1. Introduction
A web map service (WMS) is an international standard protocol for publishing and accessing geo-referenced maps on the web [
1,
2,
3]. This standard has facilitated the integration, access and value-added applications of geospatial information [
1,
4,
5]. In the past few years, an increasing volume of land cover data and maps has been made available through WMSs for facilitating on-line open data access [
6,
7], supporting collaborative data production [
8,
9], and assisting in crowd-sourcing sampling and validation [
10,
11,
12,
13]. One example is the WMS-based information service system, which enables the open access and sharing of one of the world’s first 30 m Earth land cover maps, called GlobeLand30 (
www.globeland30.org) [
14]. There are many other land cover web map services (LCWMSs) that provide global, national or local land cover data/maps. Some of these LCWMSs are registered in catalogues (e.g., the Catalogue Service for the Web, CSW) on the basis of Service-Oriented Architecture [
15,
16]. These LCWMSs can be discovered easily by matching keywords in corresponding catalogues. Some LCWMSs are dispersed in the surface web, which refers to content stored in static pages [
17]. These can be accessed directly by visiting the hyperlinks associated with these static pages [
18]. However, others are hidden in the deep web, which refers to content hidden in dynamic pages (often behind query interfaces), in script code, and so on [
17,
19]. In particular, with the rapid adoption of the Open Geospatial Consortium (OGC) standards, such services are increasingly employed by geospatial web applications that use JavaScript code supplemented by third-party JavaScript libraries (e.g., OpenLayers and ArcGIS for JavaScript) [
20,
21]. This JavaScript code and the libraries are often referenced in the form of JavaScript links, such as “<script src= ‘ ../OpenLayers.js’></script>”. Such deep web LCWMSs are difficult to discover by simply visiting hyperlinks. For example, the LCWMSs for GlobeLand30 can be discovered only by analysing the JavaScript code exposed by the service system (
www.globeland30.org).
Recently, discovery and integration of these dispersed land cover data services have been stimulated by a wide range of development agendas, research programmes and practical applications [
10,
22,
23,
24]. One example is the United Nation’s 2030 sustainable development agenda, which critically depends on the availability and utilization of land cover information at global, national and local scales. Unfortunately, no one single land cover data set or service can currently meet the needs of all users. Moreover, many LCWMSs exist as isolated “information islands” and are not well connected [
25]; therefore, it is natural to consider linking all the land cover information services scattered around the world to provide a more reliable land cover information service. This issue arose and was discussed at the 9–10 June 2015 international workshop organized by the International Society for Photogrammetry and Remote Sensing (ISPRS) and the Group on Earth Observations (GEO) [
22]. It was proposed to design and develop a Collaborative Global Land information service platform (CoGland); however, doing so faces a number of technical challenges [
22]. One of these challenges is to automate the discovery and connection of the existing but isolated LCWMSs to form a “one stop” portal for an integrated information service [
25].
Automatic discovery of LCWMSs can be realized in either a passive or active manner. The passive method uses a keyword-matching approach to discover services in registered catalogues [
15,
16,
26]. The success of this method depends largely on the willingness of service providers to register their WMSs and make them available [
15,
16,
26]. However, numerous services published on the web are not registered in any catalogues, and thus cannot be found through catalogue searches [
2,
27]. Various search engines, which use web crawlers to continuously traverse static pages [
28,
29,
30], have been developed for finding services dispersed in the surface web [
31,
32]. General-purpose search engines (such as Google and Bing), customized search engines with general crawlers and focused crawlers are the three most commonly used approaches [
16,
27,
31,
32,
33,
34]. In essence, however, these active approaches can only find geospatial web services that reside in static pages. Nevertheless, a considerable number of WMSs exist behind query interfaces and are hidden within JavaScript code [
16,
20,
21]. The key challenge here is to detect and understand the deep web query interfaces and JavaScript code that signify WMSs and to extract them. The detection and understanding of query interfaces has received some attention [
35]; however, few efforts have been devoted to the detection and understanding of JavaScript code specifically for discovering WMSs. Therefore, discovering WMSs from JavaScript code in geospatial web applications remains an open question [
21].
This paper aims to solve this problem. It proposes a focused deep web crawler that can find more LCWMSs from both the deep web’s JavaScript code and from the surface web. First, a group of JavaScript link names are abstracted as initial judgements. Through name matching, these judgements are used to judge whether a fetched webpage contains a predefined JavaScript link that may execute other JavaScript code to potentially invoke WMSs. Secondly, some JavaScript invocation functions and URL formats for WMS are summarized as rules from prior knowledge of how WMSs are employed and presented in JavaScript code. Through rule matching, the rules can be used to understand how geospatial web applications invoke WMSs using JavaScript code for extracting candidate WMSs. The above operations are fused into a traditional focused crawling strategy situated between the tasks of fetching webpages and parsing webpages. Thirdly, LCWMSs are selected from the list of extracted candidate WMSs through WMS validation and matching land cover keywords. Finally, a LCWMS search engine (LCWMS-SE) is designed and implemented that uses a rule-based approach to assist users in retrieving the discovered LCWMSs.
The remainder of this paper is organized as follows.
Section 2 reviews related work about both the surface and deep geospatial web service discovery as well as the discovery of other deep web resources from JavaScript code.
Section 3 outlines the active discovery approach, including a description of the initial judgements, the JavaScript invocation rules and the proposed focused deep web crawler. The design and implementation of the search engine that retrieves the discovered LCWMSs is described in
Section 4. Preliminary experiments and analysis are presented in
Section 5, and
Section 6 concludes the paper.
2. Related Work
A WMS provides three operations: GetCapabilities, GetMap, and GetFeatureInfo to support requests for metadata, static maps and feature information about the corresponding georeferenced maps, respectively [
1,
16]. The GetCapabilities operation is intended to request service metadata, such as service abstract, reference coordinate system, the format, etc. [
16]. The GetMap operation enables users to obtain static maps from multiple servers by submitting parameters that include layer names, bounding boxes, format, styles, etc. [
3,
16]. The GetFeatureInfo operation requests metadata for the selected features [
16]. Because metadata can help users find the service layers they need and determine how best to use them [
36], in general, discovering WMSs means finding the URLs of the GetCapabilities operation. Other OGC geospatial services such as the Web Feature Service (WFS) and the Web Coverage Service (WCS) also have GetCapabilities operations. Therefore, discovery methods for those services are analogous to the discovery methods for WMSs.
2.1. Surface Geospatial Web Services Discovery
The most notable research for actively discovering surface geospatial web services can be divided into two types of approaches. The first type of discovery approach utilizes the application programming interfaces (APIs) of general-purpose search engines, employing predefined queries to search the Internet for discovering OGC geospatial web services [
27,
32,
33,
37,
38]. For example, the Refractions Research OGC Survey [
37] used the Google web API with two queries “request = getcapabilities” and “request = capabilities” to extract the results and then used a number of Perl “regular expressions” for a complete capabilities URL in each returned page. Lopez-Pellicer et al. [
33] employed Bing, Google and Yahoo! APIs with two sets of 1000 queries to measure the performances of the three search engines in discovering OGC geospatial web services. They finally identified Yahoo! as the best performer. In the last two years, Bone et al. [
32] designed a geospatial search engine for discovering multi-format geospatial data using the Google search engine with both user-specified and predefined terms. Kliment et al. [
27,
39] used the advanced query operators “inurl:” of the Google search engine to discover specific OGC geospatial services stored in Google’s indexes. This type of discovery approach is easily implemented, is low cost and can avoid the performance issues of systems that attempt to crawl the entire web [
32]. However, a general-purpose search engine is intended to cover entire topics without considering the characteristics of OGC geospatial web services; thus, with this approach, actual OGC geospatial services will be inundated with a large amount of search results [
16]. Moreover, although general-purpose search engines (e.g., Google) have already attempted to incorporate deep web resources hidden behind hypertext markup language (HTML) forms [
35], they still ignore some resources hidden in JavaScript code, especially OGC geospatial web services invoked by JavaScript libraries. Furthermore, the public API of general-purpose search engines has some calling limitations imposed through permissions, allowed numbers of call, special policies, and so on. For instance, the API of the Google custom search engine provides only 100 free search queries per day [
40].
The second type of discovery approach is to utilize customized search engines. Customized search engines can be categorized into general-purpose and topic-specific search engines [
29]. Customized general-purpose search engines are equipped with a web crawler, which can continually collect large numbers of webpages by starting from a series of seed URLs (a list of URLs that the crawler starts with) and without a specific topic [
32,
41,
42]. For example, Sample et al. [
43] utilized Google search APIs to generate a set of candidate seed URLs for GIS-related websites and developed a web crawler to discover WMSs. Shen et al. [
15] developed a WMS crawler based on the open source software NwebCrawler to support active service evaluation and quality monitoring. Patil et al. [
44] proposed a framework for discovering WFSs using a spatial web crawler. Compared to general-purpose search engines, customized general-purpose search engines can easily control the process for discovering geospatial web services and can dramatically scale down the set of URLs to crawl. However, the crawled URLs still go far beyond only geospatial pages that contain geospatial web services [
16].
To solve the above problems, topic-specific search engines with focused crawlers were developed. With a series of seed URLs and a given topic, focused crawlers aim to continually crawl as many webpages relevant to the given topic and keep the amount of irrelevant webpages crawled to the minimum [
41]. For example, Lopez-Pellicer et al. [
26,
45] developed a focused crawler for geospatial web services. This crawler utilized Bing, Google and Yahoo! search APIs to generate seed URLs and used best first and shark-search strategies to assign priority to these URLs. Li et al. [
16], Wu et al. [
46] and Shen et al. [
34] also developed focused crawlers based on different URL priority assignment approaches to discover OGC geospatial web services. Because they further scale down the set of URLs that must be crawled, these methods can improve discovery performance in both technical and economic perspectives [
16]. However, the above crawlers in the customized search engines parse webpages solely through HTML parsing engines, which have no ability to identify and submit HTML forms and do not address JavaScript code. Therefore, these customized search engines are not able to discover WMSs in the deep web.
2.2. Deep Geospatial Web Services Discovery
The deep web refers to data hidden behind query interfaces, scripted code and other types of objects [
17,
47]. From this perspective, the underlying geospatial web services registered in catalogues are opaque because they are hidden behind catalogue query interfaces [
47,
48]; as such, geospatial web services registered in catalogues form part of the Deep Web. In general, searching services from known catalogues is implemented by keyword matching approaches [
16]. However, a number of catalogues are unknown to the public. Therefore, discovering services from these unknown catalogues depends on successfully detecting and understanding the query interfaces of these unknown catalogues [
47,
48]. In the past few years, several works have been performed to address the query interface detection and understanding problem. For example, Dong et al. [
49] proposed a novel deep web query interface matching approach based on evidence theory and task assignment. These works can be used for detecting and understanding the query interfaces of unknown catalogues, but their original purposes were not focused on discovering geospatial web services from the deep web.
Recently, some efforts have been made to discover geospatial web services from the deep web. For example, Lopez-Pellicer et al. [
20,
21] analysed the characteristics of the deep web geospatial content in detail. They pointed out that disconnected content, opaque content, ignored content, dynamic content, real-time content, contextual content, scripted content and restricted content are all part of the deep web geospatial content. Furthermore, they summarized six heuristics on the characteristics of the deep web content in the form of texts. Then, they designed an advanced geospatial crawler with plugin architecture and introduced several extension plugins for implementing some of the heuristics to discover part of geospatial contents hidden in the deep web. Finally, they indicated that discovering services in geospatial web applications based on JavaScript libraries (e.g., OpenLayers) is still one of the open questions that require further research. This was one motivation behind this study’s effort to develop a new active discovery approach. Therefore, our contribution lies in the development of a method to discover WMSs in geospatial web applications through focused crawling by inspecting the JavaScript code using a rule-matching approach.
2.3. Use of JavaScript Code in Deep Web Resources Discovery
Various resources hidden in JavaScript code comprise part of the deep web. Discovery of these resources has been the subject of research in the past few years. For example, Bhushan and Kumar [
50] developed a deep web crawler by utilizing some regular expressions (Match/Replace) to extract clear-text links hidden in JavaScript code. Hou et al. [
42] summarized matching rules formalized by a regular expression to extract the geographical coordinates of built-up areas from JavaScript code. Some resources dynamically generated by JavaScript code can be extracted using interpreters (i.e., the JavaScript parsing engine and Webkit). For instance, Hammer et al. [
51] developed a WebKit-based web crawler to extract online user discussions of news. In geospatial web applications, WMSs are rendered as maps for visualization using geospatial JavaScript libraries; hence, the WMSs are hidden in JavaScript code. In general, these JavaScript libraries have concrete functions used to invoke WMSs. Learning from the discovery experiences of other deep web resources, this paper summarizes the invocation rules to extract candidate WMSs from JavaScript code.
3. Methodology
The previous discussions and analyses conclude that numerous LCWMSs exist in the JavaScript code of geospatial web applications and must be discovered. Discovering these LCWMSs requires addressing two challenges: detecting JavaScript code and understanding what that code does.
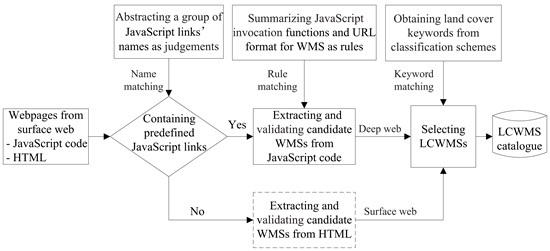
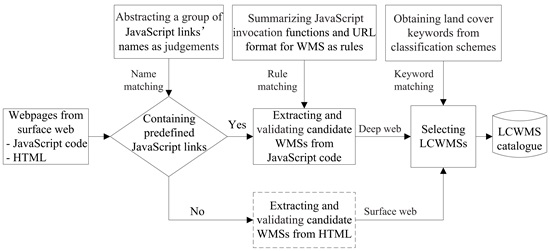
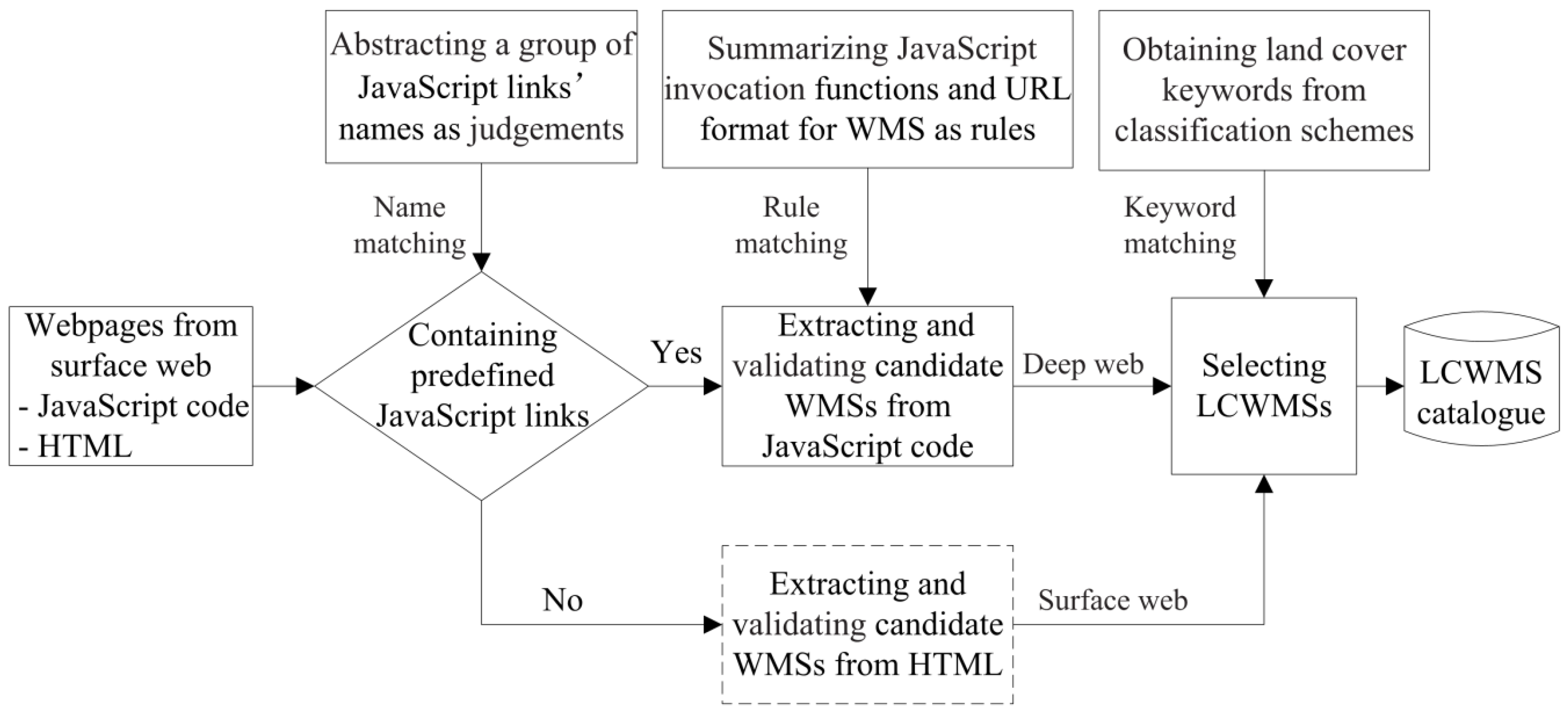
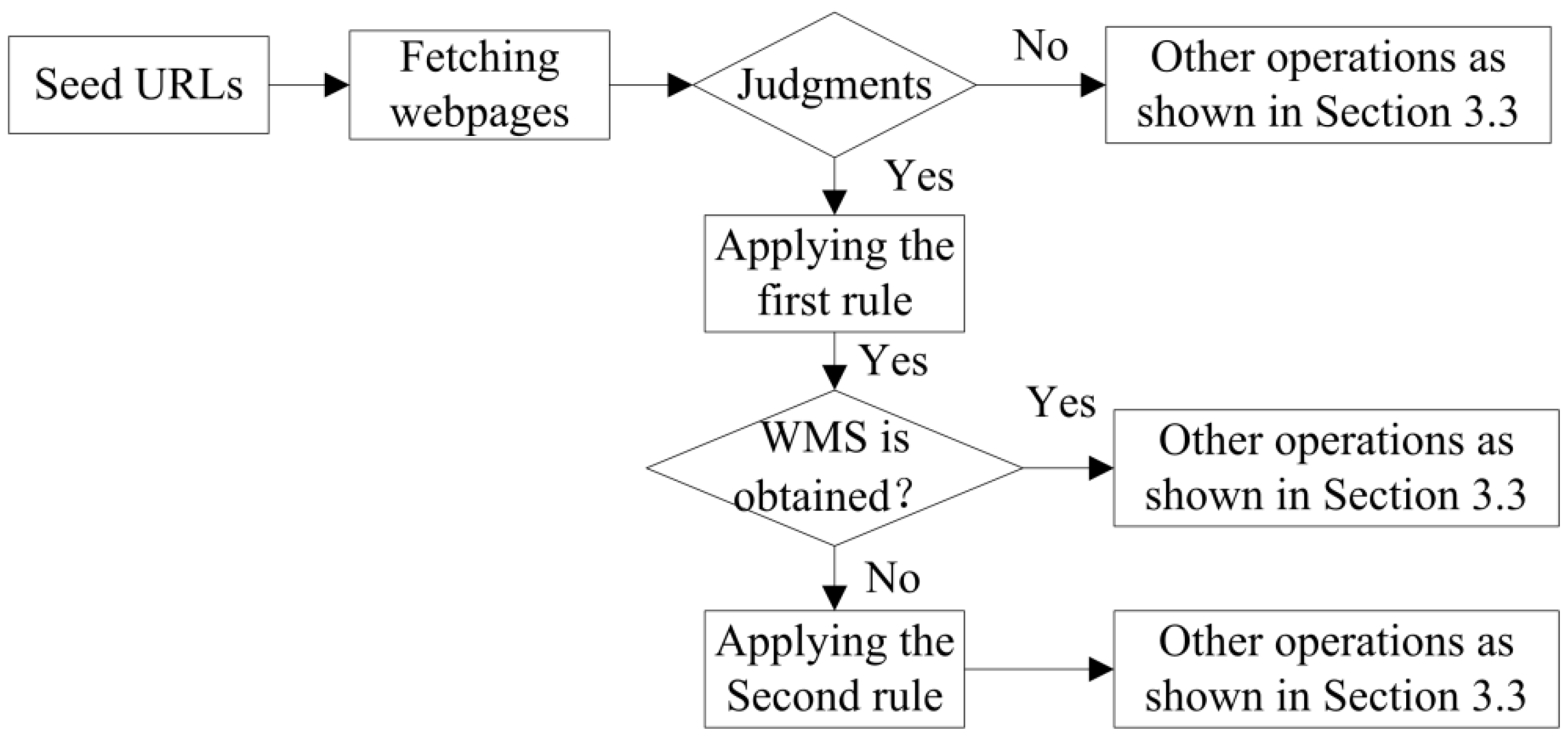
Figure 1 represents the conceptual framework for discovering LCWMSs hidden in JavaScript code and the surface web. Compared with other focused crawler-based discovery methods, the proposed approach involves three major tasks. The first task is detecting predefined JavaScript links presented in the fetched webpages. This task is responsible for judging whether other JavaScript code potentially employs WMSs by matching the code against predefined judgements, which are composed of some JavaScript link names. The second task involves understanding the detected JavaScript code. It is the responsibility of this task to extract and validate candidate WMSs from JavaScript code through rule matching. Achieving this goal depends largely on JavaScript invocation rules, which are composed of WMS functions and their URL formats. The third task is to select available LCWMSs from the extracted candidate WMSs using a land cover keyword-matching approach. In
Figure 1, the tasks in the dashed box are similar to other focused crawler-based discovery methods. More details are specified in the following subsections.
3.1. Detection of JavaScript Links Using Judgements
Most geospatial web applications use third-party JavaScript libraries to invoke WMSs for map visualization. The four best-known JavaScript libraries are OpenLayers [
52], ArcGIS API for JavaScript [
53], Leaflet [
54] and Mapbox.js [
55]. For example, the GlobeLand30 [
9,
14] and CropScape [
6] geospatial web applications were developed using OpenLayers. It is standard syntax to enclose a reference to a JavaScript library in a “<script>” tag when it is used to develop a web application with HTML [
56], as shown in
Table 1. The “src” property value of the “<script>” tag is a JavaScript link to specific external JavaScript code or library. Therefore, a webpage that refers to any of the four WMS-related JavaScript libraries is a reasonable candidate for potentially containing any WMSs. Based on this finding, this paper summarizes judgements to determine whether the fetched webpages have predefined JavaScript links that execute JavaScript code known to be related to WMSs.
The judgements are composed of some JavaScript link names that are predetermined based on the reference formats of OpenLayers, ArcGIS API for JavaScript, Leaflet and Mapbox.js as they appear in webpages, as shown in
Table 1. These judgements include “openlayers,” “ol.js,” “ol-debug.js,” “arcgis,” “leaflet,” and “mapbox.” The judgements are performed by matching names with the JavaScript links in fetched webpages. When a JavaScript link in fetched webpages contains one of the predefined names, it indicates that other JavaScript code in the webpages may employ WMSs. Therefore, the other JavaScript code will be addressed by the JavaScript invocation rules described in this paper.
Moreover, two additional measures are adopted to further avoid traversing all JavaScript links in a geospatial web application. The first is to include some WMS-related keywords extracted from the naming schemes of many actual JavaScript links known to launch WMSs. These keywords include “map,” “initial,” “wms,” “layer,” “conus,” “capabilities,” “demo,” “query,” and “content.” Only when the name of a JavaScript link contains at least one of the above WMS-related keywords will the JavaScript link itself be addressed by two subsequent JavaScript invocation rules. The second adopted limiting measure is to summarize some keywords not related to WMSs from the naming schemes of numerous well-known JavaScript libraries, such as JQuery, ExtJS, Proj4js and AngularJS. The keywords mainly consist of “jquery,” “ext-,” ”proj4js,” ”angularjs,””openlayers,” “ol.js,” “ol-debug.js,” “leaflet,” “mapbox” and so on. When the name of a JavaScript link contains one of the above WMS-unrelated keywords, the JavaScript link will be ignored.
3.2. Understanding of JavaScript Code Using Invocation Rules
Only a discovery approach that understands how geospatial web applications invoke WMSs by JavaScript libraries will be able to discover the WMSs in these applications [
57]. Therefore, two JavaScript invocation rules are summarized based on development knowledge of geospatial web applications about WMSs to understand what such JavaScript code does.
As shown in
Table 2, the first JavaScript invocation rule is derived from the OpenLayers [
52], ArcGIS API for JavaScript [
53], Leaflet [
54] and Mapbox.js [
55], all of which are JavaScript libraries that provide support for OGC’s web mapping standards [
58]. The listed total of seven common functions are often directly used to invoke WMSs in a large number of geospatial web applications. Therefore, to make the discovery method understand how geospatial web applications invoke WMSs, the seven functions collectively compose the first JavaScript invocation rule, which is formalized by the regular expression shown in
Figure 2. The rule obtains JavaScript code fragments containing the URLS of candidate WMSs using a simple rule-matching approach. For example, the JavaScript code fragment “OpenLayers.Layer.WMS.Untiled (“Rivers,” “
http://129.174.131.7/cgi/wms_conuswater.cgi”, ...)” in the CropScape geospatial web application [
6] can be extracted by simply matching the first rule.
The seven common functions are also deeply encapsulated in other functions that simply invoke WMSs. For example, in the GeoNetwork site [
59], the function “OpenLayers.Layer.WMS” is encapsulated as the function “createWMSLayer,” which takes only an array parameter as an argument to specify the base URLs of the WMS. It is impossible to exhaustively list all the encapsulated functions, because different geospatial web applications may adopt different encapsulated function names. Therefore, to make the discovery method understand how encapsulated functions invoke WMSs, the second JavaScript invocation rule is composed of the base URL formats of the WMSs and is also formalized by a regular expression, as shown in
Figure 3. The regular expressions for the two rules are compiled by following the rules of the C# language. Through a simple rule-matching approach, the second rule is used to extract http or https URLs that cannot be extracted by the first rule from JavaScript code. For example, no URL can be extracted by the first rule from the GeoNetwork site [
59]; however, a URL can be extracted by matching the second rule from the JavaScript code fragment ”GeoNetwork.WMSList.push (“Demo Cubewerx (WMS)-2,” “
http://demo.cubewerx.com/demo/cubeserv/cubeserv.cgi”)” in the GeoNetwork site [
59].
The two JavaScript invocation rules should be applied in a specific sequence, as shown in
Figure 4. Only when Javascript code referenced by a fetched webpage is identified as the potential source of a WMS will the first rule be executed. Then, only if the first rule does not yield any URLs containing candidate WMSs will the second rule be executed. This sequence is necessary because the second rule is more general than the first rule; therefore, it acts to complement the first rule to capture all the URLs in the identified JavaScript code.
Figure 5 presents the pseudocode to illustrate how to use the two JavaScript invocation rules. Steps 1–45 use the first JavaScript invocation rule to extract the URLs of potential WMSs. Steps 8–15 obtain a string for the URL of a potential WMS by splitting the matched string between the former two commas because the second argument represents the base URL for a WMS when calling functions in version 2 of the OpenLayers API (OpenLayers 2.x). Steps 16–21 also obtain a string for the URL of a potential WMS by splitting the matched string between the string “url:” and the first comma because the value of the key “url” represents the base URL for a WMS when calling functions in version 3 of the OpenLayers API (OpenLayers 3.x). Similarly, a string for the URL of a potential WMS is obtained by splitting the matched string between the first left parentheses and the first commas in Steps 22–27 because the first parameter represents the base URL for a WMS in ArcGIS API for JavaScript functions, Leaflet, and Mapbox.js. Steps 28–31 indicate that the extracted parameter is the URL of a potential WMS if it matches a URL format. When the extracted parameter is a JavaScript variable, a new function that potentially returns the URL of the WMS will be generated and executed by the Jurassic JavaScript parsing engine by calling the CallGlobalFunction function [
60], as shown in Steps 32–43. In these steps, the syntax for the new function is composed of the JavaScript variable and a return statement, as shown in Step 38. Steps 47–53 illustrate how to apply the second JavaScript invocation rule to extract the URLs of potential WMSs.
3.3. Discovery of Land Cover Web Map Services (LCWMSs) with a Focused Deep Web Crawler
A focused deep web crawler is proposed to discover LCWMSs from JavaScript code and the surface web. The focused deep web crawler mainly relies on the summarized judgements, JavaScript invocation rules and a JavaScript parsing engine for handling the JavaScript code. Moreover, as mentioned in
Section 2.1, a focused crawler is able to efficiently traverse the web to find WMSs in the surface web. Therefore, the proposed crawler uses the focused crawler to traverse the web for finding WMSs in the surface web. In the proposed crawler, the judgements serve as a bridge between the JavaScript invocation rules and the focused crawler.
Figure 6 illustrates the framework for the focused deep web crawler. The proposed crawler starts with a series of seed URLs. Next, it begins to fetch the webpages corresponding to the seed URLs or to crawled URLs. Then, the proposed crawler executes one of two branches according to certain judgements. When the judgements are fulfilled, the first branch executes. Otherwise, the second branch executes. The first branch mainly analyses any JavaScript code in the page with the Jurassic JavaScript parsing engine and the two JavaScript invocation rules, according to the pseudocode detailed above. It aims to obtain candidate WMS URLs from JavaScript code, while the second branch is intended to obtain candidate WMS URLs from the surface web. The second branch starts by parsing the HTML of webpages to extract their titles and contents. Then, a relevance calculation is executed using the traditional vector space model and the cosine formula. In this step, the vector space model is an algebraic model that represents webpages and the given topic as two vectors of keywords. The cosine function is a measure of similarity between each webpage vector and the topical vector by comparing the deviation of angles between the two vectors. This calculation is responsible for measuring the degree of similarity between the extracted webpages and the given topical keywords. If the relevance value is smaller than a given threshold, the webpage is discarded. Otherwise, when the relevance value is equal to or greater than the given threshold, the URLs in the webpage are extracted and a priority score for URLs will be assigned based on the texts in URLs, their parent webpages and anchor texts. Furthermore, to more precisely target candidate WMS URLs, any extracted URLs that end with common file extensions such as “.pdf,” ”.tif,” ”.js,” “.doc,” “.zip” and so on are discarded.
After the candidate WMS URLs are obtained from these two branches, they are submitted to the component that performs WMS validation. The WMS validation component submits a GetCapabilities request to check whether the potential WMS URL corresponds to an available WMS. When the URL is not a valid WMS, it is discarded. When the URL is an available WMS, its capability file will be parsed to obtain metadata, such as the service name, service abstract, service keywords, bounding boxes, layer names, layer titles, layer abstracts and so on. Then, the available WMSs will be classified to identify the LCWMSs through matching land cover keywords. When the WMS metadata of service/layer names, titles, abstracts and keywords contain one of the land cover keywords, the WMS is classified as a LCWMS and stored in a LCWMS catalogue. Otherwise, the WMS is stored into a separate WMS catalogue. Finally, URLs in the URL priority queue will continue to be submitted for fetching webpages until the URL priority queue is empty or other conditions are fulfilled.
A total of 97 land cover keywords in English were collected from nine well-known classification schemes, as shown in
Table 3. The nine well-known classification schemes include GlobeLand30 [
9], International Geosphere-Biosphere programme (IGBP) [
61], University of Maryland (UMD) [
62], Global Land Cover 2000 (GLC 2000) [
63], GlobCover [
64], land-use monitoring using remote sensing from the Chinese Academy of Sciences [
65], National Land Cover Database (NLCD) [
66], Earth Observation for Sustainable Development of Forests (EOSD) [
67] and the Dynamic Land Cover Dataset (DLCD) [
68].
6. Conclusions
Automatic discovery and connections to isolated land cover web map services (LCWMSs) help to potentially share land cover data, which can support the United Nations’s 2030 sustainable development agenda and conform to the goals of CoGLand. Previous active discovery approaches have been aimed primarily at finding LCWMSs located in the surface web and behind query interfaces in the deep web. However, very few efforts have been devoted to discovering LCWMSs from deep web JavaScript code, due to the challenges involved in web map service (WMS)-related JavaScript code detection and understanding. In this paper, a focused deep web crawler was proposed to solve these problems and discover additional LCWMSs. First, some judgements and two JavaScript invocation rules were created to detect and understand WMS-related JavaScript code for extracting candidate WMSs. These are composed of some names of predefined JavaScript links and regular expressions that match the invocation functions and URL formats of WMSs, respectively. Then, identified candidates are incorporated into a traditional focused crawling strategy, situated between the tasks of fetching webpages and parsing webpages. Thirdly, LCWMSs are selected by matching with land cover keywords. In addition, a LCWMS search engine was implemented based on the focused deep web crawler to assist users in retrieving and integrating the discovered LCWMSs.
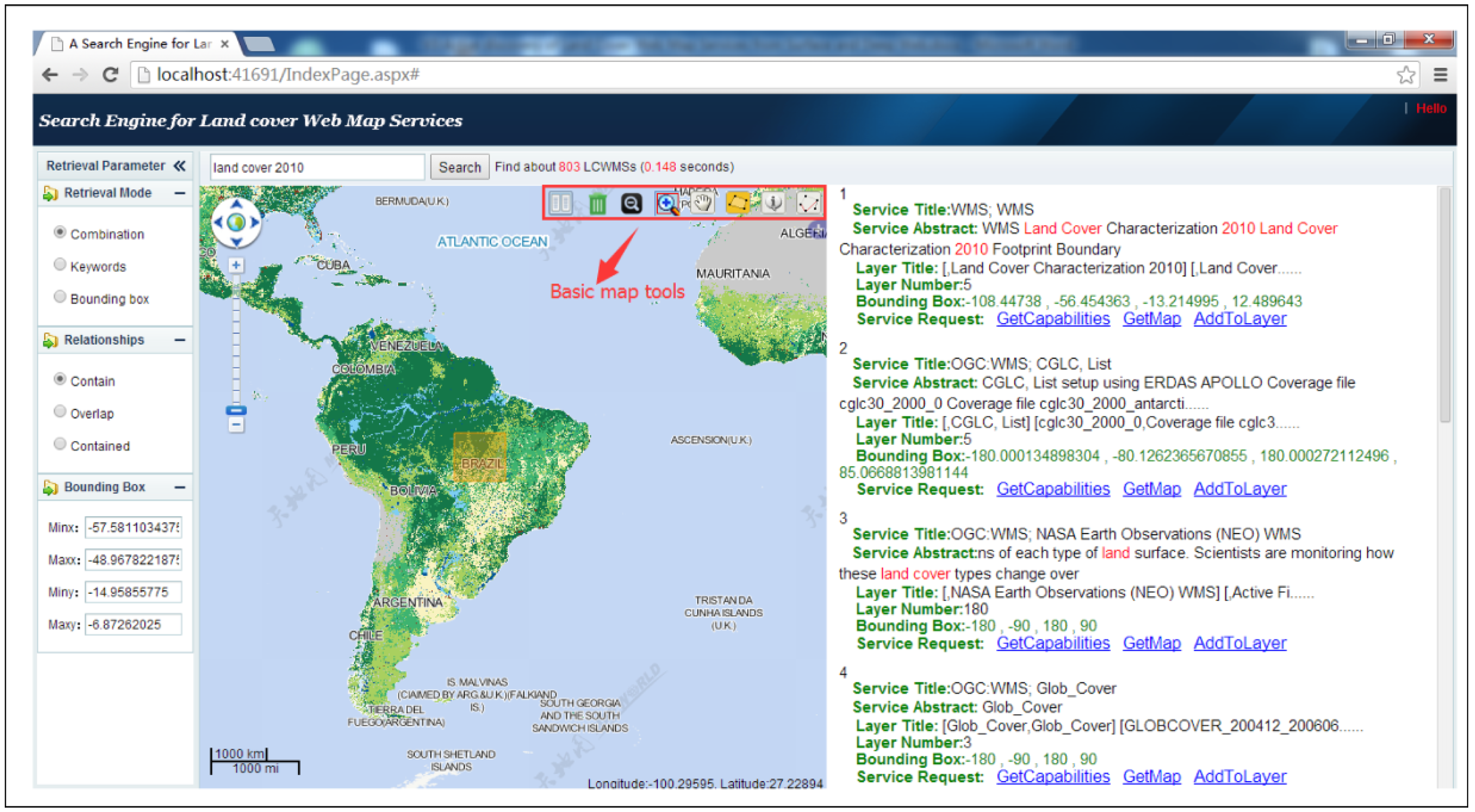
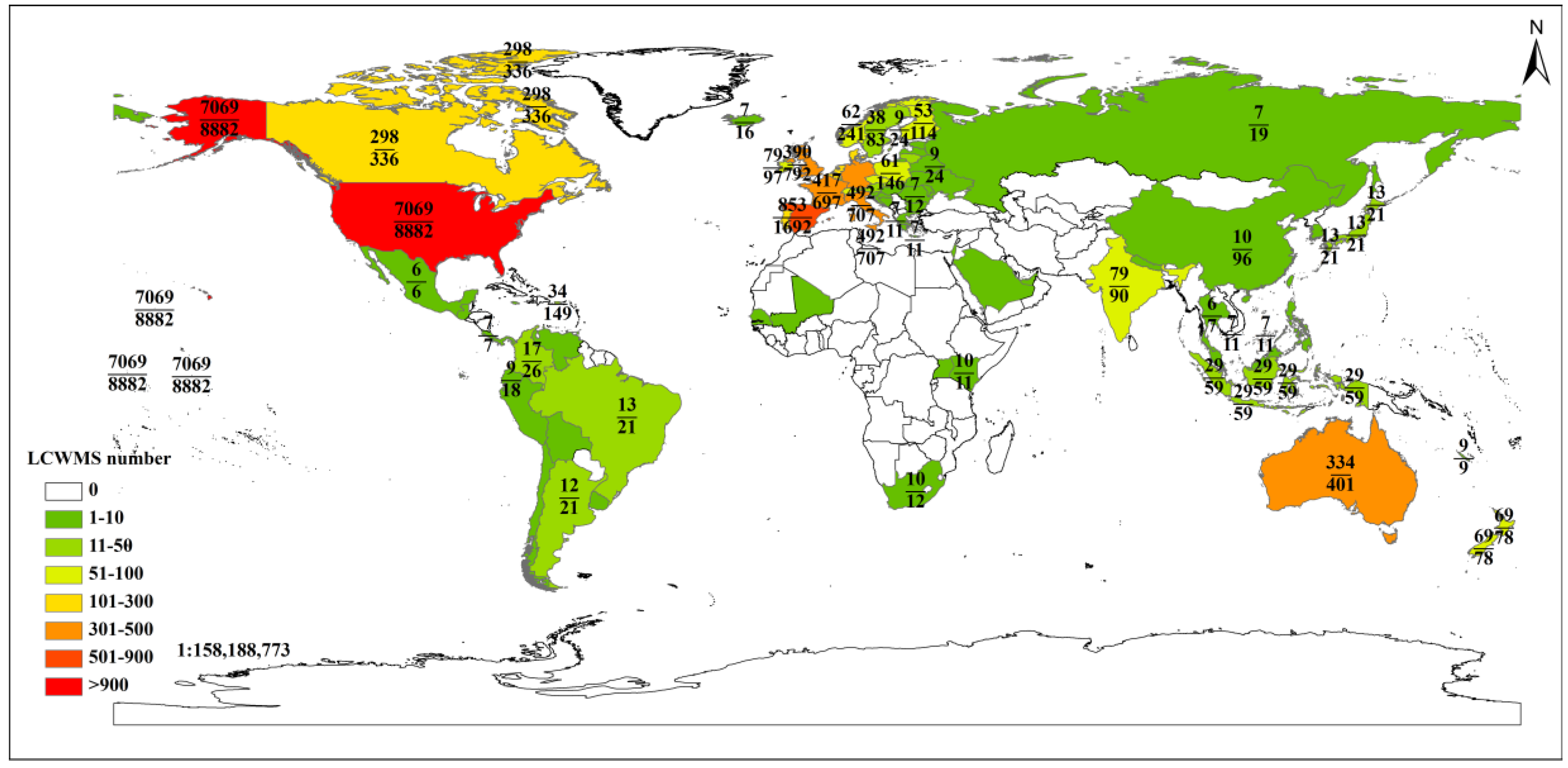
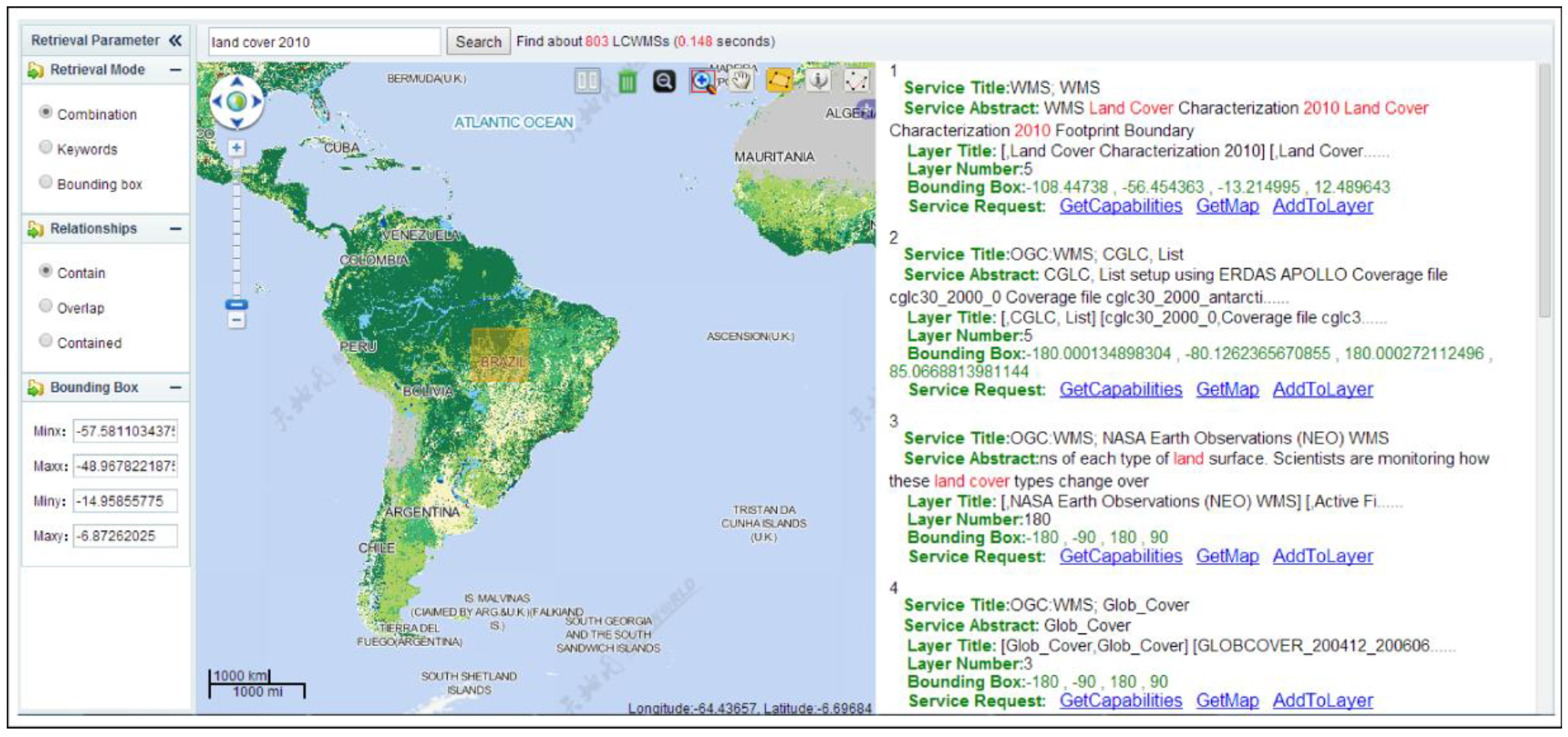
Experiments showed that the proposed focused deep web crawler has the ability to discover LCWMSs hidden in JavaScript code. By searching the worldwide web, the proposed crawler found a total of 17,874 available WMSs, of which 11,901 were LCWMS. The results of a case study for retrieving land cover datasets around Brazil indicate that the designed LCWMS search engine represents an important step towards realizing land cover information integration for global mapping and monitoring purposes.
Despite the advantages of the proposed crawler, much work remains to improve the effectiveness of discovering LCWMSs. First, the proposed crawler considers only one script type (JavaScript). However, other script types (i.e., ActionScript) can also invoke LCWMSs. In the future, additional rules will be summarized to help the proposed crawler discover LCWMSs invoked from other scripting languages. Secondly, some currently available LCWMSs may become unavailable in the future. Future work will include a monitoring mechanism to monitor and assess the quality of the discovered LCWMSs. Third, the proposed crawler utilized the cosine function to measure topical relevance and to assign priorities to URLs. Moreover, it adopted a keyword-matching approach to classify each WMS. In the future, machine-learning approaches such as support vector machines will be applied to measure topical relevance, assign URL priorities and classify WMSs.














{kind=link}
{kind=link}
{kind=link}
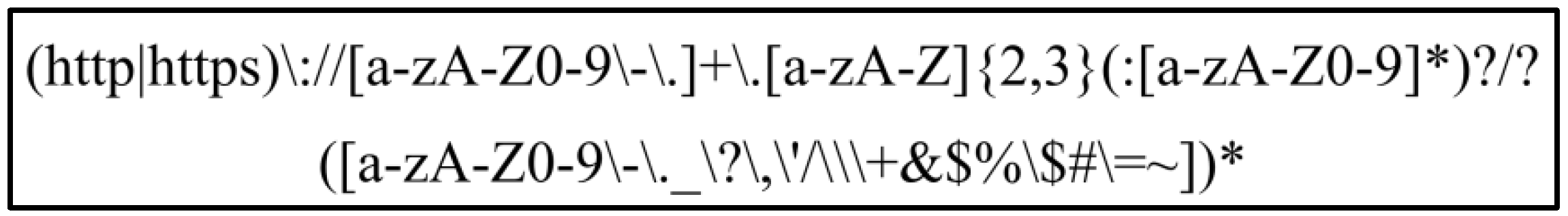{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}