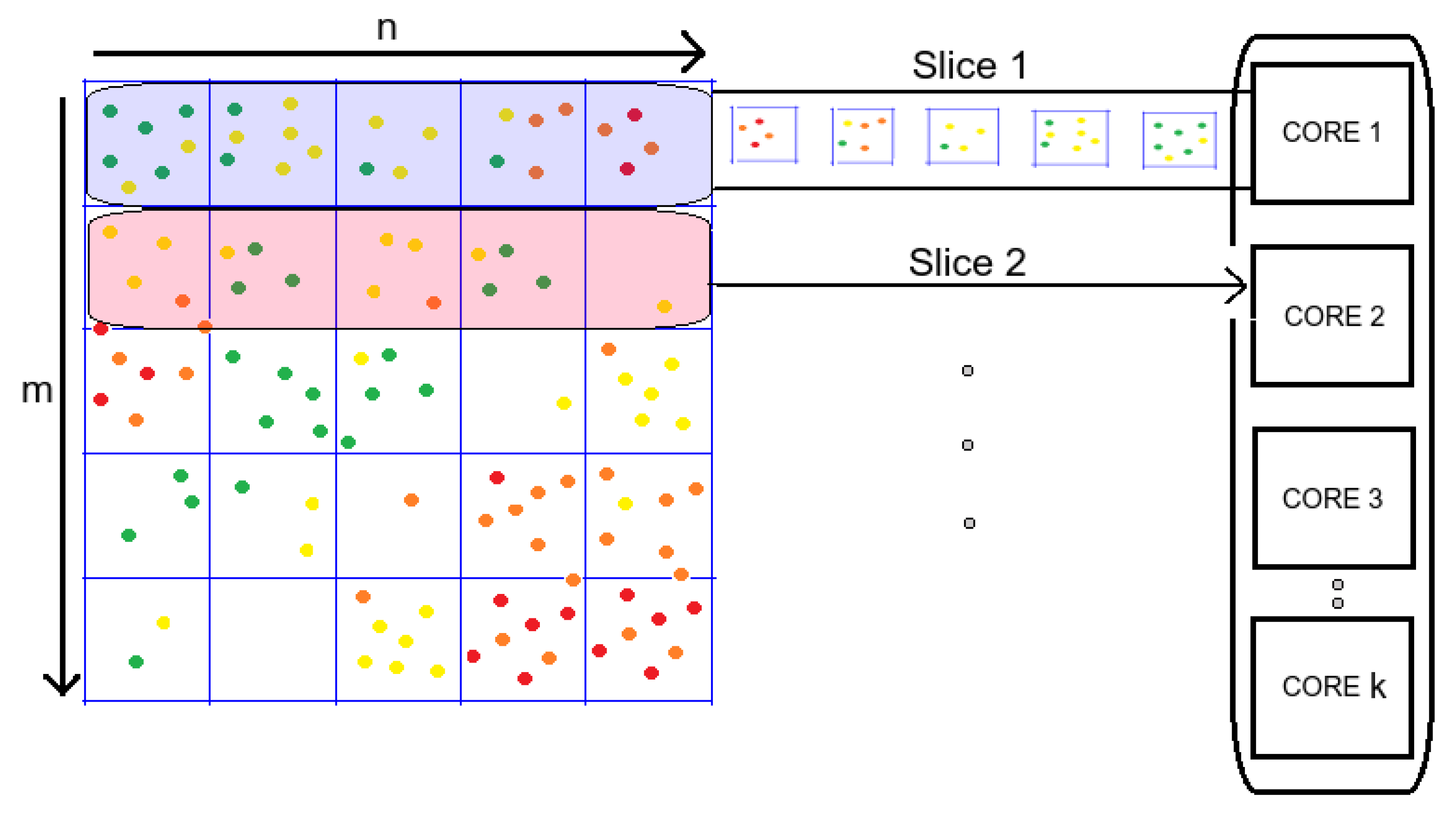
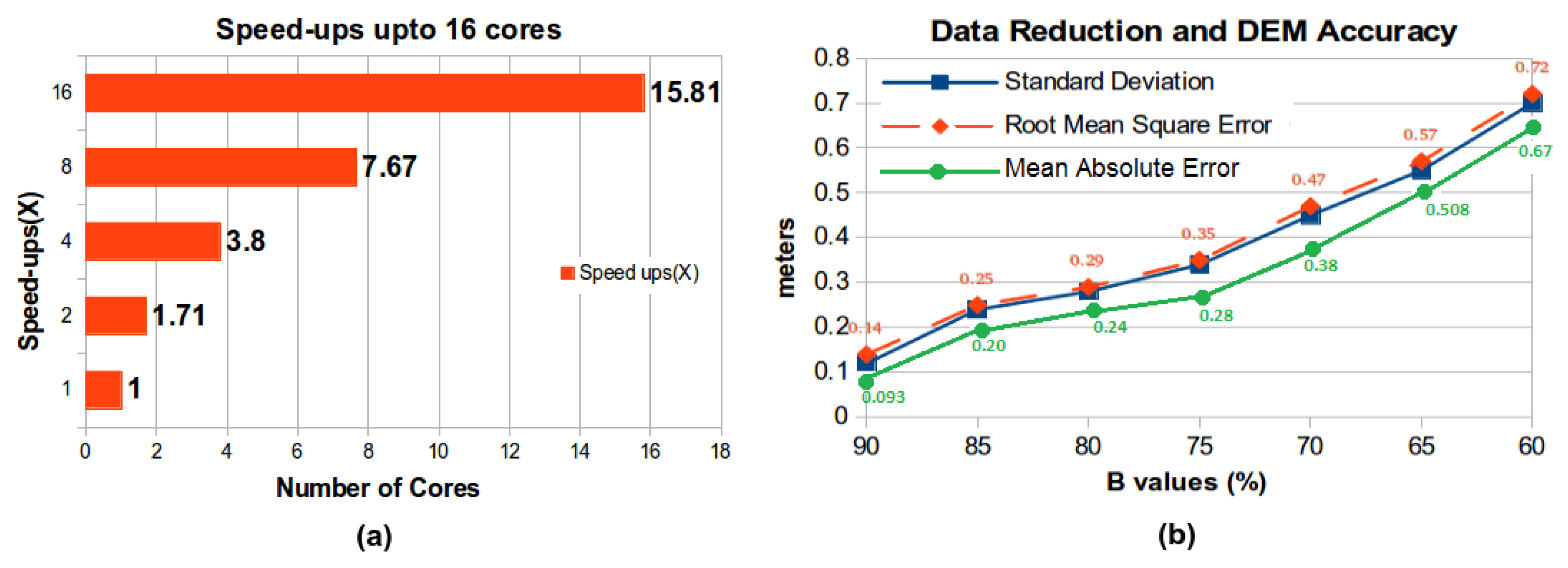
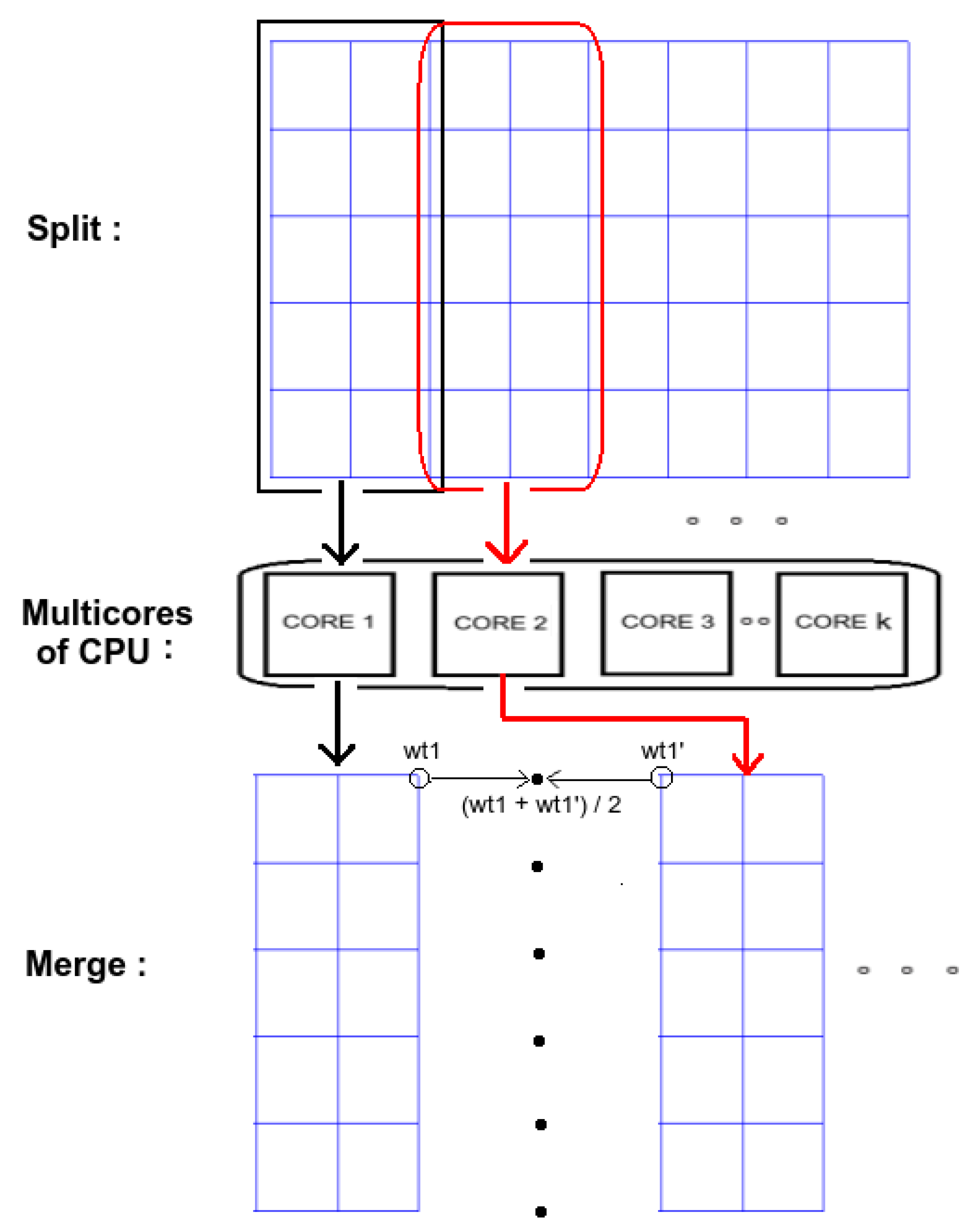
3.3. Parallel Implementation
| Algorithm 1 LiDAR data reduction algorithm. |
|
3.4. Results
4. Spatial Interpolation
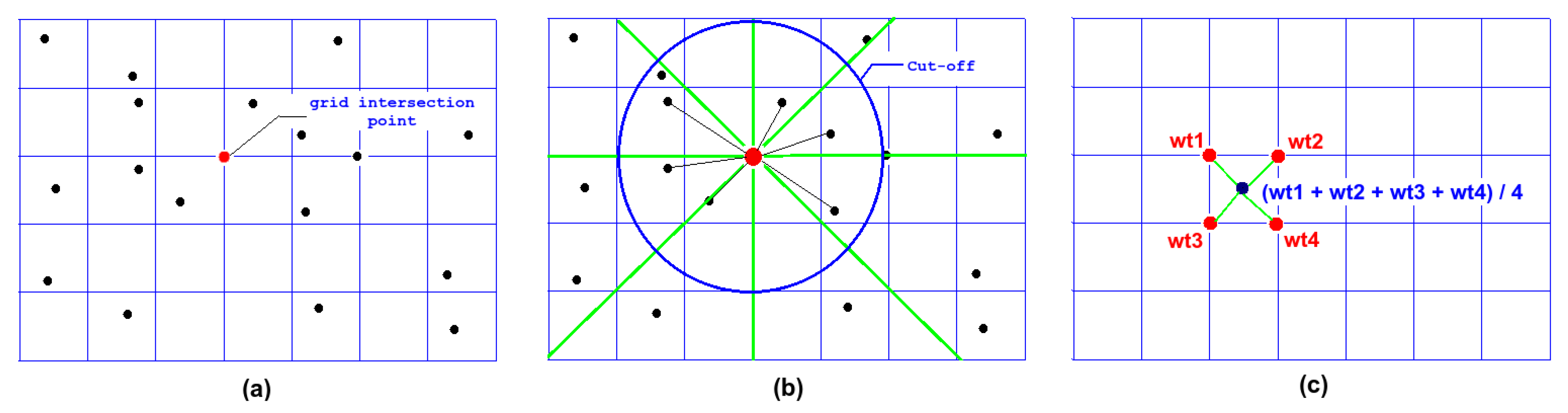
4.1. Algorithm
- Parse through the intersection points of each cell in the grid (shown in Figure 8a) in a left-right, top-bottom fashion.
- For each intersection point, we compute and assign a weight as follows:
- Initially select a cut-off radius for the circle whose center is the intersection point (it is recommended to choose small cutoff radii for very dense datasets, compared to less dense datasets).
- Then, divide the circle into eight equal sectors, and choose the closest LiDAR points in each sector, if there exist any (shown in Figure 8b). Set the grid intersection point to the average of these chosen LiDAR points weighted by 1/(distance from grid intersection)2.
- After assigning weights to all of the grid intersection points, we assign each grid cell the average weight of its four surrounding grid intersection points (shown in Figure 8c).
4.2. Parallel Implementation
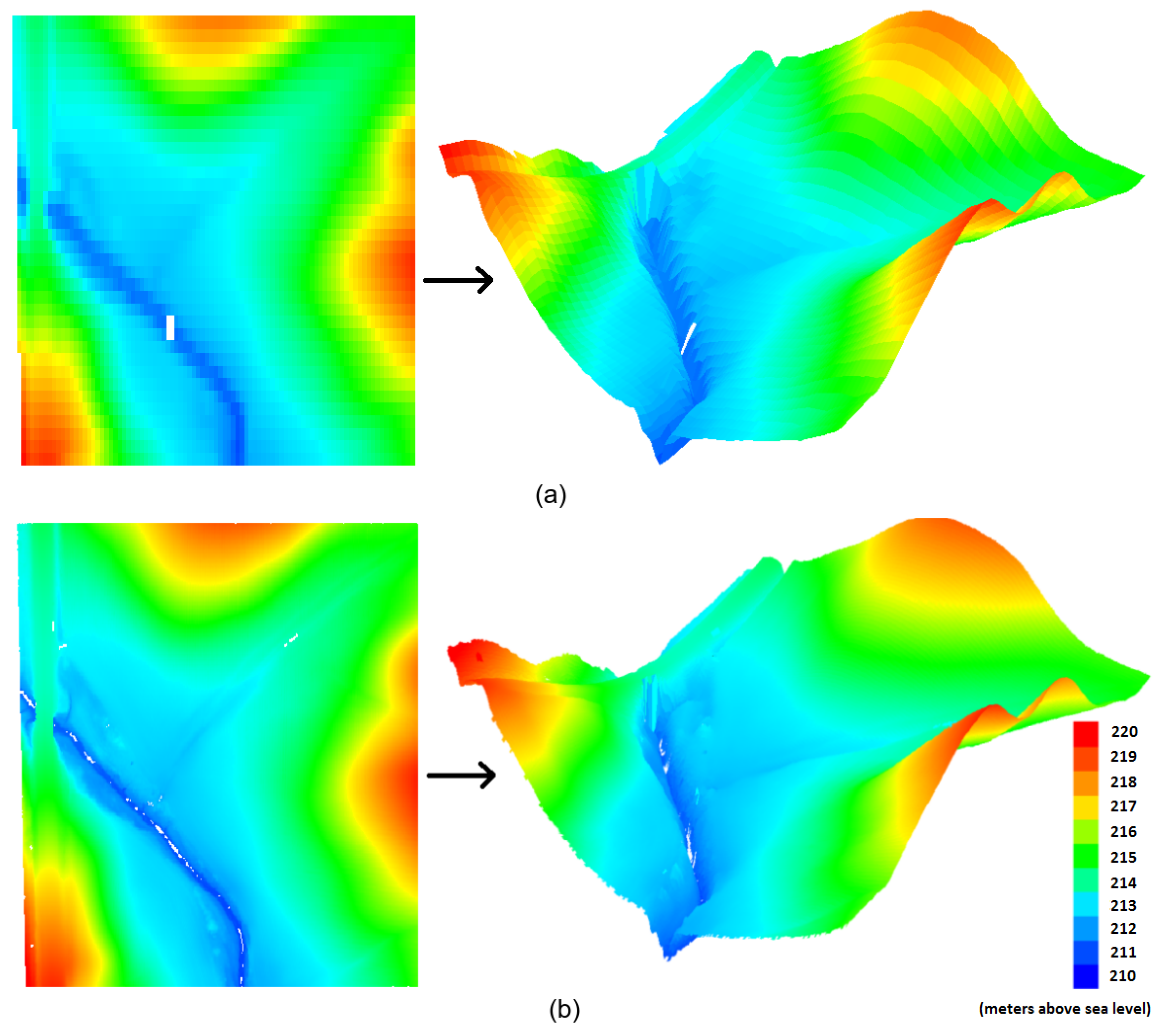
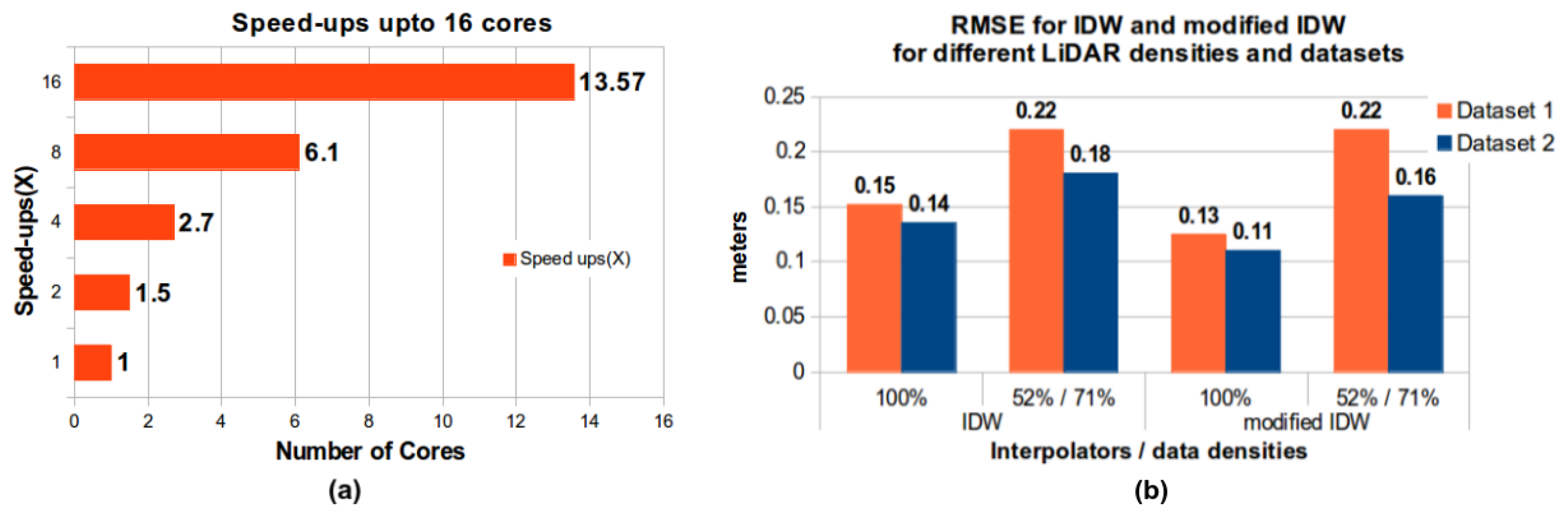
4.3. Results
- RMSEs for both the interpolation algorithms increase with the decrease in LiDAR data density for both of the datasets.
- RMSEs for the more complex terrain, i.e., Dataset 1, are higher than Dataset 2, which is relatively flat and has shallow valleys and less roughness.
- The quality of the results obtained by modified IDW is at least as good as traditional IDW for reduced density, complex terrain (ex. 52% reduced LiDAR Dataset 1 gives an RMSE of m for both of the algorithms).
- The quality of the results obtained by modified IDW is better than traditional IDW for dense, complex and relatively flatter terrains.
- The time to generate DEMs using modified IDW is much less than that used by sequential traditional IDW.
5. Conclusions and Future Work
Author Contributions
Conflicts of Interest
Abbreviations
| LiDAR | Airborne Light Detection and Ranging |
| DEM | Digital Elevation Model |
| IDW | Inverse Distance Weighted |
| TIN | Triangulating Irregular Networks |
| RMSE | Root Mean Square Error |
| GIS | Geographical Information System |
| NED | National Elevation Data |
References
- Habib, A.; Ghanma, M.; Morgan, M.; Al-Ruzouq, R. Photogrammetric and LiDAR data registration using linear features. Photogramm. Eng. Remote Sens. 2005, 71, 699–707. [Google Scholar] [CrossRef]
- Sithole, G.; Vosselman, G. The Full Report: ISPRS Comparision of Filters. Available online: http://www.itc.nl /isprswgIII-3/filtertest/ (accessed on 30 April 2016).
- Hodgson, M.E.; Bresnahan, P. Accuracy of airborne LiDAR-derived elevation. Photogramm. Eng. Remote Sens. 2004, 70, 331–339. [Google Scholar] [CrossRef]
- El-Sheimy, N.; Valeo, C.; Habib, A. Digital Terrain Modeling: Acquisition, Manipulation, and Applications; Artech House: London, UK, 2005. [Google Scholar]
- Ramirez, J.R. A new approach to relief representation. Surv. Land Inf. Sci. 2006, 66, 19–25. [Google Scholar]
- Burrough, P.A.; McDonnell, R.A. Principles of Geographical Information Systems; Oxford University Press: New York, NY, USA, 2011. [Google Scholar]
- Li, Z.; Zhu, C.; Gold, C. Digital Terrain Modeling: Principles and Methodology; CRC Press: Boca Raton, FL, USA, 2004. [Google Scholar]
- Bonham-Carter, G.F. Geographic Information Systems for Geoscientists: Modelling with GIS; Elsevier: Amsterdam, the Netherlands, 2014. [Google Scholar]
- Chou, Y.-H.; Liu, P.-S.; Dezzani, R.J. Terrain complexity and reduction of topographic data. J. Geogr. Syst. 1999, 1, 179–198. [Google Scholar] [CrossRef]
- Anderson, E.S.; Thompson, J.A.; Austin, R.E. LiDAR density and linear interpolator effects on elevation estimates. Int. J. Remote Sens. 2005, 26, 3889–3900. [Google Scholar] [CrossRef]
- Liu, X.; Zhang, Z. LiDAR data reduction for efficient and high quality DEM generation. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2008, 37, 173–178. [Google Scholar]
- Oryspayev, D.; Sugumaran, R.; DeGroote, J.; Gray, P. LiDAR data reduction using vertex decimation and processing with GPGPU and multicore CPU technology. Comput. Geosci. 2012, 43, 118–125. [Google Scholar] [CrossRef]
- Hegeman, J.W.; Sardeshmukh, V.B.; Sugumaran, R.; Armstrong, M.P. Distributed LiDAR data processing in a high-memory cloud-computing environment. Ann. GIS 2014, 20, 255–264. [Google Scholar] [CrossRef]
- Kobler, A.; Pfeifer, N.; Ogrinc, P.; Todorovski, L.; Oštir, K.; Džeroski, S. Repetitive interpolation: A robust algorithm for DTM generation from Aerial Laser Scanner Data in forested terrain. Remote Sens. Environ. 2007, 108, 9–23. [Google Scholar] [CrossRef]
- ZakÅ¡ek, K.; Pfeifer, N.; IAPÅ, Z.S. An Improved Morphological Filter for Selecting Relief Points from a LiDAR Point Cloud in Steep Areas with Dense Vegetation; Institute of Anthropological and Spatial Studies, Scientific Research Centre of the Slovenian Academy of Sciences and Arts: Luubljana, Slovenia; Institute of Geography, Innsbruck University: Innsbruck, Austria, 2006. [Google Scholar]
- Kraus, K.; Otepka, J. DTM Modelling and Visualization—The Scop Approach. In Proceedings of Photogrammetric Week 05, Heidelberg, Germany; 2005; pp. 241–252. [Google Scholar]
- Liu, X.; Zhang, Z.; Peterson, J.; Chandra, S. Lidar-derived high quality ground control information and DEM for image orthorectification. GeoInformatica 2007, 11, 37–53. [Google Scholar] [CrossRef] [Green Version]
- Zimmerman, D.; Pavlik, C.; Ruggles, A.; Armstrong, M.P. An experimental comparison of ordinary and universal kriging and inverse distance weighting. Math. Geol. 1999, 31, 375–390. [Google Scholar] [CrossRef]
- Liu, X.; Zhang, Z.; Peterson, J. Evaluation of the performance of DEM interpolation algorithms for LiDAR data. In Proceedings of the Surveying and Spatial Sciences Institute Biennial International Conference (SSC 2009), Adelaide, Australia, 28 September–2 October 2009; pp. 771–779.
- Fisher, P.F.; Tate, N.J. Causes and consequences of error in digital elevation models. Prog. Phys. Geogr. 2006, 30, 467–489. [Google Scholar] [CrossRef]
- Podobnikar, T. Suitable DEM for required application. In Proceedings of the 4th International Symposium on Digital Earth, Tokyo, Japan, 28–31 March 2005.
- Ali, T.A. On the selection of an interpolation method for creating a terrain model (TM) from LiDAR data. In Proceedings of the American Congress on Surveying and Mapping (ACSM) Conference, Nashville, TN, USA; 2004. [Google Scholar]
- The National Map–Elevation. Available online: http://ned.usgs.gov/ (accessed on 30 April 2016).
- Liu, X.; Zhang, Z.; Peterson, J.; Chandra, S. The effect of LiDAR data density on DEM accuracy. In Proceedings of the International Congress on Modelling and Simulation (MODSIM07), Christchurch, New Zealand, 10–13 December 2007; pp. 1363–1369.
- Coulthard, J. Quikgrid: 3-D Rendering of a Surface Represented by Scattered Data Points. Available online: http://www.galiander.ca/quikgrid/ (accessed on 30 April 2016).












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| diff’ = max. slope - min. slope | β Range |
|---|---|
| diff | |
| diff | |
| diff | |
| diff |
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sharma, R.; Xu, Z.; Sugumaran, R.; Oliveira, S. Parallel Landscape Driven Data Reduction & Spatial Interpolation Algorithm for Big LiDAR Data. ISPRS Int. J. Geo-Inf. 2016, 5, 97. https://0-doi-org.brum.beds.ac.uk/10.3390/ijgi5060097
Sharma R, Xu Z, Sugumaran R, Oliveira S. Parallel Landscape Driven Data Reduction & Spatial Interpolation Algorithm for Big LiDAR Data. ISPRS International Journal of Geo-Information. 2016; 5(6):97. https://0-doi-org.brum.beds.ac.uk/10.3390/ijgi5060097
Chicago/Turabian StyleSharma, Rahil, Zewei Xu, Ramanathan Sugumaran, and Suely Oliveira. 2016. "Parallel Landscape Driven Data Reduction & Spatial Interpolation Algorithm for Big LiDAR Data" ISPRS International Journal of Geo-Information 5, no. 6: 97. https://0-doi-org.brum.beds.ac.uk/10.3390/ijgi5060097