
A Point-Set-Based Footprint Model and Spatial Ranking Method for Geographic Information Retrieval


Abstract
:1. Introduction
- (a)
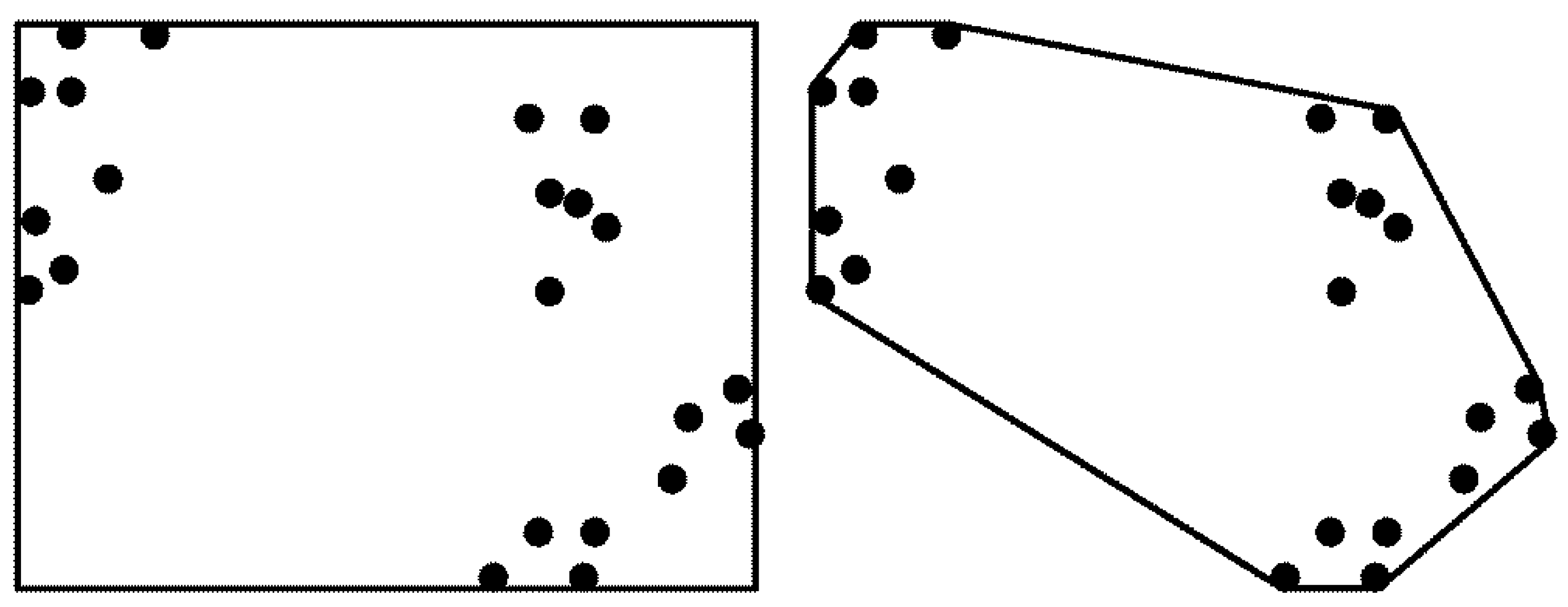
- Space redundancy. The most obvious weakness happens when polygon models represent diagonal, irregular, non-convex, or multi-part regions [12]. The polygons will cover more space than the documents refer to (Figure 1), and if the query falls in the redundant space, irrelevant documents will be retrieved.
- (b)
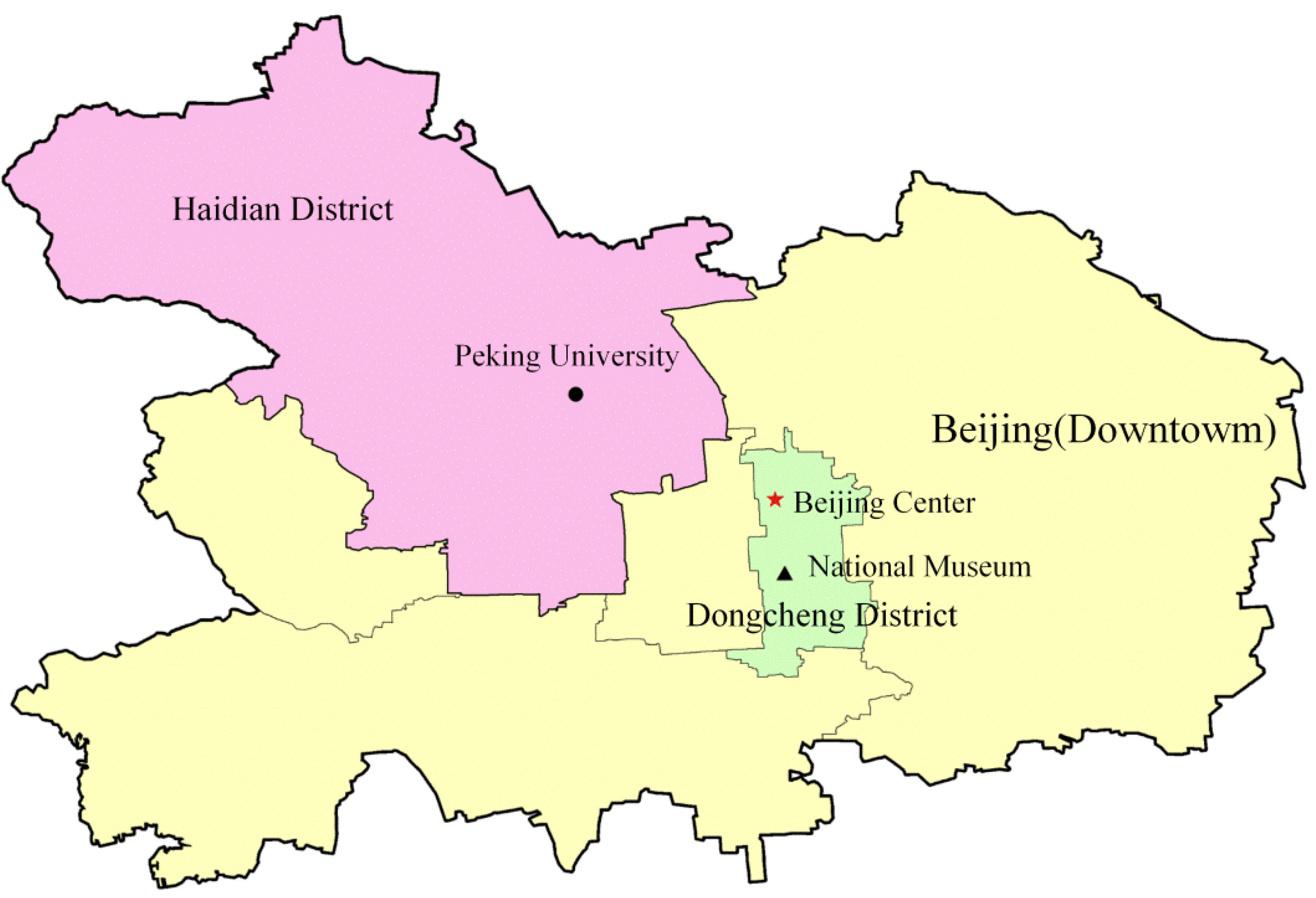
- Location swamping. The documents may contain locations on different scales, e.g., Beijing, Haidian District, and Peking University (Figure 2). However, the final polygon only represents the overall area, and inner locations will be masked, which will lead to information loss. For example, if the query is Peking University, and there are two documents both referring to Beijing, but one document mentions Peking University and the other does not, then the polygon model will be unable to discriminate between these two documents and fail to target the most relevant document, because the footprint of these two documents are presented as the same polygon.
- (c)
- Inaccuracy. The similarity evaluation based on polygon models is to examine the topological relationship, i.e., whether they touch/intersect/contain each other or not. Because this relationship is binary (0 for separation and 1 for intersection), the result is rough. This evaluation method does not discriminate the cognition of “far” or “near”, which is important with regard to spatial cognition of human beings, and the distance between two entities should be stressed. Some improvements have been made to conquer the inaccuracy of binary evaluation by examining the proximity in three scenarios: contain, overlap, and proximity [11]. Correspondingly, the evaluation function is adjusted from binary to an area ratio, which will improve the accuracy, but the result may not always conform to common sense. For example, if the query is “Beijing” and we retrieve this query from two documents, A and B, and the footprint of document A is “Dongcheng District” and the footprint of document B is “Haidian District” (Figure 2). Then when using the evaluation function of area ratio, document B will rank higher than A because the area of Haidian District is larger than the area of Dongcheng District. However, because document A and document B both refer to sub-regions of Beijing and there is no more information to discriminate the relevance, when retrieving Beijing, both sub-regions should rank the same.
- (d)
- Homogeneity. The space within a single MBR is considered equally, even though some of the places may be more important due to higher frequencies. For example, if one document mentions Haidian district 50 times, and the other document mentions Haidian district only once, then the polygon footprints for these two documents may be the same. However, in traditional text retrieval, according to the TF-IDF model [13], the entities with higher frequency tend to have higher ranking scores. Similarly, we consider the first document to be definitely more related to Haidian district than the second document, because the first document mentions the place more often.
2. Footprint Model of the Documents
3. Spatial Ranking Method
3.1. Spatial Proximity
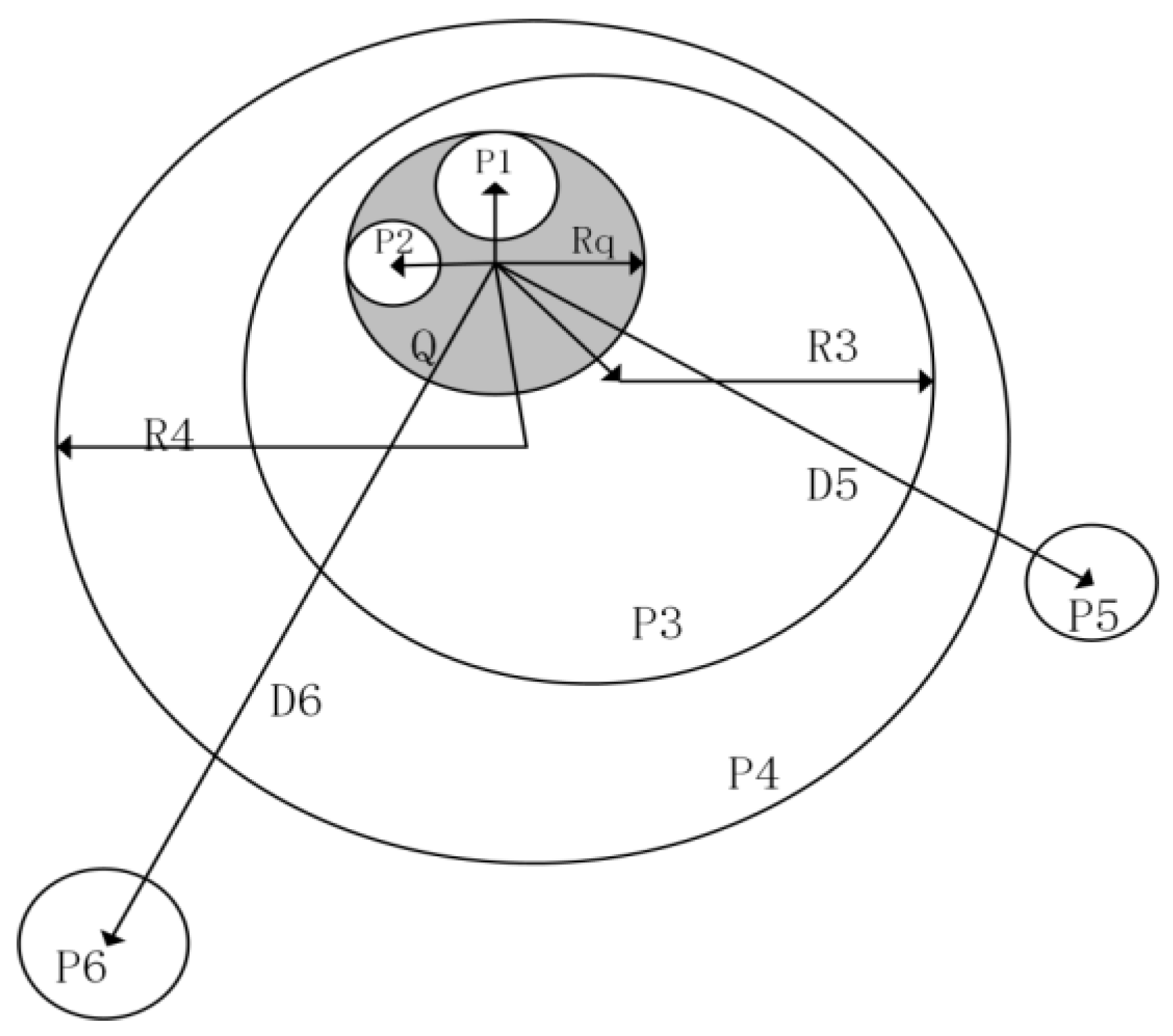
- (a)
- Scenario 1: The point m and the point i do not completely contain each other (Figure 4a), including cases of overlapping and disconnecting. In this case, we define the distance used to evaluate the similarity of these two points as .
- (b)
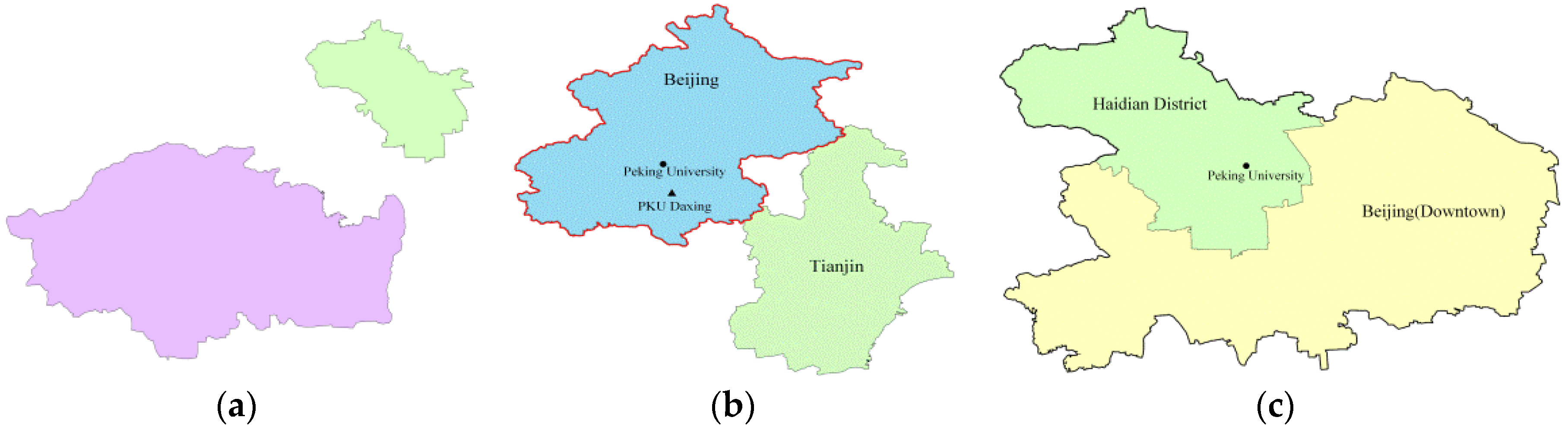
- Scenario 2: The area suggested by point m contains the area of point i. For example, the query is “Beijing”, and there are documents referring to “Peking University”, “PKU DaXing”, and “Tianjin” (Figure 4b). For these three places, “Peking University” and “PKU Daxing” are included in Beijing. Tianjin and Beijing are neighbor cities and have no overlapping areas. We define both of the distances, the distance between Beijing and Peking University and the distance between Beijing and PKU Daxing, as , because Peking University and PKU Daxing are at the same level (without containing) and both are inside Beijing. Their proximity to Beijing cannot be further differentiated. The relationship between Beijing and Tianjin fits the scenario 1, so the distance will be larger than , which will finally lead to a lower score in comparison with Peking University/PKU Daxing. To summarize, for every location within the query area, we allocate the same distance () to get the same ranking score.
- (c)
- Scenario 3: The geographic scope of point m is contained by the scope of point i. For example, the query is “Peking University” and two documents refer to Beijing and Haidian District, respectively (Figure 4c). We decide that although the two areas both contain the query area, Haidian District is more relevant because its granularity is finer. To realize this, distances are defined as . Because the fine-grained area’s radius is shorter than a coarse-grained one, the fine-grained area’s ranking will be higher.
- In scenario (2), for instance, P1 and Q, d3 < d1 < d2 and the final determined distance is d2 (or Rq).
- In scenario (3), for instance, P3 and Q, d2 < d1 < d3 and the final determined distance is d3 (or R3).
- In scenario (1), for instance, P5 and Q, d3 < d2 < d1 and the final determined distance is d1.
3.2. Frequency Weight Parameter
3.3. Ranking Method
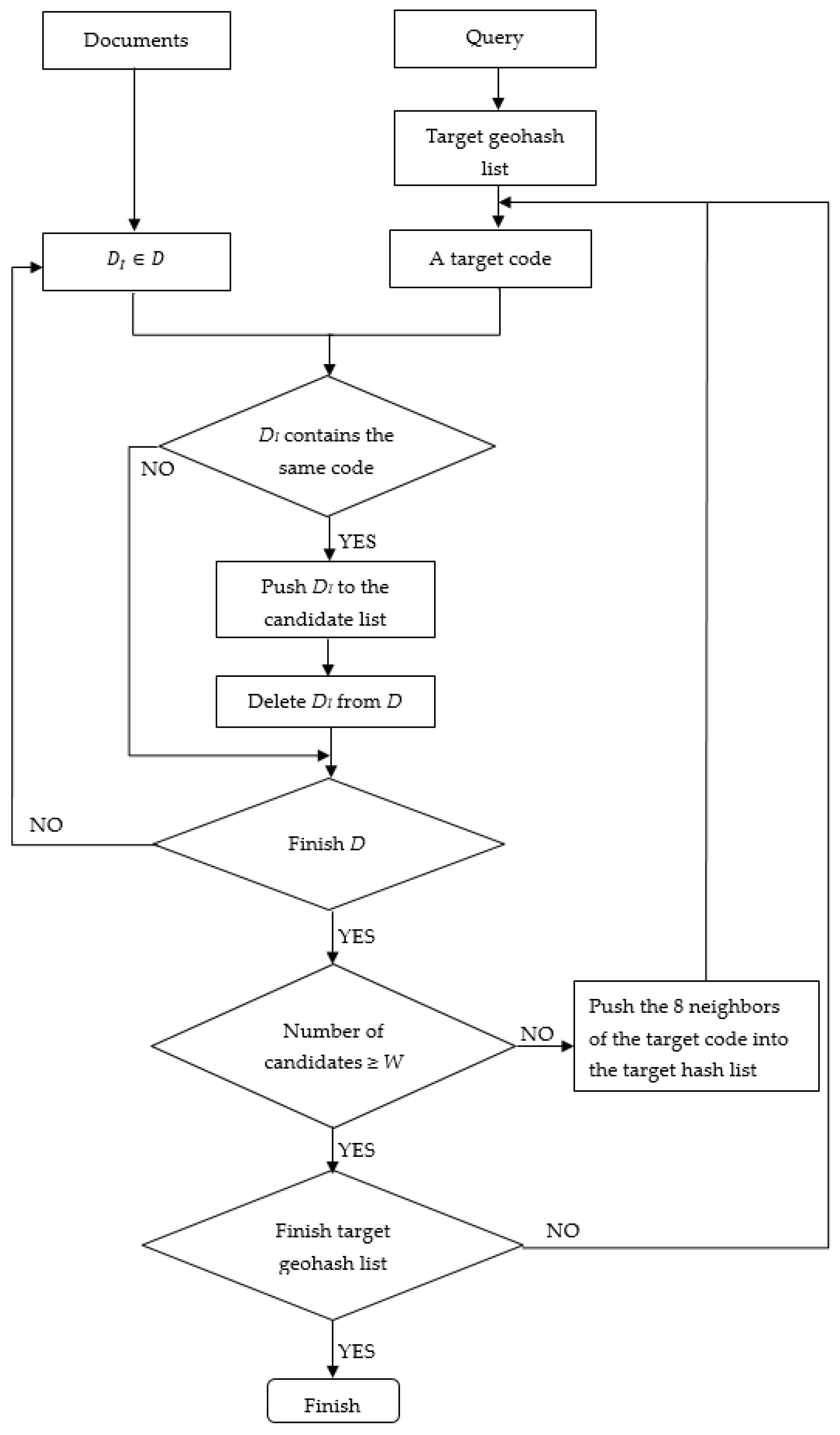
3.3.1. Pre-Filtering and Spatial Index
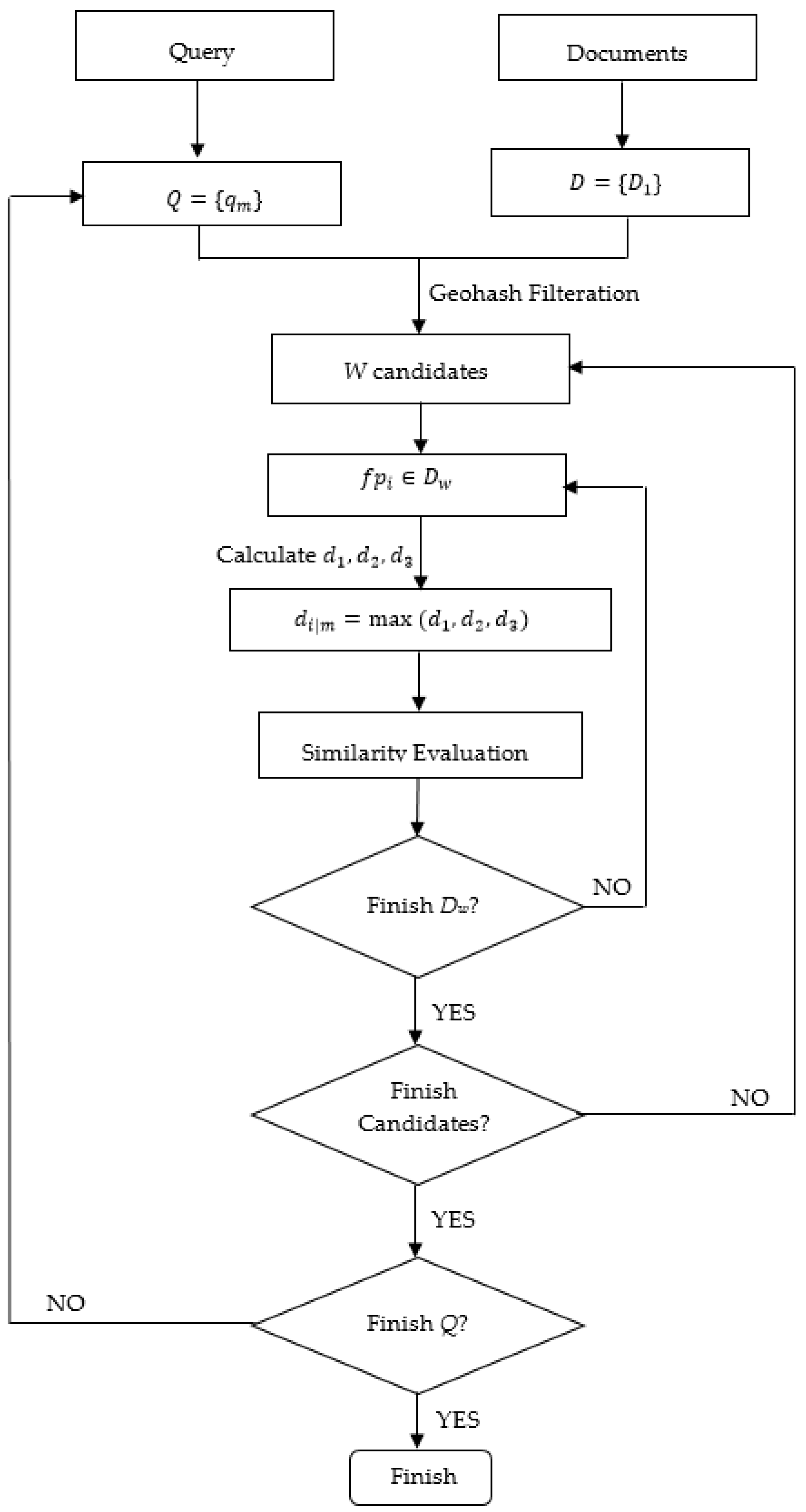
3.3.2. Ranking Procedure
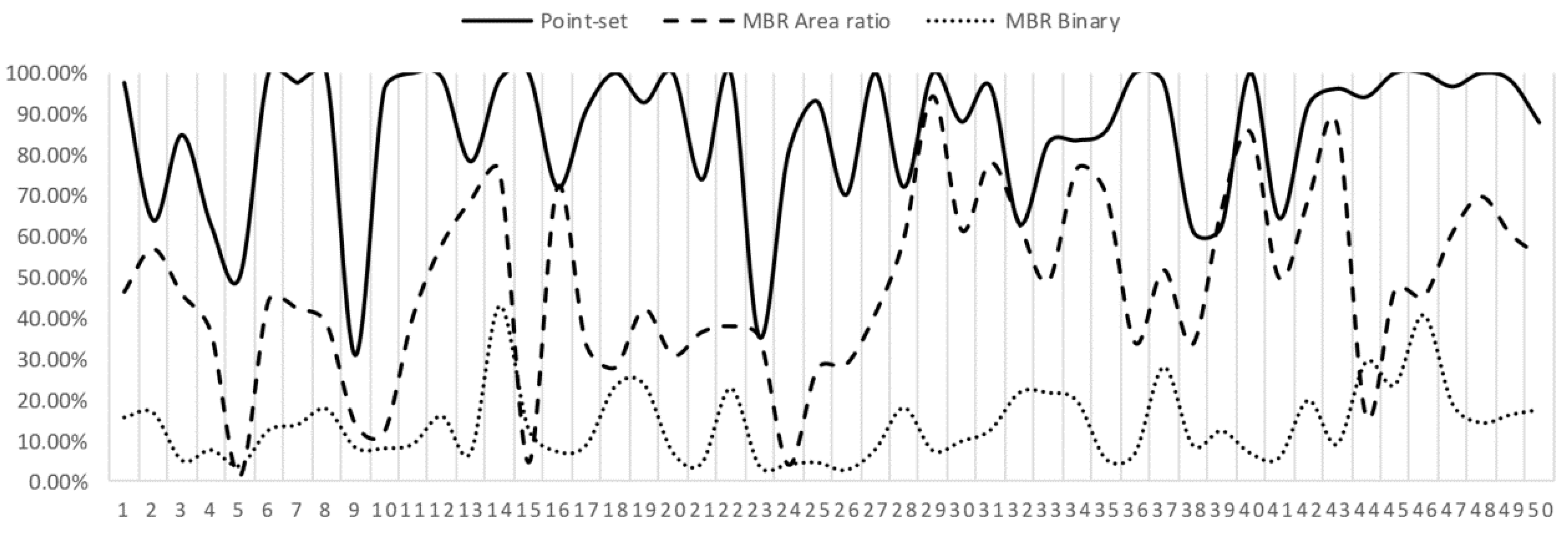
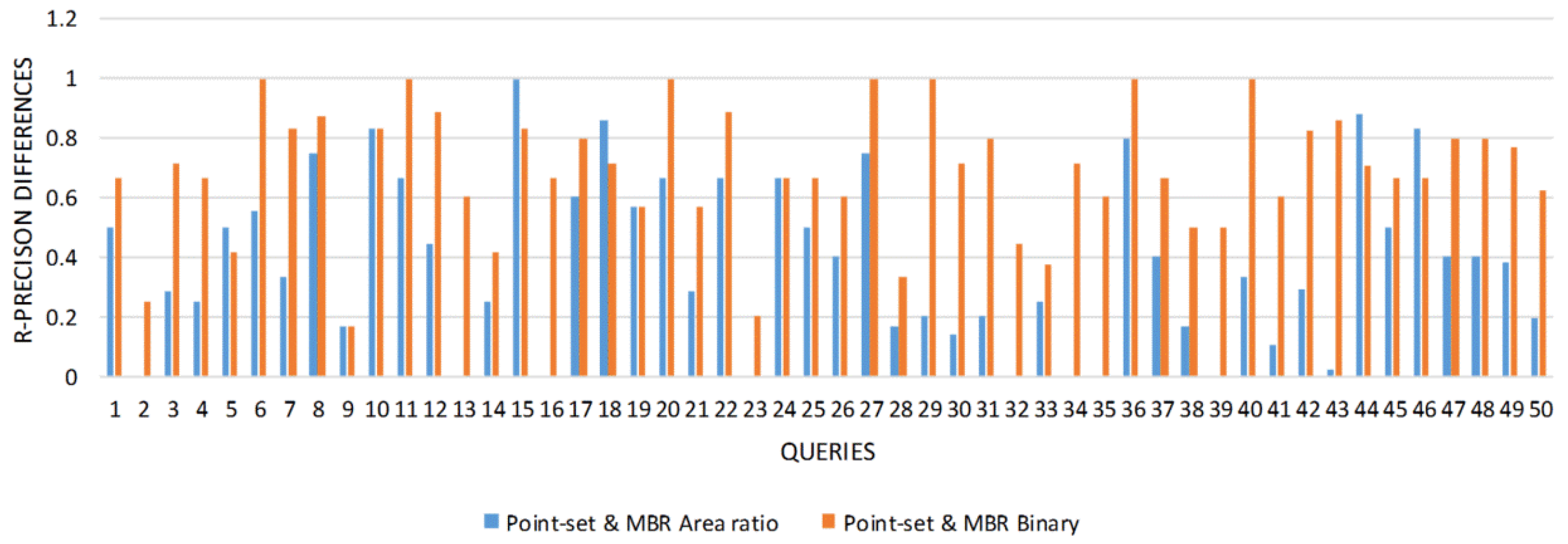
4. Experiments and Results
4.1. Data Source
4.2. Criteria
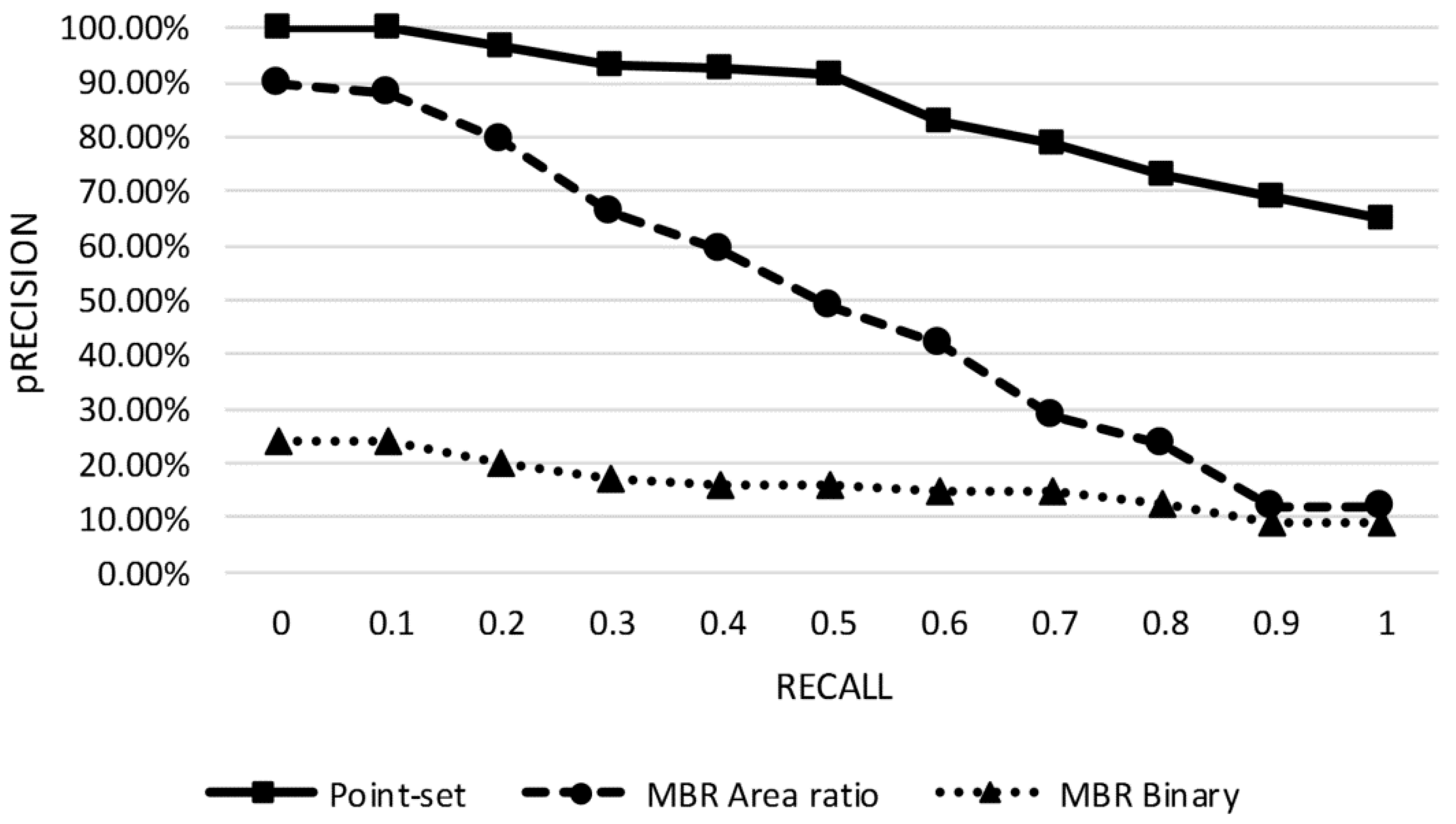
4.3. Performance Comparison
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Stats & Facts. Google Places. Available online: https://sites.google.com/a/pressatgoogle.com/googleplaces/metrics (accessed on 7 July 2014).
- Neustar Localeze. Local Search Usage Study. Available online: http://www.localsearchstudy.com/ (accessed on 7 July 2014).
- Larson, R.R. Geographic information retrieval and spatial browsing. In GIS and Libraries: Patrons, Maps and Spatial Information; Smith, L., Gluck, M., Eds.; Urbana-Champaign, University of Illinois: Champaign, IL, USA, 1995; pp. 81–124. [Google Scholar]
- Jones, C.B.; Alani, H.; Tudhope, D. Geographical information retrieval with ontologies of place. In Proceedings of the Conference on Spatial Information Theory, Morro Bay, CA, USA, 19–23 September 2001; pp. 322–335.
- Peters, C.; Clough, P.; Gey, F.C. Evaluation of Multilingual and Multi-modal Information Retrieval; Springer Science & Business Media: Medford, MA, USA, 2007. [Google Scholar]
- Gey, F.; Larson, R.; Sanderson, M.; Joho, H.; Clough, P.; Petras, V. GeoCLEF: The CLEF 2005 cross-language geographic information retrieval track overview. In Accessing Multilingual Information Repositories; Perters, C., Gey, F., Gonzalo, J., Müller, H., Jones, G.J.F., Kluck, M., Magnini, B., de Rijke, M., Eds.; Springer: Berlin, Germany, 2006; pp. 908–919. [Google Scholar]
- Guillén, R. CSUSM experiments in GeoCLEF2005: Monolingual and bilingual tasks. In Accessing Multilingual Information Repositories; Perters, C., Gey, F., Gonzalo, J., Müller, H., Jones, G.J.F., Kluck, M., Magnini, B., de Rijke, M., Eds.; Springer: Berlin, Germany, 2006; pp. 956–962. [Google Scholar]
- Kornai, A. Evaluating Geographic Information Retrieval; Springer: Berlin, Germany, 2006. [Google Scholar]
- Larson, R.R.; Frontiera, P. Spatial ranking methods for geographic information retrieval (GIR) in digital libraries. In Lecture Notes in Computer Science 3232; Heery, R., Lyon, L., Eds.; Springer: Berlin, Germany, 2004; pp. 45–57. [Google Scholar]
- Peter, C.; Deselaers, T.; Ferro, N.; Gonzalo, J.; Jones, G.J.F.; Kurimo, M.; Mandl, T.; Peas, A.; Petras, V. Evaluating Systems for Multilingual and Multimodal Information Access; Springer: Berlin, Germany, 2009. [Google Scholar]
- Martins, B.; Calado, P. Learning to rank for geographic information retrieval. In Proceedings of the 6th Workshop on Geographic Information Retrieval, Zurich, Switzerland, 28–29 January 2010; ACM: New York, NY, USA, 2010. [Google Scholar]
- Papadias, D.; Theodoridis, Y.; Sellis, T.; Egenhofer, M.J. Topological relations in the world of minimum bounding rectangles: A study with R-trees. Acm Sigmod Rec. 2010, 24, 92–103. [Google Scholar] [CrossRef]
- Salton, G.; Buckley, C. Term-weighting approaches in automatic text retrieval. Inf. Process. & Manag. 1988, 24, 513–523. [Google Scholar]
- Jones, C.B.; Abdelmoty, A.I.; Finch, D.; Fu, G.; Vaid, S. The SPIRIT spatial search engine: Architecture, ontologies and spatial indexing. Lect. Notes Comput. Sci. 2004, 3234, 125–139. [Google Scholar]
- Purves, R.S.; Clough, P.; Jones, C.B.; Arampatzis, A.; Bucher, B.; Finch, D.; Fu, G.; Joho, H.; Syed, A.K.; Vaid, S.; et al. The design and implementation of SPIRIT: A spatially aware search engine for information retrieval on the Internet. Int. J. Geogr. Inf. Sci. 2007, 21, 717–745. [Google Scholar] [CrossRef]
- Zhou, Y.; Xie, X.; Wang, C.; Gong, Y.; Ma, W. Hybrid index structures for location-based web search. In Proceedings of the 14th ACM International Conference on Information and Knowledge Management, Bremen, Germany, 31 October–5 November 2005; pp. 155–162.
- Chen, Y.; Suel, T.; Markowetz, A. Efficient query processing in geographic web search engines. In Proceedings of the ACM SIGMOD International Conference on Management of Data, Chicago, IL, USA, 27–29 June 2006; pp. 277–288.
- De Andrade, F.G.; Baptista, C.S.; Davis, C.A. Improving geographic information retrieval in spatial data infrastructures. Geoinformatica 2014, 18, 793–818. [Google Scholar] [CrossRef]
- De Sabbata, S.; Reichenbacher, T. Criteria of geographic relevance: An experimental study. Int. J. Geogr. Inf. Sci. 2013, 26, 1495–1520. [Google Scholar] [CrossRef]
- Reichenbacher, T.; De Sabbata, S.; Purves, R.S.; Fabrikant, S.I. Assessing geographic relevance for mobile search: A computational model and its validation via crowdsourcing. J. Assoc. Inf. Sci. Technol. 2016. [Google Scholar] [CrossRef]
- Ding, J.; Gravano, L.; Shivakumar, N. Computing geographical scopes of web resource. In Proceedings of the 26th International Conference on Very Large Data Bases, Cairo, Egypt, 10–14 September 2000.
- Amitay, E.; Har’El, N.; Sivan, R.; Soffer, A. Web-a-where: Geotagging web content. In Proceedings of the 27th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, Sheffield, UK, 25–29 July 2004.
- Adams, B.; Janowicz, K. Thematic signatures for cleansing and enriching place-related linked data. Int. J. Geogr. Inf. Sci. 2015, 29, 556–579. [Google Scholar] [CrossRef]
- Ferrés, D.; Rodríguez, H. Evaluating geographical knowledge re-ranking, linguistic processing and query expansion techniques for geographical information retrieval. In String Processing and Information Retrieval, Proceedings of the 22nd International Symposium, London, UK, 1–4 September 2015; Iliopoulos, C., Puglisi, S., Yilmaz, E., Eds.; pp. 311–323.
- Nguyen, T.T.; Jung, J.J. Exploiting geotagged resources to spatial ranking by extending HITS algorithm. Comput. Sci. Inf. Syst. 2014, 12, 185–201. [Google Scholar]
- Adams, B. Finding similar places using the observation-to-generalization place model. J. Geogr. Syst. 2015, 17, 137–156. [Google Scholar] [CrossRef]
- Jiang, D.; Vosecky, J.; Leung, K.W.; Yang, L.; Ng, W. SG-WSTD: A framework for scalable geographic web search topic discovery. Knowl.-Based Syst. 2015, 84, 18–33. [Google Scholar] [CrossRef]
- Rivera, F.M.; Ruiz, M.T.; Guzmám, G.; Ibarra, M.M. A collaborative learning approach for geographic information retrieval based on social networks. Comput. Hum. Behav. 2015, 51, 829–842. [Google Scholar] [CrossRef]
- Mouratidis, K.; Li, J.; Tang, Y.; Mamoulis, N. Joint search by social and spatial proximity. IEEE Trans. Knowl. Data Eng. 2015, 27, 781–793. [Google Scholar] [CrossRef]
- Liu, Y.; Yuan, Y.; Xiao, D.; Zhang, Y.; Hu, J. A point-set-based approximation for areal objects: A case study of representing localities. Comput. Environ. Urban Syst. 2010, 34, 28–39. [Google Scholar] [CrossRef]
- Tobler, W.R. A computer movie simulating urban growth in the Detroit region. Econ. Geogr. 1970, 46, 234–240. [Google Scholar] [CrossRef]
- Liu, Y.; Sui, Z.; Kang, C.; Gao, Y. Uncovering patterns of inter-urban trip and spatial interaction from social media check-in data. PLoS ONE 2014, 9, e86026. [Google Scholar] [CrossRef] [PubMed]
- Neimeyer, G. Geohash Tips & Tricks. Available online: http://geohash.org/site/tips.html (accessed on 1 June 2016).
- Sina News. Available online: http://roll.news.sina.com.cn/news/gnxw/gdxw1/index.shtml (accessed on 1 January 2015).











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Hierarchy Level | Instance |
|---|---|
| POI | Tsinghua University, PSB of Wenzhou … |
| District | Chaoyang district of Beijing, Wen’an county of Langfang … |
| City | Qingdao, Hankou … |
| Province | Ningxia Autonomous Region, Hong Kong … |
| Models | MAP |
|---|---|
| Point-set | 0.8479 |
| MBR Area-ratio | 0.4776 |
| MBR Binary | 0.1392 |
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gao, Y.; Jiang, D.; Zhong, X.; Yu, J. A Point-Set-Based Footprint Model and Spatial Ranking Method for Geographic Information Retrieval. ISPRS Int. J. Geo-Inf. 2016, 5, 122. https://0-doi-org.brum.beds.ac.uk/10.3390/ijgi5070122
Gao Y, Jiang D, Zhong X, Yu J. A Point-Set-Based Footprint Model and Spatial Ranking Method for Geographic Information Retrieval. ISPRS International Journal of Geo-Information. 2016; 5(7):122. https://0-doi-org.brum.beds.ac.uk/10.3390/ijgi5070122
Chicago/Turabian StyleGao, Yong, Dan Jiang, Xiang Zhong, and Jingyi Yu. 2016. "A Point-Set-Based Footprint Model and Spatial Ranking Method for Geographic Information Retrieval" ISPRS International Journal of Geo-Information 5, no. 7: 122. https://0-doi-org.brum.beds.ac.uk/10.3390/ijgi5070122