
Road Map Inference: A Segmentation and Grouping Framework

Abstract
:1. Introduction
- A flexible segmentation and grouping framework for map inference that is robust to noise and the variable sampling rates of GPS traces.
- An extended progressive Density-Based Spatial Clustering of Application with Noise (DBSCAN) algorithm with an orientation constraint for two-dimensional (2D) point cloud segmentation.
- A Hidden Markov Model (HMM)-based map matching algorithm for point cluster topological relationship construction.
- A progressive point cluster grouping algorithm for road map recovery according to the stroke principle [9].
2. Related Work
3. Method
3.1. DBSCAN Algorithm with an Orientation Constraint
 |
 |
3.2. Point Clusters Grouping
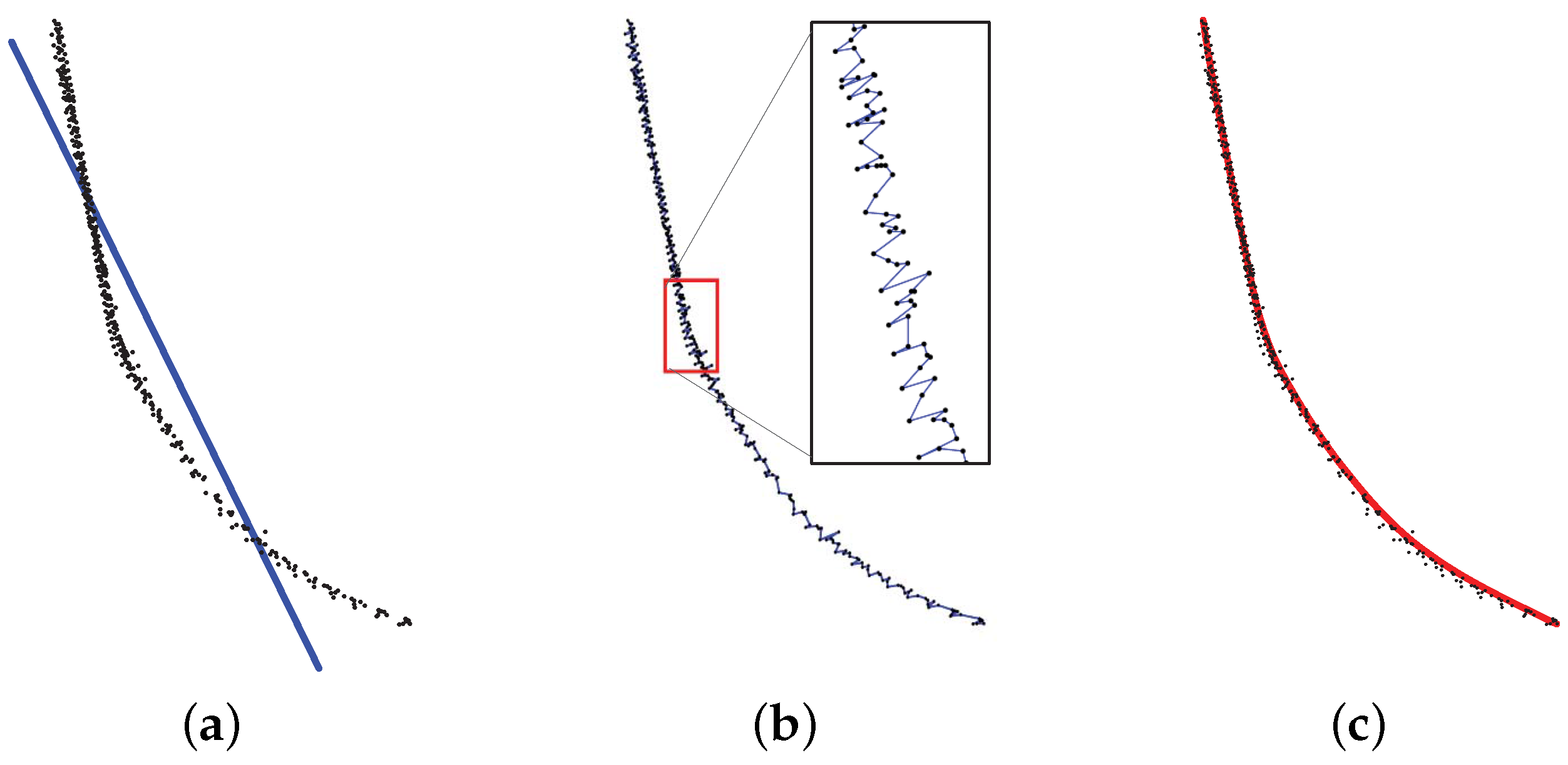
3.2.1. Centerline Generation from Point Cluster
- Apply a locally-weighted linear least-squares regression for each point to smooth the curve.
- Calculate the residual for each point according to the smoothed curve.
- Compute the value of MAD to remove outliers and update local weights. The residuals of the outliers are more than 6-times that of the value of MAD.
- Smooth the curve as described in Step 1, again using the new weights.
- Repeat Steps 2 through 4 for a total of five iterations to obtain a smooth curve.
3.2.2. Topological Relationship Construction between Clusters
- For a point cluster , obtain the number of the points included in that their successive points are not included in .
- For a point cluster , obtain the number of the points included in that have their successive points in ().
- Compute the transition probability for transitioning from centerline to , .
- Repeat Steps 2 and 3, computing transition probabilities for transiting from the to all possible .
- Define , ().
- Repeat Steps 1 to 5, computing the non-zero transition probabilities of all centerlines .
- Find minimum out-degree among all of the out-degrees of all centerlines .
- Update transition probabilities as , where , is a weight factor, and .
3.2.3. Point Cluster Grouping
| Algorithm 3: Point clusters grouping algorithm. | |
| Input: TwoPointClusters , and , β | |
| Output: NewPointClusters | |
| 1 | calculate the difference of mean orientations by points in and ; |
| 2 | if then |
| 3 | return the two clusters and ; |
| 4 | generate the centerlines and for point cluster and by robust Lowess; |
| 5 | estimate the errors and by MAD for and ; |
| 6 | generate a new centerline by ; |
| 7 | find the as the distance set ; |
| 8 | find the as the distance set ; |
| 9 | sort distances in and as and in descending order; |
| 10 | compute the mean distance of the distances from the beginning to the α-quantile in the set and as and ; |
| 11 | if + then |
| 12 | return the two clusters and ; |
| 13 | else |
| 14 | return the new grouped cluster ; |
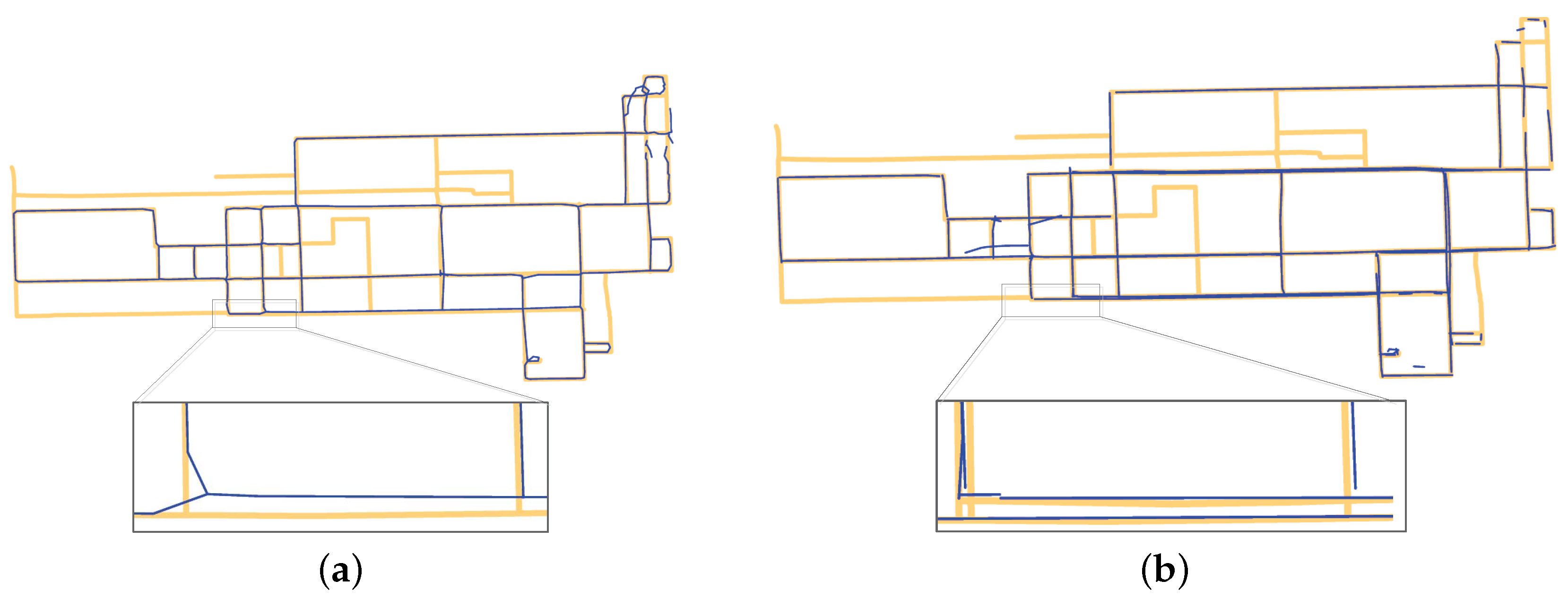
4. Experiments
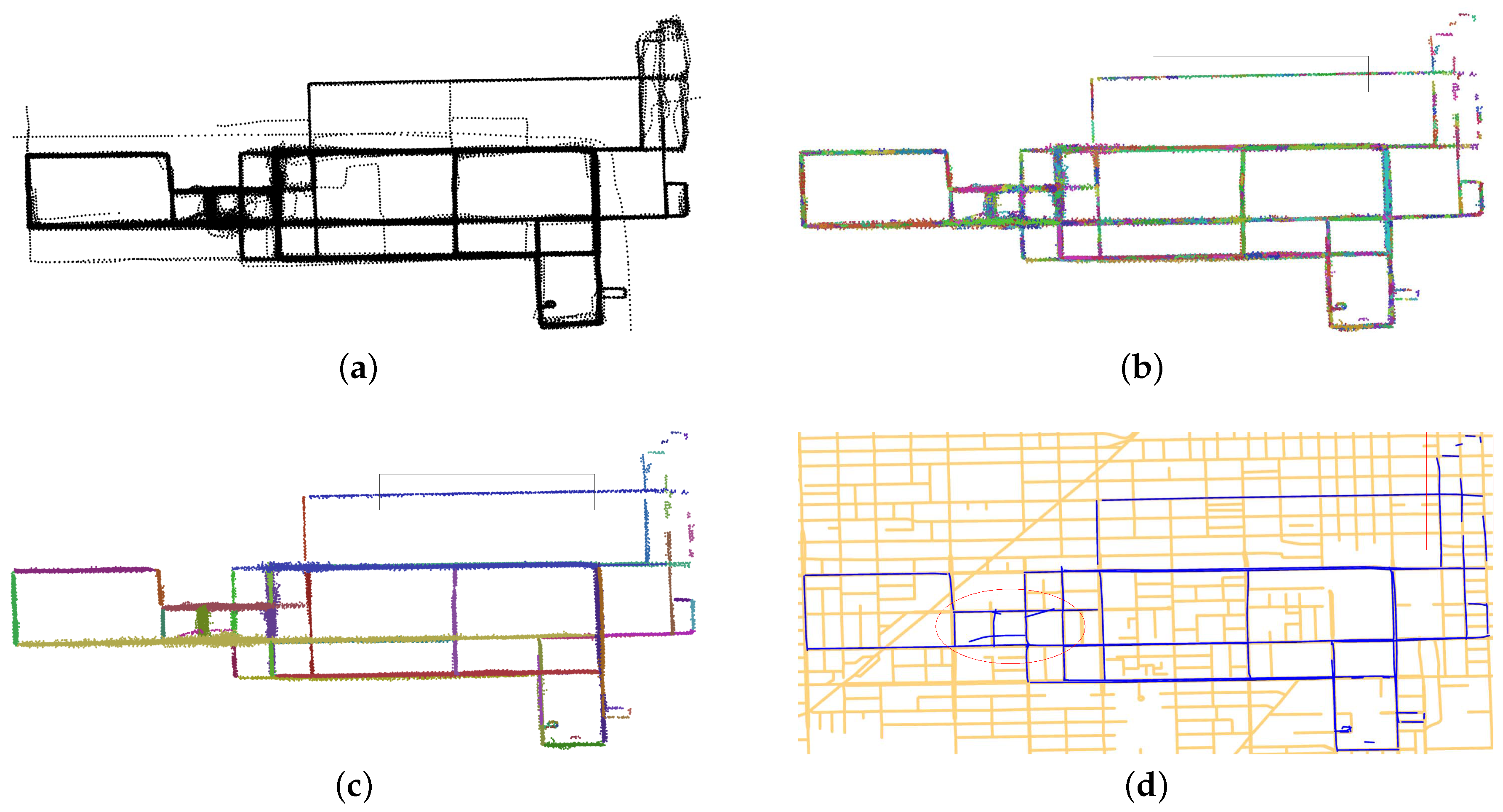
- The Chicago dataset was GPS traces from a bus serving the University of Illinois at Chicago campus [23]. The dataset covered an area of 3.8 km × 2.4 km, with the sampling rates varying from 1 s to 29 s (with a mean of 3.61 s and standard deviation of 3.67 s). The distances between two consecutive points ranged from 19.97 m to 96.6 m (with a mean of 24.4 m and standard deviation of 3.31 m). There were about 118,000 points.
- The Wuhan dataset was GPS traces collected by taxis. The dataset covered an area of 4.8 km × 5.5 km, with the sampling rates varying from 1 s to 81 s (with a mean of 37.42 s and standard deviation of 17.66 s). The distances between two consecutive points ranged from 0 m to 496.255 m (with a mean of 218.84 m and standard deviation of 140.38 m). There were about 350,000 points.
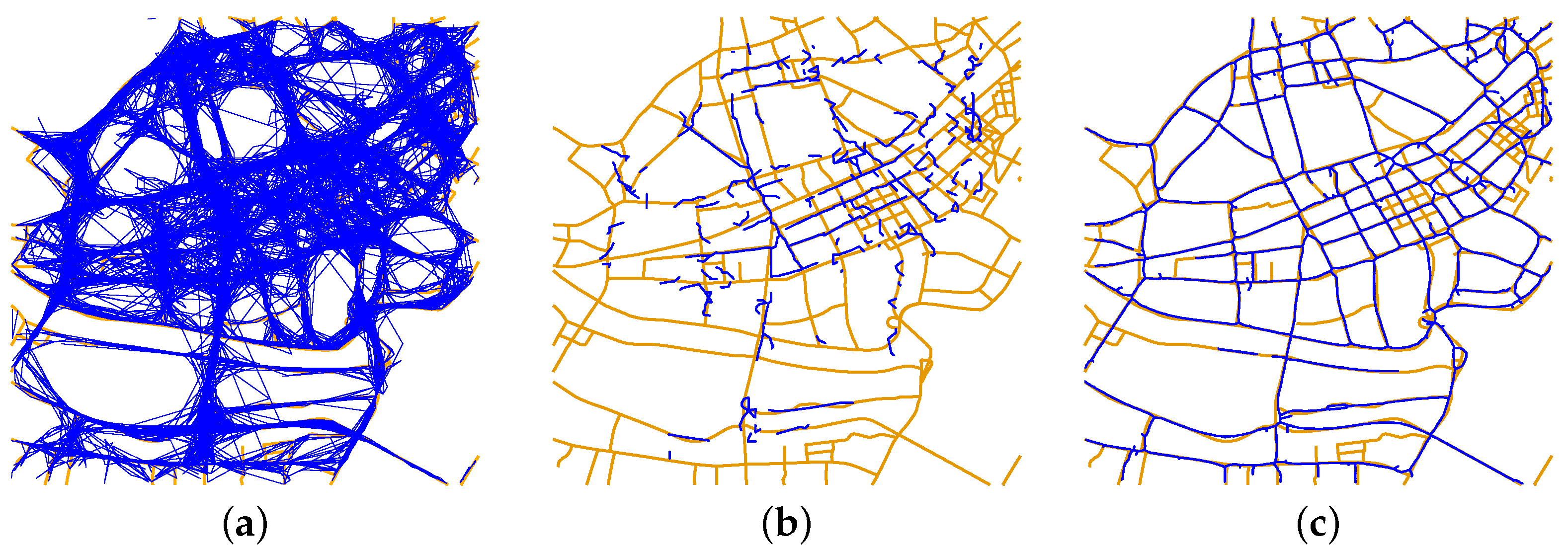
5. Evaluation
- Place points on the roads of the ground truth and inferred maps with equal intervals (i.e., 1 m).
- Compute the orientations of all points by their connections (modulo 180°).
- Match the sampled points on the inferred map with the ground truth map by nearest distance matching under the constraint of the orientation. The difference of orientations of two points that are matched with each other is no more than 60°.
- Use different distance thresholds to determine the best match proportion.
6. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
Abbreviations
| DBSCAN | Density-Based Spatial Clustering of Application with Noise |
| Lowess | Locally-Weighted Scatterplot Smooth |
| HMM | Hidden Markov Model |
| UGC | User-Generated Content |
| GPS | Global Positioning System |
| 2D | Two-Dimensional |
| KDE | Kernel Density Estimation |
| PCA | Principal Component Analysis |
| MAD | Median Absolute Deviation |
References
- Wang, Y.; Liu, X.; Wei, H.; Forman, G.; Chen, C.; Zhu, Y. CrowdAtlas: Self-Updating maps for cloud and personal use. In Proceedings of the 11th Annual International Conference on Mobile Systems, Applications, and Services, Taipei, Taiwan, 25–28 June 2013; pp. 27–40.
- Guo, T.; Iwamura, K.; Koga, M. Towards high accuracy road maps generation from massive GPS traces data. In Proceedings of the 2007 IEEE International Geoscience and Remote Sensing Symposium, Barcelona, Spain, 23–28 July 2007.
- Fernandes, R.; Premebida, C.; Peixoto, P.; Wolf, D.; Nunes, U. Road detection using high resolution LiDAR. In Proceedings of the Vehicle Power and Propulsion Conference (VPPC), Coimbra, Portugal, 27–30 October 2014; pp. 1–6.
- Hillel, A.B.; Lerner, R.; Levi, D.; Raz, G. Recent progress in road and lane detection: A survey. Mach. Vis. Appl. 2014, 25, 727–745. [Google Scholar] [CrossRef]
- Krumm, J.; Davies, N.; Narayanaswami, C. User-generated content. IEEE Pervasive Comput. 2008, 7, 10–11. [Google Scholar] [CrossRef]
- Li, J.; Qin, Q.; Han, J.; Tang, L.-A.; Lei, K.H. Mining trajectory data and geotagged data in social media for road map inference. Trans. GIS 2015, 19, 1–18. [Google Scholar] [CrossRef]
- Schrödl, S.; Wagstaff, K.; Rogers, S.; Langley, P.; Wilson, C. Mining GPS traces for map refinement. Data Min. Knowl. Discov. 2004, 9, 59–87. [Google Scholar] [CrossRef]
- Lou, Y.; Zhang, C.; Zheng, Y.; Xie, X.; Wang, W.; Huang, Y. Map-Matching for low-sampling-rate GPS trajectories. In Proceedings of the 17th ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems, Seattle, DC, USA, 4–6 November 2009; pp. 352–361.
- Thomson, R.C.; Brooks, R. Exploiting perceptual grouping for map analysis, understanding and generalization: The case of road and river networks. In Graphics Recognition Algorithms and Applications; Springer: Berlin, Germany, 2002; pp. 148–157. [Google Scholar]
- Biagioni, J.; Eriksson, J. Inferring road maps from global positioning system traces: Survey and comparative evaluation. Transp. Res. Record: J. Transp. Res. Board 2012. [Google Scholar] [CrossRef]
- Ahmed, M.; Karagiorgou, S.; Pfoser, D.; Wenk, C. A comparison and evaluation of map construction algorithms using vehicle tracking data. GeoInformatica 2015, 19, 601–632. [Google Scholar] [CrossRef]
- Edelkamp, S.; Schrödl, S. Route planning and map inference with global positioning traces. In Computer Science in Perspective; Springer: Berlin, Germany, 2003; pp. 128–151. [Google Scholar]
- Agamennoni, G.; Nieto, J.I.; Nebot, E.M. Technical Report: Inference of Principal Road Paths Using GPS Data; The University of Sydney, Australian Centre for Field Robotics: Sydney, Australia, 2010. [Google Scholar]
- Agamennoni, G.; Nieto, J.I.; Nebot, E.M. Robust inference of principal road paths for intelligent transportation systems. IEEE Trans. Intell. Transp. Syst. 2011, 12, 298–308. [Google Scholar] [CrossRef]
- Cao, L.; Krumm, J. From GPS traces to a routable road map. In Proceedings of the 17th ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems, Seattle, DC, USA, 4–6 November 2009; pp. 3–12.
- Wang, J.; Rui, X.; Song, X.; Tan, X.; Wang, C.; Raghavan, V. A novel approach for generating routable road maps from vehicle GPS traces. Int. J. Geogr. Inf. Sci. 2015, 29, 69–91. [Google Scholar] [CrossRef]
- Niehoefer, B.; Burda, R.; Wietfeld, C.; Bauer, F.; Lueert, O. GPS community map generation for enhanced routing methods based on trace-collection by mobile phones. In Proceedings of the 2009 First International Conference on Advances in Satellite and Space Communications (SPACOMM 2009), Colmar, France, 20–25 July 2009; pp. 156–161.
- Chen, D.; Guibas, L.J.; Hershberger, J.; Sun, J. Road network reconstruction for organizing paths. In Proceedings of the Twenty-First Annual ACM-SIAM Symposium on Discrete Algorithms. Society for Industrial and Applied Mathematics, Philadelphia, PA, USA, 17–19 January 2010; pp. 1309–1320.
- Liu, X.; Biagioni, J.; Eriksson, J.; Wang, Y.; Forman, G.; Zhu, Y. Mining large-scale, sparse GPS traces for map inference: Comparison of approaches. In Proceedings of the 18th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Beijing, China, 12–16 August 2012; pp. 669–677.
- Davies, J.J.; Beresford, A.R.; Hopper, A. Scalable, distributed, real-time map generation. IEEE Pervasive Comput. 2006, 5, 47–54. [Google Scholar] [CrossRef]
- Chen, C.; Cheng, Y. Roads digital map generation with multi-track GPS data. In Proceedings of the 2008 International Workshop on Education Technology and Training & 2008 International Workshop on Geoscience and Remote Sensing (ETT and GRS), Shanghai, China, 21–22 December 2008; pp. 508–511.
- Shi, W.; Shen, S.; Liu, Y. Automatic generation of road network map from massive GPS, vehicle trajectories. In Proceedings of the 12th International IEEE Conference on Intelligent Transportation Systems, Louis, MO, USA, 4–7 October 2009; pp. 1–6.
- Biagioni, J.; Eriksson, J. Map inference in the face of noise and disparity. In Proceedings of the 20th International Conference on Advances in Geographic Information Systems, Redondo Beach, CA, USA, 6–9 November 2012; pp. 79–88.
- Fathi, A.; Krumm, J. Detecting road intersections from GPS traces. In Geographic Information Science; Springer: Berlin, Germany, 2010; pp. 56–69. [Google Scholar]
- Karagiorgou, S.; Pfoser, D. On vehicle tracking data-based road network generation. In Proceedings of the 20th International Conference on Advances in Geographic Information Systems, Redondo Beach, CA, USA, 6–9 November 2012; pp. 89–98.
- Qiu, J.; Wang, R.; Wang, X. Inferring road maps from sparsely-sampled GPS traces. In Advances in Artificial Intelligence; Springer: Berlin, Germany, 2014; pp. 339–344. [Google Scholar]
- Cleveland, W.S. Robust locally weighted regression and smoothing scatterplots. J. Am. Stat. Assoc. 1979, 74, 829–836. [Google Scholar] [CrossRef]
- Newson, P.; Krumm, J. Hidden Markov map matching through noise and sparseness. In Proceedings of the 17th ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems, Seattle, DC, USA, 4–6 November 2009; pp. 336–343.
- Ester, M.; Kriegel, H.-P.; Sander, J.; Xu, X. A density-based algorithm for discovering clusters in large spatial databases with noise. KDD 1996, 96, 226–231. [Google Scholar]
- Wang, J.; Yu, Z.; Zhang, W.; Weid, M.; Tana, C.; Daia, N.; Zhange, X. Robust reconstruction of 2D curves from scattered noisy point data. Comput.-Aided Des. 2014, 50, 27–40. [Google Scholar] [CrossRef]
- Krumm, J.; Horvitz, E.; Letchner, J. Map Matching with Travel Time Constraints; SAE World Congress: Detroit, MI, USA, 2007. [Google Scholar]
- Thiagarajan, A.; Ravindranath, L.; LaCurts, K.; Madden, S.; Balakrishnan, H. VTrack: Accurate, energy-aware road traffic delay estimation using mobile phones. In Proceedings of the 7th ACM Conference on Embedded Networked Sensor Systems, Berkeley, CA, USA, 4–6 November 2009.
- Jiang, B.; Zhao, S.; Yin, J. Self-Organized natural roads for predicting traffic flow: A sensitivity study. J. Stat. Mech.: Theory Exp. 2008, 2008, P07008. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
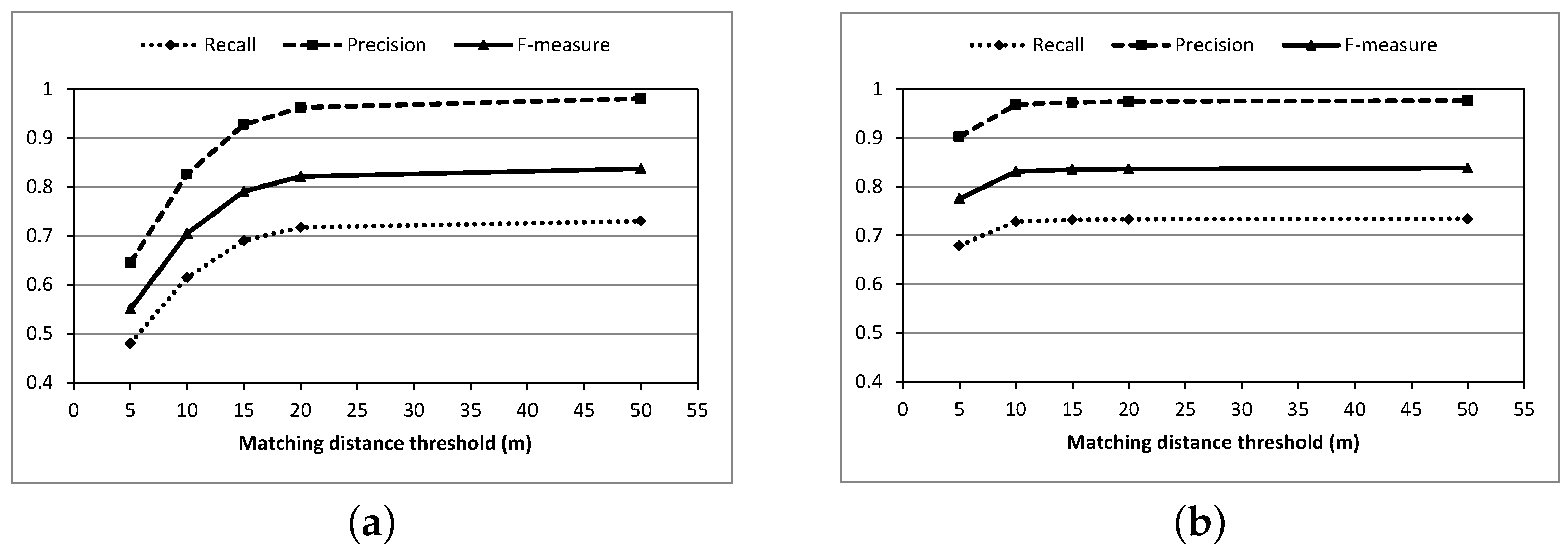
| Matching Threshold of Distance (m) | Length of Well-matched Roads (km) | Recall | Precision | F-measure |
|---|---|---|---|---|
| 5 | 15.11 | 0.459 | 0.617 | 0.526 |
| 10 | 20.22 | 0.615 | 0.826 | 0.705 |
| 15 | 22.71 | 0.690 | 0.927 | 0.791 |
| 20 | 23.57 | 0.717 | 0.962 | 0.821 |
| 50 | 24.01 | 0.730 | 0.980 | 0.837 |
| Matching Threshold of Distance (m) | Length of Well-matched Roads (km) | Recall | Precision | F-measure |
|---|---|---|---|---|
| 5 | 27.93 | 0.679 | 0.902 | 0.775 |
| 10 | 29.96 | 0.728 | 0.968 | 0.831 |
| 15 | 30.09 | 0.732 | 0.972 | 0.835 |
| 20 | 30.13 | 0.733 | 0.974 | 0.836 |
| 50 | 30.19 | 0.734 | 0.975 | 0.838 |
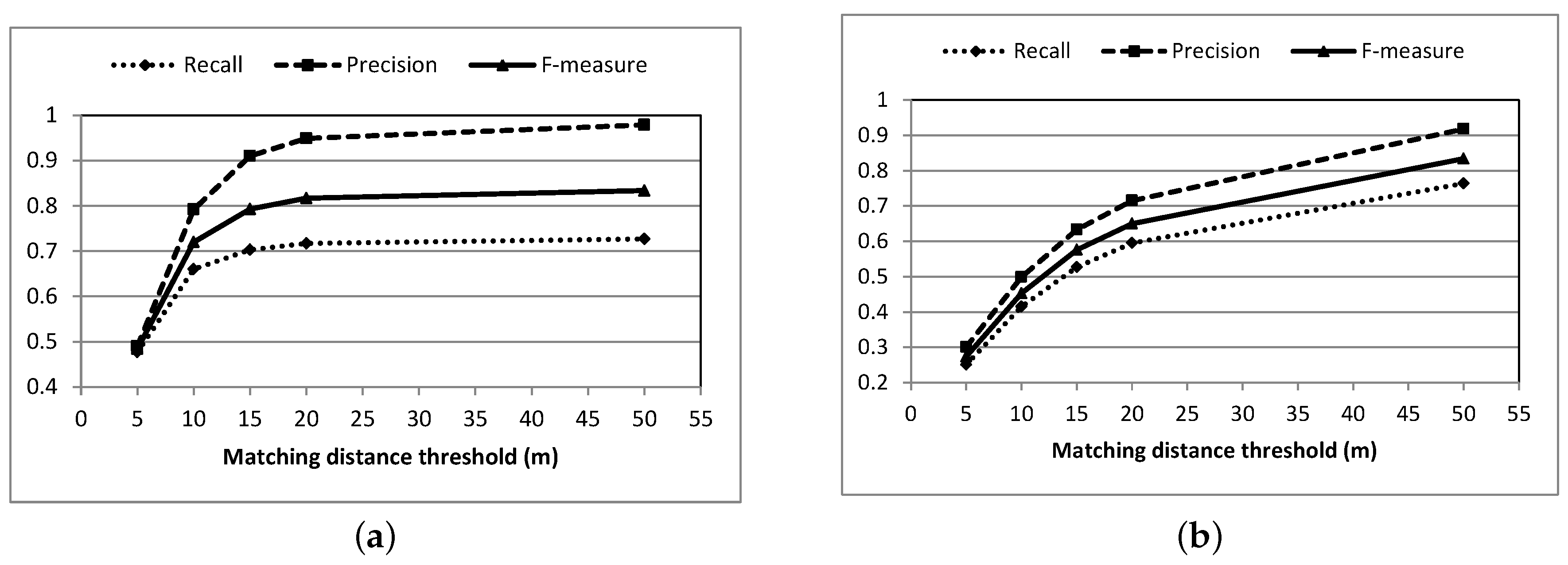
| Matching Threshold of of Distance (m) | Length of Well-Matched Roads (km) | Length of Correctly Inferred Roads (km) | Recall | Precision | F-measure |
|---|---|---|---|---|---|
| 5 | 56.14 | 72.78 | 0.477 | 0.490 | 0.484 |
| 10 | 77.61 | 117.48 | 0.660 | 0.792 | 0.720 |
| 15 | 82.74 | 135.00 | 0.703 | 0.910 | 0.793 |
| 20 | 84.37 | 140.75 | 0.717 | 0.949 | 0.817 |
| 50 | 85.52 | 145.26 | 0.727 | 0.979 | 0.834 |
| Matching Threshold of of Distance (m) | Length of Well-Matched Roads (km) | Recall | Precision | F-measure |
|---|---|---|---|---|
| 5 | 29.51 | 0.251 | 0.301 | 0.274 |
| 10 | 48.87 | 0.415 | 0.499 | 0.453 |
| 15 | 62.06 | 0.527 | 0.633 | 0.576 |
| 20 | 70.05 | 0.595 | 0.715 | 0.65 |
| 50 | 89.92 | 0.764 | 0.918 | 0.834 |
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Qiu, J.; Wang, R. Road Map Inference: A Segmentation and Grouping Framework. ISPRS Int. J. Geo-Inf. 2016, 5, 130. https://0-doi-org.brum.beds.ac.uk/10.3390/ijgi5080130
Qiu J, Wang R. Road Map Inference: A Segmentation and Grouping Framework. ISPRS International Journal of Geo-Information. 2016; 5(8):130. https://0-doi-org.brum.beds.ac.uk/10.3390/ijgi5080130
Chicago/Turabian StyleQiu, Jia, and Ruisheng Wang. 2016. "Road Map Inference: A Segmentation and Grouping Framework" ISPRS International Journal of Geo-Information 5, no. 8: 130. https://0-doi-org.brum.beds.ac.uk/10.3390/ijgi5080130