
sgdm: An R Package for Performing Sparse Generalized Dissimilarity Modelling with Tools for gdm


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
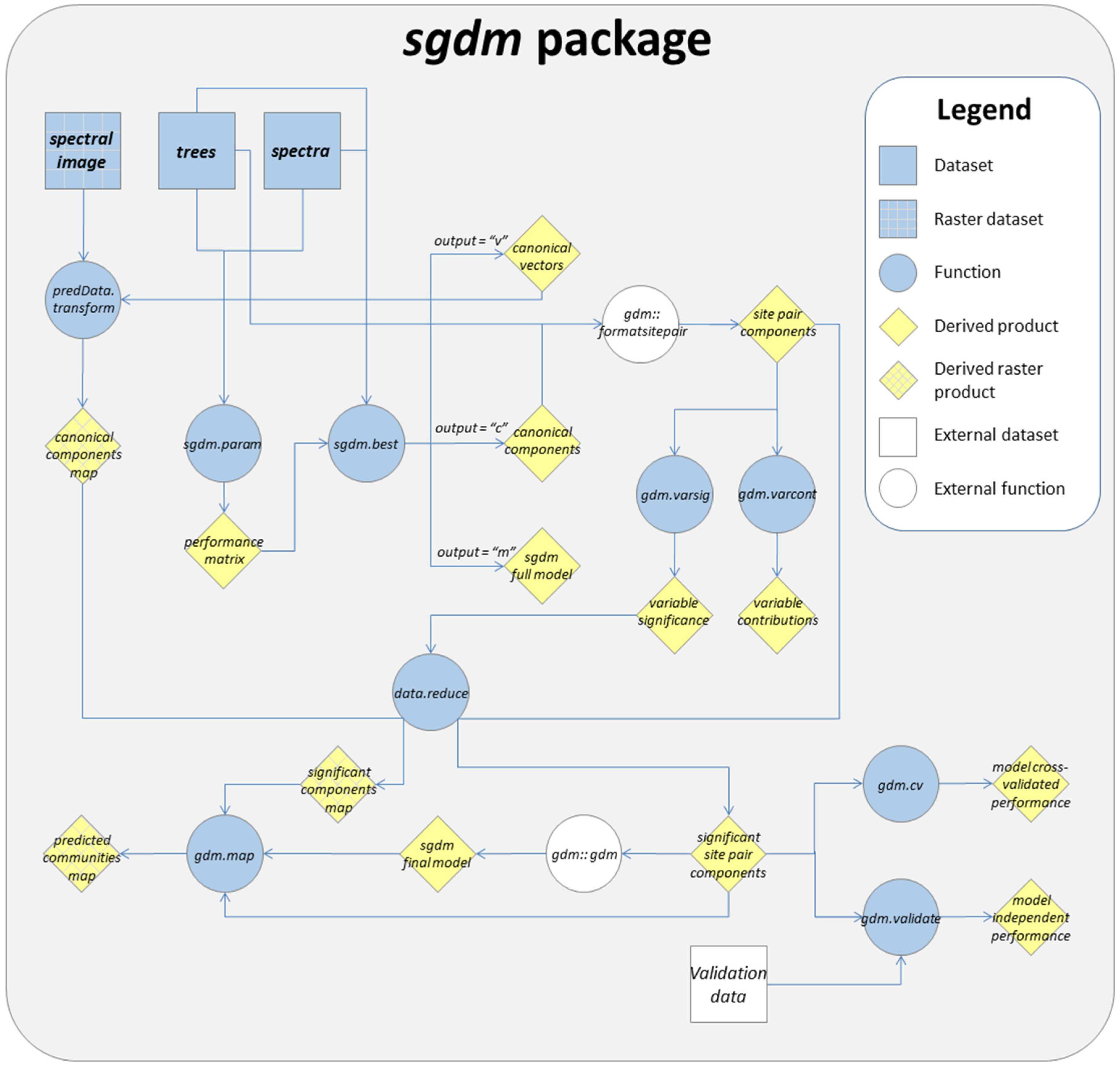
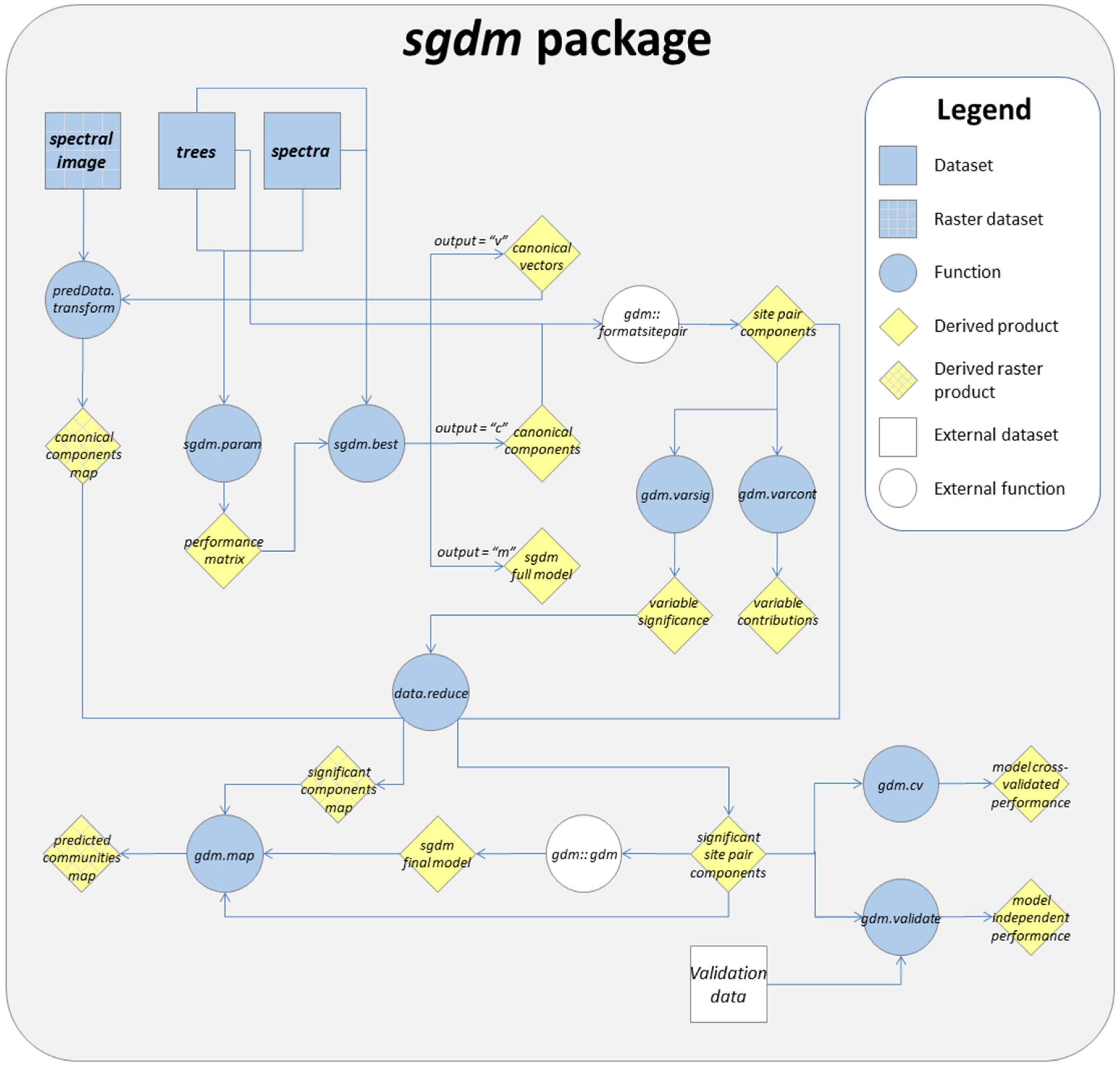
2. General sgdm Package Description
- R> # Package installation from GitHub
- R> devtools::install_github("sparsegdm/sgdm_package")
- R> Loading package
- R> library(sgdm)
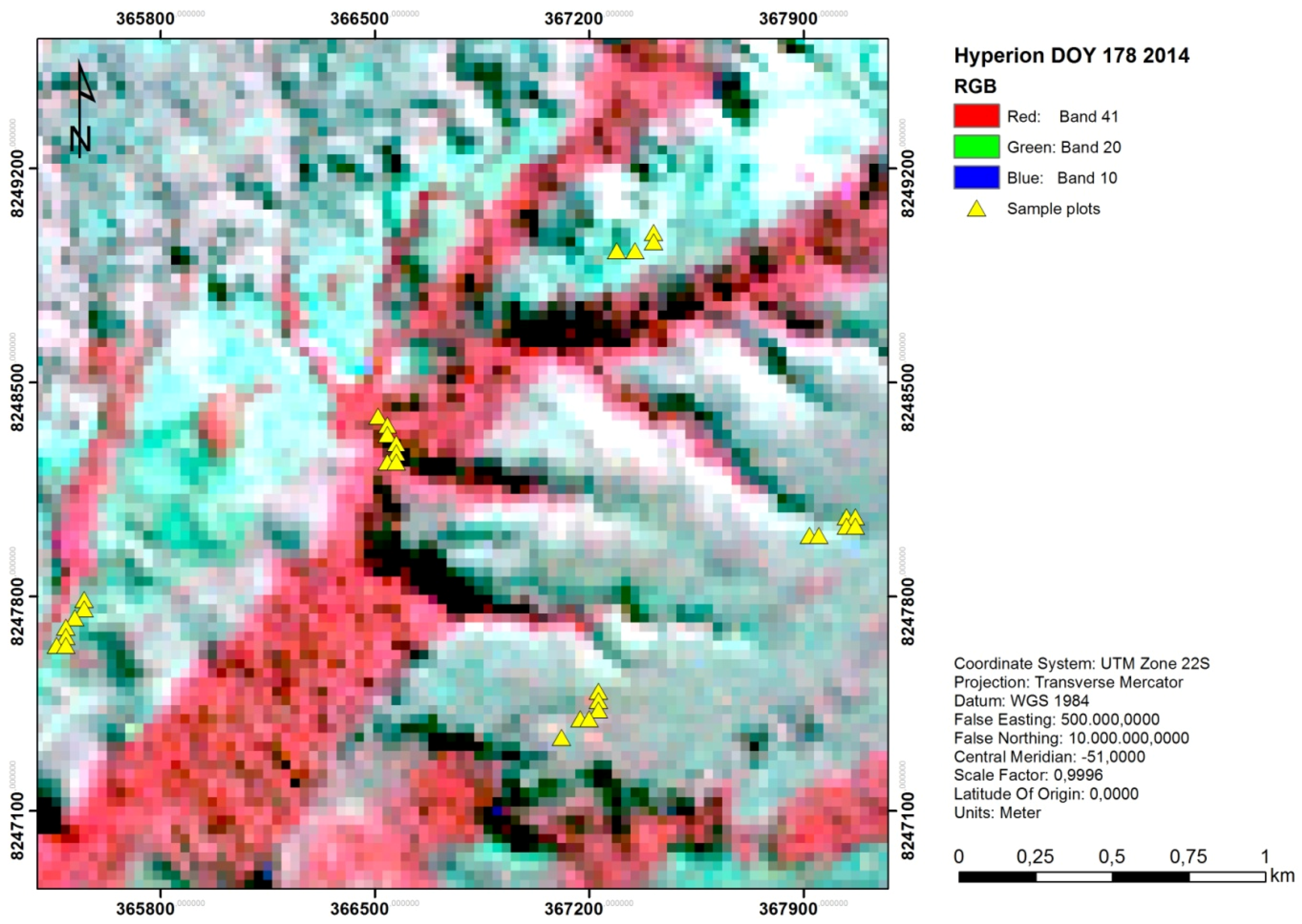
3. Running a SGDM Model in the sgdm Package
- R> # Parameterize SGDM
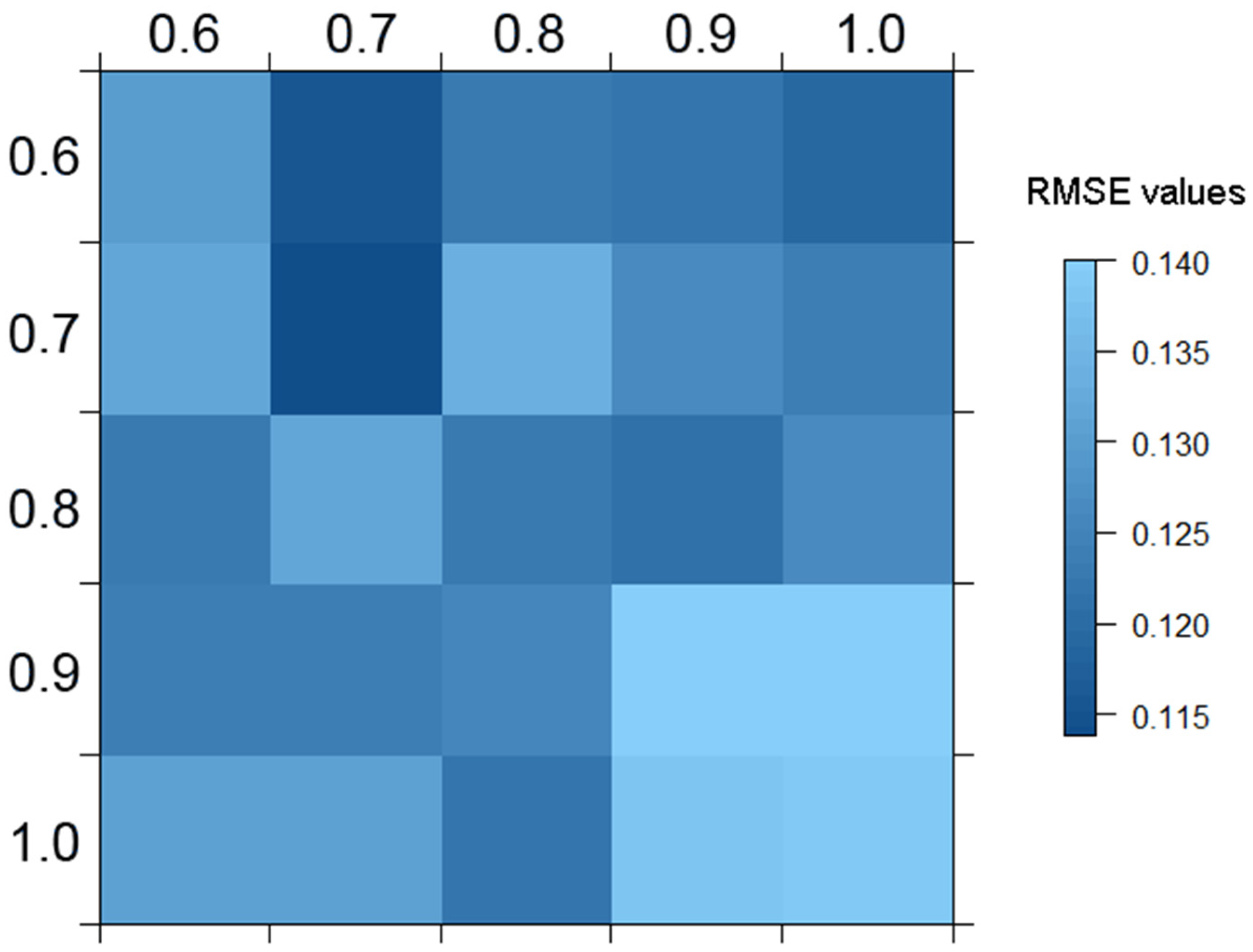
- R> sgdm.gs <− sgdm.param(predData = spectra, bioData = trees, k = 30)
- R> # Retrieving and building the best SGDM model
- R> sgdm.model <− sgdm.best(perf.matrix = sgdm.gs, predData = spectra, bioData = trees, output = ”m”, k = 30)
- R> # Retrieving the sparse canonical components corresponding to the best GDM model
- R> sgdm.sccbest <− sgdm.best(perf.matrix = sgdm.gs, predData = spectra, bioData = trees, output = ”c”, k = 30)
- R> # Retrieving the sparse canonical vectors corresponding to the best GDM model
- R> sgdm.vbest <− sgdm.best(perf.matrix = sgdm.gs, predData = spectra, bioData = trees, output = ”v”, k = 30)
- R> # Applying SCCA transformation onto the prediction map
- R> component.image <− predData.transform(predData = spectral.image, v = sgdm.vbest)
4. Additional Tools Useful for GDM and SGDM
- R> # Combining pair site data for GDM model variable contribution check
- R> spData.sccbest <− gdm:: formatsitepair(bioData = trees, bioFormat = 1, dist = "bray", abundance = TRUE, siteColumn = "Plot_ID", XColumn = "X", YColumn = "Y", predData = sgdm.sccbest)
- R> # Checking SGDM variable drop contribution
- R> gdm.varcont(spData = spData.sccbest)
- R> # Checking significance of variable contributions
- R> sigtest.sgdm <− gdm.varsig(predData = sgdm.sccbest, bioData = trees)
- R> # Excluding non-significant variables
- R> sgdm.sccbest.red <− data.reduce(data = sgdm.sccbest, datatype = "pred", sigtest = sigtest.sgdm)
- R> # Combining pair site data for input in GDM
- R> spData.sccbest.red <− gdm:: formatsitepair(bioData = trees, bioFormat = 1, dist = "bray", abundance = TRUE, siteColumn = "Plot_ID", XColumn = "X", YColumn = "Y", predData = sgdm.sccbest.red)
- R> # Final SGDM model
- R> sgdm.model.red <− gdm:: gdm(data = spData.sccbest.red)
- R> # 10-fold cross-validation of the final SGDM model
- R> gdm.cv(spData = spData.sccabest.red, nfolds = 10, performance = "r2")
- R> # Mapping community composition
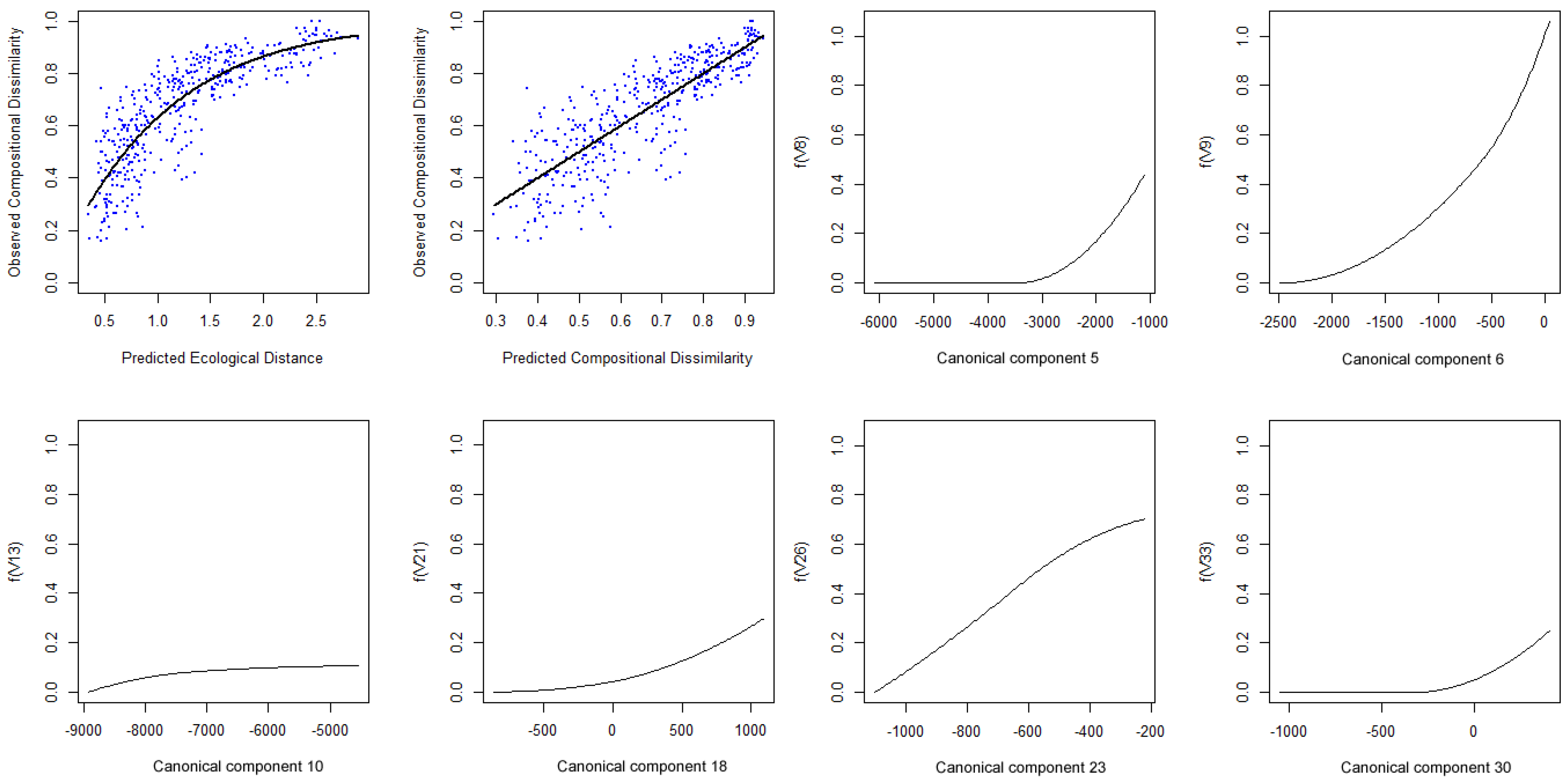
- R> map.sitepairs <− gdm.map(spData = spData.sccabest.red, model = sgdm.model.red)
- R> # Reducing canonical component map to significant components
- R> component.image.red <− data.reduce(data = component.image, datatype = "pred", igtest = sigtest.sgdm)
- R> # Mapping community composition in space
- R> map.image <− gdm.map(spData = spData.sccabest.red, predMap = component.image.red, model = sgdm.model.red, k = 8)
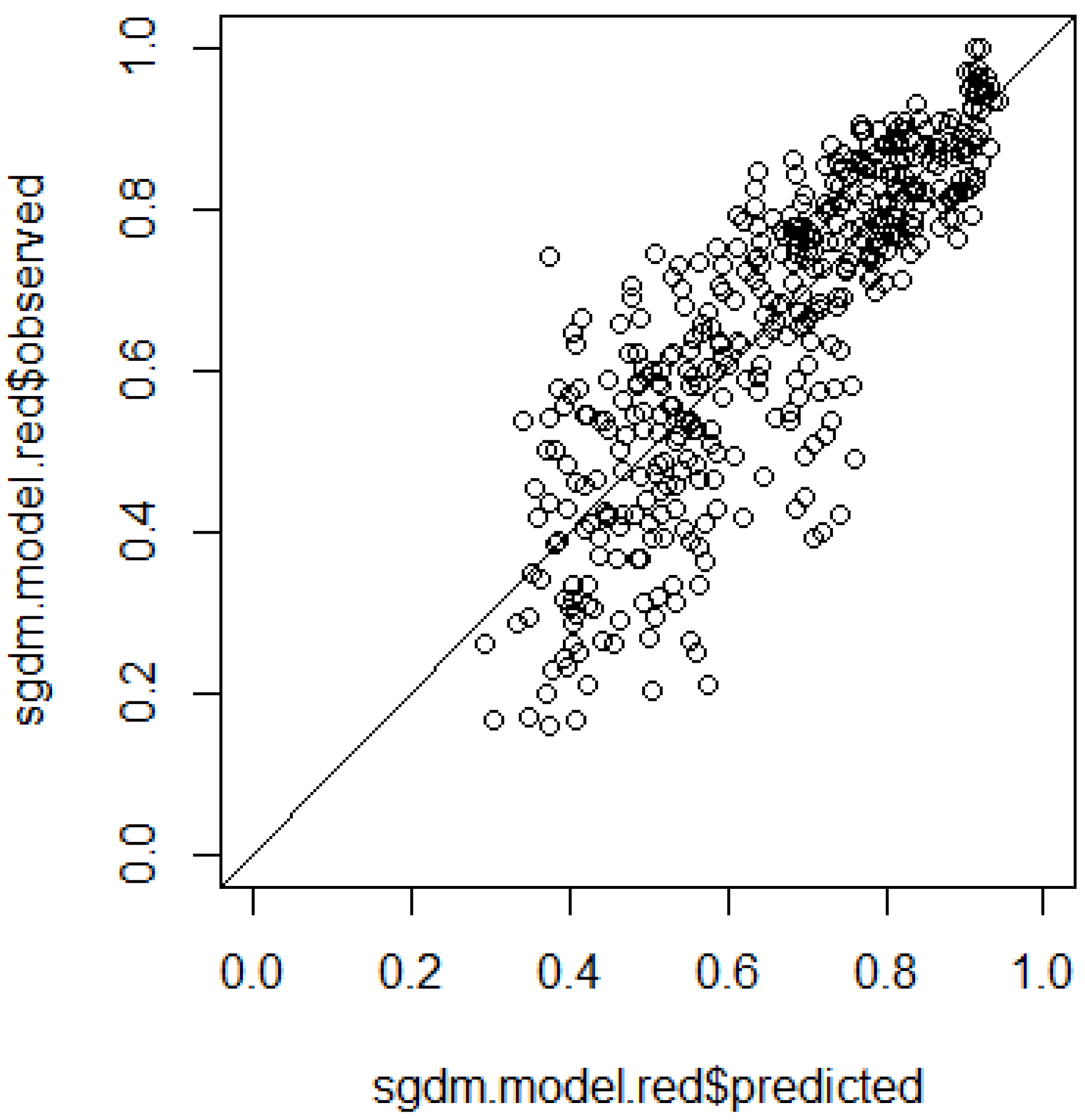
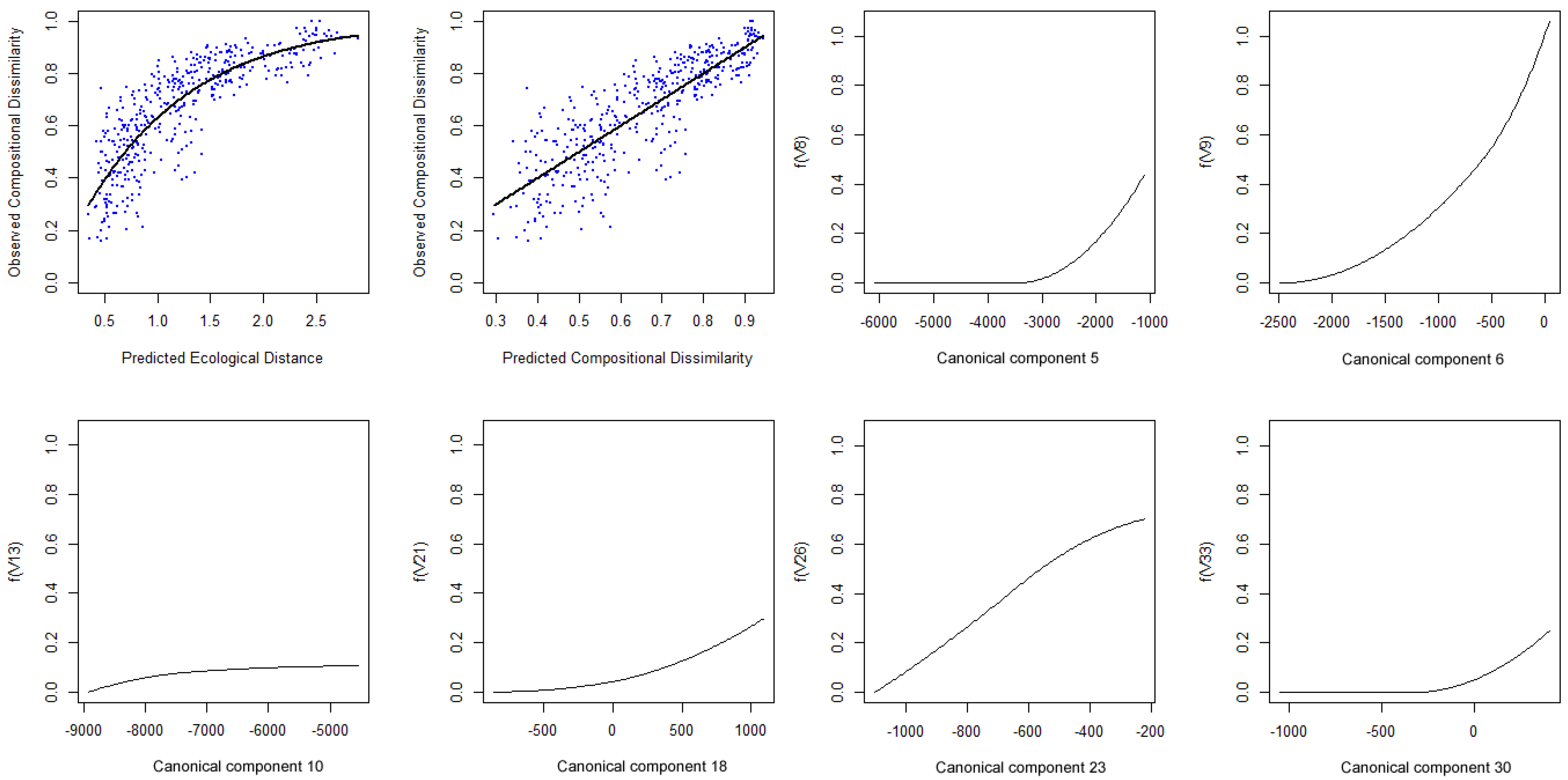
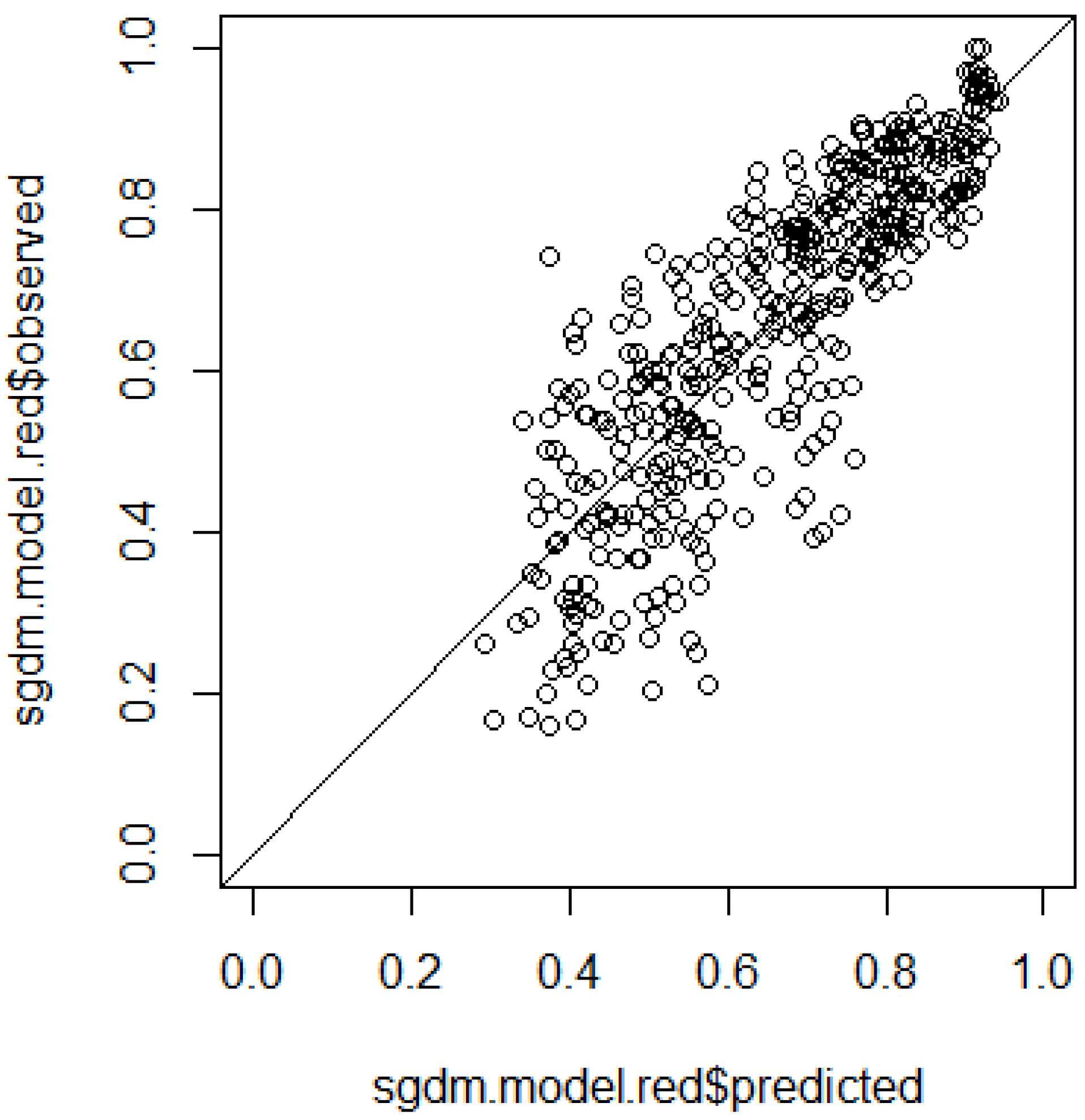
5. Discussion
6. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Chapin, F.S., III; Zavaleta, E.S.; Eviner, V.T.; Naylor, R.L.; Vitousek, P.M.; Reynolds, H.L.; Hooper, D.U.; Lavorel, S.; Sala, O.E.; Hobbie, S.E.; et al. Consequences of changing biodiversity. Nature 2000, 405, 234–242. [Google Scholar] [CrossRef] [PubMed]
- Pereira, H.M.; Navarro, L.M.; Martins, I.S. Global biodiversity change: the bad, the good, and the unknown. Annu. Rev. Environ. Resour. 2012, 37, 25–50. [Google Scholar] [CrossRef]
- Ferrier, S. Extracting more value from biodiversity change observations through integrated modeling. BioScience 2011, 61, 96–97. [Google Scholar] [CrossRef]
- Hooper, D.U.; Chapin, F.S.; Ewel, J.J.; Hector, A.; Inchausti, P.; Lavorel, S.; Lawton, J.H.; Lodge, D.M.; Loreau, M.; Naeem, S.; et al. Effects of biodiversity on ecosystem functioning: A consensus of current knowledge. Ecol. Monogr. 2005, 75, 3–35. [Google Scholar] [CrossRef] [Green Version]
- Legendre, P.; Borcard, D.; Peres-Neto, P.R. Analyzing beta diversity: Partitioning the spatial variation of community composition data. Ecol. Monogr. 2005, 75, 435–450. [Google Scholar] [CrossRef]
- Guisan, A.; Weiss, S.B.; Weiss, A.D. GLM versus CCA spatial modeling of plant species distribution. Plant Ecol. 1999, 143, 107–122. [Google Scholar] [CrossRef]
- Ferrier, S.; Guisan, A. Spatial modelling of biodiversity at the community level. J. Appl. Ecol. 2006, 43, 393–404. [Google Scholar] [CrossRef]
- Guisan, A.; Rahbek, C. SESAM—A new framework integrating macroecological and species distribution models for predicting spatio-temporal patterns of species assemblages. J. Biogeogr. 2011, 38, 1433–1444. [Google Scholar] [CrossRef]
- De Caceres, M.; Legendre, P.; He, F. Dissimilarity measurements and the size structure of ecological communities. Methods Ecol. Evolut. 2013, 4, 1167–1177. [Google Scholar] [CrossRef]
- Ferrier, S.; Manion, G.; Elith, J.; Richardson, K. Using generalized dissimilarity modelling to analyse and predict patterns of beta diversity in regional biodiversity assessment. Divers. Distrib. 2007, 13, 252–264. [Google Scholar] [CrossRef]
- Kerr, J.T.; Ostrovsky, M. From space to species: Ecological applications for remote sensing. Trends Ecol. Evolut. 2003, 18, 299–305. [Google Scholar] [CrossRef]
- Jetz, W.; Cavender-Bares, J.; Pavlick, R.; Schimel, D.; Davis, F.W.; Asner, G.P.; Guralnick, R.; Kattge, J.; Latimer, A.M.; Moorcroft, P.; et al. Monitoring plant functional diversity from space. Nat. Plants 2016, 2, 16024. [Google Scholar] [CrossRef] [PubMed]
- Wulder, M.A.; White, J.C.; Loveland, T.R.; Woodcock, C.E.; Belward, A.S.; Cohen, W.B.; Fosnight, E.A.; Shaw, J.; Masek, J.G.; Roy, D.P. The global Landsat archive: Status, consolidation, and direction. Remote Sens. Environ. 2015. [Google Scholar] [CrossRef]
- Guanter, L.; Kaufmann, H.; Segl, K.; Chabrillat, S.; Förster, S.; Rogass, C.; Kuester, T.; Hollstein, A.; Rossner, G.; Chlebek, C.; et al. The EnMAP spaceborne imaging spectroscopy mission for earth observation. Remote Sens. 2015, 7, 8830–8857. [Google Scholar] [CrossRef]
- Lausch, A.; Bannehr, L.; Beckmann, M.; Boehm, C.; Feilhauer, H.; Hacker, J.M.; Heurich, M.; Jung, A.; Klenke, R.; Neumann, C.; et al. Linking Earth Observation and taxonomic, structural and functional biodiversity: Local to ecosystem perspectives. Ecol. Indic. 2016, 70, 317–339. [Google Scholar] [CrossRef]
- Kennedy, R.E.; Andrefouet, S.; Cohen, W.B.; Gomez, C.; Griffiths, P.; Hais, M.; Healey, S.P.; Helmer, E.H.; Hostert, P.; Lyons, M.B.; et al. Bringing an ecological view of change to Landsat-based remote sensing. Front. Ecol. Environ. 2014, 12, 339–346. [Google Scholar] [CrossRef] [Green Version]
- Cord, A.F.; Meentemeyer, R.K.; Leitão, P.J.; Václavík, T. Modelling species distributions with remote sensing data: Bridging disciplinary perspectives. J. Biogeogr. 2013, 40, 2226–2227. [Google Scholar] [CrossRef]
- Parviainen, M.; Zimmermann, N.E.; Heikkinen, R.K.; Luoto, M. Using unclassified continuous remote sensing data to improve distribution models of red-listed plant species. Biodivers. Conserv. 2013, 22, 1731–1754. [Google Scholar] [CrossRef]
- Cord, A.F.; Klein, D.; Mora, F.; Dech, S. Comparing the suitability of classified land cover data and remote sensing variables for modeling distribution patterns of plants. Ecol. Model. 2014, 272, 129–140. [Google Scholar] [CrossRef]
- Dormann, C.F.; Elith, J.; Bacher, S.; Buchmann, C.; Carl, G.; Carré, G.; Marquéz, J.R.G.; Gruber, B.; Lafourcade, B.; Leitão, P.J.; et al. Collinearity: A review of methods to deal with it and a simulation study evaluating their performance. Ecography 2013, 36, 27–46. [Google Scholar] [CrossRef]
- Leitão, P.J.; Schwieder, M.; Suess, S.; Catry, I.; Milton, E.J.; Moreira, F.; Osborne, P.E.; Pinto, M.J.; van der Linden, S.; Hostert, P. Mapping beta diversity from space: Sparse Generalised Dissimilarity Modelling (SGDM) for analysing high-dimensional data. Methods Ecol. Evolut. 2015, 6, 764–771. [Google Scholar] [CrossRef]
- Witten, D.M.; Tibshirani, R.; Hastie, T. A penalized matrix decomposition, with applications to sparse principal components and canonical correlation analysis. Biostatistics 2009, 10, 515–534. [Google Scholar] [CrossRef] [PubMed]
- Tibshirani, R. Regression shrinkage and selection via the lasso. J. R. Stat. Soc. 1996, 58, 267–288. [Google Scholar]
- Reineking, B.; Schröder, B. Constrain to perform: Regularization of habitat models. Ecol. Model. 2006, 193, 675–690. [Google Scholar] [CrossRef]
- Manion, G.; Lisk, M.; Ferrier, S.; Nieto-Lugilde, D.; Fitzpatrick, M.C. GDM: Functions for Generalized Dissimilarity Modeling; R Package Version 1.2.3. Available online: http://CRAN.R-project.org/package=gdm (accessed on 18 January 2017).
- R Development Core Team R. A Language and Environment for Statistical Computing, 3.2.2; R Foundation for Statistical Computing: Vienna, Austria, 2016. [Google Scholar]
- Witten, D.; Tibshirani, R.; Gross, S.; Narasimhan, B. PMA: Penalized Multivariate Analysis; R Package Version 1.0.9. Available online: http://CRAN.R-project.org/package=PMA (accessed on 18 January 2017).
- Vegan: Community Ecology Package; R Package Version 2.3-5. Available online: http://CRAN.R-project.org/package=vegan (accessed on 18 January 2017).
- Hijmans, R.J. Raster: Geographic Data Analysis and Modeling; R Package Version 2.5-8. Available online: http://CRAN.R-project.org/package=raster (accessed on 18 January 2017).
- Crookston, N.L.; Finley, A.O. yaImpute: An R Package for kNN imputation. J. Stat. Softw. 2008, 23, 1–16. [Google Scholar] [CrossRef]
- Clarke, K.R. Non-parametric multivariate analyses of changes in community structure. Aust. J. Ecol. 1993, 18, 117–143. [Google Scholar] [CrossRef]
- Thessler, S.; Ruokolainen, K.; Tuomisto, H.; Tomppo, E. Mapping gradual landscape-scale floristic changes in Amazonian primary rain forests by combining ordination and remote sensing. Glob. Ecol. Biogeogr. 2005, 14, 315–325. [Google Scholar] [CrossRef]



© 2017 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Leitão, P.J.; Schwieder, M.; Senf, C. sgdm: An R Package for Performing Sparse Generalized Dissimilarity Modelling with Tools for gdm. ISPRS Int. J. Geo-Inf. 2017, 6, 23. https://0-doi-org.brum.beds.ac.uk/10.3390/ijgi6010023
Leitão PJ, Schwieder M, Senf C. sgdm: An R Package for Performing Sparse Generalized Dissimilarity Modelling with Tools for gdm. ISPRS International Journal of Geo-Information. 2017; 6(1):23. https://0-doi-org.brum.beds.ac.uk/10.3390/ijgi6010023
Chicago/Turabian StyleLeitão, Pedro J., Marcel Schwieder, and Cornelius Senf. 2017. "sgdm: An R Package for Performing Sparse Generalized Dissimilarity Modelling with Tools for gdm" ISPRS International Journal of Geo-Information 6, no. 1: 23. https://0-doi-org.brum.beds.ac.uk/10.3390/ijgi6010023